1. Introduction
Composite structures face many environmental challenges, e.g., debris impact in aircraft, which can lead to damage such as delamination, compromising the integrity of the structure. With Structural health monitoring (SHM) real time data can be produced and used leading to information on the status of the monitored structure. Application of composite materials have become mainstream in aerospace engineering due to their superior material properties. The Boeing 787 and Airbus 350 XWB utilize composite materials to up to and more than 50% of their volume, and the percentage is still rising [
1,
2]. SHM is receiving attention as a possible replacement to routine non-destructive inspection (NDI) for maintenance. This is due to the fact that various types of failure and damage can occur from low velocity impacts during maintenance or debris impact from takeoff and landing, that needs to be detected before they lead to failure. These can be indentation, delamination and cracking [
3,
4]. Different nondestructive inspection methods used included: eddy current, optical, ultrasonic inspection, vibration-based analysis, ultrasonic guided wave for detecting impact damage [
5,
6,
7,
8].
Depending on the type of the Transducers, SHM can be divided in two categories of Passive and Active. For active both actuator and sensors are necessary. The Monitored structure is excited by the actuator and the sensor picks up the response. The changes in signals can be used to identify the damage severity and location [
9]. For Passive on the other hand, only sensors are required, where they continually monitor the structure. In this case the system needs to generate a specific actuating signal [
10]. Transducer layout and configuration on the monitored structure can be optimized to increase detection accuracy, while avoiding unacceptable additional weight and costs [
1,
11,
12]. Printed circuit boards (PCB) have been developed that activate at the indication of an impact [
1]. This device can be used to collect impact data from piezoelectric sensors located on the body of aircraft. After data is collected, post processing in the data is crucial. After the data is cleaned up via digital filtering algorithms needs to be processed to detect Impacts within the composite structure. Interpretation of SHM data is done via measured parameters that are trained with machine-learning (ML) techniques [
13]. Various techniques have been proposed such as Image processing techniques [
14] using filtering and enhancement techniques to denoise the image and perform alignment and artefact correction [
15]. Worden and Mason have illuminated the utility of machine learning to damage identification concluding that neural networks are still popular, and systems like support vector machines are beginning to appear more regularly [
16,
17,
18].
2. Background
As a crucial step of any ML algorithm, data mining is the process of detecting patterns within data. The detected patterns will be used to predict and help with detecting outliers and hence decision making, while representing the patterns in terms of structures, facilitate the extraction of conclusions on the patterns. [
16]. Machine learning techniques can be classified into three broad categories according to the nature of learning: (1) supervised learning, (2) unsupervised learning, and (3) semi-supervised learning [
19]. Supervised learning provides a learning scheme with “labelled data”, i.e., examples that include specified outputs (pairs of input data and output data). Using labelled data, rules are developed to classify new data sets. Unsupervised learning encompasses the detection of patterns within the data sets consisting of “unlabeled data”, i.e., data sets with unspecified outputs, which fit to a general rule and can, therefore, be grouped together. Unsupervised learning is highly suitable in SHM applications for detecting unlabeled data as labeled data would be very expensive to come by, e.g., while supervised learning can be utilized to detect the type and severity of damage [
20]. Semi supervised learning, representing a combination of the two learning schemes, typically aims at obtaining a classification of data using both labelled and unlabeled data. Semi supervised learning schemes have been applied, combined with other monitoring techniques to extract information on modal characteristics of bridges [
16,
21]. Unsupervised techniques seem to fit the criteria of determining impacts and anomalies from a data set. There are various unsupervised learning techniques that can be used to detect certain patterns within a group of data and extract a specific feature from the mentioned data set. Choy [
22] has used an index-based approach whereby using Convolutional Neural Networks (CNN) on the Root Mean Square Deviation (RMSD) obtained via Impedance measured from the piezo electric sensors. Different CNN models have been implemented to improve performances especially in Image Processing. The main differences between different models are the number of layers and the interconnection structures [
19,
22,
23]. This method can be a viable method however the RMSD can be easily influenced by errors and variations within testing conditions. Furthermore, the number of layers required within the CNN can also be an issue as determining the correct number of layers can add to computational complexity, and if the algorithm is to be embedded on a chip, the extra added computational complexity can cause further difficulty.
Used for unlabeled data, clustering is a pattern detection technique with many dimensions. Interest in clustering has built among researchers in many fields such as intrusion detection and damage loculation [
24]. Clustering’s main advantage is being able to learn from and detect patterns from raw data without explicit labels [
25]. This method suggests that normal data will cluster around one another and anomalistic data are far from such clusters. Taking advantage of separability of hyperplanes in higher dimensions One-Class Support Vector Machine (1-SVM) aims to construct a hyperplane decision boundary, where the training points are assumed to belong to one class and all non-training points belong to another class [
26]. Taking its roots from isolation tree methods, binary forests such as Isolation Forest (IF) starts by utilizing all nodes to randomly select a dimension and afterwards randomly select a splitting threshold. The algorithm continue until each a single sample is allocated to each node. Via this method, an ensemble of trees is created. Samples with unusual values (or outliers) have a higher chance to be isolated earlier on in the tree growing compared to samples in clusters, therefor the average depth/length of the sample within the trees in the ensemble leads directly to an abnormality score [
26].
Based on the results by [
26], the 1-SVM and IF method seem to be the most accurate method. IF seems to be more advantageous since it requires less processing time and targets abnormalities right away rather than identifying normal data first then classifying abnormalities. Elliptic Envelope (EV) can be used to fit data to a normal distribution and identify abnormalities. Afterwards IF can be used to find impacts within anomalistic data set, however IF on its own is enough to detect anomalies which will include the impacts. While IF requires the number of trees to be determined by the user, it is needed in order to fully fetch out the anomalies within a data set which will hold the impacts. This will also reduce the need for heavy filtering. However, further steps are needed to classify the impacts and their energies. In order to have an automated process as much as possible, a Deep Learning approach is most beneficial. CNN’s have been used extensively in Image Processing for classification of different image models. The approach in [
27] has shown that CNN’s can be sued for impact detection, localization and characterization. The data needed for training the model can be collected via Piezo-Electric sensors mounted on aircraft body (either the wings or the fuselage). One way to improve on the CNN approach for detection of lower energy impacts (but still of significance) is the addition of RNN’s.
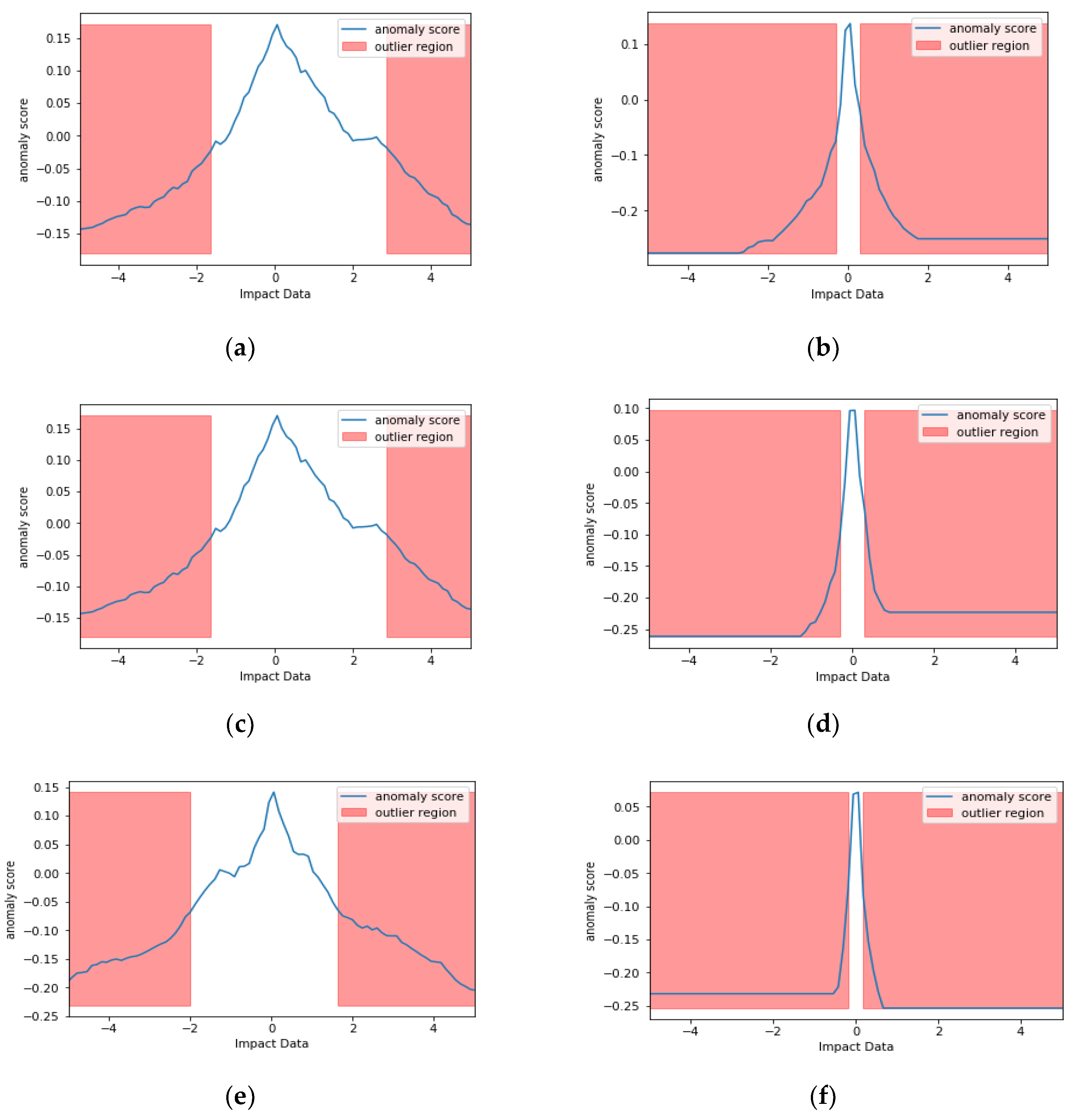
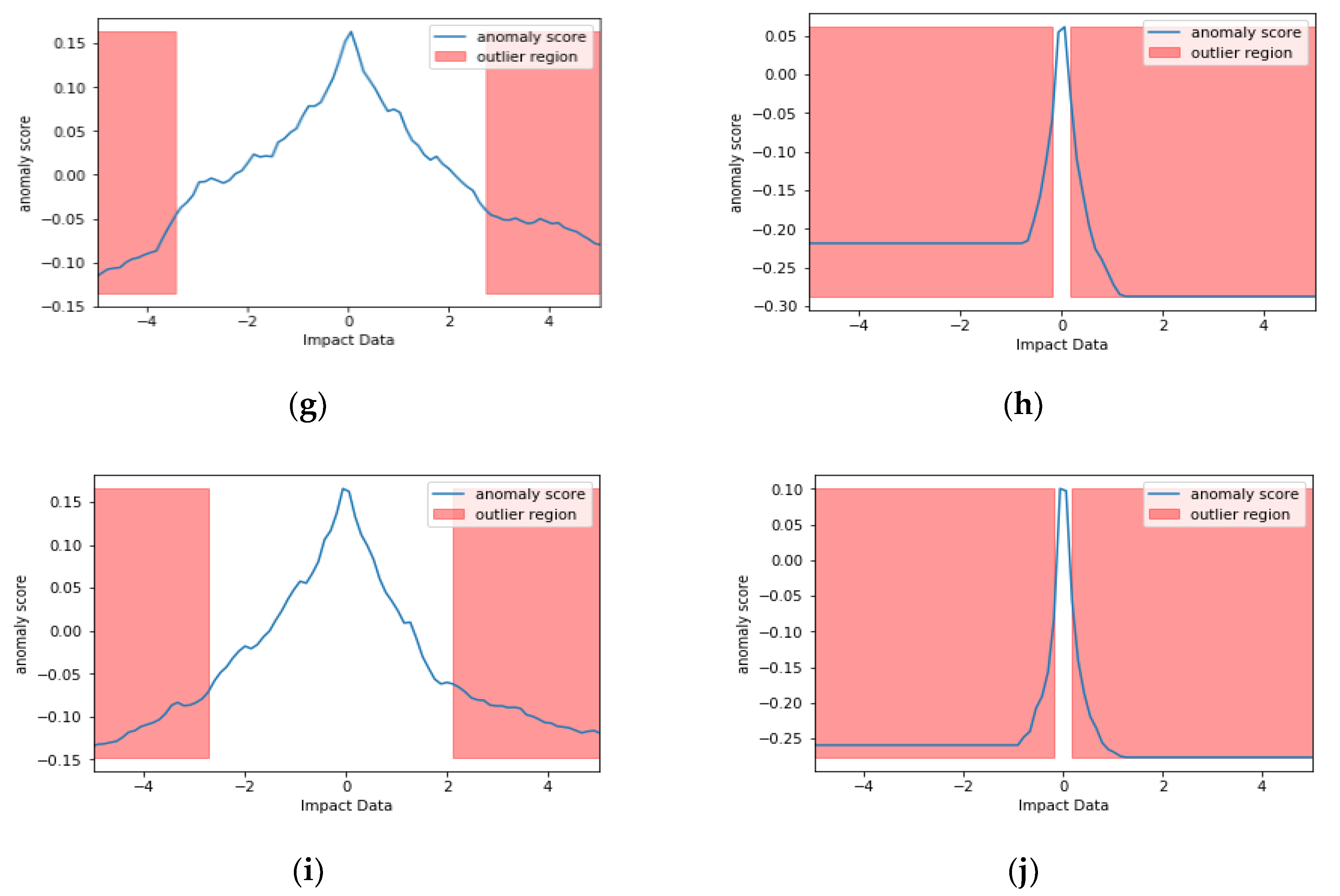
4. Isolation Forrest
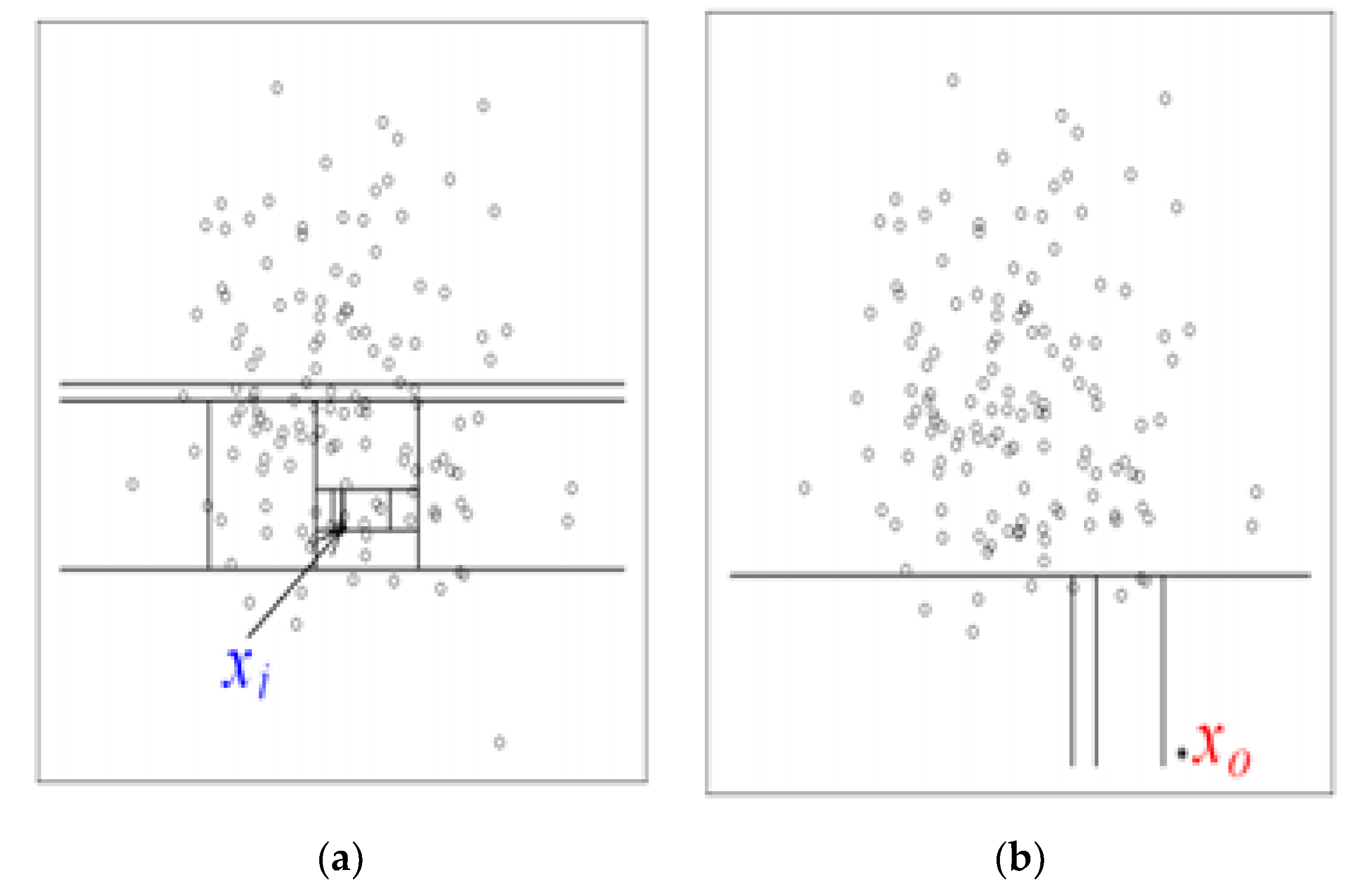
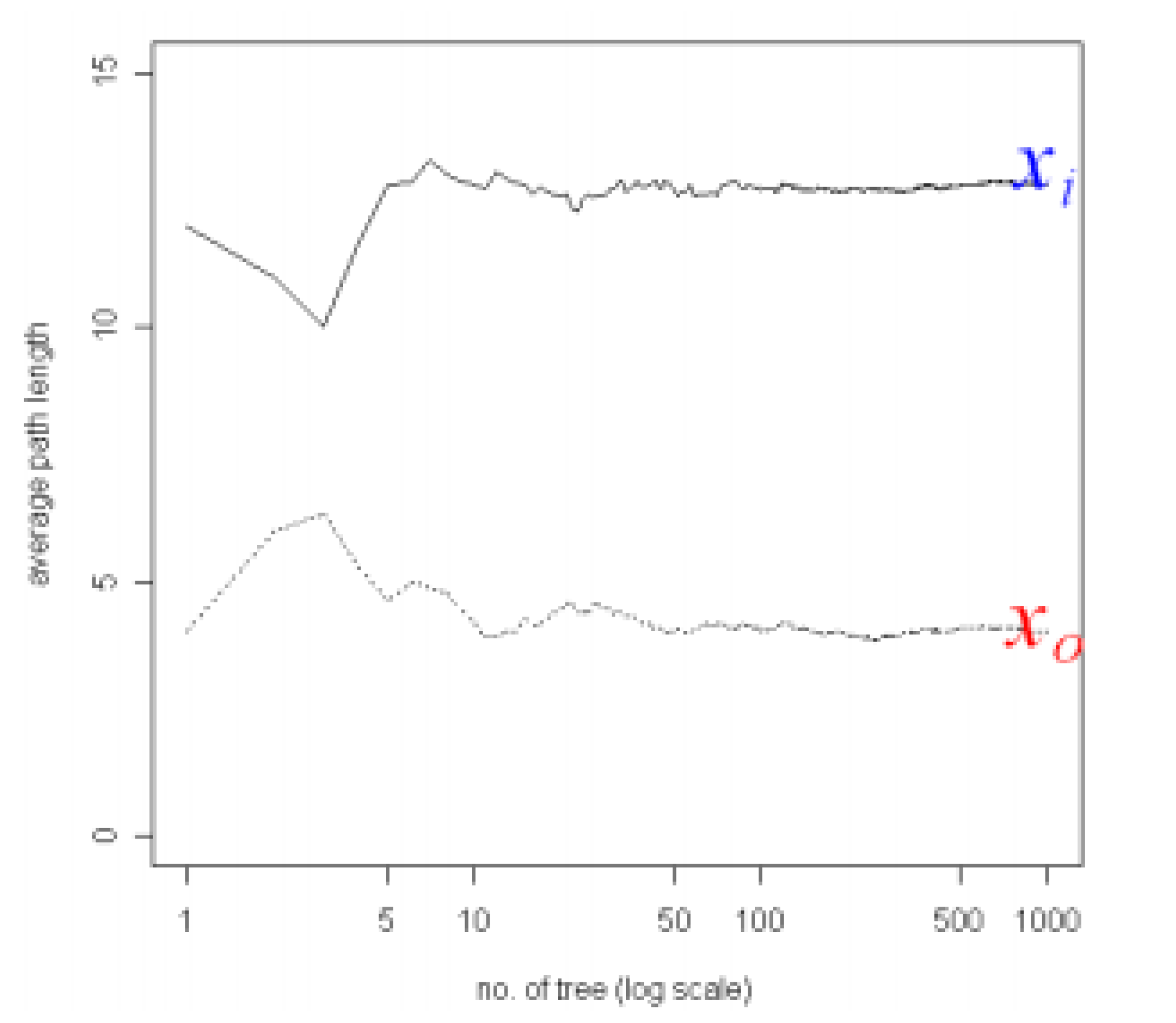
Isolation Forest (IF) is mainly based on the idea of isolation and decision trees, and how the two are utilized for anomaly or outlier detection. The trees, referred to as iTrees are built for a given data set and the anomalies are instances which have the shortest average path length on the iTrees. In principle outliers are much less frequent than the regular data points (also within the feature space), hence why such random portioning, outliers are identified closer to the root of the tree. In iTrees, partitions are created by initially randomly selecting a feature and then selecting a random split value between the min and max values of the selected features. An example of a normal vs. abnormal observation is shown in the
Figure 4 and
Figure 5 [
28].
There are two main variables involved in IF: The number of trees and the subsampling size. The path length of a point is shown as
h(x), and is known as the number of edges or paths it takes to reach a certain data point. In order to classify a point as an anomaly, an anomaly scoring method is utilized by IF, as discussed further. A way of measuring the number of nodes it takes to reach a point, should also be taken into consideration. This is shown as the average path length of an unsuccessful search, shown by
c(n), where n is the node:
where
is
. As
is the average of
, given
, it can be used to normalize
. Hence the anomaly score is obtained via:
where
is the average of
from a collection of IF’s. Hence:
Instances where S is returned close to 1: The point is an Anomaly.
Instances where S is returned close to 0: The point is Normal.
Instances where S is returned close to 0.5: The point does not have any distinct anomaly.
The Scikit Learn package within Python can be used to do this, however, the anomaly score is offset by −0.5. Usually it should be in the [0,1] range. In the case of the Python package it is offset and in the range of [−0.5, 0.5]. Negative values are outliers, positive values are inliers.
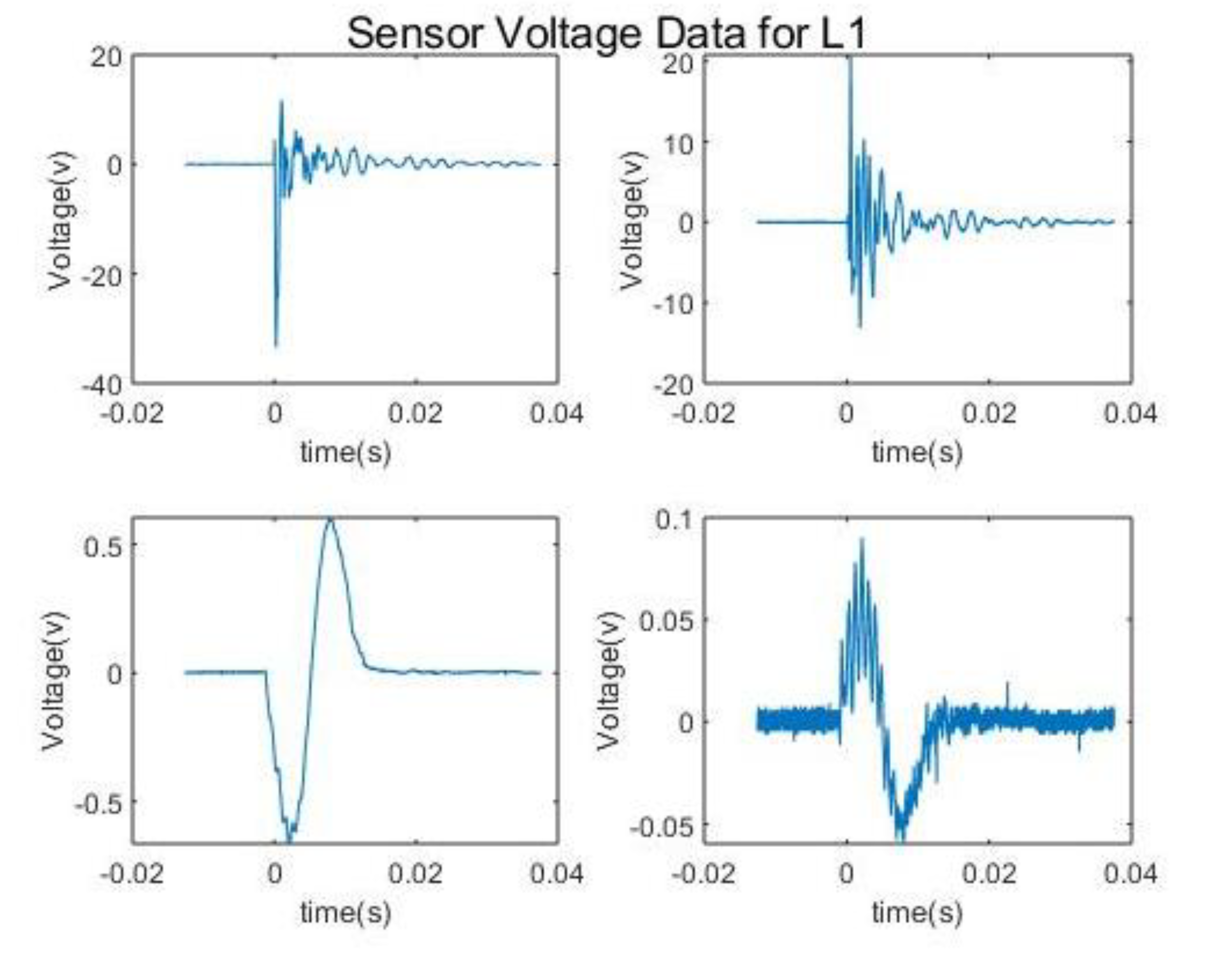
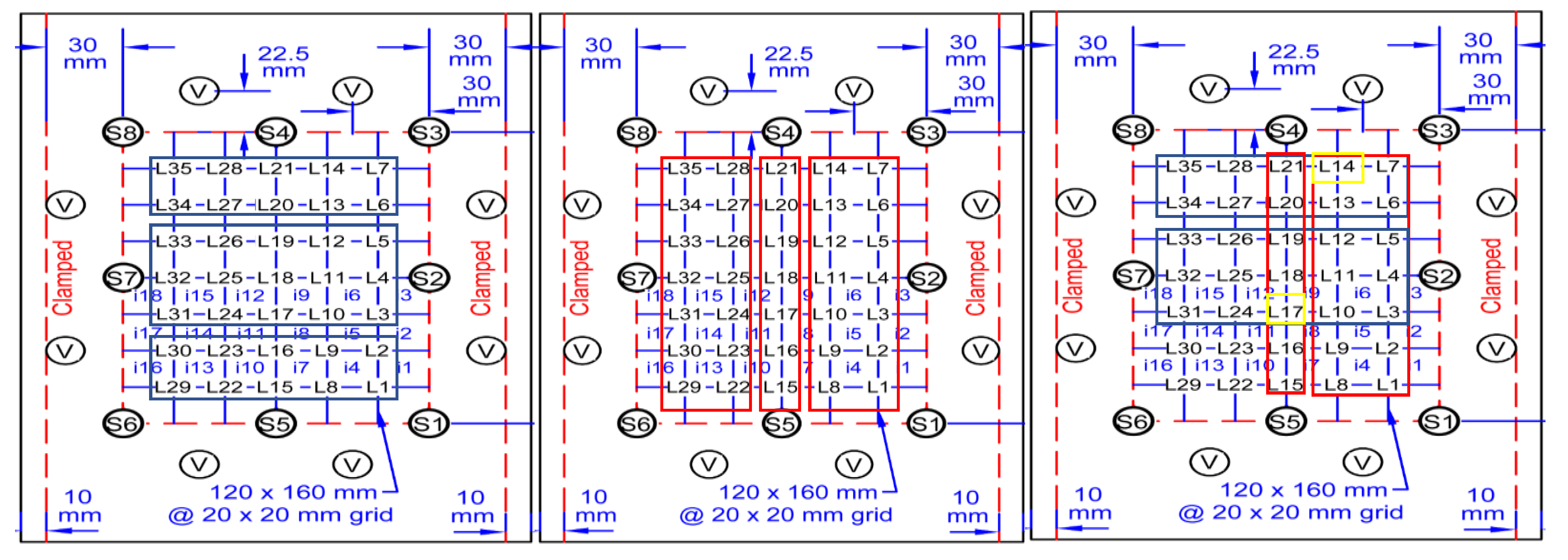
Figure 6 shows examples of IF in action on two signals impact signals produced by a hammer. Figures on the left side show the signal without vibrational noise for sensors 1, 2, 3, 7 and 8, and the ones on the right with vibrational noise for the same sensors. 100 trees where used for training with random selection of features.
So far IF has been explained through a mathematical context. In the context of SHM, IF can be highly beneficial as the important voltage data can be extracted with minimal effort from the noise and vibrations during flight. While it might be easy to assume that the algorithm simply targets the peaks of signals, through its sub sampling and random forest approach, it can also extract lower peaks that are situated out of the noise and vibrations.
As it can be seen from the data without noise, near the abnormal points there are certain number of points that have the same score at a range of voltages. The noisy data happen to have a very small set of points that are not abnormalities. Based on
Figure 2, this makes sense as there is noise added on top of the impact from the setup, hence more abnormalities, i.e., the background noise adds to the impacts signal in certain points. It should be noted that these abnormalities can contain the impacts.
5. Convolutional Neural Network (CNN)
CNN is a deep-learning algorithm that has been extensively researched in the last few years, creating many variations [
29]. The natural visual perception mechanism within living creatures was the main motivation behind the algorithm. The first CNN, influenced by the discovery of Kunihiko Fukushima was the LeNet-5, by [
30]. Kunihiko Fukushima had found that neurons in the visual cortex are responsible for detecting light in receptive fields [
31]. CNN’s are built on multi-class classifications where each image is associated to label within a class, from which the network trains its weights. Many parameters can be represented by a class, including: a point of impact, impact localization, an energy level or any other [
27].
The method in this paper utilizes a CNN as the second step for feature extraction after IF to find anomalies from the impact data. From the outputs of PZT sensors, the proposed model takes the raw data as 2D images, for different impact locations and energy levels, therefore outputs are given as the class with the highest probability [
27]. Many implementations of the CNN exist, but they all include three layers: convolution, pooling and fully connected layers. The convolution layer consists of many multiple convolution kernels that learn features of the input data via feature extraction and selection and thus generating feature maps. Feature maps are created by initially convolving the input with a learned kernel, and next, by applying on the convolved results an element-wise non-linear activation function. In mathematical terms, the feature value
at a certain location
in the
kth feature map of the
lth layer, is [
27]:
With
and
representing the weight vector and the bias term respectively of the
kth filter of the
lth layer. The kernel
is shared with the
feature maps, differing from typical ANN’s. This is advantageous since it reduces the model complexity hence making it easier to train. With the non-linear activation function called
, then the action value
of convolutional feature
, is [
27]:
The activation function is crucial since it introduces non-linearities to the CNN, making it robust for detecting non-linear features. Sigmoid, ReLu and tanh are the most used activation functions. The pooling layer between two convolution layers has the role of minimizing the feature maps resolution via shift-invariance. With the pooling function defined as pool(·), then for each feature map [
27]:
With
, a local neighborhood around location
. Pooling operations can involve Average pooling and max pooling are used for pooling operations. Usually, kernels in higher layers obtain more robust features such as energy levels or natural frequencies, while the ones in the lower layers encode more low-level features such as curves or edges. At the end of the network, the fully connected layer connects all the neurons in the previous layer to the ones in the current layer, creating global semantic information. The last layer is the output layer, where a SoftMax operator is employed (or SVM) [
27]. This reduces the quantity of network parameters due to improving the efficiency of the forward function. The difference from a typical neural network is that the CNN have neurons arranged in three dimensions: width, height and depth.
The
convolution layer is used for extracting information from raw input data utilizing multiple automatically taught filters where the data’s features are obtained. The user determines the filters size and numbers. The filters scan the input from the upper left-hand side corner to the bottom right hand side corner, each creating a feature map [
27].
The
pooling layer down-samples the width and height, reducing input dimensions hence, reducing the number of parameters to be computed. This overall reduces overfitting and the complexity of the network. This is done on each depth slice of the input separately, down-sampling them all. Various patches are created by dividing each, equal in area to the filter size set initially by the user when defining the pooling layer [
27].
The
flatten layer turns the input into an array of one neuron depth and height, equal in length by changing the inputs shape to the product between the length, depth and height of the input to that layer. The output layer in every CNN must be a one-dimensional vector, hence this step is crucial [
27,
32].
The
dropout layer randomly cuts off fractions of the nodes in the network reducing overfitting. This can be used to replicate a great number of different architectures [
27,
32].
The
densely connected layer connects each output neuron to all the neurons from the input. This is implemented at the output along with A SoftMax function to produce predictions along with the output are responsible for implementing this step. Thus, the nodes at the output of the layer contain the probabilities of the input to the CNN belonging to all classes. Each neuron, containing the convolutional and pooling layers, receives all the information from the first half of the network, since they are connected to all the neurons of the input layer [
27,
33,
34].
The instructions to create an optimum architecture of a CNN are not generally clear. The most common way of finding the best structure is via trial and error. A function which truly represents the accuracy and efficiency of the prediction is a fundamental step. One parameter which can quantify the performance of an algorithm for each class, is the Confusion matrix. To show the effectiveness of CNN on an individual HI and SI, the results of the confusion matrices is shown in
Table 1 and
Table 2Looking at the results from
Table 1 and
Table 2 the CNN algorithm is more than capable of detecting individual impacts by being trained by a set of 4000 individual impacts. For HI and SI each were trained with the same type of Impact. The training is more accurate for impacts that have been dropped from the same height as they all have the same energy. The ones dropped from different heights and using different masses have a lower accuracy as their features are harder to select and extract. Next the results for Energy classification on the individual HI and SI will be shown. In order to tackle Energy classification, initially the Energy of the individual impact must be obtained. There are various methods to do so, however, the best method would be to use the capacitance energy of the PZT sensors obtained by:
where
. Afterwards the average energy is computed for each of the channels via:
where
j = 1,2, 3…,8 is the channel number and
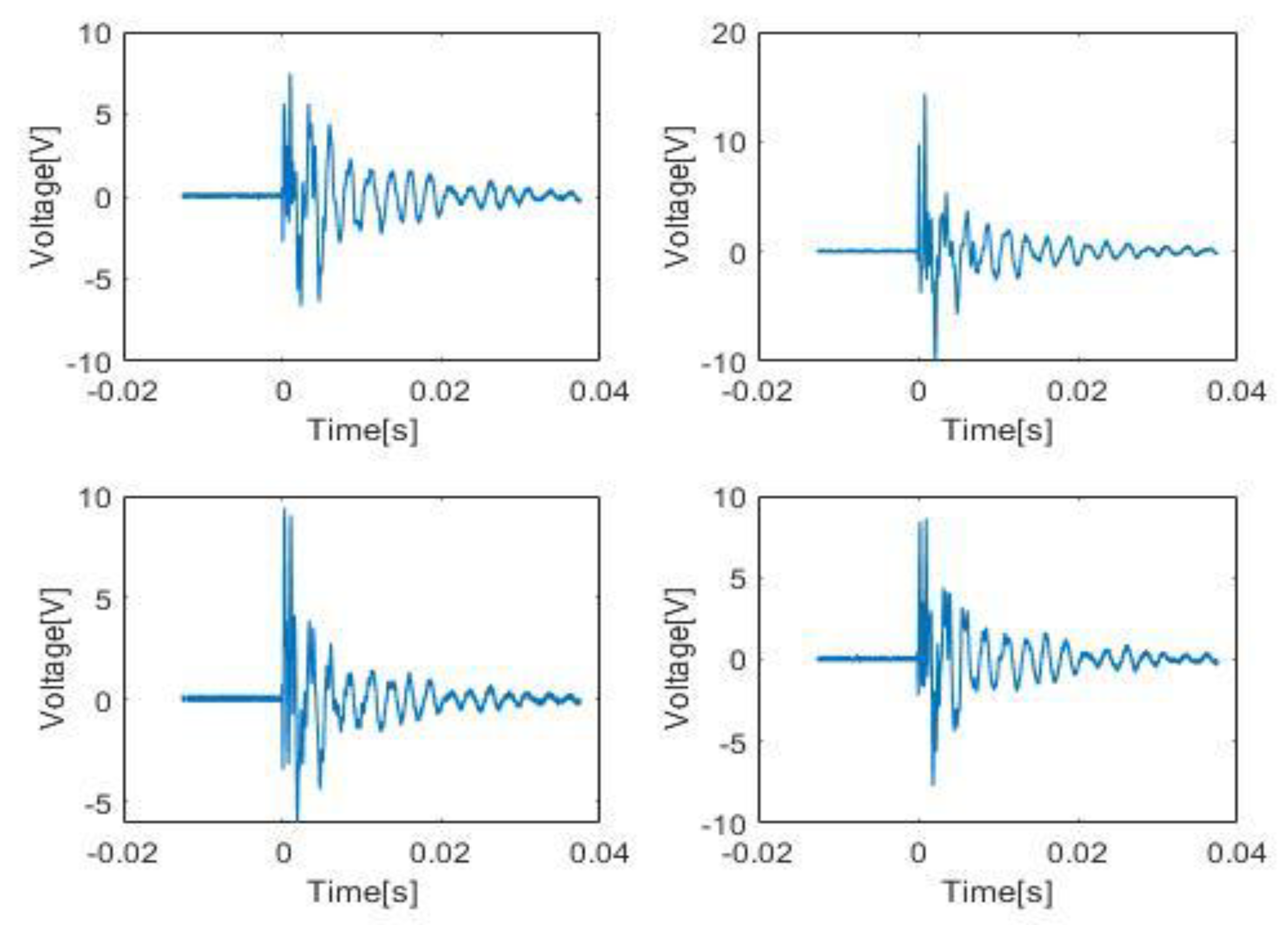
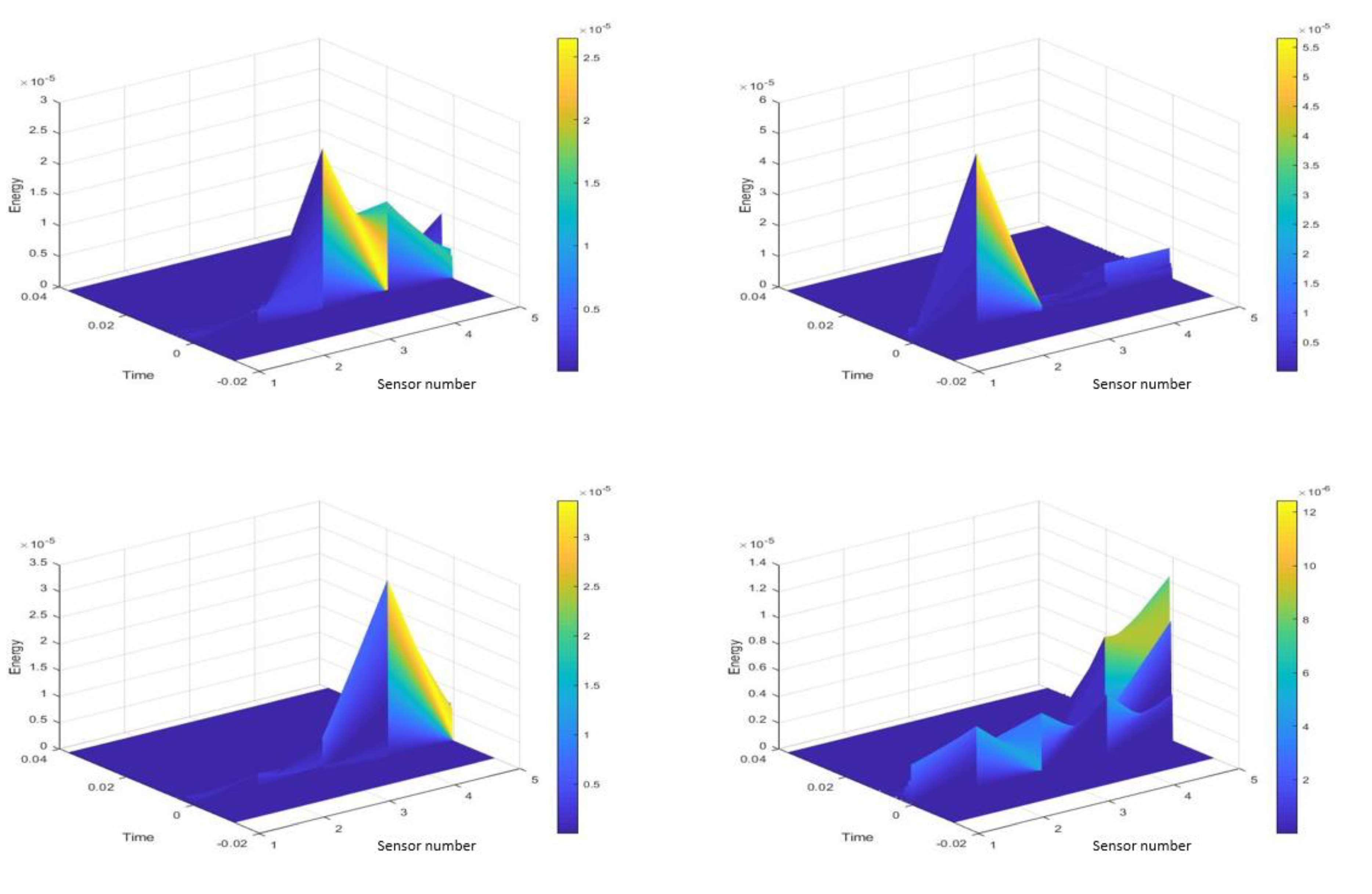
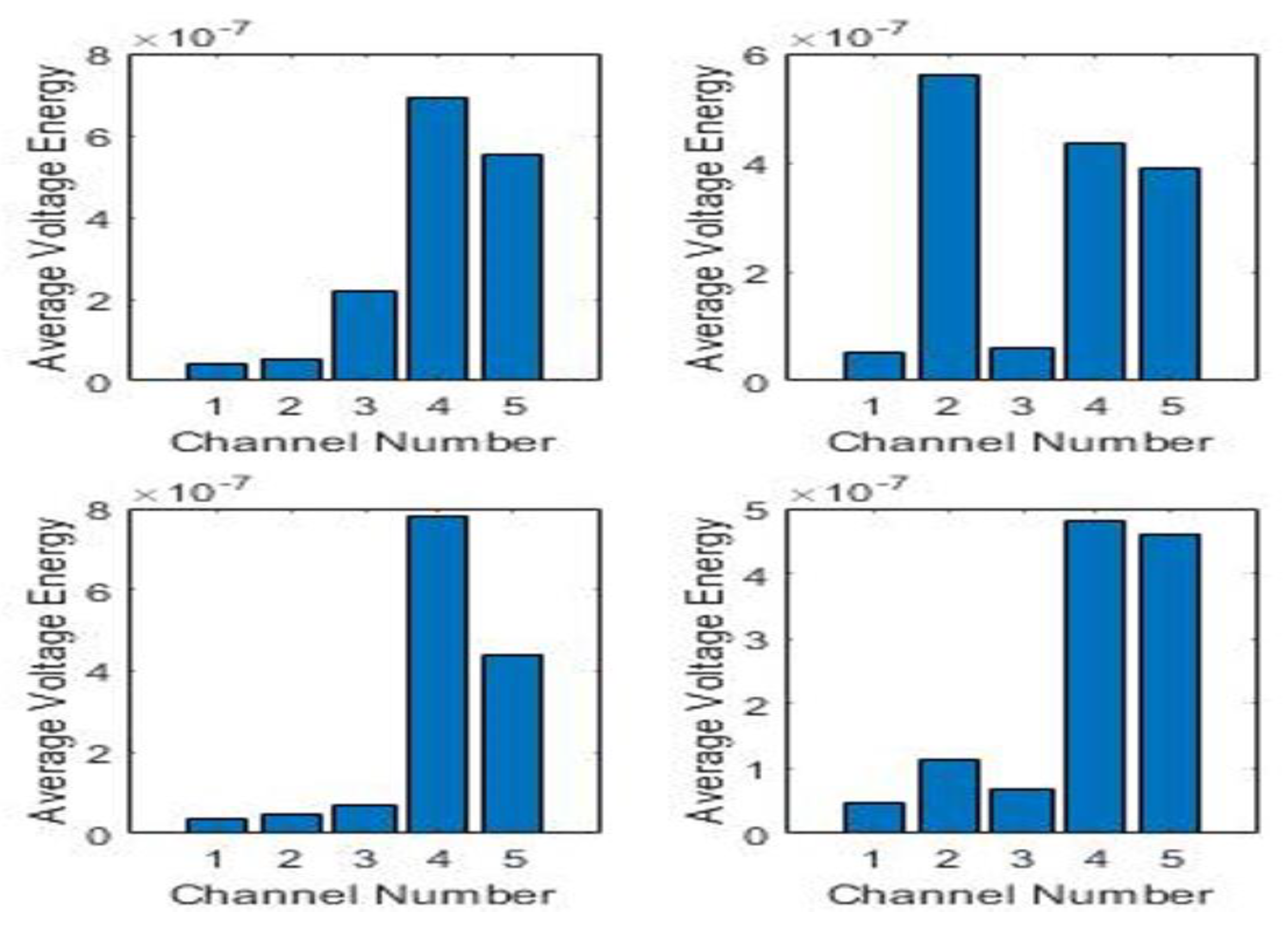
N the total number of samples per sensor, which in this case is 100,000. Aim is to divide the impacts into three energy categories: Low, Medium and High. Training for energy classification would have to take place separately from that of the impacts. Looking at the individual HI for four sensors, as shown in
Figure 7, their energy spectrum has been obtained via MATLAB as shown in
Figure 8 and their average energy using (7), is shown in
Figure 9.
Using the average energy data obtained, the training of the energy CNN can begin. The results of the training and testing for both HI and SI (SI energies also obtained with the same method) are shown in
Table 3 and
Table 4This shows that the energy CNN is more than capable of classifying the energy levels of different impacts. For SI, again since the features are less obvious, the algorithm can’t obtain as good results as the HI’s energies.
7. Final Model Structure and Results
So far, the two important components of the final model have been discussed for individual single impact HI’s and SI’s. To test the final model for robustness and more realistic data, two sets of signals are constructed:
Ten segment signals where many HI, SI and vibrational noise are included.
Ten segment signals where HI and SI are much more isolated and so the signal is more realistic.
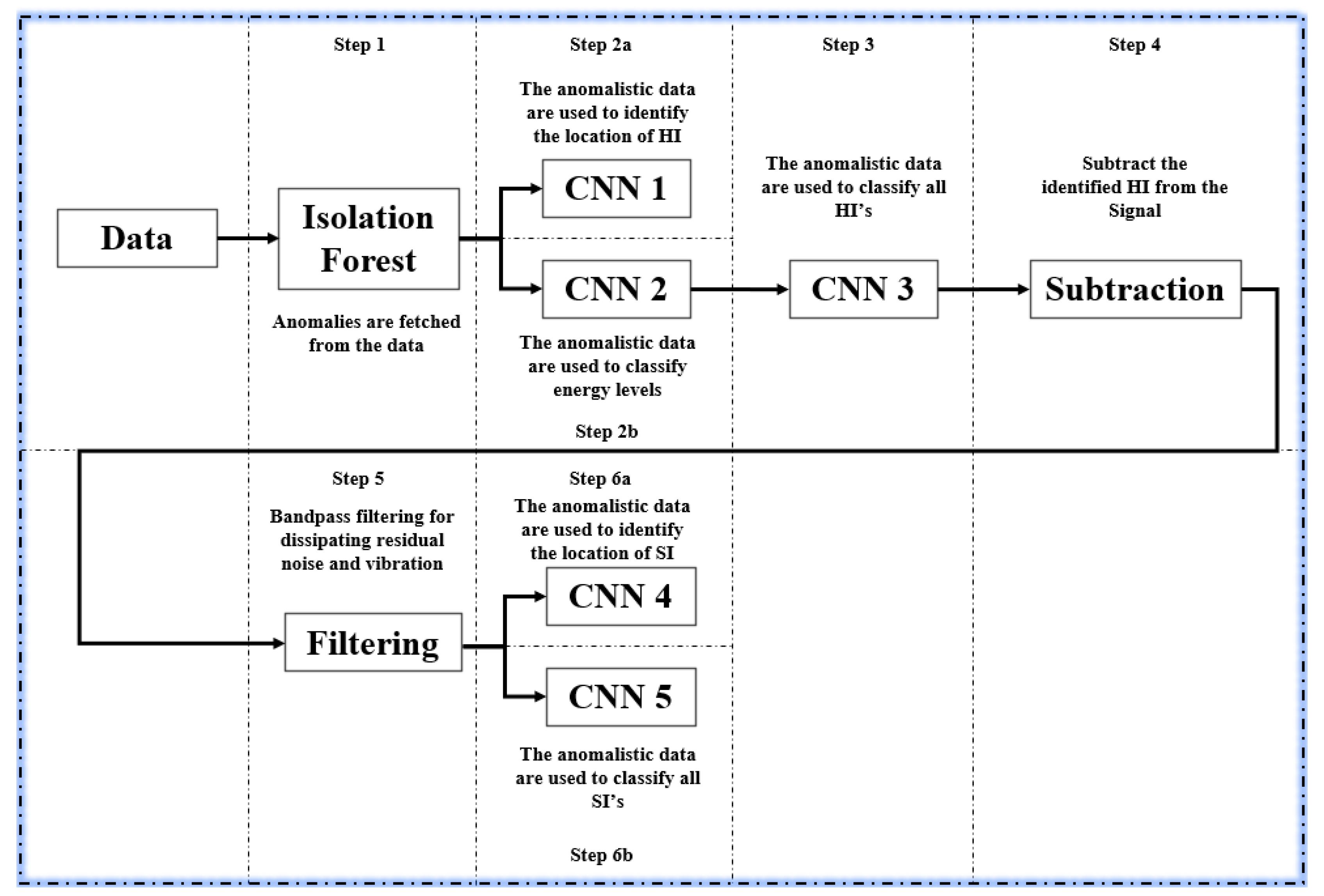
Signals are obtained by using a function to fetch signals from various impact files and stitching them up to one another. The final model can be summarized in the following steps and
Figure 11:
- (1)
The data are passed into an IF algorithm to have their anomalies fetched and moved on to the deep learning segments.
- (2)
The anomalies follow two branches:
- (a)
One branch with CNN-1 where the impact localization takes place for HI. HI impact locations can be found from this step since HI’s are easily visible to the IF, since as seen in
Figure 2, compared to SI, they have higher amplitudes.
- (b)
One branch with CNN-2 where the energy classification of the impacts take place.
- (3)
Following CNN-2, the same anomaly data are passed into CNN-3 where the CNN is specified to look only for HI.
- (4)
Once HI are found they are subtracted from the anomaly data, leaving only SI and left-over vibrations from step 1.
- (5)
The remaining data is passed through a band pass filter of cut-off frequencies 100 Hz and 300 Hz (characteristic frequencies for vibrational noise) for dissipating any residual noise and vibration.
- (6)
The remaining data passed onto:
- (a)
CNN-4 where the SI localization is done
- (b)
CNN-5 where the SI are identified.
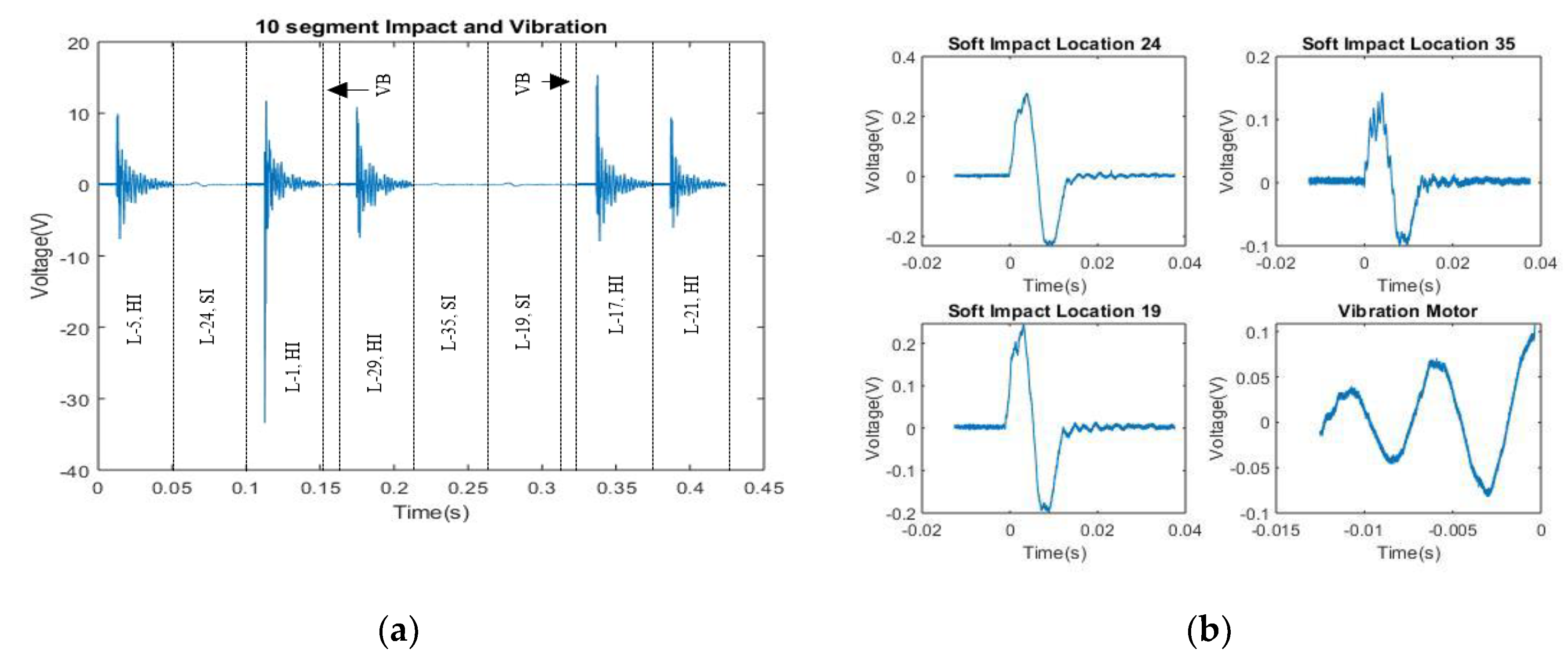
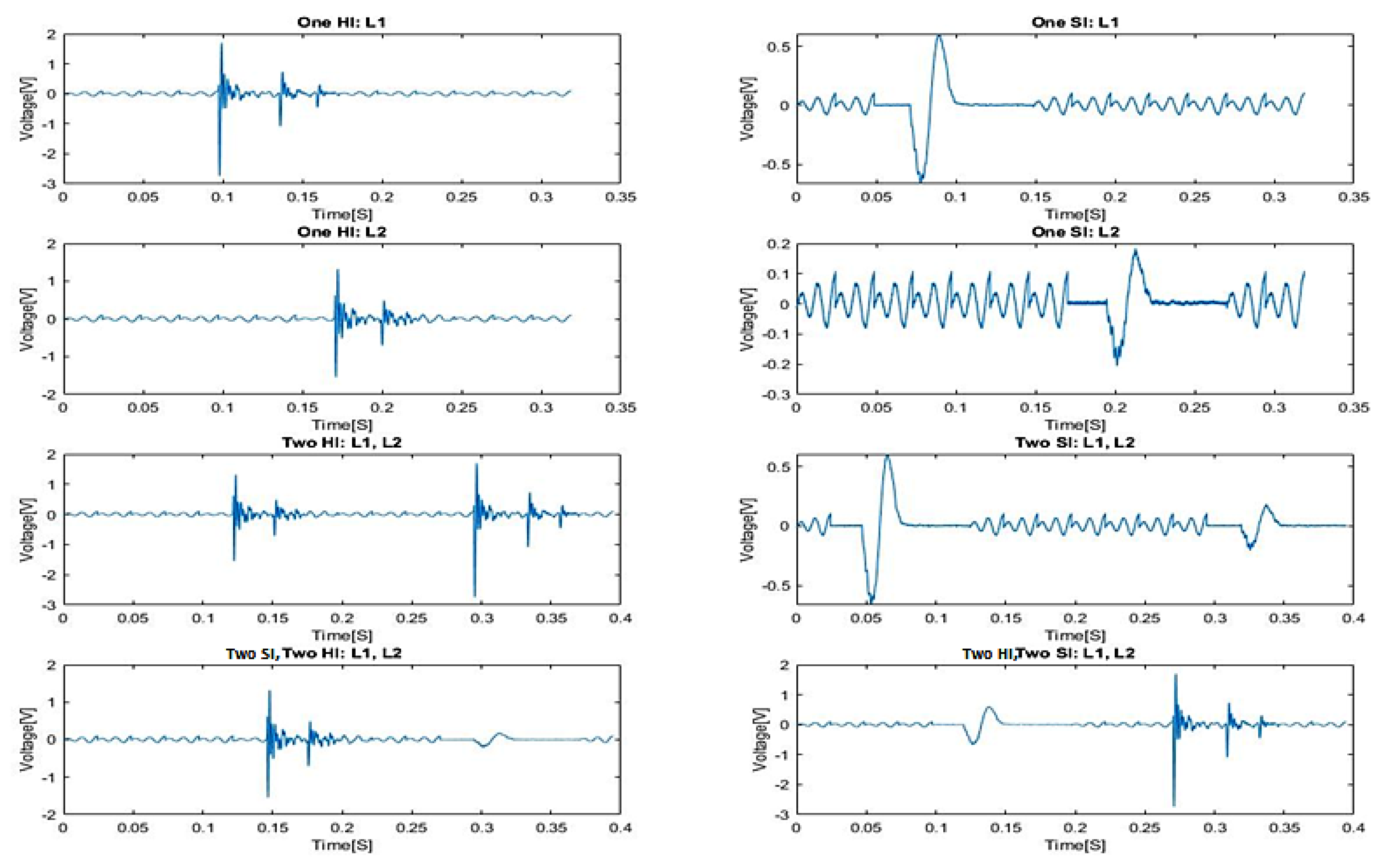
Figure 12a shows an example signal containing multiple SI’s, HI’s and vibrations, while
Figure 12b shows isolated SI’s.
Figure 13 shows a collection of isolated realistic ten segment signals.
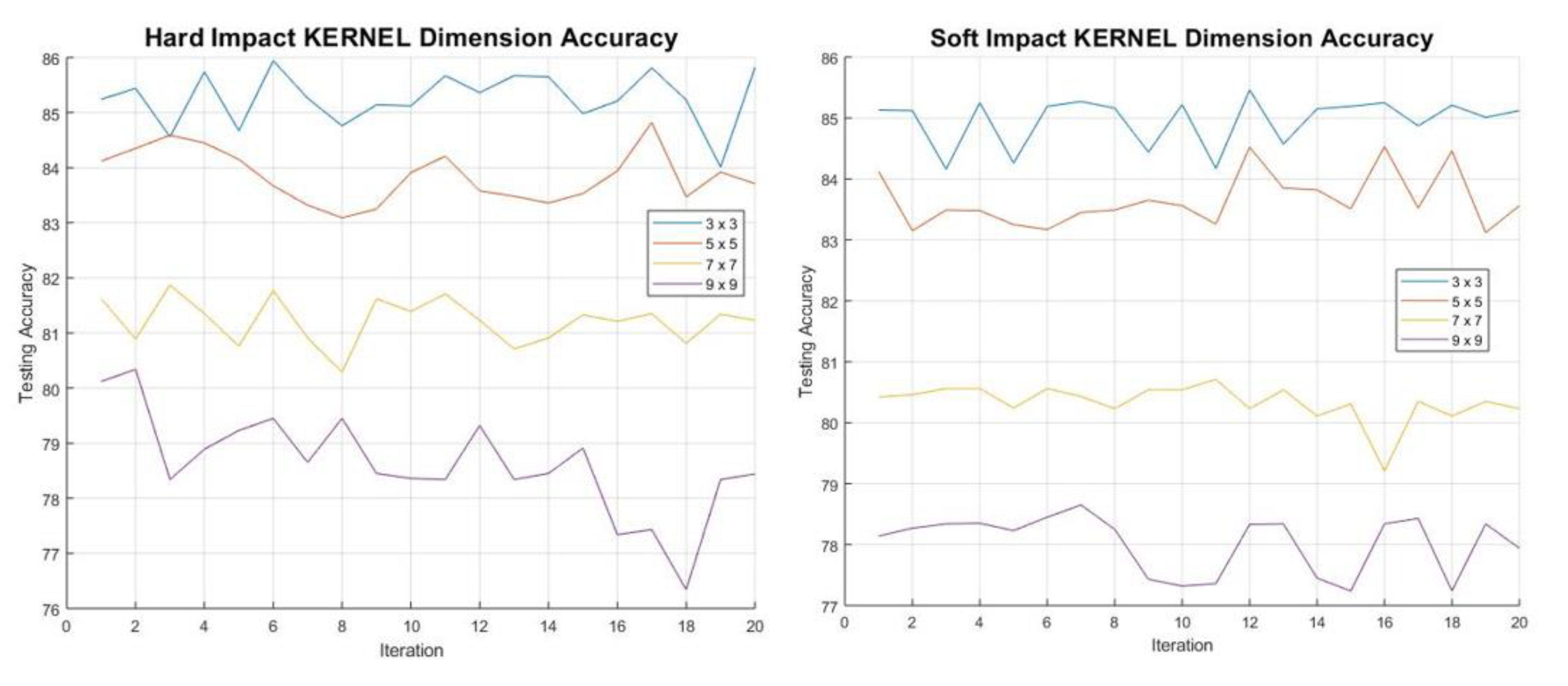
A total of 1000 data sets have been used for training the model. What needs to be determined is the dimensions of the kernel and pooling matrix. Initially the optimum kernel dimension is determined by looking at each impact type (SI and HI) separately, while keeping the pooling matrix at a minimum of 2 × 2.
Figure 13 shows that the optimum dimension for detection of both HI and SI is at 3 × 3. The higher the dimension the less the accuracy. This can be expected as the kernel of larger dimension might miss certain features, leading to lower accuracy. This can be thought of in terms of a moving average. In order to find the optimum pooling matrix, dimension the kernel used to obtain the highest accuracy has been used. The pooling matrix essentially works as a compression matrix. It can be seen in
Figure 14, that the 4 × 4 dimension gives the highest accuracy alongside the 3 × 3 kernel dimension. Since the optimum dimensions of both the kernel and pooling matrix have been determined, the model can now be trained. The main objective is for the model to determine the HI and SI with high accuracy. The table below shows the percentage accuracy and computation time for both the HI and SI. It is important to acknowledge that the data used for training and testing are picked at random from different locations and impactors. What is more significant is the height of the impactors which corresponds to the energy levels of the impacts. This has been added to the testing since it is suspected that combining impacts of different energies can affect the training.
The results for the initial sets of signals (10-segment multiple HI, SI, vibrations) is shown in
Table 7. The results of the secondary set of signals (10-segment isolated HI, SI realistic signals) is shown in
Table 8. As seen from both tables the algorithm can detect HI’s at higher accuracy compared to SI’s. This is since SI’s have less distinct features compared to HI’s and so are harder to detect. The same stands for the energy levels. This method was also compared to other methods previously considered and the comparison is shown in
Table 9.
In Recurrent learning (RL), the user must predefine a certain set of features where the algorithm cycles through and picks the ones that give better results after each stage of each cycle. Over time the algorithm converges to a certain percentage accuracy via concatenating the feature set. This method needs the user to specify certain number of features and hence is not viable for the desired function. Long Term Short Memory (LTSM) are a variant of Recurrent Neural Networks (RNN), where special units are used for memory maintenance between each stage of the algorithm. RNN’s themselves are a class of Artificial Neural Networks where the connections between the network nodes create a directed graph along a temporal sequence. This allows the network to exhibit temporal dynamic behavior. Unlike the conventional feed forward neural networks, RNN’s can use their memory to process and model variable length sequences of inputs [
35,
36,
37].



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}