Input-Adaptive Proxy for Black Carbon as a Virtual Sensor

 , , , ,
, , , ,
Abstract
1. Introduction
2. Methods
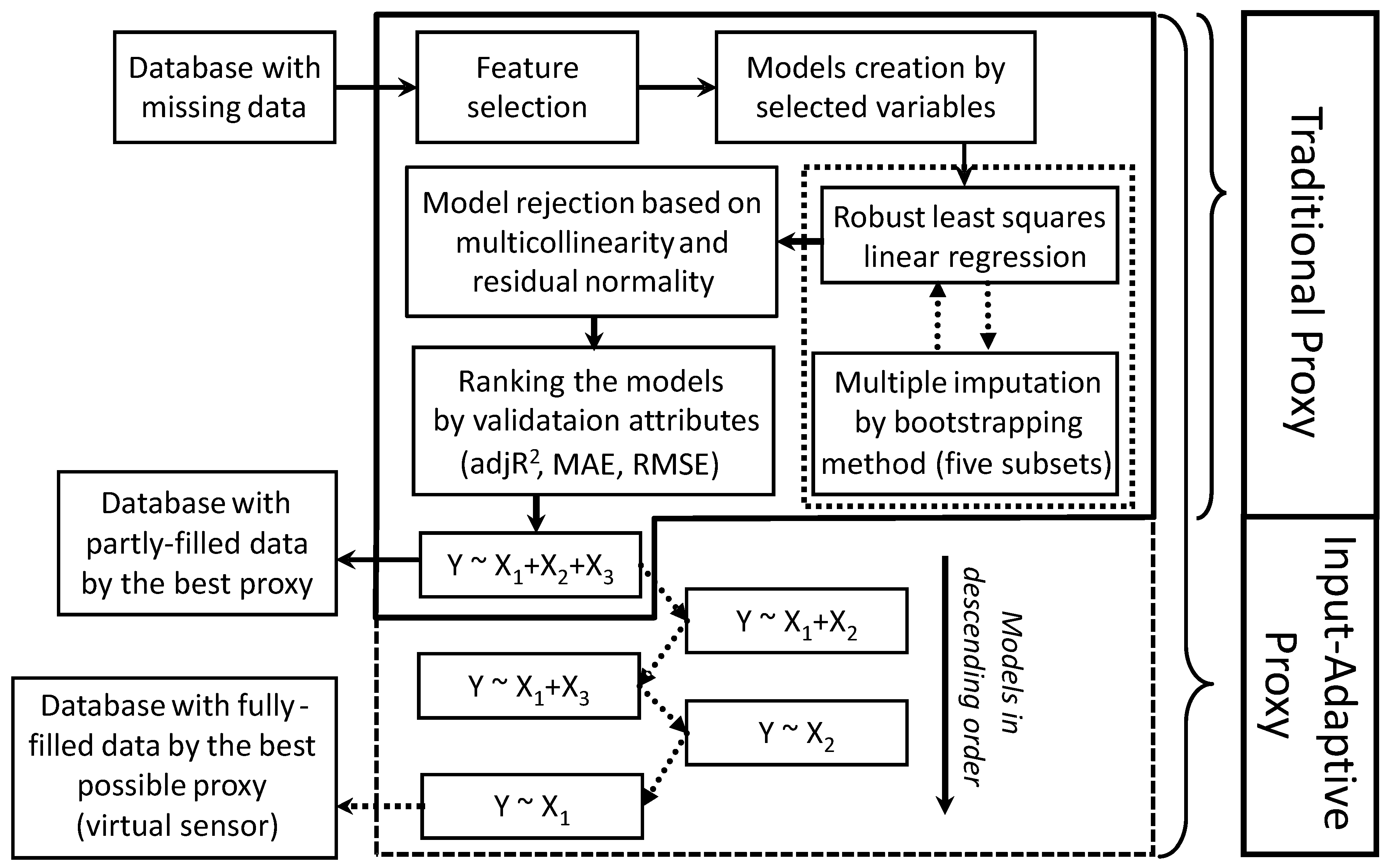
2.1. Proxy Development
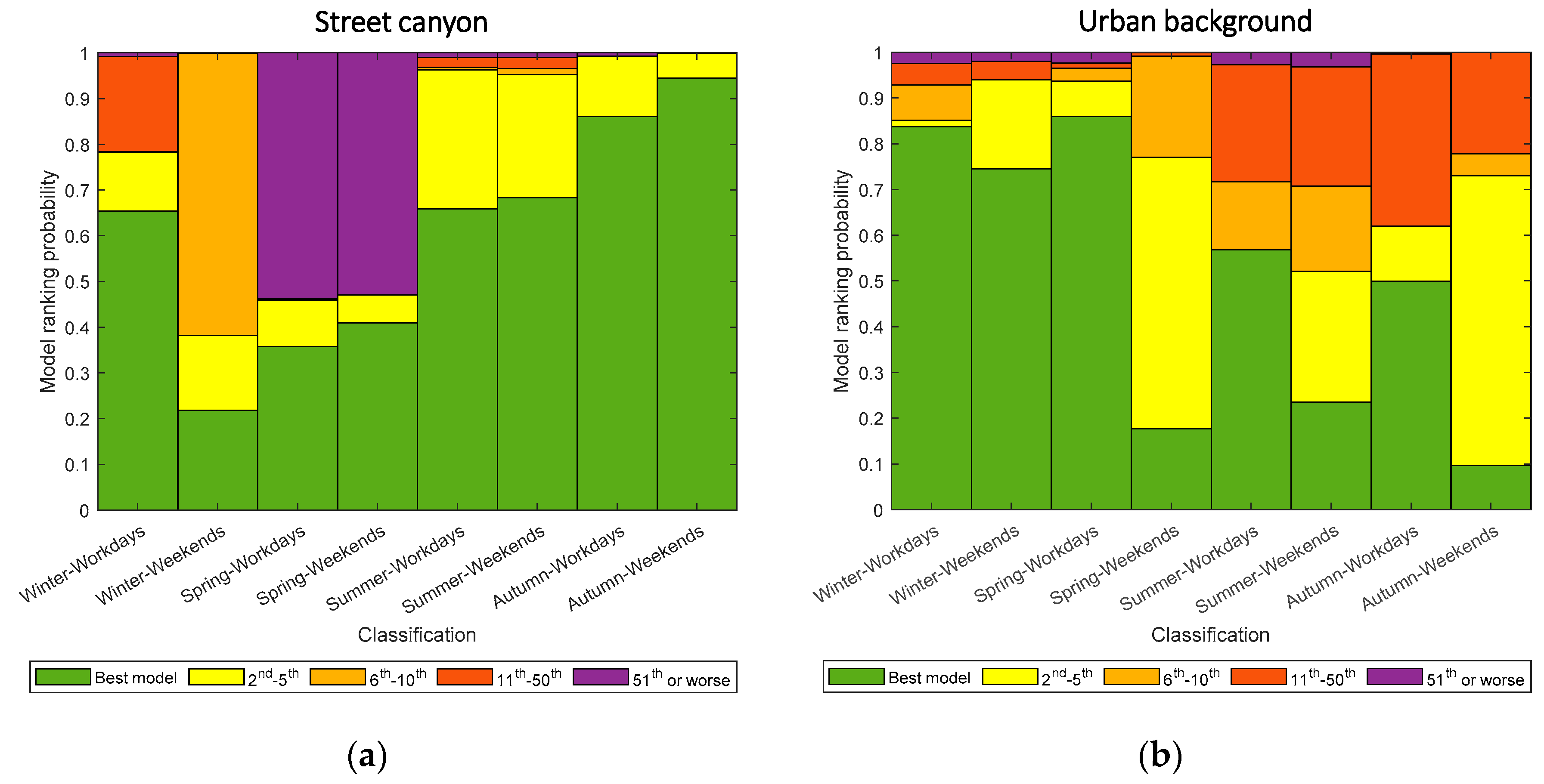
2.2. Model Rejection
2.3. Evaluation Attributes
3. Case Studies: BC in Street Canyon and Urban Background
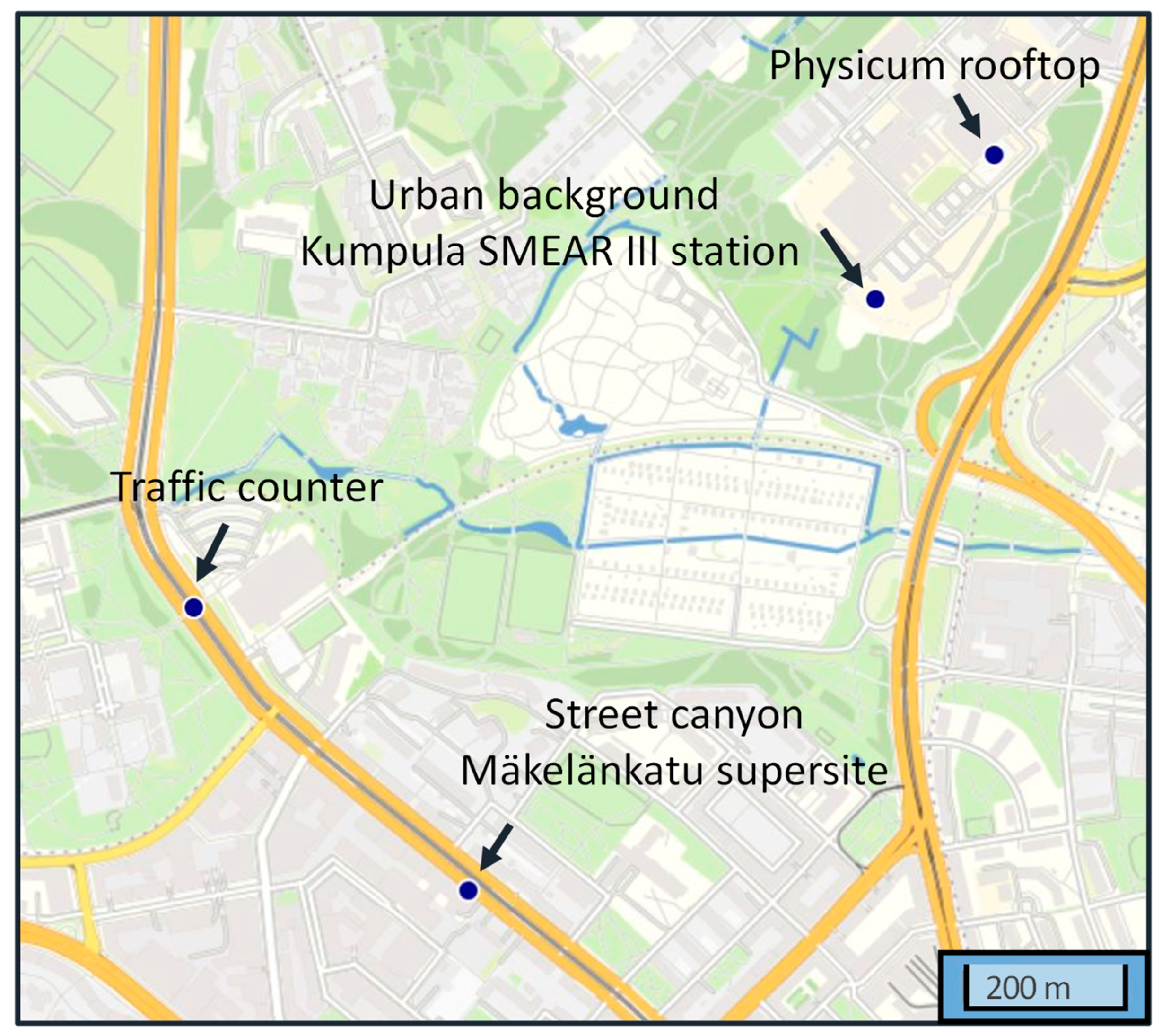
3.1. Site Description
3.2. Instruments
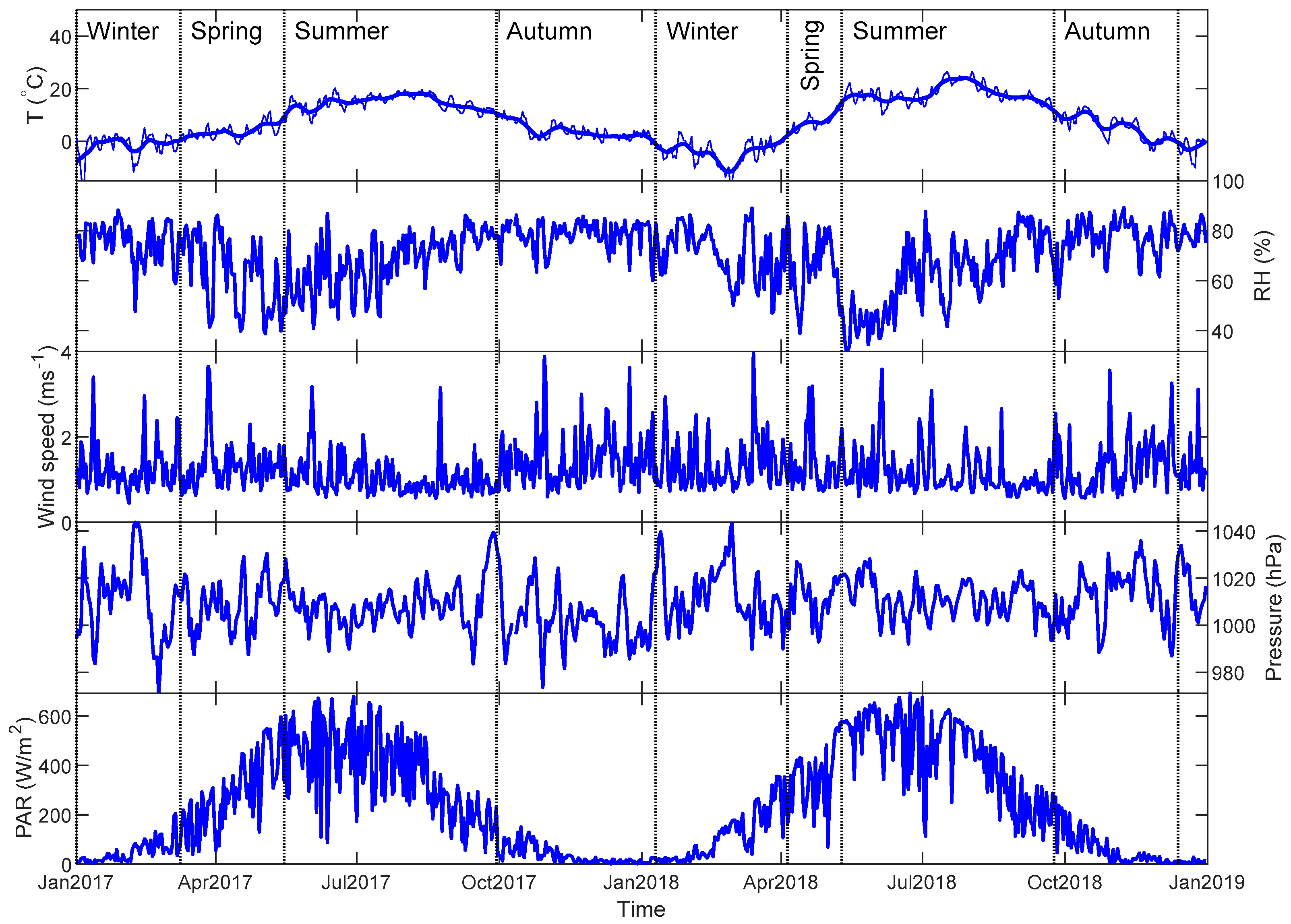
3.3. Data Pre-Processing
3.4. Data Completeness
3.5. Classification
4. Results and Discussion
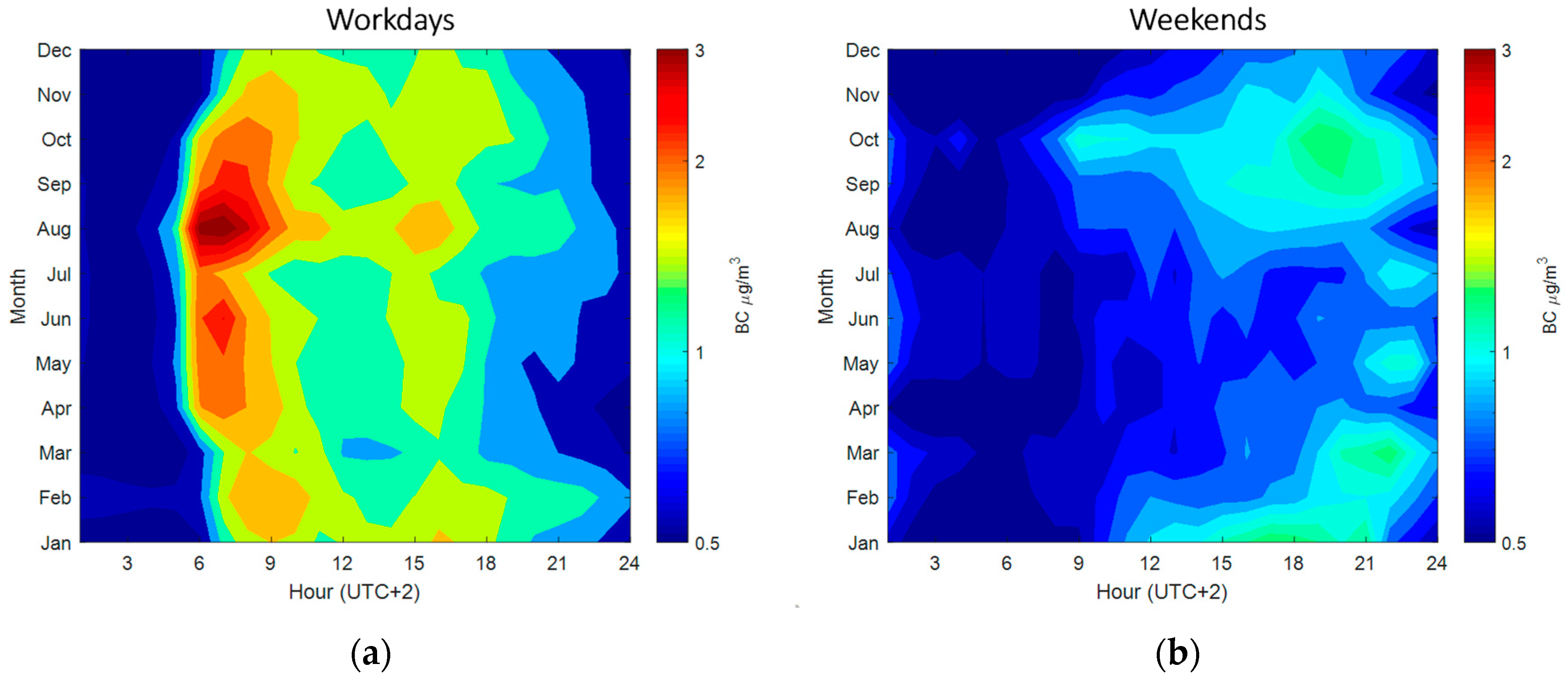
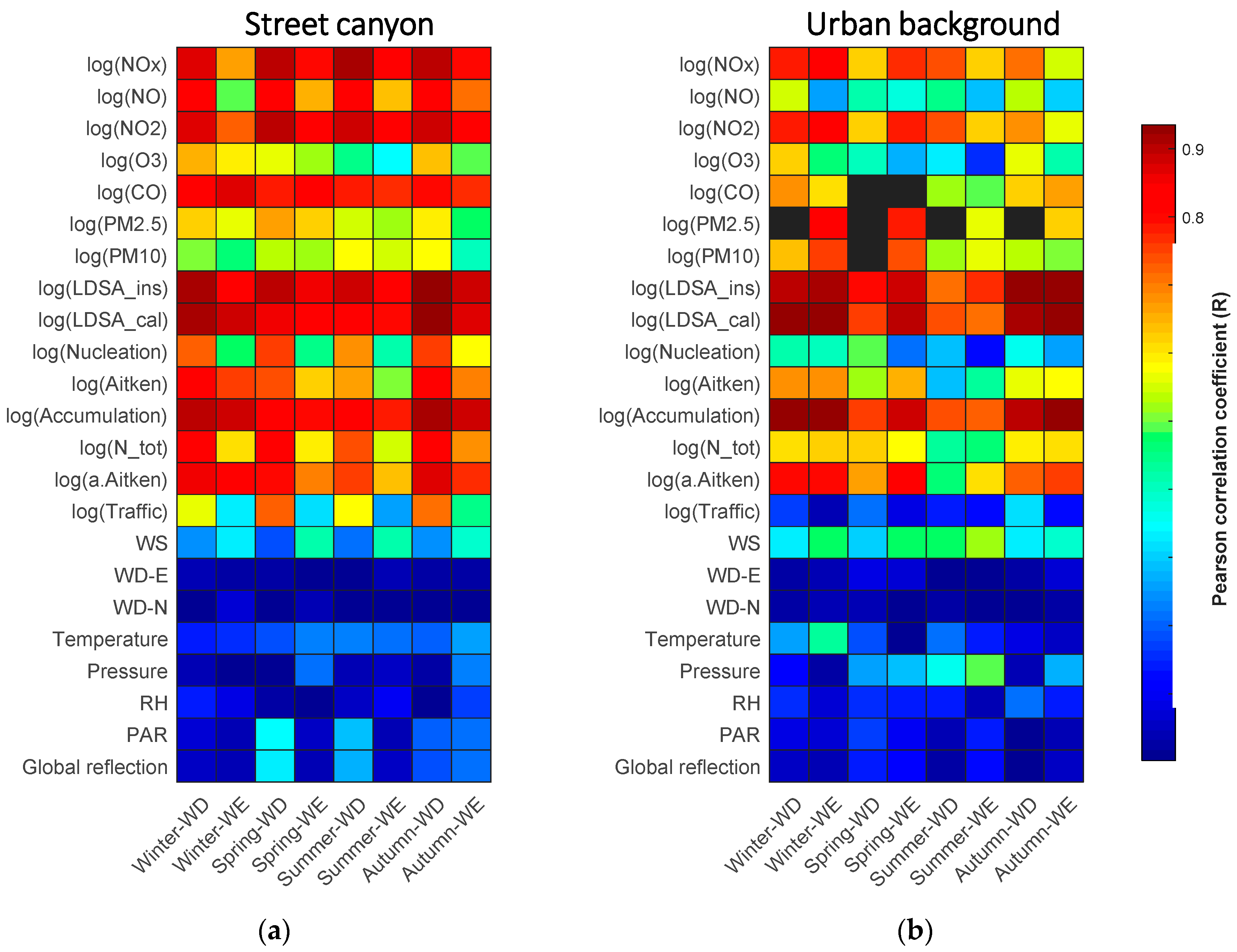
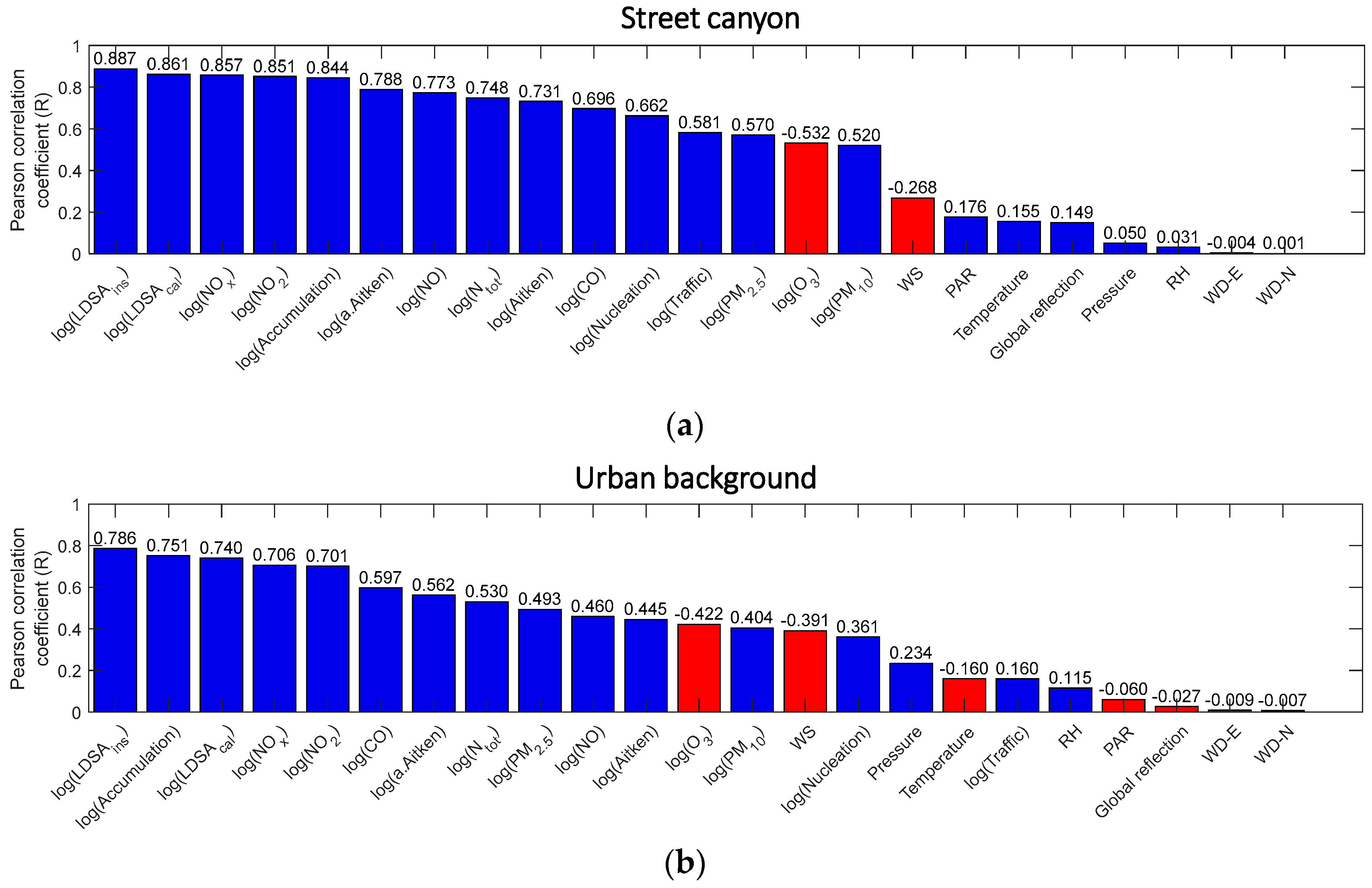
4.1. Variable Characterization
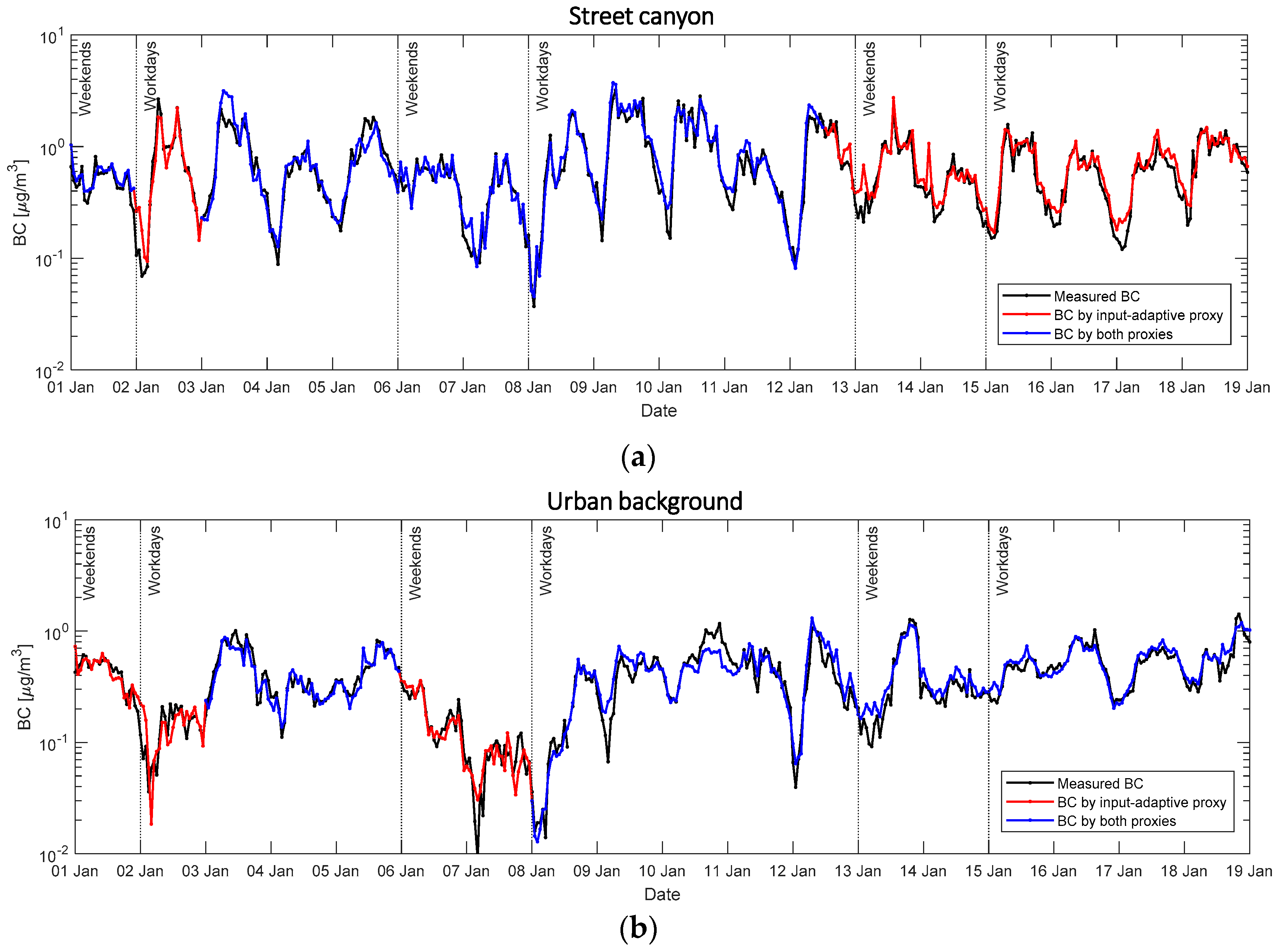
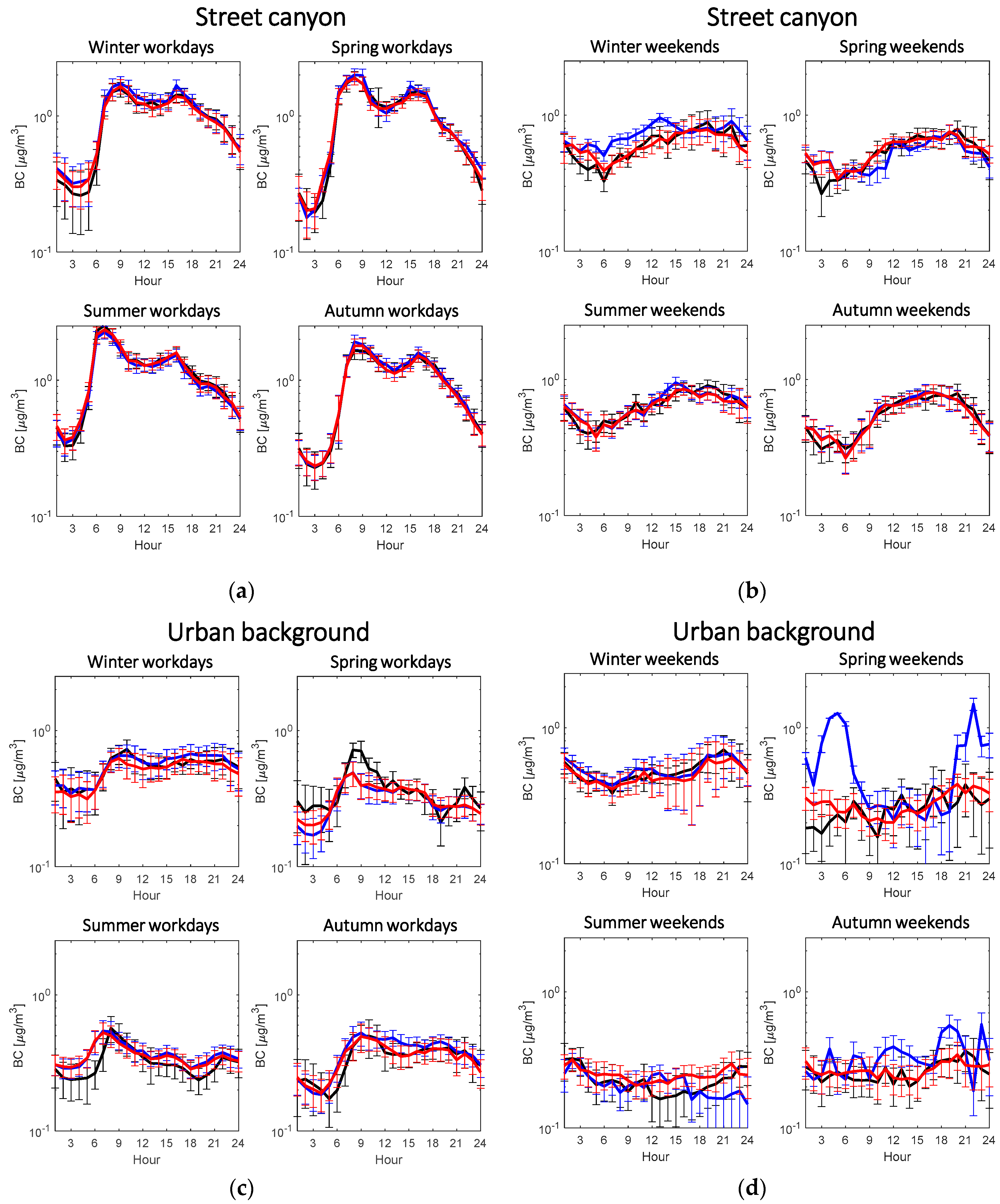
4.2. Performance of the Imputation Proxies
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| adjR2 | Adjusted coefficient of determination |
| BC | Black Carbon |
| CO | Carbon Monoxide |
| CPC | Condensation Particle Counter |
| DMPS | Differential Mobility Particle Sizer |
| GDP | Gross Domestic Profit |
| HSY | Helsinki Region Environmental Services Authority |
| LDSA | Lung Deposited Surface Area |
| MAAP | Multi-Angle Absorption Photometer |
| MAE | Mean Absolute Error |
| MAR | Missing At Random |
| NO | Nitrogen Oxide |
| NO2 | Nitrogen Dioxide |
| NOx | Sum of nitrogen oxide and nitrogen dioxide |
| Ntot | Total number of particles |
| O3 | Ozone |
| OLS | Ordinary Least Squares |
| PAR | Photosynthetically Active Radiation |
| PM | Particular Matter |
| PM2.5 | Particular Matter less than diameter 2.5 um |
| PM10 | Particular Matter less than diameter 10 um |
| PN | Particle Number |
| R | Pearson correlation coefficient |
| RH | Relative Humidity |
| RMSE | Root Mean Squared Error |
| SE | Standard Error |
| SMEAR | Station for Measuring Ecosystem-Atmosphere Relations |
| SO2 | Sulphur Dioxide |
| VIF | Variance Inflation Factor |
| WD | WorkDays |
| WD-E | Wind Direction along East |
| WD-N | Wind Direction along North |
| WE | WeekEnds |
| WHO | World Health Organisation |
References
- Health Effect Institute. State of Global Air 2019 Special Report; Health Effect Institute: Boston, MA, USA, 2019. [Google Scholar]
- World Health Organization. World Health Statistics 2019: Monitoring Health for the SDGs, Sustainable Development Goals; World Health Organization: Geneva, Switzerland, 2019. [Google Scholar]
- Hussein, T.; Johansson, C.; Morawska, L. Forecasting Urban Air Quality. Adv. Meteorol. 2012, 2012, 5–7. [Google Scholar] [CrossRef]
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for Imputation of Missing Values in Air Quality Data Sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Zaidan, M.A.; Dada, L.; Alghamdi, M.A.; Al-jeelani, H.; Hyvärinen, A.; Hussein, T. Mutual Information Input Selector and Probabilistic Machine Learning Utilisation for Air Pollution Proxies. Appl. Sci. 2019, 9, 4475. [Google Scholar] [CrossRef]
- Rubin, D.B. Inference and Missing Data. Biometrika Trust 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Donders, A.R.T.; van der Heijden, G.J.M.G.; Stijnen, T.; Moons, K.G.M. Review: A Gentle Introduction to Imputation of Missing Values. J. Clin. Epidemiol. 2006, 59, 1087–1091. [Google Scholar] [CrossRef]
- Box, G.; Jenkins, G.; Reinsel, G. Time Series Analysis. Forecasting and Control, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1994. [Google Scholar]
- Junger, W.L.; Ponce de Leon, A. Imputation of Missing Data in Time Series for Air Pollutants. Atmos. Environ. 2015, 102, 96–104. [Google Scholar] [CrossRef]
- Quinteros, M.E.; Lu, S.; Blazquez, C.; Cárdenas-R, J.P.; Ossa, X.; Delgado-Saborit, J.M.; Harrison, R.M.; Ruiz-Rudolph, P. Use of Data Imputation Tools to Reconstruct Incomplete Air Quality Datasets: A Case-Study in Temuco, Chile. Atmos. Environ. 2019, 200, 40–49. [Google Scholar] [CrossRef]
- Levy, I.; Mihele, C.; Lu, G.; Narayan, J.; Brook, J.R. Evaluating Multipollutant Exposure and Urban Air Quality: Pollutant Interrelationships, Neighborhood Variability, and Nitrogen Dioxide as a Proxy Pollutant. Environ. Health Perspect. 2014, 122, 65–72. [Google Scholar] [CrossRef]
- Streiner, D.V.L. The Case of the Missing Data: Methods of Dealing with Dropouts and Other Research Vagaries. Can. J. Psychiatry 2002, 47, 70–77. [Google Scholar] [CrossRef]
- Schafer, J.L. Analysis of Incomplete Multivariate Data, 1st ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 1997. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B.; Carlin, B.P.; Louis, T.A. Bayes and Empirical Bayes Methods for Data Analysis, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 1997. [Google Scholar]
- Mølgaard, B.; Hussein, T.; Corander, J.; Hämeri, K. Forecasting Size-Fractionated Particle Number Concentrations in the Urban Atmosphere. Atmos. Environ. 2012, 46, 155–163. [Google Scholar] [CrossRef]
- Chib, S. Bayes Regression with Autoregressive Approach Errors. J. Econom. 1993, 58, 275–294. [Google Scholar] [CrossRef]
- Zaidan, M.A.; Wraith, D.; Boor, B.E.; Hussein, T. Bayesian Proxy Modelling for Estimating Black Carbon Concentrations Using White-Box and Black-Box Models. Appl. Sci. 2019, 9, 4976. [Google Scholar] [CrossRef]
- Cabaneros, S.M.; Calautit, J.K.; Hughes, B.R. A Review of Artificial Neural Network Models for Ambient Air Pollution Prediction. Environ. Model. Softw. 2019, 119, 285–304. [Google Scholar] [CrossRef]
- Järvi, L.; Hannuniemi, H.; Hussein, T.; Junninen, H.; Aalto, P.; Hillamo, R.; Mäkelä, T.; Keronen, P.; Siivola, E.; Vesala, T.; et al. The Urban Measurement Station SMEAR II: Continuous Monitoring of Air Pollution and Surface-Atmosphere Interactions in Helsinki, Finland. Boreal Environ. Res. 2009, 14, 86–109. [Google Scholar]
- Lagerspetz, E.; Motlagh, N.H.; Zaidan, M.A.; Fung, P.L.; Mineraud, J.; Varjonen, S.; Siekkinen, M.; Nurmi, P.; Matsumi, Y.; Tarkoma, S.; et al. MegaSense: Feasibility of Low-Cost Sensors for Pollution Hot-Spot Detection. In Proceedings of the 2019 IEEE 17th International Conference on Industrial Informatics (INDIN), Helsinki, Finland, 23–25 July 2019. [Google Scholar]
- Liu, L.; Kuo, S.M.; Zhou, M.C. Virtual Sensing Techniques and Their Applications. In Proceedings of the 2009 IEEE International Conference on Networking, Sensing and Control, ICNSC 2009, Okayama, Japan, 26–29 March 2009; pp. 31–36. [Google Scholar] [CrossRef]
- Lee Rodgers, J.; NiceWander, W.A. Thirteen Ways to Look at the Correlation Coefficient. Am. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Clifford, S.; Low Choy, S.; Hussein, T.; Mengersen, K.; Morawska, L. Using the Generalised Additive Model to Model the Particle Number Count of Ultrafine Particles. Atmos. Environ. 2011, 45, 5934–5945. [Google Scholar] [CrossRef]
- Fernández-Guisuraga, J.M.; Castro, A.; Alves, C.; Calvo, A.; Alonso-Blanco, E.; Blanco-Alegre, C.; Rocha, A.; Fraile, R. Nitrogen Oxides and Ozone in Portugal: Trends and Ozone Estimation in an Urban and a Rural Site. Environ. Sci. Pollut. Res. 2016, 23, 17171–17182. [Google Scholar] [CrossRef]
- Hoaglin, D.C.; Mosteller, F.; Tukey, J.W. Understanding Robust and Exploratory Data Analysis; Wiley-Interscience: Hoboken, NJ, USA, 2000. [Google Scholar]
- Gross, A.M. Confidence Intervals for Bisquare Regression Estimates. J. Am. Stat. Assoc. 1977, 72, 341–354. [Google Scholar] [CrossRef]
- Andersen, R. Modern Methods for Robust Regression; No. 152; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2007. [Google Scholar]
- Holland, P.W.; Welsch, R.E. Robust Regression Using Iteratively Reweighted Least-Squares. Commun. Stat. Methods 1977, 813–827. [Google Scholar] [CrossRef]
- Roda, C.; Nicolis, I.; Momas, I.; Guihenneuc, C. New Insights into Handling Missing Values in Environmental Epidemiological Studies. PLoS ONE 2014, 9. [Google Scholar] [CrossRef]
- Graham, J.W.; Olchowski, A.E.; Gilreath, T.D. How Many Imputations Are Really Needed? Some Practical Clarifications of Multiple Imputation Theory. Prev. Sci. 2007, 8, 206–213. [Google Scholar] [CrossRef] [PubMed]
- Kleinbaum, D.G.; Kupper, L.L.; Muller, K.E.; Nizam, A. Applied Regression Analysis and Multivariable Methods; Duxbury Press: London, UK, 1987. [Google Scholar]
- Mohd Razali, N.; Bee Wah, Y. Power Comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling Tests. J. Stat. Model. Anal. 2011, 2, 21–33. [Google Scholar]
- Lilliefors, H.W. On the Kolmogorov-Smirnov Test for Normality with Mean and Variance Unknown. J. Am. Stat. Assoc. 1967, 62, 399–402. [Google Scholar] [CrossRef]
- Järvi, L.; Junninen, H.; Karppinen, A.; Hillamo, R.; Virkkula, A.; Mäkelä, T.; Pakkanen, T.; Kulmala, M. Temporal Variations in Black Carbon Concentrations with Different Time Scales in Helsinki during 1996–2005. Atmos. Chem. Phys. 2008, 8, 1017–1027. [Google Scholar] [CrossRef]
- Helin, A.; Niemi, J.V.; Virkkula, A.; Pirjola, L.; Teinilä, K.; Backman, J.; Aurela, M.; Saarikoski, S.; Rönkkö, T.; Asmi, E.; et al. Characteristics and Source Apportionment of Black Carbon in the Helsinki Metropolitan Area, Finland. Atmos. Environ. 2018, 190, 87–98. [Google Scholar] [CrossRef]
- WHO Regional Office for Europe. Health Effects of Black Carbon; WHO Regional Office for Europe: Copenhagen, Denmark, 2012. [Google Scholar]
- Janssen, N.A.H.; Hoek, G.; Simic-Lawson, M.; Fischer, P.; van Bree, L.; ten Brink, H.; Keuken, M.; Atkinson, R.W.; Ross Anderson, H.; Brunekreef, B.; et al. Black Carbon as an Additional Indicator of the Adverse Health Effects of Airborne Particles Compared with Pm 10 and Pm 2.5. Environ. Health Perspect. 2011, 119, 1691–1699. [Google Scholar] [CrossRef]
- Stocker, T.F.; Qin, D.; Plattner, G.K.; Tignor, M.; Allen, S.K.; Boschung, J.; Nauels, A.; Xia, Y.; Bex, V.; Midgley, P.M. Climate Change 2013: The Physical Science Basis: Working Group I Contribution to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Novakov, T.; Ramanathan, V.; Hansen, J.E.; Kirchstetter, T.W.; Sato, M.; Sinton, J.E.; Sathaye, J.A. Large Historical Changes of Fossil-Fuel Black Carbon Aerosols. Geophys. Res. Lett. 2003, 30, 1–4. [Google Scholar] [CrossRef]
- National Land Survey of Finland. Suomen Pinta-ala Kunnittain 1.1.2019. Available online: https://www.maanmittauslaitos.fi/sites/maanmittauslaitos.fi/files/attachments/2019/01/Suomen_pa_2019_kunta_maakunta.pdf (accessed on 28 November 2019).
- Hietikko, R.; Kuuluvainen, H.; Harrison, R.M.; Portin, H.; Timonen, H.; Niemi, J.V.; Rönkkö, T. Diurnal Variation of Nanocluster Aerosol Concentrations and Emission Factors in a Street Canyon. Atmos. Environ. 2018, 189, 98–106. [Google Scholar] [CrossRef]
- Kuuluvainen, H.; Poikkimäki, M.; Järvinen, A.; Kuula, J.; Irjala, M.; Dal Maso, M.; Keskinen, J.; Timonen, H.; Niemi, J.V.; Rönkkö, T. Vertical Profiles of Lung Deposited Surface Area Concentration of Particulate Matter Measured with a Drone in a Street Canyon. Environ. Pollut. 2018, 241, 96–105. [Google Scholar] [CrossRef]
- Hyvärinen, A.-P.; Vakkari, V.; Laakso, L.; Hooda, R.K.; Sharma, V.P.; Panwar, T.S.; Beukes, J.P.; van Zyl, P.G.; Josipovic, M.; Garland, R.M.; et al. Correction for a Measurement Artifact of the Multi-Angle Absorption Photometer (MAAP) at High Black Carbon Mass Concentration Levels. Atmos. Meas. Tech. 2013, 6, 81–90. [Google Scholar] [CrossRef]
- Müller, T.; Henzing, J.; Leeuw, G.; Wiedensohler, A.; Alastuey, A.; Angelov, H.; Bizjak, M.; Collaud Coen, M.; Engström, J.; Gruening, C.; et al. Characterization and Intercomparison of Aerosol Absorption Photometers: Result of Two Intercomparison Workshops. Atmos. Meas. Tech. 2011, 4, 245–268. [Google Scholar] [CrossRef]
- Hennig, F.; Quass, U.; Hellack, B.; Küpper, M.; Kuhlbusch, T.A.J.; Stafoggia, M.; Hoffmann, B. Ultrafine and Fine Particle Number and Surface Area Concentrations and Daily Cause-Specific Mortality in the Ruhr Area, Germany, 2009–2014. Environ. Health Perspect. 2009, 126, 027008. [Google Scholar] [CrossRef] [PubMed]
- Timonen, H.; Carbone, S.; Aurela, M.; Saarnio, K.; Saarikoski, S.; Ng, N.L.; Canagaratna, M.R.; Kulmala, M.; Kerminen, V.M.; Worsnop, D.R.; et al. Characteristics, Sources and Water-Solubility of Ambient Submicron Organic Aerosol in Springtime in Helsinki, Finland. J. Aerosol Sci. 2013, 56, 61–77. [Google Scholar] [CrossRef]
- Aalto, P.; Hämeri, K.; Becker, E.D.O.; Weber, R.; Salm, J.; Mäkelä, J.M.; Hoell, C.; O’Dowd, C.D.; Karlsson, H.; Hansson, H.; et al. Physical Characterization of Aerosol Particles during Nucleation Events. Tellus Ser. B Chem. Phys. Meteorol. 2001, 53, 344–358. [Google Scholar] [CrossRef]
- Bair, W.J. The Revised International Commission on Radiological Protection (ICRP) Dosimetric Model for the Human Respiratory Tract—An Overview. Ann. Occup. Hyg. 1994, 38, 251–256. [Google Scholar] [CrossRef]
- Kuula, J.; Kuuluvainen, H.; Niemi, J.V.; Saukko, E.; Portin, H.; Kousa, A.; Aurela, M.; Rönkkö, T.; Timonen, H. Long-Term Sensor Measurements of Lung Deposited Surface Area of Particulate Matter Emitted from Local Vehicular and Residential Wood Combustion Sources. Aerosol Sci. Technol. 2019, 9, 1–17. [Google Scholar] [CrossRef]
- Ding, A.J.; Huang, X.; Nie, W.; Sun, J.N.; Kerminen, V.M.; Petäjä, T.; Su, H.; Cheng, Y.F.; Yang, X.Q.; Wang, M.H.; et al. Enhanced Haze Pollution by Black Carbon in Megacities in China. Geophys. Res. Lett. 2016, 43, 2873–2879. [Google Scholar] [CrossRef]
- Jammalamadaka, S.R.; Lund, U.J. The Effect of Wind Direction on Ozone Levels: A Case Study. Env. Ecol Stat. 2006, 13, 287–298. [Google Scholar] [CrossRef]
- Hussein, T.; Puustinen, A.; Aalto, P.P.; Mäkelä, J.M.; Hämeri, K.; Kulmala, M. Urban Aerosol Number Size Distributions. Atmos. Chem. Phys. Discuss. 2003, 3, 5139–5184. [Google Scholar] [CrossRef]
- Pakkanen, T.A.; Kerminen, V.; Ojanen, C.H.; Hillamo, R.E.; Aarnio, K.; Koskentalo, T. Atmospheric Black Carbon in Helsinki. Atmos. Environ. 2000, 34, 1497–1506. [Google Scholar] [CrossRef]
- Teinilä, K.; Aurela, M.; Niemi, J.V.; Kousa, A.; Petäjä, T.; Järvi, L.; Hillamo, R.; Kangas, L.; Saarikoski, S.; Timonen, H. Concentration Variation of Gaseous and Particulate Pollutants in the Helsinki City Centre-Observations from a Two-Year Campaign from 2013–2015. Boreal Env. Res. 2019, 24, 115–136. [Google Scholar]
- Hellén, H.; Kangas, L.; Kousa, A.; Vestenius, M.; Teinilä, K.; Karppinen, A.; Kukkonen, J.; Niemi, J.V. Evaluation of the Impact of Wood Combustion on Benzo[a]Pyrene (BaP) Concentrations; Ambient Measurements and Dispersion Modeling in Helsinki, Finland. Atmos. Chem. Phys 2017, 17, 3475–3487. [Google Scholar] [CrossRef]
- Chan, T.W.; Meloche, E.; Kubsh, J.; Brezny, R. Black Carbon Emissions in Gasoline Exhaust and a Reduction Alternative with a Gasoline Particulate Filter. Environ. Sci. Technol. 2014, 48, 6027–6034. [Google Scholar] [CrossRef] [PubMed]
- Hussein, T.; Karppinen, A.; Kukkonen, J.; Härkönen, J.; Aalto, P.P.; Hämeri, K.; Kerminen, V.M.; Kulmala, M. Meteorological Dependence of Size-Fractionated Number Concentrations of Urban Aerosol Particles. Atmos. Environ. 2006, 40, 1427–1440. [Google Scholar] [CrossRef]
- Laakso, L.; Hussein, T.; Aarnio, P.; Komppula, M.; Hiltunena, V.; Viisanen, Y.; Kulmala, M. Diurnal and Annual Characteristics of Particle Mass and Number Concentrations in Urban, Rural and Arctic Environments in Finland. Atmos. Environ. 2003, 37, 2629–2641. [Google Scholar] [CrossRef]
- Mølgaard, B.; Birmili, W.; Clifford, S.; Massling, A.; Eleftheriadis, K.; Norman, M.; Vratolis, S.; Wehner, B.; Corander, J.; Hämeri, K.; et al. Evaluation of a Statistical Forecast Model for Size-Fractionated Urban Particle Number Concentrations Using Data from Five European Cities. J. Aerosol Sci. 2013, 66, 96–110. [Google Scholar] [CrossRef]
- Zaidan, M.A.; Haapasilta, V.; Relan, R.; Paasonen, P.; Kerminen, V.M.; Junninen, H.; Kulmala, M.; Foster, A.S. Exploring Non-Linear Associations between Atmospheric New-Particle Formation and Ambient Variables: A Mutual Information Approach. Atmos. Chem. Phys. 2018, 18, 12699–12714. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measured Quantity | Instruments in Mäkelänkatu | Instruments in Kumpula |
|---|---|---|
| Aerosols | ||
| BC | MAAP Thermo Scientific 5012 with a PM1 inlet | |
| LDSA | Pegasor AQ Urban sensor | |
| PM2.5 and PM10 | Continuous ambient particulate monitor Thermo TEOM 1405 | Continuous ambient particulate monitor Thermo TEOM 1405-D |
| Particle size distribution | Single DMPS (Vienna DMA and Airmodus A20 CPC) | Twin DMPS (Hauke-type DMA and TSI Model 3025 CPC + Hauke-type DMA and TSI Model 3010 CPC) |
| Trace gases | ||
| NO, NO2 and NOx | Chemiluminescence analyzer Horiba APNA-370 | Chemiluminescence analyzer Thermo TEI42S |
| O3 | UV photometric analyzers Horiba APOA-370 and Thermo Model 49i | IR-absorption photometer TEI49 |
| CO | IR-absorption analyzer Horiba APMA-360 | IR-absorption analyzer Horiba APMA-370 |
| SO2 | N/A | UV-fluorescence analyzer Horiba APSA-360 |
| Meteorological variables | ||
| Wind speed and wind direction | Weather transmitter Vaisala WXT 520 and Vaisala WXT536 | Vaisala cup anemometer |
| Air temperature | Platinum resistant thermometer Pt-100 | |
| RH | Platimun resistance thermometer and thin film polymer sensor Vaisala DPA500 | |
| Air pressure | Barometer Vaisala DPA500 | |
| Global radiation and PAR | N/A | Kipp and Zonen CNR1+PAR lite |
| Winter | Spring | Summer | Autumn | |||||
|---|---|---|---|---|---|---|---|---|
| WD | WE | WD | WE | WD | WE | WD | WE | |
| BC | 99 (59) | 100 (64) | 100 (35) | 100 (32) | 99 (75) | 99 (78) | 99 (89) | 100 (89) |
| O3 | 98 (99) | 100 (100) | 98 (99) | 99 (100) | 98 (100) | 99 (98) | 99 (100) | 100 (100) |
| CO | 59 (87) | 64 (85) | 69 (65) | 76 (68) | 96 (72) | 95 (71) | 95 (100) | 96 (100) |
| NOx | 99 (98) | 100 (99) | 99 (34) | 99 (32) | 99 (83) | 99 (80) | 99 (100) | 100 (99) |
| PM10 | 98 (47) | 99 (50) | 98 (35) | 98 (32) | 98 (48) | 98 (49) | 99 (43) | 98 (39) |
| LDSAins | 98 (51) | 99 (47) | 95 (35) | 91 (32) | 99 (52) | 97 (51) | 95 (55) | 99 (60) |
| LDSAcal | 79 (88) | 75 (79) | 46 (71) | 47 (78) | 98 (76) | 97 (64) | 100 (56) | 100 (65) |
| Mode | 79 (98) | 75 (89) | 46 (97) | 47 (100) | 98 (99) | 97 (95) | 100 (98) | 100 (100) |
| Temperature | 100 (100) | 100 (100) | 100 (100) | 100 (100) | 99 (100) | 99 (100) | 99 (100) | 100 (100) |
| Traffic 1 | 86 | 82 | 88 | 94 | 69 | 72 | 87 | 94 |
| n | 116 | 55 | 68 | 32 | 192 | 82 | 126 | 57 |
| Winter | Spring | Summer | Autumn | |||||
|---|---|---|---|---|---|---|---|---|
| WD | WE | WD | WE | WD | WE | WD | WE | |
| Mean | 1.10 (0.67) | 0.76 (0.60) | 1.07 (0.52) | 0.66 (0.47) | 1.29 (0.42) | 0.75 (0.33) | 1.12 (0.47) | 0.69 (0.37) |
| SD | 0.32 (0.38) | 0.53 (0.66) | 0.57 (0.79) | 0.64 (2.10) | 0.22 (0.11) | 0.27 (0.22) | 0.30 (0.17) | 0.40 (0.32) |
| P10 | 0.22 (0.17) | 0.26 (0.14) | 0.20 (0.13) | 0.20 (0.08) | 0.31 (0.10) | 0.22 (0.07) | 0.21 (0.10) | 0.18 (0.06) |
| P25 | 0.43 (0.29) | 0.40 (0.24) | 0.41 (0.22) | 0.31 (0.12) | 0.56 (0.17) | 0.39 (0.12) | 0.44 (0.19) | 0.32 (0.12) |
| P50 | 0.87 (0.53) | 0.62 (0.48) | 0.88 (0.37) | 0.54 (0.27) | 1.04 (0.31) | 0.64 (0.21) | 0.90 (0.35) | 0.54 (0.27) |
| P75 | 1.51 (0.85) | 0.92 (0.77) | 1.50 (0.66) | 0.82 (0.61) | 1.74 (0.54) | 0.99 (0.42) | 1.54 (0.60) | 0.884 (0.45) |
| P90 | 2.25 (1.20) | 1.29 (1.13) | 2.14 (1.16) | 1.25 (1.05) | 2.61 (0.87) | 1.38 (0.74) | 2.31 (0.98) | 1.42 (0.81) |
| X | β | SE | adjR2 | MAE | RMSE | |
|---|---|---|---|---|---|---|
| Winter Workdays | log(Traffic) | 0.07 | 0.01 | 0.92 | 0.008 | 0.26 |
| log(NOx) | 0.37 | 0.01 | ||||
| log(PN1-0.09) | 0.67 | 0.01 | ||||
| Winter Weekends | log(Traffic) | 0.08 | 0.02 | 0.89 | 0.003 | 0.19 |
| log(CO) | 1.00 | 0.11 | ||||
| log(PN1-0.09) | 0.63 | 0.04 | ||||
| Spring Workdays | log(Traffic) | 0.13 | 0.02 | 0.93 | 0.006 | 0.24 |
| log(NOx) | 0.44 | 0.02 | ||||
| log(PN1-0.09) | 0.64 | 0.03 | ||||
| Spring Weekends | log(Traffic) | 0.16 | 0.02 | 0.87 | 0.007 | 0.23 |
| log(NOx) | 0.42 | 0.02 | ||||
| log(PN1-0.09) | 0.54 | 0.02 | ||||
| Summer Workdays | log(Traffic) | 0.12 | 0.01 | 0.92 | 0.008 | 0.24 |
| log(NOx) | 0.55 | 0.01 | ||||
| log(PN1-0.09) | 0.48 | 0.01 | ||||
| Summer Weekends | log(Traffic) | 0.11 | 0.01 | 0.86 | 0.004 | 0.28 |
| log(NOx) | 0.49 | 0.01 | ||||
| log(PN1-0.09) | 0.60 | 0.02 | ||||
| Autumn Workdays | log(Traffic) | 0.07 | 0.01 | 0.94 | 0.004 | 0.23 |
| log(NOx) | 0.38 | 0.01 | ||||
| log(PN1-0.09) | 0.67 | 0.01 | ||||
| Autumn Weekends | log(Traffic) | 0.10 | 0.01 | 0.91 | 0.016 | 0.25 |
| log(NOx) | 0.37 | 0.01 | ||||
| log(PN1-0.09) | 0.74 | 0.01 |
| X | β | SE | adjR2 | MAE | RMSE | |
|---|---|---|---|---|---|---|
| Winter Workdays | log(NO2) | 0.19 | 0.01 | 0.91 | 0.008 | 0.23 |
| log(CO) | 0.54 | 0.05 | ||||
| log(PN1-0.09) | 0.77 | 0.02 | ||||
| Winter Weekends | log(CO) | 0.23 | 0.11 | 0.88 | 0.006 | 0.27 |
| log(PN1-0.09) | 1.00 | 0.02 | ||||
| log(PN0.025) | 0.16 | 0.01 | ||||
| Spring Workdays | log(Traffic) | 0.06 | 0.03 | 0.74 | 0.013 | 0.46 |
| log(PN1-0.09) | 0.95 | 0.04 | ||||
| log(PN0.025) | 0.28 | 0.03 | ||||
| Spring Weekends | Temperature | −0.05 | 0.01 | 0.84 | 0.056 | 0.43 |
| log(NO) | −0.06 | 0.03 | ||||
| log(LDSAcal) | 1.23 | 0.05 | ||||
| Summer Workdays | log(NOx) | 0.33 | 0.01 | 0.77 | 0.007 | 0.40 |
| log(CO) | 0.77 | 0.07 | ||||
| log(PN1-0.09) | 0.58 | 0.02 | ||||
| Summer Weekends | log(CO) | 1.41 | 0.12 | 0.78 | 0.001 | 0.43 |
| log(PM10) | 0.05 | 0.03 | ||||
| log(PN1-0.09) | 0.92 | 0.04 | ||||
| Autumn Workdays | log(Traffic) | 0.14 | 0.01 | 0.91 | 0.014 | 0.25 |
| log(PN0.09-0.025) | −0.46 | 0.02 | ||||
| log(LDSAins) | 1.46 | 0.02 | ||||
| Autumn Weekends | Temperature | −0.04 | 0.08 | 0.90 | 0.036 | 0.27 |
| log(PM10) | −0.01 | 0.01 | ||||
| log(LDSAcal) | 1.34 | 0.04 |
| X1 | X2 | X3 | adjR2 | MAE | RMSE | |
|---|---|---|---|---|---|---|
| 1 | log(PN1-0.09) | log(Traffic) | log(NOx) | 0.92 | 0.008 | 0.2602 |
| 2 | log(PN1-0.09) | log(NOx) | Wind speed | 0.92 | 0.010 | 0.2600 |
| 3 | log(PN1-0.09) | log(NOx) | Air pressure | 0.92 | 0.011 | 0.2568 |
| 4 | log(PN1-0.09) | log(NOx) | PAR | 0.92 | 0.013 | 0.2594 |
| 5 | log(PN1-0.09) | log(NOx) | Temperature | 0.92 | 0.014 | 0.2558 |
| 6 | log(PN1-0.09) | log(Traffic) | log(CO) | 0.92 | 0.017 | 0.2545 |
| 7 | log(PN1-0.09) | log(Traffic) | log(NO2) | 0.92 | 0.018 | 0.2567 |
| 8 | log(PN1-0.09) | log(NO2) | Wind speed | 0.91 | 0.001 | 0.2454 |
| 9 | log(PN1-0.09) | log(NOx) | log(PM2.5) | 0.91 | 0.002 | 0.2535 |
| 10 | log(PN1-0.09) | log(NO2) | Air Pressure | 0.91 | 0.006 | 0.2495 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fung, P.L.; Zaidan, M.A.; Sillanpää, S.; Kousa, A.; Niemi, J.V.; Timonen, H.; Kuula, J.; Saukko, E.; Luoma, K.; Petäjä, T.; et al. Input-Adaptive Proxy for Black Carbon as a Virtual Sensor. Sensors 2020, 20, 182. https://doi.org/10.3390/s20010182
Fung PL, Zaidan MA, Sillanpää S, Kousa A, Niemi JV, Timonen H, Kuula J, Saukko E, Luoma K, Petäjä T, et al. Input-Adaptive Proxy for Black Carbon as a Virtual Sensor. Sensors. 2020; 20(1):182. https://doi.org/10.3390/s20010182
Chicago/Turabian StyleFung, Pak Lun, Martha A. Zaidan, Salla Sillanpää, Anu Kousa, Jarkko V. Niemi, Hilkka Timonen, Joel Kuula, Erkka Saukko, Krista Luoma, Tuukka Petäjä, and et al. 2020. "Input-Adaptive Proxy for Black Carbon as a Virtual Sensor" Sensors 20, no. 1: 182. https://doi.org/10.3390/s20010182
APA StyleFung, P. L., Zaidan, M. A., Sillanpää, S., Kousa, A., Niemi, J. V., Timonen, H., Kuula, J., Saukko, E., Luoma, K., Petäjä, T., Tarkoma, S., Kulmala, M., & Hussein, T. (2020). Input-Adaptive Proxy for Black Carbon as a Virtual Sensor. Sensors, 20(1), 182. https://doi.org/10.3390/s20010182