Deep Learning-Based Positioning of Visually Impaired People in Indoor Environments



Abstract
1. Introduction
- The work proposes an audio assistant app, to be developed and deployed on a smartphone, that helps VI people move independently in a complex building.
- To the best of the author’s knowledge, this work is the first to propose and recommend regression-based neural network training for the estimation of the position of a VI person moving in an indoor environment with a smartphone.
2. Background and Motivations for This Work
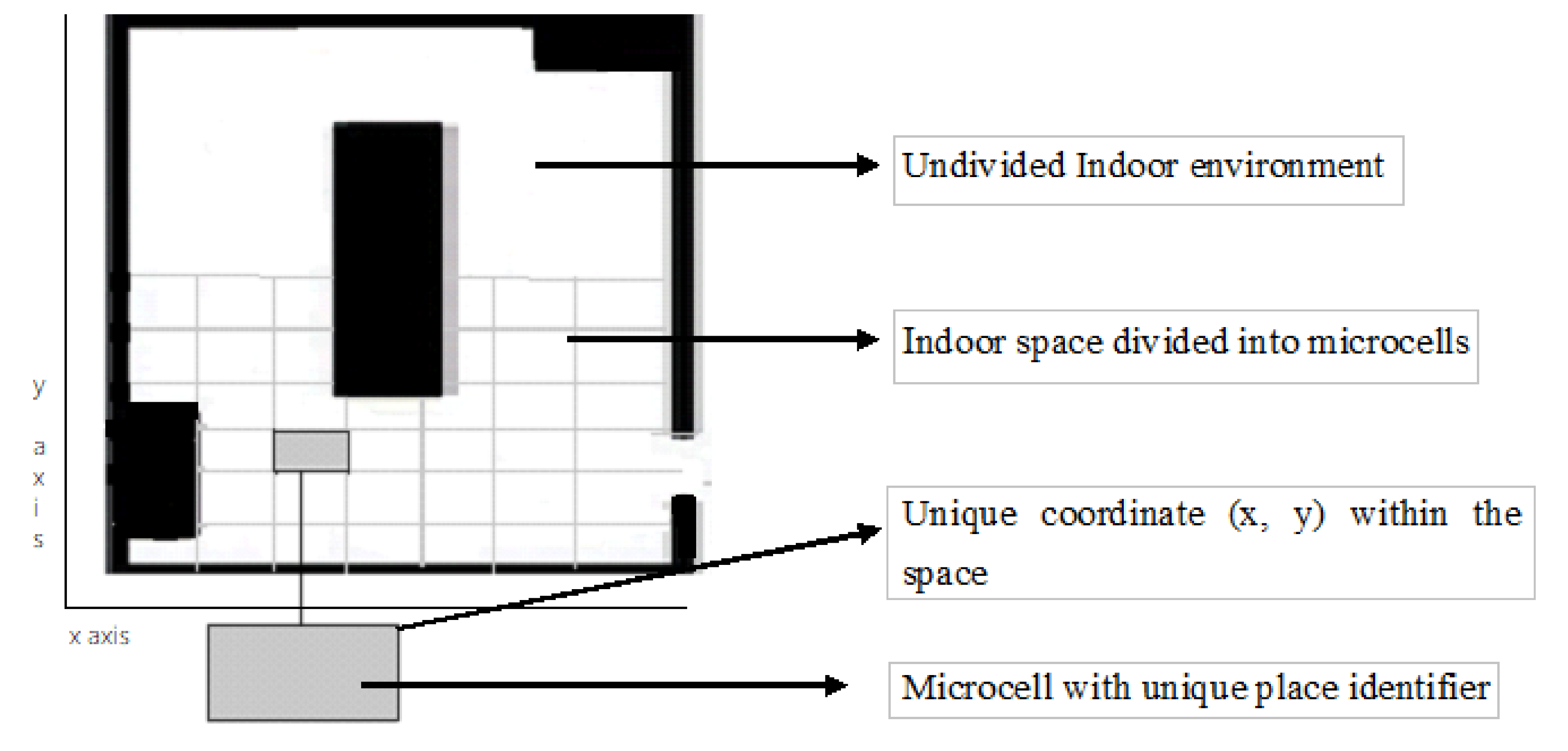
3. Characteristics of the Used Dataset
- X, Y, and Z-axis values of the accelerometer sensor;
- X, Y, and Z-axis values of the magnetometer;
- X, Y, and Z-axis values of the gyroscope;
- Roll, pitch, and azimuth values of the inertial sensor.
4. Deep Learning-Based Positioning
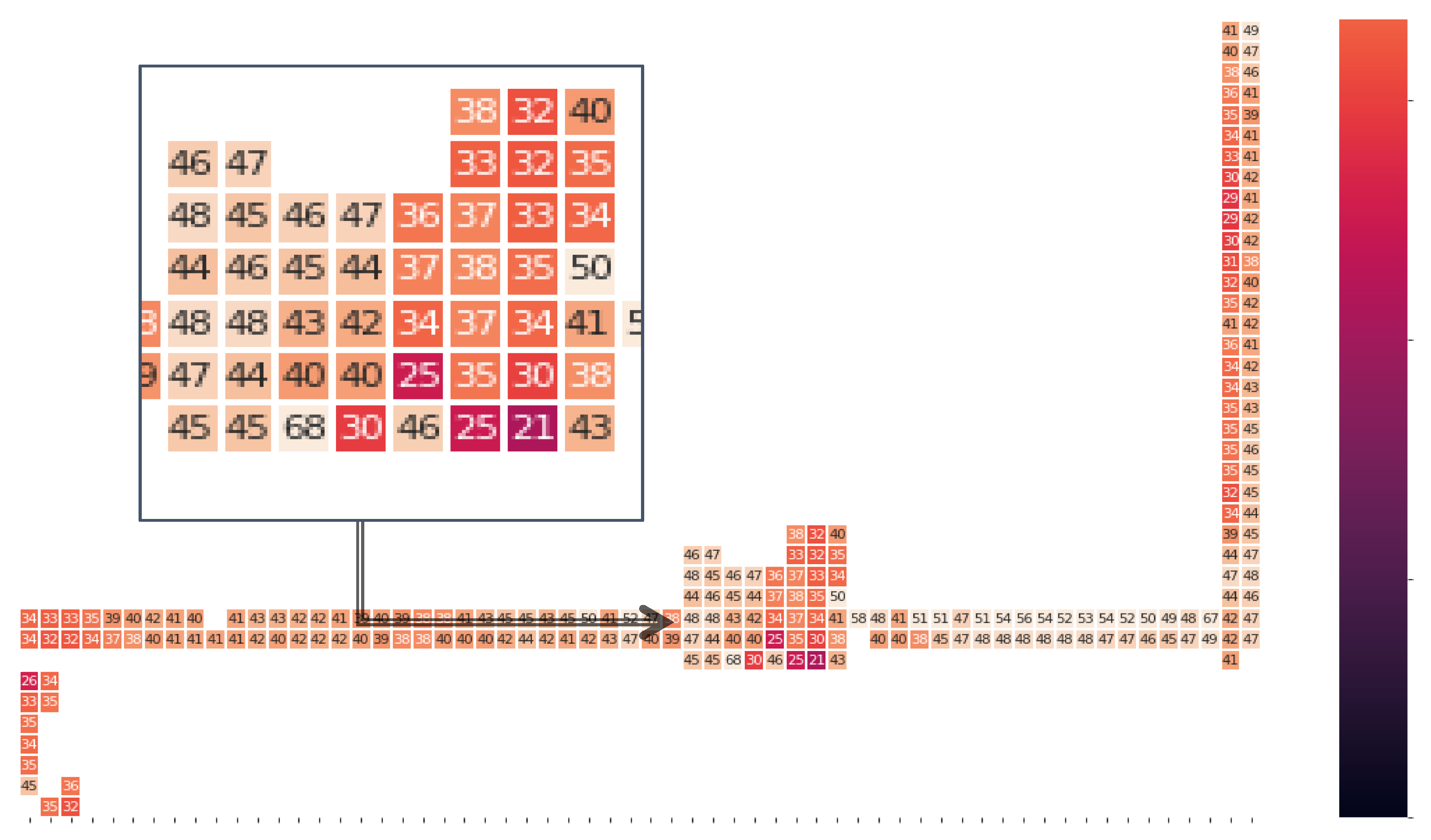
5. Setup of the Experiments and Analysis of the Results
5.1. Experimental Platform
5.2. Performance Metrics and Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Davidson, P.; Piche, R. A Survey of Selected Indoor Positioning Methods for Smartphones. IEEE Commun. Surv. Tutor. 2016, 19, 1347–1370. [Google Scholar] [CrossRef]
- Pissaloux, E.; Velázquez, R. Mobility of Visually Impaired People: Fundamentals and ICT Assistive Technologies; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Farid, Z.; Nordin, R.; Ismail, M. Recent Advances in Wireless Indoor Localization Techniques and System. J. Comput. Netw. Commun. 2013, 2013, 185138. [Google Scholar] [CrossRef]
- Brock, A.; Jouffrais, C. Interactive audio-tactile maps for visually impaired people. ACM SIGACCESS Access. Comput. 2015, 3–12. [Google Scholar] [CrossRef]
- Legge, G.E.; Beckmann, P.J.; Tjan, B.S.; Havey, G.; Kramer, K.; Rolkosky, D.; Gage, R.; Chen, M.; Puchakayala, S.; Rangarajan, A. Indoor Navigation by People with Visual Impairment Using a Digital Sign System. PLoS ONE 2013, 8, e76783. [Google Scholar] [CrossRef]
- Papadopoulos, K.; Barouti, M.; Charitakis, K. A University Indoors Audio-Tactile Mobility Aid for Individuals with Blindness. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8548, pp. 108–115. [Google Scholar] [CrossRef]
- Cecílio, J.; Duarte, K.; Furtado, P. BlindeDroid: An Information Tracking System for Real-time Guiding of Blind People. Procedia Comput. Sci. 2015, 52, 113–120. [Google Scholar] [CrossRef]
- Mahida, P.T.; Shahrestani, S.; Cheung, H.; Mahida, P.T. Localization techniques in indoor navigation system for visually impaired people. In Proceedings of the 2017 17th International Symposium on Communications and Information Technologies (ISCIT), Cairns, Australia, 25–27 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Wei, D.; Wei, D.; Lai, Q.; Li, W.; Yuan, H. A Context-Recognition-Aided PDR Localization Method Based on the Hidden Markov Model. Sensors 2016, 16, 2030. [Google Scholar] [CrossRef]
- Mahida, P.T.; Shahrestani, S.; Cheung, H. Indoor positioning framework for visually impaired people using Internet of Things. In Proceedings of the 2019 13th International Conference on Sensing Technology (ICST), Sydney, Australia, 2–4 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Mahida, P.T.; Shahrestani, S.; Cheung, H. Comparision of pathfinding algorithms for visually impaired people in IoT based smart buildings. In Proceedings of the 2018 28th International Telecommunication Networks and Applications Conference (ITNAC), Sydney, Australia, 21–23 November 2018; pp. 1–3. [Google Scholar] [CrossRef]
- Mahida, P.T.; Shahrestani, S.; Cheung, H. DynaPATH: Dynamic Learning Based Indoor Navigation for VIP in IoT Based Environments. In Proceedings of the 2018 International Conference on Machine Learning and Data Engineering (iCMLDE), Sydney, Australia, 3–7 December 2018; pp. 8–13. [Google Scholar] [CrossRef]
- Van Haute, T.; De Poorter, E.; Crombez, P.; Lemic, F.; Handziski, V.; Wirström, N.; Wolisz, A.; Voigt, T.; Moerman, I. Performance analysis of multiple Indoor Positioning Systems in a healthcare environment. Int. J. Health Geogr. 2016, 15, 1–15. [Google Scholar] [CrossRef]
- Xu, Z.; Zheng, H.; Pang, M.; Su, X.; Zhou, G.; Fang, L. Utilizing high-level visual feature for indoor shopping mall localization. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 1378–1382. [Google Scholar] [CrossRef]
- Won, S.-H.P.; Melek, W.W.; Golnaraghi, F. Remote Sensing Technologies for Indoor Applications. In Handbook of Position Location: Theory, Practice and Advance; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Guerrero, L.A.; Vasquez, F.; Ochoa, S.F. An Indoor Navigation System for the Visually Impaired. Sensors 2012, 12, 8236–8258. [Google Scholar] [CrossRef]
- Brena, R.F.; García-Vázquez, J.P.; Galván-Tejada, C.E.; Muñoz-Rodriguez, D.; Vargas-Rosales, C.; Fangmeyer, J. Evolution of Indoor Positioning Technologies: A Survey. J. Sens. 2017, 2017, 1–21. [Google Scholar] [CrossRef]
- Tsirmpas, C.; Rompas, A.; Fokou, O.; Koutsouris, D. An indoor navigation system for visually impaired and elderly people based on Radio Frequency Identification (RFID). Inf. Sci. 2015, 320, 288–305. [Google Scholar] [CrossRef]
- Chen, C.-C.; Chang, C.-Y.; Li, Y.-N. Range-Free Localization Scheme in Wireless Sensor Networks Based on Bilateration. Int. J. Distrib. Sens. Netw. 2013, 9, 620248. [Google Scholar] [CrossRef]
- Martinez-Sala, A.S.; Losilla, F.; Sánchez-Aarnoutse, J.C.; Garcia-Haro, J. Design, Implementation and Evaluation of an Indoor Navigation System for Visually Impaired People. Sensors 2015, 15, 32168–32187. [Google Scholar] [CrossRef] [PubMed]
- Nakajima, M.; Haruyama, S. New indoor navigation system for visually impaired people using visible light communication. EURASIP J. Wirel. Commun. Netw. 2013, 2013, 37. [Google Scholar] [CrossRef]
- Ahmetovic, D.; Gleason, C.; Kitani, K.M.; Takagi, H.; Asakawa, C. NavCog: Turn-by-turn smartphone navigation assistant for people with visual impairments or blindness. In Proceedings of the 13th Web for All Conference on—W4A’16, Montreal, QC, Canada, 11–13 April 2016; p. 9. [Google Scholar] [CrossRef]
- Stein, N. LowViz Guide Launched to Help Visually Impaired People Navigate. May 2015. Available online: https://indoo.rs/lowviz-guide-launched/ (accessed on 30 October 2020).
- Nowicki, M.; Wietrzykowski, J. Low-Effort Place Recognition with WiFi Fingerprints Using Deep Learning. In Advances in Intelligent Systems and Computing; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2017; Volume 550, pp. 575–584. [Google Scholar]
- Mehmood, H.; Tripathi, N.K. Optimizing artificial neural network-based indoor positioning system using genetic algorithm. Int. J. Digit. Earth 2013, 6, 158–184. [Google Scholar] [CrossRef]
- Hsieh, C.-H.; Chen, J.-Y.; Nien, B.-H. Deep Learning-Based Indoor Localization Using Received Signal Strength and Channel State Information. IEEE Access 2019, 7, 33256–33267. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Adege, A.B.; Lin, H.-P.; Tarekegn, G.B.; Jeng, S.-S. Applying Deep Neural Network (DNN) for Robust Indoor Localization in Multi-Building Environment. Appl. Sci. 2018, 8, 1062. [Google Scholar] [CrossRef]
- Alom, Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Wu, L.; Chen, C.-H.; Zhang, Q. A Mobile Positioning Method Based on Deep Learning Techniques. Electronics 2019, 8, 59. [Google Scholar] [CrossRef]
- Hoang, M.T.; Yuen, B.; Dong, X.; Lu, T.; Westendorp, R.; Reddy, K. Recurrent Neural Networks for Accurate RSSI Indoor Localization. IEEE Internet Things J. 2019, 6, 10639–10651. [Google Scholar] [CrossRef]
- Liu, W.; Chen, H.; Deng, Z.; Zheng, X.; Fu, X.; Cheng, Q. LC-DNN: Local Connection Based Deep Neural Network for Indoor Localization with CSI. IEEE Access 2020, 8, 108720–108730. [Google Scholar] [CrossRef]
- Zhang, L.; Ding, E.; Hu, Y.; Liu, Y. A novel CSI-based fingerprinting for localization with a single AP. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 51. [Google Scholar] [CrossRef]
- Subbu, K.P.; Gozick, B.; Dantu, R. LocateMe: Magnetic-fields-based indoor localization using smartphones. ACM Trans. Intell. Syst. Technol. 2013, 4, 1–27. [Google Scholar] [CrossRef]
- Shu, Y.; Shin, K.G.; He, T.; Chen, J. Last-Mile Navigation Using Smartphones. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking—MobiCom ’15, Paris, France, 7–11 September 2015; pp. 512–524. [Google Scholar] [CrossRef]
- Jang, H.J.; Shin, J.M.; Choi, L. Geomagnetic Field Based Indoor Localization Using Recurrent Neural Networks. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017. [Google Scholar]
- Zeinalipour-Yazti, D.; Laoudias, C.; Georgiou, K.; Chatzimilioudis, G. Internet-Based Indoor Navigation Services. IEEE Internet Comput. 2017, 21, 54–63. [Google Scholar] [CrossRef]
- Barsocchi, P.; Crivello, A.; La Rosa, D.; Palumbo, F. A multisource and multivariate dataset for indoor localization methods based on WLAN and geo-magnetic field fingerprinting. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcala de Henares, Spain, 4–7 October 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Shao, W.; Zhao, F.; Wang, C.; Luo, H.; Zahid, T.M.; Wang, Q.; Li, D. Location Fingerprint Extraction for Magnetic Field Magnitude Based Indoor Positioning. J. Sens. 2016, 2016, 1945695. [Google Scholar] [CrossRef]
- A Gentle Introduction to k-fold Cross-Validation. Available online: https://machinelearningmastery.com/k-fold-cross-validation/ (accessed on 21 January 2020).
- Mashlakov, A.; Tikka, V.; Lensu, L.; Romanenko, A.; Honkapuro, S. Hyper-parameter Optimization of Multi-attention Recurrent Neural Network for Battery State-of-Charge Forecasting. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11804, pp. 482–494. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Mahida, P.T.; Shahrestani, S.; Cheung, H. An improved positioning method in a smart building for Visually Impaired Users. In Proceedings of the Submitted to International Conference on Internet of Things Research and Practice (iCIOTRP2019), Sydney, Australia, 24–26 November 2019. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Hyperparameter Values in Proposed Deep MLP |
|---|---|
| Software | Python, Keras, TensorFlow |
| Training data | 29,436 |
| Validation data | 7359 |
| Epochs | 60 to 140 |
| Batch size | 20, 40, 60, 80 |
| Layers with Hidden neurons (with batch normalization) | 3 layers—128, 64 and 128 neurons 5 layers—256, 128, 64 and 128 and 256 neurons 7 layers—512, 256, 64, 128, 256 neurons |
| Drop out rate | 0.2 to 0.8 |
| Activation | Selu, elu, softplus, relu |
| Optimizer | Adam, adamax, rmsprop, adagrad |
| Loss function | MAE, MSE, RMSE |
| Optimizer | MAE (m) | RMSE (m) | MSE (m) |
| Adam | 0.71 | 1.30 | 1.70 |
| Adamax | 0.84 | 1.35 | 1.81 |
| Rmsprop | 1.04 | 1.84 | 3.39 |
| Adagrad | 5.59 | 3.25 | 3.62 |
| Activation | MAE (m) | RMSE (m) | MSE (m) |
| relu | 1.24 | 2.61 | 6.84 |
| softplus | 1.35 | 2.45 | 6.01 |
| elu | 0.92 | 1.85 | 3.45 |
| selu | 0.65 | 1.29 | 1.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahida, P.; Shahrestani, S.; Cheung, H. Deep Learning-Based Positioning of Visually Impaired People in Indoor Environments. Sensors 2020, 20, 6238. https://doi.org/10.3390/s20216238
Mahida P, Shahrestani S, Cheung H. Deep Learning-Based Positioning of Visually Impaired People in Indoor Environments. Sensors. 2020; 20(21):6238. https://doi.org/10.3390/s20216238
Chicago/Turabian StyleMahida, Payal, Seyed Shahrestani, and Hon Cheung. 2020. "Deep Learning-Based Positioning of Visually Impaired People in Indoor Environments" Sensors 20, no. 21: 6238. https://doi.org/10.3390/s20216238
APA StyleMahida, P., Shahrestani, S., & Cheung, H. (2020). Deep Learning-Based Positioning of Visually Impaired People in Indoor Environments. Sensors, 20(21), 6238. https://doi.org/10.3390/s20216238