Convolutional Neural Network for Breathing Phase Detection in Lung Sounds

 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Sets
2.2. Manual Annotation of Breathing Phases
2.3. Developed Algorithm
2.3.1. Data Pre-Processing
2.3.2. Object Detection
2.3.3. Post-Processing
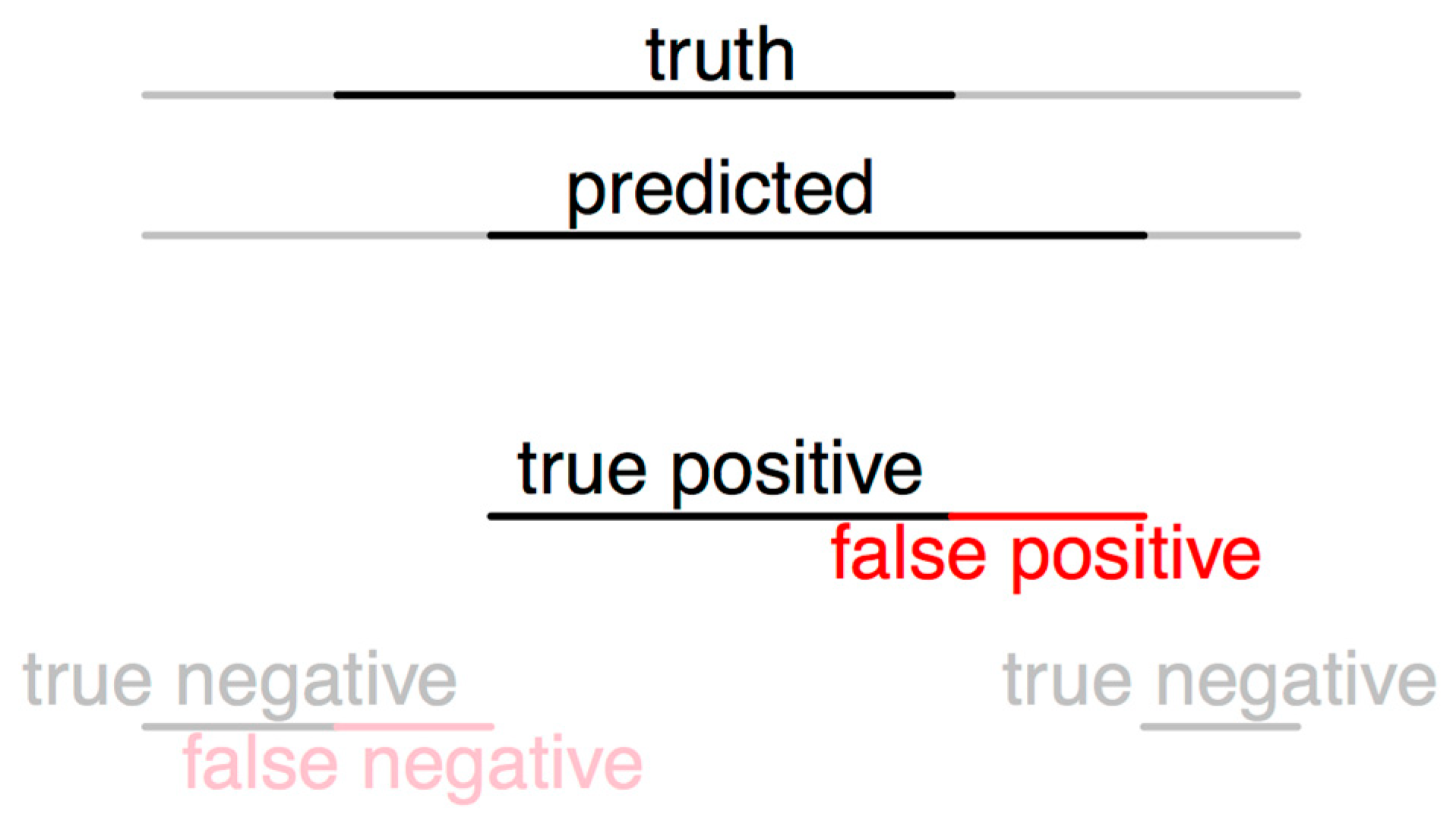
2.4. Evaluation of the Algorithm
2.4.1. Evaluation Method 1
2.4.2. Evaluation Method 2
3. Results
3.1. Evaluation Method 1
3.2. Evaluation Method 2
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bohadana, A.; Izbicki, G.; Kraman, S.S. Fundamentals of Lung Auscultation. N. Engl. J. Med. 2014, 370, 744–751. [Google Scholar] [CrossRef] [PubMed]
- Piirila, P.; Sovijarvi, A. Crackles: Recording, analysis and clinical significance. Eur. Respir. J. 1995, 8, 2139–2148. [Google Scholar] [CrossRef] [PubMed]
- Jácome, C.; Marques, A. Computerized Respiratory Sounds: Novel Outcomes for Pulmonary Rehabilitation in COPD. Respir. Care 2017, 62, 199–208. [Google Scholar] [CrossRef] [PubMed]
- Chuah, J.; Moussavi, Z. Automated Respiratory Phase Detection by Acoustical Means. Available online: https://www.researchgate.net/profile/Zahra_Moussavi/publication/228724229_Automated_respiratory_phase_detection_by_acoustical_means/links/55085b5a0cf27e990e0a83ce/Automated-respiratory-phase-detection-by-acoustical-means.pdf (accessed on 14 April 2019).
- Huq, S.; Moussavi, Z. Acoustic breath-phase detection using tracheal breath sounds. Med. Biol. Eng. Comput. 2012, 50, 297–308. [Google Scholar] [CrossRef] [PubMed]
- Reyes, B.A.; Reljin, N.; Kong, Y.; Nam, Y.; Ha, S.; Chon, K.H. Towards the Development of a Mobile Phonopneumogram: Automatic Breath-Phase Classification Using Smartphones. Ann. Biomed. Eng. 2016, 44, 2746–2759. [Google Scholar] [CrossRef] [PubMed]
- Sovijärvi, A.R.A.; Malmberg, L.P.; Charbonneau, G.; Vanderschoot, J.; Dalmasso, F.; Sacco, C.; Rossi, M.; Earis, J.E. Characteristics of breath sounds and adventitious respiratory sounds. Eur. Respir. Rev. 2000, 10, 591–596. [Google Scholar]
- Todd, S.; Walsted, E.S.; Grillo, L.; Livingston, R.; Menzies-Gow, A.; Hull, J.H. Novel assessment tool to detect breathing pattern disorder in patients with refractory asthma. Respirology 2018, 23, 284–290. [Google Scholar] [CrossRef] [PubMed]
- Dellweg, D.; Haidl, P.; Siemon, K.; Appelhans, P.; Kohler, D. Impact of breathing pattern on work of breathing in healthy subjects and patients with COPD. Respir. Physiol. Neurobiol. 2008, 161, 197–200. [Google Scholar] [CrossRef] [PubMed]
- Xiong, W.; Wu, L.; Alleva, F.; Droppo, J.; Huang, X.; Stolcke, A. The Microsoft 2017 Conversational Speech Recognition System. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgaria, AB, Canada, 15–20 April 2018; pp. 5934–5938. [Google Scholar]
- Saon, G.; Kurata, G.; Sercu, T.; Audhkhasi, K.; Thomas, S.; Dimitriadis, D.; Cui, X.; Ramabhadran, B.; Picheny, M.; Lim, L.-L.; et al. English Conversational Telephone Speech Recognition by Humans and Machines. arXiv, 2017; arXiv:1703.02136. [Google Scholar]
- Jaitly, N.; Hinton, G.E. A New Way to Learn Acoustic Events. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=2ahUKEwjh_a3X987hAhUIIIgKHa5_D4cQFjAAegQIABAC&url=https%3A%2F%2Fdeeplearningworkshopnips2011.files.wordpress.com%2F2011%2F12%2F24.pdf&usg=AOvVaw0s46muyf44MGKBfkbPf-Ez (accessed on 14 April 2019).
- Aviles-Solis, J.C.; Vanbelle, S.; Halvorsen, P.A.; Francis, N.; Cals, J.W.L.; Andreeva, E.A.; Marques, A.; Piirilä, P.; Pasterkamp, H.; Melbye, H. International perception of lung sounds: A comparison of classification across some European borders. BMJ Open Respir. Res. 2017, 4, e000250. [Google Scholar] [CrossRef] [PubMed]
- Dinis, J.; Campos, G.; Rodrigues, J.; Marques, A. Respiratory Sound Annotation Software. In Proceedings of the International Conference on Health Informatics, Vilamoura, Portugal, 7–9 November 2013; pp. 183–188. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Uijlings, J.R.; Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Alexe, B.; Deselaers, T.; Ferrari, V. Measuring the Objectness of Image Windows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2189–2202. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Efron, B. Bootstrap Methods: Another Look at the Jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Melbye, H.; Garcia-Marcos, L.; Brand, P.; Everard, M.; Priftis, K.; Pasterkamp, H. Wheezes, crackles and rhonchi: Simplifying description of lung sounds increases the agreement on their classification: A study of 12 physicians’ classification of lung sounds from video recordings. BMJ Open Respir. Res. 2016, 3, e000136. [Google Scholar] [CrossRef] [PubMed]
- Pinho, C.; Oliveira, A.; Jácome, C.; Rodrigues, J.; Marques, A. Automatic Crackle Detection Algorithm Based on Fractal Dimension and Box Filtering. Procedia Comput. Sci. 2015, 64, 705–712. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Annotation | N of Files | Duration | N of Inspiration Identified | N of Expiration Identified |
|---|---|---|---|---|---|
| Subset 1 (training) | Annotator 1 | 1022 | 10 s | 3212 | 2842 |
| Subset 2 (training) | Algorithm (inspected by Annotator 2) | 112 | 15 s | 447 | 418 |
| Subset 3 (test) | Annotator 1 | 120 | 15 s | 479 | 436 |
| Annotator 3 | 120 | 15 s | 499 | 459 |
| Agreement Using Boxes | Inspiration | Expiration | Both Phases |
|---|---|---|---|
| Annotator 1 vs. Algorithm | 98% | 95% | 96% |
| Annotator 3 vs. Algorithm | 95% | 79% | 87% |
| Annotator 1 vs. Annotator 3 | 95% | 84% | 90% |
| Sensitivity | Specificity | |||||
|---|---|---|---|---|---|---|
| Inspiration | Expiration | Both Phases | Inspiration | Expiration | Both Phases | |
| Algorithm (Annotator 1) | 97% | 94% | 96% | 86% | 87% | 87% |
| Algorithm (Annotator 3) | 98% | 97% | 98% | 84% | 78% | 81% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jácome, C.; Ravn, J.; Holsbø, E.; Aviles-Solis, J.C.; Melbye, H.; Ailo Bongo, L. Convolutional Neural Network for Breathing Phase Detection in Lung Sounds. Sensors 2019, 19, 1798. https://doi.org/10.3390/s19081798
Jácome C, Ravn J, Holsbø E, Aviles-Solis JC, Melbye H, Ailo Bongo L. Convolutional Neural Network for Breathing Phase Detection in Lung Sounds. Sensors. 2019; 19(8):1798. https://doi.org/10.3390/s19081798
Chicago/Turabian StyleJácome, Cristina, Johan Ravn, Einar Holsbø, Juan Carlos Aviles-Solis, Hasse Melbye, and Lars Ailo Bongo. 2019. "Convolutional Neural Network for Breathing Phase Detection in Lung Sounds" Sensors 19, no. 8: 1798. https://doi.org/10.3390/s19081798
APA StyleJácome, C., Ravn, J., Holsbø, E., Aviles-Solis, J. C., Melbye, H., & Ailo Bongo, L. (2019). Convolutional Neural Network for Breathing Phase Detection in Lung Sounds. Sensors, 19(8), 1798. https://doi.org/10.3390/s19081798