UnetDVH-Linear: Linear Feature Segmentation by Dilated Convolution with Vertical and Horizontal Kernels


Abstract
:1. Introduction
- A new method is proposed based on spatial convolution kernels for linear feature segmentation. It utilizes the dilated convolution [21] with a vertical and horizontal convolution block (DVH) in semantic segmentation networks. This method is more efficient than the traditional vertical and horizontal convolution kernels. Traditional vertical and horizontal convolution that use the size of 9 × 1 and 1 × 9 (v9h9) kernels can be replaced by the proposed dilated convolutions with vertical and horizontal convolution (DVH) kernels of the size and . The latter becomes more stable and is able to obtain better results on different datasets. In addition, the DVH block can be inserted into other backbone semantic segmentation networks to improve the linear feature segmentation capabilities of the segmentation networks;
- We have designed a series of experiments to observe how the positions of the DVH and v9h9 blocks impact the semantic segmentation networks for linear feature extraction. Adding spatial convolution kernels to neural networks for feature extraction is of great significance for future research.
2. Related Works
3. Proposed Method
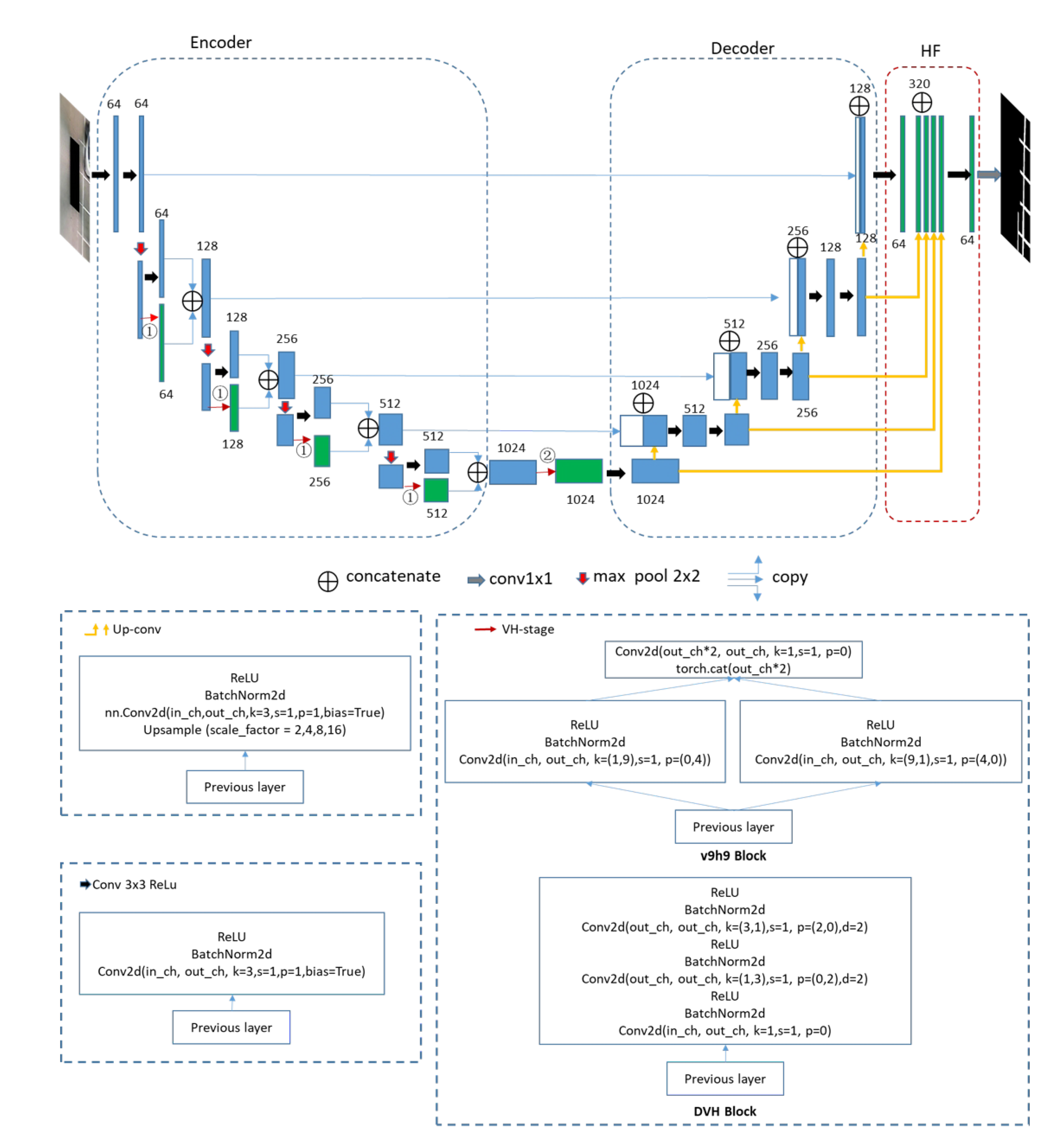
3.1. An Overview of the Method
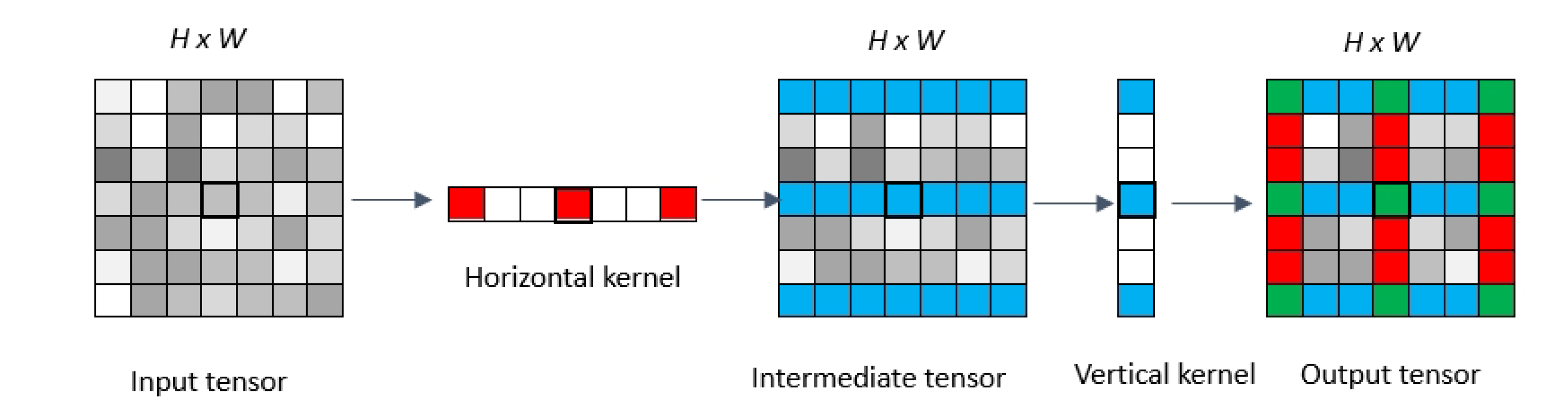
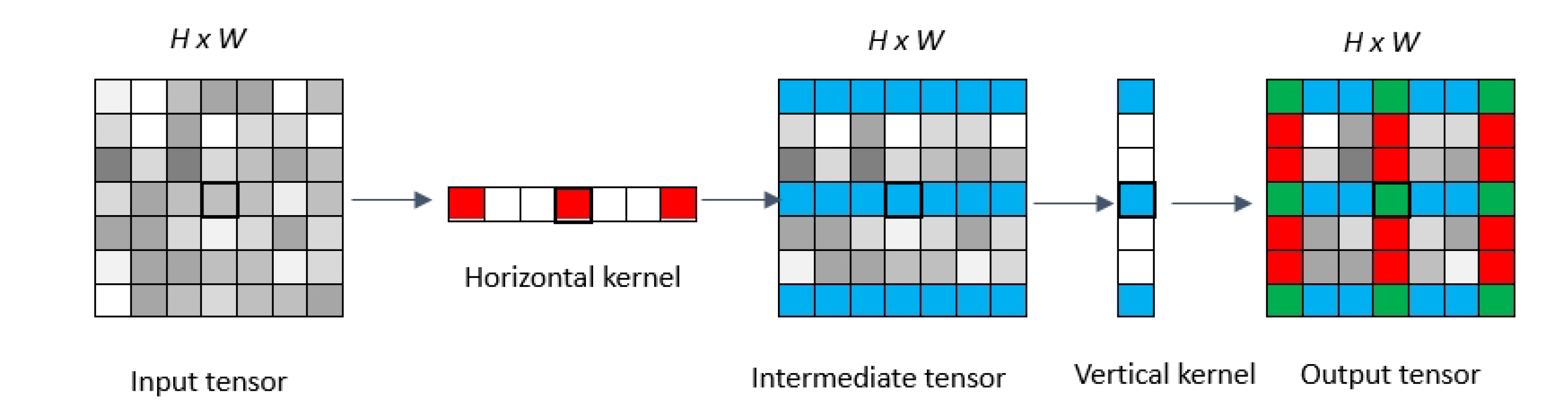
3.2. VH-Stage
3.3. The Position of the DVH Block
- Putting the DVH block in the encode layers at ➀ is shown in Figure 1. The feature extraction and the outputs of the network we designed can be expressed by the following formulaIn the above equations, x is the input of our proposed networks, represents the traditional convolution block, while represents the DVH block. and represent the encoder and decoder layers in the backbone network. means the high-fusion layer behind the up-sampling operation. and are the output of the corresponding network layer. represents the final output, while represents the whole neural networks.
- Putting the DVH block after the encoder layer at ➁ as shown in Figure 1, the feature extraction and output of the network we designed can be expressed by the following formula
- Putting the DVH block in and behind the encode layer at ➀ and ➁ is shown in Figure 1. The feature extraction process and output of the network can be expressed by the following formula
3.4. Loss Function
3.5. Datasets and Experimental Settings
3.5.1. Datasets
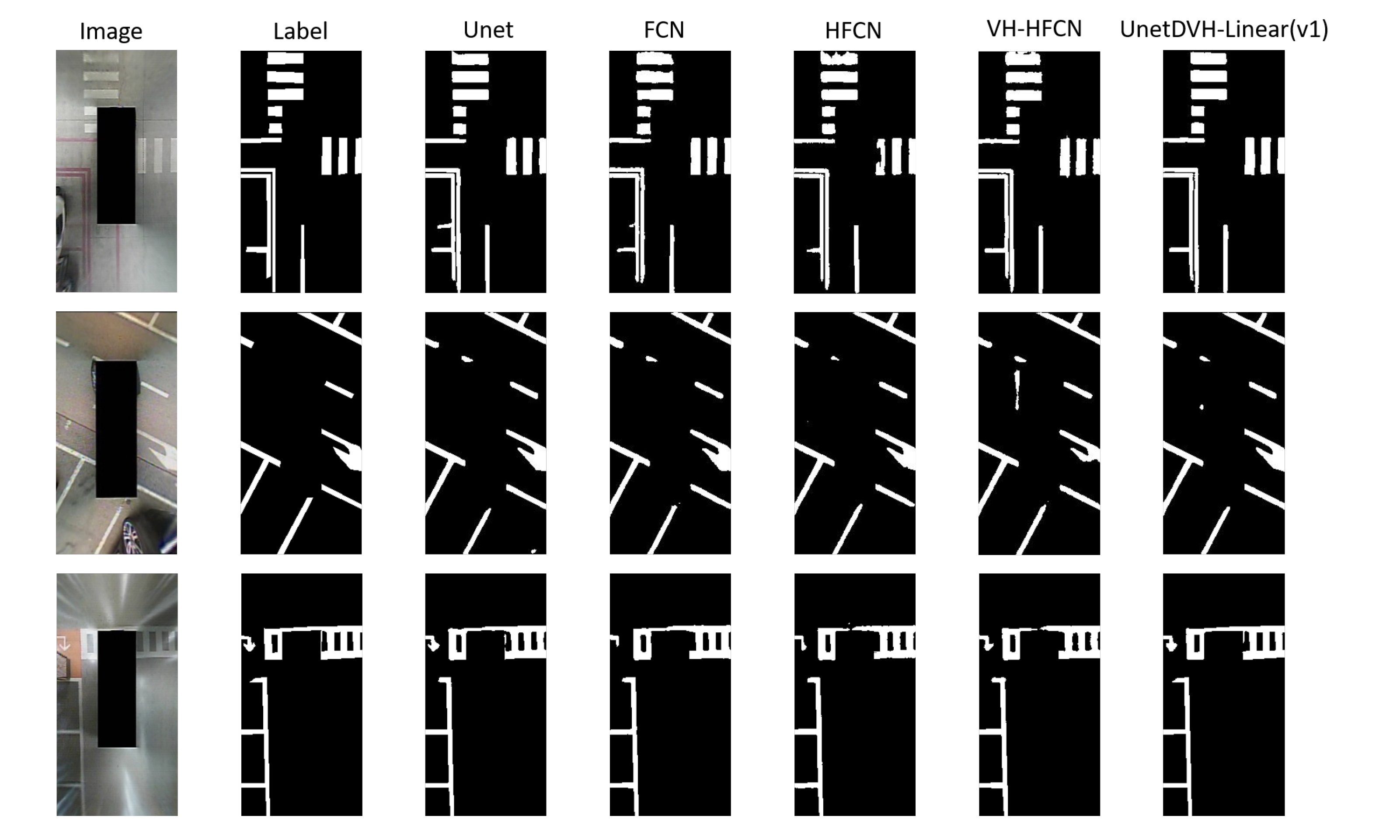
- The SS dataset [1]: The SS dataset is composed of Around View Monitor (AVM) images and corresponding annotation images that are collected from various parking conditions outdoors and indoors. This dataset contains 6763 camera images with pixels. The number of training images and test images is 4057 and 2706, respectively, among which there are four categories: free space, marker, vehicle, and other objects. Each image has a corresponding ground truth image that is composed of four-color annotations to distinguish different classes. In particular, the indoor samples are difficult to discern because the reflected light seems similar to slot markers, hence degrading the detection of slot markers;
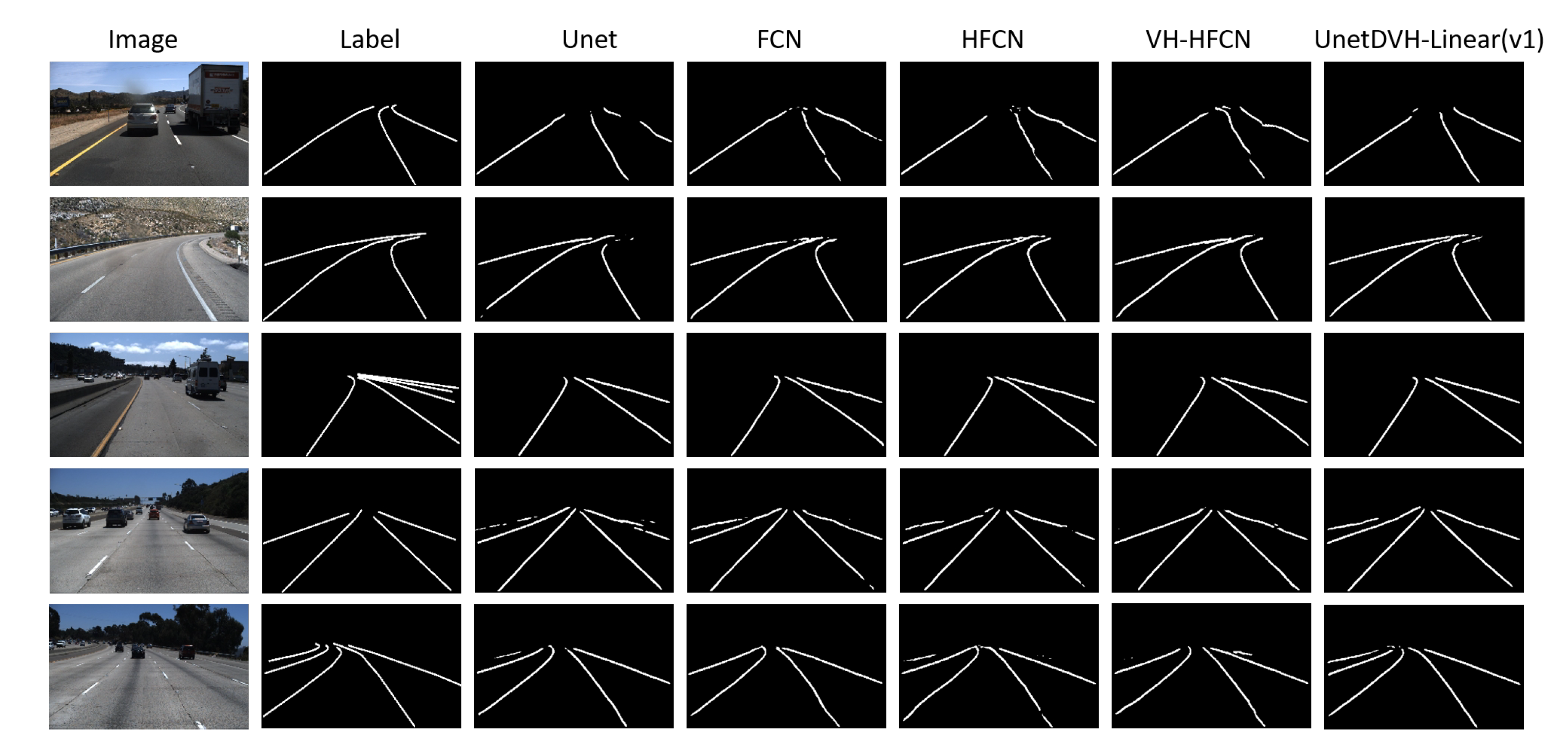
- The TuSimple lane dataset (http://benchmark.tusimple.ai/): This dataset released approximately 7000 one-second-long video clips of 20 frames each, and the last frame of each clip contains labeled lanes. This dataset contains complex weather, different daytimes, and different traffic conditions with 6408 1280 × 720 images, separated into 3626 for training, and 2782 for testing. The types of annotations are polylines for lane markings. All the annotations information is saved in a JSON file to guide researchers in how to use the data in the clips directory. The annotations and testing are focussed on the current and left/right lanes. There will be, at most, five lane markings in ‘lanes‘. The extra lane is used when changing lanes since it is confused to tell which lane is the current lane. The polylines from the recording car are organized by gaps at the same distance (’h_sample’ in each label data), and 410 images are extracted from the training set used as a validation set during training;
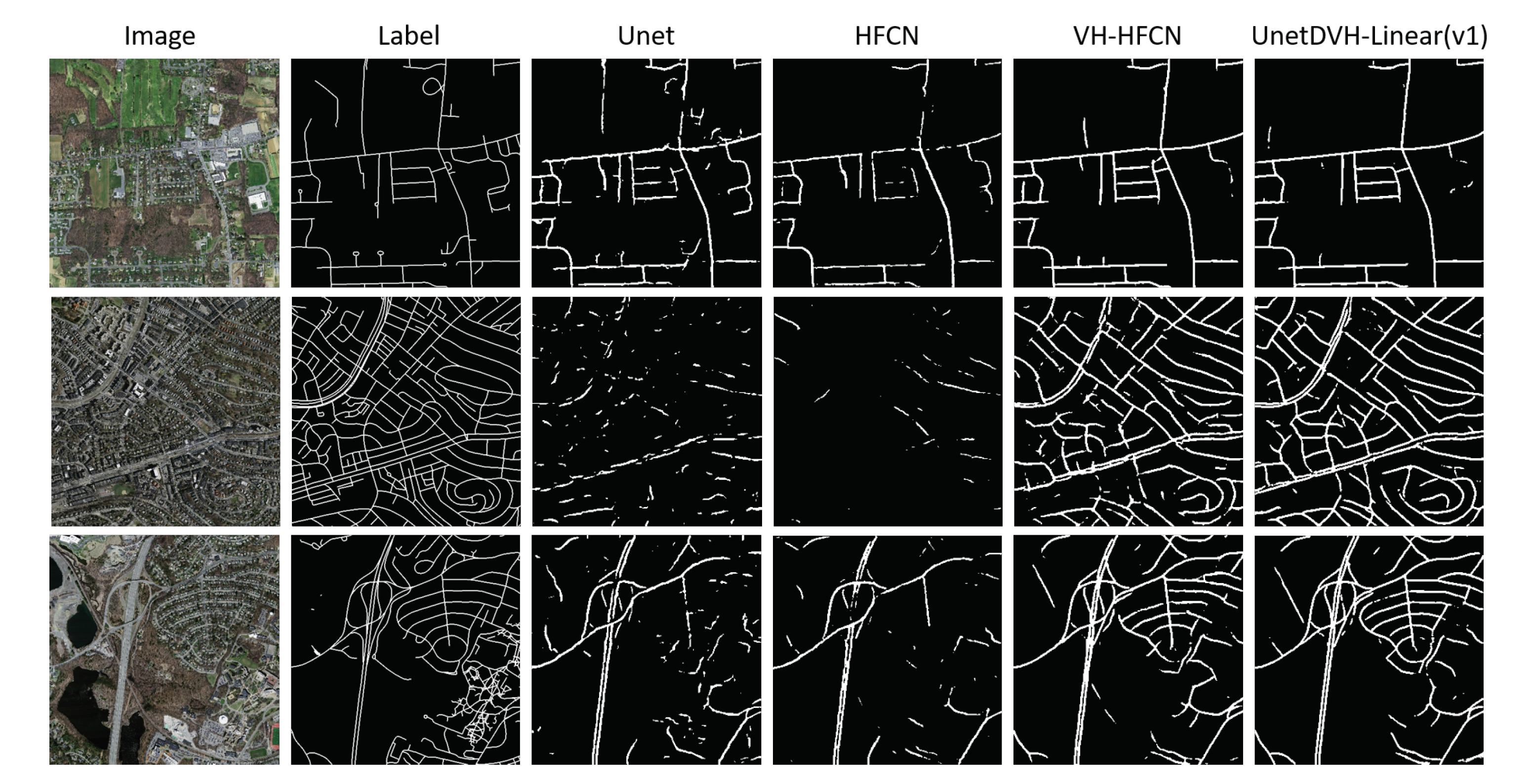
- The Massachusetts Roads Dataset [39] (https://www.cs.toronto.edu/~vmnih/data/): The Massachusetts Roads Dataset consists of 1171 aerial images. On the road data, each image is 1500 × 1500 pixels in size. The dataset is randomly split into a training set of 1108 images, a test set of 49 images, and a validation set of 14 images. The dataset covers a wide variety of urban, suburban, and rural regions with an area of over 2600 km. With the test set alone covering over 110 k2, this is by far the largest and the most challenging aerial image labeling dataset.
3.5.2. Experimental Settings
3.5.3. Experimental Models
3.6. Metrics
3.7. Results
3.7.1. Comparison with State-of-the-Art Methods
3.7.2. An Comparison with Different Models
3.7.3. Experiments with Different VH-Stage
3.7.4. An Comparison with the v9h9 and the DVH Block
3.7.5. Experiments on the Massachusetts Roads Dataset
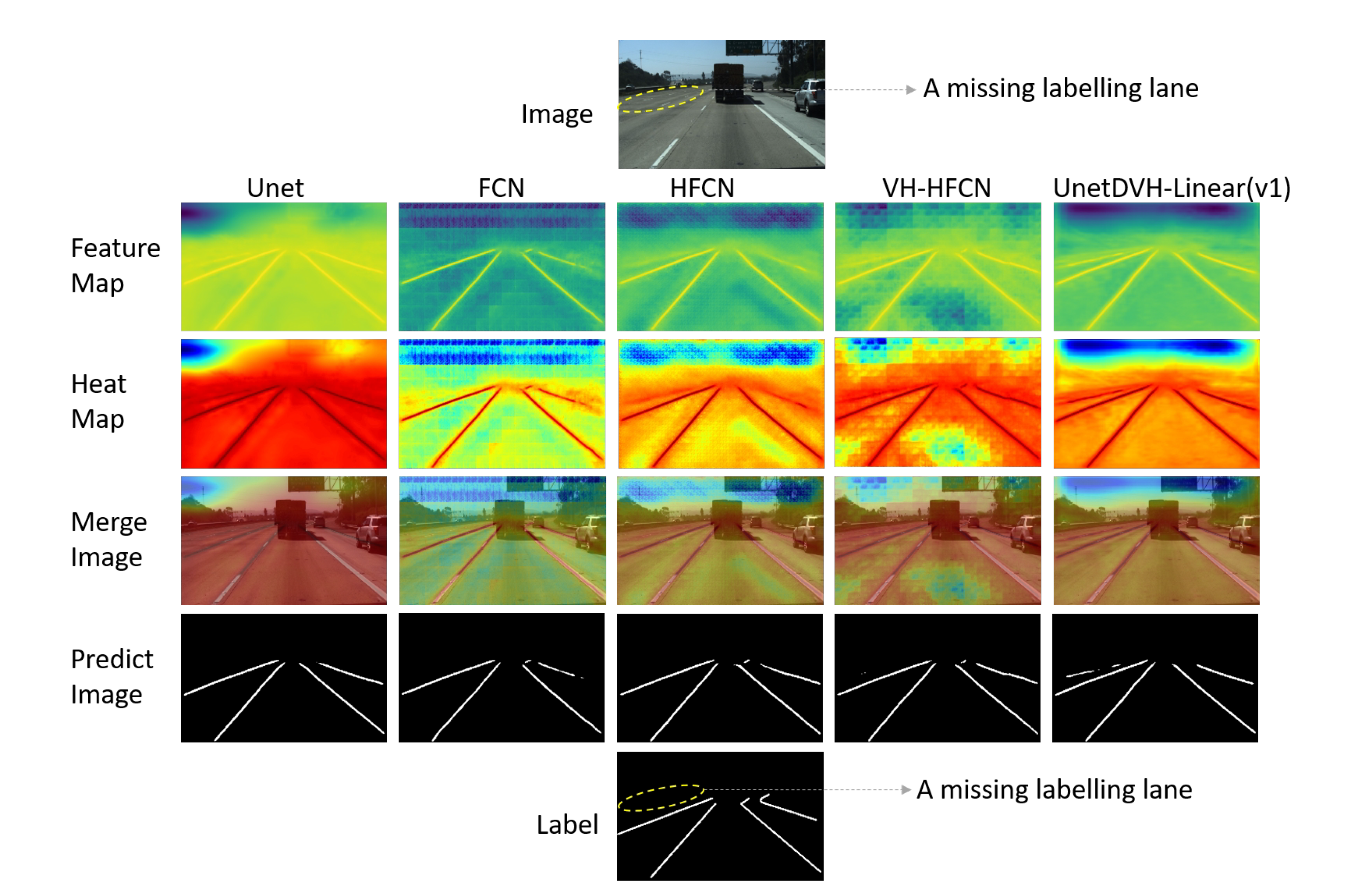
4. Visualization of Results and Discussion
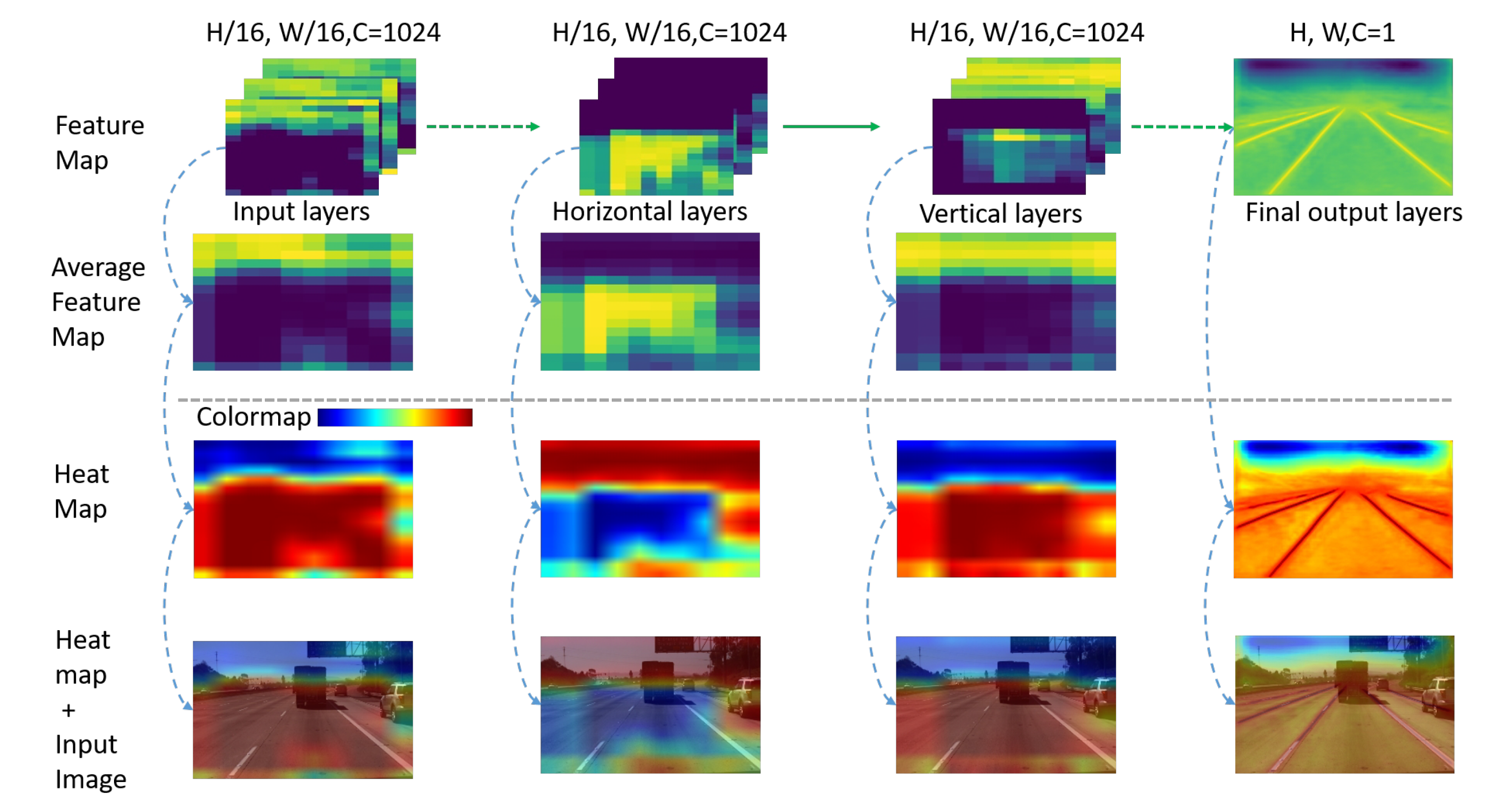
4.1. Feature Maps Visualization
4.2. Segmentation Results
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| FCN | Fully Convolutional Network |
| CNN | Comvolutional Netural Network |
| DVH | Dilated convolution with vertical and horizontal kernels |
| HOG | Histogram of Oriented Gradient |
| LSTM | Long Short-Term Memory |
| MPA | Mean Pixel Accuracy |
| PA | Pixel Accuracy |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| GAN | Generative Adversarial Network |
| BCELoss | Binary Cross-Entropy Loss |
| GPU | Graphics Processing Unit |
| RAM | Random Access Memory |
| HF | High Fusion |
| VH-stage | Vertical and Horizontal stage |
| log | Logarithmic Function |
| Set of Real Numbers | |
| A float value or a constant float tensor. The exponential decay rate for the 1st moment estimates. | |
| A float value or a constant float tensor. The exponential decay rate for the 2nd moment estimates. | |
| The multiplicative factor of the decay learning rate. | |
| Millisecond | |
| Square Kilometers | |
| r | Receptive field |
| ReLU function | |
| Dilated factor | |
| s | Stride in Convolution Layers |
| k | Kernel size |
References
- Jang, C.; Sunwoo, M. Semantic segmentation-based parking space detection with standalone around view monitoring system. Mach. Vis. Appl. 2019, 30, 309–319. [Google Scholar] [CrossRef]
- Wu, Y.; Yang, T.; Zhao, J.; Guan, L.; Jiang, W. VH-HFCN based Parking Slot and Lane Markings Segmentation on Panoramic Surround View. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards End-to-End Lane Detection: An Instance Segmentation Approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar]
- Zhang, W.; Mahale, T. End to End Video Segmentation for Driving: Lane Detection For Autonomous Car. arXiv 2018, arXiv:1812.05914. [Google Scholar]
- Chen, P.R.; Lo, S.Y.; Hang, H.M.; Chan, S.W.; Lin, J.J. Efficient road lane marking detection with deep learning. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018. [Google Scholar]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. Road networks as collections of minimum cost paths. ISPRS J. Photogramm. Remote. Sens. 2015, 108, 128–137. [Google Scholar] [CrossRef]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. A higher-order crf model for road network extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 1698–1705. [Google Scholar]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1591–1594. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 679–698. [Google Scholar] [CrossRef]
- Gupta, S.; Mazumdar, S.G. Sobel edge detection algorithm. Int. J. Comput. Sci. Manag. Res. 2013, 2, 1578–1583. [Google Scholar]
- Naegel, B.; Passat, N.; Ronse, C. Grey-level hit-or-miss transforms—Part i: Unified theory. Pattern Recognit. 2007, 40, 635–647. [Google Scholar] [CrossRef] [Green Version]
- Aptoula, E.; Lefevre, S.; Ronse, C. A hit-or-miss transform for multivariate images. Pattern Recognit. Lett. 2009, 30, 760–764. [Google Scholar] [CrossRef] [Green Version]
- Bai, X.; Zhou, F. Analysis of new top-hat transformation and the application for infrared dim small target detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Wei, Y.; Tian, Q.; Guo, J.; Huang, W.; Cao, J. Multi-vehicle detection algorithm through combining Harr and HOG features. Math. Comput. Simul. 2019, 155, 130–145. [Google Scholar] [CrossRef]
- Illingworth, J.; Kittler, J. A survey of the hough transform. Comput. Vision Graph. Image Process. 1988, 44, 87–116. [Google Scholar] [CrossRef]
- Zhang, Q.; Couloigner, I. Accurate Centerline Detection and Line Width Estimation of Thick Lines Using the Radon Transform. IEEE Trans. Image Process. 2007, 16, 310–316. [Google Scholar] [CrossRef] [PubMed]
- Cha, J.; Cofer, R.; Kozaitis, S. Extended Hough transform for linear feature detection. Pattern Recognit. 2006, 39, 1034–1043. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zubair, S.; Yan, F.; Wang, W. Dictionary learning based sparse coefficients for audio classification with max and average pooling. Digit. Signal Process. 2013, 23, 960–970. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martínez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 13–16 December 2015; pp. 2650–2658. [Google Scholar]
- Roy, A.; Todorovic, S. A Multi-scale CNN for Affordance Segmentation in RGB Images. In Proceedings of the Computer Vision – ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; pp. 186–201. [Google Scholar]
- Bian, X.; Lim, S.N.; Zhou, N. Multiscale fully convolutional network with application to industrial inspection. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016; pp. 1–8. [Google Scholar]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive Pyramid Context Network for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7519–7528. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.-M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 14–19 June 2020; pp. 4002–4011. [Google Scholar]
- Lo, S.-Y.; Hang, H.-M.; Chan, S.-W.; Lin, J.-J. Multi-Class Lane Semantic Segmentation using Efficient Convolutional Networks. In Proceedings of the 2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–6. [Google Scholar]
- Yang, T.; Wu, Y.; Zhao, J.; Guan, L. Semantic segmentation via highly fused convolutional network with multiple soft cost functions. Cogn. Syst. Res. 2019, 53, 20–30. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Yang, T.; Zhao, J.; Guan, L.; Li, J. Fully Combined Convolutional Network with Soft Cost Function for Traffic Scene Parsing. In Proceedings of the Intelligent Computing Theories and Application, Liverpool, UK, 7–10 August 2017. [Google Scholar]
- Pizzati, F.; Allodi, M.; Barrera, A.; García, F. Lane Detection and Classification Using Cascaded CNNs. arXiv 2019, arXiv:1907.01294. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.369.1363&rep=rep1&type=pdf (accessed on 10 October 2020).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, Nevada, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Wu, J.; Chung, A.C.S. Cross Entropy: A New Solver for Markov Random Field Modeling and Applications to Medical Image Segmentation. Comput. Vis. 2005, 229–237. [Google Scholar]
- Soomro, T.A.; Afifi, A.J.; Gao, J.; Hellwich, O.; Paul, M.; Zheng, L. Strided U-Net Model: Retinal Vessels Segmentation using Dice Loss. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Palm Springs, CA, USA, 26–29 October 2018; pp. 1–8. [Google Scholar]
- Roy, A.G.; Conjeti, S.; Karri, S.P.K.; Sheet, D.; Katouzian, A.; Wachinger, C.; Navab, N. ReLayNet: Retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks. Biomed. Opt. Express 2017, 8, 3627–3642. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, G.; Zhao, P.; Zhang, W.; Miao, J.; Wang, J.; Choe, T.E. Gen-LaneNet: A Generalized and Scalable Approach for 3D Lane Detection. arXiv 2020, arXiv:2003.10656. [Google Scholar]
- Qin, T.; Chen, T.; Chen, Y.; Su, Q. AVP-SLAM: Semantic Visual Mapping and Localization for Autonomous Vehicles in the Parking Lot. arXiv 2020, arXiv:2007.01813. [Google Scholar]
- Ghafoorian, M.; Nugteren, C.; Baka, N.; Booij, O.; Hofmann, M. EL-GAN: Embedding loss driven generative adversarial networks for lane detection. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 256–272. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Available online: https://static.bsteiner.info/papers/pytorch.pdf (accessed on 10 October 2020).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zou, Q.; Jiang, H.; Dai, Q.; Yue, Y.; Chen, L.; Wang, Q. Robust Lane Detection From Continuous Driving Scenes Using Deep Neural Networks. IEEE Trans. Veh. Technol. 2019, 69, 41–54. [Google Scholar] [CrossRef] [Green Version]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial CNN for traffic scene understanding. arXiv 2017, arXiv:1712.06080. [Google Scholar]
- Hsu, Y.-C.; Xu, Z.; Kira, Z.; Huang, J. Learning to Cluster for Proposal-Free Instance Segmentation. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Acre, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | ➀ | ➁ |
|---|---|---|
| VH-HFCN [2] | × | v9h9 |
| Unet-D (ours) | × | Dilated convolution [kernel size is (3,3), dilted factor is (2,2), stride=1] |
| UnetDVH-Linear (v1) (ours) | × | DVH |
| UnetDVH-Linear (v2) (ours) | DVH | × |
| UnetDVH-Linear (v3) (ours) | DVH | DVH |
| UnetDVH-Linear (v4) (ours) | × | v9h9 |
| UnetDVH-Linear (v5) (ours) | v9h9 | × |
| UnetDVH-Linear (v6) (ours) | v9h9 | v9h9 |
| UnetDVH-Linear (v7) (ours) | v9h9 | DVH |
| UnetDVH-Linear (v8) (ours) | DVH | v9h9 |
| Rank | Methods | Name on Board | Using Extra Data | Accurcay (%) | Average Inference Times (ms) | ||
|---|---|---|---|---|---|---|---|
| 2 | Zou et al. [49] | UNet ConvLSTM | True | 97.3 | 0.0416 | 47.61 | |
| 3 | Unpublished | leonardoli | - | 96.9 | 0.0442 | 0.0197 | - |
| 4 | Pan et al. [50] | SCNN | True | 96.5 | 0.0617 | 0.0180 | 18.63 |
| 5 | Hsu et al. [51] | N/A | False | 96.5 | 0.0851 | 0.0269 | - |
| 6 | Ghafoorian et al. [46] | TomTom EL-GAN | False | 96.4 | 0.0412 | 0.0336 | - |
| 7 | Neven et al. [3] | LaneNet | False | 96.4 | 0.0780 | 0.0244 | 5.04 |
| 8 | Unpublished | li | - | 96.1 | 0.2033 | 0.0387 | - |
| 9 | Pizzati et al. [38]. | Cascade-LD | False | 95.24 | 0.1197 | 0.0620 | 5.71 |
| 1 | Ours (v1) | N/A | False | 0.0339 | 12.51 |
| Methods | Precision | Recall | MPA | F1 |
|---|---|---|---|---|
| Unet [22] | 84.29 | 86.37 | 92.29 | 85.31 |
| FCN [23] | 86.02 | 92.33 | 85.52 | |
| HFCN [36] | 83.07 | 86.29 | 91.76 | 84.65 |
| VH-HFCN [2] | 81.79 | 86.94 | 91.07 | 84.29 |
| UnetDVH-Linear (v1) | 84.68 |
| Methods | Precision | Recall | MPA | F1 |
|---|---|---|---|---|
| Unet [22] | 65.41 | 77.73 | 82.40 | 71.03 |
| FCN [23] | 65.88 | 75.38 | 82.61 | 70.31 |
| HFCN [36] | 65.08 | 77.09 | 82.23 | 70.58 |
| VH-HFCN [2] | 65.57 | 76.52 | 82.47 | 70.61 |
| UnetDVH-Linear (v1) |
| Methods | Precision | Recall | MPA | F1 |
|---|---|---|---|---|
| Unet [22] | 84.29 | 86.37 | 92.29 | 85.31 |
| FCN [23] | 85.03 | 86.02 | 92.33 | 85.52 |
| HFCN [36] | 83.07 | 86.29 | 91.76 | 84.65 |
| VH-HFCN [2] | 81.79 | 86.94 | 91.07 | 84.29 |
| Unet-D | 85.38 | 87.62 | 92.84 | 86.48 |
| UnetDVH-Linear (v1) | 84.68 | 86.40 | ||
| UnetDVH-Linear (v2) | 84.81 | 87.43 | 92.57 | 86.10 |
| UnetDVH-Linear (v3) | 85.42 | 87.32 | 92.87 | 86.36 |
| UnetDVH-Linear (v4) | 85.22 | 88.12 | 92.79 | 86.64 |
| UnetDVH-Linear (v5) | 84.90 | 87.78 | 92.62 | 86.31 |
| UnetDVH-Linear (v6) | 87.59 | 93.07 |
| Methods | Precision | Recall | MPA | F1 |
|---|---|---|---|---|
| Unet [22] | 65.41 | 77.73 | 82.40 | 71.03 |
| FCN [23] | 65.88 | 75.38 | 82.61 | 70.31 |
| HFCN [36] | 65.08 | 77.09 | 82.23 | 70.58 |
| VH-HFCN [2] | 65.57 | 76.52 | 82.47 | 70.61 |
| Unet-D | 66.07 | 77.65 | 82.75 | 71.39 |
| UnetDVH-Linear (v1) | 66.31 | 78.33 | 82.87 | 71.82 |
| UnetDVH-Linear (v2) | 66.79 | 76.41 | 83.08 | 71.27 |
| UnetDVH-Linear (v3) | 76.71 | 71.48 | ||
| UnetDVH-Linear (v4) | 66.40 | 82.91 | ||
| UnetDVH-Linear (v5) | 66.14 | 77.70 | 82.78 | 71.46 |
| UnetDVH-Linear (v6) | 66.45 | 77.20 | 82.92 | 71.42 |
| Methods | Precision | Recall | MPA | F1 |
|---|---|---|---|---|
| Unet [22] | 84.29 | 86.37 | 92.29 | 83.79 |
| FCN [23] | 86.02 | 92.33 | 85.36 | |
| HFCN [36] | 83.07 | 86.29 | 91.76 | 86.04 |
| VH-HFCN [2] | 81.79 | 86.94 | 91.07 | 84.12 |
| UnetDVH-Linear (v3) | 85.42 | 87.32 | 92.87 | 86.36 |
| UnetDVH-Linear (v6) | 87.59 | |||
| UnetDVH-Linear (v7) | 85.08 | 87.75 | 92.71 | 86.40 |
| UnetDVH-Linear (v8) | 84.83 | 92.59 | 86.40 |
| Methods | Precision | Recall | MPA | F1 |
|---|---|---|---|---|
| Unet [22] | 65.41 | 77.73 | 82.40 | 71.03 |
| FCN [23] | 65.88 | 75.38 | 82.61 | 70.31 |
| HFCN [36] | 65.08 | 77.09 | 82.23 | 70.58 |
| VH-HFCN [2] | 65.57 | 76.52 | 82.47 | 70.61 |
| UnetDVH-Linear (v3) | 76.00 | 71.48 | ||
| UnetDVH-Linear (v6) | 66.45 | 77.20 | 82.92 | 71.42 |
| UnetDVH-Linear (v7) | 66.61 | 76.70 | 83.00 | 71.30 |
| UnetDVH-Linear (v8) | 66.20 | 82.81 |
| Methods | Data Augmentation | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| Jan et al. [7] | False | 82.5 | 40.5 | 32.2 | 35.9 |
| Jan et al. [6] | False | 89.9 | 47.1 | 67.9 | 55.6 |
| Zhong et al. [8] | False | 90.4 | 43.5 | 68.6 | 53.2 |
| Wei et al. [9] | False | 92.4 | 60.6 | 72.9 | 66.2 |
| UnetDVH-Linear (v1) | False |
| Methods | Data Augmentation | Precision | Recall | F1 |
|---|---|---|---|---|
| Unet [22] | False | 65.40 | 63.91 | 64.64 |
| HFCN [36] | False | 73.00 | 65.32 | 68.94 |
| VH-HFCN [2] | False | 75.85 | 77.07 | 76.45 |
| Unet-D | False | 57.61 | 72.12 | 64.05 |
| UnetDVH-Linear (v1) | False |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, J.; Cao, L.; Li, W.; Luo, X.; Feng, X. UnetDVH-Linear: Linear Feature Segmentation by Dilated Convolution with Vertical and Horizontal Kernels. Sensors 2020, 20, 5759. https://doi.org/10.3390/s20205759
Liao J, Cao L, Li W, Luo X, Feng X. UnetDVH-Linear: Linear Feature Segmentation by Dilated Convolution with Vertical and Horizontal Kernels. Sensors. 2020; 20(20):5759. https://doi.org/10.3390/s20205759
Chicago/Turabian StyleLiao, Jiacai, Libo Cao, Wei Li, Xiaole Luo, and Xiexing Feng. 2020. "UnetDVH-Linear: Linear Feature Segmentation by Dilated Convolution with Vertical and Horizontal Kernels" Sensors 20, no. 20: 5759. https://doi.org/10.3390/s20205759
APA StyleLiao, J., Cao, L., Li, W., Luo, X., & Feng, X. (2020). UnetDVH-Linear: Linear Feature Segmentation by Dilated Convolution with Vertical and Horizontal Kernels. Sensors, 20(20), 5759. https://doi.org/10.3390/s20205759