BioMove: Biometric User Identification from Human Kinesiological Movements for Virtual Reality Systems



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Kinesiologically designed VR environment: We implemented a carefully designed VR environment to ensure the observation and recording of kinesiologically based movement patterns. We derived a set of typical tasks for an experiment that emphasize various movements of the head, eyes, arms, wrist, torso and legs [22] (see Figure 1).
- Focused tasks for data collection: The participants were engaged in the task of placing the red balls into the cylindrical containers (see Figure 1) and the green/blue cubes into the rectangular enclosure. These tasks can be broken down primitively into elliptical movements on the XY-axis and rotational movements on the XZ-axis. We tracked and recorded various data from the head-mounted-display (HMD) VR device, an eye gaze tracker (GAZE) and the hand-held-controller (HHC) as the users interacted and moved items within the VR environment (see Section 4.2.1 and Section 4.6).
- VR identity model: The data derived from the task sessions were passed to a k-Nearest Neighbor (kNN) classifier to build an identity model, which was then used to identify the user during a future activity based on a preset threshold level of confidence (see Section 4.7).
2. Threat Model
3. Related Works
3.1. Eye Movement Biometric
3.2. Head Movement Identification
3.3. VR Movement or Task Driven Biometric Identification
3.4. Contribution of Our Work
- Biometric data sources: Mustafa et al. [41], Li et al. [38], Sluganovic et al. and Yi et al. [42] solely relied on head movements to gather the unique significant biometric features. This singular data input source increases the probability of malicious attacks. Our solution extracted biometric data from users’ head, eyes and hands in a kinesiologically conformative manner.
- Applicable to VR environments that are based on active body movements: Mustafa et al. [41] pointed out that their solution focuses on a particular VR environment, whereas our solution can be used to authenticate in any VR environment where kinesiologically active movements exist or are used. Additionally, we track head and eye movements, which are basic actions exhibited while using a VR system.
- Identification domain: The solutions of Li et al. [38] and Yi et al. [42] require the identification to occur in the physical domain via smart glasses and wearable devices, whereas our solution uses the virtual domain, such as any applicable VR experience for identification, making our application more scalable and adaptable.
- Multiple tasks: Kupin et al. [8] based their identification on a singular task of throwing the ball at a target, whereas our study involved six different VR tasks that include a variety of kinesiological movements.
4. Materials and Methods
4.1. Goals
4.2. Experimental Design
4.2.1. User Tasks
4.2.2. The Raw Data Sources
- Task 1: Interacting with Balls in VR environment.
- Task 2: Interacting with Cubes in VR environment.
- Participant static metrics such as height, arm length and waist height.
4.2.3. The Features Tracked
- Head-Mounted Display positional and rotational data.
- Eye tracking gaze positional data.
- Hand-Held Controller positional and rotational data.
4.2.4. Movements
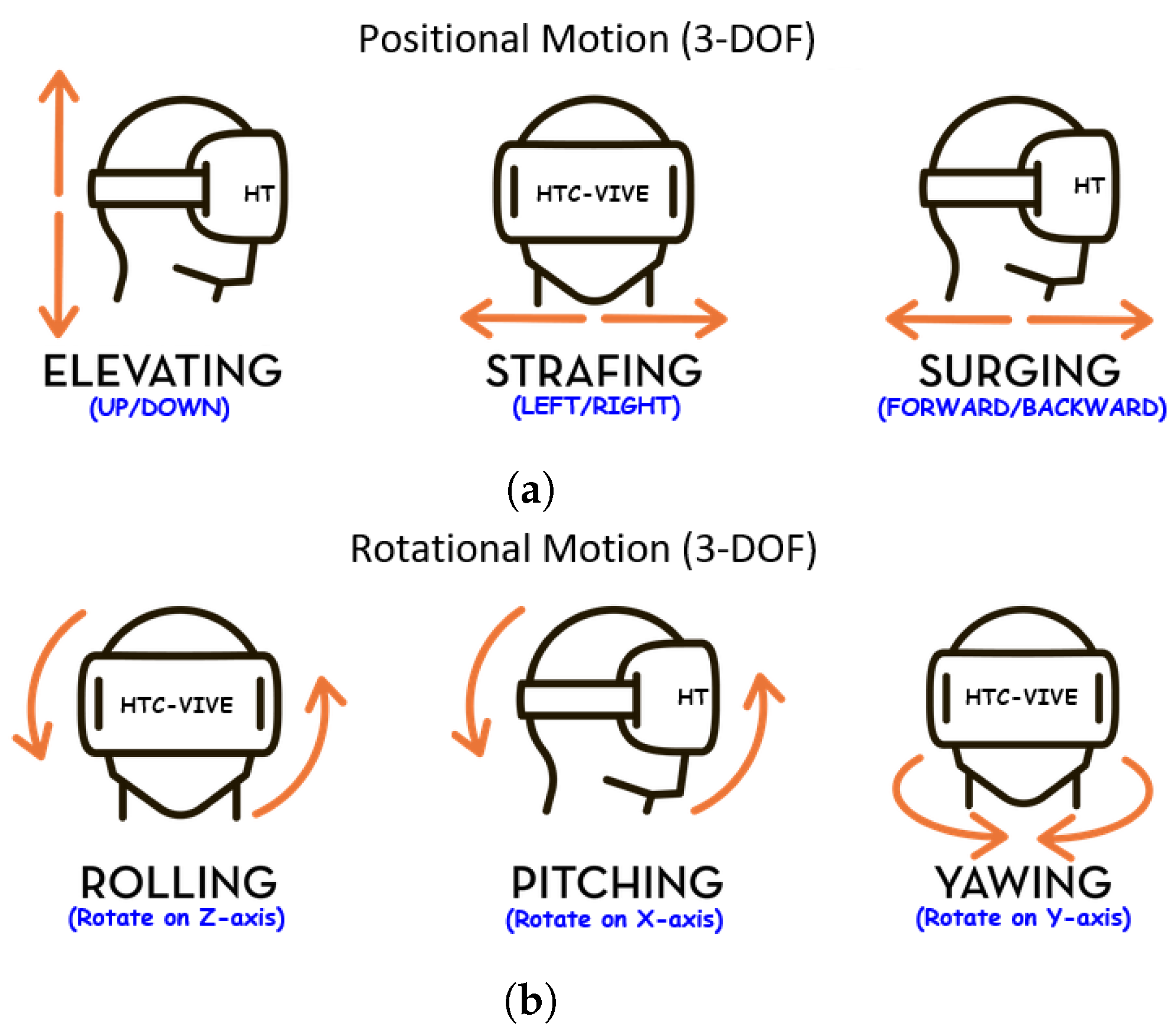
- Head Movements: The head moves through the possible six degree of freedom (6-DOF) while the participant targets, rotates and translates within the VR environment (see Figure 3). This was captured via the sensors in the HMD.
- Eye Movements: The eyes move as the participant locates, targets, grabs and moves the objects within the VR environment. This was captured using an eye tracking system embedded in the HMD (Figure 4a).
4.3. Research Ethics
4.4. Apparatus
4.4.1. The Virtual Reality Environment
4.4.2. The Interaction Devices
- Head: The VR headset containing the HMD has inertial motion sensors to estimate the participant’s head position and rotation. These sensors can capture data concerning the HMD and constantly update the VR environment according to head movements. The HMD allowed us to extract the positional coordinate and rotational, acceleration and velocity data for our experiment (see Figure 3).
- Eyes: The eye-tracking hardware, called aGlass [44], was installed inside the HMD to track the participants’ gaze as they performed the tasks. It can track the the positional coordinates (x,y) or direction where the participant is looking at within the virtual scene. The eye tracker was calibrated with a nine-point accuracy method (see Figure 4a).
- Hands: The hand-held controller (HHC) allowed participants to replicate their hand motion and usage within the VR scene to grab, move and release VR objects. The HHC also provided the positional coordinates, rotational, acceleration and velocity data during the experiment (see Figure 4b).
4.5. Participants
4.6. Task and Procedures
4.7. Data and Feature Processing
- HHC and HMD:
- -
- Positional Data: x, y, z.
- -
- Rotational Data: x, y, z, w. (Quaternion format)
- Eye Tracking Device:
- -
- Positional Data: x, y.
- Miscellaneous Metadata:
- -
- Task performed: t, (where 1 ≤ t ≤ 6). (We have six different tasks that are performed in a session.)
- -
- Time Stamp: yyyy-mm-dd-hh-M-ss-zzz.
4.7.1. Motion Data Resampling
- Session: A Session S is a set of tasks T (see Equation (1)).
- Task: A Task T is a set of movement vectors m (see Equation (2)).
- Median: The median D of the cardinality of movement vectors for each type of tasks across all sessions S in the experiment are determined as follows: For Each Task type (where 1 ≤ x ≤ 6) in the Experimentwhere is the cardinality of a set of movements of task type x.
- Resampling Process: The median or sample size was determined for each Task type (see Equation (3)). The Task movement count was resampled to the relevant movement count. Therefore, at the end of the resampling process, each task group had movement vectors with the same cardinality, which in this case is the median value D, across all participants. Because resampled points will rarely, if ever, line up exactly with the original sample points, we used simple linear interpolation to calculate the value of the resampled point based on the values of the left and right nearest points in the original sequence. This allowed us to handle vectors that are both larger and smaller than the median size.
4.8. Machine Learning Classification Framework
Identification
- Task Identification Model: This model is trained on identifying the task performed by the participants based of the movement vector streams. The resulting model makes a prediction of the task from the set of all possible tasks T. This stage allows a practical implementation where the results of this stage are used to select the correct participant identification model, thereby increasing accuracy and response time.
- Participant Identification Model: This model is trained to identify participants performing a particular task. The resulting model makes a prediction of the participant from the set of all participants P. In this scenario we have tasks, thus resulting in six different participant identification models. We argue that task specific model results in higher accuracy and faster identification systems.
5. Whitebox Penetration Testing
6. Results and Discussion
6.1. Identification Performance Evaluation
6.2. BioMove as an Authentication Mechanism
7. Limitations and Future Work
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| TNI | Transparent Non-intrusive Identification |
| VR | Virtual Reality |
| EEG | Electroencephalogram |
| KNN | k-Nearest Neighbor |
| HHC | Hand Held Controller |
| HMD | Head Mounted Display |
| HCI | Human Computer interaction |
| DOF | Degree Of Freedom |
| FAR | False Acceptance Rate |
| FRR | False Rejection Rate |
| EER | Equal Error Rate |
| OBS | Open Broadcaster Software |
| OSVR | Open Source Virtual Reality |
| API | Application Programming Interface |
References
- Greenleaf, W. How VR technology will transform healthcare. In Proceedings of the ACM SIGGRAPH 2016 VR Village, Anaheim, CA, USA, 24–28 July 2016; p. 5. [Google Scholar]
- Chandramouli, M.; Heffron, J. A desktop vr-based hci framework for programming instruction. In Proceedings of the 2015 IEEE Integrated STEM Education Conference, Princeton, NJ, USA, 7 March 2015; pp. 129–134. [Google Scholar]
- Fang, H.; Zhang, J.; Şensoy, M.; Magnenat-Thalmann, N. Evaluating the effects of collaboration and competition in navigation tasks and spatial knowledge acquisition within virtual reality environments. Electron. Commer. Res. Appl. 2014, 13, 409–422. [Google Scholar] [CrossRef]
- Sangani, S.; Fung, J.; Kizony, R.; Koenig, S.; Weiss, P. Navigating and shopping in a complex virtual urban mall to evaluate cognitive functions. In Proceedings of the 2013 International Conference on Virtual Rehabilitation (ICVR), Philadelphia, PA, USA, 26–29 August 2013; pp. 9–14. [Google Scholar]
- Liang, H.N.; Lu, F.; Shi, Y.; Nanjappan, V.; Papangelis, K. Navigating and shopping in a complex virtual urban mall to evaluate cognitive functions. Future Gener Comput. Syst. 2019, 95, 855–866. [Google Scholar] [CrossRef]
- Berg, L.P.; Vance, J.M. Industry use of virtual reality in product design and manufacturing: A survey. Virtual Real. 2017, 21, 1–17. [Google Scholar] [CrossRef]
- Yu, Z.; Liang, H.N.; Fleming, C.; Man, K.L. An exploration of usable authentication mechanisms for virtual reality systems. In Proceedings of the 2016 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Jeju, Korea, 26–28 October 2016; pp. 458–460. [Google Scholar]
- Kupin, A.; Moeller, B.; Jiang, Y.; Banerjee, N.K.; Banerjee, S. Task-Driven Biometric Authentication of Users in Virtual Reality (VR) Environments. In MultiMedia Modeling; Springer International Publishing: Cham, Switzerland, 2019; pp. 55–67. [Google Scholar]
- Yu, D.; Liang, H.N.; Fan, K.; Zhang, H.; Fleming, C.; Papangelis, K. Design and Evaluation of Visualization Techniques of Off-Screen and Occluded Targets in Virtual Reality Environments. IEEE Trans. Visual Comput. Graphics 2019. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Liang, H.N.; Zhao, Y.; Zhang, T.; Yu, D.; Monteiro, D. RingText: Dwell-free and hands-free Text Entry for Mobile Head-Mounted Displays using Head Motions. IEEE Trans. Visual Comput. Graphics 2019, 25, 1991–2001. [Google Scholar] [CrossRef] [PubMed]
- Yu, D.; Liang, H.N.; Lu, X.; Zhang, T.; Xu, W. DepthMove: Leveraging Head Motions in the Depth Dimension to Interact with Virtual Reality Head-Worn Displays. In Proceedings of the 2019 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Beijing, China, 14–18 October 2019; pp. 103–114. [Google Scholar]
- Xu, W.; Liang, H.N.; Zhao, Y.; Yu, D.; Monteiro, D. DMove: Directional Motion-based Interaction for Augmented Reality Head-Mounted Displays. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–14. [Google Scholar]
- Yu, D.; Liang, H.N.; Lu, X.; Fan, K.; Ens, B. Modeling endpoint distribution of pointing selection tasks in virtual reality environments. ACM Trans. Graphics (TOG) 2019, 38, 1–13. [Google Scholar] [CrossRef]
- Rajruangrabin, J.; Popa, D.O. Realistic and robust head-eye coordination of conversational robot actors in human tracking applications. In Proceedings of the 2nd International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 26–29 June 2009; pp. 1–7. [Google Scholar] [CrossRef]
- Mason, A.H.; Walji, M.A.; Lee, E.J.; MacKenzie, C.L. Reaching movements to augmented and graphic objects in virtual environments. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Seattle, WA, USA, 31 March–5 April 2001; pp. 426–433. [Google Scholar] [CrossRef]
- Wang, Y.; MacKenzie, C.L.; Summers, V.A.; Booth, K.S. The structure of object transportation and orientation in human-computer interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Los Angeles, CA, USA, 18–23 April 1998; pp. 312–319. [Google Scholar] [CrossRef]
- Mann, S.; Hao, M.L.; Tsai, M.; Hafezi, M.; Azad, A.; Keramatimoezabad, F. Effectiveness of Integral Kinesiology Feedback for Fitness-Based Games. In Proceedings of the 2018 IEEE Games, Entertainment, Media Conference (GEM), Galway, Ireland, 15–17 August 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Rallis, I.; Langis, A.; Georgoulas, I.; Voulodimos, A.; Doulamis, N.; Doulamis, A. An Embodied Learning Game Using Kinect and Labanotation for Analysis and Visualization of Dance Kinesiology. In Proceedings of the 2018 10th International Conference on Virtual Worlds and Games for Serious Applications (VS-Games), Würzburg, Germany, 5–7 September 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Keshner, E.A.; Slaboda, J.C.; Buddharaju, R.; Lanaria, L.; Norman, J. Augmenting sensory-motor conflict promotes adaptation of postural behaviors in a virtual environment. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 1379–1382. [Google Scholar] [CrossRef]
- Yu, Z.; Olade, I.; Liang, H.N.; Fleming, C. Usable Authentication Mechanisms for Mobile Devices: An Exploration of 3D Graphical Passwords. In Proceedings of the 2016 International Conference on Platform Technology and Service (PlatCon), Jeju, Korea, 15–17 February 2016; pp. 1–3. [Google Scholar] [CrossRef]
- Olade, I.; Liang, H.N.; Fleming, C. A Review of Multimodal Facial Biometric Authentication Methods in Mobile Devices and Their Application in Head Mounted Displays. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence Computing, Advanced Trusted Computing, Scalable Computing Communications, Cloud Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 1997–2004. [Google Scholar] [CrossRef]
- BenAbdelkader, C.; Cutler, R.; Davis, L. View-invariant estimation of height and stride for gait recognition. In International Workshop on Biometric Authentication; Springer: Berlin/Heidelberg, Germany, 2002; pp. 155–167. [Google Scholar]
- Pfeuffer, K.; Geiger, M.J.; Prange, S.; Mecke, L.; Buschek, D.; Alt, F. Behavioural Biometrics in VR: Identifying People from Body Motion and Relations in Virtual Reality. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems; ACM: New York, NY, USA, 2019; pp. 110:1–110:12. [Google Scholar] [CrossRef]
- Xu, W.; Liang, H.N.; Yu, Y.; Monteiro, D.; Hasan, K.; Fleming, C. Assessing the effects of a full-body motion-based exergame in virtual reality. In Proceedings of the 7th International Symposium of Chinese CHI (Chinese CHI’19), Florence, Italy, 28 July–2 August 2019; pp. 1–6. [Google Scholar]
- Xu, W.; Liang, H.N.; Zhang, Z.; Baghaei, N. Studying the Effect of Display Type and Viewing Perspective on User Experience in Virtual Reality Exergames. Games Health J. 2020, 9. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.; Huang, J.; Saha, T.; Nachman, L. Unobtrusive gait verification for mobile phones. In Proceedings of the 2014 ACM International Symposium on Wearable Computers, Seattle, WA, USA, 13–17 September 2014; pp. 91–98. [Google Scholar]
- Tamviruzzaman, M.; Ahamed, S.I.; Hasan, C.S.; O’brien, C. ePet: When cellular phone learns to recognize its owner. In Proceedings of the 2nd ACM Workshop on Assurable and Usable Security Configuration, Chicago, IL, USA, 9 November 2009; pp. 13–18. [Google Scholar]
- Monrose, F.; Reiter, M.K.; Wetzel, S. Password hardening based on keystroke dynamics. Int. J. Inf. Secur. 2002, 1, 69–83. [Google Scholar] [CrossRef][Green Version]
- Messerman, A.; Mustafić, T.; Camtepe, S.A.; Albayrak, S. Continuous and non-intrusive identity verification in real-time environments based on free-text keystroke dynamics. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–8. [Google Scholar]
- Roth, J.; Liu, X.; Metaxas, D. On continuous user authentication via typing behavior. IEEE Trans. Image Process. 2014, 23, 4611–4624. [Google Scholar] [CrossRef] [PubMed]
- Mock, K.; Hoanca, B.; Weaver, J.; Milton, M. Real-time continuous iris recognition for authentication using an eye tracker. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 1007–1009. [Google Scholar]
- Eberz, S.; Rasmussen, K.; Lenders, V.; Martinovic, I. Preventing lunchtime attacks: Fighting insider threats with eye movement biometrics. In Proceedings of the NDSS Symposium 2015, San Diego, CA, USA, 8–11 February 2015. [Google Scholar]
- Serwadda, A.; Phoha, V.V.; Wang, Z. Which verifiers work? A benchmark evaluation of touch-based authentication algorithms. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–8. [Google Scholar]
- Frank, M.; Biedert, R.; Ma, E.; Martinovic, I.; Song, D. Touchalytics: On the applicability of touchscreen input as a behavioral biometric for continuous authentication. IEEE Trans. Inf. Forensics Secur. 2013, 8, 136–148. [Google Scholar] [CrossRef]
- Nakanishi, I.; Baba, S.; Miyamoto, C. EEG based biometric authentication using new spectral features. In Proceedings of the 2009 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Kanazawa, Japan, 7–9 December 2009; pp. 651–654. [Google Scholar]
- Serwadda, A.; Phoha, V.V.; Poudel, S.; Hirshfield, L.M.; Bandara, D.; Bratt, S.E.; Costa, M.R. fNIRS: A new modality for brain activity-based biometric authentication. In Proceedings of the 2015 IEEE 7th International Conference on Biometrics Theory, Applications and Systems (BTAS), Arlington, VA, USA, 8–11 September 2015; pp. 1–7. [Google Scholar]
- Sluganovic, I.; Roeschlin, M.; Rasmussen, K.B.; Martinovic, I. Using Reflexive Eye Movements for Fast Challenge-Response Authentication. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; ACM: New York, NY, USA, 2016; pp. 1056–1067. [Google Scholar] [CrossRef]
- Li, S.; Ashok, A.; Zhang, Y.; Xu, C.; Lindqvist, J.; Gruteser, M. Whose move is it anyway? Authenticating smart wearable devices using unique head movement patterns. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, Australia, 14–18 March 2016; pp. 1–9. [Google Scholar]
- Saeed, U.; Matta, F.; Dugelay, J. Person Recognition based on Head and Mouth Dynamics. In Proceedings of the 2006 IEEE Workshop on Multimedia Signal Processing, Victoria, BC, Canada, 3–6 October 2006; pp. 29–32. [Google Scholar] [CrossRef]
- Li, S.; Ashok, A.; Zhang, Y.; Xu, C.; Lindqvist, J.; Gruteser, M. Demo of Headbanger: Authenticating smart wearable devices using unique head movement patterns. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), Sydney, Australia, 14–18 March 2016; pp. 1–3. [Google Scholar]
- Mustafa, T.; Matovu, R.; Serwadda, A.; Muirhead, N. Unsure How to Authenticate on Your VR Headset? Come on, Use Your Head! In Proceedings of the Fourth ACM International Workshop on Security and Privacy Analytics, Tempe, AZ, USA, 19–21 March 2018; pp. 23–30. [Google Scholar] [CrossRef]
- Yi, S.; Qin, Z.; Novak, E.; Yin, Y.; Li, Q. Glassgesture: Exploring head gesture interface of smart glasses. In Proceedings of the IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–15 April 2016; pp. 1–9. [Google Scholar]
- BioMove Source Code. Available online: https://github.com/ilesanmiolade/BioMove.git (accessed on 18 May 2020).
- aGlass Eyetracking (7invensun) Upgrade kit. HTC Vive HMD- aGlass Eyetracking Kit. 2018. Available online: http://www.aglass.com/ (accessed on 4 April 2019).
- OPEN VR SDL API. OpenVR SDK and API by Valve for SteamVR. 2018. Available online: http://valvesoftware.com/ (accessed on 11 November 2018).
- OSVR VR Gaming API. OSVR—Open-Source Virtual Reality for Gaming. 2018. Available online: http://www.osvr.org/ (accessed on 19 November 2018).
- Media Video Games and Gaming. Virtual Reality (VR) and Augmented Reality (AR) Device Ownership and Purchase Intent among Consumers in the United States as of 1st Quarter 2017, by Age Group. 2018. Available online: https://www.statista.com/statistics/740760/vr-ar-ownership-usa-age/ (accessed on 28 February 2020).










© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olade, I.; Fleming, C.; Liang, H.-N. BioMove: Biometric User Identification from Human Kinesiological Movements for Virtual Reality Systems. Sensors 2020, 20, 2944. https://doi.org/10.3390/s20102944
Olade I, Fleming C, Liang H-N. BioMove: Biometric User Identification from Human Kinesiological Movements for Virtual Reality Systems. Sensors. 2020; 20(10):2944. https://doi.org/10.3390/s20102944
Chicago/Turabian StyleOlade, Ilesanmi, Charles Fleming, and Hai-Ning Liang. 2020. "BioMove: Biometric User Identification from Human Kinesiological Movements for Virtual Reality Systems" Sensors 20, no. 10: 2944. https://doi.org/10.3390/s20102944
APA StyleOlade, I., Fleming, C., & Liang, H.-N. (2020). BioMove: Biometric User Identification from Human Kinesiological Movements for Virtual Reality Systems. Sensors, 20(10), 2944. https://doi.org/10.3390/s20102944