1. Introduction
The autonomy and intelligent development of the coordinated control of multi-agent systems such as multi-unmanned aerial vehicle (UAV) and multi-robot have received more and more attention. To solve the problem of coordinated control and obstacle avoidance of multiagent systems, researchers have proposed various solutions, including rule-based methods, field methods, geometric methods, numerical optimization methods, and so on [
1,
2].
In recent years, the application and development of reinforcement learning (RL) in the field of robotics has attracted more and more attention. La et al. [
3] integrated high-level behaviors by RL and low-level behaviors by flocking control to allow robots to learn to avoid predators/enemies collaboratively. Hung et al. [
4] proposed a method of using the RL algorithm to fixed-wing UAV flocking, but the velocity and height of the UAV were set as constant to reduce the complexity of UAV control. Pham et al. [
5] provided a framework for integrating Q-learning and Proportion Integration Differentiation (PID) to allow the UAV to navigate successfully. Koch et al. [
6] investigated the performance and accuracy of the inner control loop, providing attitude control. Their investigations encompassed flight control systems trained with RL algorithms, including Deep Deterministic Gradient Policy (DDGP), Trust Region Policy Optimization (TRPO), and Proximal Policy Optimization (PPO) compared with PID controller. Fang Bin et al. studied the application of RL in the field of multi-UAV collaborative obstacle avoidance [
2].
The success of reinforcement learning (RL) in the field of multiagent has been witnessed. However, it must also be pointed out that the development of multiagent reinforcement learning (MARL) is influenced by single-agent RL, which is the cornerstone of MARL development. There are three task environments in the multiagent field: cooperative tasks, competitive tasks, and mixed tasks [
7]. We mainly consider the cooperative task environment. RL in the topic of multiagent cooperation is mainly used to optimize a common reward signal. The non-stationary environment due to the change of the policies of learning agents in a multiagent environment leads to the failure or difficulty of convergence of most single-agent RL algorithms in a multiagent environment [
8,
9]. Therefore, it is inevitable that we must find RL algorithms suitable for a multiagent environment.
Tan [
10] explored the multiagent setting using independent Q-learning to complete some cooperative tasks in a 2D grid world. Tampuu et al. [
11] manipulated the classical rewarding scheme of Pong to demonstrate how competitive and collaborative behaviors emerge by independent Q-learning (IQL). Foerster et al. [
12] proposed a counterfactual multiagent (COMA) policy gradients algorithm by using a centralized critic to estimate the Q-function and decentralized actors to optimize the agents’ policies and evaluated on StarCraft. Lowe et al. [
13] extended Deep Deterministic Policy Gradient (DDPG) to a multiagent setting with a centralized Q-function and evaluated 2D games. Li et al. [
14] proposed a novel minimax learning objective based on the multiagent deep deterministic policy gradient algorithm for robust policy learning. Yang et al. [
15] proposed the Mean Field Reinforcement Learning (MFRL) algorithm to address MARL on a very large population of agents. Value-Decomposition Networks (VDN) [
16] learned a centralized action–value function as a sum of individual action–value functions and a decentralized policy. QMIX [
17] is an effective improvement of the VDN algorithm but unlike VDN. QMIX can learn a complex centralized action–value function with a factored representation that scales well in the number of agents and allows decentralized policies to be easily extracted via linear-time individual argmax operations. Hong et al. [
18] introduced a deep policy inference Q-network (DPIQN) and its enhanced version deep recurrent policy inference Q-network (DRPIQN) to employ “policy features” learned from observations of collaborators and opponents by inferring their policies. Bansal et al. [
19] explored that a competitive multiagent environment trained with self-play can produce complex behaviors than the environment itself using Proximal Policy Optimization (PPO). There are also many review articles [
7,
8,
9] that explore the research and application of RL in the field of multiagent.
In order to make RL algorithms useful in the real world, researchers have exerted a lot of effort [
3,
5,
6]. The unmanned aerial vehicle (UAV) is a popular tool in the military and civilian fields, and it is also the representation of agents in the real world. The UAV, as the research object of RL algorithms, has attracted the attention of many researchers [
5,
6,
20]. Multi-UAV formation can accomplish many tasks that cannot be completed by a single UAV [
21,
22].
This paper proposes the Multiagent Joint Proximal Policy Optimization (MAJPPO) algorithm, which uses the moving window average of the state–value functions of different agents to get the centralized state–value function to solve the problem of multi-UAV cooperative control. The algorithm can effectively improve the collaboration among agents in the multiagent system than the multiagent independent PPO (MAIPPO) algorithm. Since the PPO algorithm uses a state–value function as the evaluation function, it is different from Deep Q-Network (DQN) [
23], which uses the action–value function as the evaluation function. Therefore, the centralization value function of the MAJPPO algorithm does not require the policies of collaborative agents during training, thereby reducing the complexity of the algorithm. Finally, we use algorithms to train multi-UAV formation through a multi-obstacle environment to evaluate the performance of the algorithm. In the process of reinforcement learning of UAV, there are two choices of the controlled object. One is the use of the UAV dynamics model with an attitude control loop, and the other is the use of the UAV dynamics model without an attitude control loop. We use the UAV dynamics model with the attitude control loop as the control object of multi-UAV cooperative control. This is mainly because the UAV dynamic model with the attitude control loop has less freedom and fewer optimization targets.
Therefore, the main contributions of the paper are as follows:
- 1
The development of the MAJPPO algorithm; and,
- 2
The MARL algorithm is applied to the multi-UAV formation and obstacle avoidance field.
In regards to the rest of the paper, we will firstly introduce the background related to this paper in
Section 2.
Section 3 describes the PPO algorithm.
Section 4 presents the independent PPO algorithm for the multiagent environment.
Section 5 describes the novel MAJPPO algorithm, and it brings in some discussion.
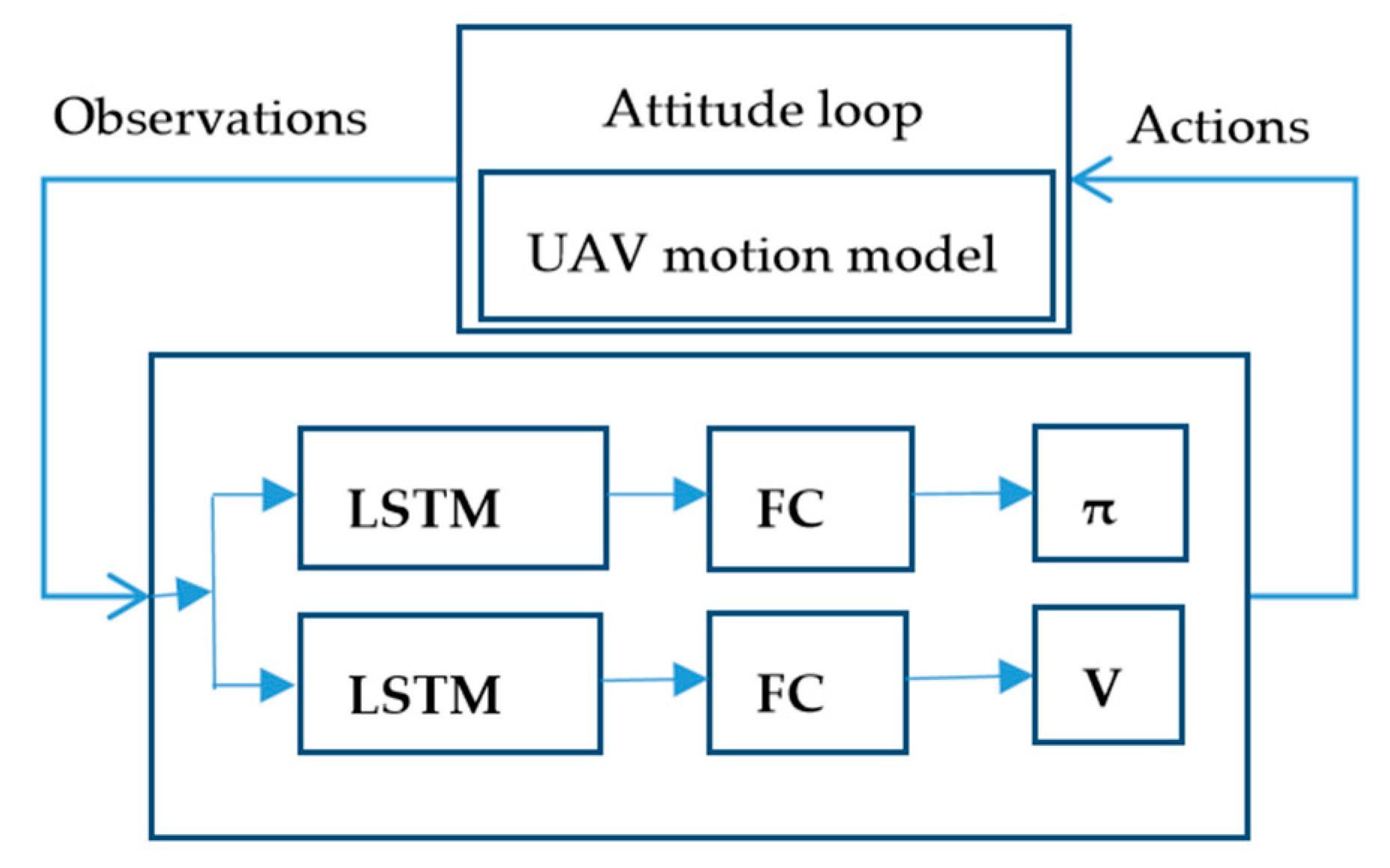
Section 6 describes the dynamics model of small UAV with the attitude control loop, RL of a single UAV, and the basic settings of the formation.
Section 7 introduces experiments and analysis. The conclusions appear in
Section 8.
2. Background and Preliminary
In the field of RL, the Markov decision process (MDP) is a key concept. RL enables the agent to learn a policy with good profits through interaction with the environment in an unknown environment. Such environments are often formalized as Markov Decision Processes (MDPs), described by a five-tuple (
S; A; P; R; γ). At each time step
t, an agent interacting with the environment observes a state
, and chooses an action
, which determines the reward
and next state
. The purpose of RL is to maximize the cumulative discount rewards
, where
T is the time step when an episode ends,
t denotes the current time step,
γ ∈ [0, 1] is the discount factor, and
is the reward received at the time step
τ. The action–value function (abbreviated as Q-function) of a given policy π is defined as the expected return starting from a state–action pair
, expressed as
. Q-learning is a widely used RL algorithm. Q-learning mainly uses the action–value function
to learn the policy [
24]. DQN [
23] is a kind of RL algorithm combining Q-learning and neural network, which learns the action–value function Q * corresponding to the optimal policy by minimizing the loss:
, where
, and y represents the Q-learning target value.
In the real world, the agent often cannot obtain all the information of the environment, or the environment information obtained by the agent is incomplete and noisy, that is, only part of the environment can be observed. In this case, we can use the partially observable Markov decision process (POMDP) to model such problems. A POMDP can be described as a six-tuple 〈
S; A; P; R; γ; O〉, where
O is the observation perceived by the agent. The deep recurrent Q-network (DRQN) [
25] is proposed to deal with partially observable problems and POMDP problems, which extends the architecture of DQN with Long Short-Term Memory (LSTM).
In a multiagent learning domain, the POMDP generalizes to a stochastic game or a Markov game.
A multiagent learning environment can be modeled as a decentralized POMDP (Dec-POMDP) framework [
26]. The Dec-POMDP model extends single-agent POMDP models by considering joint actions and observations.
Solving the Dec-POMDP problem is at the core of the MARL algorithms. The mainstream solution is to optimize the decentralized policy by centralized learning, such as MADDPG, VDN, and QMIX.
3. PPO Algorithm
Policy gradient (PG) methods are the same as Q-learning in the sense that they explicitly learn a stochastic policy distribution
parametrized by θ. The objective of PG is to maximize the expected return over the trajectories induced by the policy
. If we denote the reward of a trajectory τ generated by policy
as
, the policy gradient estimator has the form
. This is the REINFORCE algorithm [
27]. However, the REINFORCE algorithm has a high variance. A baseline, such as a value function baseline, can be used to improve the shortcomings of this type of algorithm. A generalized advantage estimate [
28] is to use this method at the expense of some bias to reduce variance.
Schulman et al. [
29] proposed that the TRPO algorithm can solve the shortcomings of the PG method that needs to be carefully adjusted for the step size. The PPO algorithm [
30,
31] is a simplification of the TRPO algorithm, which has a simpler execution method and sampling method.
The PPO algorithm optimizes the surrogate objective (1):
where
denotes the likelihood ratio and
is the generalized advantage estimate.
Similar to the DRQN algorithm, the combination of PPO and LSTM has a good effect on solving the POMDP problem [
19,
31].
4. Multiagent Independent PPO Algorithm
Tampuu et al. [
11] demonstrate how competitive and collaborative behaviors emerge by independent Q-learning. Bansal et al. [
19] explored that a multiagent environment produces complex behaviors by independent Proximal Policy Optimization (PPO) algorithm (MAIPPO).
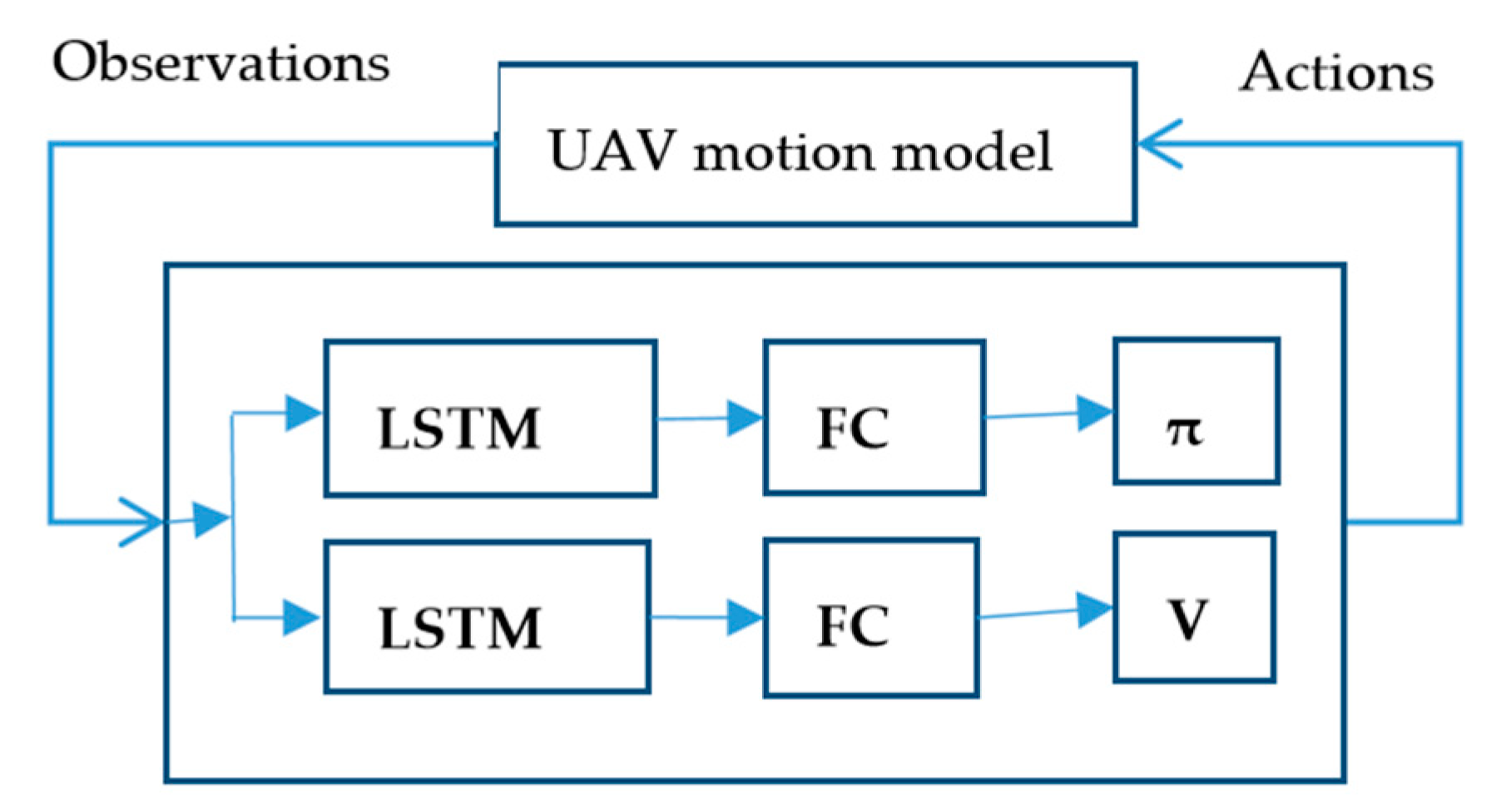
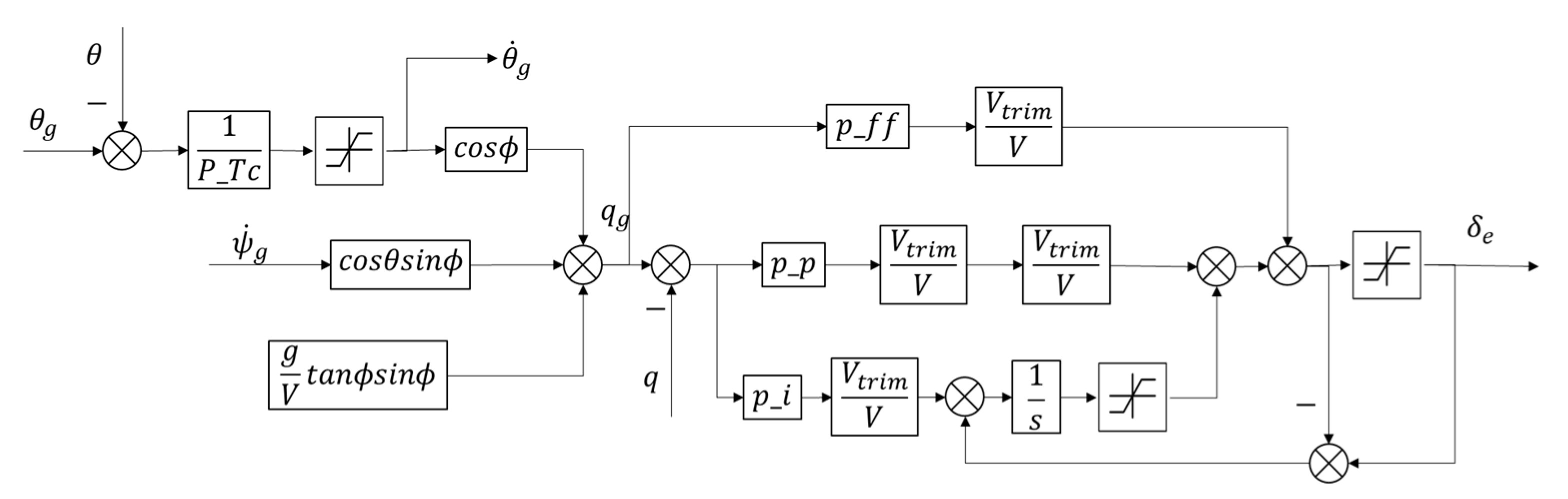
Of course, the MAIPPO algorithm may also cause policies to fail to converge due to environmental non-stationary caused by the changing policies of the learning agents. The network structure of MAIPPO is shown in
Figure 1.
The structure of the MAIPPO algorithm we construct is relatively simple. Actor and critic networks of the MAIPPO algorithm are composed of LSTM layers and a series of fully-connected layers (abbreviated as FC layers). The critic network obtains state–value function and optimizes the critic network by minimizing the loss. The generalized advantage estimate is calculated from the value function and then to optimize the actor network by the surrogate objective.
To update the critic network by minimizing the loss function (2):
To update the actor network by optimizing the surrogate objective (4):
where
S denotes an entropy bonus, and c is coefficient. We can use a truncated version of generalized advantage estimation (5), so:
in the above formulas has the following expressions for agent
i and agent
j:
where
represents the observation of agent
i, which is the union of the state
of agent
i and the partial state
of the state
of agent
j.
is the same. According to the theory of RL, we know that agent
i selects policy
from
, and gets the reward and the next state
. That is to say, the policy
of agent
i has no direct influence on
.
In other words, obtained by the critic network of agent i evaluates of the partial state of agent j. However, the policy obtained by the actor network only affects the state of agent i. This creates a division between critic and actor, which is one of the directions in which various MARL algorithms strive to improve.
5. Multiagent Joint PPO Algorithm
In a multiagent learning environment, the environment becomes the non-stationary due to the changing policies of the learning agents. For the independent Q-learning algorithm, agents optimize policies through the local action–value function, which obstructs convergence.
There are a series of improved algorithms whose main purpose is to learn the centralized critic. The counterfactual multiagent (COMA) policy gradients algorithm and the multiagent Deep Deterministic Policy Gradient (MADDPG) use a centralized critic to estimate the Q-function and decentralized actors to optimize the agents’ policies. VDN is to optimize the decentralized policies by using the sum of Q-value functions of each agent as a centralized evaluation function. QMIX is an improved algorithm of VDN, which learns a more complex joint action–value function by constructing a mixed network. DPIQN and DRPIQN propose to employ policy features of collaborators and opponents to infer and predict their policies.
The MAJPPO algorithm is proposed based on the MAIPPO algorithm. Different from the Q-learning algorithm, which uses the action–value function to evaluate and optimize policy, the PPO algorithm mainly uses the state–value function and the generalized advantage estimate to evaluate and optimize a policy. The MAJPPO algorithm learns mostly to obtain the joint state–value function and the generalized advantage estimate to evaluate and optimize the distribution policies.
To enhance the stability of training and the cooperative between agents, we use the moving window average of the state–value functions of different agents to obtain joint state–value functions
(8) and
(9):
where
is constant.
Agent i and agent j simultaneously obtain their respective observations and , which include both observations of their own and partial observations of other agents. The state–value functions and are obtained through the processing of their respective critic networks. Then, to obtain the joint state–value functions and through the weighted average of the state–value functions. The joint state–value function includes both the evaluation of the state of agent i and the evaluation of the state of other agents. The small (1 − ) in is mainly to reduce the effect of the evaluation of the remaining state of the state of agent j except for on the joint state–value function. The state–value function obtained by the agent j includes both the evaluation of the state of agent j and the evaluation of the partial state of other agents. The surrogate objective obtained by and optimize the actor networks to get the cooperative policy.
The value function that the MAJPPO algorithm learns through critic networks is a combination of state features with its states and other agents. The VDN’s paper pointers out that lazy agents arise due to the partial observability of state. The critic networks of the MAJPPO algorithm use global information to learn the value function. The advantage functions deriving from the value function are used to update actor networks. This can solve the lazy agent problem to some extent. The MAJPPO algorithm and VDN algorithm or QMIX algorithm have similarities. MAJPPO uses the weighted average of the state–value function of each agent to replace the local state–value function of each agent to achieve the goal of centralized learning.
7. Experiments
7.1. Experimental Condition
7.1.1. Network Settings
Critic network architectures first process the input using an LSTM layer with 128 hidden units, and then a fully connected linear layer with 128 hidden units followed by a TanH layer, and then a fully connected linear layer with 128 hidden units followed by a TanH layer.
The actor consists of two parts: a neural network and a normal distribution. The actor network has an LSTM layer with 128 hidden units, and then a fully connected linear layer with 128 hidden units followed by a TanH layer. The output of the network is the mean value of the normal distribution with covariance matrix
C = 0.05
I, where
I is the identity matrix [
33]. The distribution generates actions. The output range of the angles
in the actor output is limited to [−0.5, 0.5], and the range of the throttle
is limited to [0, 1]. Therefore, the mean value of the angle uses TanH as the activation function, and the mean of the throttle uses sigmoid as the activation function.
Due to the computational complexity of the UAV motion model, to shorten the training time, the use of multiple processes is inevitable.
7.1.2. Parameter Settings
The learning rate of Adam is 0.0001. The clipping parameter , discounting factor and generalized advantage estimate parameter . We use large batch sizes, which can improve the variance problem to some extent and help to explore. In each iteration, we collect 1000 samples or 20 episodes, and 50 steps as one episode, and perform 20 episodes of training in mini-batches consisting of 512 samples. We found l2 regularization with parameter 0.01 of the policy and value network parameters to be useful. The coefficient of the entropy is . the parameters in the reward function are set to . The sampling time is set to .
7.2. Mission Environment
Assume that the three UAVs fly from the initial area to the target area at a certain speed and a stable attitude as required by the formation, and pass through the area with six obstacles. The following initial values are assumed to simplify the task environment:
- (1)
and of UAV1 are uniformly distributed in the interval [0, 100] and [0, 100] respectively,
- (2)
The initial values of and of UAV2 are uniformly distributed in the interval [−100, 0] and [0, 100] correspondingly, and
- (3)
The initial values of and of UAV3 are uniformly distributed in the interval [−50, 50] and [−100, 0].
The initial values of , , and of UAV1, UAV2, and UAV3 are uniformly distributed in the interval [160, 240]. The initial values of velocity u, v and w of UAV1, UAV2 and UAV3 are uniformly distributed in the interval [10, 40], [1, 5] and [1, 5], the initial values of angle and angular velocity φ, θ, ψ, p, q, and r are uniformly distributed in the interval [−0.5, 0.5]. The target area is set to , and . We assume that the safety distance between UAVs is . The formation flight velocity is . Six spherical obstacle centers with a radius of 20 are uniformly distributed in a range of obstacles [400, 700] × [−200, 200] × [150, 250] in a uniformly distributed manner. The maximum detection distance of UAV to obstacles is .
7.3. Experimental Comparison and Analysis
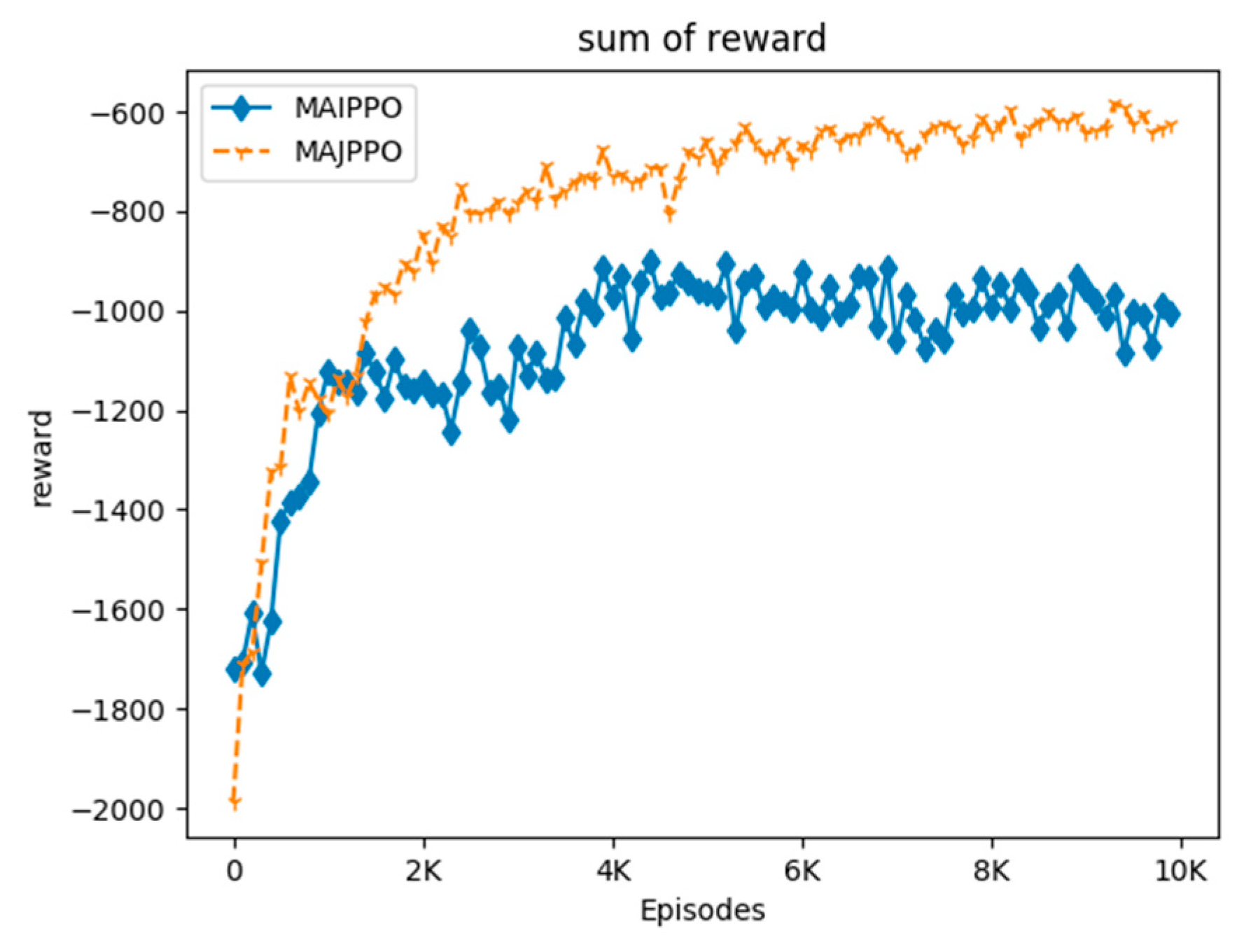
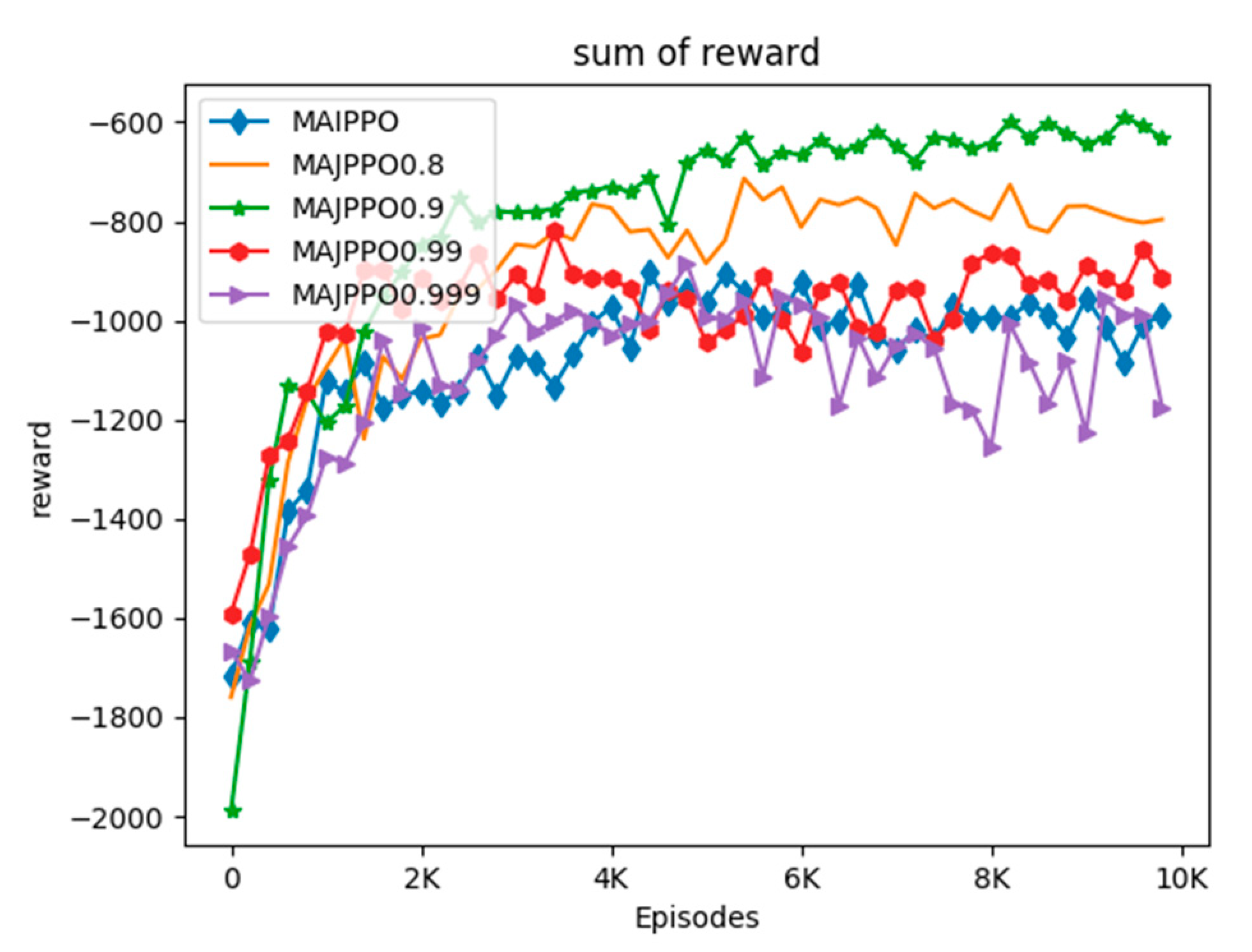
In order to compare the performance of the algorithm intuitively, we use the above parameters and task environment to perform experiments on the MAIPPO and MAJPPO algorithms until convergence, where the parameter in the MAJPPO algorithm is
. The learning curves of the algorithms are revealed in
Figure 4. It should be noted that the reward in
Figure 4 is the sum of the rewards of three UAVs. We performed 10,000 iterations for the MAIPPO algorithm and the MAJPPO algorithm. It can be clearly seen from
Figure 4 that the MAJPPO algorithm demonstrates better performance than the MAIPPO algorithm in dealing with multi-UAV collaboration and obstacle avoidance problems. It can also be seen from
Figure 4 that the learning curve of the MAIPPO algorithm is not stable after convergence, and the MAJPPO algorithm can get higher reward value and convergence more stable. Therefore, the MAJPPO algorithm can get better results than the MAIPPO algorithm when dealing with this Dec-POMDP environment. The training learning curve of the MAIPPO algorithm cannot converge well because of the instability of the environment.
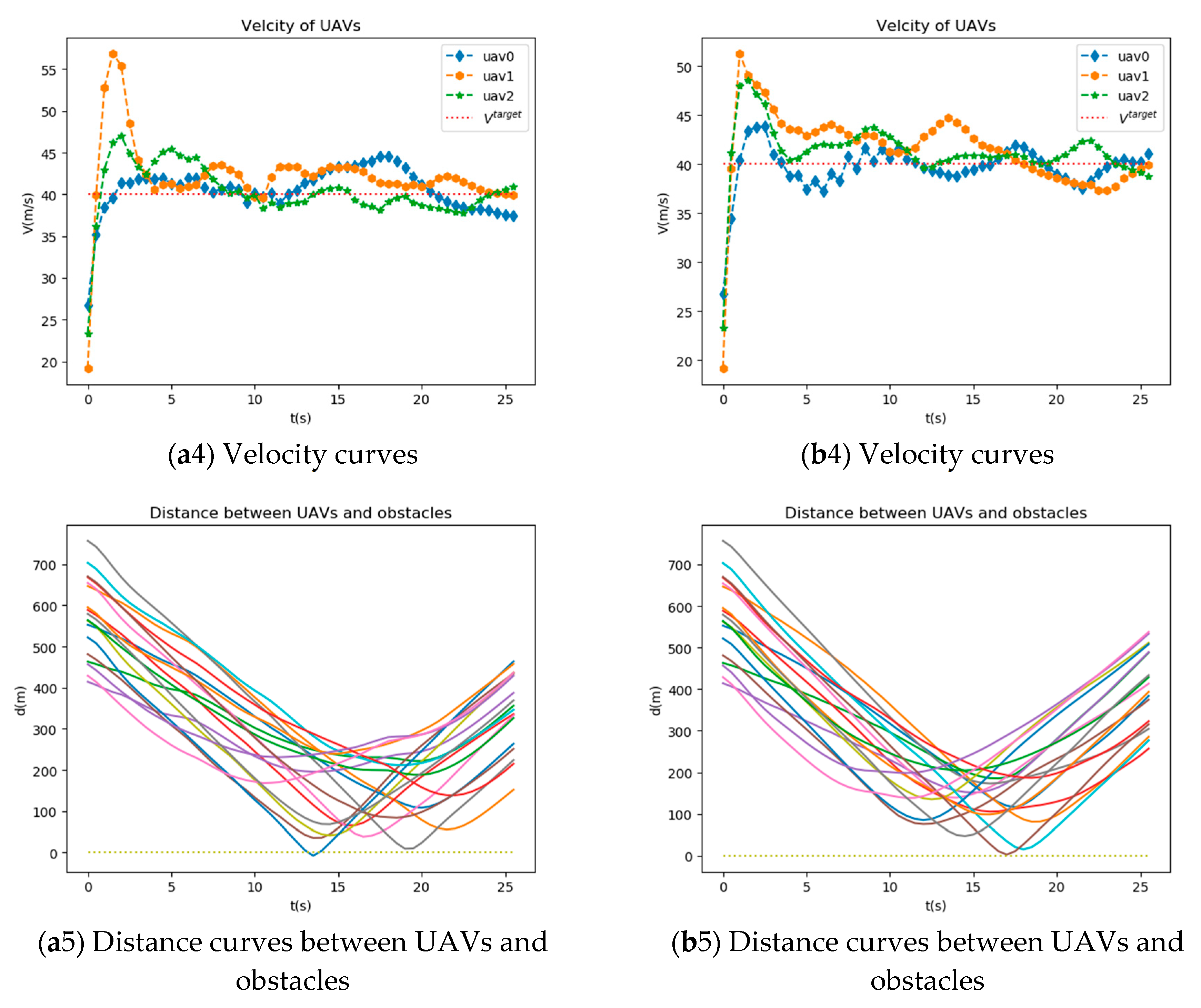
Figure 5 shows trajectory curves, distance curves, altitude curves, velocity curves, and distance curves between UAVs and obstacles of UAVs after training using MAIPPO algorithm and MAJPPO algorithm. As can be seen from
Figure 5, these three UAVs can fulfill the mission requirements well.
It can be seen from
Figure 5 that the network trained by the MAJPPO algorithm performs better in the multi-obstacle environment for multi-UAV obstacle avoidance control. To specifically evaluate the performance of distance, altitude, and velocity of UAVs, we calculate the sum of first-order absolute center moment separately as (17), (18), and (19).
As can be seen from
Table 1,
of the MAJPPO algorithm improve by 42.72% ((5408.17–3097.77)/5408.17 × 100%), 39.66%, and 8.23% compared with the MAIPPO algorithm. This shows that MAJPPO algorithm has better performance.
7.4. Parameter Evaluation
Since the weighted average parameter
in the MAJPPO algorithm has a great influence on the performance of the algorithm, we discuss and analyze it. The learning curves of MAIPPO and MAJPPO for
= 0.8, 0.9, 0.99, and 0.999 are shown in
Figure 6.
In the MAJPPO algorithm, when
= 1, it is actually the independent PPO algorithm. This can be seen from
Figure 6, when the value of
is closer to 1. The performance of the algorithm will also show similar performance to the independent PPO algorithm, such as
= 0.999. However, the performance of the algorithm does not become better as the value of
becomes smaller. For example, when
= 0.8, the performance of the algorithm is not as good as
= 0.9.
8. Conclusions and Future Work
Based on the MAIPPO algorithm, we propose the MAJPPO algorithm that uses the moving window averaging of state-valued function to obtain a centralized state value function to deal with multiagent coordination problems. The MAJPPO algorithm is also a kind of centralized training and distributed execution algorithm. We also presented a new cooperative multi-UAV simulation environment, where multi-UAV work together to accomplish formation and obstacle avoidance. In order to accomplish this task, we use the dynamic model of the UAV with attitude control capability as the control object. It can be seen from the experimental comparison that the MAJPPO algorithm can better deal with the partial observability of the state in the multiagent system and obtain better experimental results.
The comparison of the MAJPPO algorithm with other multi-agent reinforcement learning algorithms, such as MADDPG, VDN, and QMIX, is left for future work.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






