5.2. Bluetooth Model for Distance Deduction
In the first part, the model parameters for estimating the distance from RSS value need to be determined. From Equation (10), it is mandatory to find the appropriate
and corresponding RSS value at
, namely
. In this experiment, we take the path loss exponent
as the default parameter for the indoor office, as suggested by [
6].
A test device is set to scan the other visible Bluetooth devices that are set up so that there is no obstacle between the two ends, thus, the effect of non-line-of-sight propagation is ignored. For each distance, the collection period is set to 300 s. With the devices in use, the Bluetooth inquiry cycle takes around 12 s on average. This results in around 25 to 30 samples per distance. However, when the distance is too large, the number of collected samples reduces. At the distance of 20 m, there are only 10 inquiry samples.
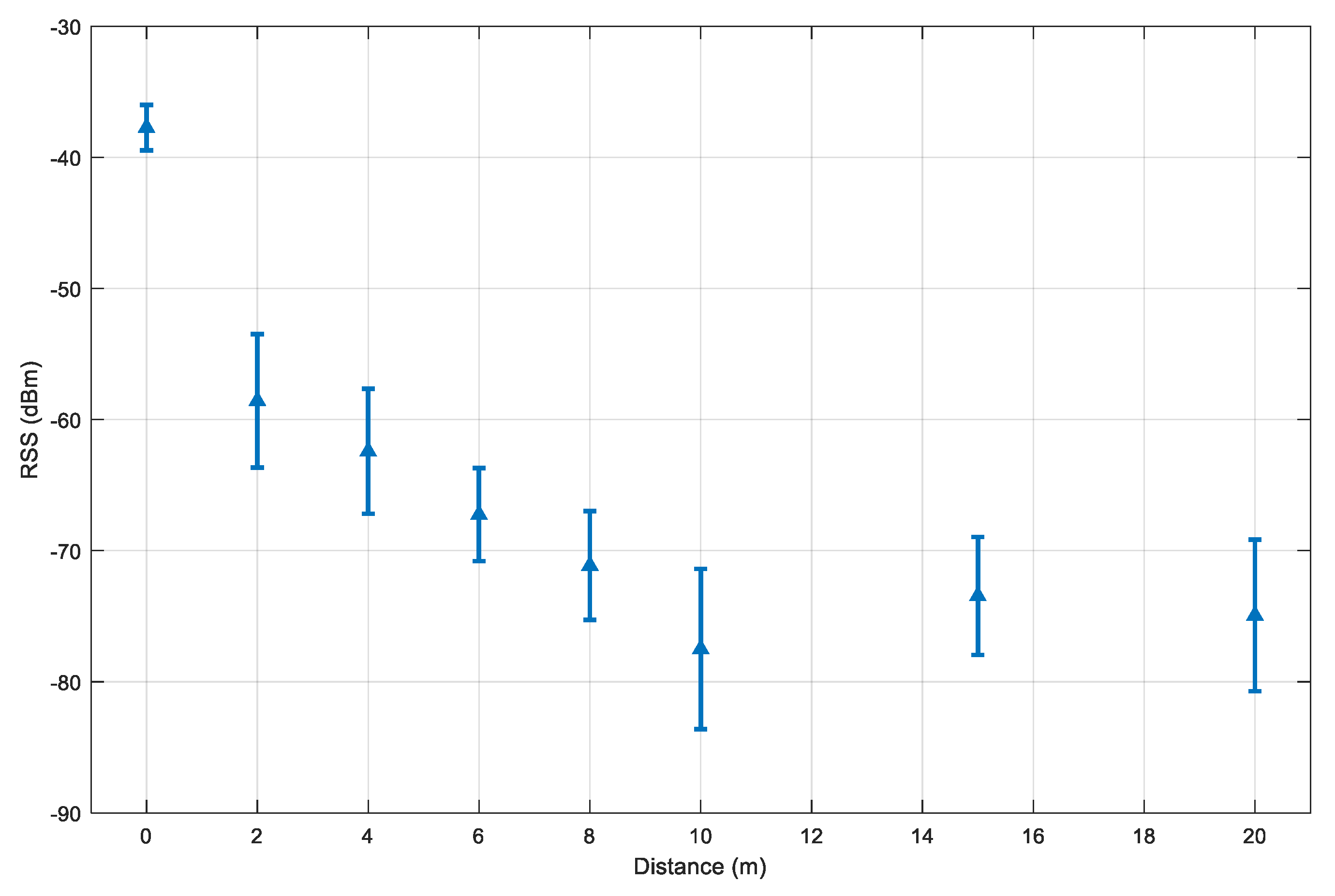
Figure 8 illustrates the experiment results.
The distance of 0 m has the highest RSS value and the lowest standard deviation. The decrement pattern becomes more stable for the distance from 2 m to 10 m. Beyond the range of 10 m, the RSS value starts to be less predictable and packages are dropped. This explains why the mean distances at 15 m and 20 m are higher than at the 10 m. With this consideration, we selected and .
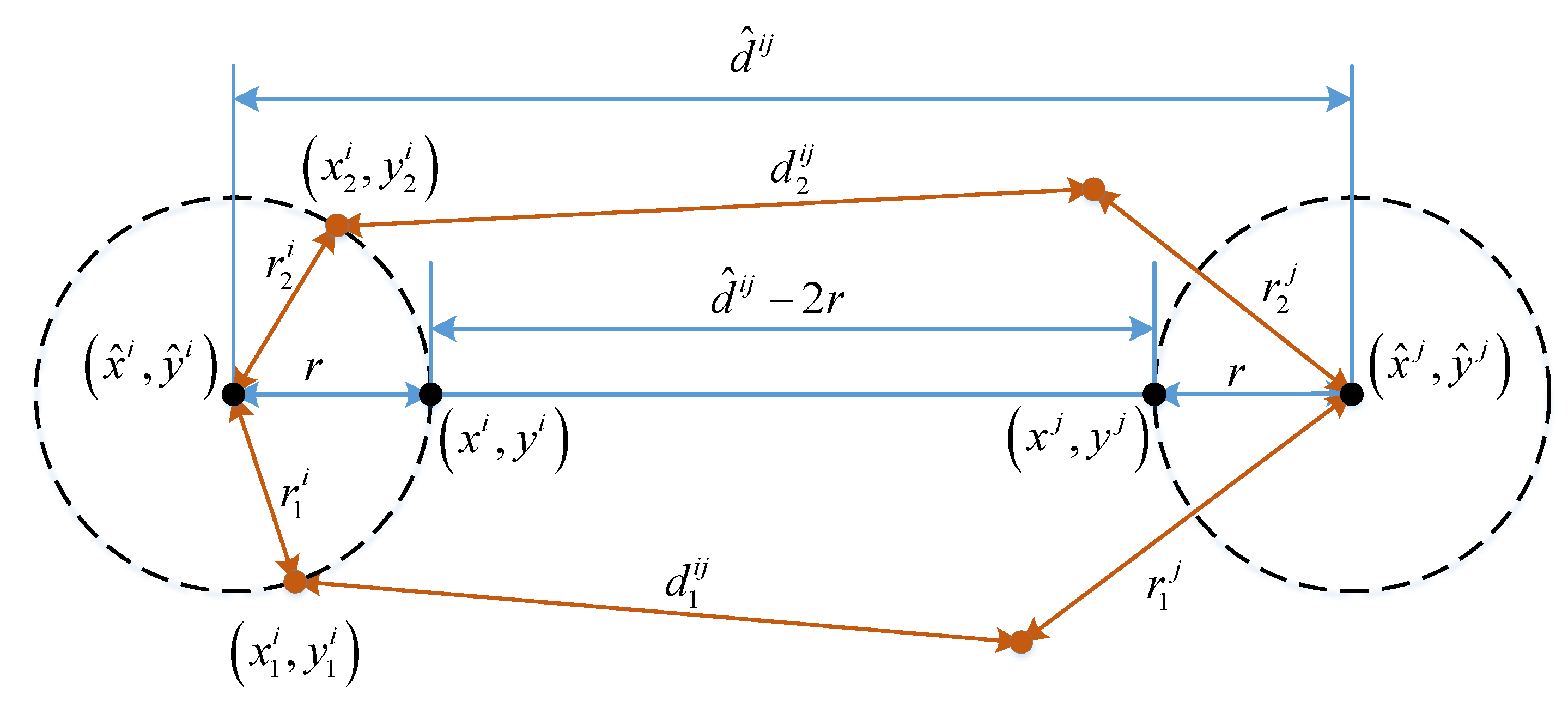
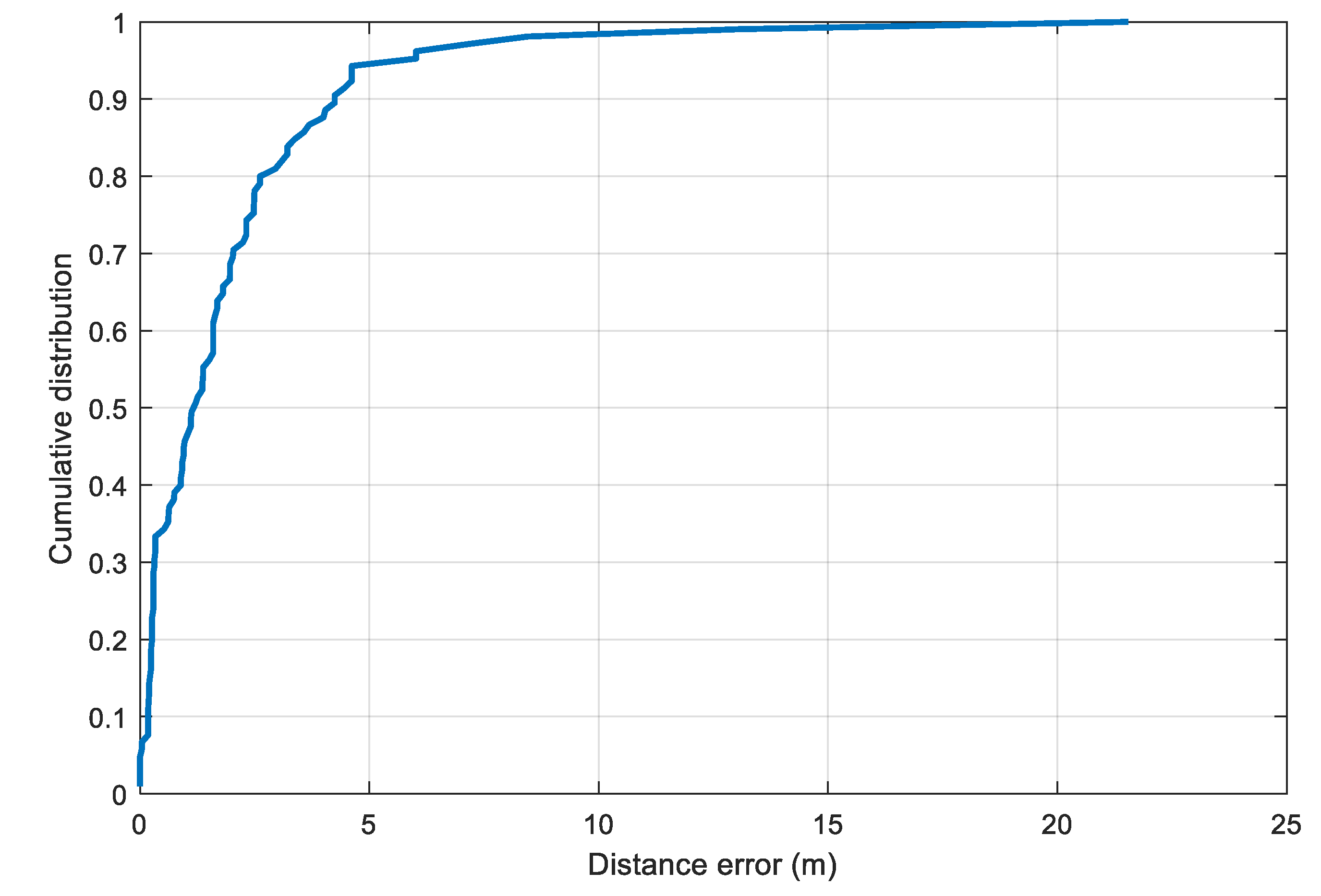
To estimate the distance error, the two selected parameters
and
are substituted into the model in Equation (10) to compute the distance from the RSS value. The cumulative distance error distribution is illustrated in
Figure 9. From the plot, we set the value of
in Equation (12) to 4.2 m, which corresponds to the 90th percentile of the distance error distribution.
5.3. Baseline Wi-Fi Fingerprinting Model
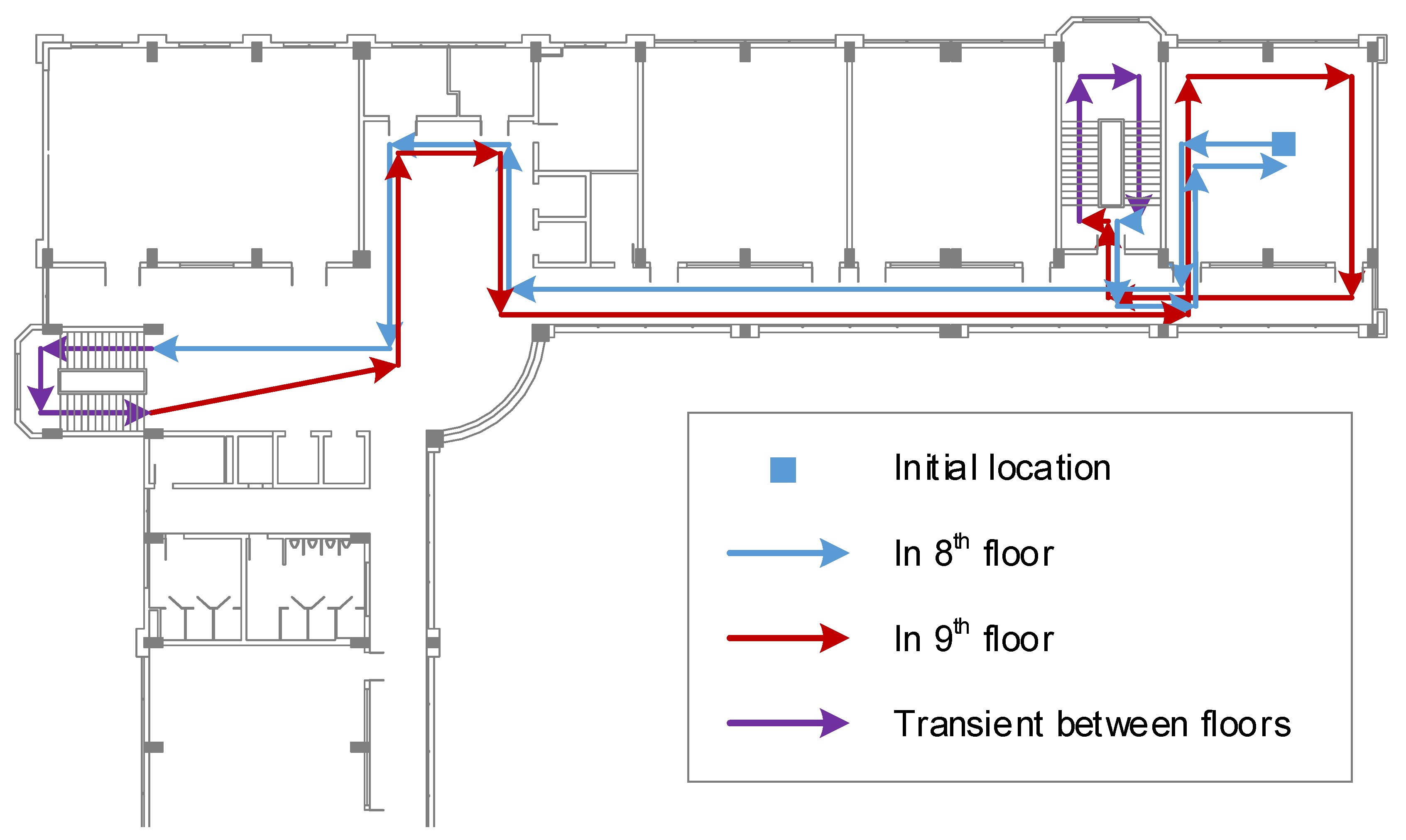
A Wi-Fi fingerprinting model is trained as a baseline model for the later fusion step with Bluetooth data. For building the Wi-Fi fingerprinting database, Device 1 (Samsung Galaxy Note 3) and Device 3 (Asus ME) are used. The database is built by using interpolation. First, one user is asked to carry the device and walk along the test path. The test path is predefined by several checkpoints (see
Figure 7). Every time a checkpoint is reached, a timestamp is recorded and then used to interpolate the full moving path in a later stage. The database building process therefore does not take much time. There are six training log files in total. Given the specific testing path, all the data are collected in almost 1 h.
Table 3 gives an overview of the collected Wi-Fi database. A time threshold of 5 s is used to group RSS values into one complete fingerprint scan. There are around 400 fingerprints in six training files. The number of completed Wi-Fi scans per user’s walks varies between 50 and 100. Besides, the number of visible Wi-Fi access points also varies depending on the user location and the device in use. In our database, the average number of visible Wi-Fi access points per scan is almost 7, while the minimum is 3 and maximum is 12.
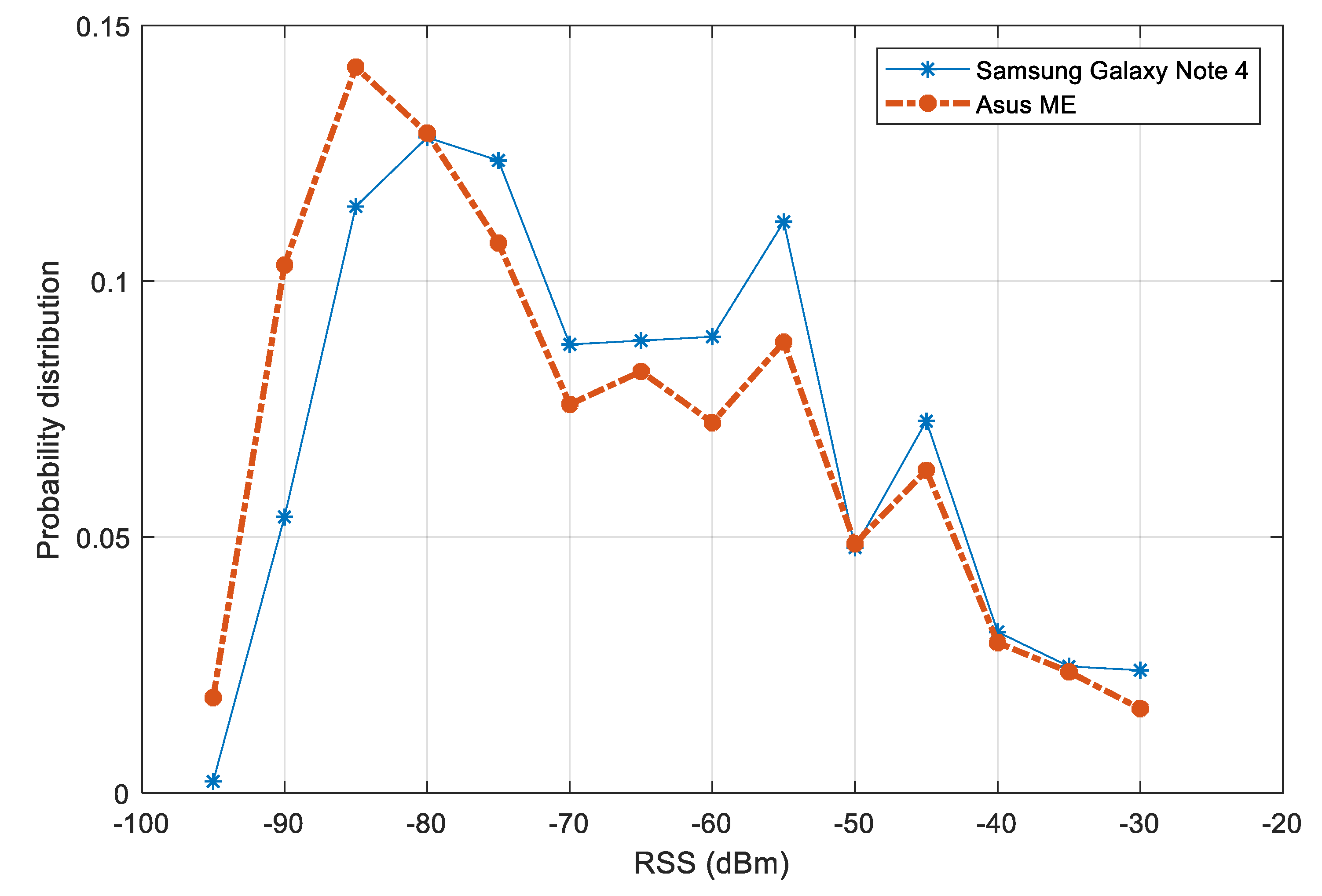
The distributions of RSS values from two devices is plotted
Figure 10. A variation between the distributions of the two devices can be noticed. The variation is more significant in the range of signal strength from
dBm to
dBm. In a multiple-device context, this variation may affect the performance of fingerprinting models. To reduce the effect of device diversity, we first filter out the RSS values below
dBm. Second, a normalization step is carried out, so that for each participating device, it is assumed that the mean RSS value over the test area is known. The raw RSS values are then subtracted by this mean. Other alternative approaches such as finding the linear transformation or using HLF features would be suitable for improving the later step of fingerprinting model training.
For the fingerprinting model, we use Random Forest as the training model. The Random Forest is trained with 500 trees. Both the raw and the mean normalized RSS features are used in the K-fold cross validation testing with
. As the path contains two floors with some transient segments within stairs, the target position is treated as a 2.5D coordinate. For a triplet
, the
component is normalized to receive only one of three values: 0, 0.5, and 1. The values 0 and 1 represent the points in the eighth and ninth floors, respectively, while the value 0.5 indicates that the user is somewhere on the stairs. The distance error between the target point
and the output position
is calculated by:
where
is a floor multiplier. In our experiment,
is set to 10.
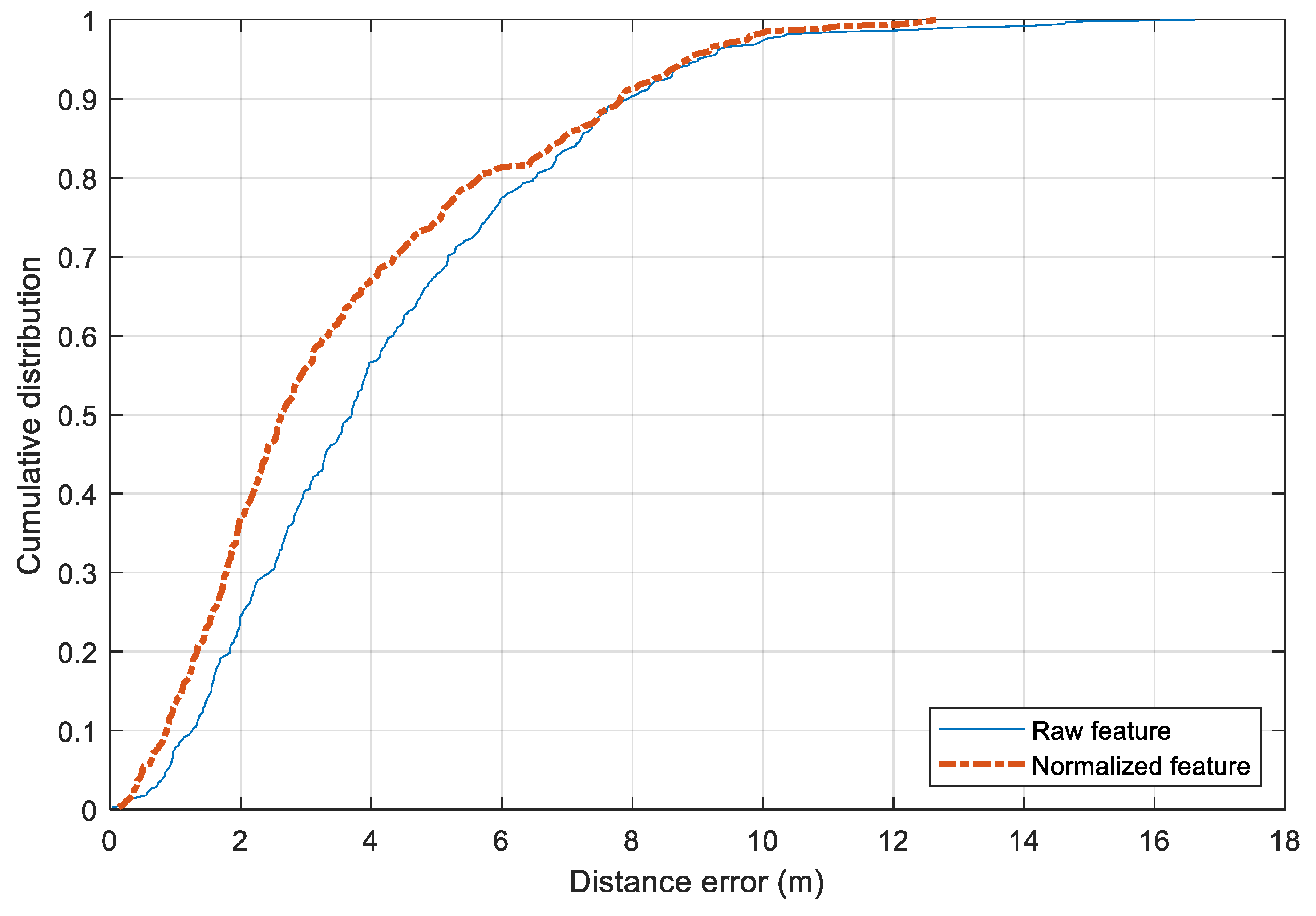
The performance of the two preprocessing feature approaches is shown in
Figure 11. The standard raw features result in a mean distance error of 4.21 m while the mean normalized one has a mean error of 3.61 m. The former has a standard deviation of 2.65 m and the latter of 2.53 m. There is a slight improvement by changing from the raw features to the preprocessed one. In terms of maximum distance error, both approaches suffer from large errors that exceed 10 m. Compared with the published dataset of IPIN 2016 [
1], the performance of the Random Forest model with the preprocessing features is comparable. To reduce the error further, it would require a larger amount of training data.
5.4. Evaluation Setup
Three approaches are used to localize the users: Wi-Fi only, Non-temporal and Temporal. In the Wi-Fi only approach, the output of the Wi-Fi fingerprinting method is provided as the reference tracking results to evaluate the performance of the two other approaches. First, the data is collected along the designed walking path. The baseline Random Forest (RF) regressor model is used without utilizing the Bluetooth data. In the testing phase, for each incoming Wi-Fi scan from the test devices, the RF model is used to estimate the user position.
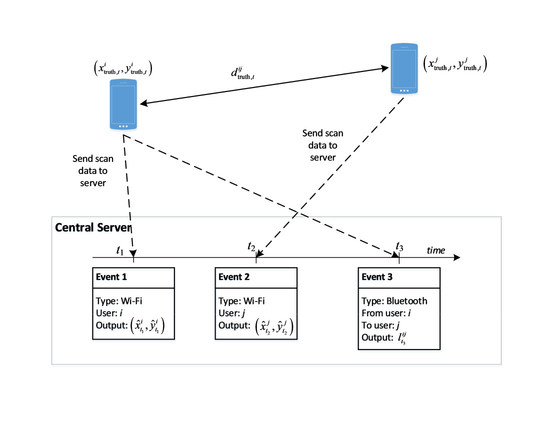
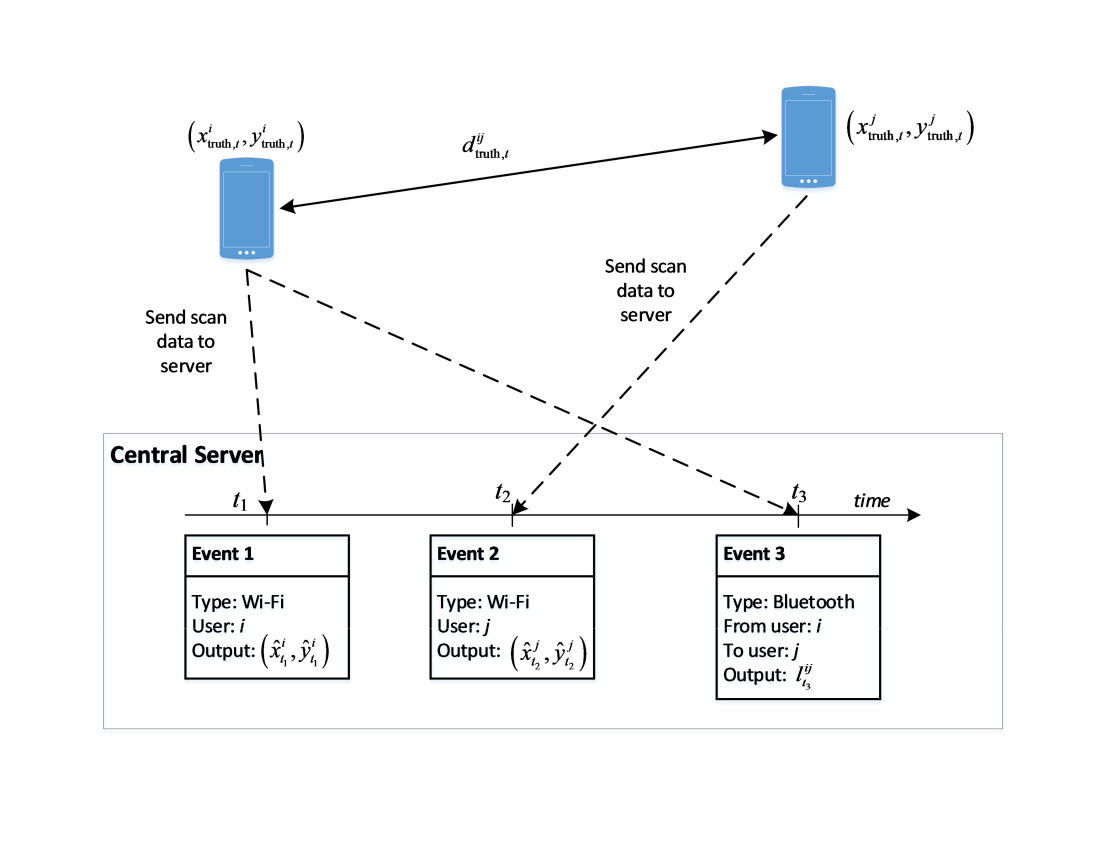
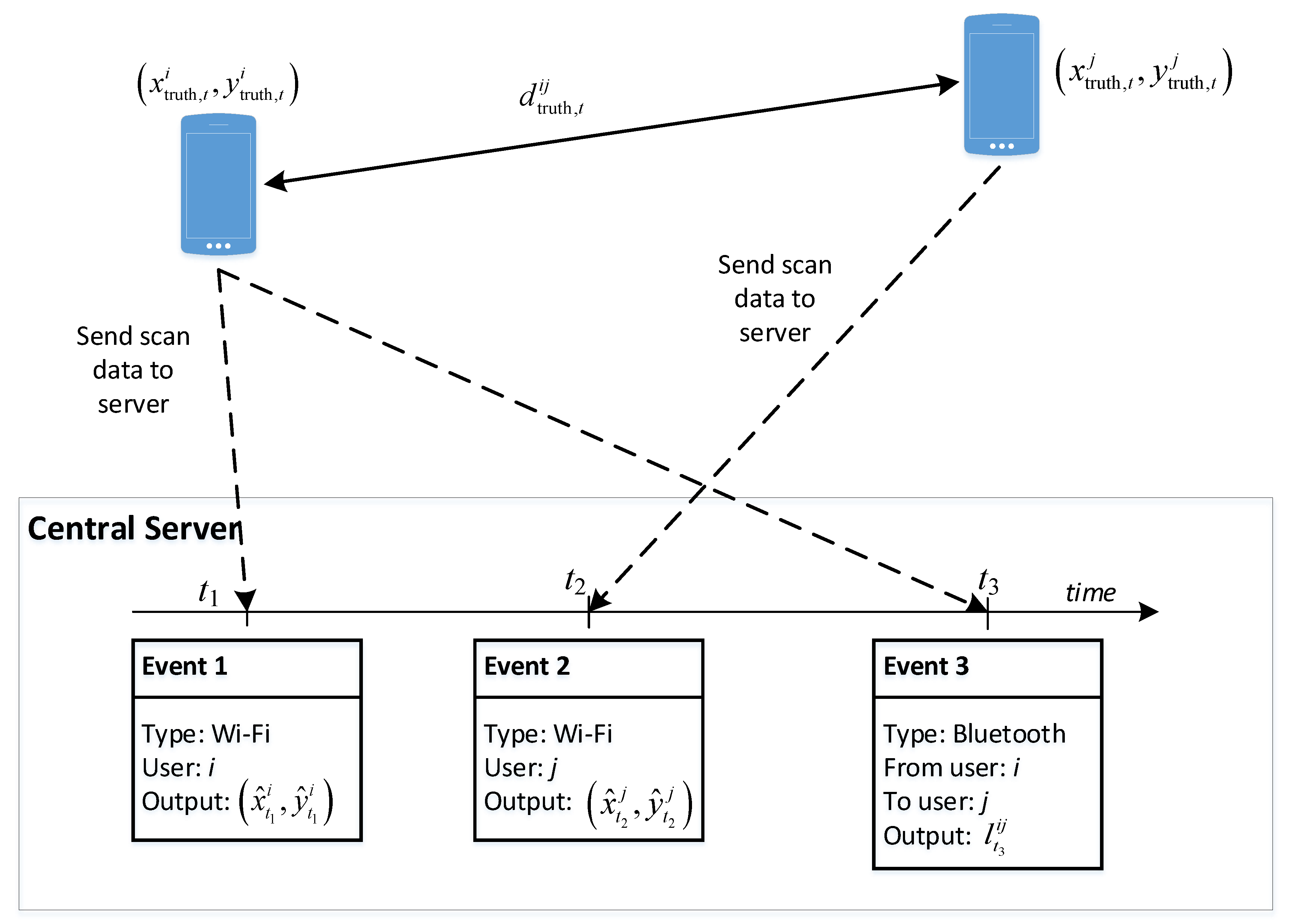
In the Non-temporal approach, the output positions from the pre-trained RF regressor model on Wi-Fi are calculated for each device. If there is any Bluetooth data available, the Bluetooth scanned information is used for adjusting the positions of two involved devices. To solve the problem of non-simultaneous events between Wi-Fi and Bluetooth scans, we use a time window of length of 10 s for grouping successive events into the same timestamp. The resulting position is calculated as the mean value of these positions.
In the Temporal approach, a RF classifier model is built on top of the RF regressor model. To transform the real-world coordinates to a label index, we perform K-means clustering of all the available training positions from the training data. The new learning targets are the indices of the corresponding clusters. In our experiments, we use for clustering all the available points in the tested area. The radius of each cluster in this configuration is 4.0 m approximately. The probability output of the classifier model is then used to update the Particle Filter within a time window of 10 s. If there are multiple completed scans in this time window, the closest completed scan is used. The Bluetooth data have the effective time set to 2.0 s. Regarding the moving model, the average speed of each particle is set to 1 m/s. In the simulation step, the number of particles is set to 1000.
5.5. Results and Discussion
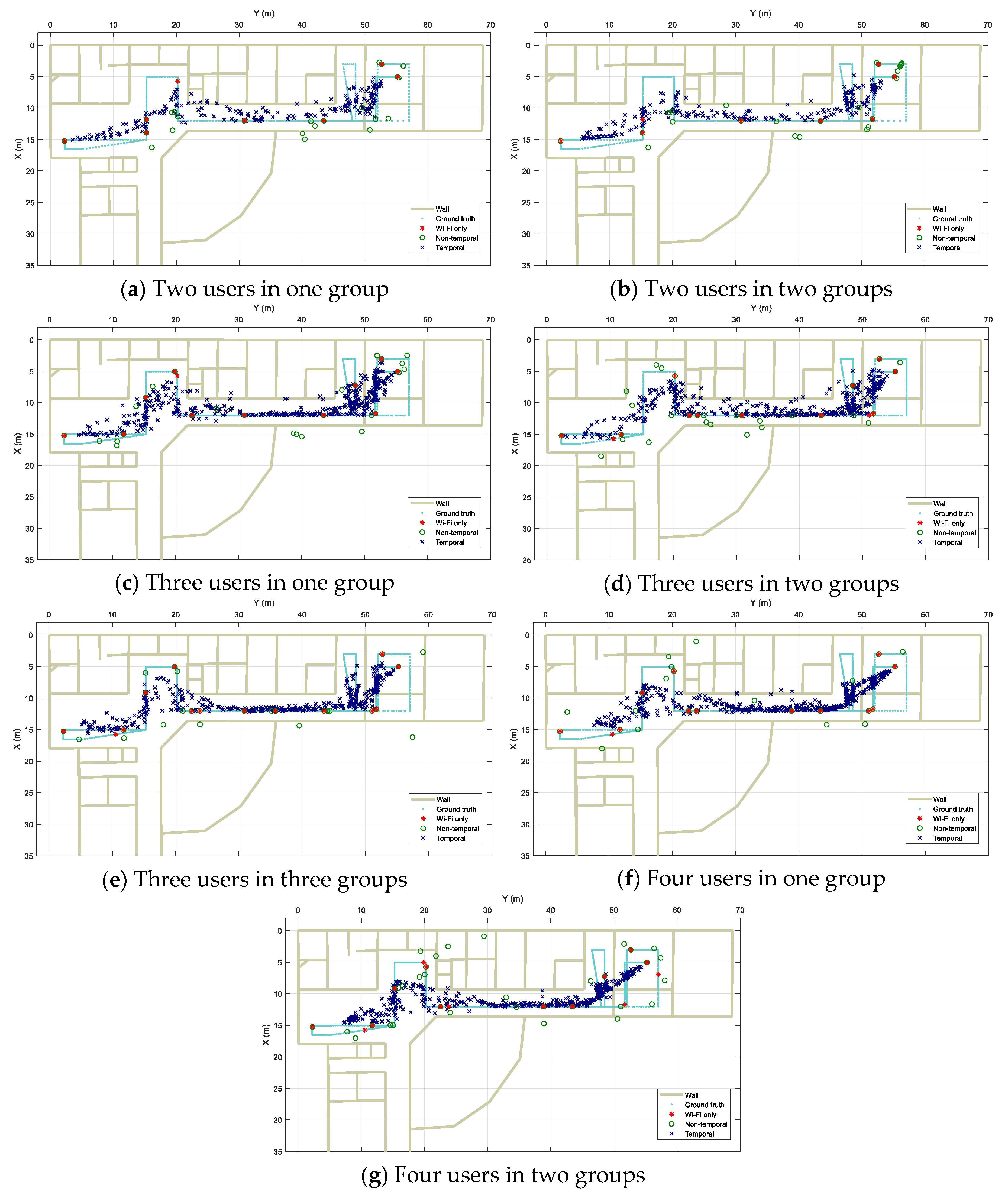
Figure 12 shows the localization output results along with the users’ walking ground truth from the three approaches for different scenarios. Visually, it can be observed that in all the experiments,
Wi-Fi only performs very poorly with highly disjointed spots as multiple data scans result in fixed pre-trained locations due to the nature of the fingerprinting method in use. When fusion is applied, the Wi-Fi based results are combined with Bluetooth-based ones and spread along the real path. However, for the
Non-temporal approach, because of the grouping of data using time windows, the resulting locations are much more disjointed in comparison with those from the
Temporal approach. It is clear in the figure that the
Temporal results track the real path more continuously.
A summary of the tracking results using the three mentioned approaches is presented in
Table 4. In the configurations with only one user per group (i.e., number of users equals number of groups), the users are asked to move separately. In other configurations, users are asked to move with distance to each other kept under 10 m. The last scenario is with four users divided into two groups of two, which lets the system use Bluetooth data to identify both close and distant devices. The results are reported as the mean average distance errors across all the testing devices in the specific situation.
The Wi-Fi only approach reaches a stable performance of under 4.0 m in mean distance error. Both Non-temporal and Temporal approaches have better results than the Wi-Fi only one. However, the Non-temporal approach’s results are not as stable as the Temporal one. In the setup where the users’ distance could change within a specific time interval, the Non-temporal approach has a similar performance to the output from the Wi-Fi fingerprinting model. In this case, a difficulty is raised in measuring the distance in Equation (11). Meanwhile, the Temporal approach has a more consistent performance by reducing the errors from 25% to 50% depending on different scenarios. The biggest relative improvement is the scenario of three users moving in one group.
In the experiments with two users, Devices 1 and 3 are used, where the results for each approach per device are given in
Table 5. In the first scenario, they walk together while keeping their distance under 1 m. In the other scenario, they walk separately and keep their distance in the range of 5–10 m. As both devices are also used in collecting the training data, the Wi-Fi fingerprinting model is unaffected by the device diversity in this case. When the information from the Bluetooth scanning process is added, the distance error is reduced in both
Non-temporal and
Temporal approaches. The
Non-temporal has a clear improvement in the one-group scenario. However, the impact of Bluetooth data when discarding the temporal relationship is insignificant in the two-group scenario. With the
Temporal approach, we have stable improvements across the two scenarios.
For experiments with three users, Devices 1, 3 and 4 are used, and the results are summarized in
Table 6. With the
Wi-Fi only approach, the RF regressor model results in similar distance errors for Devices 1 and 3. The positioning results for Device 4 are not as good as the other two devices because the data does not contain training samples for Device 4. Compared to the
Wi-Fi only approach, there is a slight improvement by using the
Non-temporal one. Across all the devices and scenarios, the average improvement is around 0.5 m in mean distance error. The appearance of Device 4 with high distance error clearly affects the performance of the other two devices. The
Temporal approach provides more stable improvement compared to the
Wi-Fi only by outperforming the two other approaches in all scenarios. The highest improvement is with Device 1 in one-group and Device 3 in three-group settings. With the contribution of the motion model and the Bluetooth-based distance, the
Temporal approach could make the effect of non-training data on Device 4 minimal.
Results for four users are shown in
Table 7. Compared to the previous one-group scenarios with two or three users, it is difficult to keep a close relative distance in this step. The group is supposed to move within a circle of 2 m in radius. In the second scenario with two groups, the first group uses Devices 1 and 2 whereas the second uses Devices 3 and 4. The distance between the two groups is kept in a range of 5–10 m. Similar results for the three-user case can be seen for the
Wi-Fi only approach. Both new Devices 2 and 4 have larger distance errors than the two others. Devices 1 and 3 have a similar performance to the five-fold cross validation testing. It is noticeable that the RF fingerprinting model has trouble in tracking Devices 2 and 4, which are not present in the training data. High errors from RF fingerprinting model add more noise into the later fusion step with the Bluetooth information. The
Non-temporal approach can improve the results in most cases. However, its impact is quite low. There are several exceptions where using the Bluetooth data makes the results worse. For example, the results from Device 1 increase from 3.05 m to 3.46 m in the one-group setting. The
Temporal approach results in lower errors than the two others. In general, good results are obtained with Devices 1 and 3, whose RSS data are present in the training phase. There is an exception for the results of Device 2 in the one-group scenario, that is the
Temporal mean error is slightly higher than that of the
Non-temporal. Nevertheless, it is able to reduce to errors compared with the
Wi-Fi only approach.
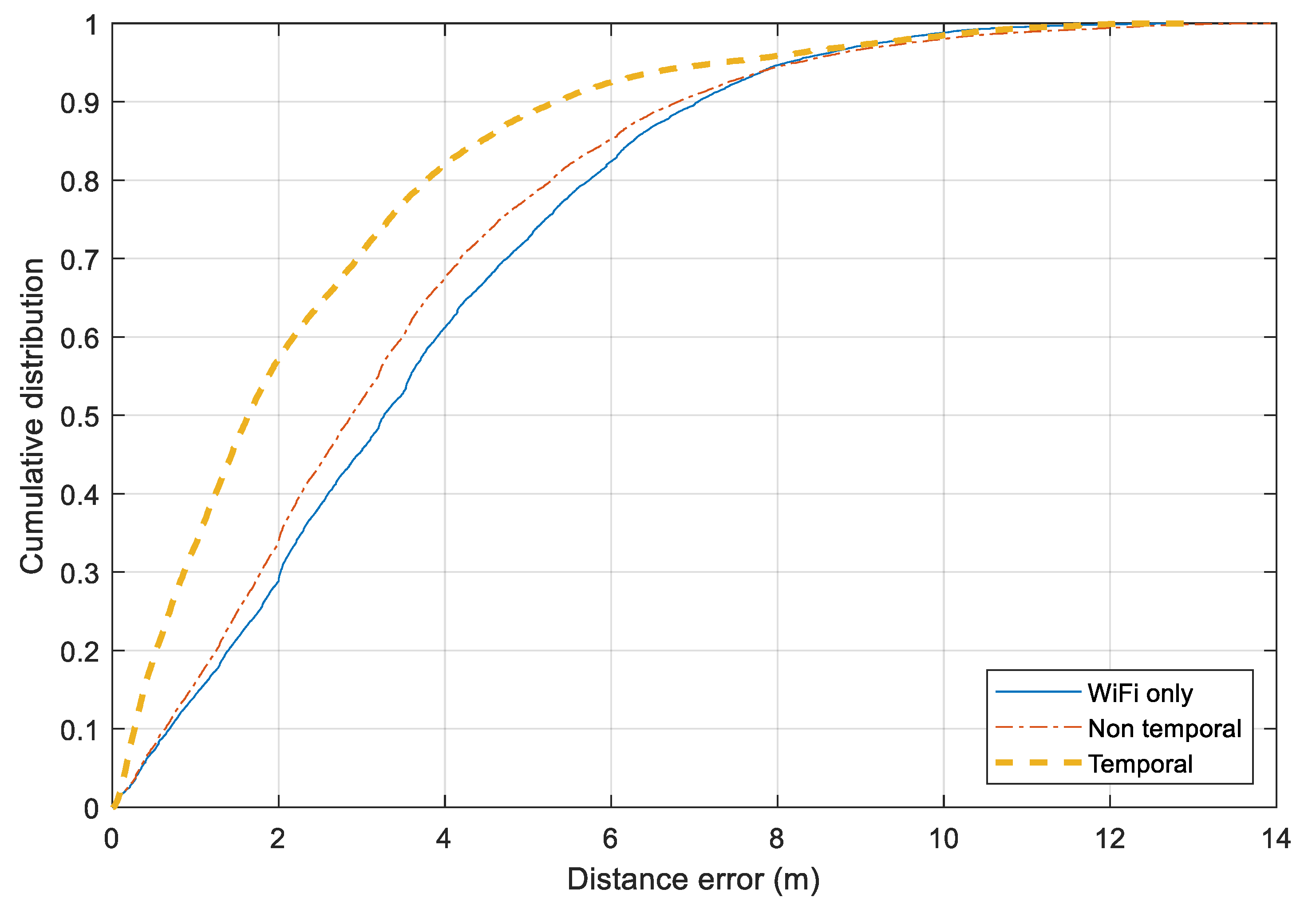
Figure 13 illustrates the distance error for three approaches over all the scenarios together. The
Wi-Fi only and
Non-temporal approaches perform similarly. For 75% of the time, the distance errors of two approaches are around 5 m. The Bluetooth-based relative distance is employed more efficiently in the
Temporal approach. It has a significant improvement from the Wi-Fi-based tracking. For 75% and 90% of the time, the errors of the
Temporal and
Non-temporal approaches remain under 3.0 m and 5.0 m, respectively. Besides the Bluetooth information, employing map information and moving model constraints also help to reduce noisy output from the standard Wi-Fi fingerprinting model.
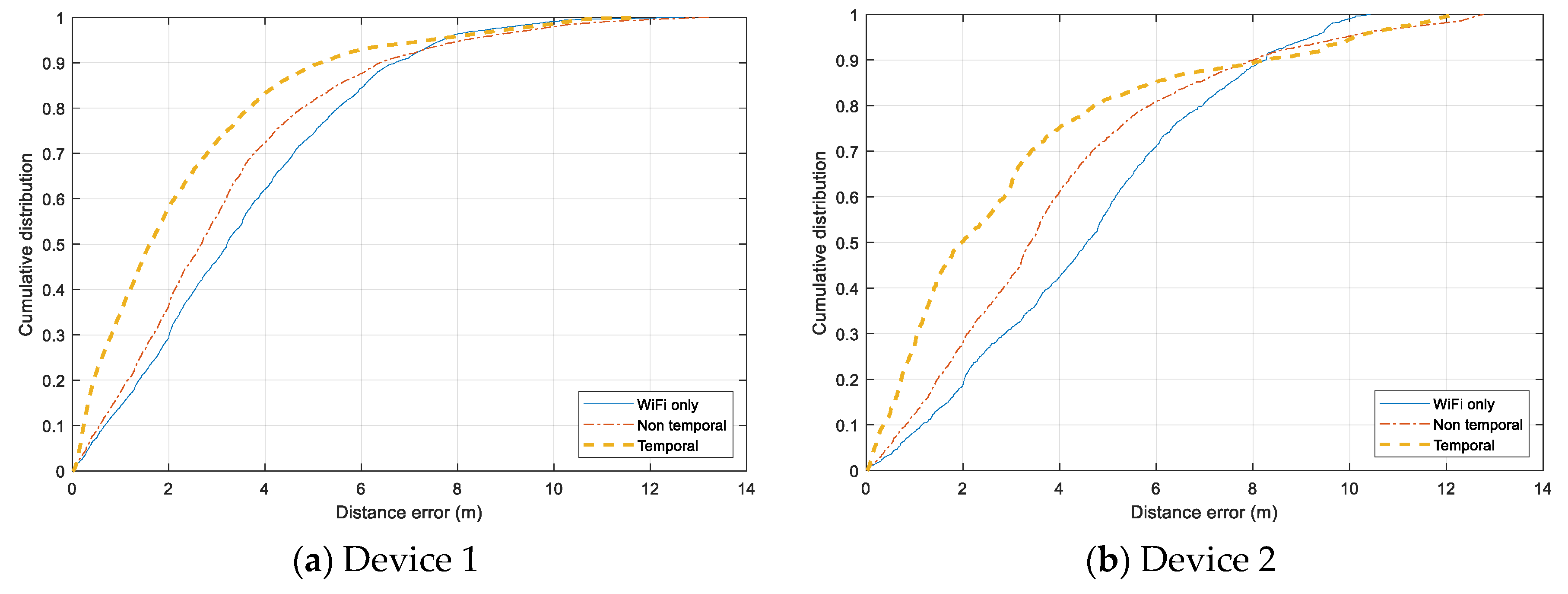
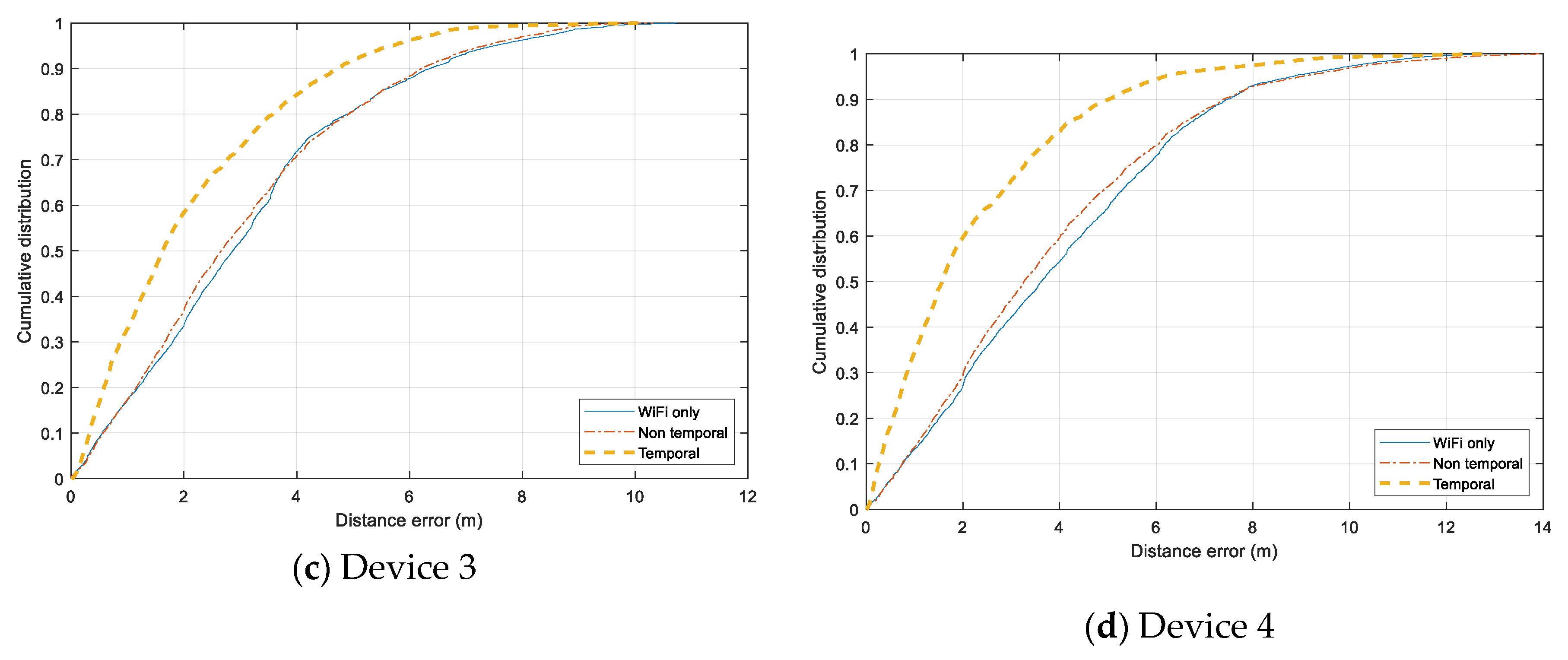
Individual error distribution for each test device is given in
Figure 14. Both smartphones, Samsung Galaxy Note 4 (Device 1) and HTC One ME (Device 2) have a similar distribution. The
Non-temporal approach gains a slight improvement from using only Wi-Fi data, and the
Temporal approach can reduce the error significantly for the range under 7.5 m. However, the additional Bluetooth data does not help when the tracking error exceed 8 m, and the error of all three models are distributed similarly in the range above 10 m. It even adds more noise to the tracking results of Device 2. In the case of Device 3 and Device 4, both
Non-temporal and
Wi-Fi only have nearly identical distributions while the
Temporal one outperforms the two others. The
Temporal has the highest improvement with Device 4, which can overcome the issue of non-training data.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}