In the following, the two different methods are explained in more detail and evaluated with regard to their application for GMA.
5.2.2. Marker-Free Approaches
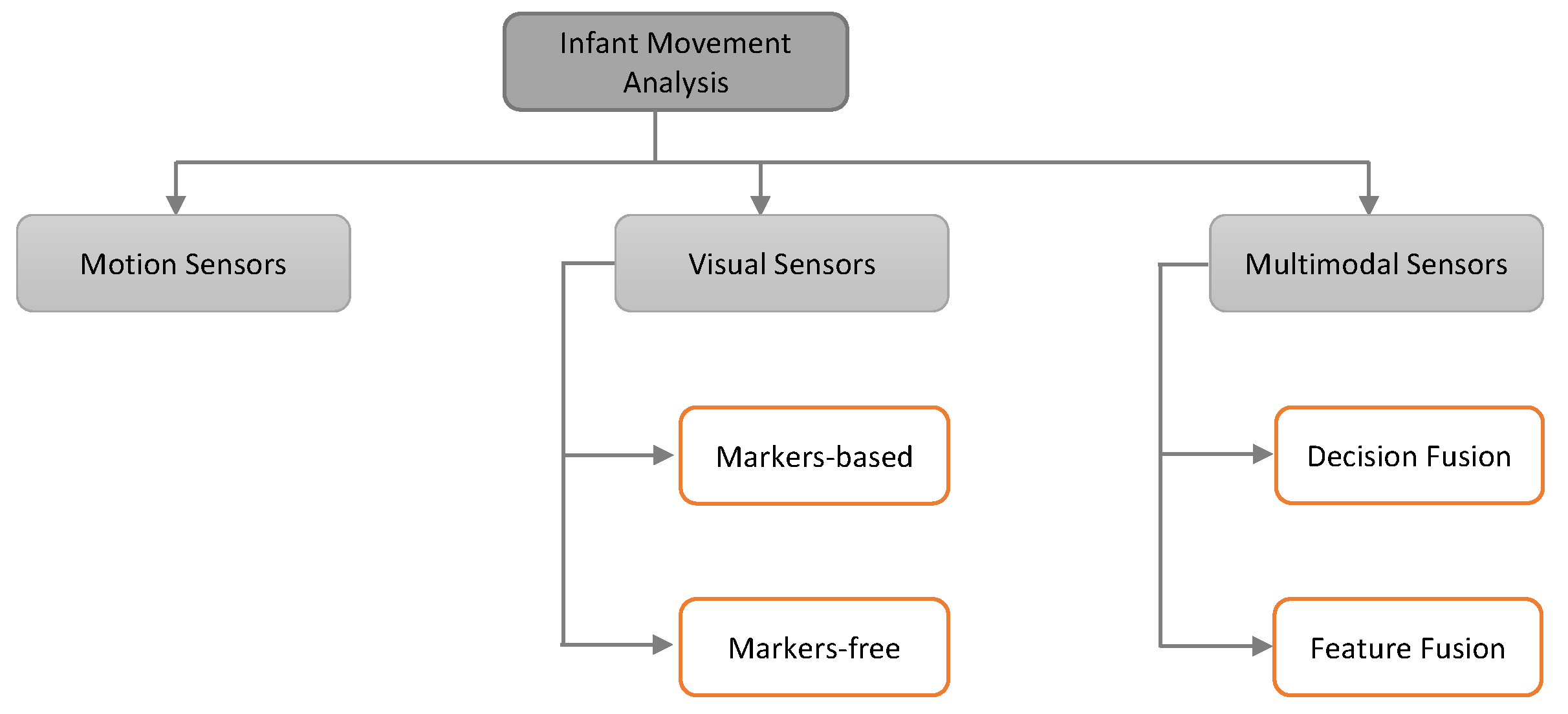
Over the last decade, marker-free approaches have become very attractive in the research community for various applications of computer vision. Instead of applying specific markers on the human body, they make use of image features like shape, edges, and pixel location to detect and track the human body parts. Marker-free techniques have the advantage that they do not intervene and therefore do not interfere with the spontaneous movements of the infants. Often stationary digital video cameras are placed above the infant to record it in supine position, being awake but not distracted. Cameras can be distinguished in mainly two section, simple RGB and depth cameras. Furthermore, deep learning approaches have been summarized in an additional paragraph.
RGB Cameras: Adde et al. [
22] were the first to use computer-based video analysis to classify infants’ movements according to the GMA. A total of 137 video recordings of 82 infants (10–18 weeks post-term age) were labeled with observable FMs or not observable FMs according to the GMA (119 with and 27 without FMs). A General Movement Toolbox (GMT) was implemented to view, crop, preprocess, and extract features to classify videos into non-fidgety or fidgety. The analysis was mainly built upon calculated motion images, where each pixel represent whether there is movement or not. From this several features, for example the quantity of motion as “the sum of all pixels that change between frames in the motion image divided by the total number of pixels in the image” [
22], were extracted. It could be shown that the videos of infants lacking FMs had a significant lower mean quantity of motion compared to infants with FMs. Furthermore, the variability of centroid was determined to have the strongest association with the absence of FMs across all tested variables using a logistic regression. In conclusion, it has been shown that a non-intrusive computerized analysis can yield features associated with the absence of FMs. Thus, showing that the GMA could be replaced in theory. In [
14], the authors further extended their work to predict CP as well. They used 2D videos and a simple frame differencing software without any instrumentation to calculate a motion image. Several hand-crafted features from motion images in addition to the velocity and acceleration of the centroid of the motion were extracted. The best performance was achieved using a cerebral palsy predictor (CPP), consisting of a combination of the centroid of motion standard deviation, the quantity of motion mean, and the quantity of motion standard deviation computed from the motion image. CP was predicted with 85% sensitivity and 88% specificity. The development outcome was defined as an examination at 4–7 years of age. While the performance metrics look promising, the small sample size for this study of 30 high-risk infants can be questioned. Using recordings of 150 infants (10–15 weeks), Støen et al. [
89] elevated their work by incorporating sporadic FMs as well. These recently defined movements characterized by short FMs (1–3 s) with up to 1-min intermediate pauses and the absence of FMs were accounted for 48 of the infants by two certified observers. The absence of normal FMs could be associated with a large variability of the spatial center of movements. In contrast, normal FMs lead to an evenly distributed movement and thus for a more stable center of motion. Additionally, they showed that it is not possible to distinguish between healthy and abnormal movement based on the quantity of motion, as it is not correlating with the presence of FMs. Further automated analysis of sporadic FMs could help to understand their nature, as it is not clear whether they are clinically relevant or not [
90]. Stahl et al. [
16] also recorded 2D videos but an optical flow method to detect moving objects within the scene was realized. The optical flow provides the speed and direction of the object as compared with a frame-differencing method. Visible differences between healthy and affected children were recognized by plotting only the
x or
y components of the movement trajectories. While healthy children had smaller and more frequencies in their components, there were parts of no movement and a more discontinuous signal over time for affected infants. Moreover, they computed wavelet and frequency features and identified three feature values for the analysis of FMs using a support vector machine. By using a 10-fold cross-validation, they achieved 93% accuracy to distinguish impaired from unimpaired infants. In this study, the use of 3 features is questionable, and study samples in terms of the number of children with CP (15 infants with and 67 infants without CP) are too small. Furthermore, the proposed data analysis methods [
14,
16] are sensitive to lighting conditions, cloths, and skin color. Dai et al. [
21] evaluated the use of a Kernel Correlation Filter (KCF) [
91] to track trajectories of the limbs and whole body of infants to classify their movement as normal or abnormal. Motion trajectories were split in their X and Y components and the X axis discarded for later computations. Features were extracted using Discrete Wavelet Transform (DWT) which considers both frequency and time information and calculation of the square of the amplitude spectrum to retrieve a characteristic of the energy of the signal (power spectrum). PCA was then applied to reduce the dimensionality of the features space. The authors were the only ones to implement Stacking, a type of Ensemble Learning where classifiers are piled in layers. They created a stacked training model consisting of SVM, RF, and AB in the first layer, feeding their output to a second layer consisting of XGBoost which yields the final classification. In addition, a model for the wavelet and power spectrum features each and a weighted combination has been trained. Testing on 120 video samples (60 normal-behavior, 60 abnormal infants, age 10–20 weeks) a best accuracy of 93.3% with the combined model was achieved. Although it could be shown that KCF and Stacking yield high accuracy in classifying normal and abnormal behavior, no detailed information about the involved ground truth is given.
In clinical observations, CS and FM are early markers for later development of CP [
11,
92]. Therefore, to get a good feature set that represents the full clinical insight, the authors in [
32] implemented a motion segmentation method proposed in [
93]. They collected a dataset of 78 infants recorded with a 2D monocular camera. They also captured motion sensor data simultaneously. The authors computed the dense trajectories by using the Large Displacement Optical Flow (LDOF) and then applied a graph-based segmentation algorithm to segment them into groups of individual body parts. Three types of features (area out of standard deviation (STD) from moving-average, periodicity, and correlation between trajectories) proposed in [
7] were extracted. The first two features were chosen to detect a lack of fluent movement, the last one to detect high correlation between two limbs which can be a predictor for CP [
92] and abnormal behavior [
94] respectively. By using a Support Vector Machine (SVM), they got 87% accuracy on the motion segmentation dataset. Despite the excellent accuracy, the user must label a small number of trajectories. Rahmati et al. [
33] made use of the same dataset, as mentioned in [
32], to propose an intelligent feature set for the prediction of CP. They extracted the motion data out of video by using the similar method proposed in [
93]. A Fast Fourier Transform (FFT) to extract the final feature from motion data was applied. The authors computed 2376 features from video data and performed a Partial Least Square Regression (PLSR) along with a cross-validation to estimate the predictability of the model. They claim that they achieved 91% accuracy for their CP prediction. These results should be received with caution, as the number of children with CP (14 infants) is very low compared to the one without CP (64 infants). Such a class imbalance can introduce certain tendencies towards the dominant class in classifier and the evaluation by accuracy can be misleading [
32,
33]. Orlandi et al. [
13] screened 523 videos of babies at 3–5 months corrected age and selected 127 of them for automatic analysis. During the selection process several criteria, for example if the complete infant is always visible or light conditions, were checked. Each infant was categorized by a certified observer according to the criteria described by Hadders-Algra [
95] having typical (98 infants) or atypical (29 infants) movements. The creation of the automated system included 5 steps: a motion estimation with LDOF which uses pixel displacement between frames, an infant segmentation to remove the background, feature extraction of 643, feature selection to reduce the number of features, and classification. Using a Leave-one-out cross-validation (LOO-CV) several classifiers (Logistic, AdaBoost, LogitBoost, and Random Forest) were trained to distinguish between “typical” vs. “atypical” movement and “CP” vs. “no CP”. While the best accuracy of 85.83% for the GMA was achieved with the AdaBoost classifier, the Random Forest yielded the best result (92.13% accuracy) in classifying CP even outperforming the clinical GMA itself (85.04% accuracy). Being one of the first studies to include more than 100 preterm infants in their tests, Orlandi et al. [
13] show that an automated procedure could possibly replace the clinical GMA. Moreover, Random Forest and AdaBoost seem to be a good choice of classifier, but the method lacks kinematic features that could be introduced by using depth cameras. A new model called Computer-based Infant Movement Assessment (CIMA) was introduced and evaluated on even more infants (377 high-risk infants) by Ihlen et al. [
18]. The 1–5 min video recording of 9–15 weeks corrected age infants were used to predict CP. Pixel movements were tracked using a large displacement optical flow and six body parts (arms, legs, head, and torso) were segmented in a non-automatic way, having two assistance manually annotating the videos. A total of 990 features, including the temporal variation, multivariate empirical mode decomposition (MEMD), and Hilbert–Huang transformation of the six body parts, were extracted for 5 s non-overlapping windows of the videos. Two certified GMA observers rated the videos according to classify FMs (FM−, FM+/−, FM+, FM++) using the GMA as comparison to the model. Forty-one (11%) of 377 infants were diagnosed with CP according to a Decision Tree published by the Surveillance of cerebral palsy in Europe by pediatricians (unaware of the GMA outcome) [
96]. CIMA model yielded comparable results to the GMA having 92.7% sensitivity and 81.6% specificity rate in CP prediction. Raghuram et al. [
15] introduced a more general analysis by building a predictive model for motor impairment (MI) rather than just a CP prediction. RGB videos of 152 infants (3–5 months) were analyzed to predict MI, defined as Bayley motor composite score <85 or CP. The movement analysis contained a pixel tracking using LDOF, a skin model for segmentation and finally an extraction of movement related features. Using logistic regression and a backward selection method to reduce the feature space, 3 mainly contributing values have been identified. The minimum velocity, mean velocity of the infant’s silhouette, and the mean vertical velocity yielded the best results in MI prediction. The presented automated method performed better (79% sensitivity and 91% negative predictive value (NPV) for MI) than the clinical GMA in relation to MI prediction.
Schmidt et al. [
17] relied on 2445 video segments for their study. To reduce the data per input video, they further sampled the segment producing 145 frames per segment video. The authors are the only ones to implement a transfer learning approach, which means that a network trained for another task is reused and adopted. The model was built applying Keras VGG19 [
97] and trained on the ImageNet dataset classes. Image features were picked up from Layer eight of VGG19, went through a max-pooling layer and normalized before being presented to an LSTM layer for the classification of the images. They reported 65.1% accuracy using a 10-fold cross validation (CV) for their method. In addition, the model seems to prioritize sensitivity (50.8%) over specificity (27.4%). Summarizing the results, the presented work performs worse compared to previous studies and is not feasible in its preliminary state. Especially, the unbalanced class distribution (approximately 15% natural occurrence rate of CP) makes the training of data intensive neural networks more difficult. Therefore, further investigation is required to check if transfer learning-based approaches are suitable for the problem in hand.
Depth Cameras: With the invention of the Microsoft Kinect sensor in 2010, motion tracking has become a relatively easy problem to solve [
19,
44]. Without much effort, it is possible to compute pose and motion parameters using its
depth images, which are recorded at 30 frames per second [
98]. Olsen et al. [
99] introduced a 3D model-based on simple geometries, like spheres and cylinders, to describe the infants body using the Kinect sensor. A stomach body part was matched as the only spatial free object. Remaining parts followed constraints due to a hierarchical model for arms, feet, and the head. While body parameters, like position of the stomach and rotation of the remaining parts, were iteratively improved by the Levenberg Marquardt method [
100,
101], size parameters for the objects are either given or estimated in the beginning. Using the Kinect sensor, RGB-D videos of 7 infants have been recorded and some frames manually annotated to receive the ground truth of the infants poses. The authors compared a graph-based method and model-based method to estimate the location of the extremities. The performance of the models is estimated by calculating the euclidean distance between the manual annotated points and the estimation of joint locations. It could be shown that the model-based method yielded smoother tracking. Based upon this model, Olsen et al. [
19] proposed a method to detect spontaneous movements of infants using motion tracking. They computed several features based on the angular velocities and acceleration from their infants’ model. An RGB-D dataset of 11 infants was analyzed. The labeling consisted of two classes (spontaneous movement or not spontaneous) and was done by one of the authors of this study. They reported good performance of 92–98% accuracy for their sequence segmentation method. Nevertheless, it must be emphasized that the method was evaluated on a very small dataset. Khan et al. [
102] proposed a method for monitoring infants at home. They collected RGB data of 10 subjects using an additional RGB camera included in Microsoft Kinect. After data preprocessing, 9 geometric ratio features were computed and then presented to an SVM for classification. A 5-fold cross-validation was performed to validate the system and found to be classified at around 80% accuracy. Although the proposed method shows good results, the number of subjects is critically low, and no healthy infants have been observed as all subjects had movement disorders.
Pose Reconstruction: Furthermore, different works have attempted to evaluate the accuracy of Prechtl’s GMA by human experts based upon pose reconstruction models. Therefore, outcomes yielded by the classical GMA based on RGB videos have been compared to experts’ analysis of pose estimations extracted from the same videos. Such reconstructed models anonymize the infant’s person-specific information (for example, faces are disguised) while remaining movement related data to access GMs. Thus, these approaches enable data sharing and reduce privacy concerns in large clinical trials or research projects. Using archived videos from 21 infants (8–17 weeks), a computational pose estimation model was elaborated to extract skeleton information by Marchi et al. [
103]. The original and skeleton videos of the 14 low-risk and 7 atypical movement babies were assessed by two blind scorers (qualitative assessment of GMs). An agreement of Cohen’s K of 0.90 between both lead to the conclusion that the skeleton estimation comprises the clinically relevant movement. In comparison, Schroeder et al. [
104] recently evaluated a Skinned Multi-Infant Linear Model (SMIL) including 3D body surface additionally to the skeleton of the infant. SMIL model creation consists out of several steps, including background and clothing segmentation, landmark (body, face and hand) estimation and a personalization step, where an initial base template is transferred to the “infant specific shape space by performing PCA on all personalized shapes” [
105]. The base template represents an infant-based model instead of just downsampling already existing adult models. A total of 29 high-risk infants (2–4-month corrected age) were recorded for 3 min using Microsoft Kinect V1. A GMA expert rated both (first all SMIL, afterwards all RGB videos) in a randomized order. To evaluate the agreement between general and fidgety movement ratings of the sequences, the Intraclass Correlation Coefficient (ICC) was computed. ICC was 0.874 and 0.926 respectively for GM-complexity and FM. In additions, the authors published the Moving INfants In RGB-D (MINI-RGBD) dataset [
106], consisting of SMIL applied to 12 sequences of moving infants up to the age of 7 months. These results suggest that the golden standard for the GMA, which is represented by RGB videos, is similar and thus can be replaced by SMIL. While such abstractions of videos seem to retrain the relevant information and thus look promising, the presented methods did not include a fully automated solution based on AI. Classification rates of machine learning algorithm or DL methods need to be tested on the presented pose estimation models in the future.
Deep Learning: With the increasing computing power of Graphics processing units (GPUs) in recent years, the training of Neural Networks (NNs) became possible. These DL approaches aim to learn complex problems in an end-to-end manner using great number of data samples with according class labels (supervised). Although it has been shown that NN can perform excellent results in various tasks, they lack the ability to justify their yielded outcomes. Thus, they are also referred to as black box. DL approaches have been used for GMA based on visual sensors in two different ways. First, NNs can function as pose estimation or other feature extraction method. Secondly, some paper implemented NNs as classifier to directly return the classification output.
Deep Learning for Pose Estimation: Chambers et al. [
36] built a Convolutional Neural Network to extract the pose of infants. They were the only ones to publish an unsupervised approach as preprint and showed that they can distinguish unhealthy movement from infants based on an NB classifier exclusively trained on healthy children. Therefore, 420 videos of assuming healthy infants were collected from YouTube from which 95 were selected, checking that there is more than 5 s of video data and quality is sufficient to extract pose estimation. The age of the infants was estimated by two physical therapists and averaged for the two resulting values. In addition, a clinical dataset was created to evaluate the model after training. The recorded videos of 19 infants (6 preterm, 13 full-term) were evaluated according to the Bayley Infant Neurodevelopmental Screener by an experienced pediatric physical therapist into different risk groups. It compromises a test for neurological and expressive functions and cognitive processes. The approach compromises OpenPose [
107], a Convolutional Neural Network trained to locate joint positions. The author adapted it for infants using YouTube and 17 out the 19 clinical videos with manual annotated joint locations. Using the pose estimation, 38 features (posture, acceleration, velocity, etc.) were extracted to train the NB and check if the individuals in the clinical dataset are part of the (assumed healthy) YouTube set. In other words, they classified infants as unhealthy when their movement was different from the healthy reference dataset. In addition to finding important movement features, a Kruskal–Wallis test between the infants risk groups and the calculated Naive Bayes score show significant association (
). While the study offers a promising unsupervised approach to analyze infants’ movements that overcomes the obstacle of collecting sufficient data of unhealthy children, the study faces some problems. First, the clinical dataset of 19 infants seems in terms of participants too small. Secondly, the use of YouTube data could be considered as not reliable for medical diagnostic, especially with missing background information as age and health status of the children. Finally, the chosen unsupervised approach reveals whether infants differ from the healthy reference group but does not make statements how they differ. McCay et al. [
24] applied OpenPose on the 12 sequences of the MINI-RGBD dataset. An independent expert annotated the videos using the GMA into categories normal and abnormal. Two pose-based histogram features to retrieve a dense representation of the posture of the infants were introduced. They calculated the Histogram of Joint Orientation 2D (HOJO2D) and Histogram of Joint Displacement 2D (HOJD2D) to train KNN, LDA and an Ensemble classifier (MATLAB, not specified in detail). Using leave-one-out cross validation, a best accuracy of 91.67% was achieved for the Ensemble classifier. The promising feature choice and the good performance results are only compromised by the used dataset which lacks a large number of infants. In addition, the data are synthetic which can introduce a degree of uncertainty in the ground truth and missing information for the classifier.
Deep Learning for GMA Classification: McCay et al. [
23] extended their work by enhancing the preprocessing pipeline and evaluating different kinds of NN architectures for classification on their feature extraction approach. The confidence score of the OpenPose software was used to find anomalous joint positions and correct them by interpolating successfully interpreted frames. Afterwards, the feature vector computed by HOJO2D, HOJD2D, and a concatenation of both was fed to an NN and CNN architecture and compared to standard machine learning algorithms (DT, SVM, LDA, KNN, Ensemble). They have shown high performance and robustness of the DL approaches. In addition, the CNN and NN architectures yielded better results compared to the standard machine learning algorithms. Tsuji et al. [
20] recorded 21 infants and labeled intervals of 30 s according Prechtl’s assessment by the help of a physical therapist. An Artificial Neural Network with a stochastic structure was trained on the resulting dataset containing 4 classes (WMs: 193; FMs: 279; CS: 31; and PR: 66). The proposed method compromises a conversion to grayscale with background subtraction, resulting in a binary image where 0 is coded as background and 1 as infant. Several movement features in the categories movement magnitude, movement balance, movement rhythm, and movement of the body center are extracted afterwards. Features are fed to a Log-Linearized Gaussian Mixture Network (LLGMN) which estimates the probabilistic distribution of every data point. After the training, classification can be given by the highest posterior probability of the model. In addition, a threshold for the entropy is given to identify ambiguous input as additional class (Type 0). This class is also addressed when there is no movement in the data. A classification accuracy of 90.2% for the task normal vs. abnormal motions was achieved. To date they are the only ones to create a model distinguishing 4 types of GMs (WMs, FMs, CS, and PR) and retrieve an accuracy of 83.1%. The proposed model trained on a dataset with more infants and additional movement types could lead to a promising approach to automate the GMA.
In general, most visual-based works so far rely on marker-less approaches. While initially good results could be yielded, most obstacles arise with the limited datasets used. Research and especially deep learning approach could benefit from publicly available large datasets. Privacy concerns could be overcome by transforming video data to 3D infant’s models, like SMIL. So far, an automated recognition system utilizing smartphones has not been evaluated. Yeh et al. [
108] and Spittle et al. [
109] have already shown, that smartphone videos recorded by instructed parents are valid for clinical GMA. Such a system could provide more people, especially in rural areas, access to GMA. GMA could be used as screening for every newborn and be a benefit for the health system. Moreover, non-intrusive markers created for the infant’s special needs could be used to boost the performance of visual system.

 ,
, 



{kind=link}
{kind=link}
{kind=link}