Enhancing the Accuracy and Robustness of a Compressive Sensing Based Device-Free Localization by Exploiting Channel Diversity


Abstract
:1. Introduction
- To enhance the localization accuracy and robustness of CS-based DFL, a novel ComDec method is proposed, which leverages the channel diversity of CSI measurements. In ComDec, the CS-based DFL problem is extended to multi-channel scenario. It is formulated as a joint sparse recovery problem that recovers multiple jointly sparse vectors over two known dictionaries.
- To simultaneously recover the jointly sparse vectors, we develop a novel joint sparse recovery algorithm. The joint sparsity of the sparse vectors is induced by a novel two-layer hierarchical prior model. Then, the common support set of the sparse vectors is estimated by inferring the posteriors of the hidden variables that defined in the proposed prior model.
- To mitigate the influence of environmental dynamics in changing environments, the dictionary parameters with respect to multiple channels are modelled as tunable parameters to adapt the environmental changes and different channel characteristics. In this way, the dictionary mismatch problem can be solved without the need of explicitly estimating the dictionary parameters.
- To reduce the computational complexity, we introduce four methods in the proposed joint sparse recovery algorithm. Among them, the grid pruning method can improve the convergence speed of the proposed joint sparse recovery algorithm.
2. Related Work
3. Preliminaries and Problem Formulation
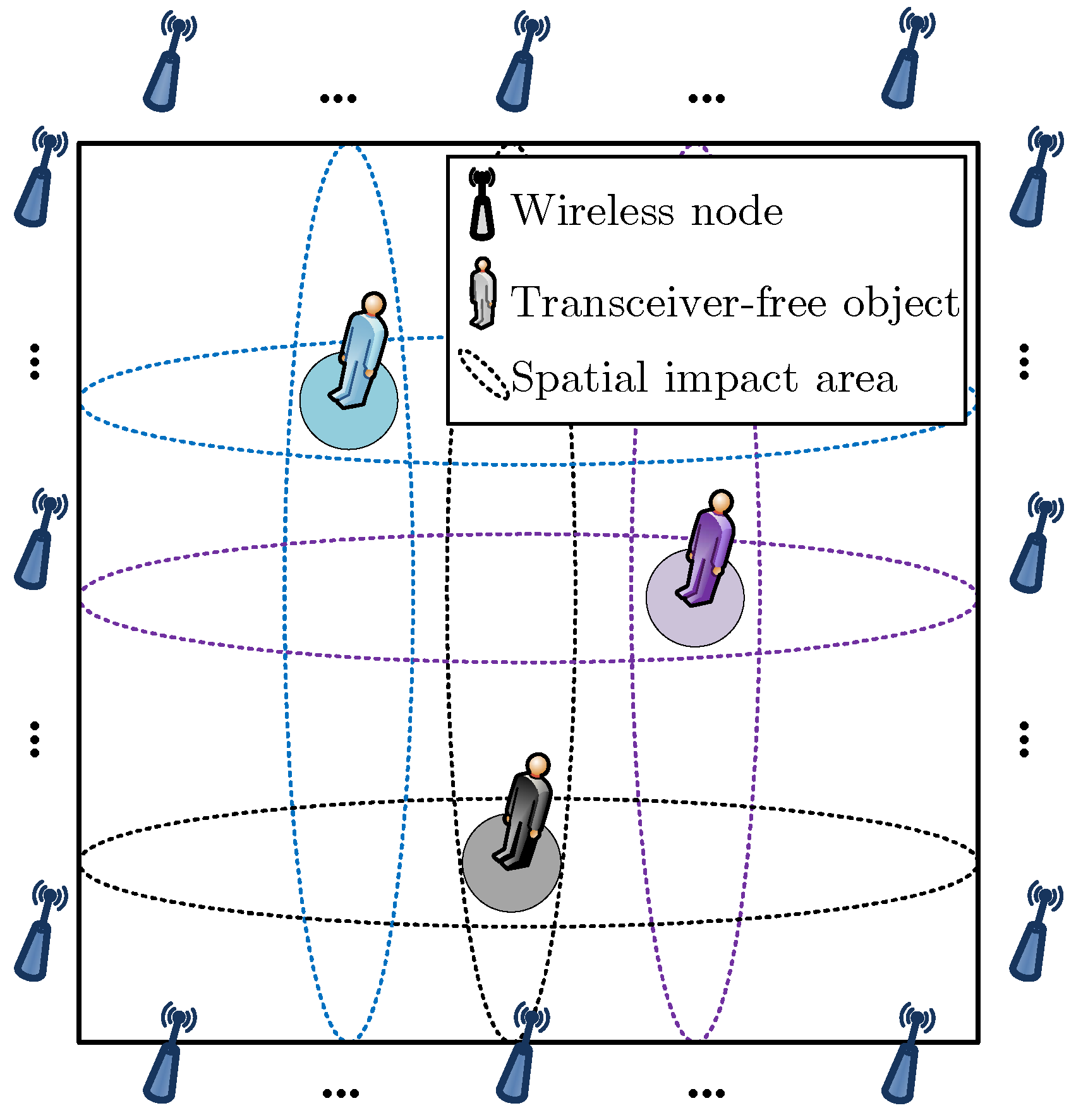
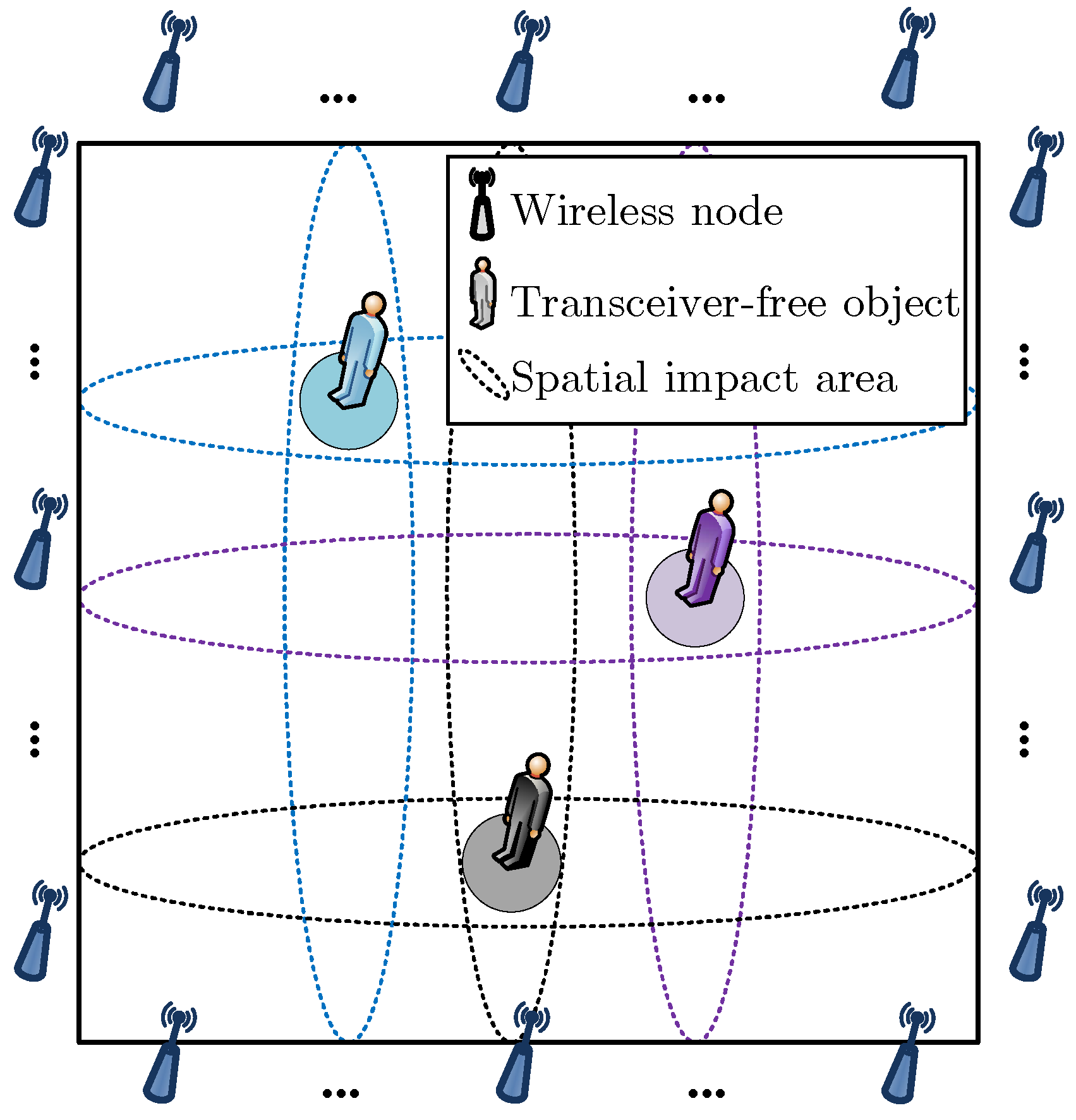
3.1. Overview of Multi-Target Device-Free Localization
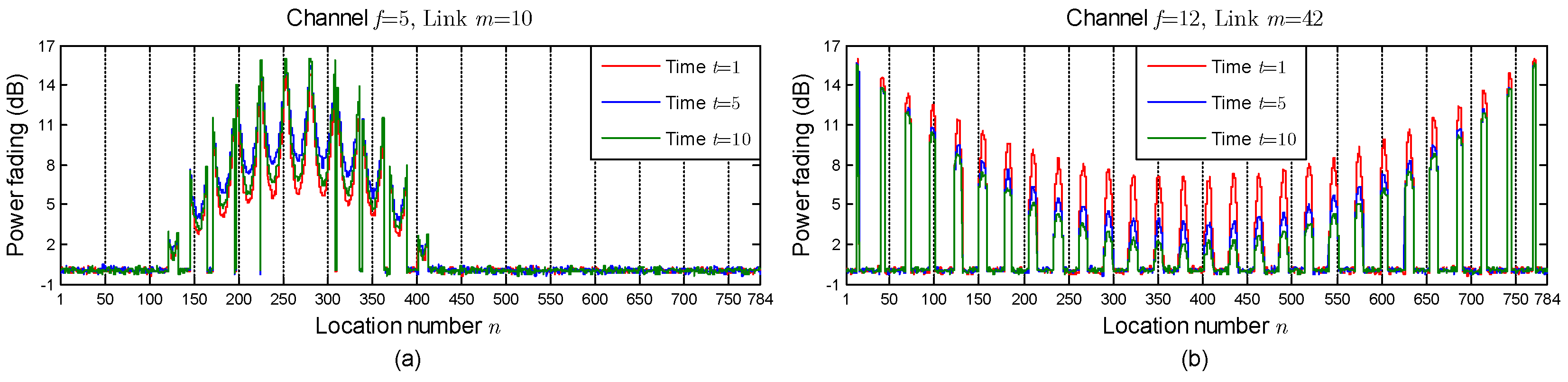
3.2. CSI Collection and Feature Extraction
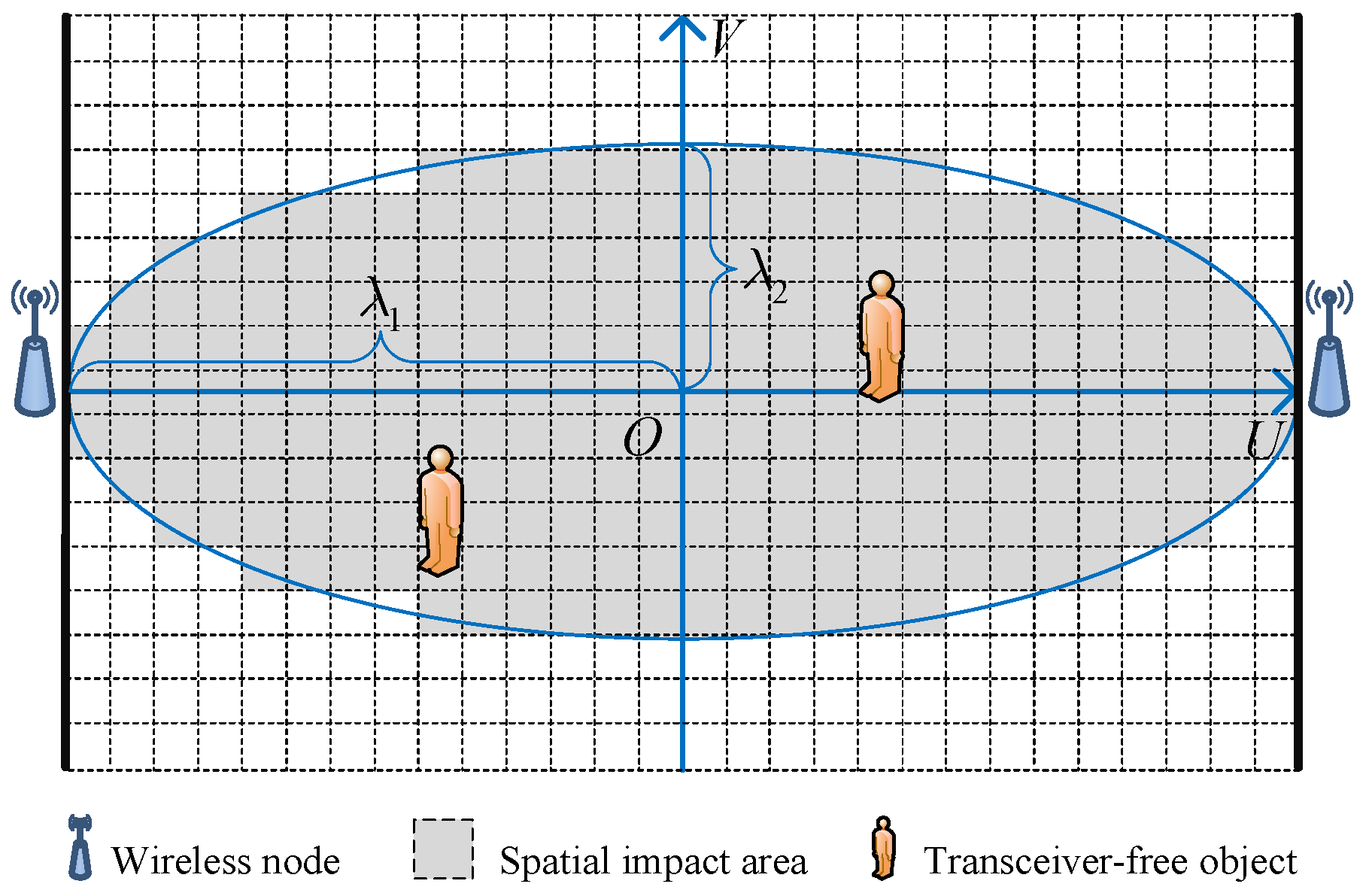
3.3. Problem Formulation
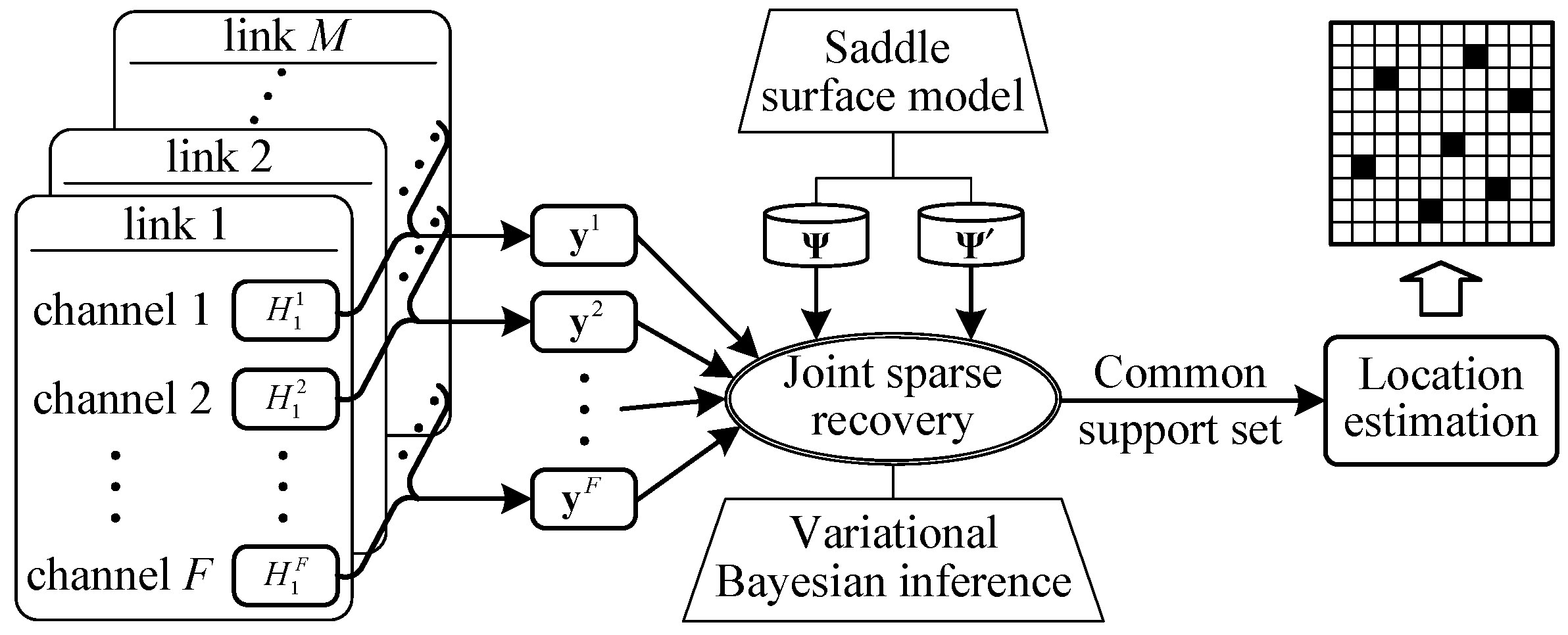
4. Target Localization via Variational Bayesian Inference
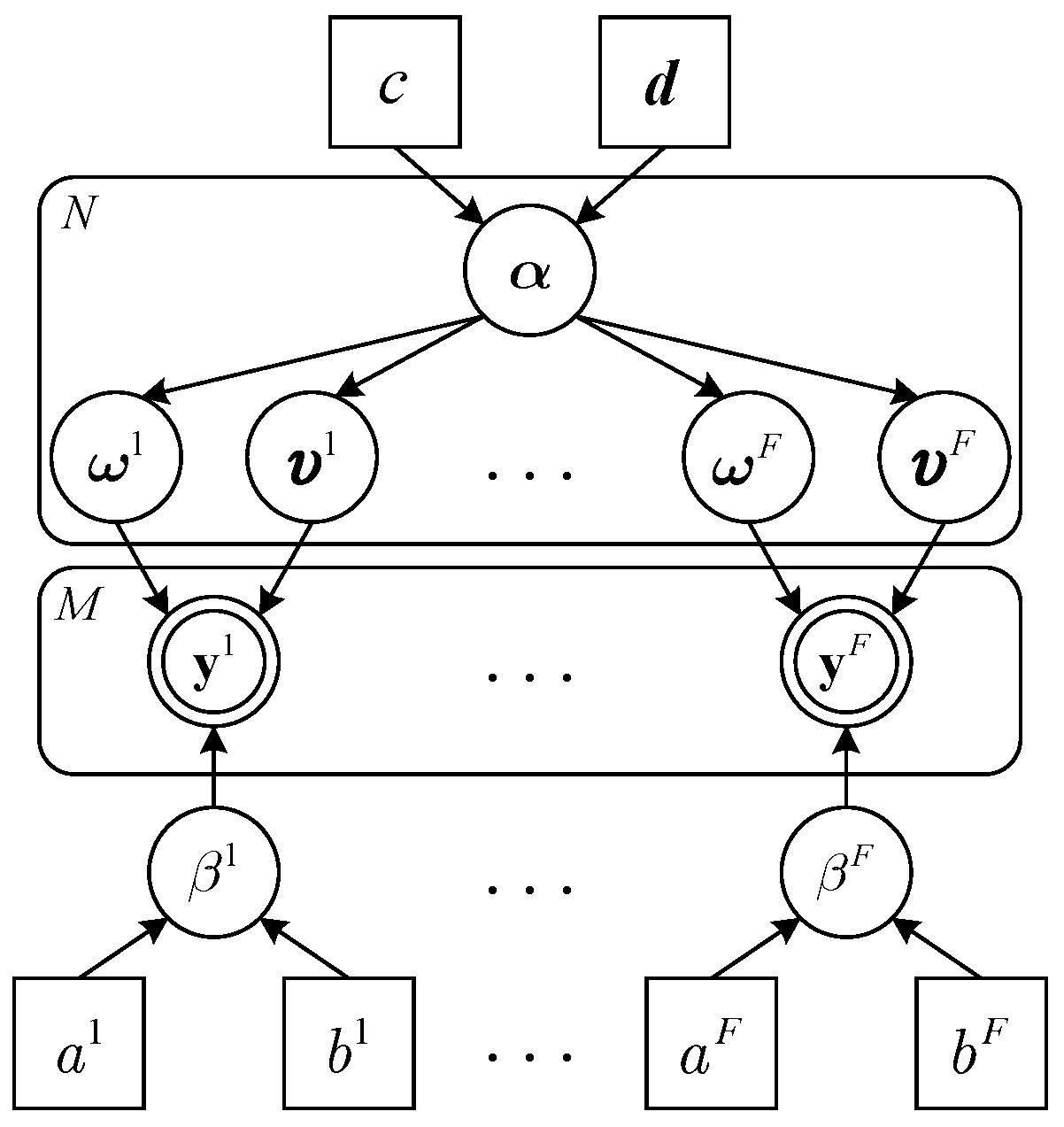
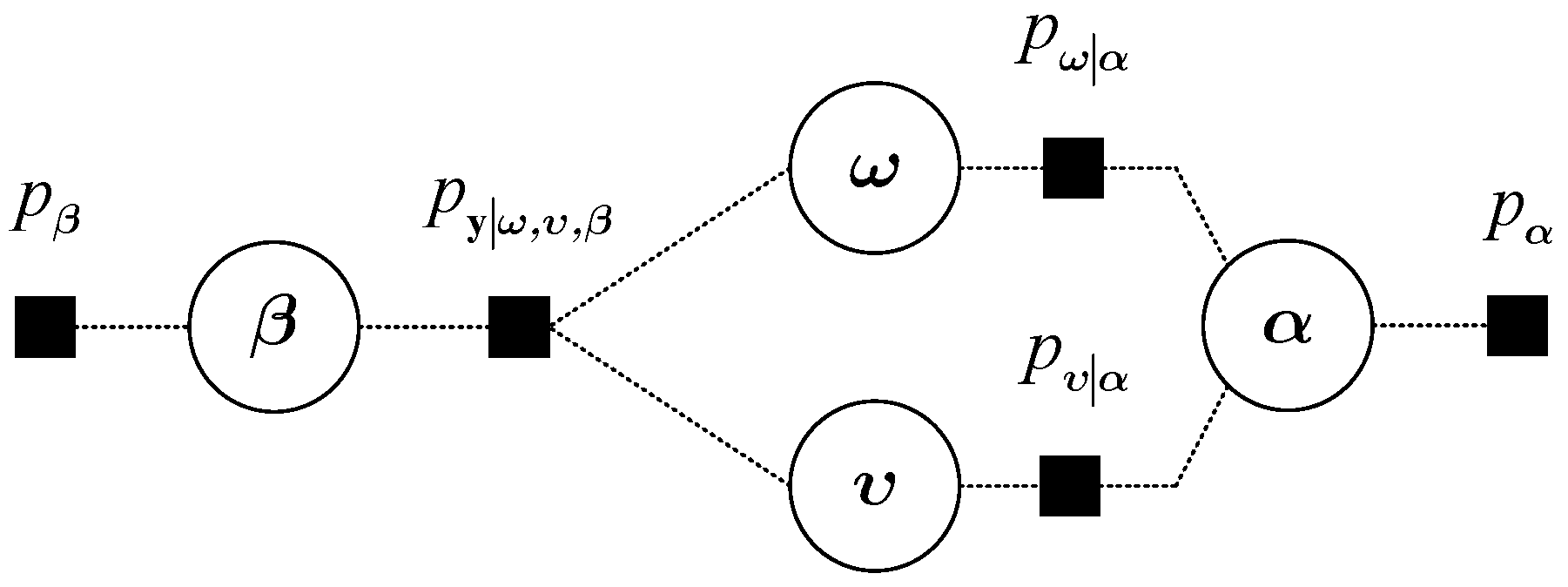
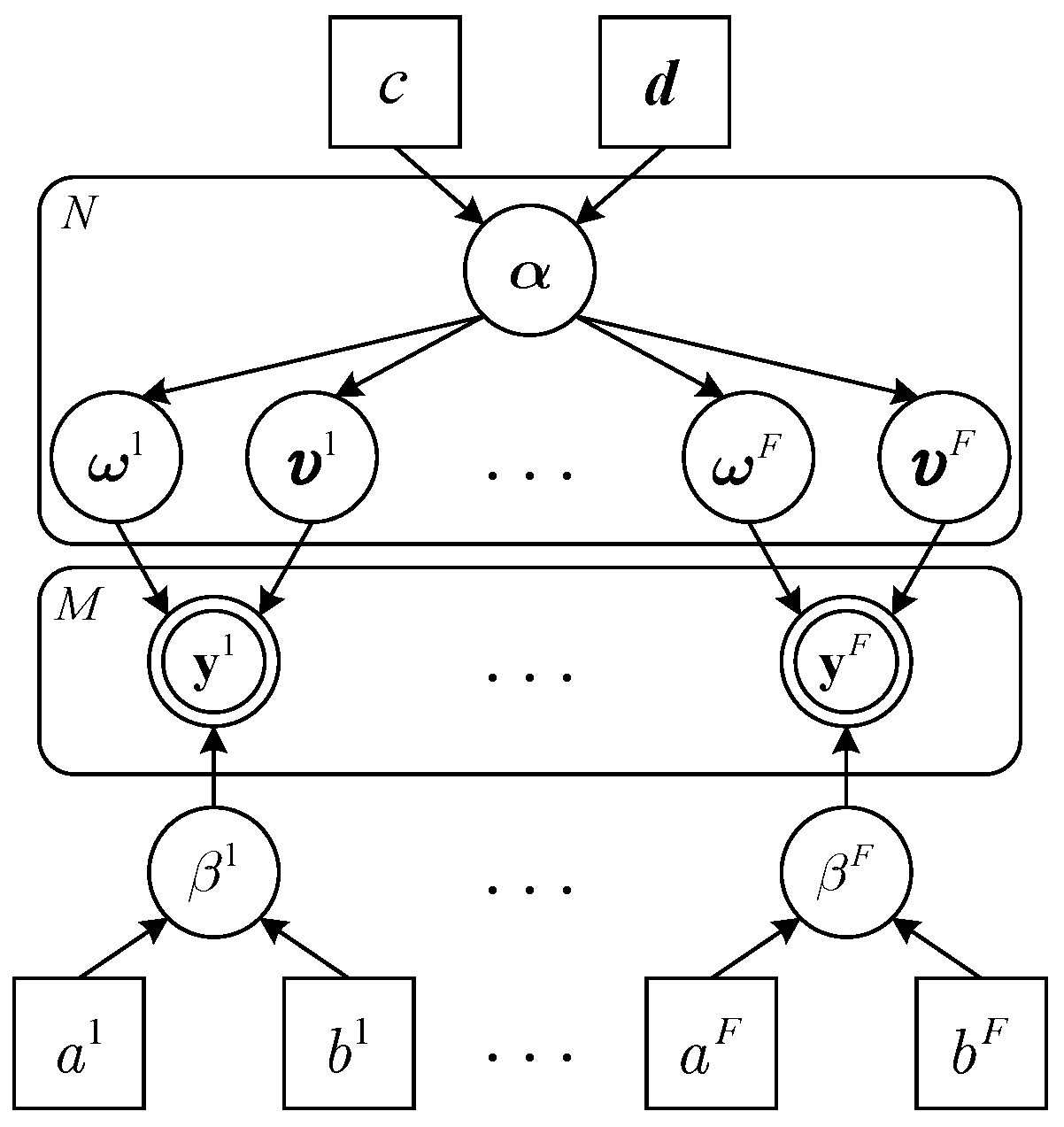
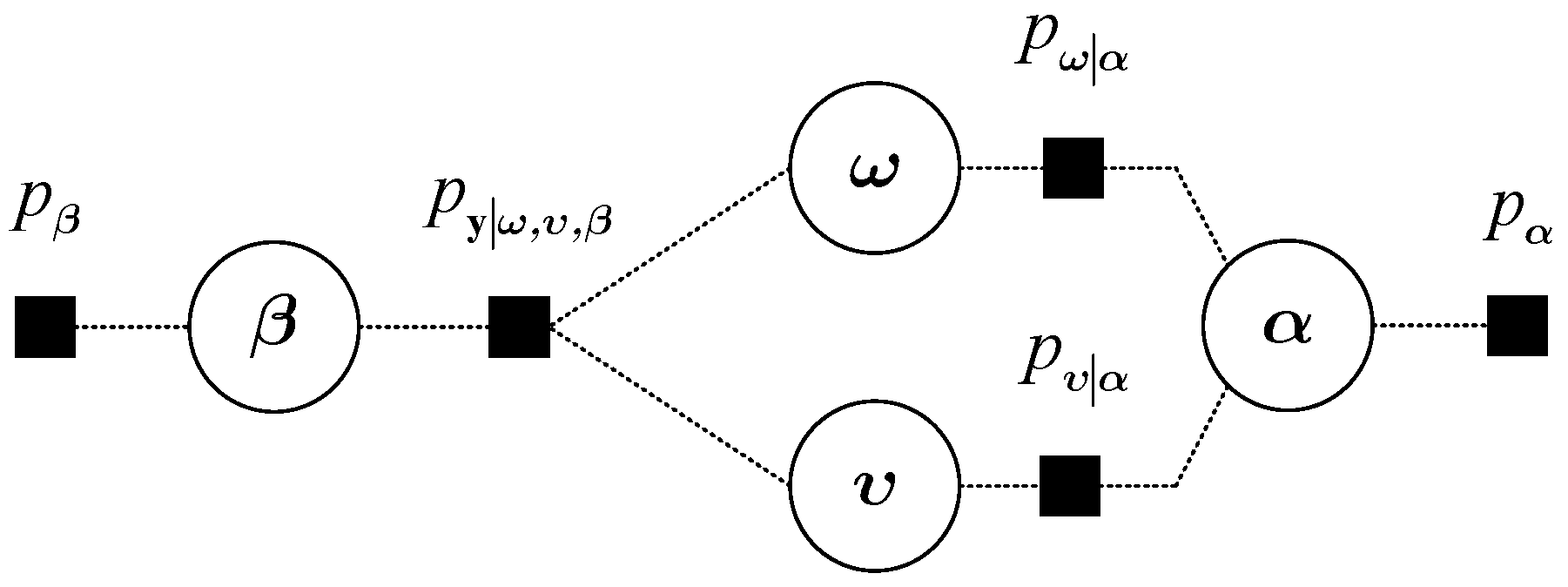
4.1. Hierarchical Prior Model
4.2. Variational Bayesian Inference
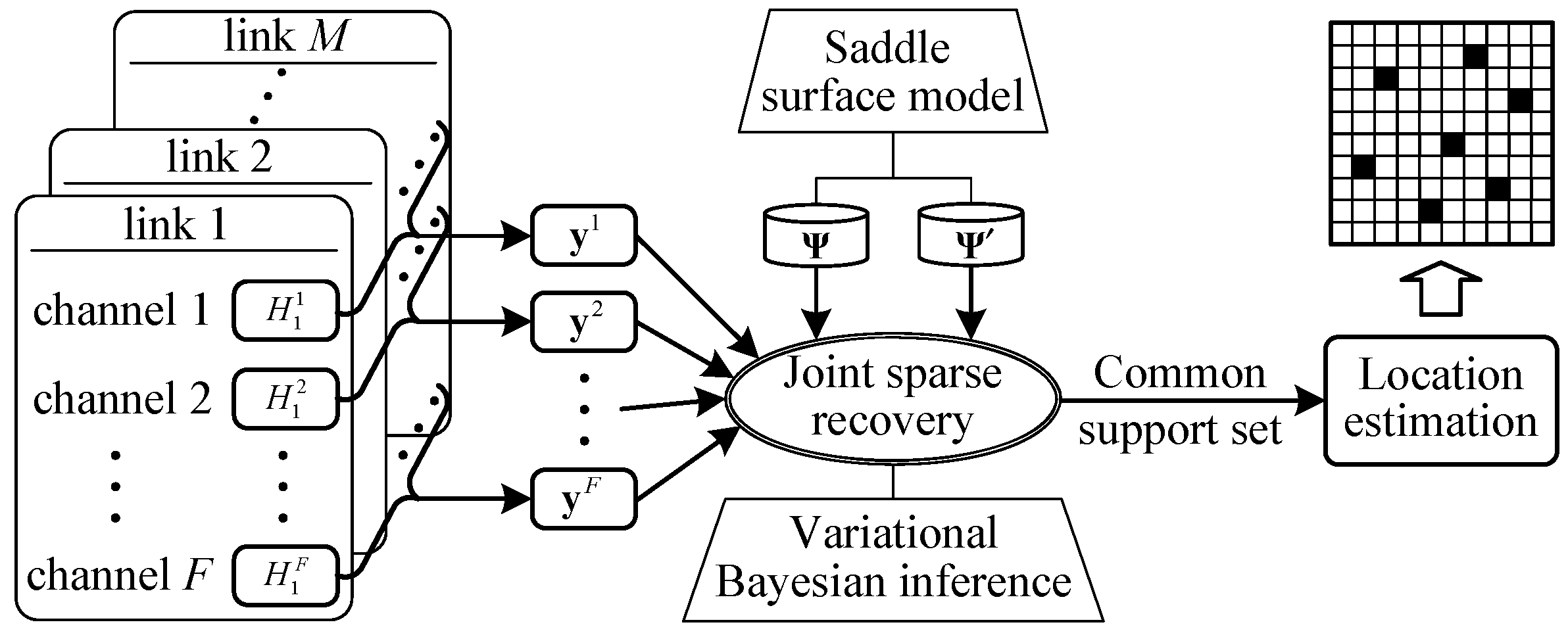
4.3. Joint Sparse Reconstruction
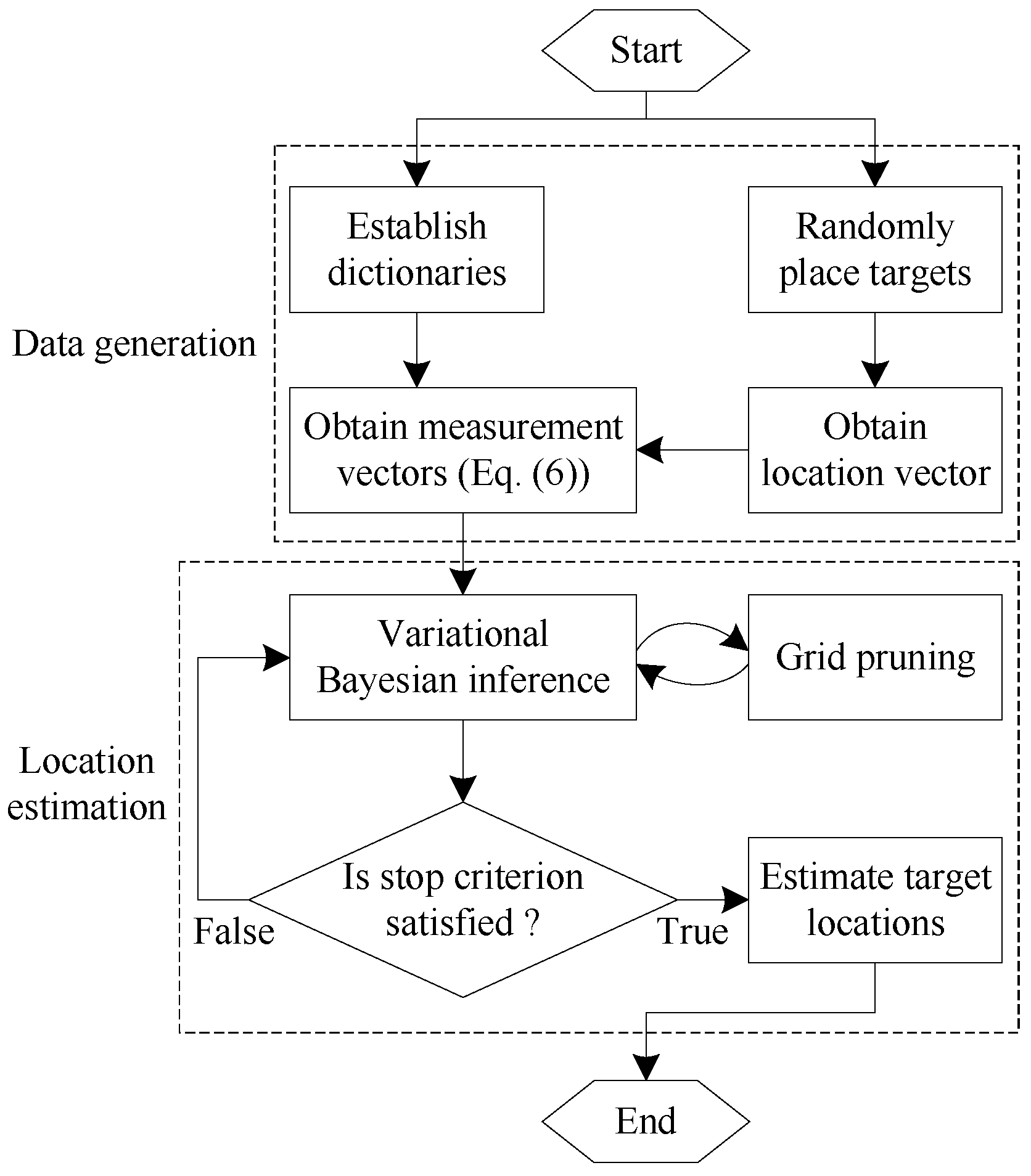
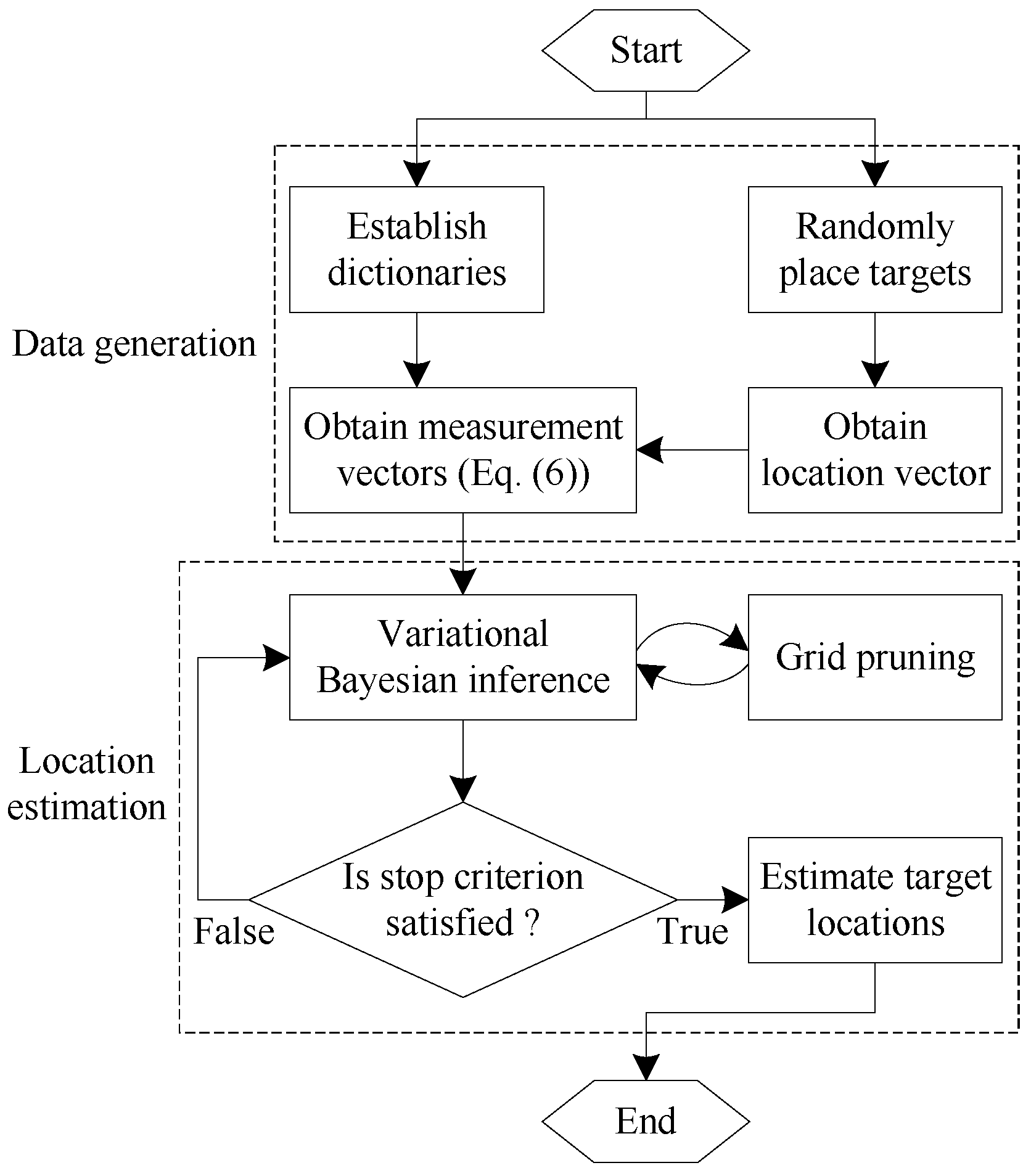
- For , update by using (35) and (36); update by using (39) and (40). and are obtained based on the current posteriors of and .
- For , update according to (44), (45) and the current posteriors of and .
- Update according to (49), (50) and the current posteriors of and .
- If a convergence criterion has been met, terminate and choose the posterior means of and as the estimation of . Otherwise, go to step .
4.4. Target Counting and Localization
5. Numerical Evaluation
5.1. Simulation Setup
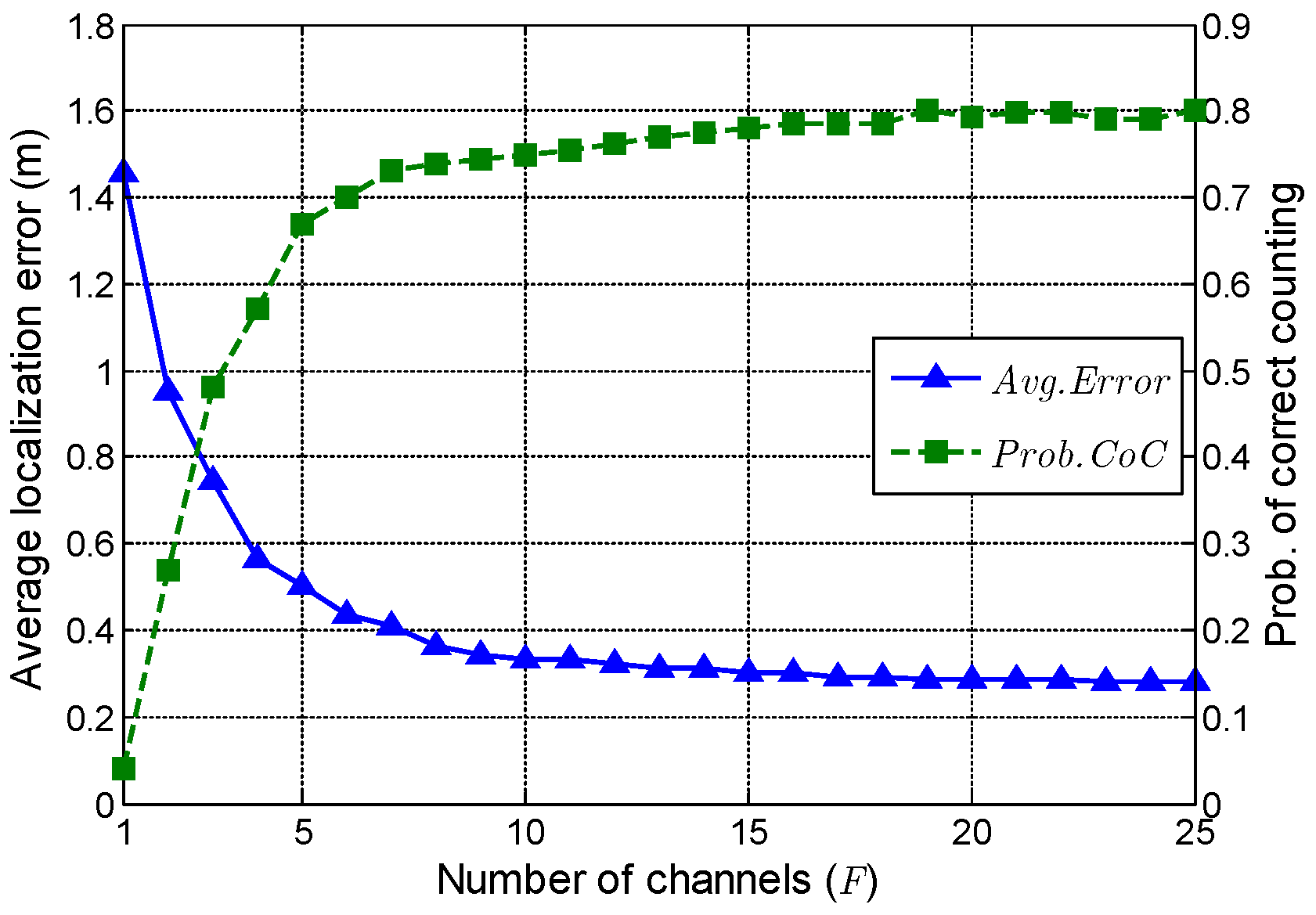
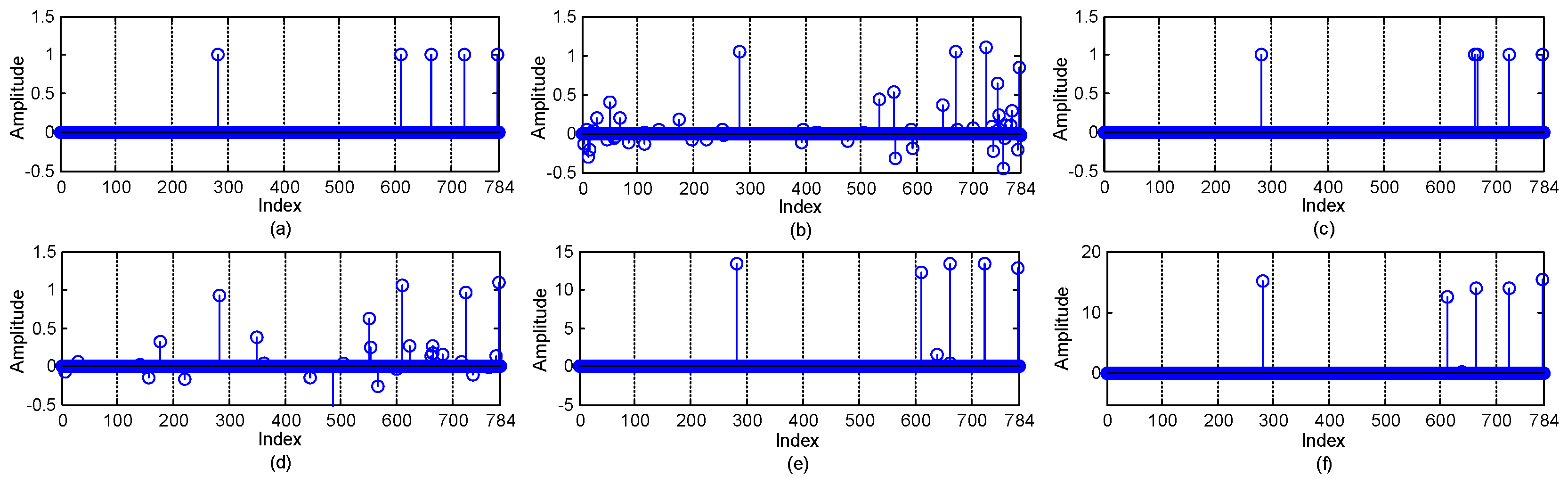
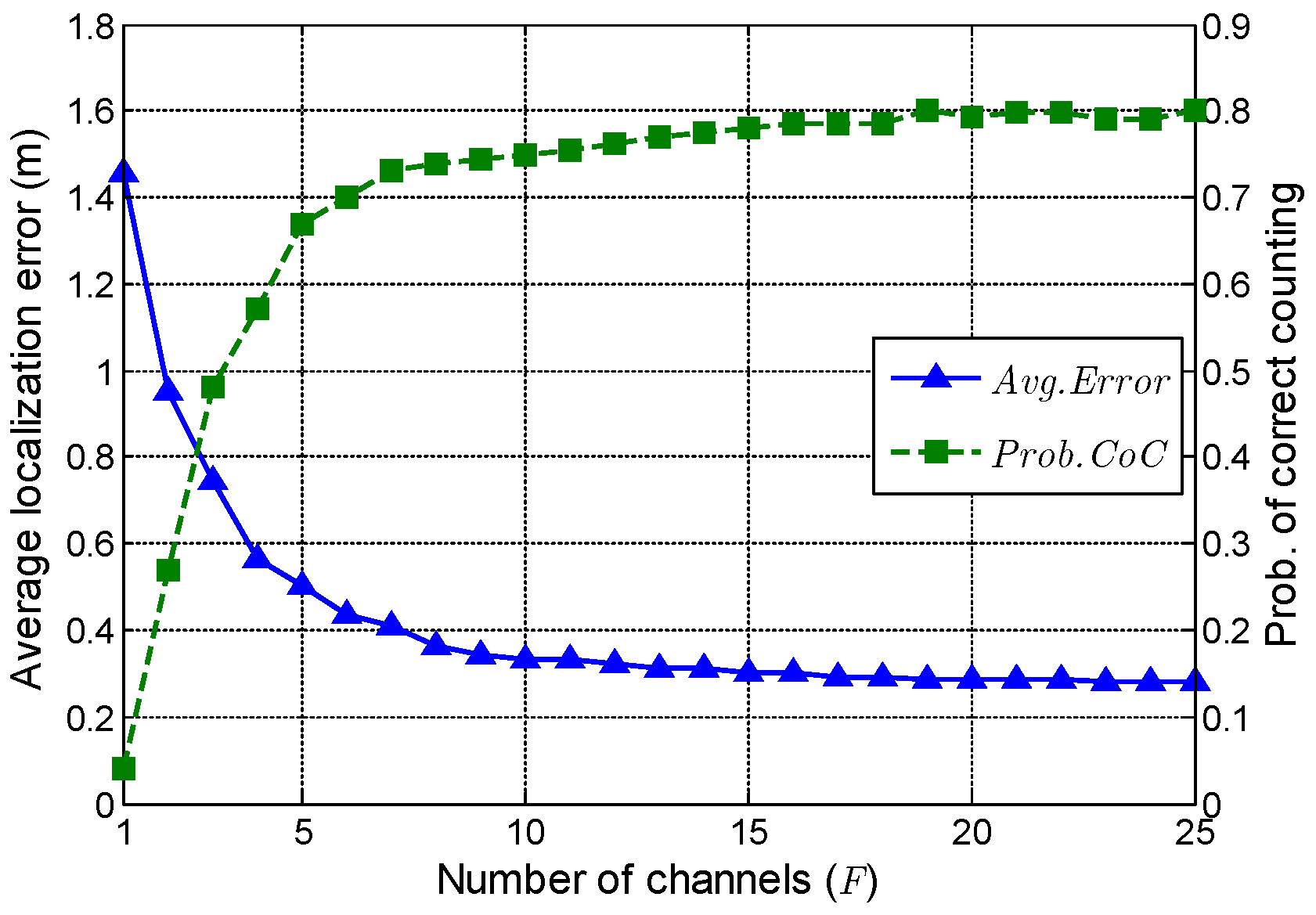
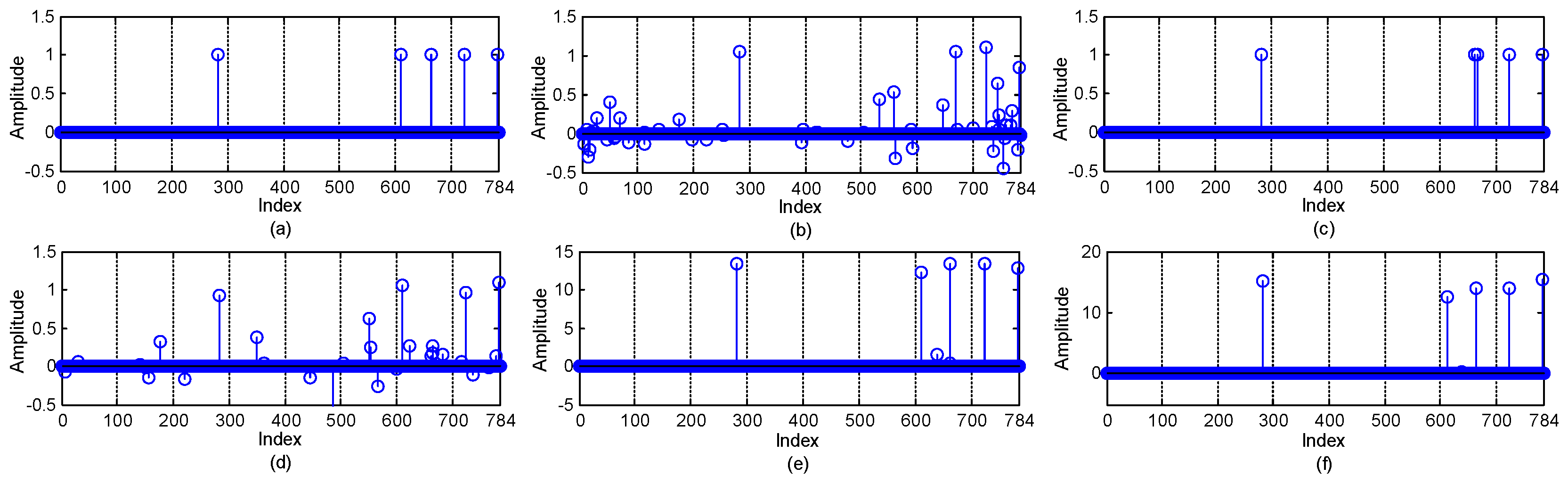
5.2. Impact of the Number of Channels
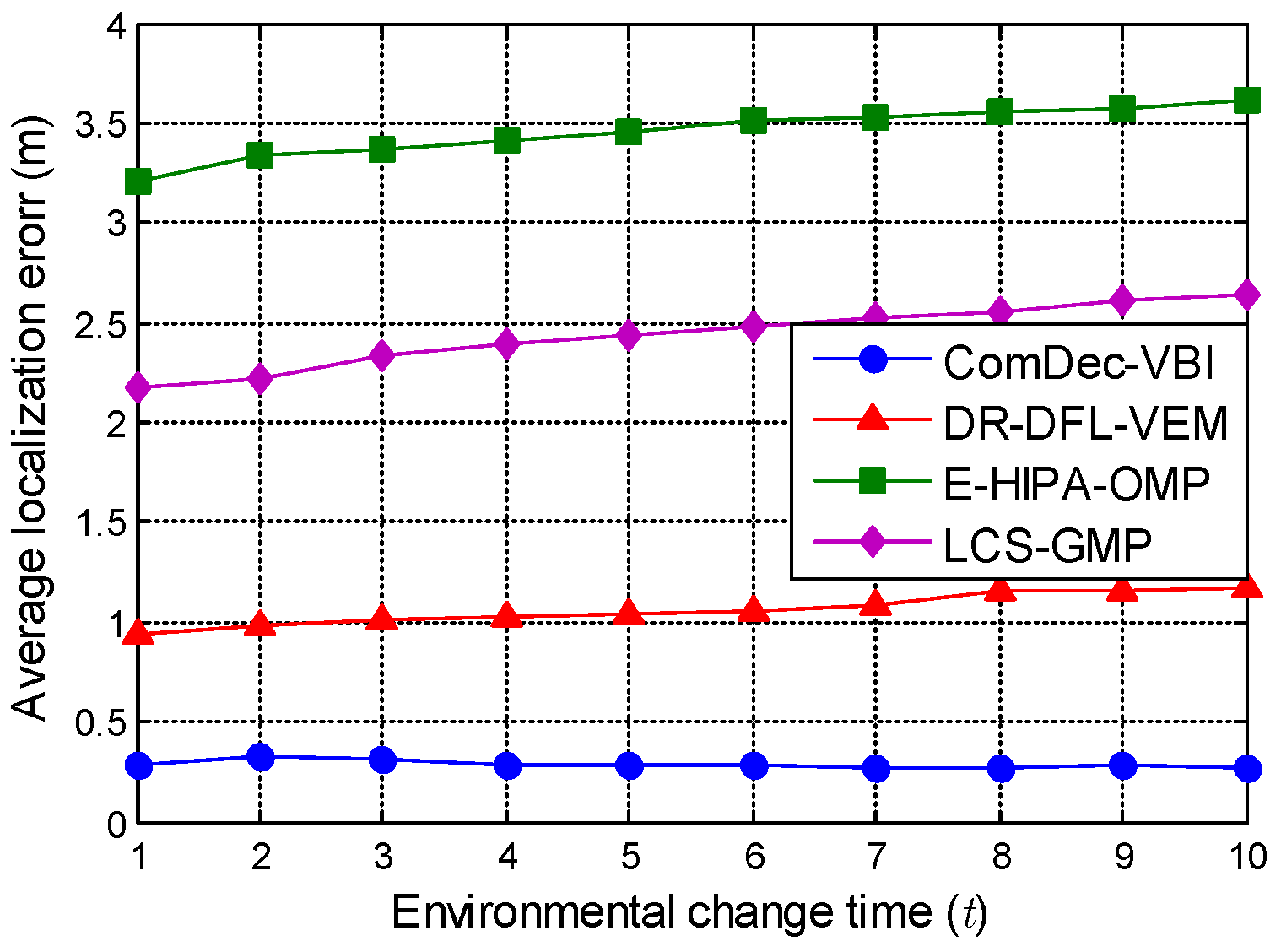
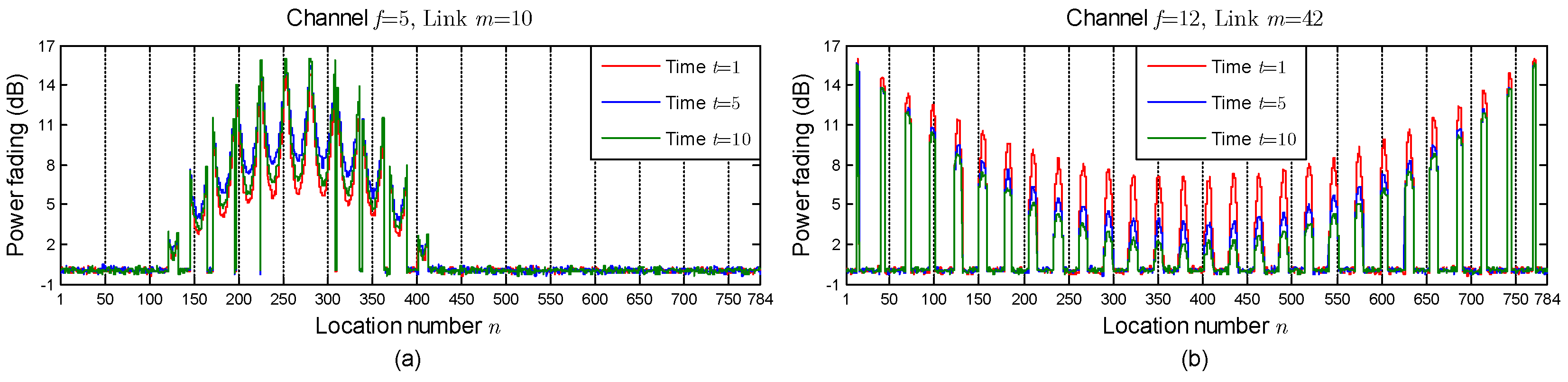
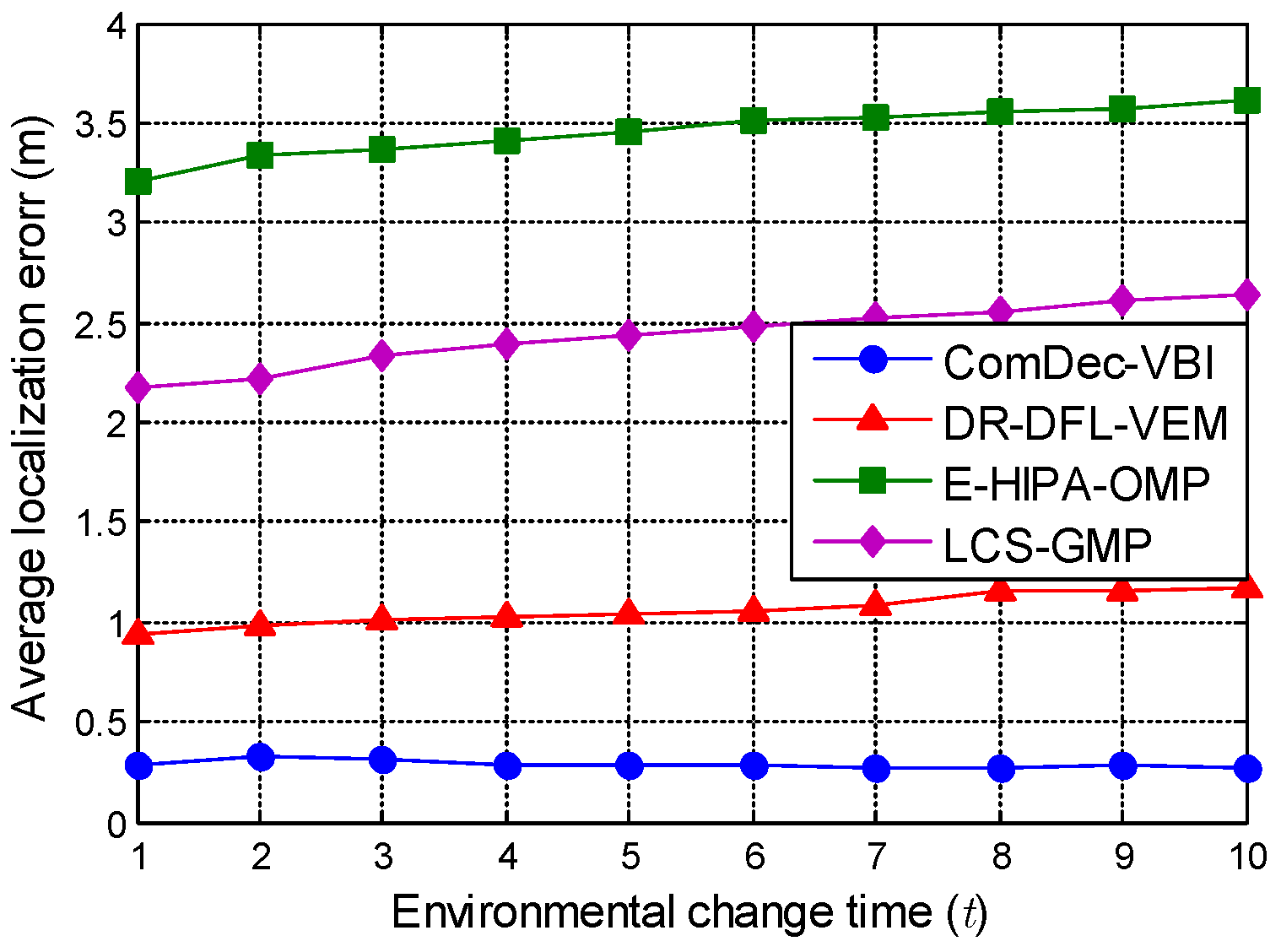
5.3. Effectiveness of ComDec in Changing Environments
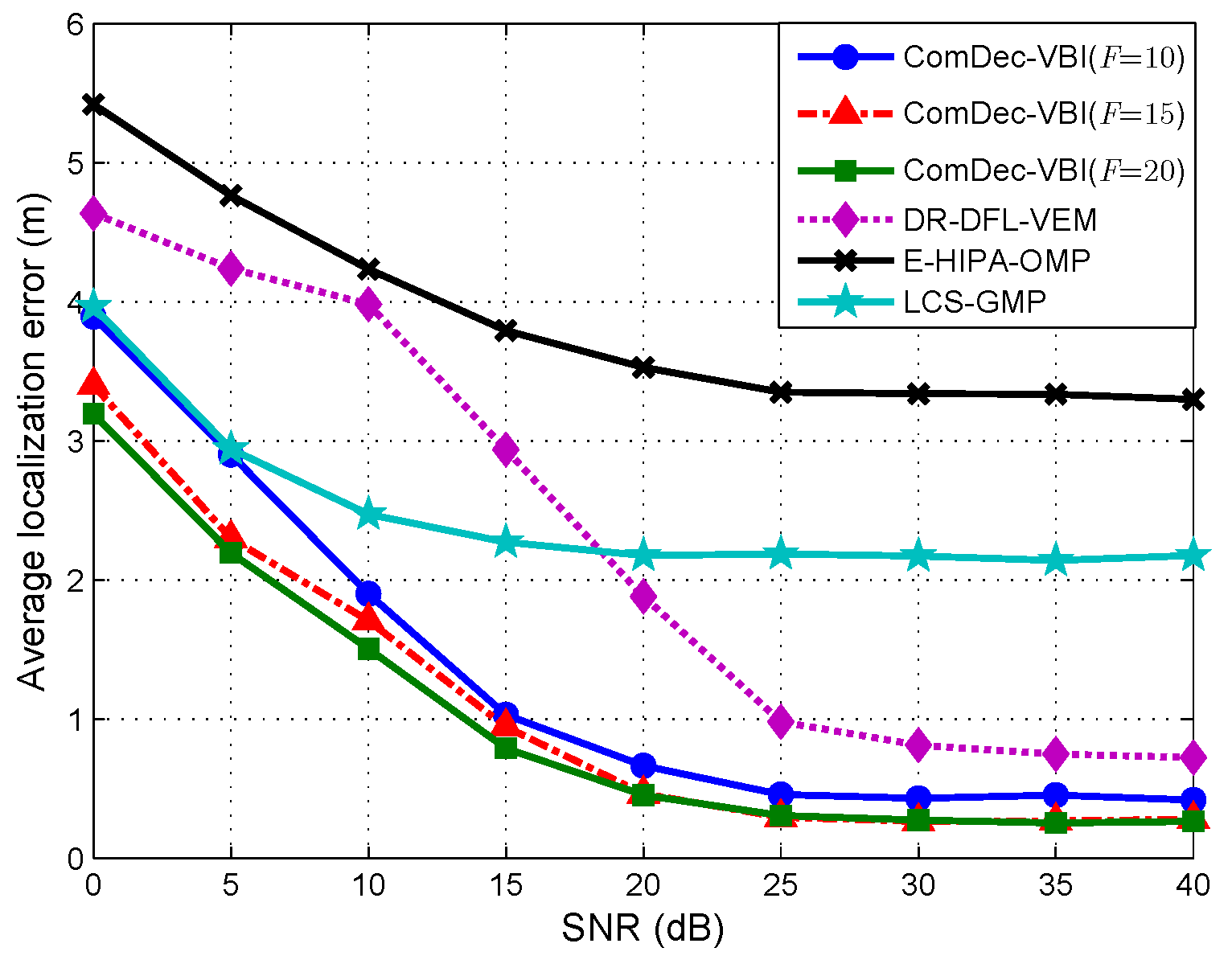
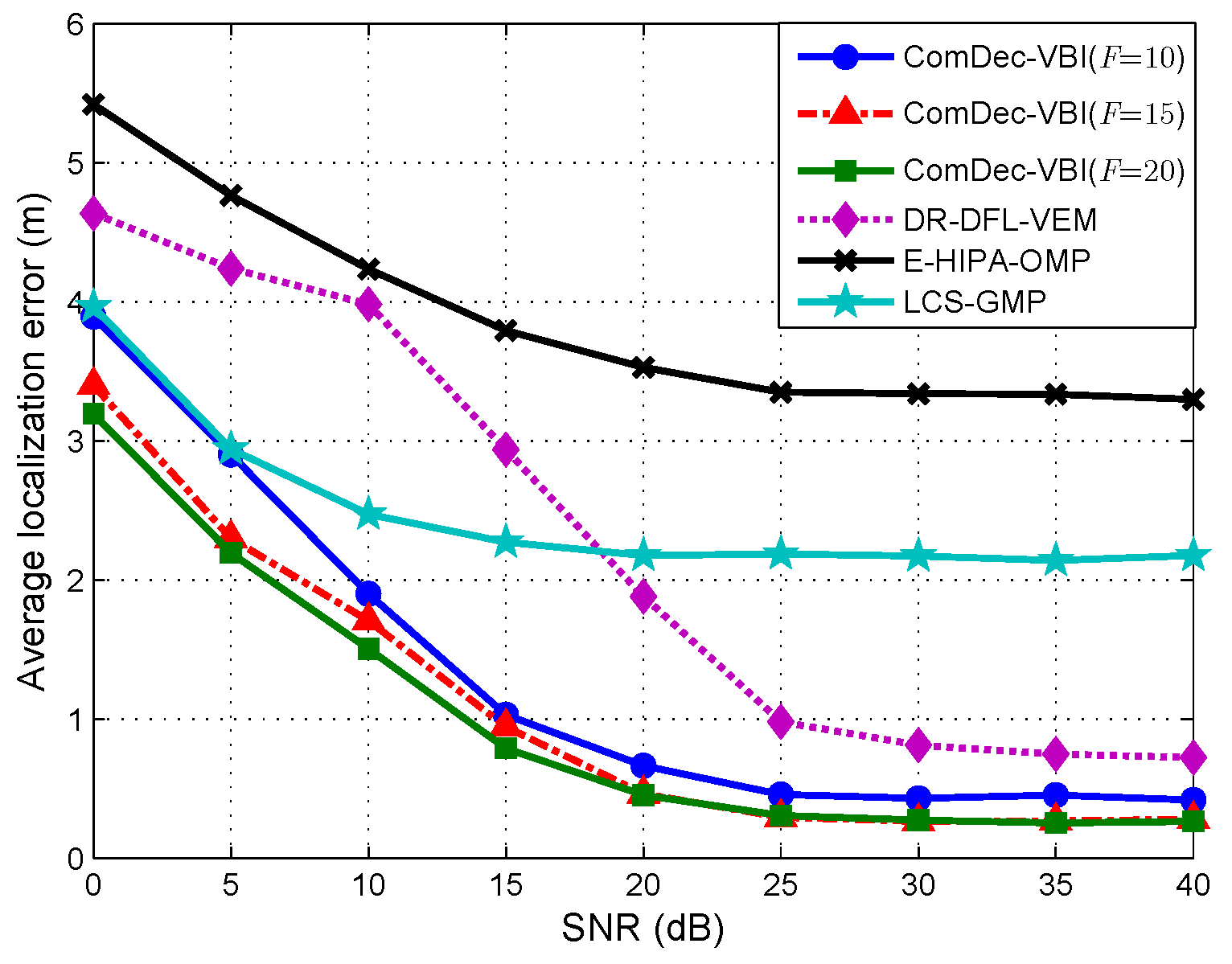
5.4. Localization Error vs. SNR
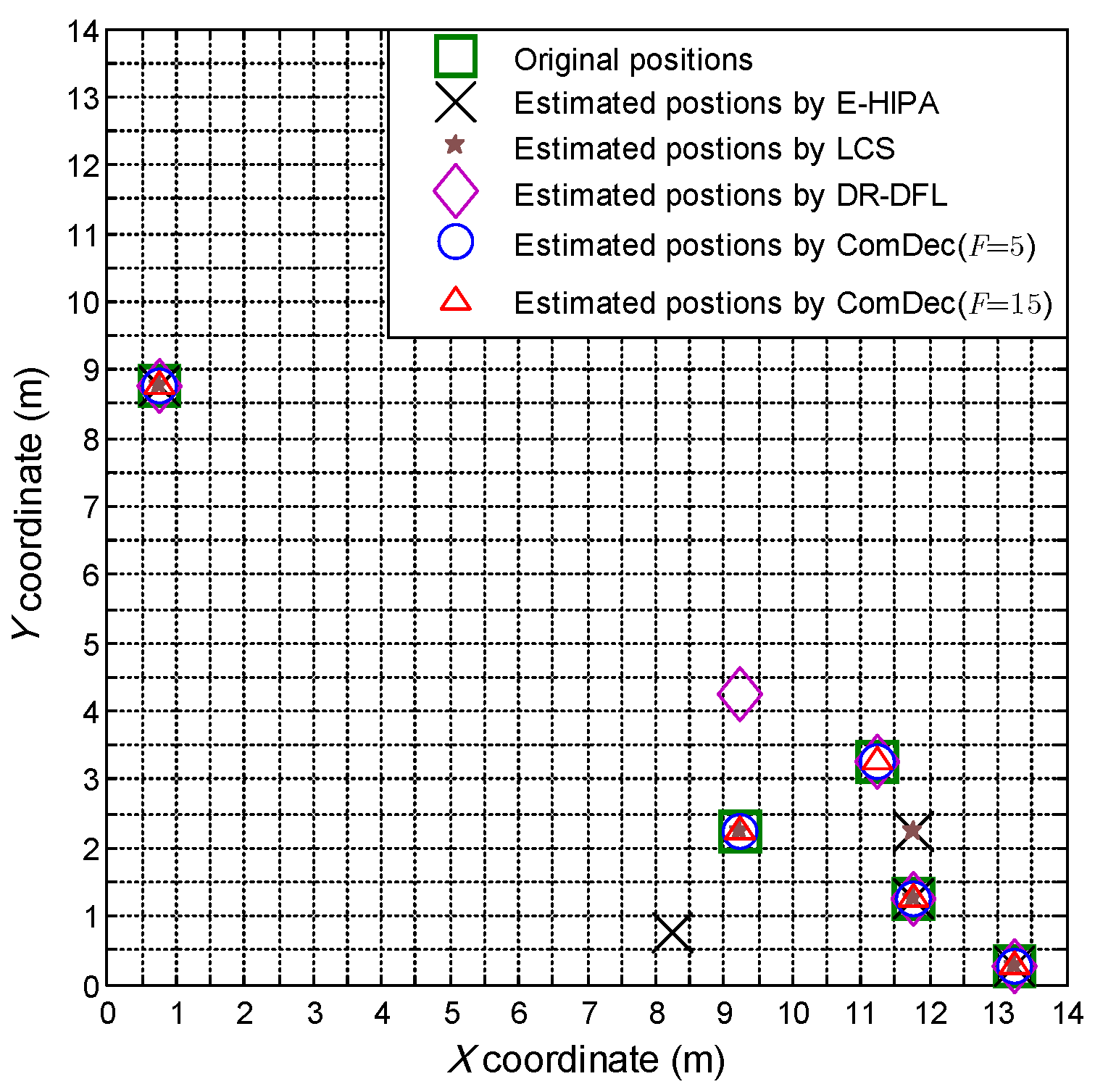
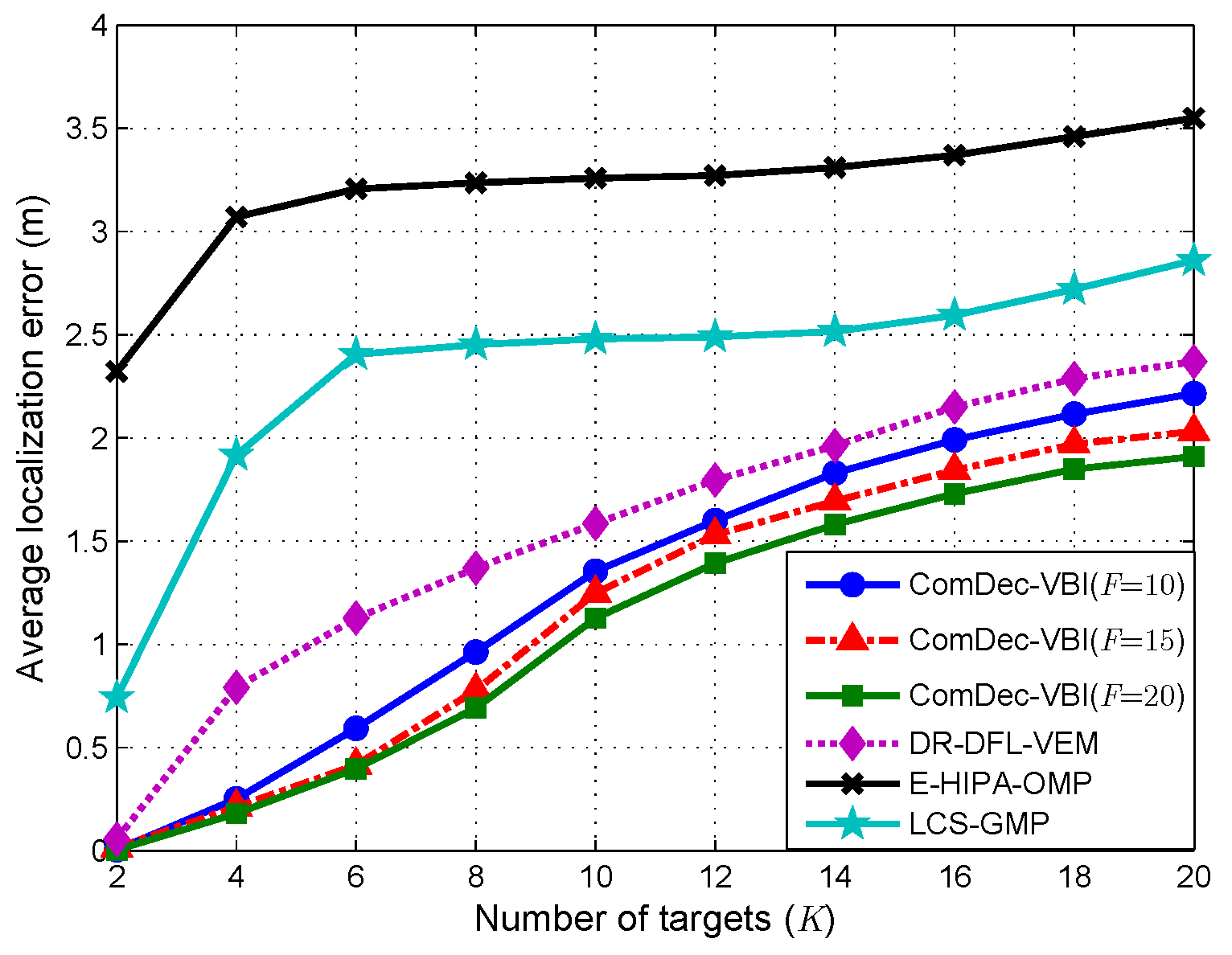
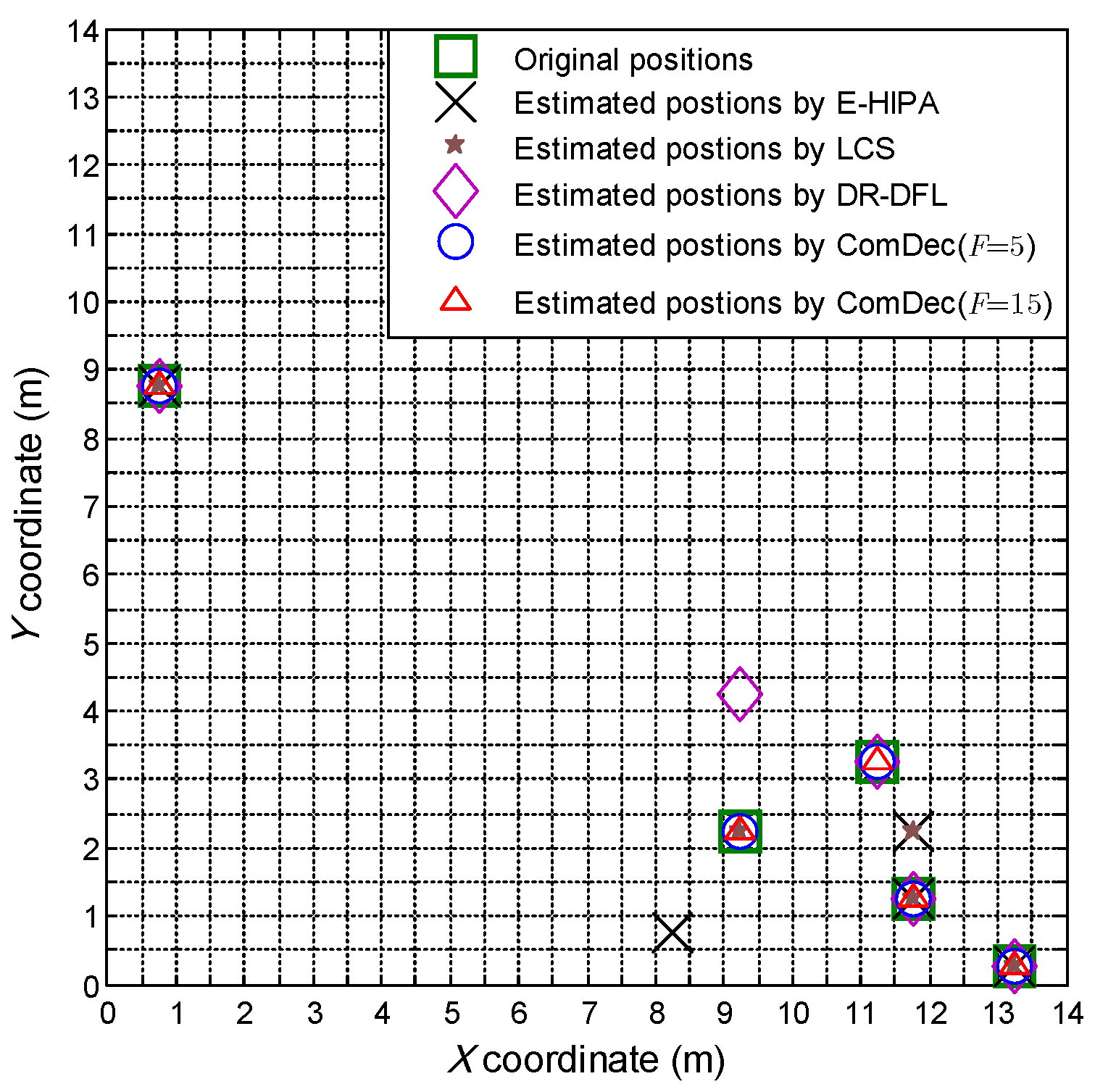
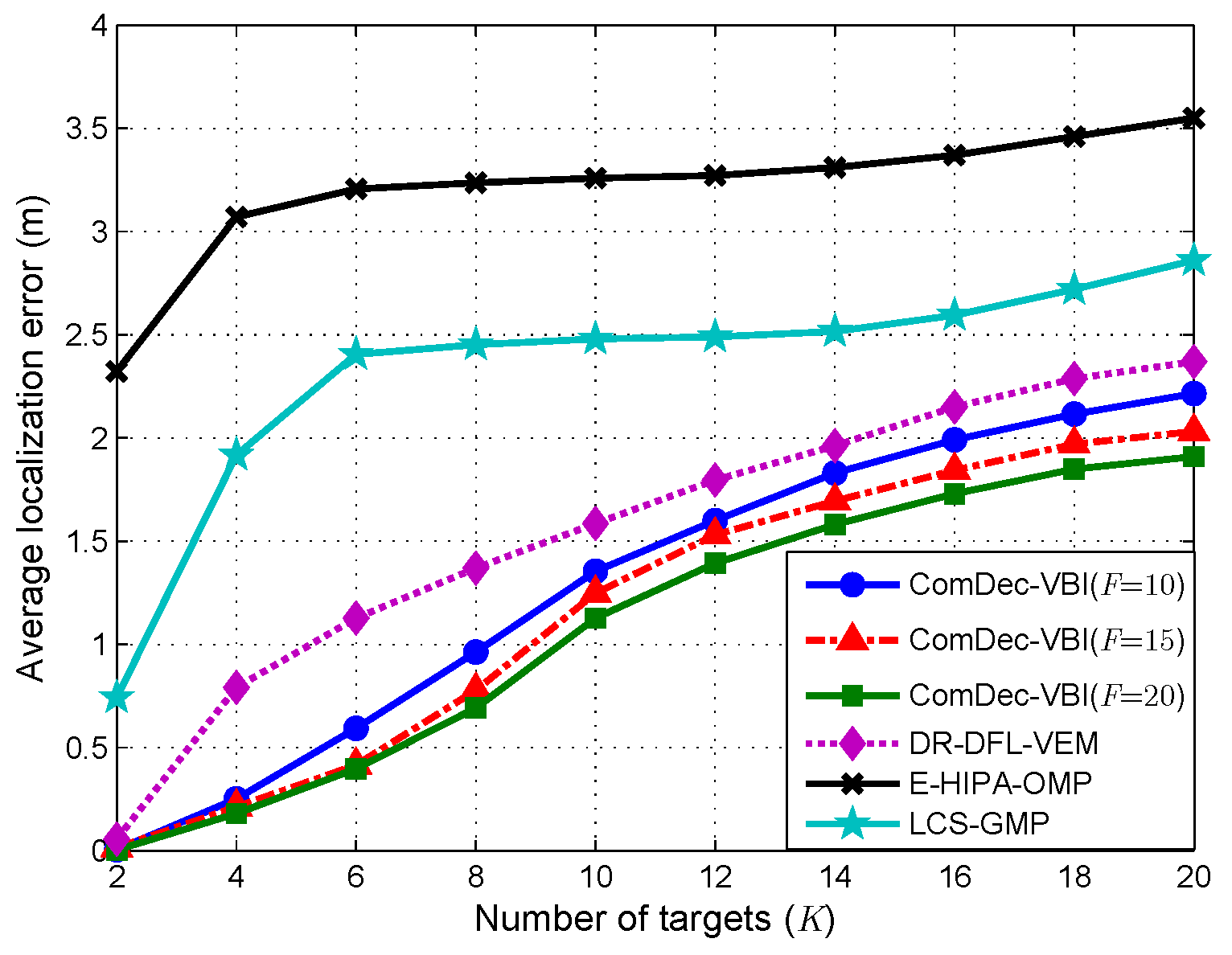
5.5. Localization Error vs. Number of Targets
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DFL | Device-free localization |
| VBI | Variational Bayesian inference |
| LBS | Location-based service |
| OFDM | Orthogonal Frequency Division Multiplexing |
| LTE | Long Term Evolution |
| SNR | Signal-to-noise ratio |
| CS | Compressive sensing |
| RIP | Restricted isometry property |
| RTI | Radio tomographic imaging |
| GMP | Greedy matching pursuit |
| LCS | Device-free localization based on compressive sensing |
| Probability density function | |
| CG | Conjugate gradient |
| OMP | Orthogonal matching pursuit |
| E-HIPA | The energy-efficient framework for high-precision multi-target-adaptive device-free localization |
| VEM | Variational expectation-maximization |
| DR-DFL | Dictionary refinement based device-free localization |
| ComDec | Compressive sensing-based multi-target device-free localization |
| M-OMP | Multiple measurement vector orthogonal matching pursuit |
| MMV | Multiple measurement vector |
| COTS | Commercial off-the-shelf |
| RSS | Received signal strength |
| WSN | Wireless sensor networks |
| CSI | Channel state information |
| LASSO | Least absolute shrinkage and selection operator |
| LOS | Line-of-sight |
| M-SBL | Multiple sparse Bayesian learning |
| KLD | Kullback-Leibler divergence |
| M-BMP | Multiple measurement vector basic matching pursuit |
References
- Youssef, M.; Mah, M.; Agrawala, A. Challenges: Device-Free Passive Localization for Wireless Environments. In Proceedings of the 13th Annual ACM International Conference on Mobile Computing and Networking (MobiCom’07), Montreal, QC, Canada, 9–14 September 2007; pp. 222–229. [Google Scholar] [CrossRef]
- Zhang, D.; Ma, J.; Chen, Q.; Ni, L. An RF-Based System for Tracking Transceiver-Free Objects. In Proceedings of the Fifth Annual IEEE International Conference on Pervasive Computing and Communications (PerCom’07), White Plains, NY, USA, 19–23 March 2007; pp. 135–144. [Google Scholar] [CrossRef]
- Lei, Q.; Zhang, H.; Sun, H.; Tang, L. Fingerprint-Based Device-Free Localization in Changing Environments using Enhanced Channel Selection and Logistic Regression. IEEE Access 2018, 6, 2569–2577. [Google Scholar] [CrossRef]
- Sun, B.; Guo, Y.; Li, N.; Fang, D. Multiple Target Counting and Localization Using Variational Bayesian EM Algorithm in Wireless Sensor Networks. IEEE Trans. Commun. 2017, 65, 2985–2998. [Google Scholar] [CrossRef]
- Qian, P.; Guo, Y.; Li, N. Multitarget Localization with Inaccurate Sensor Locations via Variational EM Algorithm. IEEE Sens. Lett. 2019, 3, 1–4. [Google Scholar] [CrossRef]
- Guo, Y.; Sun, B.; Li, N.; Fang, D. Variational Bayesian Inference-based Counting and Localization for Off-Grid Targets with Faulty Prior Information in Wireless Sensor Networks. IEEE Trans. Commun. 2018, 66, 1273–1283. [Google Scholar] [CrossRef]
- Lin, A.; Ling, H. Doppler and Direction-Of-Arrival (DDOA) Radar for Multiple-Mover Sensing. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 1496–1509. [Google Scholar] [CrossRef]
- Krumm, J.; Harris, S.; Meyers, B.; Brumitt, B.; Hale, M.; Shafer, S. Multi-Camera Multi-Person Tracking for EasyLiving. In Proceedings of the IEEE 3rd International Workshop on Visual Surveillance, Dublin, Ireland, 1 July 2000; pp. 3–10. [Google Scholar] [CrossRef]
- Want, R.; Hopper, A.; Falco, V.; Gibbons, J. The Active Badge Location System. ACM Trans. Inf. Syst. 1992, 10, 91–102. [Google Scholar] [CrossRef]
- Botta, M.; Simek, M. Adaptive Distance Estimation Based on RSSI in 802.15.4 Network. Radioengineering 2013, 22, 1162–1168. [Google Scholar]
- Neburka, J.; Tlamse, Z.; Benes, V.; Polak, L.; Kaller, O.; Bolecek, L.; Sebesta, J.; Kratochvil, T. Study of the Performance of RSSI Based Bluetooth Smart Indoor Positioning. In Proceedings of the IEEE 26th International Conference Radioelektronika (RADIOELEKTRONIKA), Kosice, Slovakia, 19–20 April 2016; pp. 121–125. [Google Scholar] [CrossRef]
- Zhang, D.; Liu, Y.; Guo, X.; Ni, L.M. RASS: A Real-Time, Accurate, and Scalable System for Tracking Transceiver-Free Objects. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 996–1008. [Google Scholar] [CrossRef]
- Mager, B.; Lundrigan, P.; Patwari, N. Fingerprint-Based Device-Free Localization Performance in Changing Environments. IEEE J. Sel. Areas Commun. 2015, 33, 2429–2438. [Google Scholar] [CrossRef]
- Yu, D.; Guo, Y.; Li, N.; Fang, D. Dictionary Refinement for Compressive Sensing Based Device-Free Localization via the Variational EM Algorithm. IEEE Access 2016, 4, 9743–9757. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, Z.; Liu, Y. From RSSI to CSI: Indoor Localization via Channel Response. ACM Comput. Surv. 2013, 46, 1–32. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Mao, S.; Pandey, S. CSI-Based Fingerprinting for Indoor Localization: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2017, 66, 763–776. [Google Scholar] [CrossRef]
- Guo, Y.; Yu, D.; Li, N. Exploiting Fine-Grained Subcarrier Information for Device-Free Localization in Wireless Sensor Networks. Sensors 2018, 18, 3110. [Google Scholar] [CrossRef]
- Candes, E.; Wakin, M. An Introduction to Compressive Sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Q.; Pan, M.; Zhang, X.; Yu, Y.; Wang, H. Towards Accurate Device-Free Wireless Localization with a Saddle Surface Model. IEEE Trans. Veh. Technol. 2016, 65, 6665–6677. [Google Scholar] [CrossRef]
- Tzikas, D.G.; Likas, A.C.; Galatsanos, N.P. The Variational Approximation for Bayesian Inference. IEEE Signal Process. Mag. 2008, 25, 131–146. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, X.; Gao, Q.; Ma, X.; Feng, X.; Wang, H. Device-Free Simultaneous Wireless Localization and Activity Recognition with Wavelet Feature. IEEE Trans. Veh. Technol. 2017, 66, 1659–1669. [Google Scholar] [CrossRef]
- Wang, J.; Fang, D.; Chen, X.; Yang, Z.; Xing, T.; Cai, L. LCS: Compressive Sensing Based Device-Free Localization for Multiple Targets in Sensor Networks. In Proceedings of the IEEE INFOCOM 2013, Turin, Italy, 14–19 April 2013; pp. 145–149. [Google Scholar] [CrossRef]
- Wang, J.; Fang, D.; Yang, Z.; Jiang, H.; Chen, X.; Xing, T.; Cai, L. E-HIPA: An Energy-Efficient Framework for High-Precision Multi-Target-Adaptive Device-Free Localization. IEEE Trans. Mob. Comput. 2017, 16, 716–729. [Google Scholar] [CrossRef]
- Xiao, J.; Wu, K.; Yi, Y.; Wang, L.; Ni, L. Pilot: Passive Device-Free Indoor Localization Using Channel State Information. In Proceedings of the IEEE 33rd International Conference on Distributed Computing Systems, Philadelphia, PA, USA, 8–11 July 2013; pp. 236–245. [Google Scholar] [CrossRef]
- Abdel-Nasser, H.; Samir, R.; Sabek, I.; Youssef, M. Monophy: Mono-Stream-Based Device-Free WLAN Localization via Physical Layer Information. In Proceedings of the IEEE Wireless Communication Network Conference (WCNC), Shanghai, China, 7–10 July 2013; pp. 4546–4551. [Google Scholar] [CrossRef]
- Gao, Q.; Wang, J.; Ma, X.; Feng, X.; Wang, H. CSI-Based Device-Free Wireless Localization and Activity Recognition Using Radio Image Features. IEEE Trans. Veh. Technol. 2017, 66, 10346–10356. [Google Scholar] [CrossRef]
- Wang, J.; Xiong, J.; Jiang, H.; Jamieson, K.; Chen, X.; Fang, D.; Wang, C. Low Human-Effort, Device-Free Localization with Fine-Grained Subcarrier Information. IEEE Trans. Mob. Comput. 2018, 17, 2550–2563. [Google Scholar] [CrossRef]
- Wilson, J.; Patwari, N. Radio Tomographic Imaging with Wireless Networks. IEEE Trans. Mob. Comput. 2010, 9, 621–632. [Google Scholar] [CrossRef]
- Wipf, D.; Rao, B.; Nagarajan, S. Latent Variable Bayesian Models for Promoting Sparsity. IEEE Trans. Inf. Theory 2011, 57, 6236–6255. [Google Scholar] [CrossRef]
- Wipf, D.; Rao, B. Sparse Bayesian Learning for Basis Selection. IEEE Trans. Signal Process. 2004, 52, 2153–2164. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Explains | Values |
|---|---|---|
| F | number of channels | 15 |
| K | number of targets | 5 |
| M | number of links | 56 |
| N | number of grids | 784 |
| l | link length | 14 m |
| W | iteration number of CG algorithm | 17 |
| pruning threshold | 10 | |
| maximum number of iteration | 600 | |
| residual error threshold | ||
| sparsity threshold | dB |
| DFL Method | Sparse Recovery Algorithm | Computational Complexity | ||
|---|---|---|---|---|
| ComDec | VBI | m | m | |
| DR-DFL | VEM | m | m | |
| E-HIPA | OMP | m | m | |
| LCS | GMP | m | m |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, D.; Guo, Y.; Li, N.; Yang, X. Enhancing the Accuracy and Robustness of a Compressive Sensing Based Device-Free Localization by Exploiting Channel Diversity. Sensors 2019, 19, 1828. https://doi.org/10.3390/s19081828
Yu D, Guo Y, Li N, Yang X. Enhancing the Accuracy and Robustness of a Compressive Sensing Based Device-Free Localization by Exploiting Channel Diversity. Sensors. 2019; 19(8):1828. https://doi.org/10.3390/s19081828
Chicago/Turabian StyleYu, Dongping, Yan Guo, Ning Li, and Xiaoqin Yang. 2019. "Enhancing the Accuracy and Robustness of a Compressive Sensing Based Device-Free Localization by Exploiting Channel Diversity" Sensors 19, no. 8: 1828. https://doi.org/10.3390/s19081828
APA StyleYu, D., Guo, Y., Li, N., & Yang, X. (2019). Enhancing the Accuracy and Robustness of a Compressive Sensing Based Device-Free Localization by Exploiting Channel Diversity. Sensors, 19(8), 1828. https://doi.org/10.3390/s19081828