1. Introduction
Rolling bearings are extremely vital components in rotating machinery that join the moving parts and fixing parts to maintain the normal operation of running machines. The failures of bearings can undoubtedly cause the shutdown of the whole working systems and induce other chain breaking effects, resulting in huge economical losses and occasional casualties. According to the statistics of historical rotating machinery failures, rolling bearing fault is the most commonly occurring accident that accounts for over 45 percent of failures [
1]. Thus, the fault diagnosis of rolling bearing is of great importance to maximize the productivity benefits and minimize the maintenance cost.
For years, fault diagnosis in rolling bearings has been widely studied by using signal processing methods plus machine learning (ML) algorithms [
2,
3,
4]. A typical rolling bearing fault diagnosis mainly contains three main steps: data acquisition, feature extraction and fault diagnosis. In the data acquisition step, vibration signals, motor current signals, temperature signals and acoustic emission signals are frequently used for analysis [
5,
6]. In the feature extraction step, statistical time domain features such as root mean square, skewness as well as kurtosis [
7] and frequency domain features exposed by Fourier transform [
8] are the common choices to feed to the diagnosis models. To some extent, these features can effectively distinguish the primary differences between various health conditions. However, due to the non-stationary and non-linear characteristics of the collectable signals in practical industrial applications, either time domain features or frequency domain features have their inherent limitations for completely representing the signals. Therefore, time-frequency analysis methods that can decompose the collected signals into a series of components which both contain time domain and frequency domain information are preferred in the field of fault diagnosis. Usual time-frequency analysis methods include short-time Fourier transform (STFT), wavelet transform (WT), wavelet packet transform (WPT), empirical mode decomposition (EMD) [
9,
10,
11], etc. In the fault diagnosis step, ML algorithms are the theoretical supports for building a precise fault classification model. For example, Deng et al. [
12] presented a new diagnosis approach for motor bearing which utilized empirical wavelet transform to decompose vibration signal, fuzzy entropy to compute the model input, and support vector machine to classify the fault and predict the conditions. Yan et al. [
13] used an extreme learning machine to build a fault diagnosis classifier and sensitive multi-scale fault features were efficiently extracted from raw vibration signal. Li et al. [
14] proposed a novel hierarchical symbol dynamic entropy to extract the fault information both in low and high frequency components and then used a binary tree support vector machine to complete the early fault diagnosis of rolling bearings. Although the ML-based fault diagnosis methods are well-developed and achieved wonderful performance, there are two deficiencies worth to consider: First, the ML-based approach inevitably needs to resort to the signal processing methods for generating discriminative features, but the manual feature extraction work needs high expertise and costs too much in terms of labor. Second, manual features extraction and selection are carefully performed based on request of the specific task, the final obtained features are not always effective when faced with the unknown working conditions or application scenarios.
Deep learning (DL), originated from the field of ML, has been found as a promising tool to automatically learn representative features from original signals [
15,
16]. Different from ML, DL can achieve the processes of multi-scale feature representation and final pattern recognition all at once through stacking multiple layers of information processing modules in an overall hierarchical architecture [
17]. DL frameworks used in bearing fault diagnosis can be divided into three kinds: deep auto-encoder (DAE), deep belief network (DBN) and convolutional neural network (CNN). For each of them, several successful applications have been published in recent years. For instance, Chen et al. [
18] used sparse auto-encoder and DBN together for multi-sensor bearing fault diagnosis, of which the former fused time and frequency domain features from different signals and the latter received fused feature vectors for further classification. Wen et al. [
19] introduced a new deep transfer learning method for data-driven fault diagnosis based on sparse auto-encoder. Yu et al. [
20] proposed an intelligent fault diagnosis scheme combining DBN with Dempster-Shafer theory for bearing fault conditions and fault severities classifications. Xu et al. [
21] developed a novel unsupervised deep learning bearing fault diagnosis method based on DBN and a clustering algorithm. Compared with the DNN-based methods, CNN-based methods take advantage of the sparse connection, weight sharing, etc., which largely eases the training difficulty, thus, it is powerful in more complex issues. Guo et al. [
22] developed a hierarchical CNN that extracted features automatically from raw vibration data and diagnosed bearing faults plus severity at the same time. Peng et al. [
23] proposed a deeper residual one-dimensional CNN for adaptively learning fault features of original vibration signal meanwhile obtaining very high diagnostic accuracy for the fault diagnosis of wheelset bearings in high speed trains. Zhang et al. [
24] considered the domain properties of raw vibration signals and proposed a deep CNN with wide first-layer kernels for improving domain adaptation ability and suppressing high frequency noise, promoting the accuracy of CNN-based fault diagnosis methods greatly. Khan et al. [
25] developed a new dilated convolutional neural network-based deep learning model for detecting bearing faults in induction motors and achieved higher performance than conventional techniques under noisy conditions. However, noise interference and working condition variation make the original signals variegated, which increases the demand of the feature extraction ability of CNN and decreases the reliability of fault diagnosis performance. To tackle this, some domain adaptation processing algorithms are introduced. Li et al. [
26] constructed a novel ST-CNN method for fault diagnosis of bearings by fusing S-transform (ST) and CNN, in which a ST layer converted sensor data into a two-dimensional time-frequency matrix and the following CNN model performed diagnosis results. Zhao et al. [
27] calculated the envelope time-frequency representations of the vibration signal using Hilbert transform and synchro-squeezing transform and then built a deep CNN to learn the underlying features and determine the fault types automatically. Zhu et al. [
28] presented a new bearing remaining useful life estimation method through time-frequency representation and multiscale CNN, in which the time-series signals revealed the nonstationary properties using wavelet transform. Despite converting vibration signal into time-frequency coefficient matrix having the benefits of easily exposing fault sensitive and interference-robust components, these methods also have their limitations. One is that the manual work of obtaining time-frequency information increases the overall complexity of the DL-based fault diagnosis methods, just like the manual feature extraction work does to the ML-based methods. The other is that the correlation of time-frequency information with the analyzed fault diagnosis task challenges the final accuracy of the CNN-based method.
In this paper, we proposed a novel end-to-end bearing fault diagnosis method based on WPT and CNN, named WPT-CNN. Unlike other diagnostic methods that treat the time-frequency analysis method as an independent module [
26,
27,
28], the WPT-CCN encapsulates time-frequency decomposition and feature classification in a single network by implementing the function of WPT in the form of a modified convolutional neural layer embedded in the overall structure. WPT not only inherits the merits of WT, in that it has a good time resolution in high frequency bands and a good frequency resolution in low frequency bands, but also compensates for the shortage of WT that lacks the capacity of further decomposing the frequency components in higher frequency bands, leading to better information refinement. Many studies [
29,
30,
31,
32,
33] have adopted the WPT as their preferred choice for enhancing the quality of inputs. Compared to other existing WPT-based studies, a unique point of our proposed WPT-CNN is that the WPT function in the network is self-adaptive to the request of specific tasks, since the layer that achieves the WPT function can be also trained by gradient descent backpropagation optimizing algorithms. The optimizing direction of the wavelet filter coefficients is towards higher fault classification accuracies, so it does not need to worry that the alteration of the coefficients destroys the validity of the WPT. Instead, the coefficients could appropriately learn the characters of the dataset during the optimizing procedure, resulting in a better generalization performance. Based on the above, the WPT-CNN could surpass other time-frequency analysis-based bearing fault diagnosis methods in two aspects: First, it could achieve higher and more robust diagnosis accuracies than other methods. Second, it could directly receive original signal data as input while other methods need to transform signals into time-frequency matrices ahead of time.
The remainder of this paper is summarized as follows.
Section 2 overviews the theories of CNN and WPT.
Section 3 describes the framework of the proposed WPT-CNN-based bearing fault diagnosis method. In the
Section 4, the performance of the raised method is verified by experiments on two rolling bearing fault test rigs. Finally,
Section 5 provides the discussion.

 ,
, 




















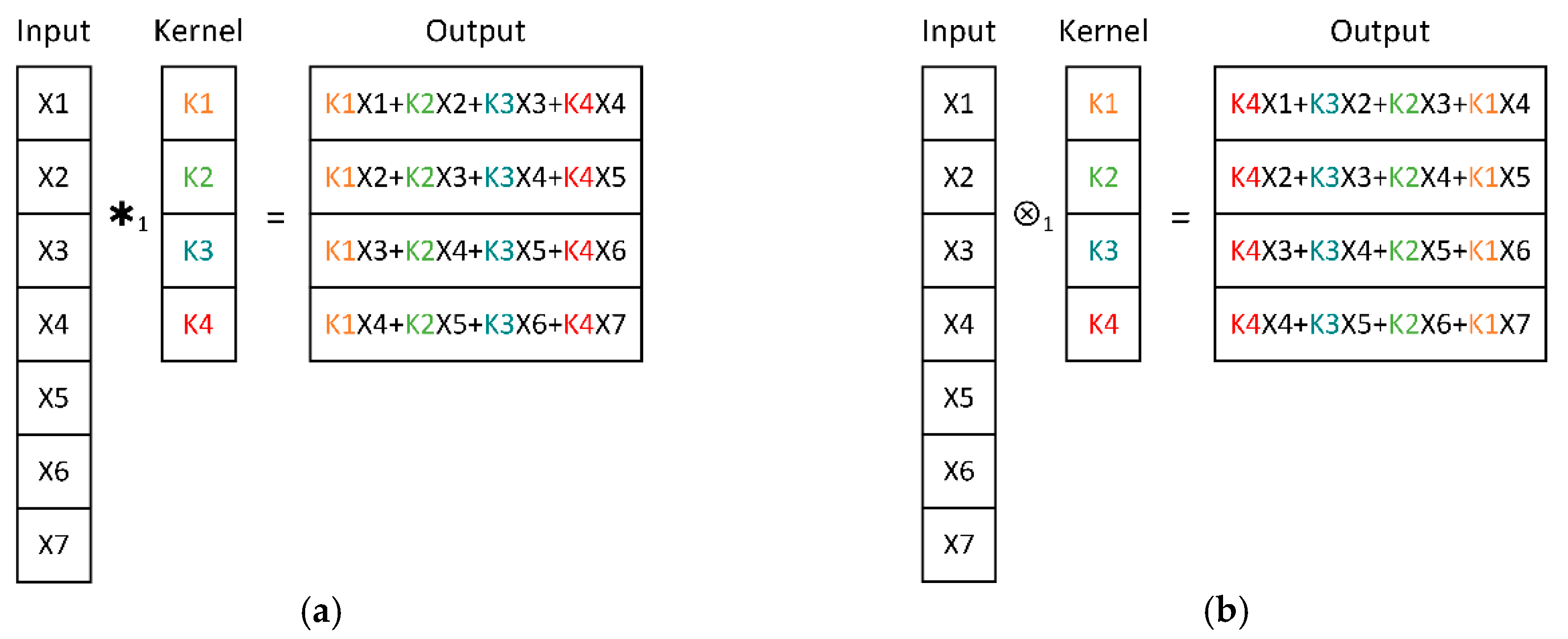{kind=link}
{kind=link}
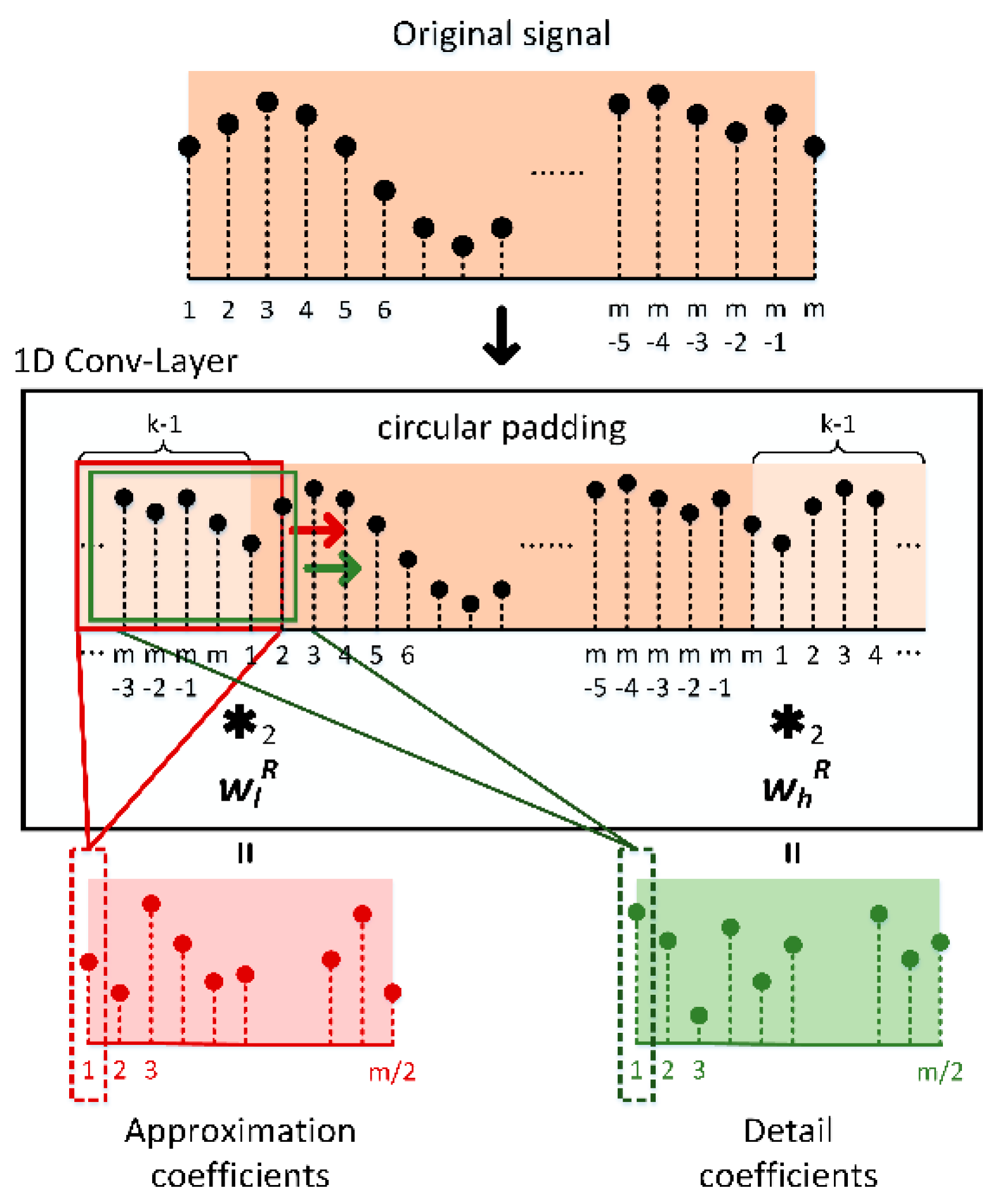{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
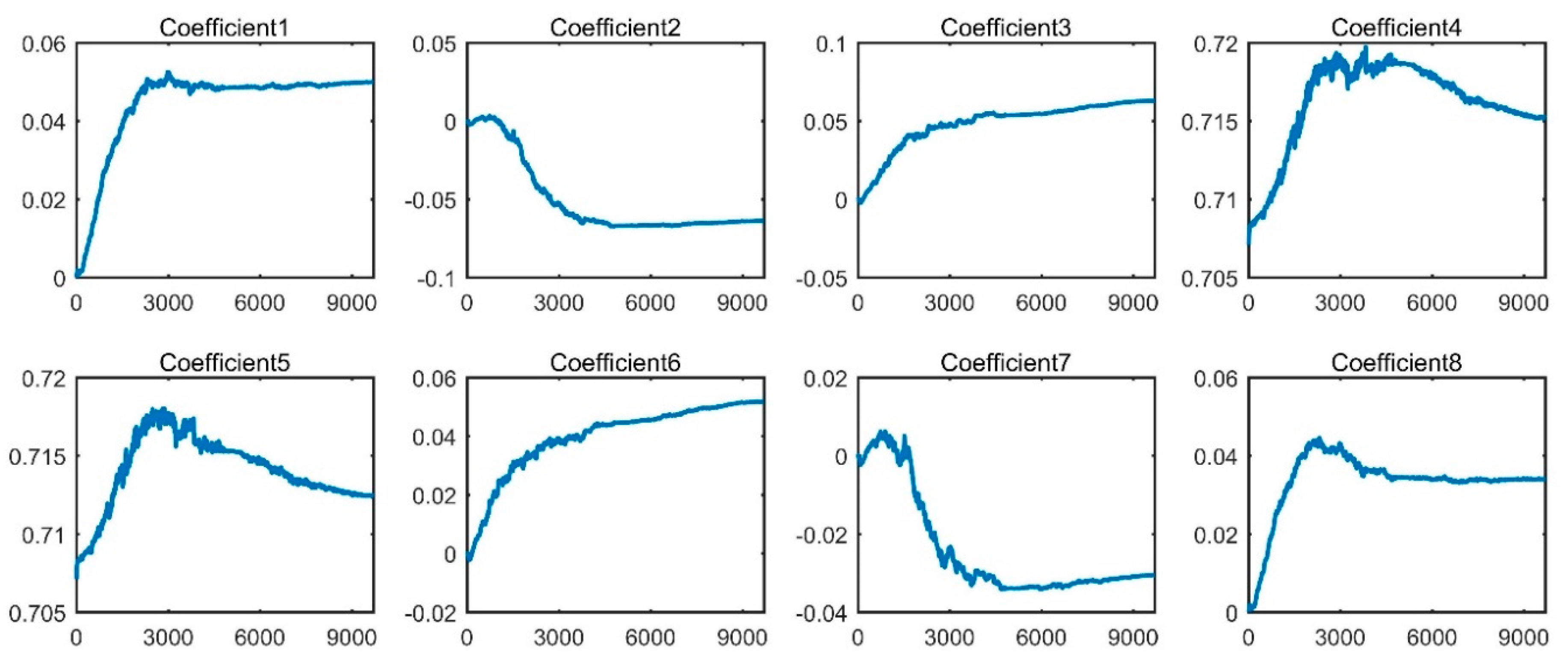{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}