Convolutional-Neural Network-Based Image Crowd Counting: Review, Categorization, Analysis, and Performance Evaluation


Abstract
1. Introduction
- We specifically reviewed recent CNN-CC techniques in order to highlight deficiencies, advantages, disadvantages, and key features in each category.
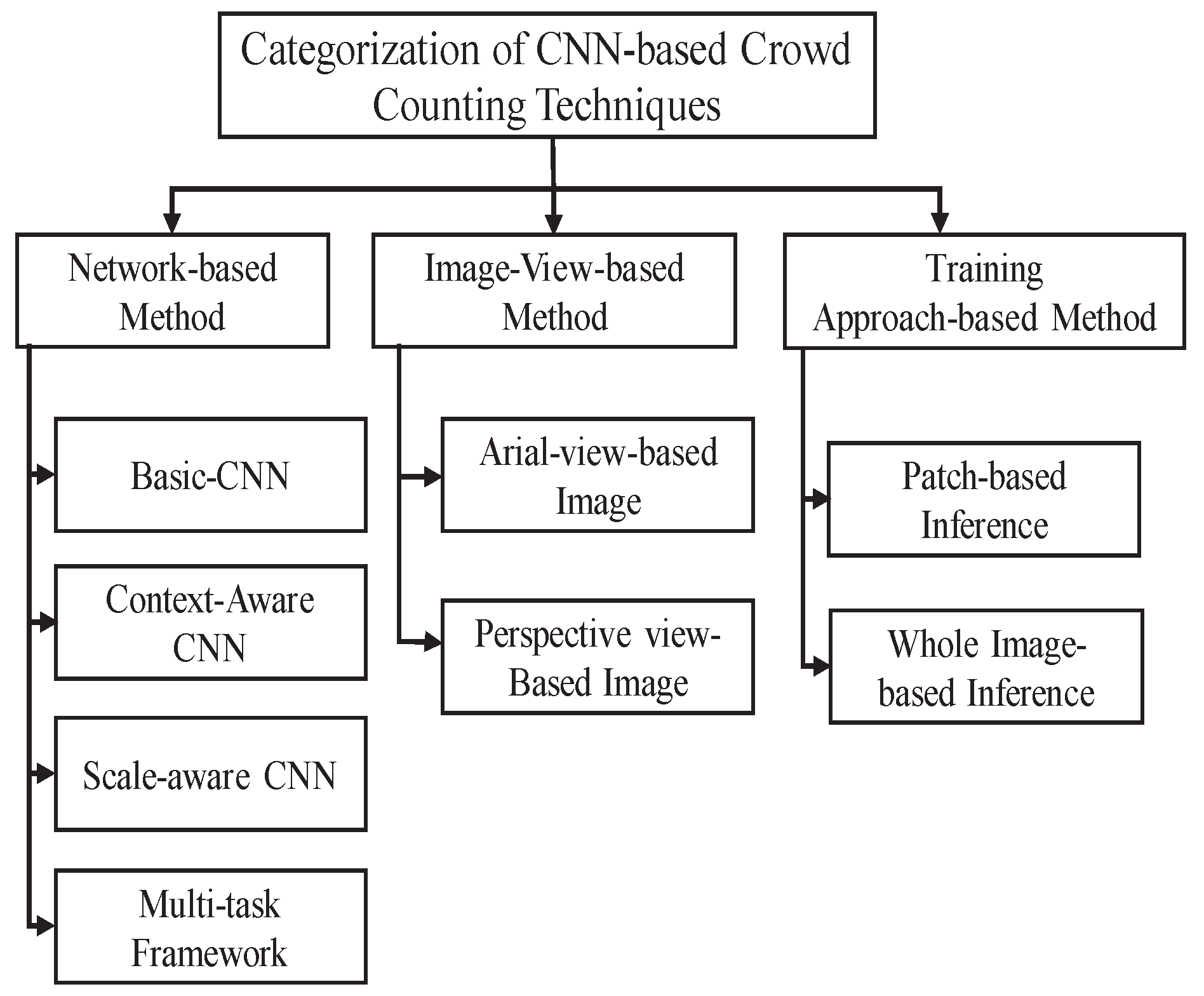
- We categorized CNN-based methods into three main categories to fully understand evolving research aspects. Previously, authors in [26] categorized CNN-based approaches into two main categories (network-based and training-approach-based). However, by reviewing the literature and observing the overall crowd-counting mechanism from different perspectives, we realized the need for a new category, and thus introduced image-view-based methods.
- Image-view-based CNN-CC techniques (Image-view-CNN-CC) were further subdivided into arial-view-based (camera and object are perpendicular to each other) and perspective-view-based (camera and object are parallel to each other) methods. Due to this inclusion, crowd counting in health care (microscopic images), counting through unmanned aerial vehicles (UAVs) is further investigated under arial-view-based methods. Moreover, scale-varying issues caused by different perspectives can be further investigated in detail under perspective-view-based methods.
- We provide detailed quantitative comparison (in term of n Mean Absolute Error (nMAE) within each subcategory of the three main categories, and overall performance-based conclusion under different datasets, such as UCF, WE, STA, and STB.
- By observing different aspects of CNN-CC, we also highlighted the features of each subcategory with quantitative comparison that provides a strong foundation for future research in highly diverse and robust scenarios.
2. Traditional Crowd Counting and Image Analysis
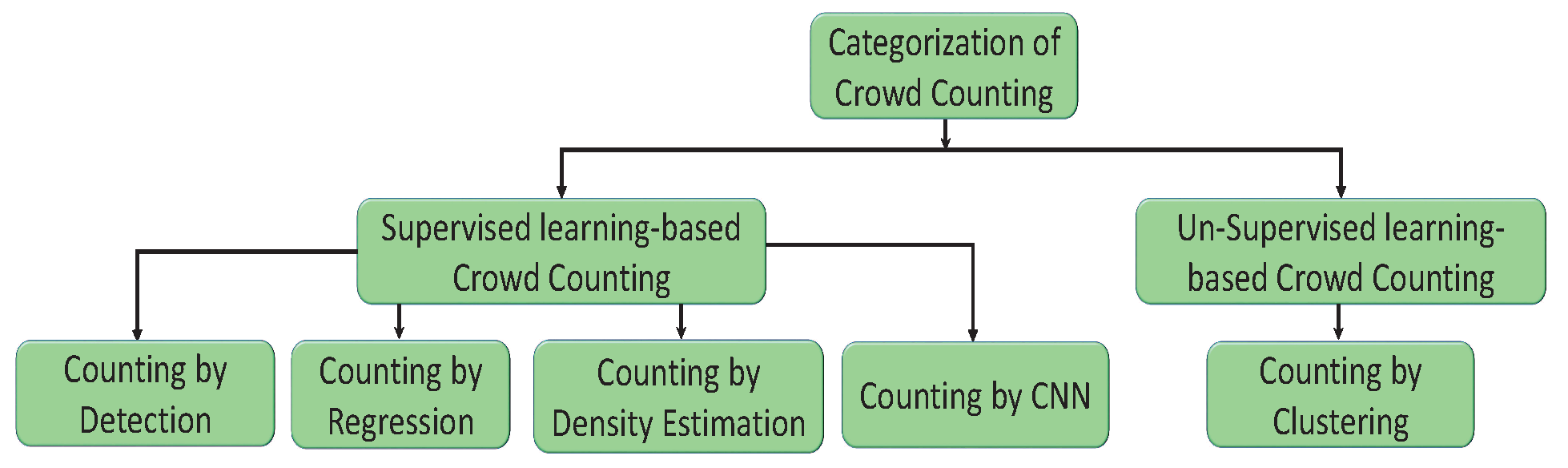
2.1. Crowd Counting
2.1.1. Counting by Detection
2.1.2. Counting by Regression
2.1.3. Counting by Density Estimation
2.1.4. Counting by CNN
2.1.5. Counting by Clustering
2.2. Image Analysis
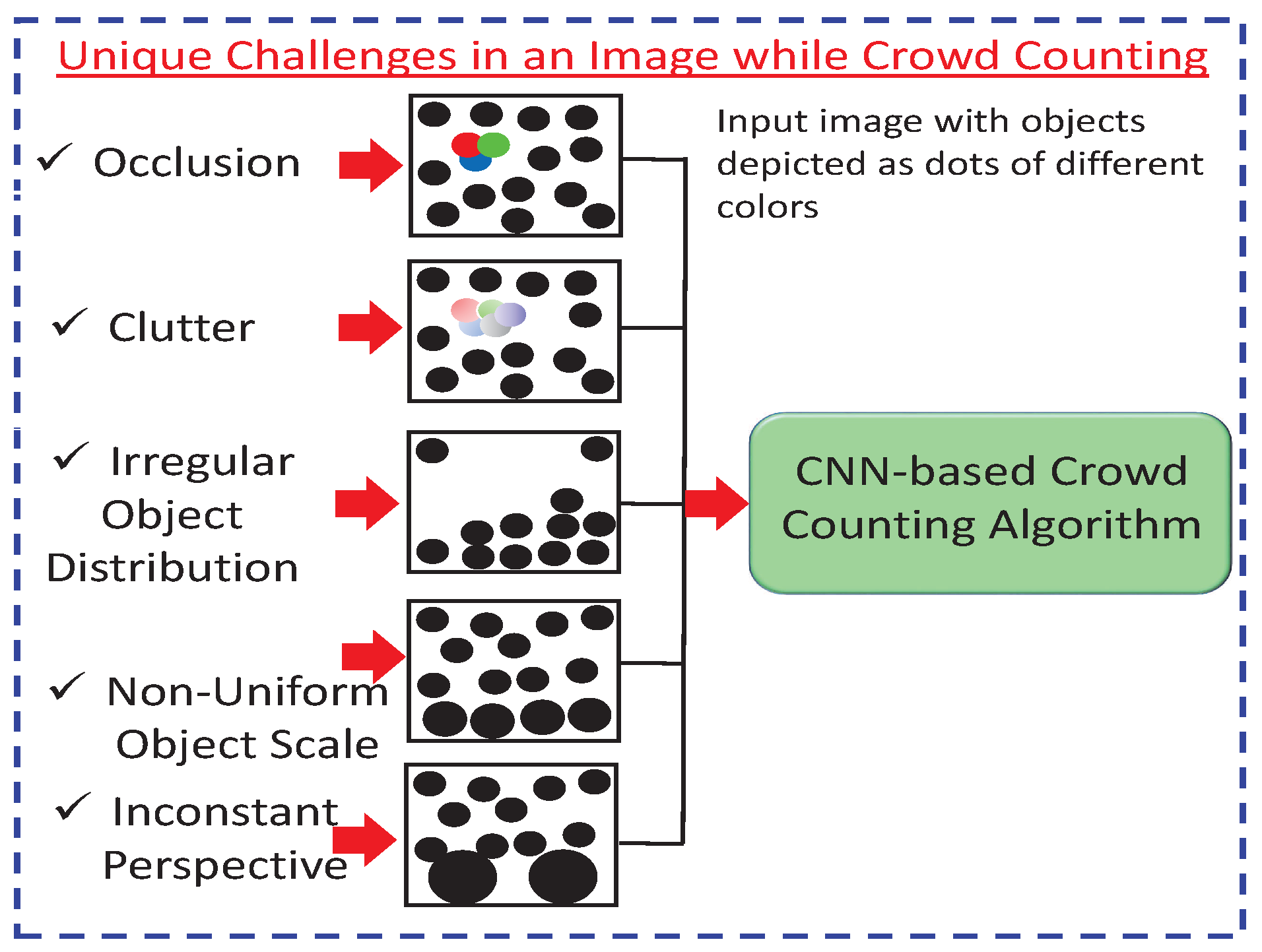
2.3. Unique Challenges of CNN-Based Image Crowd Counting
- Occlusion occurs when two or more objects come very close to each other and merge, so that it is hard to recognize individual objects. Thus, crowd-counting accuracy is decreased [18].
- Clutter is a kind of nonuniform arrangement of objects that are close to each other. It is also related to image noise, making recognition and counting tasks more challenging [19].
- Irregular object distribution refers to varying density distribution in an image or a video. For irregular objects, counting through detection is only viable in sparse areas. On the other hand, counting by regression overestimates the sparse areas and is only viable in dense areas. Thus, the irregular distribution of an object is a challenging task for crowd counting [20].
- Nonuniform object scales often occur due to different perspectives. In counting, objects close to the camera look larger when compared to ones farther away. The nearest objects have more pixels than far-away objects. Thus, ground-truth and actual-density estimations are affected by the nonuniform pixel distribution of the same object [21].
- An inconstant perspective occurs due to different camera angles, tilt, and the up–down movement of the camera position. Object recognition and counting accuracy are greatly affected by varying perspectives [22].
2.4. Motivation for Employing CNN-Based Image Crowd Counting
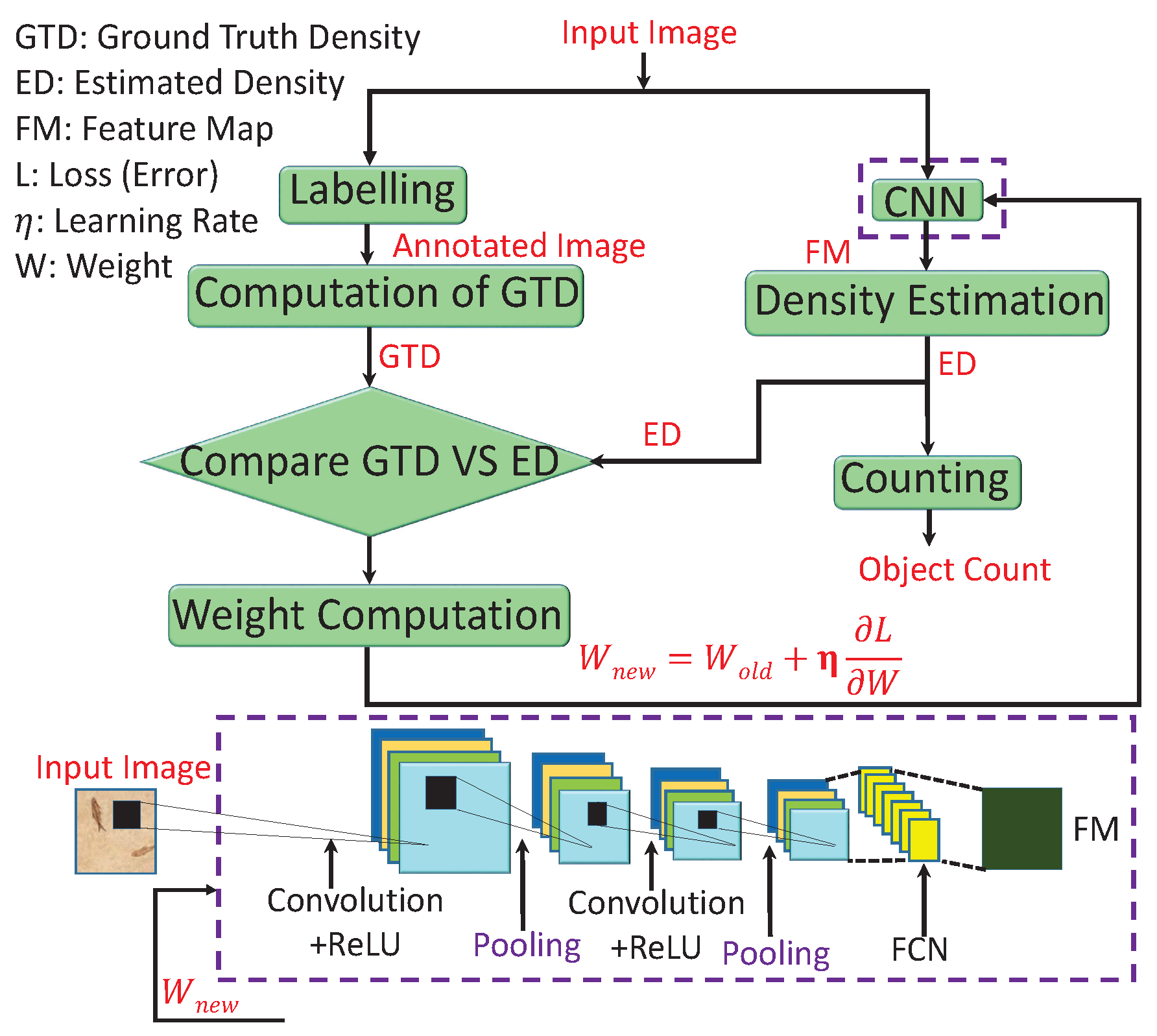
3. CNN-Based Crowd Counting: Overview
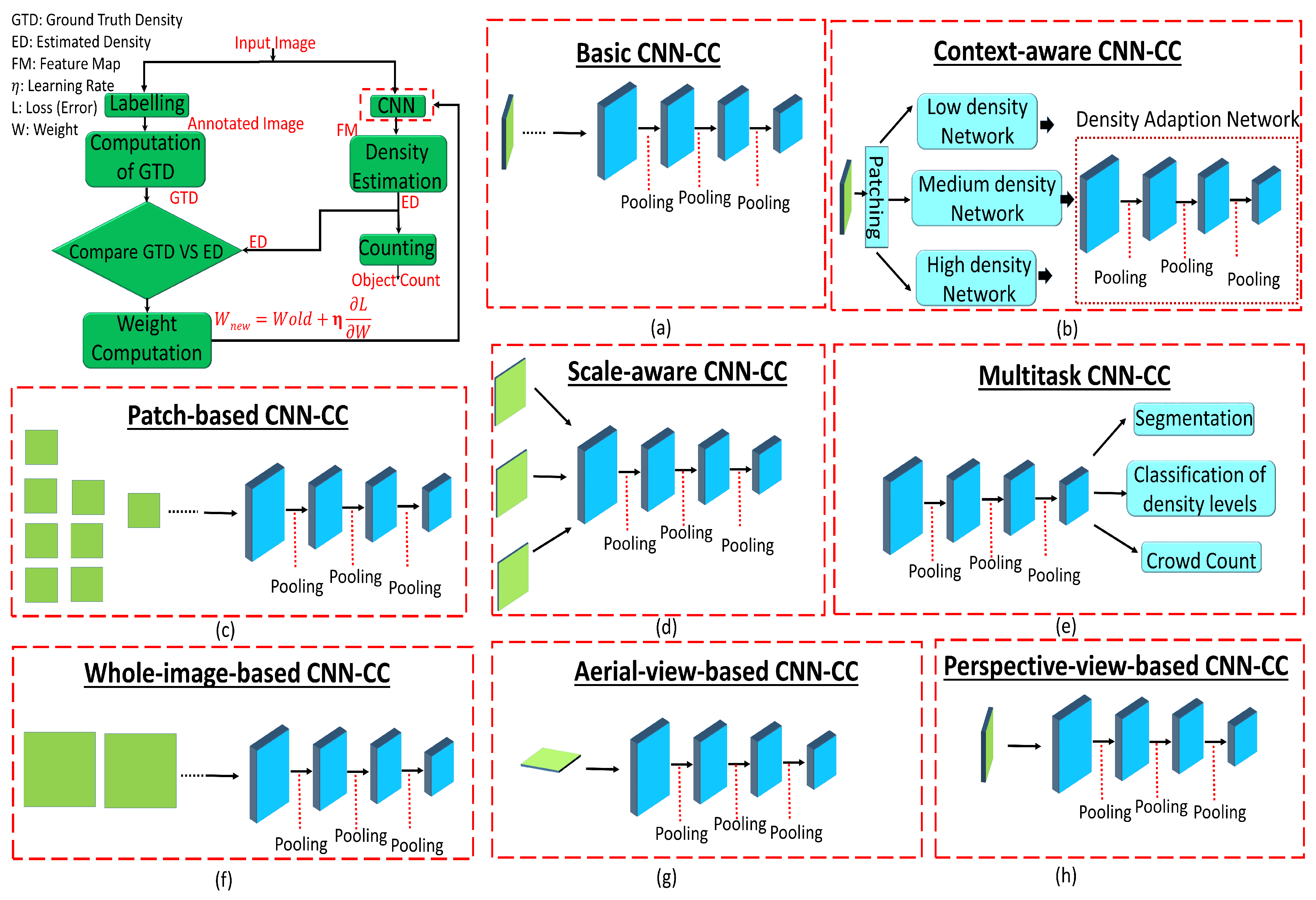
4. Categorization of CNN-CC Techniques
4.1. Network-CNN-CC Techniques
4.1.1. Basic-CNN-CC Techniques
4.1.2. Context-CNN-CC Techniques
4.1.3. Scale-CNN-CC Techniques
4.1.4. Multitask-CNN-CC Techniques
4.2. Image-View-CNN-CC Techniques
4.2.1. aerial-View-CNN-CC Techniques
4.2.2. Perspective-CNN-CC Techniques
4.3. T-CNN-NN Techniques
4.3.1. Patch-Based-CNN-CC Techniques
4.3.2. Whole-Image-CNN-CC Techniques
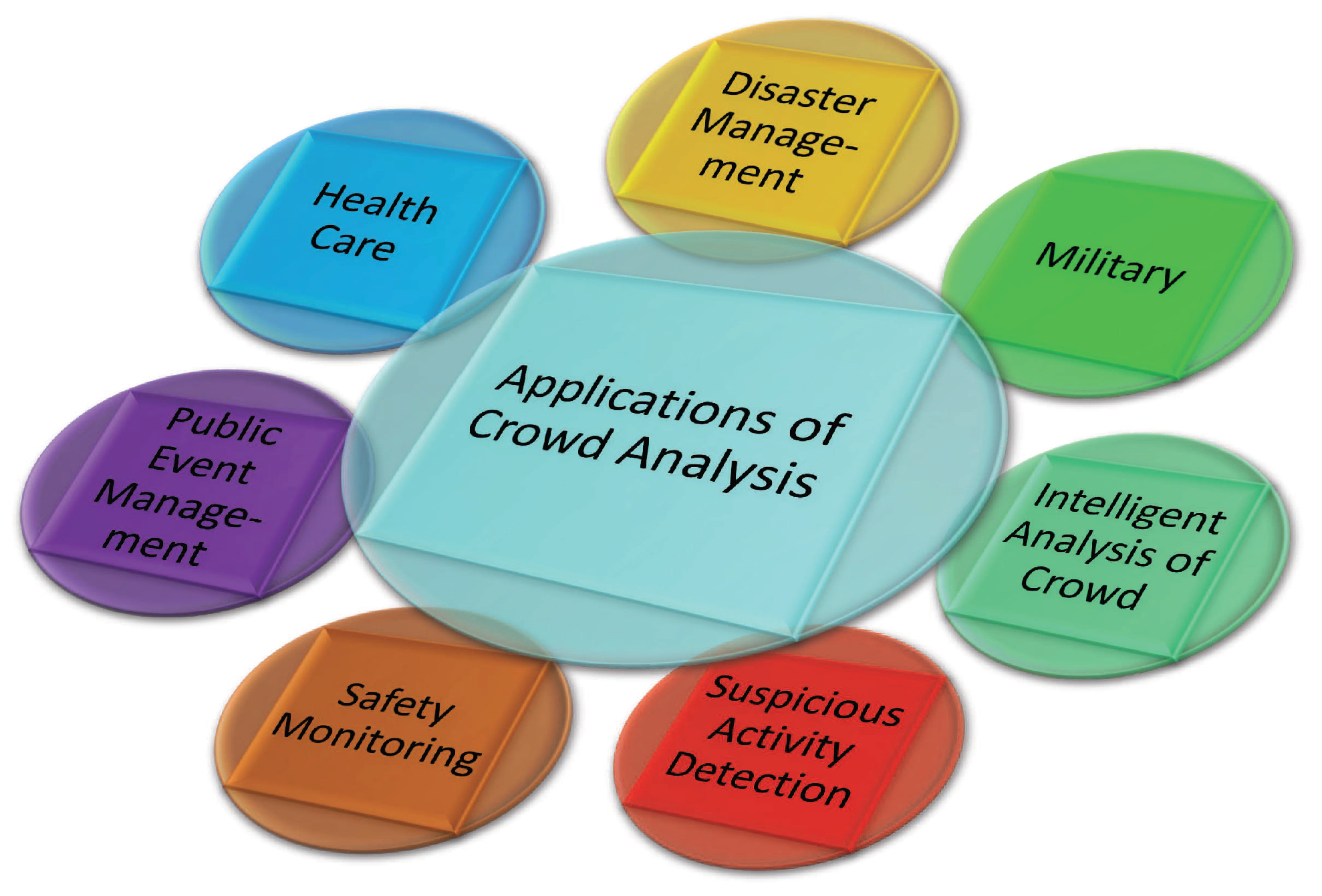
5. Applications of CNN-CC Algorithms
6. Three-Dimensional Crowd Counting
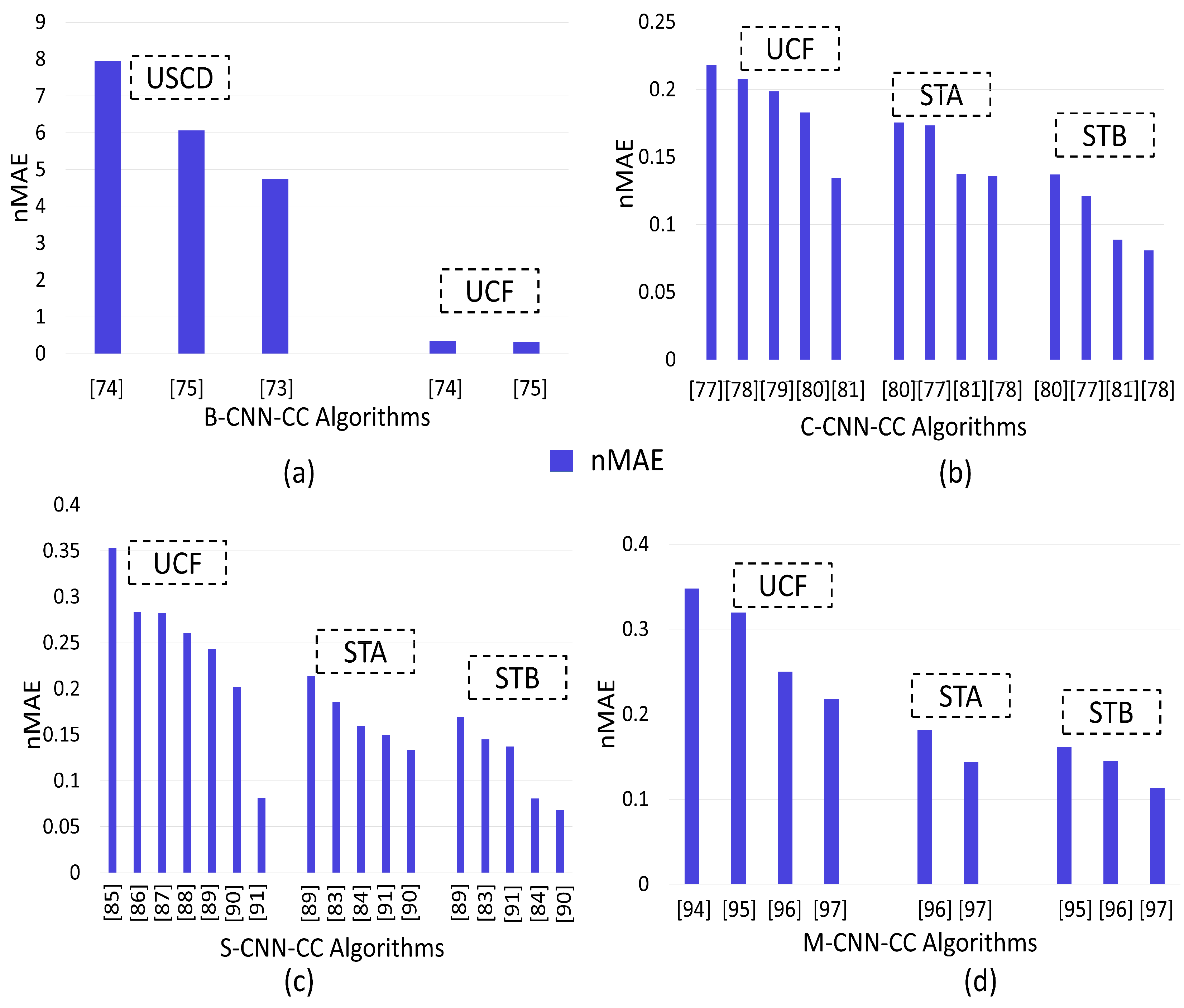
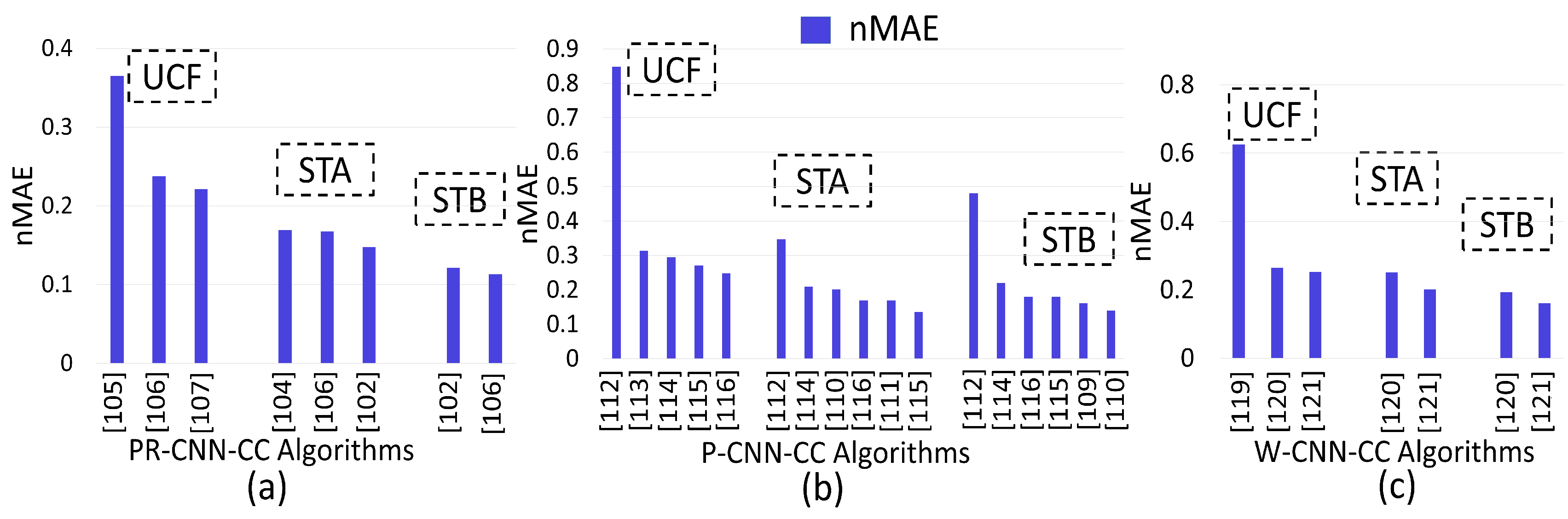
7. Performance Evaluation of CNN-CC Algorithms
8. Conclusions and Key Observations
- Counting accuracy of basic-CNN-CC is enhanced by removing redundant samples, while multitasking improves the overall accuracy of an algorithm.
- The quality of a density map in context-CNN-CC is enhanced by using a deeper dilated CNN, while counting accuracy is enhanced by using an adaptive-density network through pose-variation-based solutions.
- By investigating scale-CNN-CC, we observed that counting accuracy is improved by using stacked pooling that reduces computational cost. Moreover, concatenated-scale aggregation modules increase accuracy, and the quality of the density map is enhanced.
- Counting the accuracy of multitask-CNN-CC is increased by using self-supervised learning, inter-relations between multiple tasks, and up- and downsampling. However, multitasking makes the system more complex for real-time applications. Density-map quality is also enhanced by using deconvolution layers.
- Performance i of aerial-view-CNN-CC n terms of nMAE is increased by using multiple regression models, and occlusion is handled by feeding the downsampled patches in the CNN.
- Counting accuracy of the PRCC is enhanced by inserting a perspective-aware layer in the deconvolution network, parameter sharing within different domains, and retrieving training scenes from all training datasets that have similar perspective maps with target scenes.
- The nMAE of patch-based-CNN-CC is increased by using detection and regression depending on image density and the optimal transfer of information within CNN layers. For dense datasets, the combination of density-level classification, a specific task-oriented regressor, and deconvolution increase accuracy with the estimation of high-quality density maps. Density datasets are tackled by using a patch-based augmentation (varying scale) strategy.
- The counting accuracy of whole-image-CNN-CC is improved by exploiting semantic and locality-aware features, and density-level classification. Diverse-crowd-density issues are also fixed to some extent by varying image scales, making these techniques highly applicable in real-time applications.
Author Contributions
Funding
Conflicts of Interest
Acronyms
| NNs | Neural Networks |
| CNNs | Convolutional NNs |
| RNNs | Recurrent NNs |
| FCL | Fully Connected Layer |
| UAV | Unmanned Aerial Vehicle |
| ReLU | Rectified Linear Unit |
| GTD | Ground Truth Density |
| ED | Estimated Density |
| GLCM | Gray Level Co-Occurrence Metrics |
| HOG | Histogram Oriented Gradient |
| LBP | Local Binary Pattern |
| KLT | Kanade–Lucas–Tomasi |
| GANs | Generative Adversarial Networks |
| MAE | Mean Absolute Error |
| MSE | Mean Square Error |
| STA | ShanghaiTech-A (a dataset) |
| STB | ShanghaiTech-B (a dataset) |
| WE | World Expo 10 (a dataset) |
| CNN-CC | CNN Crowd Counting |
| Network-CNN-CC | Network-based CNN-CC techniques |
| Basic-CNN-CC | Basic CNN-CC techniques |
| Context-CNN-CC | Context-aware CNN-CC techniques |
| Scale-CNN-CC | Scale-aware CNN-CC techniques |
| Multi-task-CNN-CC | Multitask CNN-CC techniques |
| Image-view-CNN-CC | Image-view-based CNN-CC techniques |
| Aerial-view-CNN-CC | Aerial-view-based CNN-CC techniques |
| Perspective-CNN-CC | Perspective-view-based CNN-CC techniques |
| Patch-based-CNN-CC | Patch-based CNN-CC techniques |
| Whole-image-CNN-CC | Whole-image-based CNN-CC techniques |
| Training-CNN-CC | Training-approach-based CNN-CC techniques |
References
- Wang, H.; Roa, A.C.; Basavanhally, A.N.; Gilmore, H.L.; Shih, N.; Feldman, M.; Tomaszewski, J.; Gonzalez, F.; Madabhushi, A. Mitosis detection in breast cancer pathology images by combining handcrafted and convolutional neural network features. J. Med. Imaging 2014, 1, 034003. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Cruz-Roa, A.; Basavanhally, A.; Gilmore, H.; Shih, N.; Feldman, M.; Tomaszewski, J.; Gonzalez, F.; Madabhushi, A. Cascaded ensemble of convolutional neural networks and handcrafted features for mitosis detection. In Medical Imaging 2014: Digital Pathology; International Society for Optics and Photonics: San Diego, CA, USA, 2014; Volume 9041, p. 90410B. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localised crowd counting. In Proceedings of the BMVC, Surrey, UK, 3–7 September 2012; Volume 1, p. 3. [Google Scholar]
- Fiaschi, L.; Köthe, U.; Nair, R.; Hamprecht, F.A. Learning to count with regression forest and structured labels. In Proceedings of the 2012 21st International Conference on Pattern Recognition (ICPR), Tsukuba Science City, Japan, 11–15 November 2012; pp. 2685–2688. [Google Scholar]
- Giuffrida, M.V.; Minervini, M.; Tsaftaris, S.A. Learning to count leaves in rosette plants. In Proceedings of the Computer Vision Problems in Plant Phenotyping (CVPPP), Swansea, UK, 7–10 September 2015. [Google Scholar]
- Cheng, Z.; Qin, L.; Huang, Q.; Yan, S.; Tian, Q. Recognizing human group action by layered model with multiple cues. Neurocomputing 2014, 136, 124–135. [Google Scholar] [CrossRef]
- Chan, A.B.; Vasconcelos, N. Bayesian poisson regression for crowd counting. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 545–551. [Google Scholar]
- Wu, X.; Liang, G.; Lee, K.K.; Xu, Y. Crowd density estimation using texture analysis and learning. In Proceedings of the 2006 IEEE International Conference on Robotics and Biomimetics, Kunming, China, 17–20 December 2006; pp. 214–219. [Google Scholar]
- Lempitsky, V.; Zisserman, A. Learning to count objects in images. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–11 December 2010; pp. 1324–1332. [Google Scholar]
- Duygulu, P.; Barnard, K.; de Freitas, J.F.; Forsyth, D.A. Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary. In Proceedings of the European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002; pp. 97–112. [Google Scholar]
- Moosmann, F.; Triggs, B.; Jurie, F. Fast discriminative visual codebooks using randomized clustering forests. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 985–992. [Google Scholar]
- Rabaud, V.; Belongie, S. Counting crowded moving objects. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 1, pp. 705–711. [Google Scholar]
- Brostow, G.J.; Cipolla, R. Unsupervised bayesian detection of independent motion in crowds. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 1, pp. 594–601. [Google Scholar]
- Abbott, F.T.; Johnson, A.H.; Prior, S.D.; Steiner, D.D. Integrated Biological Warfare Technology Platform (IBWTP). Intelligent Software Supporting Situation Awareness, Response, and Operations; Technical Report; Quantum Leap Innovations Inc.: Newark, NJ, USA, 2007. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Sam, D.B.; Sajjan, N.N.; Maurya, H.; Babu, R.V. Almost Unsupervised Learning for Dense Crowd Counting. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Bour, P.; Cribelier, E.; Argyriou, V. Crowd behavior analysis from fixed and moving cameras. In Multimodal Behavior Analysis in the Wild; Elsevier: Amsterdam, The Netherlands, 2019; pp. 289–322. [Google Scholar]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the Exclusively Dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, C.; Chang, F.; Kot, A.C. Multi-resolution attention convolutional neural network for crowd counting. Neurocomputing 2019, 329, 144–152. [Google Scholar] [CrossRef]
- Bharti, Y.; Saharan, R.; Saxena, A. Counting the Number of People in Crowd as a Part of Automatic Crowd Monitoring: A Combined Approach. In Information and Communication Technology for Intelligent Systems; Springer: Singapore, 2019; pp. 545–552. [Google Scholar]
- Zhan, B.; Monekosso, D.N.; Remagnino, P.; Velastin, S.A.; Xu, L.Q. Crowd analysis: A survey. Mach. Vis. Appl. 2008, 19, 345–357. [Google Scholar] [CrossRef]
- Zitouni, M.S.; Bhaskar, H.; Dias, J.; Al-Mualla, M.E. Advances and trends in visual crowd analysis: A systematic survey and evaluation of crowd modelling techniques. Neurocomputing 2016, 186, 139–159. [Google Scholar] [CrossRef]
- Ryan, D.; Denman, S.; Sridharan, S.; Fookes, C. An evaluation of crowd counting methods, features and regression models. Comput. Vis. Image Underst. 2015, 130, 1–17. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef]
- Shao, J.; Kang, K.; Change Loy, C.; Wang, X. Deeply learned attributes for crowded scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4657–4666. [Google Scholar]
- Zhang, C.; Kang, K.; Li, H.; Wang, X.; Xie, R.; Yang, X. Data-driven crowd understanding: A baseline for a large-scale crowd dataset. IEEE Trans. Multimed. 2016, 18, 1048–1061. [Google Scholar] [CrossRef]
- Kannan, P.G.; Venkatagiri, S.P.; Chan, M.C.; Ananda, A.L.; Peh, L.S. Low cost crowd counting using audio tones. In Proceedings of the 10th ACM Conference on Embedded Network Sensor Systems, oronto, ON, Canada, 6–9 November 2012; pp. 155–168. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; Volume 2010, pp. 253–256. [Google Scholar]
- Cai, M.; Shi, Y.; Liu, J. Deep maxout neural networks for speech recognition. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Olomouc, Czech Republic, 8–12 December 2013; pp. 291–296. [Google Scholar]
- Sainath, T.N.; Kingsbury, B.; Saon, G.; Soltau, H.; Mohamed, A.R.; Dahl, G.; Ramabhadran, B. Deep convolutional neural networks for large-scale speech tasks. Neural Netw. 2015, 64, 39–48. [Google Scholar] [CrossRef] [PubMed]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Penn, G. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012; pp. 4277–4280. [Google Scholar]
- Mousas, C.; Newbury, P.; Anagnostopoulos, C.N. Evaluating the covariance matrix constraints for data-driven statistical human motion reconstruction. In Proceedings of the 30th Spring Conference on Computer Graphics, Mikulov, Czech Republic, 28–30 May 2014; pp. 99–106. [Google Scholar]
- Mousas, C. Full-body locomotion reconstruction of virtual characters using a single inertial measurement unit. Sensors 2017, 17, 2589. [Google Scholar] [CrossRef] [PubMed]
- Abdulhussain, S.H.; Ramli, A.R.; Mahmmod, B.M.; Saripan, M.I.; Al-Haddad, S.; Baker, T.; Flayyih, W.N.; Jassim, W.A. A Fast Feature Extraction Algorithm for Image and Video Processing. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Zhang, W.; Tang, P.; Zhao, L. Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- Kim, I.; Rajaraman, S.; Antani, S. Visual Interpretation of Convolutional Neural Network Predictions in Classifying Medical Image Modalities. Diagnostics 2019, 9, 38. [Google Scholar] [CrossRef]
- Wu, B.; Nevatia, R. Detection of multiple, partially occluded humans in a single image by bayesian combination of edgelet part detectors. In Proceedings of the Tenth IEEE International Conference on Computer Vision, San Diego, CA, USA, 17–21 October 2005; pp. 90–97. [Google Scholar]
- Sabzmeydani, P.; Mori, G. Detecting pedestrians by learning shapelet features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Lin, S.F.; Chen, J.Y.; Chao, H.X. Estimation of number of people in crowded scenes using perspective transformation. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2001, 31, 645–654. [Google Scholar]
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection. In Proceedings of the 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Paragios, N.; Ramesh, V. A MRF-based approach for real-time subway monitoring. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Bilmes, J.A.; Bartels, C. Graphical model architectures for speech recognition. IEEE Signal Process. Mag. 2005, 22, 89–100. [Google Scholar] [CrossRef]
- Razzak, M.I.; Naz, S.; Zaib, A. Deep learning for medical image processing: Overview, challenges and the future. In Classification in BioApps; Springer: Berlin/Heidelberg, Germany, 2018; pp. 323–350. [Google Scholar]
- Chéron, G.; Laptev, I.; Schmid, C. P-cnn: Pose-based cnn features for action recognition. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 3218–3226. [Google Scholar]
- Li, Z.; Zhou, Y.; Xiao, S.; He, C.; Li, H. Auto-conditioned lstm network for extended complex human motion synthesis. arXiv 2017, arXiv:1707.05363. [Google Scholar]
- Saito, S.; Wei, L.; Hu, L.; Nagano, K.; Li, H. Photorealistic facial texture inference using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5144–5153. [Google Scholar]
- Rekabdar, B.; Mousas, C. Dilated Convolutional Neural Network for Predicting Driver’s Activity. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3245–3250. [Google Scholar]
- Rekabdar, B.; Mousas, C.; Gupta, B. Generative Adversarial Network with Policy Gradient for Text Summarization. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 204–207. [Google Scholar]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep learning based oil palm tree detection and counting for high-resolution remote sensing images. Remote Sens. 2016, 9, 22. [Google Scholar] [CrossRef]
- Fan, C.; Tang, J.; Wang, N.; Liang, D. Rich Convolutional Features Fusion for Crowd Counting. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 394–398. [Google Scholar]
- Stahl, T.; Pintea, S.L.; van Gemert, J.C. Divide and Count: Generic Object Counting by Image Divisions. IEEE Trans. Image Process. 2019, 28, 1035–1044. [Google Scholar] [CrossRef]
- Chua, L.O. CNN: A Paradigm for Complexity; World Scientific: Singapore, 1998; Volume 31. [Google Scholar]
- Hu, L.; Bell, D.; Antani, S.; Xue, Z.; Yu, K.; Horning, M.P.; Gachuhi, N.; Wilson, B.; Jaiswal, M.S.; Befano, B.; et al. An Observational Study of Deep Learning and Automated Evaluation of Cervical Images for Cancer Screening. JNCI J. Natl. Cancer Inst. 2019, 74, 343–344. [Google Scholar]
- Cust, E.E.; Sweeting, A.J.; Ball, K.; Robertson, S. Machine and deep learning for sport-specific movement recognition: A systematic review of model development and performance. J. Sport. Sci. 2019, 37, 568–600. [Google Scholar] [CrossRef] [PubMed]
- Raina, P.; Mudur, S.; Popa, T. Sharpness fields in point clouds using deep learning. Comput. Graph. 2019, 78, 37–53. [Google Scholar] [CrossRef]
- Biswas, M.; Kuppili, V.; Saba, L.; Edla, D.; Suri, H.; Cuadrado-Godia, E.; Laird, J.; Marinhoe, R.; Sanches, J.; Nicolaides, A.; et al. State-of-the-art review on deep learning in medical imaging. Front. Biosci. 2019, 24, 392–426. [Google Scholar]
- Sinha, H.; Manekar, R.; Sinha, Y.; Ajmera, P.K. Convolutional Neural Network-Based Human Identification Using Outer Ear Images. In Soft Computing for Problem Solving; Springer: Berlin/Heidelberg, Germany, 2019; pp. 707–719. [Google Scholar]
- Nijhawan, R.; Joshi, D.; Narang, N.; Mittal, A.; Mittal, A. A Futuristic Deep Learning Framework Approach for Land Use-Land Cover Classification Using Remote Sensing Imagery. In Advanced Computing and Communication Technologies; Springer: Berlin/Heidelberg, Germany, 2019; pp. 87–96. [Google Scholar]
- Li, Y.; Xu, L.; Rao, J.; Guo, L.; Yan, Z.; Jin, S. A Y-Net deep learning method for road segmentation using high-resolution visible remote sensing images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]
- Verma, N.K.; Dev, R.; Maurya, S.; Dhar, N.K.; Agrawal, P. People Counting with Overhead Camera Using Fuzzy-Based Detector. In Computational Intelligence: Theories, Applications and Future Directions-Volume I; Springer: Berlin/Heidelberg, Germany, 2019; pp. 589–601. [Google Scholar]
- Shukla, R.; Lipasti, M.; Van Essen, B.; Moody, A.; Maruyama, N. REMODEL: Rethinking deep CNN models to detect and count on a NeuroSynaptic system. Front. Neurosci. 2019, 13, 4. [Google Scholar] [CrossRef]
- Zhu, L.; Li, C.; Yang, Z.; Yuan, K.; Wang, S. Crowd density estimation based on classification activation map and patch density level. Neural Comput. Appl. 2019. [Google Scholar] [CrossRef]
- Hagiwara, A.; Otsuka, Y.; Hori, M.; Tachibana, Y.; Yokoyama, K.; Fujita, S.; Andica, C.; Kamagata, K.; Irie, R.; Koshino, S.; et al. Improving the Quality of Synthetic FLAIR Images with Deep Learning Using a Conditional Generative Adversarial Network for Pixel-by-Pixel Image Translation. Am. J. Neuroradiol. 2019, 40, 224–230. [Google Scholar] [CrossRef]
- Hanbury, A. A survey of methods for image annotation. J. Vis. Lang. Comput. 2008, 19, 617–627. [Google Scholar] [CrossRef]
- Loy, C.C.; Chen, K.; Gong, S.; Xiang, T. Crowd counting and profiling: Methodology and evaluation. In Modeling, Simulation and Visual Analysis of Crowds; Springer: Berlin/Heidelberg, Germany, 2013; pp. 347–382. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar]
- Fu, M.; Xu, P.; Li, X.; Liu, Q.; Ye, M.; Zhu, C. Fast crowd density estimation with convolutional neural networks. Eng. Appl. Artif. Intell. 2015, 43, 81–88. [Google Scholar] [CrossRef]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A large contextual dataset for classification, detection and counting of cars with deep learning. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–16 October 2016; pp. 785–800. [Google Scholar]
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep people counting in extremely dense crowds. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1299–1302. [Google Scholar]
- Zhao, Z.; Li, H.; Zhao, R.; Wang, X. Crossing-line crowd counting with two-phase deep neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 712–726. [Google Scholar]
- Hu, Y.; Chang, H.; Nian, F.; Wang, Y.; Li, T. Dense crowd counting from still images with convolutional neural networks. J. Vis. Commun. Image Represent. 2016, 38, 530–539. [Google Scholar] [CrossRef]
- Walach, E.; Wolf, L. Learning to count with CNN boosting. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 660–676. [Google Scholar]
- Chattopadhyay, P.; Vedantam, R.; Selvaraju, R.R.; Batra, D.; Parikh, D. Counting Everyday Objects in Everyday Scenes. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4428–4437. [Google Scholar]
- Zhang, Y.; Zhou, C.; Chang, F.; Kot, A.C. Attention to Head Locations for Crowd Counting. arXiv 2018, arXiv:1806.10287. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 1091–1100. [Google Scholar]
- Han, K.; Wan, W.; Yao, H.; Hou, L. Image Crowd Counting Using Convolutional Neural Network and Markov Random Field. arXiv 2017, arXiv:1706.03686. [Google Scholar] [CrossRef]
- Wang, L.; Shao, W.; Lu, Y.; Ye, H.; Pu, J.; Zheng, Y. Crowd Counting with Density Adaption Networks. arXiv 2018, arXiv:1806.10040. [Google Scholar]
- Liu, L.; Wang, H.; Li, G.; Ouyang, W.; Lin, L. Crowd Counting using Deep Recurrent Spatial-Aware Network. arXiv 2018, arXiv:1807.00601. [Google Scholar]
- Liu, W.; Lis, K.; Salzmann, M.; Fua, P. Geometric and Physical Constraints for Head Plane Crowd Density Estimation in Videos. arXiv 2018, arXiv:1803.08805. [Google Scholar]
- Huang, S.; Li, X.; Cheng, Z.Q.; Zhang, Z.; Hauptmann, A. Stacked Pooling: Improving Crowd Counting by Boosting Scale Invariance. arXiv 2018, arXiv:1808.07456. [Google Scholar]
- Kang, D.; Chan, A. Crowd Counting by Adaptively Fusing Predictions from an Image Pyramid. arXiv 2018, arXiv:1805.06115. [Google Scholar]
- Boominathan, L.; Kruthiventi, S.S.; Babu, R.V. Crowdnet: A deep convolutional network for dense crowd counting. In Proceedings of the 2016 ACM on Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016; pp. 640–644. [Google Scholar]
- Zeng, L.; Xu, X.; Cai, B.; Qiu, S.; Zhang, T. Multi-scale convolutional neural networks for crowd counting. arXiv 2017, arXiv:1702.02359. [Google Scholar]
- Kumagai, S.; Hotta, K.; Kurita, T. Mixture of Counting CNNs: Adaptive Integration of CNNs Specialized to Specific Appearance for Crowd Counting. arXiv 2017, arXiv:1703.09393. [Google Scholar]
- Onoro-Rubio, D.; López-Sastre, R.J. Towards perspective-free object counting with deep learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 615–629. [Google Scholar]
- Shi, Z.; Zhang, L.; Sun, Y.; Ye, Y. Multiscale Multitask Deep NetVLAD for Crowd Counting. IEEE Trans. Ind. Inf. 2018, 14, 4953–4962. [Google Scholar] [CrossRef]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale Aggregation Network for Accurate and Efficient Crowd Counting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Shen, Z.; Xu, Y.; Ni, B.; Wang, M.; Hu, J.; Yang, X. Crowd Counting via Adversarial Cross-Scale Consistency Pursuit. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5245–5254. [Google Scholar]
- Arteta, C.; Lempitsky, V.; Zisserman, A. Counting in the wild. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–498. [Google Scholar]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Maadeed, S.; Rajpoot, N.; Shah, M. Composition loss for counting, density map estimation and localization in dense crowds. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 544–559. [Google Scholar]
- Zhu, J.; Feng, F.; Shen, B. People counting and pedestrian flow statistics based on convolutional neural network and recurrent neural network. In Proceedings of the 2018 33rd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Nanjing, China, 18–20 May 2018. [Google Scholar]
- Huang, S.; Li, X.; Zhang, Z.; Wu, F.; Gao, S.; Ji, R.; Han, J. Body structure aware deep crowd counting. IEEE Trans. Image Process. 2018, 27, 1049–1059. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Cao, J.; Wang, N.; Zhang, Y.; Zou, L. Counting challenging crowds robustly using a multi-column multi-task convolutional neural network. Signal Process. Image Commun. 2018, 64, 118–129. [Google Scholar] [CrossRef]
- Liu, X.; van de Weijer, J.; Bagdanov, A.D. Leveraging Unlabeled Data for Crowd Counting by Learning to Rank. arXiv 2018, arXiv:1803.03095. [Google Scholar]
- Khan, A.; Gould, S.; Salzmann, M. Deep convolutional neural networks for human embryonic cell counting. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 339–348. [Google Scholar]
- Ribera, J.; Chen, Y.; Boomsma, C.; Delp, E.J. Counting Plants Using Deep Learning. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing, Montreal, QC, Canada, 14–16 November 2017. [Google Scholar]
- Hernández, C.X.; Sultan, M.M.; Pande, V.S. Using Deep Learning for Segmentation and Counting within Microscopy Data. arXiv 2018, arXiv:1802.10548. [Google Scholar]
- Xie, W.; Noble, J.A.; Zisserman, A. Microscopy cell counting and detection with fully convolutional regression networks. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2018, 6, 283–292. [Google Scholar] [CrossRef]
- Kang, D.; Dhar, D.; Chan, A.B. Crowd Counting by Adapting Convolutional Neural Networks with Side Information. arXiv 2016, arXiv:1611.06748. [Google Scholar]
- Zhao, M.; Zhang, J.; Porikli, F.; Zhang, C.; Zhang, W. Learning a perspective-embedded deconvolution network for crowd counting. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 403–408. [Google Scholar]
- Marsden, M.; McGuinness, K.; Little, S.; Keogh, C.E.; O’Connor, N.E. People, Penguins and Petri Dishes: Adapting Object Counting Models To New Visual Domains And Object Types Without Forgetting. arXiv 2017, arXiv:1711.05586. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 833–841. [Google Scholar]
- Shi, M.; Yang, Z.; Xu, C.; Chen, Q. Perspective-Aware CNN For Crowd Counting. arXiv 2018, arXiv:1807.01989. [Google Scholar]
- Yao, H.; Han, K.; Wan, W.; Hou, L. Deep Spatial Regression Model for Image Crowd Counting. arXiv 2017, arXiv:1710.09757. [Google Scholar]
- Cohen, J.P.; Boucher, G.; Glastonbury, C.A.; Lo, H.Z.; Bengio, Y. Count-ception: Counting by fully convolutional redundant counting. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 18–26. [Google Scholar]
- Liu, J.; Gao, C.; Meng, D.; Hauptmann, A.G. Decidenet: Counting varying density crowds through attention guided detection and density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5197–5206. [Google Scholar]
- Oñoro-Rubio, D.; Niepert, M.; López-Sastre, R.J. Learning Short-Cut Connections for Object Counting. arXiv 2018, arXiv:1805.02919. [Google Scholar]
- Xu, M.; Ge, Z.; Jiang, X.; Cui, G.; Lv, P.; Zhou, B. Depth Information Guided Crowd Counting for Complex Crowd Scenes. arXiv 2018, arXiv:1803.02256. [Google Scholar] [CrossRef]
- Shami, M.; Maqbool, S.; Sajid, H.; Ayaz, Y.; Cheung, S.C.S. People Counting in Dense Crowd Images using Sparse Head Detections. IEEE Trans. Circuits Syst. Video Technol. 2018. [Google Scholar] [CrossRef]
- Zhang, Y.; Chang, F.; Wang, M.; Zhang, F.; Han, C. Auxiliary learning for crowd counting via count-net. Neurocomputing 2018, 273, 190–198. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 589–597. [Google Scholar]
- Wang, L.; Yin, B.; Guo, A.; Ma, H.; Cao, J. Skip-connection convolutional neural network for still image crowd counting. Appl. Intell. 2018, 48, 3360–3371. [Google Scholar] [CrossRef]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching convolutional neural network for crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 6. [Google Scholar]
- Rahnemoonfar, M.; Sheppard, C. Deep count: Fruit counting based on deep simulated learning. Sensors 2017, 17, 905. [Google Scholar] [CrossRef]
- Sheng, B.; Shen, C.; Lin, G.; Li, J.; Yang, W.; Sun, C. Crowd counting via weighted vlad on dense attribute feature maps. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 1788–1797. [Google Scholar] [CrossRef]
- Marsden, M.; McGuinness, K.; Little, S.; O’Connor, N.E. ResnetCrowd: A residual deep learning architecture for crowd counting, violent behaviour detection and crowd density level classification. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–7. [Google Scholar]
- Marsden, M.; McGuiness, K.; Little, S.; O’Connor, N.E. Fully convolutional crowd counting on highly congested scenes. arXiv 2016, arXiv:1612.00220. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Cnn-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Mongeon, M.C.; Loce, R.P.; Shreve, M.A. Busyness Defection and Notification Method and System. U.S. Patent 9,576,371, 21 February 2017. [Google Scholar]
- Barsoum, E.; Zhang, C.; Ferrer, C.C.; Zhang, Z. Training deep networks for facial expression recognition with crowd-sourced label distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 279–283. [Google Scholar]
- Albert, A.; Kaur, J.; Gonzalez, M.C. Using convolutional networks and satellite imagery to identify patterns in urban environments at a large scale. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1357–1366. [Google Scholar]
- Kellenberger, B.; Marcos, D.; Tuia, D. Detecting mammals in UAV images: Best practices to address a substantially imbalanced dataset with deep learning. Remote Sens. Environ. 2018, 216, 139–153. [Google Scholar] [CrossRef]
- Boulos, M.N.K.; Resch, B.; Crowley, D.N.; Breslin, J.G.; Sohn, G.; Burtner, R.; Pike, W.A.; Jezierski, E.; Chuang, K.Y.S. Crowdsourcing, citizen sensing and sensor web technologies for public and environmental health surveillance and crisis management: Trends, OGC standards and application examples. Int. J. Health Geogr. 2011, 10, 67. [Google Scholar] [CrossRef]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Sadeghian, A.; Alahi, A.; Savarese, S. Tracking the untrackable: Learning to track multiple cues with long-term dependencies. arXiv 2017, arXiv:1701.01909. [Google Scholar]
- Perez, H.; Hernandez, B.; Rudomin, I.; Ayguade, E. Task-based crowd simulation for heterogeneous architectures. In Innovative Research and Applications in Next-Generation High Performance Computing; IGI Global: Hershey, PA, USA, 2016; pp. 194–219. [Google Scholar]
- Martani, C.; Stent, S.; Acikgoz, S.; Soga, K.; Bain, D.; Jin, Y. Pedestrian monitoring techniques for crowd-flow prediction. Proc. Inst. Civ. Eng.-Smart Infrastruct. Constr. 2017, 170, 17–27. [Google Scholar] [CrossRef]
- Khouj, M.; Lopez, C.; Sarkaria, S.; Marti, J. Disaster management in real time simulation using machine learning. In Proceedings of the 2011 24th Canadian Conference on Electrical and Computer Engineering (CCECE), Niagara Falls, ON, Canada, 8–11 May 2011; pp. 001507–001510. [Google Scholar]
- Barr, J.R.; Bowyer, K.W.; Flynn, P.J. The effectiveness of face detection algorithms in unconstrained crowd scenes. In Proceedings of the 2014 IEEE Winter Conference on Applications of Computer Vision (WACV), Steamboat Springs, CO, USA, 24–26 March 2014; pp. 1020–1027. [Google Scholar]
- Ng, H.W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep learning for emotion recognition on small datasets using transfer learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 443–449. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Chackravarthy, S.; Schmitt, S.; Yang, L. Intelligent Crime Anomaly Detection in Smart Cities Using Deep Learning. In Proceedings of the 2018 IEEE 4th International Conference on Collaboration and Internet Computing (CIC), Philadelphia, PA, USA, 18–20 October 2018; pp. 399–404. [Google Scholar]
- Dong, B.; Shao, L.; Da Costa, M.; Bandmann, O.; Frangi, A.F. Deep learning for automatic cell detection in wide-field microscopy zebrafish images. In Proceedings of the 2015 IEEE 12th International Symposium on Biomedical Imaging (ISBI), New York, NY, USA, 16–19 April 2015; pp. 772–776. [Google Scholar]
- Litjens, G.; Sánchez, C.I.; Timofeeva, N.; Hermsen, M.; Nagtegaal, I.; Kovacs, I.; Hulsbergen-Van De Kaa, C.; Bult, P.; Van Ginneken, B.; Van Der Laak, J. Deep learning as a tool for increased accuracy and efficiency of histopathological diagnosis. Sci. Rep. 2016, 6, 26286. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115. [Google Scholar] [CrossRef]
- Kumar, S.; Moni, R.; Rajeesh, J. An automatic computer-aided diagnosis system for liver tumours on computed tomography images. Comput. Electr. Eng. 2013, 39, 1516–1526. [Google Scholar] [CrossRef]
- Zhou, B.; Tang, X.; Wang, X. Learning collective crowd behaviors with dynamic pedestrian-agents. Int. J. Comput. Vis. 2015, 111, 50–68. [Google Scholar] [CrossRef]
- Danilkina, A.; Allard, G.; Baccelli, E.; Bartl, G.; Gendry, F.; Hahm, O.; Hege, G.; Kriegel, U.; Palkow, M.; Petersen, H.; et al. Multi-Camera Crowd Monitoring: The SAFEST Approach. In Proceedings of the Workshop Interdisciplinaire sur la Sécurité Globale, Institut, Paris, 3–4 February 2015. [Google Scholar]
- Song, H.; Liu, X.; Zhang, X.; Hu, J. Real-time monitoring for crowd counting using video surveillance and GIS. In Proceedings of the 2012 2nd International Conference on Remote Sensing, Environment and Transportation Engineering (RSETE), Nanjing, China, 1–3 June 2012; pp. 1–4. [Google Scholar]
- Ihaddadene, N.; Djeraba, C. Real-time crowd motion analysis. In Proceedings of the 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Suk, H.I.; Wee, C.Y.; Lee, S.W.; Shen, D. State-space model with deep learning for functional dynamics estimation in resting-state fMRI. NeuroImage 2016, 129, 292–307. [Google Scholar] [CrossRef]
- Rachmadi, M.F.; Valdés-Hernández, M.d.C.; Agan, M.L.F.; Di Perri, C.; Komura, T.; Initiative, A.D.N. Segmentation of white matter hyperintensities using convolutional neural networks with global spatial information in routine clinical brain MRI with none or mild vascular pathology. Comput. Med. Imaging Graph. 2018, 66, 28–43. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Cao, L.; Chua, K.S.; Chong, W.; Lee, H.; Gu, Q. A comparison of PCA, KPCA and ICA for dimensionality reduction in support vector machine. Neurocomputing 2003, 55, 321–336. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Mousas, C.; Anagnostopoulos, C.N. Learning Motion Features for Example-Based Finger Motion Estimation for Virtual Characters. 3D Res. 2017, 8, 25. [Google Scholar] [CrossRef]
- Nam, J.; Herrera, J.; Slaney, M.; Smith, J.O. Learning Sparse Feature Representations for Music Annotation and Retrieval. In Proceedings of the ISMIR, Porto, Portugal, 8–12 October 2012; pp. 565–570. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataets | USCD [17] | Mall [4] | UCF [69] | WE [28] | STA [26] | STB [26] |
|---|---|---|---|---|---|---|
| No. of images (NOI) | 2000 | 2000 | 50 | 3980 | 482 | 716 |
| Resolution | 158 × 238 | 320 × 240 | Varied | 576 × 720 | Varied | 768 × 1024 |
| Minimum head count | 11 | 13 | 94 | 1 | 33 | 9 |
| Average head count | 25 | - | 1279 | 50 | 501 | 123 |
| Maximum head count | 46 | 53 | 4543 | 253 | 3139 | 578 |
| Total head count (THC) | 49,885 | 62,325 | 63,974 | 199,923 | 241,677 | 88,488 |
| Qualitative features | Collected from video camera, ground-truth annotation, low-density dataset, no perspective variation | Collected from surveillance camera, diverse illumination condition; compared to USCD, it has higher density, no scene-perspective variations | Collected from various places like concerts, marathons, diverse scenes with wide range of densities, challenging datasets as compared to USCD and Mall | Specific for cross-scene crowd-counting large diversity, but limited as compared to UCF, not dense as compared to UCF, more images | Chosen from Internet, large scale, largest in terms of number of annotated people, large density as compared to (B), diverse scenes, and varying densities | Collected from Shanghai, varying scale and perspective, nonuniform density level in many images, making it tilt towards the low-density level |
| Technique | Features | Datasets | Negative Samples | Data Driven | Architecture | ||
|---|---|---|---|---|---|---|---|
| Yes | No | Yes | No | ||||
| Fu et al. [70] | Real-time approach | PETS_2009, Subway video, Chunix_Road video | ✓ | ✓ | ConvNets | ||
| Mundhenk et al. [71] | Contextual information, creation of large datasets of cars | Cars Overhead with Context (COWC), | ✓ | ✓ | AlexNet, Inception | ||
| Wang et al. [72] | End-to-end deep CNN regression model | UCF | ✓ | ✓ | FCN | ||
| Zhao et al. [73] | Joint learning of crowd density and velocity | USCD, [LHI, TS, CNN] * | ✓ | ✓ | FlowNet | ||
| Hu et al. [74] | Two supervisory signals: crowd count and crowd density | UCF, USCD | ✓ | ✓ | ConvNets | ||
| Walach et al. [75] | Gradient boosting and selective sampling, and elimination of low-quality training samples | UCF, USCD, [Bacterial Cell, Make 3D] * | ✓ | ✓ | Boosting Net | ||
| Technique | Features | Datasets | Negative Samples | Data Driven | Architecture | ||
|---|---|---|---|---|---|---|---|
| Yes | No | Yes | No | ||||
| Chattopadhyay et al. [76] | Associative subitizing | PASCAL VOC, COCO | ConvNet | ||||
| Zhang et al. [77] | Attention model for head detection | UCF, STA, STB | AM-CNN | ||||
| Li et al. [78] | Dilated convolution and multiscale contextual information | UCF, STA, STB, WE | CSRNet | ||||
| Han et al. [79] | Combination of correlation and MRF | UCF | ResNet | ||||
| Wang et al. [80] | Density adaption network | ST, UCF | DAN, LCN, HCN | ||||
| Liu et al. [81] | Spatially aware network | ST, UCF, WE | Local Refinement Network | ||||
| Technique | Features | Datasets | Negative Samples | Data Driven | Architecture | ||
|---|---|---|---|---|---|---|---|
| Yes | No | Yes | No | ||||
| Liu et al. [82] | Geometry-aware crowd counting | ST, WE, Venice | ✓ | ✓ | Siamese | ||
| Huang et al. [83] | Exploits cross-scale similarity | ST, WE | ✓ | ✓ | Wide and Deep | ||
| Kang et al. [84] | Image pyramid to deal with scale variation | ST, WE, USCD | ✓ | ✓ | VGG network | ||
| Boominathan et al. [85] | Combination of deep and shallow networks | UCF | ✓ | ✓ | VGG-16 | ||
| Zeng et al. [86] | Single multiscale column | ST, UCF | ✓ | ✓ | Inception | ||
| Kumagai et al. [87] | Integration of multiple CNNs (gating and expert CNN) | UCF, Mall | ✓ | ✓ | MoC-CNN | ||
| Onoro-Rubio et al. [88] | CCNN for mapping the appearance of image patch to its density map; Hydra CNN is scale-aware model | UCF, USCD, TRANCOS | ✓ | ✓ | CCNN, Hydra | ||
| Shi et al. [89] | Dynamic data-augmentation strategy, NetVLAD | ST, UCF, WE | ✓ | ✓ | VGG-like net | ||
| Cao et al. [90] | Multi-scale feature extraction with scale aggregation modules | UCF, STA, STB, USCD | ✓ | ✓ | SANet | ||
| Shen et al. [91] | GANs-based network, novel regularizer | ST, UCF, USCD | ✓ | ✓ | ACSCP | ||
| Technique | Features | Datasets | Negative Samples | Data Driven | Architecture | ||
|---|---|---|---|---|---|---|---|
| Yes | No | Yes | No | ||||
| Arteta et al. [92] | Multitasking: foreground and background segmentation, uncertainty, and density estimation | Penguins dataset | ✓ | ✓ | ConvNet | ||
| Idrees et al. [93] | Multitasking with loss optimization | UCF-QNRF | ✓ | ✓ | DenseNet | ||
| Zhu et al. [94] | Combination of pedestrian flow statistics task with people counting | UCF, [DH302IMG, DH302VID] * | ✓ | ✓ | VGGNet-16 | ||
| Huang et al. [95] | Body structure-aware methods | STB, UCF, USCD | ✓ | ✓ | Multi-column body-part aware model | ||
| Yang et al. [96] | Multicolumn multitask CNN focusing on drastic scale variation | ST, UCF, USCD, MALL, WE | ✓ | ✓ | MMCNN | ||
| Liu et al. [97] | Self-supervised tasking | UCF, STA, STB | ✓ | ✓ | VGG-16 | ||
| Technique | Features | Datasets * | Negative Samples | Data Driven | Architecture | ||
|---|---|---|---|---|---|---|---|
| Yes | No | Yes | No | ||||
| Khan et al. [98] | Automatic approach to select a region of interest by computing a bounding box that encloses the embryo | Time-lapse image sequences | ✓ | ✓ | Architecture of Krizhevsky | ||
| Ribera et al. [99] | Plants are estimated by using the regression model instead of classification | RGB UAV images of sorghum plants | ✓ | ✓ | Inception-v2 | ||
| Hernnandez et al. [100] | Feature pyramid network | BBBC005 | ✓ | ✓ | VGG-Style NN | ||
| Xie et al. [101] | Two convolutional regression networks | RPE, T and LBL cells | ✓ | ✓ | VGG-net | ||
| Technique | Features | Datasets | Negative Samples | Data Driven | Architecture | ||
|---|---|---|---|---|---|---|---|
| Yes | No | Yes | No | ||||
| Kang et al. [102] | Incorporating side information (perspective weights) in CNN by using adaptive convolutional layers | USCD | ✓ | ✓ | ACNN | ||
| Zhao et al. [103] | Perspective embedded deconvolution network | WE | ✓ | ✓ | PE-CFCN-DCN | ||
| Marsden et al. [104] | Multidomain patch-based regressor | ST, Penguin, Dublin cell * | ✓ | ✓ | VGG16 | ||
| Zhang et al. [105] | Cross scene crowd counting, human body shape and perspective variation are considered | UCF | ✓ | ✓ | Crowd CNN model | ||
| Shi et al. [106] | Perspective-aware weighting layer | UCF, WE, STA, STB | ✓ | ✓ | PACNN | ||
| Yao et al. [107] | General model based on CNN and LSTM | ST, UCF, WE | ✓ | ✓ | DSRM with ResNet | ||
| Technique | Features | Datasets | Negative Samples | Data Driven | Architecture | ||
|---|---|---|---|---|---|---|---|
| Yes | No | Yes | No | ||||
| Cohen et al. [108] | Smaller network used for estimation in given receptive field | [VGG, MBM] * | ✓ | ✓ | Count-ception | ||
| Liu et al. [109] | Detection and density-estimation network | Mall, STB, WE | ✓ | ✓ | DecideNet | ||
| Onro-Rubio et al. [110] | Joint feature extraction and pixelwise object density | ST, USCD, TRANSCOS | ✓ | ✓ | GU-Net | ||
| Xu et al. [111] | Depth-information-based method | STB, Mall, ZZU-CIISR | ✓ | ✓ | Multi-scale network | ||
| Shami et al. [112] | Head-detector-based crowd-estimation method | ST, UCF | ✓ | ✓ | ImagNet | ||
| Zhang et al. [113] | Aggregated framework | UCF, AHU-CROWD | ✓ | ✓ | count-net | ||
| Zhang et al. [114] | Multicolumn CNN with varying receptive fields | ST, UCF | ✓ | ✓ | MCNN | ||
| Wang et al. [115] | Skip-connection CNN with scale-related training | ST, UCF | ✓ | ✓ | SCNN | ||
| Sam et al. [116] | Switch CNN multidomain patch-based regressor | ST, UCF, WE | ✓ | ✓ | Switch CNN | ||
| Technique | Features | Datasets | Negative Samples | Data Driven | Architecture | ||
|---|---|---|---|---|---|---|---|
| Yes | No | Yes | No | ||||
| Rahnmonfar et al. [117] | Simulated learning, and synthetic data for training, tested on real images | Fruit dataset * | ✓ | ✓ | Inception-ResNet | ||
| Sheng et al. [118] | Pixel-level semantic-feature map, learning locality-aware features | USCD, Mall | ✓ | ✓ | Semantic-feature map and W-VLAD encoding | ||
| Marsden et al. [119] | Simultaneous multiobjective method for violent-behavior detection, crowd counting and density-level classification, creation of new dataset | UCF | ✓ | ✓ | ResNetCrowd | ||
| Marsden et al. [120] | Multiscale averaging to handle scale variation | ST, UCF | ✓ | ✓ | FCN | ||
| Sindagi et al. [121] | Multitask end-to-end cascaded network of CNNs to learn both crowd-count classification and density estimation | ST, UCF | ✓ | ✓ | Cascaded network | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ilyas, N.; Shahzad, A.; Kim, K. Convolutional-Neural Network-Based Image Crowd Counting: Review, Categorization, Analysis, and Performance Evaluation. Sensors 2020, 20, 43. https://doi.org/10.3390/s20010043
Ilyas N, Shahzad A, Kim K. Convolutional-Neural Network-Based Image Crowd Counting: Review, Categorization, Analysis, and Performance Evaluation. Sensors. 2020; 20(1):43. https://doi.org/10.3390/s20010043
Chicago/Turabian StyleIlyas, Naveed, Ahsan Shahzad, and Kiseon Kim. 2020. "Convolutional-Neural Network-Based Image Crowd Counting: Review, Categorization, Analysis, and Performance Evaluation" Sensors 20, no. 1: 43. https://doi.org/10.3390/s20010043
APA StyleIlyas, N., Shahzad, A., & Kim, K. (2020). Convolutional-Neural Network-Based Image Crowd Counting: Review, Categorization, Analysis, and Performance Evaluation. Sensors, 20(1), 43. https://doi.org/10.3390/s20010043