Spectral Reflectance Reconstruction Using Fuzzy Logic System Training: Color Science Application




Abstract
1. Introduction
2. Fuzzy Logic Inference Modeling Tool
- Experimental Dataset: This is an important initial step for any identification method, since it determines the information content of the identification data set. In this work we use CIEXYZ/RGB as inputs and Spectral data as desired outputs.
- Fuzzy Structure Selection: In this step, the relevant variables with respect to the aim of the modeling are determined—based on prior knowledge regarding the process, or by trial and error. Also, the structure is selected as a Takagi–Sugeno (TS) fuzzy model [33]. The TS structures define the fuzzification/defuzzification method as well as the use of a fuzzy proposition in the antecedents and crisp functions in the consequents [34].
- Dataset Preprocessing: Usually, the normalization of datasets helps the clustering process [31]. However, in this particular case no normalization has been applied, using the original dataset directly.
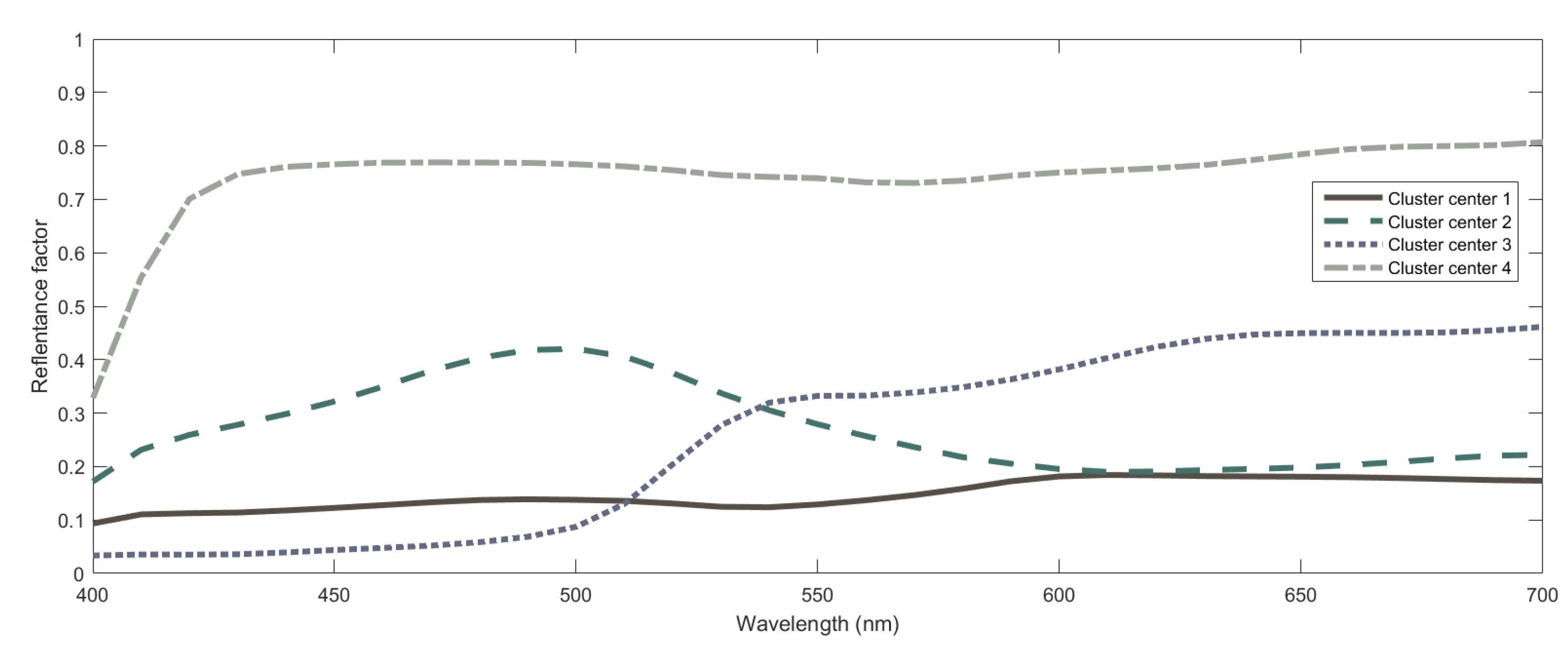
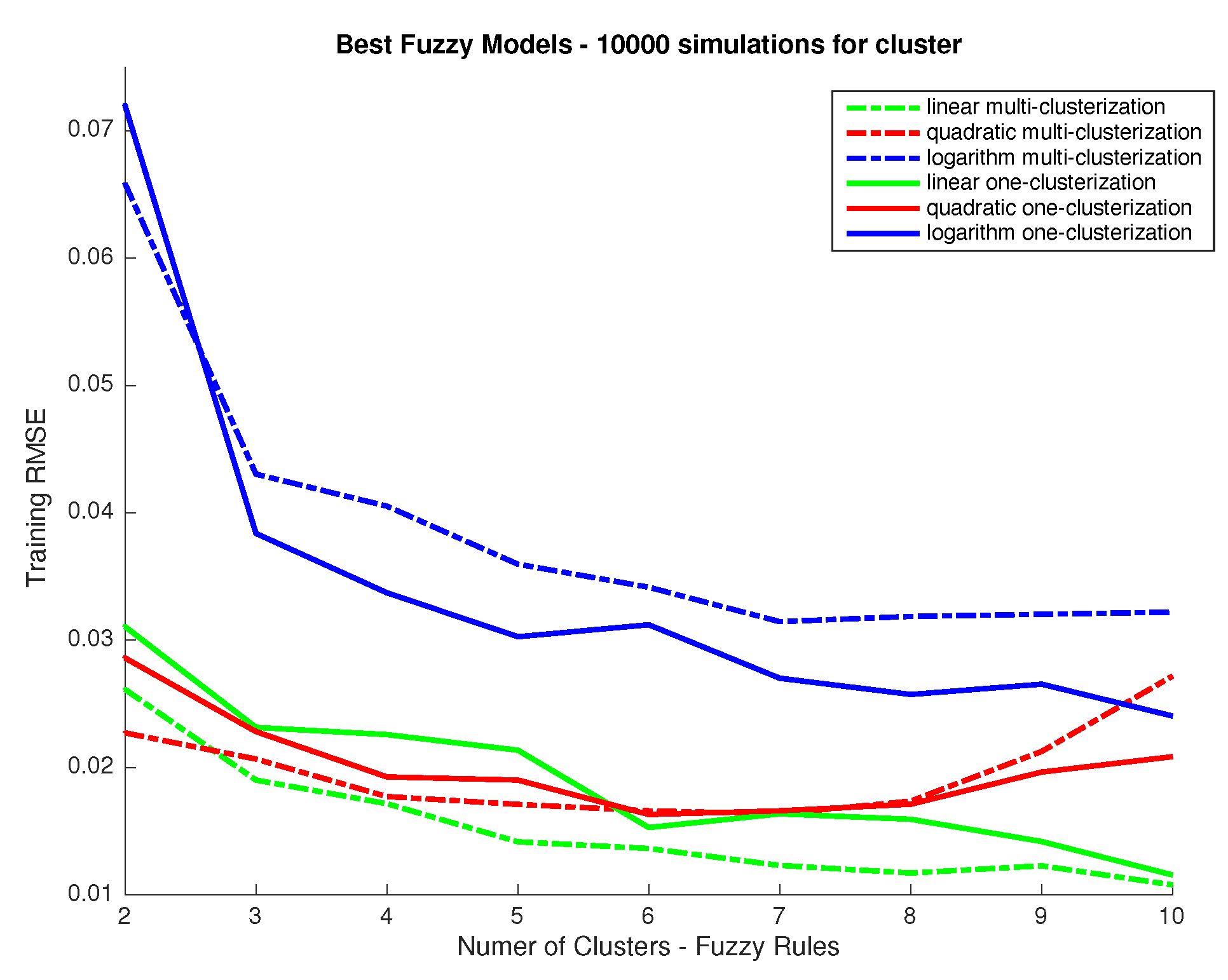
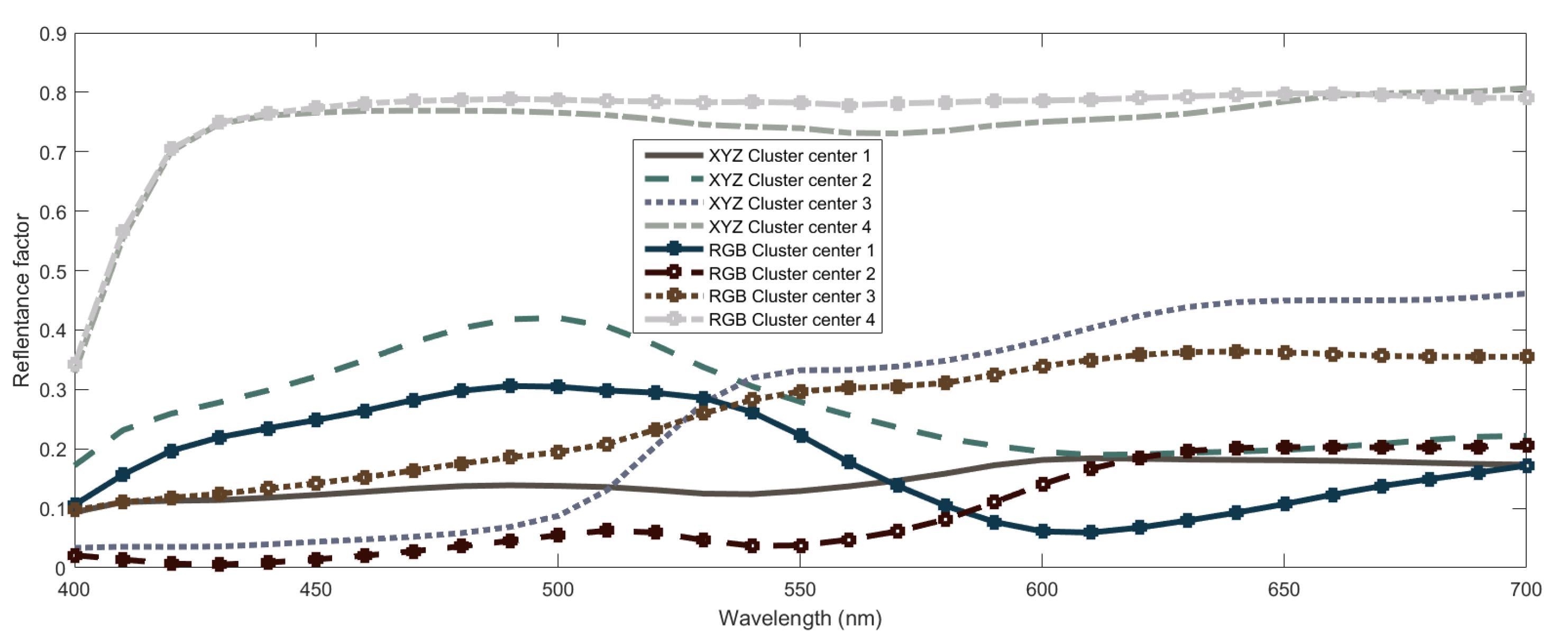
- Fuzzy Clustering: The main goal is to obtain a partition of the dataset in a set of clusters, using fuzzy clustering. The designer determines a priori the number of clusters to obtain, and the clusters defining the number of local linear submodels of the fuzzy model, since the antecedent and consequent terms are obtained using the clustering results. The partition is obtained by using the Gustalfson-Kessel (GK) algorithm, first introduced in [28], and used frequently in clustering tasks [25,26,31]. This algorithm computes the fuzzy partition of the dataset to obtain the antecedent membership functions and consequent parameters. It is very important to point out that in a multiple input and multiple output system, such as our case, each different output can be associated to a different number of rules and, consequently, to a different clusterization of the input data space. This is a point that we study in detail in the next section and that is of key importance to the problem of spectral recovery. In particular, it is interesting to find out whether all outputs could be predicted using the same number of rules or not and, so, whether the clusterization used can be common to all outputs, which could lead to a more meaningful model than otherwise.
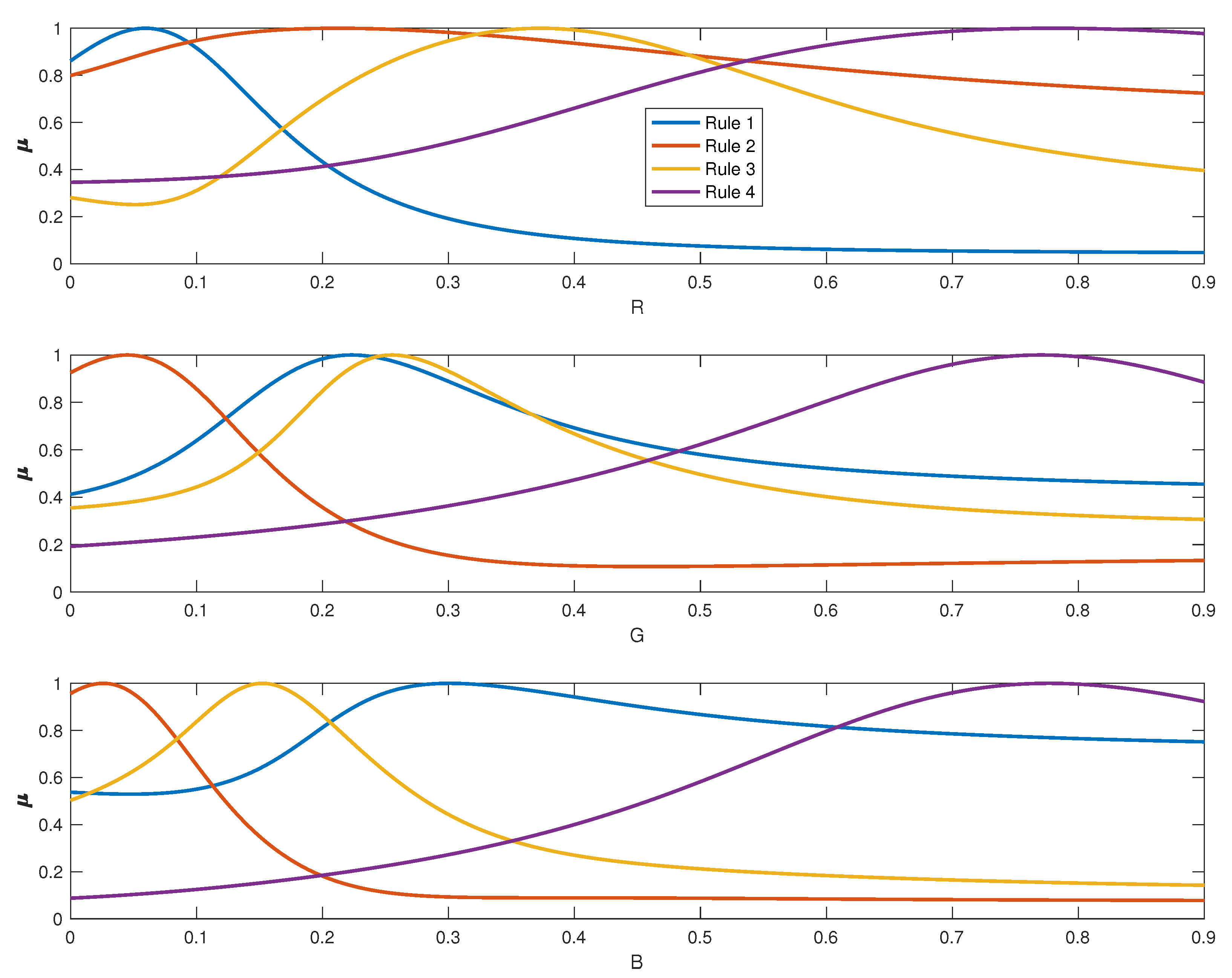
- Fuzzy Membership Functions: To obtain the membership functions, the multidimensional fuzzy sets defined point-wise by the GK algorithm can be projected onto the space variables, using the point-wise projection operation introduced in [35]. The point-wise defined fuzzy sets obtained after the projection are approximated by a suitable parametric function, in order to be able to obtain a continuous function over the range of the regression variables. This method to obtain the membership functions is defined as Product Space Clustering and was first introduced in [26].
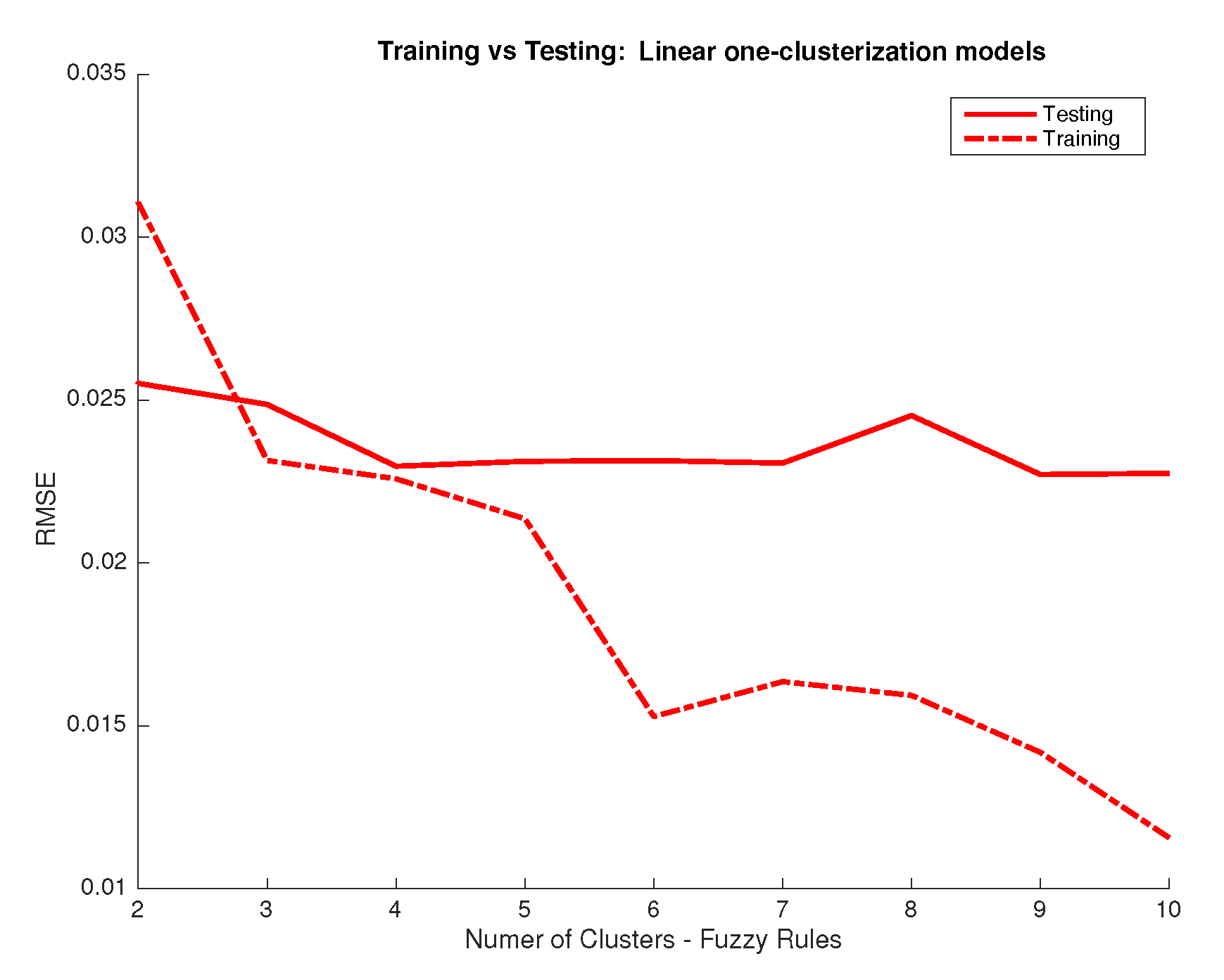
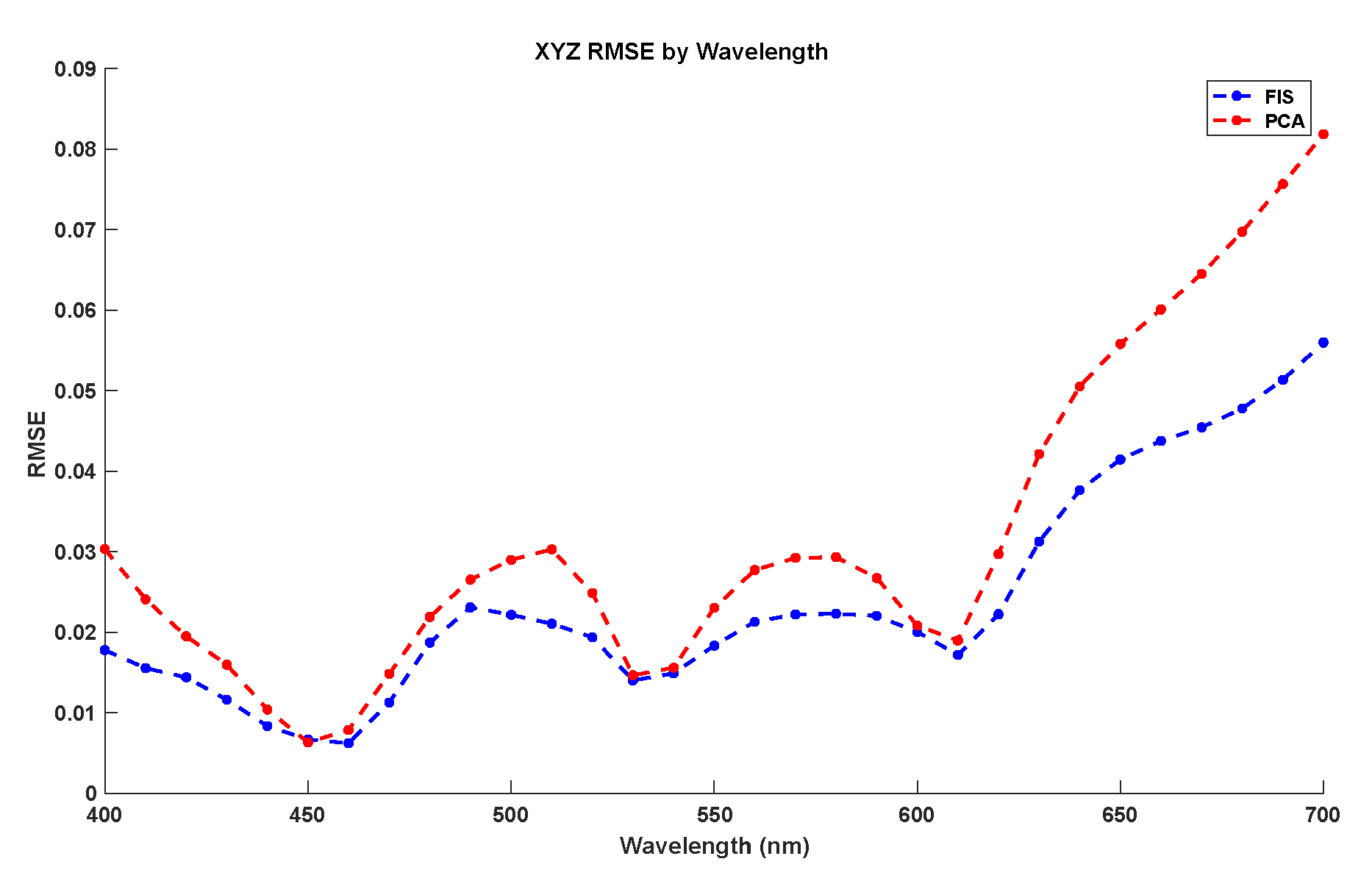
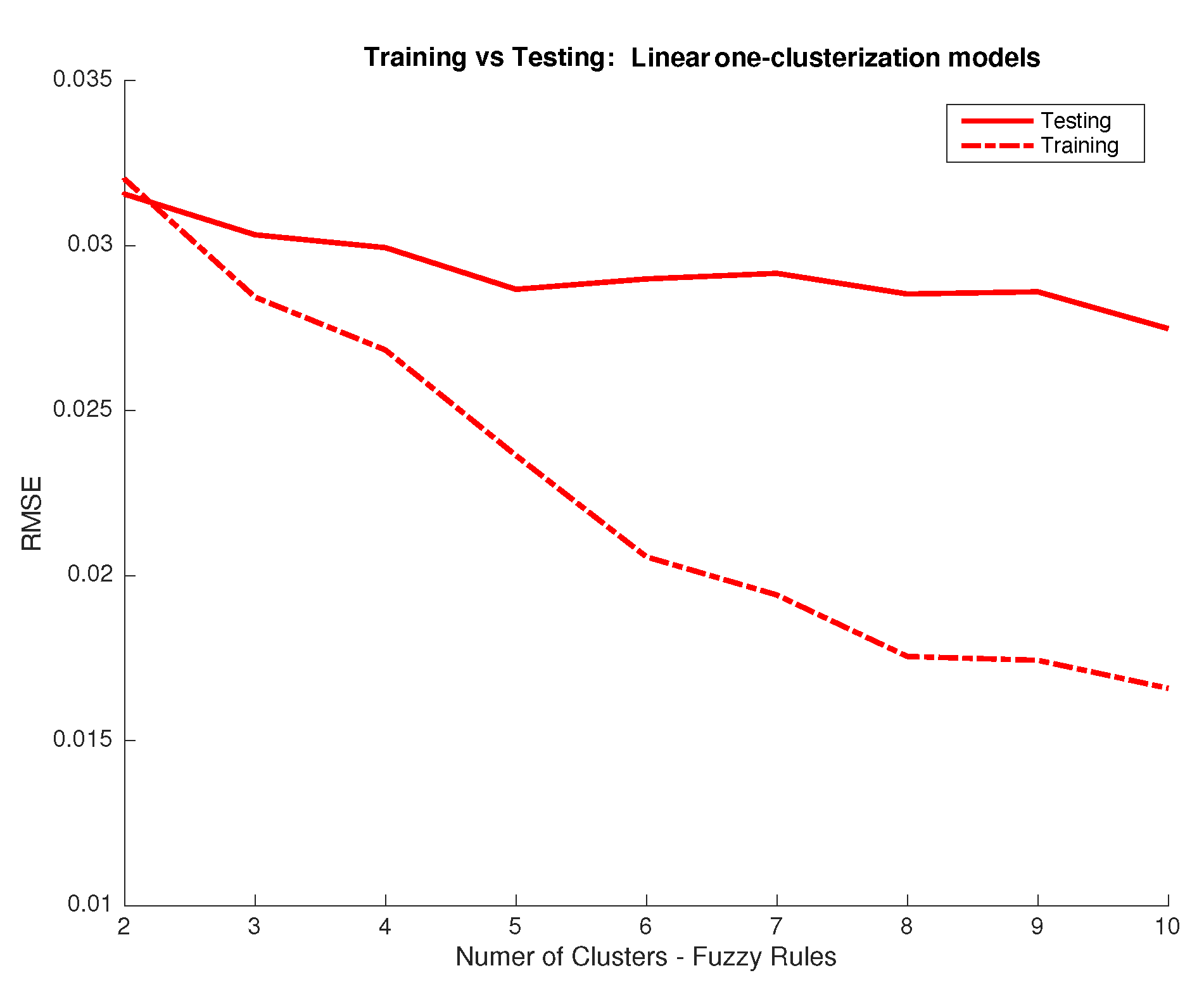
- Model Validation: Once the whole set of parameters for the fuzzy model are defined (antecedents, consequents, etc.), the next step is to validate the result using a different, independent, set of inputs (RGB/XYZ). The testing set is inputted to the trained system to obtain predictions of the associated output (spectral data). The performance index used to define the degree of accuracy obtained by the model is the root mean squared error (RMSE) [36]. When the validation step determines a poor value of index RMSE, or an unbalanced result for the different outputs, the designer should reject this model and return to the structure model selection step.
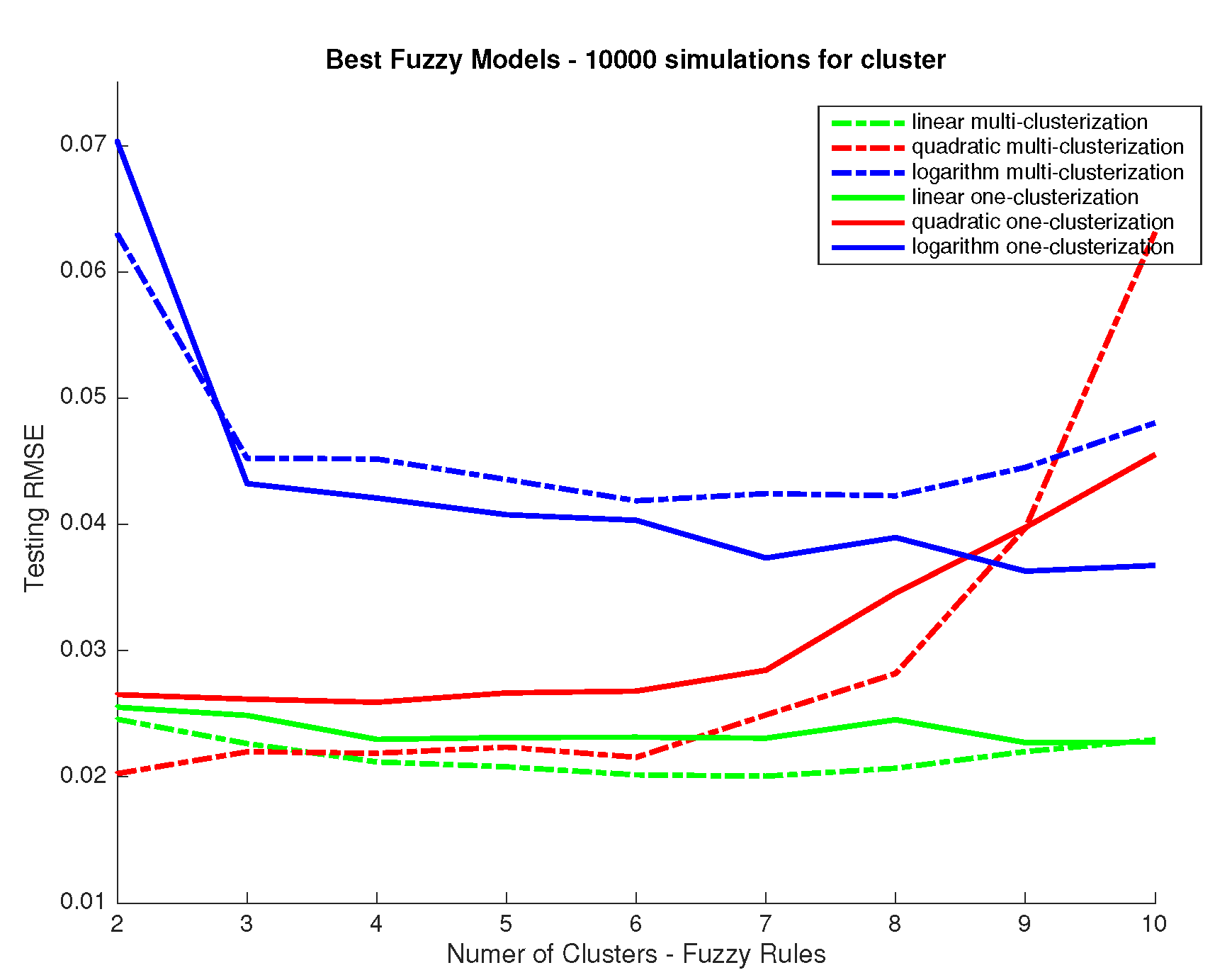
- Accuracy vs. Complexity: Finally, the design procedure ends with a qualitative study for the trade-off between accuracy vs. complexity of the fuzzy model. In this paper, the number of fuzzy rules is the parameter that determines the level of accuracy and complexity. A high number of rules allows the system for representing more information and input/output relations where a lower number limits its performance. However, an excessive number of rules can lead the system to training data overfitting which should be avoided, meaning that the number of rules should be limited and ideally, kept as low as necessary.Obviously, this procedure is not automatic and exact, but it helps to select the most appropriate fuzzy model from the designer point of view. However, the authors consider as a future work tackling this step as a multiobjective optimization problem, where the goal is to obtain a Pareto frontier for the accuracy-complexity problem [37].
3. Fiss Training and Test
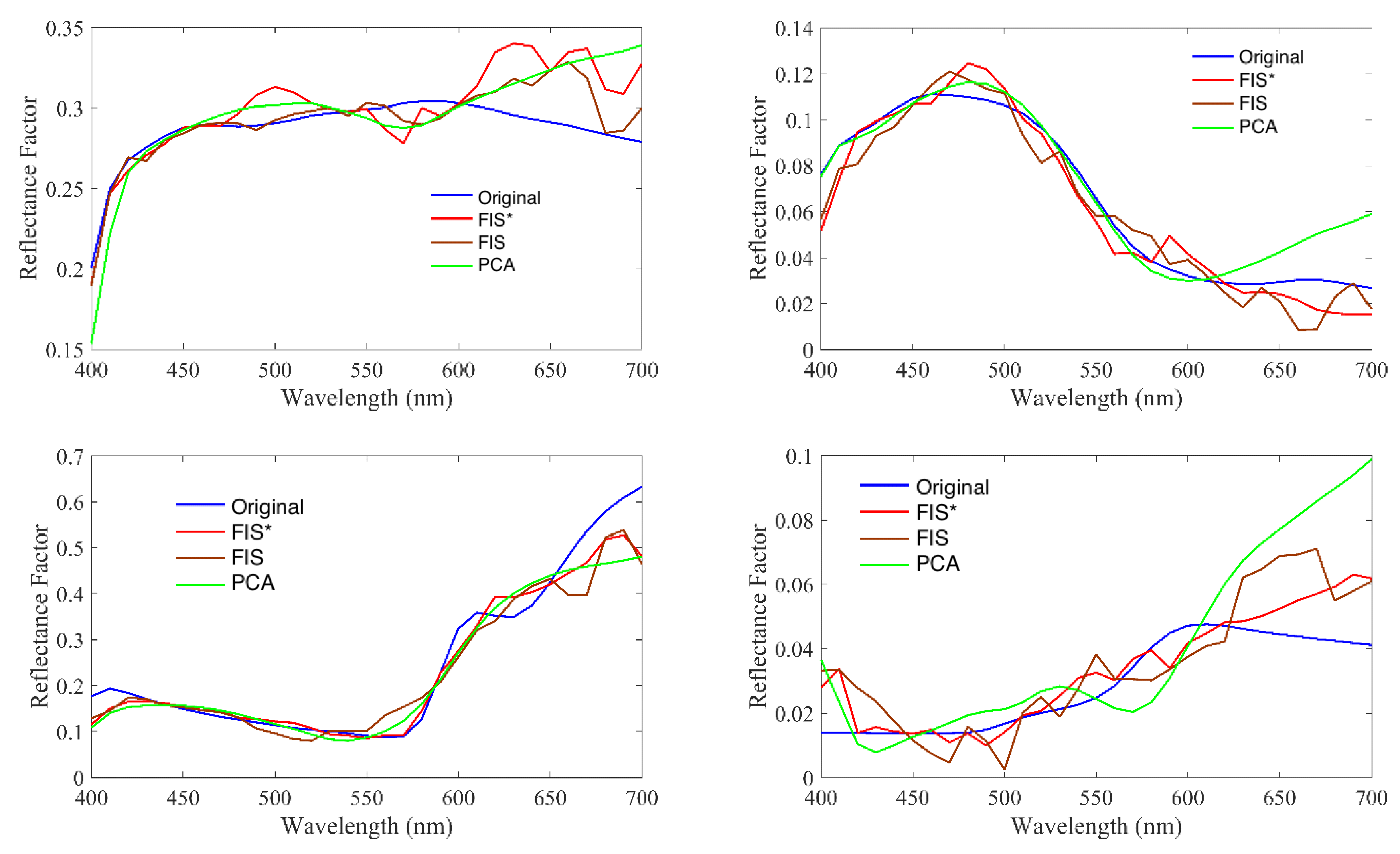
3.1. Spectral Recovery from Ciexyz Values
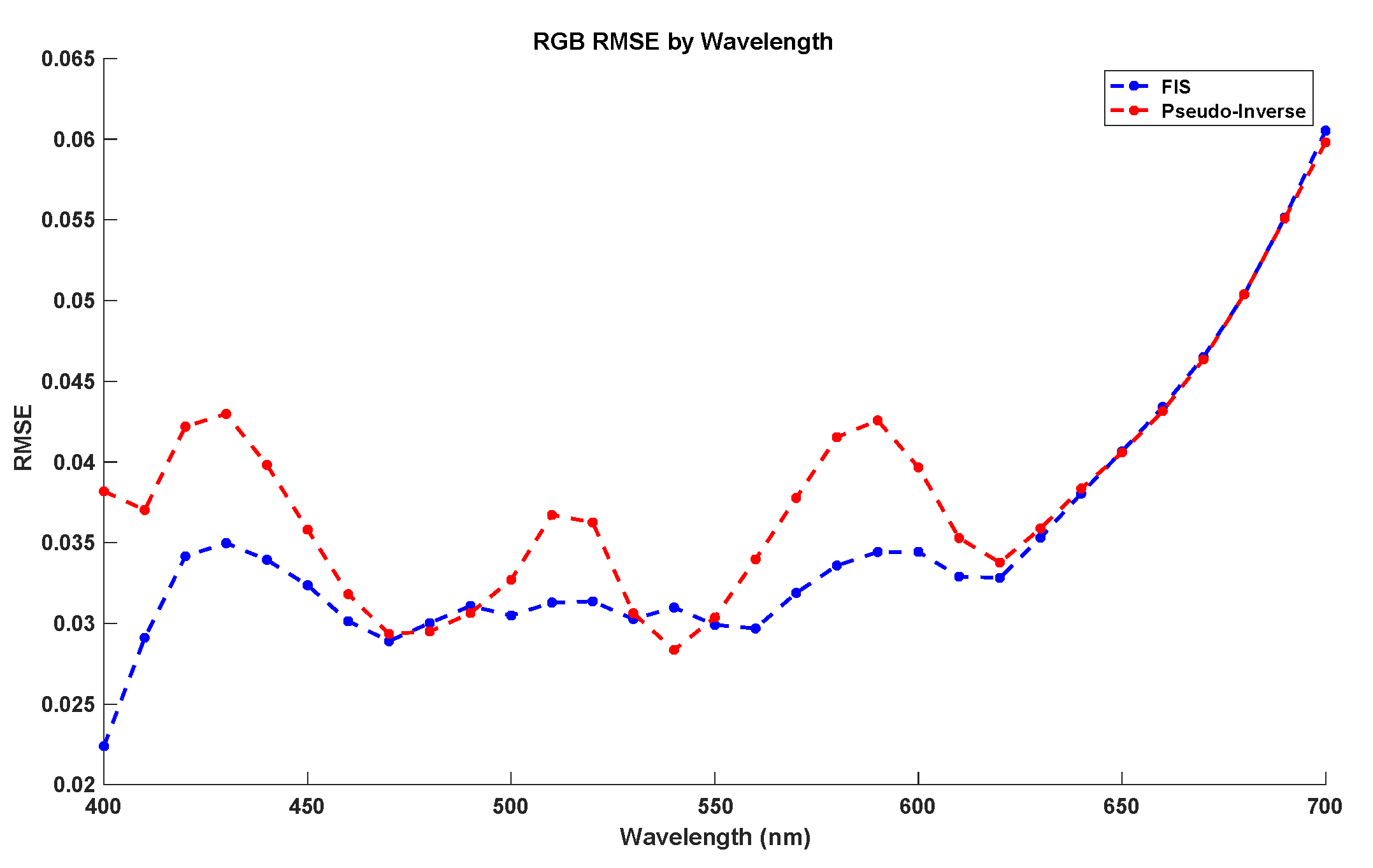
3.2. Spectral Recovery from Rgb Values
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Amiri, M.M.; Amirshahi, S.H. A hybrid of weighted regression and linear models for extraction of reflectance spectra from CIEXYZ tristimulus values. Opt. Rev. 2014, 21, 816–825. [Google Scholar] [CrossRef]
- Martínez-Domingo, M.Á.; Melgosa, M.; Okajima, K.; Medina, V.J.; Collado-Montero, F.J. Spectral Image Processing for Museum Lighting Using CIE LED Illuminants. Sensors 2019, 19, 5400. [Google Scholar] [CrossRef] [PubMed]
- Domingo, M.M.; Valero, E.; Huertas, R.; Durbán, M.; Espejo, T.; Blanc, R. Spectral information to get beyond color in the analysis of water-soluble varnish degradation. Herit. Sci. 2019, 7, 79. [Google Scholar] [CrossRef]
- Johnson, G.M.; Fairchild, M.D. Full-spectral color calculations in realistic image synthesis. IEEE Comput. Graph. Appl. 1999, 19, 47–53. [Google Scholar] [CrossRef]
- Kolås, T.; Røyset, A.; Grandcolas, M.; ten Cate, M.; Lacau, A. Cool coatings with high near infrared transmittance for coil coated aluminium. Sol. Energy Mater. Sol. Cells 2019, 196, 94–104. [Google Scholar] [CrossRef]
- Babaei, V.; Amirshahi, S.H.; Agahian, F. Using weighted pseudo-inverse method for reconstruction of reflectance spectra and analyzing the dataset in terms of normality. Color Res. Appl. 2011, 36, 295–305. [Google Scholar] [CrossRef]
- Harifi, T.; Amirshahi, S.H.; Agahian, F. Recovery of reflectance spectra from colorimetric data using principal component analysis embedded regression technique. Opt. Rev. 2008, 15, 302–308. [Google Scholar] [CrossRef]
- Amiri, M.M.; Amirshahi, S.H. A step by step recovery of spectral data from colorimetric information. J. Opt. 2015, 44, 373–383. [Google Scholar] [CrossRef]
- Shimano, N. Recovery of spectral reflectances of objects being imaged without prior knowledge. IEEE Trans. Image Process. 2006, 15, 1848–1856. [Google Scholar] [CrossRef]
- Shimano, N.; Terai, K.; Hironaga, M. Recovery of spectral reflectances of objects being imaged by multispectral cameras. JOSA A 2007, 24, 3211–3219. [Google Scholar] [CrossRef]
- Kim, B.G.; Han, J.W.; Park, S.B. Spectral reflectivity recovery from the tristimulus values using a hybrid method. JOSA A 2012, 29, 2612–2621. [Google Scholar] [CrossRef] [PubMed]
- Bianco, S. Reflectance spectra recovery from tristimulus values by adaptive estimation with metameric shape correction. JOSA A 2010, 27, 1868–1877. [Google Scholar] [CrossRef] [PubMed]
- Amirshahi, S.H.; Amirhahi, S.A. Adaptive non-negative bases for reconstruction of spectral data from colorimetric information. Opt. Rev. 2010, 17, 562–569. [Google Scholar] [CrossRef]
- Cao, B.; Liao, N.; Li, Y.; Cheng, H. Improving reflectance reconstruction from tristimulus values by adaptively combining colorimetric and reflectance similarities. Opt. Eng. 2017, 56, 053104. [Google Scholar] [CrossRef]
- Fairman, H.S.; Brill, M.H. The principal components of reflectances. Color Res. Appl. 2004, 29, 104–110. [Google Scholar] [CrossRef]
- Abed, F.M.; Amirshahi, S.H.; Abed, M.R.M. Reconstruction of reflectance data using an interpolation technique. JOSA A 2009, 26, 613–624. [Google Scholar] [CrossRef]
- Zhao, Y.; Berns, R.S. Image-based spectral reflectance reconstruction using the matrix R method. Color Res. Appl. 2007, 32, 343–351. [Google Scholar] [CrossRef]
- Valero, E.M.; Nieves, J.L.; Nascimento, S.M.; Amano, K.; Foster, D.H. Recovering spectral data from natural scenes with an RGB digital camera and colored filters. Color Res. Appl. 2007, 32, 352–360. [Google Scholar] [CrossRef]
- Cao, B.; Liao, N.; Cheng, H. Spectral reflectance reconstruction from RGB images based on weighting smaller color difference group. Color Res. Appl. 2017, 42, 327–332. [Google Scholar] [CrossRef]
- Amiri, M.M.; Fairchild, M.D. Use of spectral sensitivity variability in reflectance recovery from colorimetric information. JOSA A 2017, 34, 1224–1235. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy logic. Computer 1988, 21, 83–93. [Google Scholar] [CrossRef]
- Kerre, E. Fuzzy Sets and Approximate Reasoning; Xian Jiaotong University Press: Xi’an, China, 1999; 245p. [Google Scholar]
- Babuška, R.; Verbruggen, H. Fuzzy set methods for local modeling and identification. In Multiple Model Approaches to Nonlinear Modeling and Control; Taylor & Francis: London, UK, 1997; pp. 75–100. [Google Scholar]
- Babuška, R. Fuzzy Modeling for Control; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 12. [Google Scholar]
- Babuska, R.; Verbruggen, H. An overview of fuzzy modeling for control. Control. Eng. Pract. 1996, 4, 1593–1606. [Google Scholar] [CrossRef]
- Babuska, R. Fuzzy Modeling for Control; Kluwer Academic Publishers: Boston, MA, USA, 1998. [Google Scholar]
- Babuska, R. Fuzzy Algorithms for Multi-Input-Multi-Output Processes. 2017. Available online: http://iridia.ulb.ac.be/~famimo (accessed on 30 November 2017).
- Gustafson, D.; Kessel, W. Fuzzy clustering with a fuzzy covariance matrix. Proc. IEEE CDC 1979, 2, 761–766. [Google Scholar]
- Zhao, J.; Wertz, V.; Gorez, R. A fuzzy clustering method for the identification of fuzzy models for dynamical systems. In Proceedings of the 9th IEEE International Symposium on Intelligent Control, Columbus, OH, USA, 16–18 August 1994. [Google Scholar]
- Yu, W.; Li, X. On-line fuzzy modeling via clustering and support vector machines. Inf. Sci. 2008, 178, 4264–4279. [Google Scholar] [CrossRef]
- Abonyi, J. Fuzzy Model Identification for Control; Birkhauser: Boston, MA, USA, 2003. [Google Scholar]
- García-Nieto, S.; Salcedo, J.; Martínez, M.; Laurí, D. Air management in a diesel engine using fuzzy control techniques. Inf. Sci. 2009, 179, 3392–3409. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, 1, 116–132. [Google Scholar] [CrossRef]
- Babuška, R. Fuzzy Systems, Modeling and Identification; Delft University of Technology, Department of Electrical Engineering Control Laboratory Mekelweg: Delft, The Netherlands, 1996; Volume 4. [Google Scholar]
- Godfrey, K. Introduction to perturbation signals for frequency-domain system identification. In Perturbation Signals for System Identification; Prentice Hall International Ltd: Hemel Hempstead, UK, 1993; pp. 60–125. [Google Scholar]
- Chai, T.; Draxler, R. Root mean square error (RMSE) or mean absolute error (MAE)? Geosci. Model Dev. 2014, 7. [Google Scholar] [CrossRef]
- Blasco, X.; Herrero, J.M.; Sanchis, J.; Martínez, M. A new graphical visualization of n-dimensional Pareto front for decision-making in multiobjective optimization. Inf. Sci. 2008, 178, 3908–3924. [Google Scholar] [CrossRef]
- Maali Amiri, M. Novel Approaches to the Spectral and Colorimetric Color Reproduction. Master’s Thesis, Rochester Institute of Technology, Rochester, NY, USA, 2017. [Google Scholar]
- Sharma, G.; Wu, W.; Dalal, E.N. The CIEDE2000 color-difference formula: Implementation notes, supplementary test data, and mathematical observations. Color Res. Appl. 2015, 30, 21–30. [Google Scholar] [CrossRef]
- Gao, B.C.; Liu, M. A Fast Smoothing Algorithm for Post-Processing of Surface Reflectance Spectra Retrieved from Airborne Imaging Spectrometer Data. Sensors 2013, 30, 13879–13891. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rule/Cluster | X | Y | Z |
|---|---|---|---|
| 1 | 1.4×10e+1 | 1.4×10e+1 | 1.3×10e+1 |
| 2 | 2.2×10e+1 | 2.8×10e+1 | 3.5×10e+1 |
| 3 | 2.9×10e+1 | 2.8×10e+1 | 5.1×10e+0 |
| 4 | 7.0×10e+1 | 7.4×10e+1 | 8.0×10e+1 |
| Method | Mean RMSE | Mean CIEDE2000 |
|---|---|---|
| PCA | 0.0311 | 2.46 |
| FIS | 0.0221 | 1.85 |
| FIS* | 0.0220 | 1.83 |
| Rule | R | G | B |
|---|---|---|---|
| 1 | 5.9×10e−2 | 2.2×10e−1 | 3.0×10e−1 |
| 2 | 2.1×10e−1 | 4.4×10e−2 | 2.5×10e−2 |
| 3 | 3.7×10e−1 | 2.5×10e−1 | 1.5×10e−1 |
| 4 | 7.8×10e−1 | 7.7×10e−1 | 7.7×10e−1 |
| Method | Mean RMSE | Mean CIEDE2000 |
|---|---|---|
| Pseudo-Inverse | 0.0319 | 3.96 |
| FIS | 0.0281 | 3.30 |
| FIS* | 0.0278 | 3.35 |
| Cao’s method | 0.0791 | 9.30 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maali Amiri, M.; Garcia-Nieto, S.; Morillas, S.; Fairchild, M.D. Spectral Reflectance Reconstruction Using Fuzzy Logic System Training: Color Science Application. Sensors 2020, 20, 4726. https://doi.org/10.3390/s20174726
Maali Amiri M, Garcia-Nieto S, Morillas S, Fairchild MD. Spectral Reflectance Reconstruction Using Fuzzy Logic System Training: Color Science Application. Sensors. 2020; 20(17):4726. https://doi.org/10.3390/s20174726
Chicago/Turabian StyleMaali Amiri, Morteza, Sergio Garcia-Nieto, Samuel Morillas, and Mark D. Fairchild. 2020. "Spectral Reflectance Reconstruction Using Fuzzy Logic System Training: Color Science Application" Sensors 20, no. 17: 4726. https://doi.org/10.3390/s20174726
APA StyleMaali Amiri, M., Garcia-Nieto, S., Morillas, S., & Fairchild, M. D. (2020). Spectral Reflectance Reconstruction Using Fuzzy Logic System Training: Color Science Application. Sensors, 20(17), 4726. https://doi.org/10.3390/s20174726