Multiple Object Detection Based on Clustering and Deep Learning Methods


Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Deep Learning
3.1.1. Convolutional Neural Network
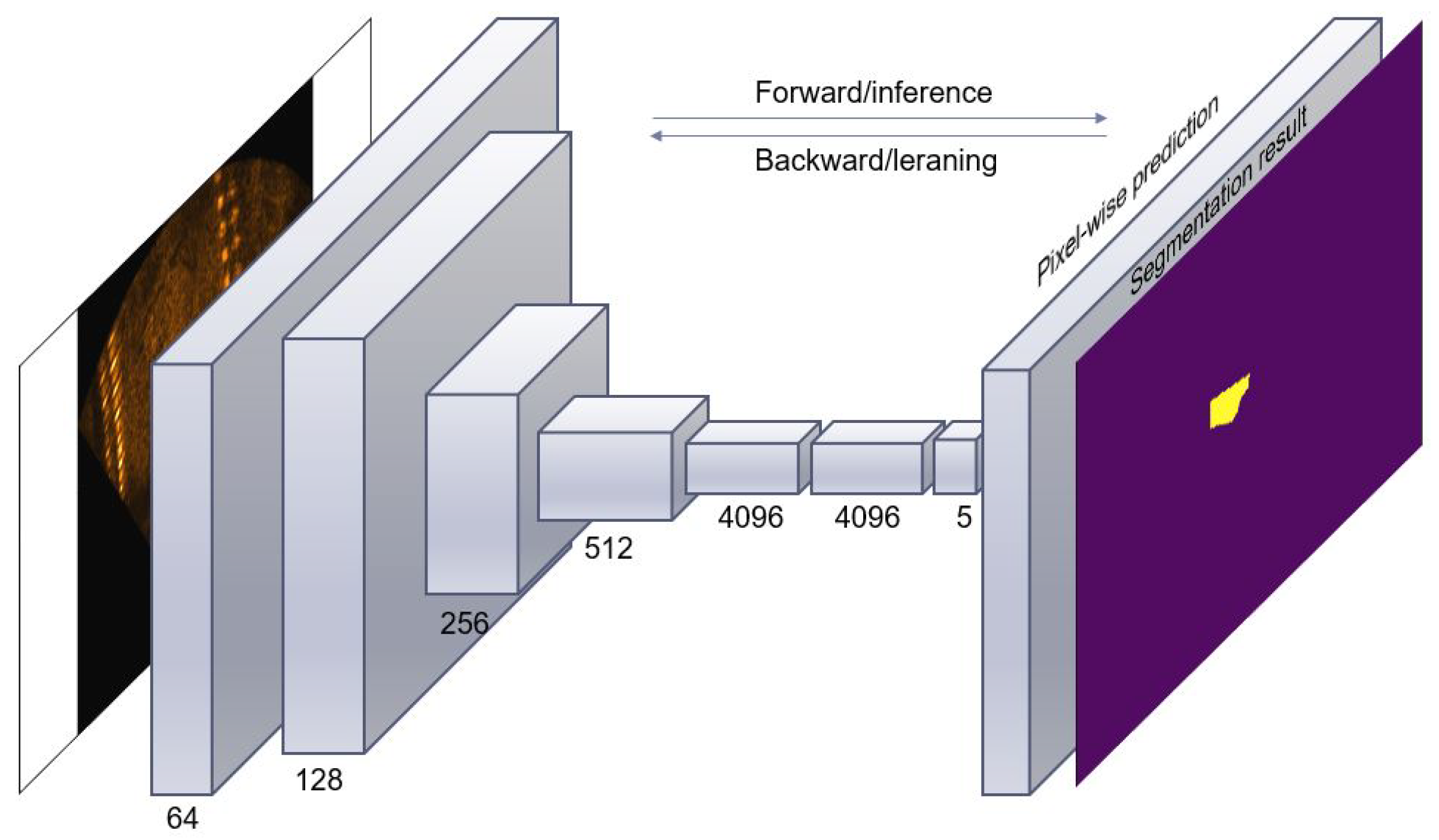
3.1.2. Fully Convolutional Network
3.2. Clustering
3.2.1. K-Means Clustering
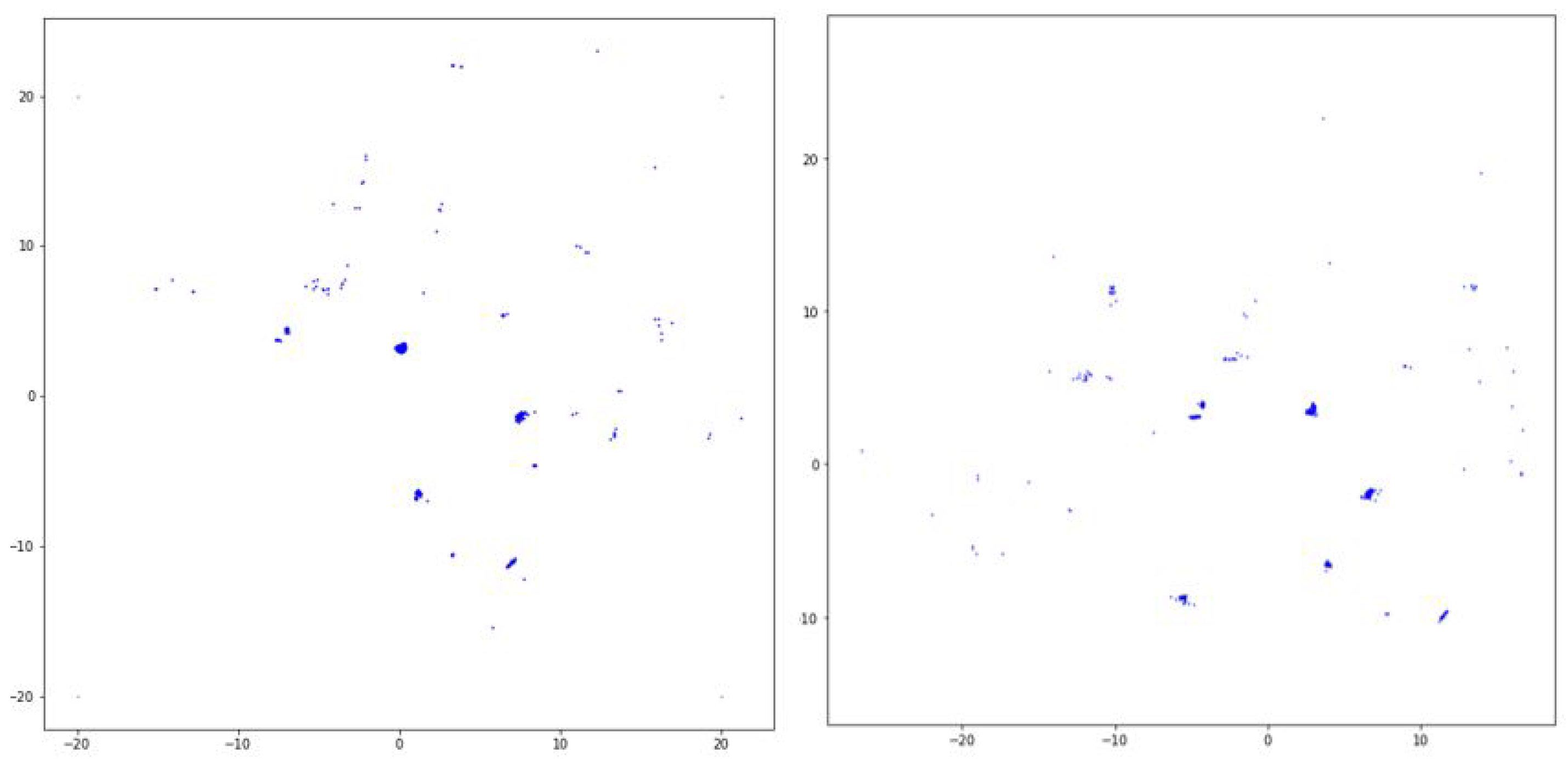
3.2.2. DBSCAN
3.2.3. Silhouette Analysis
4. Experiment Result
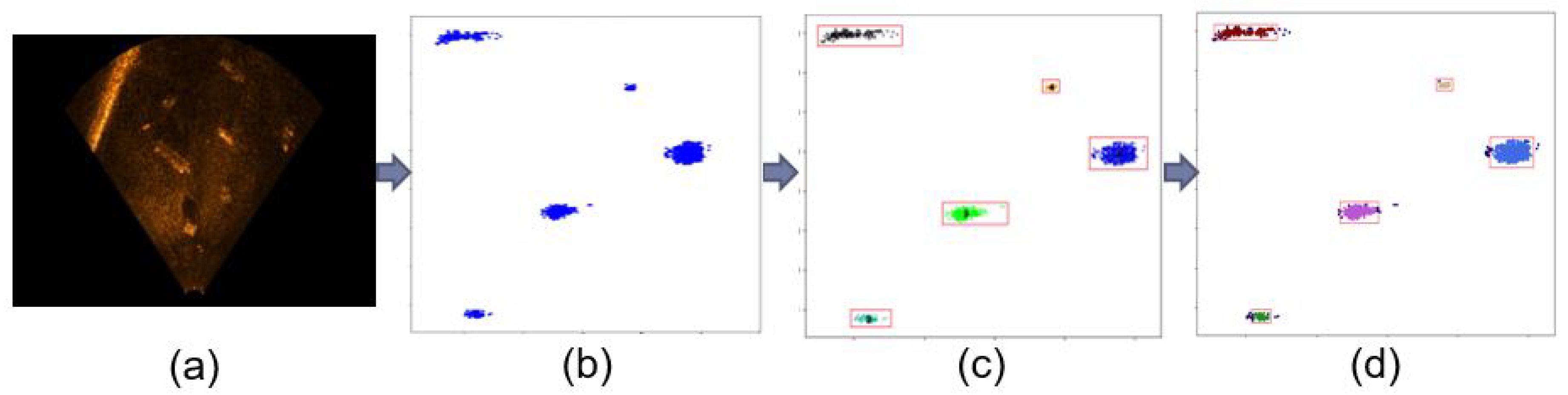
4.1. Data Preparation
4.2. Experiment Result
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Bae, C.; Lee, S. A Study of 3D Point Cloud Classification of Urban Structures Based on Spherical Signature Descriptor Using LiDAR Sensor Data. Trans. KSME A 2019, 43, 85–91. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. A k-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. KDD 1996, 96, 226–231. [Google Scholar]
- Lee, S.; Park, B.; Kim, A. Deep Learning from Shallow Dives: Sonar Image Generation and Training for Underwater Object Detection. arXiv 2018, arXiv:abs/1810.07990. [Google Scholar]
- Nguyen, H.; Lee, E.; Lee, S. Study on the Classification Performance of Underwater Sonar Image Classification Based on Convolutional Neural Networks for Detecting a Submerged Human Body. Sensors 2020, 20, 94. [Google Scholar] [CrossRef] [PubMed]
- Martin, A.; An, E.; Nelson, K.; Smith, S. Obstacle detection by a forward looking sonar integrated in an autonomous underwater vehicle. In Proceedings of the OCEANS 2000 MTS/IEEE Conference and Exhibition, Providence, RI, USA, 11–14 September 2000; pp. 337–341. [Google Scholar] [CrossRef]
- DeMarco, K.J.; West, M.E.; Howard, A.M. Sonar-Based Detection and Tracking of a Diver for Underwater Human-Robot Interaction Scenarios. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 2378–2383. [Google Scholar]
- Wang, X.; Zhao, J.; Zhu, B.; Jiang, T.; Qin, T. A Side Scan Sonar Image Target Detection Algorithm Based on a Neutrosophic Set and Diffusion Maps. Remote Sens. 2018, 10, 295. [Google Scholar] [CrossRef]
- Galceran, E.; Djapic, V.; Carreras, M.; Williams, D.P. A real-time underwater object detection algorithm for multi-beam forward looking sonar. IFAC Proc. Vol. 2012, 45, 306–311. [Google Scholar] [CrossRef]
- Fuchs, L.R.; Gällström, A.; Folkesson, J. Object Recognition in Forward Looking Sonar Images using Transfer Learning. In Proceedings of the 2018 IEEE/OES Autonomous Underwater Vehicle Workshop (AUV), Porto, Portugal, 6–9 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Valdenegro-Toro, M. Learning Objectness from Sonar Images for Class-Independent Object Detection. In Proceedings of the 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 4–6 September 2019; pp. 1–6. [Google Scholar]
- Moosmann, F.; Pink, O.; Stiller, C. Segmentation of 3D lidar data in non-flat urban environments using a local convexity criterion. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 215–220. [Google Scholar] [CrossRef]
- Strom, J.H.; Richardson, A.; Olson, E. Graph-based segmentation for colored 3D laser point clouds. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2131–2136. [Google Scholar] [CrossRef]
- Douillard, B.; Underwood, J.P.; Kuntz, N.; Vlaskine, V.; Quadros, A.J.; Morton, P.; Frenkel, A. On the segmentation of 3D LIDAR point clouds. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2798–2805. [Google Scholar] [CrossRef]
- Zelener, A.; Stamos, I. CNN-Based Object Segmentation in Urban LIDAR with Missing Points. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 417–425. [Google Scholar] [CrossRef]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 770–779. [Google Scholar]
- He, Q.; Wang, Z.; Zeng, H.; Zeng, Y.; Liu, S.; Zeng, B. SVGA-Net: Sparse Voxel-Graph Attention Network for 3D Object Detection from Point Clouds. arXiv 2020, arXiv:abs/2006.04043. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Lloyd, S.P. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–136. [Google Scholar] [CrossRef]
- Rousseeuw, P. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Ling, R.F. On the theory and construction of k-clusters. Comput. J. 1972, 15, 326–332. [Google Scholar] [CrossRef]
- Ester, M. A Density-based spatial clustering of applications with noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; Volume 240, pp. 226–231. [Google Scholar]
- The KITTI Vision Benchmark Suite. Available online: http://www.cvlibs.net/datasets/kitti/ (accessed on 7 August 2020).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | K-Means Clustering | DBSCAN(%) | |
|---|---|---|---|
| Elbow(%) | Silhouette(%) | ||
| Objects without background | 72.61 | 84.13 | 92.86 |
| With background | 60.84 | 78.57 | 91.67 |
| Type | KNU | KITTI | |||||
|---|---|---|---|---|---|---|---|
| Data Set | 1 | 2 | 1 | 2 | 3 | 4 | 5 |
| Number of images | 15 | 15 | 12 | 12 | 12 | 12 | 12 |
| Total people | 18 | 16 | 56 | 52 | 47 | 54 | 63 |
| Mistype of people | 0 | 2 | 1 | 0 | 3 | 1 | 0 |
| Accuracy (%) | 100 | 88.89 | 98.25 | 100 | 94 | 98.18 | 100 |
| Outlier points | 56 | 95 | 354 | 284 | 367 | 349 | 233 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.T.; Lee, E.-H.; Bae, C.H.; Lee, S. Multiple Object Detection Based on Clustering and Deep Learning Methods. Sensors 2020, 20, 4424. https://doi.org/10.3390/s20164424
Nguyen HT, Lee E-H, Bae CH, Lee S. Multiple Object Detection Based on Clustering and Deep Learning Methods. Sensors. 2020; 20(16):4424. https://doi.org/10.3390/s20164424
Chicago/Turabian StyleNguyen, Huu Thu, Eon-Ho Lee, Chul Hee Bae, and Sejin Lee. 2020. "Multiple Object Detection Based on Clustering and Deep Learning Methods" Sensors 20, no. 16: 4424. https://doi.org/10.3390/s20164424
APA StyleNguyen, H. T., Lee, E.-H., Bae, C. H., & Lee, S. (2020). Multiple Object Detection Based on Clustering and Deep Learning Methods. Sensors, 20(16), 4424. https://doi.org/10.3390/s20164424