PMK—A Knowledge Processing Framework for Autonomous Robotics Perception and Manipulation



Abstract
:1. Introduction
- Knowledge formulation includes:(1) Standardized framework: the formalization of a previously introduced ontology framework [12] in such a way that it follows the standardized concepts of representing the knowledge for the autonomous robotics domain.(2) Knowledge representation for perception: the extension of the previous framework [12] to include the perceived information from sensors. Particularly, a sensing class has been added to define sensors, measurements processes, and their relation with the robot, e.g., the representation is workable for cameras or Radio Frequency Identification (RFID), and may include any implemented sensing library such as Yolo.
- Reasoning includes:(1) Situation analysis: the development of inference process predicates based on Description Logic (DL) to evaluate the objects’ situation in the environment based on spatial reasoning, and to relate the classes entities and reason over them. Moreover, potential placement region and spatial reachability of the robot are introduced.(2) Planning enhancement: the use of PMK as a black-box for any planner to reason about TAMP inference requirements, such as robot capabilities, action constraints, action feasibility, and manipulation behaviors.
2. Related Work
2.1. The Use of Knowledge in Different Domains
2.2. Standardization Efforts
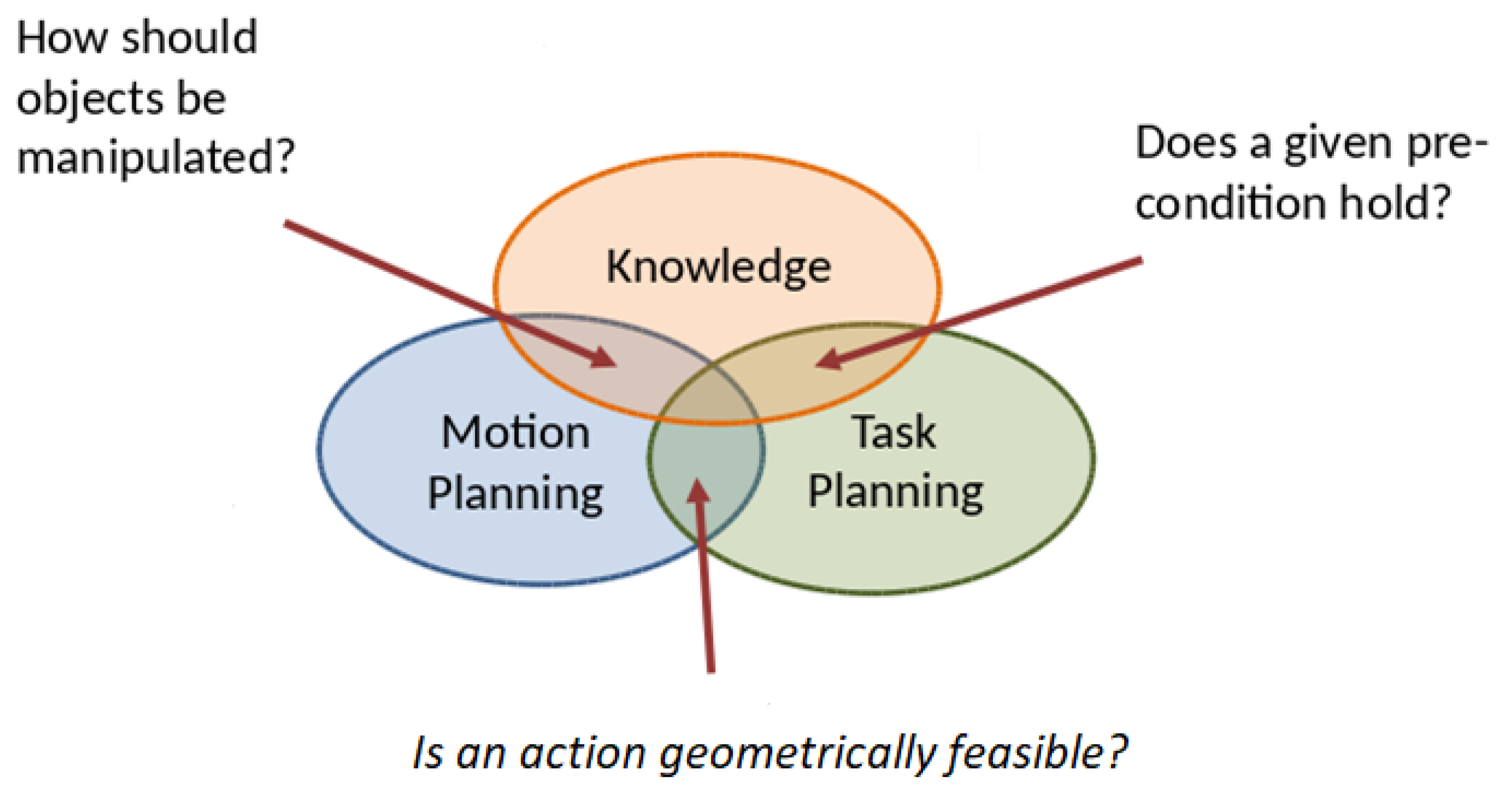
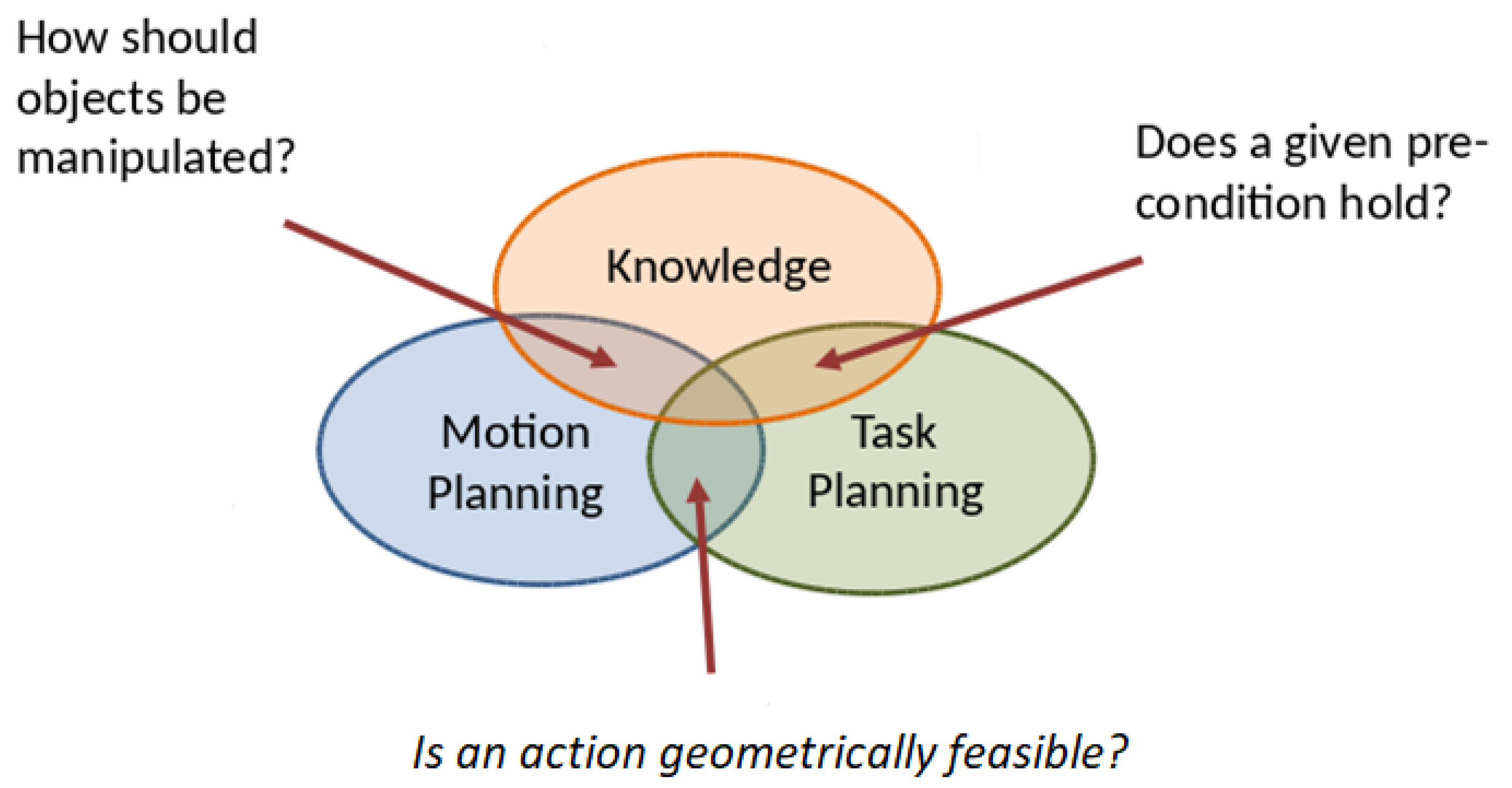
2.3. Task and Motion Planning Inference Requirements
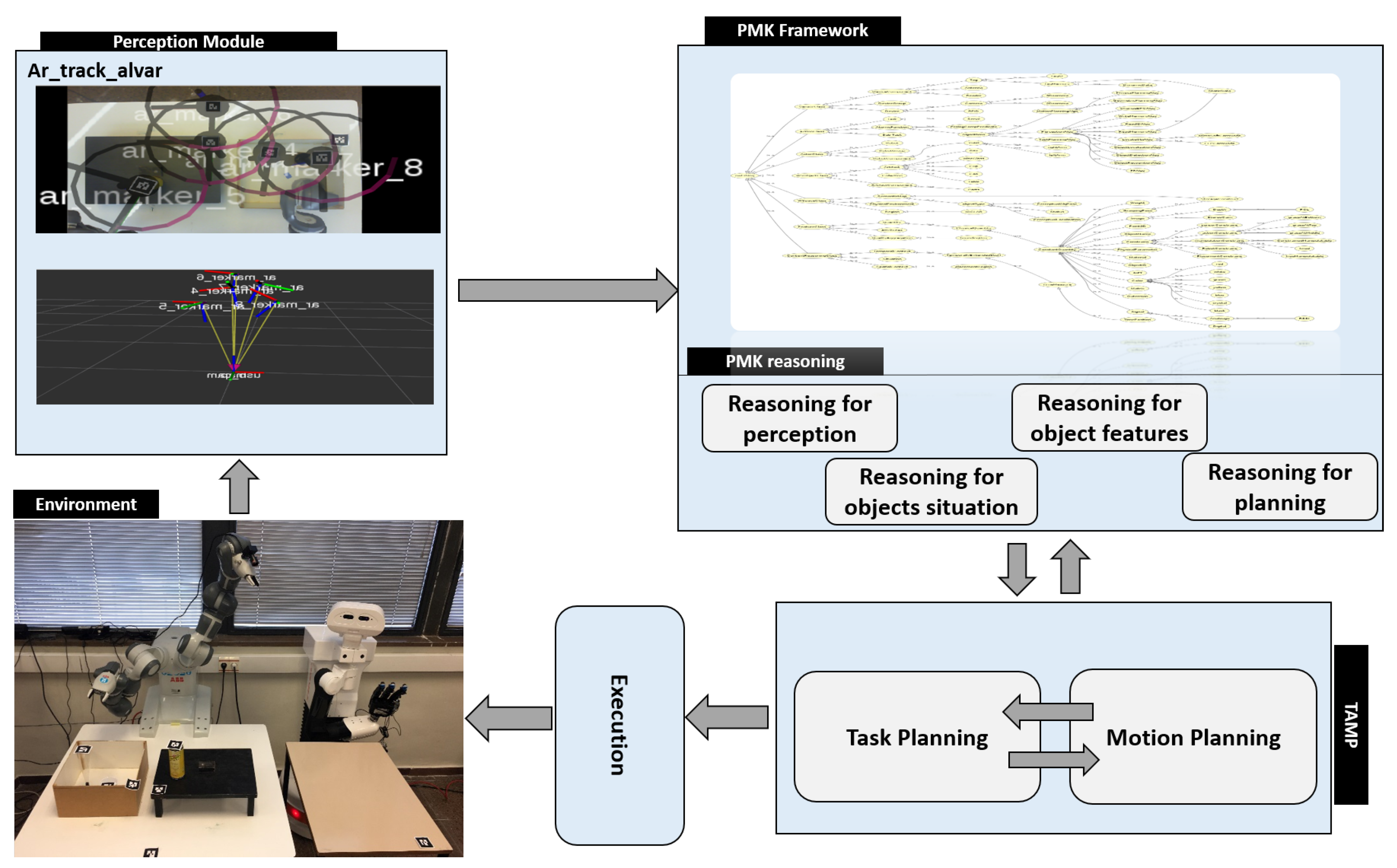
3. System Formulation
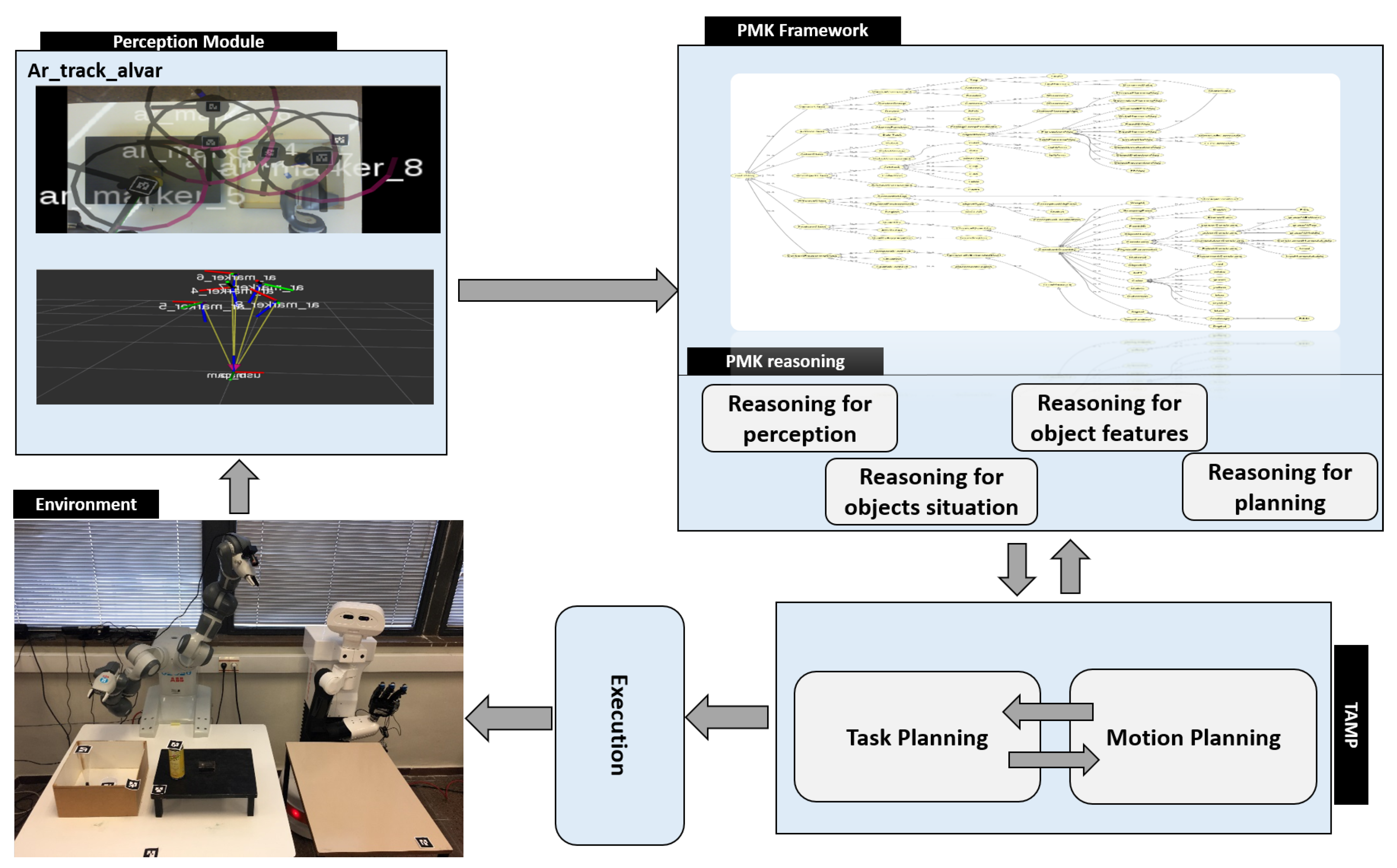
3.1. System Overview
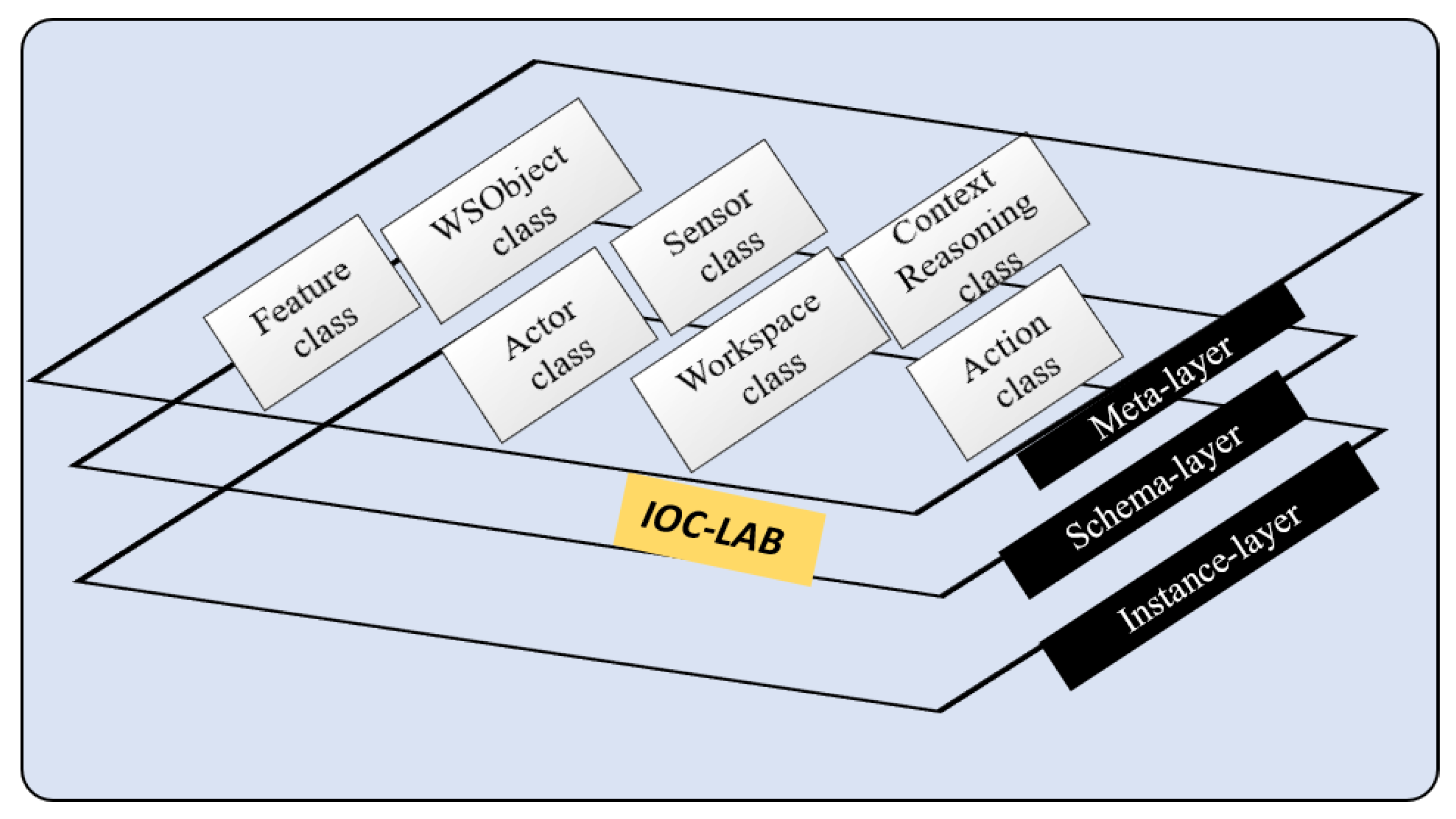
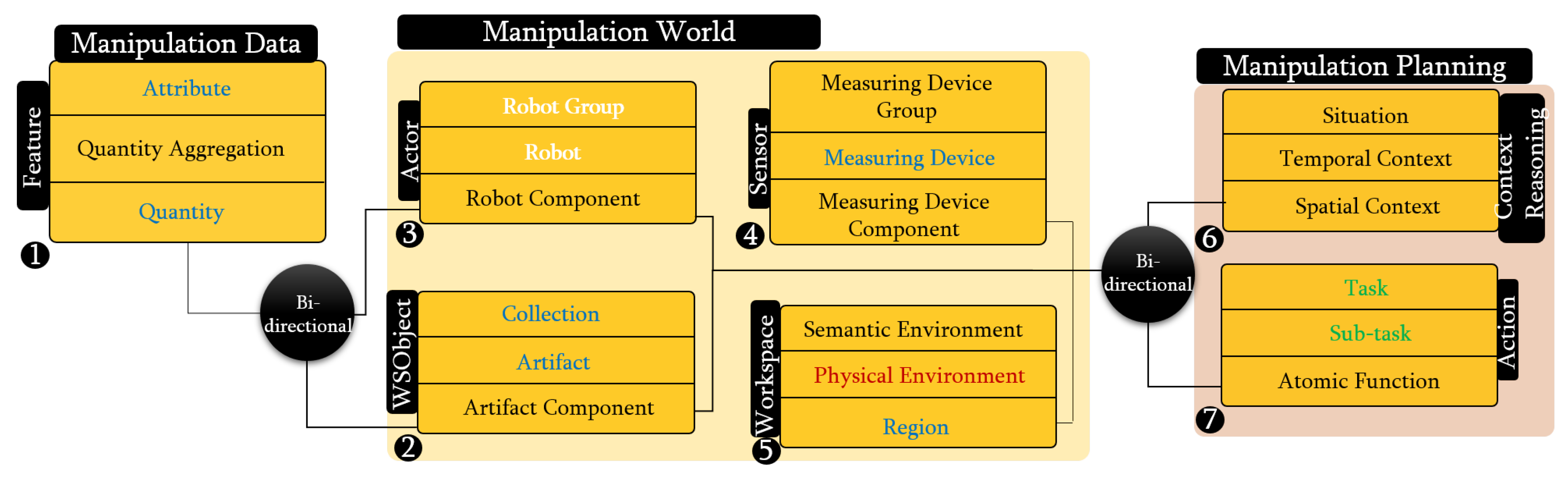
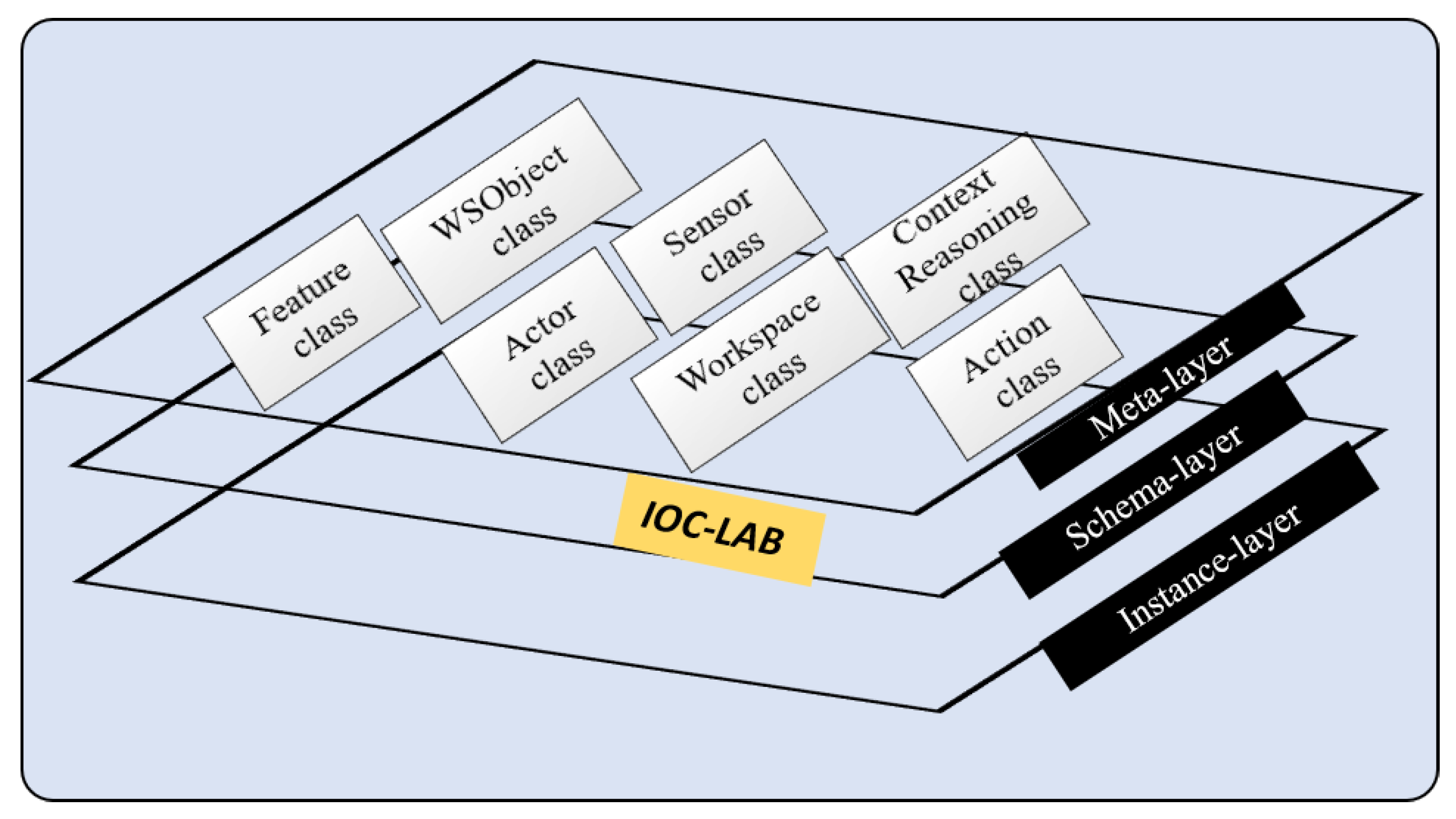
3.2. PMK Knowledge Structure
3.3. PMK Reasoning Mechanism
3.4. Why PMK?
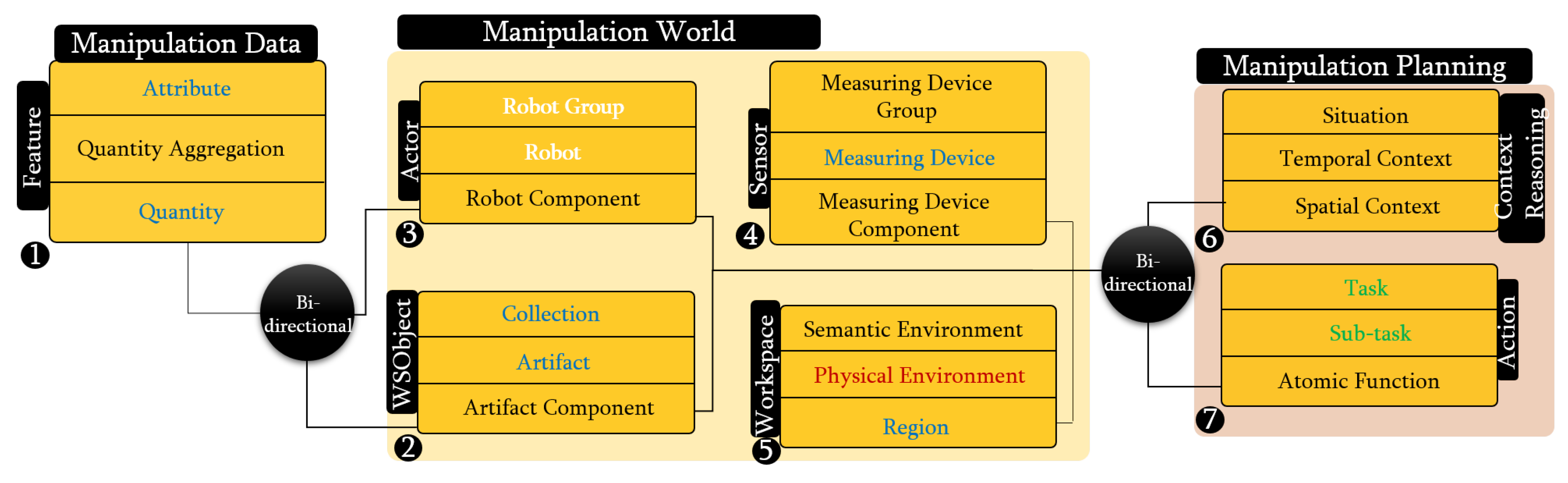
4. Knowledge Formulation
4.1. Manipulation Data Knowledge
4.2. Manipulation World Knowledge
4.3. Manipulation Planning Knowledge
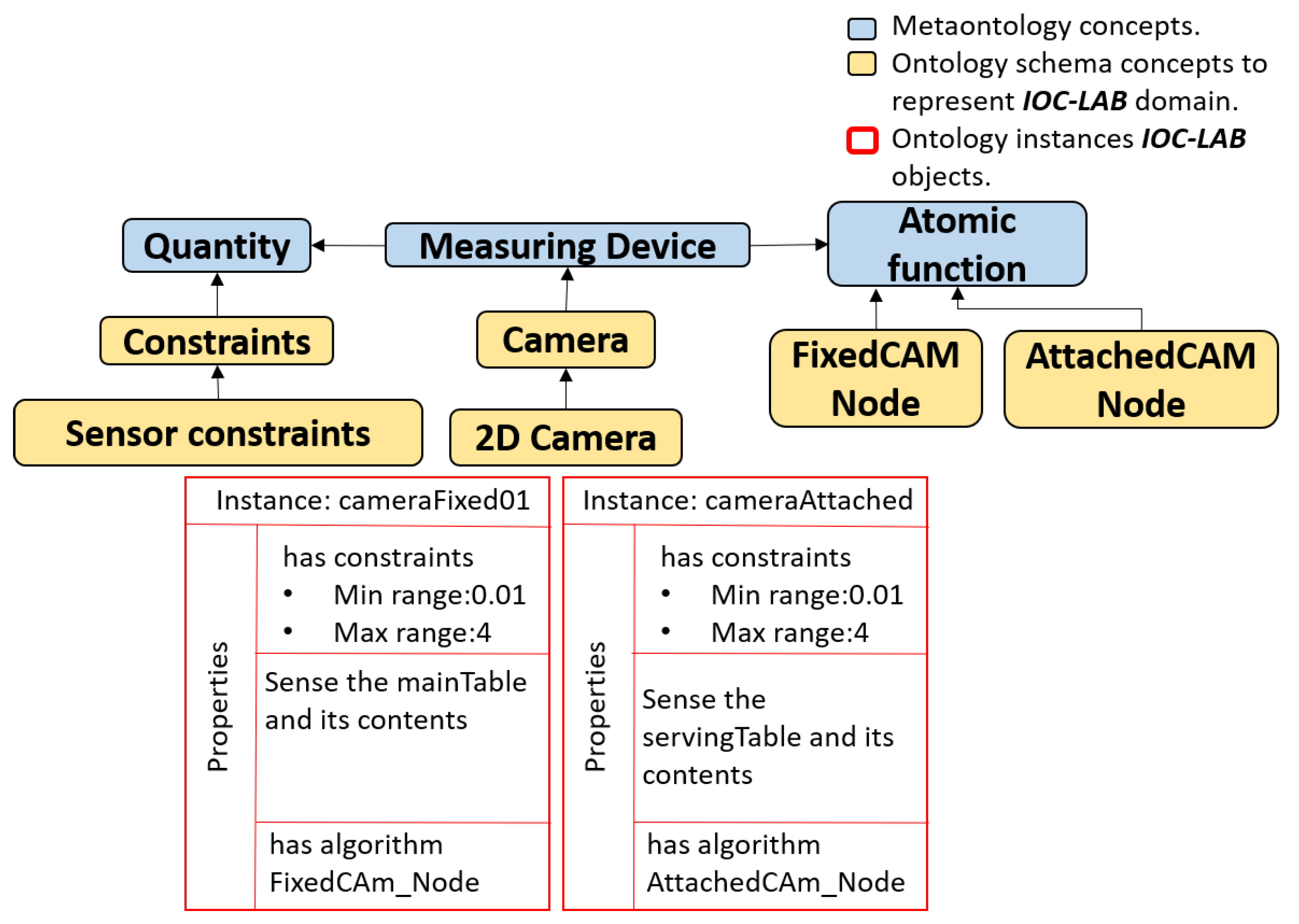
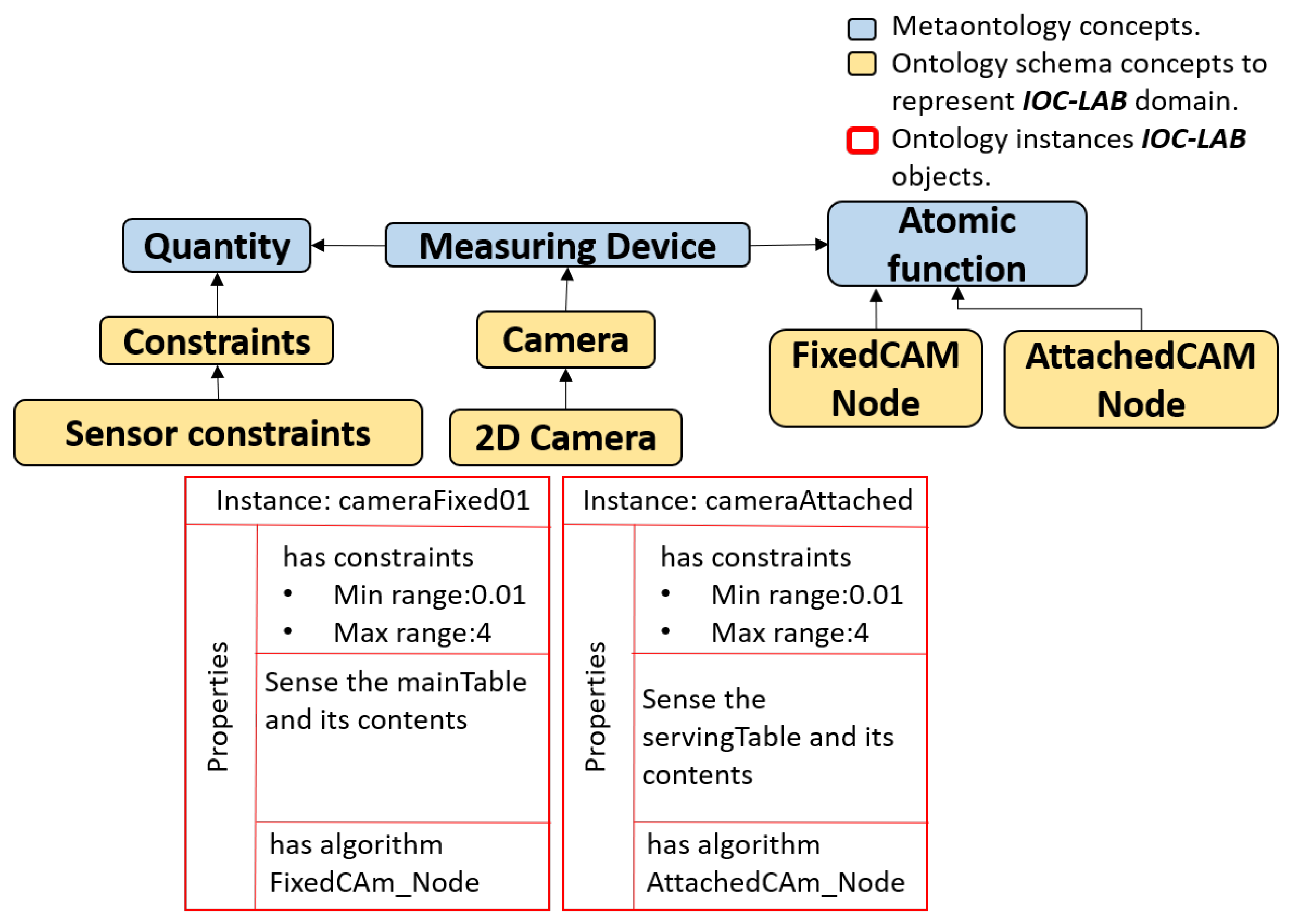
4.4. Knowledge Representation for Perception
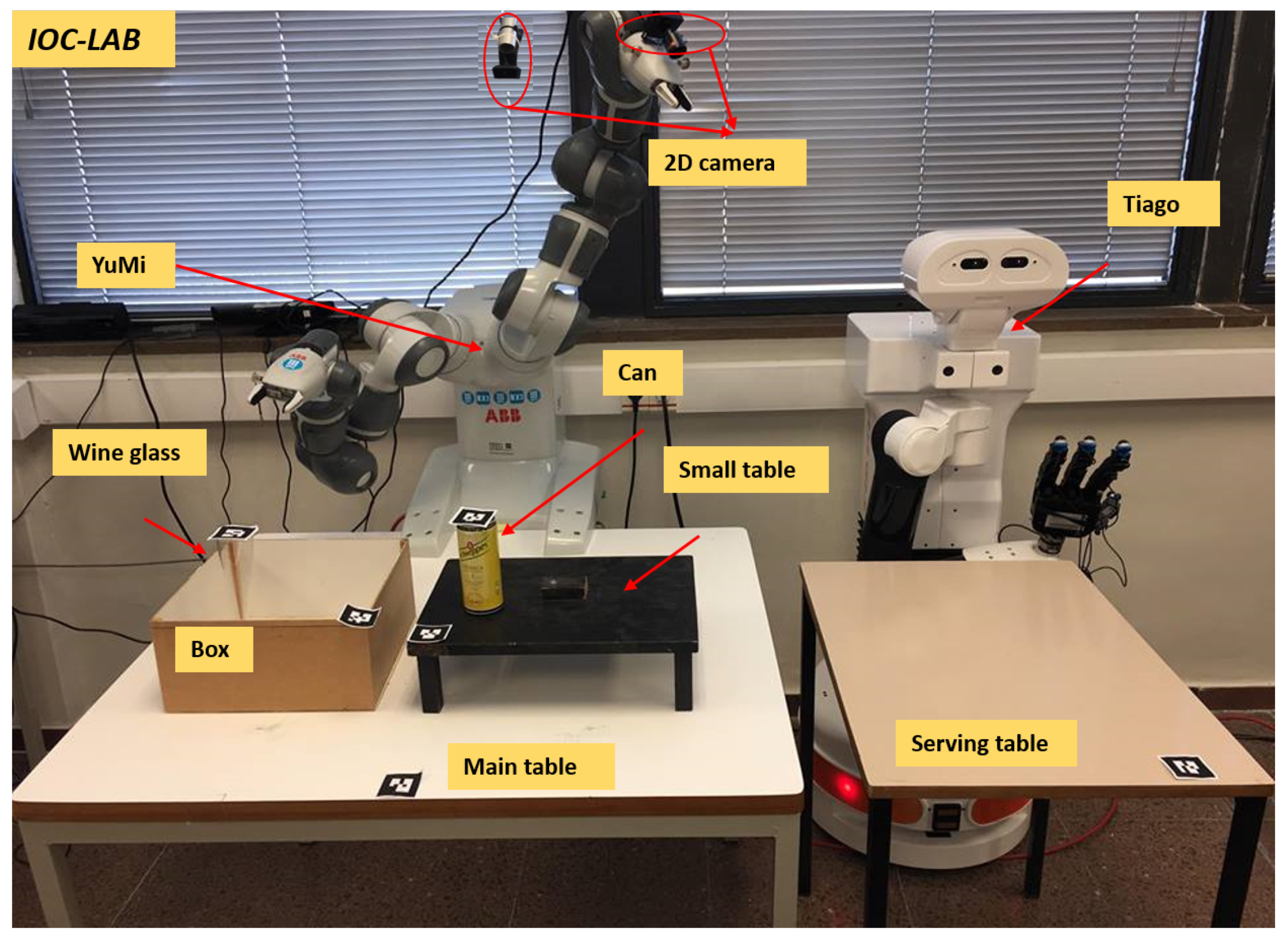
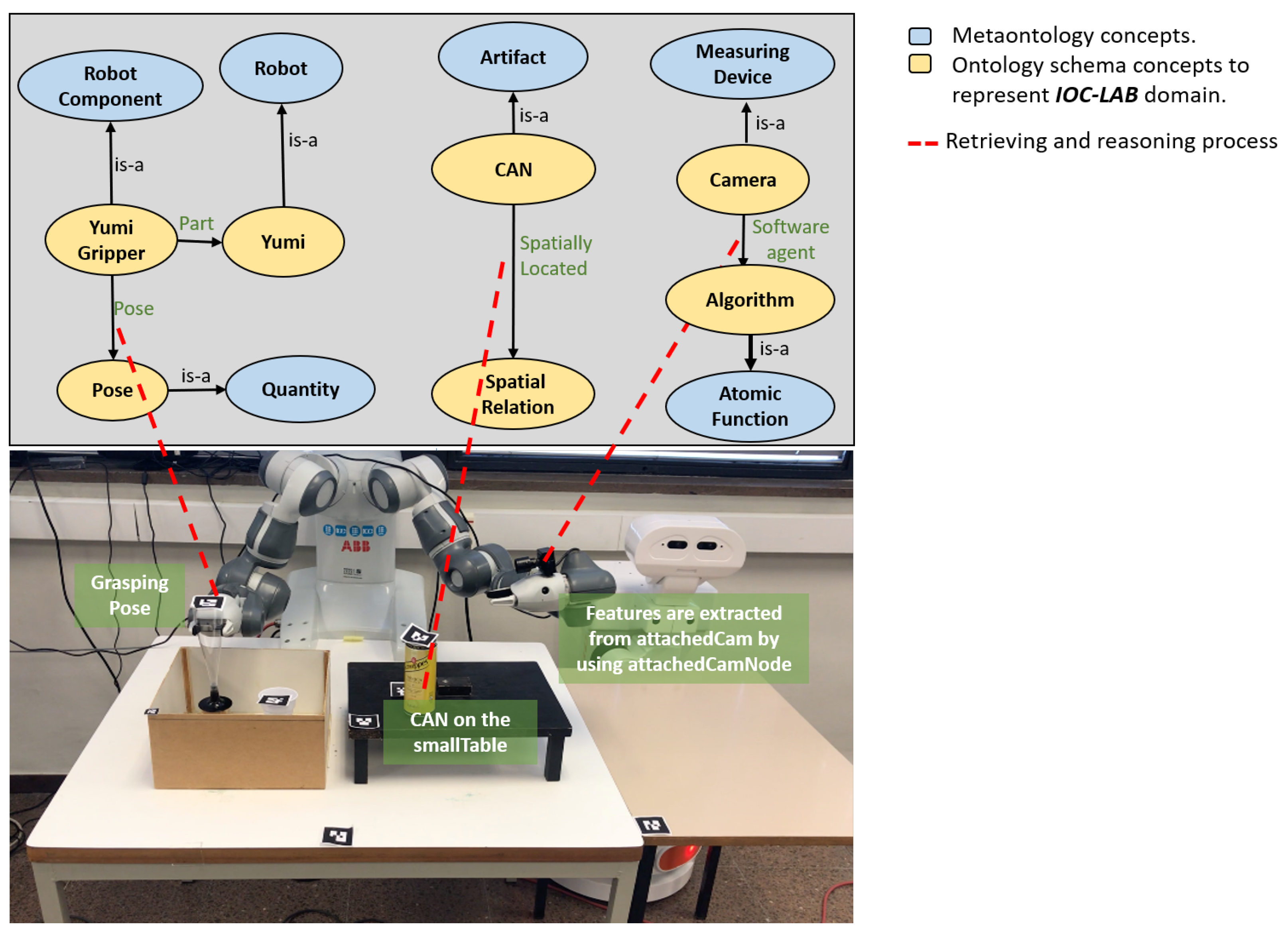
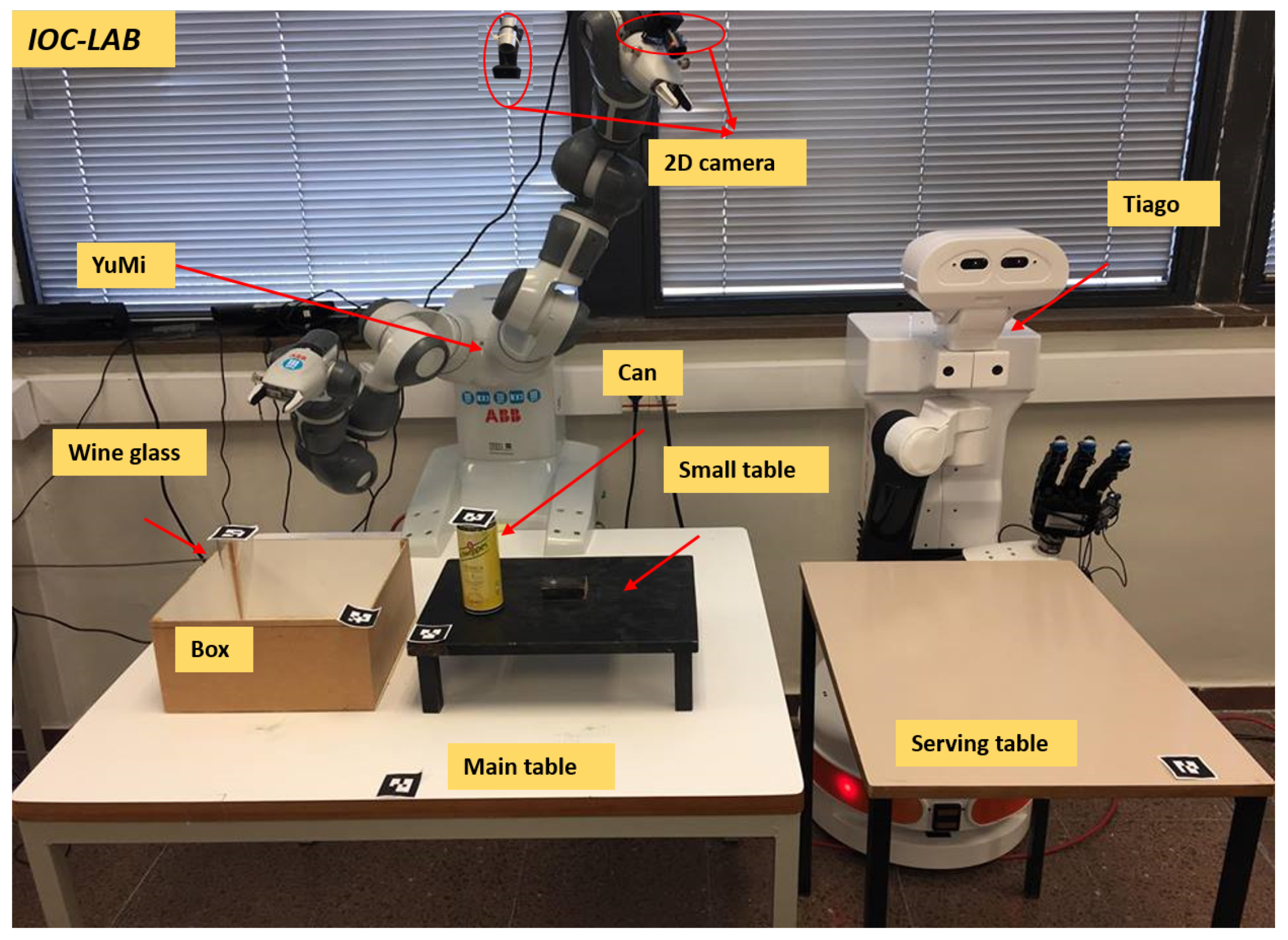
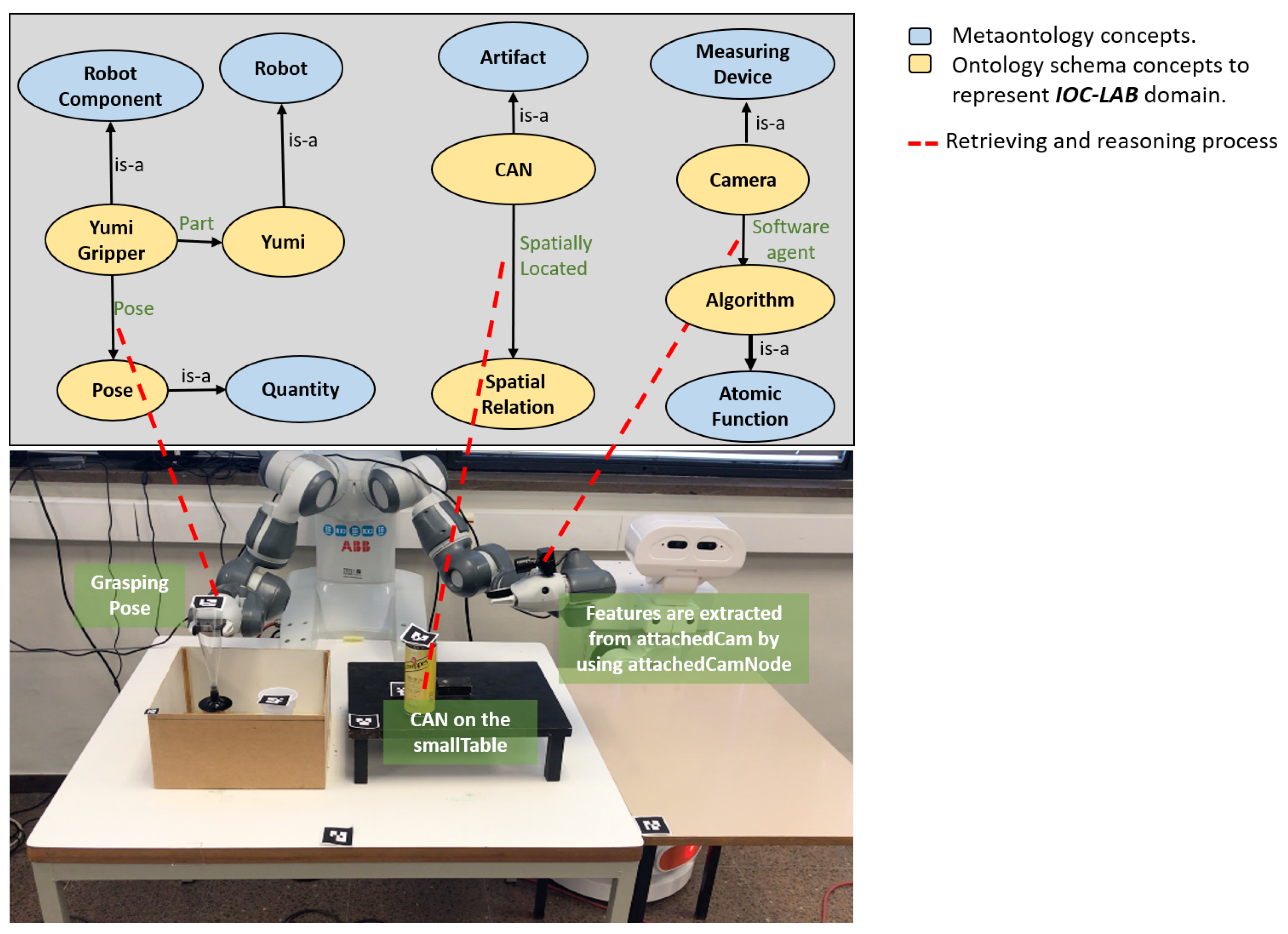
5. Case Study
5.1. Task Description
5.2. Implementation
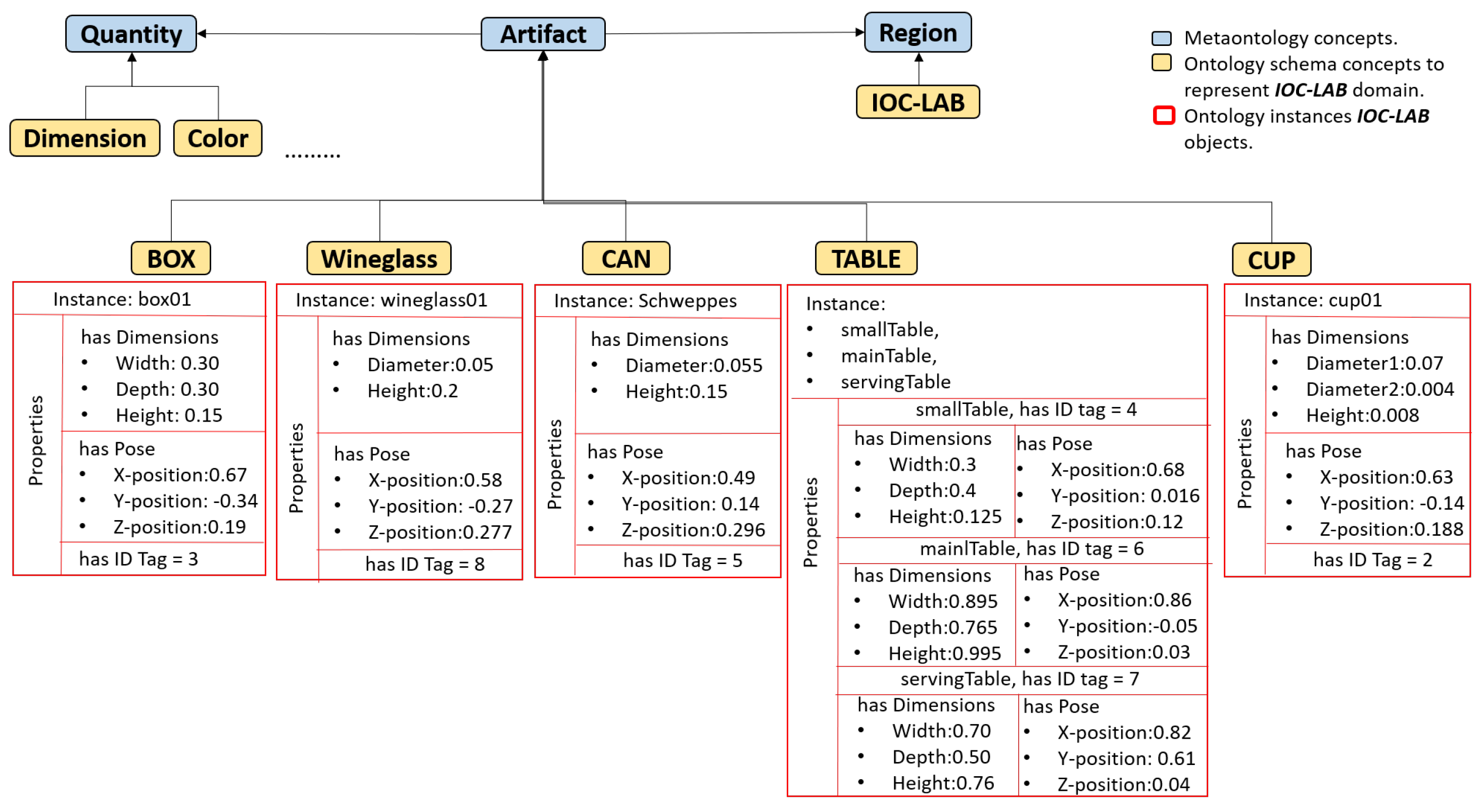
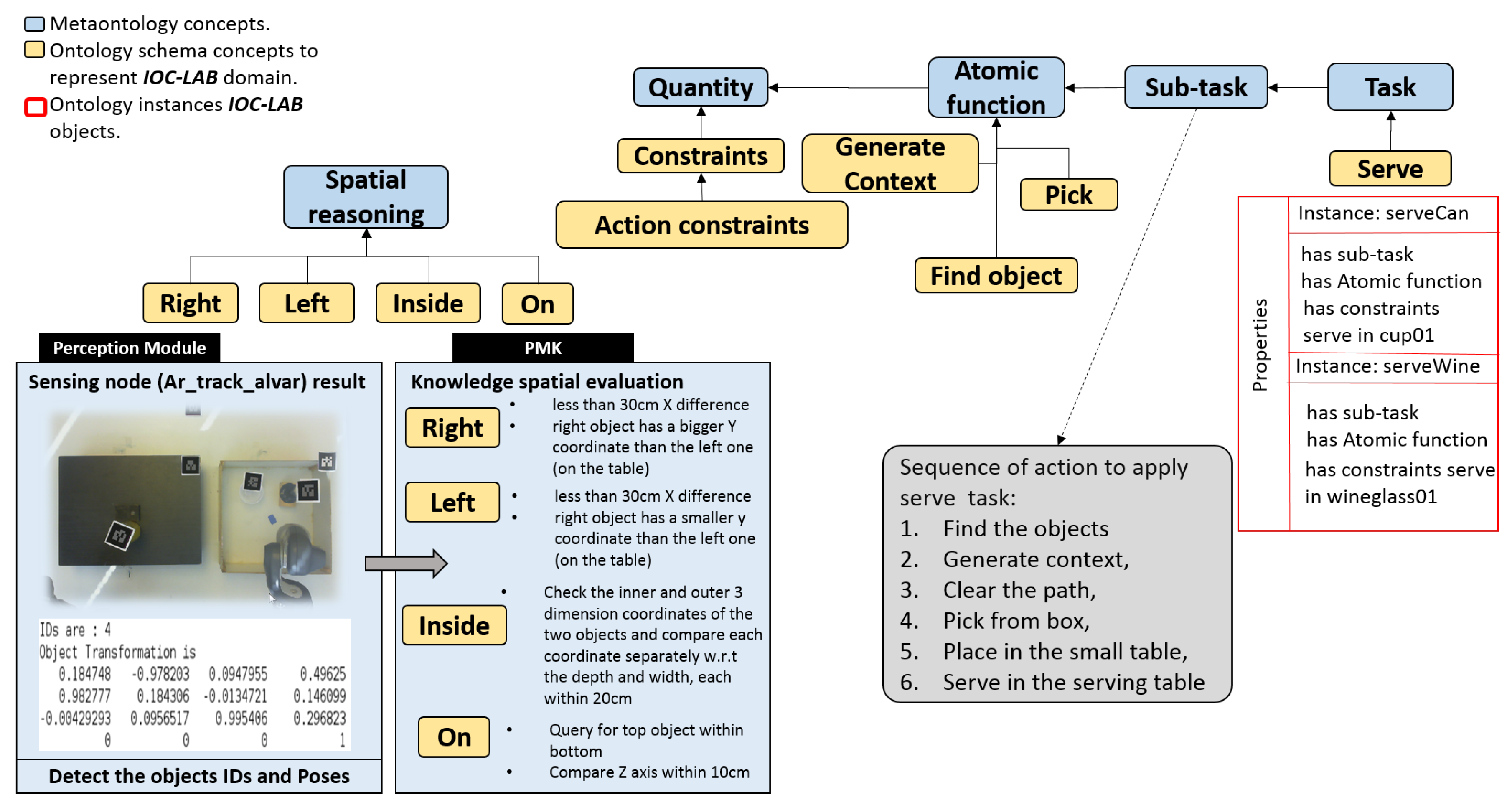
5.3. PMK Ontology Representation
5.4. Reasoning Process on Perception
5.5. Reasoning Process on Situation
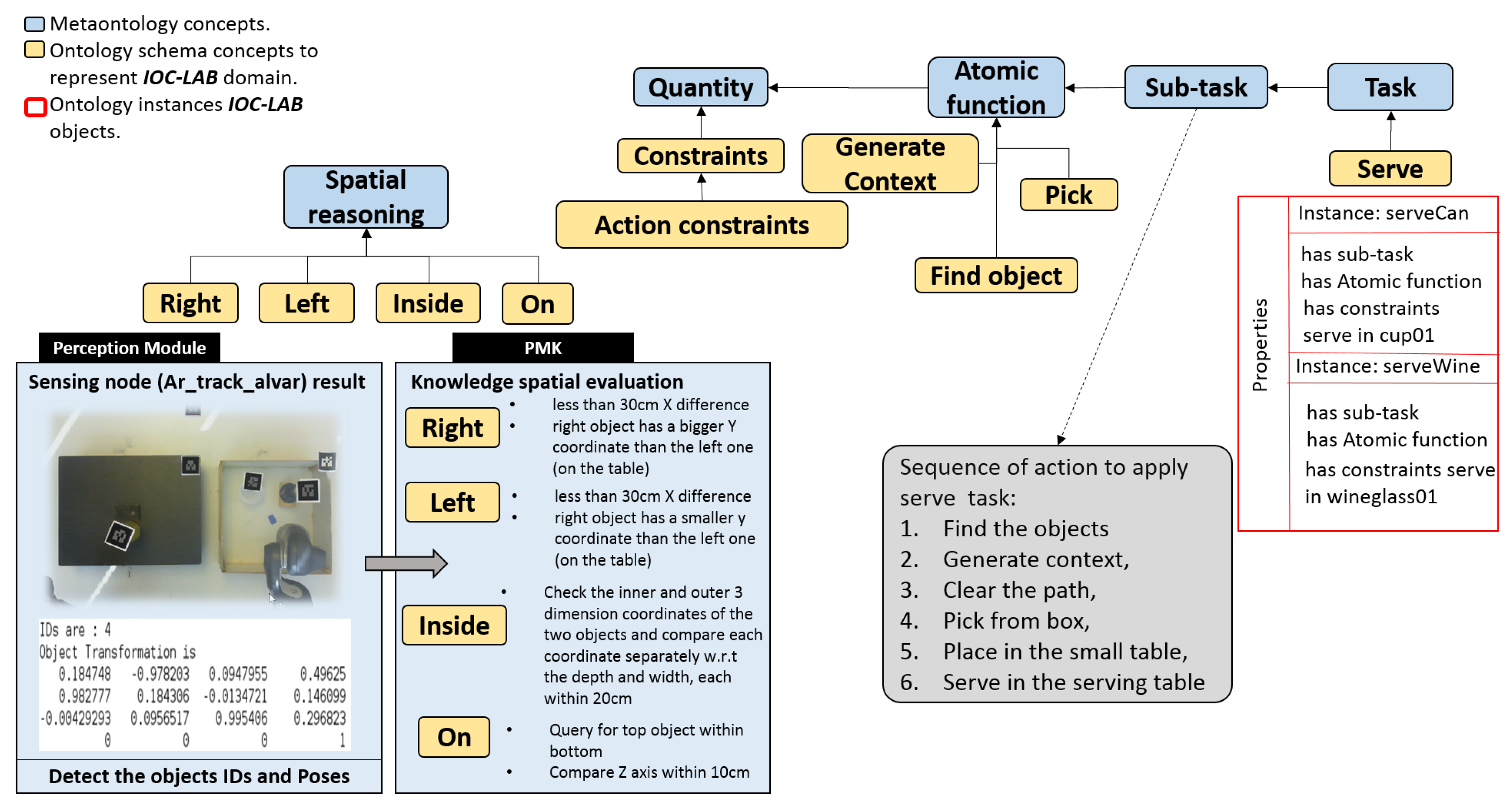
5.6. Reasoning Process on Discrete Actions
5.7. Reasoning Process on Motions
5.8. Extended Spatial Reasoning
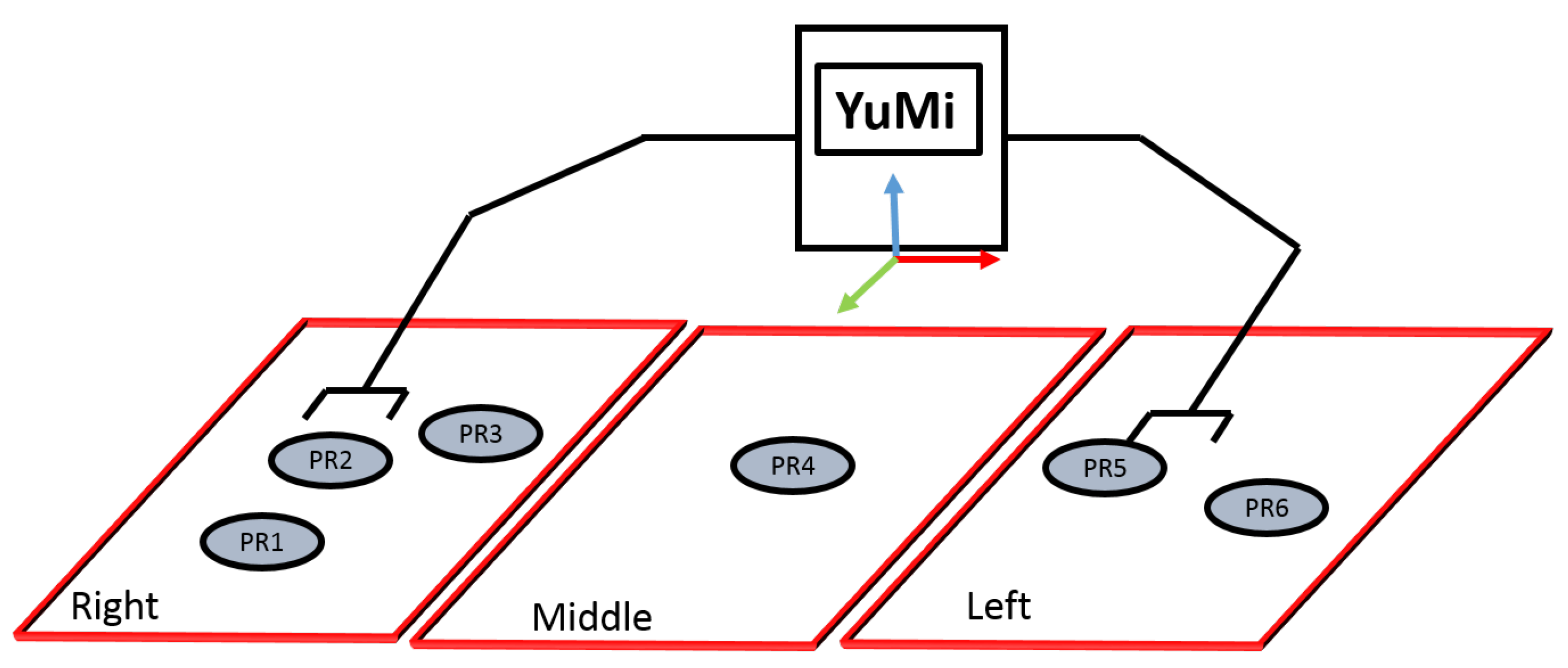
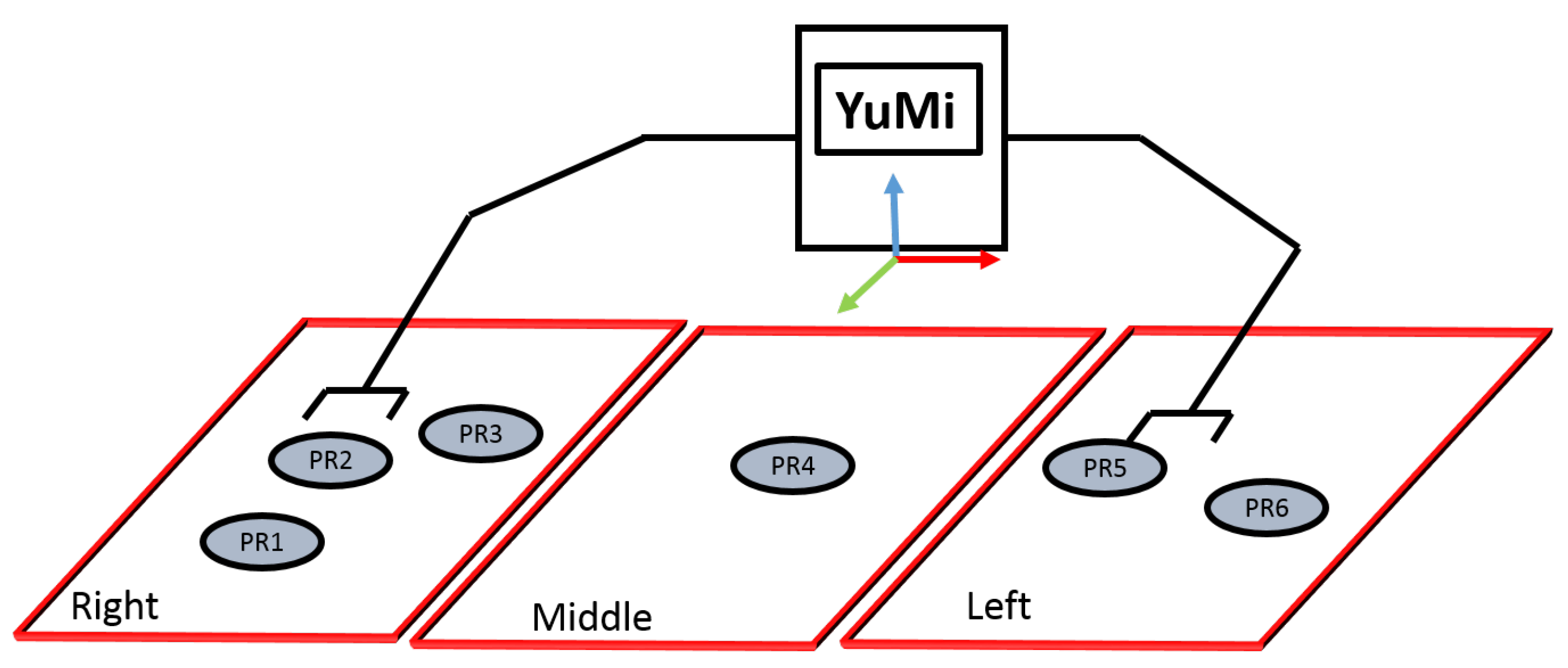
- Reachability Space Representation: As shown in Figure 11, the three regions have been introduced; right, left, and middle, and a given set of labels per region indicate where objects can be placed. The right arm is responsible for tackling the objects in the right area, while the left arm is responsible for grappling with the objects in the left area. Both arms can be used to handle the objects in the middle area. The predicate robot-reachability-grasping(Artifact, ?reachableArm) has been used to figure out which arm can be used to grasp an object, while robot-reachability-placement(Arm, ?PlacementTargetRgn) has been used to figure out the target placement regions to place an object.
5.9. Task Planning and Execution using PMK
5.10. System Flexibility
6. Discussion
6.1. Discussion about the Results
- Manipulation constraints such as: From where the object can be interacted?, What are the interaction parameters?
- Geometric constraints such as: What is the spatial robot reachability? Where can the objects be placed?
- Action constraints such as: From where can the actions be applied?
- Perception reasoning such as: What is the sensor attached to the robot? How does it work? What are its constraints, such as the sensor range measurement?
6.2. Discussion about the System
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| TAMP | Task and Motion Planning |
| FF | Fast Forward |
| PMK | Perception and Manipulation Knowledge |
| RFID | Radio Frequency Identification |
| PDDL | Planning Domain Definition Language |
Appendix A. Vocabulary of PMK levels
- Quantity: [11] Any specification of how many or how much of something there is. Accordingly, there are two subclasses of quantity: number (how many) and physical quantity (how much).
- Quantity Aggregation: A single quantity that represents a set of quantities such as Pose that represents the 3D location of the objects in the environment.
- Attribute: [11] Abstract qualities that can not or are chosen not to be considered as sub classes of Object.
- Artifact Component: [11] Representation of the parts of the workspace object in the world.
- Artifact: [11] An object that is the product of a making.
- Collection: [11] Collections have members like classes, but, unlike classes, they have a position in space-time and members can be added and subtracted without thereby changing the identity of the collection.
- Robot Component: Representation of the parts of the robot in the world.
- Robot: [11] A device in the world that is responsible for executing the tasks.
- Robot Group: [11] A group of robots organized to achieve at least one common goal.
- Measuring Device Component: Representation of the parts of the measuring device (sensor).
- Measuring Device: [11] Any device whose purpose is to measure a physical quantity.
- Device Group: A group of measuring devices that supply the robot information to achieve one common goal.
- Region: [11] A topographic location. Regions encompass surfaces of objects, imaginary places, and geographic areas.
- Physical Environment: [11] A physical environment is an object that has at least one specific part: a region in which it is located. In addition, a physical environment relates to at least one reference object based on which region is defined.
- Semantic Environment: A physical environment with data (feature) of the artifacts.
- Spatial Context: The circumstances that form the setting for an event that is related to space and which it can be fully understood. Specifically, a representation of the world in terms of space.
- Temporal Context: The circumstances that form the setting for an event that is related to time and which it can be fully understood. Specifically, a representation of the world in terms of time.
- Situation: The physical object situation in the environment that represents spatially and temporally the relation of the objects each others.
- Atomic Function: A representation of the processes for motion, manipulation and perception, such as task planners, motion planners or perceptual algorithms. Moreover, it includes primitive actions, preconditions and postconditions related to task planning.
- Sub-task [20] The summarization of the typical definition is, a representation of a short-term sequence of action.
- Task [20] The summarization of the typical definition is, a representation of a long-term goals of the symbolic preconditions and effects.
References
- Hoffmann, J.; Nebel, B. The FF planning system: Fast plan generation through heuristic search. J. Artif. Intel. Res. 2001, 14, 253–302. [Google Scholar] [CrossRef]
- McDermott, D.; Ghallab, M.; Howe, A.; Knoblock, C.; Ram, A.; Veloso, M.; Weld, D.; Wilkins, D. PDDL-the Planning Domain Definition Language; Yale University: Yale, CT, USA, 1998. [Google Scholar]
- Tenorth, M.; Beetz, M. Representations for robot knowledge in the KnowRob framework. Artif. Intel. Robot. 2017, 247, 151–169. [Google Scholar] [CrossRef]
- Lagriffoul, F.; Dantam, N.T.; Garrett, C.; Akbari, A.; Srivastava, S.; Kavraki, L.E. Platform-Independent Benchmarks for Task and Motion Planning. IEEE Robot. Automat. Lett. 2018, 3, 3765–3772. [Google Scholar] [CrossRef]
- Akbari, A.; Muhayyuddin; Rosell, J. Knowledge-oriented task and motion planning for multiple mobile robots. J. Experiment. Theoret. Artif. Intel. 2019, 31, 137–162. [Google Scholar] [CrossRef]
- Lim, G.H.; Suh, I.H.; Suh, H. Ontology-Based Unified Robot Knowledge for Service Robots in Indoor Environments. IEEE Trans. Syst. Man Cybernet. Part A Syst. Humans 2011, 41, 492–509. [Google Scholar] [CrossRef] [Green Version]
- Gruber, T.R. Toward principles for the design of ontologies used for knowledge sharing. Int. J. Hum. Comp. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Prestes, E.; Carbonera, J.L.; Fiorini, S.R.; Jorge, V.A.M.; Abel, M.; Madhavan, R.; Locoro, A.; Goncalves, P.; Barreto, M.E.; Habib, M.; et al. Towards a core ontology for robotics and automation. Robot. Auton. Syst. 2013, 61, 1193–1204. [Google Scholar] [CrossRef]
- Akbari, A.; Fabien, L.; Rosell, J. Combined heuristic task and motion planning for bi-manual robots. Auton. Robot. [CrossRef]
- Muhayyuddin; Moll, M.; Kavraki, L.; Rosell, J. Randomized Physics-Based Motion Planning for Grasping in Cluttered and Uncertain Environments. IEEE Robot. Automat. Lett. 2018, 3, 712–719. [Google Scholar] [CrossRef] [Green Version]
- IEEE-SA. IEEE Standard Ontologies for Robotics and Automation. Artif. Intel. Robot. 2015, 1–60. [Google Scholar] [CrossRef]
- Diab, M.; Muhayyuddin; Akbari, A.; Rosell, J. An Ontology Framework for Physics-BasedManipulation Planning; Springer: Berlin, Germany, 2017; pp. 452–464. [Google Scholar]
- Tenorth, M.; Beetz, M. KNOWROB: knowledge processing for autonomous personal robots. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, LO, USA, 11–15 October 2009; pp. 4261–4266. [Google Scholar]
- Ruiz-Sarmiento, J.R.; Galindo, C.; Gonzalez-Jimenez, J. Building Multiversal Semantic Maps for Mobile Robot Operation. Knowl. Based Syst. 2017, 119, 257–272. [Google Scholar] [CrossRef]
- Gemignani, G.; Capobianco, R.; Bastianelli, E.; Bloisi, D.D.; Iocchi, L.; Nardi, D. Living with robots: Interactive environmental knowledge acquisition. Robot. Auton. Syst. 2016, 78, 1–16. [Google Scholar] [CrossRef]
- Muhayyuddin; Akbari, A.; Rosell, J. κ-PMP: Enhancing Physics-based Motion Planners with Knowledge- Based Reasoning. J. Intel. Robot. Syst. 2017, 91, 459–477. [Google Scholar] [CrossRef]
- Schlenoff, C.; Prestes, E.; Madhavan, R.; Goncalves, P.; Li, H.; Balakirsky, S.; Kramer, T.; Miguelanez, E. An IEEE standard ontology for robotics and automation. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 1337–1342. [Google Scholar]
- Niles, I.; Pease, A. Towards a Standard Upper Ontology. In Proceedings of the International Conference on Formal Ontology in Information Systems—Volume 2001, Ogunquit, MN, USA, 17–19 October 2001. [Google Scholar]
- Fiorini, S.R.; Carbonera, J.L.; Gonçalves, P.; Jorge, V.A.; Rey, V.F.; Haidegger, T.; Abel, M.; Redfield, S.A.; Balakirsky, S.; Ragavan, V.L.; et al. Extensions to the core ontology for robotics and automation. Robot. Comp. Integr. Manuf. 2015, 33, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Olszewska, J.I.; Barreto, M.; Bermejo-Alonso, J.; Carbonera, J.; Chibani, A.; Fiorini, S.; Goncalves, P.; Habib, M.; Khamis, A.; Olivares, A.; et al. Proceedings of the 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisabon, Portugal, 28 August–1 September 2017.
- Dornhege, C.; Eyerich, P.; Keller, T.; Trüg, S.; Brenner, M.; Nebel, B. Semantic Attachments for Domain- independent Planning Systems. In Proceedings of the Nineteenth International Conference on International Conference on Automated Planning and Scheduling. AAAI Press, ICAPS’09, Thessaloniki, Greece, 19–23 September 2009; pp. 114–121. [Google Scholar]
- Tosello, E.; Fan, Z.; Association of Greece Central Educational Professionals. RTASK: A Cloudbased Knwoledge Engine for Robot Task and Motion Planning. Fields Robot. J. 2018. under review. [Google Scholar]
- Dantam, N.T.; Kingston, Z.K.; Chaudhuri, S.; Kavraki, L.E. Incremental Task and Motion Planning: A Constraint-Based Approach. In Proceedings of the Robotics: Science and Systems, Cambridge, MA, USA, 18–22 June 2016; pp. 1–6. [Google Scholar]
- Lagriffoul, F.; Dimitrov, D.; Saffiotti, A.; Karlsson, L. Constraint propagation on interval bounds for dealing with geometric backtracking. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 957–964. [Google Scholar]
- Akbari, A.; Muhayyuddin; Rosell, J. Task planning using physics-based heuristics on manipulation actions. Emerging Technologies and Factory Automation (ETFA). In Proceedings of the 2016 IEEE 21st International Conference on. IEEE, Berlin, Germany, 6–9 September 2016; pp. 1–8. [Google Scholar]
- Akbari, A.; Muhayyuddin; Rosell, J. Reasoning-Based Evaluation of Manipulation Actions for Efficient Task Planning. In Robot 2015: Second Iberian Robotics Conference; Springer: Berlin, Germany, 2016; pp. 69–80. [Google Scholar]
- Quispe, A.H.; Amor, H.B.; Christensen, H.I. A Taxonomy of Benchmark Tasks for Robot Manipulation. In Robotics Research; Springer: Berlin, Germany, 2018; pp. 405–421. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DL Description | Condition | Effect |
|---|---|---|
| (On, Subjective, Objective) :- , , . | The X and Y ranges of the bounding box of the Subjective artifact must be within those of the Objective, and the Z-ranges must be contiguous. | t artifact01 On artifact02 |
| (inside, Subjective, Objective) :- , , . | The X and Y ranges of the bounding box of the Subjective artifact must be within those of the Objective, and the Z-ranges must overlap. | t artifact01 inside artifact02 |
| (Right, Subjective, Objective) :- , , . | The X and Z ranges of the bounding box of the Subjective artifact must overlap those of the Objective, and the X-range of the bounding box of the Subjective must have its minimum value greater than the maximum value of the X-range of the Objective. | t artifact01 right artifact02 |
| (left, Subjective, Objective) :- , , . | The X and Z ranges of the bounding box of the Subjective artifact must overlap those of the Objective, and the X-range of the bounding box of the Subjective must have its maximum value lower than the minimum value of the X-range of the Objective. | artifact01 left artifact02 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diab, M.; Akbari, A.; Ud Din, M.; Rosell, J. PMK—A Knowledge Processing Framework for Autonomous Robotics Perception and Manipulation. Sensors 2019, 19, 1166. https://doi.org/10.3390/s19051166
Diab M, Akbari A, Ud Din M, Rosell J. PMK—A Knowledge Processing Framework for Autonomous Robotics Perception and Manipulation. Sensors. 2019; 19(5):1166. https://doi.org/10.3390/s19051166
Chicago/Turabian StyleDiab, Mohammed, Aliakbar Akbari, Muhayy Ud Din, and Jan Rosell. 2019. "PMK—A Knowledge Processing Framework for Autonomous Robotics Perception and Manipulation" Sensors 19, no. 5: 1166. https://doi.org/10.3390/s19051166
APA StyleDiab, M., Akbari, A., Ud Din, M., & Rosell, J. (2019). PMK—A Knowledge Processing Framework for Autonomous Robotics Perception and Manipulation. Sensors, 19(5), 1166. https://doi.org/10.3390/s19051166