A Dynamic Part-Attention Model for Person Re-Identification


Abstract
:1. Introduction
2. Related Work
2.1. Features Representation
2.2. Segmentation Models
2.3. Loss Function
3. Methodology
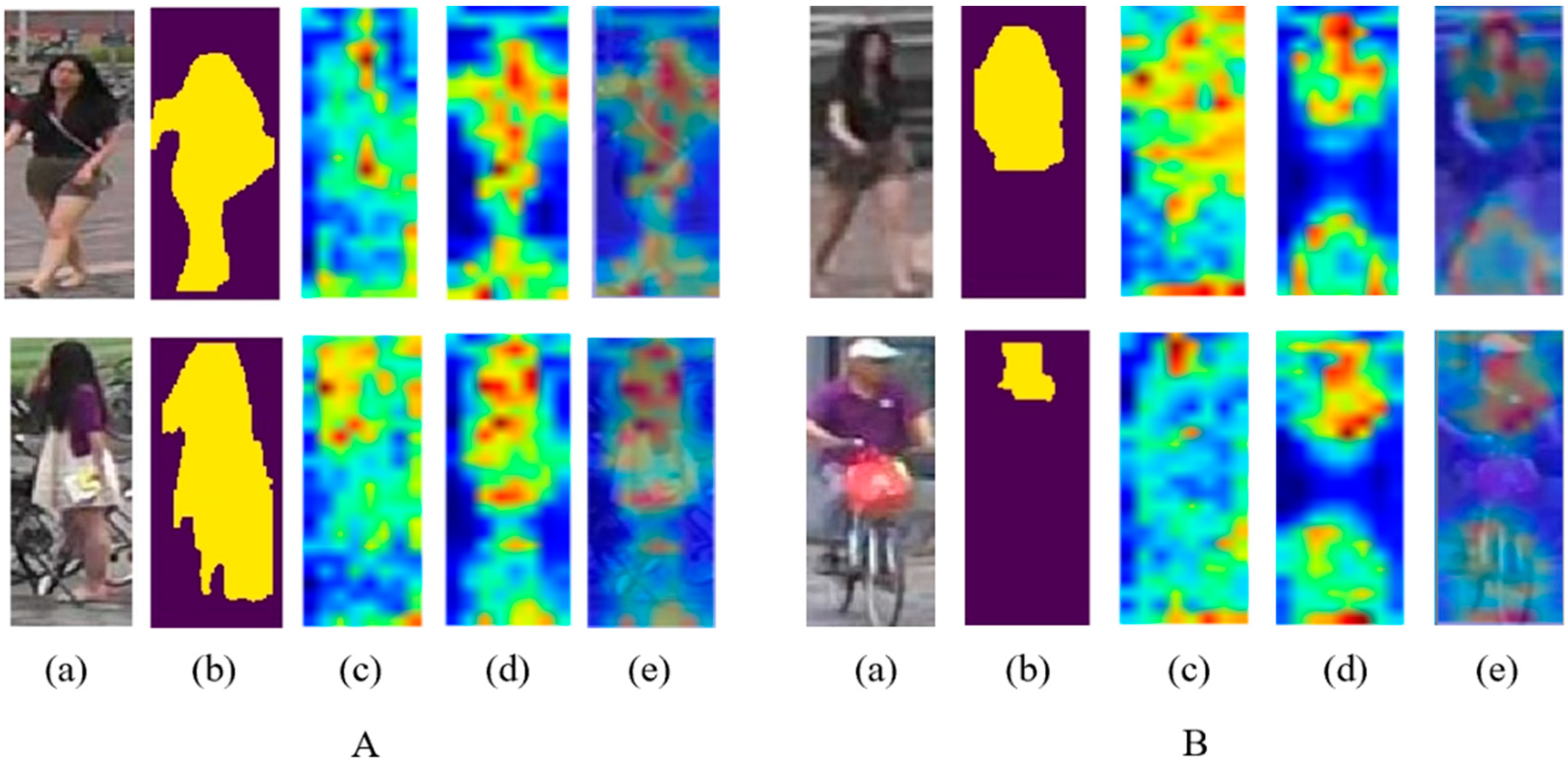
3.1. Mask Acquisition
3.2. Global Description Branch
3.3. Dynamic Part-Attention Branch
3.4. Dynamic Loss Combination
4. Experiments
4.1. Datasets and Protocols
4.2. Implementation Details
4.3. Effectiveness Analysis
4.4. Comparison with Other Methods
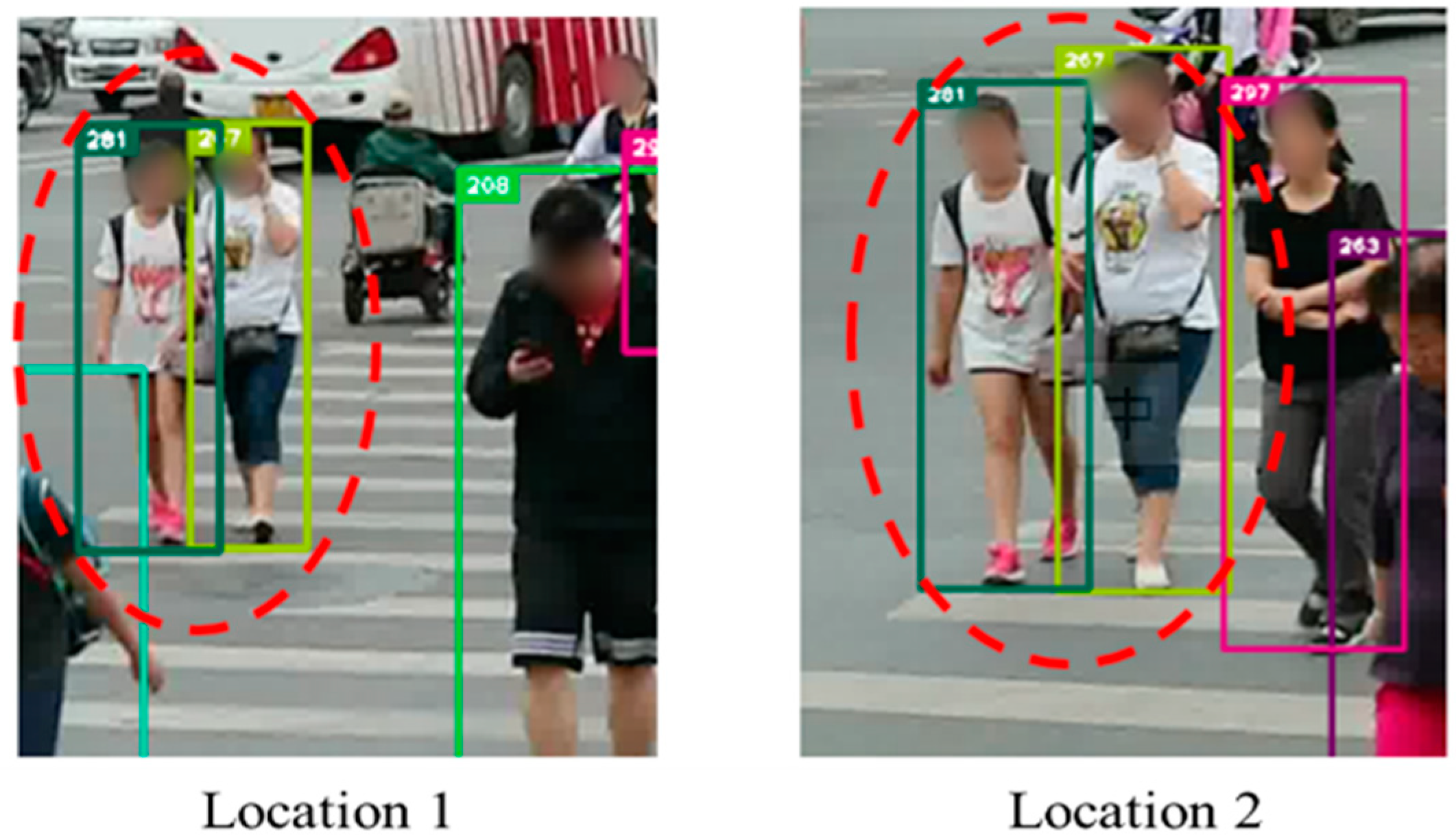
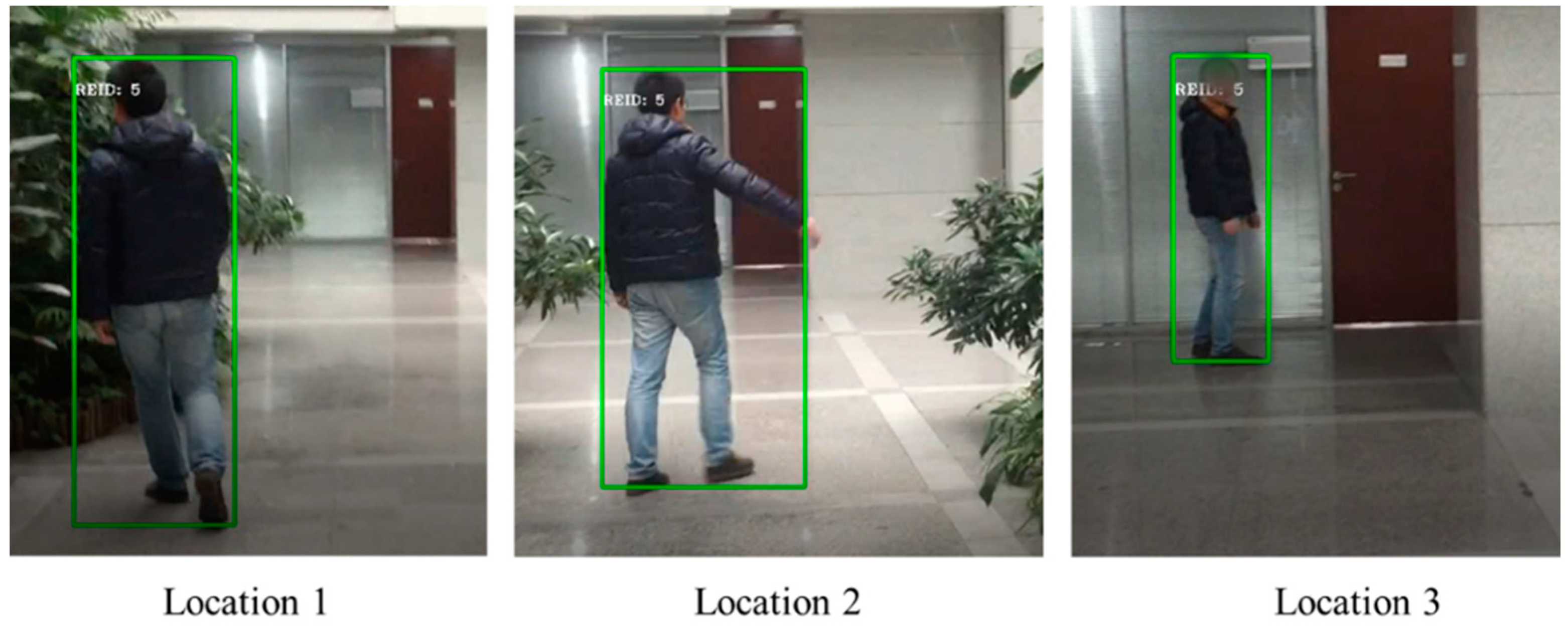
4.5. Practical Applications with Own Datasets
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Varior, R.R.; Haloi, M.; Gang, W. Gated Siamese Convolutional Neural Network Architecture for Human Re-Identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Varior, R.R.; Shuai, B.; Lu, J.; Xu, D.; Wang, G. A Siamese Long Short-Term Memory Architecture for Human Re-identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 135–153. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning deep context-aware features over body and latent parts for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 384–393. [Google Scholar]
- Yao, H.; Zhang, S.; Hong, R.; Zhang, Y.; Xu, C.; Tian, Q. Deep representation learning with part loss for person re-identification. IEEE Trans. Image Process. 2019, 28, 2860–2871. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Luo, H.; Fan, X.; Xiang, W.; Sun, Y.; Xiao, Q.; Jiang, W.; Zhang, C.; Sun, J. Alignedreid: Surpassing human-level performance in person re-identification. arXiv 2017, arXiv:1711.08184. [Google Scholar]
- Zhao, H.; Tian, M.; Sun, S.; Shao, J.; Yan, J.; Yi, S.; Wang, X.; Tang, X. Spindle net: Person re-identification with human body region guided feature decomposition and fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 1077–1085. [Google Scholar]
- Wei, L.; Zhang, S.; Yao, H.; Gao, W.; Tian, Q. Glad: Global-local-alignment descriptor for pedestrian retrieval. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 420–428. [Google Scholar]
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose invariant embedding for deep person re-identification. arXiv 2017, arXiv:1701.07732. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Zheng, L.; Yang, Y. Pedestrian alignment network for large-scale person re-identification. arXiv 2017, arXiv:1707.00408. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Matsukawa, T.; Okabe, T.; Suzuki, E.; Sato, Y. Hierarchical gaussian descriptor for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1363–1372. [Google Scholar]
- Xiong, F.; Gou, M.; Camps, O.; Sznaier, M. Person re-identification using kernel-based metric learning methods. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 1–16. [Google Scholar]
- Yang, Y.; Yang, J.; Yan, J.; Liao, S.; Yi, D.; Li, S.Z. Salient color names for person re-identification. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 536–551. [Google Scholar]
- Ahmed, E.; Jones, M.; Marks, T.K. An improved deep learning architecture for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, NV, USA, 7–12 June 2015; pp. 3908–3916. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Person re-identification by deep learning multi-scale representations. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2590–2600. [Google Scholar]
- Mao, C.; Li, Y.; Zhang, Y.; Zhang, Z.; Li, X. Multi-channel pyramid person matching network for person re-identification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning deep feature representations with domain guided dropout for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1249–1258. [Google Scholar]
- Bai, X.; Yang, M.; Huang, T.; Dou, Z.; Yu, R.; Xu, Y. Deep-person: Learning discriminative deep features for person re-identification. arXiv 2017, arXiv:1711.10658. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1179–1188. [Google Scholar]
- Qi, L.; Huo, J.; Wang, L.; Shi, Y.; Gao, Y. Maskreid: A mask based deep ranking neural network for person re-identification. arXiv 2018, arXiv:1804.03864. [Google Scholar]
- Dai, J.; He, K.; Li, Y.; Ren, S.; Sun, J. Instance-sensitive fully convolutional networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 534–549. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vision 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Pinheiro, P.O.; Collobert, R.; Dollár, P. Learning to segment object candidates. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1990–1998. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 2359–2367. [Google Scholar]
- Fathi, A.; Wojna, Z.; Rathod, V.; Wang, P.; Song, H.O.; Guadarrama, S.; Murphy, K.P. Semantic instance segmentation via deep metric learning. arXiv 2017, arXiv:1703.10277. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative embedding: End-to-end learning for joint detection and grouping. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 3–9 December 2017; pp. 2277–2287. [Google Scholar]
- Harley, A.W.; Derpanis, K.G.; Kokkinos, I. Segmentation-aware convolutional networks using local attention masks. In Proceedings of Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5038–5047.
- Kirillov, A.; Levinkov, E.; Andres, B.; Savchynskyy, B.; Rother, C. Instancecut: From edges to instances with multicut. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 5008–5017. [Google Scholar]
- Jin, L.; Chen, Z.; Tu, Z. Object detection free instance segmentation with labeling transformations. arXiv 2016, arXiv:1611.08991. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. A multi-task deep network for person re-identification. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- McLaughlin, N.; del Rincon, J.M.; Miller, P.C. Person reidentification using deep convnets with multitask learning. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 525–539. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vision 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 2117–2125. [Google Scholar]
- Russakovsky, O.; Lin, Y.; Yu, K.; Fei-Fei, L. Object-centric spatial pooling for image classification. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; pp. 1–15. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 1318–1327. [Google Scholar]
- Jose, C.; Fleuret, F. Scalable metric learning via weighted approximate rank component analysis. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 875–890. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. Svdnet for pedestrian retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3800–3808. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Person re-identification by deep joint learning of multi-loss classification. arXiv 2017, arXiv:1705.04724. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4320–4328. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2285–2294. [Google Scholar]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-level factorisation net for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2109–2118. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Rank-1 (%) | mAP (%) |
|---|---|---|
| Baseline | 85.30 | 68.50 |
| Ours | 89.72 | 73.83 |
| Layer Name | Rank-1 (%) | mAP (%) |
|---|---|---|
| RGB-mask | 88.71 | 73.11 |
| Conv1 | 89.72 | 73.83 |
| Layer1 | 88.74 | 73.31 |
| Layer2 | 88.01 | 73.60 |
| Layer3 | 87.64 | 71.59 |
| Layer4 | 89.44 | 74.81 |
| Ratio (Global: Part) | Rank-1 (%) | mAP (%) |
|---|---|---|
| Dynamic Dynamic | 89.72 | 73.83 |
| 2:1 | 88.86 | 73.21 |
| 3:2 | 88.39 | 73.05 |
| 1:1 | 88.53 | 73.71 |
| 1:2 | 88.36 | 72.04 |
| 1:3 | 87.63 | 70.68 |
| Image Size | Rank-1 (%) | mAP (%) |
|---|---|---|
| 128 × 64 | 80.14 | 58.14 |
| 256 × 128 | 86.31 | 68.23 |
| 224 × 224 | 87.77 | 70.32 |
| 384 × 128 | 89.72 | 73.83 |
| 384 × 192 | 89.07 | 73.24 |
| 512 × 256 | 87.47 | 68.55 |
| Methods | Single Query | Multiple Query | ||
|---|---|---|---|---|
| Rank-1 (%) | mAP (%) | Rank-1 (%) | mAP (%) (%) | |
| BOW + kISSME [45] | 44.4 | 20.8 | - | - |
| WARCA [49] | 45.16 | - | ||
| Siamese LSTM [2] | - | - | 61.6 | 45.3 |
| Gated [1] | 65.88 | 39.55 | 76.04 | 48.45 |
| Spindle [6] | 76.9 | - | - | - |
| MSCAN [3] | 80.31 | 57.53 | 86.79 | 66.70 |
| SVDNet [50] | 82.30 | 62.10 | - | - |
| MultiLoss [51] | 83.9 | 64.4 | 89.7 | 74.5 |
| Triplet Loss [52] | 84.92 | 69.14 | 90.53 | 76.42 |
| Deep Mutual [53] | 87.73 | 68.83 | 91.66 | 77.14 |
| ours | 89.72 | 73.83 | 93.23 | 82.45 |
| Ours + Re-ranking | 91.68 | 88.29 | 94.14 | 90.31 |
| Methods | Rank-1 (%) | mAP (%) |
|---|---|---|
| BOW + kISSME [45] | 25.13 | 12.17 |
| LOMO + XQDA [54] | 30.75 | 17.04 |
| GAN [45] | 67.7 | 47.1 |
| PAN [9] | 71.6 | 51.5 |
| SVDNet [50] | 76.7 | 56.8 |
| MultiScale [16] | 79.2 | 60.6 |
| Ours | 79.0 | 62.1 |
| Ours+Re-ranking | 84.2 | 78.8 |
| Methods | Detected | Labeled | ||
|---|---|---|---|---|
| Rank-1 (%) | mAP (%) | Rank-1 (%) | mAP (%) | |
| BOW+XQDA [44] | 6.36 | 6.39 | 7.93 | 7.29 |
| LOMO+XQDA [54] | 12.8 | 11.5 | 14.8 | 13.6 |
| PAN [9] | 36.3 | 34.0 | 36.9 | 35.0 |
| SVDNet [50] | 41.5 | 37.26 | 40.93 | 37.83 |
| HA-CNN [55] | 41.7 | 38.6 | 44.3 | 41.0 |
| MLFN [56] | 52.8 | 37.8 | 54.7 | 49.2 |
| Ours | 53.04 | 48.32 | 54.27 | 49.96 |
| Ours + Re-ranking | 62.39 | 60.57 | 63.04 | 61.73 |
| Methods | ID-Switch | Improvement |
|---|---|---|
| Track only | 56 | - |
| Track + ours | 33 | 41% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Z.; Wu, X.; Xiong, Z.; Ma, Y. A Dynamic Part-Attention Model for Person Re-Identification. Sensors 2019, 19, 2080. https://doi.org/10.3390/s19092080
Yao Z, Wu X, Xiong Z, Ma Y. A Dynamic Part-Attention Model for Person Re-Identification. Sensors. 2019; 19(9):2080. https://doi.org/10.3390/s19092080
Chicago/Turabian StyleYao, Ziying, Xinkai Wu, Zhongxia Xiong, and Yalong Ma. 2019. "A Dynamic Part-Attention Model for Person Re-Identification" Sensors 19, no. 9: 2080. https://doi.org/10.3390/s19092080
APA StyleYao, Z., Wu, X., Xiong, Z., & Ma, Y. (2019). A Dynamic Part-Attention Model for Person Re-Identification. Sensors, 19(9), 2080. https://doi.org/10.3390/s19092080