A Multi-Task Framework for Facial Attributes Classification through End-to-End Face Parsing and Deep Convolutional Neural Networks



Abstract
1. Introduction
- We propose a new face parsing method through DCNNs, known as MCFP-DCNNs. We develop a unified human face analysis framework using the face parts information provided by a prior MCFP-DCNNs model. The multi-task framework is addressing the three demographic tasks (race, age, and gender) in a single architecture, which we named RAG-MCFP-DCNNs.
- We conduct detailed experiments on state-of-the-art (SOA) databases for face parsing, race, age, and gender classification. We obtained significant improvement in performance on both controlled and unconstrained databases for all four tasks.
2. Related Work
2.1. Face Parsing
2.2. Race Classification
2.3. Age Classification
2.4. Gender Classification
2.5. Multi Tasks Framework
3. Used Datasets
3.1. Face Parsing
- LFW-PL: We evaluate our face parsing part with LFW-PL [27]. Some recent methods [26,74] already use the LFW-PL [27] for face parsing. We use a subset of training and testing images. For fair and more exact comparisons, we conduct experiments on the same set of images as in [75]. The LFW-PL contains 2927 images with size , which are all collected in the wild conditions. The ground truth data are created manually through commercial editing software. All face images are labeled to three classes, including back, skin and hair.
- HELEN: The HELEN [28] database contains class labels for 11 categories. This database contains 2330 images, each with size . These images are also manually labeled. The database is divided into a training set (2000) and a validation set (330). We keep the experimental setup as in [75]. Although the HELEN database is a comparatively large database having 11 dense classes, the ground truth labeling is not very precise. Especially the hair class is mostly mislabeled with skin in most of the cases.
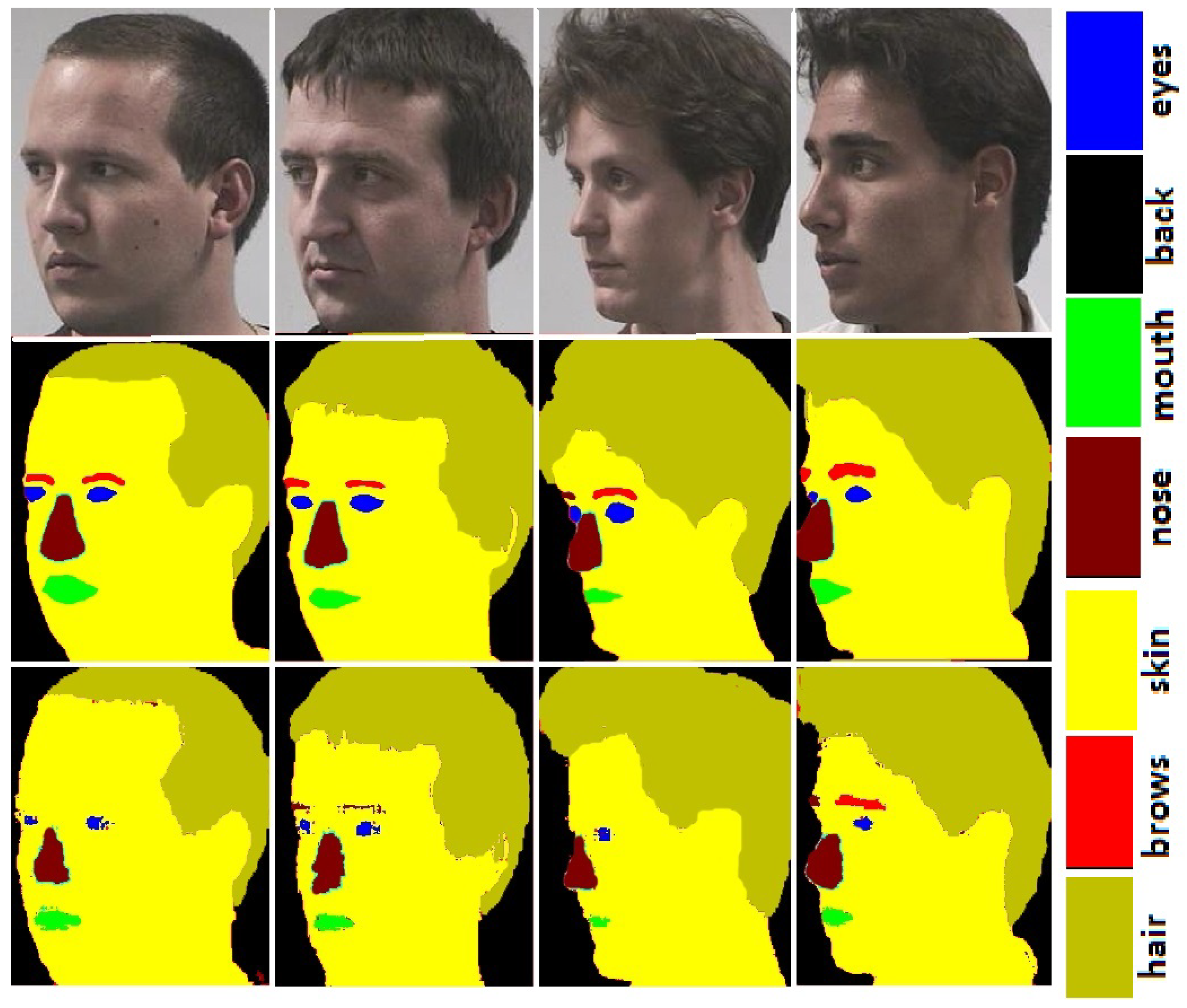
- FASSEG: The FASSEG [29] consists of both frontal and profile face images. Frontal01, frontal02, and frontal03 contain frontal images of 220 faces along with ground truth data. The subset multipose01 contains profile face images of more than 200 faces. The FASSEG images are taken from other publically available datasets, and ground truth data is created through manual editing tool. The images contain both high and low-resolution data. The illumination conditions and facial expressions are also changing in some cases. The dataset is very precise as ground truth data is created with extreme care. Figure 1 and Figure 2 show some images from the FASSEG [29] database. Original images are shown in row 1, ground truth in row 2 and the segmentation results in row 3.
3.2. Race, Age, and Gender
- CAS-PEAL The CAS-PEAL [32] is a face database used for various tasks such as head pose estimation, gender recognition, race classification, etc. It is a larger dataset with 99,594 face images. The CAS-PEAL [32] is collected with a large number of face images having 1040 subjects. The dataset is sufficiently large, but the complexity level of the images is not higher, making the dataset a bit simple. We used CAS-PEAL [32] for race classification in the proposed work. Figure 3, row 1 shows some images from the CAS-PEAL [32] database. The ground truth images manually labeled to build DCNNs model are shown in row 2, whereas the segmentation results with proposed DCNNs model are shown in row 3.
- FERET: This is an old dataset which is used for various face analysis tasks such as face recognition, head pose estimation, gender recognition, etc. The FERET [31] dataset is collected in very constrained lab conditions, and gender information is also provided for each participant. It is a medium-sized dataset with 14,126 face images. However a sufficient number of participants are included in the database collection with 1199 subjects. We use the colored version of the FERET [31]. The participants include variations in facial expressions, changing in lighting conditions, which make the database a bit challenging. we evaluate our race and gender recognition part with FERET [31] database. Figure 4, row 1 shows some face images from the FERET [31] database. The ground truth images manually annotated are shown in row 2, whereas the segmentation results in row 3.
- LFW: The LFW [76] database consists of 13,233 face image collected from 5749 participants. The dataset is collected in very unconstrained environmental conditions. All the face images are collected from the internet, with very poor resolution. The LFW [76] is a very unbalanced database, as the number of female participants are 2977, whereas male candidates are 102,566. We use this database for evaluating our gender recognition part.
- Adience: The Adience [71] is a new database that was released in 2018. We evaluate our age and gender classification part with Adience [71]. The database is collected in the wild and real-world conditions. The images are collected through smart phones Much complexities are added to the images to make the database rather challenging; such as pose variation, changing lighting conditions, noise, etc. are present in the images. It is a comparatively larger dataset with more than 25,580 face images. Sufficient number of candidates are included (2284) in the dataset collection. Information about the exact age of each participant is not provided, instead each participant is assigned to eight age groups, i.e., [0,2], [4,6], [8,13], [15,20], [25,32], [38,43], [48,53], [60,+]. The database is freely available for downloading from the Open University of Israel.
4. Proposed Face Parsing Framework (MCFP-DCNNs)
Architecture
5. Proposed RAG-MCFP-DCNNs
| Algorithm 1 proposed RAG-MCFP-DCNNs algorithm |
| Input:M = {(I,T)}, M where the DCNNs model is trained through training data represented as M and tested through M. The input training image is represented as I and the ground truth data is T(i,j)∈ {1,2,3,4,5,6,7}. a: Face parsing part: Step a.1: Training a face parsing model DCNNs through training images and class labels. Step a.2: Using the probabilistic classification strategy and producing PMAPs for each semantic class, represented as: PMAP, PMAP, PMAP, PMAP, PMAP, PMAP, and PMAP b. race, age and gender classification part: Training a second DCNNs for each demographic class (race, age, and gender) by extracting infomration from PMAPs of the corresponding classes such that; if race classification: PMAP + PMAP + PMAP + PMAP + PMAP + PMAP Else if age classification: PMAP + PMAP + PMAP + PMAP + PMAP Else if gender recognition: PMAP + PMAP + PMAP + PMAP + PMAP where f is the feature vector. Output: estimated race, age and gender. |
5.1. Race Classification
5.2. Age Classification
5.3. Gender Recognition
- Face anatomy reports that the male forehead is more significant than the female forehead. In most of the cases, male hairline lags behind as compared to female. Is the case of baldness (males only) hairline is missing entirely. All this results in a more massive forehead in males compared to females. We assigned to all forehead a skin label. Hence our MCFP-DCNNs model creates a probability map for skin, which is on the larger brighter area in males compared to females.
- Visually, female eyelashes are curly and comparatively larger. These eyelashes are misclassified with hair and in some cases with eyebrows. Although, labeling accuracy is reduced for segmentation part with this misclassification, however, this misclassification helps in gender classification. The MCFP-DCNNs model generated a brighter PMAPS for males as compared to females.
- Qualitative results reveal that the male nose is larger than the female nose. The male body is larger, which needs a sufficient supply of air towards the lungs. This results in larger nostrils and a giant nose for males compared to females. We also encode this information in the form of PMAPs through MCFP-DCNNs.
- Literature reports very complex geometry for hair. For humans, it is easy to identify the region between hair and face parts, but for the computer, it is not an easy task. Our MCFP-DCNNs model reports excellent labeling accuracy for hair class. From segmented images it can be seen how efficiently hairline is detected by MCFP-DCNNs. We also encoded this information in PMAPs for hair class and used it in gender classification.
- Eyebrows is another class that helps immensely in gender classification. It is generally noticed that female eyebrows are thinner, well managed, and curly at the ends. On the other hand, male eyebrows are thicker, mismanaged. We obtained better labeling accuracy for eyebrow from our face parsing model.
- Mouth is another class that also helps in gender recognition. Female lips are visible and very clear; in the male in some cases (in images), the upper lip is even missing. We encoded this information as well and used it in our modeling process.
6. Results and Discussion
6.1. Experimental Setup
6.2. Face Parsing Results
Race, Age, and Gender Classification Experimental Setup
6.3. Race Classification
6.4. Age Classification
6.5. Gender Recognition
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Bonham, V.L.; Knerr, S. Social and ethical implications of genomics, race, ethnicity, and health inequities. Semin. Oncol. Nurs. 2008, 24, 254–261. [Google Scholar] [CrossRef] [PubMed]
- Rebbeck, T.R.; Halbert, C.H.; Sankar, P. Genetics, epidemiology and cancer disparities: Is it black and white? J. Clin. Oncol. 2006, 24, 2164–2169. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, N.T.; Basuray, M.T.; Smith, W.P.; Kopka, D.; McCulloh, D. Moral Issues and Gender Differences in Ethical Judgement Using Reidenbach and Robin’s (1990) Multidimensional Ethics Scale: Implications in Teaching of Business Ethics. J. Bus. Ethics 2008, 77, 417–430. [Google Scholar] [CrossRef]
- Huffman, M.L.; Torres, L. Job Search Methods: Consequences for Gender-Based Earnings Inequality. J. Vocat. Behav. 2001, 58, 127–141. [Google Scholar] [CrossRef]
- Asthana, A.; Zafeiriou, S.; Cheng, S.; Pantic, M. Robust discriminative response map fitting with constrained local models. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Belhumeur, P.N.; Jacobs, D.W.; Kriegman, D.J.; Kumar, N. Localizing parts of faces using a consensus of exemplars. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011. [Google Scholar]
- Cao, X.; Wei, Y.; Wen, F.; Sun, J. Face alignment by explicit shape regression. In Proceedings of the CVPR 2012, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Dantone, M.; Gall, J.; Fanelli, G.; van Gool, L. Real-time facial feature detection using conditional regression forests. In Proceedings of the CVPR 2012, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Murphy-Chutorian, E.; Trivedi, M.M. Head pose estimation in computer vision: A survey. IEEE TPAMI 2009, 31, 607–626. [Google Scholar] [CrossRef]
- Saragih, J.M.; Lucey, S.; Cohn, J.F. Deformable model fitting by regularized landmark mean-shift. IJCV 2011, 91, 200–215. [Google Scholar] [CrossRef]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. IVC 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Xiong, X.; de la Torre, F. Supervised descent method and its applications to face alignment. In Proceedings of the CVPR 2013, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Davies, G.; Ellis, H.; Shepherd, J. Perceiving and Remembering Faces; Academic Press: Cambridge, MA, USA, 1981. [Google Scholar]
- Sinha, P.; Balas, B.; Ostrovsky, Y.; Russell, R. Face recognition by humans: Nineteen results all computer vision researchers should know about. Proc. IEEE 2006, 94, 1948–1962. [Google Scholar] [CrossRef]
- Gross, R.; Baker, S. Generic vs. person specific active appearance models. IVC 2005, 23, 1080–1093. [Google Scholar] [CrossRef]
- Haj, M.A.; Gonzalez, J.; Davis, L.S. On partial least squares in head pose estimation: How to simultaneously deal with misalignment. In Proceedings of the CVPR 2012, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Khan, K.; Mauro, M.; Leonardi, R. Multi-class semantic segmentation of faces. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 827–831. [Google Scholar]
- Khan, K.; Ahmad, N.; Ullah, K.; Din, I. Multiclass semantic segmentation of faces using CRFs. Turk. J. Electr. Eng. Comput. Sci. 2017, 25, 3164–3174. [Google Scholar] [CrossRef]
- Khan, K.; Mauro, M.; Migliorati, P.; Leonardi, R. Head pose estimation through multi-class face segmentation. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 253–258. [Google Scholar]
- Luo, P.; Wang, X.; Tang, X. Hierarchical face parsing via deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2480–2487. [Google Scholar]
- Zhou, Y.; Hu, X.; Zhang, B. Interlinked convolutional neural networks for face parsing. In Proceedings of the International Symposium on Neural Networks, Jeju, Korea, 15–18 October 2015; pp. 222–231. [Google Scholar]
- Liu, S.; Shi, J.; Liang, J.; Yang, M.-H. Face parsing via recurrent propagation. arXiv 2017, arXiv:1708.01936. [Google Scholar]
- Warrell, J.; Prince, S.J.D. Labelfaces: Parsing facial features by multiclass labeling with an epitome prior. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 2481–2484. [Google Scholar]
- Smith, B.M.; Zhang, L.; Brandt, J.; Lin, Z.; Yang, J. Exemplar-based face parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3484–3491. [Google Scholar]
- Jackson, A.S.; Valstar, M.; Tzimiropoulos, G. A CNN cascade for landmark guided semantic part segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 143–155. [Google Scholar]
- Saito, S.; Li, T.; Li, H. Real-time facial segmentation and performance capture from rgb input. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 244–261. [Google Scholar]
- Kae, A.; Sohn, K.; Lee, H.; Learned-Miller, E. Augmenting CRFs with Boltzmann machine shape priors for image labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2019–2026. [Google Scholar]
- Smith, B.; Zhang, L.; Brandt, J.; Lin, Z.; Yang, J. Exemplarbased face parsing. In Proceedings of the CVPR 2013, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Benini, S.; Khan, K.; Leonardi, R.; Mauro, M.; Migliorati, P. FASSEG: A FAce semantic SEGmentation repository for face image analysis. Data Brief 2019, 24, 103881. [Google Scholar] [CrossRef] [PubMed]
- Mezzoudj, S.; Ali, B.; Rachid, S. Towards large-scale face-based race classification on spark framework. Multimed. Tools Appl. 2019. [Google Scholar] [CrossRef]
- Phillips, P.J.; Wechsler, H.; Huang, J.; Rauss, P.J. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis. Comput. 1998, 16, 295–306. [Google Scholar] [CrossRef]
- Gao, W.; Cao, B.; Shan, S.; Chen, X.; Zhou, D.; Zhang, X.; Zhao, D. The cas-peal large-scale chinese face database and baseline evaluations. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2008, 38, 149–161. [Google Scholar]
- Gutta, S.; Huang, J.; Jonathon, P.; Wechsler, H. Mixture of experts for classification of gender, ethnic origin, and pose of human faces. IEEE Trans. Neural Netw. 2000, 11, 948–960. [Google Scholar] [CrossRef]
- Gutta, S.; Wechsler, H. Gender and ethnic classification of human faces using hybrid classifiers. In Proceedings of the IJCNN’99 International Joint Conference on Neural Networks, Washington, DC, USA, 10–16 July 1999; Volume 6, pp. 4084–4089. [Google Scholar]
- Gutta, S.; Wechsler, H.; Phillips, P.J. Gender and ethnic classification of face images. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 194–199. [Google Scholar]
- Lu, X.; Jain, A.K. Ethnicity identification from face images. Proc. SPIE 2004, 5404, 114–123. [Google Scholar]
- Ou, Y.; Wu, X.; Qian, H.; Xu, Y. A real time race classification system. In Proceedings of the 2005 IEEE International Conference on Information Acquisition, Hong Kong, China, 27 June–3 July 2005; p. 6. [Google Scholar]
- Manesh, F.S.; Ghahramani, M.; Tan, Y.-P. Facial part displacement effect on template-based gender and ethnicity classification. In Proceedings of the 2010 11th International Conference on Control Automation Robotics & Vision, Singapore, 7–10 December 2010; pp. 1644–1649. [Google Scholar]
- Roomi, S.M.M.; Virasundarii, S.; Selvamegala, S.; Jeevanandham, S.; Hariharasudhan, D. Race classification based on facial features. In Proceedings of the 2011 Third National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics, Hubli, India, 15–17 December 2011; pp. 54–57. [Google Scholar]
- Minear, M.; Park, D.C. A lifespan database of adult facial stimuli. Behav. Res. Methods Instrum. Comput. 2004, 36, 630–633. [Google Scholar] [CrossRef]
- Salah, S.H.; Du, H.; Al-Jawad, N. Fusing local binary patterns with wavelet features for ethnicity identification. World Acad. Sci. Eng. Technol. Int. J. Comput. Inf. Syst. Control. Eng. 2013, 7, 471. [Google Scholar]
- Anwar, I.; Islam, N.U. Learned features are better for ethnicity classification. Cybern. Inf. Technol. 2017, 17, 152–164. [Google Scholar] [CrossRef]
- Chen, H.; Gallagher, A.; Girod, B. Face modeling with first name attributes. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1860–1873. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Huh, J.-H. An effective security measures for nuclear power plant using big data analysis approach. J. Supercomput. 2019, 75, 4267–4294. [Google Scholar] [CrossRef]
- Xie, Y.; Luu, K.; Savvides, M. A robust approach to facial ethnicity classification on large scale face databases. In Proceedings of the 2012 IEEE Fifth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 23–27 September 2012; pp. 143–149. [Google Scholar]
- Han, H.; Otto, C.; Liu, X.; Jain, A.K. Demographic estimation from face images: human vs. machine performance. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1148–1161. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Paluri, M.; Ranzato, M.; Darrell, T.; Bourdev, L. Panda: Pose aligned networks for deep attribute modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1637–1644. [Google Scholar]
- Wei, Y.; Xia, W.; Lin, M.; Huang, J.; Ni, B.; Dong, J.; Zhao, Y.; Yan, S. HCP: A flexible CNN framework for multi-label image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1901–1907. [Google Scholar] [CrossRef] [PubMed]
- Ragheb, A.R.; Kamsin, A.; Ismail, M.A.; Abdelrahman, S.A.; Zerdoumi, S. Face recognition and age estimation implications of changes in facial features: A critical review study. IEEE Access 2018, 6, 28290–28304. [Google Scholar]
- Fu, Y.; Guo, G.; Huang, T.S. Age synthesis and estimation via faces: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1955–1976. [Google Scholar]
- Kwon, Y.H.; da Vitoria Lobo, N. Age classification from facial images. In Proceedings of the CVPR 1994, Seattle, WA, USA, 21–23 June 1994; pp. 762–767. [Google Scholar]
- Ramanathan, N.; Chellappa, R. Modeling age progression in young faces. In Proceedings of the CVPR 2006, New York, NY, USA, 17–22 June 2006; pp. 387–394. [Google Scholar]
- Geng, X.; Zhou, Z.H.; Smith-Miles, K. Automatic age estimation based on facial aging patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2234–2240. [Google Scholar] [CrossRef]
- Guo, G.; Fu, Y.; Dyer, C.R.; Huang, T.S. Image-based human age estimation by manifold learning and locally adjusted robust regression. IEEE Trans. Image Process. 2008, 17, 1178–1188. [Google Scholar]
- Chang, K.Y.; Chen, C.S. A learning framework for age rank estimation based on face images with scattering transform. IEEE Trans. Image Process. 2015, 24, 785–798. [Google Scholar] [CrossRef]
- Li, C.; Liu, Q.; Dong, W.; Zhu, X.; Liu, J.; Lu, H. Human age estimation based on locality and ordinal information. IEEE Trans. Cybern. 2015, 45, 2522–2534. [Google Scholar] [CrossRef]
- Kumar, N.; Berg, A.; Belhumeur, P.; Nayar, S. Attribute and smile classifiers for face verification. In Proceedings of the ICCV 2009, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Demirkus, M.; Precup, D.; Clark, J.J.; Arbel, T. Soft Biometric trait classification from real worl face videos conditioned on head pose estimation. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Ricanek, K.; Tesafaye, T. Morph: A longitudinal image database of normal adult age-progression. In Proceedings of the Seventh International Conference on Automatic Face and Gesture Recognition, Southampton, UK, 10–12 April 2006; pp. 341–345. [Google Scholar]
- Makinen, E.; Raisamo, R. Evaluation of gender classification methods with automatically detected and aligned faces. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 541–547. [Google Scholar] [CrossRef]
- Golomb, B.A.; Lawrence, D.T.; Sejnowski, T.J. Sexnet: A neural network identifies sex from human faces. In Proceedings of the 1990 Conference on Advances in Neural Information Processing Systems 3, Denver, CO, USA, 26–29 November 1990; pp. 572–577. [Google Scholar]
- Jia, S.; Lansdall-Welfare, T.; Cristianini, N. Gender classification by deep learning on millions of weakly labelled images. In Proceedings of the IEEE International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 462–467. [Google Scholar]
- Moghaddam, B.; Yang, M.-H. Learning gender with support faces. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 707–711. [Google Scholar] [CrossRef]
- Baluja, S.; Rowley, H.A. Boosting sex identification performance. Int. J. Comput. Vis. 2006, 71, 111–119. [Google Scholar] [CrossRef]
- Antipov, G.; Berrani, S.A.; Dugelay, J.L. Minimalistic cnnbased ensemble model for gender prediction from face images. Pattern Recognit. Lett. 2016, 70, 59–65. [Google Scholar] [CrossRef]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Khan, K.; Attique, M.; Syed, I.; Gul, A. Automatic Gender Classification through Face Segmentation. Symmetry 2019, 11, 770. [Google Scholar] [CrossRef]
- Khan, K.; Attique, M.; Syed, I.; Sarwar, G.; Irfan, M.A.; Khan, R.U. A Unified Framework for Head Pose, Age and Gender Classification through End-to-End Face Segmentation. Entropy 2019, 21, 647. [Google Scholar] [CrossRef]
- Toews, M.; Arbel, T. Detection, localization, and sex classification of faces from arbitrary viewpoints and under occlusion. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1567–1581. [Google Scholar] [CrossRef]
- Yu, S.; Tan, T.; Huang, K.; Jia, K.; Wu, X. A study on gait-based gender classification. IEEE Trans. Image Process. 2009, 18, 1905–1910. [Google Scholar] [PubMed]
- Eidinger, E.; Enbar, R.; Hassner, T. Age and gender estimation of unfiltered faces. IEEE Trans. Inf. Forensics Secur. 2014, 9, 2170–2179. [Google Scholar] [CrossRef]
- Khan, F.S.; van de Weijer, J.; Anwer, R.M.; Felsberg, M.; Gatta, C. Semantic pyramids for gender and action recognition. IEEE Trans. Image Process. 2014, 23, 3633–3645. [Google Scholar] [CrossRef] [PubMed]
- Duan, M.; Li, K.; Yang, C.; Li, K. A hybrid deep learning CNN–ELM for age and gender classification. Neurocomputing 2018, 275, 448–461. [Google Scholar] [CrossRef]
- Lin, J.; Yang, H.; Chen, D.; Zeng, M.; Wen, F.; Yuan, L. Face Parsing with RoI Tanh-Warping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5654–5663. [Google Scholar]
- Liu, S.; Yang, J.; Huang, C.; Yang, M.-H. Multi-objective convolutional learning for face labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3451–3459. [Google Scholar]
- Huang, G.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in’RealLife’Images: Detection, Alignment, and Recognition, Marseille, France, 12–18 October 2008. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Yamashita, T.; Nakamura, T.; Fukui, H.; Yamauchi, Y.; Fujiyoshi, H. Cost-alleviative learning for deep convolutional neural network-based facial part labeling. IPSJ Trans. Comput. Vis. Appl. 2015, 7, 99–103. [Google Scholar] [CrossRef][Green Version]
- Khan, K.; Ahmad, N.; Khan, F.; Syed, I. A framework for head pose estimation and face segmentation through conditional random fields. Signal Image Video Process. 2019, 1–8. [Google Scholar] [CrossRef]
- Zhou, L.; Liu, Z.; He, X. Face parsing via a fully-convolutional continuous CRF neural network. arXiv 2017, arXiv:1708.03736. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Barron, J.T.; Papandreou, G.; Murphy, K.; Yuille, A.L. Semantic image segmentation with task-specific edge detection using CNNs and a discriminatively trained domain transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4545–4554. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. arXiv 2016, arXiv:1606.00915. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Muhammad, G.; Hussain, M.; Alenezy, F.; Bebis, G.; Mirza, A.M.; Aboalsamh, H. Race classification from face images using local descriptors. Int. J. Artif. Intell. Tools 2012, 21, 1250019. [Google Scholar] [CrossRef]
- Dehghan, A.; Ortiz, E.G.; Shu, G.; Masood, S.Z. Dager: Deep age, gender and emotion recognition using convolutional neural network. arXiv 2017, arXiv:1702.04280. [Google Scholar]
- Hou, L.; Yu, C.P.; Samaras, D. Squared earth mover’s distance-based loss for training deep neural networks. arXiv 2016, arXiv:1611.05916. [Google Scholar]
- Hassner, T.; Harel, S.; Paz, E.; Enbar, R. Effective face frontalization in unconstrained images. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Hernández, S.; Vergara, D.; Valdenegro-Toro, M.; Jorquera, F. Improving predictive uncertainty estimation using Dropout–Hamiltonian Monte Carlo. Soft Comput. 2018, 1–16. [Google Scholar] [CrossRef]
- Levi, G.; Hassner, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar]
- Lapuschkin, S.; Binder, A.; Muller, K.-R.; Samek, W. Understanding and comparing deep neural networks for age and gender classification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1629–1638. [Google Scholar]
- Van de Wolfshaar, J.; Karaaba, M.F.; Wiering, M.A. Deep convolutional neural networks and support vector machines for gender recognition. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015; pp. 188–195. [Google Scholar]
- Ranjan, R.; Patel, V.M.; Chellappa, R. Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 121–135. [Google Scholar] [CrossRef] [PubMed]
- Kumar, N.; Belhumeur, P.N.; Nayar, S.K. FaceTracer: A Search Engine for Large Collections of Images with Faces. In Proceedings of the European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008; pp. 340–353. [Google Scholar]
- Moeini, H.; Mozaffari, S. Gender dictionary learning for gender classification. J. Vis. Commun. Image Represent. 2017, 42, 1–13. [Google Scholar] [CrossRef]
- Rai, P.; Khanna, P. An illumination, expression, and noise invariant gender classifier using two-directional 2DPCA on real Gabor space. J. Vis. Lang. Comput. 2015, 26 (Suppl. C), 15–28. [Google Scholar] [CrossRef]
- Tapia, J.E.; Perez, C.A. Gender classification based on fusion of different spatial scale features selected by mutual information from histogram of lbp, intensity, and shape. IEEE Trans. Inf. Forensics Secur. 2013, 8, 488–499. [Google Scholar] [CrossRef]
- Afifi, M.; Abdelhamed, A. AFIF4: Deep gender classification based on AdaBoost-based fusion of isolated facial features and foggy faces. arXiv 2017, arXiv:1706.04277. [Google Scholar] [CrossRef]
- Thomaz, C.; Giraldi, G.; Costa, J.; Gillies, D. A priori-driven PCA. In Proceedings of the Computer Vision ACCV 2012 Workshops, Lecture Notes in Computer Science, Daejeon, Korea, 5–9 November 2013; pp. 236–247. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | kernel Size | Stride | Feature Maps | Output Size |
|---|---|---|---|---|
| Input image | – | – | – | |
| C-1 | 2 | 96 | ||
| P-1 | 2 | 96 | ||
| C-2 | 2 | 256 | ||
| P-2 | 2 | 256 | ||
| C-3 | 2 | 512 | ||
| P-3 | 2 | 512 |
| Parameters | Vales |
|---|---|
| Epochs | 30 |
| Batch size | 125 |
| Momentum | 0.9 |
| Base learning rate |
| Method | Eyes | Brows | Mouth | Nose | Skin | Hair | Back | Overall |
|---|---|---|---|---|---|---|---|---|
| Khan et al. [80] | 60.75 | – | 84.2 | 61.25 | 94.66 | 95.81 | 91.50 | – |
| MCFP-DCNNs | 84.30 | 86.25 | 89.30 | 87.8 | 96.58 | 98.2 | 94.54 | 95.12 |
| Method | Eyes | Brows | Mouth | Nose | Skin | Hair | Back | Overall |
|---|---|---|---|---|---|---|---|---|
| Smith et al. [24] | 78.5 | 92.2 | 85.7 | 92.2 | 88.2 | – | – | 80.4 |
| Zhou et al. [81] | 87.4 | 81.3 | 92.6 | 95.0 | – | – | – | 87.3 |
| Liu et al. [75] | 76.8 | 71.3 | 84.1 | 90.9 | 91.0 | – | – | 84.7 |
| Liu et al. [22] | 86.8 | 77.0 | 89.1 | 93.0 | 92.1 | – | – | 88.6 |
| Wei et al. [48] | 84.7 | 78.6 | 89.1 | 93.0 | 91.5 | – | – | 90.2 |
| Jonathan et al. [23] | 89.7 | 85.9 | 95.2 | 95.6 | 95.3 | 88.7 | – | 93.1 |
| MCFP-DCNN | 78.6 | 83.2 | 88.5 | 97.2 | 96.2 | 98.4 | 86.2 | 95.2 |
| Method | Eyes | Brows | Mouth | Nose | Skin | Hair | Back | Overall |
|---|---|---|---|---|---|---|---|---|
| Liu et al. [75] | – | – | – | – | 93.93 | 80.70 | 97.10 | 95.12 |
| Long et al. [82] | – | – | – | – | 92.91 | 82.69 | 96.32 | 94.13 |
| Chen et al. [83] | – | – | – | – | 92.54 | 80.14 | 95.65 | 93.44 |
| Chen et al. [84] | – | – | – | – | 91.17 | 78.85 | 94.95 | 92.49 |
| Zhou et al. [81] | – | – | – | – | 94.10 | 85.16 | 96.46 | 95.28 |
| Liu et al. [22] | – | – | – | – | 97.55 | 83.43 | 94.37 | 95.46 |
| Jonathan et al. [23] | – | – | – | – | 98.77 | 88.31 | 98.26 | 96.71 |
| MCFP-DCNN | 78.2 | 68.3 | 72.5 | 85.7 | 96.8 | 94.2 | 97.2 | 93.25 |
| Database | Method | Asian (Accuracy%) | Non-Asian (Accuracy%) |
|---|---|---|---|
| RAG-MCFP-DCNNs | – | 100 | 96.4 |
| Manesh et al. [38] | FERET [31] and CAS-PEAL [32] | 98 | 96 |
| Muhammed et al. [86] | FERET [31] | 99.4 | – |
| Chen and Ross [43] | CAS-PEAL [32] | 98.7 | – |
| Anwar and Naeem [42] | FERET | 98.28 | – |
| Database | Method | Classification Aaccuracy (%) |
|---|---|---|
| Adience | RAG-MCFP-DCNNs | 69.4 |
| Dehghan et al. [87] | 61.3 | |
| Hou et al. [88] | 61.1 | |
| Hassner et al. [89] | 50.7 | |
| Hernandez et al. [90] | 51.6 | |
| CNN-ELM [73] | 52.3 |
| Database | Method | Classification Accuracy (%) |
|---|---|---|
| Adience | RAG-MCFP-DCNNs | 93.6 |
| Levi et al. [91] | 86.8 | |
| Lapuschkin et al. [92] | 85.9 | |
| CNNs-EML [73] | 77.8 | |
| Hassner et al. [89] | 79.3 | |
| LFW | Van et al. [93] | 94.4 |
| RAG-MCFP-DCNNs | 94.1 | |
| HyperFace [94] | 94.0 | |
| LNets+ANet [95] | 94.0 | |
| Moeini et al. [96] | 93.6 | |
| PANDA-1 [47] | 92.0 | |
| ANet [56] | 91.0 | |
| Rai and Khanna [97] | 89.1 | |
| FERET | RAG-MCFP-DCNNs | 100 |
| Moeini et al. [96] | 99.5 | |
| Tapia and Perez [98] | 99.1 | |
| Rai and Khanna [97] | 98.4 | |
| Afifi and Abdelrahman [99] | 99.4 | |
| A priori-driven PCA [100] | 84.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, K.; Attique, M.; Khan, R.U.; Syed, I.; Chung, T.-S. A Multi-Task Framework for Facial Attributes Classification through End-to-End Face Parsing and Deep Convolutional Neural Networks. Sensors 2020, 20, 328. https://doi.org/10.3390/s20020328
Khan K, Attique M, Khan RU, Syed I, Chung T-S. A Multi-Task Framework for Facial Attributes Classification through End-to-End Face Parsing and Deep Convolutional Neural Networks. Sensors. 2020; 20(2):328. https://doi.org/10.3390/s20020328
Chicago/Turabian StyleKhan, Khalil, Muhammad Attique, Rehan Ullah Khan, Ikram Syed, and Tae-Sun Chung. 2020. "A Multi-Task Framework for Facial Attributes Classification through End-to-End Face Parsing and Deep Convolutional Neural Networks" Sensors 20, no. 2: 328. https://doi.org/10.3390/s20020328
APA StyleKhan, K., Attique, M., Khan, R. U., Syed, I., & Chung, T.-S. (2020). A Multi-Task Framework for Facial Attributes Classification through End-to-End Face Parsing and Deep Convolutional Neural Networks. Sensors, 20(2), 328. https://doi.org/10.3390/s20020328