A Comparative Analysis of Machine/Deep Learning Models for Parking Space Availability Prediction



Abstract
1. Introduction
1.1. Background
1.2. Contribution
- Identification of the best performing, among well-known and generally used ones, AI/ML algorithm for the problem at hand;
- -
- An analysis and evaluation of various ML/DL models (e.g., KNN, Random Forest, MLP, Decision Tree) for the problem of predicting parking space availability;
- -
- An analysis/assessment of the Ensemble Learning approach and its comparison with other ML/DL models; and
- -
- Recommendation of the most appropriate ML/DL model to predict parking space availability.
- Recommending top-k parking spots with respect to distance between the current position of vehicle and available parking spots;
- Application of the algorithms in order to demonstrate how satisfactory prediction of availability of parking spaces can be achieved using real data from Santander;
1.3. Impact of Our Parking Prediction Model on Smart Cities
1.4. Organization
2. Related Work
3. Overview of ML/DL Techniques
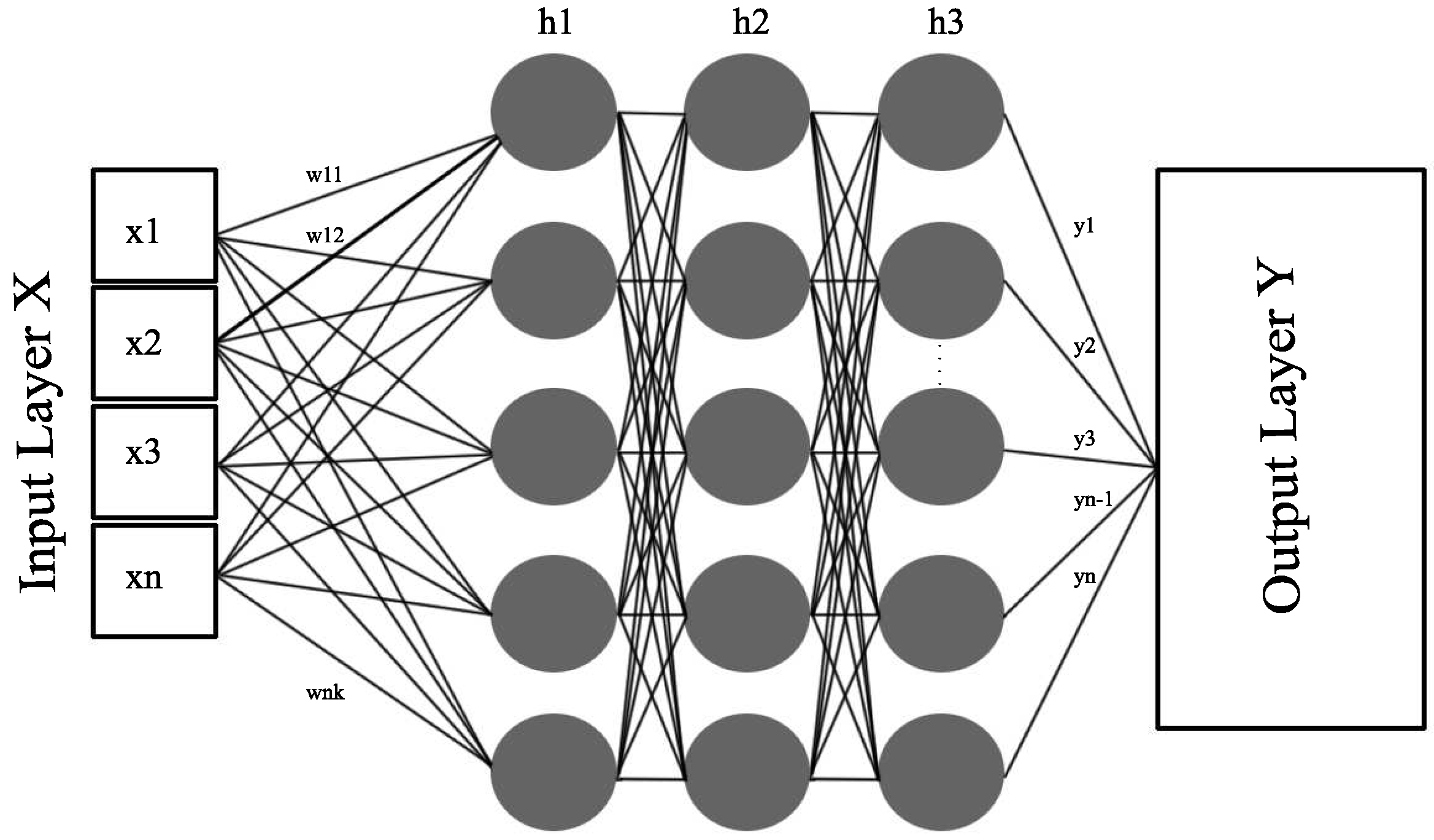
3.1. Multilayer Perceptron (MLP) Neural Network
3.2. K-Nearest Neighbors (KNN)
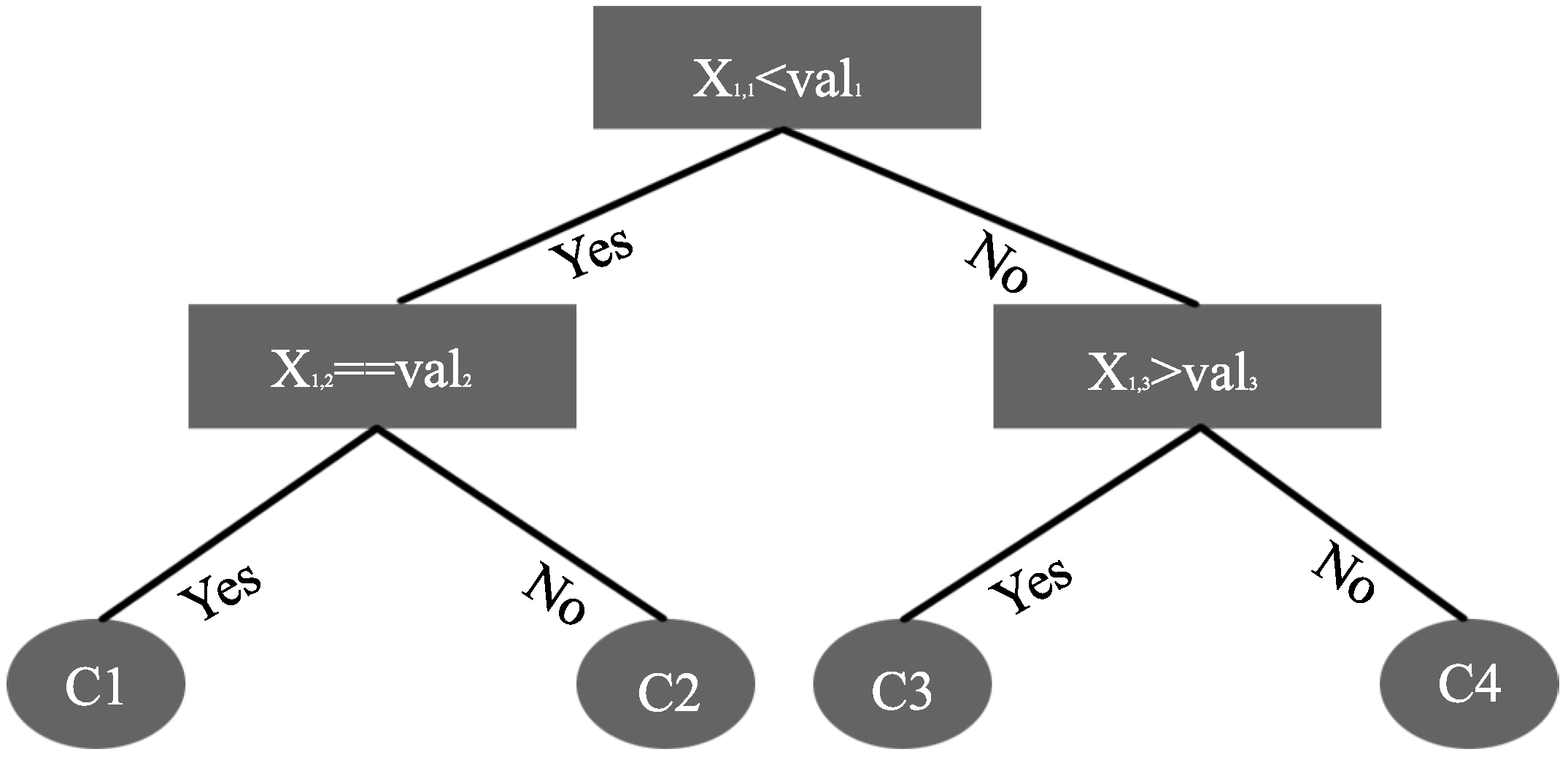
3.3. Decision Tree and Random Forest
3.4. Ensemble Learning Approach (Voting Classifier)
4. Results and Evaluation
4.1. Parking Space Data Set
- Parking ID: Refers to the unique ID associated with each parking space.
- Timestamp: The Timestamp of the parking space data collection.
- Start Time/End Time: Start Time and End Time refer to the time interval during which a parking space’s status remained the same, i.e., available or occupied.
- Duration: Refers to the total duration in seconds during which a specific parking space remained available or remained occupied.
- Status: This feature represents the status of a parking space, e.g., available or occupied.
4.2. Hyper-Parameters of ML/DL Techniques
4.3. Evaluation Metrics
- Precision can be defined as the fraction of all the samples labelled as positive and that are actually positive [27]. It can be mathematically presented as follows:
- Recall, in contrast, is defined as the fraction of all the positive samples; they are also labeled as positive [27]. Mathematical presentation of recall is given below:
- The F1-Score is defined as the harmonic mean of recall and precision [27], defined mathematically as:
- Accuracy is the measure of the correctly predicted samples among all the samples, expressed in an equation as:
- K-fold cross-validation is a method for checking the overfitting and evaluating how consistent a specific model is. In K-fold validation, a data set is divided into K equal sets. Among those K sets, each set is used once as testing data and the remaining sets are used as training data. In this paper, we used 5-fold cross-validation.
4.4. Performance Evaluation
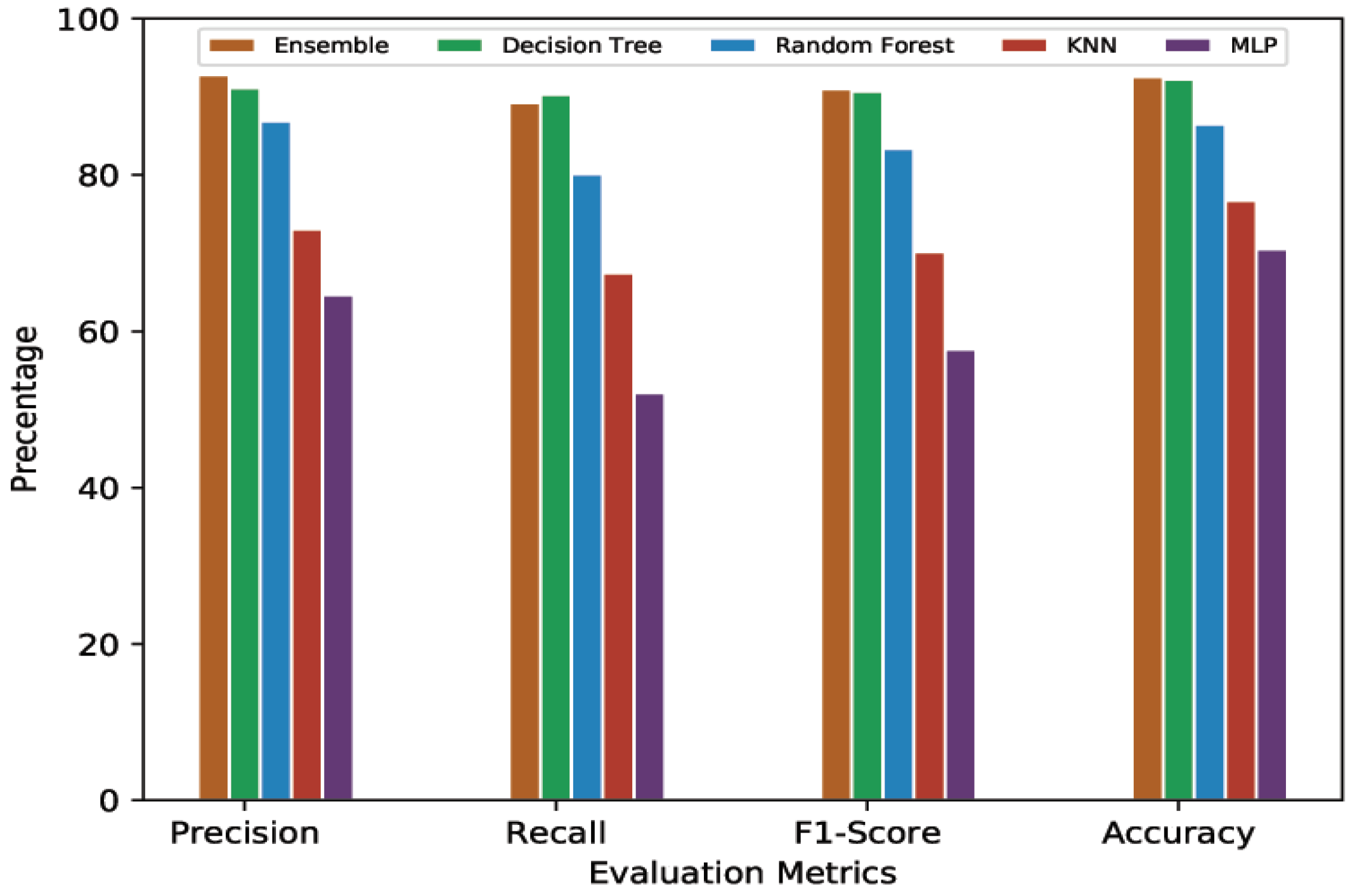
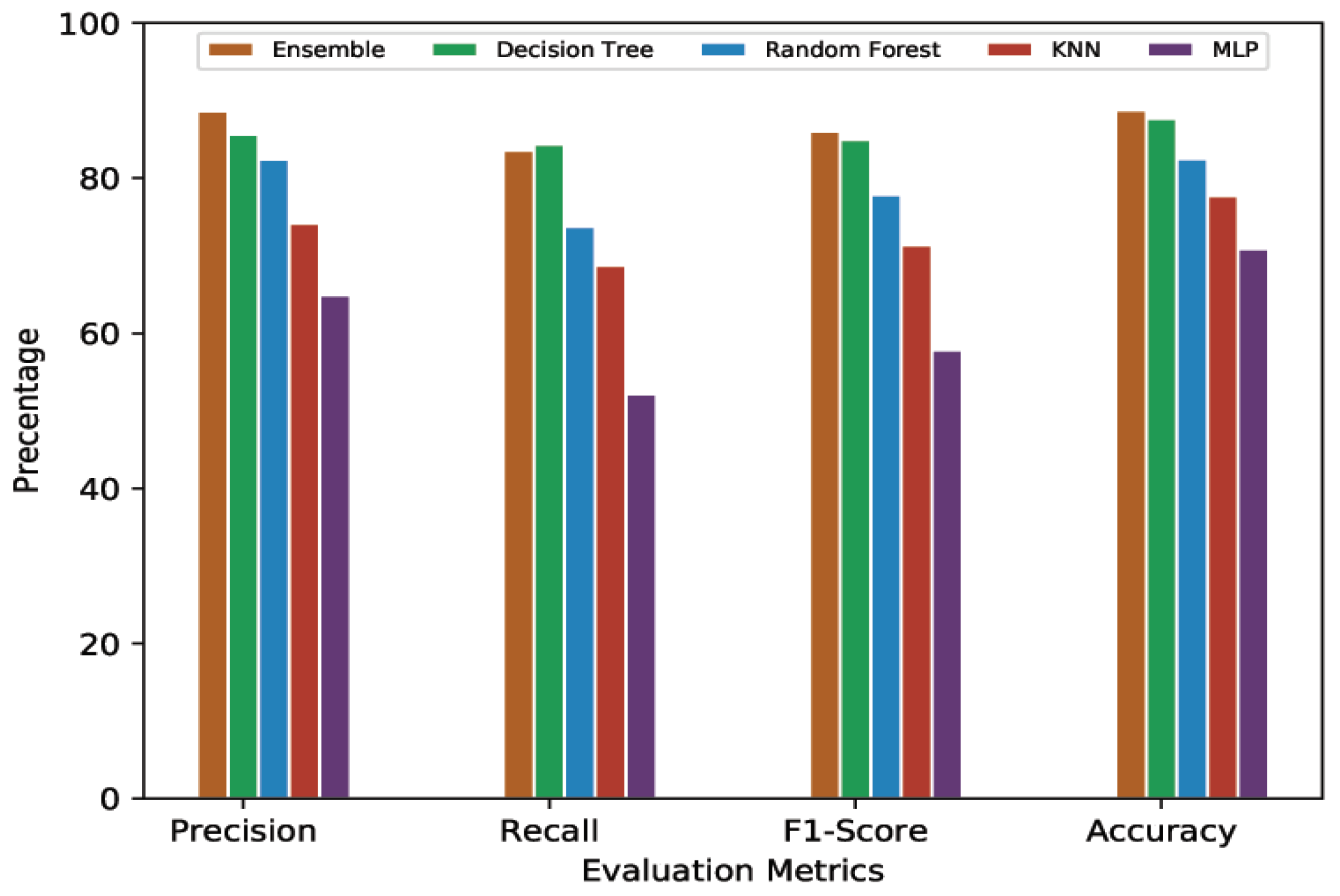
4.4.1. 10-Min Prediction Validity (60% Threshold)
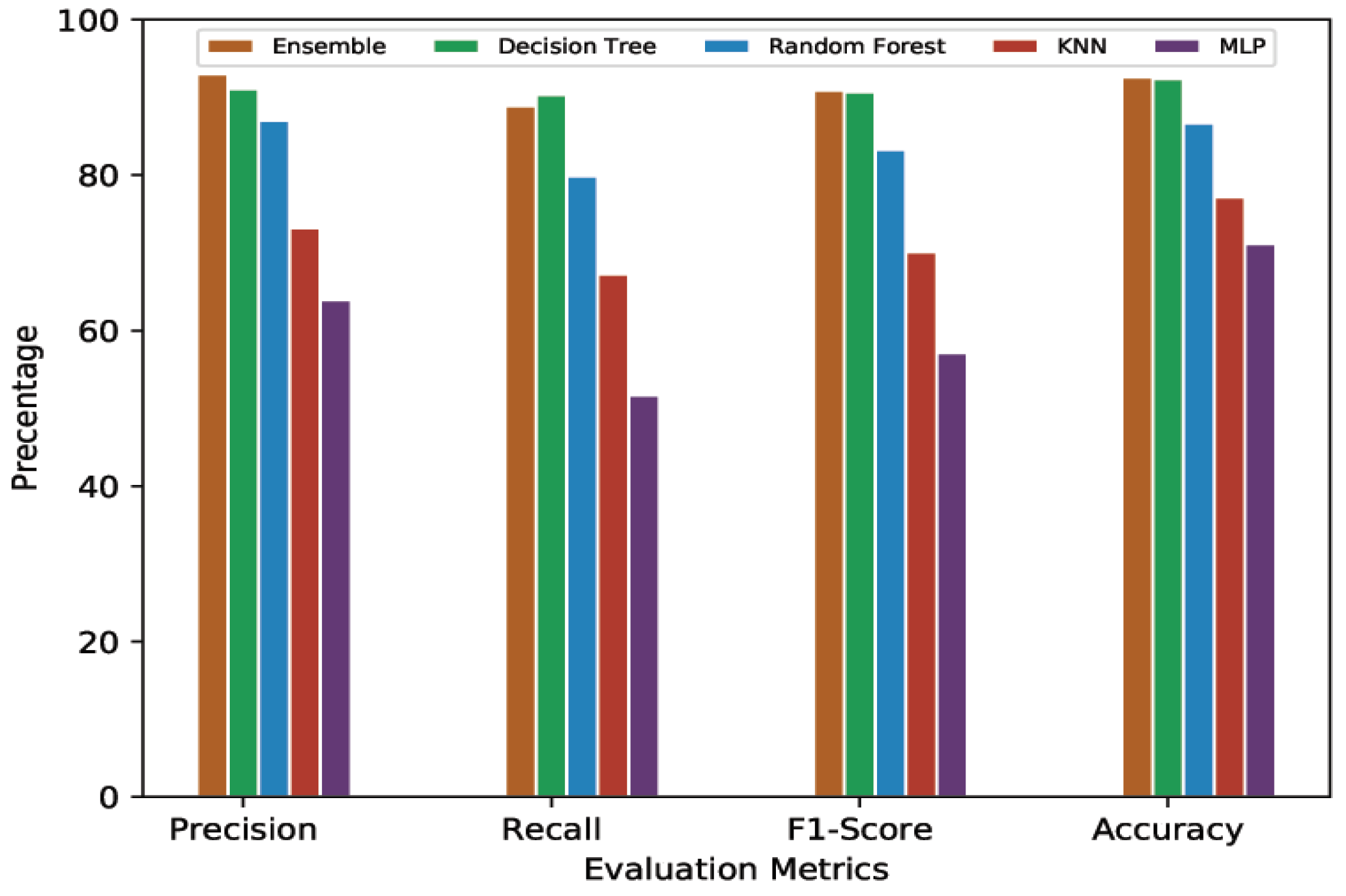
4.4.2. 10-Min Prediction Validity (80% Threshold)
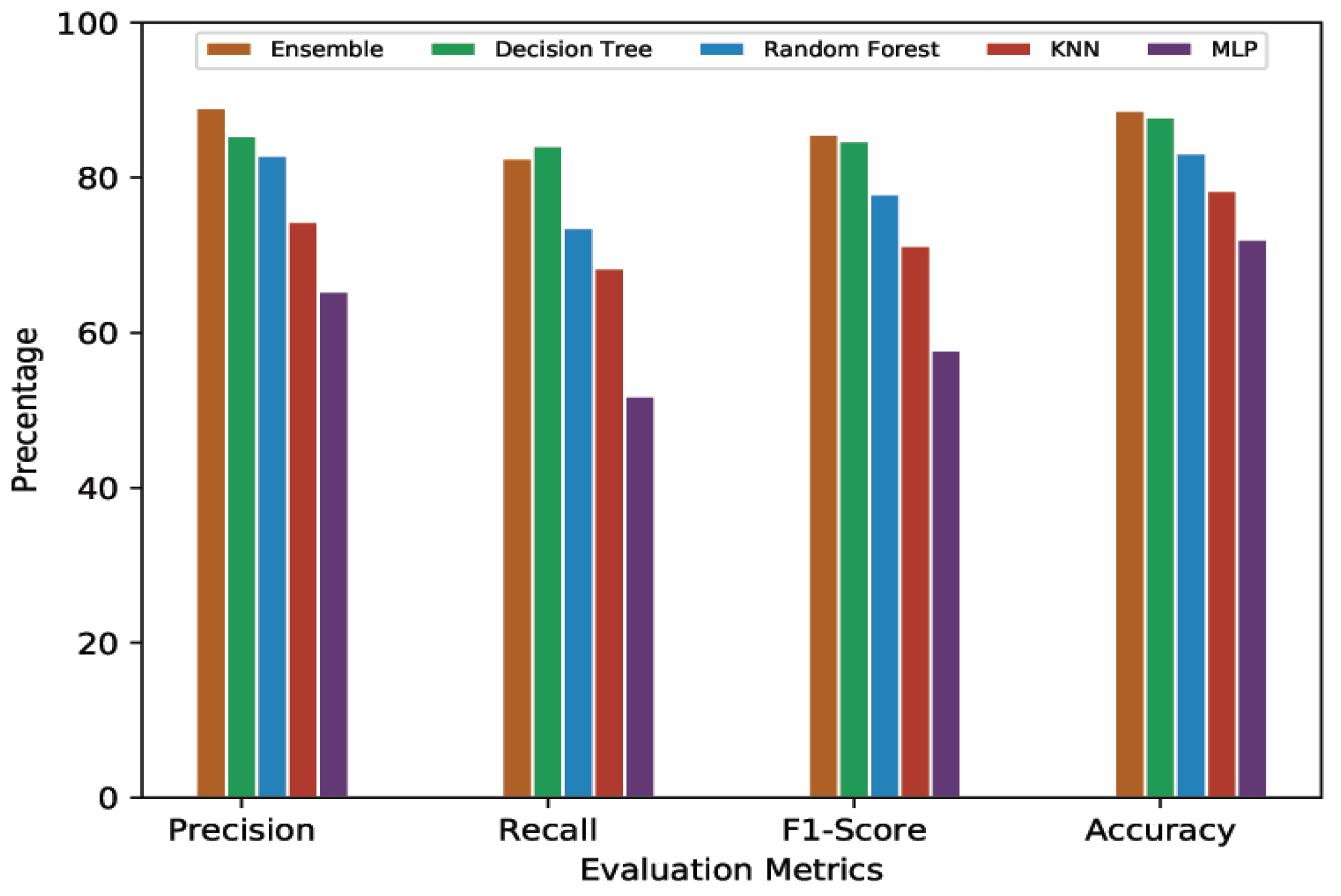
4.4.3. 20-Min Prediction Validity (60% Threshold)
4.4.4. 20-Min Prediction Validity (80% Threshold)
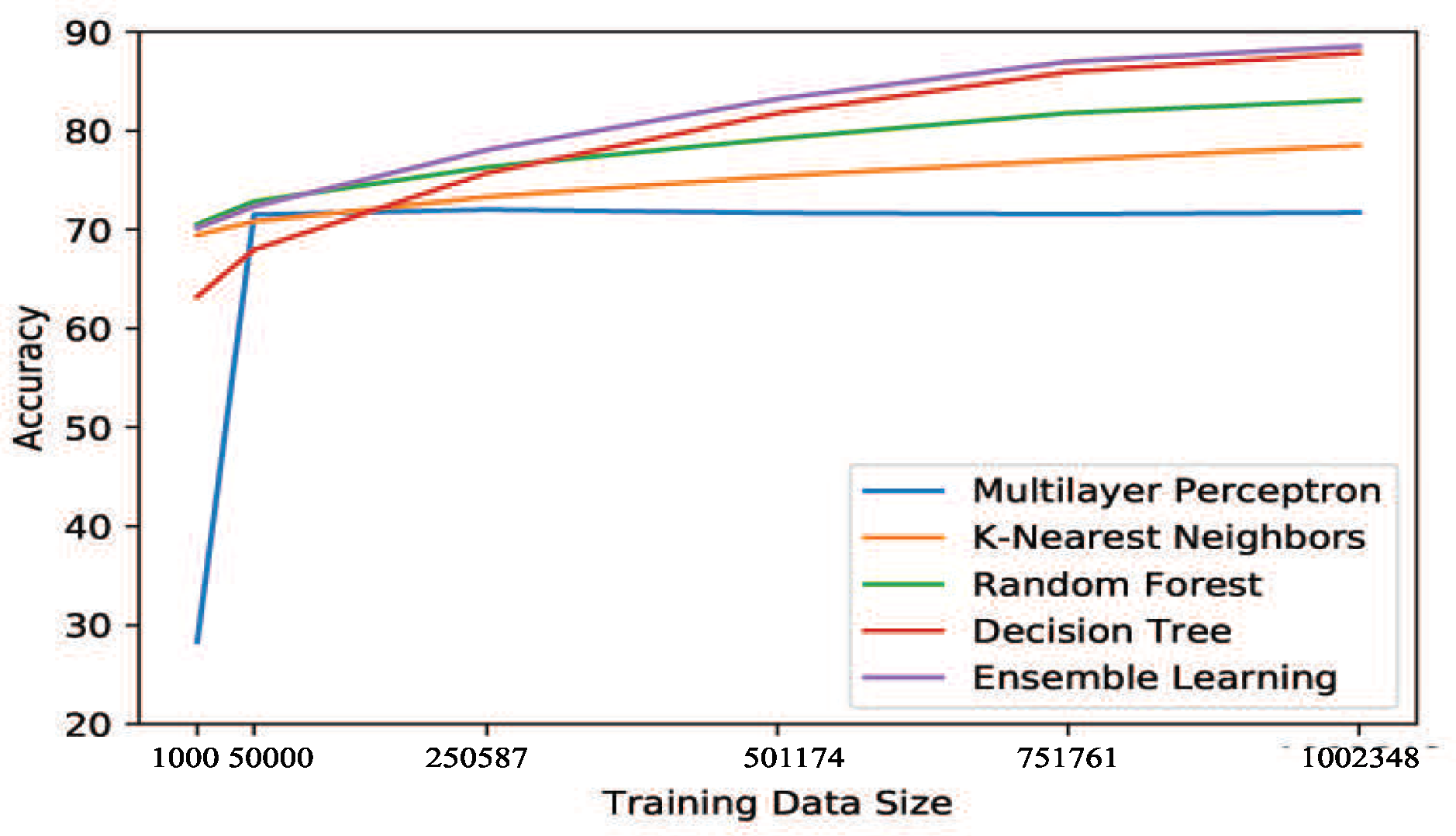
4.4.5. Training Data Evaluation
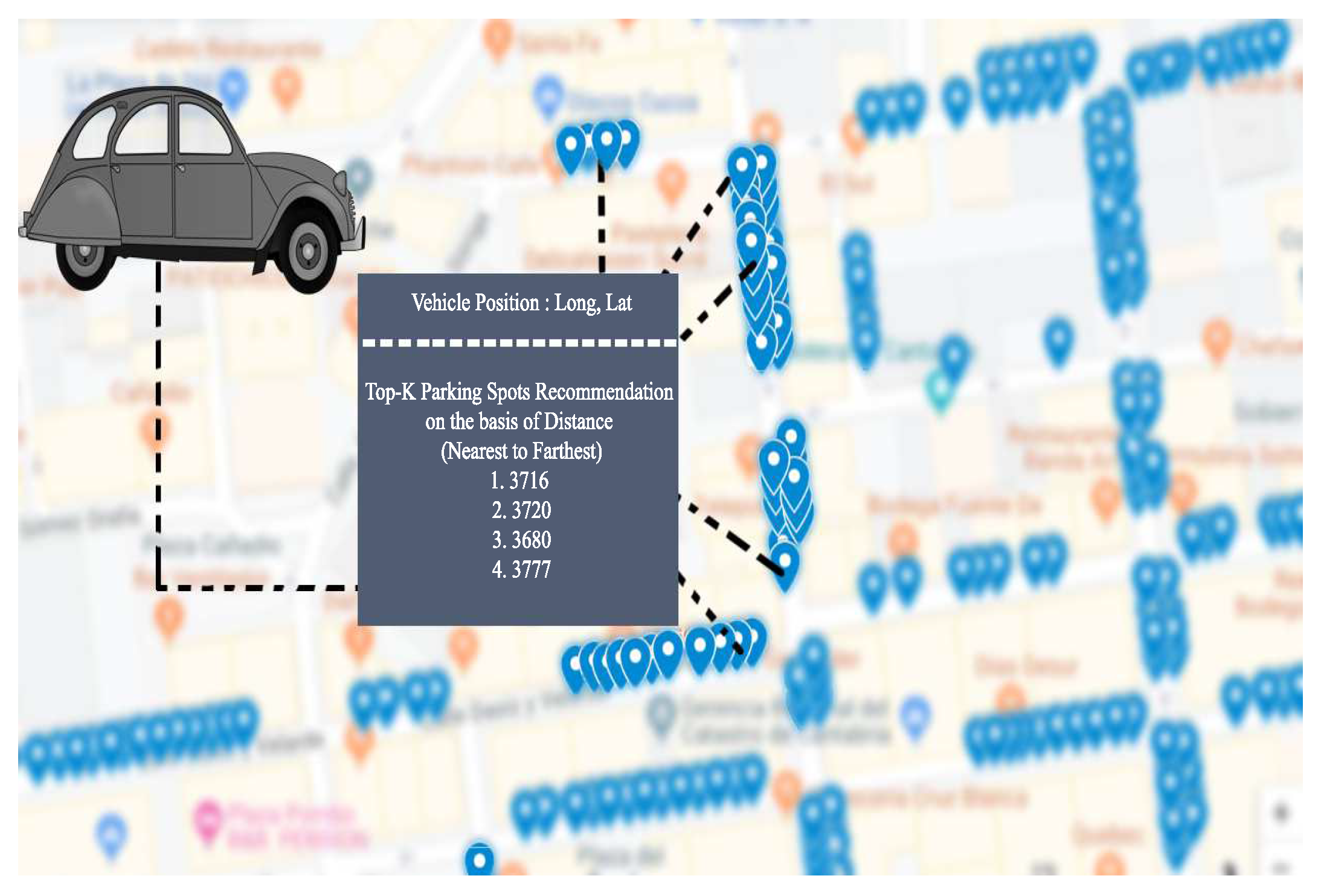
4.4.6. Distance Based Recommendation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- IBM Survey. Available online: https://www-03.ibm.com/press/us/en/pressrelease/35515.wss (accessed on 20 August 2019).
- Koster, A.; Oliveira, A.; Volpato, O.; Delvequio, V.; Koch, F. Recognition and recommendation of parking places. In Proceedings of the Ibero-American Conference on Artificial Intelligence, Santiago de Chile, Chile, 24–27 November 2014; pp. 675–685. [Google Scholar]
- Park, W.; Kim, B.; Seo, D.; Kim, D.; Lee, K. Parking space detection using ultrasonic sensor in parking assistance system. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 1039–1044. [Google Scholar] [CrossRef]
- Rinne, M.; Törmä, S.; Kratinov, D. Mobile crowdsensing of parking space using geofencing and activity recognition. In Proceedings of the 10th ITS European Congress, Helsinki, Finland, 16–19 June 2014; pp. 16–19. [Google Scholar]
- Hazar, M.A.; Odabasioglu, N.; Ensari, T.; Kavurucu, Y.; Sayan, O.F. Performance analysis and improvement of machine learning algorithms for automatic modulation recognition over Rayleigh fading channels. Neural Comput. Appl. 2018, 29, 351–360. [Google Scholar] [CrossRef]
- Narayanan, B.N.; Djaneye-Boundjou, O.; Kebede, T.M. Performance analysis of machine learning and pattern recognition algorithms for Malware classification. In Proceedings of the 2016 IEEE National Aerospace and Electronics Conference (NAECON) and Ohio Innovation Summit (OIS), Dayton, OH, USA, 25–29 July 2016; pp. 338–342. [Google Scholar] [CrossRef]
- Barone, R.E.; Giuffrè, T.; Siniscalchi, S.M.; Morgano, M.A.; Tesoriere, G. Architecture for parking management in smart cities. IET Intell. Transp. Syst. 2013, 8, 445–452. [Google Scholar] [CrossRef]
- Yang, J.; Portilla, J.; Riesgo, T. Smart parking service based on Wireless Sensor Networks. In Proceedings of the 38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, 25–28 October 2012; pp. 6029–6034. [Google Scholar] [CrossRef]
- Dong, S.; Chen, M.; Peng, L.; Li, H. Parking rank: A novel method of parking lots sorting and recommendation based on public information. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Lyon, France, 20–22 February 2018; pp. 1381–1386. [Google Scholar] [CrossRef]
- Vlahogianni, E.; Kepaptsoglou, K.; Tsetsos, V.; Karlaftis, M. A Real-Time Parking Prediction System for Smart Cities. J. Intell. Transp. Syst. 2016, 20, 192–204. [Google Scholar] [CrossRef]
- Badii, C.; Nesi, P.; Paoli, I. Predicting Available Parking Slots on Critical and Regular Services by Exploiting a Range of Open Data. IEEE Access 2018, 6, 44059–44071. [Google Scholar] [CrossRef]
- Zheng, Y.; Rajasegarar, S.; Leckie, C. Parking availability prediction for sensor-enabled car parks in smart cities. In Proceedings of the IEEE Tenth International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), Singapore, 7–9 April 2015; pp. 1–6. [Google Scholar]
- Camero, A.; Toutouh, J.; Stolfi, D.H.; Alba, E. Evolutionary deep learning for car park occupancy prediction in smart cities. In Proceedings of the International Conference on Learning and Intelligent Optimization, Kalamata, Greece, 10–15 June 2018; pp. 386–401. [Google Scholar]
- Yu, F.; Guo, J.; Zhu, X.; Shi, G. Real time prediction of unoccupied parking space using time series model. In Proceedings of the 2015 International Conference on Transportation Information and Safety (ICTIS), Wuhan, China, 25–28 June 2015; pp. 370–374. [Google Scholar]
- Bibi, N.; Majid, M.N.; Dawood, H.; Guo, P. Automatic parking space detection system. In Proceedings of the 2017 2nd International Conference on Multimedia and Image Processing (ICMIP), Wuhan, China, 17–19 March 2017; pp. 11–15. [Google Scholar]
- Tătulea, P.; Călin, F.; Brad, R.; Brâncovean, L.; Greavu, M. An Image Feature-Based Method for Parking Lot Occupancy. Future Internet 2019, 11, 169. [Google Scholar] [CrossRef]
- Huang, K.; Chen, K.; Huang, M.; Shen, L. Multilayer perceptron with particle swarm optimization for well log data inversion. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 6103–6106. [Google Scholar] [CrossRef]
- Jain, A.K.; Mao, J.; Mohiuddin, K. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef]
- Lau, M.M.; Lim, K.H. Investigation of activation functions in deep belief network. In Proceedings of the 2017 2nd International Conference on Control and Robotics Engineering (ICCRE), Bangkok, Thailand, 1–3 April 2017; pp. 201–206. [Google Scholar]
- Singh, A.; Yadav, A.; Rana, A. K-means with Three different Distance Metrics. Int. J. Comput. Appl. 2013, 67, 13–17. [Google Scholar] [CrossRef]
- Sharma, R.; Ghosh, A.; Joshi, P. Decision tree approach for classification of remotely sensed satellite data using open source support. J. Earth Syst. Sci. 2013, 122, 1237–1247. [Google Scholar] [CrossRef]
- Santander Facility, Smart Santander. Available online: http://www.smartsantander.eu/index.php/testbeds/item/132-santander-summary (accessed on 18 March 2019).
- Worldwide Interoperability for Semantics IoT (WISE-IoT), H2020 EU-KR Project. Available online: http://wise-iot.eu/en/home/ (accessed on 18 March 2019).
- Parking Sensors at Santander, Spain. Available online: https://mu.tlmat.unican.es:8443/v2/entities?limit=1000&type=ParkingSpot (accessed on 15 June 2018).
- Scikit Learn. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html (accessed on 25 September 2019).
- Heaton, J. Artificial Intelligence for Humans, Volume 3: Deep Learning and Neural Networks; Artificial Intelligence for Humans Series; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2015. [Google Scholar]
- Lipton, Z.C.; Elkan, C.; Naryanaswamy, B. Optimal thresholding of classifiers to maximize F1 measure. In Proceedings of the Joint European Conf. on Machine Learning and Knowledge Discovery in Databases, Nancy, France, 15–19 September 2014; pp. 225–239. [Google Scholar]
- Anisya; Yoga Swara, G. Implementation Of Haversine Formula And Best First Search Method In Searching Of Tsunami Evacuation Route. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Pekanbaru, Indonesia, 26–27 July 2017; Volume 97, p. 012004. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Value/Range |
|---|---|
| Parking Spot ID | Unique ID of Sensor |
| Day | 1–7 (Day of the week) |
| Start Hour | 0–23 |
| Start Minute | 0–59 |
| End Hour | 0–23 |
| End Minute | 0–59 |
| Status | 0–1 (Occupied or Free) |
| MLP | KNN | Decision Tree | Random Forest | Voting Classifier | |||||
|---|---|---|---|---|---|---|---|---|---|
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| activation | ReLU | n_neighbors | 11 | max_depth | 100 | max_depth | 100 | estimators | MLP, KNN, Random Forest, Decision Tree |
| early_stopping | True | metric | euclidean | criterion | entropy | criterion | entropy | voting | soft |
| hidden_layer_sizes | (5,5,5) | n-jobs | None | min_samples_leaf | 5 | min_samples_leaf | 1 | weights | 1,1,1,2 |
| learning_rate | Adaptive | weights | uniform | n_estimators | 200 | ||||
| learning_rate_init | 0.001 | ||||||||
| solver | sgd | ||||||||
| tol | 0.0001 | ||||||||
| Metrics | MLP | KNN | RF | DT | EL |
|---|---|---|---|---|---|
| Precision | 64.63 | 73.04 | 86.90 | 91.12 | 92.79 |
| Recall | 52.09 | 67.46 | 80.11 | 90.28 | 89.24 |
| F1-Score | 57.68 | 70.14 | 83.37 | 90.69 | 90.98 |
| Accuracy | 70.48 | 76.71 | 86.50 | 92.25 | 92.54 |
| Metrics | MLP | KNN | RF | DT | EL |
|---|---|---|---|---|---|
| Precision | 63.92 | 73.19 | 87.01 | 91.11 | 93.01 |
| Recall | 51.64 | 67.23 | 79.86 | 90.32 | 88.87 |
| F1-Score | 57.13 | 70.08 | 83.28 | 90.71 | 90.89 |
| Accuracy | 71.14 | 77.18 | 86.70 | 92.39 | 92.60 |
| Metrics | MLP | KNN | RF | DT | EL |
|---|---|---|---|---|---|
| Precision | 64.87 | 74.15 | 82.44 | 85.64 | 88.65 |
| Recall | 52.16 | 68.76 | 73.78 | 84.37 | 83.56 |
| F1-Score | 57.83 | 71.35 | 77.87 | 85.00 | 86.03 |
| Accuracy | 70.83 | 77.71 | 82.49 | 87.66 | 88.73 |
| Metrics | MLP | KNN | RF | DT | EL |
|---|---|---|---|---|---|
| Precision | 65.33 | 74.36 | 82.86 | 85.42 | 89.02 |
| Recall | 51.83 | 68.36 | 73.56 | 84.13 | 82.52 |
| F1-Score | 57.80 | 71.24 | 77.93 | 84.77 | 85.64 |
| Accuracy | 72.07 | 78.38 | 83.15 | 87.82 | 88.70 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awan, F.M.; Saleem, Y.; Minerva, R.; Crespi, N. A Comparative Analysis of Machine/Deep Learning Models for Parking Space Availability Prediction. Sensors 2020, 20, 322. https://doi.org/10.3390/s20010322
Awan FM, Saleem Y, Minerva R, Crespi N. A Comparative Analysis of Machine/Deep Learning Models for Parking Space Availability Prediction. Sensors. 2020; 20(1):322. https://doi.org/10.3390/s20010322
Chicago/Turabian StyleAwan, Faraz Malik, Yasir Saleem, Roberto Minerva, and Noel Crespi. 2020. "A Comparative Analysis of Machine/Deep Learning Models for Parking Space Availability Prediction" Sensors 20, no. 1: 322. https://doi.org/10.3390/s20010322
APA StyleAwan, F. M., Saleem, Y., Minerva, R., & Crespi, N. (2020). A Comparative Analysis of Machine/Deep Learning Models for Parking Space Availability Prediction. Sensors, 20(1), 322. https://doi.org/10.3390/s20010322