Joint Demosaicing and Denoising Based on a Variational Deep Image Prior Neural Network

Abstract
1. Introduction
2. Related Works
2.1. Deep Image Prior
2.2. Variational Auto Encoder
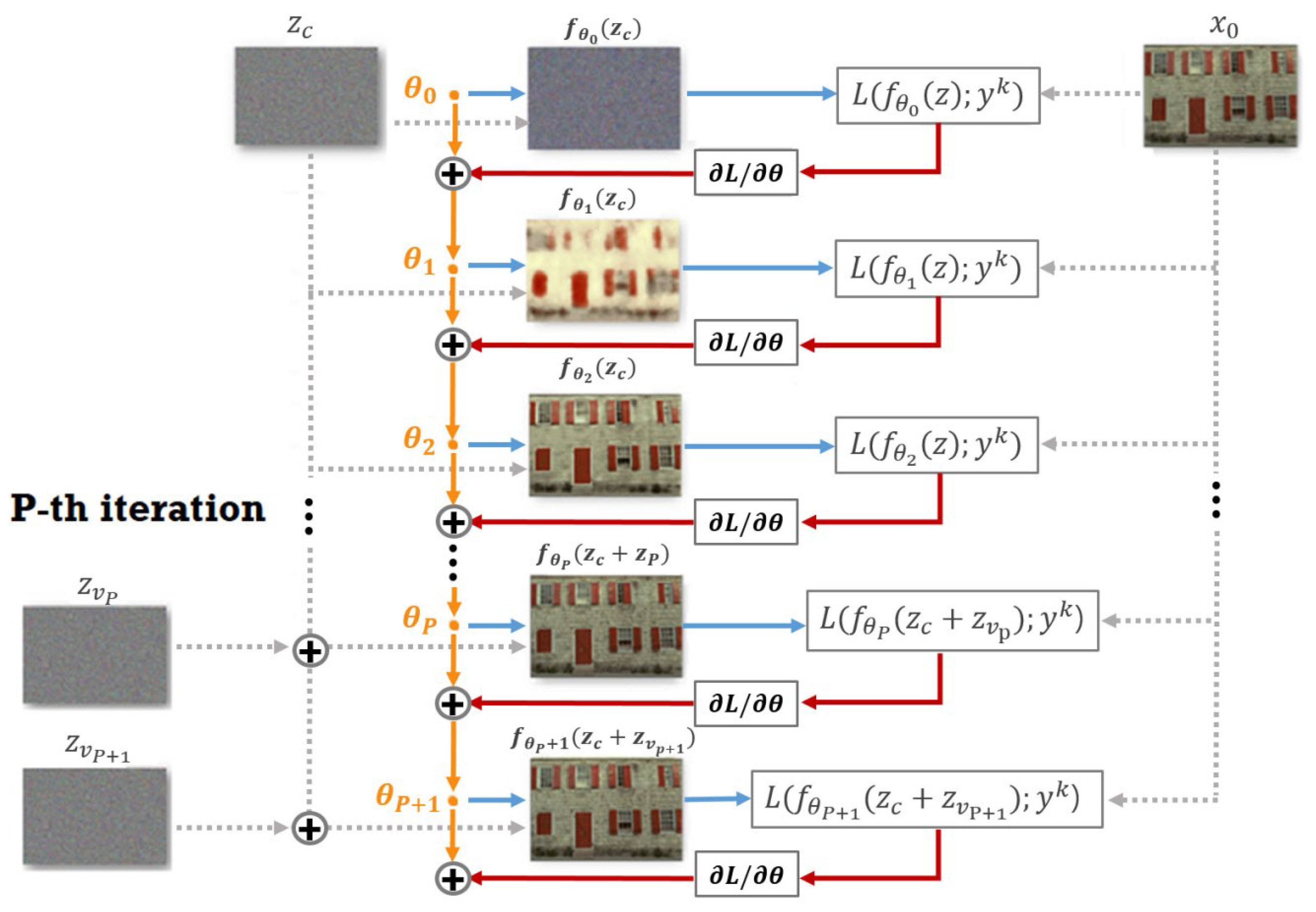
3. Variational Deep Image Prior for Joint Demosaicing and Denoising
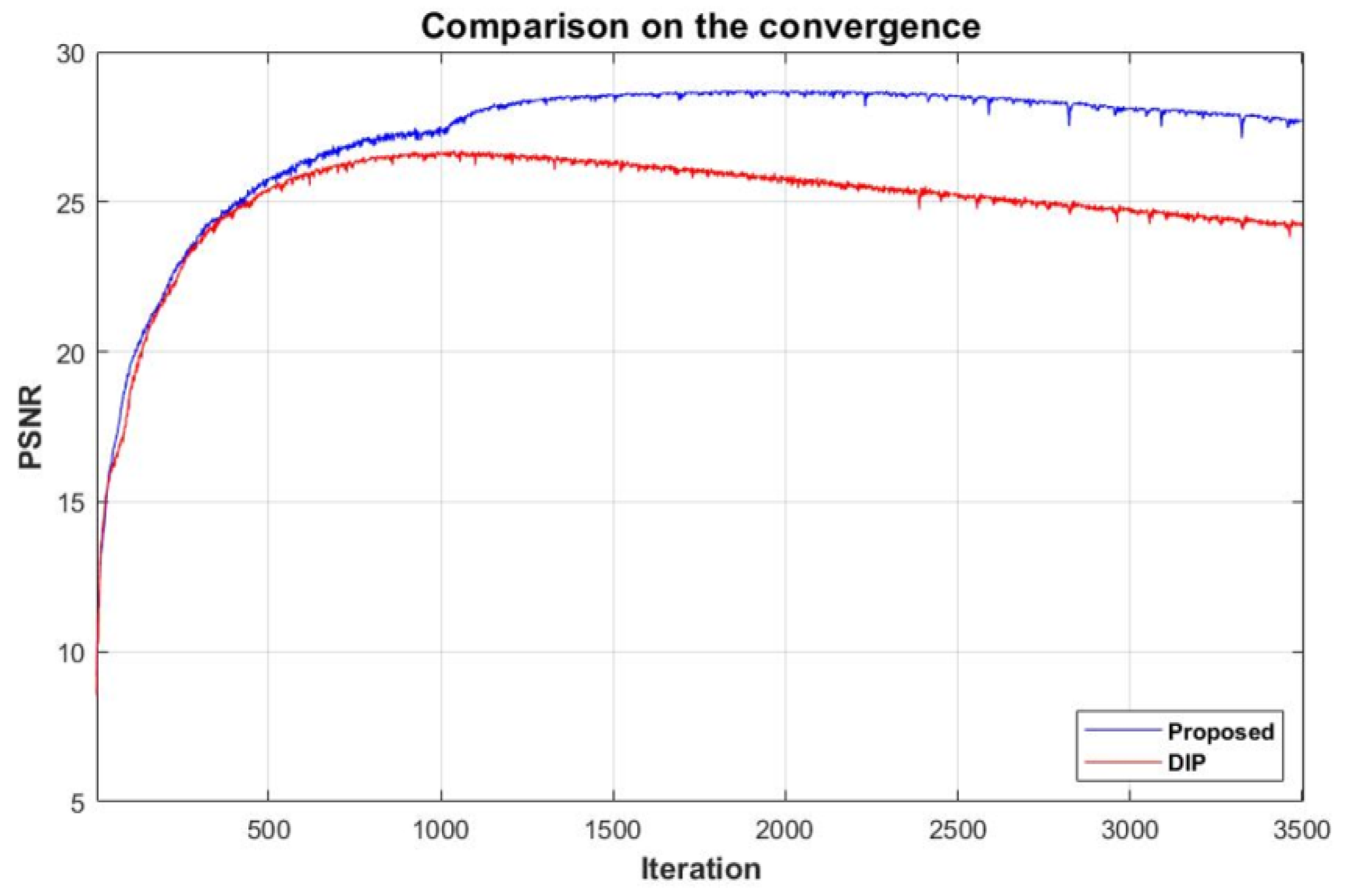
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pekkucuksen, I.; Altunbasak, Y. Multiscale gradients-based color filter array interpolation. IEEE Trans. Image Process. 2013, 22, 157–165. [Google Scholar] [CrossRef] [PubMed]
- Kiku, D.; Monno, Y.; Tanaka, M.; Okutomi, M. Beyond color difference: Residual interpolation for color image demosaicking. IEEE Trans. Image Process. 2016, 25, 1288–1300. [Google Scholar] [CrossRef] [PubMed]
- Gunturk, B.K.; Altunbasak, Y.; Mersereau, R.M. Color plane interpolation using alternating projections. IEEE Trans. Image Process. 2002, 11, 997–1013. [Google Scholar] [CrossRef] [PubMed]
- Alleysson, D.; Süsstrunk, S.; Hérault, J. Linear demosaicing inspired by the human visual system. IEEE Trans. Image Process. 2005, 14, 439–449. [Google Scholar] [PubMed]
- Gunturk, B.K.; Glotzbach, J.; Altunbasak, Y.; Schafer, R.W.; Mersereau, R.M. Demosaicking: Color filter array interpolation. IEEE Signal Process. Mag. 2005, 22, 44–54. [Google Scholar] [CrossRef]
- Kimmel, R. Demosaicing: Image reconstruction from color ccd samples. IEEE Trans. Image Process. 1999, 8, 1221–1228. [Google Scholar] [CrossRef] [PubMed]
- Pei, S.-C.; Tam, I.-K. Effective color interpolation in ccd color filter arrays using signal correlation. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 503–513. [Google Scholar]
- Menon, D.; Calvagno, G. Color image demosaicking: An overview. Signal Process Image 2011, 26, 518–533. [Google Scholar] [CrossRef]
- Dubois, E. Frequency-domain methods for demosaicking of bayer-sampled color images. IEEE Signal Process. Lett. 2005, 12, 847–850. [Google Scholar] [CrossRef]
- Hirakawa, K.; Parks, T.W. Joint demosaicing and denoising. IEEE Trans. Image Process. 2006, 15, 2146–2157. [Google Scholar] [CrossRef] [PubMed]
- Jeon, G.; Dubois, E. Demosaicking of noisy bayer sampled color images with least-squares luma-chroma demultiplexing and noise level estimation. IEEE Trans. Image Process. 2013, 22, 146–156. [Google Scholar] [CrossRef] [PubMed]
- Buades, A.; Duran, J. CFA Video Denoising and Demosaicking Chain via Spatio-Temporal Patch-Based Filtering. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef]
- Khashabi, D.; Nowozin, S.; Jancsary, J.; Fitzgibbon, A.W. Joint demosaicing and denoising via learned nonparametric random fields. IEEE Trans. Image Process. 2014, 23, 4968–4981. [Google Scholar] [CrossRef] [PubMed]
- Klatzer, T.; Hammernik, K.; Knobelreiter, P.; Pock, T. Learning joint demosaicing and denoising based on sequential energy minimization. In Proceedings of the 2016 IEEE International Conference on Computational Photography (ICCP), Evanston, IL, USA, 13–15 May 2016; pp. 1–11. [Google Scholar]
- Gharbi, M.; Chaurasia, G.; Paris, S.; Durand, F. Deep Joint Demosaicking and Denoising. ACM Trans. Graph. (TOG) 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Huang, T.; Wu, F.; Dong, W.; Guangming, S.; Li, X. Lightweight Deep Residue Learning for Joint Color Image Demosaicking and Denoising. In Proceedings of the 2018 International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 127–132. [Google Scholar]
- Ehret, T.; Davy, A.; Arias, P.; Facciolo, G. Joint Demosaicking and Denoising by Fine-Tuning of Bursts of Raw Images. In Proceedings of the 2019 International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8868–8877. [Google Scholar]
- Kokkinos, F.; Lefkimmiatis, S. Iterative Joint Image Demosaicking and Denoising Using a Residual Denoising Network. IEEE Trans. Image Process. 2019, 28, 4177–4188. [Google Scholar] [CrossRef] [PubMed]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep Image Prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 9446–9454. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations(ICLR 2014), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Ye, J.C.; Han, Y.S. Deep Convolutional Framelets: A General Deep Learning for Inverse Problems. SIAM J. Imaging Sci. 2017, 11, 991–1048. [Google Scholar] [CrossRef]
- Zhou, J.; Kwan, C.; Ayhan, B. A High Performance Missing Pixel Reconstruction Algorithm for Hyperspectral Images. In Proceedings of the 2nd International Conference on Applied and Theoretical Information Systems, Taipei, Taiwan, 10–12 February 2012; pp. 1–10. [Google Scholar]
- Lukac, R.; Konstantinos, N.P. Color Filter Arrays: Design and Performance Analysis. IEEE Trans. Consum. Electron. 2005, 51, 1260–1267. [Google Scholar] [CrossRef]
- Vaughn, I.J.; Alenin, A.S.; Tyo, J.S. Focal plane filter array engineering I: Rectangular lattices. Opt. Express 2017, 25, 11954–11968. [Google Scholar] [CrossRef] [PubMed]
- Hirakawa, K.; Wolfe, P.J. Spatio-Spectral Color Filter Array Design for Optimal Image Recovery. IEEE Trans. Image Process. 2008, 17, 1876–1890. [Google Scholar] [CrossRef] [PubMed]
- Bayer, B. Color Imaging Array. U.S. Patent 3,971,065, 20 July 1976. [Google Scholar]
- Fujifilm X-Pro1. Available online: http://www.fujifilmusa.com/products/digital_cameras/x/fujifilm_x_pro1/features (accessed on 23 May 2020).
- Tan, H.; Zeng, X.; Lai, S.; Liu, Y.; Zhang, M. Joint demosaicing and denoising of noisy bayer images with ADMM. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP 2017), Beijing, China, 17–20 September 2017; pp. 2951–2955. [Google Scholar]
- Kostadin, D.; Alessandro, F.; Vladimir, K.; Karen, E. Image denoising by sparse 3D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Noise Level | Measure | Bayer | Xtrans | Lukac | HirakawaA | HirakawaB | Random1 | Random2 |
|---|---|---|---|---|---|---|---|---|
| CPSNR | 31.4386 | 32.1435 | 31.8650 | 32.5018 | 32.0552 | 32.1918 | 32.1410 | |
| = 9.83 | SSIM-R | 0.8543 | 0.8719 | 0.8596 | 0.8827 | 0.8750 | 0.8718 | 0.8709 |
| = 6.24 | SSIM-G | 0.8870 | 0.8769 | 0.8839 | 0.8972 | 0.8823 | 0.8861 | 0.8863 |
| = 6.84 | SSIM-B | 0.8530 | 0.8744 | 0.8590 | 0.8854 | 0.8863 | 0.8719 | 0.8749 |
| FSIMc | 0.9771 | 0.9789 | 0.9759 | 0.9368 | 0.9740 | 0.9775 | 0.9775 | |
| CPSNR | 29.2582 | 29.3572 | 29.4057 | 29.7132 | 29.5584 | 29.3914 | 29.3710 | |
| = 19.67 | SSIM-R | 0.7724 | 0.7719 | 0.7745 | 0.8257 | 0.8275 | 0.7750 | 0.7927 |
| = 12.48 | SSIM-G | 0.8217 | 0.8207 | 0.8244 | 0.8452 | 0.8402 | 0.8230 | 0.8206 |
| = 13.67 | SSIM-B | 0.7948 | 0.7992 | 0.7992 | 0.8328 | 0.8239 | 0.8028 | 0.8084 |
| FSIMc | 0.9537 | 0.9541 | 0.9548 | 0.9532 | 0.9516 | 0.9548 | 0.9548 | |
| CPSNR | 28.0037 | 28.0340 | 28.0733 | 27.9030 | 27.5895 | 27.9799 | 28.2210 | |
| = 26.22 | SSIM-R | 0.7184 | 0.7126 | 0.7180 | 0.7682 | 0.7631 | 0.7127 | 0.7013 |
| = 16.64 | SSIM-G | 0.7801 | 0.7743 | 0.7782 | 0.7682 | 0.7785 | 0.7751 | 0.7809 |
| = 18.23 | SSIM-B | 0.7556 | 0.7517 | 0.7543 | 0.7645 | 0.7596 | 0.7542 | 0.7670 |
| FSIMc | 0.9364 | 0.9354 | 0.9358 | 0.9415 | 0.9616 | 0.9354 | 0.9372 |
| Noise Level | Dataset | Measure | ADMM | SEM | DNetB | DNetX | DIP | Proposed | Proposed +BM3D |
|---|---|---|---|---|---|---|---|---|---|
| Kodak | cPSNR | 31.3370 | 32.5468 | 31.4053 | 31.3766 | 30.4512 | 32.1410 | 32.6103 | |
| PSNR-R | 30.9196 | 31.6351 | 30.3037 | 30.4766 | 29.5487 | 31.5406 | 32.2743 | ||
| = 9.83 | PSNR-G | 31.9553 | 33.2664 | 32.1838 | 32.0917 | 31.1663 | 32.5779 | 32.8726 | |
| = 6.24 | PSNR-B | 31.2722 | 32.9731 | 32.0131 | 31.7628 | 30.9852 | 32.4079 | 32.7272 | |
| = 6.84 | McMaster | cPSNR | 32.1258 | 30.7908 | 31.1171 | 31.0155 | 29.6490 | 32.6603 | 33.0659 |
| PSNR-R | 31.8458 | 29.7472 | 29.9868 | 29.9864 | 28.7221 | 32.2605 | 32.9728 | ||
| PSNR-G | 33.2163 | 32.1750 | 32.2558 | 32.1366 | 30.1651 | 33.1813 | 33.4180 | ||
| PSNR-B | 31.6661 | 30.9114 | 31.5195 | 31.2861 | 30.4179 | 32.8239 | 33.0647 | ||
| Kodak | cPSNR | 30.1883 | 26.1682 | 25.9266 | 25.8636 | 27.2001 | 29.3710 | 30.2026 | |
| PSNR-R | 29.5430 | 25.1485 | 24.5928 | 24.9497 | 26.1787 | 28.7261 | 29.6902 | ||
| = 19.67 | PSNR-G | 30.7728 | 26.4776 | 26.6385 | 26.2463 | 27.8791 | 29.9587 | 30.4681 | |
| = 12.48 | PSNR-B | 30.3904 | 27.1772 | 26.9603 | 26.5889 | 27.9003 | 29.9483 | 30.5204 | |
| = 13.67 | McMaster | cPSNR | 30.5794 | 25.7280 | 26.1234 | 26.0321 | 26.7356 | 29.7984 | 30.4533 |
| PSNR-R | 29.9344 | 24.4154 | 24.6482 | 24.8721 | 25.5419 | 28.9401 | 29.9461 | ||
| PSNR-G | 31.5879 | 26.5727 | 27.0705 | 26.6617 | 27.3464 | 30.4840 | 30.9327 | ||
| PSNR-B | 30.5402 | 26.6814 | 27.2079 | 26.9079 | 27.8159 | 30.3375 | 30.7383 | ||
| Kodak | cPSNR | 29.3247 | 23.2843 | 23.4976 | 23.4724 | 25.6570 | 28.2210 | 29.0672 | |
| PSNR-R | 28.5560 | 22.3131 | 22.0491 | 22.5529 | 24.7341 | 27.3588 | 28.4363 | ||
| = 26.22 | PSNR-G | 29.9424 | 23.5352 | 24.2448 | 23.7847 | 26.1365 | 28.7616 | 29.3628 | |
| = 16.64 | PSNR-B | 29.6403 | 24.3010 | 24.6938 | 24.2836 | 26.2839 | 28.8031 | 29.5067 | |
| = 18.23 | McMaster | cPSNR | 29.5312 | 23.2554 | 23.8799 | 23.7807 | 25.4785 | 28.2050 | 29.0961 |
| PSNR-R | 28.6716 | 21.8944 | 22.2896 | 22.6013 | 24.2930 | 27.1305 | 28.4053 | ||
| PSNR-G | 30.5938 | 23.9948 | 24.8180 | 24.2958 | 26.0823 | 29.0621 | 29.6725 | ||
| PSNR-B | 29.6901 | 24.3931 | 25.1801 | 24.8034 | 26.5224 | 28.9340 | 29.4845 |
| Noise Level | Dataset | Measure | ADMM | SEM | DNetB | DNetX | DIP | Proposed | Proposed +BM3D |
|---|---|---|---|---|---|---|---|---|---|
| Kodak | SSIM-R | 0.8613 | 0.8581 | 0.7774 | 0.7834 | 0.7977 | 0.8709 | 0.8871 | |
| = 9.83 | SSIM-G | 0.8840 | 0.8785 | 0.8267 | 0.8154 | 0.8625 | 0.8863 | 0.8891 | |
| = 6.24 | SSIM-B | 0.8524 | 0.8802 | 0.8288 | 0.8209 | 0.8469 | 0.8749 | 0.8794 | |
| = 6.84 | McMaster | SSIM-R | 0.8846 | 0.8016 | 0.7612 | 0.7662 | 0.8017 | 0.8805 | 0.8993 |
| SSIM-G | 0.9132 | 0.8577 | 0.8222 | 0.8134 | 0.8657 | 0.9013 | 0.9074 | ||
| SSIM-B | 0.8624 | 0.8192 | 0.8068 | 0.8000 | 0.8407 | 0.8758 | 0.8822 | ||
| Kodak | SSIM-R | 0.8253 | 0.5630 | 0.5372 | 0.5405 | 0.6490 | 0.7927 | 0.8300 | |
| = 19.67 | SSIM-G | 0.8535 | 0.6007 | 0.6087 | 0.5762 | 0.7501 | 0.8206 | 0.8372 | |
| = 12.48 | SSIM-B | 0.8264 | 0.6256 | 0.6218 | 0.5931 | 0.7320 | 0.8084 | 0.8270 | |
| = 13.67 | McMaster | SSIM-R | 0.8416 | 0.5258 | 0.5320 | 0.5385 | 0.6529 | 0.8104 | 0.8378 |
| SSIM-G | 0.8817 | 0.6083 | 0.6185 | 0.5919 | 0.7725 | 0.8467 | 0.8588 | ||
| SSIM-B | 0.8288 | 0.5941 | 0.6209 | 0.6007 | 0.7485 | 0.8241 | 0.8221 | ||
| Kodak | SSIM-R | 0.7972 | 0.4296 | 0.4240 | 0.4319 | 0.5881 | 0.7013 | 0.7948 | |
| = 26.22 | SSIM-G | 0.8315 | 0.4642 | 0.4972 | 0.4657 | 0.6875 | 0.7809 | 0.8074 | |
| = 16.64 | SSIM-B | 0.8058 | 0.4858 | 0.5093 | 0.4819 | 0.6706 | 0.7670 | 0.7978 | |
| = 18.23 | McMaster | SSIM-R | 0.8091 | 0.4066 | 0.4289 | 0.4364 | 0.5915 | 0.7463 | 0.7961 |
| SSIM-G | 0.8579 | 0.4828 | 0.5173 | 0.4864 | 0.7156 | 0.8116 | 0.8265 | ||
| SSIM-B | 0.8031 | 0.4672 | 0.5213 | 0.4962 | 0.6863 | 0.7839 | 0.7873 |
| Noise Level | Dataset | Measure | ADMM | SEM | DNetB | DNetX | DIP | Proposed | Proposed +BM3D |
|---|---|---|---|---|---|---|---|---|---|
| Kodak | FSIMc | 0.9722 | 0.9792 | 0.9743 | 0.9730 | 0.9666 | 0.9775 | 0.9764 | |
| FSIM-R | 0.9580 | 0.9635 | 0.9469 | 0.9471 | 0.9469 | 0.9665 | 0.9705 | ||
| = 9.83 | FSIM-G | 0.9729 | 0.9794 | 0.9738 | 0.9734 | 0.9639 | 0.9736 | 0.9737 | |
| = 6.24 | FSIM-B | 0.9574 | 0.9728 | 0.9650 | 0.9607 | 0.9606 | 0.9704 | 0.9708 | |
| = 6.84 | McMaster | FSIMc | 0.9807 | 0.9788 | 0.9756 | 0.9746 | 0.9708 | 0.9824 | 0.9824 |
| FSIM-R | 0.9650 | 0.9565 | 0.9478 | 0.9481 | 0.9540 | 0.9716 | 0.9756 | ||
| FSIM-G | 0.9802 | 0.9773 | 0.9743 | 0.9743 | 0.9667 | 0.9779 | 0.9784 | ||
| FSIM-B | 0.9629 | 0.9600 | 0.9613 | 0.9587 | 0.9638 | 0.9749 | 0.9754 | ||
| Kodak | FSIMc | 0.9598 | 0.9232 | 0.9225 | 0.9175 | 0.9276 | 0.9548 | 0.9562 | |
| FSIM-R | 0.9399 | 0.8936 | 0.8654 | 0.8738 | 0.8978 | 0.9548 | 0.9463 | ||
| = 19.67 | FSIM-G | 0.9603 | 0.9266 | 0.9217 | 0.9210 | 0.9270 | 0.9514 | 0.9540 | |
| = 12.48 | FSIM-B | 0.9471 | 0.9259 | 0.9068 | 0.9014 | 0.9245 | 0.9490 | 0.9520 | |
| = 13.67 | McMaster | FSIMc | 0.9695 | 0.9290 | 0.9304 | 0.9268 | 0.9378 | 0.9625 | 0.9656 |
| FSIM-R | 0.9462 | 0.8911 | 0.8749 | 0.8803 | 0.9086 | 0.9467 | 0.9525 | ||
| FSIM-G | 0.9683 | 0.9315 | 0.9277 | 0.9284 | 0.9345 | 0.9582 | 0.9618 | ||
| FSIM-B | 0.9509 | 0.9197 | 0.9085 | 0.9056 | 0.9320 | 0.9554 | 0.9591 | ||
| Kodak | FSIMc | 0.9502 | 0.8811 | 0.8835 | 0.8776 | 0.9007 | 0.9372 | 0.9433 | |
| FSIM-R | 0.9255 | 0.8479 | 0.8148 | 0.8272 | 0.8687 | 0.9042 | 0.9305 | ||
| = 26.22 | FSIM-G | 0.9508 | 0.8868 | 0.8848 | 0.8832 | 0.8981 | 0.9352 | 0.9417 | |
| = 16.64 | FSIM-B | 0.9383 | 0.8876 | 0.8676 | 0.8607 | 0.8969 | 0.9329 | 0.9406 | |
| = 18.23 | McMaster | FSIMc | 0.9601 | 0.8919 | 0.8971 | 0.8929 | 0.9164 | 0.9470 | 0.9530 |
| FSIM-R | 0.9309 | 0.8462 | 0.8291 | 0.8379 | 0.8855 | 0.9258 | 0.9351 | ||
| FSIM-G | 0.9588 | 0.8982 | 0.8946 | 0.8964 | 0.9132 | 0.9437 | 0.9500 | ||
| FSIM-B | 0.9402 | 0.8869 | 0.8727 | 0.8700 | 0.9092 | 0.9403 | 0.9473 |
| Method | ADMM | SEM | DNetB | DNetX | DIP | Proposed |
|---|---|---|---|---|---|---|
| Time Cost | 567 s | 465 s | 8 s | 8 s | 525 s | 647 s |
| Software Tool | MATLAB | Python | Python | Python | Pytorch | Pytorch |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.; Lee, S.; Jeong, B.; Yoon, J. Joint Demosaicing and Denoising Based on a Variational Deep Image Prior Neural Network. Sensors 2020, 20, 2970. https://doi.org/10.3390/s20102970
Park Y, Lee S, Jeong B, Yoon J. Joint Demosaicing and Denoising Based on a Variational Deep Image Prior Neural Network. Sensors. 2020; 20(10):2970. https://doi.org/10.3390/s20102970
Chicago/Turabian StylePark, Yunjin, Sukho Lee, Byeongseon Jeong, and Jungho Yoon. 2020. "Joint Demosaicing and Denoising Based on a Variational Deep Image Prior Neural Network" Sensors 20, no. 10: 2970. https://doi.org/10.3390/s20102970
APA StylePark, Y., Lee, S., Jeong, B., & Yoon, J. (2020). Joint Demosaicing and Denoising Based on a Variational Deep Image Prior Neural Network. Sensors, 20(10), 2970. https://doi.org/10.3390/s20102970