Correntropy-Induced Discriminative Nonnegative Sparse Coding for Robust Palmprint Recognition

Abstract
1. Introduction
1.1. Research Actuality
1.2. Motivations and Contributions
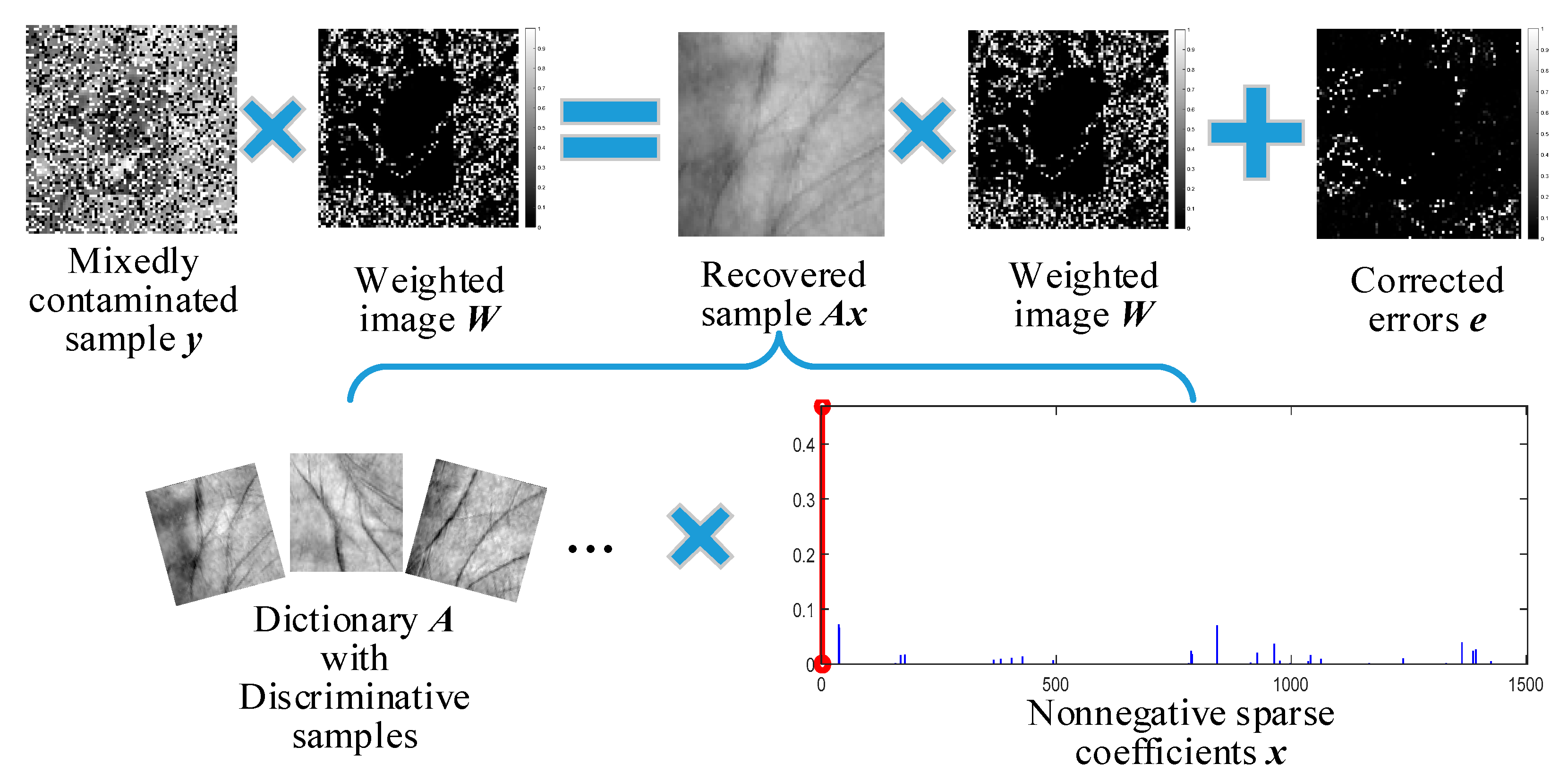
- The correntropy metric and l1-norm are combined to compose an error estimator for cooperative error detection and correction. We further equip the estimator with a discriminative nonnegative sparse regularizer to propose CDNSC to address various contaminations, like dense corruption, gross occlusion, and the mixture of them.
- To obtain the analytical solution of the unified scheme, we propose an efficient method to address the nonnegative constraint, namely, converting it into a nontrivial equality constraint. Then, with some self-developed skills, the new nondifferentiable equality constraint problem is expressed with a continuous formulation. Thus, combined with half-quadratic optimization, a reweighted alternating direction method of multipliers (ADMM) can be derived to obtain the closed-form solution of the reformulated problem.
- The proposed CDNSC is extended for robust multispectral palmprint recognition. We develop a constrained particle swarm optimizer to search for the feasible parameters to fuse the extracted robust features of different spectrums. This provides a new idea for extending the single-mode biometric recognition methods to multimodal biometric recognition.
2. Related Work
2.1. Coding Regularization
2.2. Nonnegative Sparse Representation
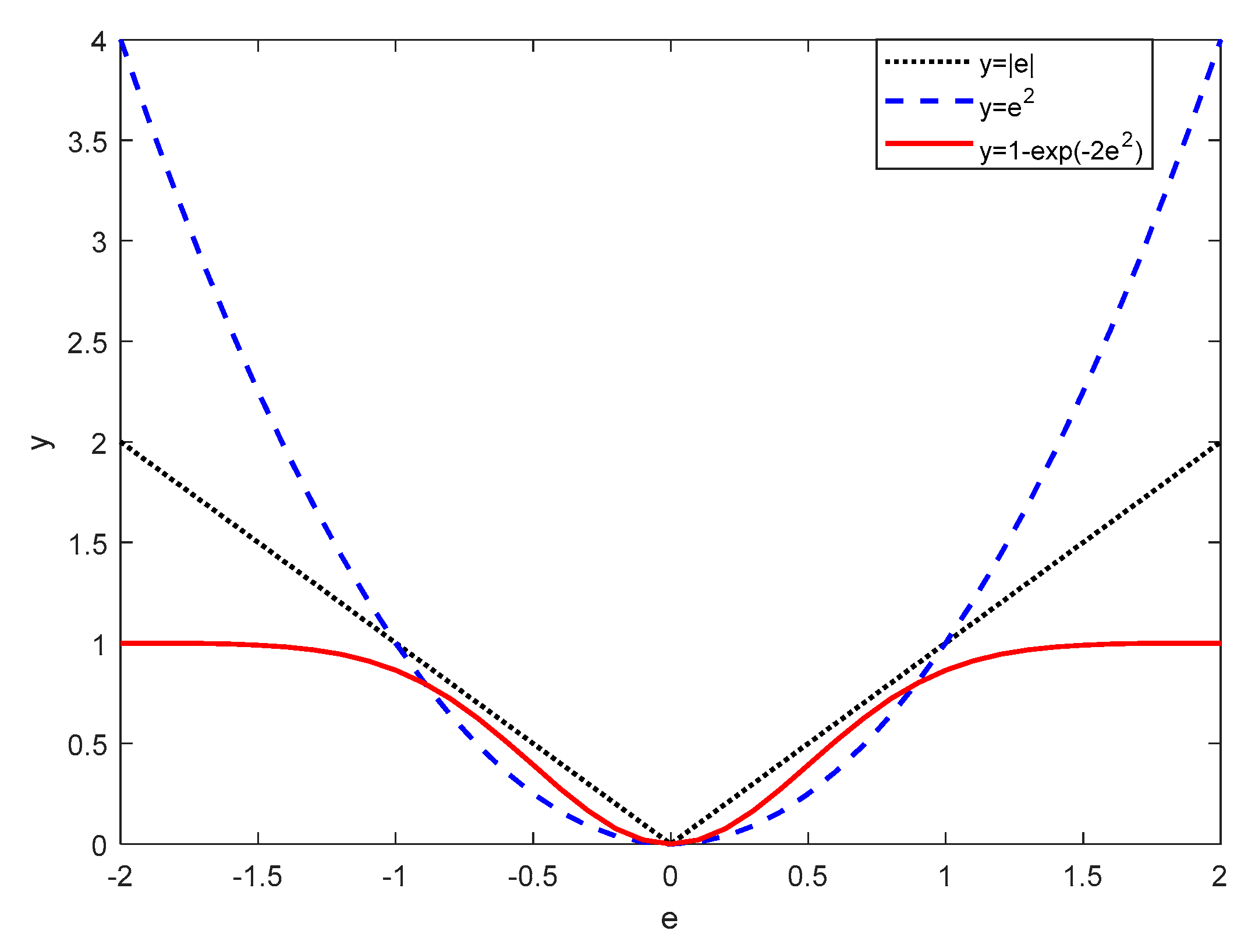
2.3. Error Estimation
3. Correntropy-Induced Discriminative Nonnegative Sparse Coding
3.1. Cooperative Error Estimator
3.2. Discriminative Nonnegative Sparse Regularizer
3.3. Optimization of CDNSC
| Algorithm 1. Optimization of CDNSC via ADMM |
| Input:, and . |
| Output: The optimal , , , and . |
| Initialization:, . |
| Repeat |
| 1: ; |
| 2: Estimate weight matrix by (17) and (20); |
| Update: and . |
| Initialization:, , , , , and . |
| Repeat |
| 3: ; |
| 4: Estimate by (43); |
| 5: Update by (32); |
| 6: Estimate by (45); |
| 7: Estimate by (48); |
| 8: Update , , , and by (38), (39), (40), and (41); |
| 9: Check the termination criterion by (49); |
| Until convergence |
| 11: |
| Until |
3.4. Extended CDNSC
| Algorithm 2. Optimization of (53) via CPSO |
| Input:, and |
| Output: The optimal |
| Initialization:, particle swarm |
| Repeat |
| 1: Calculate the fitness value of each individual in on (53); |
| 2: Find the individual in with least fitness value; |
| 3: ; |
| 4: ; |
| 5: Reproduce particle swarm around ; |
| 6: Update by (55); |
| 7: Check the termination criterion by (54); |
| Until convergence |
4. Analysis of CDNSC
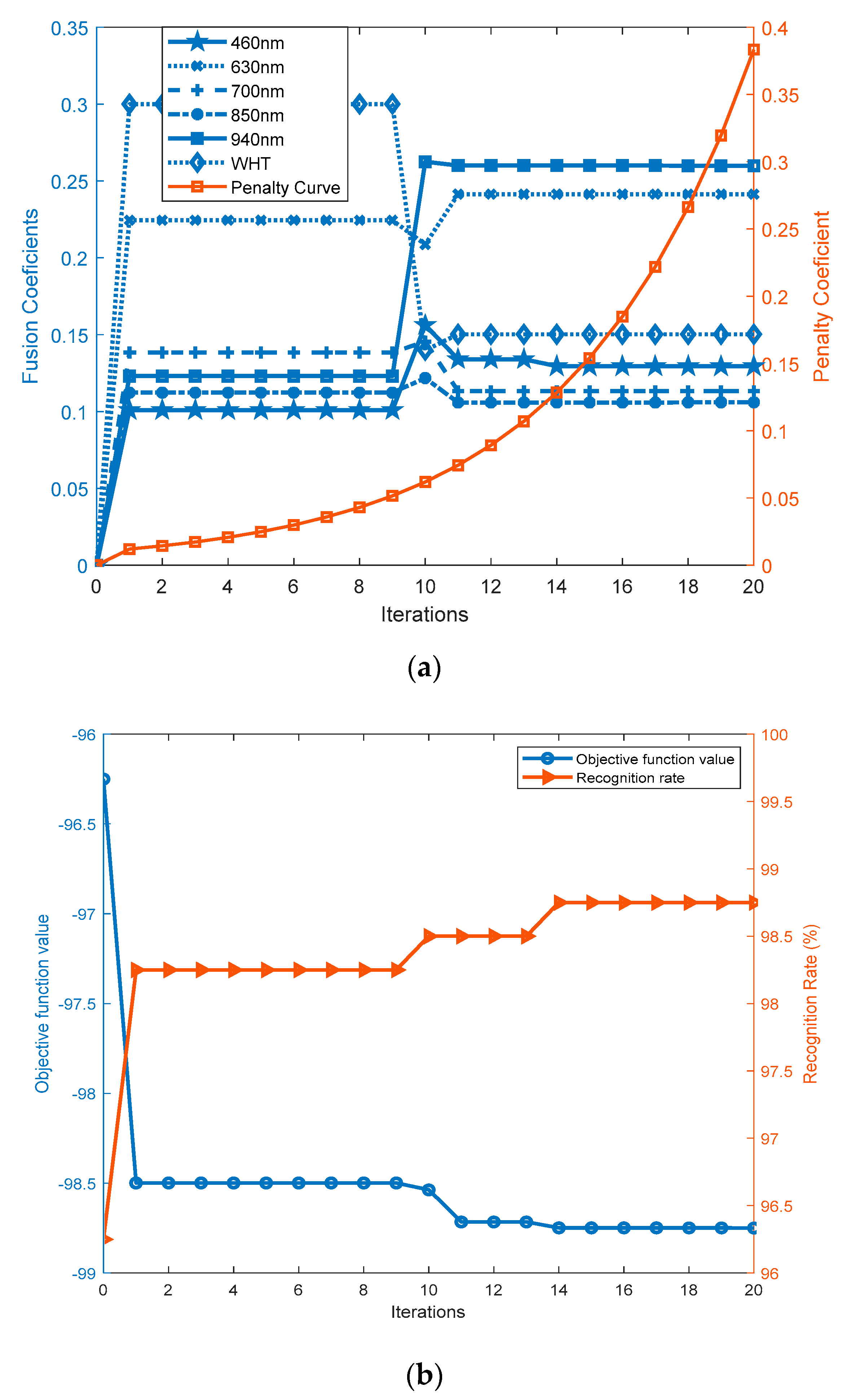
4.1. Complexity and Convergence of CDNSC
4.2. Positive Effect of DNSR to CEE
5. Experiments
5.1. Experimental Settings
5.1.1. CASIA Database
5.1.2. PolyU Database
5.1.3. Compared Methods
5.1.4. Parameter Settings and Experimental Platform
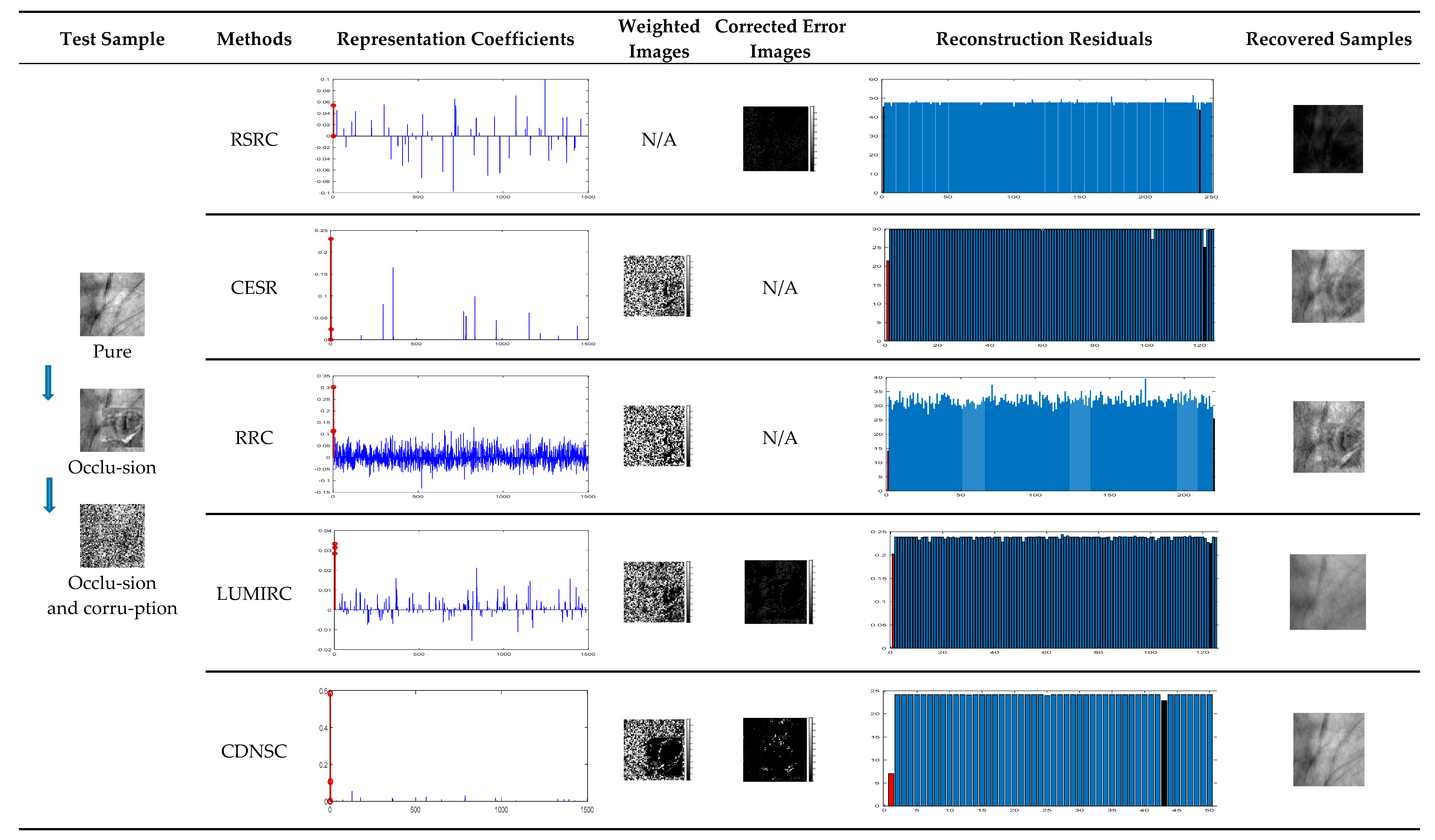
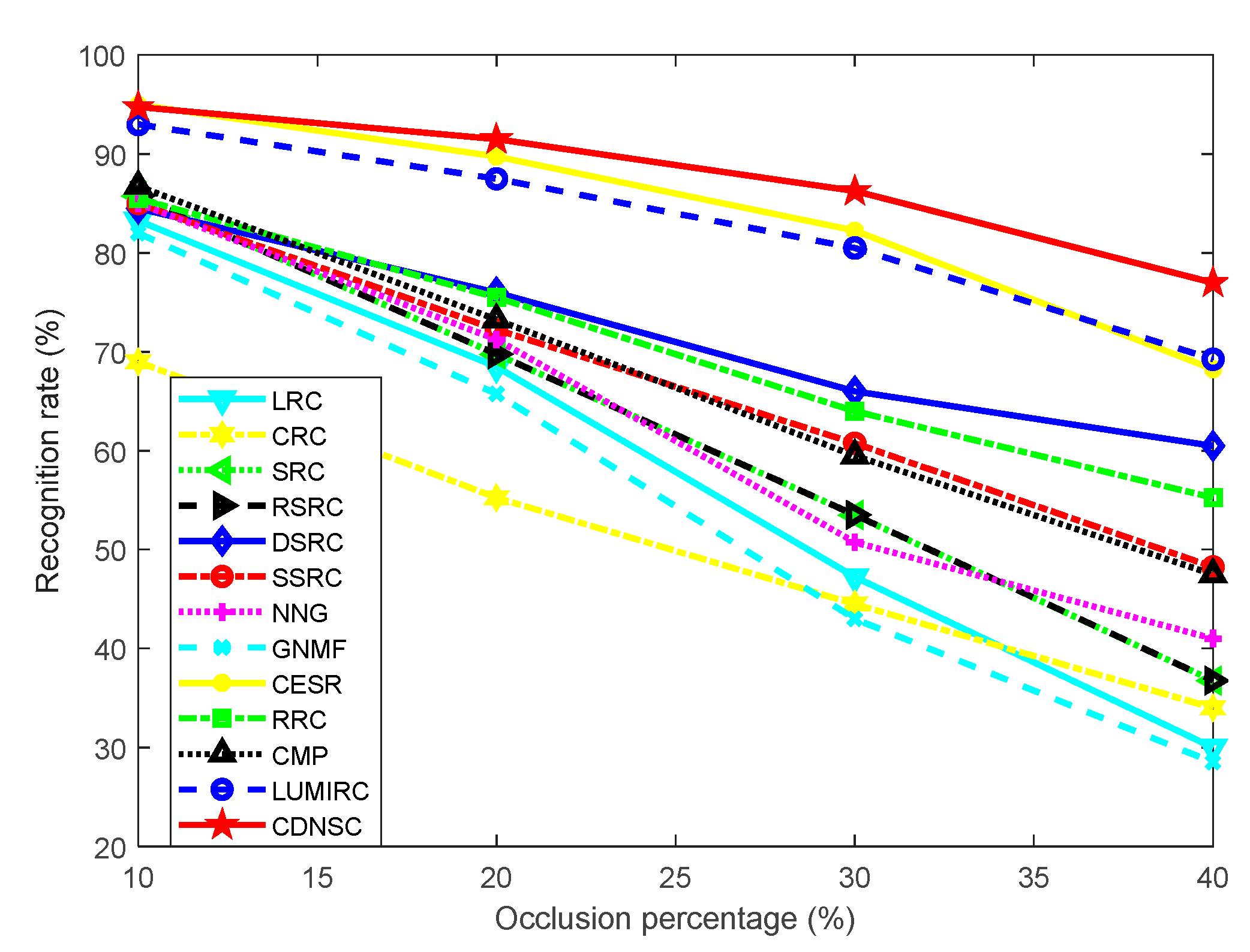
5.2. Robust Contactless Palmprint Recognition
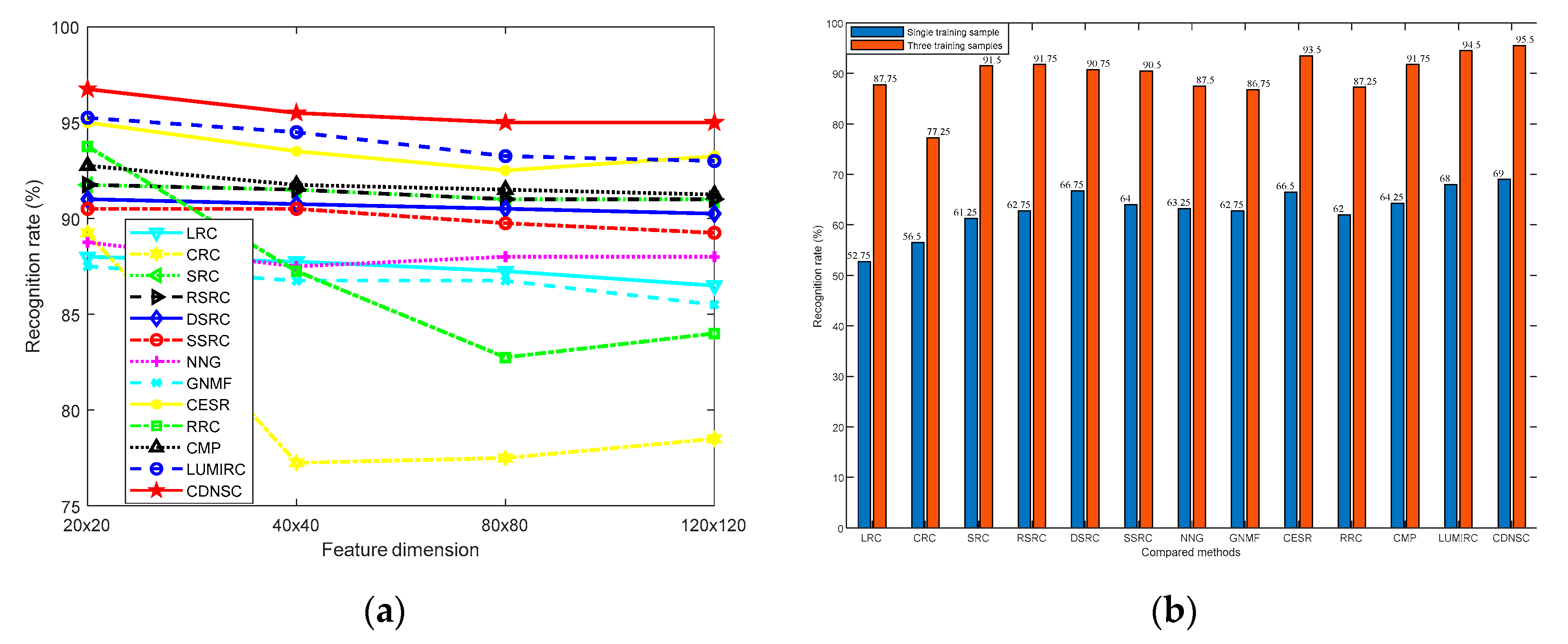
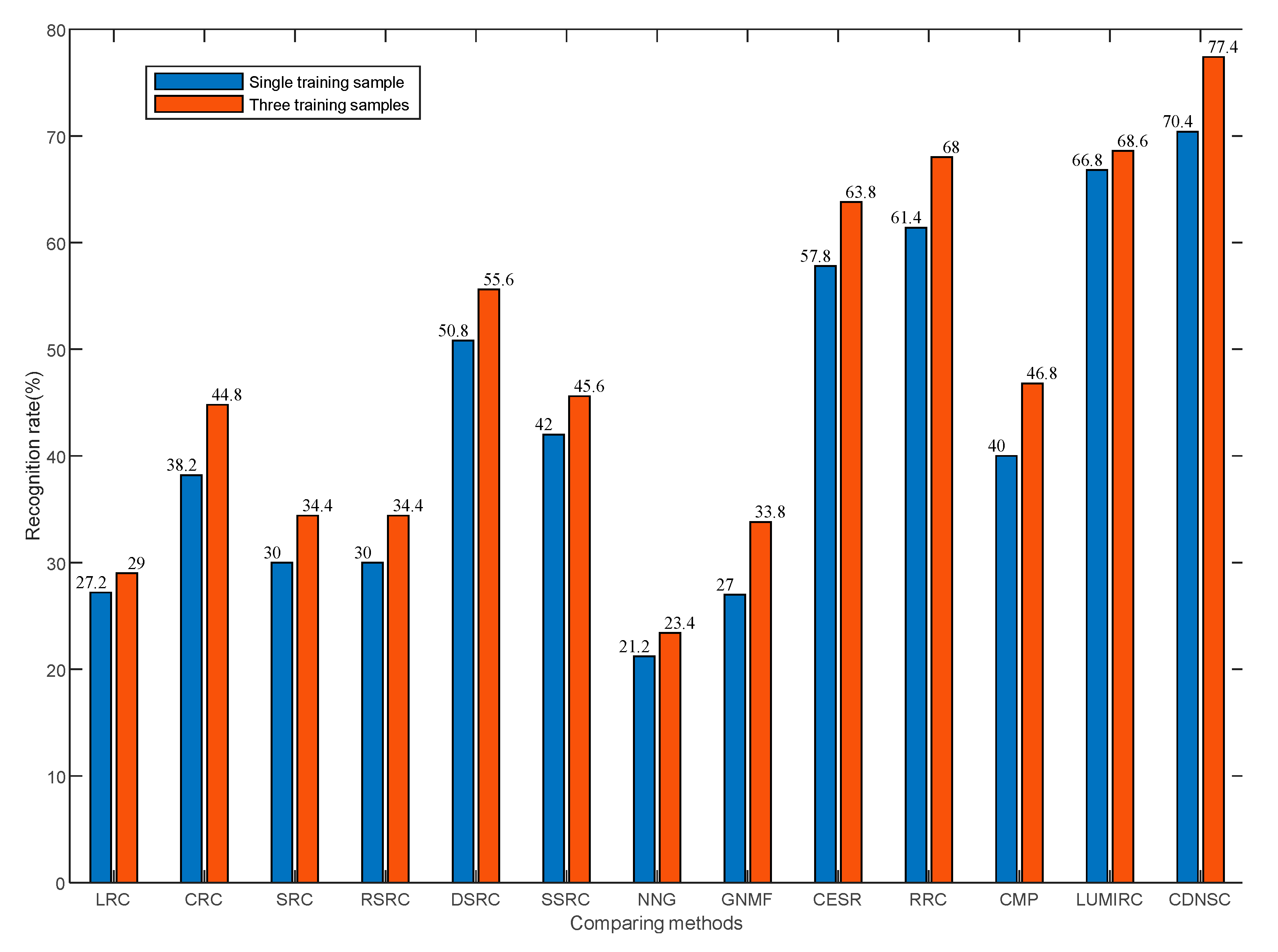
5.2.1. Dimension and Number of Training Samples
5.2.2. Continuous Scar Occlusion
5.2.3. Dense Corruption and the Mixed-Contaminations
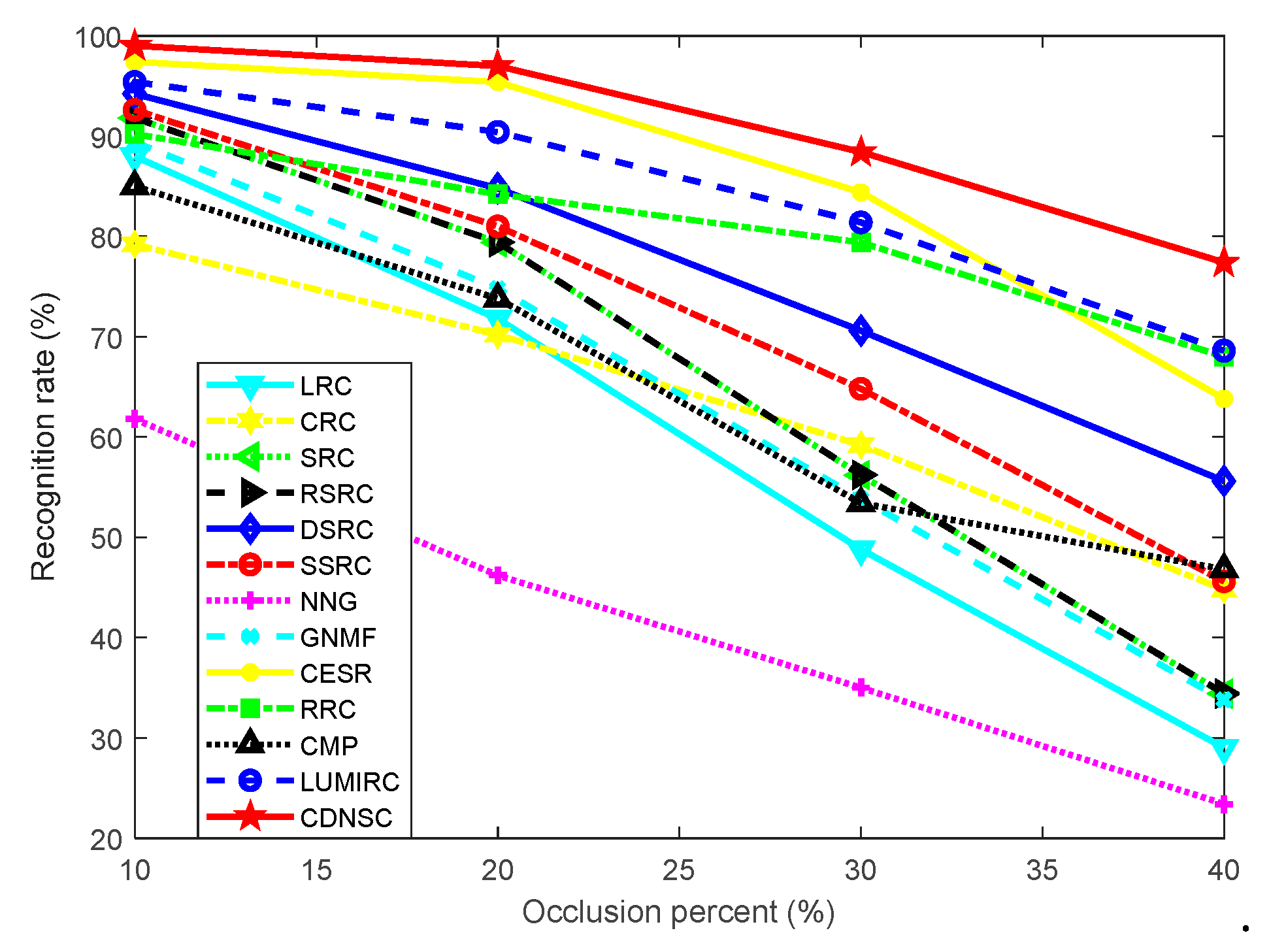
5.3. Robust Contact-Based Palmprint Recognition
5.3.1. Continuous Camera Lens Occlusion
5.3.2. Training Sample Number
5.3.3. Dense Corruption and the Mixed-Contaminations
5.4. Comparison of Running Times
5.5. Multispectral Contactless and Contact-Based Palmprint Recognitions
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Acronym Definitions
| Acronym | Definition | Acronym | Definition |
| ADMM | Alternating direction method of multipliers | KKT | Karush-Kuhn-Tucker |
| CDNSC | Correntropy-induced Discriminative nonnegative sparse coding | LAR | Least angle regression |
| CEE | Cooperative error estimator | LRC | Linear regression classifier |
| CESR | Correntropy-based sparse representation | LUMIRC | Laplacian-uniform mixture driven iterative robust coding |
| CIM | Correntropy-induced metric | MSE | Mean squared error |
| CMP | Correntropy matching pursuit | NMF | Nonnegative matrix factorization |
| CPSO | Constrained PSO | NMR | Nuclear norm-based matrix regression |
| CRC | Collaborative representation classifier | NNG | Nonnegative garrote |
| DNSR | Discriminative nonnegative sparse regularizer | Probability densities functions | |
| DSRC | Discriminative SRC | RRC | Regularized robust coding |
| E-CDNSC | Extended CDNSC | RSC | Robust sparse coding |
| ECP | Equality constraint problem | RSRC | robust SRC |
| GNMF | Graph regularized nonnegative matrix factorization | SRC | Sparse representation classifier |
| HQ | Half-quadratic | SSRC | Superposed SRC |
| ICP | Inequality constraint problem | TPNMF | Topology-preserving nonnegative matrix factorization |
Appendix A
Proof of Proposition 1
Appendix B
Proof of Lemma 1
Appendix C
Proof of Proposition 2
References
- Zhang, L.; Li, L.; Yang, A.; Shen, Y.; Yang, M. Towards contactless palmprint recognition: A novel device, a new benchmark, and a collaborative representation based identification approach. Pattern Recognit. 2017, 69, 199–212. [Google Scholar] [CrossRef]
- Fei, L.; Lu, G.; Jia, W.; Teng, S.; Zhang, D. Feature Extraction Methods for Palmprint Recognition: A Survey and Evaluation. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 346–363. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, B. Learning Salient and Discriminative Descriptor for Palmprint Feature Extraction and Identification. Available online: https://ieeexplore.ieee.org/document/8976291 (accessed on 3 January 2020).
- Jing, X.; Zhang, D. A face and palmprint recognition approach based on discriminant DCT feature extraction. IEEE Trans. Syst., Man, Cybern. B Cybern. 2004, 34, 2405–2415. [Google Scholar] [CrossRef] [PubMed]
- Huang, D.; Jia, W.; Zhang, D. Palmprint verification based on principal lines. Pattern Recognit. 2008, 41, 1316–1328. [Google Scholar] [CrossRef]
- Hennings-Yeomans, P.; Kumar, B.; Savvides, M. Palmprint classification using multiple advanced correlation filters and palmspecific segmentation. IEEE Trans. Inf. Fore. Secur. 2007, 2, 613–622. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, L.; Tan, T. Ordinal feature selection for iris and palmprint recognition. IEEE Trans. Image Process. 2014, 23, 3922–3934. [Google Scholar] [CrossRef]
- Fei, L.; Zhang, B.; Zhang, W.; Teng, S. Local apparent and latent direction extraction for palmprint recognition. Inf. Sci. 2019, 473, 59–72. [Google Scholar] [CrossRef]
- Fei, L.; Zhang, B.; Xu, Y.; Yan, L. Palmprint Recognition Using Neighboring Direction Indicator. IEEE Trans. Hum. Mach. Syst. 2016, 46, 787–798. [Google Scholar] [CrossRef]
- Lu, G.; Zhang, D.; Wang, K. Palmprint recognition using eigenpalms features. Pattern Recognit. Lett. 2003, 24, 1463–1467. [Google Scholar] [CrossRef]
- Yang, J.; Frangi, A.; Yang, J.; Zhang, D.; Jin, Z. KPCA plus LDA: A complete kernel Fisher discriminant framework for feature extraction and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 230–244. [Google Scholar] [CrossRef]
- Hu, D.; Feng, G.; Zhou, Z. Two-dimensional locality preserving projections (2DLPP) with its application to palmprint recognition. Pattern Recognit. 2007, 40, 339–342. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, B. Deep discriminative representation for generic palmprint recognition. Pattern Recognit. 2020, 98, 107071. [Google Scholar] [CrossRef]
- Wu, X.; Zhao, Q.; Bu, W. A SIFT-based contactless palmprint verification approach using iterative RANSAC and local palmprint descriptors. Pattern Recognit. 2014, 47, 3314–3326. [Google Scholar] [CrossRef]
- Jia, W.; Hu, R.; Lei, Y.; Zhao, Y.; Gui, J. Histogram of oriented lines for palmprint recognition. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 385–395. [Google Scholar] [CrossRef]
- Zheng, Q.; Kumar, A.; Pan, G. A 3D feature descriptor recovered from a single 2D palmprint image. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1272–1279. [Google Scholar] [CrossRef] [PubMed]
- Fei, L.; Zhang, B.; Xu, Y.; Guo, Z.; Wen, J.; Jia, W. Learning discriminant direction binary palmprint descriptor. IEEE Trans. Image Process. 2019, 28, 3808–3820. [Google Scholar] [CrossRef]
- Fei, L.; Zhang, B.; Xu, Y.; Huang, D.; Jia, W.; Wen, J. Local Discriminant Direction Binary Pattern for Palmprint Representation and Recognition. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 468–481. [Google Scholar] [CrossRef]
- Hong, D.; Liu, W.; Wu, X.; Pan, Z.; Su, J. Robust Palmprint Recognition based on the Fast Variation Vese-Osher Model. Neurocomputing 2016, 174, 999–1012. [Google Scholar] [CrossRef]
- Zheng, J.; Lou, K.; Yang, X.; Bai, C.; Tang, J. Weighted Mixed-Norm Regularized Regression for Robust Face Identification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3788–3802. [Google Scholar] [CrossRef]
- Naseem, I.; Togneri, R.; Bennamoun, M. Linear regression for face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2106–2112. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.; Ganesh, A.; Sastry, S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Yang, M.; Feng, X. Sparse representation or collaborative representation: Which helps face recognition? In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 471–478. [Google Scholar]
- Huang, J.; Nie, F.; Huang, H.; Ding, C. Supervised and projected sparse coding for image Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013; pp. 438–444. [Google Scholar]
- Xu, Y.; Zhong, Z.; Yang, J.; You, J.; Zhang, D. A New Discriminative Sparse Representation Method for Robust Face Recognition via l2 Regularization. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2233–2242. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Hu, J.; Guo, J. In defense of sparsity based face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 399–406. [Google Scholar]
- Yang, M.; Zhang, L.; Yang, J.; Zhang, D. Robust sparse coding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 625–632. [Google Scholar]
- Yang, M.; Zhang, L.; Yang, J.; Zhang, D. Regularized robust coding for face recognition. IEEE Trans. Image Process. 2013, 22, 1753–1766. [Google Scholar] [CrossRef] [PubMed]
- He, R.; Zheng, W.; Hu, B. Maximum correntropy criterion for robust face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1561–1576. [Google Scholar] [PubMed]
- Wang, Y.; Tang, Y.; Li, L. Correntropy Matching Pursuit with Application to Robust Digit and Face Recognition. IEEE Trans. Cybern. 2016, 47, 1354–1366. [Google Scholar] [CrossRef] [PubMed]
- Jing, K.; Zhang, X.; Xu, X. An overview of multimode biometric recognition technology. In Proceedings of the IEEE Conference on Information Technology, Hong Kong, China, 29–31 December 2018; pp. 168–172. [Google Scholar]
- He, R.; Zheng, W.; Tan, T.; Sun, Z. Half-quadratic-based iterative minimization for robust sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 261–275. [Google Scholar]
- Zheng, H.; Lin, D.; Lian, L.; Dong, J.; Zhang, P. Laplacian-Uniform Mixture-Driven Iterative Robust Coding with Applications to Face Recognition Against Dense Errors. Available online: https://ieeexplore.ieee.org/document/8891717 (accessed on 6 January 2020).
- Zhang, D.; Guo, Z.; Lu, G.; Zhang, L. An online system of multispectral palmprint verification. IEEE Trans. Instrum. Meas. 2010, 59, 480–490. [Google Scholar] [CrossRef]
- Raghavendra, R.; Busch, C. Novel image fusion scheme based on dependency measure for robust multispectral palmprint recognition. Pattern Recognit. 2014, 47, 2205–2221. [Google Scholar] [CrossRef]
- Bounneche, M.; Boubchir, L.; Bouridane, A.; Nekhoul, B.; Alicherif, A. Multi-spectral palmprint recognition based on oriented multiscale log-Gabor filters. Neurocomputing 2016, 205, 274–286. [Google Scholar] [CrossRef]
- Zhou, N.; Xu, Y.; Cheng, H.; Yuan, Z.; Chen, B. Maximum Correntropy Criterion-Based Sparse Subspace Learning for Unsupervised Feature Selection. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 404–416. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.; Principe, J. Correntropy: Properties and Applications in Non-Gaussian Signal Processing. IEEE Trans. Signal Process. 2007, 55, 5286–5299. [Google Scholar] [CrossRef]
- Charbonnier, P.; Blanc-Feraud, L.; Aubert, G.; Barlaud, M. Deterministic edge-preserving regularization in computed imaging. IEEE Trans. Image Process. 1997, 6, 298–311. [Google Scholar] [CrossRef] [PubMed]
- Shastri, B.; Levine, M. Face recognition using localized features based on nonnegative sparse coding. IEEE Trans. Image Process. 2006, 18, 107–122. [Google Scholar]
- Kawakami, R.; Wright, J.; Tai, Y.; Matsushita, Y.; Ben-Ezra, M.; Ikeuchi, K. High-resolution hyperspectral imaging via matrix factorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 2329–2336. [Google Scholar]
- Donoho, D. For Most Large Underdetermined Systems of Linear Equations the Minimal l1-Norm Solution Is Also the Sparsest Solution. Comm. Pure. Appl. Math. 2006, 59, 797–829. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the LASSO. J. R. Stat. Soc. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least Angle Regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar]
- Liu, Y.; Wu, F.; Zhang, Z.; Zhang, Y.; Yan, S. Sparse representation using nonnegative curds and whey. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3578–3585. [Google Scholar]
- Zhang, T.; Fang, B.; Tang, Y.; He, G.; Wen, J. Topology Preserving Nonnegative Matrix Factorization for Face Recognition. IEEE Trans. Image Process. 2008, 17, 574–586. [Google Scholar] [CrossRef]
- Zhang, B.; Mu, Z.; Li, C.; Zeng, H. Robust classification for occluded ear via Gabor scale feature-based nonnegative sparse representation. Opt. Eng. 2014, 53, 1548–1561. [Google Scholar]
- Ji, Y.; Lin, F.; Zha, H. Mahalanobis Distance Based Nonnegative Sparse Representation for Face Recognition. In Proceedings of the IEEE Conference on Machine Learning Application, Miami Beach, FL, USA, 13–15 December 2009; pp. 41–46. [Google Scholar]
- Breiman, L. Better subset regression using the nonnegative garrote. Technometrics 1995, 37, 373–384. [Google Scholar] [CrossRef]
- Nikolova, M. Analysis of half-quadratic minimization methods for signal and image recovery. SIAM J. Sci. Comput. 2005, 27, 937–966. [Google Scholar] [CrossRef]
- Lu, C.; Tang, J.; Lin, M.; Lin, L.; Yan, S.; Lin, Z. Correntropy Induced L2 Graph for Robust Subspace Clustering. In Proceedings of the IEEE Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1801–1808. [Google Scholar]
- Cai, D.; He, X.; Han, J.; Thomas, S. Graph Regularized Nonnegative Matrix Factorization for Data Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 30, 1548–1561. [Google Scholar]
- Bertsekas, D. Nonlinear Programming. Athena Sci. 1999, 277–315. [Google Scholar] [CrossRef]
- Wimalajeewa, T.; Jayaweera, S. Optimal Power Scheduling for Correlated Data Fusion in Wireless Sensor Networks via Constrained PSO. IEEE Trans. Wirel. Commun. 2008, 7, 3608–3618. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Hao, Y.; Sun, Z.; Tan, T. Comparative Studies on Multispectral Palm Image Fusion for Biometrics. In Proceedings of the Asian Conferernce on Computer Vision, Tokyo, Japan, 18–22 November 2007; pp. 12–21. [Google Scholar]
- Zhang, D.; Kong, W.; You, J.; Wong, M. Online palmprint identification. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1041–1050. [Google Scholar] [CrossRef]
- The Matlab Source Code. Available online: http://www.openpr.org.cn/index/php/All/69-CESR/View-detials.html (accessed on 29 July 2020).
- Non-Negative Matrix Factoriaztion on Manifold (Graph). Available online: http://www.cad.zju.edu.cn/home/dengcai/Data/GNMF.html (accessed on 29 July 2020).
- The Matlab Source Code. Available online: http://www.comp.polyu.edu.hk/ cslzhang/code.html (accessed on 29 July 2020).
- Laplacian-Uniform Mixture-Driven Iterative Robust Coding With Applications to Face Recognition Against Dense Errors. Available online: https://github.com/sysuzhc/LUMIRC (accessed on 29 July 2020).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Corruption (50%) | Mixture (10%) | Mixture (20%) | Mixture (30%) | Mixture (40%) |
|---|---|---|---|---|---|
| LRC | 34.5 | 79.75 | 59 | 27 | 8.5 |
| CRC | 3.5 | 27 | 11 | 4.25 | 3 |
| SRC | 43.75 | 85.25 | 67.5 | 37 | 12 |
| RSRC | 48.25 | 86 | 68.75 | 40.5 | 19.75 |
| DSRC | 43 | 81.75 | 65.75 | 47.25 | 24 |
| SSRC | 53.25 | 83.25 | 69.5 | 52.75 | 28 |
| NNG | 6.25 | 55.75 | 22 | 8.25 | 3.75 |
| GNMF | 18 | 72.5 | 43.25 | 16.75 | 7.25 |
| CESR | 83 | 92.75 | 88.75 | 78.25 | 55.75 |
| RRC | 62.5 | 74.25 | 63.25 | 58 | 50.75 |
| CMP | 38.5 | 91.75 | 85.5 | 76.75 | 34 |
| LUMIRC | 90 | 92 | 87.5 | 80.5 | 68.5 |
| CDNSC | 94.75 | 94.5 | 90.5 | 85 | 75.25 |
| Method | Corruption (50%) | Mixture (10%) | Mixture (20%) | Mixture (30%) | Mixture (40%) |
|---|---|---|---|---|---|
| LRC | 27 | 85.2 | 55.8 | 19.6 | 5.8 |
| CRC | 3.8 | 16.8 | 6.8 | 2.6 | 1.4 |
| SRC | 51.8 | 92.2 | 79.2 | 43 | 13.4 |
| RSRC | 56.4 | 92.8 | 80.4 | 46.2 | 20.2 |
| DSRC | 46.4 | 91.8 | 77.6 | 47.6 | 14.4 |
| SSRC | 59.6 | 93 | 81.6 | 56.6 | 23.8 |
| NNG | 5.6 | 50.6 | 21.6 | 6.4 | 2.8 |
| GNMF | 11.8 | 79.8 | 39.6 | 13.4 | 3.6 |
| CESR | 90.2 | 97.8 | 93.2 | 80 | 52.2 |
| RRC | 58.6 | 73.2 | 55.6 | 44.6 | 37 |
| CMP | 43 | 97 | 92.8 | 82 | 38.6 |
| LUMIRC | 94.2 | 94.2 | 88.6 | 76.2 | 63 |
| CDNSC | 97.6 | 97.8 | 95.2 | 86.5 | 75.4 |
| Method | CASIA Database | PolyU Database | ||
|---|---|---|---|---|
| Palm Scar Occlusion (40%) | Mixture (40%) | Camera Lens Occlusion (40%) | Mixture (40%) | |
| LRC | 0.0002885 | 0.0002950 | 0.001936 | 0.002198 |
| CRC | 0.0001210 | 0.0001185 | 0.0007160 | 0.0007155 |
| SRC | 0.0498 | 0.0702 | 0.1723 | 0.1932 |
| RSRC | 0.1963 | 0.1997 | 0.2881 | 0.2983 |
| DSRC | 0.0005825 | 0.0005855 | 0.004967 | 0.005208 |
| SSRC | 0.07915 | 0.0894 | 0.2135 | 0.2192 |
| NNG | 0.7897 | 0.9998 | 12.9199 | 16.7413 |
| GNMF | 0.02232 | 0.02551 | 0.1554 | 0.1582 |
| CESR | 0.1939 | 0.1953 | 0.5578 | 0.4518 |
| RRC | 0.5808 | 1.2743 | 4.1873 | 8.1859 |
| CMP | 0.9250 | 0.9514 | 3.1124 | 3.2647 |
| LUMIRC | 0.6391 | 0.5990 | 2.6096 | 2.6455 |
| CDNSC | 0.4452 | 0.4484 | 2.3214 | 2.5753 |
| Spectrum | Pure | Occlusion (40%) | Corruption (50%) | Mixture (40%) |
|---|---|---|---|---|
| 460 | 95.5 | 77 | 94.75 | 75.25 |
| 630 | 95 | 73.75 | 94.5 | 71.25 |
| 700 | 93.25 | 68.5 | 92.25 | 68.25 |
| 850 | 93.5 | 71.25 | 92 | 70.75 |
| 940 | 96.25 | 77.25 | 94.75 | 74.5 |
| WHT | 93.75 | 75 | 93.25 | 72 |
| Multi-spectrum | 98.5 | 89.25 | 97.75 | 85.75 |
| Spectrum | Pure | Occlusion (40%) | Corruption (50%) | Mixture (40%) |
|---|---|---|---|---|
| Blue | 99.25 | 77.4 | 97.6 | 75.4 |
| Green | 97.8 | 76 | 95.8 | 73.2 |
| Nir | 98.8 | 78.8 | 96.8 | 73.8 |
| Red | 97.6 | 75.4 | 96.2 | 72.2 |
| Multi-spectrum | 99.8 | 91.2 | 99.2 | 87.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, K.; Zhang, X.; Song, G. Correntropy-Induced Discriminative Nonnegative Sparse Coding for Robust Palmprint Recognition. Sensors 2020, 20, 4250. https://doi.org/10.3390/s20154250
Jing K, Zhang X, Song G. Correntropy-Induced Discriminative Nonnegative Sparse Coding for Robust Palmprint Recognition. Sensors. 2020; 20(15):4250. https://doi.org/10.3390/s20154250
Chicago/Turabian StyleJing, Kunlei, Xinman Zhang, and Guokun Song. 2020. "Correntropy-Induced Discriminative Nonnegative Sparse Coding for Robust Palmprint Recognition" Sensors 20, no. 15: 4250. https://doi.org/10.3390/s20154250
APA StyleJing, K., Zhang, X., & Song, G. (2020). Correntropy-Induced Discriminative Nonnegative Sparse Coding for Robust Palmprint Recognition. Sensors, 20(15), 4250. https://doi.org/10.3390/s20154250