Ghost Detection and Removal Based on Two-Layer Background Model and Histogram Similarity




Abstract
1. Introduction
2. Methodology
2.1. Sample-Based Two-Layer Background Model and Background/Foreground Classification
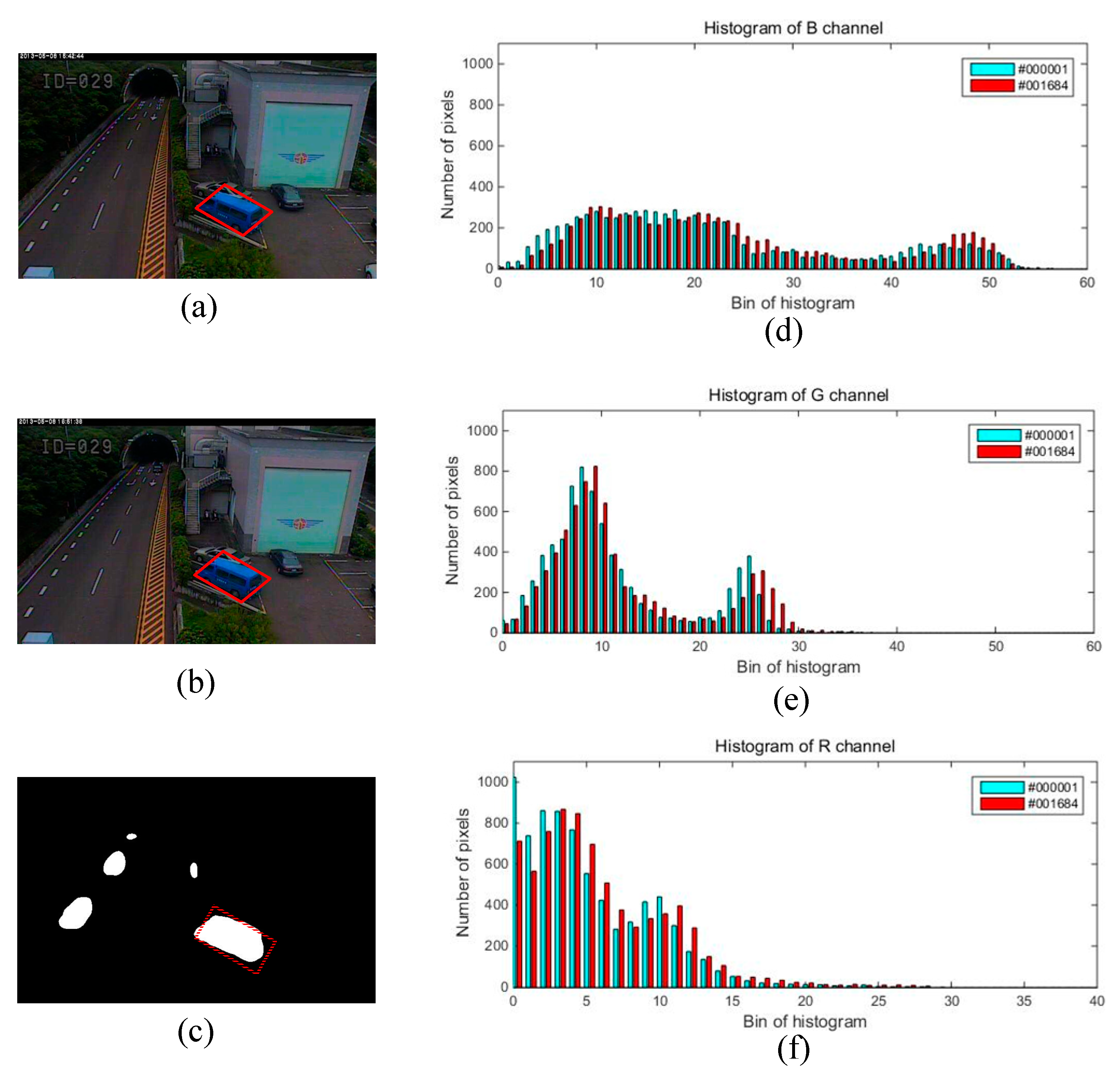
2.2. Detection and Removal of the Second Type of Ghost
2.3. Background Model Update
2.4. Parameter Analysis
2.4.1. Similarity Threshold of LBSP
2.4.2. Distance Threshold
2.4.3. Time Subsampling Factor
3. Experimental Analysis
3.1. Dataset and Evaluation Metrics
3.2. Discussion
3.2.1. How to Determine and
3.2.2. Threshold Performance Analysis
3.3. Experimental Results
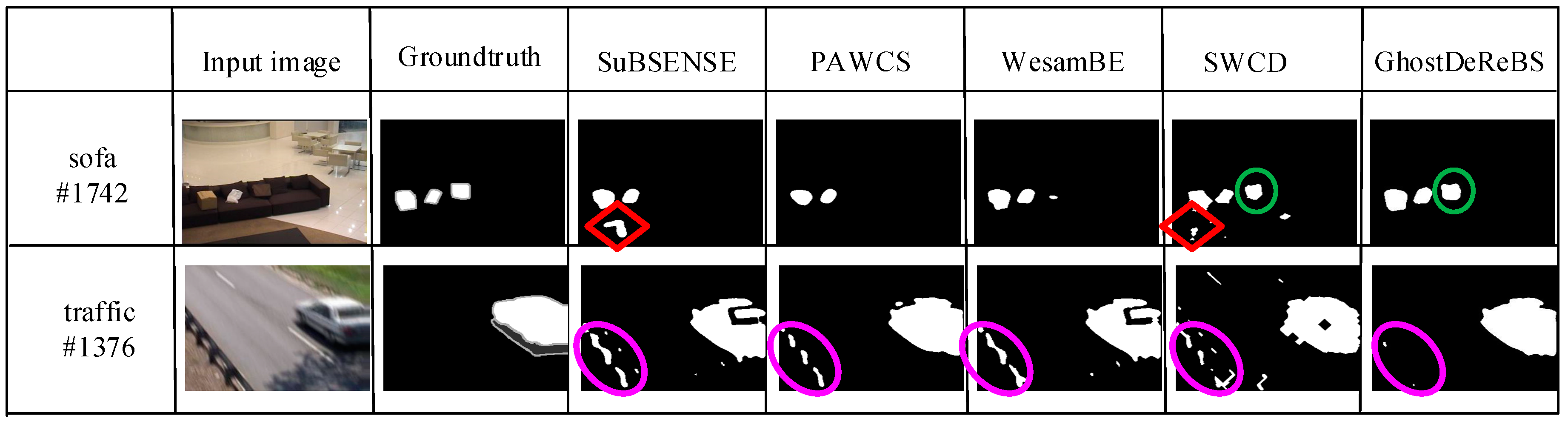
3.3.1. Ghost Removal
3.3.2. Average Performance on CDnet2014 Dataset
3.3.3. Processing Speed
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Collins, R.T.; Lipton, A.J.; Kanade, T.; Fujiyoshi, H.; Duggins, D.; Tsin, Y.; Tolliver, D.; Enomoto, N.; Hasegawa, O.; Burt, P.; et al. A System for Video Surveillance and Monitoring; Carnegie Mellon University Press: Pittsburgh, PA, USA, 2000. [Google Scholar]
- Sivaraman, S.; Trivedi, M.M. Looking at Vehicles on the Road: A Survey of Vision-Based Vehicle Detection, Tracking, and Behavior Analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world Anomaly Detection in Surveillance Videos. arXiv 2019, arXiv:1801.0426. Available online: https://arxiv.org/abs/1801.04264 (accessed on 14 February 2019).
- Meng, F.; Wang, X.; Wang, D.; Shao, F.; Fu, L. Spatial-Semantic and Temporal Attention Mechanism-Based Online Multi-Object Tracking. Sensors 2020, 20, 1653. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.G.; Ji, H.B.; Zhang, W.B. Nonlinear Gated Channels Networks for Action Recognition. Neurocomputing 2020, 386, 325–332. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, J.; Lu, H. Learning Sharable Models for Robust Background Subtraction. In Proceedings of the 2015th IEEE International Conference on Multimedia and Expo, Torino, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Wang, R.; Bunyak, F.; Seetharaman, G.; Palaniappan, K. Static and Moving Object Detection Using Flux Tensor with Split Gaussian Models. In Proceedings of the 2014th IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 420–424. [Google Scholar]
- Azzam, R.; Kemouche, M.S.; Aouf, N.; Richardson, M. Efficient visual object detection with spatially global Gaussian mixture models and uncertainties. J. Vis. Commun. Image. 2016, 36, 90–106. [Google Scholar] [CrossRef]
- Martins, I.; Carvalho, P.; Corte-Real, L.; Luis Alba-Castro, J. BMOG: Boosted Gaussian Mixture Model with Controlled Complexity. In Proceedings of the 2017th Iberian Conference on Pattern Recognition and Image Analysis, Faro, Portugal, 20–23 June 2017; pp. 50–57. [Google Scholar]
- Hofmann, M.; Tiefenbacher, P.; Rigoll, G. Background Segmentation with Feedback: The Pixel-Based Adaptive Segmenter. In Proceedings of the 2012th Computer Vision and Pattern Recognition Workshops, Providence, Rhode Island, 16–21 June 2012; pp. 38–43. [Google Scholar]
- St-charles, P.L.; Bilodeau, G.A. SuBSENSE: A Universal Change Detection Method with Local Adaptive Sensitivity. IEEE Trans. Image Process. 2015, 24, 359–373. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Lu, X. WeSamBE: A Weight-Sample-Based Method for Background Subtraction. IEEE Trans. Circuits Syst. Video Technol. 2018, 8, 2105–2115. [Google Scholar] [CrossRef]
- Işık, Ş.; Özkan, K.; Günal, S. SWCD: A sliding window and self-regulated learning-based background updating method for change detection in videos. J. Electron. Imaging 2018, 27, 1–11. [Google Scholar] [CrossRef]
- Kumar, A.N.; Sureshkumar, C. Background Subtraction Based on Threshold Detection Using Modified K-Means Algorithm. In Proceedings of the 2013th International Conference on Pattern Recognition, Informatics and Mobile Engineering, Salem, MA, USA, 21–22 February 2013; pp. 378–382. [Google Scholar]
- Soeleman, M.A.; Hariadi, M.; Purnomo, M.H. Adaptive Threshold for Background Subtraction in Moving Object Detection Using Fuzzy C-Means Clustering. In Proceedings of the TENCON 2012 IEEE Region 10 Conference, Cebu, Philippines, 19–22 November 2012; pp. 1–5. [Google Scholar]
- St-charles, P.L.; Bilodeau, G.A. Universal Background Subtraction Using Word Consensus Models. IEEE Trans. Image Process. 2016, 25, 4768–4781. [Google Scholar] [CrossRef]
- Zeng, Z.; Jia, J.Y.; Zhu, Z.F.; Yu, D.L. Adaptive maintenance scheme for codebook-based dynamic background subtraction. Comput. Vis. Image Understand. 2016, 152, 58–66. [Google Scholar] [CrossRef]
- Babaee, M.; Dinh, T.D.; Rigoll, G. A Deep Convolutional Neural Network for Video Sequence Background Subtraction. Pattern Recognit. 2018, 76, 635–649. [Google Scholar] [CrossRef]
- Tezcan, M.O.; Ishwar, P.; Konrad, J. BSUV-Net: A Fully-Convolutional Neural Network for Background Subtraction of Unseen Videos. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Village, CO, USA, 1–5 March 2020. [Google Scholar]
- De Gregorioa, M.; Giordano, M. Background estimation by weightless neural networks. Pattern Recogn. Lett. 2017, 96, 55–65. [Google Scholar] [CrossRef]
- Ramirez-Quintana, J.A.; Chacon-Murguia, M.I.; Ramirez-Alonso, G.M. Adaptive background modeling of complex scenarios based on pixel level learning modeled with a retinotopic self-organizing map and radial basis mapping. Appl. Intell. 2018, 48, 4976–4997. [Google Scholar] [CrossRef]
- Maddalena, L.; Petrosino, A. The SOBS Algorithm: What are the Limits? In Proceedings of the 2012th IEEE Computer Vision and Pattern Recognition Workshops, Providence, Rhode Island, 16–21 June 2012; pp. 21–26. [Google Scholar]
- Xu, Y.; Dong, J.; Zhang, B.; Xu, D. Background modeling methods in video analysis: A review and comparative evaluation. CAAI Trans. Intell. Syst. Technol. 2016, 1, 43–60. [Google Scholar] [CrossRef]
- Varghese, A.; Sreelekha, G. Sample-based integrated background subtraction and shadow detection. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 25. [Google Scholar] [CrossRef]
- Zhang, W.; Sun, X.; Yu, Q. Moving Object Detection under a Moving Camera via Background Orientation Reconstruction. Sensors 2020, 20, 3103. [Google Scholar] [CrossRef] [PubMed]
- Cucchiara, R.; Grana, C.; Piccardi, M.; Prati, A. Detecting Moving Objects, Ghosts, and Shadows in Video Streams. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1337–1342. [Google Scholar] [CrossRef]
- Wang, Y.; Jodoin, P.M.; Porikli, F.; Konrad, J. CDnet 2014: An Expanded Change Detection Benchmark Dataset. In Proceedings of the 2014th IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–27 June 2014; pp. 393–400. [Google Scholar]
- Varcheie, P.D.Z.; Sills-Lavoie, M.; Bilodeau, G.A. A Multiscale Region-Based Motion Detection and Background Subtraction Algorithm. Sensors 2010, 10, 1041–1061. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SuBSENSE | Our Proposed Algorithm with Outliers | Our Proposed Algorithm without Outliers (GhostDeReBS) |
|---|---|---|---|
| highway | color: 24.55 LBSP: 3.16 | color: 23.36 LBSP: 3.79 | color: 21.57 LBSP: 3.32 |
| sofa | color: 28.21 LBSP: 0.28 | color: 21.79 LBSP: 1.93 | color: 1.64 LBSP: 1.79 |
| 0 | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 0.7046 | 0.7653 | 0.7679 | 0.7662 | 0.7660 | 0.7718 | 0.7719 | 0.7735 | 0.7725 | 0.7753 | 0.7778 | |
| 10 | 0.7715 | 0.8144 | 0.8239 | 0.8302 | 0.8251 | 0.8300 | 0.8313 | 0.8332 | 0.8329 | 0.8352 | 0.8371 | |
| 15 | 0.8027 | 0.8400 | 0.8497 | 0.8496 | 0.8519 | 0.8508 | 0.8522 | 0.8538 | 0.8529 | 0.8530 | 0.8524 | |
| 20 | 0.8190 | 0.8484 | 0.8560 | 0.8537 | 0.8577 | 0.8589 | 0.8586 | 0.8601 | 0.8598 | 0.8589 | 0.8577 | |
| 25 | 0.8277 | 0.8533 | 0.8541 | 0.8586 | 0.8582 | 0.8586 | 0.8603 | 0.8613 | 0.8610 | 0.8615 | 0.8619 | |
| 30 | 0.8335 | 0.8521 | 0.8581 | 0.8599 | 0.8625 | 0.8615 | 0.8619 | 0.8625 | 0.8647 | 0.8634 | 0.8638 | |
| 35 | 0.8417 | 0.8587 | 0.8605 | 0.8609 | 0.8620 | 0.8641 | 0.8631 | 0.8627 | 0.8623 | 0.8658 | 0.8629 | |
| 40 | 0.8441 | 0.8575 | 0.8602 | 0.8634 | 0.8615 | 0.8626 | 0.8635 | 0.8645 | 0.8627 | 0.8643 | 0.8630 | |
| 45 | 0.8442 | 0.8566 | 0.8601 | 0.8584 | 0.8657 | 0.8644 | 0.8631 | 0.8597 | 0.8577 | 0.8640 | 0.8598 | |
| 50 | 0.8430 | 0.8489 | 0.8518 | 0.8435 | 0.8530 | 0.8535 | 0.8570 | 0.8544 | 0.8549 | 0.8558 | 0.8543 | |
| 0 | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 0.7505 | 0.7723 | 0.7911 | 0.8019 | 0.8146 | 0.8235 | 0.8292 | 0.8308 | 0.8340 | 0.8319 | 0.8313 | |
| 10 | 0.7812 | 0.8041 | 0.8253 | 0.8496 | 0.8592 | 0.8644 | 0.8657 | 0.8679 | 0.8658 | 0.8611 | 0.8613 | |
| 15 | 0.7995 | 0.8231 | 0.8558 | 0.8714 | 0.8782 | 0.8783 | 0.8786 | 0.8803 | 0.8750 | 0.8755 | 0.8702 | |
| 20 | 0.8095 | 0.8398 | 0.8676 | 0.8800 | 0.8832 | 0.8851 | 0.8852 | 0.8845 | 0.8820 | 0.8820 | 0.8800 | |
| 25 | 0.8252 | 0.8529 | 0.8797 | 0.8848 | 0.8873 | 0.8873 | 0.8861 | 0.8866 | 0.8862 | 0.8844 | 0.8836 | |
| 30 | 0.8448 | 0.8667 | 0.8825 | 0.8874 | 0.8900 | 0.8897 | 0.8904 | 0.8911 | 0.8891 | 0.8886 | 0.8861 | |
| 35 | 0.8589 | 0.8757 | 0.8861 | 0.8895 | 0.8922 | 0.8921 | 0.8921 | 0.8891 | 0.8898 | 0.8853 | 0.8837 | |
| 40 | 0.8685 | 0.8799 | 0.8859 | 0.8926 | 0.8927 | 0.8935 | 0.8919 | 0.8910 | 0.8904 | 0.8850 | 0.8855 | |
| 45 | 0.8754 | 0.8846 | 0.8894 | 0.8931 | 0.8922 | 0.8940 | 0.8923 | 0.8909 | 0.8891 | 0.8868 | 0.8843 | |
| 50 | 0.8756 | 0.8867 | 0.8912 | 0.8922 | 0.8945 | 0.8923 | 0.8940 | 0.8900 | 0.8895 | 0.8877 | 0.8854 | |
| 0 | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 0.6487 | 0.6965 | 0.6885 | 0.6993 | 0.7162 | 0.7432 | 0.7631 | 0.7729 | 0.7793 | 0.7888 | 0.7925 | |
| 10 | 0.6374 | 0.6513 | 0.6569 | 0.7040 | 0.7235 | 0.7420 | 0.7548 | 0.7643 | 0.7801 | 0.7941 | 0.8025 | |
| 15 | 0.6932 | 0.6956 | 0.7007 | 0.7103 | 0.7325 | 0.7485 | 0.7511 | 0.7782 | 0.7965 | 0.8003 | 0.8085 | |
| 20 | 0.7030 | 0.7003 | 0.7039 | 0.7101 | 0.7210 | 0.7414 | 0.7516 | 0.7800 | 0.7848 | 0.8064 | 0.8020 | |
| 25 | 0.7071 | 0.7020 | 0.7053 | 0.7078 | 0.7252 | 0.7402 | 0.7530 | 0.7722 | 0.7937 | 0.7984 | 0.7978 | |
| 30 | 0.7119 | 0.7159 | 0.7198 | 0.7079 | 0.7406 | 0.7319 | 0.7811 | 0.7927 | 0.7838 | 0.7983 | 0.8056 | |
| 35 | 0.7067 | 0.7101 | 0.7170 | 0.7064 | 0.7159 | 0.7396 | 0.7599 | 0.7870 | 0.7857 | 0.7946 | 0.7985 | |
| 40 | 0.7189 | 0.7138 | 0.7218 | 0.7169 | 0.7213 | 0.7402 | 0.7658 | 0.7646 | 0.7914 | 0.7965 | 0.8009 | |
| 45 | 0.7149 | 0.7017 | 0.7150 | 0.7182 | 0.7258 | 0.7495 | 0.7751 | 0.7791 | 0.7817 | 0.7954 | 0.7977 | |
| 50 | 0.7053 | 0.7209 | 0.7203 | 0.7229 | 0.7228 | 0.7376 | 0.7661 | 0.7769 | 0.7924 | 0.7935 | 0.7979 | |
| 0 | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 0.8405 | 0.8495 | 0.8524 | 0.8529 | 0.8540 | 0.8535 | 0.8534 | 0.8528 | 0.8527 | 0.8528 | 0.8521 | |
| 10 | 0.8628 | 0.8684 | 0.8692 | 0.8690 | 0.8681 | 0.8668 | 0.8666 | 0.8657 | 0.8639 | 0.8636 | 0.8636 | |
| 15 | 0.8734 | 0.8762 | 0.8751 | 0.8743 | 0.8734 | 0.8722 | 0.8714 | 0.8704 | 0.8696 | 0.8688 | 0.8675 | |
| 20 | 0.8776 | 0.8796 | 0.8792 | 0.8769 | 0.8750 | 0.8744 | 0.8731 | 0.8723 | 0.8715 | 0.8706 | 0.8694 | |
| 25 | 0.8807 | 0.8828 | 0.8819 | 0.8811 | 0.8793 | 0.8775 | 0.8767 | 0.8757 | 0.8745 | 0.8739 | 0.8732 | |
| 30 | 0.8840 | 0.8667 | 0.8852 | 0.8845 | 0.8828 | 0.8815 | 0.8795 | 0.8787 | 0.8771 | 0.8762 | 0.8749 | |
| 35 | 0.8857 | 0.8869 | 0.8853 | 0.8830 | 0.8813 | 0.8813 | 0.8801 | 0.8789 | 0.8766 | 0.8773 | 0.8760 | |
| 40 | 0.8865 | 0.8879 | 0.8861 | 0.8841 | 0.8829 | 0.8809 | 0.8791 | 0.8785 | 0.8775 | 0.8756 | 0.8750 | |
| 45 | 0.8886 | 0.8883 | 0.8871 | 0.8845 | 0.8826 | 0.8808 | 0.8786 | 0.8774 | 0.8770 | 0.8751 | 0.8750 | |
| 50 | 0.8888 | 0.8893 | 0.8872 | 0.8850 | 0.8823 | 0.8800 | 0.8779 | 0.8760 | 0.8748 | 0.8742 | 0.8733 | |
| Method | Re | Sp | FPR | FNR | PWC | Pr | F-Measure |
|---|---|---|---|---|---|---|---|
| (1) | 0.7569 | 0.9930 | 0.0070 | 0.2431 | 1.4777 | 0.8177 | 0.7535 |
| (2) | 0.7752 | 0.9944 | 0.0056 | 0.2248 | 1.2644 | 0.8172 | 0.7681 |
| (3) | 0.8420 | 0.9914 | 0.0086 | 0.1580 | 1.3260 | 0.7920 | 0.7890 |
| (4) | 0.8456 | 0.9908 | 0.0091 | 0.1544 | 1.3704 | 0.7892 | 0.7898 |
| Method | Re | Sp | FPR | FNR | PWC | Pr | F-Measure |
|---|---|---|---|---|---|---|---|
| SuBSENSE | 0.8124 | 0.9904 | 0.0096 | 0.1876 | 1.6780 | 0.7509 | 0.7408 |
| PAWCS | 0.7718 | 0.9949 | 0.0051 | 0.2282 | 1.1992 | 0.7857 | 0.7403 |
| SharedModel | 0.8098 | 0.9912 | 0.0088 | 0.1902 | 1.4996 | 0.7503 | 0.7474 |
| WeSamBE | 0.7955 | 0.9924 | 0.0076 | 0.2045 | 1.5105 | 0.7679 | 0.7446 |
| SWCD | 0.7839 | 0.9930 | 0.0070 | 0.2161 | 1.3414 | 0.7527 | 0.7583 |
| BSUV-Net | 0.8203 | 0.9946 | 0.0054 | 0.1797 | 1.1402 | 0.8113 | 0.7868 |
| GhostDeReBS | 0.8456 | 0.9908 | 0.0092 | 0.1544 | 1.3704 | 0.7892 | 0.7898 |
| Category | SuBSENSE | PAWCS | SharedModel | WeSamBE | SWCD | BSUV-Net | GhostDeReBS |
|---|---|---|---|---|---|---|---|
| BW | 0.8619 | 0.8152 | 0.8480 | 0.8608 | 0.8233 | 0.8713 | 0.8718 |
| baseline | 0.9503 | 0.9397 | 0.9522 | 0.9413 | 0.9214 | 0.9693 | 0.9517 |
| CJ | 0.8152 | 0.8137 | 0.8141 | 0.7976 | 0.7411 | 0.7743 | 0.8583 |
| DB | 0.8177 | 0.8938 | 0.8222 | 0.7440 | 0.8645 | 0.7967 | 0.8817 |
| IOM | 0.6569 | 0.7764 | 0.6727 | 0.7392 | 0.7092 | 0.7499 | 0.7841 |
| LF | 0.6445 | 0.6588 | 0.7286 | 0.6602 | 0.7374 | 0.6797 | 0.7923 |
| NV | 0.5599 | 0.4152 | 0.5419 | 0.5929 | 0.5807 | 0.6987 | 0.5141 |
| PTZ | 0.3476 | 0.4615 | 0.3860 | 0.3844 | 0.4545 | 0.6282 | 0.4112 |
| shadow | 0.8986 | 0.8913 | 0.8898 | 0.8999 | 0.8779 | 0.9233 | 0.9131 |
| thermal | 0.8171 | 0.8324 | 0.8319 | 0.7962 | 0.8581 | 0.8581 | 0.8190 |
| turbulence | 0.7792 | 0.6450 | 0.7339 | 0.7737 | 0.7735 | 0.7051 | 0.8907 |
| Method | Highway (240*320) | Skating (360*540) | Fall (480*720) |
|---|---|---|---|
| SuBSENSE | 15.3 fps | 6.7 fps | 4.2 fps |
| GhostDeReBS | 12.6 fps | 5.2 fps | 2.8fps |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Ji, H.; Zhang, W. Ghost Detection and Removal Based on Two-Layer Background Model and Histogram Similarity. Sensors 2020, 20, 4558. https://doi.org/10.3390/s20164558
Xu Y, Ji H, Zhang W. Ghost Detection and Removal Based on Two-Layer Background Model and Histogram Similarity. Sensors. 2020; 20(16):4558. https://doi.org/10.3390/s20164558
Chicago/Turabian StyleXu, Yiping, Hongbing Ji, and Wenbo Zhang. 2020. "Ghost Detection and Removal Based on Two-Layer Background Model and Histogram Similarity" Sensors 20, no. 16: 4558. https://doi.org/10.3390/s20164558
APA StyleXu, Y., Ji, H., & Zhang, W. (2020). Ghost Detection and Removal Based on Two-Layer Background Model and Histogram Similarity. Sensors, 20(16), 4558. https://doi.org/10.3390/s20164558