A Hierarchical Learning Approach for Human Action Recognition



Abstract
1. Introduction
- Section 2 quickly reviews the literature.
- Section 3 provides a detailed explanation of the method.
- Section 4 details the temporal analysis, showing how feature elements can be localized in time and that they report the dynamics of different durations.
- Section 5 provides the results in order to validate both the performances and properties of the proposed method.
- Section 6 summarizes the important results and their implications and provides ideas for future work.
2. Related Works
2.1. Neural Network Based HAR
2.2. Temporal Normalization
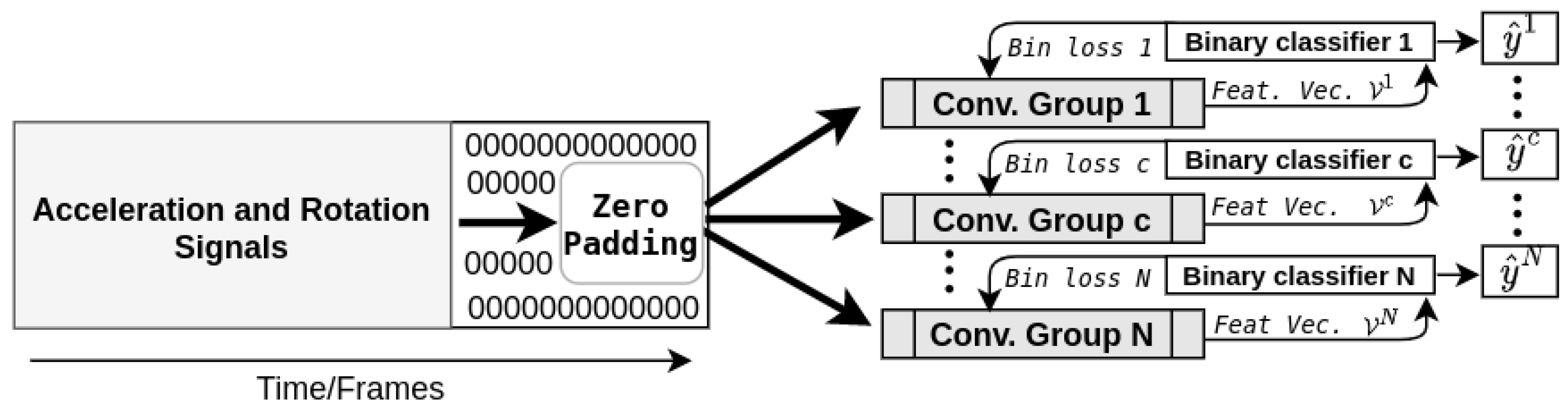
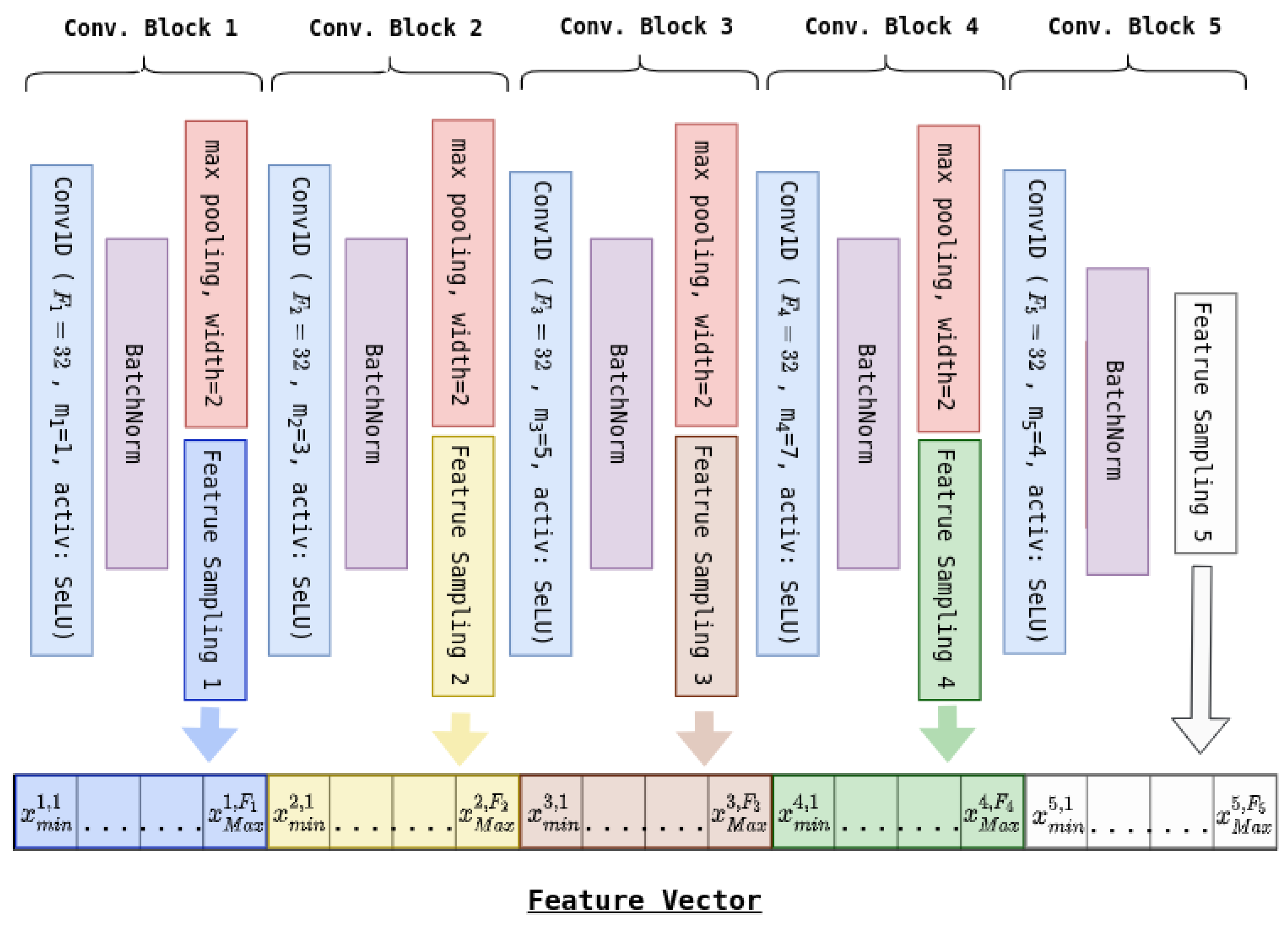
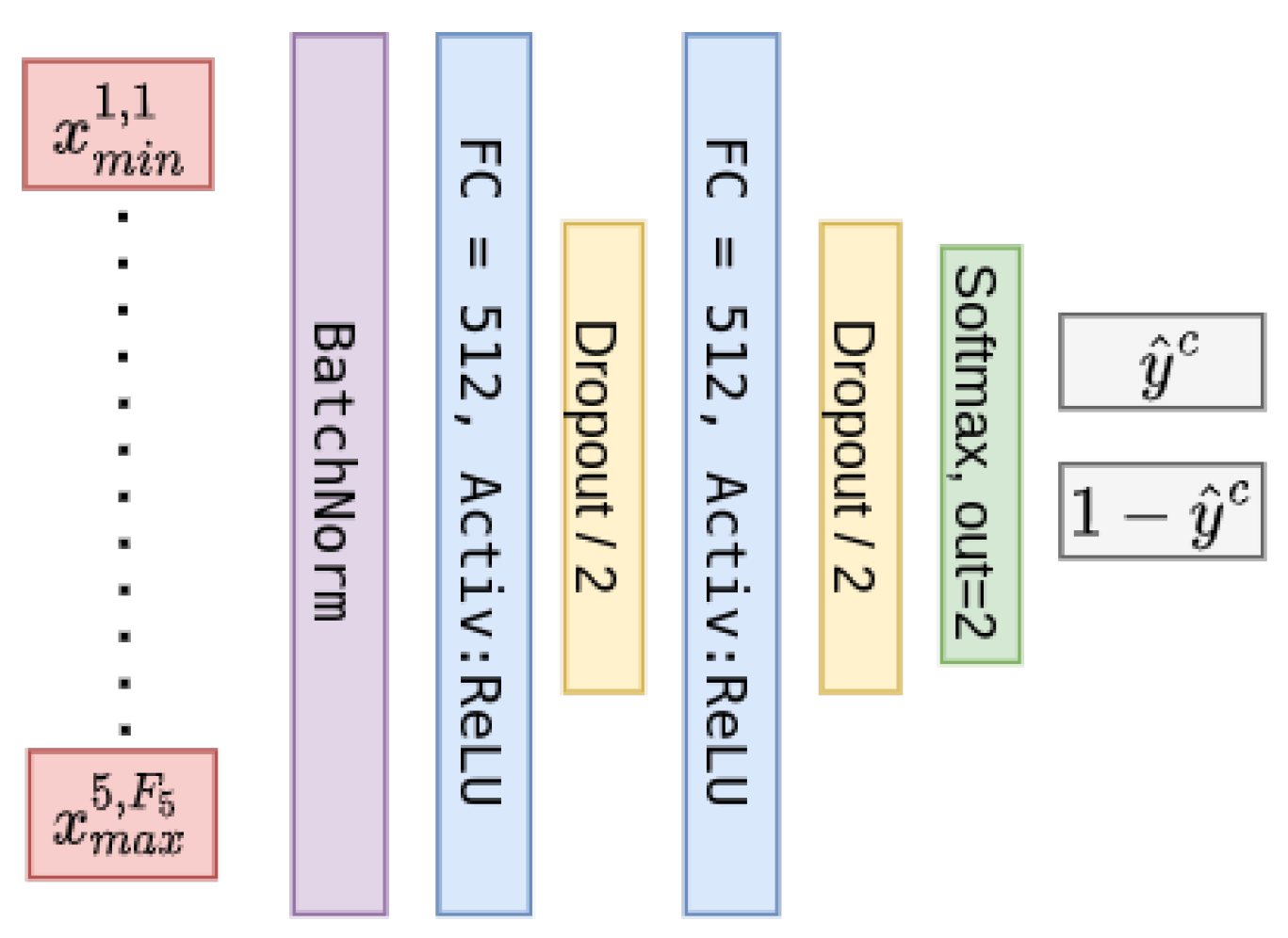
3. Proposed Method
| Algorithm 1: Feature vector harvesting method. |
 |
- A multi-channel 1D convolution layer
- Batch normalization
- Max pooling
- Feature sampling
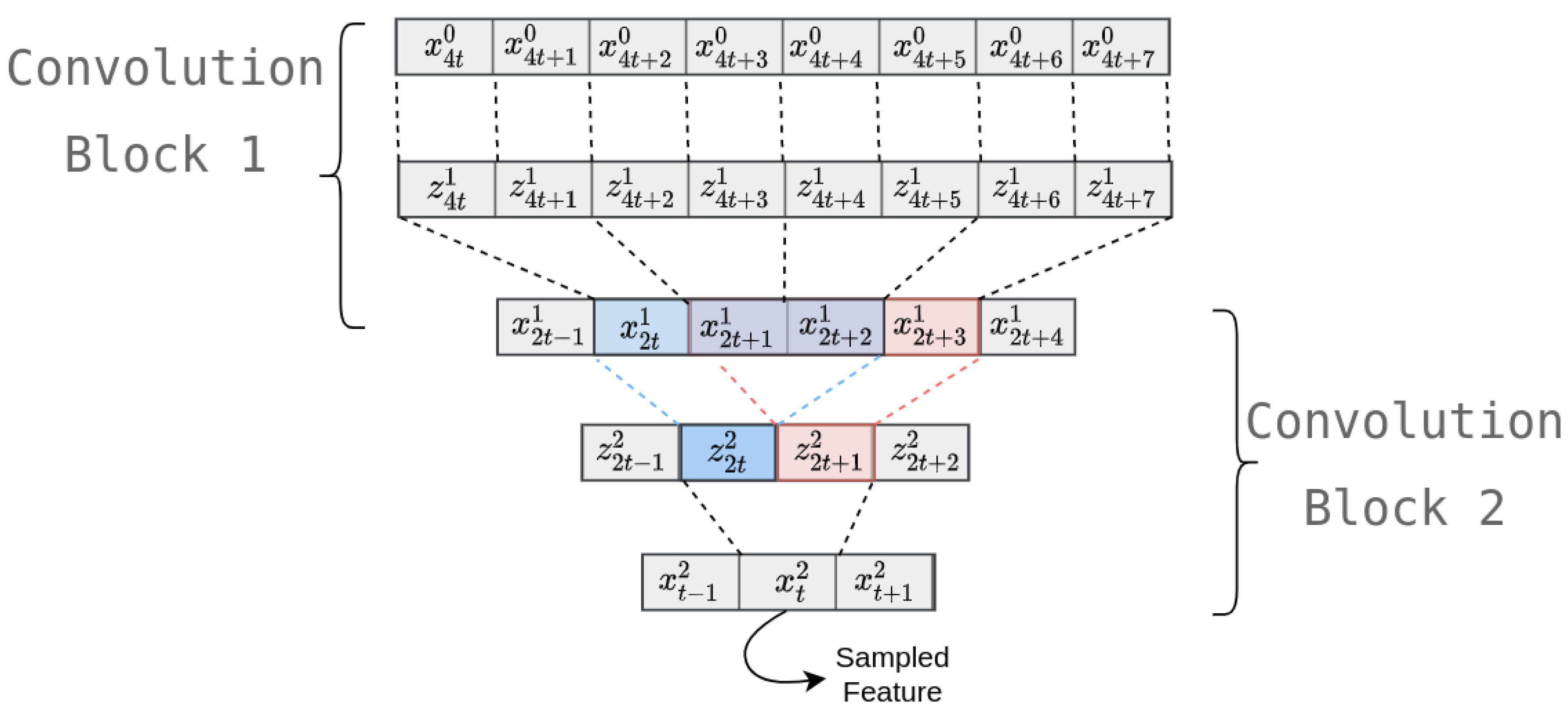
4. Temporal Analysis
5. Experiments
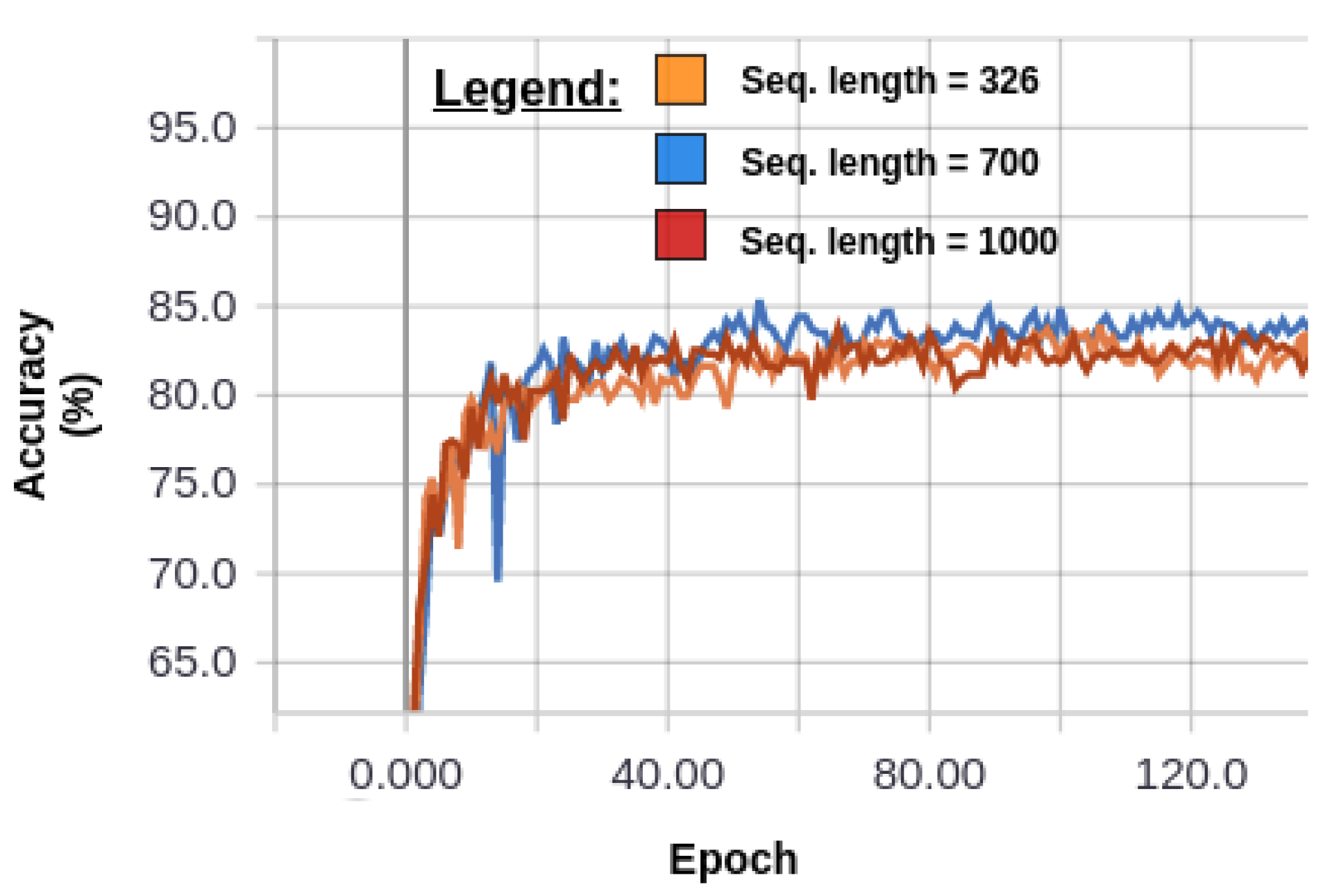
5.1. Robustness against Zero-Padding and Flexibility towards the Input’s Length
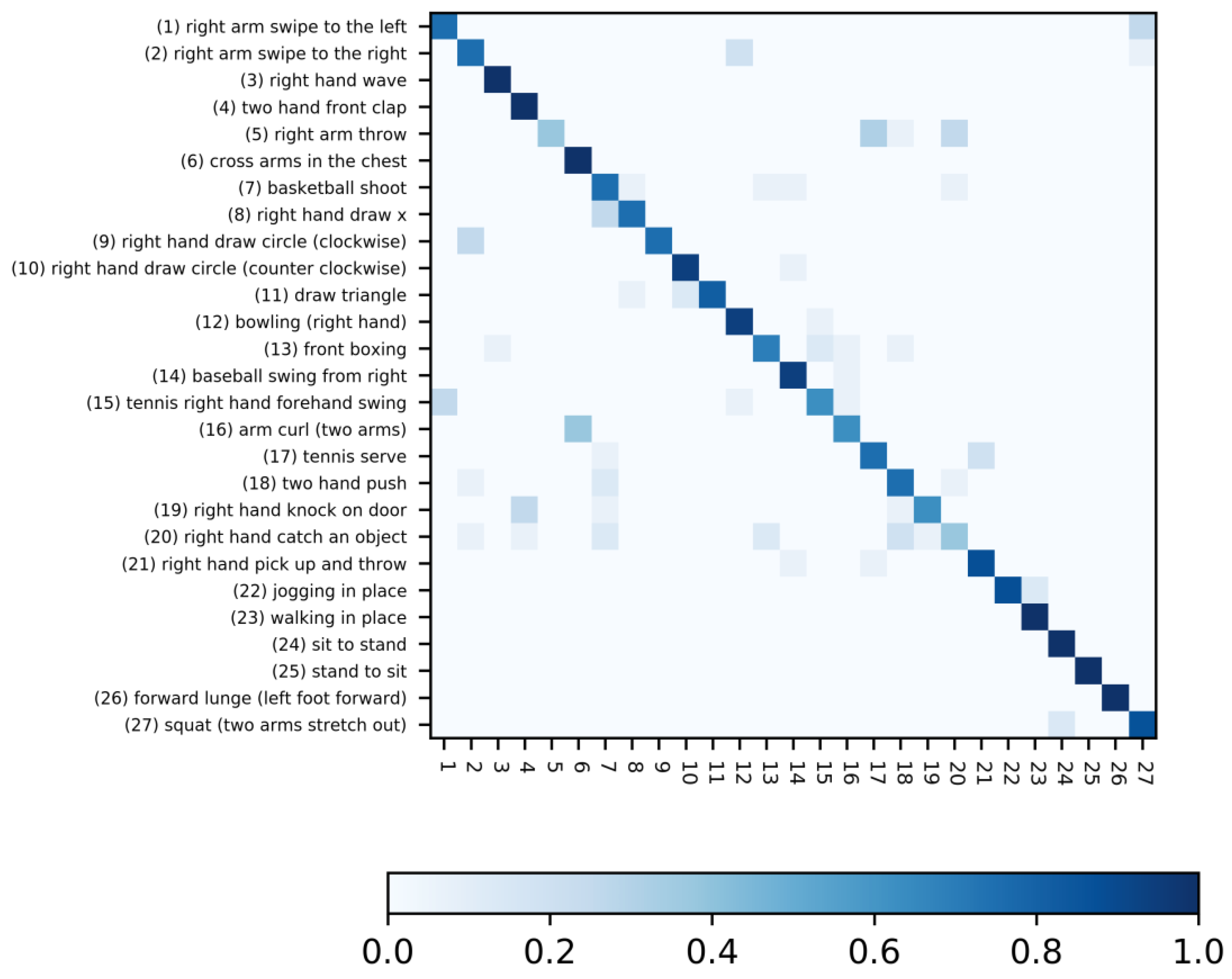
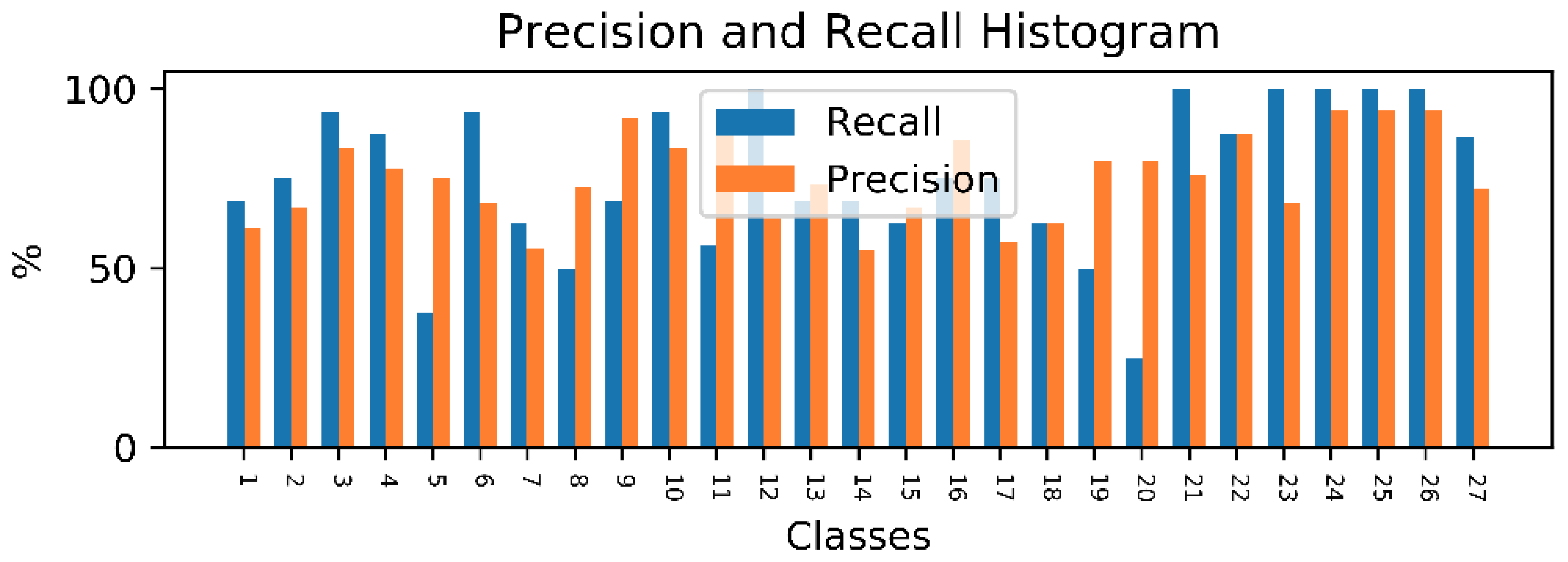
5.2. Performances
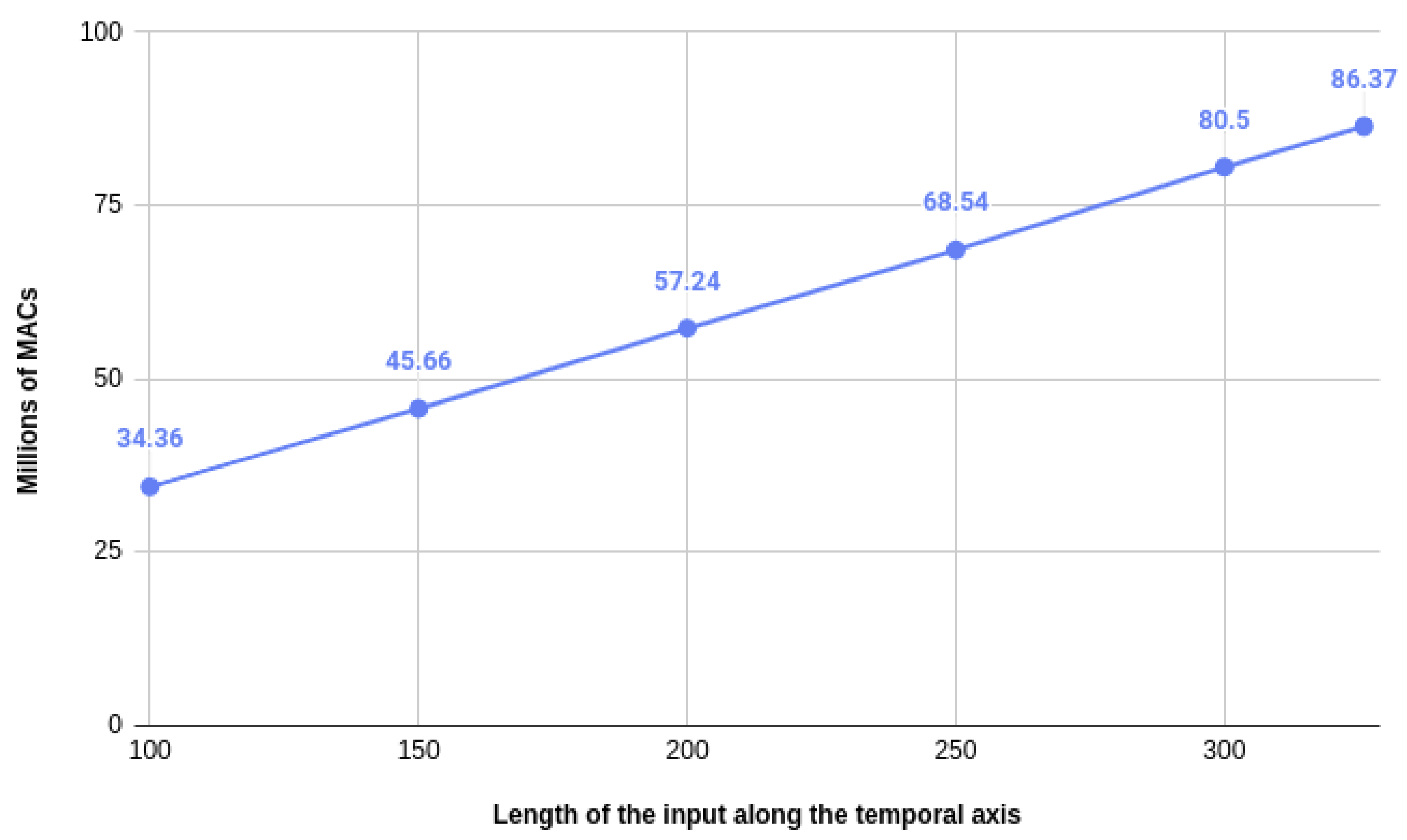
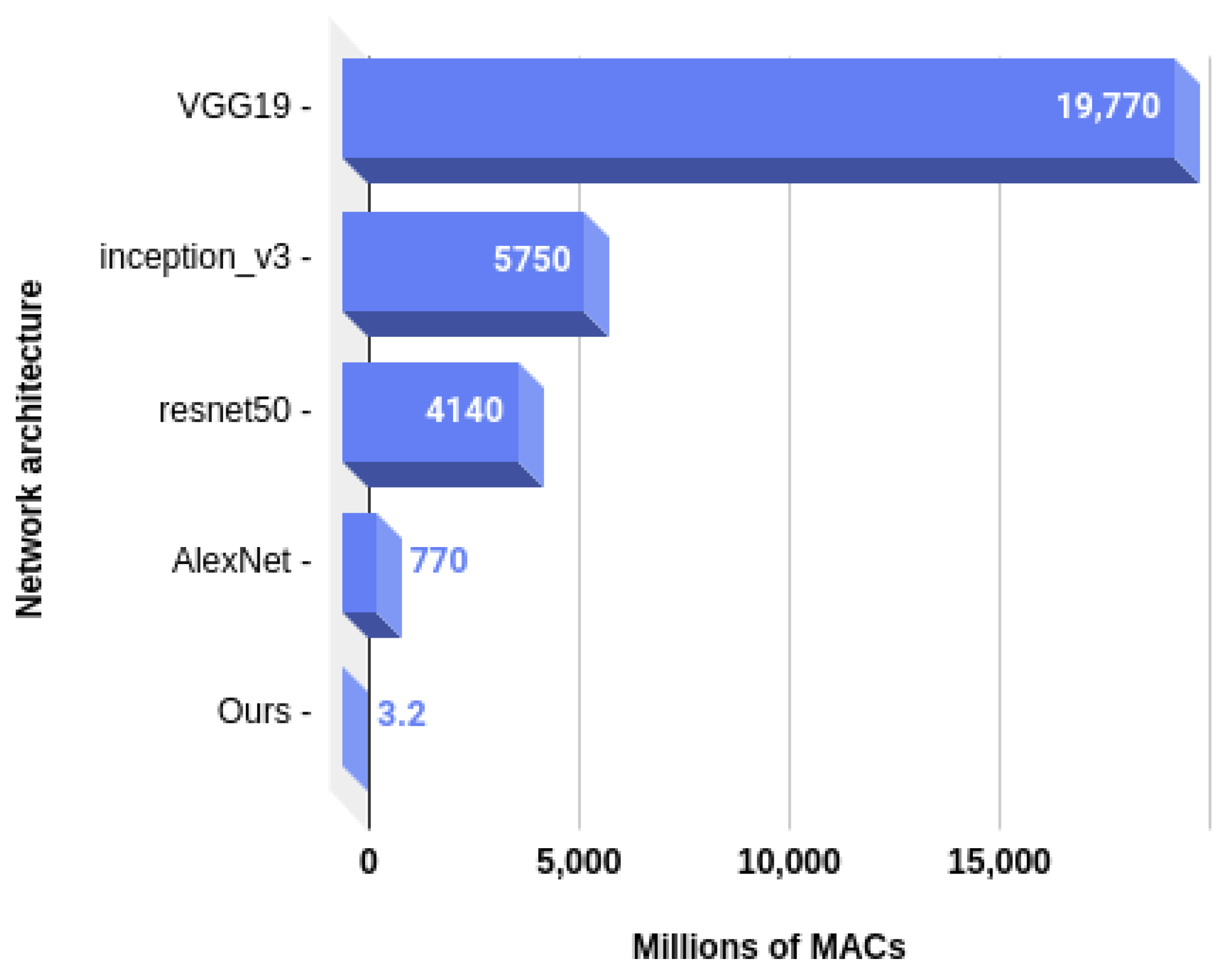
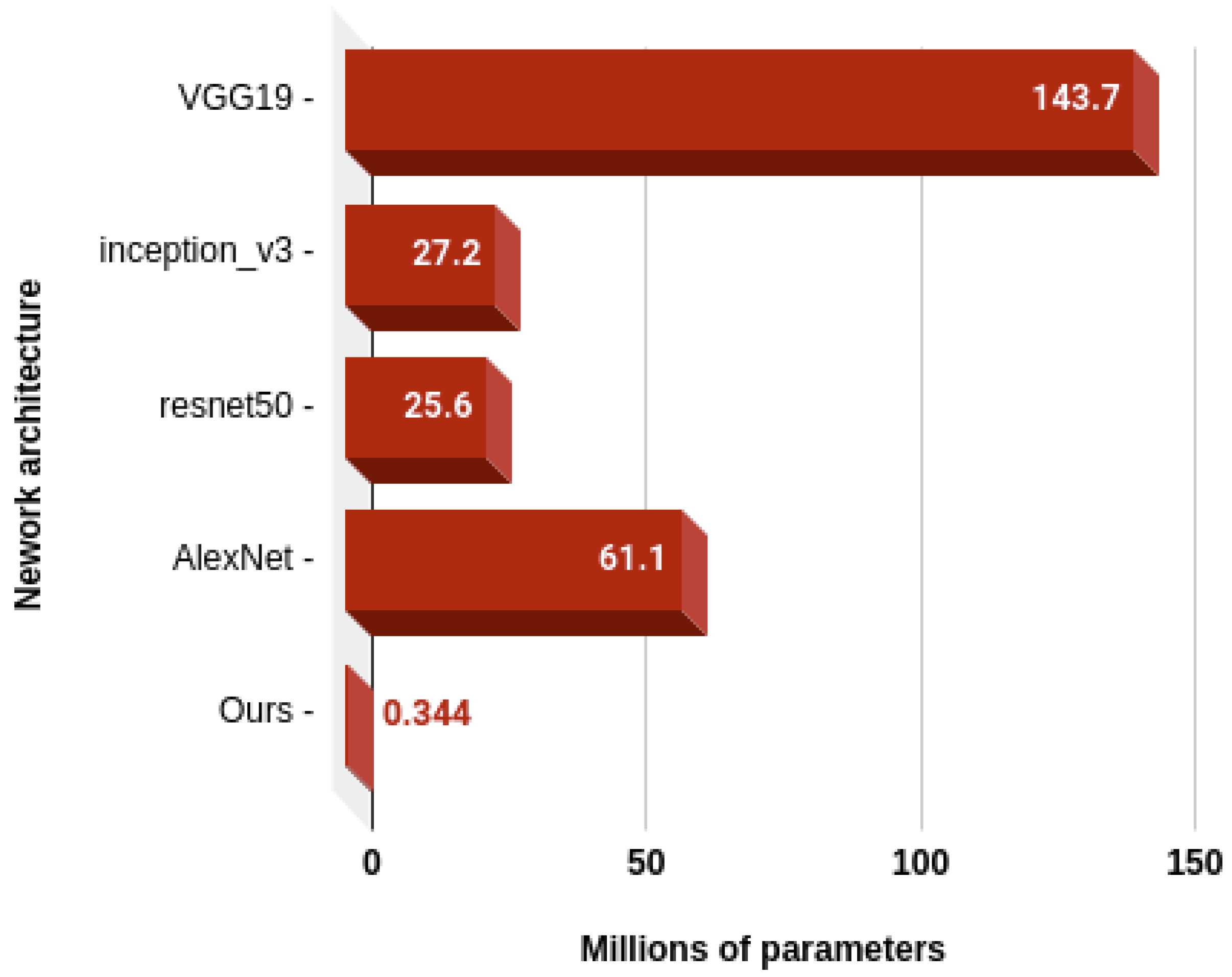
5.3. Computational Complexity Analysis
6. Discussion
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| 1D-CNN | One-dimensional convolution network |
| HAR | Human action recognition |
| IMU | Inertial measurement unit |
| IoT | Internet of Things |
| k-NN | k-nearest neighbour |
| LSTM | Long short-term memory |
| MLP | Multi-layer-perceptron |
| MAC | Multiply–Accumulate operation |
| ReLU | Rectified Linear Unit |
| RNN | Recurrent neural network |
| SeLU | Scaled exponential linear unit |
| SVM | Support vector machine |
| UTD-MHAD | University of Texas at Dallas-Multimodal Human Action Dataset |
References
- Nishida, T. Social intelligence design and human computing. In Artifical Intelligence for Human Computing; Springer: Berlin/Heidelberg, Germany, 2007; pp. 190–214. [Google Scholar]
- Vermesan, O.; Friess, P. Internet of Things-from Research and Innovation to Market Deployment; River Publishers: Aalborg, Denmark, 2014; Volume 29. [Google Scholar]
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.L.; Wang, G.; Duan, L.Y.; Kot Chichung, A. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. Acm Sigkdd Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Weiss, G.M.; Lockhart, J. The Impact of Personalization on Smartphone-Based Activity Recognition. In Proceedings of the Workshops at the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Imran, J.; Raman, B. Evaluating fusion of RGB-D and inertial sensors for multimodal human action recognition. J. Ambient Intell. Humaniz. Comput. 2020, 11, 189–208. [Google Scholar] [CrossRef]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional Neural Networks for human activity recognition using mobile sensors. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Jiang, W.; Yin, Z. Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks. In Proceedings of the 23rd ACM International Conference on Multimedia; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1307–1310. [Google Scholar]
- Murad, A.; Pyun, J.Y. Deep recurrent neural networks for human activity recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef] [PubMed]
- Hammerla, N.Y.; Halloran, S.; Ploetz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition using Wearables. arXiv 2016, arXiv:cs.LG/1604.08880. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. arXiv 2017, arXiv:cs.LG/1706.02515. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:cs.LG/1502.03167. [Google Scholar]
- Graham, B. Fractional Max-Pooling. arXiv 2014, arXiv:cs.CV/1412.6071. [Google Scholar]
- Aurelio, Y.S.; de Almeida, G.M.; de Castro, C.L.; Braga, A.P. Learning from Imbalanced Data Sets with Weighted Cross-Entropy Function. Neural Process. Lett. 2019, 50, 1937–1949. [Google Scholar] [CrossRef]
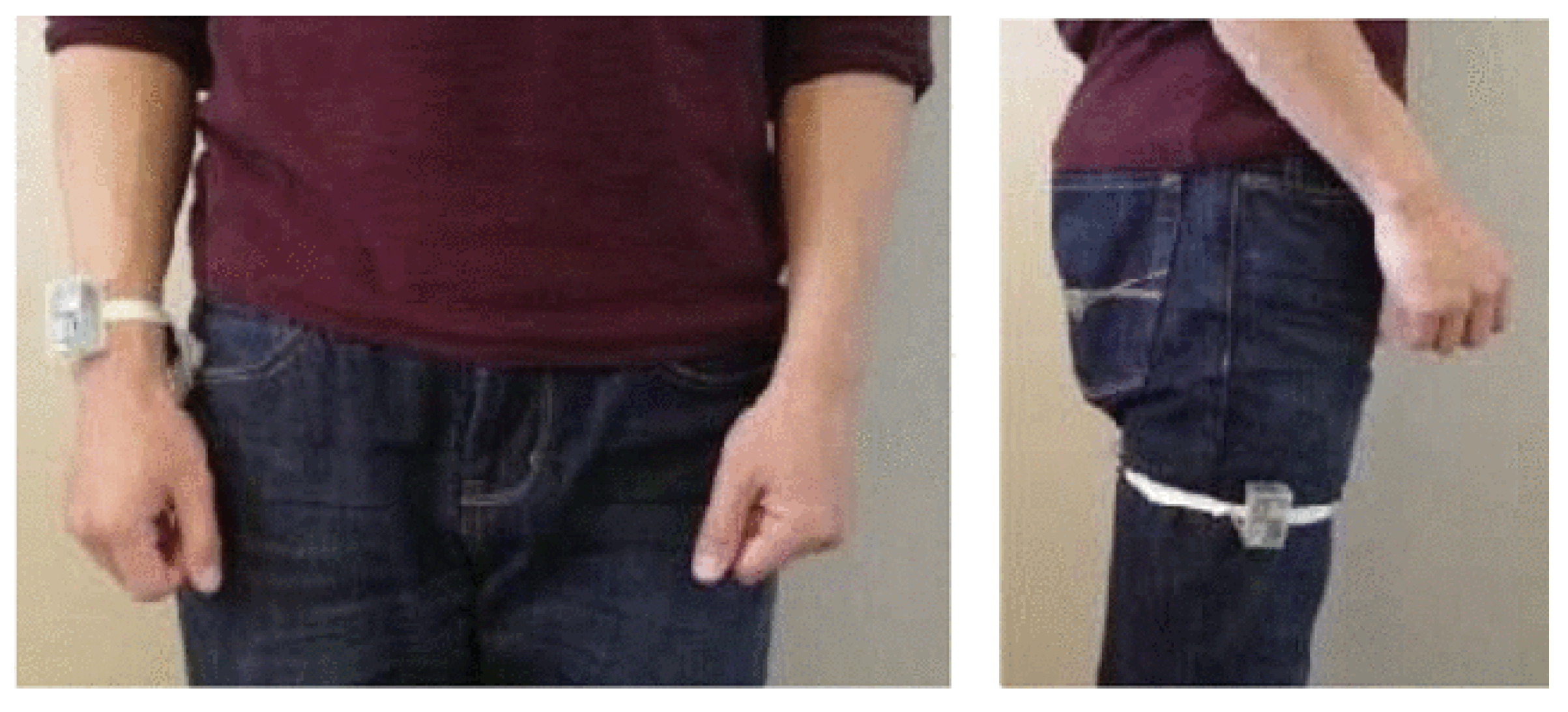
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Hussein, M.E.; Torki, M.; Gowayyed, M.A.; El-Saban, M. Human Action Recognition Using a Temporal Hierarchy of Covariance Descriptors on 3D Joint Locations. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Wang, P.; Li, W.; Li, C.; Hou, Y. Action Recognition Based on Joint Trajectory Maps with Convolutional Neural Networks. arXiv 2016, arXiv:cs.CV/1612.09401. [Google Scholar]
- Hou, Y.; Li, Z.; Wang, P.; Li, W. Skeleton Optical Spectra-Based Action Recognition Using Convolutional Neural Networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 807–811. [Google Scholar] [CrossRef]
- Li, C.; Hou, Y.; Wang, P.; Li, W. Multiview-Based 3-D Action Recognition Using Deep Networks. IEEE Trans. Hum. Mach. Syst. 2019, 49, 95–104. [Google Scholar] [CrossRef]
- Wang, P.; Wang, S.; Gao, Z.; Hou, Y.; Li, W. Structured images for RGB-D action recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1005–1014. [Google Scholar]
- El Din El Madany, N.; He, Y.; Guan, L. Human action recognition via multiview discriminative analysis of canonical correlations. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4170–4174. [Google Scholar]
- Wei, H.; Jafari, R.; Kehtarnavaz, N. Fusion of Video and Inertial Sensing for Deep Learning-Based Human Action Recognition. Sensors 2019, 19, 3680. [Google Scholar] [CrossRef] [PubMed]
- Song, D.; Kim, C.; Park, S.K. A multi-temporal framework for high-level activity analysis: Violent event detection in visual surveillance. Inf. Sci. 2018, 447, 83–103. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Conv. Block (l) | Kernel Width (m) | Relative Duration (D) | Relative Uncertainty (E) | Feature Duration |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 0.033 s |
| 2 | 3 | 6 | 2 | 0.2 s |
| 3 | 5 | 22 | 4 | 0.73 s |
| 4 | 7 | 70 | 8 | 2.33 s |
| 5 | 4 | 118 | 16 | 3.93 s |
| Normalized Sequence Length | 107 | 180 | 250 | 326 |
| Max. Accuracy | 83.99% | 80.05% | 78.42% | 77.04% |
| Buffer Size | Modality | UTD-MHAD | NTU-RGB-D (CS/CV) |
|---|---|---|---|
| Chen et al. [21] | Inertial | 67.20% | |
| Imran et al. [9] (w/o data augmentation) | Inertial | 83.02% | |
| Imran et al. [9] (with data augmentation) | Inertial | 86.51% | |
| Hussein et al. [22] | Skeleton | 85.58% | |
| Wang et al. [23] | Skeleton | 87.90% | 76.32%/81.08% |
| Hou et al. [24] | Skeleton | 86.97% | |
| Imran et al. [9] | Skeleton | 93.48% | |
| Li et al. [25] | Skeleton | 95.58% | 82.96%/90.12% |
| Chen et al. [21] | Depth + inertial | 79.10% | |
| Wang et al. [26] | Depth + skeleton | 89.04% | |
| El Madany et al. [27] | Depth + Inertial + Skeleton | 93.26% | |
| Imran et al. [9] | RGB + inertial + skeleton | 97.91% | |
| Proposed method | Inertial | 85.35% |
| Test Subject | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 96.3% | 89.8% | 88.0% | 90.7% | 94.4% | 91.6% | 90.7% | 85.1% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lemieux, N.; Noumeir, R. A Hierarchical Learning Approach for Human Action Recognition. Sensors 2020, 20, 4946. https://doi.org/10.3390/s20174946
Lemieux N, Noumeir R. A Hierarchical Learning Approach for Human Action Recognition. Sensors. 2020; 20(17):4946. https://doi.org/10.3390/s20174946
Chicago/Turabian StyleLemieux, Nicolas, and Rita Noumeir. 2020. "A Hierarchical Learning Approach for Human Action Recognition" Sensors 20, no. 17: 4946. https://doi.org/10.3390/s20174946
APA StyleLemieux, N., & Noumeir, R. (2020). A Hierarchical Learning Approach for Human Action Recognition. Sensors, 20(17), 4946. https://doi.org/10.3390/s20174946