A Novel Bilinear Feature and Multi-Layer Fused Convolutional Neural Network for Tactile Shape Recognition

Abstract
:1. Introduction
2. The Proposed BMF-CNN
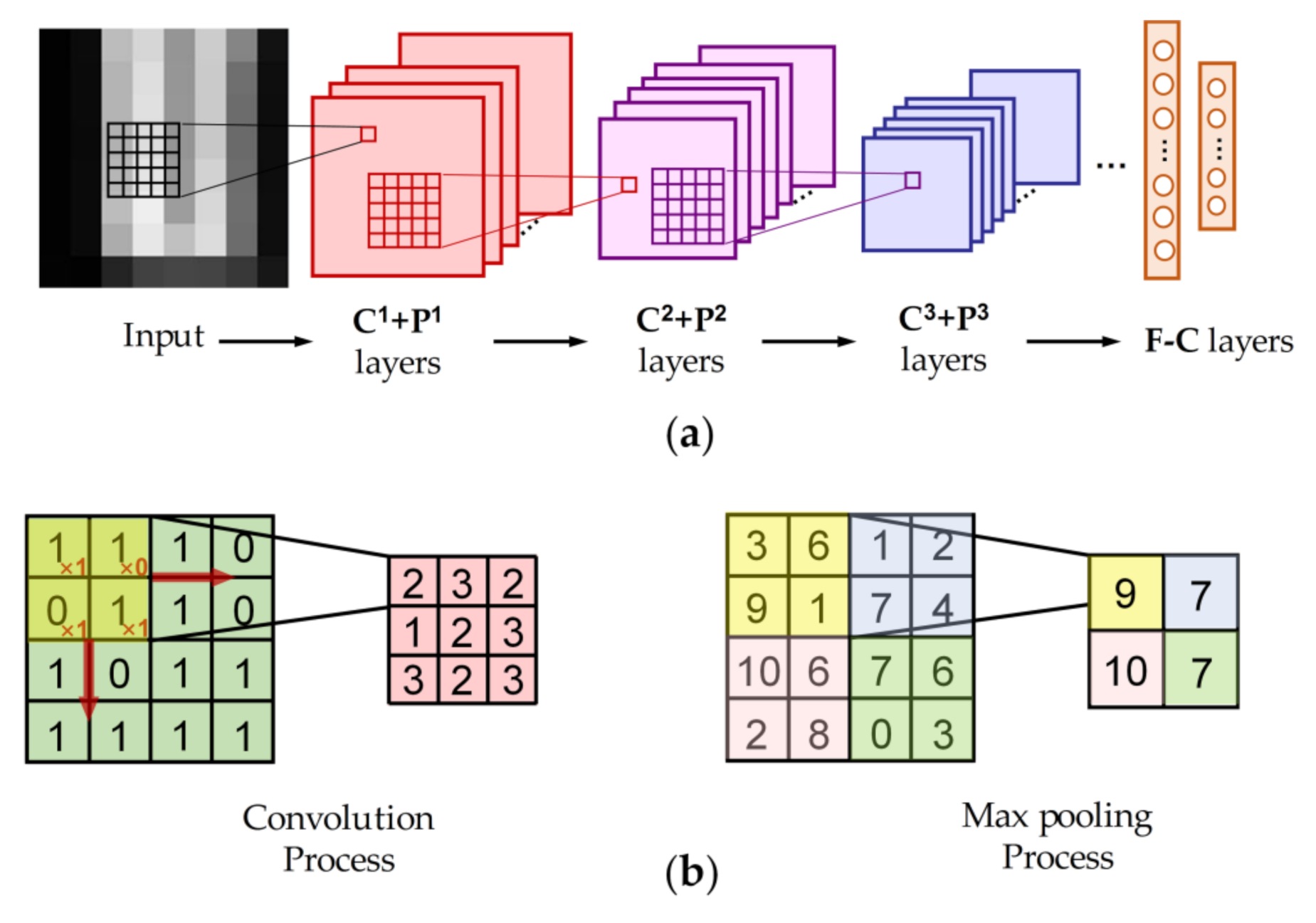
2.1. Introduction to CNNs
2.2. Single-Mode Bilinear Feature
2.3. Multi-Layer Feature Fusion
2.4. The BMF-CNN Framework
3. Experiment and Results
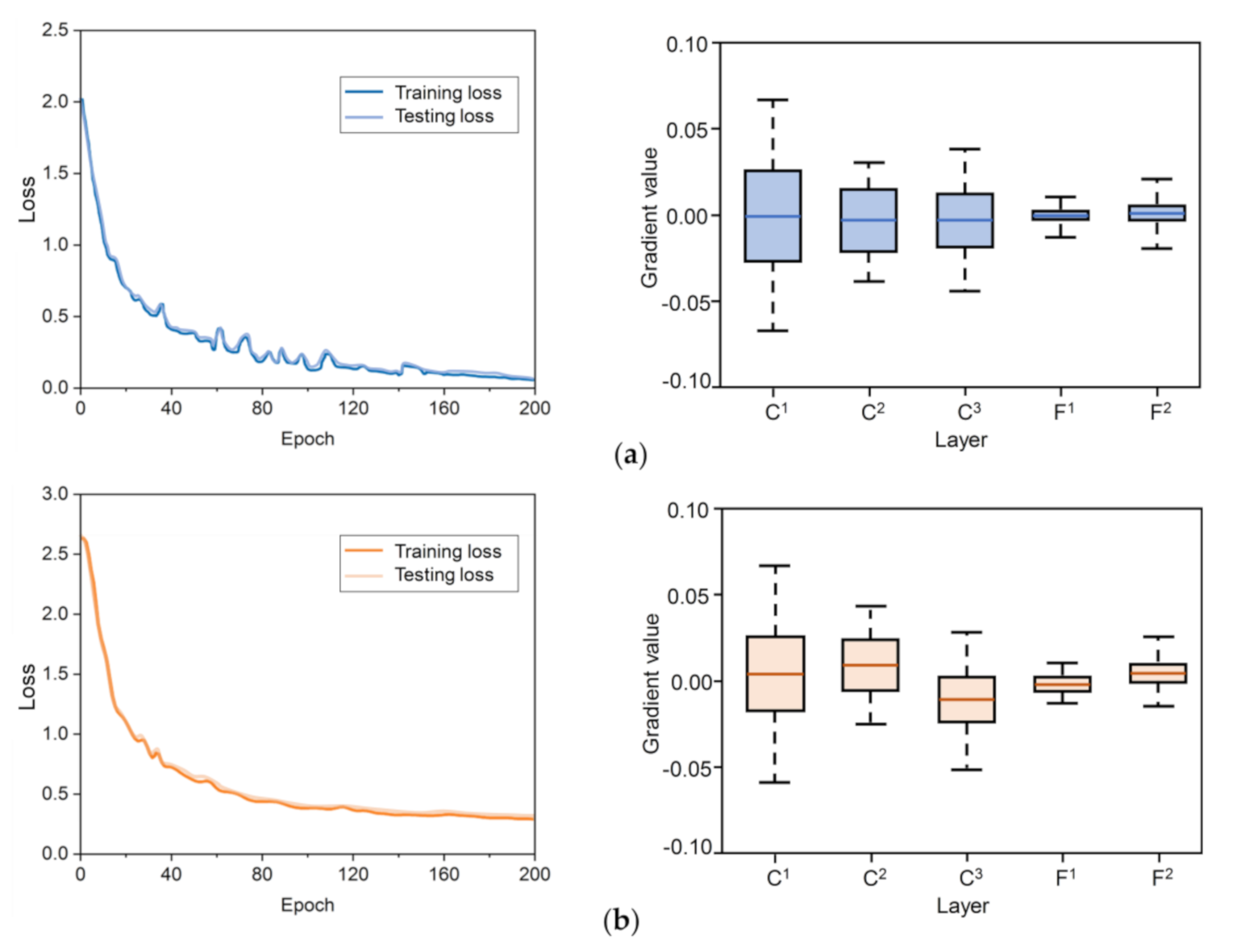
3.1. Dataset and BMF-CNN Training
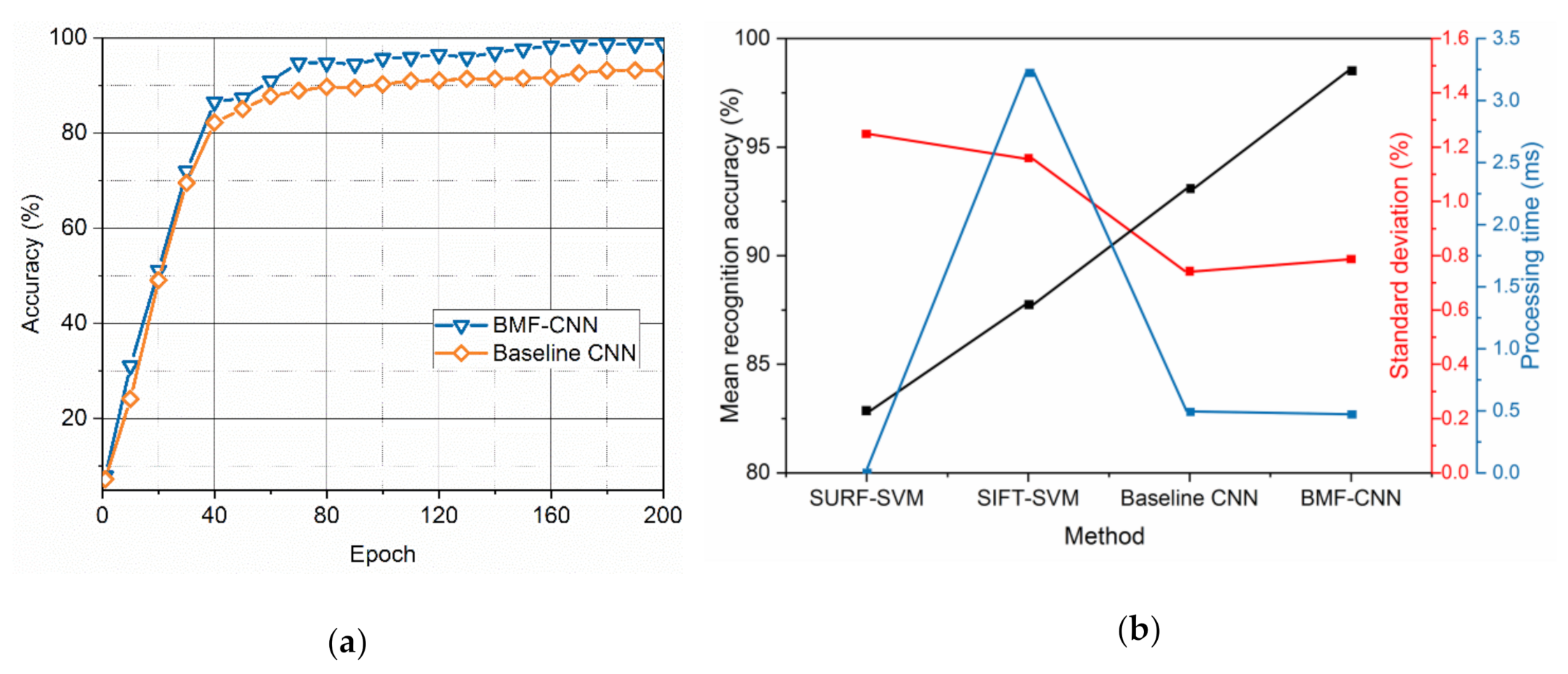
3.2. Performance of the BMF-CNN
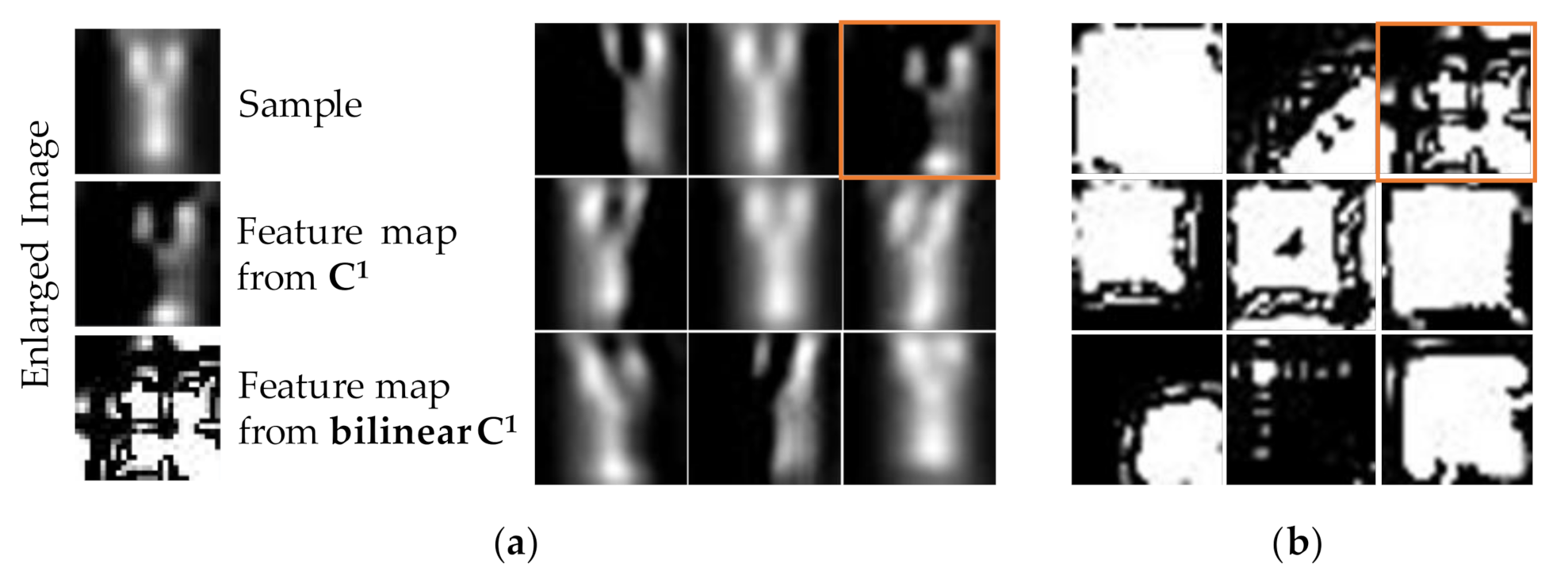
3.3. The Contribution of the Bilinear Features and Multi-Layer Fusion Strategies
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Choi, S.; Lee, H.; Ghaffari, R.; Hyeon, T.; Kim, D.H. Recent Advances in Flexible and Stretchable Bio-Electronic Devices Integrated with Nanomaterials. Adv. Mater. 2016, 28, 4203–4218. [Google Scholar] [CrossRef]
- Yang, J.C.; Mun, J.; Kwon, S.Y.; Park, S.; Bao, Z.N.; Park, S. Electronic Skin: Recent Progress and Future Prospects for Skin-Attachable Devices for Health Monitoring, Robotics, and Prosthetics. Adv. Mater. 2019, 31, 1904765. [Google Scholar] [CrossRef] [Green Version]
- Chortos, A.; Liu, J.; Bao, Z.A. Pursuing prosthetic electronic skin. Nat. Mater. 2016, 15, 937–950. [Google Scholar] [CrossRef]
- Pezzementi, Z.; Plaku, E.; Reyda, C.; Hager, G.D. Tactile-Object Recognition from Appearance Information. IEEE Trans. Robot 2011, 27, 473–487. [Google Scholar] [CrossRef] [Green Version]
- Suto, S.; Watanabe, T.; Shibusawa, S.; Kamada, M. Multi-Touch Tabletop System Using Infrared Image Recognition for User Position Identification. Sensors 2018, 18, 1559. [Google Scholar] [CrossRef] [Green Version]
- Gastaldo, P.; Pinna, L.; Seminara, L.; Valle, M.; Zunino, R. A Tensor-Based Pattern-Recognition Framework for the Interpretation of Touch Modality in Artificial Skin Systems. IEEE Sens. J. 2014, 14, 2216–2225. [Google Scholar] [CrossRef]
- Luo, S.; Mou, W.X.; Althoefer, K.; Liu, H.B. Novel Tactile-SIFT Descriptor for Object Shape Recognition. IEEE Sens. J. 2015, 15, 5001–5009. [Google Scholar] [CrossRef]
- Gandarias, J.M.; Gomez-de-Gabriel, J.M.; Garcia-Cerezo, A. Human and Object Recognition with a High-Resolution Tactile Sensor. In Proceedings of the 2017 IEEE Sensor, Glasgow, UK, 29 October–1 November 2017; pp. 981–983. [Google Scholar]
- Khasnobish, A.; Jati, A.; Singh, G.; Konar, A.; Tibarewala, D.N. Object-Shape Recognition by Tactile Image Analysis Using Support Vector Machine. Int. J. Pattern. Recogn. 2014, 28, 1450011. [Google Scholar] [CrossRef]
- Luo, S.; Bimbo, J.; Dahiya, R.; Liu, H.B. Robotic tactile perception of object properties: A review. Mechatronics 2017, 48, 54–67. [Google Scholar] [CrossRef] [Green Version]
- Li, P.X.; Wang, D.; Wang, L.J.; Lu, H.C. Deep visual tracking: Review and experimental comparison. Pattern Recogn. 2018, 76, 323–338. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intel. Neurosc. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.C.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Zhu, Z.T.; Wang, X.G.; Bai, S.; Yao, C.; Bai, X. Deep Learning Representation using Autoencoder for 3D Shape Retrieval. Neurocomputing 2016, 204, 41–50. [Google Scholar] [CrossRef] [Green Version]
- Gandarias, J.M.; Garcia-Cerezo, A.J.; Gomez-de-Gabriel, J.M. CNN-Based Methods for Object Recognition With High-Resolution Tactile Sensors. IEEE Sens. J. 2019, 19, 6872–6882. [Google Scholar] [CrossRef]
- Pastor, F.; Gandarias, J.M.; Garcia-Cerezo, A.J.; Gomez-de-Gabriel, J.M. Using 3D Convolutional Neural Networks for Tactile Object Recognition with Robotic Palpation. Sensors 2019, 19, 5356. [Google Scholar] [CrossRef] [Green Version]
- Cao, L.L.; Sun, F.C.; Liu, X.L.; Huang, W.B.; Kotagiri, R.; Li, H.B. End-to-End ConvNet for Tactile Recognition Using Residual Orthogonal Tiling and Pyramid Convolution Ensemble. Cogn. Comput. 2018, 10, 718–736. [Google Scholar] [CrossRef]
- Tsuji, S.; Kohama, T. Using a convolutional neural network to construct a pen-type tactilesensor system for roughness recognition. Sens. Actuators A Phys. 2019, 291, 7–12. [Google Scholar] [CrossRef]
- Hui, W.; Li, H.; Chen, M.; Song, A. Robotic tactile recognition and adaptive grasping control based on CNN-LSTM. Chin. J. Entific. Instrum. 2019, 40, 211–218. [Google Scholar]
- Funabashi, S.; Yan, G.; Geier, A.; Schmitz, A.; Ogata, T.; Sugano, S. Morphology-Specific Convolutional Neural Networks for Tactile Object Recognition with a Multi-Fingered Hand. In Proceedings of the 2019 IEEE Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; p. 18904260. [Google Scholar]
- Alameh, M.; Valle, M.; Ibrahim, A.; Moser, G. DCNN for Tactile Sensory Data Classification based on Transfer Learning. In Proceedings of the 2019 15th Conference on Ph.D Research in Microelectronics and Electronics (PRIME), Lausanne, Switzerland, 15–18 July 2019; pp. 237–240. [Google Scholar]
- Wang, S.H.; Xu, J.; Wang, W.C.; Wang, G.J.N.; Rastak, R.; Molina-Lopez, F.; Chung, J.W.; Niu, S.M.; Feig, V.R.; Lopez, J.; et al. Skin electronics from scalable fabrication of an intrinsically stretchable transistor array. Nature 2018, 555, 83–90. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 21–27 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, 1409, 1556. [Google Scholar]
- Brahimi, S.; Ben Aoun, N.; Ben Amar, C. Improved Very Deep Recurrent Convolutional Neural Network for Object Recognition. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 2497–2502. [Google Scholar]
- Chu, J.; Cai, J.P. Flexible pressure sensors with a highly pressure- and strain-sensitive layer based on nitroxyl radical-grafted hollow carbon spheres. Nanoscale 2020, 12, 9375–9384. [Google Scholar] [CrossRef]
- Li, F.Y.; Akiyama, Y.; Wan, X.L.; Okamoto, S.; Yamada, Y. Measurement of Shear Strain Field in a Soft Material Using a Sensor System Consisting of Distributed Piezoelectric Polymer Film. Sensors 2020, 20, 3484. [Google Scholar] [CrossRef]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN Models for Fine-grained Visual Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar]
- Zhang, W.X.; Ma, K.D.; Yan, J.; Deng, D.X.; Wang, Z. Blind Image Quality Assessment Using a Deep Bilinear Convolutional Neural Network. IEEE Trans. Circ. Syst. Vid. 2020, 30, 36–47. [Google Scholar] [CrossRef] [Green Version]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for Object Segmentation and Fine-grained Localization. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Yu, W.; Yang, K.Y.; Yao, H.X.; Sun, X.S.; Xu, P.F. Exploiting the complementary strengths of multi-layer CNN features for image retrieval. Neurocomputing 2017, 237, 235–241. [Google Scholar] [CrossRef]
- Sermanet, P.; LeCun, Y. Traffic Sign Recognition with Multi-Scale Convolutional Networks. In Proceedings of the 2011 International Joint Conference on Neural Networks (IJCNN), San Jose, CA, USA, 31 July–5 August 2011; pp. 2809–2813. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Glorot, X.; Bordes, A. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS), Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Laurens, V.D.M.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Lecun, Y. MNIST Handwritten Digit Database. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 22 September 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | BMF-CNN | CNN (Traditional) |
|---|---|---|
| Input | 32 × 32 × 1 | 32 × 32 × 1 |
| C1 | 5 × 5/16 | 5 × 5/16 |
| Batch normalization (BN) | BN | BN |
| Bilinear | 28 × 28/16 | / |
| P1 | 2 × 2, stride 2 | 2 × 2, stride 2 |
| C2 | 3 × 3/32 | 3 × 3/32 |
| P2 | 2 × 2, stride 2 | 2 × 2, stride 2 |
| C3 | 3 × 3/64 | 3 × 3/64 |
| F-C1 | 120 (Fusion) | 120 (No Fusion) |
| F-C2 | 26 | 26 |
| Parameter | Value |
|---|---|
| Pressure range | 0–100 kPa |
| Temperature range | −25 to + 60 °C |
| Density | 64 pixels/cm2 |
| Sensitive pixel size | 0.7 × 0.7 mm |
| Sensitive pixel repeatability | −2% to +6% |
| Number of signal lines | 64 |
| Sensor array height | 5 mm |
| Sensor array height | 5 mm |
| Sensor array thickness | 0.1 mm |
| Method | C1 | Bilinear (C1) | C2 | C3 | F-C1 |
|---|---|---|---|---|---|
| CNN (traditional) | 0.457 | / | 0.646 | 0.807 | 0.908 |
| BMF-CNN | 0.456 | 0.637 | 0.647 | 0.807 | 0.953 |
| Layers | C3 | Bilinear (C1) + C3 | C1 + C3 | Bilinear (C2) + C3 | C2 + C3 |
|---|---|---|---|---|---|
| Accuracy | 0.908 | 0.953 | 0.927 | 0.931 | 0.916 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, J.; Cai, J.; Song, H.; Zhang, Y.; Wei, L. A Novel Bilinear Feature and Multi-Layer Fused Convolutional Neural Network for Tactile Shape Recognition. Sensors 2020, 20, 5822. https://doi.org/10.3390/s20205822
Chu J, Cai J, Song H, Zhang Y, Wei L. A Novel Bilinear Feature and Multi-Layer Fused Convolutional Neural Network for Tactile Shape Recognition. Sensors. 2020; 20(20):5822. https://doi.org/10.3390/s20205822
Chicago/Turabian StyleChu, Jie, Jueping Cai, He Song, Yuxin Zhang, and Linyu Wei. 2020. "A Novel Bilinear Feature and Multi-Layer Fused Convolutional Neural Network for Tactile Shape Recognition" Sensors 20, no. 20: 5822. https://doi.org/10.3390/s20205822
APA StyleChu, J., Cai, J., Song, H., Zhang, Y., & Wei, L. (2020). A Novel Bilinear Feature and Multi-Layer Fused Convolutional Neural Network for Tactile Shape Recognition. Sensors, 20(20), 5822. https://doi.org/10.3390/s20205822