Learning Environmental Field Exploration with Computationally Constrained Underwater Robots: Gaussian Processes Meet Stochastic Optimal Control


Abstract
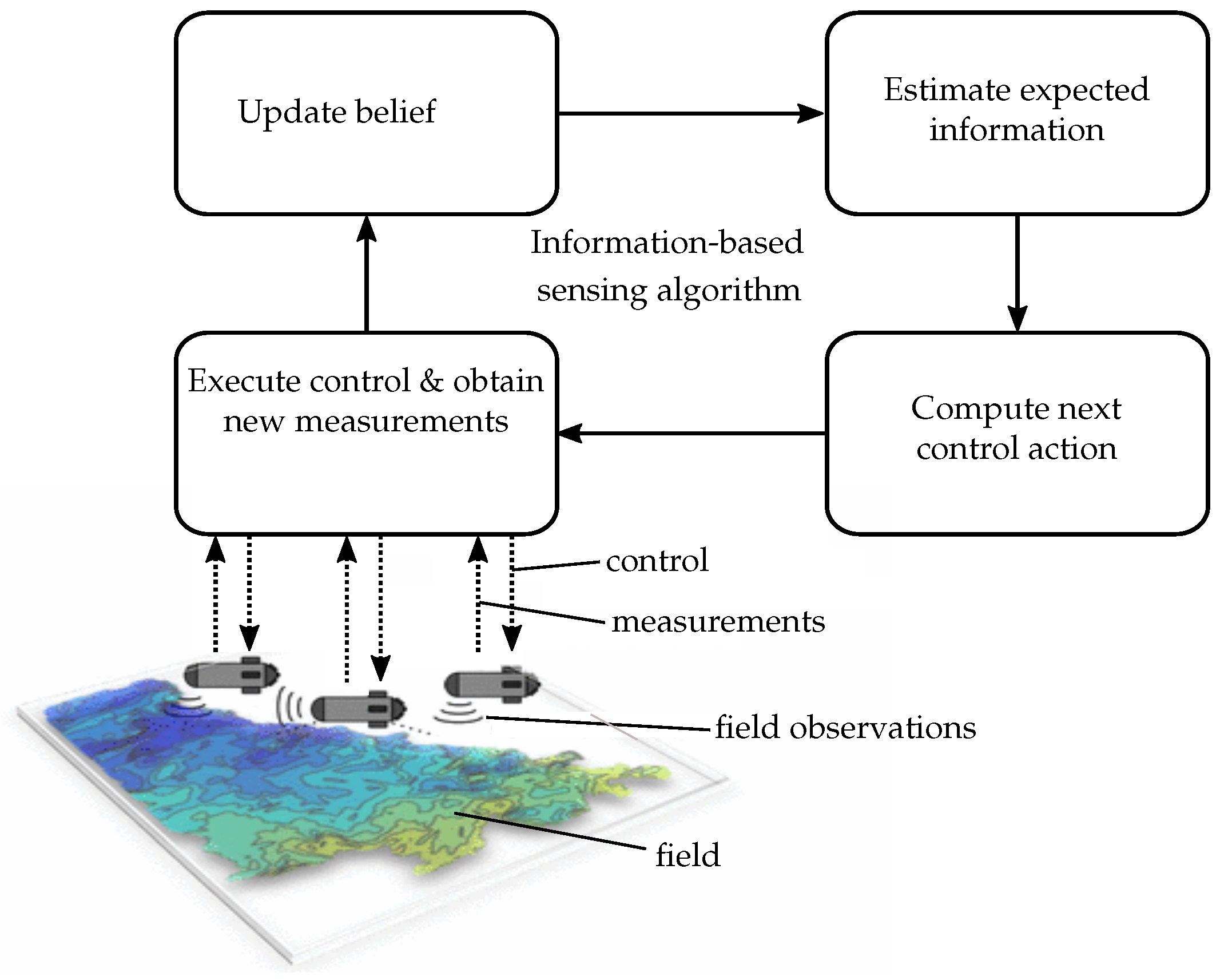
1. Introduction
1.1. Related Work
1.2. Contributions
- a constant computational complexity over time,
- a continuous spatial belief representation which allows efficient path planning.
1.3. Paper Structure
2. Problem Statement
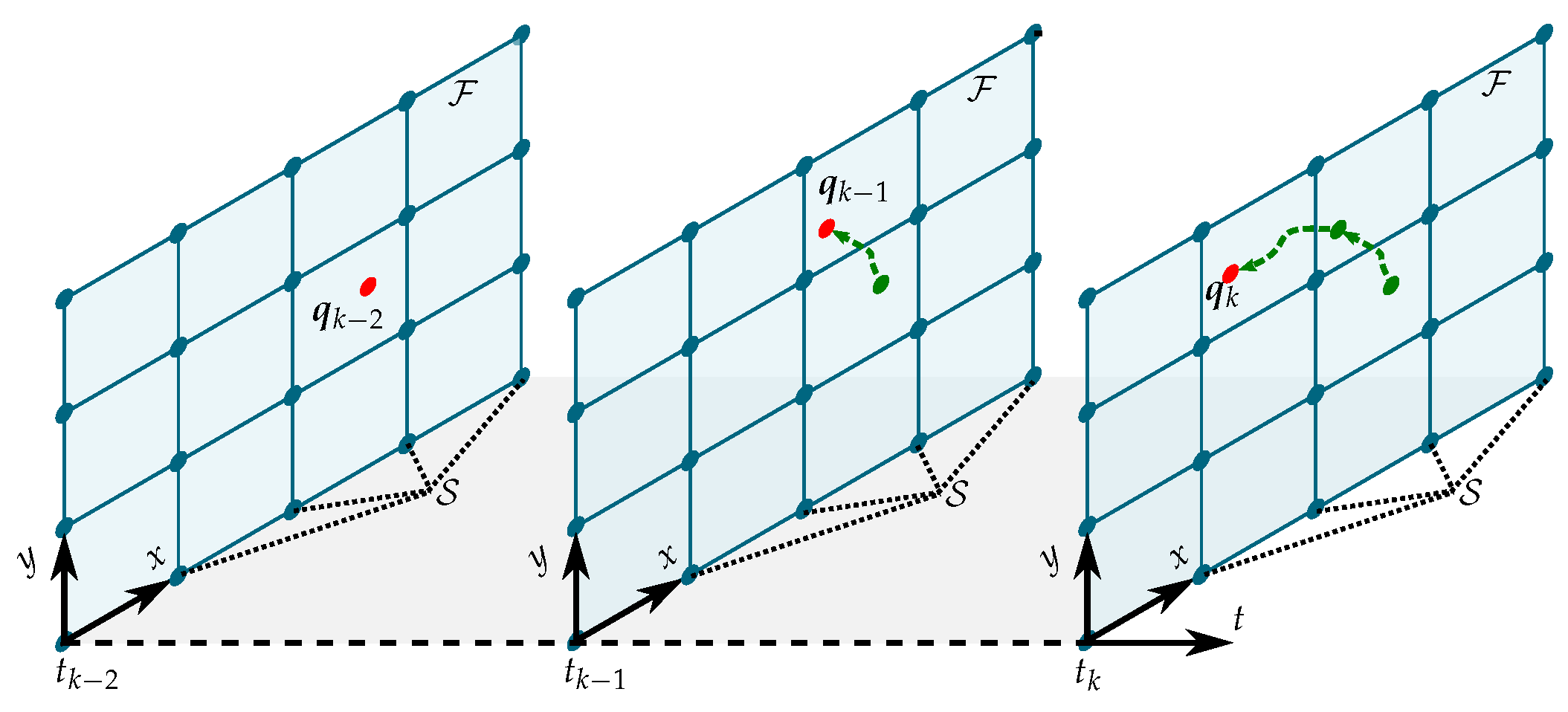
2.1. Robot Model and Problem Formulation
2.2. Field Belief Representation
2.3. Stochastic Optimal Control Problem
3. Probabilistic Belief Modeling for Field Exploration
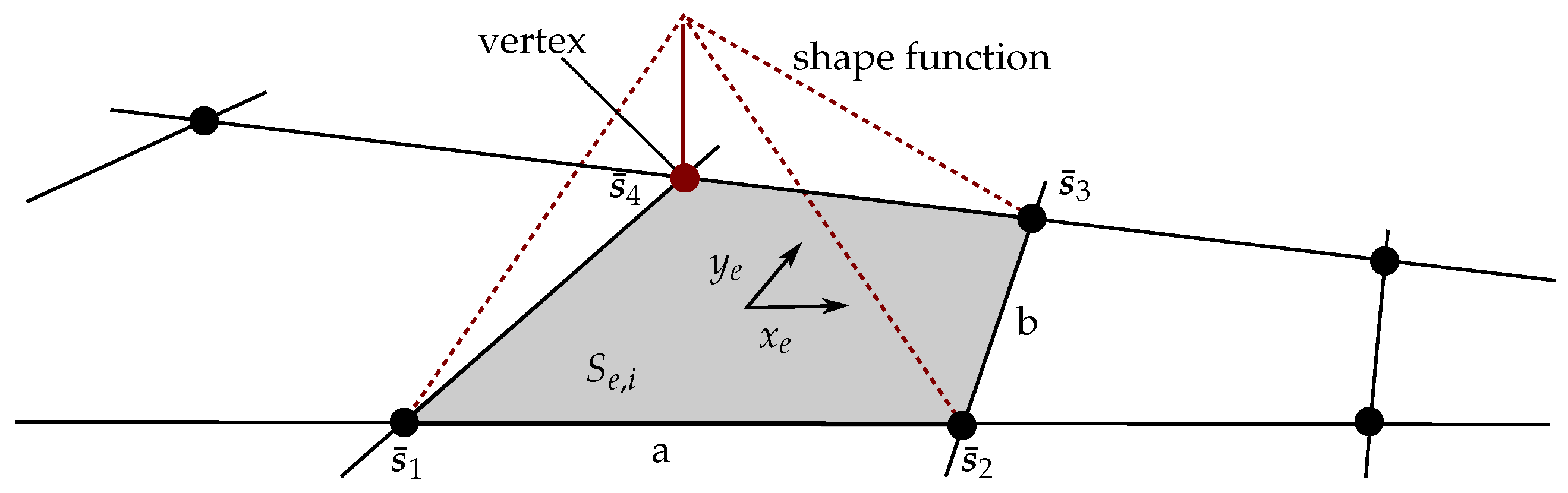
3.1. Shape Functions
3.2. Gaussian Markov Random Field Regression
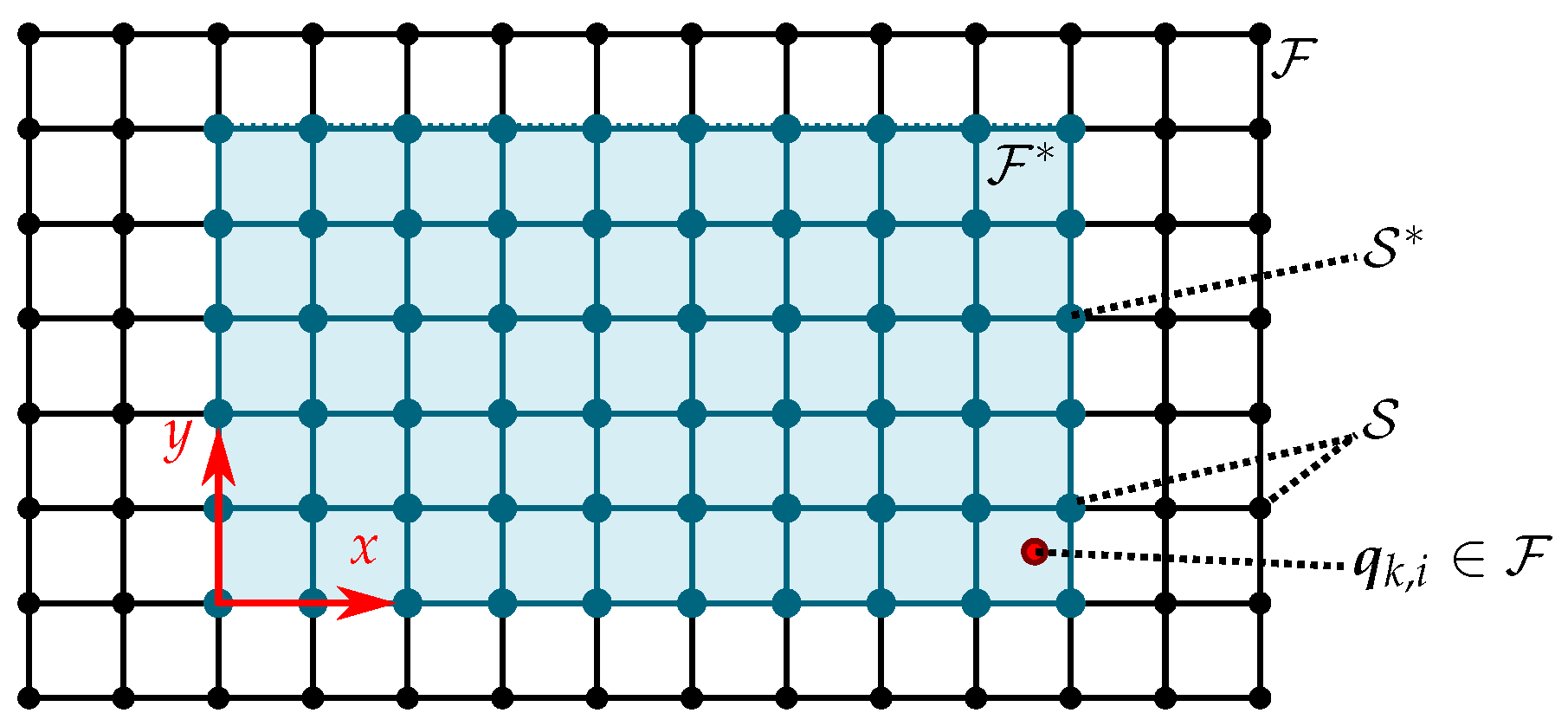
3.2.1. Sequential GMRF Regression
| Algorithm 1 Sequential GMRF Regression |
| Require: Hyperparameter vector , Extended field grid , Regression function vector Measurement variance , ,
|
3.2.2. Hyperparameter Estimation for Sequential GMRF Regression
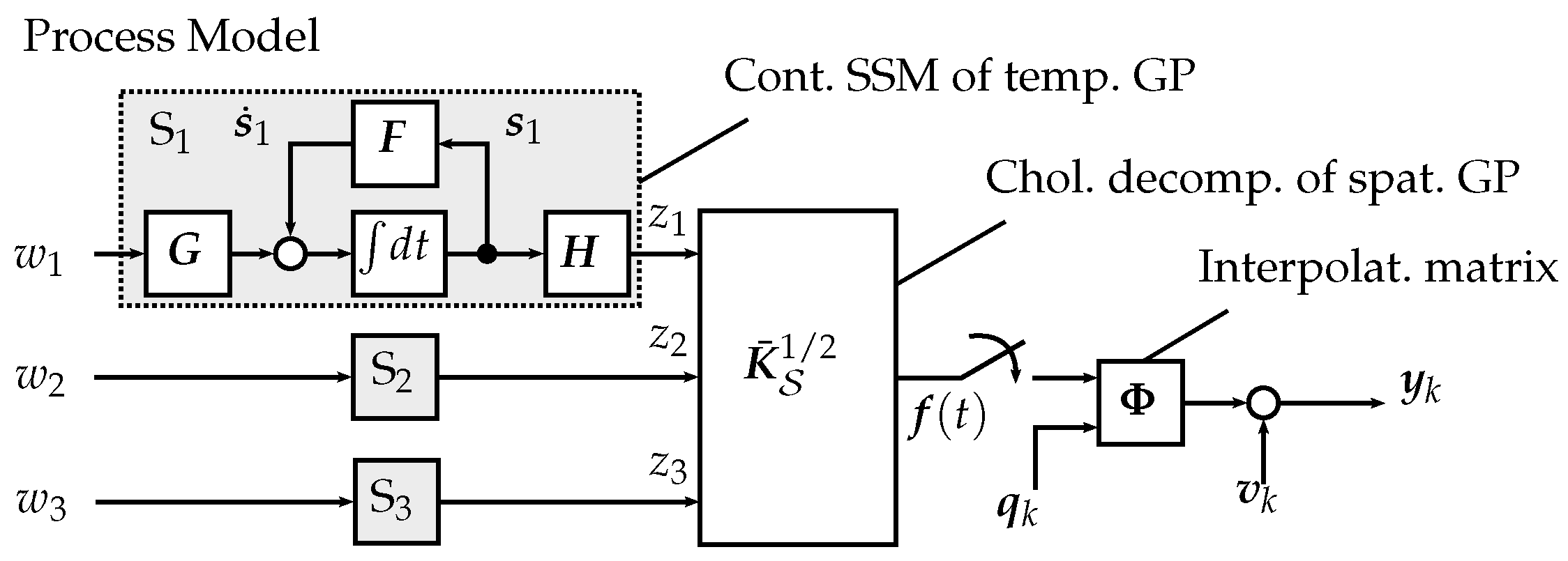
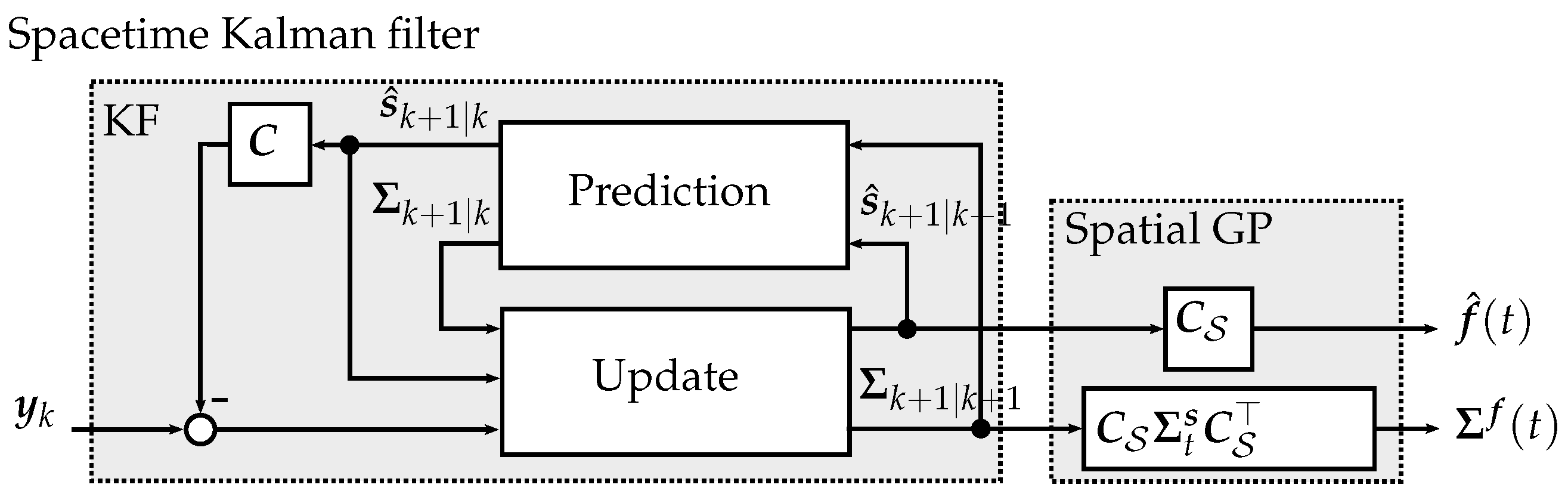
3.3. Kalman Regression for Field Estimation
3.3.1. Process Model
3.3.2. Kalman Regression
| Algorithm 2 Kalman regression |
Require: state-space model of , measurement noise variance , input location set spatial, time kernels , and
|
3.3.3. Hyperparameter Estimation in Kalman Regression
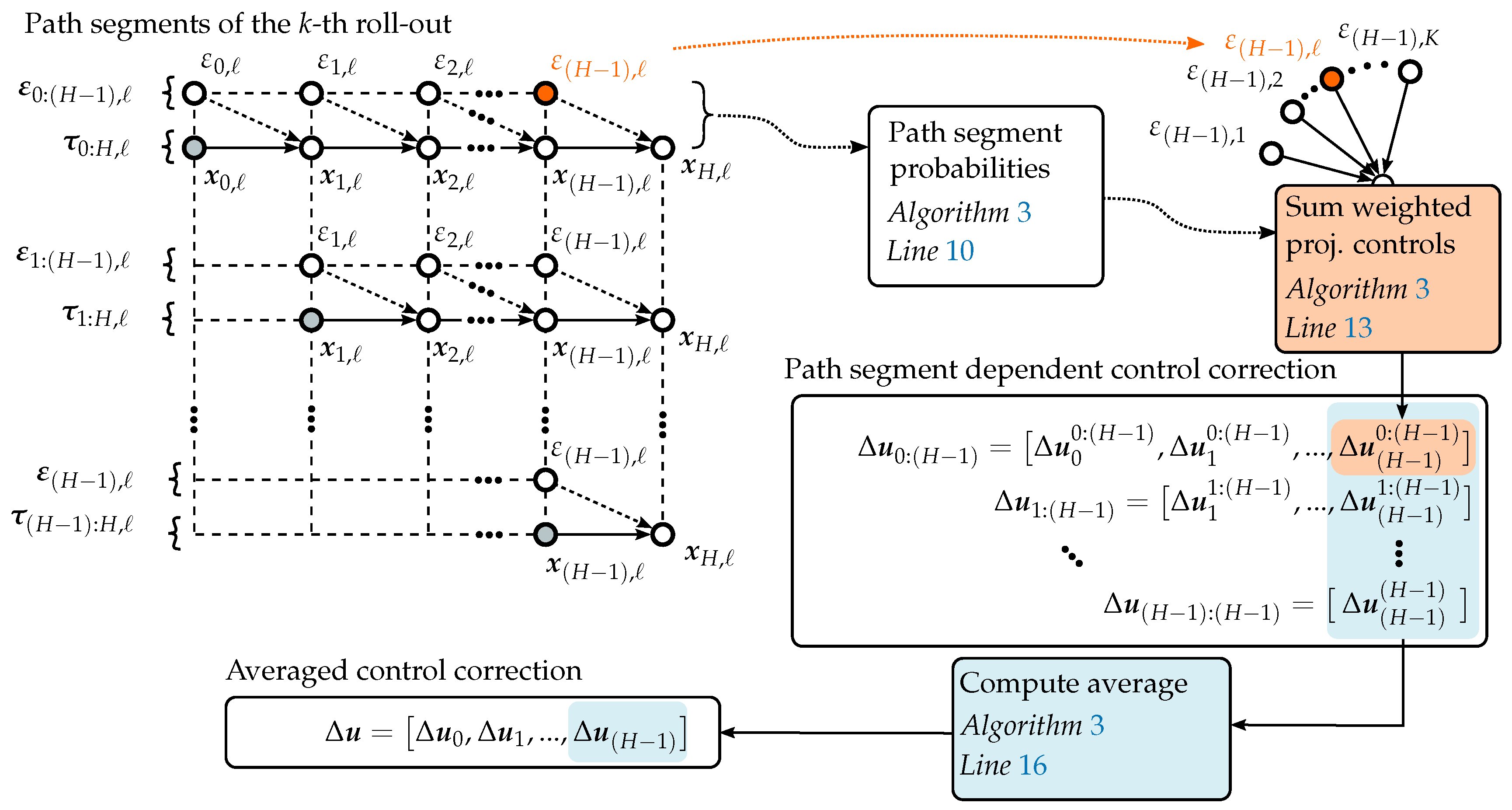
4. Path Integral Control for Exploratory Path Planning
| Algorithm 3 PI for path planning |
Require: Cost function , unicycle exploration policy , exploration noise variance , sampling time , initial optimal control sequence , number of sampled paths K, control horizon steps H, control computation iterations
|
5. Field Belief Comparison
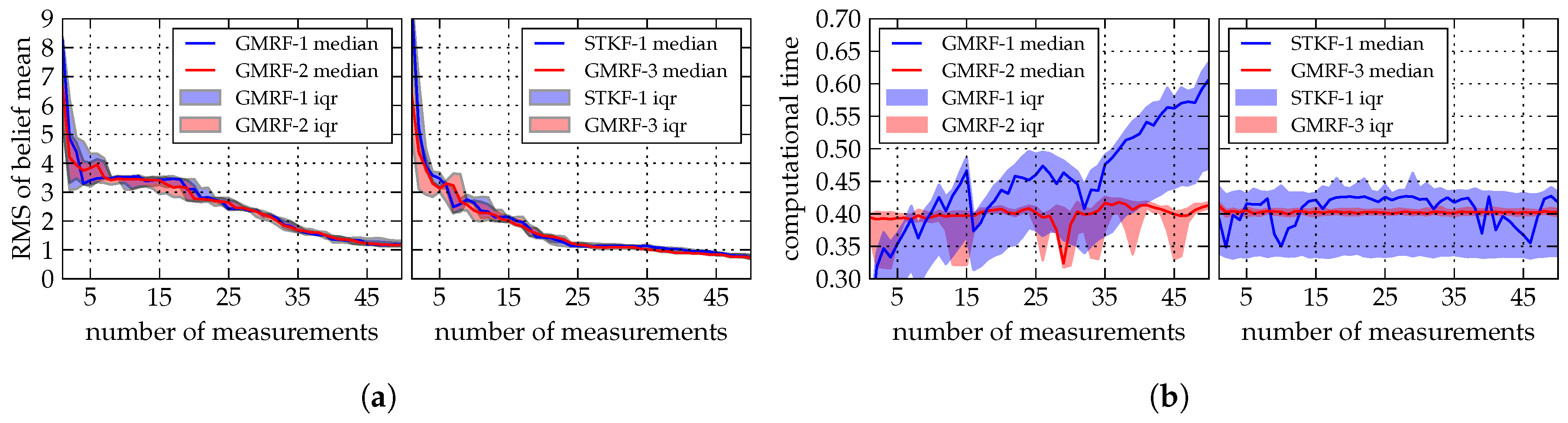
5.1. Computational Complexity
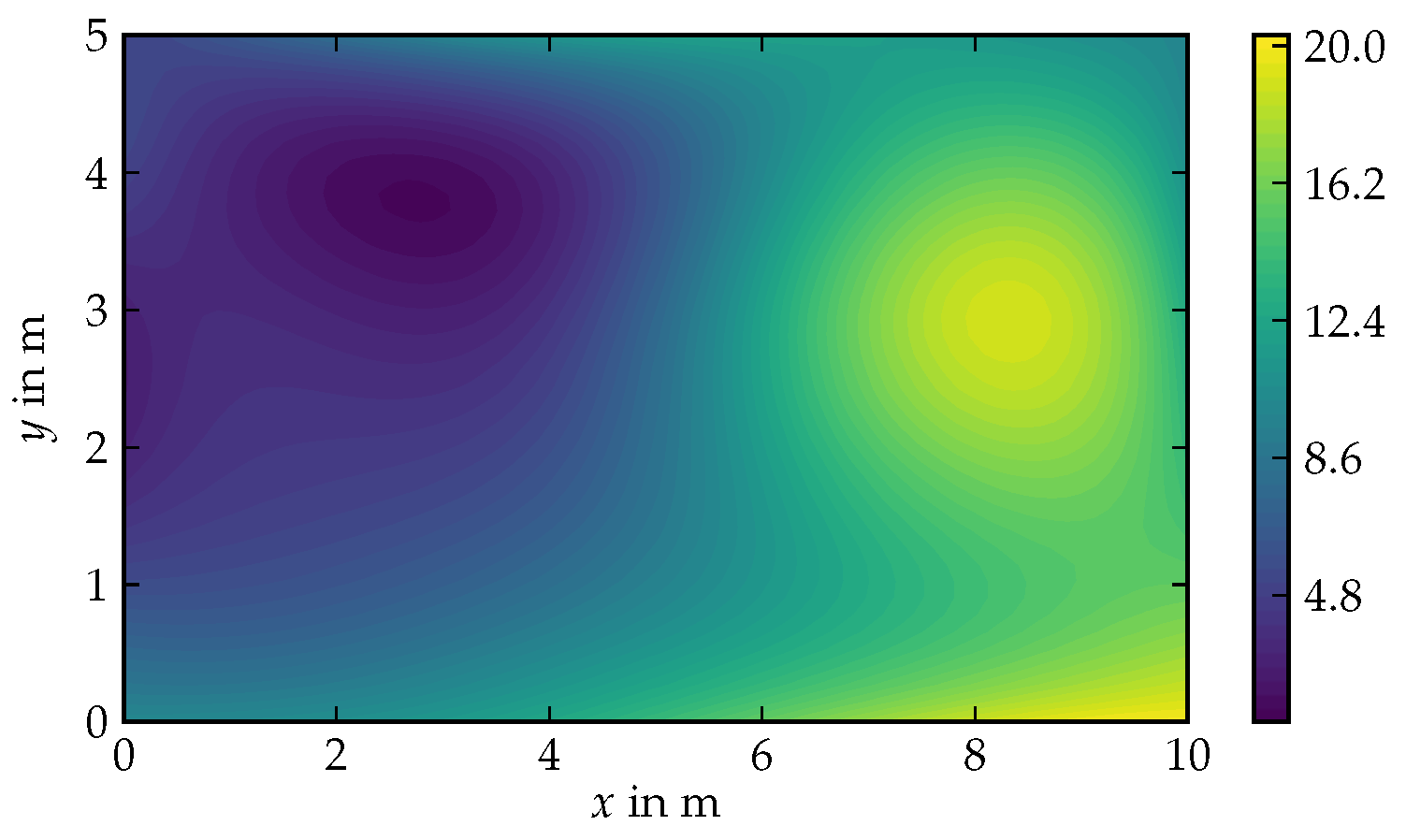
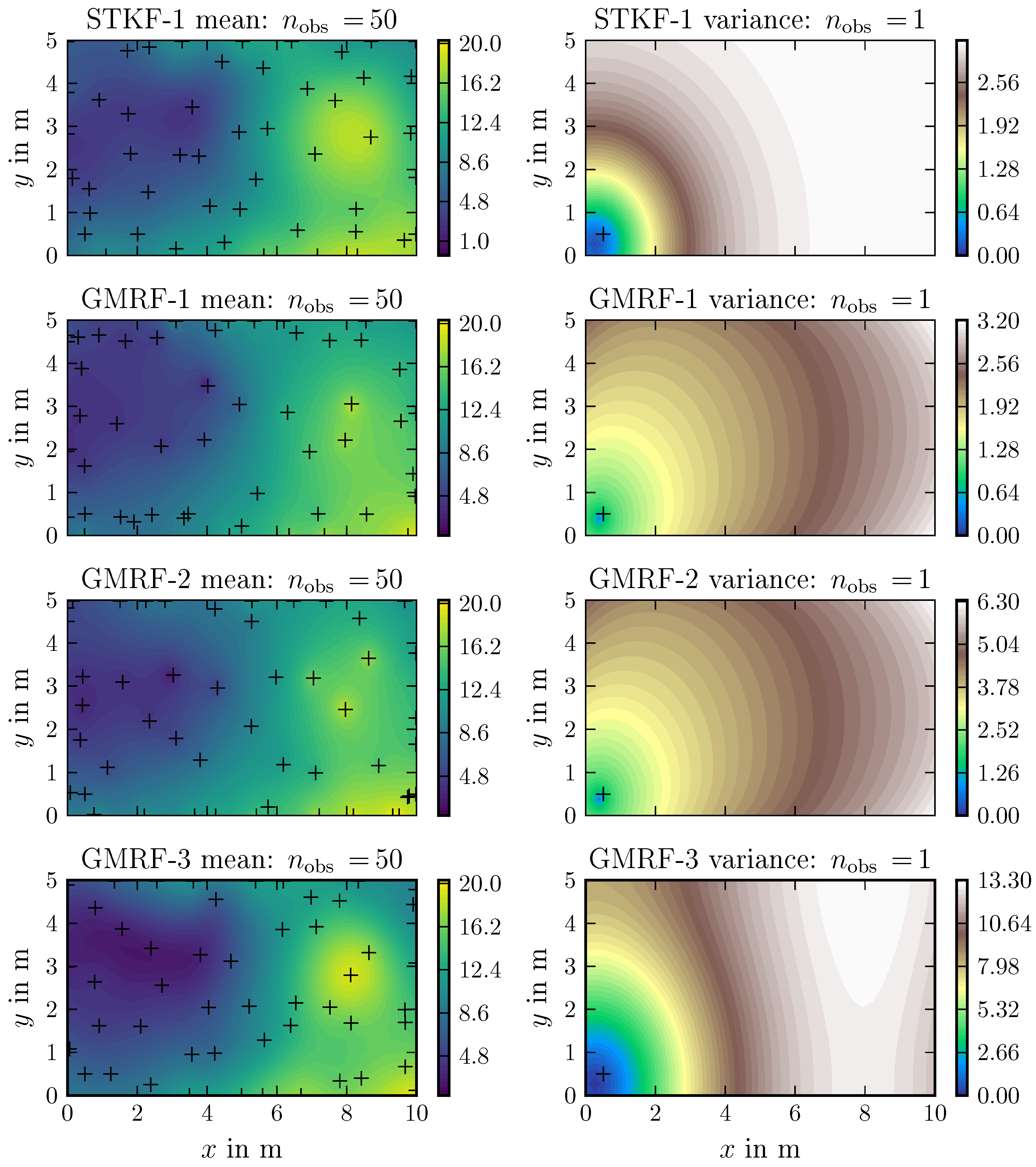
5.2. Environmental Field Estimation
6. Analysis of the Exploration Algorithm
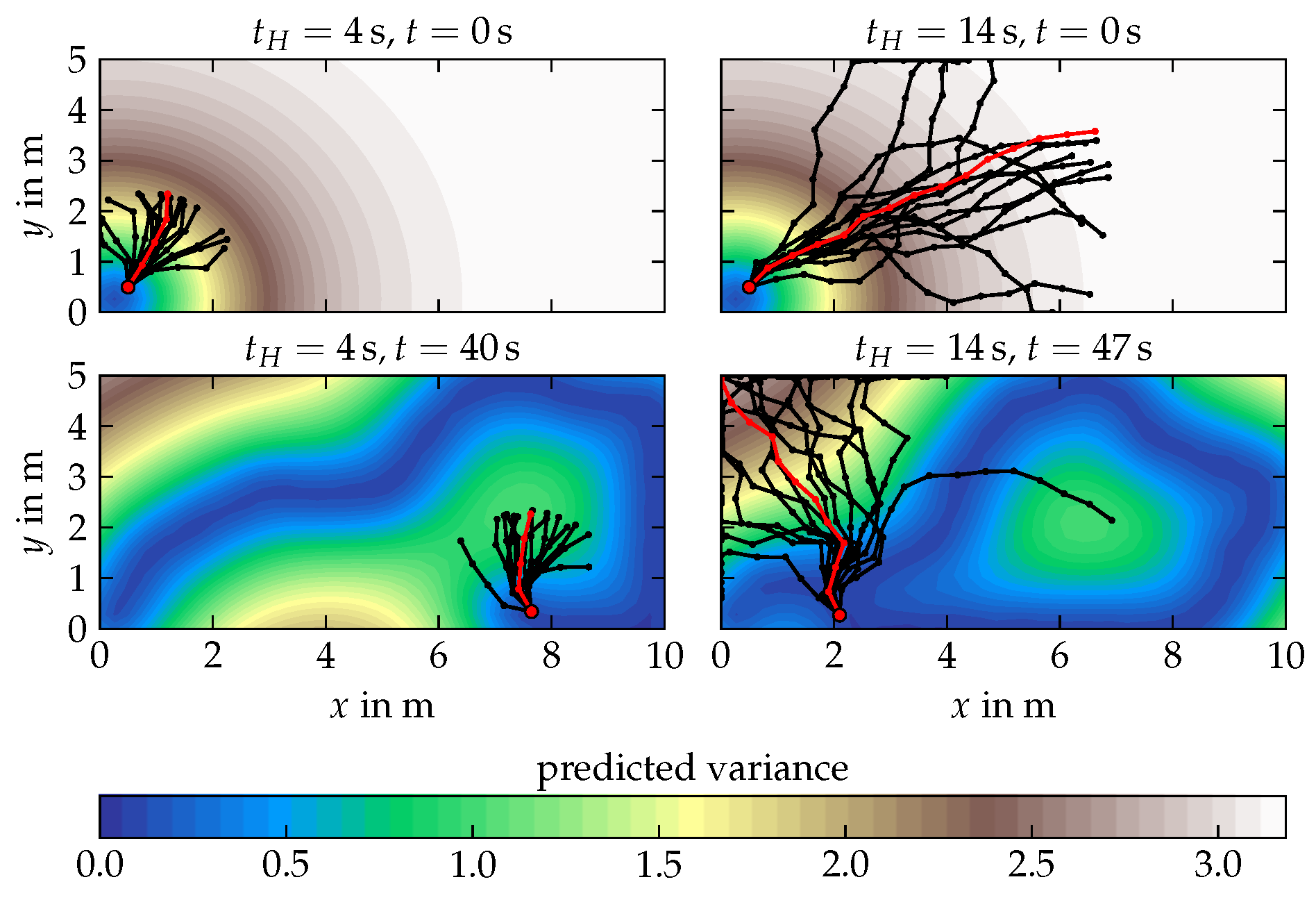
6.1. Analytical Field Exploration
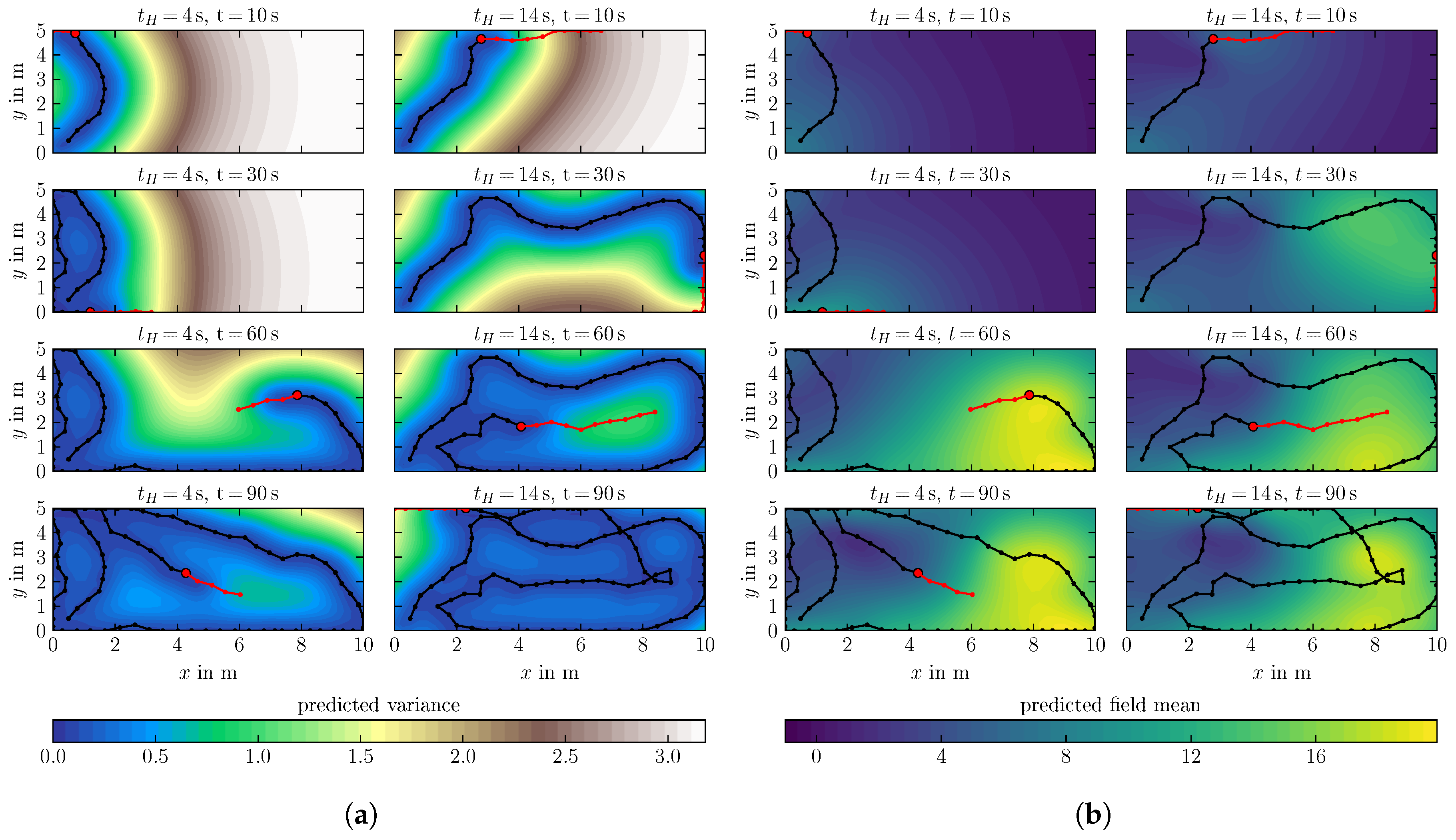
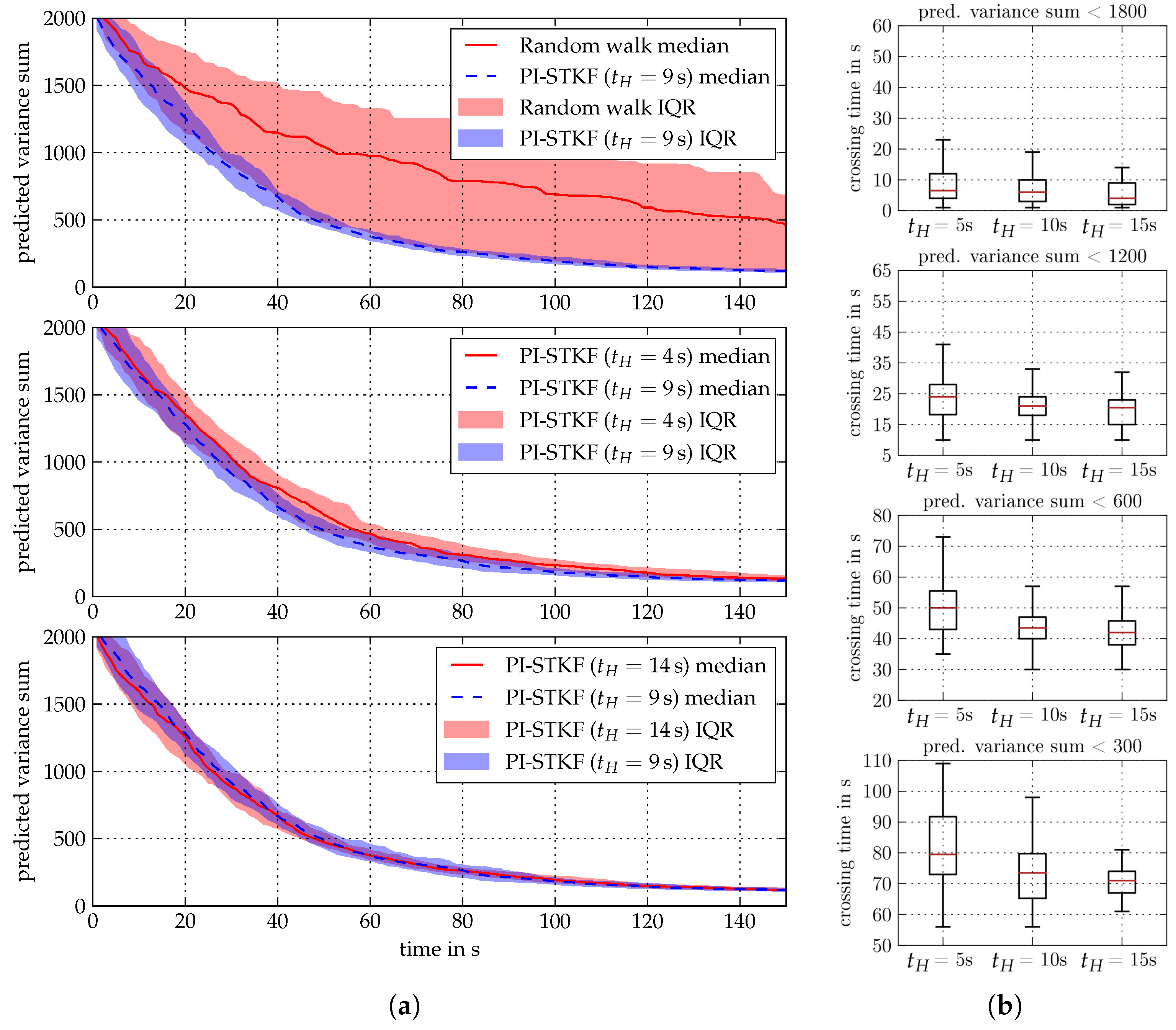
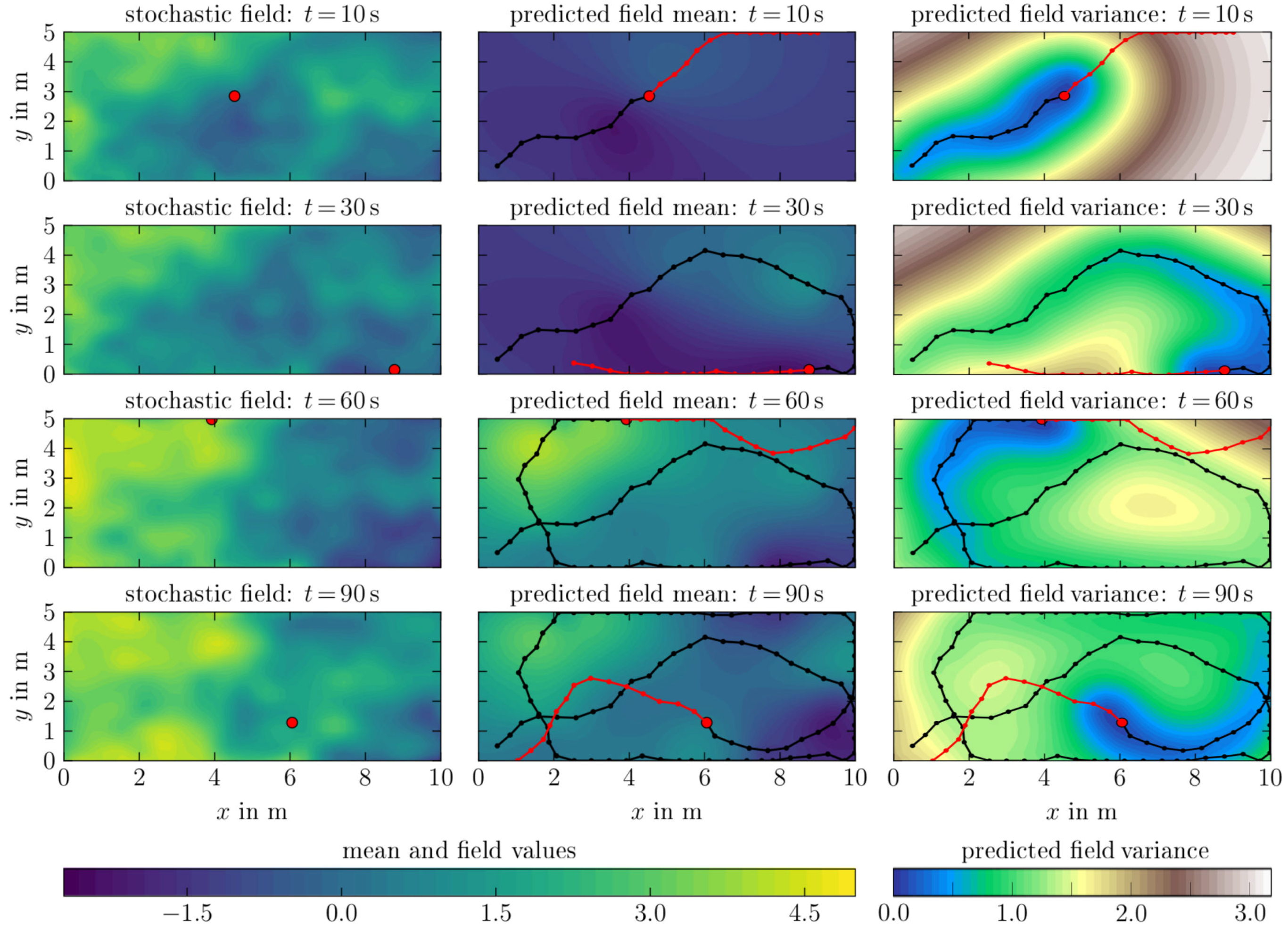
6.2. Spatio-Temporal Field Exploration
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| GP | Gaussian process |
| GMRF | Gaussian Markov random field |
| STKF | Spacetime Kalman filter |
| SSM | State Space Model |
| CAR | Conditional auto-regressive |
| PI | Policy improvement with path integrals |
| PI-GMRF | Combination of the GMRF belief model with the PI path planning algorithm |
| PI-STKF | Combination of the STKF belief model with the PI path planning algorithm |
| RMS | Root mean square |
| RL | Reinforcement learning |
| IQR | Inter-quarter range |
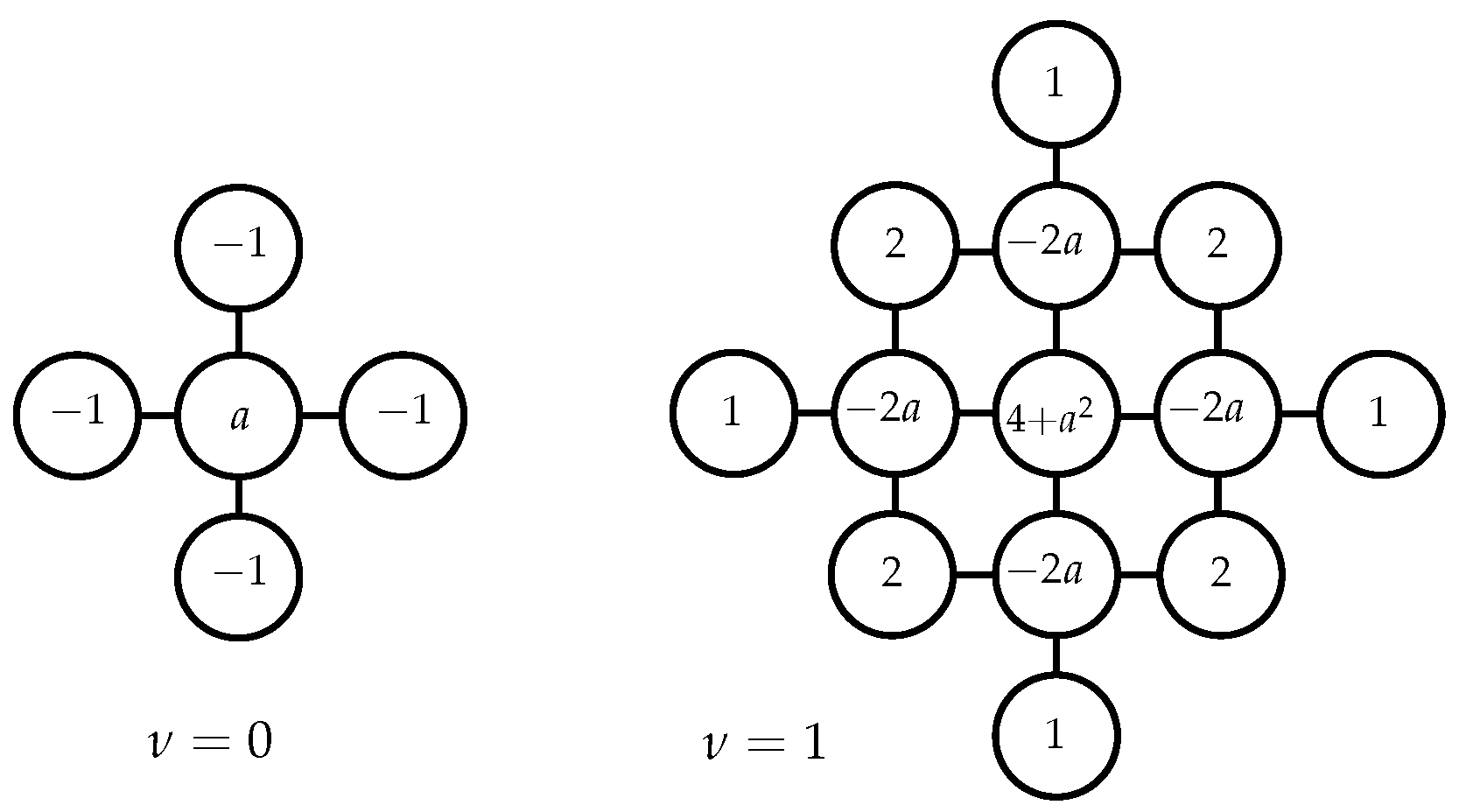
Appendix A. Sequential Update Rule for Continuous GMRF Algorithm
Appendix B. Estimation Examples of the Different Belief Models

References
- Gifford, C.M.; Webb, R.; Bley, J.; Leung, D.; Calnon, M.; Makarewicz, J.; Banz, B.; Agah, A. A novel low-cost, limited-resource approach to autonomous multi-robot exploration and mapping. Robot. Autonomous Syst. 2010, 58, 186–202. [Google Scholar] [CrossRef]
- Griffiths, A.; Dikarev, A.; Green, P.R.; Lennox, B.; Poteau, X.; Watson, S. AVEXIS—Aqua vehicle explorer for in-situ sensing. IEEE Robot. Autom. Lett. 2016, 1, 282–287. [Google Scholar] [CrossRef]
- Duecker, D.A.; Hackbarth, A.; Johannink, T.; Kreuzer, E.; Solowjow, E. Micro Underwater Vehicle Hydrobatics: A Submerged Furuta Pendulum. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7498–7503. [Google Scholar]
- Wang, H.; Liu, P.X.; Xie, X.; Liu, X.; Hayat, T.; Alsaadi, F.E. Adaptive fuzzy asymptotical tracking control of nonlinear systems with unmodeled dynamics and quantized actuator. Inf. Sci. 2018, in press. [Google Scholar] [CrossRef]
- Zhao, X.; Shi, P.; Zheng, X. Fuzzy Adaptive Control Design and Discretization for a Class of Nonlinear Uncertain Systems. IEEE Trans. Cybern. 2016, 46, 1476–1483. [Google Scholar] [CrossRef] [PubMed]
- Hackbarth, A.; Kreuzer, E.; Gray, A. Multi-Agent Motion Control of Autonomous Vehicles in 3D Flow Fields. PAMM 2012, 12, 733–734. [Google Scholar] [CrossRef]
- Krige, D.G. A Statistical Approach to some Basic Mine Valuation Problems on the Witwatersrand. J. S. Afr. Inst. Mining Metall. 1951, 52, 119–139. [Google Scholar]
- Zhang, B.; Sukhatme, G.S. Adaptive Sampling for Estimating a Scalar Field using a Robotic Boat and a Sensor Network. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 3673–3680. [Google Scholar]
- Xu, Y.; Choi, J.; Oh, S. Mobile Sensor Network Navigation using Gaussian Processes with Truncated Observations. IEEE Trans. Robot. 2011, 27, 1118–1131. [Google Scholar] [CrossRef]
- Xu, Y.; Choi, J.; Dass, S.; Maiti, T. Bayesian Prediction and Adaptive Sampling Algorithms for Mobile Sensor Networks: Online Environmental Field Reconstruction in Space and Time; Springer: Heidelberg, Germany, 2015. [Google Scholar]
- Cameletti, M.; Lindgren, F.; Simpson, D.; Rue, H. Spatio-temporal Modeling of Particulate Matter Concentration through the SPDE Approach. AStA Adv. Stat. Anal. 2013, 97, 109–131. [Google Scholar] [CrossRef]
- Lindgren, F.; Rue, H.; Lindström, J. An Explicit Link between Gaussian Fields and Gaussian Markov Random Fields: the Stochastic Partial Differential Equation Approach. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2011, 73, 423–498. [Google Scholar] [CrossRef]
- Xu, Y.; Choi, J.; Dass, S.; Maiti, T. Efficient Bayesian Spatial Prediction with Mobile Sensor Networks using Gaussian Markov Random Fields. Automatica 2013, 49, 3520–3530. [Google Scholar] [CrossRef]
- Jadaliha, M.; Jeong, J.; Xu, Y.; Choi, J.; Kim, J. Fully Bayesian Prediction Algorithms for Mobile Robotic Sensors under Uncertain Localization Using Gaussian Markov Random Fields. Sensors 2018, 18, 2866. [Google Scholar] [CrossRef] [PubMed]
- Todescato, M.; Carron, A.; Carli, R.; Pillonetto, G.; Schenato, L. Efficient Spatio-Temporal Gaussian Regression via Kalman Filtering. arXiv 2017, arXiv:1705.01485. [Google Scholar]
- Hollinger, G.A.; Sukhatme, G.S. Sampling-based robotic information gathering algorithms. Int. J. Robot. Res. 2014, 33, 1271–1287. [Google Scholar] [CrossRef]
- Marchant, R.; Ramos, F. Bayesian Optimisation for informative continuous path planning. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6136–6143. [Google Scholar] [CrossRef]
- Marchant, R.; Ramos, F.; Sanner, S. Sequential Bayesian Optimisation for Spatial-Temporal Monitoring. In Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI), Quebec, QC, Canada, 23–27 July 2014; pp. 553–562. [Google Scholar]
- Cui, R.; Li, Y.; Yan, W. Mutual Information-Based Multi-AUV Path Planning for Scalar Field Sampling Using Multidimensional RRT-Star. IEEE Trans. Syst. Man. Cybern. Syst. 2016, 46, 993–1004. [Google Scholar] [CrossRef]
- Xu, Y.; Choi, J. Spatial prediction with mobile sensor networks using Gaussian processes with built-in Gaussian Markov random fields. Automatica 2012, 49, 1735–1740. [Google Scholar] [CrossRef]
- Theodorou, E.; Buchli, J.; Schaal, S. A Generalized Path Integral Control Approach to Reinforcement Learning. J. Mach. Learn. Res. 2010, 11, 3137–3181. [Google Scholar]
- Kappen, H.J. An Introduction to Stochastic Control Theory, Path Integrals and Reinforcement Learning. AIP Conf. Proc. 2007, 887, 149–181. [Google Scholar]
- Kreuzer, E.; Solowjow, E. Learning Environmental Fields with Micro Underwater Vehicles: A Path Integral—Gaussian Markov Random Field Approach. Auton. Robots 2018, 42, 761–780. [Google Scholar] [CrossRef]
- Krause, A.; Singh, A.; Guestrin, C. Near-Optimal Sensor Placements in Gaussian Processes: Theory, Efficient Algorithms and Empirical Studies. J. Mach. Learn. Res. 2008, 9, 235–284. [Google Scholar]
- Rue, H.; Held, L. Gaussian Markov Random Fields: Theory and Applications; CRC Press: Boca Rato, FL, USA, 2005. [Google Scholar]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Sarkka, S.; Solin, A.; Hartikainen, J. Spatiotemporal Learning via Infinite-dimensional Bayesian Filtering and Smoothing: A look at Gaussian Process Regression through Kalman Filtering. IEEE Signal Process. Mag. 2013, 30, 51–61. [Google Scholar] [CrossRef]
- Turchetta, M.; Berkenkamp, F.; Krause, A. Safe exploration in finite markov decision processes. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Barcelona, Spain, 2016; pp. 4312–4320. [Google Scholar]
- Zimmer, C.; Meister, M.; Nguyen-Tuong, D. Safe Active Learning for Time-Series Modeling with Gaussian Processes. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Montreal, QC, Canada, 2018; pp. 2730–2739. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Belief Algorithm | 2d | 3d |
|---|---|---|
| GP Regression | ||
| Empirical GMRF Regression | ||
| Bayesian GMRF Regression | ||
| STKF |
| Acronym | Belief Algorithm | Process Type | Boundary Cond. | ||
|---|---|---|---|---|---|
| GMRF-1 | Empirical GMRF | Matérn CAR(1) | Neumann | ||
| GMRF-2 | Bayesian GMRF | Matérn CAR(1) | Neumann | ||
| GMRF-3 | Bayesian GMRF | Matérn CAR(2) | Torus | ||
| STKF-1 | STKF | Spat.: Matérn Cov. () Temp.: Exp. Cov. | - | ||
| Acronym | l | ||||
| GMRF-1 | 1 | - | - | ||
| GMRF-2 | 0.5 | - | - | ||
| GMRF-3 | 0.01 | 1 | - | - | |
| STKF-1 | - | - | Spat.: 1.8 Temp.: 1 | Spat.: 3.2 Temp.: | |
| PI-Control Parameters | Symbol | Value |
|---|---|---|
| Control Horizon | 4 s | 9 s | 14 s | |
| Agent velocity | v | |
| Simulation time | - | 150 s |
| Time step | 1 s | |
| Trajectory roll-outs | K | 15 |
| Control loop updates | 10 | |
| Measurement variance | 0.3 | |
| Exploration noise | ||
| Control cost | R | 1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duecker, D.A.; Geist, A.R.; Kreuzer, E.; Solowjow, E. Learning Environmental Field Exploration with Computationally Constrained Underwater Robots: Gaussian Processes Meet Stochastic Optimal Control. Sensors 2019, 19, 2094. https://doi.org/10.3390/s19092094
Duecker DA, Geist AR, Kreuzer E, Solowjow E. Learning Environmental Field Exploration with Computationally Constrained Underwater Robots: Gaussian Processes Meet Stochastic Optimal Control. Sensors. 2019; 19(9):2094. https://doi.org/10.3390/s19092094
Chicago/Turabian StyleDuecker, Daniel Andre, Andreas Rene Geist, Edwin Kreuzer, and Eugen Solowjow. 2019. "Learning Environmental Field Exploration with Computationally Constrained Underwater Robots: Gaussian Processes Meet Stochastic Optimal Control" Sensors 19, no. 9: 2094. https://doi.org/10.3390/s19092094
APA StyleDuecker, D. A., Geist, A. R., Kreuzer, E., & Solowjow, E. (2019). Learning Environmental Field Exploration with Computationally Constrained Underwater Robots: Gaussian Processes Meet Stochastic Optimal Control. Sensors, 19(9), 2094. https://doi.org/10.3390/s19092094