Iterative Pose Refinement for Object Pose Estimation Based on RGBD Data


Abstract

1. Introduction
2. Related Works
2.1. RGB-Based Pose Estimation
2.2. RGBD-Based Pose Estimation
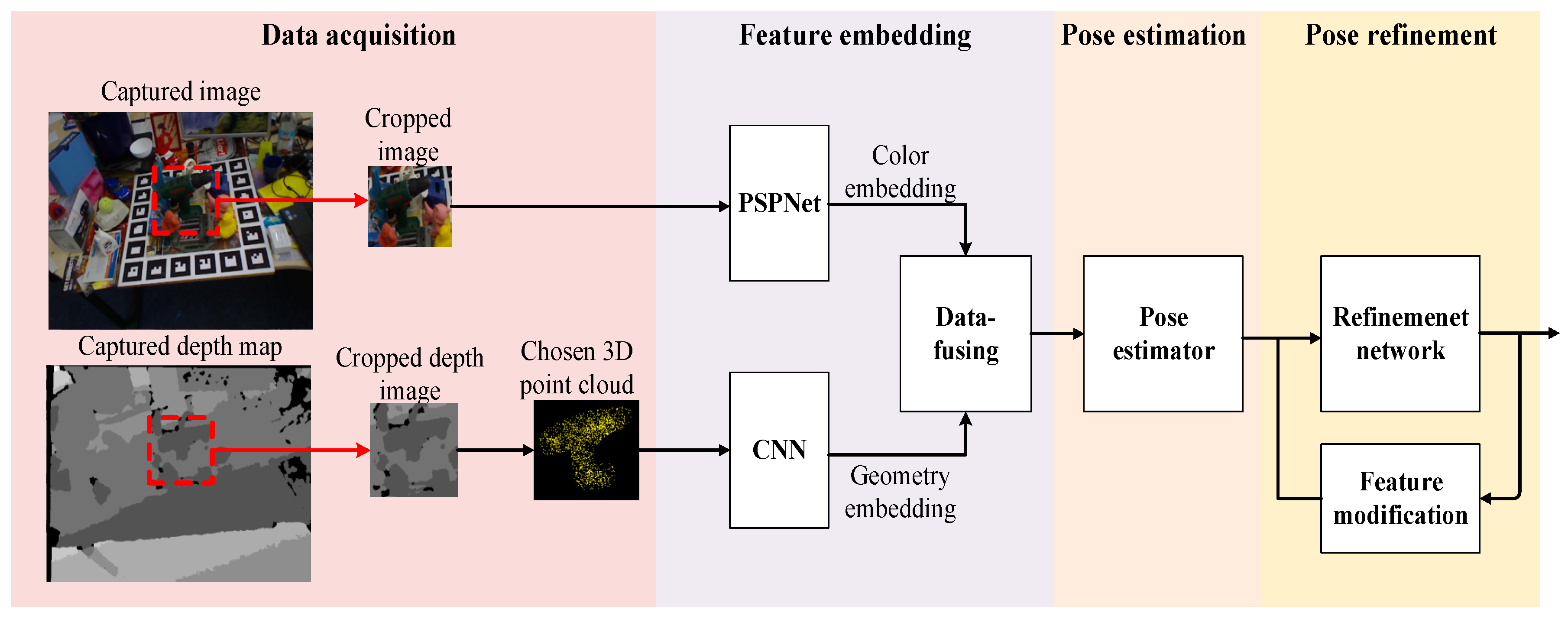
3. Methods
3.1. Data Acquisition
3.2. Feature Embedding and 6D Pose Estimation
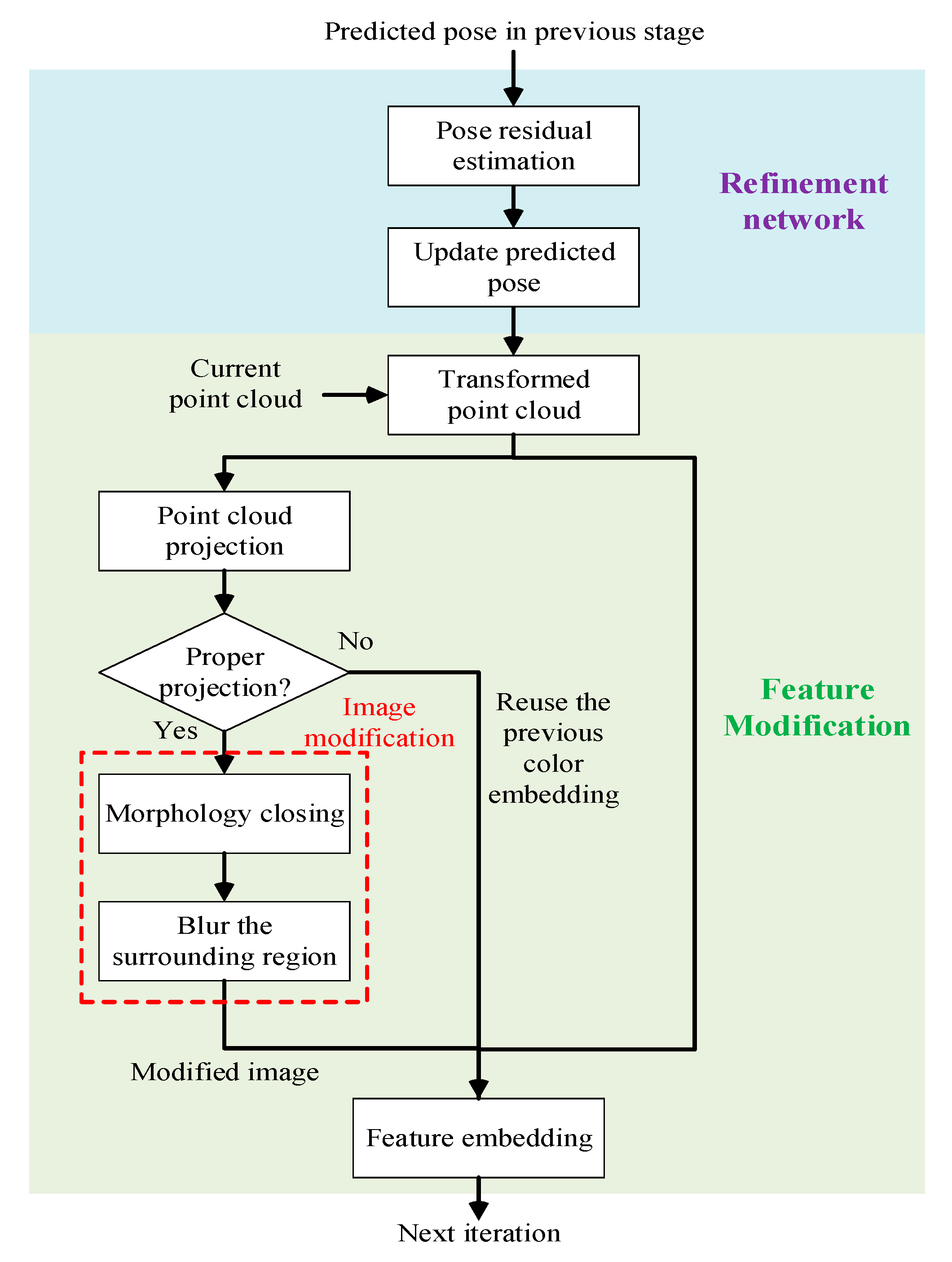
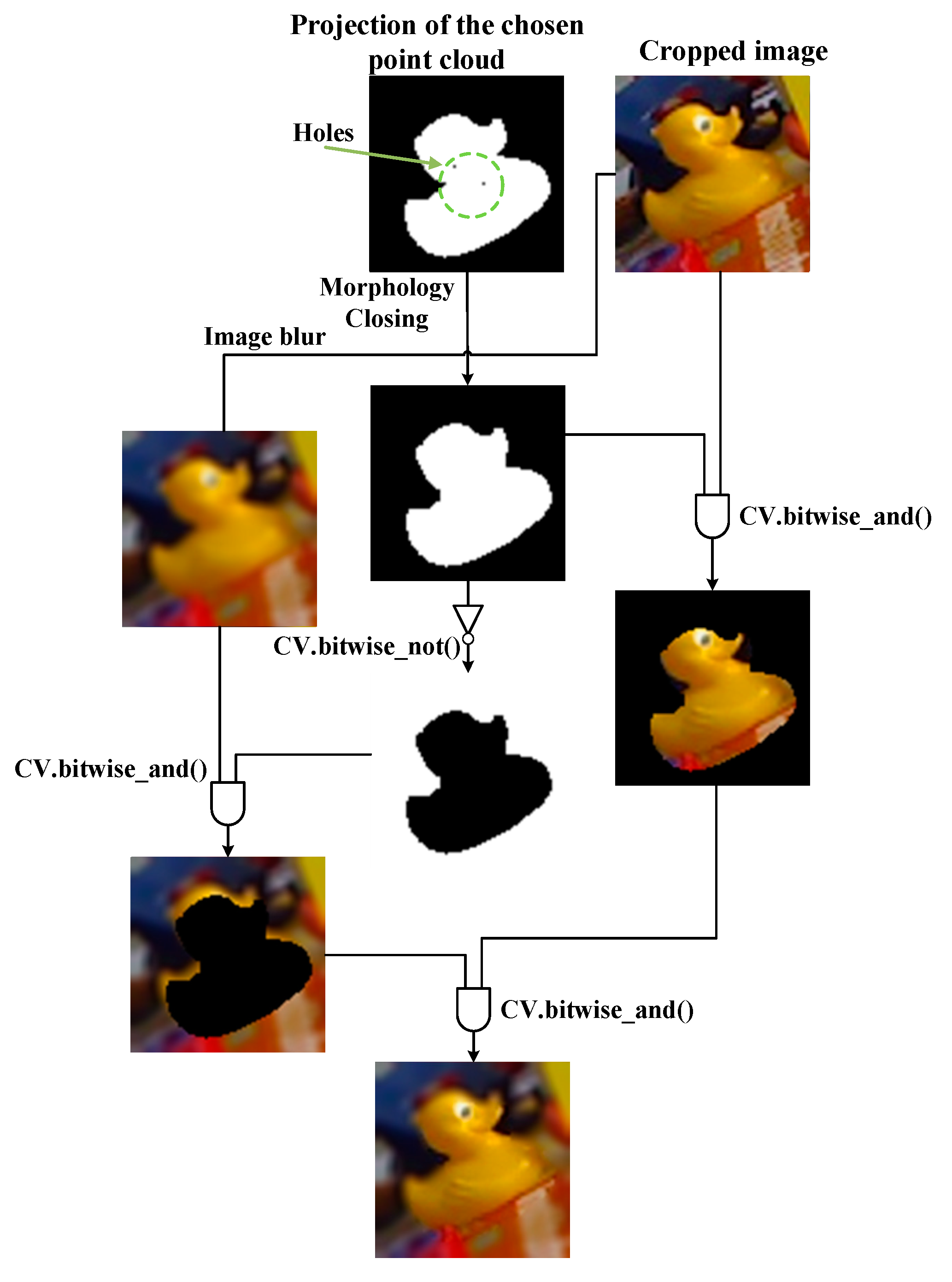
3.3. Pose Refinement
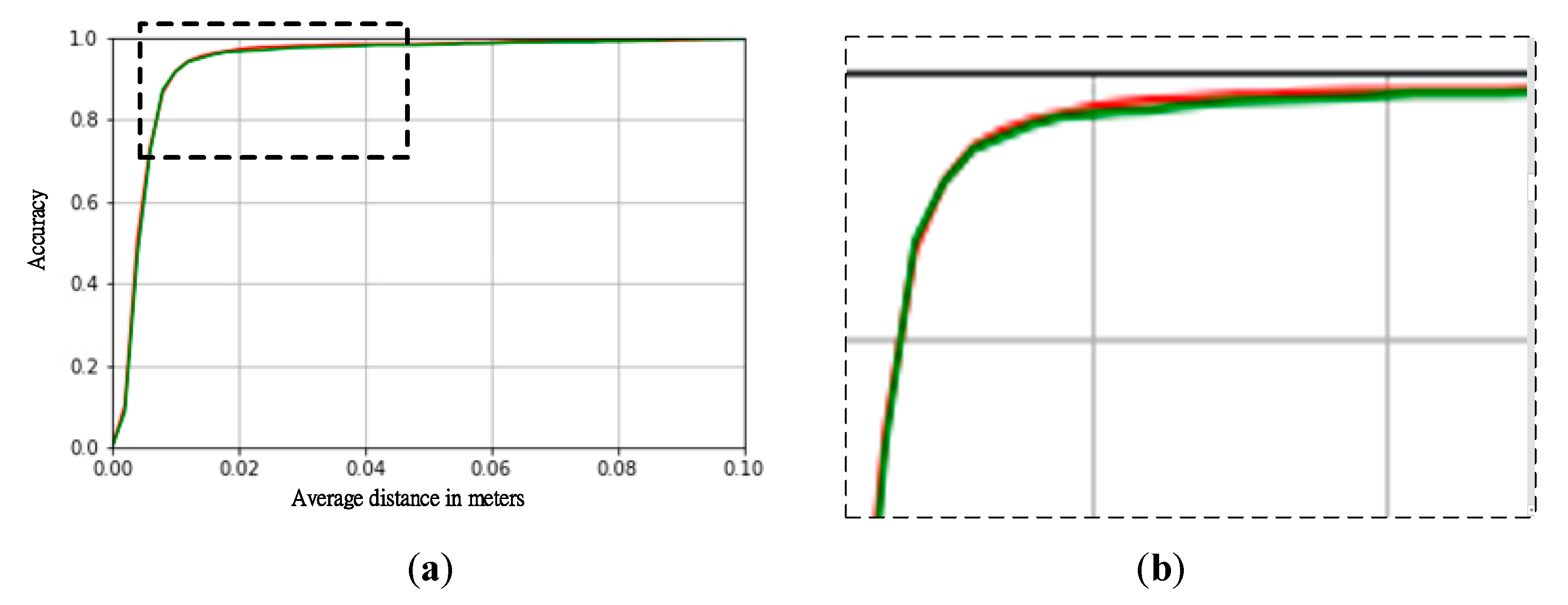
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, H.; Hsu, C.; Wang, W. Object Pose Estimation System for Pick and Place Automation. In Proceedings of the International Conference on System Science and Engineering 2020 (ICSSE 2020), Sunport Hall Takamatsu, Japan, 5–8 July 2020. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Tulsiani, S.; Malik, J. Viewpoints and keypoints. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Chan, A.; Derpanis, K. G.; Daniilidis, K. 6-DOF object pose from semantic keypoints. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, 29 May–32 June 2017. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes. Available online: http://www.stefan-hinterstoisser.com/papers/hinterstoisser2012accv.pdf (accessed on 2 May 2020).
- Cao, Z.; Sheikh, Y.; Banerjee, N.K. Real-time scalable 6DoF pose estimation for texture-less objects. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D object pose estimation using 3D object coordinates. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Ge, L.; Cai, Y.; Weng, J.; Yuan, J. PointNet: 3D Hand Pose Estimation using Point Sets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chen, Y.; Tu, Z.; Ge, L.; Zhang, D.; Chen, R.; Yuan, J. SO-HandNet: Self-Organizing Network for 3D Hand Pose Estimation with Semi-Supervised Learning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Tian, M.; Pan, L.; Ang Jr, M.H.; Lee, G.H. Robust 6D Object Pose Estimation by Learning RGB-D Features. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–4 June 2020. to be published. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martín-Martín, R.; Lu, C.; Fei-Fei, L.; Savarese, S. DenseFusion: 6D object pose estimation by iterative dense fusion. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. in press. [Google Scholar]
- Brachmann, E.; Michel, F.; Krull, A.; Ying Yang, M.; Gumhold, S. Uncertainty-driven 6D pose estimation of objects and scenes from a single RGB image. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016. [Google Scholar]
- Peng, S.; Liu, Y.; Huang, Q.; Zhou, X.; Bao, H. Pvnet: pixel-wise voting network for 6dof pose estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Wohlhart, P.; Lepetit, V. Learning descriptors for object recognition and 3D pose estimation. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Rad, M.; Lepetit, V. BB8: A scalable, accurate, robust to partial occlusion method for predicting the 3D poses of challenging objects without using depth. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. SSD-6D: making RGB-based 3D detection and 6D pose estimation great again. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-time seamless single shot 6D object pose prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Sundermeyer, M.; Marton, Z.; Durner, M.; Brucker, M.; Triebel, R. Implicit 3D orientation learning for 6D object detection from RGB images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. DeepIM: deep iterative matching for 6D pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Castro, P.; Armagan, A.; Kim, T. Accurate 6D object pose estimation by pose conditioned mesh reconstruction. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Tong, X.; Li, R.; Ge, L.; Zhao, L.; Wang, K.A. New Edge Patch with Rotation Invariance for Object Detection and Pose Estimation. Sensors 2020, 20, 887. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Hashimoto, K. Accurate Object Pose Estimation Using Depth Only. Sensors 2018, 18, 1045. [Google Scholar] [CrossRef] [PubMed]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. In Proceedings of the Robotics: Science and System XIV, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Hu, Y.; Hugonot, J.; Fua, P.; Salzmann, M. Segmentation-driven 6D object pose estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–21 June 2019. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Pauwels, K.; Rubio, L.; Díaz, J.; Ros, E. Real-time model-based rigid object pose estimation and tracking combining dense and sparse visual cues. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Besl, P.J.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Generalized-icp. Available online: http://www.robots.ox.ac.uk/~avsegal/resources/papers/Generalized_ICP.pdf (accessed on 2 May 2020).
- Hodaň, T.; Michel, F.; Brachmann, E.; Kehl, W.; GlentBuch, A.; Kraft, D.; Drost, B.; Vidal, J.; Ihrke, S.; Zabulis, X.; et al. BOP: benchmark for 6D object pose estimation. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A convolutional network for real-time 6-DOF camera relocalization. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D object detection from RGB-D data. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Michel, F.; Kirillov, A.; Brachmann, E.; Krull, A.; Gumhold, S.; Savchynskyy, B.; Rother, C. Global hypothesis generation for 6d object pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, Hawaii, 21–26 July 2017. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BB8 w/Ref. [15] | SSD-6D w/Ref. [16] | PVNet [13] | Tien [10] | DenseFusion [11] | Proposed Method | |
|---|---|---|---|---|---|---|
| Ape | 40.4 | 65 | 43.62 | 85.03 | 92 | 92.95 |
| Bench vise | 91.8 | 80 | 99.90 | 95.54 | 93 | 92.05 |
| Cam | 55.7 | 78 | 86.86 | 91.27 | 94 | 96.96 |
| Can | 64.1 | 86 | 95.47 | 95.18 | 93 | 93.31 |
| Cat | 62.6 | 70 | 79.34 | 93.61 | 97 | 96.31 |
| Driller | 74.4 | 73 | 96.43 | 82.56 | 87 | 88.80 |
| Duck | 44.3 | 66 | 52.58 | 88.08 | 92 | 92.95 |
| Eggbox * | 57.8 | 100 | 99.15 | 99.90 | 100 | 99.71 |
| Glue * | 41.2 | 100 | 95.66 | 99.61 | 100 | 99.90 |
| Hole pucher | 67.2 | 49 | 81.92 | 92.58 | 92 | 91.15 |
| Iron | 84.7 | 78 | 98.88 | 95.91 | 97 | 96.32 |
| Lamp | 76.5 | 73 | 99.33 | 94.43 | 95 | 94.91 |
| Phone | 54.0 | 79 | 92.41 | 93.56 | 93 | 96.34 |
| Average | 62.7 | 79 | 86.27 | 92.87 | 94 | 94.74 |
| Tien [10] | Posecnn+ICP [23] | DenseFusion [11] | Proposed Method | |
|---|---|---|---|---|
| 002_master_chef_can | 93.9 | 95.8 | 96.4 | 96.4 |
| 003_cracker_box | 92.9 | 91.8 | 95.5 | 95.8 |
| 004_sugar_box | 95.4 | 98.2 | 97.5 | 97.6 |
| 005_tomato_soup_can | 93.3 | 94.5 | 94.6 | 94.5 |
| 006_mustard_bottle | 95.4 | 98.4 | 97.2 | 97.4 |
| 007_tuna_fish_can | 94.9 | 97.1 | 96.6 | 97.1 |
| 008_pudding_box | 94.0 | 97.9 | 96.5 | 96.0 |
| 009_gelatin_box | 97.6 | 98.8 | 98.1 | 98.0 |
| 010_potted_meat_can | 90.6 | 92.8 | 91.3 | 90. 7 |
| 011_banana | 91.7 | 96.9 | 96.6 | 96.1 |
| 019_pitcher_base | 93.1 | 97.8 | 97.1 | 97.5 |
| 021_bleach_cleanser | 93.4 | 96.8 | 95.8 | 95.9 |
| 024_bowl | 92.9 | 78.3 | 88.2 | 89.5 |
| 025_mug | 96.1 | 95.1 | 97.1 | 96.7 |
| 035_power_drill | 93.3 | 98.0 | 96.0 | 96.1 |
| 036_wood_block | 87.6 | 90.5 | 89.7 | 92.8 |
| 037_scissors | 95.7 | 92.2 | 95.2 | 92.1 |
| 040_large_marker | 95.6 | 97.2 | 97.5 | 97.6 |
| 051_large_clamp | 75.4 | 75.4 | 72.9 | 72.5 |
| 052_extra_large_clamp | 73.0 | 65.3 | 69.8 | 70.0 |
| 061_foam_brick | 94.2 | 97.1 | 92.5 | 92.0 |
| Average | 91.8 | 93.0 | 93.1 | 93.2 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.-K.; Hsu, C.-C.; Wang, W.-Y.; Lin, C.-H. Iterative Pose Refinement for Object Pose Estimation Based on RGBD Data. Sensors 2020, 20, 4114. https://doi.org/10.3390/s20154114
Huang S-K, Hsu C-C, Wang W-Y, Lin C-H. Iterative Pose Refinement for Object Pose Estimation Based on RGBD Data. Sensors. 2020; 20(15):4114. https://doi.org/10.3390/s20154114
Chicago/Turabian StyleHuang, Shao-Kang, Chen-Chien Hsu, Wei-Yen Wang, and Cheng-Hung Lin. 2020. "Iterative Pose Refinement for Object Pose Estimation Based on RGBD Data" Sensors 20, no. 15: 4114. https://doi.org/10.3390/s20154114
APA StyleHuang, S.-K., Hsu, C.-C., Wang, W.-Y., & Lin, C.-H. (2020). Iterative Pose Refinement for Object Pose Estimation Based on RGBD Data. Sensors, 20(15), 4114. https://doi.org/10.3390/s20154114