The detail of the feature selection algorithms that were used for comparison is described in
Section 4.1.
Section 4.2 compares the proposed algorithm with the well-known algorithms on multiple assessment indicators over three data sets. In
Section 4.3, the effect and superiority of proposed binary transform approaches on GWO based feature selection algorithm will be discussed. Some useful information will be provided in
Section 4.4 by analyzing the adaptive restart approach.
4.1. Description of the Compared Algorithm
In the experiment, except for the original BGWO, two widely used algorithms for gas sensor data feature selection and two efficient meta-heuristic algorithms were also used to compare with the proposed algorithm, which is summarized as:
Support Vector Machine-Recursive Feature Elimination (SVM-RFE) [
42],
Max-Relevance and Min-Redundancy (mRMR) [
43],
Binary Grey Wolf Optimization (BGWO) [
27],
Discrete Binary Particle Swarm Optimization (BPSO) [
44],
Genetic Algorithm (GA) [
45].
KNN is a classifier with few parameters and high classification accuracy, so it was used as a wrapper method of all meta-heuristic algorithms in this study; the experimental results show that the classification achieves the best performance when
k is 5. Each data set was divided into train set and test set with the ratio of 7:3. The error rate of the test set and the number of selected features were used to guide the search direction of all meta-heuristic algorithms, and all of them have been run independently 20 times. mRMR and SVM-RFE are calculated on the complete datasets. Gaussian kernel and linear kernel were used in SVM-RFE, and the optimal feature subset selected from the two kernel functions was taken as the final result. The parameter settings for all algorithms are outlined in
Table 5. All parameters were set according to multiple experiments and relevant literature to ensure the fairness of the experiment. The 10-fold cross-validation was conducted on all algorithms in order to eliminate the influence of over fitting.
4.2. Comparison of the Proposed Algorithm and Other Algorithms
In the first experiment, adaptive restart GWO with two binary transform approaches (ARGWO1 and ARGWO2) which have been proposed in
Section 2 were compared with five feature selection algorithms (mRMR, SVM-RFE, BPSO, GA, BGWO) on three electronic nose datasets.
KNN [
46], SVM [
47], and Random Forest (RF) [
48] were used to calculate the classification accuracy of the feature subset selected by each algorithm to ensure the reliability of accuracy evaluation. Each data set was randomly divided into the training set and testing set with the ratio of 7:3, the classification accuracy of test set was used for the evaluation of feature subset to prove its future performance on the unseen data. The feature subset which gets the least number of features on the premise of the maximum classification accuracy under multiple runs was regarded as the optimal result of each algorithm. The classification accuracy of the optimal feature subset selected by each algorithm on three data sets is as shown in
Table 6. We can see that ARGWO1 and ARGWO2 achieve excellent performance: ARGWO2 achieves the highest average classification accuracy on all data sets and the average classification accuracy of ARGWO1 on dataset2 and dataset3 is only less than ARGWO2. In order to judge whether there is over fitting in different models, the accuracy of training sets under different training models is as shown in
Table 7, and we can remark that the training was not overfitted.
In order to evaluate the feature subset more comprehensively in classification performance, F1-score was used in this experiment. F1-score is the harmonic mean of precision and recall rate [
49], and it can be formulated as in Equation (
19):
where
F1 is the
F1-score obtained by each classifier under each data set,
TP is the number of samples that is correctly predicted,
FP is the number of samples that errors predicted as class
k,
FN is the number of samples belonging to class
k but is predicted by other classes. The
F1-score of the optimal feature subsets selected by each algorithm are outlined in
Table 8. We can see that ARGWO2 and ARGWO1 achieve the first and second best average
F1-score. From
Table 6 and
Table 8, we can see that the classification performance of dataset1 on different classifiers is far lower than other datasets, which is mainly due to the impact of sensor drift on classification accuracy. The experimental results show that selecting appropriate features through the feature selection algorithm can suppress the impact of sensor drift in a certain extent, and the proposed algorithm achieves positive performance in compensating the drift effect.
Table 9 shows the length of the optimal feature subset selected by each algorithm. We can see that the ARGWO2 achieves the minimum average length of the eigenvector. In fact, the classification performance is more important than the length of the feature subset in the assessment indicators system of the feature selection algorithm. Therefore, in the process of determining the optimal result from each algorithm, the classification performance was given priority, and the shortest one was chosen in the feature subsets with the highest classification performance, which also explains the reasons for setting the values of parameters
and
in the fitness function.
Table 10 outlines the Wilcoxon test calculated on the classification accuracy and average fitness obtained by the different algorithms. In this experiment, the average classification accuracy of the feature subsets obtained by multiple runs under each dataset and each classifier was regarded as the individual element presented to the Wilcoxon test, and we can remark that the ARGWO2 achieves a significant enhancement over most of the other approaches.
From the above experiments, we can conclude that the proposed algorithm outperforms other methods in classification performance and number of selected features. In addition, ARGWO2 achieves less features while obtaining the highest classification performance on all data sets, which indicates that ARGWO2 can achieve a positive performance on the data collected by different types of electronic nose. By using the proposed algorithm for feature selection, the useful information can be extracted from the gas response signal to enhance the performance of the electronic nose. The feature subset selected by the algorithms with the KNN wrapper method has a similar classification accuracy ranking on three classifiers, which proves that KNN is an effective wrapper method of the meta-heuristics algorithm. The effect of the two proposed mechanisms on the GWO based feature selection algorithm will be discussed in the following subsections.
4.3. The Effect of Binary Transform Approach on the Proposed Algorithm
Section 4.2 shows that the proposed algorithm outperforms the original BGWO algorithm in classification performance and the number of selected features. In this section, GWO with sigmoid function (BGWO), GWO with approach1 (GWO1), and GWO with approach2 (GWO2) were used to study the effect of binary transform approach on the GWO for feature selection. In order to control the variables, GWO1 and GWO2 did not add the adaptive restart approach in this experiment. Fitness value is a comprehensive evaluation of the accuracy and length of feature subsets to guide the search direction of the proposed algorithm; thus, it is an important index for the evaluation of the GWO based algorithm, and three fitness related assessment indicators were used in this experiment [
27]:
The best fitness is the minimum fitness value obtained by running the algorithm for
M times, and it can be formulated in Equation (
22):
The worst fitness is the maximum fitness value obtained by running the algorithm for
M times, and it can be formulated in Equation (
23):
The mean fitness is the average fitness value obtained by running the algorithm for
M times, and it can be formulated in Equation (
24).
Figure 2 shows the fitness value obtained by three algorithms in 20 independent runs over all the datasets. In addition, according to Equation (
10), we can remark that the feature subset with lower fitness, which means lower error rate and fewer selected features, represents the better search performance. We can see from the figure that the overall performance of GWO1 and GWO2 is better than BGWO.
Figure 3,
Figure 4 and
Figure 5 outline the best, mean, and worst fitness value obtained by three algorithms over all the data sets. We can see that GWO1 has a slight advantage over BGWO. In addition, GWO2 achieves much better performance than the other two algorithms. The Wilcoxon test was used to verify the significant difference between the above algorithms, and the average fitness over three datasets was regarded as the individual element presented to the Wilcoxon test, and the average fitness values under multiple runs were used to calculate the
p-value between different algorithms. From the experiment results, we can remark that the GWO1 and GWO2 achieve significant enhance over the BGWO by achieving the
p-value of 0.0081 and 0.0076. We can remark that the binary transform approach has a positive influence on the search capability of GWO for feature selection, and it is more advantageous to find the optimal feature subset by using the appropriate approaches. Compared with sigmoid function, the search capability of the algorithm can be improved more by approach1 or approach2. Moreover, approach2 achieves an outstanding advantage, and it is possible that approach2 takes into account the information on the position vector of search agents rather than relying on only one element of the position vector in the process of binary transformation. Therefore, we take the attitude that it may be a good way to control the binary transform process by combining more information related to search agents.
4.4. The Effect of Adaptive Restart Approach on the Proposed Algorithm
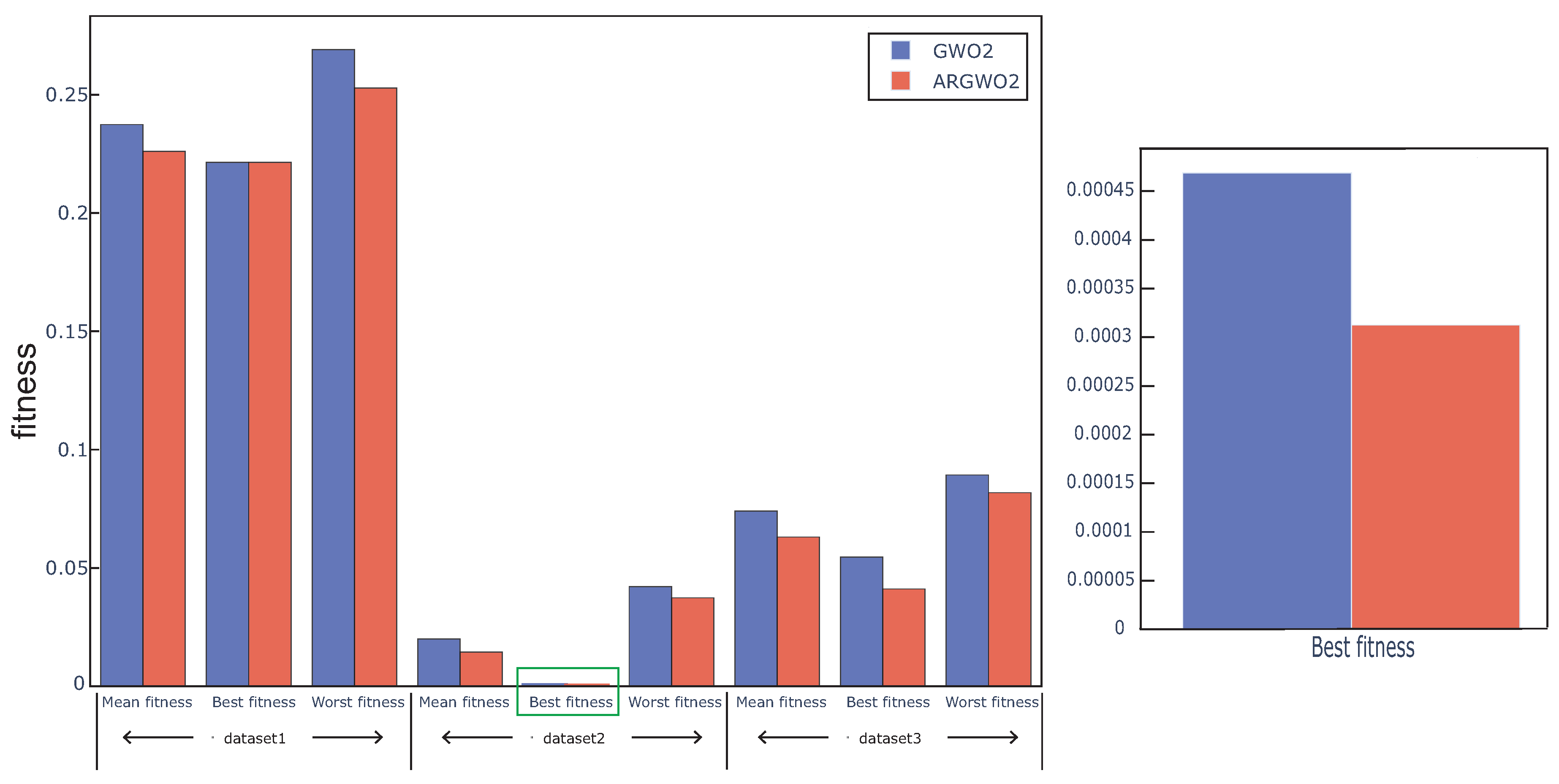
In this section, GWO with an adaptive restart approach(ARGWO1, ARGWO2) and without an adaptive restart approach (GWO1, GWO2) were used to study the effect of the adaptive restart approach on the algorithm.
Figure 6 and
Figure 7 show the best, worst, and average fitness value obtained by the above four algorithms over all the data sets. We can see that the mean fitness and the worst fitness of the algorithm are reduced by using an adaptive restart approach, and the best fitness is also reduced in some cases, which proves that the adaptive restart approach effectively improves the search capability. The Wilcoxon test was also used in this experiment, the average fitness over three datasets was regarded as the individual element presented to the Wilcoxon test, and the average fitness values under multiple runs were used to calculate the
p-value between the proposed algorithm with and without adaptive restart. The
p-value between ARGWO1 and GWO1 achieved 0.0288, and the
p-value between ARGWO2 and GWO2 achieved 0.0036. We can remark that the performance of the proposed algorithm is significantly improved by using adaptive restart.
Std is a measure for the variation of the optimal result obtained by the algorithm under multiple runs [
50]. In addition, it was used as the index to evaluate the stability of the algorithm in this experiment.
Std is formulated as in Equation (
25).
where
is the final fitness value of the independent operation
i,
is the mean fitness. The average
Std value over all data sets obtained by the above four algorithms in this experiment are outlined in
Figure 8. We can see from the figure that the stability and repeatability of the GWO based algorithm can be improved by using an adaptive restart approach. The adaptive restart approach is based on the optimal fitness value and the number of search agents in each iteration to determine the number of search agents that need to be reinitialized. By analyzing the current search effect, adaptive restart can dynamically affect the search direction of the algorithm when the algorithm has already or has a tendency to fall into the local optimum, so as to prevent falling into the local optimal solution and select more useful features from the gas response signal.
From all these experiments, we can conclude that the proposed algorithm outperforms other algorithms over all datasets, which indicates that the proposed algorithm can be applied to different types of electronic nose and effectively enhance their performance of gas sensing. The performance of the GWO based algorithm for feature selection of electronic nose data are effectively improved by proposed binary transform approaches and adaptive restart. The fitness value of the selected feature subset can be reduced by using proposed binary transform approaches, especially in approach2. The stability and search capability of the GWO based feature selection algorithm can be further enhanced by using adaptive restart approach. Throughout the paper, the proposed algorithm can effectively select more favorable feature subsets for gas recognition, but, because the adaptive restart approach does not add too much influence to the search behavior of GWO, there is still a certain probability of falling into local optimum in the process of searching. In order to obtain the optimal feature subsets, it is usually necessary to run multiple times.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}