Population Graph-Based Multi-Model Ensemble Method for Diagnosing Autism Spectrum Disorder


Abstract
1. Introduction
1.1. Statistical Models and Deep Neural Networks Using Imaging Information
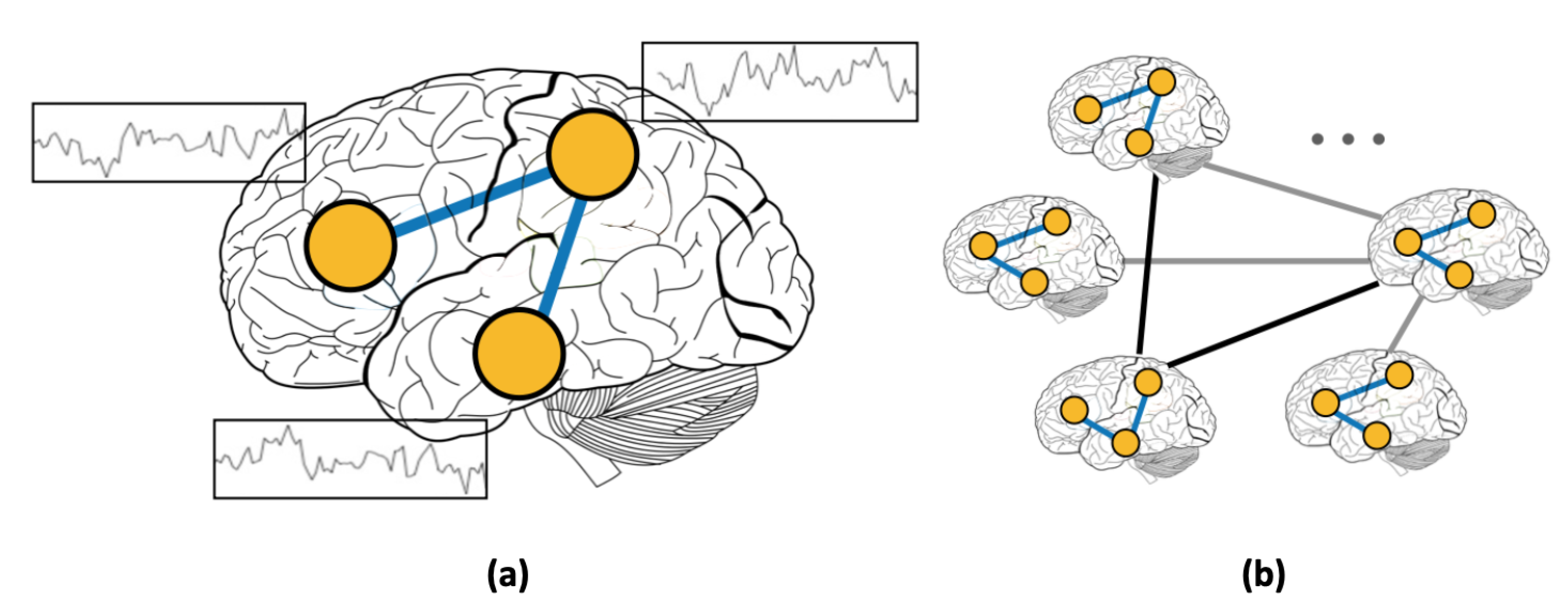
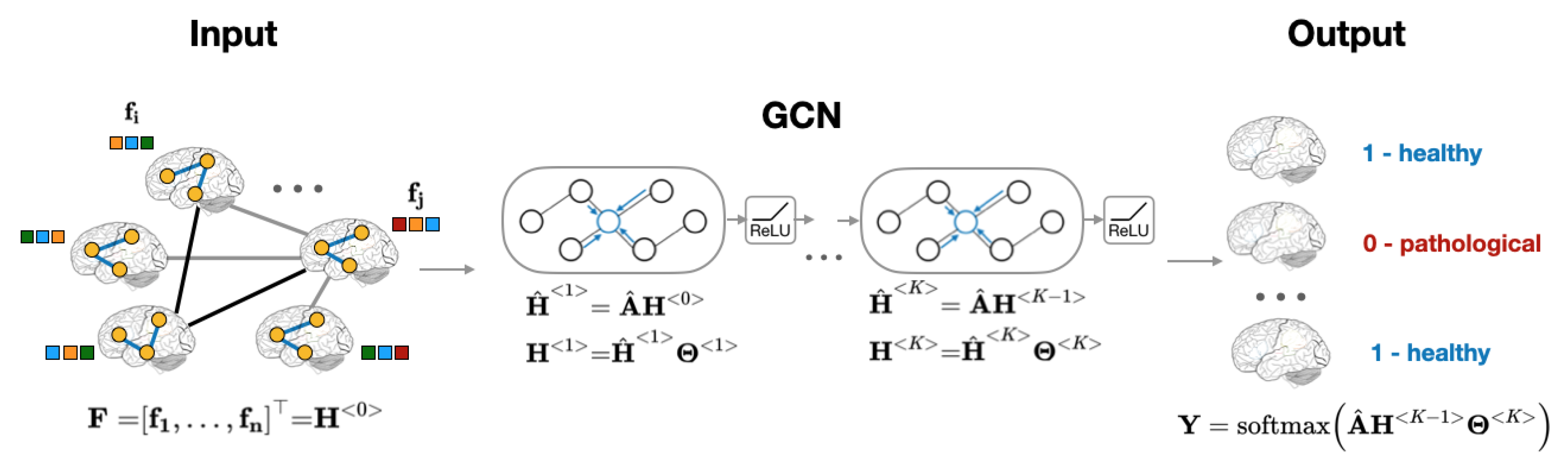
1.2. Graphs and Graph Neural Networks Using Both Imaging and Non-Imaging Information
- An evaluation of the graph spectrum of population graphs using tools from the field of GSP. Using frequency filtering, we improve the model’s accuracy and computational speed.
- An end-to-end deep neural network-based ensemble model with a weighting mechanism.
- State-of-the-art performance on the ABIDE dataset. Our results show that using both graph signal filtering and an end-to-end ensemble method leads to improved classification accuracy, resulting in a state-of-the-art classification accuracy of 73.13% accuracy for the ABIDE dataset (2.91% improvement as compared to the best result reported in related works [2]).
2. Methods
2.1. Dataset
2.2. Graph Construction
- sim_RSFC: a fully connected weighted graph constructed using correlation between RSFC features. This corresponds to using a weight function .
- sim_phenotype graphs: graphs which are constructed using a combination of phenotypic features (site, sex, age). The graph construction corresponds to taking only the second part of the Equation (1), i.e when . In total, there are seven sim_phenotype graphs constructed while using combinations of three phenotypic features: sim_site, sim_age, sim_sex, sim_site_age, sim_site_sex, sim_sex_age, and sim_site_age_sex.
- sim_RSFC_phenotype graphs: graphs which utilize the combination of RSFC features and phenotypic features for edge definition. Similarly, there are seven sim_RSFC_phenotype graphs in total: sim_RSFC_site, sim_RSFC_age, sim_RSFC_sex, sim_RSFC_site_age, sim_RSFC_site_sex, sim_RSFC_sex_age, and sim_RSFC_site_age_sex. Note that when we are not using any features, the graph becomes sim_RSFC, which corresponds to the first group.
- Baseline graphs: (a) FC—a fully connected graph with edge weight equal to 1, (b) identity graph—a fully disconnected graph with adjacency matrix equal to identity matrix, and (c) random graph, constructed by randomly assigning binary edges in identity graph.
2.3. Graph Signal Processing
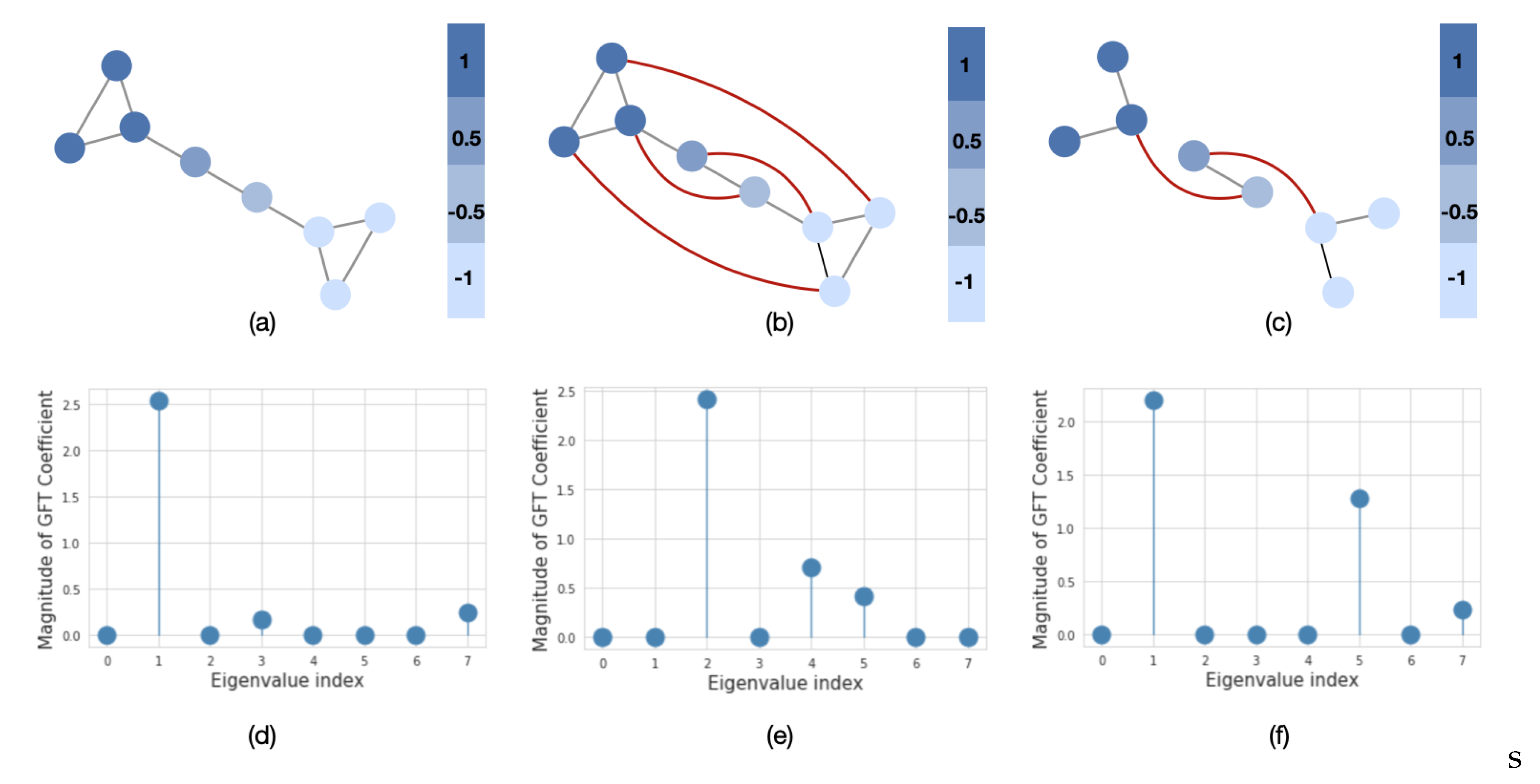
2.3.1. Graph Fourier Transform
2.3.2. Graph Filtering
2.4. Analysis of Population Graphs Using GSP
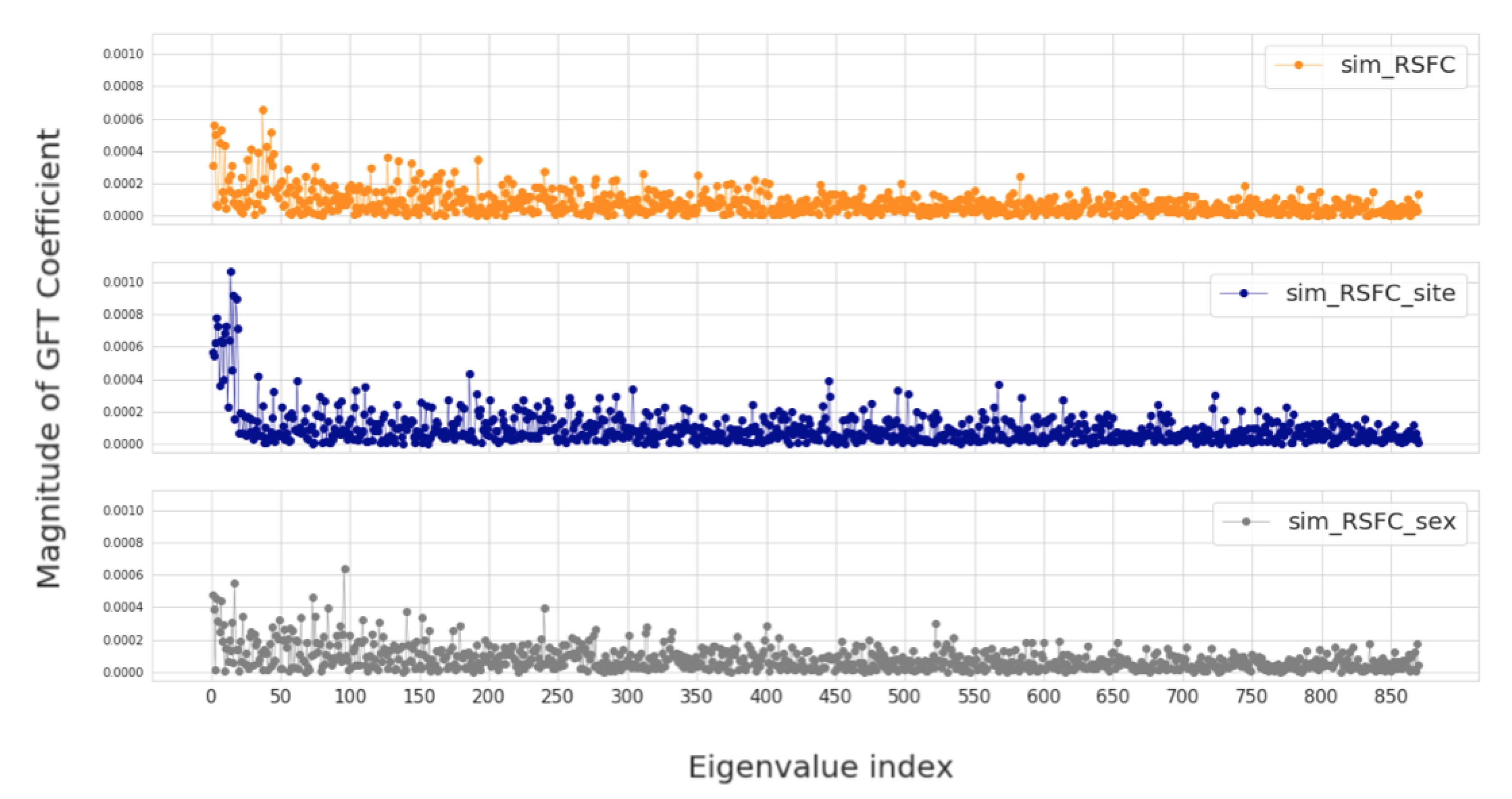
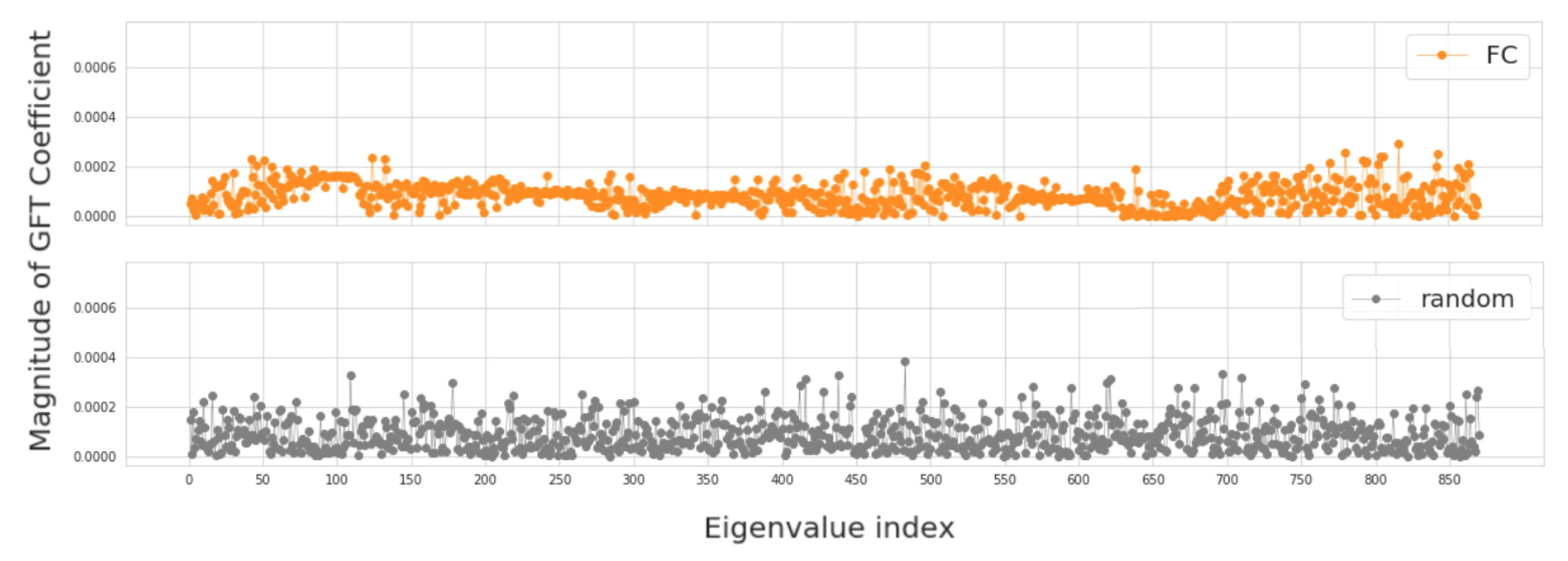
2.4.1. Evaluation of Fourier Transform Coefficients
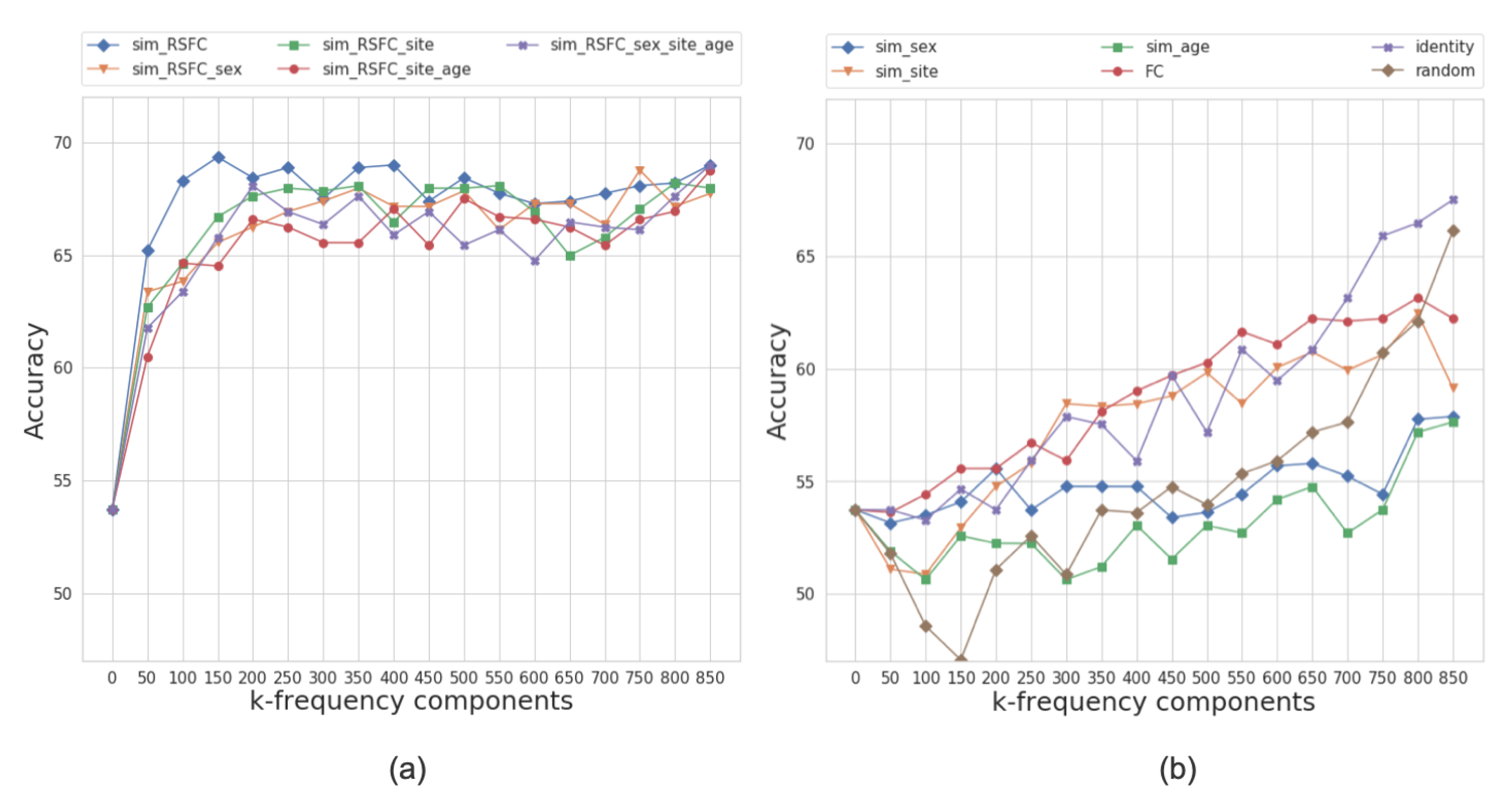
2.4.2. Classification Using Low Frequency Components
- Using Equation (4), we filter the graph signal incrementally using the first k-frequency components.
- We train a multi-layer feedforward neural network on the reconstructed features and report test accuracy.
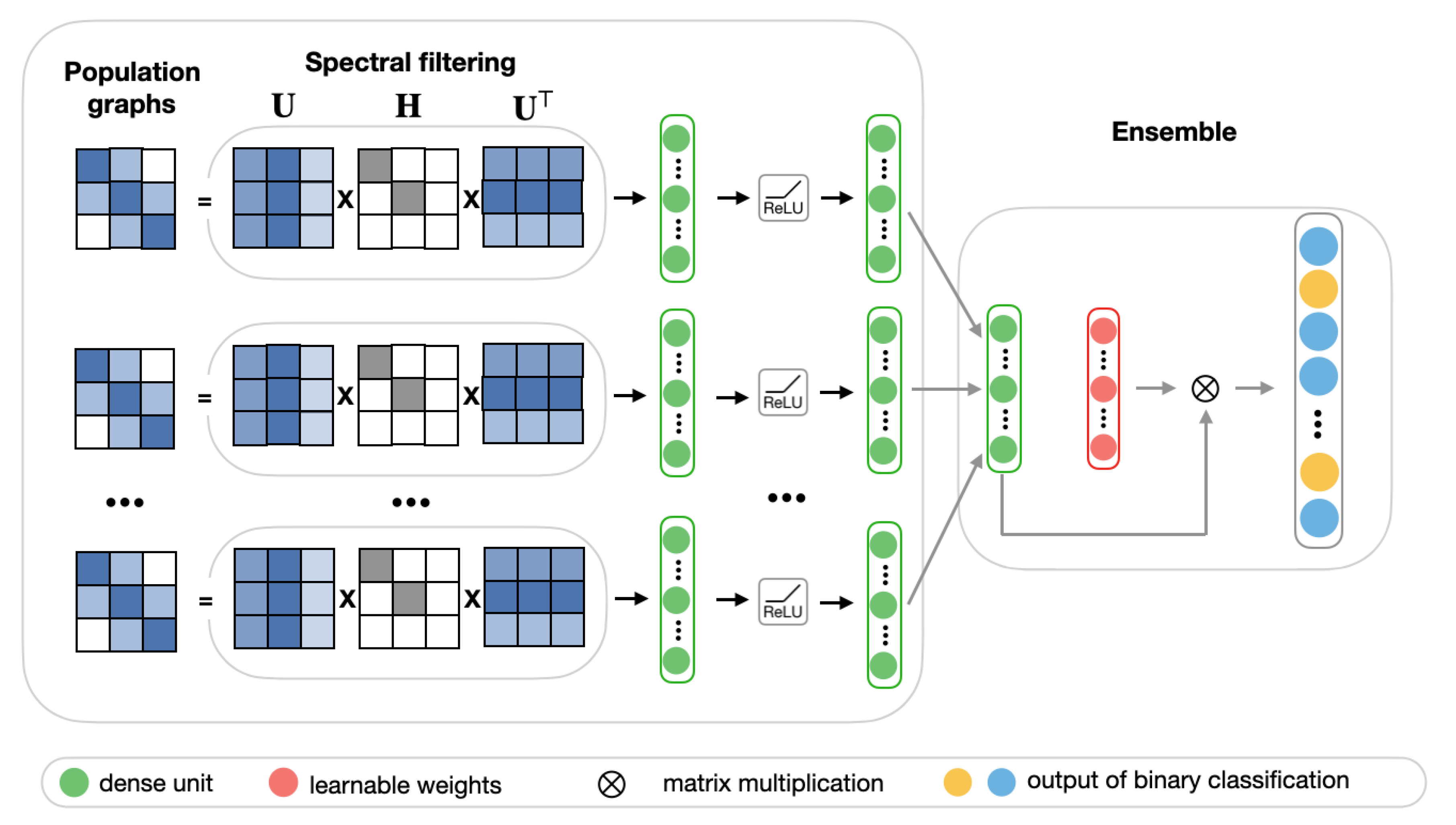
2.4.3. Population Graph-Based Multi-Model Ensemble for ASD Prediction
3. Results
3.1. Training Setup
3.2. The Baselines Used for Comparison
- Kernel regression [43] is a classical machine learning algorithm used by the authors for predicting subject phenotypes from RSFC. It achieved comparable performance to several deep neural networks on several brain imaging datasets. We include this model as a baseline for classifying ASD while using the ABIDE dataset.
- DNN [15] utilized RSFC features to build an autoencoder-based deep neural network for classifying ASD. The authors used a subset of 964 subjects from the ABIDE dataset and achieved a classification accuracy of 70%.
- CNN [2] proposed a convolutional neural network architecture in order to classify ASD patients and control subjects while using RSFC. The authors reported the classification accuracy of 70.22% on a subset of 871 subjects from the ABIDE dataset.
- GCN [4] introduced a graph neural network that allowed incorporating both RSFC and phenotypic features. The authors tested the model on a set of 871 subjects from the ABIDE dataset.
- Ensemble_mv [44] utilized multiple discriminative restricted Boltzmann machines (DRBM) to classify 263 subjects from the ABIDE dataset. The majority voting strategy was used for combining the prediction outputs of individual DRBMs.
- Ensemble_bootstrap [31] proposed a bootstrapping approach by generating twenty randomized graphs from the initial population graph. Each randomized graph was passed through a graph neural network. The final output of the ensemble was determined by averaging the probability estimates of each of the networks.
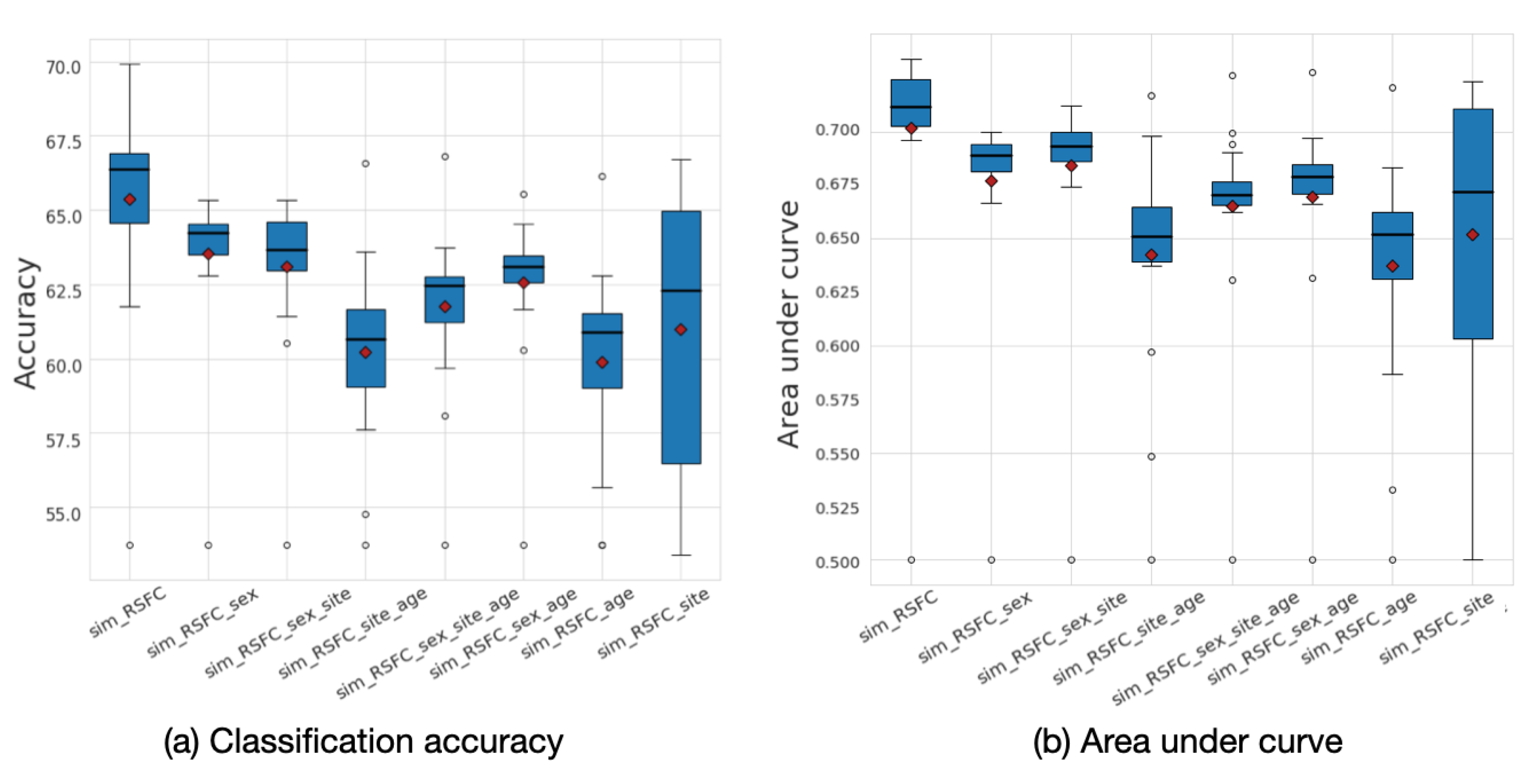
3.3. Comparison with the Baselines
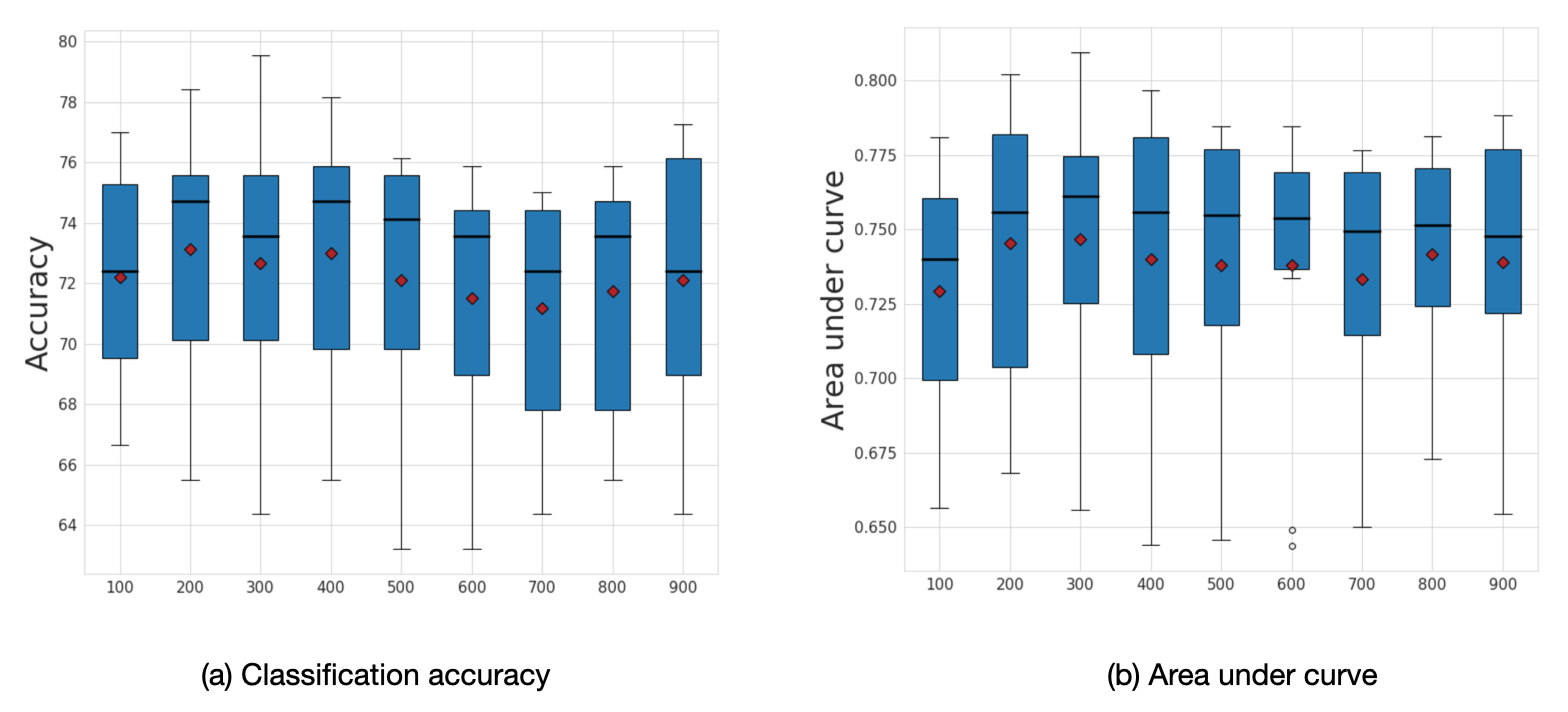
3.4. Sensitivity to Frequency Filtering
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Horikawa, T.; Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 2017, 8, 1–15. [Google Scholar] [CrossRef]
- Sherkatghanad, Z.; Akhondzadeh, M.; Salari, S.; Zomorodi-Moghadam, M.; Abdar, M.; Acharya, U.R.; Khosrowabadi, R.; Salari, V. Automated Detection of Autism Spectrum Disorder Using a Convolutional Neural Network. Front. Neurosci. 2020, 13, 1325. [Google Scholar] [CrossRef]
- Khosla, M.; Jamison, K.; Kuceyeski, A.; Sabuncu, M.R. 3D Convolutional Neural Networks for Classification of Functional Connectomes. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2018; Volume 11045 LNCS, pp. 137–145. [Google Scholar] [CrossRef]
- Parisot, S.; Ktena, S.I.; Ferrante, E.; Lee, M.; Guerrero, R.; Glocker, B.; Rueckert, D. Disease prediction using graph convolutional networks: Application to Autism Spectrum Disorder and Alzheimer’s disease. Med. Image Anal. 2018, 48, 117–130. [Google Scholar] [CrossRef]
- Rakhimberdina, Z.; Murata, T. Linear Graph Convolutional Model for Diagnosing Brain Disorders. In Studies in Computational Intelligence; Springer: Cham, Switzerland, 2020; Volume 882 SCI, pp. 815–826. [Google Scholar] [CrossRef]
- Biswal, B.; Zerrin Yetkin, F.; Haughton, V.M.; Hyde, J.S. Functional connectivity in the motor cortex of resting human brain using echo-planar mri. Magn. Reson. Med. 1995, 34, 537–541. [Google Scholar] [CrossRef]
- Bassett, D.S.; Bullmore, E.T. Human brain networks in health and disease. Curr. Opin. Neurol. 2009, 22, 340–347. [Google Scholar] [CrossRef]
- Hulvershorn, L.A.; Cullen, K.R.; Francis, M.M.; Westlund, M.K. Developmental Resting State Functional Connectivity for Clinicians. Curr. Behav. Neurosci. Rep. 2014, 1, 161–169. [Google Scholar] [CrossRef][Green Version]
- Bullmore, E.; Sporns, O. Complex brain networks: Graph theoretical analysis of structural and functional systems. Nat. Rev. Neurosci. 2009, 10, 186–198. [Google Scholar] [CrossRef]
- Di Martino, A.; Yan, C.G.; Li, Q.; Denio, E.; Castellanos, F.X.; Alaerts, K.; Anderson, J.S.; Assaf, M.; Bookheimer, S.Y.; Dapretto, M.; et al. The autism brain imaging data exchange: Towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol. Psychiatry 2014, 19, 659–667. [Google Scholar] [CrossRef]
- Werling, D.M.; Geschwind, D.H. Sex differences in autism spectrum disorders. Curr. Opin. Neurol. 2013, 26, 146–153. [Google Scholar] [CrossRef]
- He, T.; Kong, R.; Holmes, A.J.; Nguyen, M.; Sabuncu, M.R.; Eickhoff, S.B.; Bzdok, D.; Feng, J.; Yeo, B.T. Deep neural networks and kernel regression achieve comparable accuracies for functional connectivity prediction of behavior and demographics. NeuroImage 2020, 206, 116276. [Google Scholar] [CrossRef]
- Ktena, S.I.; Parisot, S.; Ferrante, E.; Rajchl, M.; Lee, M.; Glocker, B.; Rueckert, D. Metric learning with spectral graph convolutions on brain connectivity networks. NeuroImage 2018, 169, 431–442. [Google Scholar] [CrossRef] [PubMed]
- Iidaka, T. Resting state functional magnetic resonance imaging and neural network classified autism and control. Cortex 2015, 63, 55–67. [Google Scholar] [CrossRef] [PubMed]
- Heinsfeld, A.S.; Franco, A.R.; Craddock, R.C.; Buchweitz, A.; Meneguzzi, F. Identification of autism spectrum disorder using deep learning and the ABIDE dataset. NeuroImage Clin. 2018, 17, 16–23. [Google Scholar] [CrossRef]
- Eslami, T.; Mirjalili, V.; Fong, A.; Laird, A.R.; Saeed, F. ASD-DiagNet: A Hybrid Learning Approach for Detection of Autism Spectrum Disorder Using fMRI Data. Front. Neuroinform. 2019, 13. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Duan, X.; Liu, F.; Lu, F.; Ma, X.; Zhang, Y.; Uddin, L.Q.; Chen, H. Multivariate classification of autism spectrum disorder using frequency-specific resting-state functional connectivity-A multi-center study. Prog. Neuro-Psychopharmacol. Biol. Psychiatry 2016, 64, 1–9. [Google Scholar] [CrossRef]
- Kawahara, J.; Brown, C.J.; Miller, S.P.; Booth, B.G.; Chau, V.; Grunau, R.E.; Zwicker, J.G.; Hamarneh, G. BrainNetCNN: Convolutional neural networks for brain networks; towards predicting neurodevelopment. NeuroImage 2017, 146, 1038–1049. [Google Scholar] [CrossRef] [PubMed]
- Parisot, S.; Ktena, S.I.; Ferrante, E.; Lee, M.; Moreno, R.G.; Glocker, B.; Rueckert, D. Spectral graph convolutions for population-based disease prediction. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2017; Volume 10435 LNCS, pp. 177–185. [Google Scholar] [CrossRef]
- Leskovec, J.; Huttenlocher, D.; Kleinberg, J. Predicting Positive and Negative Links. In Proceedings of the International World Wide Web Conference, Raleigh, NC, USA, 26–30 April 2010; pp. 641–650. [Google Scholar] [CrossRef]
- Escala-Garcia, M.; Abraham, J.; Andrulis, I.L.; Anton-Culver, H.; Arndt, V.; Ashworth, A.; Auer, P.L.; Auvinen, P.; Beckmann, M.W.; Beesley, J.; et al. A network analysis to identify mediators of germline-driven differences in breast cancer prognosis. Nat. Commun. 2020, 11, 1–14. [Google Scholar] [CrossRef]
- Amato, F.; Moscato, V.; Picariello, A.; Sperlí, G. Recommendation in social media networks. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017; pp. 213–216. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations—Conference Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Maurya, S.K.; Liu, X.; Murata, T. Fast approximations of betweenness centrality with graph neural networks. In International Conference on Information and Knowledge Management, Proceedings; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2149–2152. [Google Scholar] [CrossRef]
- Moscato, V.; Picariello, A.; Sperlí, G. Community detection based on game theory. Eng. Appl. Artif. Intell. 2019, 85, 773–782. [Google Scholar] [CrossRef]
- Choong, J.J.; Liu, X.; Murata, T. Learning community structure with variational autoencoder. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 69–78. [Google Scholar]
- Mercorio, F.; Mezzanzanica, M.; Moscato, V.; Picariello, A.; Sperli, G. DICO: A graph-db framework for community detection on big scholarly data. IEEE Trans. Emerg. Top. Comput. 2019. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Ribeiro, L.F.; Saverese, P.H.; Figueiredo, D.R. struc2vec: Learning node representations from structural identity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 385–394. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3844–3852. [Google Scholar]
- Anirudh, R.; Thiagarajan, J.J. Bootstrapping Graph Convolutional Neural Networks for Autism Spectrum Disorder Classification. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Brighton, UK, 12–17 May 2019; Volume 2019, pp. 3197–3201. [Google Scholar] [CrossRef]
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef]
- Ortega, A.; Frossard, P.; Kovacevic, J.; Moura, J.M.F.; Vandergheynst, P. Graph Signal Processing: Overview, Challenges, and Applications. Proc. IEEE 2018, 106, 808–828. [Google Scholar] [CrossRef]
- Kowsari, K.; Heidarysafa, M.; Brown, D.E.; Meimandi, K.J.; Barnes, L.E. RMDL. In Proceedings of the 2nd International Conference on Information System and Data Mining—ICISDM ’18, Denver, CO, USA, 18 November 2019; ACM Press: New York, NY, USA, 2018; pp. 19–28. [Google Scholar] [CrossRef]
- Chung, F. Spectral Graph Theory; CBMS Regional Conference Series in Mathematics; American Mathematical Society: Providence, RI, USA, 1996; Volume 92. [Google Scholar] [CrossRef]
- Dong, X.; Thanou, D.; Rabbat, M.; Frossard, P. Learning Graphs from Data: A Signal Representation Perspective. IEEE Signal Process. Mag. 2019, 36, 44–63. [Google Scholar] [CrossRef]
- Zhu, X.; Rabbat, M. Approximating signals supported on graphs. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; Volume 3, pp. 3921–3924. [Google Scholar] [CrossRef]
- Shuman, D.I.; Ricaud, B.; Vandergheynst, P. Vertex-frequency analysis on graphs. Appl. Comput. Harmon. Anal. 2016, 40, 260–291. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–14 December 2002; Volume 14, pp. 849–856. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; Facebook, Z.D.; Research, A.I.; Lin, Z.; Desmaison, A.; Antiga, L.; et al. Automatic differentiation in PyTorch. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 8024–8035. [Google Scholar]
- He, T.; Kong, R.; Holmes, A.J.; Sabuncu, M.R.; Eickhoff, S.B.; Bzdok, D.; Feng, J.; Yeo, B.T.T. Is deep learning better than kernel regression for functional connectivity prediction of fluid intelligence? In Proceedings of the 2018 International Workshop on Pattern Recognition in Neuroimaging (PRNI), Singapore, 12–14 June 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Kam, T.E.; Suk, H.I.; Lee, S.W. Multiple functional networks modeling for autism spectrum disorder diagnosis. Hum. Brain Mapp. 2017, 38, 5804–5821. [Google Scholar] [CrossRef]
- Xiao, Y.; Wu, J.; Lin, Z.; Zhao, X. A deep learning-based multi-model ensemble method for cancer prediction. Comput. Methods Programs Biomed. 2018, 153, 1–9. [Google Scholar] [CrossRef]
- Dong, X.; Thanou, D.; Frossard, P.; Vandergheynst, P. Learning Laplacian Matrix in Smooth Graph Signal Representations. IEEE Trans. Signal Process. 2016, 64, 6160–6173. [Google Scholar] [CrossRef]
- Kalofolias, V. How to learn a graph from smooth signals. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 920–929. [Google Scholar]
- Kalofolias, V.; Perraudin, N. Large Scale Graph Learning from Smooth Signals. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total subjects | 871 |
| Patients/Healthy controls | 403/468 |
| Female/Male | 144/727 |
| Age range | 6–58 |
| Age mean | 16.94 |
| Imaging sites | 17 |
| Accuracy (%) | AUC | Sensitivity | Specificity | F-Score | Time (s) | Performance Gain (%) | |
|---|---|---|---|---|---|---|---|
| Kernel Regression [43] | 67.50 ± 5.51 | 0.73 ± 0.06 | 0.79 ± 0.06 | 0.53 ± 0.07 | 0.72 ± 0.05 | 4 | 5.63 |
| GCN [4] | 69.11 ± 4.38 | 0.73 ± 0.05 | 0.75 ± 0.06 | 0.57 ± 0.05 | 0.70 ± 0.04 | 892 | 4.02 |
| CNN[2] | 70.22 ± 8.55 | 0.74 ± 0.01 | 0.77 ± 0.01 | 0.61 ± 0.01 | 0.73 ± n.a | 45000 | 2.91 |
| DNN [15] | 70.00 ± n.a | 0.74 ± n.a | 0.74 ± n.a | 0.63 ± n.a | n.a | 118356 | 3.13 |
| ASD-DiagNet [16] | 69.59 ± 4.90 | 0.67 ± 0.23 | 0.65 ± 0.06 | 0.72 ± 0.07 | 0.66 ± 0.03 | 1452 | 3.54 |
| No graph | 67.50 ± 4.42 | 0.74 ± 0.05 | 0.76 ± 0.33 | 0.31 ± 0.40 | 0.60 ± 0.14 | 62 | 7.34 |
| Random graph | 66.12 ± 4.97 | 0.74 ± 0.05 | 0.86 ± 0.10 | 0.25 ± 0.17 | 0.68 ± 0.02 | 63 | 8.15 |
| FC graph | 62.23 ± 5.92 | 0.66 ± 0.04 | 0.86 ± 0.07 | 0.34 ± 0.10 | 0.71 ± 0.02 | 53 | 11.81 |
| Ensemble_mv [45] | 65.78 ± 4.44 | 0.72 ± 0.04 | 0.68 ± 0.07 | 0.63 ± 0.09 | 0.68 ± 0.04 | 255 | 7.35 |
| Ensemble_bootsrap [31] | 68.19 ± 3.82 | 0.73 ± 0.04 | 0.75 ± 0.05 | 0.59 ± 0.05 | 0.72 ± 0.03 | 16,138 | 4.94 |
| Ensemble_no_gsp (ours) | 72.09 ± 4.30 | 0.74 ± 0.04 | 0.74 ± 0.13 | 0.69 ± 0.11 | 0.74 ± 0.06 | 140 | 1.04 |
| Ensemble_gsp (ours) | 73.13 ± 4.31 | 0.75 ± 0.04 | 0.76 ± 0.07 | 0.69 ± 0.05 | 0.75 ± 0.04 | 276 | – |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rakhimberdina, Z.; Liu, X.; Murata, T. Population Graph-Based Multi-Model Ensemble Method for Diagnosing Autism Spectrum Disorder. Sensors 2020, 20, 6001. https://doi.org/10.3390/s20216001
Rakhimberdina Z, Liu X, Murata T. Population Graph-Based Multi-Model Ensemble Method for Diagnosing Autism Spectrum Disorder. Sensors. 2020; 20(21):6001. https://doi.org/10.3390/s20216001
Chicago/Turabian StyleRakhimberdina, Zarina, Xin Liu, and Tsuyoshi Murata. 2020. "Population Graph-Based Multi-Model Ensemble Method for Diagnosing Autism Spectrum Disorder" Sensors 20, no. 21: 6001. https://doi.org/10.3390/s20216001
APA StyleRakhimberdina, Z., Liu, X., & Murata, T. (2020). Population Graph-Based Multi-Model Ensemble Method for Diagnosing Autism Spectrum Disorder. Sensors, 20(21), 6001. https://doi.org/10.3390/s20216001