Design and Implementation of Fast Fault Detection in Cloud Infrastructure for Containerized IoT Services


Abstract
1. Introduction
- (a)
- We analyze the fault-detection architecture in a container environment and highlight its limitations
- (b)
- We design and implement Fast Fault Detection Manager (FFDM) using OpenStack and Kubernetes; an integrated architecture which provides an automated monitoring function for quick fault detection and recovery.
- (c)
- Design and implementation of an architecture for fault information delivery according to the monitoring results.
- (d)
- We evaluate the performance of our proposed architecture against the current state of the art approaches and show that it can improve both the fault-detection speed and fault-recovery time.
2. State of the Art: Fault Detection and Recovery Mechanisms in Container Infrastructure
3. Proposed Architecture
4. System Validation
4.1. Implementation Environment and Methodology
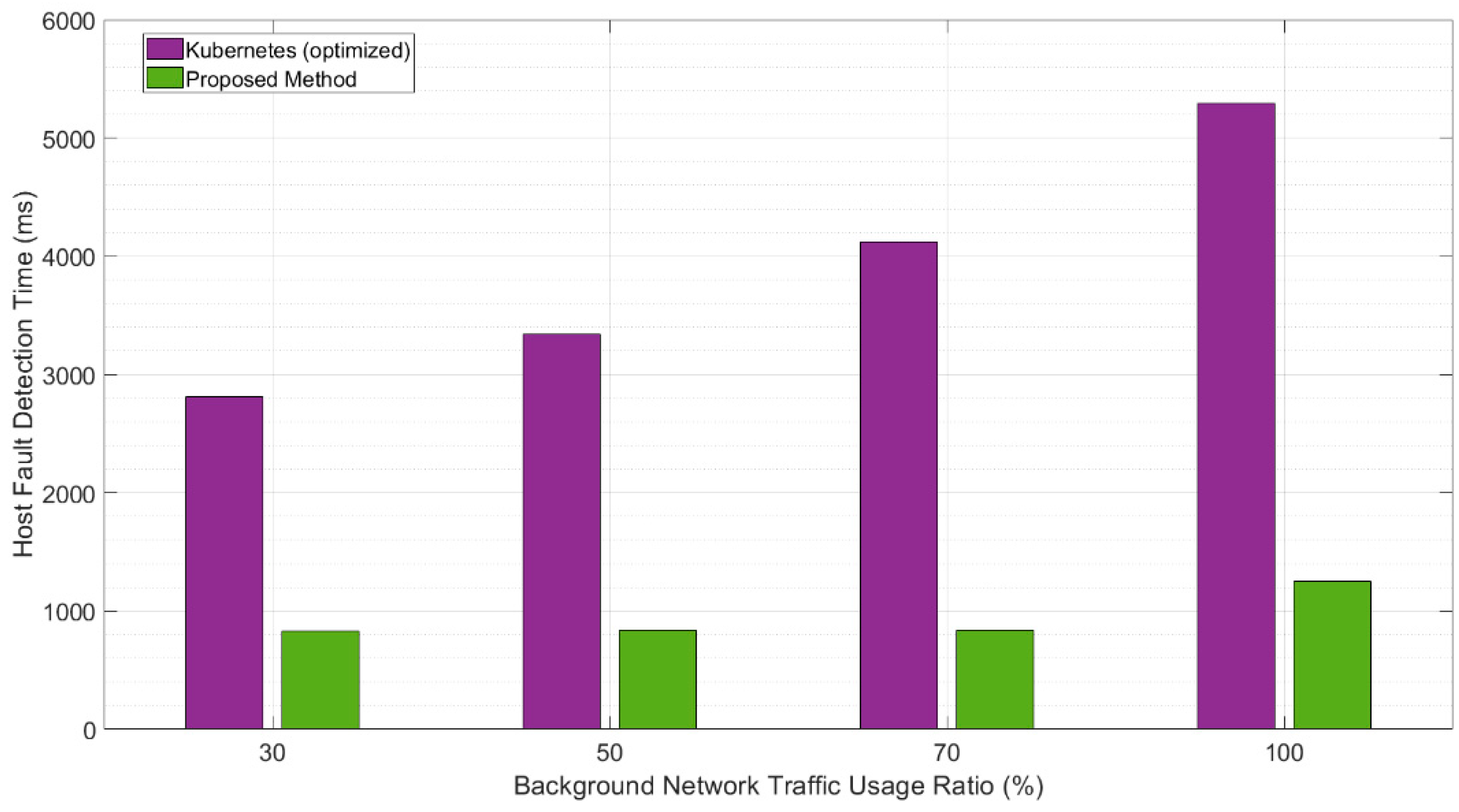
4.2. Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bolivar, L.T.; Tselios, C.; Mellado Area, D.; Tsolis, G. On the deployment of an open-source, 5g-aware evaluation testbed. In Proceedings of the 2018 6th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (MobileCloud), Bamberg, Germany, 26 March 2018; pp. 51–58. [Google Scholar]
- Salah, T.; Zemerly, M.J.; Yeun, C.Y.; Al-Qutayri, M.; Al-Hammadi, Y. Performance comparison between container-based and VM-based services. In Proceedings of the 2017 20th Conference on Innovations in Clouds, Internet and Networks (ICIN), Paris, France, 26–29 March 2017; pp. 185–190. [Google Scholar]
- Li, Z.; Kihl, M.; Lu, Q.; Andersson, J.A. Performance overhead comparison between hypervisor and container based virtualization. In Proceedings of the 2017 IEEE 31st International Conference on Advanced Information Networking and Applications (AINA), Taipei, Taiwan, 27–29 March 2017; pp. 955–962. [Google Scholar]
- Kaur, K.; Dhand, T.; Kumar, N.; Zeadally, S. Container-as-a-Service at the edge: Trade-off between energy efficiency and service availability at fog nano data centers. IEEE Wireless Commun. 2017, 24, 48–56. [Google Scholar] [CrossRef]
- Xiong, Y.; Sun, Y.; Xing, L.; Huang, Y. Extend cloud to edge with KubeEdge. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25 October 2018; pp. 373–377. [Google Scholar]
- Fu, J.; Liu, Y.; Chao, H.; Bhargava, B.K.; Zhang, J. Secure data storage and searching for industrial IoR by integrating fog computing and cloud computing. IEEE Trans. Ind. Informat. 2018, 14, 4519–4528. [Google Scholar] [CrossRef]
- Whaiduzzaman, M.; Sookhak, M.; Gani, A.; Buyya, R. A survey on vehicular cloud computing. J. Netw. Comput. Appl. 2014, 40, 325–344. [Google Scholar] [CrossRef]
- Tian, G.; Jiang, M.; Ouyang, W.; Ji, G.; Xie, H.; Rahmanim, A.M.; Liljebe, P. IoT-based remote pain monitoring system: From device to cloud platform. IEEE J. Biomed. Health 2018, 22, 1711–1719. [Google Scholar]
- Botta, A.; de Donato, W.; Persico, V.; Pescape, A. Integration of cloud computing and Internet of Things: A survey. Future Gener. Comput. Syst. 2016, 56, 684–700. [Google Scholar] [CrossRef]
- Palattella, M.R.; Mischa, D.; Grieco, A.; Rizzo, G.; Torsner, J.; Engel, T.; Ladid, L. Internet of Things in the 5G era: Enablers, architecture, and business models. IEEE J. Sel. Areas Commun. 2016, 24, 510–527. [Google Scholar] [CrossRef]
- Dinh, N.T.; Kim, Y. An energy efficient integration model for sensor cloud systems. IEEE Access 2019, 7, 3018–3030. [Google Scholar] [CrossRef]
- Jhawar, R.; Piuri, V. Fault tolerance and resilience in cloud computing environments. In Computer and Information Security Handbook, 3nd ed.; John, R., Ed.; Elsevier: Amsterdam, The Netherlands, 2017; pp. 125–141. [Google Scholar]
- Jung, G.; Rahimzadeh, P.; Liu, Z.; Ha, S.; Joshi, K.; Hiltunen, M. Virtual redundancy for active-standby cloud applications. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 1916–1924. [Google Scholar]
- Xu, Y.; Helal, A. Scalable cloud-sensor architecture for the Internet of Things. IEEE Internet Things J. 2016, 3, 285–298. [Google Scholar] [CrossRef]
- Alcaraz, C.J.M.; Aguado, J.G. MonPaaS: An adaptive monitoring platform as a service for cloud computing infrastructures and services. IEEE Trans. Serv. Comput. 2015, 8, 65–78. [Google Scholar] [CrossRef]
- Yang, H.; Kim, Y. Design and implementation of high-availability architecture for IoT-cloud services. Sensors 2019, 19, 3276. [Google Scholar] [CrossRef] [PubMed]
- Kubernetes. Available online: https://kubernetes.io/docs/home/ (accessed on 3 January 2020).
- Abdollahi Vayghan, L.; Saied, M.A.; Toeroe, M.; Khendek, F. Deploying microservice based applications with Kubernetes: Experiments and lessons learned. In Proceedings of the 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), San Francisco, CA, USA, 2–7 July 2018; pp. 970–973. [Google Scholar]
- Vayghan, L.A.; Saied, M.A.; Toeroe, M.; Khendek, F. Kubernetes as an availability manager for microservice applications. arXiv 2019, arXiv:1901.04946. [Google Scholar]
- Abdollahi Vayghan, L.; Saied, M.A.; Toeroe, M.; Khendek, F. Microservice based architecture: Towards high-availability for stateful applications with Kubernetes. In Proceedings of the 2019 IEEE 19th International Conference on Software Quality, Reliability and Security (QRS), Sofia, Bulgaria, 22–26 July 2019; pp. 176–185. [Google Scholar]
- Prometheus. Available online: https://prometheus.io/ (accessed on 3 January 2020).
- OpenStack Tacker. Available online: https://wiki.openstack.org/wiki/Tacker (accessed on 3 January 2020).
- OPNFV Doctor. Available online: https://wiki.opnfv.org/display/doctor/Doctor+Home (accessed on 5 January 2020).
- Openstack Ceilometer. Available online: https://docs.openstack.org/ceilometer/latest/ (accessed on 5 January 2020).
- Openstack Aodh. Available online: https://docs.openstack.org/aodh/latest/ (accessed on 5 January 2020).
- Stress-ng. Available online: http://kernel.ubuntu.com/~cking/stress-ng/ (accessed on 5 January 2020).
- Iperf3. Available online: https://iperf.fr/ (accessed on 5 January 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level. | Fault Type | Manager | Fault Detection Method | Fault Recovery Method |
|---|---|---|---|---|
| Application | Application (service) | Health Check Daemon | TCP/HTTP/CMD | Restart |
| External monitoring function | External monitoring matrix | External tool function | ||
| Infrastructure | Container | Kubelet (cAdvisor) | Process list | Restart |
| Pod | Kubelet (cAdvisor) | Process list | Respawn | |
| Node | Node controller | Message (Node to Kubelet) | Notification | |
| External monitoring function | External monitoring matrix | External tool function |
| Parameter | Meaning |
|---|---|
| The node-status-update-frequency (duration: seconds) | |
| The node-monitor-period (seconds) | |
| The node-monitor-grace-period (seconds) | |
| The pod-eviction-timeout (seconds) | |
| The time interval between the fault occurrence point and the grace period endpoint (seconds) |
| Entity | Condition | Version |
|---|---|---|
| Physical Server (3) | Controller Node (1) Intel® Xeon® processor D-1557, Single-socket FCBGA 1667; 12-core, 24 threads RAM: 64 GB Disk space: 1TB Compute Node (2) Intel® Xeon® processor D-1557, Single-socket FCBGA 1667; 12-core, 24 threads, RAM: 64 GB Disk space: 1TB | |
| Cloud OS | OpenStack stable | Stein |
| Container infrastructure | Kubernetes (Master Node: 1EA/Worker Node: 20EA) | 1.17.1 |
| Parameter | Fault-Detection Time (FDT) | ||||
|---|---|---|---|---|---|
| Scenario | |||||
| Scenario 1 | 10 s | 40 s | 5 s | MIN = 40 s | |
| Scenario 2 | 1 s | 1 s | 1 s | Error | |
| Scenario 3 | 1 s | 2 s | 1 s | Error | |
| Scenario 4 | 1 s | 3 s | 1 s | MIN = 3 s | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Kim, Y. Design and Implementation of Fast Fault Detection in Cloud Infrastructure for Containerized IoT Services. Sensors 2020, 20, 4592. https://doi.org/10.3390/s20164592
Yang H, Kim Y. Design and Implementation of Fast Fault Detection in Cloud Infrastructure for Containerized IoT Services. Sensors. 2020; 20(16):4592. https://doi.org/10.3390/s20164592
Chicago/Turabian StyleYang, Hyunsik, and Younghan Kim. 2020. "Design and Implementation of Fast Fault Detection in Cloud Infrastructure for Containerized IoT Services" Sensors 20, no. 16: 4592. https://doi.org/10.3390/s20164592
APA StyleYang, H., & Kim, Y. (2020). Design and Implementation of Fast Fault Detection in Cloud Infrastructure for Containerized IoT Services. Sensors, 20(16), 4592. https://doi.org/10.3390/s20164592