Robust and Efficient Indoor Localization Using Sparse Semantic Information from a Spherical Camera


 ,
,  ,
,  and
and
Abstract
1. Introduction
- It is based on the idea that semantic information, even in sparse amounts, provides more information gain, reduces uncertainty more efficiently than other input formats and can be used directly in the sensor model for efficient localization.
- It uses a large-FOV camera that is robust to the blocked view problem in indoor environments, where the users generally move close to objects and walls.
- It uses a minimal human-level data representation such that, given a 2D blueprint of the environment, users can easily prepare annotated maps by simply marking the approximate object centers on the blueprint. The localization method is robust to possible geometrical errors arising from approximations and minor mistakes during map preparation.
2. Related Works
3. Sparse Semantic Localization
3.1. Approach
3.2. Sparse Semantic Information
3.3. Localization
3.3.1. Sensor Model
3.3.2. Motion
4. Experiments
4.1. Environment
4.2. Ground Truth
4.3. Sensors
4.4. Experimental Setting
4.5. Results
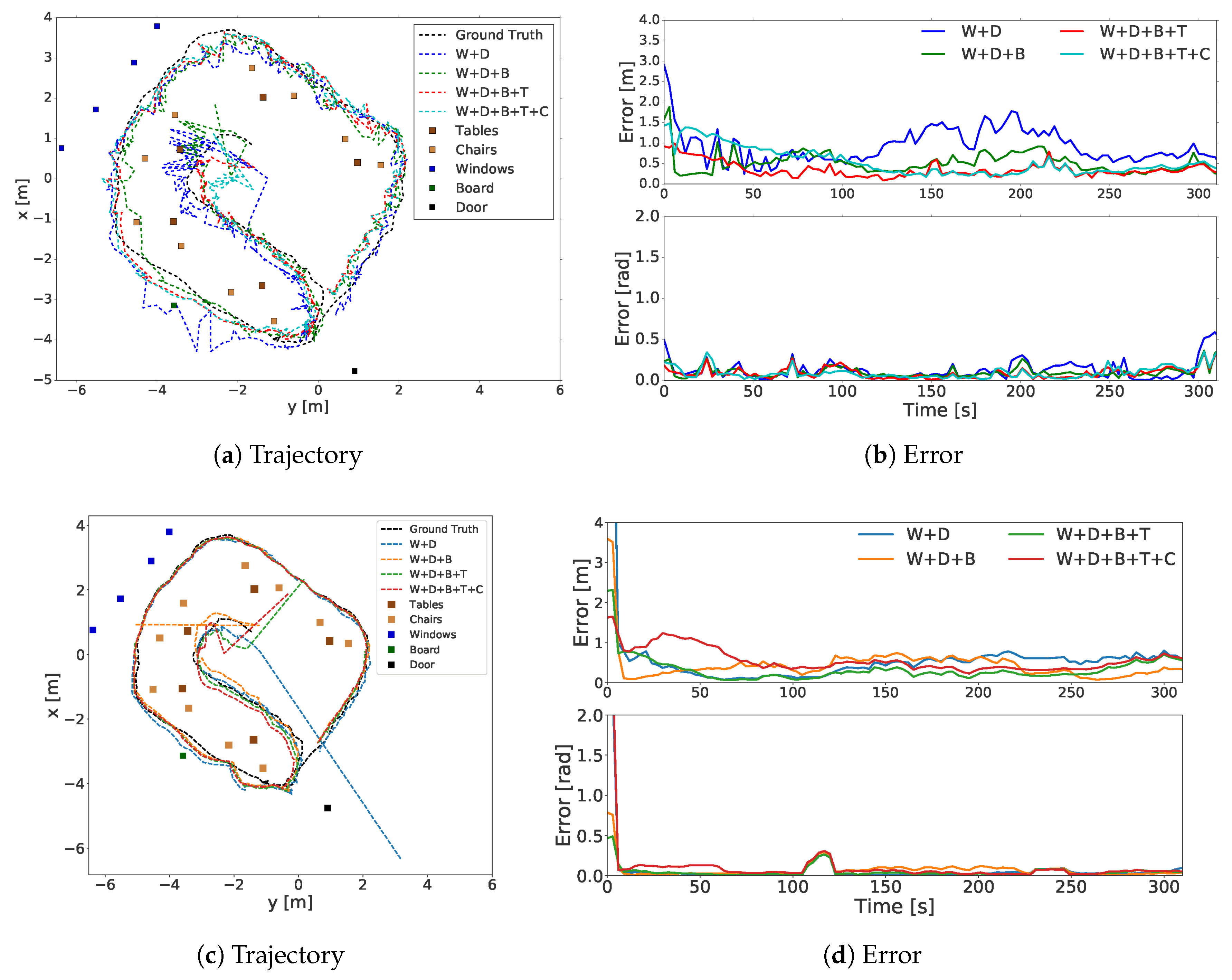
4.5.1. Robustness to Crude Maps and Partial View Blockages
4.5.2. Robustness to Different Object Classes
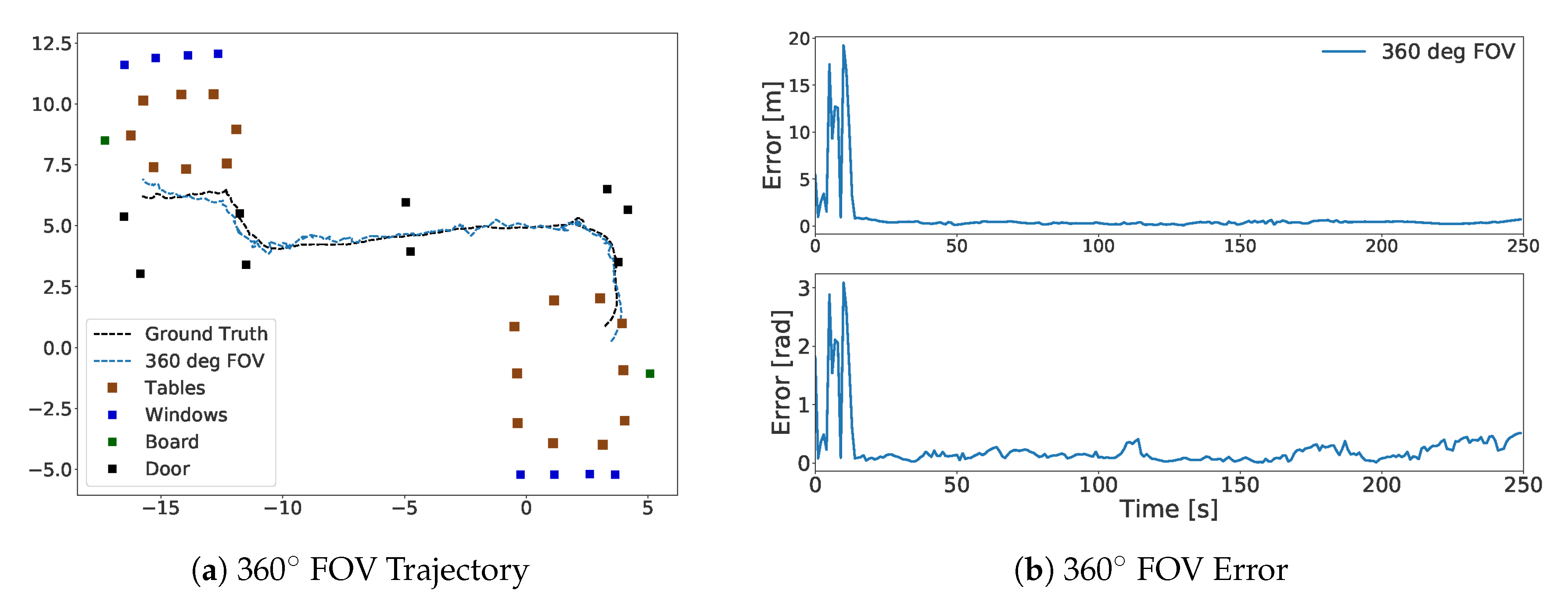
4.5.3. Relocalization
4.5.4. Symmetric Rooms
4.5.5. Efficiency
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MCL | Monte Carlo Localization |
| IMU | Inertial Measurement Unit |
| FOV | Field of View |
References
- López-de Ipiña, D.; Lorido, T.; López, U. Indoor Navigation and Product Recognition for Blind People Assisted Shopping. In International Workshop on Ambient Assisted Living; Springer: Berlin/Heidelberg, Germany, 2011; pp. 33–40. [Google Scholar]
- Wang, J.; Takahashi, Y. Indoor Mobile Robot Self-Localization Based on a Low-Cost Light System with a Novel Emitter Arrangement. ROBOMECH J. 2018, 5, 17. [Google Scholar] [CrossRef]
- Yayan, U.; Yucel, H.; Yazici, A. A Low Cost Ultrasonic Based Positioning System for the Indoor Navigation of Mobile Robots. J. Intell. Robot. Syst. 2015, 78, 541–552. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, Y.; Lv, Q.; Deveerasetty, K.K. A Review of V-SLAM*. In Proceedings of the 2018 IEEE International Conference on Information and Automation (ICIA), Wuyishan, China, 11–13 August 2018; pp. 603–608. [Google Scholar]
- Gil, A.; Reinoso, Ó.; Vicente, A.; Fernández, C.; Payá, L. Monte Carlo Localization Using SIFT Features. In Pattern Recognition and Image Analysis; Marques, J.S., Pérez de la Blanca, N., Pina, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 623–630. [Google Scholar]
- Menegatti, E.; Pretto, A.; Pagello, E. A New Omnidirectional Vision Sensor for Monte-Carlo Localization. In Robot Soccer World Cup; Springer: Berlin/Heidelberg, Germany, 2004; pp. 97–109. [Google Scholar]
- Gross, H.; Koenig, A.; Boehme, H.; Schroeter, C. Vision-based Monte Carlo Self-Localization for a Mobile Service Robot Acting as Shopping Assistant in a Home Store. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Lausanne, Switzerland, 30 September–4 October 2002; Volume 1, pp. 256–262. [Google Scholar]
- Winterhalter, W.; Fleckenstein, F.; Steder, B.; Spinello, L.; Burgard, W. Accurate Indoor Localization for RGB-D Smartphones and Tablets Given 2D Floor Plans. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 3138–3143. [Google Scholar] [CrossRef]
- Chu, H.; Ki Kim, D.; Chen, T. You Are Here: Mimicking the Human Thinking Process in Reading Floor-Plans. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2210–2218. [Google Scholar]
- Goto, T.; Pathak, S.; Ji, Y.; Fujii, H.; Yamashita, A.; Asama, H. Line-Based Global Localization of a Spherical Camera in Manhattan Worlds. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2296–2303. [Google Scholar]
- Andreasson, H.; Treptow, A.; Duckett, T. Localization for Mobile Robots Using Panoramic Vision, Local Features and Particle Filter. In Proceedings of the IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 3348–3353. [Google Scholar]
- Nüchter, A.; Hertzberg, J. Towards Semantic Maps for Mobile Robots. Robot. Auton. Syst. 2008, 56, 915–926. [Google Scholar] [CrossRef]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.; Davison, A.J. Slam++: Simultaneous Localisation and Mapping at the Level of Objects. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359. [Google Scholar]
- Schneider, T.; Dymczyk, M.; Fehr, M.; Egger, K.; Lynen, S.; Gilitschenski, I.; Siegwart, R. Maplab: An Open Framework for Research in Visual-Inertial Mapping and Localization. IEEE Robot. Autom. Lett. 2018, 3, 1418–1425. [Google Scholar] [CrossRef]
- Fioraio, N.; Di Stefano, L. Joint Detection, Tracking and Mapping by Semantic Bundle Adjustment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1538–1545. [Google Scholar]
- Yu, C.; Liu, Z.; Liu, X.J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual Slam Towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Atanasov, N.; Zhu, M.; Daniilidis, K.; Pappas, G.J. Semantic Localization Via the Matrix Permanent. In Proceedings of the Robotics: Science and Systems, Berkeley, CA, USA, 12–16 July 2014; Volume 2. [Google Scholar]
- Gawel, A.; Del Don, C.; Siegwart, R.; Nieto, J.; Cadena, C. X-View: Graph-Based Semantic Multi-View Localization. IEEE Robot. Autom. Lett. 2018, 3, 1687–1694. [Google Scholar] [CrossRef]
- Himstedt, M.; Maehle, E. Semantic Monte-Carlo Localization in Changing Environments Using RGB-D Cameras. In Proceedings of the 2017 European Conference on Mobile Robots (ECMR), Paris, France, 6–8 September 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Pöschmann, J.; Neubert, P.; Schubert, S.; Protzel, P. Synthesized Semantic Views for Mobile Robot Localization. In Proceedings of the 2017 European Conference on Mobile Robots (ECMR), Paris, France, 6–8 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Mendez, O.; Hadfield, S.; Pugeault, N.; Bowden, R. SeDAR: Reading Floorplans Like a Human—Using Deep Learning to Enable Human-Inspired Localisation. Int. J. Comput. Vis. 2020, 128, 1286–1310. [Google Scholar] [CrossRef]
- Jüngel, M.; Risler, M. Self-localization Using Odometry and Horizontal Bearings to Landmarks. In RoboCup 2007: Robot Soccer World Cup XI; Visser, U., Ribeiro, F., Ohashi, T., Dellaert, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 393–400. [Google Scholar]
- Stroupe, A.W.; Balch, T. Collaborative Probabilistic Constraint-based Landmark Localization. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Lausanne, Switzerland, 30 September–4 October 2002; Volume 1, pp. 447–453. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Dellaert, F.; Fox, D.; Burgard, W.; Thrun, S. Monte Carlo Localization for Mobile Robots. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Detroit, MI, USA, USA, 10–15 May 1999; Volume 2, pp. 1322–1328. [Google Scholar]
- Miyagusuku, R.; Yamashita, A.; Asama, H. Data Information Fusion From Multiple Access Points for WiFi-Based Self-localization. IEEE Robot. Autom. Lett. 2019, 4, 269–276. [Google Scholar] [CrossRef]
- Miyagusuku, R.; Yamashita, A.; Asama, H. Improving Gaussian Processes Based Mapping of Wireless Signals Using Path Loss Models. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, South Korea, 9–14 October 2016; pp. 4610–4615. [Google Scholar]
- He, M.; Zhu, C.; Huang, Q.; Ren, B.; Liu, J. A Review of Monocular Visual Odometry. Vis. Comput. 2020, 36, 1053–1065. [Google Scholar] [CrossRef]
- Yang, N.; Wang, R.; Gao, X.; Cremers, D. Challenges in Monocular Visual Odometry: Photometric Calibration, Motion Bias, and Rolling Shutter Effect. IEEE Robot. Autom. Lett. 2018, 3, 2878–2885. [Google Scholar] [CrossRef]
- Valenti, R.G.; Dryanovski, I.; Xiao, J. Keeping a Good Attitude: A Quaternion-based Orientation Filter for IMUs and MARGs. Sensors 2015, 15, 19302–19330. [Google Scholar] [CrossRef] [PubMed]
- Garrido-Jurado, S.; Muñoz-Salinas, R.; Madrid-Cuevas, F.; Marín-Jiménez, M. Automatic Generation and Detection of Highly Reliable Fiducial Markers Under Occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-Time Loop Closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Filipenko, M.; Afanasyev, I. Comparison of Various Slam systems for Mobile Robot in an Indoor Environment. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal, Portugal, 25–27 September 2018; pp. 400–407. [Google Scholar]
- Uygur, I.; Miyagusuku, R.; Pathak, S.; Moro, A.; Yamashita, A.; Asama, H. A Framework for Bearing-Only Sparse Semantic Self-Localization for Visually Impaired People. In Proceedings of the 2019 IEEE/SICE International Symposium on System Integration (SII), Paris, France, 14–16 January 2019; pp. 319–324. [Google Scholar]
- Behzadian, B.; Agarwal, P.; Burgard, W.; Tipaldi, G.D. Monte Carlo Localization in Hand-Drawn Maps. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4291–4296. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Localization Error | ||||||
|---|---|---|---|---|---|---|
| Map Noise | FOV | FOV | FOV | |||
| Error [m] | Error [rad] | Error [m] | Error [rad] | Error [m] | Error [rad] | |
| 0 | 0.62 ± 0.22 | 0.24 ± 0.22 | 0.49 ± 0.20 | 0.23 ± 0.23 | 0.36 ± 0.15 | 0.21 ± 0.24 |
| 0.1 | 0.67 ± 0.23 | 0.24 ± 0.22 | 0.47 ± 0.17 | 0.23 ± 0.22 | 0.38 ± 0.14 | 0.21 ± 0.24 |
| 0.3 | 0.72 ± 0.22 | 0.25 ± 0.22 | 0.52 ± 0.17 | 0.23 ± 0.23 | 0.45 ± 0.13 | 0.21 ± 0.23 |
| 0.5 | 0.87 ± 0.18 | 0.28 ± 0.20 | 0.66 ± 0.14 | 0.26 ± 0.22 | 0.67 ± 0.12 | 0.24 ± 0.21 |
| 0.7 | 1.05 ± 0.17 | 0.32 ± 0.19 | 0.83 ± 0.13 | 0.28 ± 0.19 | 0.74 ± 0.12 | 0.26 ± 0.21 |
| 1 | 1.32 ± 0.14 | 0.36 ± 0.18 | 1.09 ± 0.14 | 0.33 ± 0.18 | 1.21 ± 0.18 | 0.27 ± 0.21 |
| Localization Error of Different Object Classes | ||||
|---|---|---|---|---|
| Perception Models | W+D | W+D+B | W+D+B+T | W+D+B+T+C |
| Error (Tiny YOLO) [m] | 0.68 ± 0.30 | 0.50 ± 0.19 | 0.38 ± 0.16 | 0.37 ± 0.15 |
| Error (Tiny YOLO) [rad] | 0.24 ± 0.29 | 0.21 ± 0.25 | 0.21 ± 0.25 | 0.21 ± 0.25 |
| Error (Annotations) [m] | 0.40 ± 0.18 | 0.26 ± 0.16 | 0.21 ± 0.14 | 0.22 ± 0.15 |
| Error (Annotations) [rad] | 0.04 ± 0.08 | 0.04 ± 0.08 | 0.03 ± 0.07 | 0.04 ± 0.07 |
| Localization Error After Jump in Position | ||||||
|---|---|---|---|---|---|---|
| 1st Position | 2nd Position | 3rd Position | ||||
| Range | Error [m] | Error [rad] | Error [m] | Error [rad] | Error [m] | Error [rad] |
| 3 m | 0.37 ± 0.14 | 0.12 ± 0.11 | 0.38 ± 0.14 | 0.12 ± 0.11 | 0.39 ± 0.13 | 0.12 ± 0.11 |
| 5 m | 0.36 ± 0.14 | 0.12 ± 0.11 | 0.43 ± 0.13 | 0.12 ± 0.11 | 0.56 ± 0.14 | 0.12 ± 0.10 |
| 7 m | 0.37 ± 0.13 | 0.12 ± 0.11 | 0.41 ± 0.13 | 0.12 ± 0.11 | 0.53 ± 0.17 | 0.13 ± 0.10 |
| Localization Error: Symmetric Rooms | |
|---|---|
| Sensor Model | FOV with W+D+B+T |
| Error [m] | 0.38 ± 0.17 |
| Error [rad] | 0.17 ± 0.13 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uygur, I.; Miyagusuku, R.; Pathak, S.; Moro, A.; Yamashita, A.; Asama, H. Robust and Efficient Indoor Localization Using Sparse Semantic Information from a Spherical Camera. Sensors 2020, 20, 4128. https://doi.org/10.3390/s20154128
Uygur I, Miyagusuku R, Pathak S, Moro A, Yamashita A, Asama H. Robust and Efficient Indoor Localization Using Sparse Semantic Information from a Spherical Camera. Sensors. 2020; 20(15):4128. https://doi.org/10.3390/s20154128
Chicago/Turabian StyleUygur, Irem, Renato Miyagusuku, Sarthak Pathak, Alessandro Moro, Atsushi Yamashita, and Hajime Asama. 2020. "Robust and Efficient Indoor Localization Using Sparse Semantic Information from a Spherical Camera" Sensors 20, no. 15: 4128. https://doi.org/10.3390/s20154128
APA StyleUygur, I., Miyagusuku, R., Pathak, S., Moro, A., Yamashita, A., & Asama, H. (2020). Robust and Efficient Indoor Localization Using Sparse Semantic Information from a Spherical Camera. Sensors, 20(15), 4128. https://doi.org/10.3390/s20154128