1. Introduction
Visual object tracking is an important area of computer vision with applications in robotics [
1], autonomous driving [
2,
3], video surveillance [
4], pose estimation [
5], medicine [
6,
7], activity recognition [
8], and many others. Visual object tracking refers to locating a region of interest, typically a bounding box around the tracked object, in a sequence of frames. Visual tracking is challenging due to variations in appearance, illumination and scaling, changes in zoom, rotation, distortions, occlusion, abrupt motion, similar looking distractors, out of frame movement, etc.
Early visual tracking methods relied on hand crafted features, such as optical flow, and keypoints, and related benchmarking studies analyzed their performance [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25]. Popular trackers such as Kernelized Correlation Filters (KCF) [
20], Structured output tracking with Kernels (STRUCK) [
21], Spatially Regularized Discriminative Correlation Filters (SRDCF) [
23], and Background-Aware Correlation Filters (BACF) [
22] used hand-crafted features. However, traditional methods may fail in challenging situations, such as those encountered in the 2018 Visual Object Tracking (VOT 2018) challenge [
26] and the 2015 Object Tracking Benchmark (OTB 2015) challenge [
27]. In recent years, deep learning has advanced object detection and other computer vision tasks, including tracking, semantic segmentation, pose estimation, visual question answering, and style transfer. In the VOT 2018 challenge, almost all of the top performing trackers used deep learning features based on convolutional neural networks (CNN) [
26]. In our study, we focus on trackers based on such deep learning features.
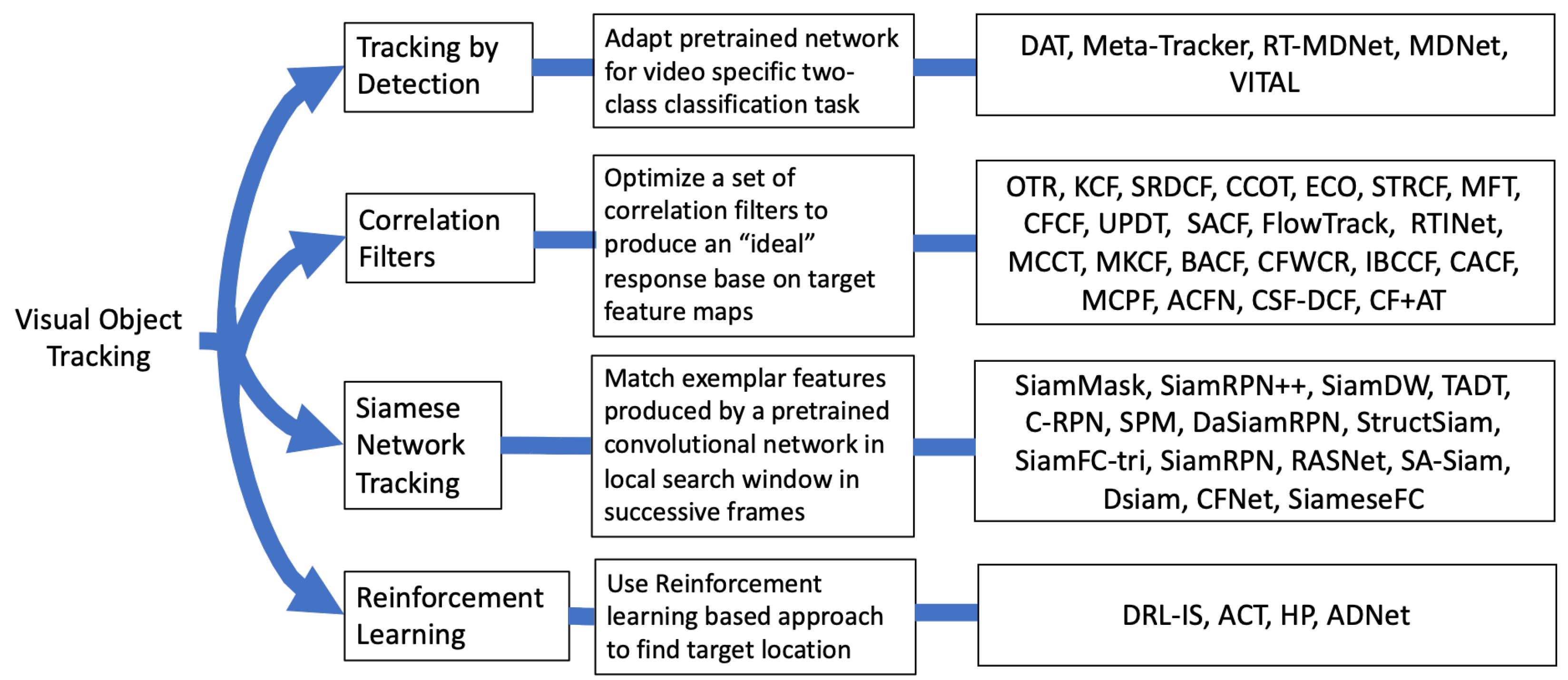
Recent CNN based trackers can be broadly categorized into four groups, as illustrated in
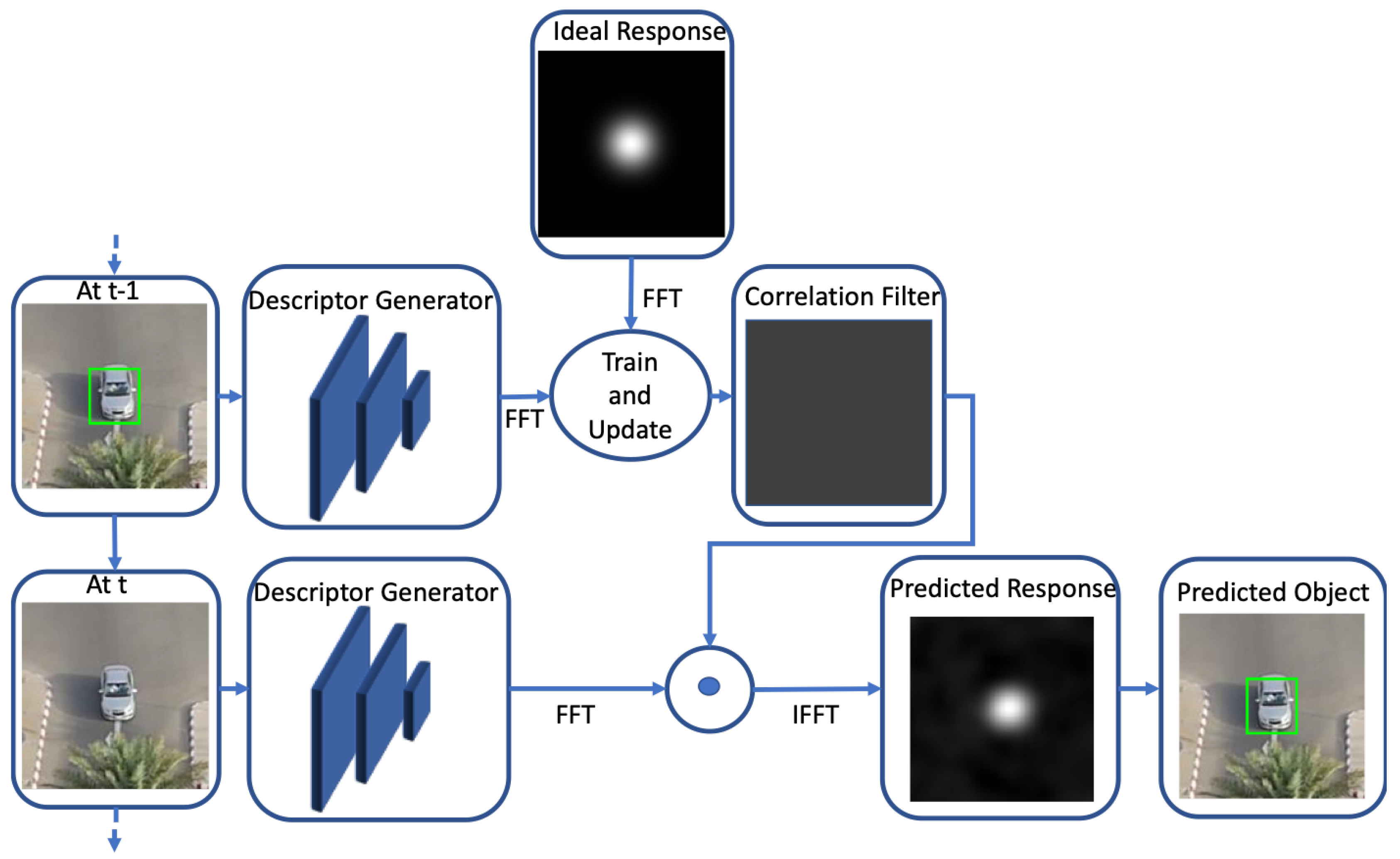
Figure 1: (i) Tracking by detection (TD), (ii) Correlation Filters (CF), (iii) Siamese networks (SN), and (iv) Reinforcement learning (RL). In CF based trackers, correlation filters are learned to match the target distribution aiming for a response that is Gaussian distributed. The implementation of the CF trackers is usually done in the Fourier domain for computational efficiency and filters are updated during online tracking. However, the filter update reduces the speed of the tracking procedure [
23,
28,
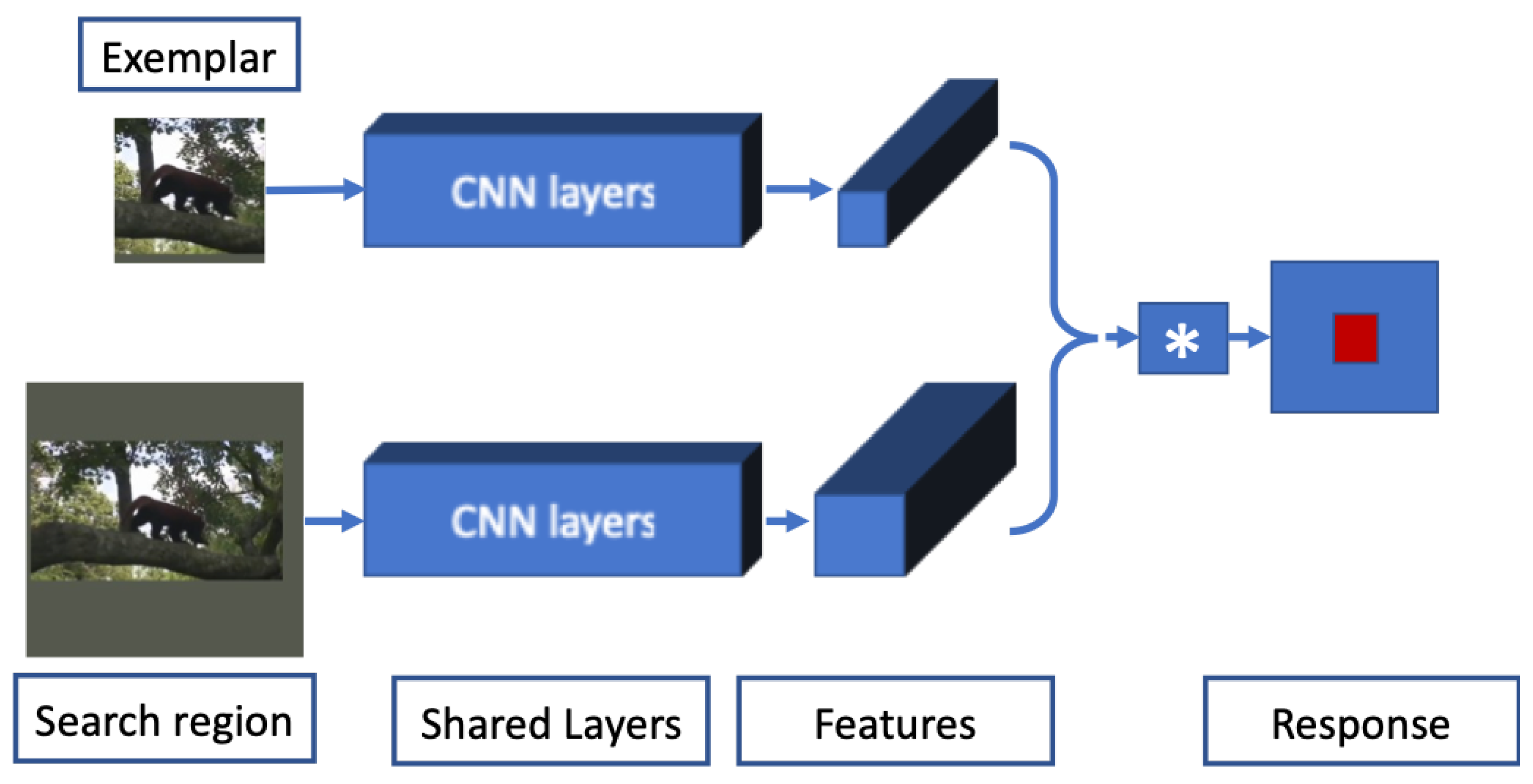
29]. SN-based trackers approach tracking as a similarity learning problem, where matching is done in feature space. SN trackers are trained offline and are not updated online, which is efficient but may reduce tracking performance [
30,
31,
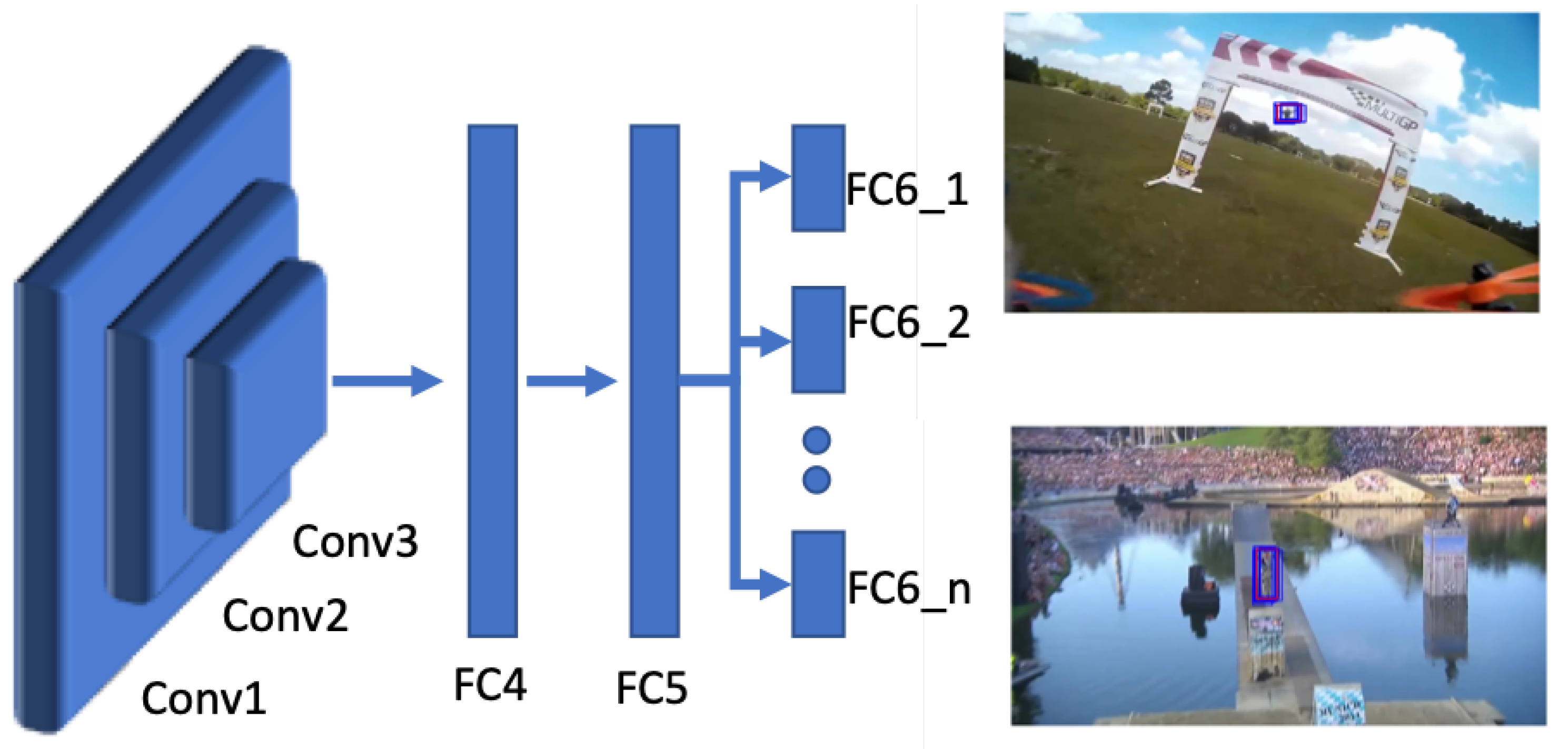
32]. TD-based trackers treat tracking as a binary classification problem that aims to separate the target from the background. Multiple patches are taken in the target frame (
frame) near the target location in the previous frame (
frame) and the patch with the highest score is selected as the target patch [
33,
34,
35]. RL-based trackers learn an optimal path to the tracked object, either by moving the predicted location to the target location or by learning hyperparameters for tracking [
36,
37].
Evaluating tracking algorithms requires large and diverse datasets with annotated ground truth of the target location at every frame. Additionally, attribute annotation is important to fully assess tracker performance in different challenging situations, such as occlusion, illumination variation, etc. There are several tracking benchmarks in the literature [
10,
26,
27,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54]. Two of the most popular tracking benchmarks are the OTB [
27,
38] and the VOT challenge [
26,
39,
40,
41,
42,
43] datasets. In our study we benchmark various trackers on aerial datasets, another important category of datasets that consist of sequences taken from aerial platforms. We consider a video to be aerial if the camera is on an airplane or unmanned aerial vehicle (UAV). To include a greater variety of datasets, we broaden this definition to include cases where the camera is located anywhere above the ground ranging from a roof to a satellite.
There are some key factors that make aerial tracking different from tracking in standard ground level videos. In the aerial videos, the area covered by the field of view of the camera is usually much larger than that of ground level videos. More importantly, in aerial videos, the tracked object is much smaller in size in terms of pixels. Due to the smaller object size, it is more difficult to generate discriminative features, which adversely affects tracking performance. The object’s size and viewpoint can change significantly and quickly in aerial videos. Additionally, the tracked object may be occluded for a long time and even disappear for several frames. Camera motion often causes abrupt changes in the object appearance and may result in out-of-frame movement for the tracked object. These characteristics present a unique set of challenges for aerial tracking compared to standard tracking on ground level videos. Initial work by Minnehan et al. [
55] indicated that the performance of deep trackers varies significantly when tracking in aerial videos. Popular trackers, such as tracking by detection MDNet [
33], or CF-based CCOT [
29], were not as effective when tracking in aerial videos due to occlusion, smaller target size, and camera motion [
55]. Our study differs from [
55] in various aspects. We consider a larger number of more recent trackers from four general groups. We perform our benchmarking on multiple datasets and conduct detailed evaluation for various attributes of aerial imagery.
Several review papers exist in the literature that overview visual object tracking research [
9,
10,
56,
57]. Li et al. [
56] studied deep learning trackers based on network architecture, network training, and network function and ran experiments on OTB100, TC-128 [
46], and VOT2015 [
41] to compare different deep learning based trackers. Fiaz et al. [
57] performed an extensive review that compared various trackers based on different feature extraction methods. Trackers based on both deep learning and hand crafted features were evaluated on benchmarks, such as OTB 2015, OTB 2013 [
38], TC-128, OTTC [
57], and VOT 2017 [
39]. VOT challenges compare many different trackers and provide a good overview of the performance of recent trackers.
However, these review papers and tracker benchmark studies deal with datasets that are ground based. In this work, we focus on aerial tracking because the conditions encountered vary significantly from ground level situations. The main contributions of this paper can be described as follows.
We focus on aerial tracking using videos taken from aerial platforms. To our knowledge, this is the first comprehensive benchmarking study of visual object tracking on aerial videos.
We benchmark ten recent deep learning based trackers from four tracking groups.
We consider four different aerial benchmarks and compare the trackers’ performance in various challenging situations which provides a better understanding of the state-of-the-art of visual object tracking on aerial videos.
The rest of the paper is organized as follows. In
Section 2, we discuss the relevant tracking algorithms we incorporated in our benchmarking. In
Section 3, we discuss the datasets used in our experiments and the evaluation metrics. In
Section 4, we show the evaluation results on different benchmarks and discuss the comparison among different trackers on different benchmarks as well as specific attributes present within the datasets. In
Section 5, we present final remarks based on our evaluation.
3. Experiments
In our experiments, we evaluated a subset of the OTB 2015 [
27] dataset, the DTB70 [
48] dataset, the UAV123 [
47] dataset and the UAV20L [
47] dataset as our benchmark datasets. For the aerial style subset of OTB 2015 dataset, we selected the sequences where the camera is above the ground. The chosen sequences are: Basketball, Bolt, CarScale, Couple, Crossing, Crowds, Human3, Human4-2, Human5, Human6, Jogging-1, RedTeam, Subway, SUV, Walking, Walking2, and Woman.
The DTB70 dataset contains 70 sequences of UAV collected data where the bounding boxes are drawn manually. Some of the sequences are collected from YouTube. Different types of camera motion, including translation and rotation, are incorporated to make the dataset more challenging. Three types of targets appear in the videos: human, animal, and rigid objects.
The UAV123 dataset contains 123 video sequences taken from UAV platforms. Note that we excluded the seven synthetic sequences from the UAV123 dataset for our evaluation. A subset of the UAV123 dataset, UAV20L, is also evaluated for long-term tracking analysis.
The attributes of the aerial datasets are listed in
Table 1. These attributes make aerial tracking more challenging and their annotations are available within the corresponding datasets. The comparison of different trackers with these attributes provide better understanding of their performance under different tracking scenarios. Comparisons across UAV123 and DTB70 will indicate the generalizability of different trackers. For long-term tracking, an important consideration is consistent performance in a long temporal span, which tests the tracker’s ability to create a robust model and perform efficient model updates. Some trackers may drift a little from one frame to the next, which may not be noticeable in short term sequences, but eventually could result in target loss during long-term tracking.
Regarding the datasets, there are inherent differences between the OTB aerial subset and other aerial datasets in terms of resolution, attributes, and size of the objects to be tracked. In the standard OTB sequences, the objects are much larger and occupy a larger portion of the image frame, while in aerial datasets such as DTB70, UAV123, and UAV20L, the object to track takes a smaller portion of the image because the camera is higher and covers a larger area. Another important distinction of the DTB or UAV sequences is that the camera rotates around the object, whereas none of the videos in OTB sequences have this attribute. Additionally, the OTB benchmark sequences have minimal camera jitter and less clutter in the background.
Tracker codes were obtained from their Github repository at the URLs provided in
Table 2. None of the algorithms in our implementation were trained from scratch. All of the trackers were implemented in a server workstation with NVIDIA TITAN-V GPU. The CF-based algorithms were implemented using MATLAB and MATConvNet, whereas the other trackers are implemented using Python and PyTorch. Readers are referred to the Github pages in
Table 2 for further implementation details.
All the trackers were evaluated using one pass evaluation (OPE) introduced by the OTB benchmark evaluation procedure. The trackers were initialized in the very first frame and never re-initialized after a tracking failure. All the trackers were set to provide the output in the OTB format , where and are the coordinates of the top left corner of the bounding box, respectively, and w and h are the width and height of the box, respectively.
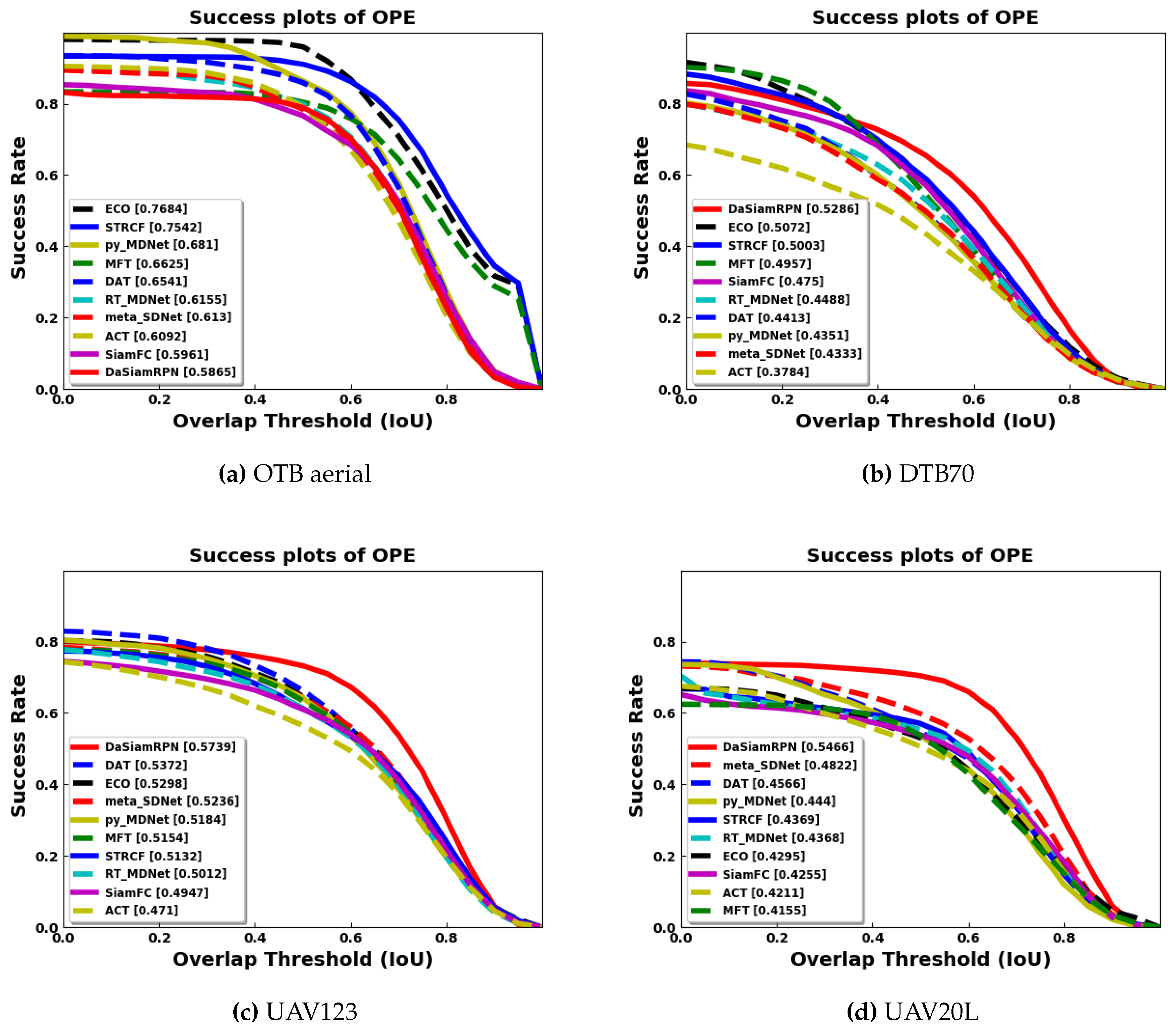
To evaluate tracker performance on the aerial benchmarking datasets, we examined visual examples as well as results based on evaluation metrics. To assess overlap performance, successful tracking is considered if the predicted bounding box and the groundtruth bounding box have an intersection over union (IOU) overlap greater than or equal to some threshold (e.g., 0.5). The tracker is evaluated for different thresholds and the success vs. threshold plot is obtained. The area under the curve (AUC) is computed based on the success vs. threshold plot and the trackers are ranked based on this value.
4. Results and Discussion
In this section, we have present our benchmarking results. In
Figure 5, the overlap success plot is shown for all benchmark datasets. The AUC, computed for each of the trackers, is indicated in brackets in the legends. The results show that DaSiamRPN outperforms the other trackers in three out of four datasets. In
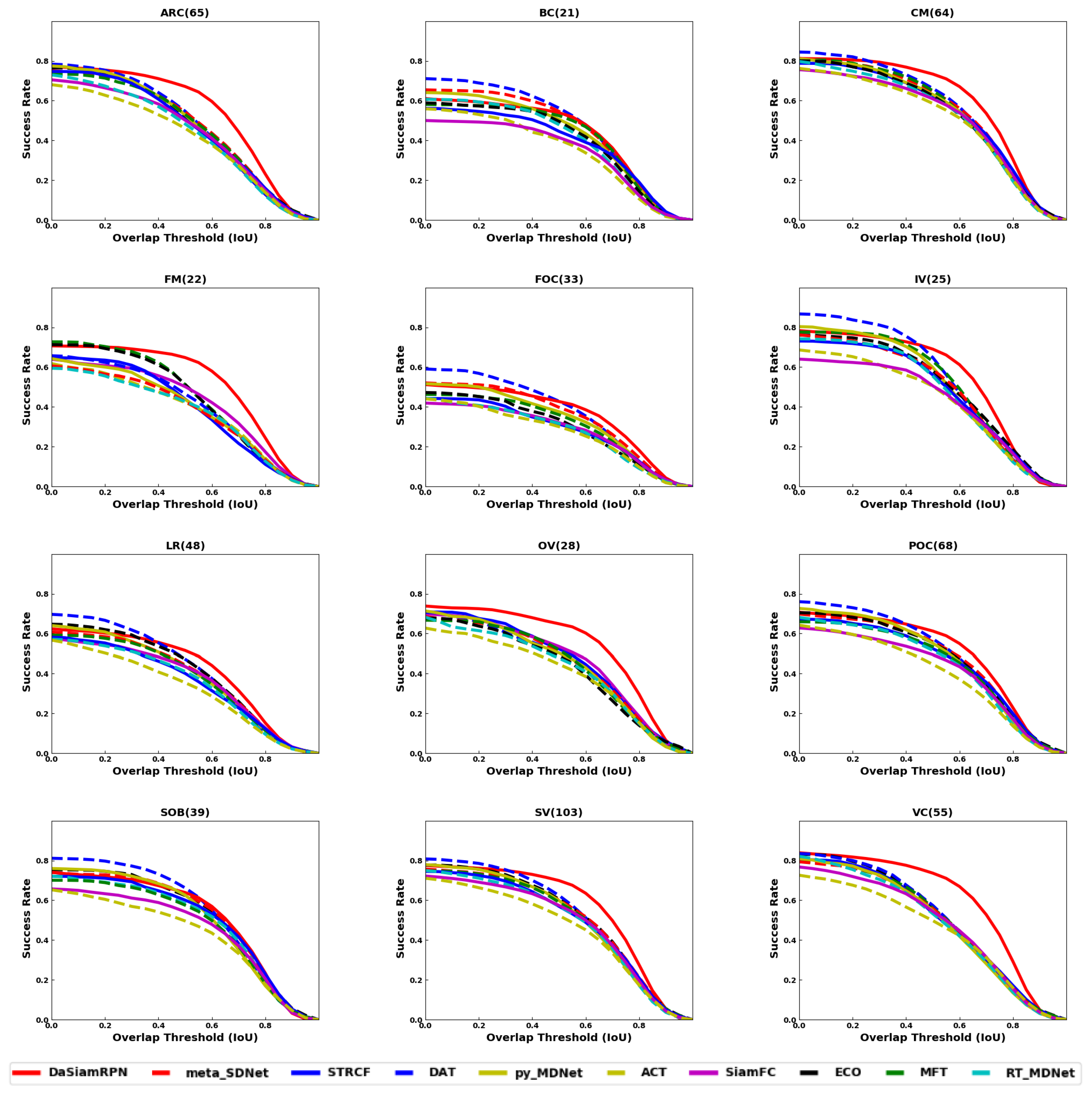
Figure 6, the overlap success plot is shown for various attributes in the UAV123 dataset. The AUC is computed and shown in the legends. This plot shows how well various trackers perform in specific challenges such as occlusion, out of view, fast motion, etc. It can be seen from these results that DaSiamRPN does the best in most of the challenges. In
Table 3, tracker performance (in terms of AUC) is compared for the ground based OTB dataset and the aerial datasets. The results show that even though the AUC for all trackers is high for OTB datasets, their performance was significantly reduced in the aerial datasets.
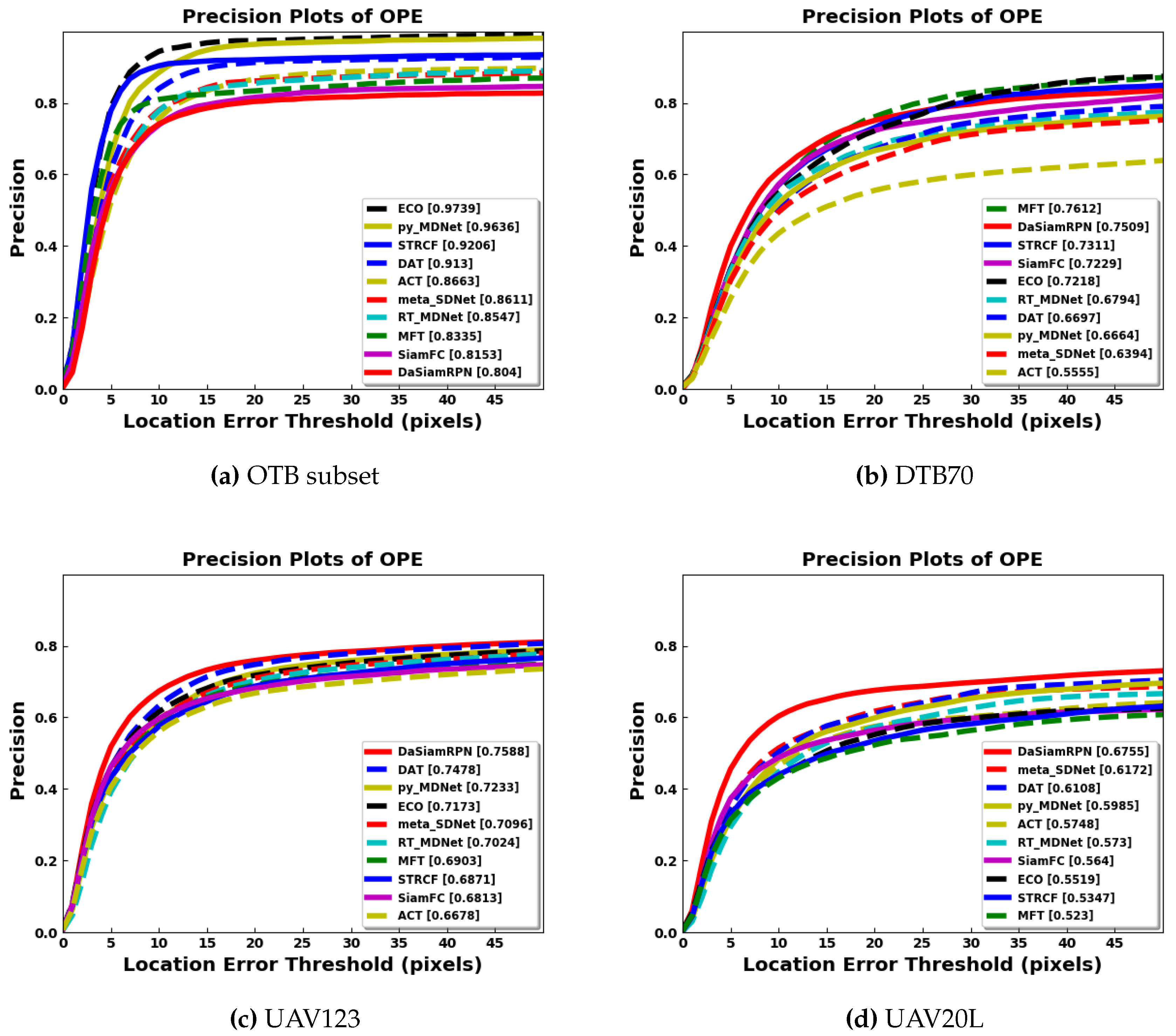
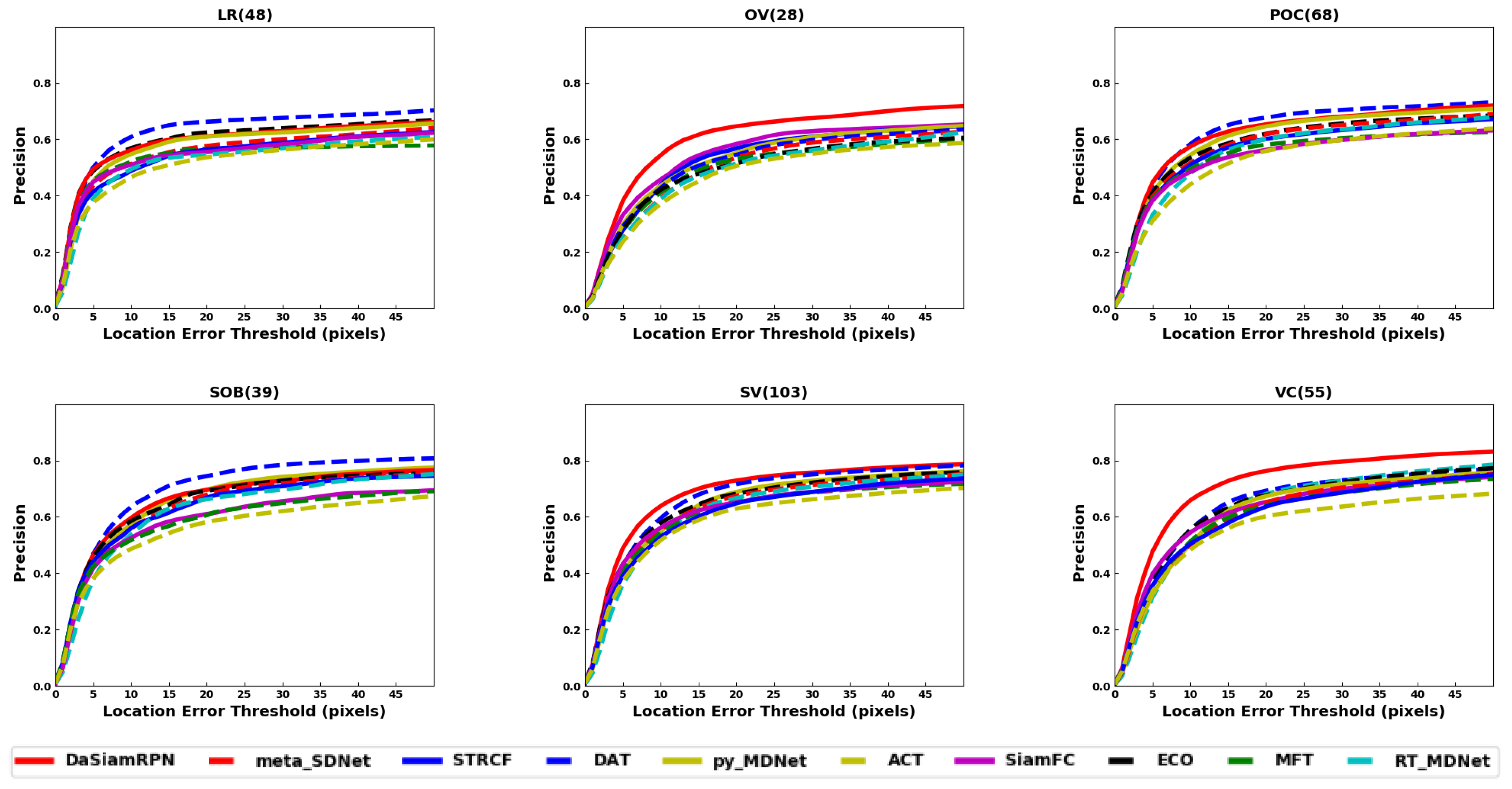
In terms of precision, the success rate of each tracker is evaluated based on the center to center distance, between the predicted bounding box and the groundtruth bounding box, compared to some predefined threshold in pixels. The center distance threshold is swept to find the precision vs. threshold plots. The precision values for a threshold of 20 pixels are shown in the brackets of the legends in the precision plots.
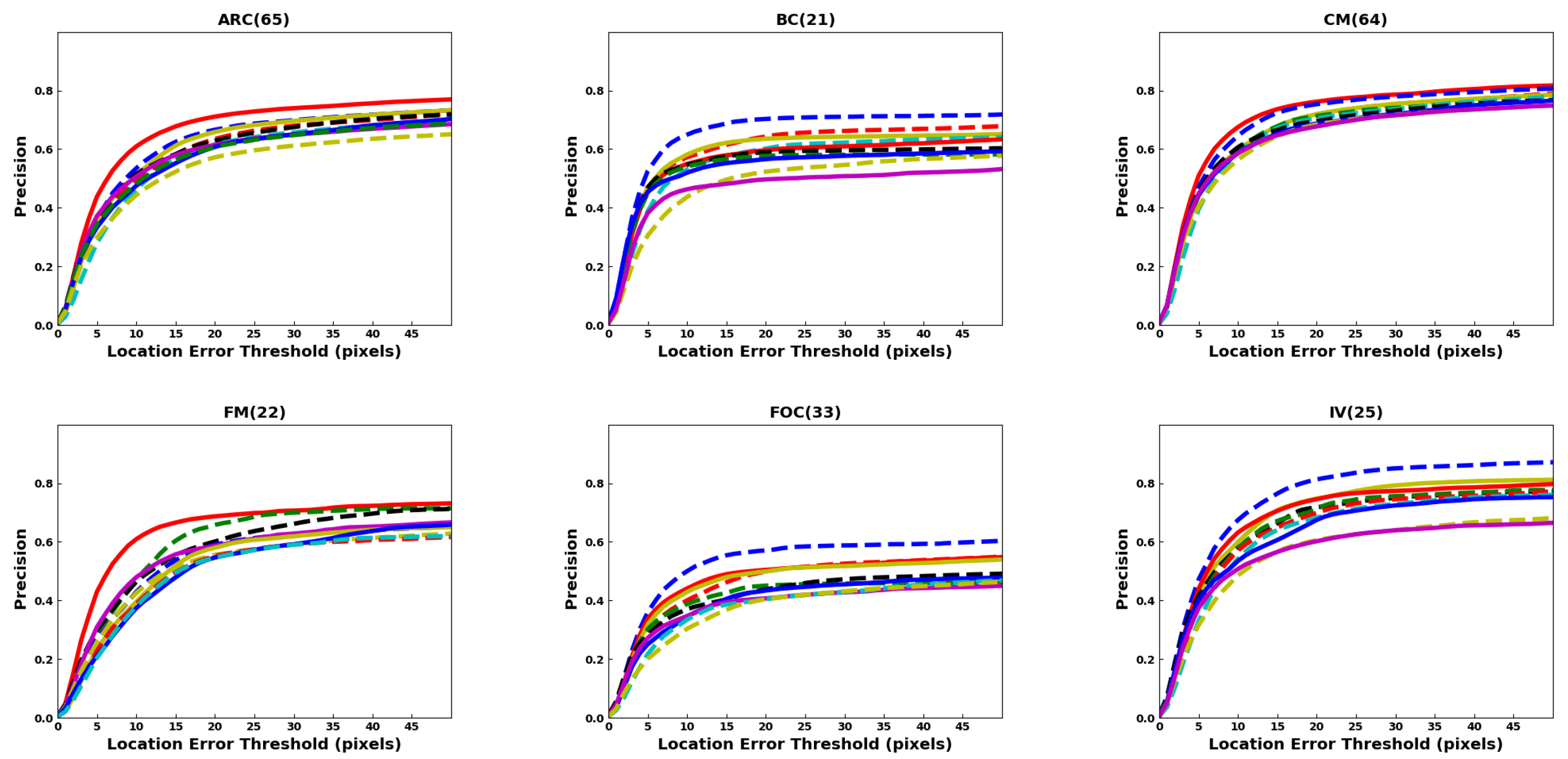
Figure 7 shows the precision plots for all the benchmark datasets. It is seen that DaSiamRPN outperforms the other trackers in terms of precision as well. In
Figure 8, the precision plots for different attributes of UAV123 dataset are depicted. The results show that DaSiamRPN outperforms the other tracker in most of the challenges.
In
Table 4, the AUC of overlap success is shown for various attributes present in the UAV123 dataset. In
Table 5, the precision at 20 pixel threshold is shown for the UAV123 dataset attributes. Both DaSiamRPN and DAT trackers perform well in these challenges. In
Table 6, the AUC of overlap success is provided for various attributes in the DTB70 dataset. In
Table 7, the precision at the 20 pixel threshold is provided for different challenges present in the DTB70 dataset. DaSiamRPN achieved better results in terms of both overlap success and precision in most of the challenges of the DTB70 dataset.
Visual results on the aerial datasets are shown in
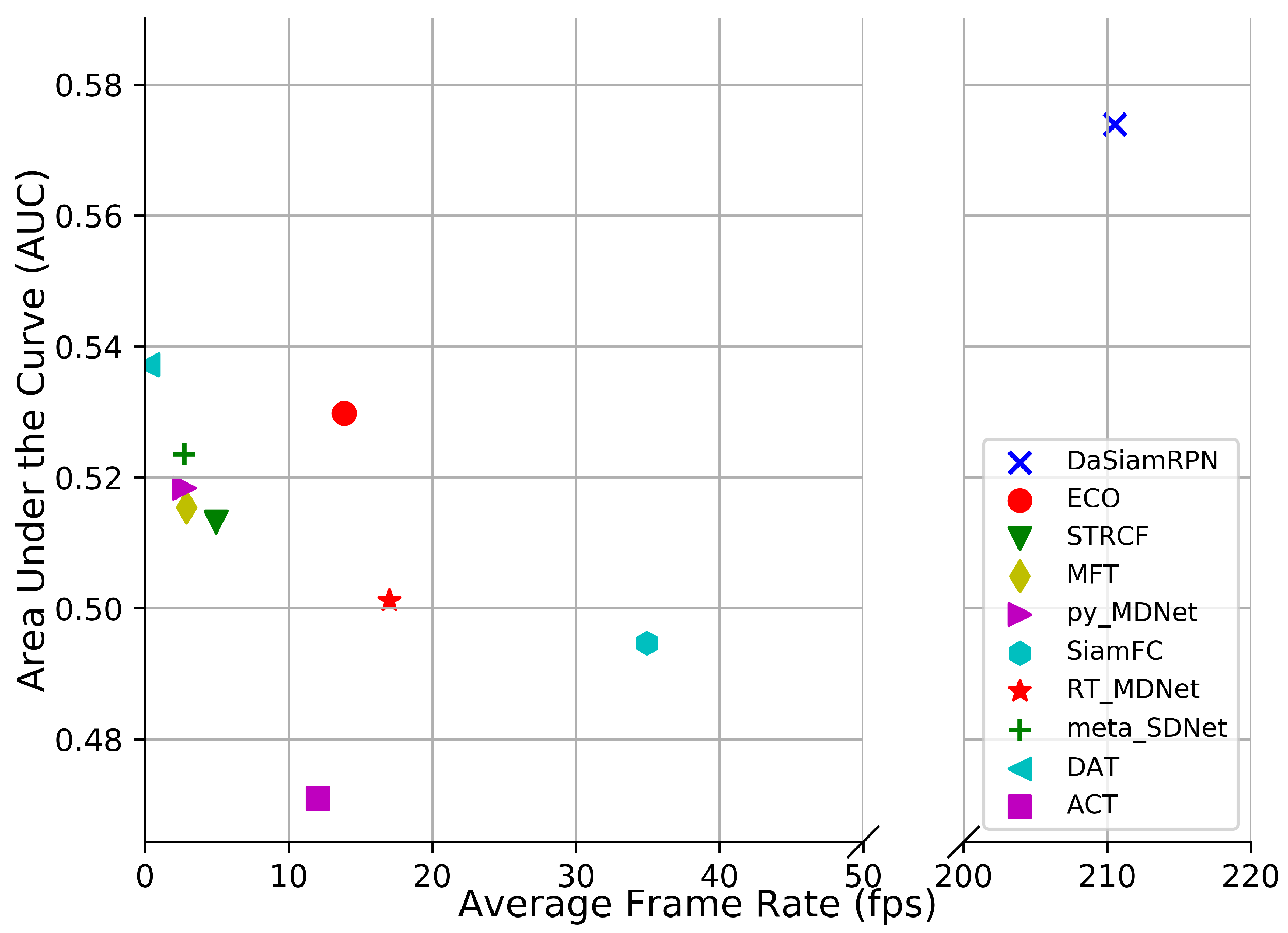
Figure 9. These illustrate the challenges for trackers due to the small target size, image rotation change in zoom level, and presence of similar looking distractors. The speed comparison is provided in
Figure 10 on the UAV123 dataset. The fastest tracker is DaSiamRPN which runs above 200 fps and the slowest tracker is DAT which runs below 1 fps. The ECO and DAT trackers achieve good tracking performance at lower speeds.
4.1. Overall Comparison
The overall quantitative comparison of the trackers is shown in
Table 3 for all benchmark datasets. The results for the OTB aerial subset are slightly worse than the overall OTB results. As the OTB subset does not exhibit all the attributes of the other aerial datasets, tracker performance remains similar with respect to the overall ground level OTB dataset. The evaluation plots in
Figure 5 and
Figure 7 showed that the ECO tracker performs the best and STRCF is the second best for the OTB subset.
Tracker performance degrades consistently for the aerial datasets compared to ground level tracking. For the DTB70 dataset, the DaSiamRPN and MFT trackers perform the best for overlap and precision respectively. The DaSiamRPN tracker performs the best for the UAV123 dataset and UAV20L datasets. The distractor aware training, region proposal network for better IoU, and local to global search for redetection make the DaSiamRPN the best overall performer for aerial tracking.
4.2. Attribute Comparison
Attributes are annotated in the datasets, as shown in
Table 1, and are used to evaluate the tracker performance under various challenging conditions. In different sequences, one or several attributes may be present. The evaluation of trackers based on specific video attributes is shown in
Figure 6 and
Figure 8 and
Table 4 and
Table 5 for UAV123 and in
Table 6 and
Table 7 for DTB70. These results provide insights in the performance of the trackers under various conditions.
The aspect ratio change (ARC-UAV123) and the aspect ratio variation (ARV-DTB70) attributes specify the target’s aspect ratio change over the temporal span of the sequence. The evaluation shows that the DaSiamRPN outperforms all the other trackers on this challenge. The region proposal network helps DaSiamRPN achieve better performance in terms of aspect ratio change. Note that in this specific challenge, in the UAV123 dataset, CF-based trackers and MDNet-based trackers perform similarly, whereas CF-based trackers perform relatively well compared to the MDNet-based trackers in the DTB70 dataset. We conclude that the model update strategy of the CF-based trackers help to achieve relatively better performance compared to he MDNet-based trackers.
The Background Clutter (BC) attribute is present in both datasets. This attribute specifies instances where the target is hardly distinguishable from the background. Based on the evaluation, DAT outperforms the other trackers for UAV123 and SiamFC does best for DTB70, for both overlap and precision. Note that SiamFC performs the worst for UAV123 sequences where BC is present.
Camera motion (CM-UAV123), fast motion (FM-UAV123), and fast camera motion (FCM-DTB70) attributes are evaluated. These attributes specify faster relative speed between the camera and the target. The DaSiamRPN tracker outperforms the other trackers for both datasets. However, MDNet based trackers performed comparatively well in the UAV123 dataset when camera motion is involved. However, when the relative motion is fast, the CF-based trackers outperform the MDNet based trackers in both datasets. We attribute this to the better model update strategy of the correlation filter based trackers.
Full occlusion (FOC-UAV123), partial occlusion (POC-UAV123), and Occlusion (OCC-DTB70) attributes are also evaluated. In POC, the target becomes partially occluded and then reappears without full occlusion, whereas in FOC, the target may be fully occluded for several frames and then reappears. The OCC attribute in DTB70 addresses both full and partial occlusion. It is important for the tracker to have redetection capabilities and stop updating the appearance model during full or partial occlusion to prevent drift from the target. Based on the tracker evaluation on these datasets, we find that for full occlusion DAT performed well, whereas for partial occlusion, DaSiamRPN performed well. For OCC in the DTB70 dataset, ECO performed best.
The Out of View (OV) attribute is present in both datasets. This attribute specifies that the target is no longer within the field of view of the camera, which is particularly challenging for most trackers. To do well in this challenge, the tracker must have redetection capabilities and be discriminative enough to distinguish the target from other similar looking objects. DaSiamRPN outperforms all the other trackers in this challenge, because it incorporates local-to-global search strategy.
The attributes Similar Object (SOB-UAV123) and Similar Object Around (SOA-DTB70) indicate that objects with shape and appearance similar to the target appear near the target. These objects are also called distractors. Tracking is more challenging when the target is partially occluded and distractors are present close to the target. The object may also be fully occluded by the distractor. For this challenge, the results show that CF-based trackers perform well in the DTB70 dataset, whereas MDNet-based trackers perform well in the UAV123 dataset. The performance of the Siamese trackers is comparatively lower because the correlation map generally provides high scores on the distractors, which sometimes causes tracker failure.
The Scale Variation (SV) attribute is present in both datasets. It specifies those sequences where the scale of the target changes over time. The results show that DaSiamRPN is significantly better than other trackers. Again, we attribute this to the Region Proposal Network architecture of the DaSiamRPN tracker. Illumination variation (IV), low resolution (LR), and viewpoint change (VC) are some other attributes that are present in the UAV123 dataset. IV specifies the sequences where illumination change is involved related to the target and LR specifies those sequences where the target has low resolution. VC specifies the changes in the camera viewpoint over the temporal span of a sequence. In terms of overlap, DaSiamRPN outperforms the other trackers in these challenges. However, for the precision, MDNet outperforms the other trackers for LR and IV attributes.
Deformation (DEF), In-plane Rotation (IPR), Out of Plane Rotation (OPR), and Motion Blur (MB) are some other attributes present in the DTB70 dataset. Deformation specifies the shape change of the object, in-plane and out-of-plane rotation specifies whether the target object is rotating inside or outside from the image plane, and motion blur specifies blurred target during tracking. For deformation, out-of-plane rotation, and in-plane-rotation, DaSiamRPN performs best. For MB, ECO performs best among the compared trackers for overlap success. However, for the precision success, MFT performs best. The results show that trackers perform much better in the IPR challenges compared to the OPR challenges. In presence of the MB attribute, CF-based trackers generally performs better compared to the other trackers.
4.3. Visual Comparison
We present visual examples of the results for all trackers in
Figure 9. The Basketball sequence is taken from the OTB dataset. Although it is not an aerial image, it contains distractors that are large enough to observe. Partial occlusion and distractor attributes are present in this sequence. SiamFC and some MDNet based trackers lost the target by the end of the sequence.
The Car2 sequence from DTB70 dataset specifies the camera motion where the camera rotates around the target. The results show that eight out of 10 trackers lost track as soon as there is significant rotation of the camera in this sequence.
The Boat8 and Car7 sequences are taken from the UAV123 dataset. Boat8 has significant scale and aspect ratio change where the appearance of the target also changed. These results show that ECO and MFT trackers perform well but eventually drift. Surprisingly, DaSiamRPN got stuck on small part of the object, most likely due to a proposal generated for that region. In Car7, the target was occluded by a tree while another distractor appeared at the same time. Only the ECO and the DaSiamRPN trackers were able to successfully handle the situation, whereas all other trackers started to track the distractor. In cases of full occlusion, all the trackers lost the target.
Finally, the bird1 sequence from UAV123 dataset is evaluated. Here the target is moving fast and went out-of-view multiple times for several frames. It is seen that due to the small target size, fast motion and partial occlusion, only STRCF and RT-MDNet successfully track the object until it goes out-of-view, but no tracker can redetect the target when it reappears.
4.4. Speed Comparison
The speed comparison among all the trackers is shown in
Figure 10 where the AUC vs. frame rate is plotted for the UAV123 dataset. SN-based trackers have higher frame rate compared to the other trackers. This is because the network parameters are not updated during online tracking. The DaSiamRPN achieves significantly higher frame rate because of its approach to online tracking as one shot learning. Among the CF-based trackers, ECO has the highest frame rate and outperforms the other CF-based trackers. The factorized convolution operation makes the tracker more efficient, thereby allowing it to achieve a higher frame rate and better performance. Among the MDNet based trackers, RT-MDNet achieves real-time performance with a small accuracy drop from the the original MDNet tracker. It is also seen that DAT performs well, but it has the lowest frame rate due to the update strategy of the tracker where the tracker updates on all the frames with score lower than a certain threshold.
5. Conclusions
In this study, we benchmarked ten state-of-the-art CNN-based visual object trackers from four different classes: Siamese Network-based, Tracking by Detection-based, Correlation Filter-based, and Reinforcement Learning. We considered four datasets: a subset of OTB, DTB70, UAV123, and UAV20L datasets for testing and comparing the tracking algorithms. Visual examples of different trackers are shown and the results of an One Pass Evaluation (OPE) are reported. We compared the results among different datasets as well as specific attribute challenges within the datasets. Trackers performed worse in the aerial datasets than in the typical ground level videos.
In our study, we found that Siamese network based trackers face difficulty when there are distractors present within the sequence. This is because the cross-correlation operation will create strong peaks on the distractors and drift may occur particularly when the main target is occluded. Siamese trackers do not have any online model update, which makes them fast but occasionally cannot handle significant appearance change of the object. However, DaSiamRPN performs well due to distractor aware training and accurate localization based on the RPN. The challenge for the CF-based trackers is to find a proper update strategy such that the tracker does not update the appearance model when the target is absent. Among MDNet based trackers, py-MDNet and DAT are computationally expensive where RT-MDNet and meta-tracker run at higher frame rate with relatively lower accuracy. Finally, the RL-based tracker is yet to achive the desired accuracy.
It is notable that none of the trackers is designed for reidentification, which is needed for target reacquisition when the target goes out of view and reappears.
The overall performance of the implemented trackers indicates that further research is needed to reach the full potential of deep learning tracking on aerial sequences.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}