1. Introduction
Rolling element bearings are the key components widely used in rotating machines. A sudden breakdown of the mechanical system or even a severe catastrophe, may be caused due to an unexpected failure of the rolling element bearings. Therefore, many bearing fault diagnosis methods have been developed based on vibration signal analysis and feature extraction [
1,
2,
3]. However, some of them are performed manually with low efficiency by means of knowledge and experiences of experts, which are not practical in real applications. Thus, there is still growing attention towards the development of bearing intelligent fault diagnosis techniques. For example, a novel intelligent fault diagnosis method has been proposed based on the affinity propagation clustering algorithm and the adaptive feature selection technique [
4]. Qin et al. [
5] proposed a model for fault diagnosis of gearboxes in wind turbines based on deep belief networks (DBNs), using improved logistic sigmoid units and the impulsive signatures. In addition, a three-stage intelligent fault diagnosis clustering technique has been proposed for the industrial process monitoring [
6]. Generally, the diagnosis results achieved by using a single-stage classifier may still be precarious [
7,
8,
9,
10]. According to Wolpert’s theorem, there is not a single classifier approach that can be successfully applied for all pattern recognition tasks since each has its own domain of competence [
11].
Nowadays, many different combinations of several different learning algorithms, such as the hybrid or ensemble systems, have been highlighted as a hot topic and promising trend in the fields of pattern recognition. The hybrid intelligent systems offer many alternatives for unorthodox handling of realistic increasingly complex problems, involving ambiguity, uncertainty, and high-dimensionality of data [
12]. Nevertheless, the accuracy of the existing techniques needs to be further improved, since the structure of rotating machinery becomes increasingly complicated. Therefore, a novel hybrid classifier ensemble (HCE) algorithm has been developed in this work, which can perform fault diagnosis under an improved framework of information fusion.
Actually, there are various strategies for information fusion, such as the simple voting procedure [
13]. The Dempster-Shafer theory (DST) has been also widely used as a combining decision method due to its uncertainty processing ability [
14]. In recent years, DST has attracted lots of attention and has been used in fault diagnosis for different industrial equipment. For example, a fusion approach was proposed for fault diagnosis of roller bearing in the aeroengine based on
n-dimensional characteristic parameter distance [
15]. Since a hybrid technique can substantially increase the accuracy of fault detection, DST combined with Support Vector Machine (SVM) has been applied for bearing multi-fault diagnosis [
16]. A fault diagnosis method was proposed for the reactor coolant system of a nuclear power plant based on DST and fuzzy function in reference [
17]. DST is well suitable for information fusion, but it may generate counter-intuitive results for highly conflicting and unreliable pieces of evidence [
18,
19]. Thus, conflict management has always been an unavoidable problem in information fusion using DST, which is also the main limitation of DST. To solve this issue, many improved versions of DST have been proposed, such as the average approach in reference [
20], the weighted average based on the evidence distance in reference [
21], and the vector space introduced in reference [
22]. Most of the available methods employed distance of the evidences as a critical factor to determine the weights, such as the Jousselme distance [
23] and the MaxDiff distance [
24]. Then, the support degrees of the evidences can be adjusted and be used to generate the appropriate weights with regard to the evidences. It can be found that a bigger weight is set to the reliable evidence and a smaller weight is set to the unreliable evidence. Although these techniques can reduce the influence of the unreliable evidence, they rarely consider the effects of the uncertain information of the evidences.
Many fuzzy modeling approaches have been successfully utilized in various applications in the past decades, since fuzzy sets technique also plays an important role in the decision-making process and can deal well with uncertain information. Qian etc. [
25] successfully utilized the advantages of group decision making via fuzzy preference. The fuzzy preference relations (FPR) has been constructed for multiple pieces of evidence based on the variance of information entropy. However, according to reference [
23], there are three drawbacks of this approach. (i) It does not satisfy the property of the additive consistency and the order consistency; (ii) It cannot calculate the preference values in some situations; (iii) The preference values in the consistency matrix are not always between zero and one. Therefore, a new improved DST approach is proposed in this paper inspired by reference [
26], which well considers the combination of unreliable evidence in the group decision making under the framework of FPR.
Two major contributions have been made in this work. First, a new hybrid classifier ensemble (HCE) method is proposed based on entropy features to improve the performance and accuracy of fault diagnosis. Second, an improved DST has been proposed to perform information fusion of classification decisions obtained by HCE, which considers the combination of unreliable and conflictive evidence sources, the uncertainty information of basic probability assignment (BPA) and the relative credibility of the evidence on the weights under the framework of FPR. The novel HCE model combined with the improved DST technique has been utilized to automatically identify bearing faults in a rotating machine. Results have demonstrated well the effectiveness of the proposed method.
This work is organized as follows. Theories of entropy feature extraction and single-stage classifier have been briefly reviewed in
Section 2. The improved DST for dealing with conflicting evidence has been given in
Section 3, where the performance of the proposed approaches has also been demonstrated using two examples. The HCE approach combined with the improved DST is adopted to identify bearing fault automatically, whose effectiveness was demonstrated on a test-rig in
Section 4. Conclusions are drawn in
Section 5.
4. Experimental Analysis
The effectiveness of the improved Dempster-Shafer (D-S) evidence theory in dealing with conflicting evidence has been verified in the previous section. The proposed HCE framework in roller bearing fault diagnosis and the robustness of improved DST in information fusion will be illustrated in this section. The present technique is then applied for the rolling bearing fault diagnosis experiments on the Machinery Fault Simulator Magnum (MFS-MG) test-rig. The flowchart of the fault diagnosis using the proposed procedure is shown as
Figure 5.
4.1. The Experimental Set-Up
As shown in
Figure 6, the vibration data set were acquired on the MFS-MG test rig, and the defective bearing of the type ER-12K was installed on the left side of the shaft. Accelerometer sensors were installed in vertical and horizontal on bearing seats. Sampling frequency was set to 25,600 Hz, and the rotating frequency of the motor was 29.87 Hz (about 1792 rpm). The fault types: Ball (B), cage (C), inner race (IR) and outer race (OR), as well as a normal (N) condition were used in the experiments. Each segment of the collected original vibration signal had 10,240 data points. The original vibration data and their frequency spectra are shown in
Figure 7.
4.2. Entropy Feature Sets
We could obtain four entropy features, the features of vibration signals. The original vibration signal was decomposed with the VMD method, and the decomposed intrinsic mode function (IMF) were achieved. The key parameters used in VMD should be selected based on the empirical value, interested readers can refer to reference [
47]. Assume
, where
K is the number of data points of
. The SSE, PSE, and TFE of each
were extracted using Equations (2), (5), and (6), respectively. Moreover, the WPESE of each original segment was also obtained using Equation (8). Here, a 3-level decomposition was used in WPT with the selected mother wavelet Db10. Since there were 112 samples for each experimental condition, the numbers of rows and columns in the feature matrix were 560 and 4, respectively.
Figure 8 shows the entropy feature sets. The datasets were divided into two parts, and the former 75% of each class of data was randomly selected as training data, while the remaining 25% was testing data. The training data and the testing data was defined as a 420(row)–5(column) matrix and a 140(row)–5(column) matrix, respectively. The desirable classes were labeled with 1, 2, 3, 4, and 5. For example, outputs 1 and 3 were separately related to the first and the third class. In this way, three supervised classifiers could be used to identify the bearing faults.
4.3. Classification Using Single-Stage Classifier
DNN, SVM, and ELM were separately adopted in the single-stage classification based on the above achieved entropy signatures. In this work, a large number of neurons were tested to find an optimal structure of DNN. The number of hidden layer neurons which resulted in the highest classification accuracy was selected as the optimum number. Then, the optimum DNN structure was constructed based on the obtained number of hidden layer neurons.
Figure 9 shows the classification accuracies of DNN based on the different numbers of hidden layer neurons and mini-batch gradient descent (MBGD) algorithm. It can be seen in
Figure 10 that the determined optimal number of hidden layer neurons is set to 13.
In the SVM technique, the Gaussian radial basis function (RBF) was selected as the kernel function, and the particle swarm optimization (PSO) was used to determine the optimized parameters in the SVM. The population size (pop), maximum number of iterations (maxgen), two acceleration constants (), and the inertia weightwere set toand pop = 20, maxgen = 100, respectively. In addition, the parameters of FOA used in ELM, such as the population size (pop) and maximum number of iterations (maxgen) were set to 20, 100, while the initial positions were set randomly.
After data training using each classifier, the testing data set was used to validate the accuracy of each classifier model for bearing fault diagnosis. The aim of classification was to assign an input pattern to one of the 5 classes concerned in the present study and represented by the classification labels. The classification results of the testing data set obtained by preliminary diagnosis are shown in
Figure 10,
Figure 11 and
Figure 12. The performances of DNN, ELM, and SVM are illustrated in
Table 8,
Table 9 and
Table 10, respectively. The meaning of Y-axis in
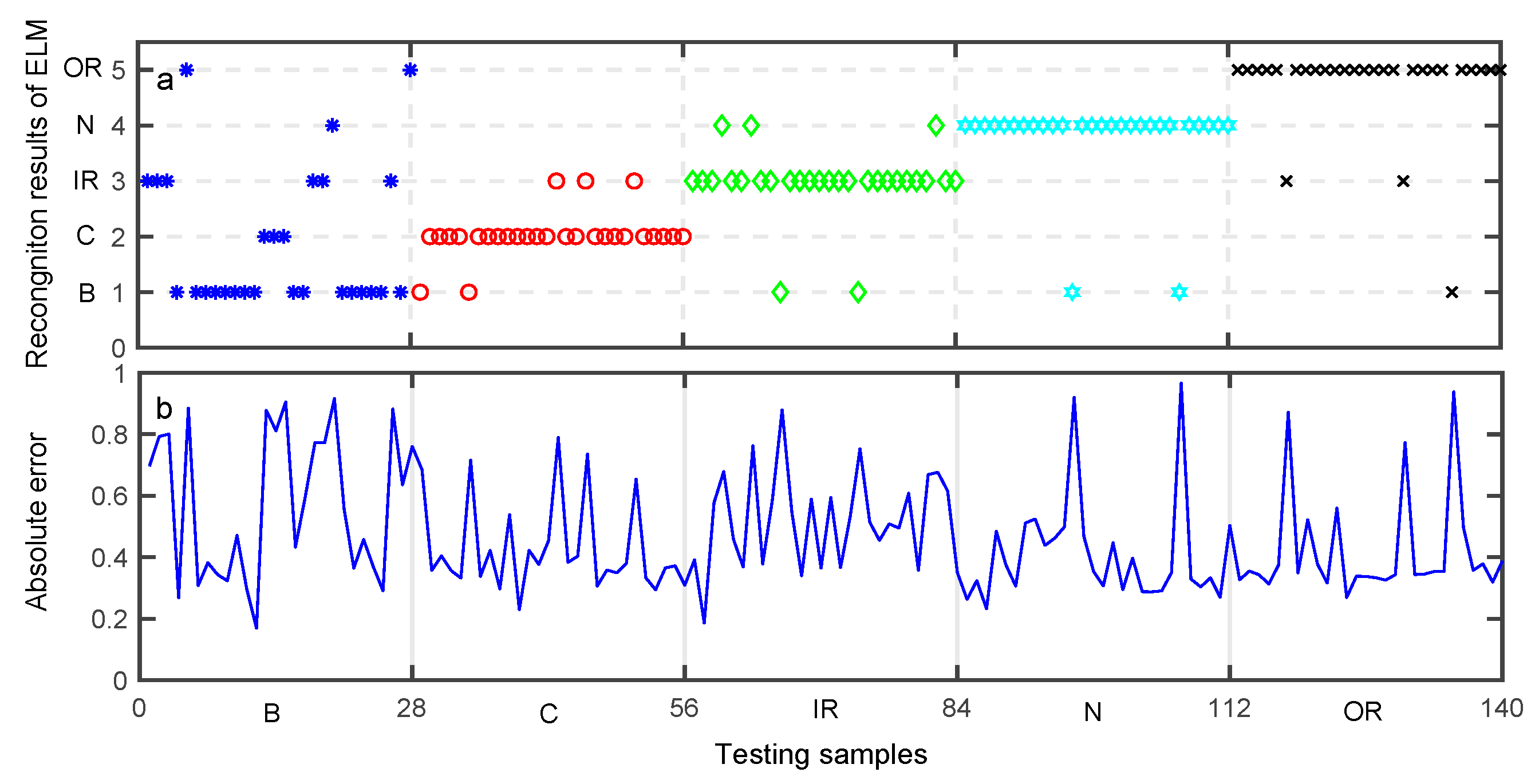
Figure 10a,
Figure 11a, and
Figure 12a represents five bearing conditions, denoted by four fault types B, C, IR, OR as well as a normal condition (N).
Figure 10a shows the desired output and the output of the trained DNN.
Figure 10b shows the absolute error of the DNN output with respect to the desired output, where a sample is misclassified when the absolute error is large. As can be seen from
Table 8, the average classification accuracy of DNN is 88.57%.
Figure 11a illustrates the desired output and the output of the trained ELM, while
Figure 11b shows the absolute error of the ELM output with respect to the desired output. As can be seen from
Table 9, the average classification accuracy of the testing data set using the ELM approach is about 80.81%. Similarly,
Figure 12a shows the desired output and the output of the trained SVM, and
Figure 12b shows the absolute error of the SVM output with respect to the desired output. As can be seen from
Table 10, the average classification accuracy of the testing data set using the SVM approach is only 77.14%.
It can be found that the classification rates separately using these three techniques were not good enough. Among them, DNN achieved the best classification results based on the deep learning technique as well as its optimal structures, compared with SVM and the ELM. The accuracy using single-stage classifier was still not good enough. Therefore, the data fusion method is necessary to be employed to increase the classification accuracy.
4.4. Results Using the HCE Algorithm and the Improved DST
Since the classification results were separately obtained using a single classifier, their results can be syncretized further. In this work, the fusion of the primary classification results was carried out using the improved DST method. First, three types of evidence were introduced as follows. , and were the classification results using the supervised classifiers DNN, ELM, and SVM, respectively. The original Dempster’s rule and the proposed method were both used to achieve the fusion results. In fact, the counter-intuitive results are often obtained when Dempster’s rule of combination is utilized in some cases, especially, when the BOEs to be combined are highly conflicting.
In order to improve the diagnostic accuracy, DST and the proposed DST were used to fuse the preliminary diagnosis of HCE. The results of different methods are given in
Table 11. In the fusion stage, each testing sample corresponded to a probabilistic output, which was the body of evidence. The meaning of X-axis in
Figure 13,
Figure 14 and
Figure 15 represents 140 bodies of evidence, while the meaning of Y-axis in
Figure 13,
Figure 14 and
Figure 15 represents fusion results of evidence using different methods. The fusion result of HCE by the proposed DST is shown in
Figure 13, while the fusion result using HCE and the original DST is shown in
Figure 14. A sample is misclassified when its fusion result is smaller than or equal to 0.5. It can be seen in
Figure 13 and
Figure 14 that the classification accuracy using the proposed HCE and the improved DST is the highest, about 97.86%. In addition, the accuracy using the original DST is about 92.86%, which is also better than those using a single-stage classifier.
Figure 15 illustrates the results using the technique given in reference [
25]. We can find the result is better than those achieved using original DST, but it is still worse compared with our proposed methods. This well demonstrated that the proposed HCE approach combined with the improved DST can reliably be automatically used for roller bearing fault detection. It means that the fault detection accuracy can significantly be improved by applying HCE approach.
5. Conclusions
It is crucial to detect the relatively reliable evidence with the collected multi-source evidence in the process of information fusion. The HCE approach combined with the improved DST has been proposed for the fault diagnosis of roller bearings. The effects of support degree among the pieces of evidence, the uncertainty information of BPA, and the relative credibility of the evidence on the weights are all considered in this improved DST. The improved DST can effectively deal with conflicts between the evidences and then improve the diagnostic accuracy. The cosine similarity is employed to indicate the confidence degree between the pieces of evidence. Entropy features are used to measure the quantitative uncertainty of BPA in the improved DST. In addition, entropy based FPR is employed to indicate the relative reliability preference between BOEs. Thus, the improved DST is much more reasonable in dealing with conflicts compared with the original DST. The effectiveness of the improved Dempster-Shafer theory has been verified via two examples.
In addition, SSE, PSE, TFE, and WPESE features have been utilized in the single-stage classification with DNN, SVM, and ELM in this work. Performances of the proposed HCE approach combined with the improved DST has been demonstrated on a bearing test-rig, compared with the original DST. It can be found that the overall error rate of the HCE approach can be greatly reduced using the improved DST, while the accuracy of the rolling element bearings diagnosis is successfully raised. Since there is not enough (complete) fault data for a rotating machine in practice, it is usually difficult dealing with a small sample and incomplete data in the process of decision-making. The proposed technique will be further investigated under these cases in the future.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}