Detection and Quantification of Tomato Paste Adulteration Using Conventional and Rapid Analytical Methods

 ,
,  , , , , ,
, , , , , 
Abstract
1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Methods
2.2.1. Preliminary Experiments with Rotational Rheometer Development of Adulterant Mixtures
2.2.2. Determination of Water-Soluble Solids Content
2.2.3. Determination of Bostwick Consistency
2.2.4. Near Infrared Spectroscopy (NIRS) Measurements
2.2.5. Electronic Tongue Measurements
2.2.6. Statistical Analysis
3. Results
3.1. Results of Conventional Methods
3.1.1. Results of Soluble Solid Content Determination
3.1.2. Results of Bostwick Consistency Determination
3.2. Results of Rapid Analytical Methods
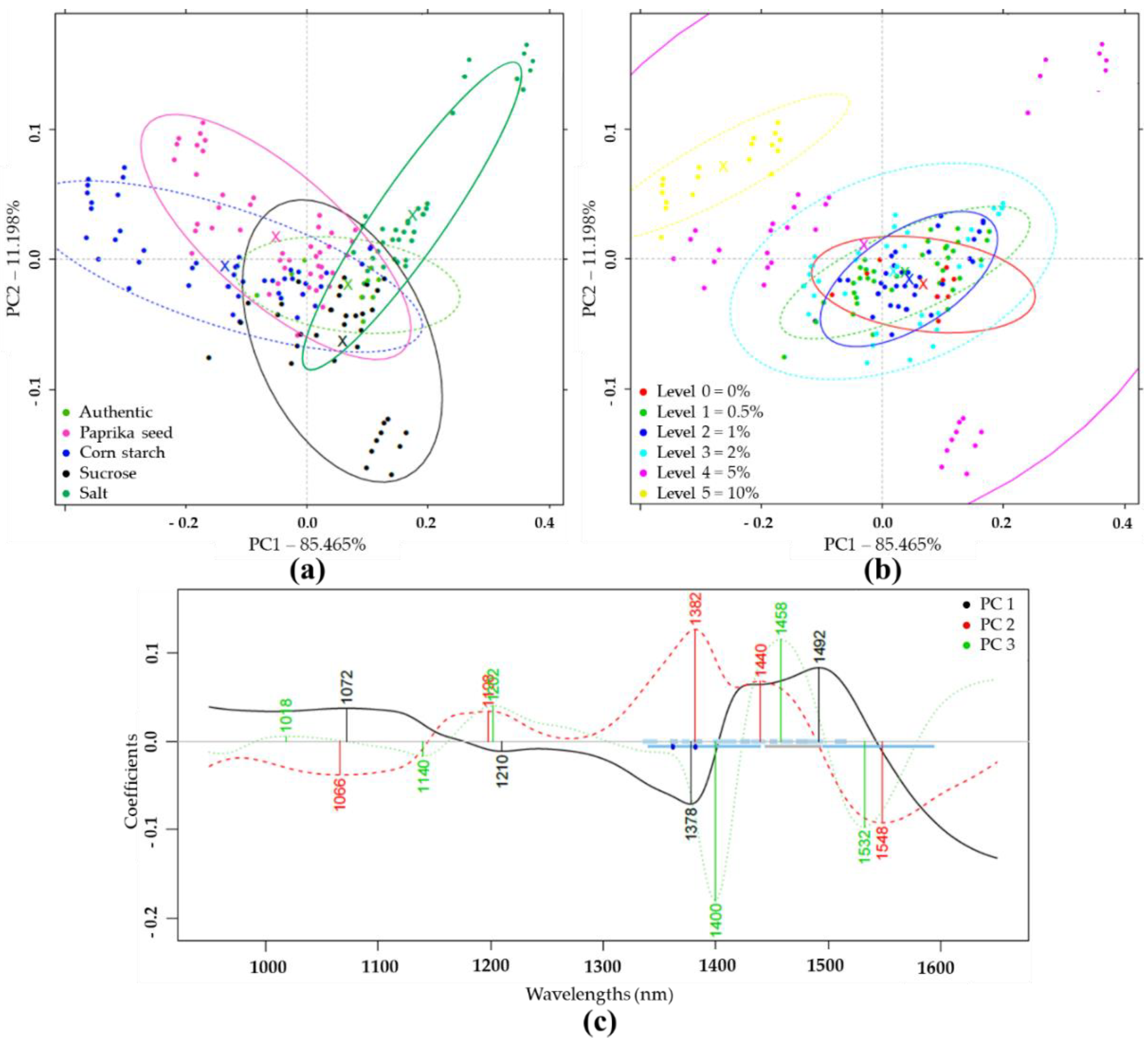
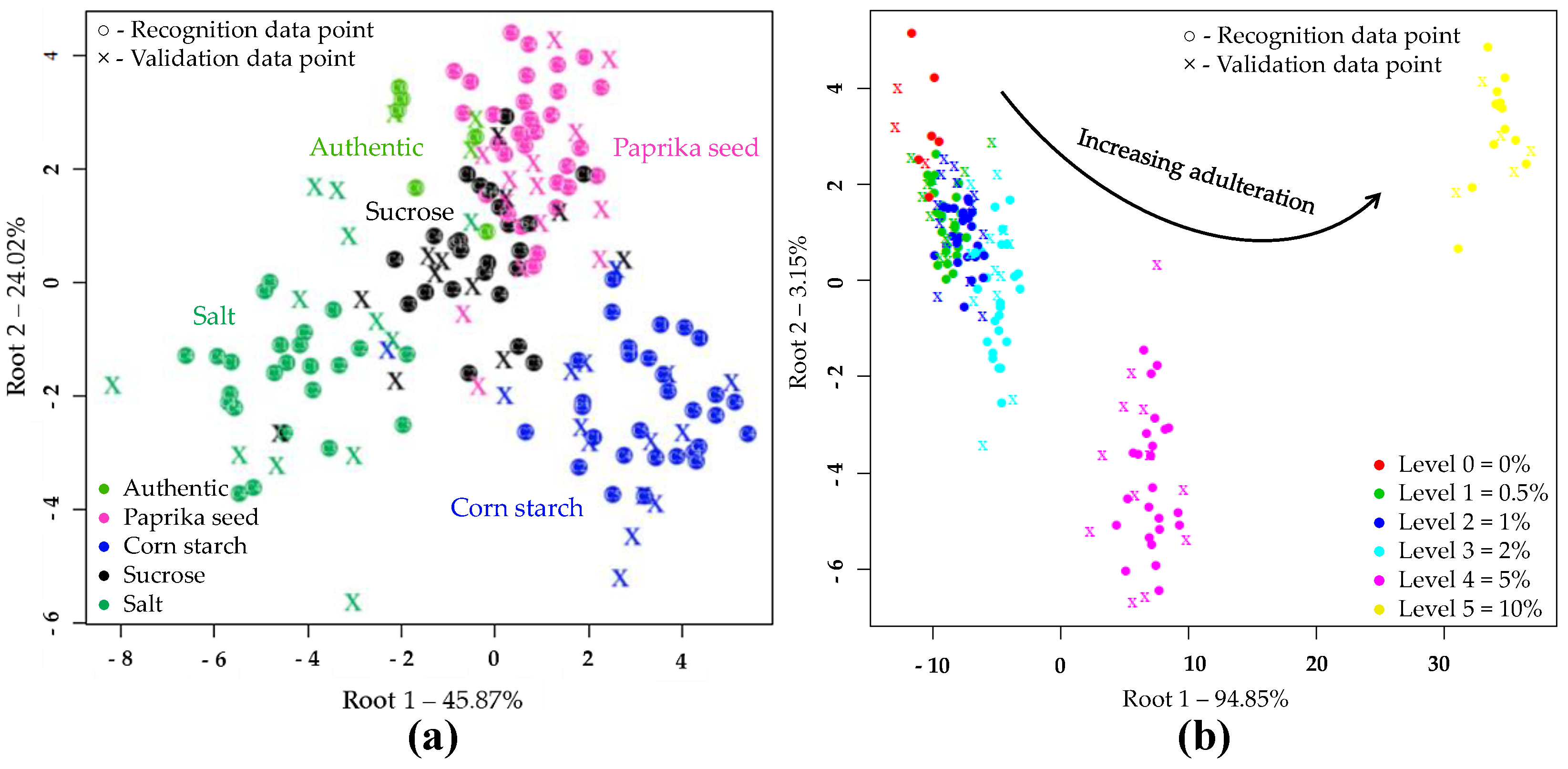
3.2.1. Results of Near-Infrared Spectroscopic Analysis
PCA and LDA Results of NIRS Analysis
PLSR Results of NIRS Analysis
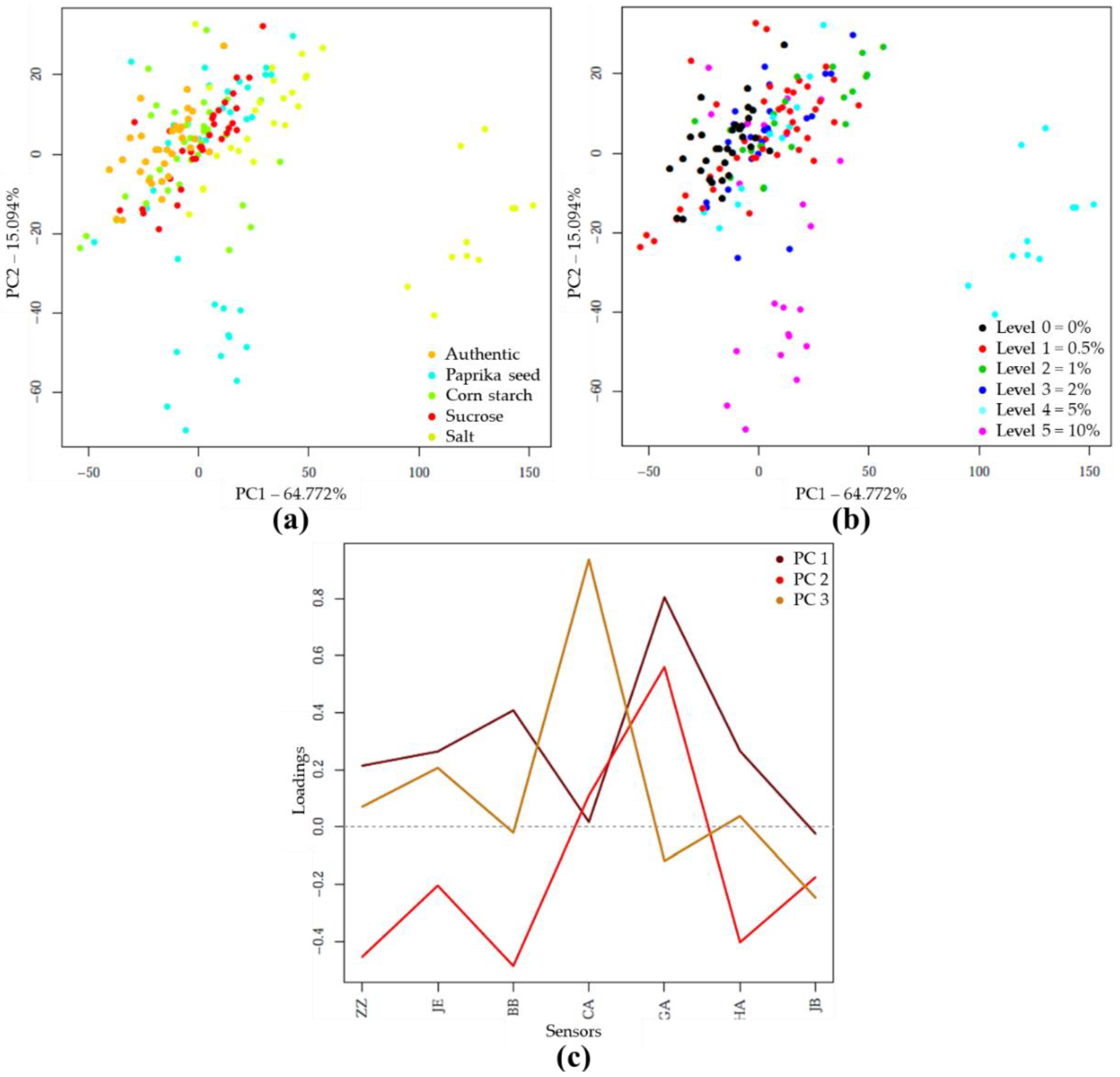
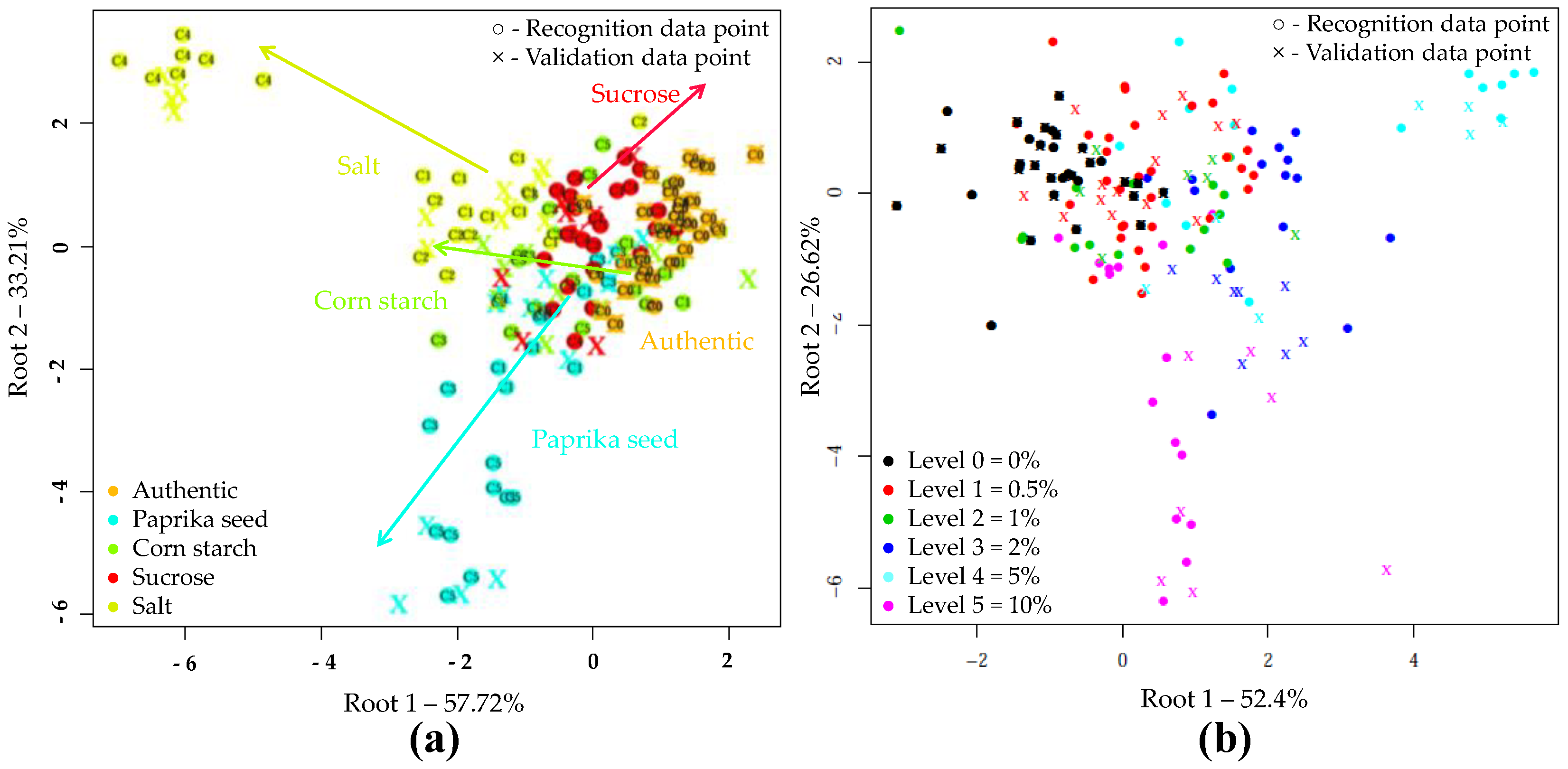
3.2.2. Results of Electronic Tongue Analysis
PCA and LDA Results of E-Tongue Analysis
PLSR Results of E-Tongue Analysis
4. Discussion
4.1. Results of Conventional Methods
4.1.1. Soluble Solid Content
4.1.2. Bostwick Consistency
4.2. Results of Analytical Rapid Methods
4.2.1. Near-Infrared Spectroscopic Analysis
PCA and LDA Results with NIRS
PLSR results with NIRS
4.2.2. E-Tongue Analysis
PCA and LDA Results with E-Tongue
PLSR Results with E-Tongue
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Omondi, S. The Most Popular Vegetables in the World. World Atlas 2018. Available online: https://www.worldatlas.com/articles/the-most-popular-vegetables-in-the-world.html (accessed on 15 October 2020).
- IndexBox Global Tomato Market 2019—Robust Consumption Growth in China and India Drives the Global Market. Available online: https://www.globaltrademag.com/global-tomato-market-2019-robust-consumption-growth-in-china-and-india-drives-the-global-market/ (accessed on 27 April 2020).
- FAO. Stat Crops Tomatoes. Available online: http://www.fao.org/faostat/en/#data/QC (accessed on 27 April 2020).
- Bertin, N.; Genard, M. Tomato quality as influenced by preharvest factors. Sci. Hortic. 2018, 233, 264–276. [Google Scholar] [CrossRef]
- Fernández-García, E.; Carvajal-Lérida, I.; Jarén-Galán, M.; Garrido-Fernández, J.; Pérez-Gálvez, A.; Hornero-Méndez, D. Carotenoids bioavailability from foods: From plant pigments to efficient biological activities. Food Res. Int. 2012, 46, 438–450. [Google Scholar] [CrossRef]
- Abdulmalik, I.O.; Amonye, M.C.; Ambali, A.O.; Umeanuka, P.O.; Mahdi, M. Appropriate technology for tomato powder production. Int. J. Eng. Invent. 2014, 3, 29–34. [Google Scholar]
- FAO; WHO. Codex Alimentarius International Food Standards. Available online: http://www.fao.org/fao-who-codexalimentarius (accessed on 13 September 2019).
- Alimentarius, C. Codex Alimentarius Standard for Processed Tomato Concentrates. Codex Stan 2017, 1981, 1–6. [Google Scholar]
- EC COMMISSION REGULATION (EU). No 1129/2011 of 11 November 2011 Amending Annex II to Regulation (EC) No 1333/2008 of the European Parliament and of the Council by Establishing a Union List of Food Additives. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:32011R1129&qid=1597164722424&from=HU (accessed on 11 August 2020).
- EC REGULATION (EC). No 1333/2008 of the European Parliament and of the Council of 16 December 2008 on Food Additives. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32008R1333&qid=1588007840949&from=EN (accessed on 11 August 2020).
- Spink, J.; Moyer, D.C. Defining the Public Health Threat of Food Fraud. J. Food Sci. 2011, 76, R157–R163. [Google Scholar] [CrossRef]
- Constable, K. Food Fraud Risk Information—Tomatoes and Tomato Paste. Available online: https://trello.com/c/0BBkItvu/410-tomatoes-and-tomato-paste (accessed on 17 September 2019).
- Thakur, B.R.; Singh, R.K.; Nelson, P.E. Quality attributes of processed tomato products: A review. Food Rev. Int. 1996, 12, 375–401. [Google Scholar] [CrossRef]
- Barringer, S.A.; Azam, A.T.M.S.; Heskitt, B.; Sastry, S. On-line prediction of bostwick consistency from pressure differential in pipe flow for ketchup and related tomato products. J. Food Process. Preserv. 1998, 22, 211–220. [Google Scholar] [CrossRef]
- Barringer, S.A. Vegetables: Tomato Processing. In Food Processing: Principles and Applications; Smith, J.S., Hui, Y.H., Eds.; Blackwell Publishing: Hoboken, NJ, USA, 2004; pp. 473–490. [Google Scholar]
- Berta, M.; Wiklund, J.; Kotzé, R.; Stading, M. Correlation between in-line measurements of tomato ketchup shear viscosity and extensional viscosity. J. Food Eng. 2016, 173, 8–14. [Google Scholar] [CrossRef]
- Arvanitoyannis, I.S.; Vaitsi, O.B. A review on tomato authenticity: Quality control methods in conjunction with multivariate analysis (chemometrics). Crit. Rev. Food Sci. Nutr. 2007, 47, 675–699. [Google Scholar] [CrossRef]
- Callao, M.P.; Ruisánchez, I. An overview of multivariate qualitative methods for food fraud detection. Food Control 2018, 86, 283–293. [Google Scholar] [CrossRef]
- Osborne, B.G. Near-Infrared Spectroscopy in Food Analysis. Encycl. Anal. Chem. 2006. [Google Scholar] [CrossRef]
- Davies, A.M.C.; Dennis, C.; Grant, A.; Hall, M.N.; Robertson, A. Screening of tomato purée for excessive mould content by near infrared spectroscopy: A preliminary evaluation. J. Sci. Food Agric. 1987, 39, 349–355. [Google Scholar] [CrossRef]
- Goula, A.M.; Adamopoulos, K.G. Estimating the composition of tomato juice products by near infrared spectroscopy. J. Near Infrared Spectrosc. 2003, 11, 123–136. [Google Scholar] [CrossRef]
- Jha, S.N.; Matsuoka, T. Non-destructive determination of acid–brix ratio of tomato juice using near infrared spectroscopy. Int. J. Food Sci. Technol. 2004, 39, 425–430. [Google Scholar] [CrossRef]
- De Nardo, T.; Shiroma-Kian, C.; Halim, Y.; Francis, D.; Rodriguez-Saona, L.E. Rapid and simultaneous determination of lycopene and β-carotene contents in tomato juice by infrared spectroscopy. J. Agric. Food Chem. 2009, 57, 1105–1112. [Google Scholar] [CrossRef]
- Deák, K.; Szigedi, T.; Pék, Z.; Baranowski, P.; Helyes, L. Carotenoid determination in tomato juice using near infrared spectroscopy. Int. Agrophys. 2015, 29, 275–282. [Google Scholar] [CrossRef]
- Pedro, A.M.K.; Ferreira, M.M.C. Nondestructive determination of solids and carotenoids in tomato products by near-infrared spectroscopy and multivariate calibration. Anal. Chem. 2005, 77, 2505–2511. [Google Scholar] [CrossRef]
- Pedro, A.M.K.; Ferreira, M.M.C. Simultaneously calibrating solids, sugars and acidity of tomato products using PLS2 and NIR spectroscopy. Anal. Chim. Acta 2007, 595, 221–227. [Google Scholar] [CrossRef]
- Sirisomboon, P.; Tanaka, M.; Kojima, T.; Williams, P. Nondestructive estimation of maturity and textural properties on tomato ‘Momotaro’by near infrared spectroscopy. J. Food Eng. 2012, 112, 218–226. [Google Scholar] [CrossRef]
- Pasquini, C. Near infrared spectroscopy: A mature analytical technique with new perspectives—A review. Anal. Chim. Acta 2018, 1026, 8–36. [Google Scholar] [CrossRef] [PubMed]
- Escuder-Gilabert, L.; Peris, M. Highlights in recent applications of electronic tongues in food analysis. Anal. Chim. Acta 2010, 665, 15–25. [Google Scholar] [CrossRef]
- Peris, M.; Escuder-Gilabert, L. Electronic noses and tongues to assess food authenticity and adulteration. Trends Food Sci. Technol. 2016, 58, 40–54. [Google Scholar] [CrossRef]
- Liu, T.; Zhu, W.; Huang, J.; Chen, H.; Nie, R.; Li, C. Comparison of the nutritional as well as the volatile composition of in-season and off-season Hezuo 903 tomato at red stage. Eur. Food Res. Technol. 2017, 243, 203–214. [Google Scholar] [CrossRef]
- Beullens, K.; Mészáros, P.; Vermeir, S.; Kirsanov, D.; Legin, A.; Buysens, S.; Cap, N.; Nicolaï, B.M.; Lammertyn, J. Analysis of tomato taste using two types of electronic tongues. Sens. Actuators B Chem. 2008, 131, 10–17. [Google Scholar] [CrossRef]
- Xu, S.; Li, J.; Baldwin, E.A.; Rosskopf, E.; Hong, J.C.; Bai, J. Differentiation of taste profiles by electronic tongue of full ripe tomato samples from different cultivars and harvest maturities. In Proceedings of the Florida State Horticultural Society, Proceedings of the 130th Annual Meeting of the Florida State Horticultural Society, Tampa, FL, USA, 4–6 June 2017; Florida State Horticultural Society: Tampa, FL, USA, 2017; Volume 130, pp. 165–168. [Google Scholar]
- Xu, S.; Li, J.; Baldwin, E.A.; Plotto, A.; Rosskopf, E.; Hong, J.C.; Bai, J. Electronic tongue discrimination of four tomato cultivars harvested at six maturities and exposed to blanching and refrigeration treatments. Postharvest Biol. Technol. 2018, 136, 42–49. [Google Scholar] [CrossRef]
- Beullens, K.; Kirsanov, D.; Irudayaraj, J.; Rudnitskaya, A.; Legin, A.; Nicolaï, B.M.; Lammertyn, J. The electronic tongue and ATR–FTIR for rapid detection of sugars and acids in tomatoes. Sens. Actuators B Chem. 2006, 116, 107–115. [Google Scholar] [CrossRef]
- EU COMMISSION REGULATION (EEC). No 1764/86—Laying down minimum quality requirements for products processed from tomatoes under the production aid scheme. Official Journal of the European Communities, 2001, 1–23. Available online: https://www.legislation.gov.uk/eur/1986/1764/pdfs/eur_19861764_2001-05-26_en.pdf (accessed on 23 October 2020).
- ASTM. Standard Test Method for Determining the Consistency of Viscous Liquids Using a Consistometer. Available online: https://cds.cern.ch/record/1461360 (accessed on 14 September 2020).
- McCarthy, K.L.; Sacher, R.F.; Garvey, T.C. Relationship between rheological behavior and Bostwick measurement during manufacture of ketchup. J. Texture Stud. 2008, 39, 480–495. [Google Scholar] [CrossRef]
- Magwaza, L.S.; Opara, U.L. Analytical methods for determination of sugars and sweetness of horticultural products—A review. Sci. Hortic. 2015, 184, 179–192. [Google Scholar] [CrossRef]
- USDA. Methods of Analysis for Tomato Products; United States Department of Agriculture, Food Safety and Quality Service: Washington, DC, USA, 1971.
- Alpha, M.O.S. αAstree Electronic Tongue User Manual; Toulouse, France, 2003; Available online: https://www.alpha-mos.com/astree-taste-analysis (accessed on 5 July 2020).
- Piepho, H.-P. An algorithm for a letter-based representation of all-pairwise comparisons. J. Comput. Graph. Stat. 2004, 13, 456–466. [Google Scholar] [CrossRef]
- Assaad, H.I.; Zhou, L.; Carroll, R.J.; Wu, G. Rapid publication-ready MS-Word tables for one-way ANOVA. Springerplus 2014, 3, 474. [Google Scholar] [CrossRef] [PubMed]
- Savitzky, A.; Golay, M.J.E. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Dhanoa, M.S.; Lister, S.J.; Sanderson, R.; Barnes, R.J. The link between multiplicative scatter correction (MSC) and standard normal variate (SNV) transformations of NIR spectra. J. Near Infrared Spectrosc. 1994, 2, 43–47. [Google Scholar] [CrossRef]
- Kovács, Z. Módszer Elektronikus Nyelvvel Végzett Méréseknél Fellépő Zavaró Hatások Csökkentésére = Method to Decrease the Disturbing Effects Occurring by the Electronic Tongue Measurement; Budapesti Corvinus Egyetem: Budapest, Hungary, 2012. [Google Scholar]
- Kovacs, Z.; Szöllősi, D.; Zaukuu, J.-L.Z.; Bodor, Z.; Vitális, F.; Aouadi, B.; Zsom-Muha, V.; Gillay, Z. Factors Influencing the Long-Term Stability of Electronic Tongue and Application of Improved Drift Correction Methods. Biosensors 2020, 10, 74. [Google Scholar] [CrossRef]
- Kovacs, Z.; Pollner, B. Aquaphotomics-Software R-Package “aquap2”. In Proceedings of the Understanding Water in Biology 2nd International Symposium, Kobe, Japan, 26–29 November 2016; pp. 26–29. [Google Scholar]
- Workman, J.J., Jr. Interpretive spectroscopy for near infrared. Appl. Spectrosc. Rev. 1996, 31, 251–320. [Google Scholar] [CrossRef]
- Galicia-Cabrera, R.M. Tomato Processing. In Handbook of Food Products Manufacturing; John Wiley & Sons: Hoboken, NJ, USA, 2007; Volume 1, pp. 1091–1107. ISBN 978-0-470-12524-3. [Google Scholar]
- Anthon, G.E.; Barrett, D.M. Changes in tomato paste during storage and the effects of heating on consistency of reconstituted tomato paste. J. Texture Stud. 2010, 41, 262–278. [Google Scholar] [CrossRef]
- Sobowale, S.S.; Olatidoye, O.P.; Odunmbaku, L.A.; Raji, O.H. A comparative study on physicochemical and rheological properties of imported tomato paste in Nigeria. Sustain. Agric. Res. 2012, 1, 526. [Google Scholar]
- Goodman, C.L.; Fawcett, S.; Barringer, S.A. Flavor, Viscosity, and Color Analyses of Hot and Cold Break Tomato Juices. J. Food Sci. 2002, 67, 404–408. [Google Scholar] [CrossRef]
- Juszczak, L.; Oczadły, Z.; Gałkowska, D. Effect of modified starches on rheological properties of ketchup. Food Bioprocess Technol. 2013, 6, 1251–1260. [Google Scholar] [CrossRef]
- Gujral, H.S.; Sharma, A.; Singh, N. Effect of hydrocolloids, storage temperature, and duration on the consistency of tomato ketchup. Int. J. Food Prop. 2002, 5, 179–191. [Google Scholar] [CrossRef]
- Diantom, A.; Curti, E.; Carini, E.; Vittadini, E. Effect of added ingredients on water status and physico-chemical properties of tomato sauce. Food Chem. 2017, 236, 101–108. [Google Scholar] [CrossRef]
- Xie, L.; Ying, Y. Use of near-infrared spectroscopy and least-squares support vector machine to determine quality change of tomato juice. J. Zhejiang Univ. Sci. B 2009, 10, 465–471. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Hao, G.; Su, M.; Chen, Y.; Zheng, L. Potential of multispectral imaging combined with chemometric methods for rapid detection of sucrose adulteration in tomato paste. J. Food Eng. 2017, 215, 78–83. [Google Scholar] [CrossRef]
- Workman, J. 14. SW-NIR for Organic Composition Analysis. In The Handbook of Organic Compounds: NIR, IR, R, and UV-Vis Spectra Featuring Polymers and Surfactants; Academic Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Ribeiro, J.S.; Ferreira, M.M.C.; Salva, T.J.G. Chemometric models for the quantitative descriptive sensory analysis of Arabica coffee beverages using near infrared spectroscopy. Talanta 2011, 83, 1352–1358. [Google Scholar] [CrossRef]
- Tsenkova, R. Aquaphotomics: Dynamic spectroscopy of aqueous and biological systems describes peculiarities of water. J. Near Infrared Spectrosc. 2009, 17, 303–313. [Google Scholar] [CrossRef]
- Hong, X.; Wang, J. Use of electronic nose and tongue to track freshness of cherry tomatoes squeezed for juice consumption: Comparison of different sensor fusion approaches. Food Bioprocess Technol. 2015, 8, 158–170. [Google Scholar] [CrossRef]
- Hong, X.; Wang, J. Detection of adulteration in cherry tomato juices based on electronic nose and tongue: Comparison of different data fusion approaches. J. Food Eng. 2014, 126, 89–97. [Google Scholar] [CrossRef]
- Winquist, F.; Krantz-Rülcker, C.; Lundström, I. Electronic tongues. MRS Bull. 2004, 29, 726–731. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Adulterants | Analyzed Concentrations (%w/w) | |||||
|---|---|---|---|---|---|---|
| Paprika seed | 0 | 0.5 | - | 2 | - | 10 |
| Corn starch | 0 | 0.5 | - | 2 | - | 10 |
| Sucrose | 0 | 0.5 | 1 | - | 5 | - |
| Salt | 0 | 0.5 | 1 | - | 5 | - |
| Adulterant Concentration | Paprika Seed | Corn Starch | Sucrose | Salt | |
|---|---|---|---|---|---|
| -WP- | -WK- | -C- | -S- | ||
| 0. | 0% | 30.967 ± 1.358 a, b | 30.967 ± 1.358 a, b | 30.967 ± 1.358 a | 30.967 ± 1.358 a |
| 1. | 0.5% | 31.200 ± 1.015 a | 31.833 ± 0.153 a | 32.167 ± 0.611 a, b | 31.733 ± 0.493 a |
| 2. | 1% | 31.900 ± 0.557 a | 31.433 ± 0.551 a | 31.500 ± 1.664 a | 33.367 ± 1.419 a |
| 3. | 2% | 30.100 ± 1.153 a, b | 30.233 ± 0.404 a, b | 32.067 ± 1.966 a, b | 30.033 ± 4.629 a |
| 4. | 5% | 30.133 ± 0.493 a, b | 28.900 ± 0.436 b | 35.967 ± 2.136 b | 34.467 ± 2.203 a |
| 5. | 10% | 28.367 ± 1.193 b | 28.933 ± 0.896 b | — | — |
| Adulterant Concentration | Paprika Seed | Corn Starch | Sucrose | Salt | |
|---|---|---|---|---|---|
| -WP- | -WK- | -C- | -S- | ||
| 0. | 0% | 5.833 ± 0.577 a | 5.833 ± 0.577 a | 5.833 ± 0.577 a | 5.833 ± 0.577 a |
| 1. | 0.5% | 6.533 ± 0.950 a | 7.00 ± 0.781 a | 6.733 ± 0.929 a | 7.500 ± 0.500 a |
| 2. | 1% | 7.033 ± 0.473 a | 6.633 ± 1.415 a | 7.133 ± 0.635 a | 7.467 ± 0.896 a |
| 3. | 2% | 5.933 ± 0.757 a | 5.933 ± 0.058 a | 7.167 ± 0.503 a | 6.100 ± 1.389 a |
| 4. | 5% | 6.467 ± 0.252 a | 6.000 ± 0.500 a | 10.433 ± 1.582 b | 8.100 ± 0.755 a |
| 5. | 10% | 6.300 ± 0.265 a | 5.567 ± 0.751 a | — | — |
| Accuracy | Authentic | Paprika Seed | Corn Starch | Sucrose | Salt | Average Classification | |
|---|---|---|---|---|---|---|---|
| Recognition | Authentic | 100 | 0 | 0 | 0 | 0 | 100% |
| Paprika seed | 0 | 100 | 0 | 0 | 0 | ||
| Corn starch | 0 | 0 | 100 | 0 | 0 | ||
| Sucrose | 0 | 0 | 0 | 100 | 0 | ||
| Salt | 0 | 0 | 0 | 0 | 100 | ||
| Validation | Authentic | 100 | 6.67 | 0 | 2.75 | 0 | 86.68% |
| Paprika seed | 0 | 77.8 | 4.47 | 11.09 | 5.58 | ||
| Corn starch | 0 | 6.67 | 88.87 | 2.75 | 0 | ||
| Sucrose | 0 | 6.67 | 4.47 | 75.06 | 2.75 | ||
| Salt | 0 | 2.2 | 2.2 | 8.34 | 91.67 |
| Adulterant | Accuracy | 0% | 0.5% | 1% | 2% | 5% | Average Classification | |
|---|---|---|---|---|---|---|---|---|
| Paprika seed | Recognition | 0% | 100 | 0 | 0 | 0 | 0 | 100% |
| 0.5% | 0 | 100 | 0 | 0 | 0 | |||
| 1% | 0 | 0 | 100 | 0 | 0 | |||
| 2% | 0 | 0 | 0 | 100 | 0 | |||
| 5% | 0 | 0 | 0 | 0 | 100 | |||
| 10% | 0 | 0 | 0 | 0 | 0 | |||
| Validation | 0% | 98.4 | 11 | 0 | 0 | 0 | 86.83% | |
| 0.5% | 1.6 | 55.67 | 11.04 | 0 | 0 | |||
| 1% | 0 | 33.33 | 77.93 | 11 | 0 | |||
| 2% | 0 | 0 | 11.04 | 89 | 0 | |||
| 5% | 0 | 0 | 0 | 0 | 100 | |||
| 10% | 0 | 0 | 0 | 0 | 0 | |||
| Corn starch | Recognition | 0% | 100 | 0 | 0 | 0 | 0 | 100% |
| 0.5% | 0 | 100 | 0 | 0 | 0 | |||
| 1% | 0 | 0 | 100 | 0 | 0 | |||
| 2% | 0 | 0 | 0 | 100 | 0 | |||
| 5% | 0 | 0 | 0 | 0 | 100 | |||
| 10% | 0 | 0 | 0 | 0 | 0 | |||
| Validation | 0% | 93.64 | 55.67 | 11.04 | 0 | 0 | 78.64% | |
| 0.5% | 3.98 | 33.33 | 11.04 | 0 | 0 | |||
| 1% | 2.38 | 0 | 66.89 | 11 | 0 | |||
| 2% | 0 | 11 | 11.04 | 89 | 11 | |||
| 5% | 0 | 0 | 0 | 0 | 89 | |||
| 10% | 0 | 0 | 0 | 0 | 0 |
| Adulterant | Accuracy | 0% | 0.5% | 1% | 2% | 5% | Average Classification | |
|---|---|---|---|---|---|---|---|---|
| Sucrose | Recognition | 0% | 100 | 0 | 0 | 0 | 0 | 100% |
| 0.5% | 0 | 100 | 0 | 0 | 0 | |||
| 1% | 0 | 0 | 100 | 0 | 0 | |||
| 2% | 0 | 0 | 0 | 100 | 0 | |||
| 5% | 0 | 0 | 0 | 0 | 100 | |||
| Validation | 0% | 95.56 | 44.48 | 0 | 0 | 0 | 76.94% | |
| 0.5% | 3.71 | 44.48 | 11 | 0 | 0 | |||
| 1% | 0.73 | 11.04 | 55.67 | 11 | 0 | |||
| 2% | 0 | 0 | 33.33 | 89 | 0 | |||
| 5% | 0 | 0 | 0 | 0 | 100 | |||
| Salt | Recognition | 0% | 100 | 0 | 0 | 0 | 0 | 100% |
| 0.5% | 0 | 100 | 0 | 0 | 0 | |||
| 1% | 0 | 0 | 100 | 0 | 0 | |||
| 2% | 0 | 0 | 0 | 100 | 0 | |||
| 5% | 0 | 0 | 0 | 0 | 100 | |||
| Validation | 0% | 99.27 | 11 | 0 | 0 | 0 | 97.65% | |
| 0.5% | 0.73 | 89 | 0 | 0 | 0 | |||
| 1% | 0 | 0 | 100 | 0 | 0 | |||
| 2% | 0 | 0 | 0 | 100 | 0 | |||
| 5% | 0 | 0 | 0 | 0 | 100 |
| Constituent | R2C | RMSEC (%w/w) | R2CV | RMSECV (%w/w) | LV | N |
|---|---|---|---|---|---|---|
| Paprika seed | 0.9953 | 0.238 | 0.9849 | 0.429 | 6 | 54 |
| Corn starch | 0.9897 | 0.354 | 0.9679 | 0.626 | 6 | 54 |
| Sucrose | 0.9887 | 0.189 | 0.9668 | 0.324 | 5 | 45 |
| Salt | 0.9937 | 0.141 | 0.9835 | 0.228 | 5 | 45 |
| Tomato | 0.9906 | 0.602 | 0.9796 | 0.886 | 14 | 171 |
| Constituent | Wavelengths (nm) | |
|---|---|---|
| Paprika seed | - | 988, 1042, 1114, 1156, 1210, 1272, 1374, 1404, 1430, 1454, 1504, 1584 |
| Corn starch | - | 1108, 1158, 1270, 1380, 1416, 1490, 1518, 1560, 1590, 1612 |
| Sucrose | - | 1020, 1160, 1324, 1378, 1418, 1484, 1532, 1586 |
| Salt | - | 994, 1136, 1188, 1306, 1366, 1398, 1428, 1480, 1532, 1588 |
| Tomato paste | - | 1016, 1068, 1138, 1172, 1208, 1246, 1316, 1344, 1370, 1408, 1430, 1446, 1462, 1480, 1500, 1518, 1532, 1550, 1568, 1600 |
| Accuracy | Authentic | Paprika Seed | Corn Starch | Sucrose | Salt | Average Classification | |
|---|---|---|---|---|---|---|---|
| Recognition | Authentic | 98.04 | 19.11 | 35.29 | 67.18 | 8.83 | 60.73% |
| Paprika seed | 0 | 61.78 | 0 | 0 | 0 | ||
| Corn starch | 1.96 | 14.7 | 61.76 | 12.52 | 5.87 | ||
| Sucrose | 0 | 4.41 | 2.96 | 20.3 | 23.52 | ||
| Salt | 0 | 0 | 0 | 0 | 61.78 | ||
| Validation | Authentic | 97.66 | 17.64 | 41.18 | 78.07 | 5.91 | 52.56% |
| Paprika seed | 0 | 58.82 | 8.82 | 0 | 2.91 | ||
| Corn starch | 2.34 | 17.64 | 41.18 | 15.65 | 11.74 | ||
| Sucrose | 0 | 5.91 | 8.82 | 6.28 | 20.56 | ||
| Salt | 0 | 0 | 0 | 0 | 58.87 |
| Adulterant | Accuracy | 0% | 0.5% | 2% | 10% | Average Classification | |
|---|---|---|---|---|---|---|---|
| Paprika seed | Recognition | 0% | 96.86 | 20.88 | 4.5 | 0 | 90.59% |
| 0.5% | 3.14 | 79.12 | 9.14 | 0 | |||
| 2% | 0 | 0 | 86.36 | 0 | |||
| 10% | 0 | 0 | 0 | 100 | |||
| Validation | 0% | 90.63 | 25 | 18.26 | 0 | 75.72% | |
| 0.5% | 6.28 | 66.75 | 27.25 | 0 | |||
| 2% | 3.09 | 8.25 | 45.5 | 0 | |||
| 10% | 0 | 0 | 8.99 | 100 | |||
| Corn starch | Recognition | 0% | 93.76 | 40.93 | 0 | 9.13 | 84.89% |
| 0.5% | 4.69 | 59.07 | 0 | 0 | |||
| 2% | 1.55 | 0 | 95.88 | 0 | |||
| 10% | 0 | 0 | 4.12 | 90.87 | |||
| Validation | 0% | 87.52 | 63.66 | 0 | 45.5 | 54.28% | |
| 0.5% | 12.48 | 36.34 | 0 | 0 | |||
| 2% | 0 | 0 | 75 | 36.24 | |||
| 10% | 0 | 0 | 25 | 18.26 |
| Adulterant | Accuracy | 0% | 0.5% | 1% | 5% | Average Classification | |
|---|---|---|---|---|---|---|---|
| Sucrose | Recognition | 0% | 96.86 | 14.99 | 9.13 | 0 | 80.22% |
| 0.5% | 0 | 64.92 | 9.13 | 13.64 | |||
| 1% | 3.14 | 10.04 | 77.25 | 4.5 | |||
| 5% | 0 | 10.04 | 4.5 | 81.86 | |||
| Validation | 0% | 93.81 | 9.88 | 18.26 | 0 | 56.39% | |
| 0.5% | 3.1 | 50 | 18.26 | 45.5 | |||
| 1% | 3.1 | 20.06 | 36.24 | 8.99 | |||
| 5% | 0 | 20.06 | 27.25 | 45.5 | |||
| Salt | Recognition | 0% | 100 | 0 | 0 | 0 | 94.49% |
| 0.5% | 0 | 91.62 | 13.64 | 0 | |||
| 1% | 0 | 8.38 | 86.36 | 0 | |||
| 5% | 0 | 0 | 0 | 100 | |||
| Validation | 0% | 96.9 | 0 | 8.99 | 0 | 86.16% | |
| 0.5% | 3.1 | 75 | 18.26 | 0 | |||
| 1% | 0 | 25 | 72.75 | 0 | |||
| 5% | 0 | 0 | 0 | 100 |
| Constituent | R2C | RMSEC (%w/w) | R2CV | RMSECV (%w/w) | LV | N |
|---|---|---|---|---|---|---|
| Paprika seed | 0.9397 | 0.929 | 0.9304 | 0.998 | 2 | 58 |
| Corn starch | 0.6357 | 2.215 | 0.5061 | 2.574 | 4 | 57 |
| Sucrose | 0.4925 | 1.199 | 0.3305 | 1.375 | 4 | 56 |
| Salt | 0.9703 | 0.307 | 0.9622 | 0.346 | 4 | 66 |
| Tomato | 0.7888 | 2.625 | 0.7716 | 2.730 | 6 | 231 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vitalis, F.; Zaukuu, J.-L.Z.; Bodor, Z.; Aouadi, B.; Hitka, G.; Kaszab, T.; Zsom-Muha, V.; Gillay, Z.; Kovacs, Z. Detection and Quantification of Tomato Paste Adulteration Using Conventional and Rapid Analytical Methods. Sensors 2020, 20, 6059. https://doi.org/10.3390/s20216059
Vitalis F, Zaukuu J-LZ, Bodor Z, Aouadi B, Hitka G, Kaszab T, Zsom-Muha V, Gillay Z, Kovacs Z. Detection and Quantification of Tomato Paste Adulteration Using Conventional and Rapid Analytical Methods. Sensors. 2020; 20(21):6059. https://doi.org/10.3390/s20216059
Chicago/Turabian StyleVitalis, Flora, John-Lewis Zinia Zaukuu, Zsanett Bodor, Balkis Aouadi, Géza Hitka, Timea Kaszab, Viktoria Zsom-Muha, Zoltan Gillay, and Zoltan Kovacs. 2020. "Detection and Quantification of Tomato Paste Adulteration Using Conventional and Rapid Analytical Methods" Sensors 20, no. 21: 6059. https://doi.org/10.3390/s20216059
APA StyleVitalis, F., Zaukuu, J.-L. Z., Bodor, Z., Aouadi, B., Hitka, G., Kaszab, T., Zsom-Muha, V., Gillay, Z., & Kovacs, Z. (2020). Detection and Quantification of Tomato Paste Adulteration Using Conventional and Rapid Analytical Methods. Sensors, 20(21), 6059. https://doi.org/10.3390/s20216059