1. Introduction
Vehicular networks enable various applications such as road safety, traffic jam reporting, public aid units guiding, entertainments, and autonomous driving, etc. [
1,
2]. Vehicular networks aim to provide sustainable and reliable communications for smart vehicles. They are basic building blocks in the cooperative intelligent transportation systems (ITS) of future smart cities. The vehicle-to-vehicle (V2V) communication in vehicular networks was standardized in the form of an amendment to the IEEE 802.11 standard. Specifically, the IEEE 802.11p defines V2V augmentations to the IEEE 802.11 standard in order to enable dedicated short-range communication (DSRC) for vehicular networks [
3].
In wireless communication systems, the varying nature of wireless channels calls for link adaptations in order to improve both the spectrum efficiency and the communication reliability. There are many link adaptation schemes developed using traditional model-based approaches (e.g., [
4,
5]). However, modeling practical wireless communication systems incorporating varying wireless channels is complicated. Therefore, these model-based approaches make approximations on the model and consequently the system performance will be impacted. Another possible approach is to establish look-up tables for link adaptations. However, in practical wireless systems with high dimensions, getting a look up table that cover the whole range of link quality metrics will be prohibitively huge. Recently, learning-based approaches are employed to improve the effectiveness of wireless link adaptations. The authors in [
6] proposed a supervised learning approach for adaptive modulation and coding (AMC) in the IEEE 802.11n wireless local area networks (WLANs). The target is to select the best modulation and coding scheme (MCS) in order to maximize the throughput under certain frame error rate (FER) constraint. They have utilized the k-nearest neighbors (k-NN) classification algorithm for AMC. In [
7], the authors solved the same AMC problem using the algorithm of support vector machines (SVM). However, the works in [
6,
7] both assumed nonrealistic assumptions such as fixed frame length, perfect synchronization, and perfect channel knowledge. The work in [
8] presented a deep convolutional neural network (DCNN) approach for AMC in MIMO-OFDM systems. The authors considered practical timing synchronization, carrier frequency offset and channel estimation at receivers. However, the authors did not consider the effect of frame length. Furthermore, they evaluated their approach for indoor WLANs applications.
It should be noted that the V2V communications are more challenging compared to the indoor WLANs. The V2V communication channel is doubly selective (i.e., in both of the frequency and the time domains). This means that the channel fluctuates considerably within the transmission bandwidth (frequency-selective fading) and within the frame duration (fast fading) [
9]. This is due to the combined effects of the multipath nature of V2V propagation channels, along with the high mobility of radio terminals in the vehicles and some scatterers around [
10]. Thus, advanced link adaptation schemes are crucial for V2V communications in order to deal with the varying V2V links under the stringent V2V communication requirements, such as high effective throughput and reliability. For instance, an adaptive frame length scheme for vehicular networks has been presented in [
11]. The authors in [
11] show that the adaptive frame length scheme outperforms non-adaptive frame length schemes for vehicular networks in terms of throughput, retransmissions, and overheads. However, the authors in [
11] did not consider the effect of the MCS.
Another challenging task for V2V communications is the channel estimation. In traditional channel estimation techniques, transmitters add training sequences, i.e., preamble, at the beginning of each frame; then, receivers can utilize this preamble to estimate the channel and use the channel estimates to decode the following data symbols in the same frame. However, this is not optimal for a quickly varying V2V channel, where the channel estimates from the preamble at the beginning of the frame may be significantly different from the actual channels encountered by the subsequent symbols within the same frame. As a consequence, utilizing the initial channel estimates from the preamble to decode the subsequent symbols in the frame may lead to decoding errors. This leads to a significant degradation in the frame error rate performance of V2V links. Therefore, channel tracking techniques have been presented such as [
12,
13], where the initial channel estimates from the training sequences of the preamble are updated within the duration of the frame. In particular, the work in [
12] presents a number of dynamic data-aided equalization techniques. The authors in [
12] evaluated these techniques by empirical experiments in practical V2V environments and concluded that their equalization techniques outperform traditional preamble-based least squares (LS) [
14] and pilot aided equalizers. Furthermore, they reported that their spectral temporal averaging (STA) technique gives the best performance compared to other equalization techniques presented in their paper. However, the work in [
12] considered only the MCS of the lowest data rate, namely
, where the binary phase shift keying (BPSK) modulation and
channel coding rate were assumed. Furthermore, they did not consider the effect of the frame length. In [
13], the authors extended the scheme of [
12] to different MCSs of higher data rates and showed that the STA channel tracking algorithm outperforms the traditional preamble-based LS channel estimation. Moreover, they have studied the effect of different fixed payload lengths with different fixed MCSs on the V2V links. However, they did not study the effect of link adaptation schemes in either the MCS or the payload length on the performance of V2V communications.
Recently, the application of machine learning to vehicular networks has attracted the attention of the research community [
15,
16]. In this paper, we present a joint adaptive MCS and payload length selection (AMCPLS) scheme. The proposed AMCPLS attempts to select the payload length, the modulation order, and the channel coding rate based on the V2V channel condition so as to achieve both reliability and high effective throughput. While the concept of the AMCPLS can be applied to both the 5G-V2V and the DSRC IEEE 802.11p V2V, in this paper, we will concentrate on the DSRC IEEE 802.11p V2V since its standard is more well-established and its specifications are more well-defined [
17,
18]. Furthermore, we are concentrating on safety-related applications and it has been reported in the literature that the DSRC IEEE 802.11p V2V outperforms the 4G-LTE V2V for the safety-related applications [
19,
20]. The contribution of this paper can be summarized as follows.
First, we develop a novel link adaptation scheme for V2V communications, namely the AMCPLS scheme, that enables transmitters to adaptively select not only the MCS but also the payload length of the transmission frame. We consider practical receivers that involve realistic timing synchronization, carrier frequency offset correction and channel estimation. The proposed AMCPLS scheme is evaluated under traditional preamble-based LS channel estimation [
14] and STA channel tracking [
13]. In both cases, our adaptive AMCPLS scheme outperforms the non-adaptive schemes in terms of FER and effective throughput.
Moreover, we propose a machine learning framework for the proposed AMCPLS scheme, where past observations of channel state information (CSI) along with achieved FER and effective throughput are used as training data. This training data can be utilized to predict the best combination of the payload length, the modulation order, and the channel coding rate for future V2V transmissions by leveraging machine learning tools. Specifically, a deep convolutional neural network (DCNN) has been designed for implementing the proposed AMCPLS scheme. Our DCNN-based AMCPLS scheme can achieve better performance compared to other machine learning based schemes, (such as k-NN and SVM).
We performed extensive numerical evaluations to verify our DCNN-based AMCPLS scheme. The remainder of this paper is organized as follows.
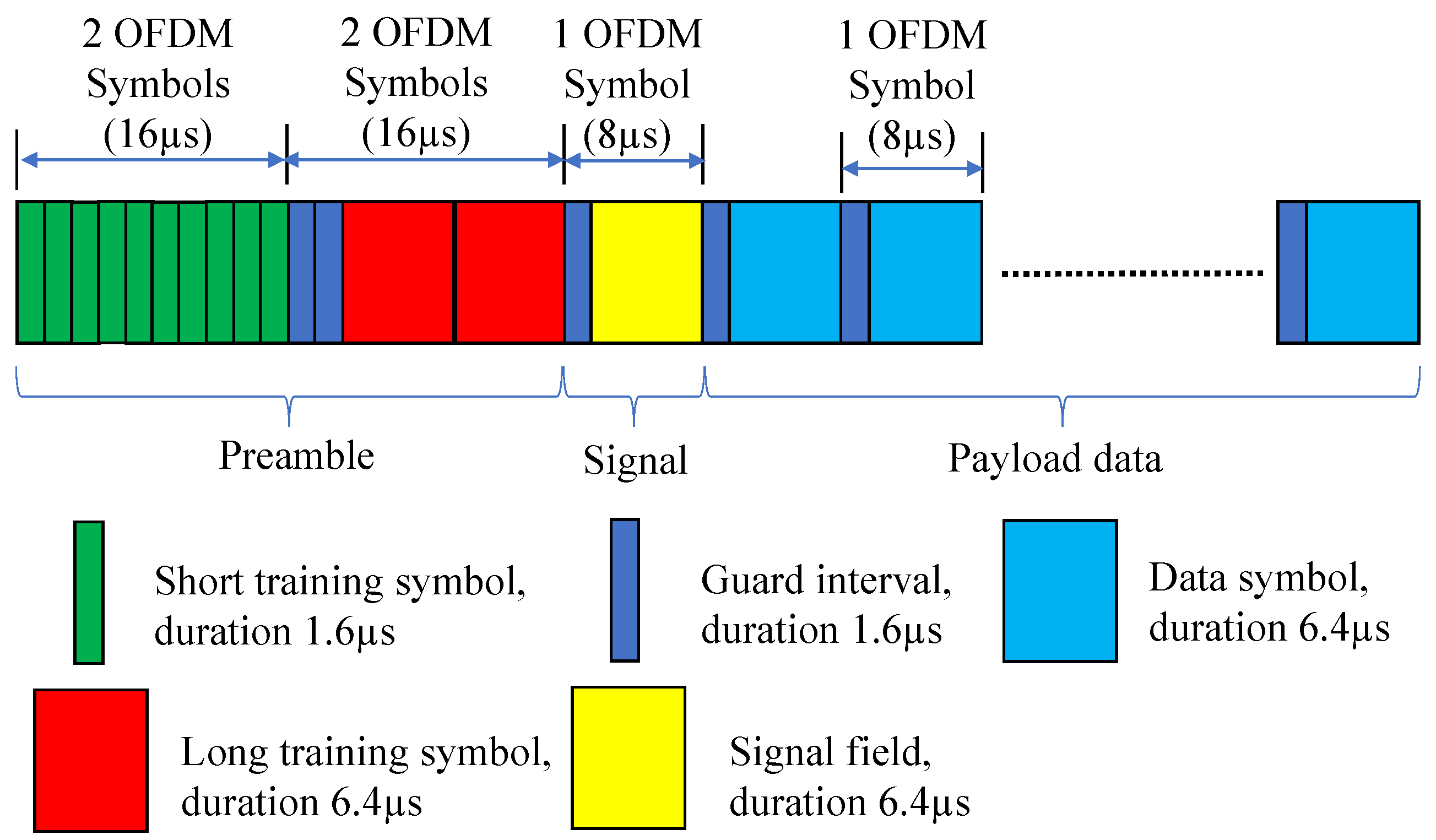
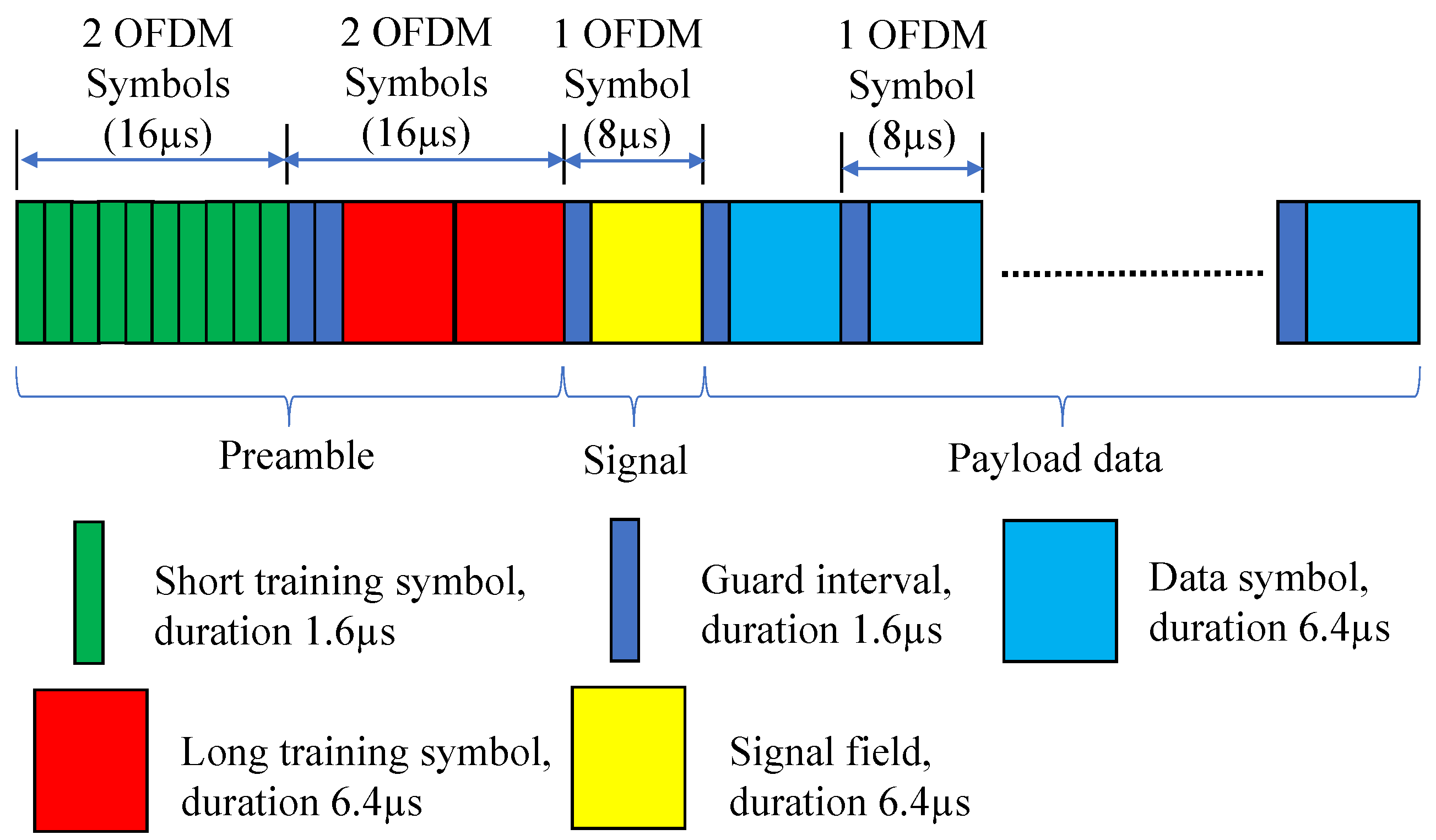
Section 2 presents an overview of the IEEE 802.11p standard and the considered system model. In
Section 3, we discuss the joint adaptive MCS and payload length scheme for V2V communications. Then,
Section 4 presents our deep learning approach for AMCPLS. After that, simulation results are shown in
Section 5. Finally,
Section 6 concludes the paper.
3. Joint MCS and Payload Length Adaptation for IEEE 802.11p V2V Networks
In this section, we present our joint adaptive modulation and coding scheme (MCS) and payload length selection (AMCPLS) for IEEE 802.11p V2V networks, where the communication channel is highly varying. Based on the channel condition, our AMCPLS approach selects both the MCS and the payload length. The aim of AMCPLS is to maximize the effective physical layer throughput and to fulfill a predefined frame error rate (FER).
We consider that the set of all available MCSs,
, is given by
, where
is the cardinality of
, which is the number of the available MCSs. The set of the allowable payload lengths,
, is given by
, where
is the number of the allowable payload lengths. Assume that the MCS
and the payload length
are utilized. The total number of information data bits in a single IEEE 802.11p frame,
, is given by
where
is obtained from (
1) and
is as shown in
Table 1. Furthermore, the total IEEE 802.11p frame duration,
, is given by
where
is the OFDM symbol duration which is 8 µs, and
K is calculated as in (
2). Thus, the effective data rate,
, is given by
Therefore, the effective physical layer throughput,
, is given by
where
is the frame error rate. Note that both
and
are constants for the IEEE 802.11p, and thus
does not depend on them. From Equation (
7), it is clear that the three parameters that affect the effective physical layer throughput are
,
, and
. From (
1), it is clear that
is dependent on
l and
. Taking into account that
depends on the used MCS as detailed in
Table 1, we can conclude that the effective physical layer throughput is dependent on the utilized MCS, the utilized payload length and the FER. Moreover, the FER is affected by three main factors, namely, the MCS, the payload length, and the transmission channel condition. Therefore, the effective physical layer throughput can be controlled by the MCS, the payload length, and the channel condition. The channel condition is determined by the surrounding wireless environment. This motivates us to jointly adapt both the MCS and the payload length based on the channel condition to maximize the effective physical layer throughput under a predefined FER constraint. The proposed AMCPLS scheme can be formulated as follows
where
is the target FER,
is the vector that represents the channel condition, and
is the optimum combination of the MCS and the payload length. The channel condition vector
needs to include the effects of both the channel fading and the AWGN.
We refer to the optimum solution of the problem expressed in (
8) as the ideal AMCPLS. Practically, this ideal AMCPLS can not be implemented due to the following two obstacles. The first is that it is very challenging to correctly derive the FER of a wireless communication system, since the FER is a complicated function of the channel condition, the modulation and coding scheme, and the payload length. The second obstacle is that the actual channel condition,
, for the next frame cannot be assumed to be perfectly known in practice, since the channel is varying over different frames. In
Section 5.1, we evaluate the ideal AMCPLS using numerical enumerations, where we assume that the channel condition for the next frame can be obtained. Although this solution to the ideal AMCPLS may not be practical, we treat the performance of this ideal AMCPLS as a benchmark. In next section, we resort to a deep learning approach to solve the AMCPLS scheme, which is more practical.
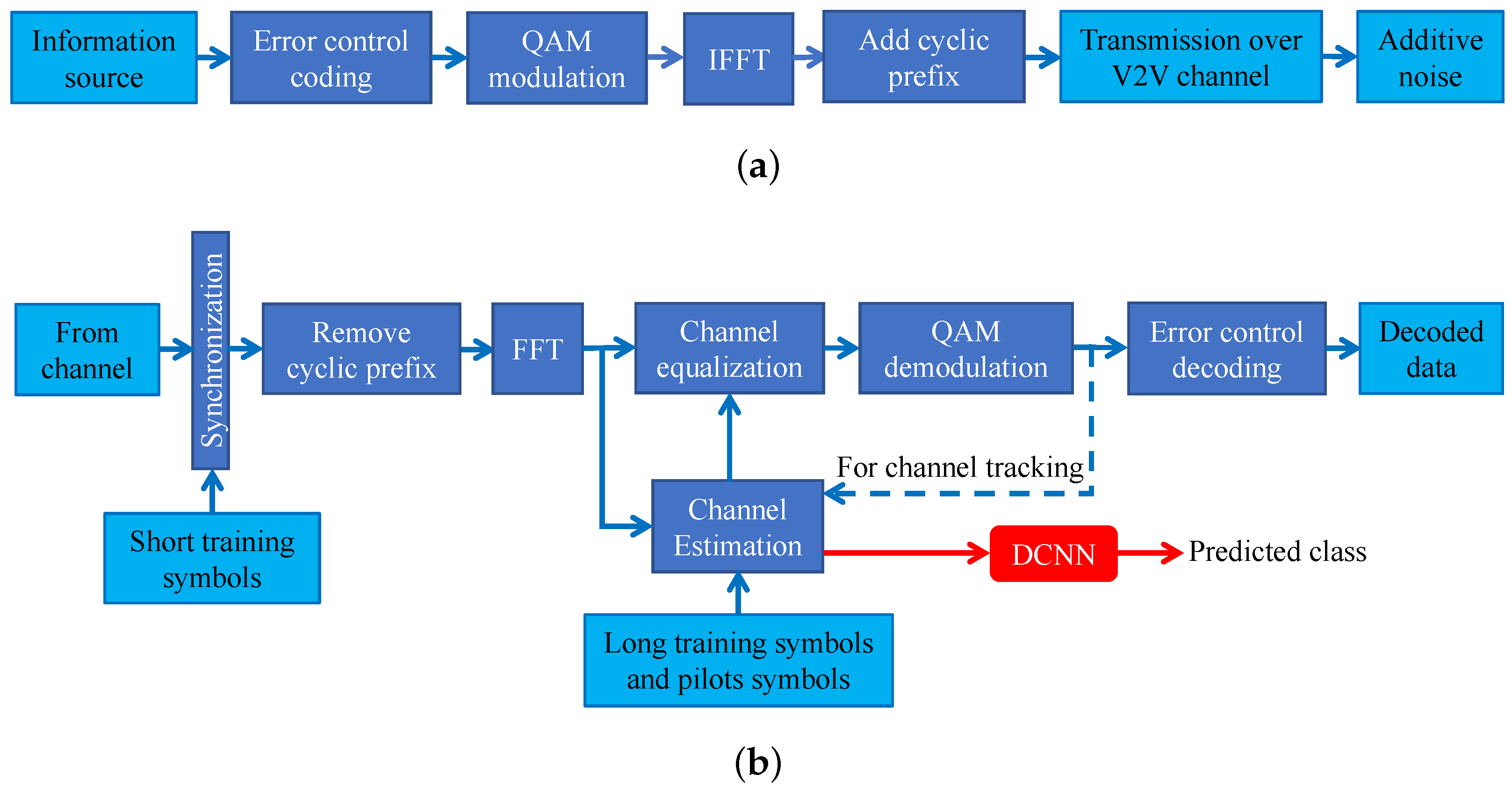
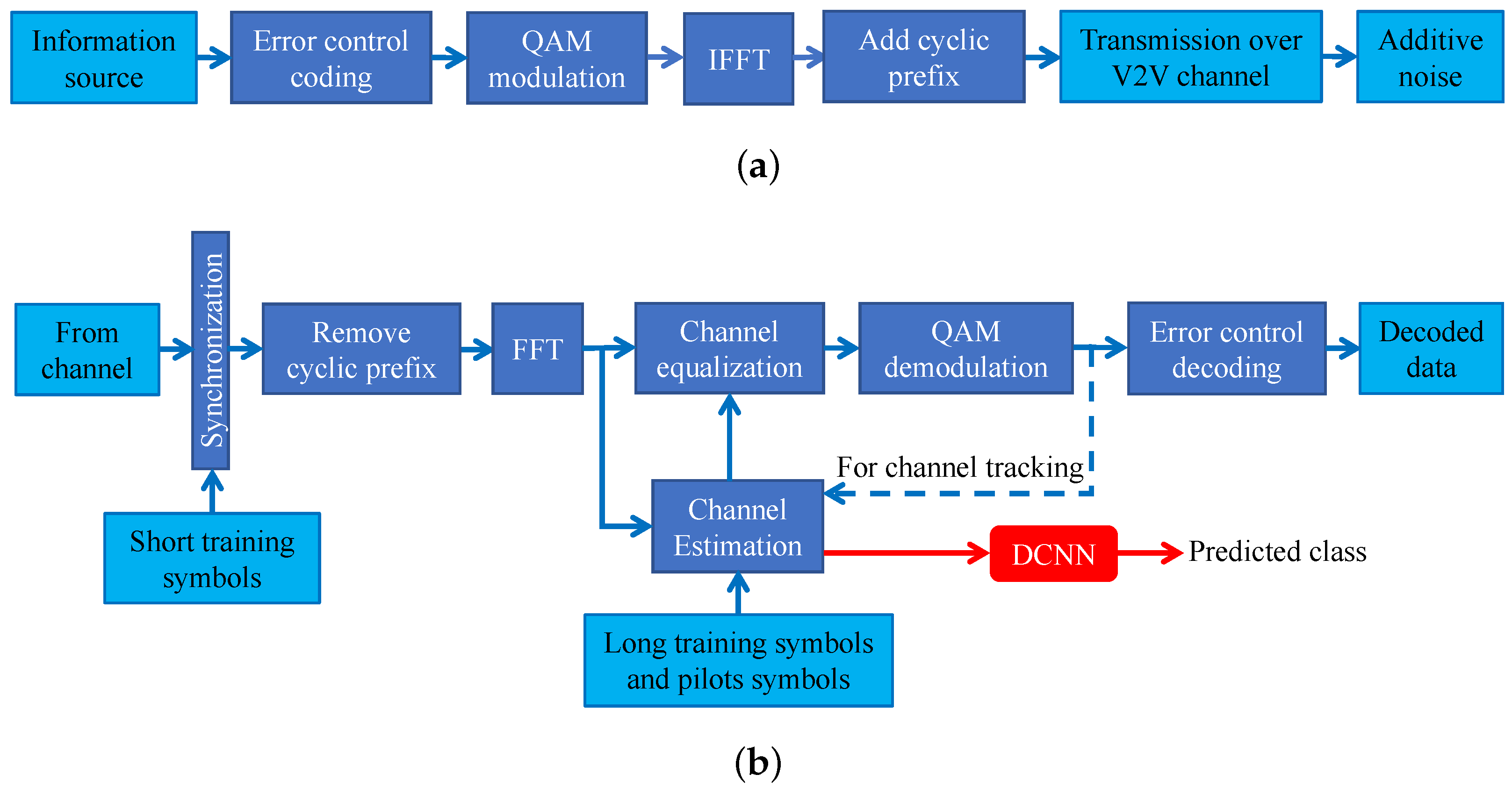
4. Deep Learning for AMCPLS in IEEE 802.11p V2V Networks
In this section, we present our deep learning approach to tackle the AMCPLS problem in IEEE 802.11p V2V networks. Generally speaking, a machine learning algorithm can learn the input-output relationship of a certain system directly from the previous observations (training data) without any previous knowledge about the model of the underlying system. If the adopted machine learning algorithm is sufficiently powerful, it can accurately learn the model of the underlying system utilizing the training data. Deep learning with deep nerual networks [
22] has emerged as a powerful machine learning tool and has achieved impressive performance in many fields such as computer vision [
23], speech recognition [
24], and many other fields. Recently, the wireless communication community pays a considerable attention to deep learning in order to harness its capabilities in designing future wireless communication systems. In this work, we present a deep convolutional neural network (DCNN) approach for implementing AMCPLS in V2V networks. We formulate the AMCPLS problem as a multiclass classification problem and solve it by training the DCNN under the framework of supervised learning. For the multiclass classification problem, a certain class,
, defines a combination of a MCS
i and a payload length
l, where
is the set of the possible classes and
is the number of classes. The features are extracted from the estimated channel state information and estimated noise standard deviation. The target of our approach is to increase the effective throughput and satisfy a predefined FER constraint.
4.1. Features Preparation
For the sake of training our DCNN model, we need to construct a training set that includes
M training examples,
, where
is the features vector of the training example
m,
is the class label of the training example
m, and
. Each class
incorporates the optimal combination of the MCS and the payload length for the corresponding features vector
. The features of the training example
m can be extracted from the corresponding estimated OFDM channel coefficients,
, at the all
used subcarriers and the estimated noise standard deviation,
. It can be represented by
where
is the magnitude of the estimated channel coefficient
. The key performance metrics that we use to classify the training examples are the effective throughput,
, and the FER. The class label
of training example
m is the optimal combination of the MCS and the payload length that achieves the maximum throughput and complies with a predefined FER constraint,
, as expressed by the following equation
where
is the throughput achieved at the channel condition corresponding to the features vector
with the transmission class
a, and
is the FER at the channel condition corresponding to the features vector
with the transmission class
a. Note that (
10) is similar to (
8), except that the class
replaces
and the features vector
is used instead of the intractable actual channel condition. With (
9) and (
10), we can generate many training examples
to train the DCNN for AMCPLS. (The generation of the training set is described in detail in
Section 5.2).
4.2. Deep Convolutional Neural Network Structure
The structure of the used deep convolutional neural network (DCNN) incorporates six convolutional layers, two average pooling layers, and two fully connected layers, as depicted in
Figure 3 and Algorithm 1. Particularly, each of the first, third and fifth convolutional layers has 15 filters. Also, each of the second, fourth, and sixth convolutional layers has 10 filters. All convolutional layers utilize filters of size
and rectified linear unit (ReLU) activation function. One of the average pooling layers is after the second convolutional layer, and the second average pooling layer is after the third convolutional layer. Each of the pooling layers has a pool size of four. The first fully connected layer has 50 neurons with ReLU activations. The last layer is a fully connected layer with a number of neurons that is equal to the number of classes. This last layer utilizes softmax activation function. The second norm regularization is adopted in the two fully connected layers in order to alleviate the effect of overfitting [
22]. The adam optimizer [
25] along with the categorical cross entropy loss function are used for training the DCNN. The DCNN is trained for 100 epochs with a batch size of 100.
After the DCNN is trained, the receiver can employ it to anticipate the appropriate transmission class, i.e., the optimal combination of MCS and payload length. Then, the receiver feedbacks the MCS and payload length to the transmitter for considering them in the transmission of the next frame. Note that although the channel is varying over different frames, we use the channel estimates of the current frame to construct the input features to DCNN for predicting the suitable transmission class of the next frame. Since the channels between two adjacent frames have high correlations, this feedback mechanism is still rather robust (please see the performance evaluation of our DCNN based AMCPLS scheme in
Section 5.2).
| Algorithm 1 Proposed DCNN structure |
- 1:
Input layer - 2:
First convolutional layer with 15 filters, each of size 5 × 1, and relu activation. - 3:
Second convolutional layer with 10 filters, each of size 5 × 1, and relu activation. - 4:
First average pooling layer with pool size of 4. - 5:
Third convolutional layer with 15 filters, each of size 5 × 1, and relu activation. - 6:
Second average pooling layer with pool size of 4. - 7:
Fourth convolutional layer with 10 filters, each of size 5 × 1, and relu activation. - 8:
Fifth convolutional layer with 15 filters, each of size 5 × 1, and relu activation. - 9:
Sixth convolutional layer with 10 filters, each of size 5 × 1, and relu activation. - 10:
Flatten layer. - 11:
First fully connected layer with 50 neurons, relu activation, and regularization. - 12:
Second fully connected layer with A neurons, softmax activation, and regularization.
|
We remark here that although the training of the DCNN for AMCPLS needs extensive computational resources and is time-consuming, it can be implemented offline in clouds. After the DCNN weights are finalized by the training process, we deploy the trained DCNN in the receiver of vehicles for making online AMCPLS. The implementation of DCNN on vehicels can employ FPGA or ASIC that can be optimized to compute the outputs of neurons in parallel. Furthermore, unlike the training process, the prediction process of DCNN does not require heavy processing as it involves only matrix multiplication, addition and nonlinear activation. Therefore, the proposed DCNN for AMCPLS can actually have a lower computation latency.
5. Numerical Results
In this section, we utilize simulations to evaluate the proposed AMCPLS scheme for the IEEE 802.11p V2V communications. The simulation parameters of the considered IEEE 802.11p system are shown in
Table 2. We consider channel equalizations that are based on both traditional LS channel estimation [
14] and STA channel tracking [
13]. Furthermore, we compare the performance of our proposed DCNN based AMCPLS with the performance of other rival machine learning algorithms such as k-NN and SVM. In our evaluations we assume that the set of allowable payload lengths is
Bytes. Furthermore, for the IEEE 802.11p, the set of available MCSs is
. Thus the set of all possible classes is
. In our simulations, we assume that the target FER,
is 0.05. Furthermore, we assume a rural LOS environment [
9,
26]. In our evaluations, we utilize both the effective throughput and the FER. We have used the FER rather than the bit error rate (BER) because our target is to select both the MCS and the payload length to maximize the effective throughput under FER constraint and the BER is independent on the payload length.
5.1. Performance of Ideal AMCPLS
Practically, the ideal AMCPLS expressed in (
8) can not be implemented as we do not know the actual channel condition and the FER. However, we can evaluate it using numerical enumerations, i.e., we try all possible combinations of the MCSs and payload lengths at every SNR value; then, we select the combination of the MCS and payload length that achieves the maximum effective throughput and satisfies the predefined FER. In this regard, we evaluate the performance of ideal AMCPLS, where we assume that both the actual channel and the FER can be obtained beforehand (the FER is obtained from simulations using the actual channel) and thus the ideal combination of the MCS and the payload length can be determined for the transmission of the current frame.
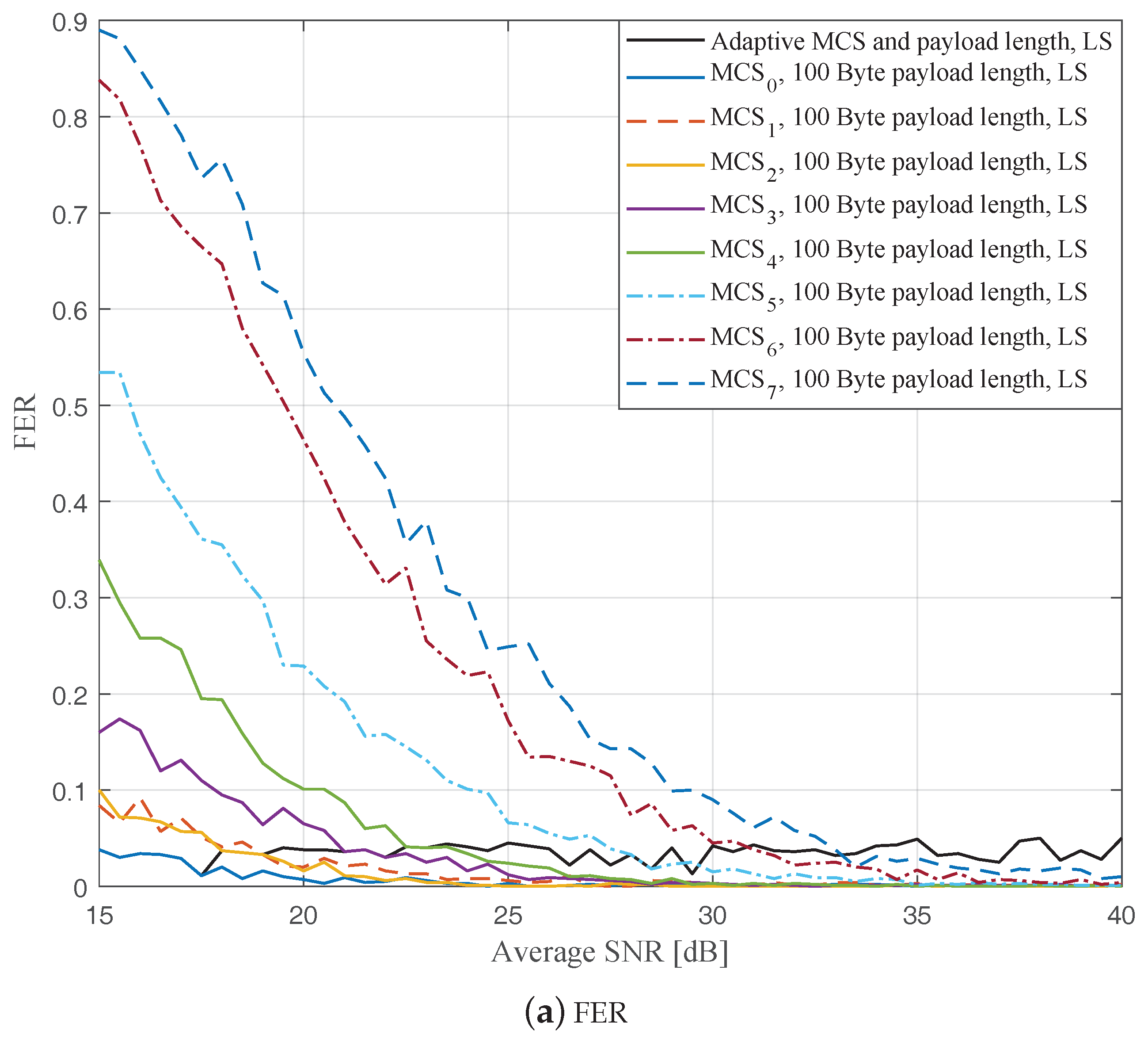
In this part, we perform simulations to evaluate the ideal AMCPLS scheme considering both the traditional LS channel estimation [
14] and the STA channel tracking [
13]. We consider the V2V communication in the rural LOS environment at different signal to noise ratios (SNR) that range from 15 dB to 40 dB. Specifically,
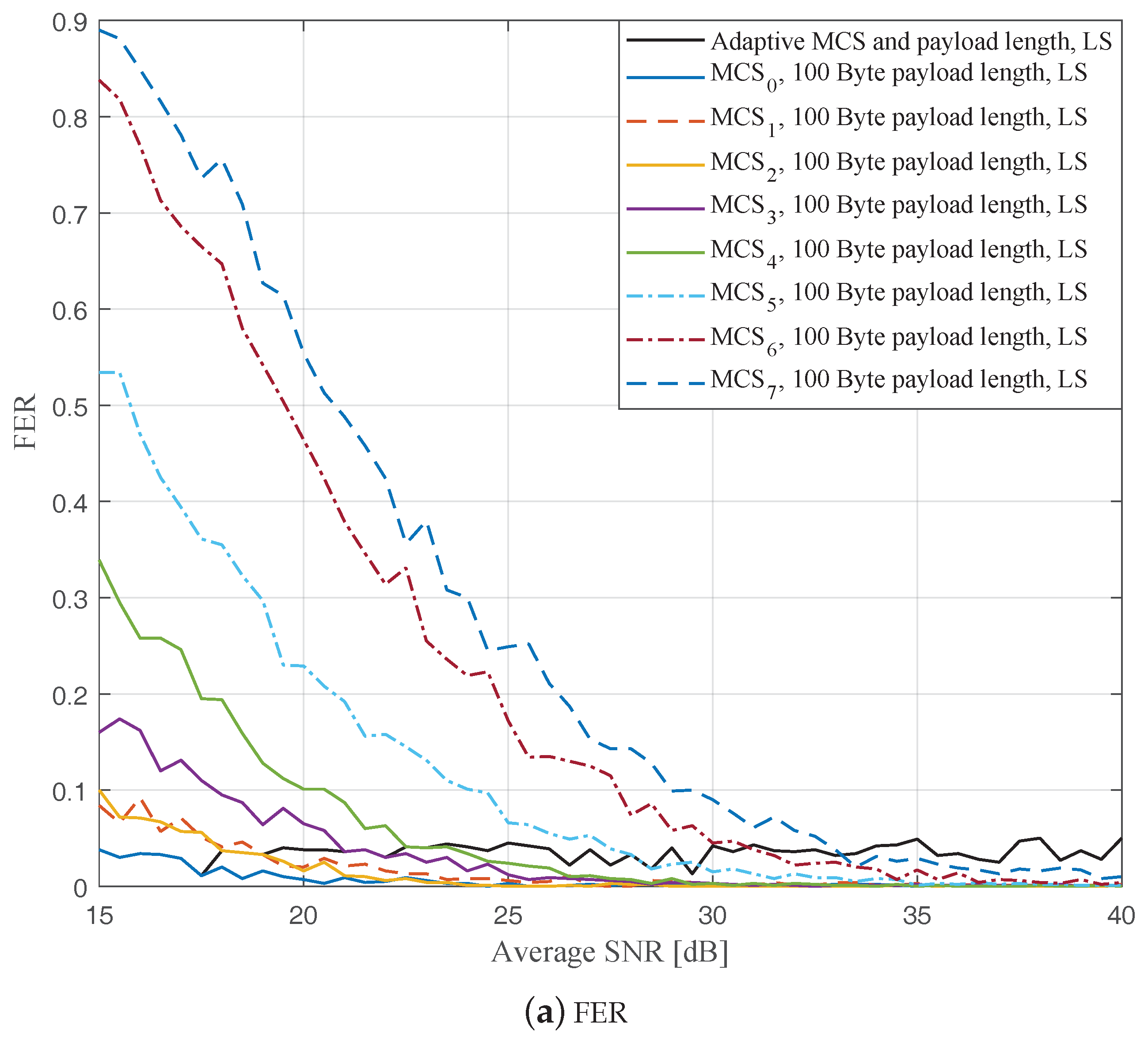
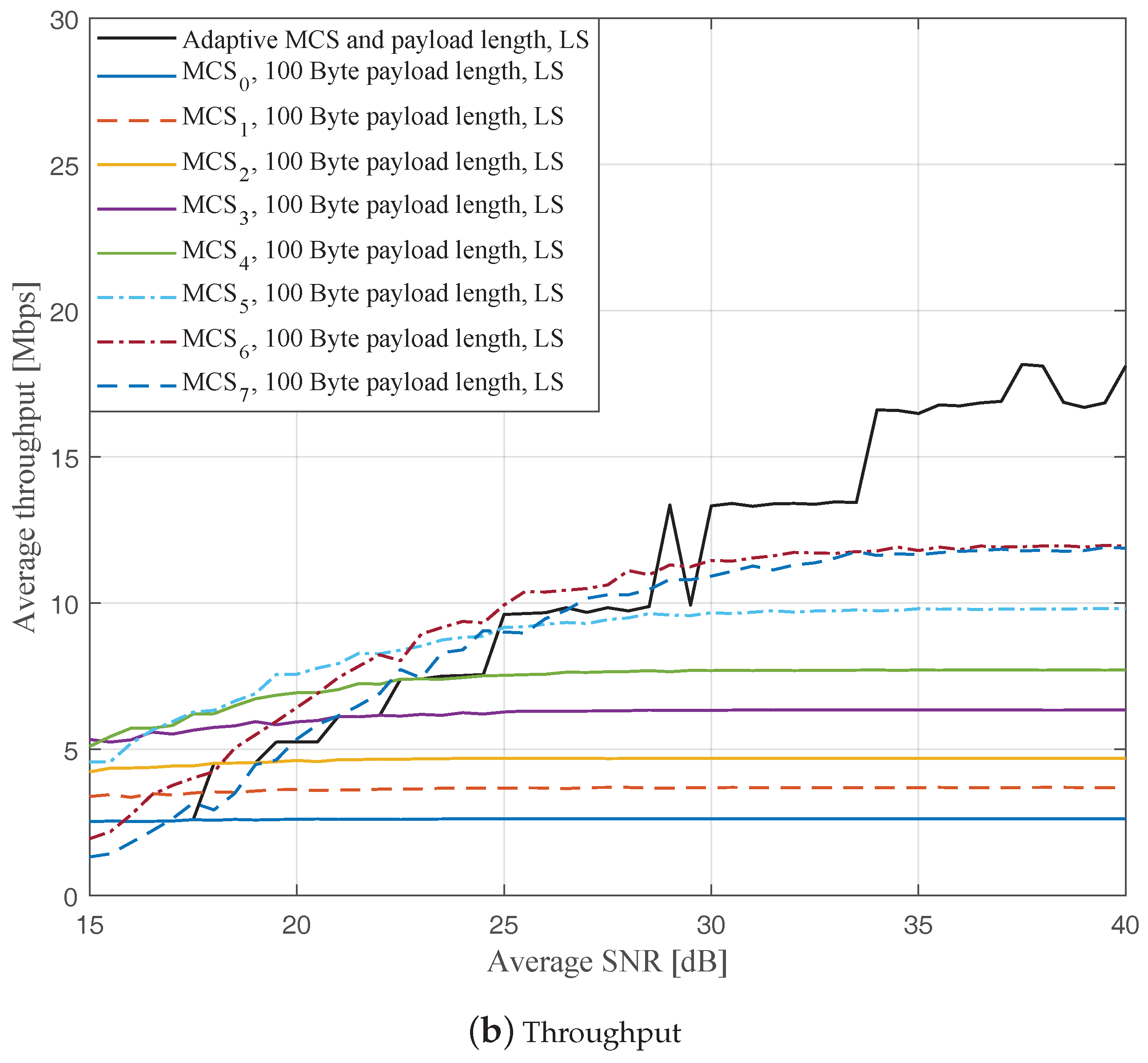
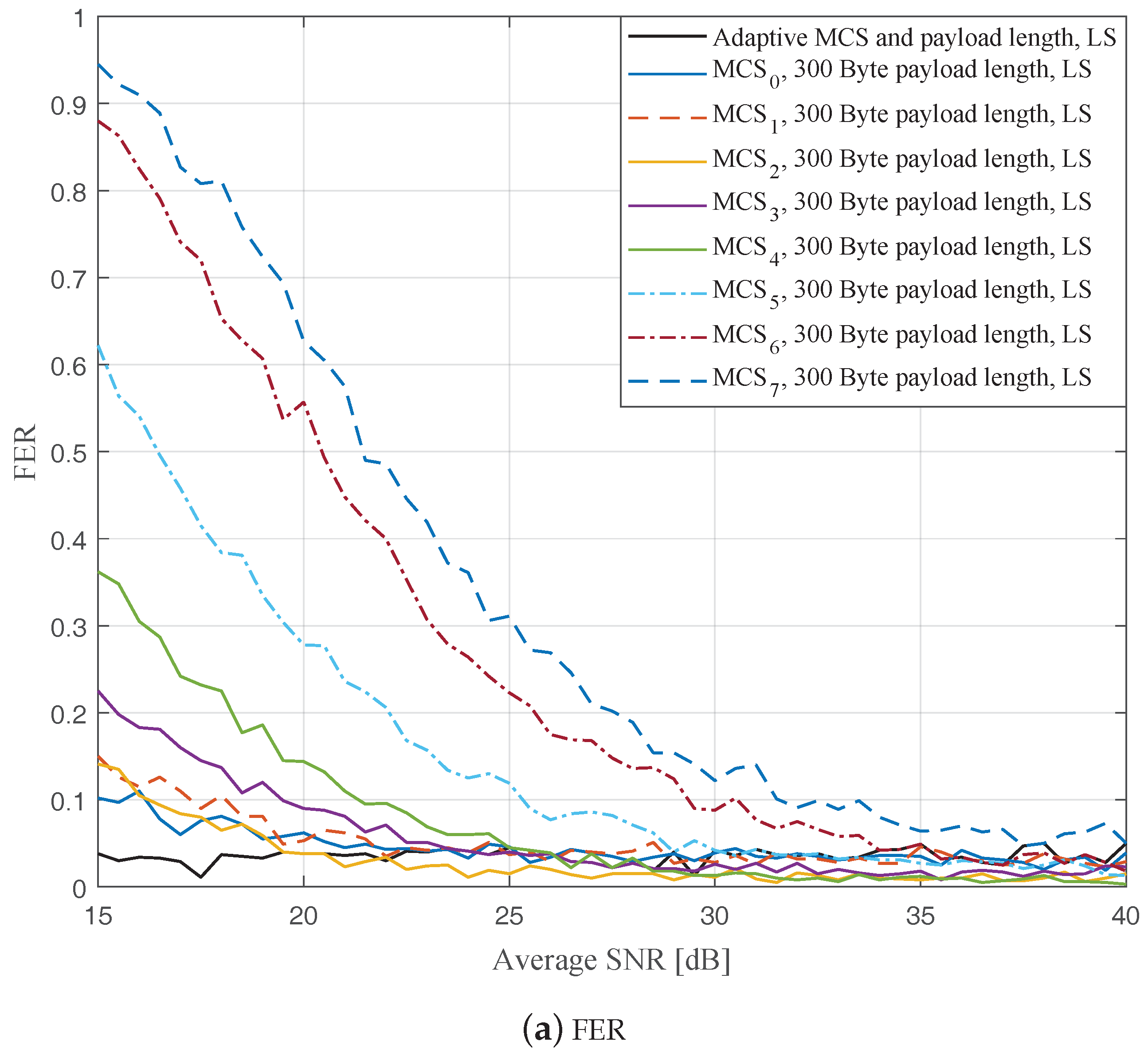
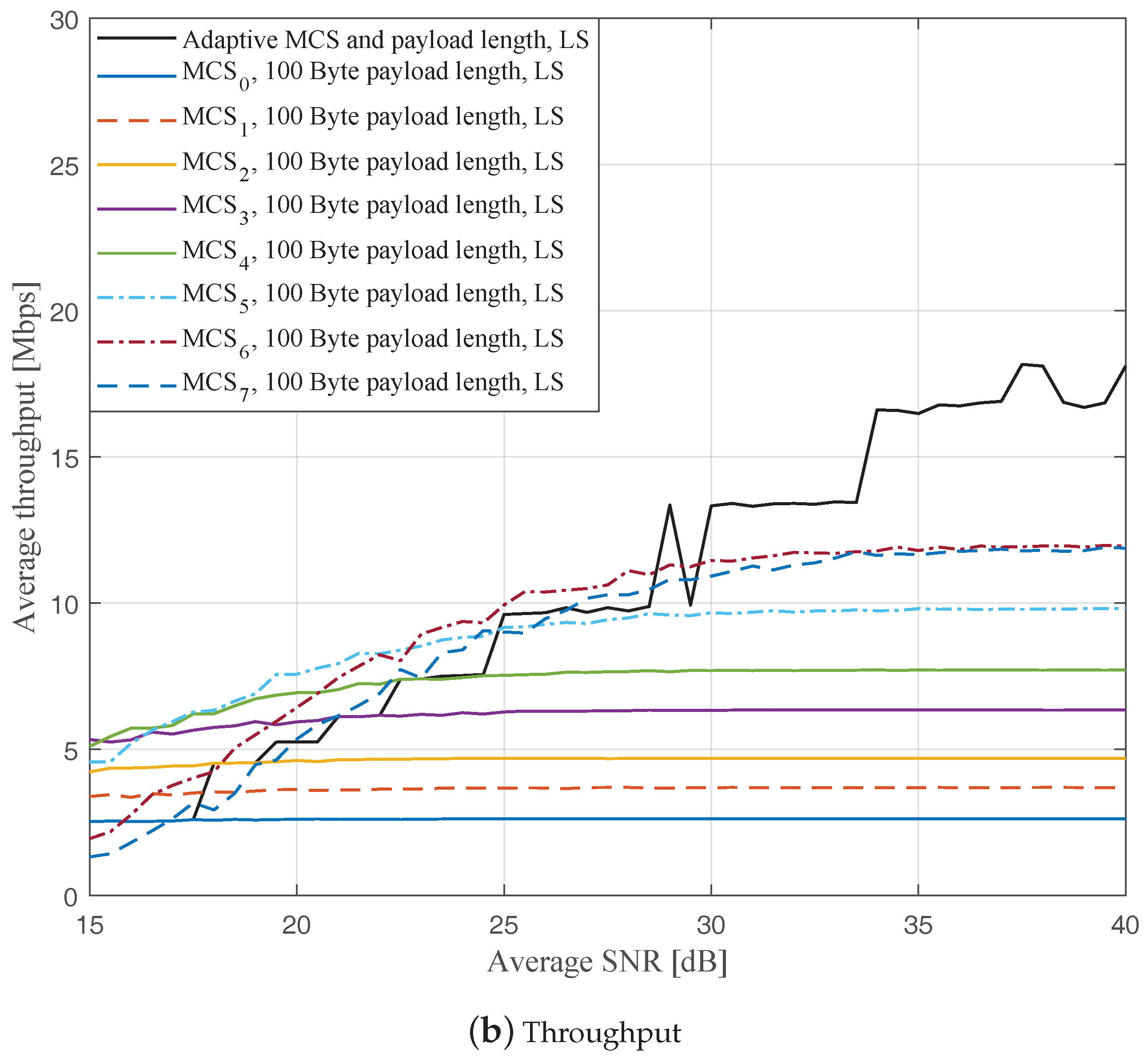
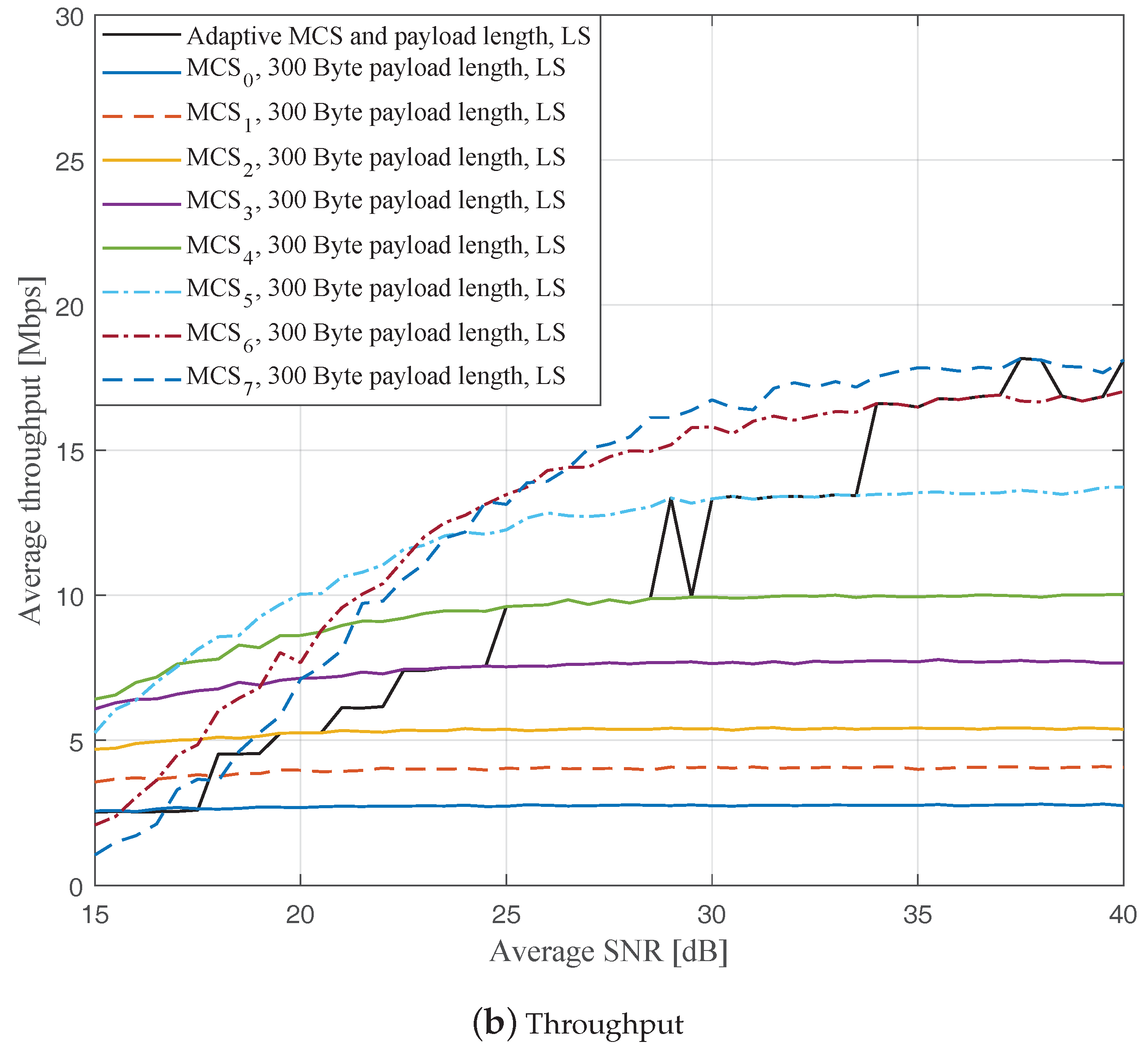
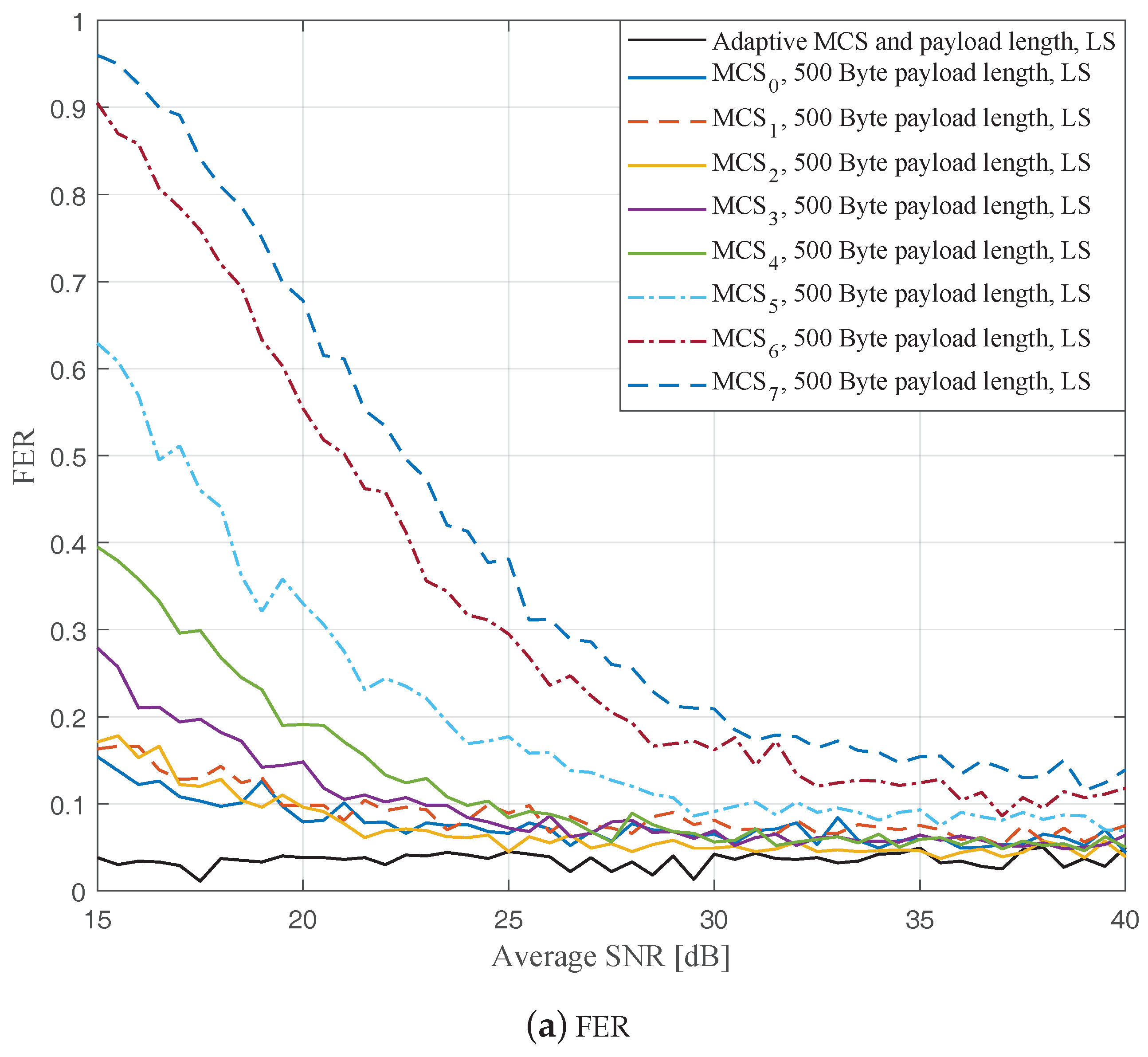
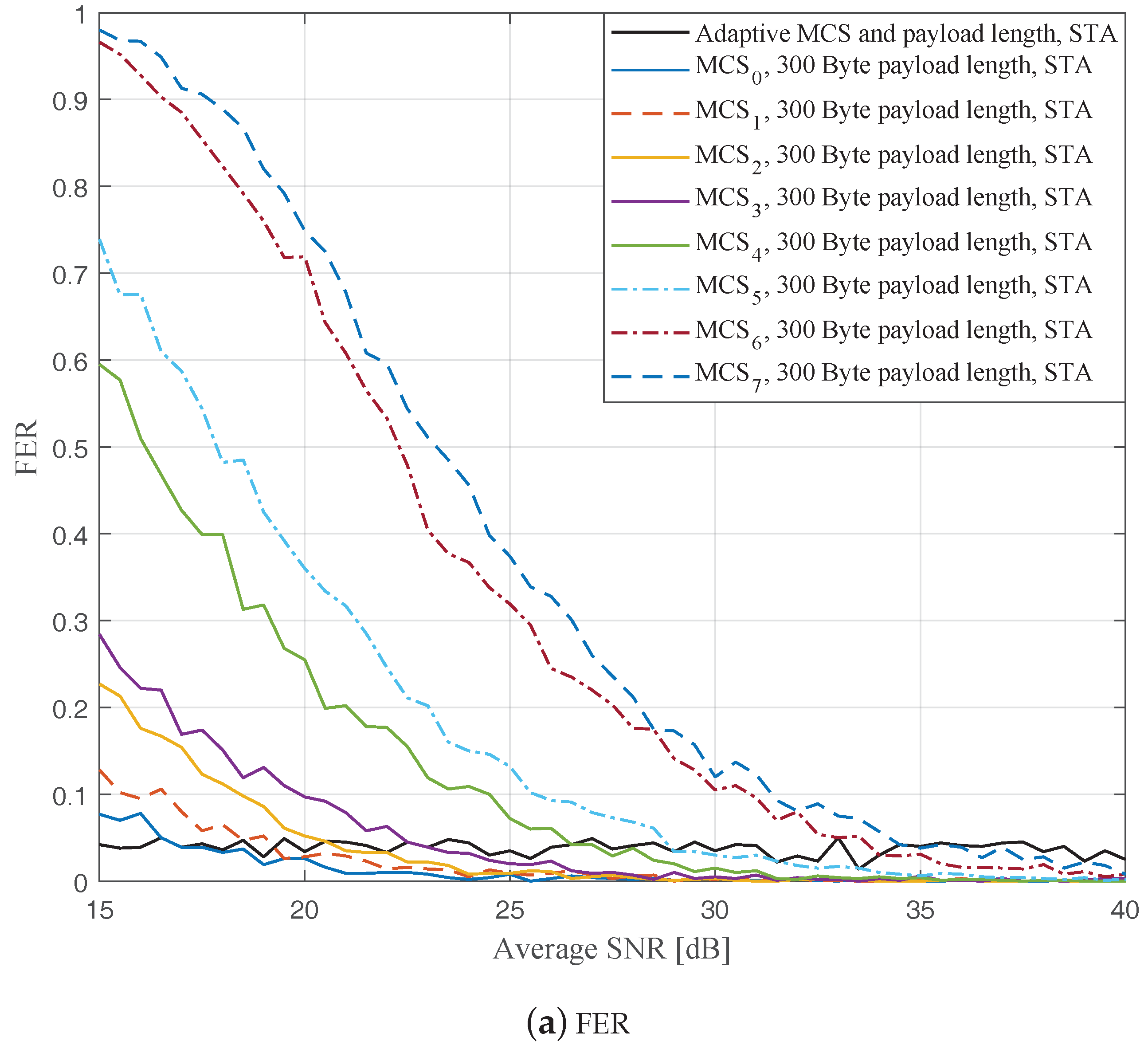
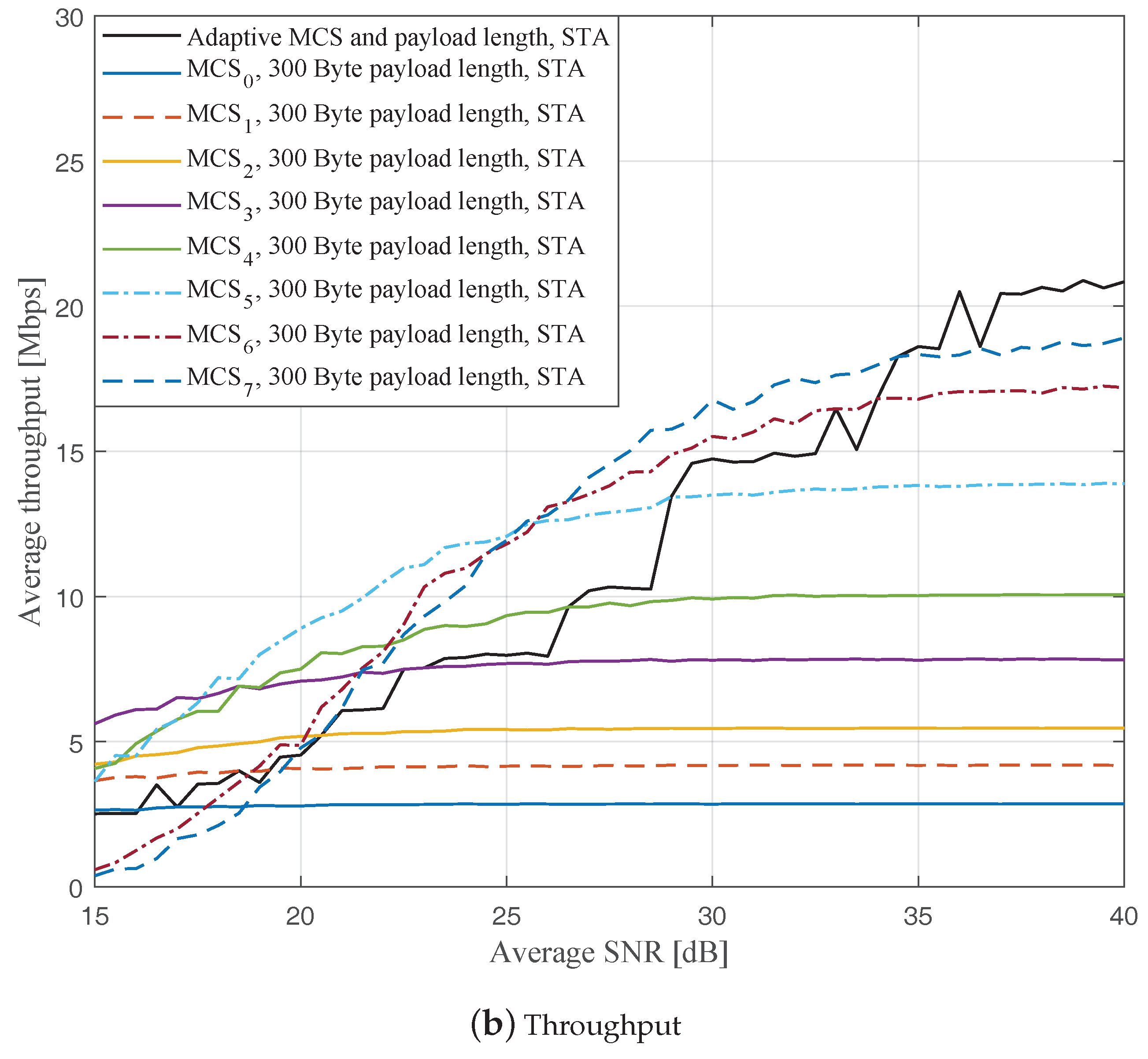
Figure 4,
Figure 5 and
Figure 6 depict the FERs and effective throughputs of the proposed AMCPLS scheme compared to fixed MCSs with fixed payload lengths of 100, 300, and 500 Bytes, respectively, when the traditional LS channel estimation is employed. It can be observed from the results that for most of the fixed schemes, the FER decreases and the throughput increases as the SNR increases. Furthermore, increasing the payload length when a specific MCS is utilized leads to an increase in the effective throughput due to the overhead reduction; at the same time, the FERs for most of the fixed MCSs increase as well, which impact the reliability and energy efficiency of the V2V communication link. On the other hand, the proposed AMCPLS scheme always satisfies the predefined target FER,
and provides satisfactory throughputs. Similarly,
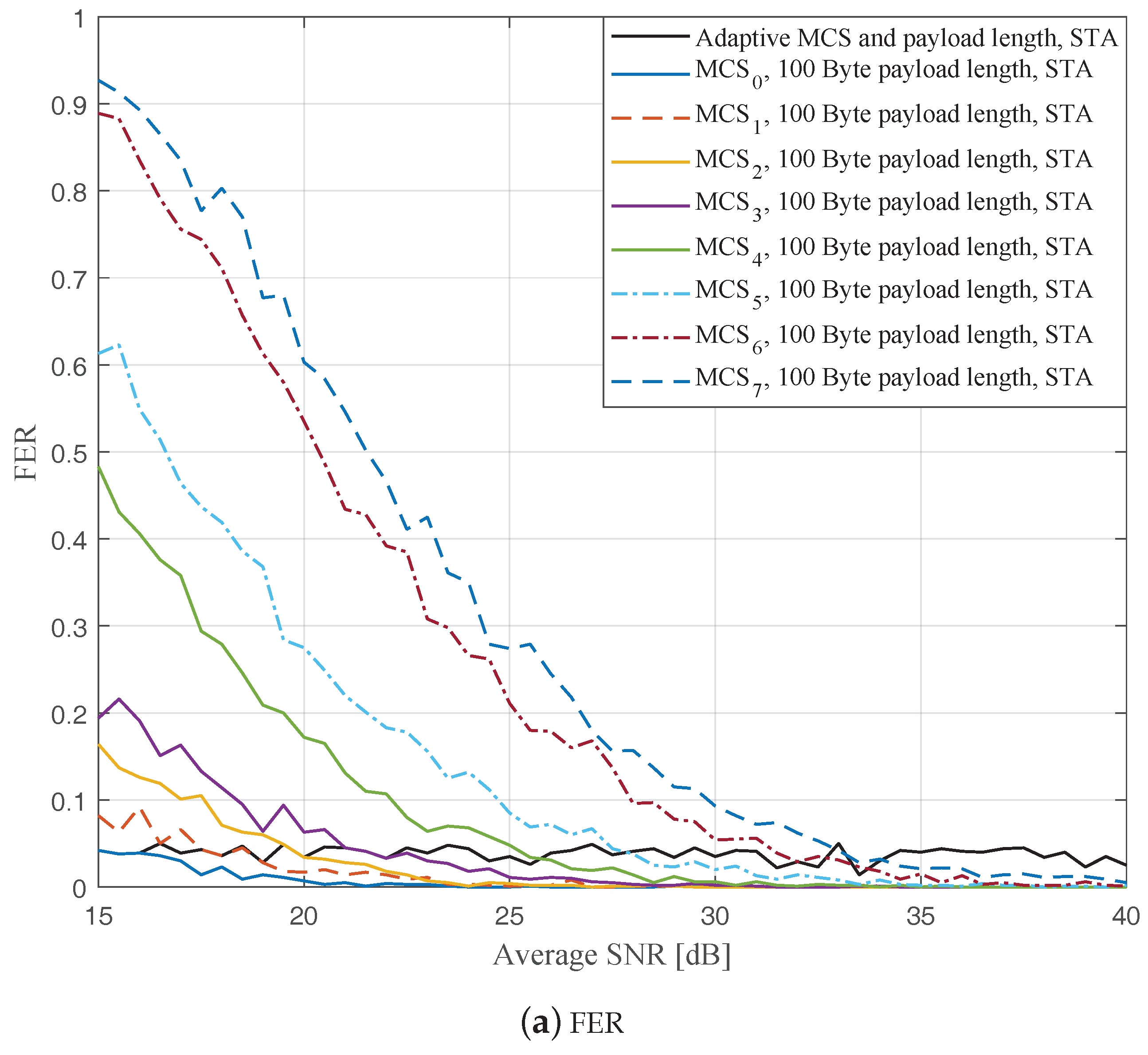
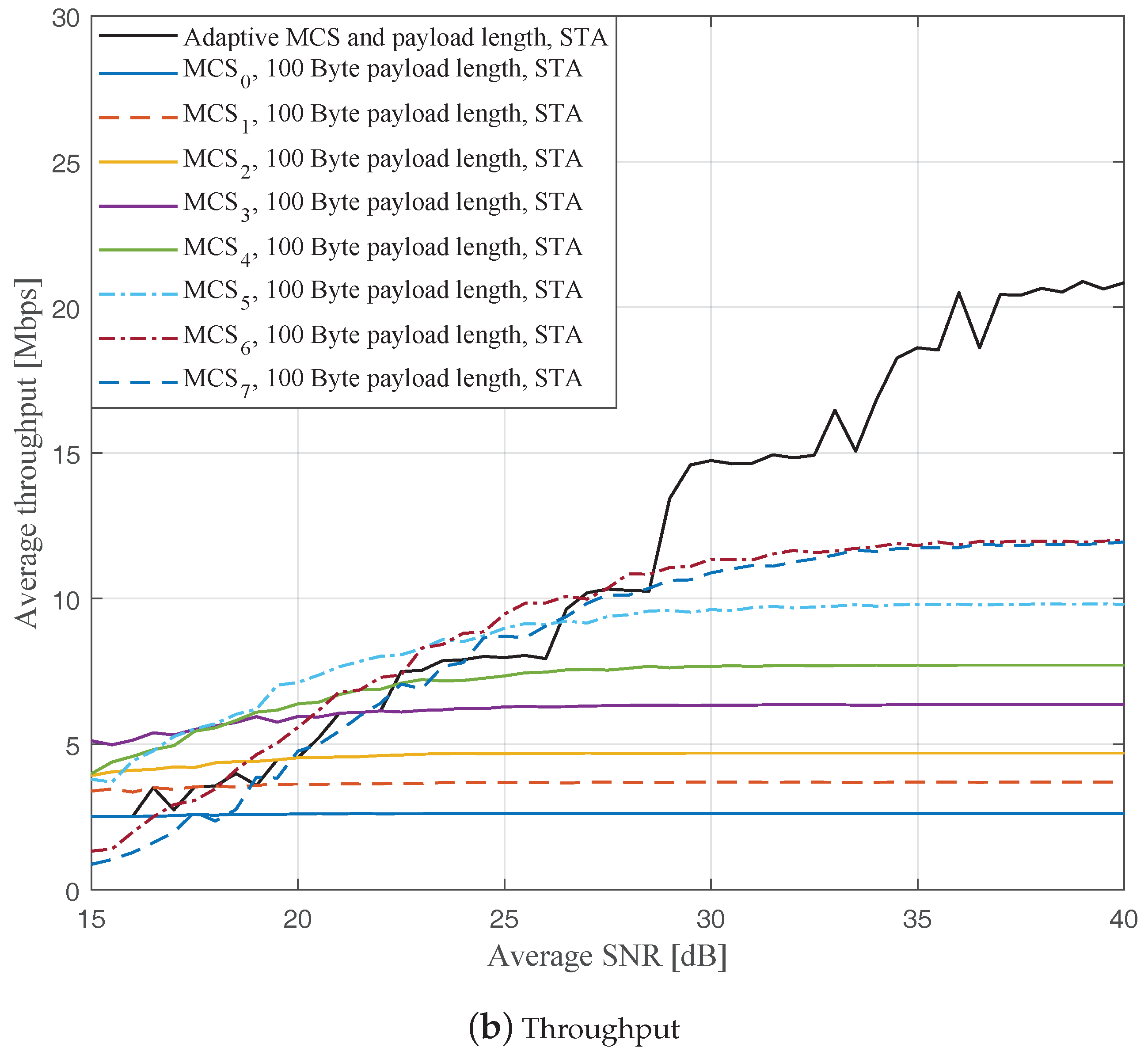
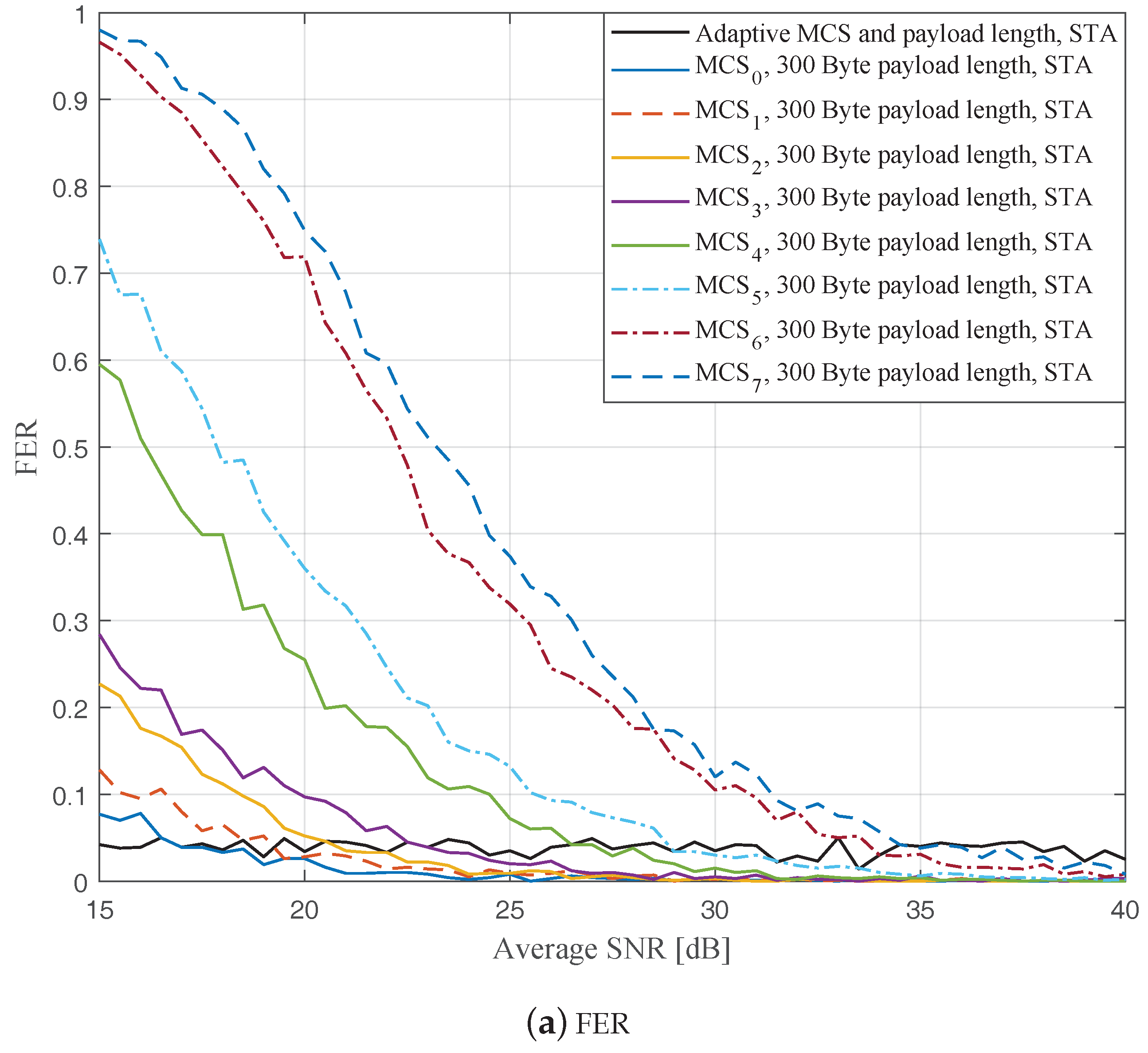
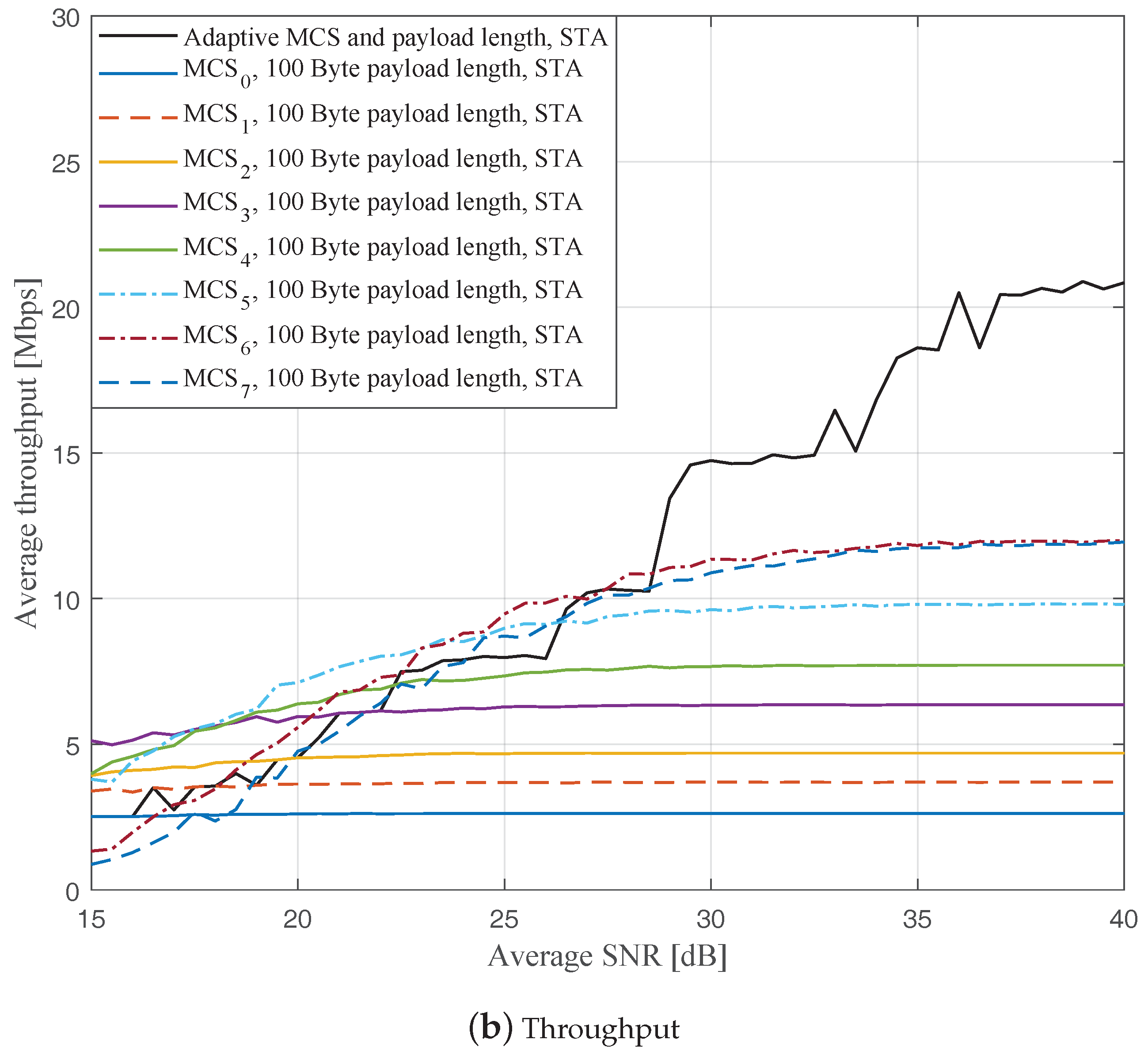
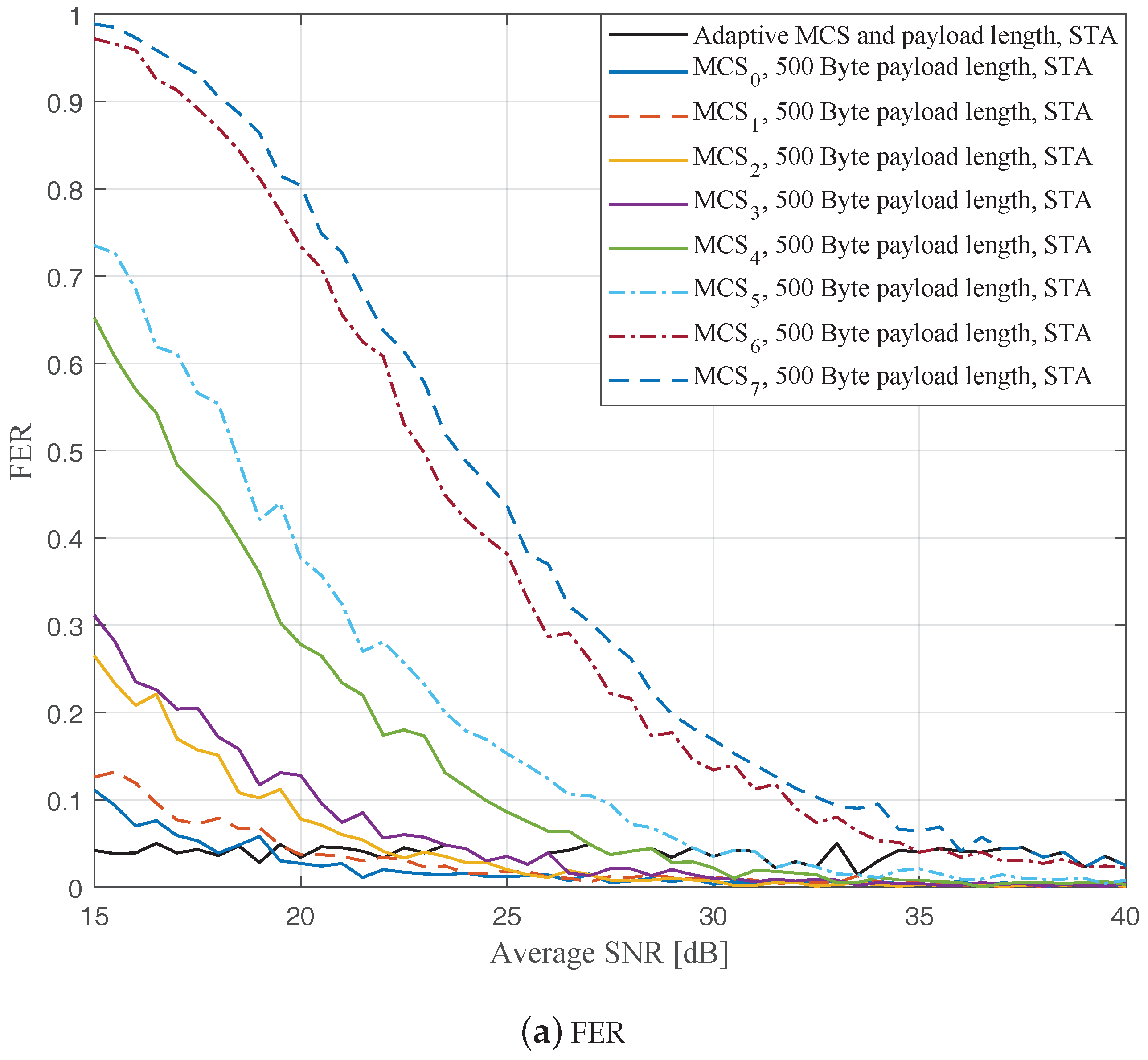
Figure 7,
Figure 8 and
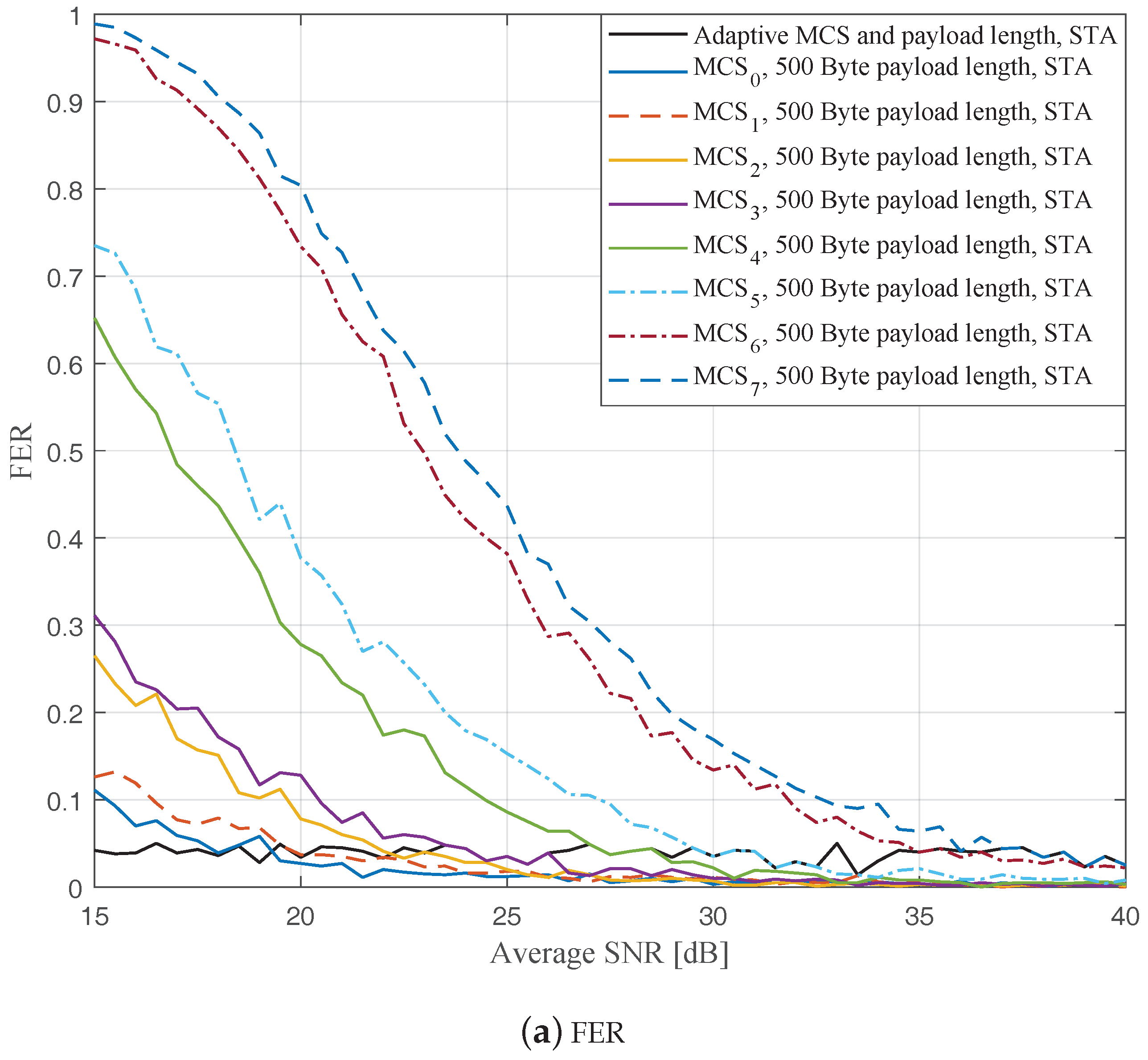
Figure 9 show the FERs and effective throughputs of the proposed AMCPLS scheme compared to fixed MCSs with fixed payload lengths of 100, 300, and 500 Bytes, respectively, when the STA channel tracking is utilized. It is noteworthy that, for fixed MCS with fixed payload length schemes, the improvements in the FERs and throughputs of the STA channel tracking compared to that of the traditional LS channel estimation appears significantly at high SNR values especially when a long payload length is used. For the AMCPLS, the FER constraint is always satisfied for both the STA channel tracking and the traditional LS channel estimation. The AMCPLS when combined with the STA channel tracking can provide significant improvement in the effective physical layer throughput when compared to traditional LS channel estimation, specifically at high SNR values.
It is noteworthy that the effective throughput of the ideal AMCPLS scheme sometimes fluctuates even for an increase in the average SNR value when both LS channel estimation and STA channel tracking are considered as depicted in
Figure 4b,
Figure 5b,
Figure 6b,
Figure 7b,
Figure 8b and
Figure 9b. These fluctuations are for small SNR variations where the fading effect has the dominant impact on the channel condition. At these fluctuation points, the fading effect may make the channel condition accompanied with the low average SNR value better than the channel condition accompanied with the high average SNR value because the difference in the SNR is small (about 0.5 dB).
5.2. Performance Evaluation of Machine Learning Based AMCPLS
In this part, we evaluate the proposed DCNN based AMCPLS approach. The k-NN based AMCPLS and the SVM based AMCPLS are also evaluated and their performance are used as benchmarks. We perform simulations for IEEE 802.11p V2V communication systems in the rural LOS environment. The training examples
are generated as follows. We simulate the IEEE 802.11p V2V system at different SNR values that range from 15 dB to 40 dB with a 1 dB step. For every SNR value, transmission using all possible classes (indexed from 0 to 23) is performed for different 1000 channel realizations and the FER of each class is calculated. Then, the ideal class, that corresponds to the maximum throughput and at the same time satisfies the target FER,
, is selected as the label for the channel realizations of the corresponding SNR. For every frame received correctly, the features
are computed and saved along with the corresponding label
. The feature set extracted as in (
9) is used to train the DCNN, k-NN, and SVM for AMCPLS.
After we have finished the training, in order to evaluate the proposed DCNN AMCPLS approach, we generate new 1000 channel realizations for each SNR value that ranges from 15 dB to 40 dB with a 0.5 dB step. Transmissions are performed over all channel realizations. At the receiver, the features are computed from the received signal. Then, the features are used as the input to the trained DCNN, k-NN, and SVM for predicting the corresponding class, i.e., optimal combination of MCS and payload length that should be utilized in the next frame.
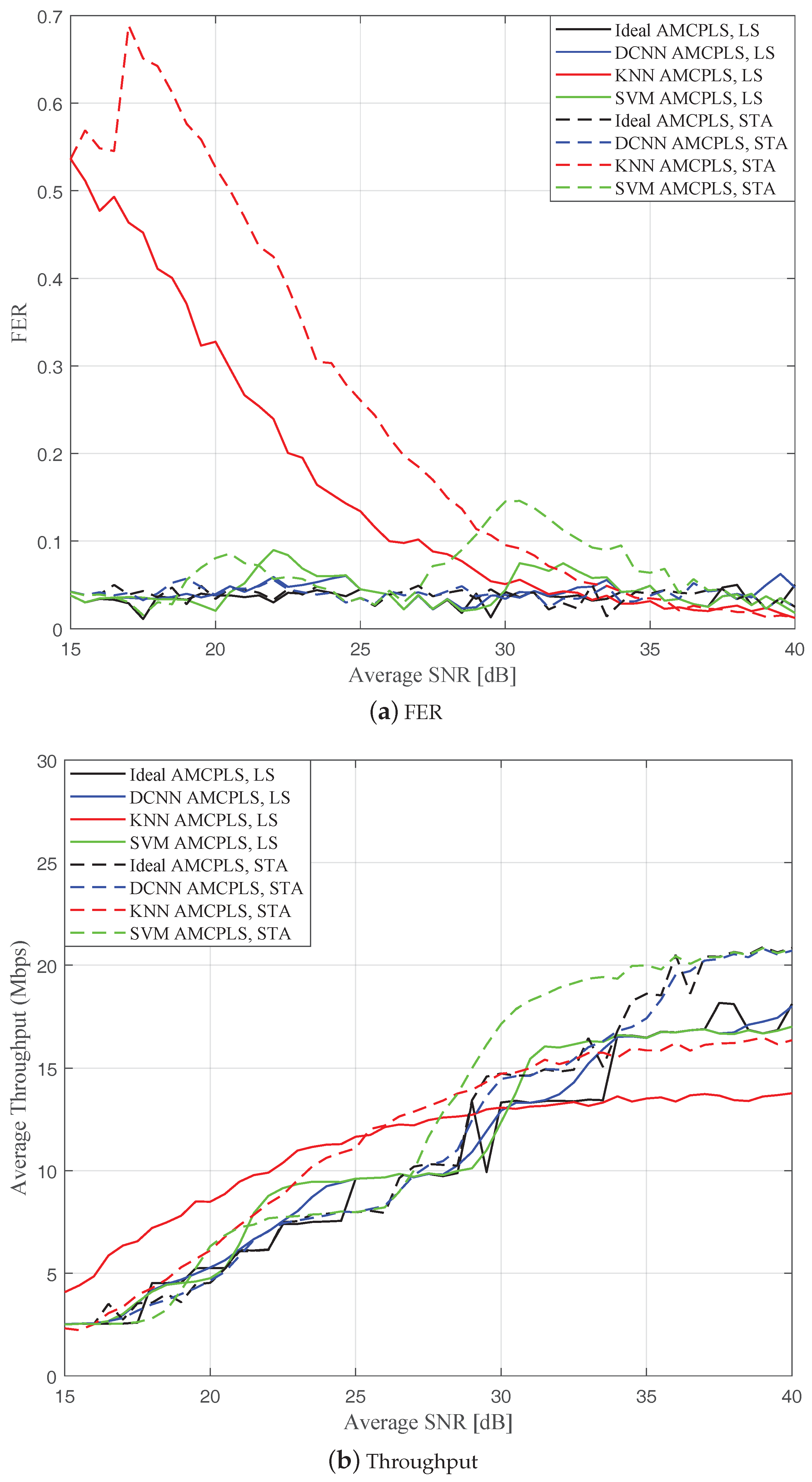
Figure 10 depicts the FER and effective throughput performance of the proposed DCNN AMCPLS, k-NN AMCPLS, and SVM AMCPLS when both traditional LS channel estimation and STA channel tracking are used. Particularly,
Figure 10a shows that k-NN AMCPLS and SVM AMCPLS failed to fulfill the target FER constraint for a considerable range of SNR values when both traditional LS channel estimation and STA channel tracking are considered. On the other hand, the proposed DCNN AMCPLS approach has better FER performance compared to both k-NN AMCPLS and SVM AMCPLS for both the traditional LS channel estimation and STA channel tracking. From
Figure 10b, it is noted that the k-NN AMCPLS and SVM AMCPLS can provide higher throughput than the proposed DCNN AMCPLS at some ranges of SNR values for both traditional LS channel estimation and STA channel tracking at the price of the increased FER. The increased FERs of both k-NN AMCPLS and SVM AMCPLS affect their reliability in V2V communications and requires multiple frame retransmissions that affects the system latency and energy efficiency.
In order to assess the computational cost of the DCNN AMCPLS, the k-NN AMCPLS, and the SVM AMCPLS, we evaluated the average time required by each approach for predicting the transmission mode class of more than 49,000 channel realizations on an Intel core i3-6100 with speed 3.7 GHz processor. We found that the average prediction times of the DCNN AMCPLS, k-NN AMCPLS, and SVM AMCPLS are 64 µs, 480 µs, and 1194 µs, respectively. It is clear that the proposed DCNN AMCPLS has reduced prediction time and reduced FER compared to both k-NN AMCPLS and SVM AMCPLS. This means the proposed DCNN AMCPLS is more reliable than both k-NN AMCPLS and SVM AMCPLS for safety related related applications, where the increased FER and the increased transmission mode class prediction time may lead to severe consequences such as cars collisions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}