1. Introduction
Cybersecurity issues in the Internet of Things (IoT) are an increasingly prominent challenge due to the continuous development and sophistication of network penetration methods and attack technologies [
1]. How to quickly identify intrusions in the IoT has become one of the urgent problems in the field of network security. It is critical to develop more effective detection technology. Signature-based network intrusion detection systems (NIDSs) and anomaly-based NIDSs are two types of NIDS. A key technical issue is that NIDSs need to identify never-before-seen network attacks. In a signature-based NIDS, the system detects attacks based on pre-installed rules. The NIDS detects the intrusion in the network traffic dataset by comparing the network traffic with the updated attack signature database.
Anomaly-based NIDSs distinguish whether the network traffic is normal or abnormal by learning the abnormal data in the network data stream. Network behavior deviating from the normal data pattern is considered to be abnormal behavior. We have mainly studied anomaly-based NIDSs because of their ability to detect unknown or abnormal attacks. Anomaly detection methods are used in national security departments, banking, finance, securities, communications, and medical applications [
2]. In fact, the IDS mainly detects whether the network traffic is normal or abnormal, so that the IDS can be attributed to a classification problem.
Many machine learning algorithms have been applied to IDSs to improve their performance, resulting in breakthroughs [
2]. However, traditional machine learning methods work better when dealing with small datasets. They are less efficient when dealing with the classification of massive intrusion data in an actual network application environment. Conventional machine learning algorithms usually have problems with high time complexity and space complexity when large-scale data have high-dimensional properties or nonlinear feature spaces. Therefore, proposing or adopting a more effective method to reduce the dimensionality of high-dimensional data is an indispensable step in the construction of NIDSs.
Deep learning (DL) theory was first proposed by Professor Hinton [
3] in 2006. Today, the DL technique is widely used in image recognition, speech recognition, machine translation, and emotion recognition. The advantage of deep learning is that it can obtain meaningful abstract representations from raw data through multilayer neural networks. The significant difference between deep learning and traditional machine learning methods is that it can extract features from raw data instead of using manually designed features. Effective features can greatly improve the intrusion detection performance of NIDS. The feature learning of deep learning is automatically completed through a multi-layer neural network. Each layer of neurons will extract features from the input data and output to the next layer. Compared to traditional machine learning, deep learning reduces the dependence on the prior distribution of the data. As the depth of the network increases, the number of nonlinear transformations of the data increases, and the stronger the model representation ability for data, thereby obtaining a more essential characterization of the data. DL also offers advantages in handling high-dimensional large-scale data. However, a major limitation of SAE is that the loss function is non-convex. Therefore, the model tends to converge to local minimum values and cannot guarantee the existence of the global minimum value. This study proposes an intrusion detection model that combines stacked autoencoder (SAE) with support vector machine (SVM), gaining the advantages of both. There are two main reasons why SVM is theoretically attractive [
4,
5]: (1) SVMs have good generalization performance when parameters are properly configured, even if there are some deviations in the training set. (2) Since the loss function is a convex function, it provides a unique solution. In principle, SVMs can model any training set when selecting the appropriate kernel.
Given the complementary advantages of the SVM and SAE models, it makes sense to study a hybrid model of these two architectures for intrusion detection. However, the previous work in this area also focused on hybrid models, but in these, the two components were trained separately, unlike in a true hybrid model. First, the DL model is trained to obtain the compression features after a dimensionality reduction, and then the extracted features are fed to the shallow model to continue training. For example, the hybrid model of a deep belief network (DBN) and One-class SVM (OC-SVM) proposed in [
6] uses a DBN to compress high-dimensional features, and uses the traditional OC-SVM for anomaly detection. However, the two-stage approach does not effectively learn the characteristics of the intrusion detection dataset, and the dimensionality grows larger due to the decoupling of the learning phase. Therefore, the kernel approximation technique is applied to approximate the kernel function of nonlinear SVM. The feature extracted by the SAE is used to construct the explicit feature map approximation for the Gaussian kernel. The linear SVM algorithm is then used to efficiently solve the large-scale nonlinear SVM. The SAE is combined with the linear SVM to implement end-to-end training.
The main contributions of this study are as follows:
- (1)
Through the kernel approximation technique, SAE and SVM are combined for joint training, and a new intrusion detection model is proposed. The effectiveness and the potential of our method for handling large-scale data are studied to improve upon traditional supervised machine learning algorithms.
- (2)
We studied the impact of the network structure of SAE and the number of random Fourier features on the accuracy of our method.
- (3)
We used the NSL-KDD dataset for experimental verification, and compared the efficiency of our approach with non-kernel approximation SVM and different classification algorithms in binary-category and five-category classification. The experimental results confirm that our model is more accurate and faster.
The remainder of this study is given as follows:
Section 2 outlines other work related to this study.
Section 3 offers background for the related technologies used in this study and discusses the proposed intrusion detection model in greater detail.
Section 4 describes the setup of the experiment.
Section 5 provides the experimental results and comparative analysis. In
Section 6, we present our conclusions and discuss potential future research.
2. Related Work
Researchers have previously used various traditional machine learning methods to construct IDS, such as SVM [
7], the k-nearest neighbor (KNN) algorithm [
8], the naive Bayes (NB) algorithm [
9], Artificial Neural Networks (ANN) [
10], Random Forest (RF) [
11], the self-organizing map (SOM) type of ANN [
12], and other related machine learning methods [
13,
14]. In all these methods, the performance of SVM was improved [
15]. For example, the results in [
16] demonstrate that SVM was better than ANN in terms of test time and accuracy on the KDD CUP 99 dataset. Kou et al. [
17] compared the performance of traditional machine learning methods such as SVM, logistic regression (LR), naive Bayes, decision tree (DT) and classification and regression tree (CART) on the KDD CUP99 dataset in terms of accuracy and false alarm rate. The experiment results confirmed that SVM had a distinct performance. Although traditional machine learning algorithms and shallow learning technologies (e.g., ANN) have improved detection accuracy and reduced false alarm rates, the detection performance of these methods is highly dependent on features. With Google’s artificial intelligence (AI) program AlphaGo defeating South Korean Li Shishi in chess, DL has become a research hotspot in the field of AI. As a branch of machine learning, DL can learn suitable and effective features from a vast amount of complex data. The DL model effectively solves the “curse of dimensionality” by learning low-dimensional feature representations and achieving good detection results in high-dimensional and complex network environments. There are already many DL methods applied in IDSs, such as the deep convolutional neural network (DCNN) [
18,
19], recurrent neural network (RNN) [
20], long short-term memory network (LSTM) [
21], and DBN [
22]. However, since the loss function of DL is non-convex, it will also face the limitation of converging to a local minimum. Therefore, many researchers use a combination of DL and other different classification algorithms such as SVM and RF to construct an IDS.
Alom et al. [
23] used a DBN and a SVM to construct a new intrusion detection model. The role of the DBN is to remove redundant features and noisy data and extract valid features, and then the SVM is used for classification. Although this model achieved better results than a single DBN and a single SVM, the DBN and SVM are trained separately rather than jointly trained together. Cao et al. [
24] used an autoencoder (AE) to extract the features of the intrusion dataset and then used the density estimation method for classification. Similarly, pertaining to large-scale training data, Shone et al. [
25] used a stacked nonsymmetric deep autoencoder (SNDAE) for unsupervised feature learning, and combined RF algorithms for intrusion detection. The results show that the model had higher accuracy, precision, and recall, and reduced training time. Compared with the method based on DBN, the model accuracy was increased by 5%, and the training time was reduced by up to 98.81%. AL-QATF et al. [
26] used a single-layer sparse AE to remove redundant dimensions and extract effective features, and replace softmax with SVM for classification. Experimental results showed that the model improved the SVM classification performance and reduced time spent. Good performance was also shown to have been achieved in the binary and five categories on the NSL-KDD dataset, compared to the other models. Zhang et al. [
27] proposed a real-time DBN-SVM intrusion detection model, and achieved good detection results on the CICIDS2017 dataset. However, the training methods of DBN and SVM in this model are separately trained.
Qiao et al. [
28] established an Internet of Things (IoT) network detection model based on a deep autoencoder (DAE) and an SVM. The DAE is used to learn the feature representation of the data, and then that is classified by a powerful SVM. The SVM uses the artificial bee colony (ABC) algorithm and the fivefold cross-validation (5FCV) statistical method to find the optimal parameters. The experimental results on the UNSW-NB15 dataset show that the model had better performance than some advanced intrusion detection methods, including principal component analysis (PCA) and other different classification algorithms. In [
29], an intrusion detection model combining a gated recurrent unit (GRU) and linear SVM was proposed. The structure of GRU RNN was improved, and the SVM was used as a classifier. In addition, the SVM replaced the edge-based function with the cross-entropy function. The results on the Kyoto2013 dataset show that the performance of the GRU_SVM model achieved significant improvement over the traditional GRU model. Chowdhury et al. [
30] trained a DCNN as a feature extractor to extract the output of each layer of the CNN as the input of the SVM. This method was inspired by small sample learning and solves the sample imbalance problem. Experimental verification was carried out on the KDD99 and NSL-KDD datasets, and the results show the effectiveness of the proposed model.
The above hybrid model by Chowdhury et al is basically a combination of a deep neural network (DNN) and an SVM. The two can complement each other, but the above models are trained separately. This training method cannot effectively learn the feature representation of sample data. Moreover, when the SVM with Gaussian kernel function is used as a classifier, the required computation is very complex, and the big data problem cannot be solved effectively. Therefore, this paper proposes an intrusion detection model combining a stacked AE and a kernel approximate linear SVM. The model adopts the joint training mode and approximates the Gaussian kernel with random Fourier features, which not only solves the problem of large-scale data processing, but also reduces the training time.
3. Materials and Methods
3.1. Stacked Autoencoder (SAE)
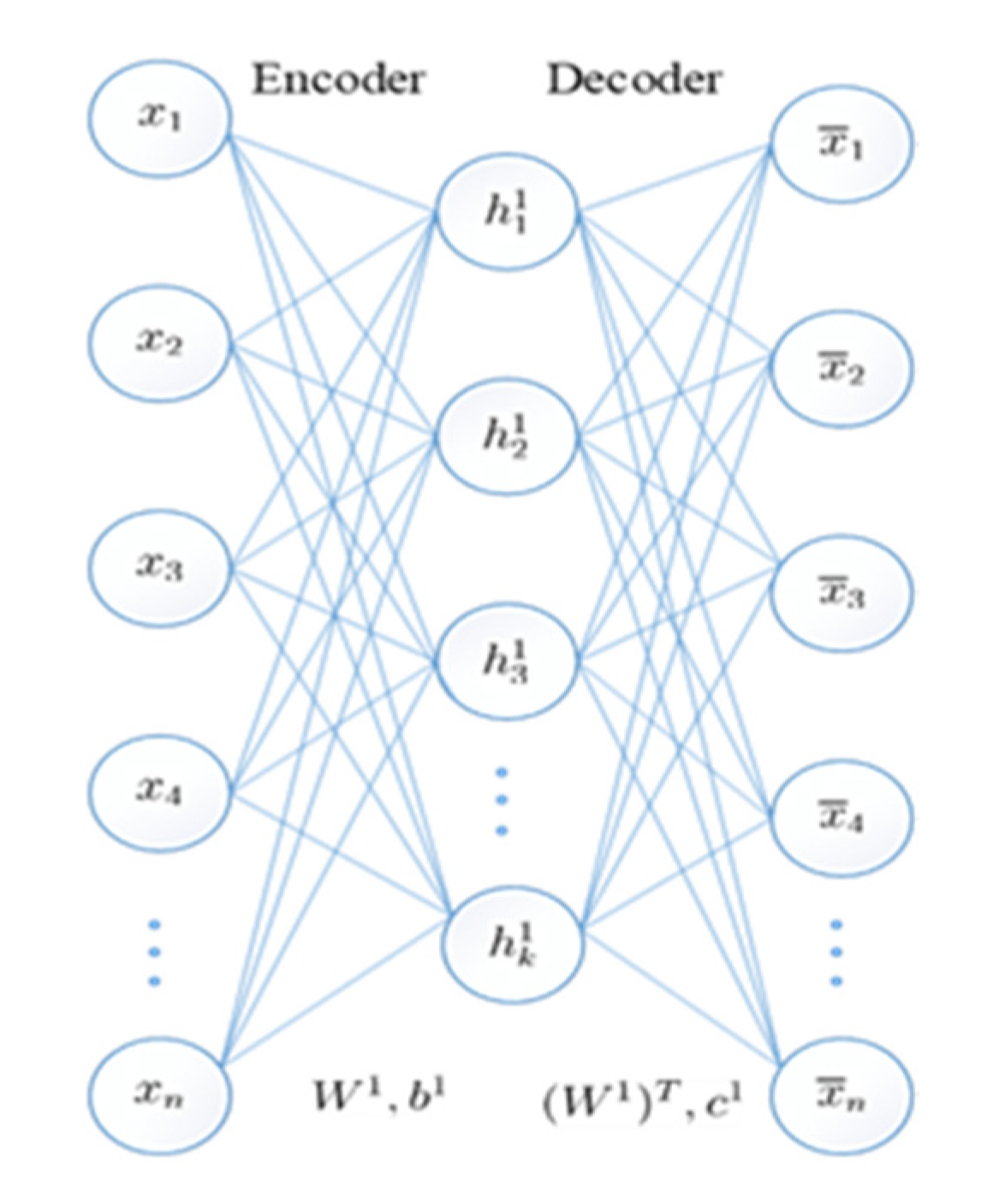
The standard AE is a multilayer feedforward network with structural symmetry on the middle layer, including input layer, hidden layer, and reconstruction layer, as shown in
Figure 1. The entire AE consists of an encoder and a decoder.
The first part of the AE is the encoder: the process of mapping input to an implicit representation. The second part of the AE is the decoder: the process of mapping an implicit representation to an output layer to reconstruct the input.
Given an N-dimensional training set , where is the -th vector in the training set. After the training set is trained by the AE, the output vector of the output layer will reconstruct the input vector as much as possible.
The process of these two parts is as shown in Equations (1) and (2):
where
and
represent weights and bias in the encoding stage,
and
represent weights and bias in the decoding stage, and
and
are activation functions in the encoding and decoding stages, respectively.
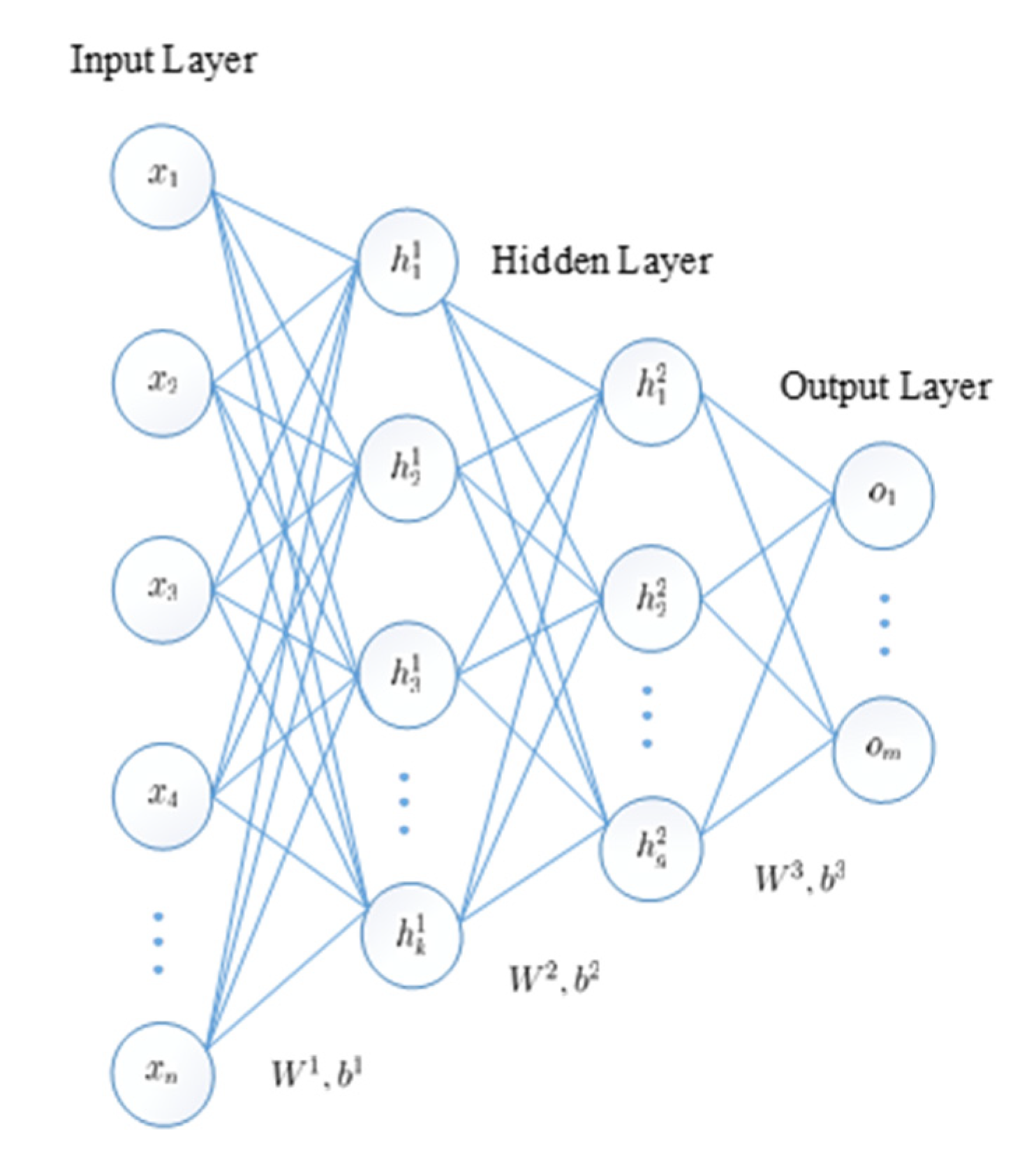
The SAE superimposes multiple AEs using the representation of the hidden layer of the previous layer as the input of the next layer, resulting in a more abstract representation, as shown in
Figure 2. The SAE initializes the network weight parameters and bias by greedy layer-wise pre-training [
31], thereby increasing the convergence speed of the deep network and slowing down the effects of gradient disappearance. The SAE is then fine-tuned using the error backpropagation method until the reconstruction error is minimized, thereby obtaining an optimal parametric model.
The SAE is an unsupervised neural network model whose core function is to learn the deep representation of input data. The input layer data
is converted to its hidden layer representation and then reconstructed by the hidden layer to restore new input data. The training goal of the SAE is to make the reconstructed data restore the input layer data as much as possible. The loss function of the SAE is usually defined by mean square error, as shown in Equation (3):
To avoid overfitting, the weight decay is usually added to the loss function, and (3) is rewritten as (4):
The equation for weight decay is expressed as follows:
where
is the
F-norm of the matrix and
is the weight decay coefficient.
Using an optimization algorithm such as gradient descent, the optimal parameters of the model can be determined.
3.2. SVM
A SVM is based on maximizing an interval and finding a hyperplane that correctly classifies the data. Since the kernel strategy is used, SVMs can usually capture nonlinearity. The kernel strategy plays a significant role in solving nonlinear inseparable mode analysis. The main idea of the kernel strategy is to map a low-dimensional linearly inseparable feature space
to a high-dimensional space
. It is expected that the data are linearly separable in the high-dimensional space. The commonly used kernel functions mainly include linear kernel functions, radial basis kernel functions, and polynomial kernel functions. This paper uses a radial basis kernel function (RBF)
. Assume that the training data is
,
,
, then the object of the nonlinear SVM is to form a problem for solving convex quadratic programming under certain constraint conditions. The formulas are as shown in (6) and (7):
where
,
,
,
, and
represent the weight vector, bias term, penalty factor, slack variable, and kernel function, respectively. In general, one can replace
with
by adding one dimension to include bias item
in
. In addition, using hinge loss instead of
, the unconstrained objective function of the nonlinear SVM is as shown in (8):
Equation (8) is essentially a convex optimization problem that can be solved by Lagrangian duality. However, dual space is directly proportional to the number of samples in the dataset. Assuming that the number of samples is , the time complexity will be .This is intolerable for large datasets.
Although there are few efficient algorithms for solving nonlinear SVM, there are many efficient algorithms for solving linear SVMs. In recent years, the feature has been explicitly used as the input of linear SVMs, which can transform the solution of a nonlinear SVM into a linear SVM in the feature space. Instead of solving the convex quadratic optimization problem, the kernel-induced feature space is embedded into a relatively low-dimensional explicit stochastic feature space, and the linear SVM is trained so that the efficient linear SVM algorithm can be applied to solve the nonlinear SVM.
3.3. Kernel Approximation Random Fourier Feature
The kernel approximation algorithm is often used to solve the scalability problem of kernel machine learning. There are two primary kernel approximation algorithms: Nystroem and random Fourier feature (RFF) [
32,
33]. This paper uses RFF since it has low complexity and does not require pre-training. Bochner’s theorem [
34] states that as long as the kernel function satisfies shift-invariance and is continuous and positive definite, there is a Fourier transform with a probability distribution
corresponding to the
function. As shown in Equation (9):
where
is the probability density function of
, for the Gaussian kernel function,
can be calculated by the inverse Fourier transform of
and we obtain
, where
represents the identity matrix.
independent and identically distributed weights
are drawn from the distribution
by Monte Carlo sampling. For sample
, its random Fourier features
are defined as follows (10):
where
is subject to normal distribution
. Applying kernel approximation mapping, the unconstrained objective function of the nonlinear SVM is transformed into the following:
In this way, the training set is converted to and as the input of the linear SVM, the efficient solving algorithm of the linear SVM can be applied to the nonlinear SVM. The optimal solution of the objective function will become simpler, although the dimension of is higher than the dimension of .
3.4. Proposed Method For Intrusion Detection
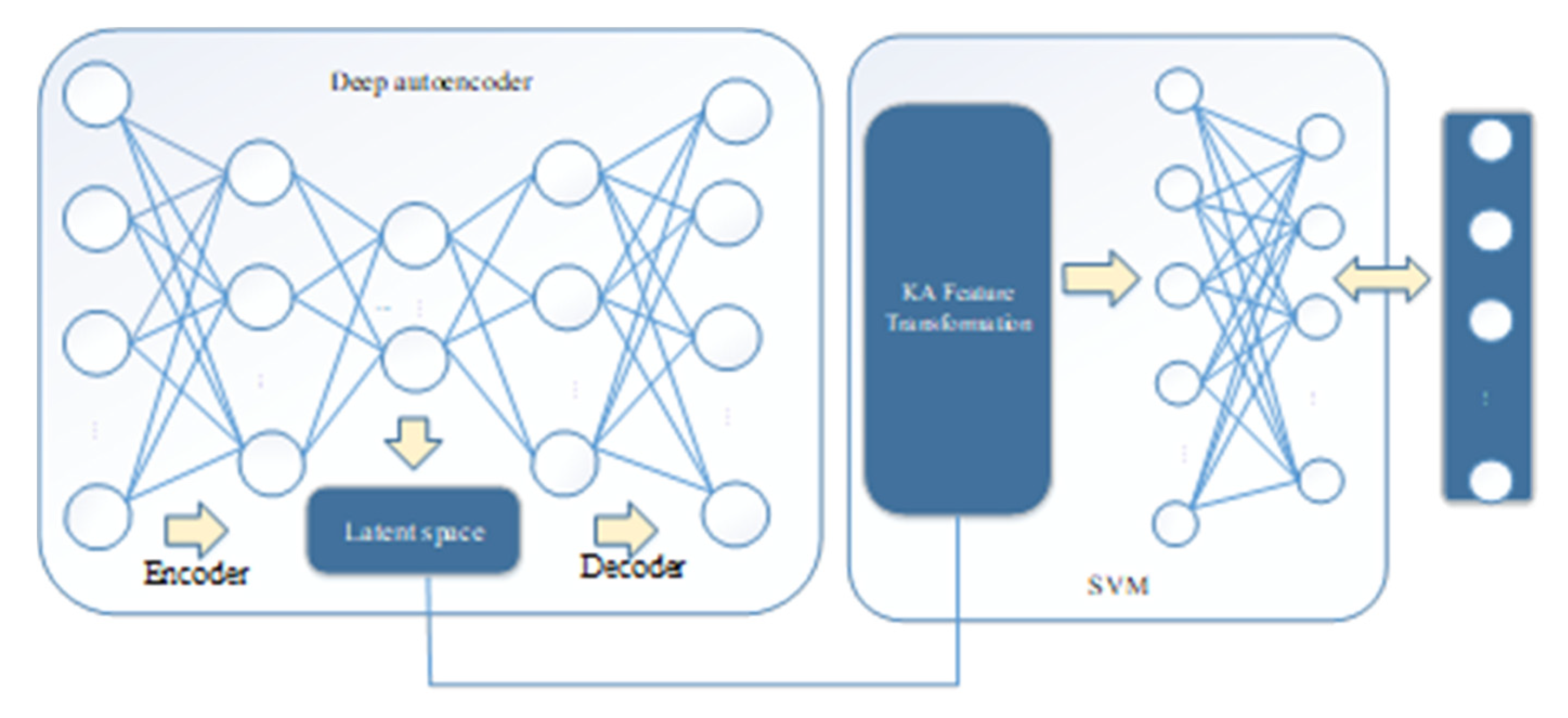
3.4.1. The Proposed Model Framework
The overall framework of the proposed model based on the SAE and the kernel approximation SVM is shown in
Figure 3, which includes five steps:
- Step 1:
Data preprocessing. The training set and test set are respectively processed for numeralization of symbolic data and normalization; see
Section 4.1.2 for details.
- Step 2:
The training set is first fed to the SAE, and forward calculation is performed to obtain a compressed representation. Then, the compressed representations with kernel approximation (KA) are used as the input of the linear SVM.
- Step 3:
Calculate the reconstructed data and the loss function.
- Step 4:
Use the gradient descent method for joint training to obtain a training model. See the next section for details.
- Step 5:
Make a prediction on the test set.
3.4.2. Joint Training Model
The joint training model based on SAE and kernel approximation SVM is shown in
Figure 4. The model is made up of an SAE, which is used for dimensionality reduction and compressed representation of the original data. The SVM with radial basis kernel function uses the random Fourier feature for kernel approximation.
In the following, we describe the model in detail.
Assume that the input vector of the SAE is
and the reconstructed vector is
.
is the feature representation of the hidden layer after dimension reduction. In addition,
is a set of parameters for the SAE and the weight matrix
is the main parameter of the SVM. Accordingly, the objective function of the model is shown in Equation (12):
The hyperparameter
is the adjustment factor between the feature dimension reduction of the SAE and the interval optimization of SVM,
as shown in Equation (4),
as shown in Equation (13):
is the Fourier feature map of the SAE compression feature, as shown in Equation (9) above.
represents the interval function of the SVM. Each
in the equation represents the feature representation of each neuron in the hidden space of the last layer of the encoder, and
,
is the activation function of the SAE. The gradient of
with respect to
,
can be derived as:
The gradient of the model loss function with respect to the SAE parameters and the SVM weight vector is as shown in Equations (17) and (18):
Finally, combining (17) and (18) with (14), we can obtain an end-to-end gradient of loss function with respect to all model parameters based on the chain rules of the derivative.
To implement this model, we use the TensorFlow open-source machine learning platform to perform automatic differentiation, to obtain the necessary gradients to minimize the loss function in the training process, and to process large datasets.
The joint training process of the model is described by Algorithm 1.
In Algorithm 1,
N represents the number of samples and
r represents the number of SAE hidden layers.
and
respectively represent the input and output of the
n-th sample in the
r-th hidden layer.
| Algorithm 1: Joint training algorithm. |
| Input: Training set , SAE structure, number of training iterations |
| Output: Model parameters |
| Training stage |
| 1. Randomly initialize and , . |
| 2. t = 0. |
| 3. While (t ≤ T) |
| 1) Forward calculation to obtain the compressed representation of SAE: |
| |
| 2) Perform kernel approximation according to Equation (10), get . |
| 3) Calculate g(x) according to Equation (14), where is the input of the SVM. |
| 4) Use the gradient descent method to obtain model parameters according to Equations (15)–(18). |
| t = t + 1 |
| End |
| 4. Get the optimal parameters of the model: and . |
| 5. According to Equations (10) and (14), calculate g(x) on the test set. |
| 6. Determine whether the sample is normal or malicious based on the value of g(x). |
5. Discussion
To verify the validity of the proposed method, we designed two sets of experiments. The purpose of the experiments was to make a comparison in the performance of the joint training model with kernel approximation (JSAE-FSVM), the separate training model with kernel approximation (SSAE-FSVM), and the separate training model without kernel approximation (SSAE-SVM) in binary-category classifications (Normal, Abnormal) and five-category classifications (Normal, DoS, R2L, U2R, and Probe). At the same time, to compare our proposed model with several conventional machine learning methods (NB, RF, KNN, DT, SVM, and MLP(multi-layered perceptron)), we designed a set of comparative experiments. The experiments in the study were designed to realize four objectives:
- (1)
Evaluate the effect of AE structure on model performance.
- (2)
Evaluate the effect of Fourier features number on model performance.
- (3)
Evaluate the binary-category and five-category performance of the joint training model.
- (4)
Analyze the advantages of the proposed model.
The experimental environment for this study was as follows: We used the extensive DL framework TensorFlow for programming. The experiment was conducted on a laptop equipped with Intel Core i7-7700HQ 2.80 GHz CPU, 8 GB RAM, and the 64-bit Windows 10 operating system, without GPU acceleration. The parameters of the SAE were set as follows: the activation function was a tanh function; batch size was 256; weight initialization was per Xavier’s method [
39]; learning rate was 0.001. The adjustment factor in Equation (12) was 10,000.
5.1. Impact of the Different Network Structures
The determination of the structure of the DNN primarily involves the determination of the depth of the networks and the width of each hidden layer. Currently, there is no mature theoretical method to select the optimal network structure for as DNN. If the model is too simple, it may not be able to effectively extract the compressed representation of the input vector—that is, it differs greatly from the probability distribution of the original data, and it cannot denote the essential representation of the original data. Conversely, deeper models mean better non-linear representation capabilities, which can learn more complex transformations, which can fit more complex feature inputs. However, if the model is too complex, the training process becomes more complex, which will dramatically increase the space-time consumption and produce overfitting. Accordingly, different network structures need to be set according to different experimental environments.
Table 3 shows the experimental results in the binary-category classifications when using different network structures in the NSL-KDD test set.
The experimental results show that as the number of hidden layers increased, the classification effect improved, but the amount of time spend on training also increased, which is not feasible in the massive intrusion data environment. In the above experiment, the training time of the five-layer SAE was 554.79 s, while the training time of the other two four-layer structures was 510.06 s and 474.52 s, respectively. When the model faces a large-scale intrusion data environment, the time complexity will increase exponentially. According to the test results of the SAE on the NSL-KDD training set in
Table 3, the SAE network structure selected in this paper was [122-110-85-55-15].
5.2. Impact of Fourier Feature Numbers
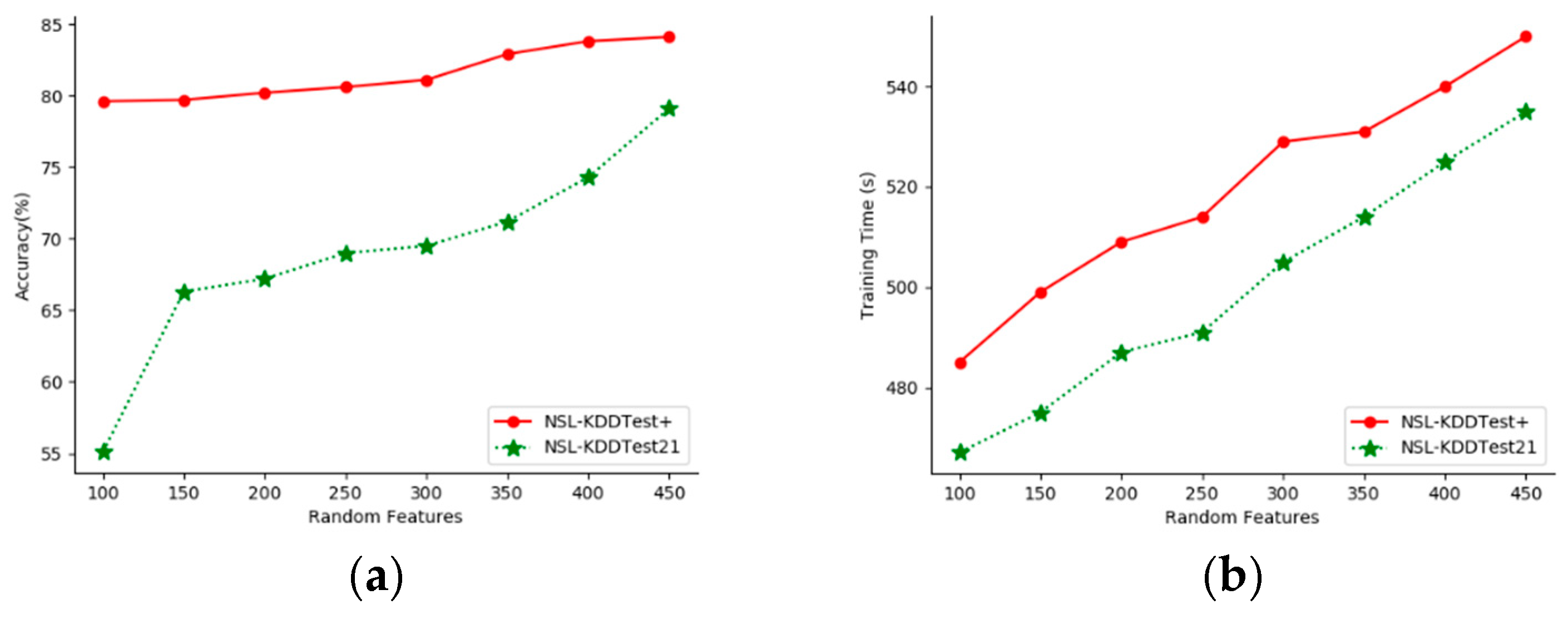
This paper evaluates the effect of random Fourier feature numbers (sample feature numbers) on the proposed model’s accuracy. We performed experiments with different feature numbers on the NSL-KDDTest+ and NSL-KDDTest21 datasets.
Figure 5 shows the classification accuracy and training time for feature numbers from 100 to 450.
As can be seen from
Figure 5, as the number of features increased, the performance of our model improved. The more sampling dimensions, the better the classification results, but the greater the cost. This means that there is a trade-off between run-time and accuracy, and the number of features selected in this paper was 400.
5.3. Classification Performance of the Model
To verify the superiority of our proposed network intrusion detection model (JSAE-FSVM), we measured the performance of our model in the binary-category and five-category classifications in NSL-KDDTest+ and NSL-KDDTest21. We compared this performance with that of the separately trained classification model (SSAE-FSVM) and the separate training model (SAE-SVM) without kernel approximation in terms of performance index and training time. The results are shown in
Table 4 and
Table 5.
It can be seen from
Table 4 and
Table 5 that all JSAE-FSVM performance metrics, except for precision and
FAR, were higher than those for the other two models. In the binary-category experiment, especially on the NSL-KDDTest21 dataset, the accuracy of our model was as high as 74.4%, which is about eight percentage points higher than the other two models, a remarkable increase. In the five-category model, the accuracy rate on the NSL-KDDTest+ dataset was better than on the other two. The
FAR of JSAE-FSVM was lower than that of SSAE-FSVM and SAE-FSVM for both binary-category and five-category experiments. The most attractive aspect of the model is that the training time of the model with approximate Gaussian kernel showed a sharp drop compared to the others. This is mainly because we used efficient linear support vector machines, which are very important in the NIDS in large-scale datasets.
5.4. Comparison with Other Models
5.4.1. Comparison with Basic Models
We also compared the accuracy of other classification algorithms in related research to verify the superiority of our model. Many algorithms have been applied to intrusion detection, including traditional machine learning algorithms such as NB, KNN, DT, RF, SVM, and MLP, and DL algorithms such as DBN, SAE, CNN, and RNN. We compared the performance of the model in terms of accuracy with other classification algorithms discussed in [
40] and [
41], as shown in
Figure 6 and
Figure 7.
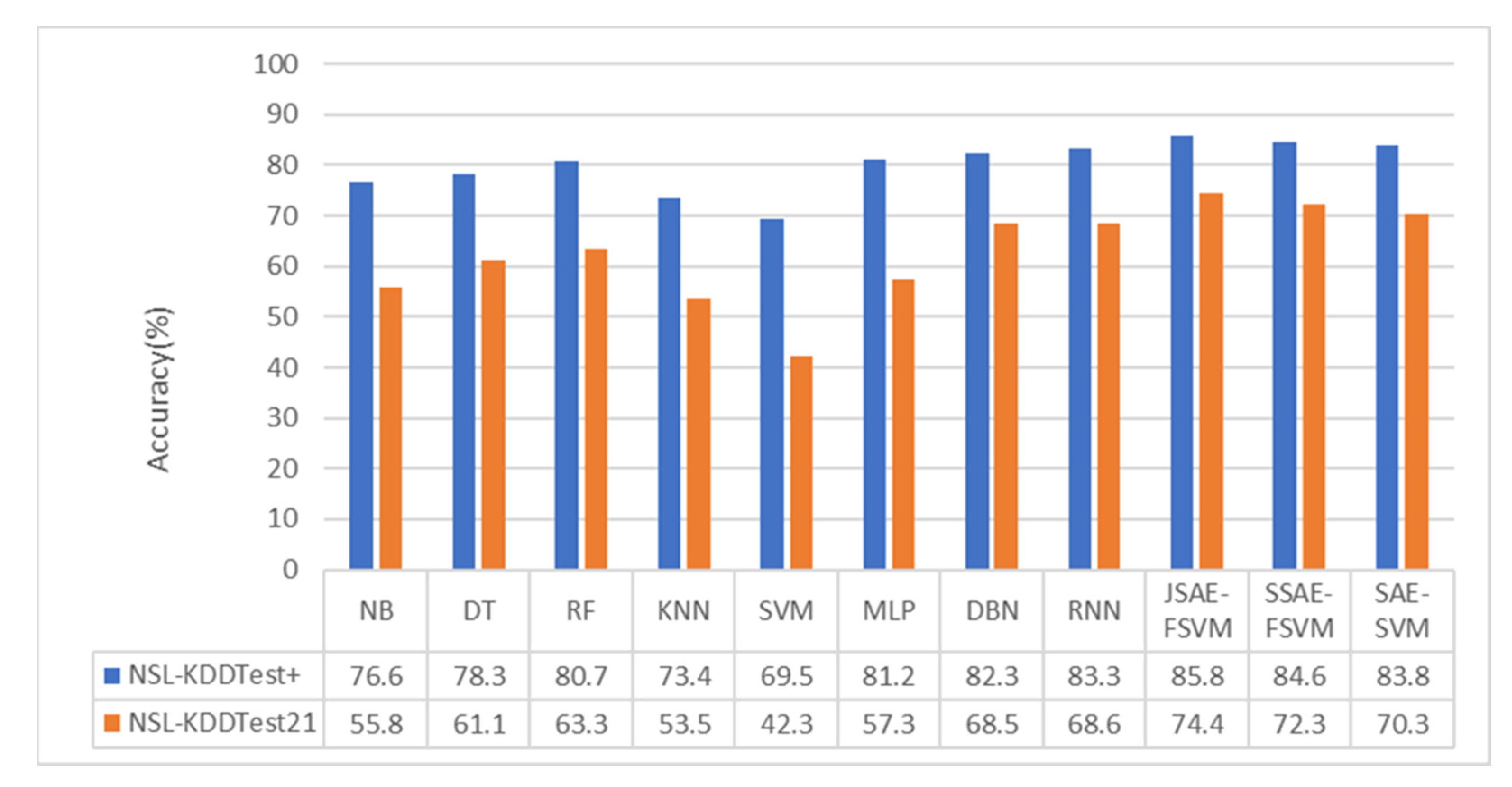
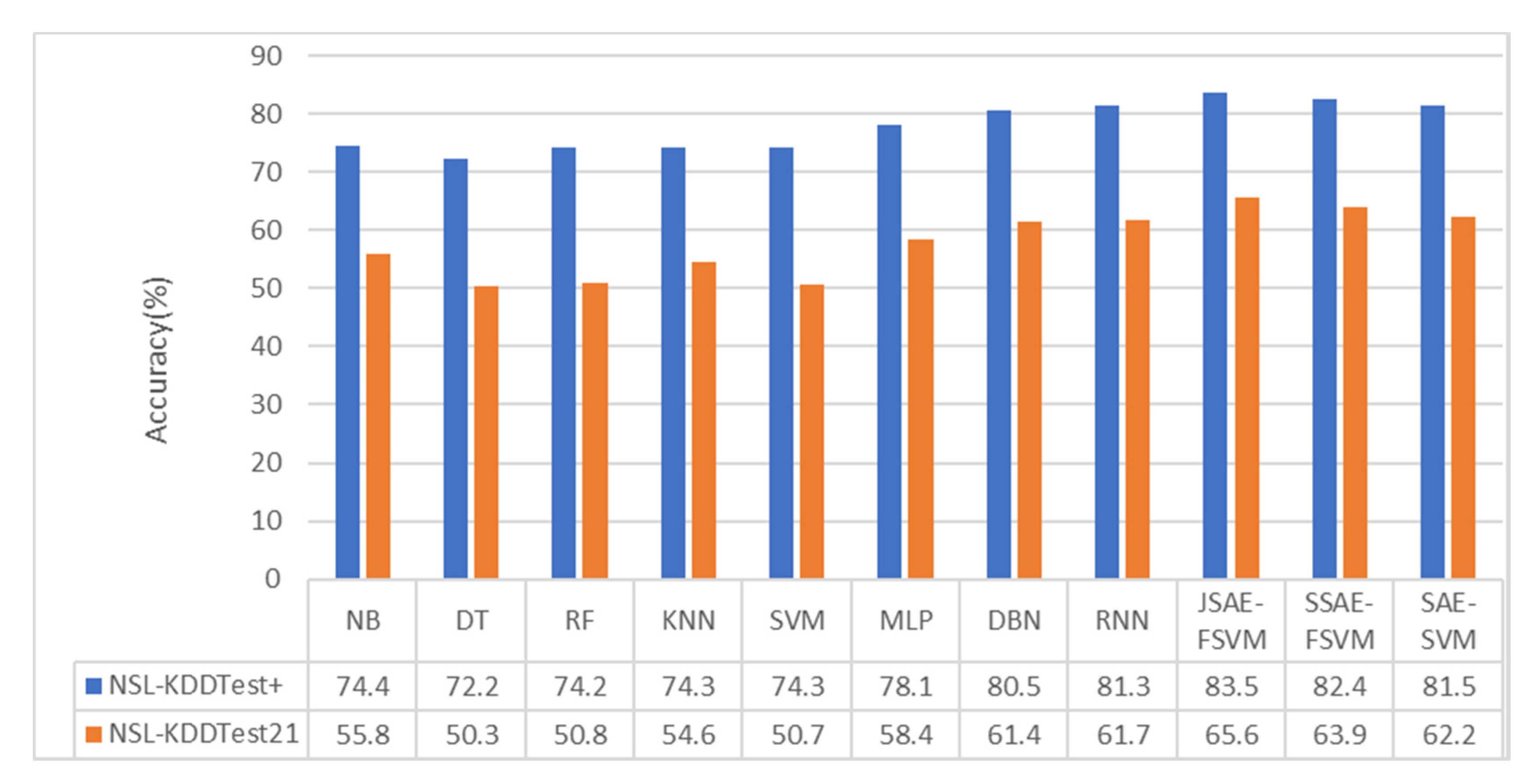
As can be seen from
Figure 6 and
Figure 7, the performance of the DL algorithms, including RNN and DBN, was superior to that of all conventional machine learning algorithms. In the binary-category experiment, the accuracy of our model was 2.5% and 5.8% higher than that of the methods in [
40] on NSL-KDDTest+ and NSL-KDDTest21. Compared with the DBN and MLP methods, the accuracy of the model in the NSL-KDDTest+ dataset increased by 3.5% and 4.6%, respectively, and increased by 6.9% and 16.9% in the NSLKDDTest21 dataset. In the five-category experiment, the accuracy of our model was 2.2% and 3.9% higher than that of the methods in [
40] on NSL-KDDTest+ and NSL-KDDTest21. Compared with the DBN and MLP methods, the model proposed in this paper increased by 3% and 4.6%, respectively, on the NSL-KDDTest+ dataset and by 4.2% and 6.8%, respectively, on the NSL-KDDTest21 dataset.
As can be seen from the above experiments, the accuracy of the proposed method was very close to or exceeded those of other state-of-the-art methods, particularly in the binary-category experiment. This is mainly because we use SAE technology to reduce the dimension, then perform kernel approximation on the features after the dimension reduction, and then finally use the linear SVM for joint training.
DR and
FAR are two important evaluation indicators in IDS.
Table 6 shows the overall performance of traditional machine learning methods and basic deep learning methods on the NSL-KDDTest+ and NSL-KDDTest21 datasets. From the table, it can be seen that JSAE-FSVM was superior to the basic classifiers in terms of
DR and
FAR.
5.4.2. Comparison with State-of-the-Art Models
In order to further verify the superiority of the proposed model, we compared the proposed model with related models in other literature, including SCDNN [
42], LSTM
4 [
43], GRU
3 [
43], CFBLS [
43], TSE-IDS [
44], ROS-DNN [
45], SMOTE-DNN [
45], and ADASYN-DNN [
45]. To be fair, all the methods were implemented on NSL-KDDTest+ and NSL-KDDTest21. The relevant index result of some methods was not given, and we have used N/A to indicate this. Detection indicators included
DR,
AC, and
FAR. The comparison results are shown in
Table 7.
Table 7 shows that, in terms of the overall accuracy of the model, the results were superior to other models, and only slightly lower than the TSE-IDS model in [
43].This fully shows that our model fully mined the essential features of the data through end-to-end training, and conducted effective learning and training on it, so as to improve the model’s overall accuracy. In terms of the FAR, our model also achieved good results, with 0.051 being the lowest among all models.
Based on the comparison, it can be seen that the model proposed in this paper was not only superior to the traditional machine learning models and deep learning models, but also had some advantages compared with the latest models in other works. The main reasons are as follows: (1) The adoption of joint training can make it possible to learn the essential features of data and improve the accuracy of the model. (2) The kernel approximation technique and linear SVM were used to accelerate the training speed of the model.
6. Conclusions
Traditional machine learning methods have low detection performance and cannot meet the requirement of real-time characteristic when an IDS faces a large-scale intrusion detection dataset. This study proposes a joint training model that combines an SAE with an SVM and kernel approximation. We verified the validity of the model on the NSL-KDD dataset. First, this study used the SAE model to perform unsupervised dimension reduction on samples. As a result, the dimension of the samples dropped from 121 to 15. Then, the 15-dimensional compressed representation was subjected to random Fourier kernel approximation, and then sent to the linear SVM for end-to-end training. In the whole processing process, the SAE reduced the scale of data, and random Fourier features and linear SVM accelerated the processing process.
The application of sparse constraints to the hidden layer enables the model to learn the best feature representation of the samples in high-dimensional and large-scale data environments, and can effectively reduce the dimension of the sample, which improves the generalization ability of the model and its feature extraction capabilities.
The experimental results show that the proposed model is highly suited for large-scale, high-dimensional task scenarios, reduces the training time and test time for the intrusion detection model, can meet the real-time requirement of intrusion detection, and provides superior detection performance to traditional machine learning algorithms. The real-time performance of the model complies with the real-time rules of vector 2 in the IoT cyber risk vectors proposed in [
46].
The proposed intrusion detection model is feasible and efficient, and provides a new research direction for intrusion detection.
In future work, we will carry out our research from two aspects:
- (1)
We will deploy the model in the cloud computing environment in accordance with the network security assessment framework standard in [
46], while adopting the latest artificial intelligence technology to design an intrusion detection system for the Internet of Things to make it more aligned with the network security standards in [
46].
- (2)
We plan on continuing to study the performance of the model with other kernel approximation methods, as well as the performance of the joint training model with one-class SVMs in anomaly detection.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}