1. Introduction
Recognition of human actions from RGB-D data has attracted increasing attention over the past years due to the fast development of easy-to-use and cost-effective RGB-D sensors such as Microsoft Kinect, Asus Xtion, and recently Intel’s RealSense. These RGB-D sensors capture RGB video together with depth sequences. The RGB modality provides appearance information whereas the depth modality, being insensitive to illumination variations, provides 3D geometric information. Skeletons can also be extracted from either depth maps [
1] or RGB video [
2] under certain conditions, for instance, the subjects being in a standing position and not being overly occluded. As the seminal work [
3], research on action recognition [
4] from RGB-D data has extensively focused on using either skeletons [
5,
6] or depth maps [
7], some work using multiple modalities including RGB video. However, single modality alone often fails to recognize some actions, such as human-object interactions, that require both 3D geometric and appearance information to characterize the body movement and the objects being interacted. Unlike most existing multimodality action recognition methods [
4] using skeletons plus depth or RGB-video, this paper presents a novel and deep neural network-based method to recognize actions from RGB video and depth maps.
Throughout the research in recent years, four promising deep neural network approaches to action recognition have emerged. They are two-stream convolutional neural networks (CNNs) [
8], 3D CNNs [
9,
10], CNNs, either 2D or 3D, combined with a recurrent neural network (RNN) [
11] and dynamic image (DI) based approaches [
12]. The two-stream CNN approach captures spatial and temporal information by two parallel streams, one being dedicated for appearance and the other for motion. The 3D CNN approach employs 3D convolutions and 3D pooling operations to learn spatiotemporal information over video segments. Both two-stream CNN and 3D CNN approaches obtained the video level prediction by averaging predictions over sampled segments, the long-term temporal information was not explicitly considered. The CNN plus RNN approach extracts spatial features from frames or short segments of frames using CNNs and feeds the spatial features to an RNN, commonly LSTM, to exploit temporal information. This architecture often tends to over-emphasize the temporal information. Dynamic image-based methods encode action instances into one or more dynamic images and employ existing CNN models directly on the dynamic images for classification. Dynamic images are good at capturing spatial information including pose and interactions with objects but tend to lose some temporal information.
As observed, each of the four approaches has its own strength and weakness in capturing and utilizing spatial, temporal and structural information required for robust action recognition. To a large extent, this explains why none of the individual approaches would perform robustly on a large-scale action dataset (e.g., ChaLearn LAP IsoGD Dataset [
13], NTU RGB-D Dataset [
14]) where discriminative power or importance of the spatial, temporal and structural information [
4] varies significantly from action to action. Considering as attributes the relative duration of discriminative motion in an action instance and involvement of interactions with objects, the types of actions in the popular RGB-D action datasets [
14] can be broadly categorized into four groups:
The discriminative motion distributes throughout an action and there is no interaction with objects. Typical examples are “stand up” and “sit down”.
The discriminative motion appears only in a short period within the duration of an action and there is no interaction with objects. Examples are “nodding” and “cough”.
The discriminative motion distributes throughout an action and it involves interaction with objects. Examples are “put on the jacket” and “take off jacket”.
The discriminative motion appears only a short period within the duration of an action and there is interaction with objects. Typical examples include “eat meals/snack” and “drink water”.
Strong temporal modelling is needed to recognize actions in
; spatial information is important for
; structural information becomes important for
;
needs the spatial information including the object pose.
Table 1 shows an empirical observation on how each of the four approaches performed on the four categories of actions, and the performance of the four approaches on the four categories of actions were evaluated in the NUT RGB-D action dataset using depth modality and cross-subject protocol. Notice that the CNN+RNN (ConvLSTM) performed well for actions in the first three groups as expected due to its ability to model temporal information throughout the actions. The poor performance for actions in
means its inability of capturing both spatial and temporal information in a short period over the entire instance of the actions.
This paper presents a novel hybrid network that takes the advantages of the four approaches. Furthermore, the conventional dynamic images (DI) are extended to weighted dynamic images (WDI) through the proposed weighted rank pooling. Unlike conventional DIs, a WDI can account for both spatial and temporal importance adaptively and, hence, improve its performance on actions in
as well as other groups. A 3D ConvLSTM is constructed where 3-D convolution [
9,
10] is used to learn short-term spatiotemporal features from the input video, and then ConvLSTM [
15] is utilized to extract long-term spatiotemporal features. Both WDI and 3D ConvLSTM are applied to RGB video and depth maps to extract features. These features are fused together using Canonical Correlation Analysis (CCA) [
16,
17] into an instance feature for classification. The proposed hybrid network is evaluated and verified on the ChaLearn LAP IsoGD Dataset [
13], NTU RGB+D Dataset [
14] and Multi-modal, Multi-view and Interactive(
) Dataset [
18]. This paper is an extension of the conference paper [
19]. The extension includes WDI, feature level fusion using Canonical Correlation Analysis, a detailed justification of the proposed network, additional experiments on the NTU RGB+D Dataset and
Dataset and comparison with the methods reported recently.
The remainder of this paper is organised as follows.
Section 2 reviews the related work on deep learning-based action recognition and fusion methods.
Section 3 describes the proposed weighted rank pooling method.
Section 4 presents the details of the hybrid network.
Section 5 presents the experimental results and discussions. The paper is concluded in
Section 6.
3. Proposed Weighted Rank Pooling
Rank pooling [
45] is usually used to capture sequence-wide temporal evolution. However, conventional rank pooling often ignores the fact that frames in a sequence are of different importance and regions in frames also are of different importance to the classification [
46]. As discussed in
Section 1, different frames in an action instance contribute differently to the recognition and some frames contain more discriminative information than others. In addition, a frame can be decomposed into salient and non-salient regions [
47]. Compared with non-salient regions, salient regions contain information of the discriminative foreground. To accommodate both frame-based and region-based importance, spatial weights and temporal weights are proposed to be integrated into the rank pooling process, referred to as weighted rank pooling. In the rest of this section, we first give a general formulation of the proposed weighted rank pooling and then discuss the two types of weights.
3.1. Formulation
Given a sequence X of n feature vectors, , where is the feature of frame i. Each of the elements may be a frame itself or the feature extracted from the frame. Spatial weight represents the importance of each element of the features in frames and . The temporal weight indicates the importance of the frames in the sequence and . In this paper, it is assumed that .
Based on the frame representations
, we define a memory map
over the time variable
i,
where
. The output of the vector-valued function
is obtained by processing all the frames up to time
i, denoted by
. In this paper, we define
as:
here * is Hadamard Product.
Rank pooling focuses on relative ordering (i.e., succeeds which forms an ordering denoted by ). Frames are ranked based on . A natural way to model such order constraints is a pairwise linear ranking machine. The ranking machine learns a linear function characterized by the parameters , namely . The ranking score of is obtained by and results in the pairwise constraints (). The learning to rank problem optimizes the parameters u of the function , such that . We argue that the importance of the ordering of each pair of frames in an instance of action should be different and dependent on the category of the action. Therefore, we propose to use as a weighting factor denoting the importance of the ordering of frames i and j.
The process of weighted rank pooling is to find
to minimize the following objective function:
here
i and
j are the indices of frames in the sequence.
is a threshold enforcing the temporal order and
C is a regularization constant. A pairwise function
computes a scalar representing the importance of the order between frame
i and frame
j. The pairwise function
can be measured by the temporal weight
and
. In this paper,
is represented by
though many other forms of the function are also feasible. As the ranking function
is sequence specific, the parameters
u would capture a sequence-wide spatially and temporally weighted representation and can be used as a descriptor of the sequence.
3.2. Optimization
Equation (
2) aims to find
u by minimizing the number of pairs of frames in the training examples that are switched their desired order. We obtain
u by solving the following optimization problem:
Equation (
3) can be solved efficiently in many ways as described in [
48]. As it is an unconstrained and differentiable objective function, Truncated Newton optimization is adopted, in which the parameter
u can be updated at each iteration as Equation (
4).
where
g is the gradient of the objective function,
H is the Hessian of the objective function. The gradient of Equation (
3) is,
and its Hessian is
can be calculated with linear conjugate gradient through the matrix-vector multiplication
for a vector
s. If we assign
,
can be computed as follows:
where
D is a diagonal matrix with
if
; 0 otherwise. Detailed steps to solve Equation (
3) is shown in Algorithm 1.
| Algorithm 1: The solution of Equation (3). The Newton step is computed with linear conjugate gradient. |
| Input: |
|
|
|
| u is randomly iniatlized |
| repeat |
| |
| |
| repeat |
| Update based on the computation of for some s. |
| until Convergence of linear conjugate gradient |
| |
| ( found by line gradient) |
| until Convergence of Newton |
| returnu |
3.3. Discussion
In this section, we discuss several possible ways to compute the spatial weight and the temporal weight in the proposed weighted rank pooling. Learning of the weights is possible, but is beyond the scope of the paper.
3.3.1. Spatial Weights
The spatial weight indicates the importance of each spatial location in frame i. When the location p in frame i is important, is assigned to a large value, otherwise, is assigned to a small value. The spatial weights can be estimated by a spatial attention model, background-foreground segmentation, salient region detection, or flow-guided aggregation.
3.3.2. Temporal Weights
The temporal weight indicates the importance of each frame in a sequence. is a scalar. When the frame i is important, is assigned to a large real number, otherwise, a smaller real number is assigned. The temporal weights could be estimated by a temporal attention model, selection of key frames, or flow-guided frame weights.
3.3.3. Weighted Rank Pooling vs. Rank Pooling
If the spatial weight is a unit matrix and the temporal weight equals to , the proposed weighted rank pooling is equivalent to rank pooling. In other words, conventional rank pooling is a special case of the proposed weighted rank pooling.
3.4. Bidirectional Weighted Rank Pooling
The weighted rank pooling ranks the accumulated feature up to the current time t, thus the pooled feature is likely biased towards the early frames and subject to the order of frames. However, future frames beyond t are also usually useful to classify frame t. To use all available input frames, the weighted rank pooling can be applied in a bidirectional way to convert one video sequence into a forward dynamic image and a backward dynamic image.
4. Proposed Hybrid Network Architecture
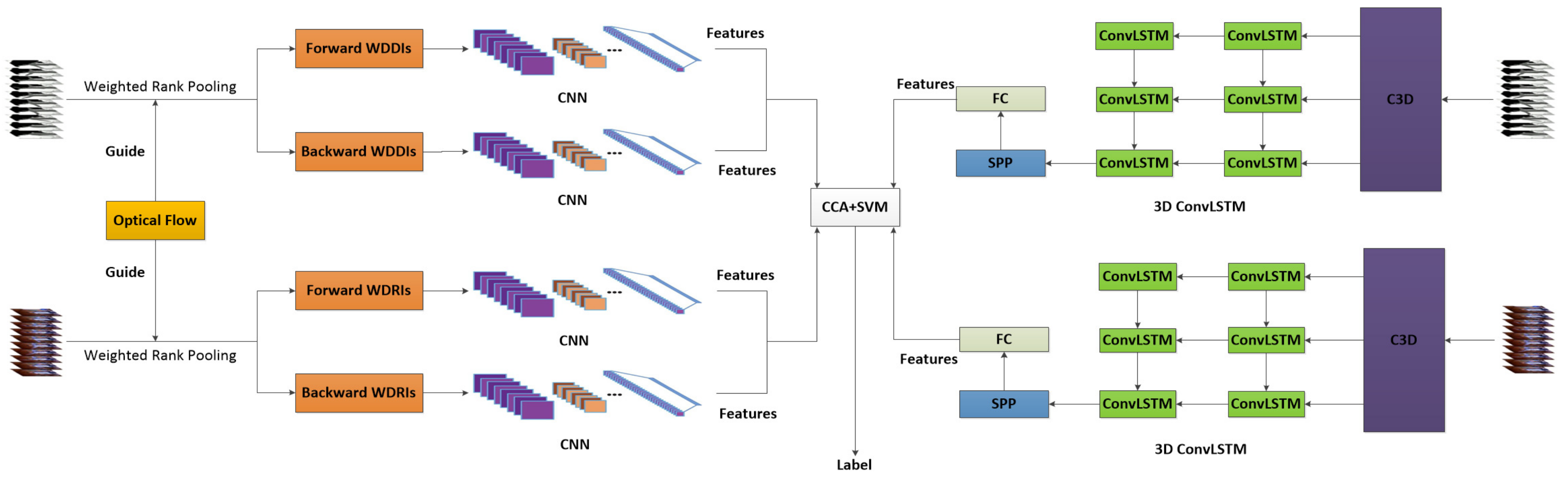
This section presents the proposed hybrid network architecture and its key components. As shown in
Figure 1, the proposed network consists of three types of components: CNN-based component that takes weighted dynamic images as input, 3D ConvLSTMs based component that takes as input video and depth sequences and the multi-stream fusion component that fuses the outputs from the CNNs and 3D ConvLSTMs for final action recognition. Weighted dynamic images are constructed from both RGB and depth sequences and fed into CNNs to extract features. At the same time, the RGB and depth sequences are input to the 3D ConvLSTMs to extract features. A canonical correlation analysis based fusion scheme is then applied to fuse the features learned from the CNNs and 3D ConvLSTMs, and the fused features are fed into a linear SVM for action classification.
4.1. CNN-Based Component
Two sets of weighted dynamic images, Weighted Dynamic Depth Images (WDDIs) and Weighted Dynamic RGB Images (WDRIs), are constructed, respectively, from depth sequences and RGB sequences through bidirectional weighted rank pooling. Given a pair of RGB and depth video sequences, the proposed bidirectional weighted rank pooling method is applied at the pixel-level to generate four weighted dynamic images, namely forward WDDI, backward WDDI, forward WDRI and backward WDRI. Specifically, in this paper, spatial and temporal weights in the weighed rank pooling are calculated from optical-flows, where the average flow magnitude of a frame is considered as temporal weight of the frame and the flow magnitude of each pixel is treated as the spatial weight of that pixel.
Different from the conventional rank pooling, weighted rank pooling can capture more effectively the discriminative spatiotemporal information. As shown in
Figure 2, the conventional dynamic image of action “eat meal/snack” from the NTU RGB+D Dataset [
14] does not capture the process of putting things into the mouth whereas the weighted dynamic image of “eat meal/snack” presents the discriminative part of eating. The hand motion around the pocket is suppressed by the head and body motion in the conventional dynamic image of action “put something inside pocket/take out something from pocket” from the NTU RGB+D Dataset, but the hand motion around pocket is encoded in the weighted dynamic image. Four ConvNets were trained on the four channels individually, forward WDDI, backward WDDI, forward WDRI and backward WDRI. ResNet-50 [
49] is adopted as the CNN model in this paper through other CNN models are also applicable. The details of ResNet-50 can be found in [
49]. The learned features from last pooling layer of the ResNets are named respectively as
,
,
and
.
4.2. 3D ConvLSTM Based Component
The 3D ConvLSTM presented in Zhu et al. [
35] is adopted to learn spatiotemporal information of actions. In particular, a 3-D convolution network is to extract short-term spatio-temporal features and the features are then fed to a ConvLSTM to model long-term temporal dynamics. Finally, the spatiotemporal features are normalized with Spatial Pyramid Pooling (SPP) [
50] for the final classification. The details of 3D ConvLSTM can refer to [
35]. In the proposed hybrid architecture, both RGB and depth sequences are processed independently in two streams. This part of the proposed hybrid network leverages the strengths of the conventional two-stream CNN and CNN+RNN approaches. The features extracted from the SPP layer on the RGB stream and depth stream are denoted as
and
, respectively.
4.3. CCA Based Feature Fusion
Considering the potential correlation between features extracted from the RGB video and depth maps by the CNNs and 3D ConvLSTMs, the simple and traditional feature concatenation is not effective as such concatenation would lead to information redundancy and high dimensionality of the fused features. Therefore, we adopt a canonical correlation analysis (CCA) [
16,
17] to remove redundancy across the features and fuse them. CCA fusion can keep effective discriminant information and reduce the dimension of the fused features at the same time.
Given two heterogeneous feature vectors
and
containing
n samples of different features. Their covariance matrix of
is denoted as
where
is the covariance matrix between
X and
Y (
), and
and
are the within-set covariance matrices of
X and
Y. CCA aims to find a pair of canonical variables with
and
to maximize the correlation across two feature sets. The goal of the CCA is to maximize the following objective function.
where
,
and
. Because the problem in (
9) is invariant with scaling of
and
, the objective function is reformulated as follows:
We can use SVD to solve the optimization problem. The variance matrices
and
are firstly transformed into identity forms.
Applying the inverses of the square root factors symmetrically on the joint covariance matrix in Equation (
8) we obtain
and
can be obtained by solving the SVD:
where the columns of
U and
V correspond to the sets of orthonormal left and right singular vectors, respectively. The singular values of matrix
S correspond to the canonical correlations.
and
can be given by
Finally, the fused feature
Z is obtained as follows.
In this paper, and , and are firstly fused into and by CCA fusion, respectively. Then and , and are fused into and , respectively. Finally, and combined into Z by CCA fusion. In this paper, , where n is the number of samples, and 512 is the dimension of the feature. A linear SVM classifier is trained on the fused feature Z for final action recognition.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}