A Heuristic Angular Clustering Framework for Secured Statistical Data Aggregation in Sensor Networks

 ,
,  ,
,  ,
,  ,
, 

Abstract
1. Introduction
- to determine the shape of the deployment area and the coverage range based on the network area to ensure that no node is left unattended and
- to select the CH with energy optimization to achieve a balanced WSN with minimal energy requirements.
2. Related Works
3. Network and Energy Model
- The radius of the circle (r)
- The angle (θ)
- The center position or midpoint of the area (x′,y′)
4. Radial-Shaped Geo Clustering and Angular Routing
| Algorithm1. Radial-shaped clustering (RSC). |
|
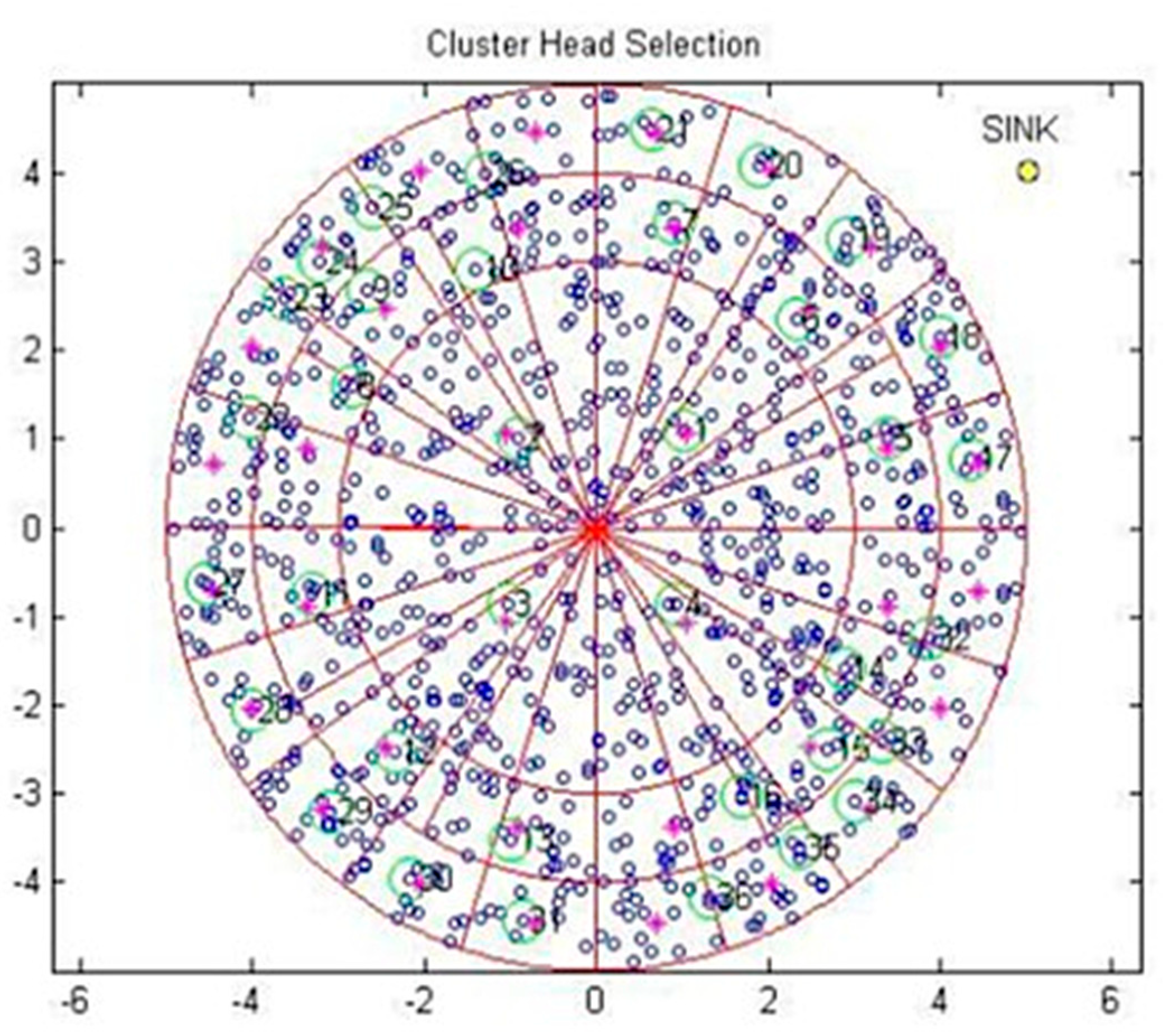
4.1. CH Selection in RSC
| Algorithm2. CH selection in radial-shaped clusters. |
|
4.2. Routing Model
| Algorithm3. Angular Routing in RSC. |
|
5. Simulation and Performance Evaluation
5.1. Behavioral Analysis of the RSC
- Live sensing nodes: the total numbers of sensing nodes with an energy level greater than the threshold are called live sensing nodes.
- Total residualenergy: this is the total energy level of all live sensing nodes measured in joules (J).
- Packetreceived ratio: the packet received ratio for each round is calculated as the ratio of the total number of packets received and the node count.
- Mean
- Median
- Mode
- Maximum
- Variance or standard deviation
5.2. Comparison of RSC with Fan-Shaped Clustering
- 1.
- none of the nodes is selected as the CH,
- 2.
- the CH node could not find the forwarder to reach the sink node, and
- 3.
- the distance to reach the relay node is much greater.
- Mean—power distribution units
- Median—capacity planning or cost predictions
- Mode—power consumption of an entire network operation center
- Maximum—domestic applications/heat transfer
- Standard deviation and/or variance—to trigger a warning or an alarm if a system operates outside an acceptable range
6. Conclusions and Future Scope
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Numan, M.; Subhan, F.; Khan, W.Z.; Hakak, S.; Haider, S.; Reddy, G.T.; Jolfaei, A.; Alazab, M. A Systematic Review on Clone Node Detection in Static Wireless Sensor Networks. IEEE Access 2020, 8, 65450–65461. [Google Scholar] [CrossRef]
- Pandita, D.; Malik, R.K. A Survey on Clustered and Energy Efficient Routing Protocols for Wireless Sensor Networks. Int. J. Trend Sci. Res. Dev. 2018, 2, 1026–1030. [Google Scholar] [CrossRef][Green Version]
- Kumar, A.; Shwe, H.Y.; Wong, K.J.; Chong, P.H.J. Location-based routing protocols for wireless sensor networks: A survey. Wirel. Sens. Netw. 2017, 9, 25–72. [Google Scholar] [CrossRef]
- Kardi, A.; Zagrouba, R. RaCH: A New Radial Cluster Head Selection Algorithm for Wireless Sensor Networks. Wirel. Pers. Commun. 2020, in press. [Google Scholar] [CrossRef]
- Farouk, F.; Rizk, R.; Zaki, F.W. Multi-level stable and energy-efficient clustering protocol in heterogeneous wireless sensor networks. IET Wirel. Sens. Syst. 2014, 4, 159–169. [Google Scholar] [CrossRef]
- Iwendi, C.; Maddikunta, P.K.R.; Gadekallu, T.R.; Lakshmanna, K.; Bashir, A.K.; Piran, M.J. A metaheuristic optimization approach for energy efficiency in the IoT networks. Softw. Pract. Exp. 2020, in press. [Google Scholar] [CrossRef]
- Patel, H.; Singh Rajput, D.; Thippa Reddy, G.; Iwendi, C.; Kashif Bashir, A.; Jo, O. A review on classification of imbalanced data for wireless sensor networks. Int. J. Distrib. Sens. Netw. 2020, 16, 1550147720916404. [Google Scholar] [CrossRef]
- Pintea, C.-M.; Pop, P.C.; Zelina, I. Denial jamming attacks on wireless sensor network using sensitive agents. Logic J. IGPL 2015, 24, 92–103. [Google Scholar] [CrossRef]
- Batra, P.K.; Kant, K. LEACH-MAC: A new cluster head selection algorithm for Wireless Sensor Networks. Wirel. Netw. 2016, 22, 49–60. [Google Scholar] [CrossRef]
- Younis, O.; Fahmy, S. HEED: A hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Trans. Mobile Comput. 2004, 3, 366–379. [Google Scholar] [CrossRef]
- Maddikunta, P.K.R.; Gadekallu, T.R.; Kaluri, R.; Srivastava, G.; Parizi, R.M.; Khan, M.S. Green communication in IoT networks using a hybrid optimization algorithm. Comput. Commun. 2020, 159, 97–107. [Google Scholar] [CrossRef]
- Sawarna Priya, R.M.; Bhattacharya, S.; Maddikunta, P.K.R.; Somayaji, S.R.K.; Lakshmanna, K.; Kaluri, R.; Hussien, A.; Gadekallu, T.R. Load balancing of energy cloud using wind driven and firefly algorithms in internet of everything. J. Parallel Distrib. Comput. 2020, 142, 16–26. [Google Scholar] [CrossRef]
- Hsiao, H.; Su, H. On Optimizing Overlay Topologies for Search in Unstructured Peer-to-Peer Networks. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 924–935. [Google Scholar] [CrossRef]
- Akl, R.; Kadiyala, P.; Haidar, M. Nonuniform Grid-Based Coordinated Routing in Wireless Sensor Networks. J. Sens. 2009, 2009, 491349. [Google Scholar] [CrossRef]
- Ma, J.; Wang, S.; Meng, C.; Ge, Y.; Du, J. Hybrid energy-efficient APTEEN protocol based on ant colony algorithm in wireless sensor network. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 102. [Google Scholar] [CrossRef]
- Liu, X. Atypical Hierarchical Routing Protocols for Wireless Sensor Networks: A Review. IEEE Sens. J. 2015, 15, 5372–5383. [Google Scholar] [CrossRef]
- Lalitha, K.; Thangarajan, R.; Udgata, S.K.; Poongodi, C.; Sahu, A.P. GCCR: An Efficient Grid Based Clustering and Combinational Routing in Wireless Sensor Networks. Wirel. Pers. Commun. 2017, 97, 1075–1095. [Google Scholar] [CrossRef]
- Lalitha, K.; Thangarajan, R.; Poongodi, C.; Anand, D.V. Sink Originated Unique Algorithm for Clustering and Routing to forward Aggregated Data in Wireless Sensor Networks. In Proceedings of the 2018 International Conference on Intelligent Computing and Communication for Smart World (I2C2SW), Erode, India, 14–15 December 2018; pp. 127–130. [Google Scholar]
- Mahajan, S.; Malhotra, J.; Sharma, S. Energy Balanced Heuristic Approach for Path Selection Using Graph Theory. Procedia Comput. Sci. 2015, 46, 101–108. [Google Scholar] [CrossRef]
- Ray, A.; De, D. Energy efficient clustering protocol based on K-means (EECPK-means)-midpoint algorithm for enhanced network lifetime in wireless sensor network. IET Wirel. Sens. Syst. 2016, 6, 181–191. [Google Scholar] [CrossRef]
- Agrawal, D.; Pandey, S. Optimization of the selection of cluster-head using fuzzy logic and harmony search in wireless sensor networks. Int. J. Commun. Syst. 2020, e4391, in press. [Google Scholar] [CrossRef]
- Farman, H.; Javed, H.; Ahmad, J.; Jan, B.; Zeeshan, M. Grid-Based Hybrid Network Deployment Approach for Energy Efficient Wireless Sensor Networks. J. Sens. 2016, 2016, 2326917. [Google Scholar] [CrossRef]
- Meng, X.; Shi, X.; Wang, Z.; Wu, S.; Li, C. A grid-based reliable routing protocol for wireless sensor networks with randomly distributed clusters. Ad Hoc Netw. 2016, 51, 47–61. [Google Scholar] [CrossRef]
- Tian, Y.; Tang, Z.; Yu, Y. Energy-balanced adaptive clustering routing for indoor wireless sensor networks. J. Electron. Inf. Technol. 2014, 35, 2992–2998. [Google Scholar] [CrossRef]
- Merzoug, M.A.; Boukerche, A.; Mostefaoui, A.; Chouali, S. Spreading Aggregation: A distributed collision-free approach for data aggregation in large-scale wireless sensor networks. J. Parallel Distrib. Comput. 2019, 125, 121–134. [Google Scholar] [CrossRef]
- Ebadi, S. A Multihop Clustering Algorithm for Energy Saving in Wireless Sensor Networks. ISRN Sens. Netw. 2012, 2012, 817895. [Google Scholar] [CrossRef][Green Version]
- Soni, V.; Mallick, D.K. A Novel Scheme to Minimize Hop Count for GAF in Wireless Sensor Networks: Two-Level GAF. J. Comput. Netw. Commun. 2015, 2015, 527594. [Google Scholar] [CrossRef]
- Lin, H.; Wang, L.; Kong, R. Energy Efficient Clustering Protocol for Large-Scale Sensor Networks. IEEE Sens. J. 2015, 15, 7150–7160. [Google Scholar] [CrossRef]
- Karakus, C.; Gurbuz, A.C.; Tavli, B. Analysis of Energy Efficiency of Compressive Sensing in Wireless Sensor Networks. IEEE Sens. J. 2013, 13, 1999–2008. [Google Scholar] [CrossRef]
- Han, Z.; Wu, J.; Zhang, J.; Liu, L.; Tian, K. A General Self-Organized Tree-Based Energy-Balance Routing Protocol for Wireless Sensor Network. IEEE Trans. Nucl. Sci. 2014, 61, 732–740. [Google Scholar] [CrossRef]
- Chen, G.; Li, C.; Ye, M.; Wu, J. An unequal cluster-based routing protocol in wireless sensor networks. Wirel. Netw. 2009, 15, 193–207. [Google Scholar] [CrossRef]
- Kumar, N.; Vasilakos, A.V.; Rodrigues, J.J.P.C. A Multi-Tenant Cloud-Based DC Nano Grid for Self-Sustained Smart Buildings in Smart Cities. IEEE Commun. Mag. 2017, 55, 14–21. [Google Scholar] [CrossRef]
- Benzaid, C.; Lounis, K.; Al-Nemrat, A.; Badache, N.; Alazab, M. Fast authentication in wireless sensor networks. Future Gener. Comput. Syst. 2016, 55, 362–375. [Google Scholar] [CrossRef]
- Kumar, N.; Chilamkurti, N.; Misra, S.C. Bayesian coalition game for the internet of things: An ambient intelligence-based evaluation. IEEE Commun. Mag. 2015, 53, 48–55. [Google Scholar] [CrossRef]
- Kumari, A.; Tanwar, S.; Tyagi, S.; Kumar, N.; Maasberg, M.; Choo, K.-K.R. Multimedia big data computing and Internet of Things applications: A taxonomy and process model. J. Netw. Comput. Appl. 2018, 124, 169–195. [Google Scholar] [CrossRef]
- Kumar, N.; Chilamkurti, N.; Park, J.H. ALCA: Agent learning―Based clustering algorithm in vehicular ad hoc networks. Pers. Ubiquitous Comput. 2013, 17, 1683–1692. [Google Scholar] [CrossRef]
- Maddikunta, P.K.R.; Srivastava, G.; Gadekallu, T.R.; Deepa, N.; Boopathy, P. Predictive Model for Battery Life in IoT Networks. In IET Intelligent Transport Systems; Institution of Engineering and Technology: London, UK, 2020; in press. [Google Scholar]
- Kumar, N.; Rodrigues, J.J.; Chilamkurti, N. Bayesian coalition game as-a-service for content distribution in internet of vehicles. IEEE Internet Things J. 2014, 1, 544–555. [Google Scholar] [CrossRef]
- Jindal, A.; Aujla, G.S.; Kumar, N. SURVIVOR: A blockchain based edge-as-a-service framework for secure energy trading in SDN-enabled vehicle-to-grid environment. Comput. Netw. 2019, 153, 36–48. [Google Scholar] [CrossRef]
- Zhongdong, H.; Hualin, W.; Zhendong, W. Energy balanced adaptive clustering routing protocol for heterogeneous wireless sensor networks. Int. J. Wirel. Mobile Comput. (IJWMC) 2019, 16, 264–271. [Google Scholar] [CrossRef]
- Oikonomou, P.; Botsialas, A.; Olziersky, A.; Kazas, I.; Stratakos, I.; Katsikas, S.; Dimas, D.; Mermikli, K.; Sotiropoulos, G.; Goustouridis, D.; et al. A wireless sensing system for monitoring the workplace environment of an industrial installation. Sens. Actuators B Chem. 2016, 224, 266–274. [Google Scholar] [CrossRef]
- Senouci, M.R.; Mellouk, A.; Senouci, H.; Aissani, A. Performance evaluation of network lifetime spatial-temporal distribution for WSN routing protocols. J. Netw. Comput. Appl. 2012, 35, 1317–1328. [Google Scholar] [CrossRef]
- Wen, W.; Wen, X.; Yuan, L.; Xu, H. Range-free localization using expected hop progress in anisotropic wireless sensor networks. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 299. [Google Scholar] [CrossRef]
- Al-Mousawi, A.J. Evolutionary intelligence in wireless sensor network: Routing, clustering, localization and coverage. Wirel. Netw. 2019. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters Used | Values |
|---|---|
| Area of deployment (x,y) | 500 m ∗ 500 m |
| Number of nodes | 1000 |
| Coordinate of the sink node ( | (260, 260) m |
| The initial energy of each sensor | 2 J (Joule) |
| 50 nJ/bit | |
| 10 pJ/bits/m2) | |
| 0.0013 pJ/bits/m4) | |
| 5 nJ/(bit ∗ signal) | |
| x,y coordinates of midpoint of grid | |
| x,y coordinates of all nodes | |
| Number of rounds | 500 |
| Control packet size | 200 bits |
| Data packet size | 3000 bits |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krishnasamy, L.; Dhanaraj, R.K.; Ganesh Gopal, D.; Reddy Gadekallu, T.; Aboudaif, M.K.; Abouel Nasr, E. A Heuristic Angular Clustering Framework for Secured Statistical Data Aggregation in Sensor Networks. Sensors 2020, 20, 4937. https://doi.org/10.3390/s20174937
Krishnasamy L, Dhanaraj RK, Ganesh Gopal D, Reddy Gadekallu T, Aboudaif MK, Abouel Nasr E. A Heuristic Angular Clustering Framework for Secured Statistical Data Aggregation in Sensor Networks. Sensors. 2020; 20(17):4937. https://doi.org/10.3390/s20174937
Chicago/Turabian StyleKrishnasamy, Lalitha, Rajesh Kumar Dhanaraj, D. Ganesh Gopal, Thippa Reddy Gadekallu, Mohamed K. Aboudaif, and Emad Abouel Nasr. 2020. "A Heuristic Angular Clustering Framework for Secured Statistical Data Aggregation in Sensor Networks" Sensors 20, no. 17: 4937. https://doi.org/10.3390/s20174937
APA StyleKrishnasamy, L., Dhanaraj, R. K., Ganesh Gopal, D., Reddy Gadekallu, T., Aboudaif, M. K., & Abouel Nasr, E. (2020). A Heuristic Angular Clustering Framework for Secured Statistical Data Aggregation in Sensor Networks. Sensors, 20(17), 4937. https://doi.org/10.3390/s20174937