ASAMS: An Adaptive Sequential Sampling and Automatic Model Selection for Artificial Intelligence Surrogate Modeling




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
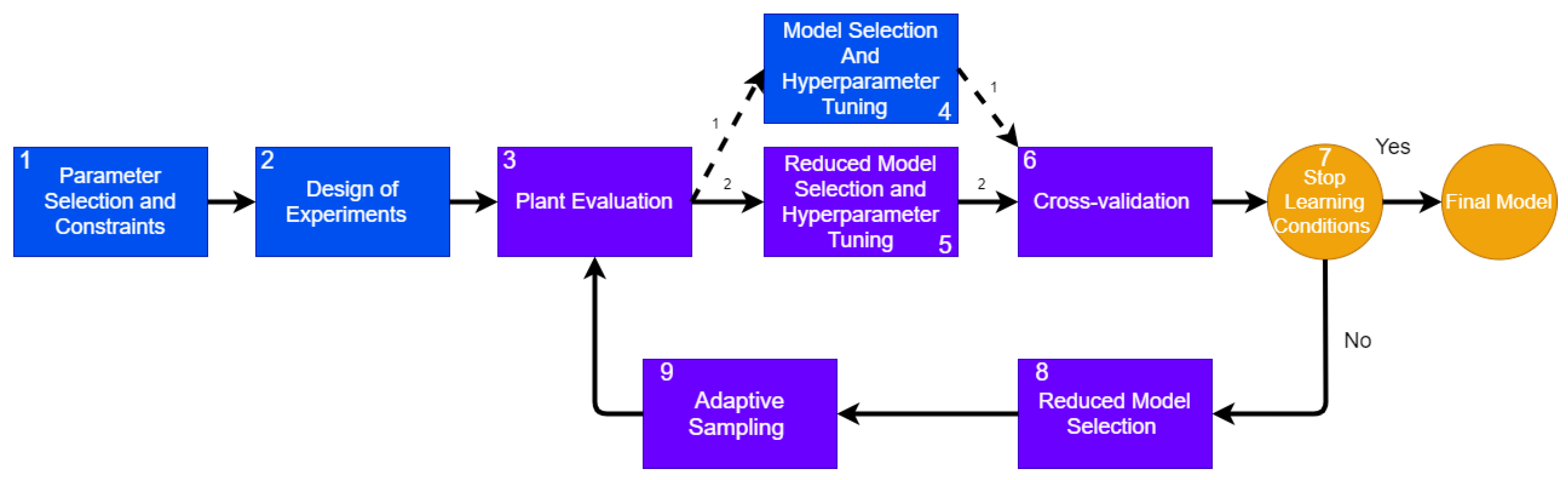
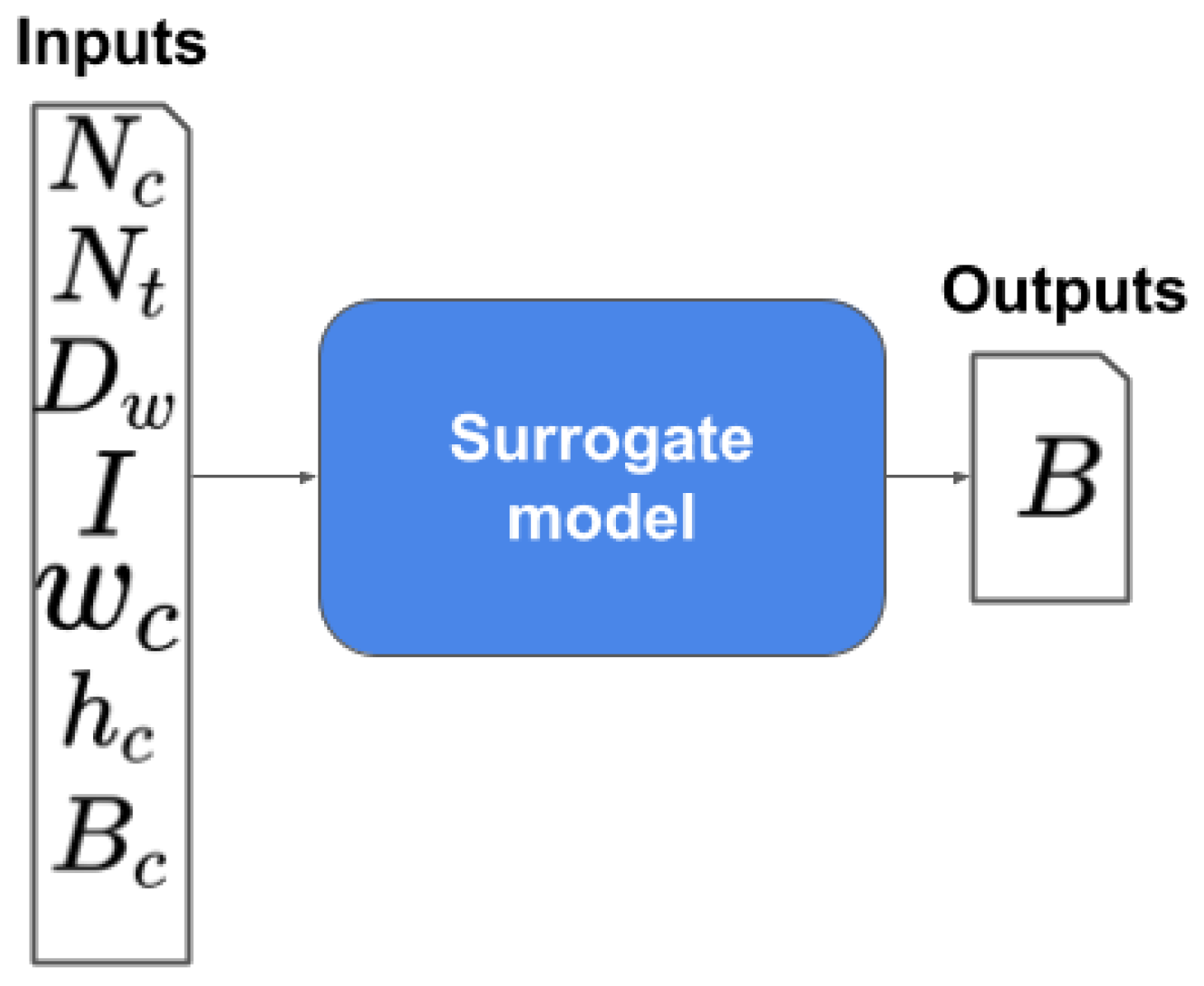
3. Proposed Method (ASAMS)
- Parameter Selection and Constraints. In this stage, the problem statement is carried out, determining the design parameters and constraining the design space. See Section 3.2 for more details.
- Design of experiments. In order to initialize the construction of the surrogate model, a small number of initial training points are generated using a one-shot sampling method or DoE. In this work, we decided to use a full factorial sampling but any other method can be applied.
- Plant Evaluation. In this stage, the response of the plant to each training point is measured and assigned as a target for the surrogate training process. The process of evaluating the plant can be online as mathematical models, computational simulations, or physical online measurements, as in DT; or it can be offline for DM. In this paper, we analyze two problems that use an online implementation: one mathematical model and one multiphysics computational simulation.
- Model Selection and Hyperparameter Tuning. In this step, an AutoML algorithm is applied to perform an algorithm selection and hyperparameter tuning for each possible algorithm. See Section 3.3 for more details.
- Reduced Model Selection and Hyperparameter Tuning. This step is similar to the Model Selection and Hyperparameter Tuning with only one difference: after the first iteration, the number of candidate models will be reduced through an elitism mechanism; this step performs the hyperparameter tuning and model selection to reduce candidates.
- Cross-validation. As a result, this process returns the best candidates and the validation score for each candidate model obtained by cross-validation.
- Stop Learning Conditions. In this step, the methodology validates if the algorithm has met any stop criteria. In this proposal, we consider three different stop conditions. See Section 3.4 for more details.
- Reduced Model Selection. The process of selecting a suitable model and the correct hyper-parametrization can be explained as an exploration–exploitation problem. During the Model Selection and Hyperparameter Tuning step, the design space is explored, and in the Reduced Model Selection phase, we propose an exploitation mechanism to reduce the search space. See Section 3.5 for a detailed explanation.
- Adaptive Sampling. In this step, a novel mechanism of adaptive sampling that combines CV and QBC generates new training points through a Voronoi approach. See Section 3.7 for a detailed explanation of the contribution.
3.1. Formal Problem Statement
3.2. Parameter Selection and Constraints
3.3. Model Selection and Hyperparameter Tuning
3.4. Stop Conditions of Learning
3.5. Reduced Model Selection
3.6. Adaptive Sampling
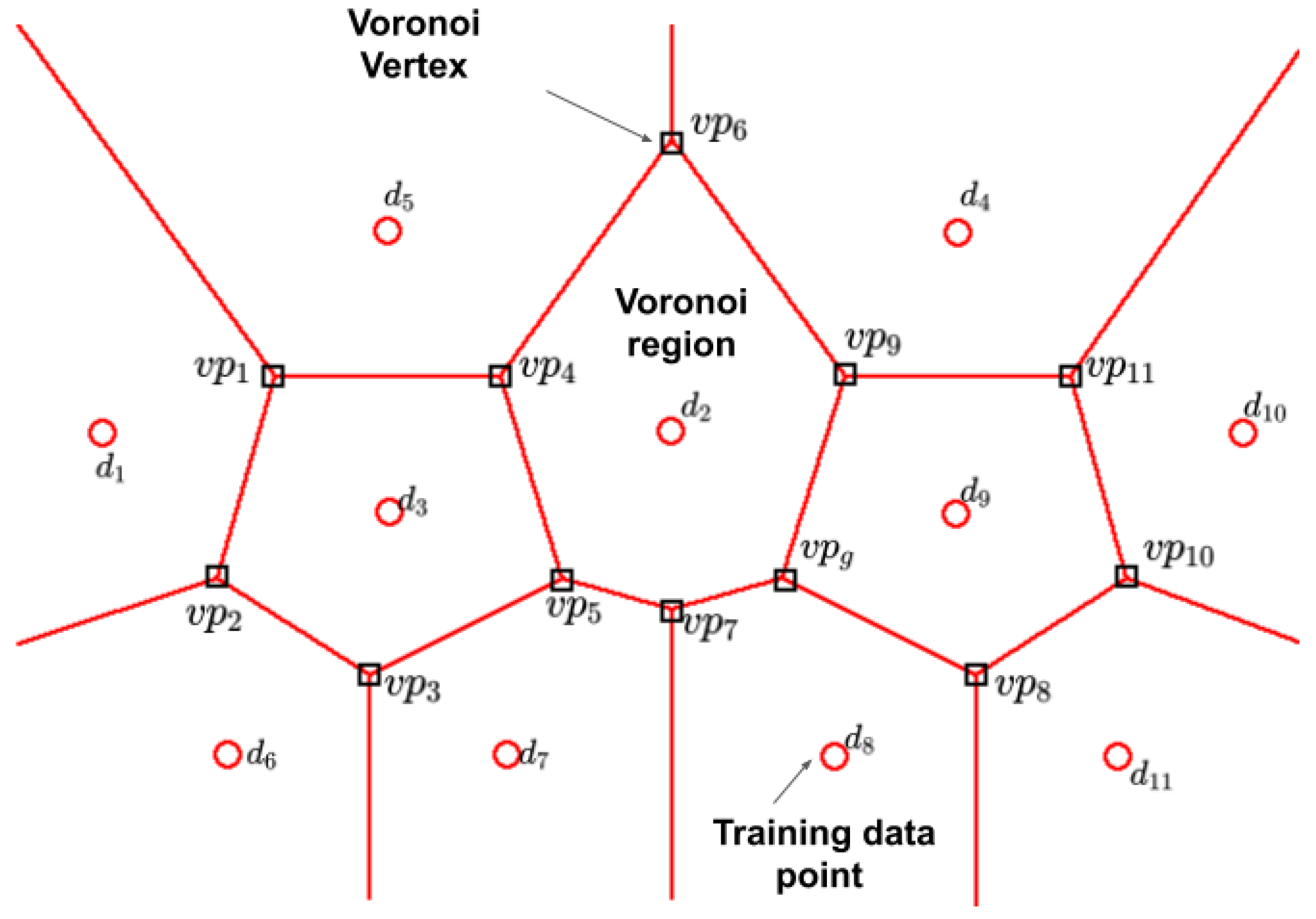
3.6.1. Partition of the Sampling Space and Candidate Points Selection
3.6.2. Region Assessment and Candidate Selection
| central point of the a-th Voronoi region | |
| best hyperparameter set for the t-th model | |
| Training data set excluding the point | |
| prediction error of the t-th model in the central point of the a-th region | |
| mean prediction error of the central point of the a-th region | |
| set of mean prediction error of the all Voronoi regions | |
| Output vector of the t-th surrogate model with the a-th input vector trained excluding the point | |
| number of Voronoi regions |
| assessment of the g-th Voronoi point | |
| set of assessments of coliding regions to the g-th candidate Voronoi point | |
| set of assessments candidate Voronoi points | |
| Number of candidate Voronoi points | |
| Number of coliding regions to the g-th candidate Voronoi point |
3.7. Step by Step Algorithm
| Algorithm 1 ASAMS |
def ASAMS(Problem,Parameters,Mdls,DoE, keepRate,maxExp,maxIter,Error,nExp): Sample=ExperimentDesign(DoE,Parameters) SEval=PlantEvaluation(Problem,Sample) (mdlGrid MdlCVS)=MdlSeletHyParm(Sample,SSEval,Mdl) StopFlag=stopCondition(MdlCVS,maxExp,maxIter,Error) while StopFlag=True: (mdlGrid,MdlCVS)=ReducedModel(mdlGrid,MdlCVS,keepRate) newPoints=AdaptativeSampling(mdlGrid,Sample,SSEval,nExp) NPEval=PlantEvaluation(Problem,newPoints) (Sample,SSEval)=joint(Sample,SSEval,newPoints,NPEval) (mdlGrid MdlCVS)=MdlSeletHyParm(Sample,SSEval,mdlGrid) StopFlag=stopCondition(MdlCVS,maxExp,maxIter,Error) return mdlGrid |
4. Case Studies
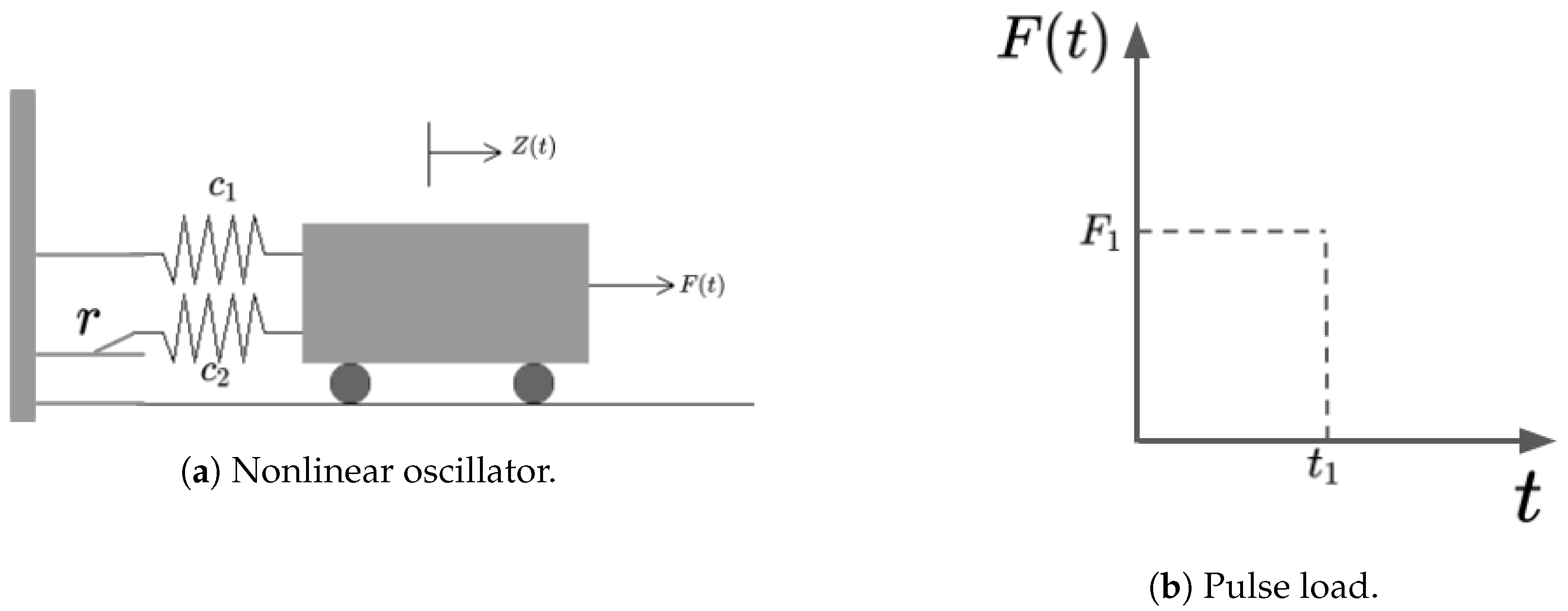
4.1. Highly Nonlinear Oscillator
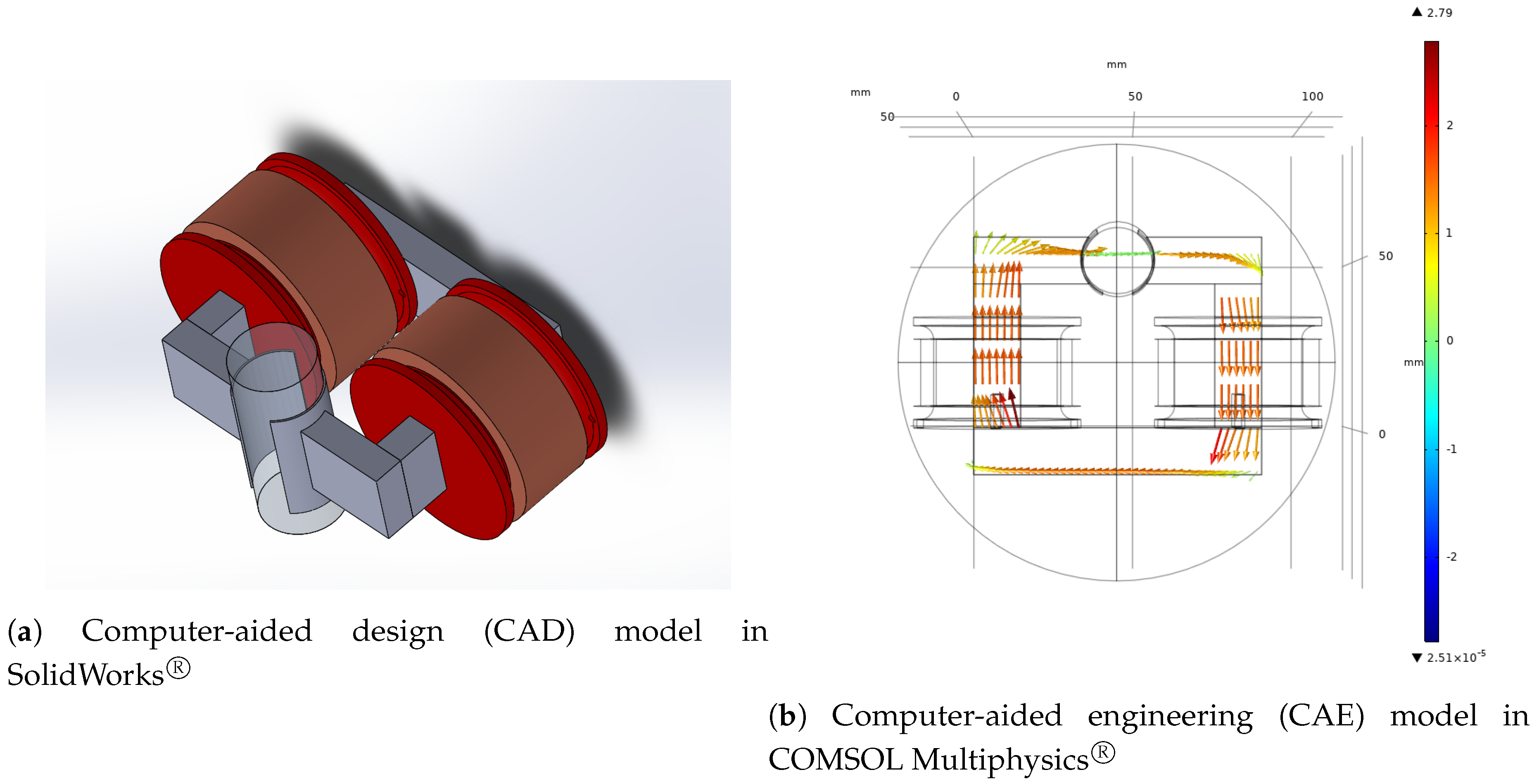
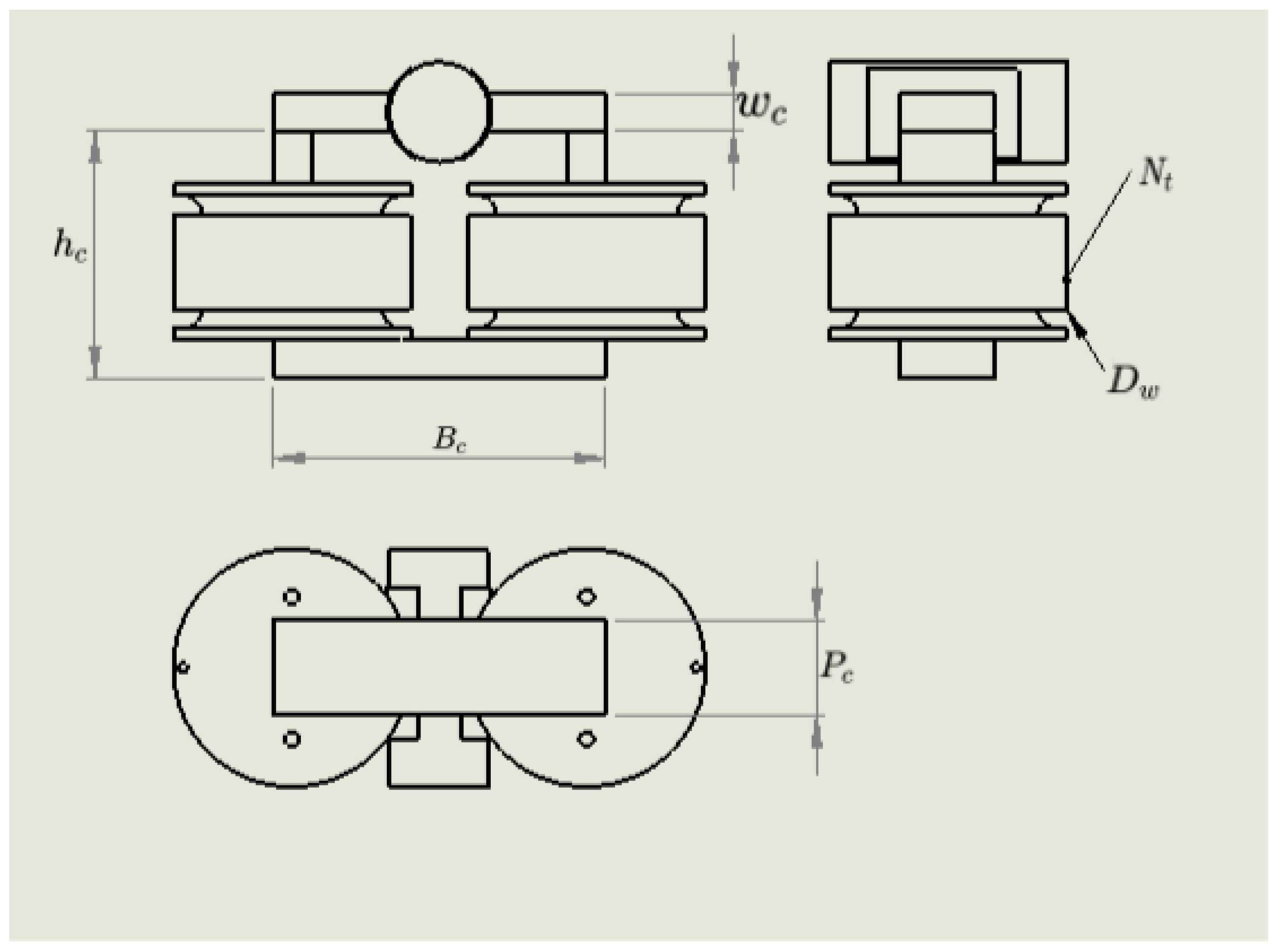
4.2. Magnetic Circuit
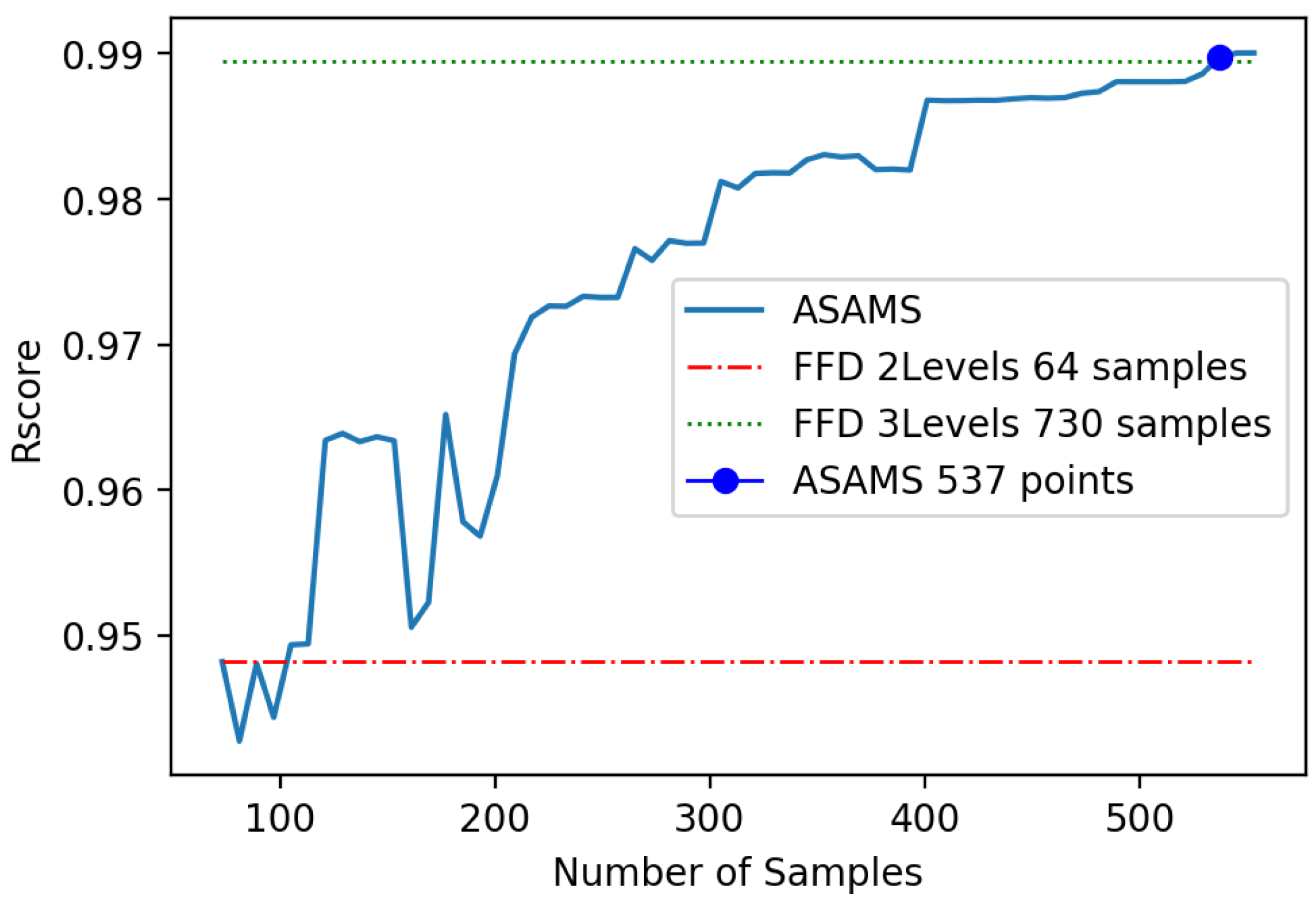
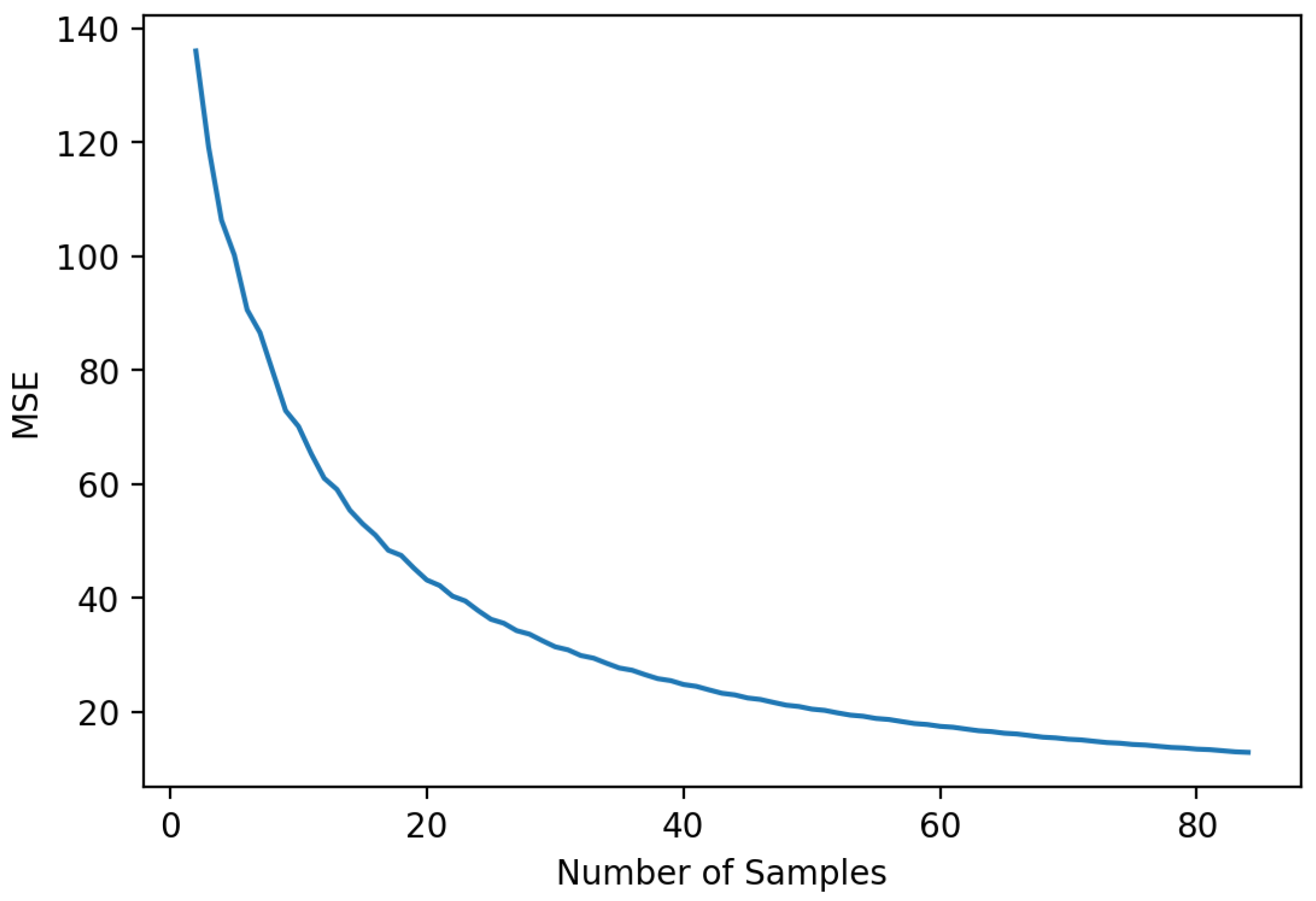
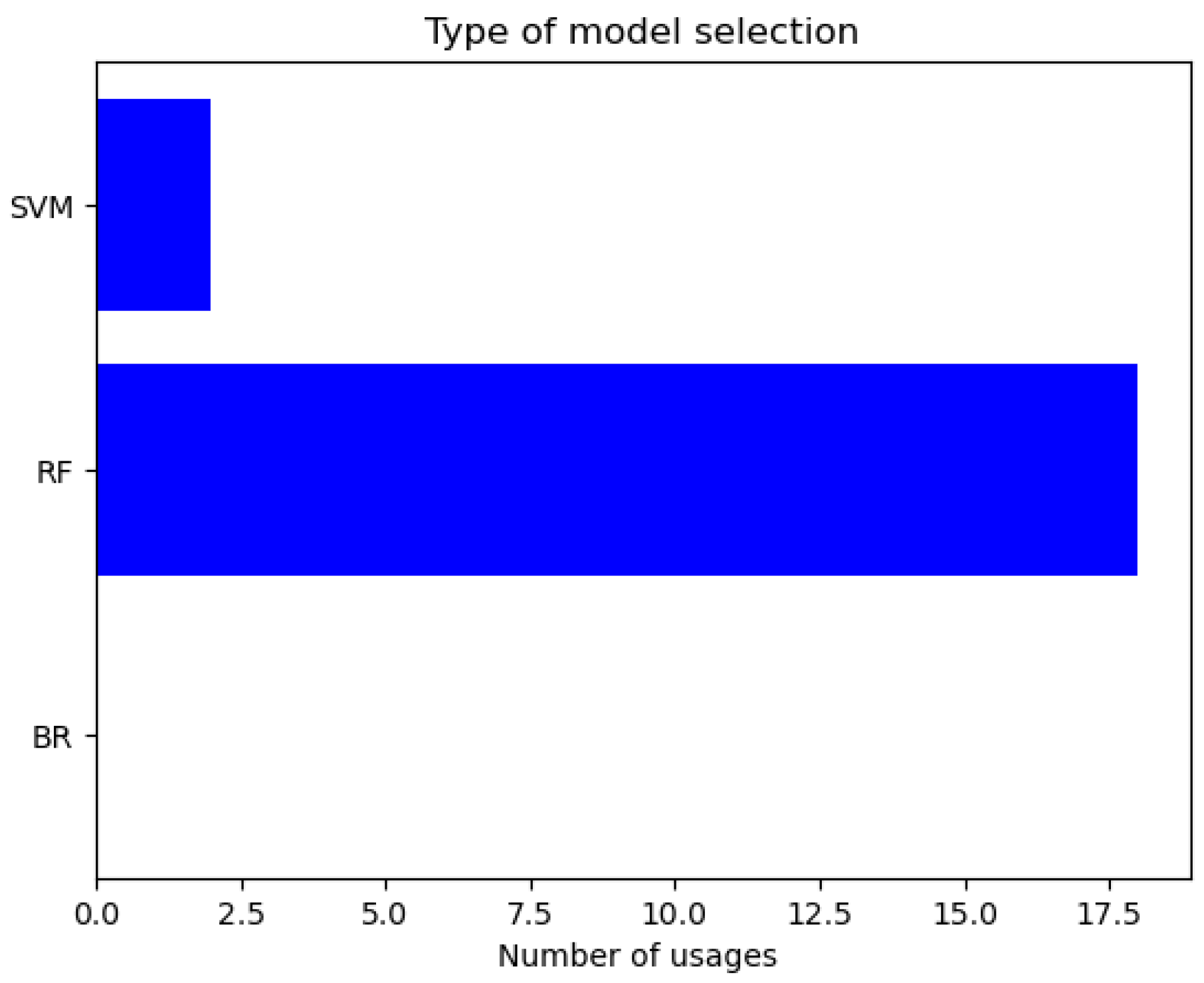
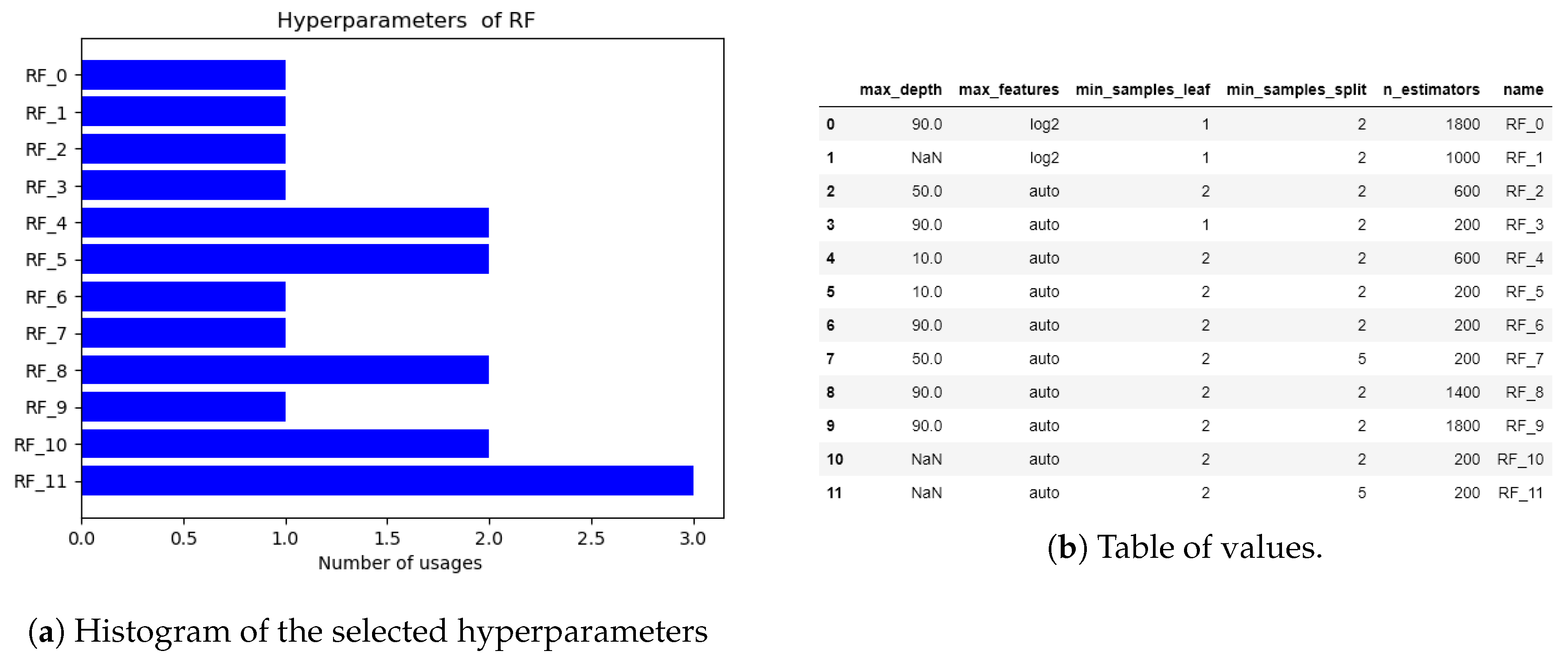
5. Experiments and Discussion
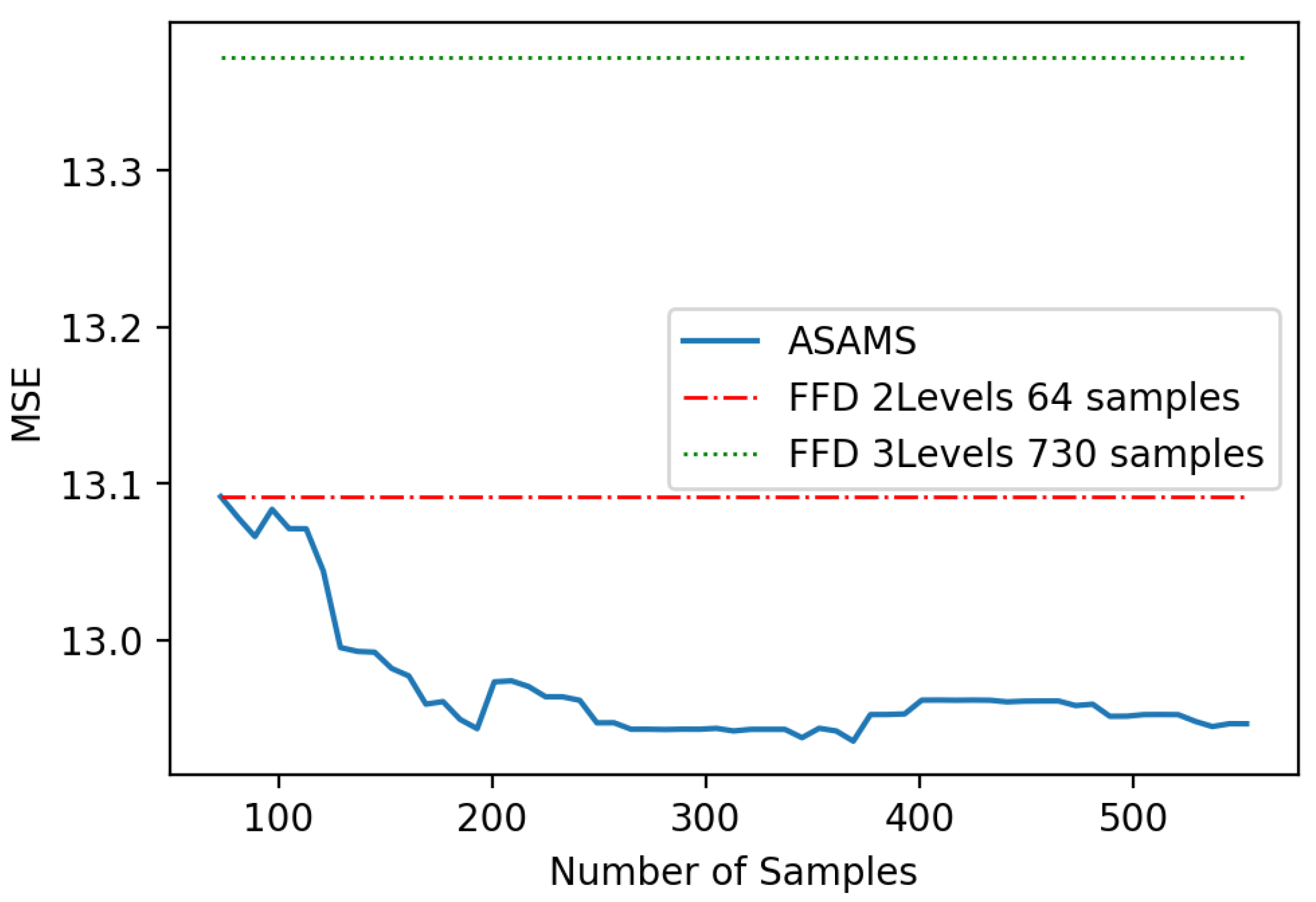
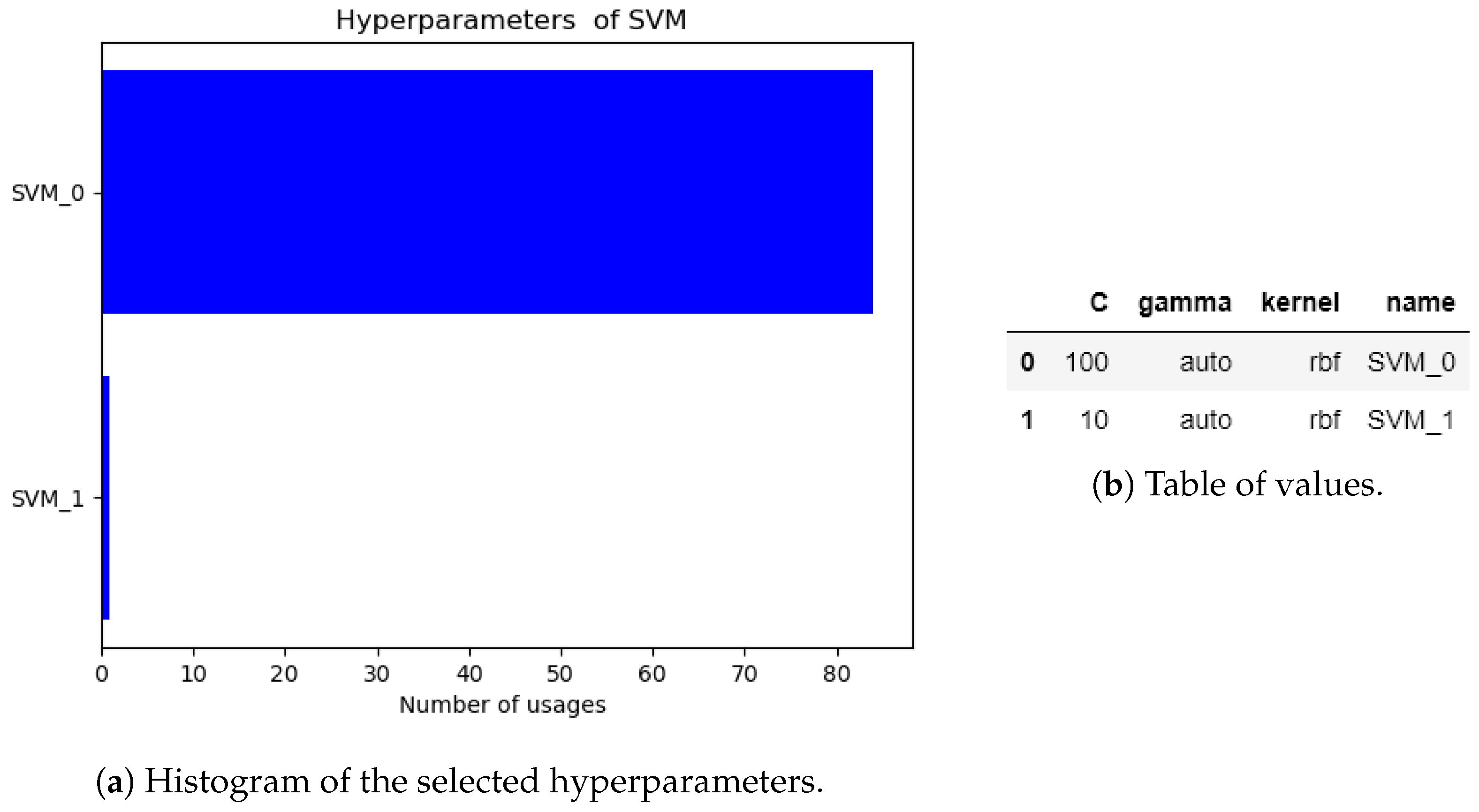
5.1. Highly Nonlinear Oscillator
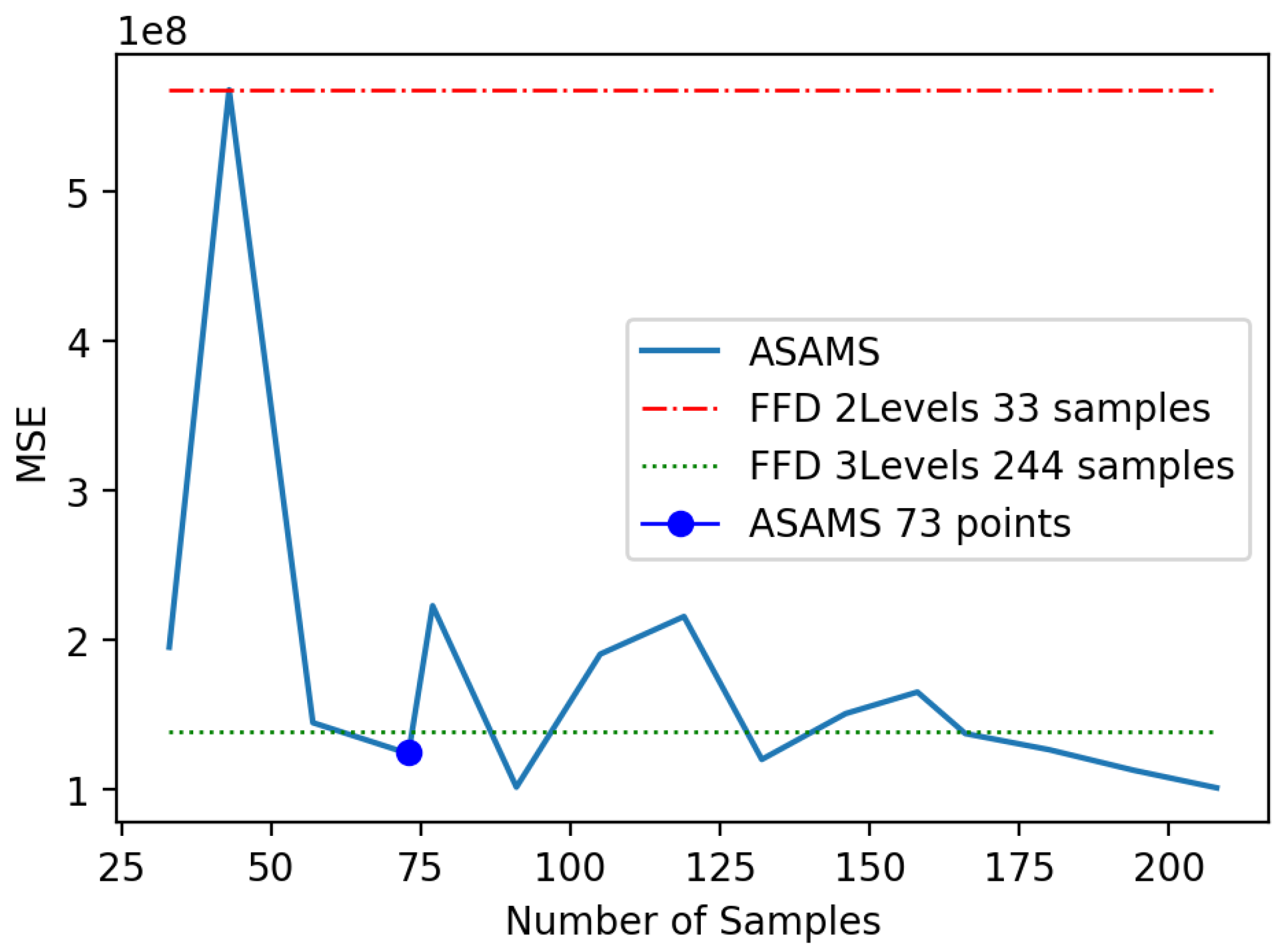
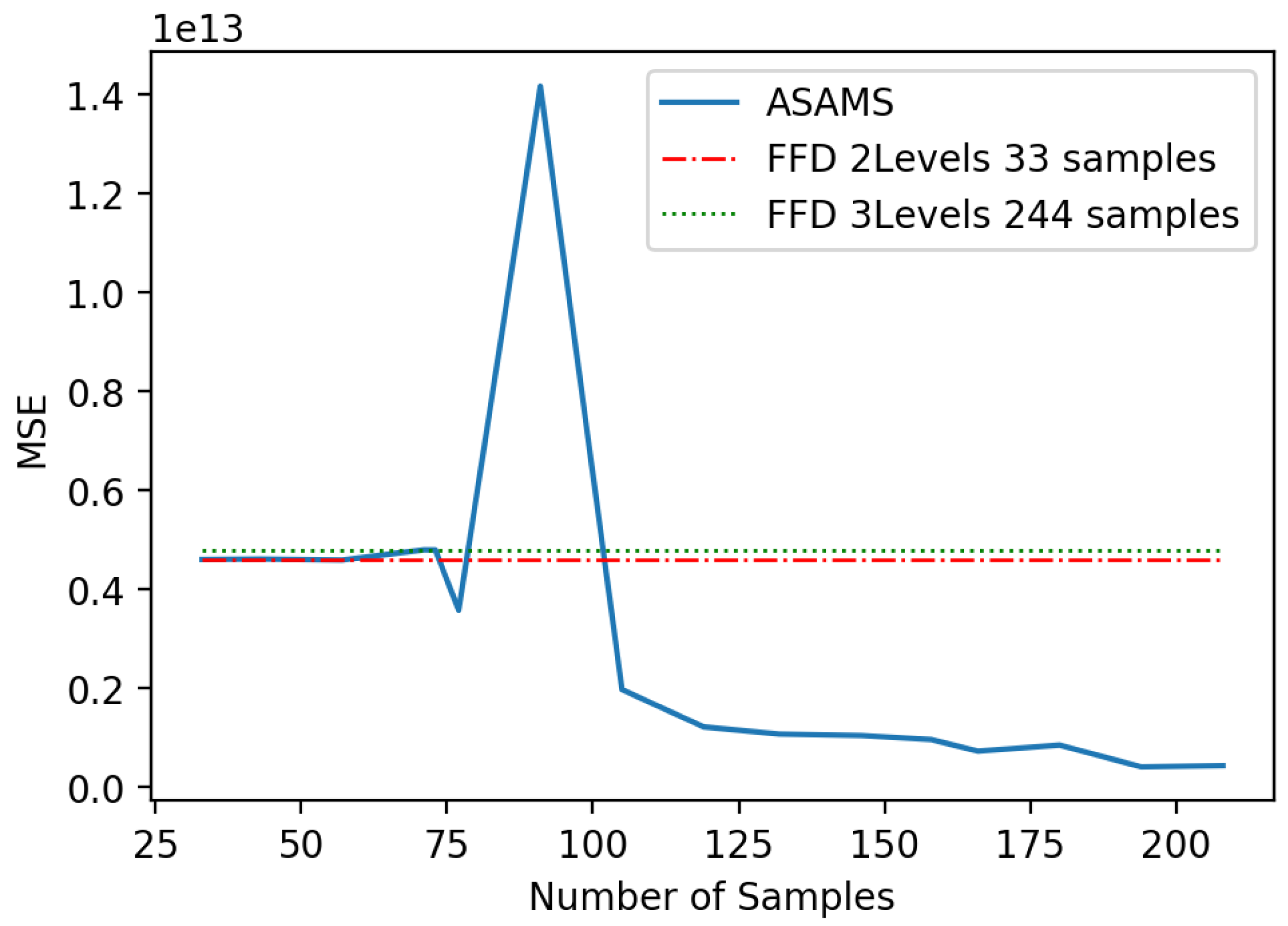
5.2. Magnetic Circuit
5.3. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Nomenclatures
| Target vector of the i-th element of the Testing data set | |
| Input vector of the i-th element of the Testing data set | |
| Output vector of the t-th surrogate model w/ the i-th input vector of the Testing data set | |
| Algorithm selected from the algorithm set | |
| Set of all hyperparameter combinations for the T candidate solutions | |
| Set of valid hyperparameter combinations for the t-th candidate model | |
| Hyperparameters selected for the model | |
| Value of the hyperparameter of the t model | |
| Training dataset | |
| Set of candidate algorithms | |
| Set of candidate values for the hyperparameter of the t model | |
| j-th element of the input vector | |
| s-th element of the target vector | |
| m-th data point of the Training dataset | |
| q-th candidate value for the hyperparameter of the t model | |
| Lower constraint for the j-th elements of the i-th input vector | |
| Upper constraint for the j-th elements of the i-th input vector | |
| M | Number of points of the training dataset |
| N | Number of points of the Testing dataset |
| T | Number of candidate algorithms |
| Number of hyperparameters of the t-th algorithm | |
| S | Number of elements of the target vector |
| J | Number of elements of the input vector |
| Number of candidate values of the hyperparameter of the t model | |
| Number of valid hyperparameter combinations for the t-th model |
References
- Song, Y.; Cheng, Q.S.; Koziel, S. Multi-fidelity local surrogate model for computationally efficient microwave component design optimization. Sensors 2019, 19, 3023. [Google Scholar] [CrossRef] [PubMed]
- Qin, S.; Zhang, Y.; Zhou, Y.L.; Kang, J. Dynamic model updating for bridge structures using the kriging model and PSO algorithm ensemble with higher vibration modes. Sensors 2018, 18, 1879. [Google Scholar] [CrossRef] [PubMed]
- Preitl, S.; Precup, R.E.; Preitl, Z.; Vaivoda, S.; Kilyeni, S.; Tar, J.K. Iterative feedback and learning control. Servo systems applications. IFAC Proc. Vol. 2007, 40, 16–27. [Google Scholar] [CrossRef]
- Ahmed, M.U.; Brickman, S.; Dengg, A.; Fasth, N.; Mihajlovic, M.; Norman, J. A machine learning approach to classify pedestrians’ events based on IMU and GPS. Int. J. Artif. Intell. 2019, 17, 154–167. [Google Scholar]
- Abonyi, J.; Nemeth, S.; Vincze, C.; Arva, P. Process analysis and product quality estimation by self-organizing maps with an application to polyethylene production. Comput. Ind. 2003, 52, 221–234. [Google Scholar] [CrossRef]
- Barricelli, B.R.; Casiraghi, E.; Fogli, D. A Survey on Digital Twin: Definitions, Characteristics, Applications, and Design Implications. IEEE Access 2019, 7, 167653–167671. [Google Scholar] [CrossRef]
- Fera, M.; Greco, A.; Caterino, M.; Gerbino, S.; Caputo, F.; Macchiaroli, R.; D’Amato, E. Towards Digital Twin Implementation for Assessing Production Line Performance and Balancing. Sensors 2020, 20, 97. [Google Scholar] [CrossRef]
- Liu, C.; Gao, J.; Bi, Y.; Shi, X.; Tian, D. A Multitasking-Oriented Robot Arm Motion Planning Scheme Based on Deep Reinforcement Learning and Twin Synchro-Control. Sensors 2020, 20, 3515. [Google Scholar] [CrossRef] [PubMed]
- Preen, R.J.; Bull, L. On design mining: Coevolution and surrogate models. Artif. Life 2017, 23, 186–205. [Google Scholar] [CrossRef]
- Preen, R.J.; Bull, L. Toward the coevolution of novel vertical-axis wind turbines. IEEE Trans. Evol. Comput. 2014, 19, 284–294. [Google Scholar] [CrossRef]
- Ong, Y.; Keane, A.J.; Nair, P.B. Surrogate-assisted coevolutionary search. In Proceedings of the IEEE 9th International Conference on Neural Information Processing, ICONIP’02, Singapore, 18–22 November 2002; Volume 3, pp. 1140–1145. [Google Scholar]
- Goh, C.K.; Lim, D.; Ma, L.; Ong, Y.S.; Dutta, P.S. A surrogate-assisted memetic co-evolutionary algorithm for expensive constrained optimization problems. In Proceedings of the 2011 IEEE Congress of Evolutionary Computation (CEC), New Orleans, LA, USA, 5–8 June 2011; pp. 744–749. [Google Scholar]
- Masuda, Y.; Kaneko, H.; Funatsu, K. Multivariate statistical process control method including soft sensors for both early and accurate fault detection. Ind. Eng. Chem. Res. 2014, 53, 8553–8564. [Google Scholar] [CrossRef]
- Luczak, T.; Burch V, R.F.; Smith, B.K.; Carruth, D.W.; Lamberth, J.; Chander, H.; Knight, A.; Ball, J.; Prabhu, R. Closing the wearable gap—Part V: Development of a pressure-sensitive sock utilizing soft sensors. Sensors 2020, 20, 208. [Google Scholar] [CrossRef] [PubMed]
- Park, W.; Ro, K.; Kim, S.; Bae, J. A soft sensor-based three-dimensional (3-D) finger motion measurement system. Sensors 2017, 17, 420. [Google Scholar] [CrossRef]
- Farahani, H.S.; Fatehi, A.; Shoorehdeli, M.A.; Nadali, A. A Novel Method For Designing Transferable Soft Sensors And Its Application. arXiv 2020, arXiv:2008.02186. [Google Scholar]
- Ajiboye, A.; Abdullah-Arshah, R.; Hongwu, Q. Evaluating the effect of dataset size on predictive model using supervised learning technique. Int. J. Softw. Eng. Comput. Sci. 2015, 1, 75–84. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. arXiv 2017, arXiv:1709.06560. [Google Scholar]
- Liaw, R.; Liang, E.; Nishihara, R.; Moritz, P.; Gonzalez, J.E.; Stoica, I. Tune: A research platform for distributed model selection and training. arXiv 2018, arXiv:1807.05118. [Google Scholar]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges; Springer Nature: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Lerman, P. Fitting segmented regression models by grid search. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1980, 29, 77–84. [Google Scholar] [CrossRef]
- Al-Fugara, A.; Ahmadlou, M.; Al-Shabeeb, A.R.; AlAyyash, S.; Al-Amoush, H.; Al-Adamat, R. Spatial mapping of groundwater springs potentiality using grid search-based and genetic algorithm-based support vector regression. Geocarto Int. 2020, 1–20. [Google Scholar] [CrossRef]
- Abas, M.A.H.; Ismail, N.; Ali, N.A.; Tajuddin, S.; Tahir, N.M. Agarwood Oil Quality Classification using Support Vector Classifier and Grid Search Cross Validation Hyperparameter Tuning. Int. J. 2020, 8. [Google Scholar] [CrossRef]
- Wei, L.; Yuan, Z.; Wang, Z.; Zhao, L.; Zhang, Y.; Lu, X.; Cao, L. Hyperspectral Inversion of Soil Organic Matter Content Based on a Combined Spectral Index Model. Sensors 2020, 20, 2777. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Zhou, Q.; Shao, X. Surrogate-Model-Based Design and Optimization. In Surrogate Model-Based Engineering Design and Optimization; Springer: Berlin/Heidelberg, Germany, 2020; pp. 135–236. [Google Scholar]
- Box, G.E.; Hunter, J.S. The 2 k—p fractional factorial designs. Technometrics 1961, 3, 311–351. [Google Scholar] [CrossRef]
- Myers, R.H.; Montgomery, D.C.; Anderson-Cook, C.M. Response Surface Methodology: Process and Product Optimization Using Designed Experiments; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Morris, M.D.; Mitchell, T.J. Exploratory designs for computational experiments. J. Stat. Plan. Inference 1995, 43, 381–402. [Google Scholar] [CrossRef]
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 2000, 42, 55–61. [Google Scholar] [CrossRef]
- Liu, H.; Ong, Y.S.; Cai, J. A survey of adaptive sampling for global metamodeling in support of simulation-based complex engineering design. Struct. Multidiscip. Optim. 2018, 57, 393–416. [Google Scholar] [CrossRef]
- Liu, H.; Xu, S.; Ma, Y.; Chen, X.; Wang, X. An adaptive Bayesian sequential sampling approach for global metamodeling. J. Mech. Des. 2016, 138. [Google Scholar] [CrossRef]
- Jin, R.; Chen, W.; Sudjianto, A. On sequential sampling for global metamodeling in engineering design. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Montreal, QC, Canada, 29 September–2 October 2002; Volume 36223, pp. 539–548. [Google Scholar]
- Viana, F.A.; Simpson, T.W.; Balabanov, V.; Toropov, V. Special section on multidisciplinary design optimization: Metamodeling in multidisciplinary design optimization: How far have we really come? AIAA J. 2014, 52, 670–690. [Google Scholar] [CrossRef]
- Echard, B.; Gayton, N.; Lemaire, M. AK-MCS: An active learning reliability method combining Kriging and Monte Carlo simulation. Struct. Saf. 2011, 33, 145–154. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey (Computer Sciences Technical Report 1648); University of Wisconsin-Madison: Madison, WI, USA, January 2009. [Google Scholar]
- Mendes-Moreira, J.; Soares, C.; Jorge, A.M.; Sousa, J.F.D. Ensemble approaches for regression: A survey. ACM Comput. Surv. (CSUR) 2012, 45, 1–40. [Google Scholar] [CrossRef]
- Jiang, P.; Shu, L.; Zhou, Q.; Zhou, H.; Shao, X.; Xu, J. A novel sequential exploration-exploitation sampling strategy for global metamodeling. IFAC-PapersOnLine 2015, 48, 532–537. [Google Scholar] [CrossRef]
- Vasile, M.; Minisci, E.; Quagliarella, D.; Guénot, M.; Lepot, I.; Sainvitu, C.; Goblet, J.; Coelho, R.F. Adaptive sampling strategies for non-intrusive POD-based surrogates. Eng. Comput. 2013, 30, 521–547. [Google Scholar]
- Xu, S.; Liu, H.; Wang, X.; Jiang, X. A robust error-pursuing sequential sampling approach for global metamodeling based on voronoi diagram and cross validation. J. Mech. Des. 2014, 136. [Google Scholar] [CrossRef]
- van der Herten, J.; Couckuyt, I.; Deschrijver, D.; Dhaene, T. A fuzzy hybrid sequential design strategy for global surrogate modeling of high-dimensional computer experiments. SIAM J. Sci. Comput. 2015, 37, A1020–A1039. [Google Scholar] [CrossRef]
- Pan, G.; Ye, P.; Wang, P.; Yang, Z. A sequential optimization sampling method for metamodels with radial basis functions. Sci. World J. 2014, 2014. [Google Scholar] [CrossRef] [PubMed]
- Kitayama, S.; Arakawa, M.; Yamazaki, K. Sequential approximate optimization using radial basis function network for engineering optimization. Optim. Eng. 2011, 12, 535–557. [Google Scholar] [CrossRef]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- MATLAB, The Math Works, Version 9.8 (R2020a); The MathWorks Inc.: Natick, MA, USA, 2010.
- Multiphysics, C. Version 5.4; COMSOL AB: Stockholm, Sweden, 2018.
- SolidWorks, Version 2020 SP2.0; Dassault Systemes: Velizy-Villacoublay, France, 2020.
- Duchanoy, C.A.; Calvo, H.; Moreno-Armendáriz, M.A. ASAMS. Available online: https://github.com/Duchanoy/ASAMS (accessed on 7 September 2020).
- Khemchandani, R.; Goyal, K.; Chandra, S. TWSVR: Regression via twin support vector machine. Neural Netw. 2016, 74, 14–21. [Google Scholar] [CrossRef] [PubMed]
- Phan, H.; Maaß, M.; Mazur, R.; Mertins, A. Random regression forests for acoustic event detection and classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 20–31. [Google Scholar] [CrossRef]
- Nguyen, H.M.; Kalra, G.; Jun, T.J.; Kim, D. A Novel Echo State Network Model Using Bayesian Ridge Regression and Independent Component Analysis. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2018; pp. 24–34. [Google Scholar]
- Jiang, C.; Qiu, H.; Yang, Z.; Chen, L.; Gao, L.; Li, P. A general failure-pursuing sampling framework for surrogate-based reliability analysis. Reliab. Eng. Syst. Saf. 2019, 183, 47–59. [Google Scholar] [CrossRef]
- Viana, F.A.; Venter, G.; Balabanov, V. An algorithm for fast optimal Latin hypercube design of experiments. Int. J. Numer. Methods Eng. 2010, 82, 135–156. [Google Scholar] [CrossRef]
- Fang, K.T.; Lin, D.K. Uniform experimental designs and their applications in industry. Handb. Stat. 2003, 22, 131–170. [Google Scholar]
- Kramer, O. A review of constraint-handling techniques for evolution strategies. Appl. Comput. Intell. Soft Comput. 2010, 2010, 185063. [Google Scholar] [CrossRef]
- Yin, X.; Zhang, J. An improved bounce-back scheme for complex boundary conditions in lattice Boltzmann method. J. Comput. Phys. 2012, 231, 4295–4303. [Google Scholar] [CrossRef]
- Galishnikova, V.V.; Pahl, P.J. Constrained construction of planar delaunay triangulations without flipping. Structural-Mechanics 2018, 14, 154–174. [Google Scholar] [CrossRef]
- Bucher, C.G.; Bourgund, U. A fast and efficient response surface approach for structural reliability problems. Struct. Saf. 1990, 7, 57–66. [Google Scholar] [CrossRef]
- Hu, Z.; Mahadevan, S. Global sensitivity analysis-enhanced surrogate (GSAS) modeling for reliability analysis. Struct. Multidiscip. Optim. 2016, 53, 501–521. [Google Scholar] [CrossRef]
- Xiao, N.C.; Zuo, M.J.; Zhou, C. A new adaptive sequential sampling method to construct surrogate models for efficient reliability analysis. Reliab. Eng. Syst. Saf. 2018, 169, 330–338. [Google Scholar] [CrossRef]
- Popescu, L.; Diodiu, L. Optimizing the magnetic circuit of an actuator. In MATEC Web of Conferences; EDP Sciences: Les Ulis, France, 2019; Volume 290, p. 01013. [Google Scholar]
- Ribas, S.; Ribeiro-Neto, B.; Ziviani, N. R-Score: Reputation-based Scoring of Research Groups. arXiv 2013, arXiv:1308.5286. [Google Scholar]





















© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duchanoy, C.A.; Calvo, H.; Moreno-Armendáriz, M.A. ASAMS: An Adaptive Sequential Sampling and Automatic Model Selection for Artificial Intelligence Surrogate Modeling. Sensors 2020, 20, 5332. https://doi.org/10.3390/s20185332
Duchanoy CA, Calvo H, Moreno-Armendáriz MA. ASAMS: An Adaptive Sequential Sampling and Automatic Model Selection for Artificial Intelligence Surrogate Modeling. Sensors. 2020; 20(18):5332. https://doi.org/10.3390/s20185332
Chicago/Turabian StyleDuchanoy, Carlos A., Hiram Calvo, and Marco A. Moreno-Armendáriz. 2020. "ASAMS: An Adaptive Sequential Sampling and Automatic Model Selection for Artificial Intelligence Surrogate Modeling" Sensors 20, no. 18: 5332. https://doi.org/10.3390/s20185332
APA StyleDuchanoy, C. A., Calvo, H., & Moreno-Armendáriz, M. A. (2020). ASAMS: An Adaptive Sequential Sampling and Automatic Model Selection for Artificial Intelligence Surrogate Modeling. Sensors, 20(18), 5332. https://doi.org/10.3390/s20185332