A PointNet-Based Solution for 3D Hand Gesture Recognition


Abstract
1. Introduction
2. Materials and Methods
2.1. The Dataset
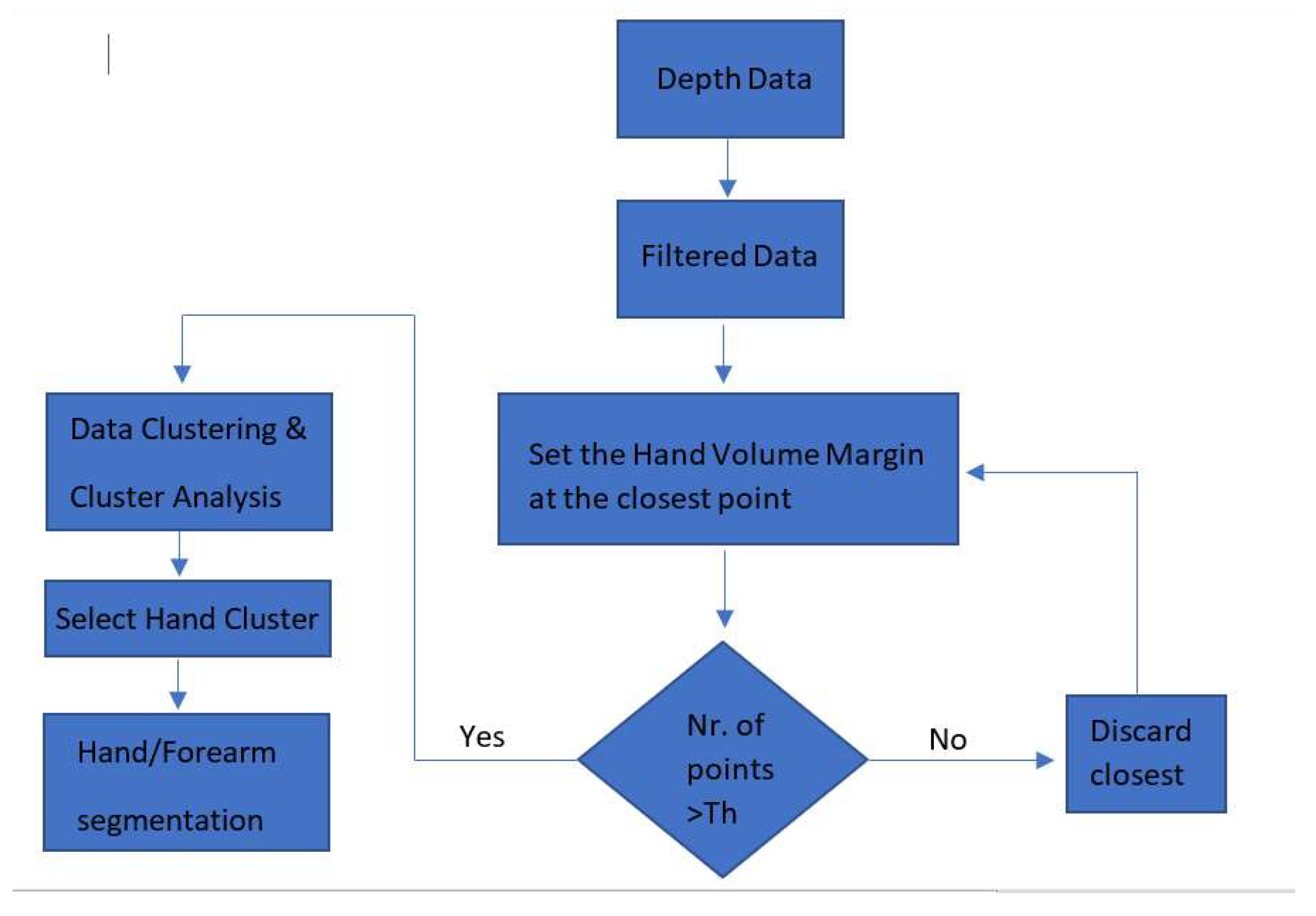
2.2. Hand Multi-Stage Segmentation
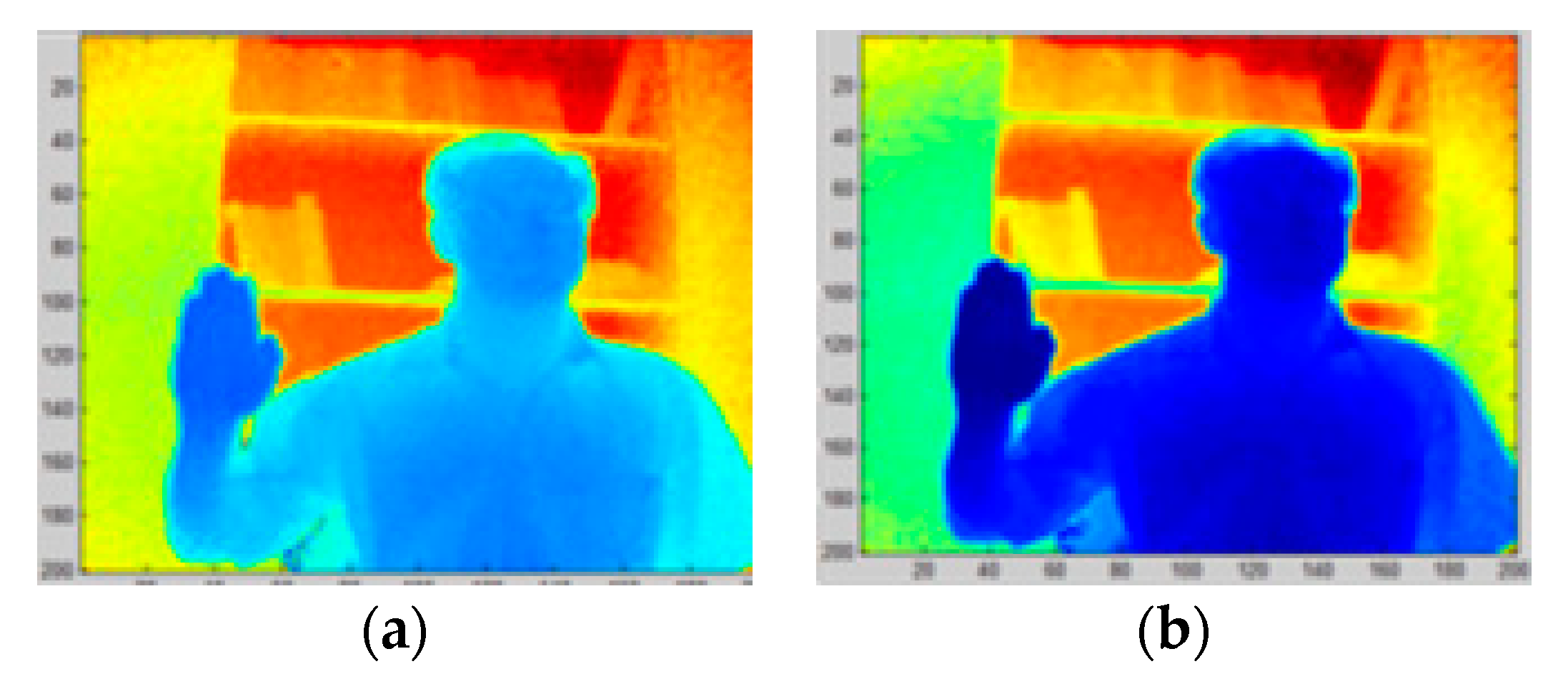
2.2.1. Filtering
2.2.2. Finding the Hand Volume of Interest
2.2.3. Clustering Inside the Hand Volume
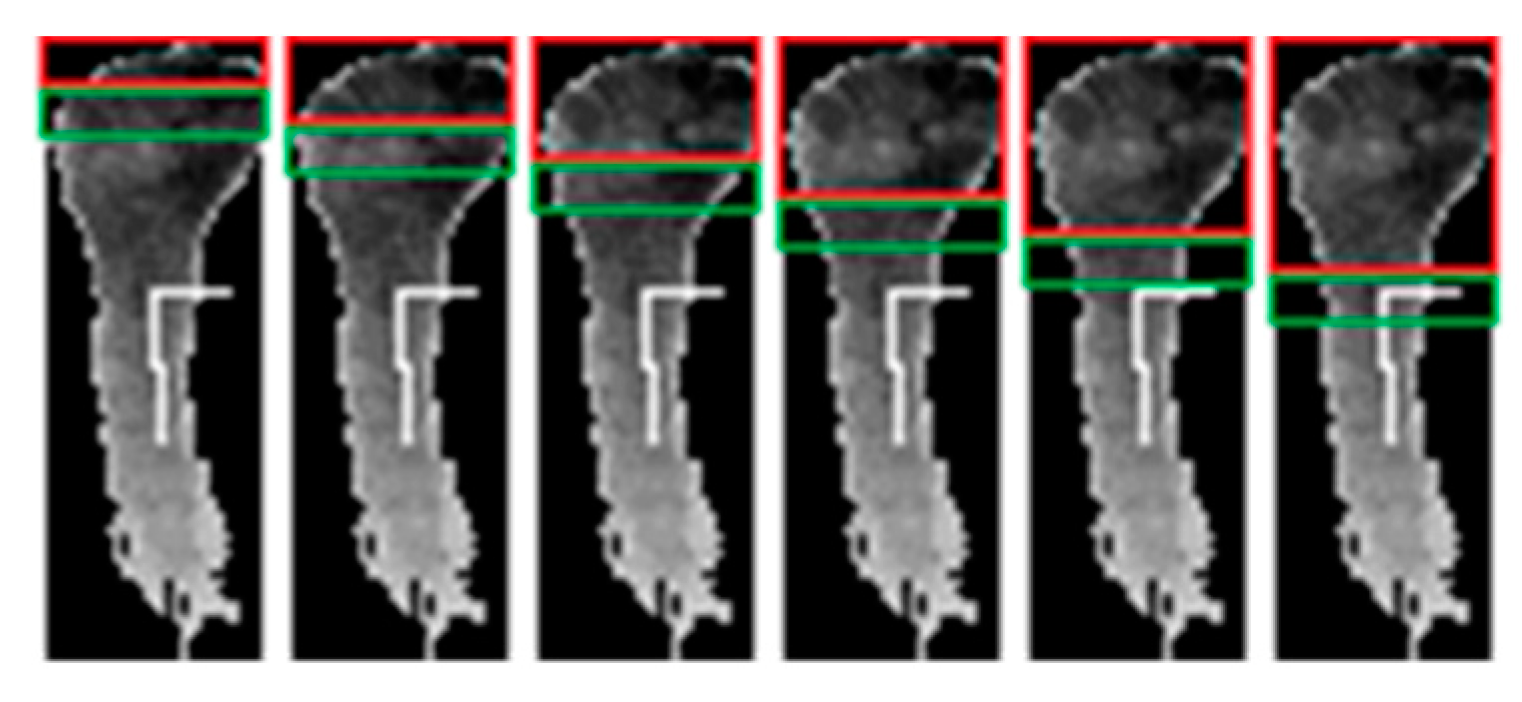
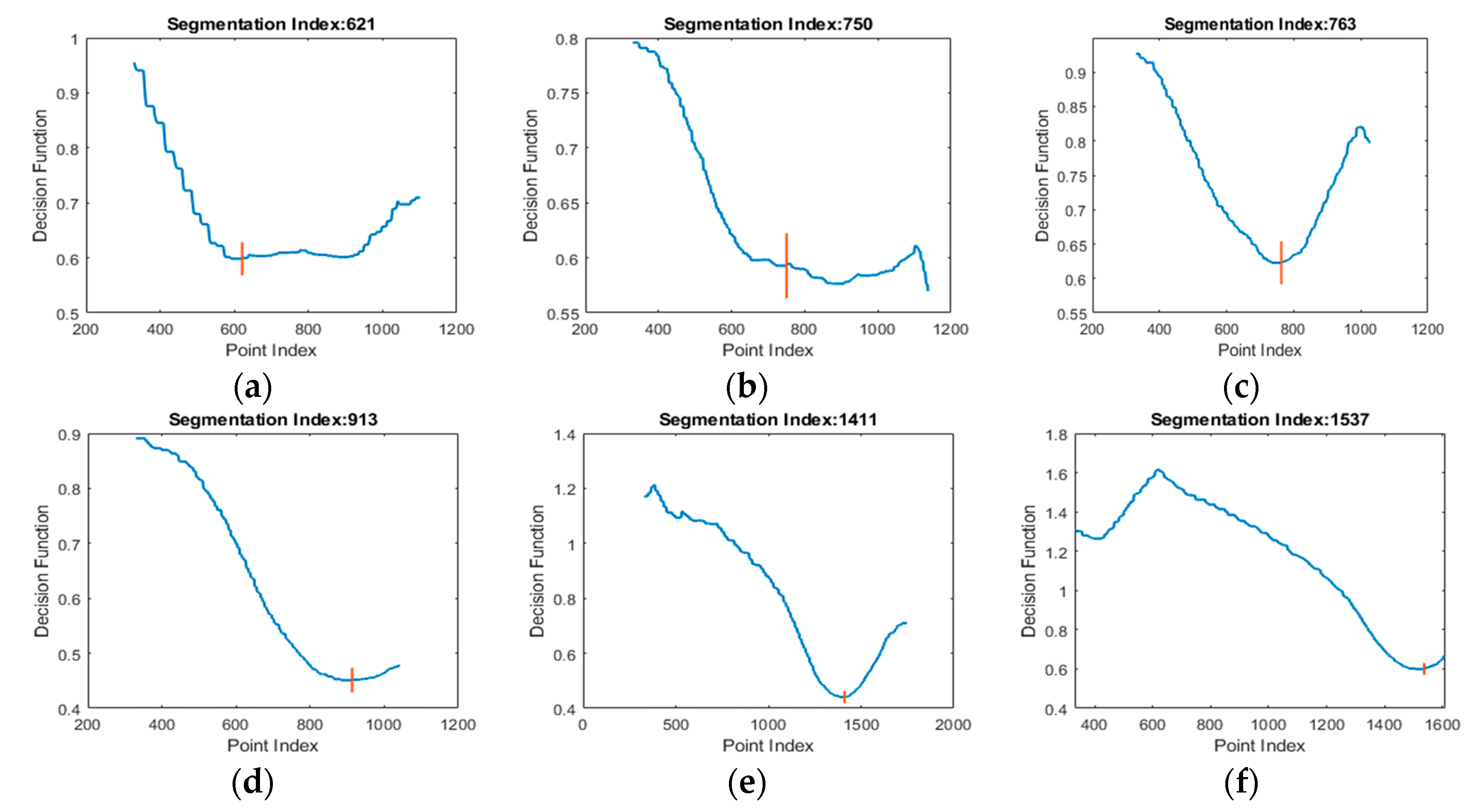
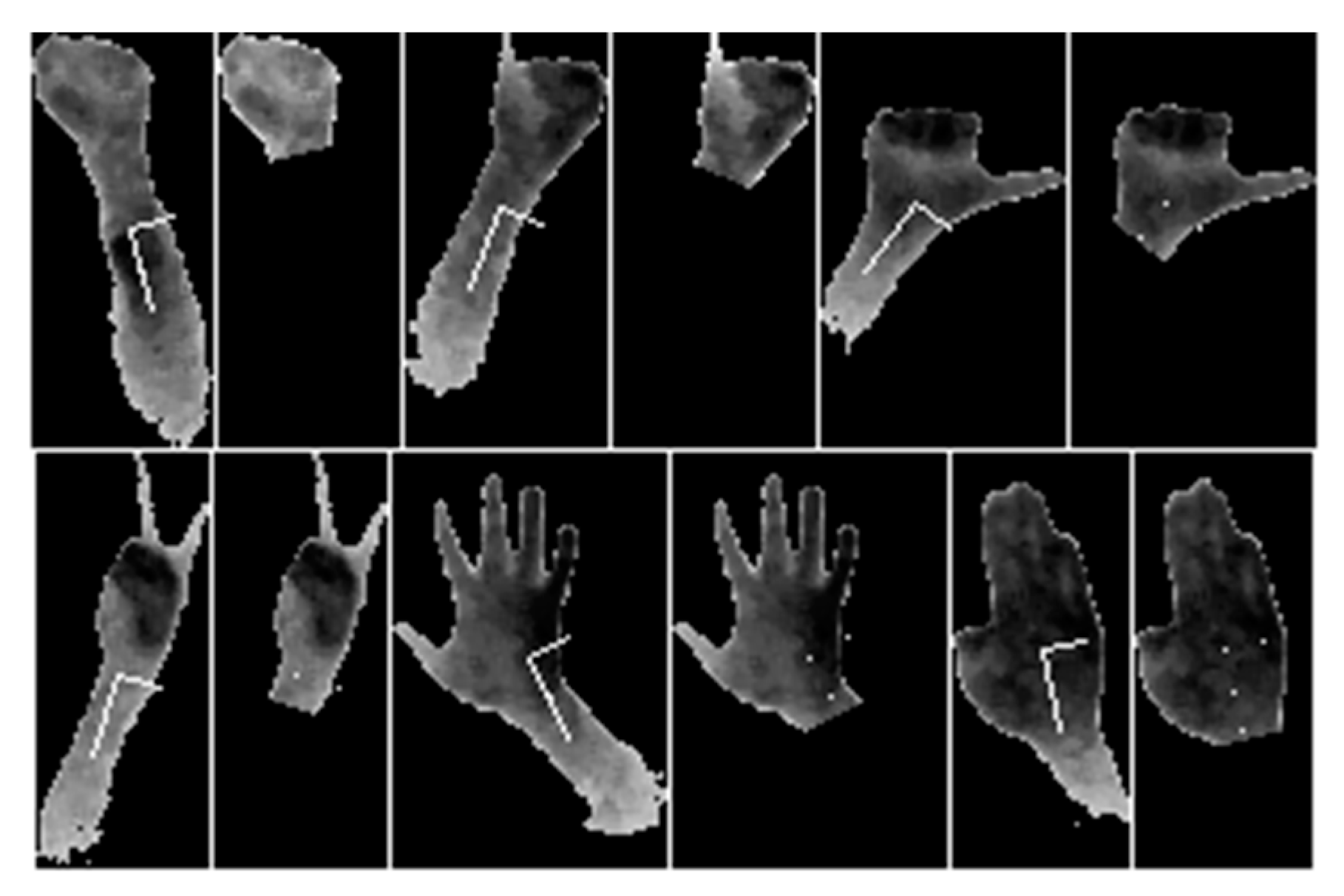
2.2.4. Hand-Forearm Segmentation
2.3. Creating the Point Cloud
2.3.1. Point Cloud Size
2.3.2. Point Cloud Scaling
2.4. PointNet Deep Neural Network as Gesture Classifier
2.4.1. PointNet Architecture
- Invariance to set order. The outcome of the network should not depend on the order of the points in the set allowing any possible permutation amongst them.
- Locality information. Even though points are processed independently, the local information brought by neighboring points or structures should not be lost.
- Invariance to transformations. Transformations like rotations or translations should not affect the outcome of the network.
2.4.2. CNN Architecture
3. Results
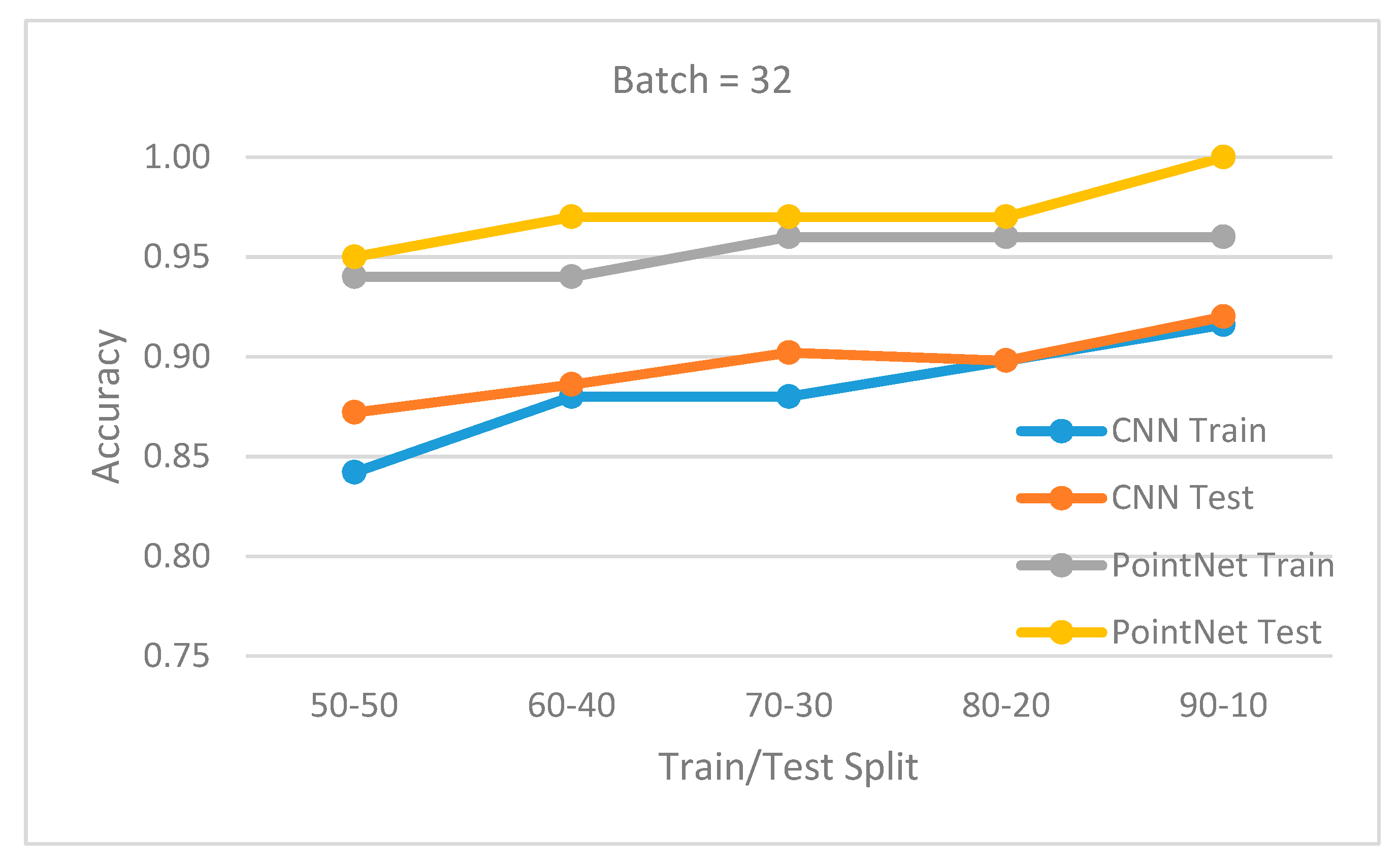
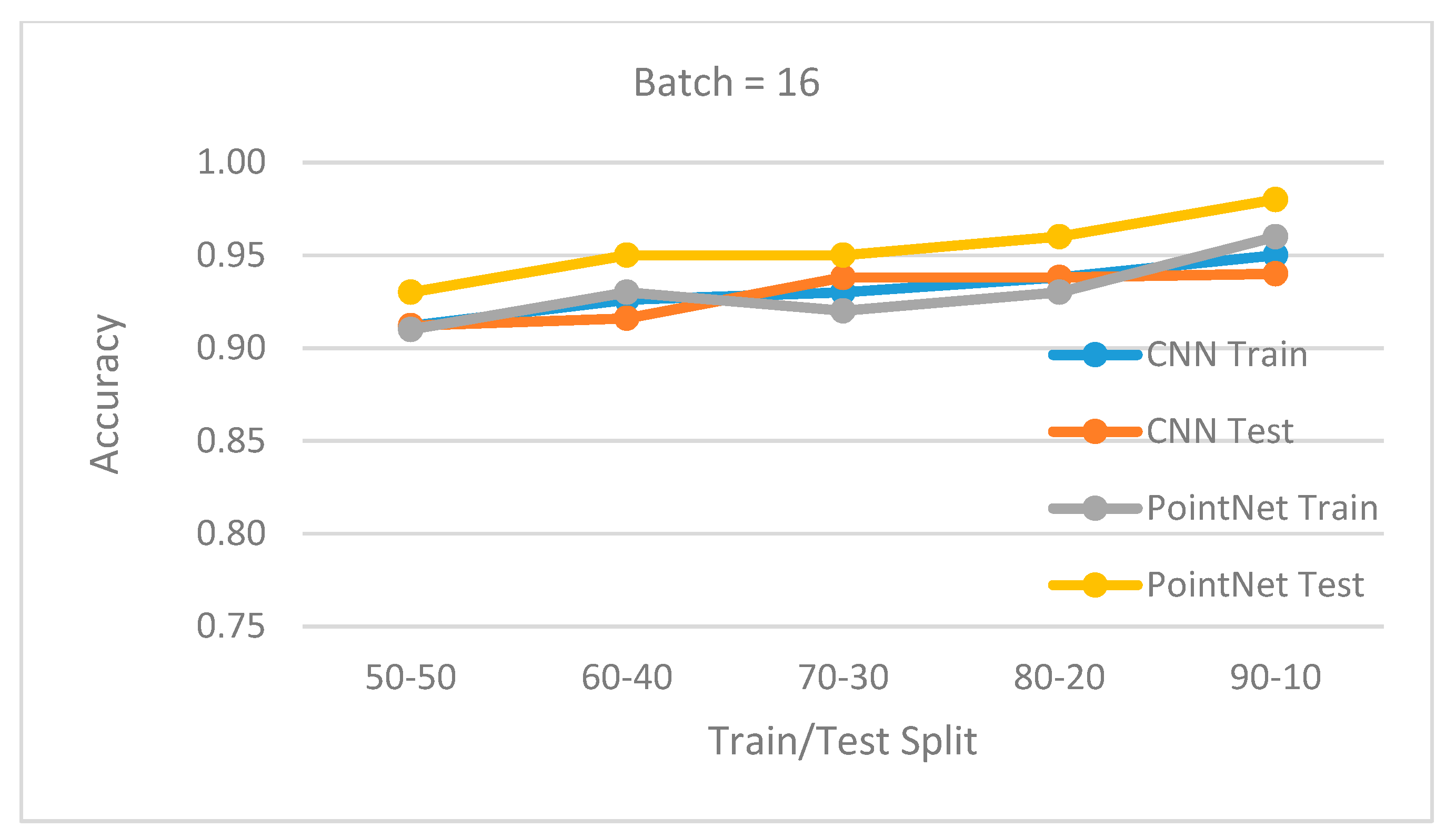
3.1. Network Training and Testing
3.2. Experiments
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Terabee 3Dcam. Available online: https://www.terabee.com/shop/3d-tof-cameras/terabee-3dcam/ (accessed on 3 March 2020).
- Priyal, S.P.; Bora, P.K. A robust static hand gesture recognition system using geometry based normalizations and Krawtchouk moments. Pattern Recognit. 2013, 46, 2202–2219. [Google Scholar] [CrossRef]
- Konecny, J.; Hagara, M. One-shot-learning gesture recognition using HOG-HOF features. J. Mach. Learn. Res. 2014, 15, 2513–2532. [Google Scholar]
- Wu, D.; Zhu, F.; Shao, L. One shot learning gesture recognition from RGB-D images. In Proceedings of the IEEE Conference Computer Vision Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 7–12. [Google Scholar]
- Wan, J.; Guo, G.; Li, S. Explore efficient local features from RGB-D data for one-shot learning gesture recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1626–1639. [Google Scholar] [CrossRef] [PubMed]
- Tamrakar, A.; Ali, S.; Yu, Q.; Liu, J.; Javed, O.; Divakaran, A.; Cheng, H.; Sawhney, H. Evaluation of low-level features and their combinations for complex event detection in opensource videos. In Proceedings of the IEEE Conference Computer Vision Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Wang, H.; Oneata, D.; Verbeek, J.; Schmid, C. A robust and efficient video representation for action recognition. IJCV 2015, 119, 219–238. [Google Scholar] [CrossRef]
- Ohn-Bar, E.; Trivedi, M. Hand gesture recognition in real time for automotive interfaces: A multimodal vision-based approach and evaluations. IEEE ITS 2014, 15, 1–10. [Google Scholar] [CrossRef]
- Wan, J.; Li, S.Z.; Zhao, Y.; Zhou, S.; Guyon, I.; Escalera, S. ChaLearn Looking at People RGB-D Isolated and Continuous Datasets for Gesture Recognition; CVPR: Boston, MA, USA, 2016; pp. 56–64. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Wu, Z. 3D ShapeNets: A Deep Representation for Volumetric Shapes; CVPR: Boston, MA, USA, 2015; pp. 1912–1920. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L. Volumetric and Multi-View Cnns for Object Classification on 3d Data; CVPR: Boston, MA, USA, 2016. [Google Scholar]
- Molchanov, P.; Gupta, S.; Kim, K.; Kautz, J. Hand gesture recognition with 3D convolutional neural networks. In Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–7. [Google Scholar]
- Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; Kautz, J. Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks; IEEE CVPR: Las Vegas, NV, USA, 2016; pp. 4207–4215. [Google Scholar]
- Zhu, G.; Zhang, L.; Shen, P.; Song, J. Multimodal Gesture Recognition Using 3-D Convolution and Convolutional LSTM. IEEE Access 2017, 5, 4517–4524. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, G.M.; Mei, L. Attention in convolutional LSTM for gesture recognition. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 4 December 2018. [Google Scholar]
- Kingkan, C.; Owoyemi, J.; Hashimoto, K. Point Attention Network for Gesture Recognition Using Point Cloud Data; BMVC: New Castle, UK, 2018; p. 118. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Robust 3Dhand Pose Estimation in Single Depth Images: From Single View CNN to Multi-View CNNs; CVPR: Boston, MA, USA, 2016. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. 3d Convolutional Neural Networks for Efficient and Robust Hand Pose Estimation from Single Depth Images; CVPR: Boston, MA, USA, 2017. [Google Scholar]
- Ge, L.; Cai, Y.; Weng, J.; Yuan, J. Hand PointNet: 3d Hand Pose Estimation Using Point Sets; CVPR: Boston, MA, USA, 2018. [Google Scholar]
- Asadi-Aghbolaghi, M.; Clapes, A.; Bellantonio, M.; Esacalnte, H.; Ponce-Lopez, V.; Baro, X.; Guyon, I.; Kasaei, S.; Escalera, S. Deep learning for action and gesture recognition in image sequences: A survey. In Gesture Recognition; Springer: Cham, Switzerland, 2017; pp. 539–578. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation; CVPR: Boston, MA, USA, 2016; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; pp. 5105–5114. [Google Scholar]
- Owoyemi, J.; Chiba, N.; Hashimoto, K. Discriminative Recognition of Point Cloud Gesture Classes through One-Shot Learning. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics, Dali, China, 6–8 December 2019; pp. 2304–2309. [Google Scholar]
- Chugunov, I.; Zakhor, A. Duodepth: Static Gesture Recognition Via Dual Depth Sensors. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3467–3471. [Google Scholar]
- UPT Time of Flight 3D Hand Gesture Database. Available online: https://www.kaggle.com/cdcaleanu/upt-tof-3d-hand-gesture-database (accessed on 3 March 2020).
- Simion, G.; Căleanu, C.D. A ToF 3D database for hand gesture recognition. In Proceedings of the 2012 10th International Symposium on Electronics and Telecommunications, Timisoara, Romania, 15–16 November 2012; pp. 363–366. [Google Scholar]
- Simion, G.; Căleanu, C. Multi-stage 3D segmentation for ToF based gesture recognition system. In Proceedings of the 2014 11th International Symposium on Electronics and Telecommunications (ISETC), Timisoara, Romania, 15–16 November 2014; pp. 1–4. [Google Scholar]
- Liu, Z.; Tang, H.; Lin, Y.; Han, S. Point-Voxel CNN for Efficient 3D Deep Learning. In Proceedings of the Advances in Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8 December 2019. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Method Summary | Dataset | Accuracy % |
|---|---|---|---|
| Molchanov et al. [13] | CNN, 2 sub-networks | Viva Challenge Dataset | 77.5 |
| Molchanov et al. [14] | Recurrent 3D CNN | SKIG/ChaLearn 2014 | 98.6/98.2 |
| Zhu et al. [15] | 3D CNN + LSTM | SKIG/ChaLearn (Lap IsoGD) | 98.89/52.01 |
| Zhang et al. [16] | ConvLSTM | Jester/IsoGD | 95.13/55.98 |
| Kingan et al. [17] | PointNet + Attention Module | Japanese Gesture Dataset | 94.2 |
| Ge et al. [18,19,20] | 3D CNN | MSRA/NYU/ICVL | - |
| Layer (Type) | Output Shape | Param# | Layer (Type) | Output Shape | Param# |
|---|---|---|---|---|---|
| Conv2d_1 (Conv2D) | (62, 44, 32) | 320 | Conv2d_5 (Conv2D) | (14, 9, 128) | 73,856 |
| Conv2d_2 (Conv2D) | (60, 42, 32) | 9248 | Conv2d_6 (Conv2D) | (12, 7, 128) | 147,584 |
| max_pooling2d_1 (MaxPooling2) | (30, 21, 32) | 0 | max_pooling2d_3 (MaxPooling2) | (6, 3, 128) | 0 |
| dropout_1 (Dropout) | (30, 21, 32) | 0 | dropout_3 (Dropout) | (6, 3, 128) | 0 |
| Conv2d_3 (Conv2D) | (30, 21, 64) | 18,496 | flatten_1 (Flatten) | (2304) | 0 |
| Conv2d_4 (Conv2D) | (28, 19, 64) | 36,928 | dense_1 (Dense) | 512 | 1,180,160 |
| max_pooling2d_2 (MaxPooling2) | (14, 9, 64) | 0 | dropout_4 (Dropout) | 512 | 0 |
| dropout_2 (Dropout) | (14, 9, 64) | 0 | dense_2 (Dense) | 6 | 3078 |
| Total params: | 1,469,670 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mirsu, R.; Simion, G.; Caleanu, C.D.; Pop-Calimanu, I.M. A PointNet-Based Solution for 3D Hand Gesture Recognition. Sensors 2020, 20, 3226. https://doi.org/10.3390/s20113226
Mirsu R, Simion G, Caleanu CD, Pop-Calimanu IM. A PointNet-Based Solution for 3D Hand Gesture Recognition. Sensors. 2020; 20(11):3226. https://doi.org/10.3390/s20113226
Chicago/Turabian StyleMirsu, Radu, Georgiana Simion, Catalin Daniel Caleanu, and Ioana Monica Pop-Calimanu. 2020. "A PointNet-Based Solution for 3D Hand Gesture Recognition" Sensors 20, no. 11: 3226. https://doi.org/10.3390/s20113226
APA StyleMirsu, R., Simion, G., Caleanu, C. D., & Pop-Calimanu, I. M. (2020). A PointNet-Based Solution for 3D Hand Gesture Recognition. Sensors, 20(11), 3226. https://doi.org/10.3390/s20113226