Microservice-Oriented Platform for Internet of Big Data Analytics: A Proof of Concept



Abstract
1. Introduction
- A new theory of a microservice-oriented platform on SDI. The theory essentially evolves the architecture of BDA implementations in general, i.e., further decoupling data processing logic from computing resource management. Such an architecturally loose coupling will generate more research opportunities in academia and will better guide BDA practices, particularly in the dynamic IoT environment.
- A functional microservice-oriented platform with predesigned microservices. In addition to facilitating IoBDA implementations for practitioners, a functional platform will, in turn, drive its own evolution along two directions. Vertically, our use cases can help validate and improve the underlying technologies (deeper-level platforms or frameworks) [12] while strengthening their compatibility with our platform. Horizontally, the initial functionalities can inspire more research efforts that aim to enrich microservice-oriented data processing logics and expand the applicability of this platform.
2. Related Work
3. Conceptual Explanation and Justification
4. Case I: Microservice-Oriented Logic for Monte Carlo Analytics
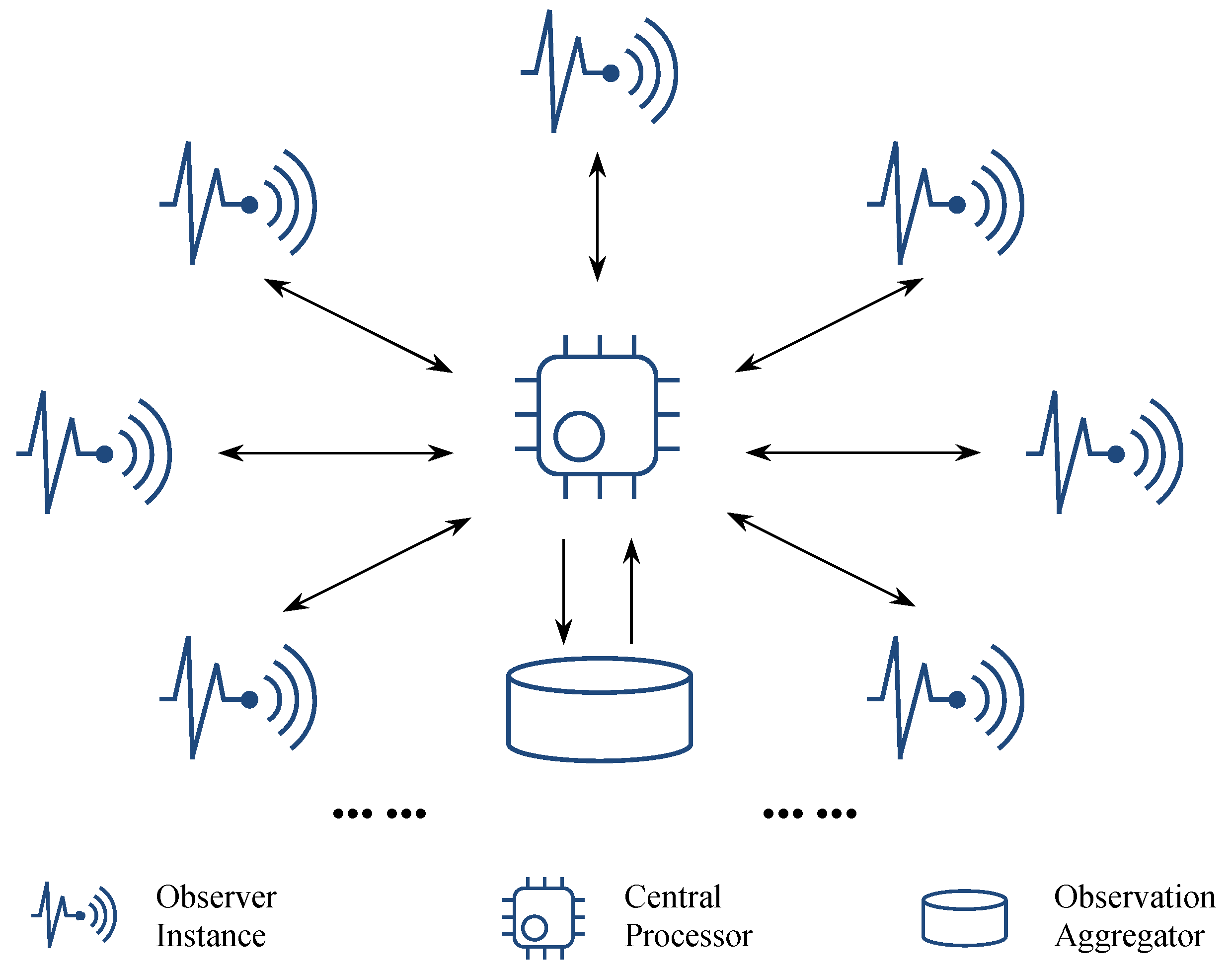
4.1. Architectural Design with Microservice Identification
- Observer is a microservice template to be instantiated for specific observation tasks. Multiple observation tasks can be accomplished either by a group of observer instances or by multiple observation activities of a single observer instance. As the name suggests, observer instances are supposed to be deployed or migrated to virtualization-friendly IoT sensors/devices or their governors.
- Central Processor splits a whole job into independent pieces as observation tasks, assigns individual tasks to available observer instances, and correspondingly receives observation results. In addition to passing the observation results to Observation Aggregator, the central processor can also incrementally retrieve and manipulate the aggregated observation results into continuous and value-added outputs if needed.
- Observation Aggregator collects, stores, and can directly output observation results if they are immediately ready to use. Note that the observation results here should not be a simple transition of original data from the observer side. Taking a sampling task as an example, the observation will send back a statistical result instead of the information about detailed samples (see the demonstration in Section 4.2). In other words, the observation aggregation here does not conflict with the principle of collectionless analytics in the IoT environment.
4.2. Conceptual Validation Using Double Integral Estimation
| Algorithm 1 Monte Carlo Approximation of Double Integral |
Input: N: the total number of trials in Monte Carlo estimation. Output: The approximation result of the predefined double integral .
|
4.3. Prospect of Practical Application
5. Case II: Microservice-Oriented Logic for Convergence Analytics
5.1. Architectural Design with Microservice Identification
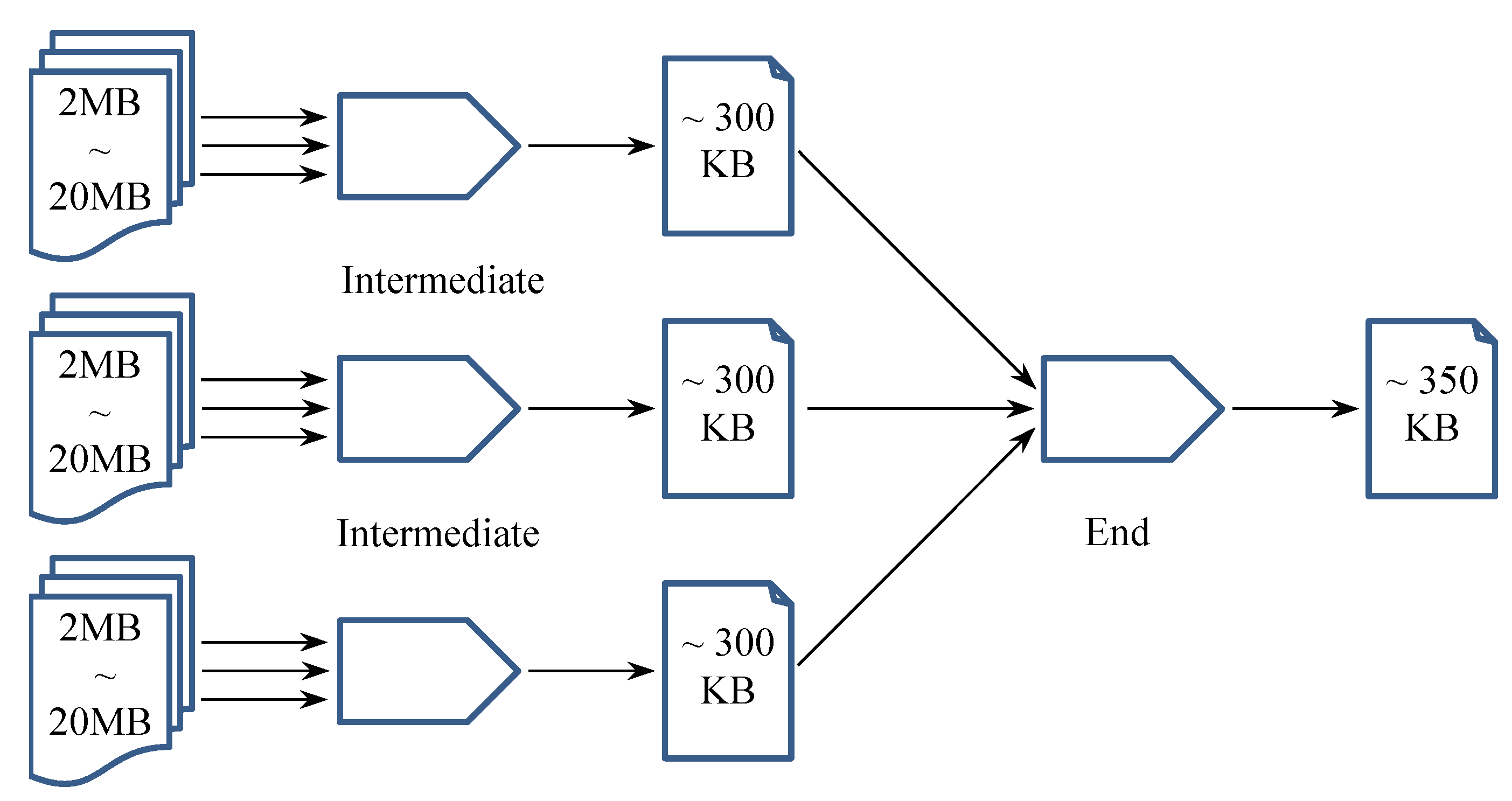
- Cache Converger prepares data blocks by merging small pieces of data from a limited range/cluster of IoT sensors/devices, whereas it does not reduce the overall data size. Cache convergers could particularly be helpful for passing a large number of discrete data records to the subsequent MapReduce logic, as dealing with tiny-data transactions would be inefficient in terms of both execution time and energy expense [25]. In fact, caching data before transmission has become an energy optimization strategy, especially for mobile devices [26]. Note that cache convergers should be located at (or at least close to) the Internet edge in order to take advantage of the relatively trivial overhead of edge communication for receiving small data pieces.
- Intermediate MapReduce Converger either receives preprocessed data blocks from observer instances and cache convergers or receives pre-converged data from antecedent (also intermediate) MapReduce convergers and then uses the MapReduce mechanism to further converge the received data. Since we do not expect cache convergers to reduce data size/amount tremendously, the outermost MapReduce convergers should also be located close to the edge of the Internet.
- End MapReduce Converger receives final-stage intermediate convergence results and still uses the MapReduce mechanism to complete the whole analytics job. In contrast, the end MapReduce converger can be located remotely from the Internet edge. There is no doubt that the region-wide and cross-region communications will incur increasingly higher overhead; however, here we can expect to transfer less data as compensation, because the intermediate convergence results should have been much smaller than the sum of their raw inputs.
5.2. Conceptual Validation Using Word Count with Cascade Convergence
| Algorithm 2 Cascade-Convergence-based Word Count |
Input: S: the continuous string-format “sensor” data. Output: The word count result.
|
5.3. Prospect of Practical Application
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| API | Application Program Interface |
| BDA | Big Data Analytics |
| IoBDA | Internet of Big Data Analytics |
| IoT | Internet of Things |
| JSON | JavaScript Object Notation |
| MSA | Microservices Architecture |
| OCR | Optical Character Recognition |
| REST | Representational State Transfer |
| SDI | Software-Defined Infrastructure |
| SDN | Software-Defined Network |
| SDS | Software-Defined Storage |
| XML | Extensible Markup Language |
References
- PAT Research. Top 50 Bigdata Platforms and Bigdata Analytics Software. 2018. Available online: https://www.predictiveanalyticstoday.com/bigdata-platforms-bigdata-analytics-software/ (accessed on 7 January 2019).
- Darabseh, A.; Al-Ayyoub, M.; Jararweh, Y.; Benkhelifa, E.; Vouk, M.; Rindos, A. SDStorage: A Software Defined Storage Experimental Framework. In Proceedings of the 3rd International Conference on Cloud Engineering (IC2E 2015), Tempe, AZ, USA, 9–13 March 2015; IEEE Computer Society: Tempe, AZ, USA, 2015; pp. 341–346. [Google Scholar]
- Djedouboum, A.C.; Ari, A.A.A.; Gueroui, A.M.; Mohamadou, A.; Aliouat, Z. Big Data Collection in Large-Scale Wireless Sensor Networks. Sensors 2018, 18, 4474. [Google Scholar] [CrossRef] [PubMed]
- Froehlich, A. How Edge Computing Compares with Cloud Computing. Available online: https://www.networkcomputing.com/networking/how-edge-computing-compares-cloud-computing/1264320109 (accessed on 7 January 2019).
- IEEE. Cloud-Link: IoT and Cloud. Available online: https://cloudcomputing.ieee.org/publications/cloud-link/march-2018 (accessed on 7 January 2019).
- Kang, J.M.; Bannazadeh, H.; Rahimi, H.; Lin, T.; Faraji, M.; Leon-Garcia, A. Software-Defined Infrastructure and the Future Central Office. In Proceedings of the 2nd Workshop on Clouds Networks and Data Centers, Budapest, Hungary, 9–13 June 2013; IEEE Press: Budapest, Hungary, 2013; pp. 225–229. [Google Scholar]
- Kang, J.M.; Lin, T.; Bannazadeh, H.; Leon-Garcia, A. Software-Defined Infrastructure and the SAVI Testbed. In TridentCom 2014: Testbeds and Research Infrastructure: Development of Networks and Communities; Leung, V.C., Chen, M., Wan, J., Zhang, Y., Eds.; Springer: Cham, Switzerland, 2014; Volume 137, pp. 3–13. [Google Scholar]
- Harris, R. Myriad Use Cases. Available online: https://cwiki.apache.org/confluence/display/MYRIAD/Myriad+Use+Cases (accessed on 7 January 2019).
- Li, C.S.; Brech, B.L.; Crowder, S.; Dias, D.M.; Franke, H.; Hogstrom, M.; Lindquist, D.; Pacifici, G.; Pappe, S.; Rajaraman, B.; et al. Software defined environments: An introduction. IBM J. Res. Dev. 2014, 58, 1–11. [Google Scholar] [CrossRef]
- Nunes, B.A.A.; Mendonca, M.; Nguyen, X.N.; Obraczka, K.; Turletti, T. A Survey of Software-Defined Networking: Past, Present, and Future of Programmable Networks. IEEE Commun. Surv. Tutor. 2014, 16, 1617–1634. [Google Scholar] [CrossRef]
- Villari, M.; Fazio, M.; Dustdar, S.; Rana, O.; Ranjan, R. Osmotic Computing: A New Paradigm for Edge/Cloud Integration. IEEE Cloud Comput. 2016, 3, 76–83. [Google Scholar] [CrossRef]
- Vögler, M.; Schleicher, J.M.; Inzinger, C.; Dustdar, S. Ahab: A Cloud-based Distributed Big Data Analytics Framework for the Internet of Things. Softw. Pract. Exp. 2017, 47, 443–454. [Google Scholar] [CrossRef]
- Le, V.D.; Neff, M.M.; Stewart, R.V.; Kelley, R.; Fritzinger, E.; Dascalu, S.M.; Harris, F.C. Microservice-based Architecture for the NRDC. In Proceedings of the 13th IEEE International Conference on Industrial Informatics (INDIN 2015), Cambridge, UK, 22–24 July 2015; IEEE Press: Cambridge, UK, 2015; pp. 1659–1664. [Google Scholar]
- Kang, R.; Zhou, Z.; Liu, J.; Zhou, Z.; Xu, S. Distributed Monitoring System for Microservices-Based IoT Middleware System. In ICCCS 2018: Cloud Computing and Security; Sun, X., Pan, Z., Bertino, E., Eds.; Springer: Cham, Switzerland, 2018; Volume 11063, pp. 467–477. [Google Scholar]
- Newman, S. Building Microservices: Designing Fine-Grained Systems; O’Reilly Media: Sebastopol, CA, USA, 2015. [Google Scholar]
- Morabito, R.; Cozzolino, V.; Ding, A.Y.; Beijar, N.; Ott, J. Consolidate IoT Edge Computing with Lightweight Virtualization. IEEE Netw. 2018, 32, 102–111. [Google Scholar] [CrossRef]
- Ding, D.; Cooper, R.A.; Pasquina, P.F.; Fici-Pasquina, L. Sensor technology for smart homes. Maturitas 2011, 69, 131–136. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.; Li, S.; Li, Z. From Monolith to Microservices: A Dataflow-Driven Approach. In Proceedings of the 24th Asia-Pacific Software Engineering Conference (APSEC 2017), Nanjing, China, 4–8 December 2017; IEEE Computer Society: Nanjing, China, 2017; pp. 466–475. [Google Scholar]
- Augusto, J.C. Past, Present and Future of Ambient Intelligence and Smart Environments. In Agents and Artificial Intelligence; Filipe, J., Fred, A., Sharp, B., Eds.; Springer International Publishing: Berlin, Germany, 2010; Volume 67, pp. 3–15. [Google Scholar]
- Viani, F.; Robol, F.; Polo, A.; Rocca, P.; Oliveri, G.; Massa, A. Wireless Architectures for Heterogeneous Sensing in Smart Home Applications: Concepts and Real Implementation. Proc. IEEE 2013, 101, 2381–2396. [Google Scholar] [CrossRef]
- Gorman, B.L.; Resseguie, D.; Tomkins-Tinch, C. Sensorpedia: Information sharing across incompatible sensor systems. In Proceedings of the 2009 International Symposium on Collaborative Technologies and Systems (CTS 2009), Baltimore, MD, USA, 18–22 May 2009; IEEE Press: Baltimore, MD, USA, 2009; pp. 448–454. [Google Scholar]
- Vresk, T.; Čavrak, I. Architecture of an Interoperable IoT Platform Based on Microservices. In Proceedings of the 39th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO 2016), Opatija, Croatia, 30 May–3 June 2016; IEEE Computer Society: Opatija, Croatia, 2016; pp. 1196–1201. [Google Scholar]
- Google. App Engine Locations. 2019. Available online: https://cloud.google.com/appengine/docs/locations (accessed on 11 February 2019).
- Butzin, B.; Golatowski, F.; Timmermann, D. Microservices approach for the Internet of Things. In Proceedings of the 21st International Conference on Emerging Technologies and Factory Automation (ETFA 2016), Berlin, Germany, 6–9 September 2016; IEEE Press: Berlin, Germany, 2016; pp. 1–6. [Google Scholar]
- Chen, F.; Grundy, J.; Yang, Y.; Schneider, J.G.; He, Q. Experimental Analysis of Task-based Energy Consumption in Cloud Computing Systems. In Proceedings of the 4th ACM/SPEC International Conference on Performance Engineering (ICPE 2013), Prague, Czech Republic, 21–24 April 2013; ACM Press: Prague, Czech Republic, 2013; pp. 295–306. [Google Scholar]
- Balasubramanian, N.; Balasubramanian, A.; Venkataramani, A. Energy Consumption in Mobile Phones: A Measurement Study and Implications for Network Applications. In Proceedings of the 9th ACM SIGCOMM conference on Internet measurement (IMC 2009), Chicago, IL, USA, 4–6 November 2009; ACM Press: Chicago, IL, USA, 2009; pp. 280–293. [Google Scholar]
- Gibbons, J. The Numbers Game: How Many Words Do I Need to Know to Be Fluent in a Foreign Language? 2018. Available online: https://www.fluentu.com/blog/how-many-words-do-i-need-to-know/ (accessed on 7 February 2019).
- Cortiñas, A.; Luaces, M.R.; Rodeiro, T.V. A Case Study on Visualizing Large Spatial Datasets in a Web-Based Map Viewer. In ICWE 2018: Web Engineering; Mikkonen, T., Klamma, R., Hernández, J., Eds.; Springer: Cham, Switzerland, 2018; Volume 10845, pp. 296–303. [Google Scholar]
- Hamilton, J. Google MapReduce Wins TeraSort. 2008. Available online: https://perspectives.mvdirona.com/2008/11/google-mapreduce-wins-terasort/ (accessed on 21 February 2019).
- Taibi, D.; Lenarduzzi, V.; Pahl, C. Architectural Patterns for Microservices: a Systematic Mapping Study. In Proceedings of the 8th International Conference on Cloud Computing and Services Science (CLOSER 2018), Madeira, Portugal, 19–21 March 2018; Science and Technology Press: Madeira, Portugal, 2018; pp. 221–232. [Google Scholar]
- Bogner, J.; Zimmermann, A. Towards Integrating Microservices with Adaptable Enterprise Architecture. In Proceedings of the 20th International Enterprise Distributed Object Computing Workshop (EDOCW 2016), Vienna, Austria, 5–9 September 2016; IEEE Computer Society: Vienna, Austria, 2016; pp. 1–6. [Google Scholar]
- Slepicka, J.; Semeniuk, M. Deploying Machine Learning Models as Microservices Using Docker; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Deployed Observer Instances | Region | Number of Deployed Observer Instances | Region |
|---|---|---|---|
| Two | us-central (Iowa) | One | us-east1 (South Carolina) |
| One | us-west2 (Los Angeles) | One | us-east4 (Northern Virginia) |
| One | northamerica-northeast1 (Montréal) | One | southamerica-east1 (São Paulo) |
| One | europe-west2 (London) | One | europe-west3 (Frankfurt) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Seco, D.; Sánchez Rodríguez, A.E. Microservice-Oriented Platform for Internet of Big Data Analytics: A Proof of Concept. Sensors 2019, 19, 1134. https://doi.org/10.3390/s19051134
Li Z, Seco D, Sánchez Rodríguez AE. Microservice-Oriented Platform for Internet of Big Data Analytics: A Proof of Concept. Sensors. 2019; 19(5):1134. https://doi.org/10.3390/s19051134
Chicago/Turabian StyleLi, Zheng, Diego Seco, and Alexis Eloy Sánchez Rodríguez. 2019. "Microservice-Oriented Platform for Internet of Big Data Analytics: A Proof of Concept" Sensors 19, no. 5: 1134. https://doi.org/10.3390/s19051134
APA StyleLi, Z., Seco, D., & Sánchez Rodríguez, A. E. (2019). Microservice-Oriented Platform for Internet of Big Data Analytics: A Proof of Concept. Sensors, 19(5), 1134. https://doi.org/10.3390/s19051134