1. Introduction
In recent years, a new framework has emerged, and mobile crowdsourcing has enable workers to perform spatiotemporal tasks. With the development of various sensors (such as GPS and TP (Temperature Probe)) and wireless mobile networks (such as 4G and 5G), the ability of smart devices to process data is getting stronger and stronger. It is easy to participate in mobile crowdsourcing for performing spatial tasks at specific locations for people, such as taking photos/videos [
1], uploading traffic information [
2], weather conditions, online courier picking, booking services and dating/meeting apps and games (e.g., Pokémon Go). It has greatly improved the quality of life and promoted the development of online technology. At the same time, the market research institute Newzoo [
3] recently released the “2018 Global Mobile Market Report”, showing that by the end of 2018, the number of global smartphone users reached 3.3 billion, which means that there will be many users in the future mobile crowdsourcing system. In general, mobile crowdsourcing systems (e.g., drip taxis [
4], hungry apps [
5], etc.) can allocate or recommend spatial tasks to active workers who are close to the task location. The mobile crowdsourcing system allocates the most suitable crowd workers to each task based on the spatiotemporal attributes and the characteristics of tasks.
The most striking difference between mobile crowdsourcing and traditional crowdsourcing is that workers can only perform the part of the spatial task close enough to them, so that workers can actually move to the spatial task’s location before the task deadline. However, workers have no spatial restrictions in traditional crowdsourcing systems. Therefore, researching and designing an effective task allocation model to allocate tasks for workers is the main goal of mobile crowdsourcing.
In [
6], tasks of mobile crowdsourcing systems can be published in two different modes: Worker Selected Tasks (WST) and Server Allocated Tasks (SAT). For WST mode, online workers can choose any spatial task published by nearby requesters without having to coordinate with the mobile crowdsourcing server. Due to the autonomy of WST, the platform cannot control the workers to achieve a global optimal allocation strategy in terms of the number of allocated tasks or some objective scores. For SAT mode, online workers will periodically report their location to the platform, so that the platform can allocate tasks to nearby workers to optimize the effectiveness of mobile crowdsourcing. In WST mode, workers do not need to report their location to the platform, but in SAT mode the platform needs to track the locations of workers and protect the spatial privacy of workers. In addition, in WST mode, certain tasks may never be selected because the platform has no control over the characteristics of workers. However, in SAT mode, the server can allocate these tasks to the workers to maximize the number of tasks allocated or maximize platform’s utility [
7]. Therefore, in our paper, we propose a task allocation model in SAT mode. Although there are many studies [
7,
8,
9,
10,
11,
12] on task allocation methods for mobile crowdsourcing, their problem settings and optimization goals are not exactly same.
At present, few research works [
7,
10,
11,
12,
13] considered the relationship between friends when allocating task in mobile crowdsourcing. A study [
14] in the journal Nature Communications pointed out that from the brain scan results, when friends react to the same thing, the brain wavelengths are extremely similar. The research team led by Carolyn Parkinson, a social psychologist at the University of California, Los Angeles, conducted experiments on 42 students. The researchers carried out each of the reaction images one by one. In comparison, brain activity patterns are used to predict who is a friend and who is a classmate. The final correct rate reached 48%. In the final report, the researchers wrote: “Neural similarity increases with the friendship between people. These results show that we are very similar to our friends in the way we perceive and respond to the world around us”. At the same time, the reaction between friends is more similar than the reaction between non-friends. The more similar the responses are, the more intimate their relationship are. Therefore, this paper deeply explores the relationship between people and their friends to allocate the same or similar tasks that the worker has performed to the workers’ friends, or allocate common tasks to the workers and his friends, thereby reducing costs. For example, car pooling behavior saves more money than special car behavior. The corresponding task/worker categories are shown in
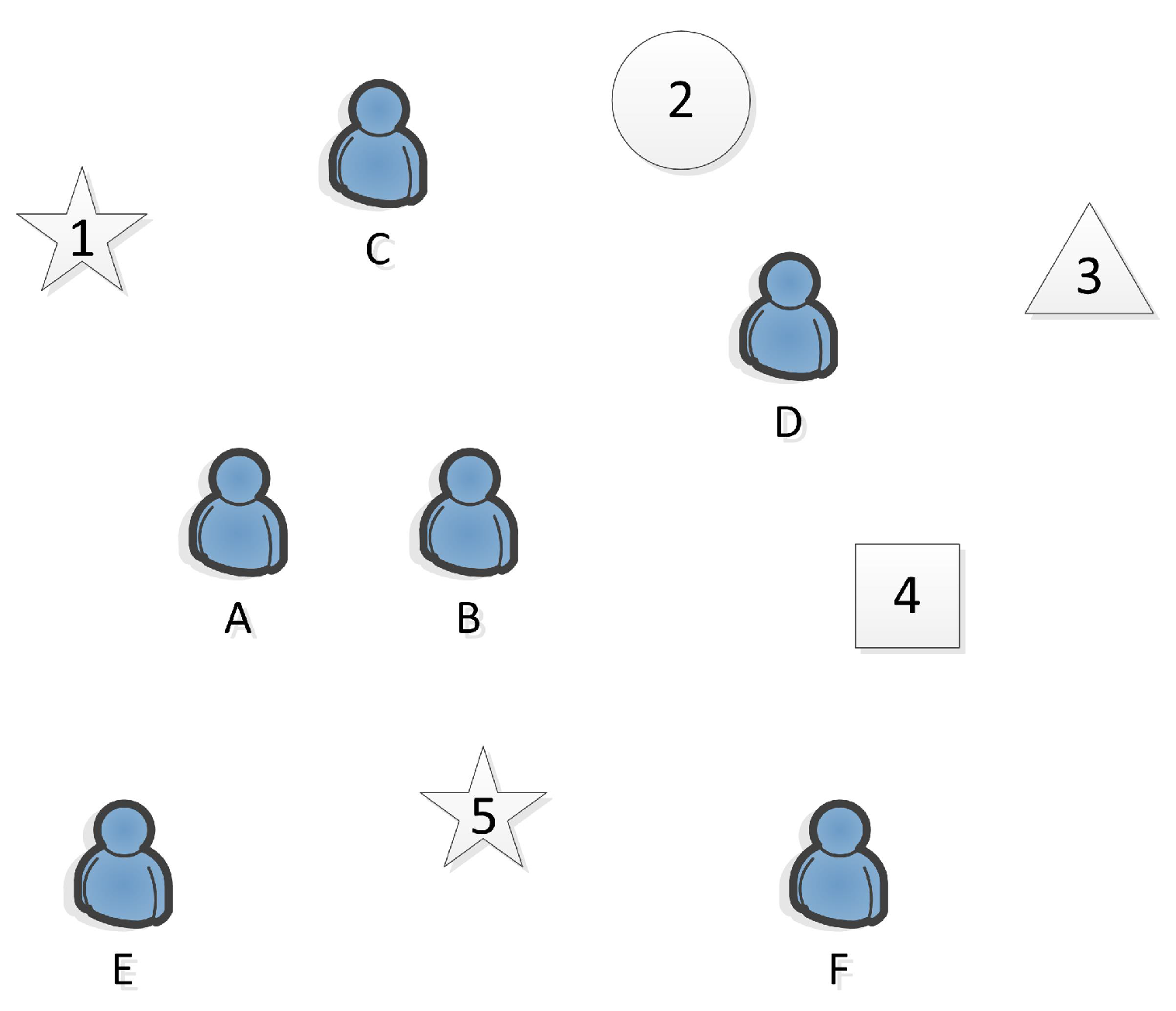
Table 1.
Example. In
Table 1, A–F represent six workers, while 1–5 represent five tasks, where Task 1 and Task 5 belong to the same category of task. As shown in
Figure 1, we assume that Worker A and Worker B are university roommates who live together everyday. They are intimate, and not only have similar professional skills, but are familiar with each other and understand each other. Completing a job will be more tacit.
In SAT mode, the mobile crowdsourcing platform can allocate Task 5 to Worker A and Worker B, so that the two workers can work together. It will not only improve the quality of sensed data and the completion rate of tasks, but also save the cost of moving to the target location, which can reduce the unnecessary overhead and maximize the use of current resources. Conversely, if Task 5 is allocated to Worker E, Worker E will be required to bear the cost of task alone. For a more specific example, if Workers A and B are classmates with the same major, they have similar professional skills. We assume that Workers A and B are majoring in computer science and technology. The five-pointed star represents the task that needs ability of repairing computers. Worker A has performed Task 5. The mobile crowdsourcing platform can allocate Task 1 to Workers A and B who have similar job skills. The effect will be perfectly reflected in the completion, professionalism, time saving and allocation matching of the tasks.
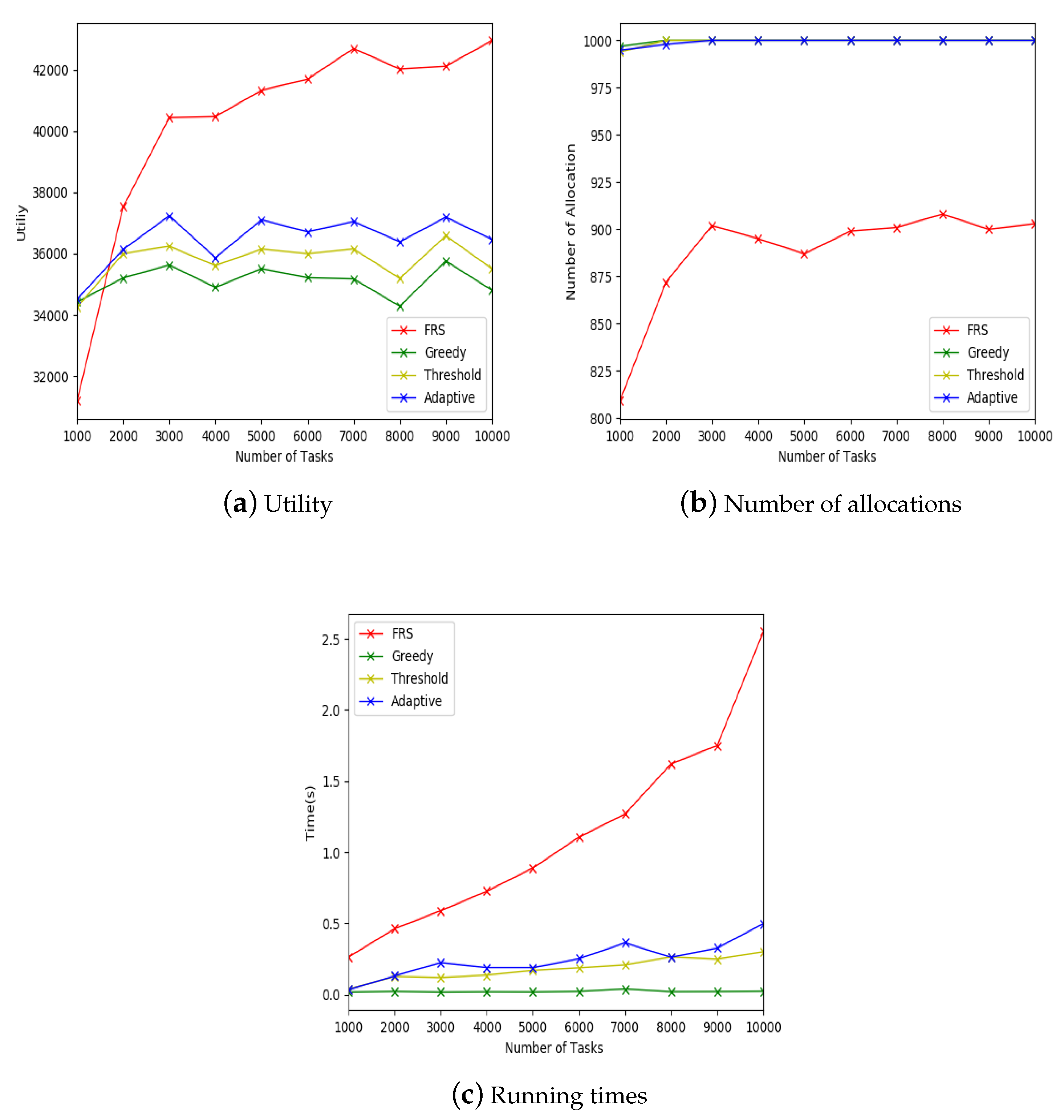
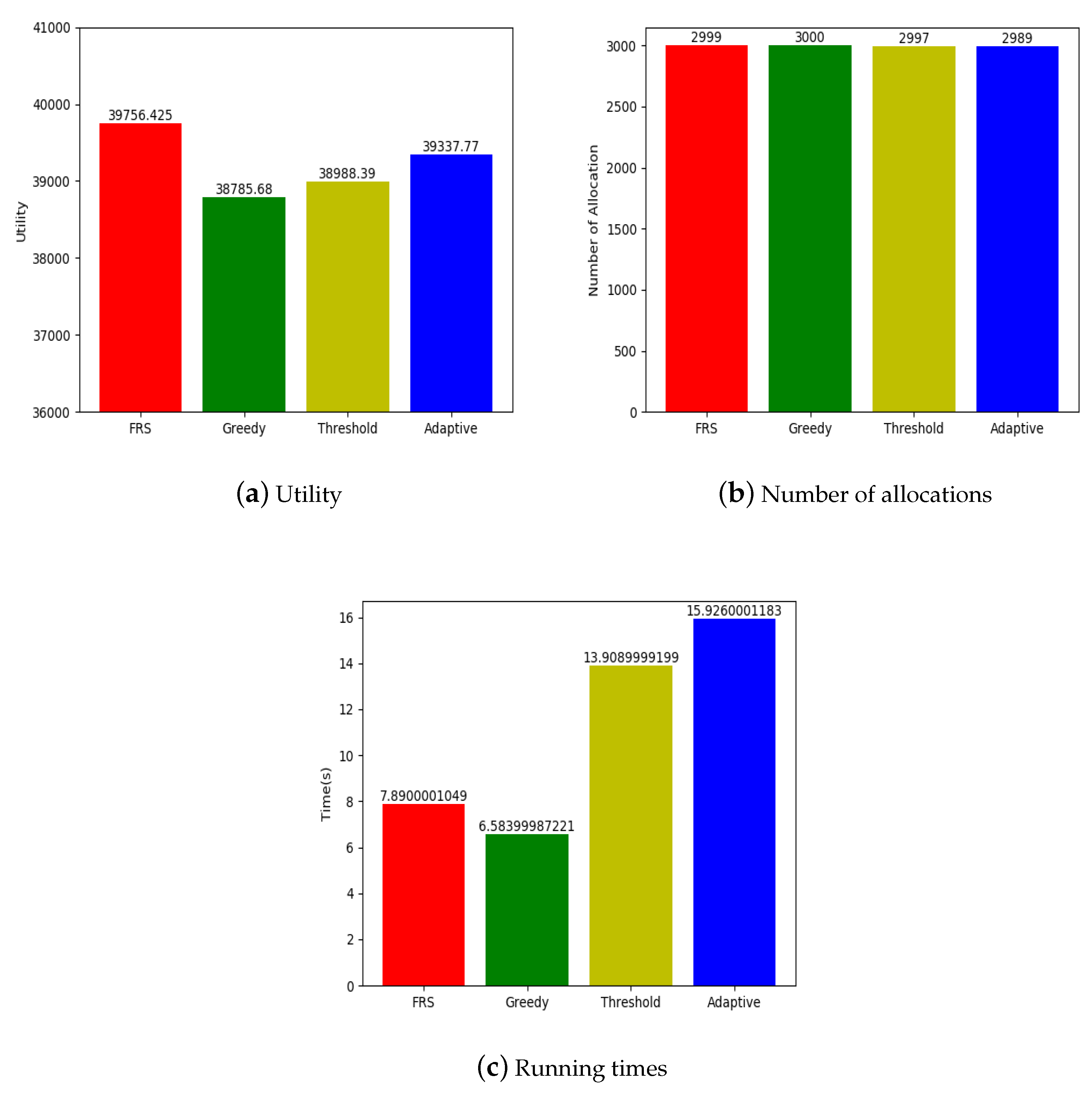
According to the above analysis, in this paper, we propose a Friend Relationship Strength Mobile Crowdsourcing (FRS-MC) combining the adaptive threshold algorithm and GeoHash coding, which aims to deeply explore the strength of the relationship between workers and their friends. Under the constraints of the deadline of task and budget, this paper applies friend relationships to the task allocation problem of mobile crowdsourcing, which can improve the accuracy of task allocation, reduce the travel cost of workers and maximize the total utilities of the allocations (defined as the total utilities of workers). Because the platform needs to track the locations of workers in SAT mode, it needs to protect the spatial privacy of workers. GeoHash coding can provide high protection of worker’s spatial location information. First, we explore the relationship strength between workers and their friends on time attribute. Then, we explore the relationship strength between workers and their friends on geographical attributes. Finally, our proposed FRS-MC algorithm is used to select the workers with the highest relationship strength.
Specifically, we make the following contributions.
We research the relationships among friends in social networks and apply them to task allocation model in mobile crowdsourcing.
The time relationship strength based on historical interaction information of friends, and the geographical relationship strength based on GeoHash coding are researched to protect the privacy of workers.
We design an algorithm for task allocation based on friend relationship strength.
Utilizing real dataset, the adaptation and effectiveness of the proposed FRS-MC algorithm are verified through comparison with other task allocation methods.
In
Section 2, we review the previous research in mobile crowdsourcing.
Section 3 introduces the definition of problems in the mobile crowdsourcing system. In
Section 4, we introduce the proposed model and give the algorithm. Finally,
Section 6 summarizes the paper.
3. Problem Definition
In this section, we present the definitions of the task allocation model based on friend relationship for mobile crowdsourcing.
3.1. Crowdsourcing Workers with Friends
First, we give the definition of crowdsourcing workers with friends in mobile crowdsourcing. Assume that is a set of all workers in timestamp t in mobile crowdsourcing, that is, there are k workers at timestamp t. Each of them can perform some types of crowdsourcing tasks.
Definition 1. (Crowdsourcing Workers with Friends) represents the set of crowdsourcing workers in the mobile crowdsourcing, each has a set of friends , which means that has r friends. The crowdsourcing worker can move with the speed and has a maximal moving distance . The service quality of is presented by .
In Definition 1, crowd workers can move dynamically with the speed in any direction, the position of is shown by .They can freely join or leave the mobile crowdsourcing system from to a maximal distance . Therefore, can be shown by .
3.2. Crowdsourcing Task with Categories
In this section, we present the definition of a crowd task with categories in a mobile crowdsourcing system. Assume that is a set of all categories of tasks in the mobile crowdsourcing, that is to say, there are o types of tasks in the mobile crowdsourcing.
Definition 2. (Crowdsourcing Tasks with Categories) denotes the crowdsourcing task set in the mobile crowdsourcing, each has a category set , which means that belongs to s categories. Each task has a budget for crowd workers.
As given in Definition 2, the task requester publishes a mobile task with the category that requires the worker to physically move to a specific location and arrive at before the arrival deadline . At the same time, the task requester also specifies the budget , which is the maximum amount he/she is willing to pay for the worker. This budget can be a bonus cash or bonus point in mobile crowdsourcing system. At the same time, this task belongs to certain categories, e.g., it can belong to both decoration and construction. Therefore, can be shown by .
3.3. Allocation Problem
Given the crowdsourcing task set T, the crowdsourcing worker set W, the crowdsourcing task and the crowdsourcing workers appear one after another in a certain order. The solution goal is to find the task allocation of T and W, and . To maximize the total utility of task allocation, it should satisfy the following constraints:
Deadline constraint: When a crowdsourcing task or a crowdsourcing worker appears, task allocations can be given, and the crowdsourcing worker’s arrival time satisfies the deadline of .
Invariant constraint: Once allocated, task allocations cannot be changed.
Spatial constraint: The task allocation needs to satisfy that the moving distance of cannot exceed his maximal moving distance.
Budget constraint: The payment paid by the requester for cannot exceed the maximal budget of .
To allocate worker to task , we need to pay his cost (the driving cost in this paper), which is related to the travel cost from ’s position to ’s position . The value of can be calculated by the gas/transport fee per kilometer and the moving distance. For public transportation, the cost of can be calculated by multiplying the cost per kilometer by the distance traveled. For walking, we can also provide workers with a compensation fee that is proportional to his/her distance traveled.
Without loss of generality, assume that the cost
is proportional to the travel distance
, where
is the distance function between
and
. Formally, we have
, where
is the constant parameter (e.g., gas/transport fee per kilometer). In our paper, we use the actual distance in the Google Maps API as the distance function. The descriptions for symbols are shown in
Table 2.
4. The Proposed Allocation Model
In this section, the corresponding solutions for the problems of time relationship strength and geographical relationship strength are presented.
4.1. Time Relationship Strength
The time relationship strength between workers and friends can be expressed by basic interactions between two workers (e.g., sending messages) or static public information (e.g., common hobbies). We represent this interaction or static information as an impact factor. The impact factor represents the identifiable and countable expression of the worker relationship. It can influence the relationship strength in a positive or negative way based on social attributes.
Impact factors can exist in multiple social networks. The impact factors of each social network may have different weights. The weight of impact factor indicates its relative impact on the strength of the final relationship. In our mobile crowdsourcing system, the weight of impact factor for each source is manually assigned. According to the behavior of workers, the weights of impact factors are determined. According to the evaluation for Facebook social network [
40], the weight of common hobbies is set as 0.3, the weight of learning in the same school is set as 0.1, and the weight of boyfriend/girlfriend relationship is set as 0.9. The final relationship strength is also affected by the number of impact factors, because the using frequency of social networks has an impact on the strength of relationships.
People’s activities are divided into short-term activities, long-term activities and permanent activities. The impact factor of a short-term activity represents a single expression of the relationship. The date and time of this event can be recognized. In addition, we can estimate the duration of relationship through experience, e.g., when sending a message, the duration of influence time is two days.
The impact factor of a long-term activity is used for the activities that we can identify the start time and end time. As the previous type, we can estimate the duration of its impact, e.g., studying at the same school from September 2017 to June 2020, which the duration of impact is estimated as three years.
The impact factor of a permanent activity represents a permanent activity or some static information, and we cannot define its start and end dates, e.g., family relations. Therefore, the relationship strength of one impact factor is shown by Equation (
1).
where
s is a social network,
is the weight of impact factor
f of social network
s,
u indicates the number of impact factors in the relationship between the worker and his friend,
is the count of instances of impact factors in social network
s, and
indicates the function expressing time impact. Because we use the time attribute to calculate the relationship strength of one impact factor, Equation (
1) is used to calculate the time relationship strength of one impact factor.
depends on the type of impact factor. We determine three time impact functions based on the types of activities.
Short-term activity:
where
is the time of the impact duration in days,
indicates the current time,
is the start time of the short-term activity, and
is the time of duration of the short-term activity.
Long-term activity:
where
is the time of the impact duration in days,
is the current time,
indicates the start time of the long-term activity, and
means the end time of the long-term activity. For example, a worker and his friend are studying at the same school from September 2017 to June 2020.
is three years,
is September 2017,
is June 2020, and
is the current system time.
Because permanent activities cannot be estimated, it can be set as a fixed value . According to the time relationship strength, its calculation method is discussed by an instance.
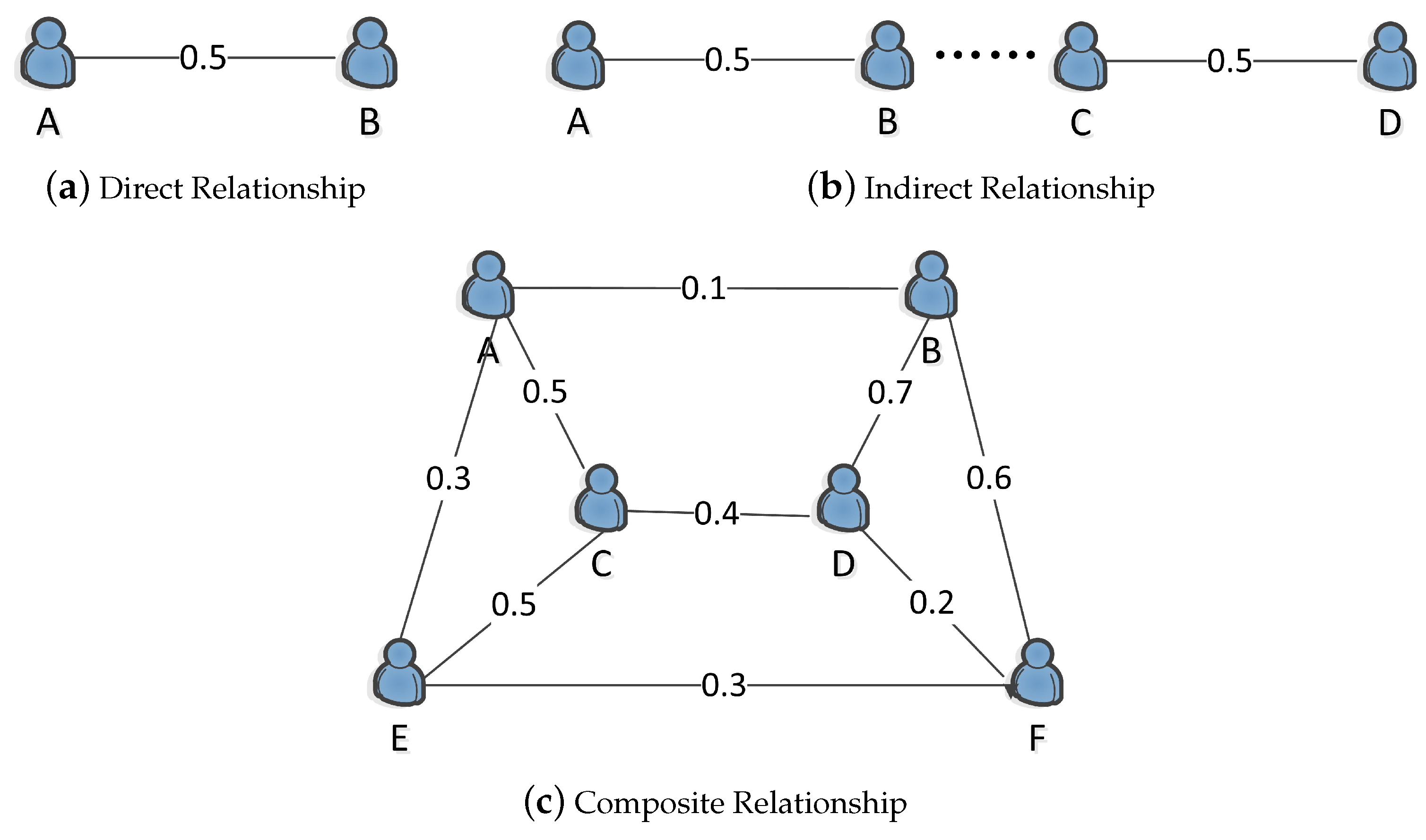
The relationships between people can be roughly divided into three types.
Figure 2a shows the direct relationship between friends. For example, Workers A and B are friends.
Figure 2b shows the indirect relationship between friends. For example, Workers A and B are not friends, but they have a common friend.
Figure 2c shows the complex relationship between friends. For example, there is a direct relationship and an indirect relationship between Workers A and E.
4.1.1. Direct Relationship Strength
The direct relationship between the two workers is obtained by Equation (
5).
where
n represents the number of social networks and
m represents the number of impact factors in the social network.
4.1.2. Indirect Relationship Strength
The indirect relationship strength between the two workers is obtained by Equation (
6).
where
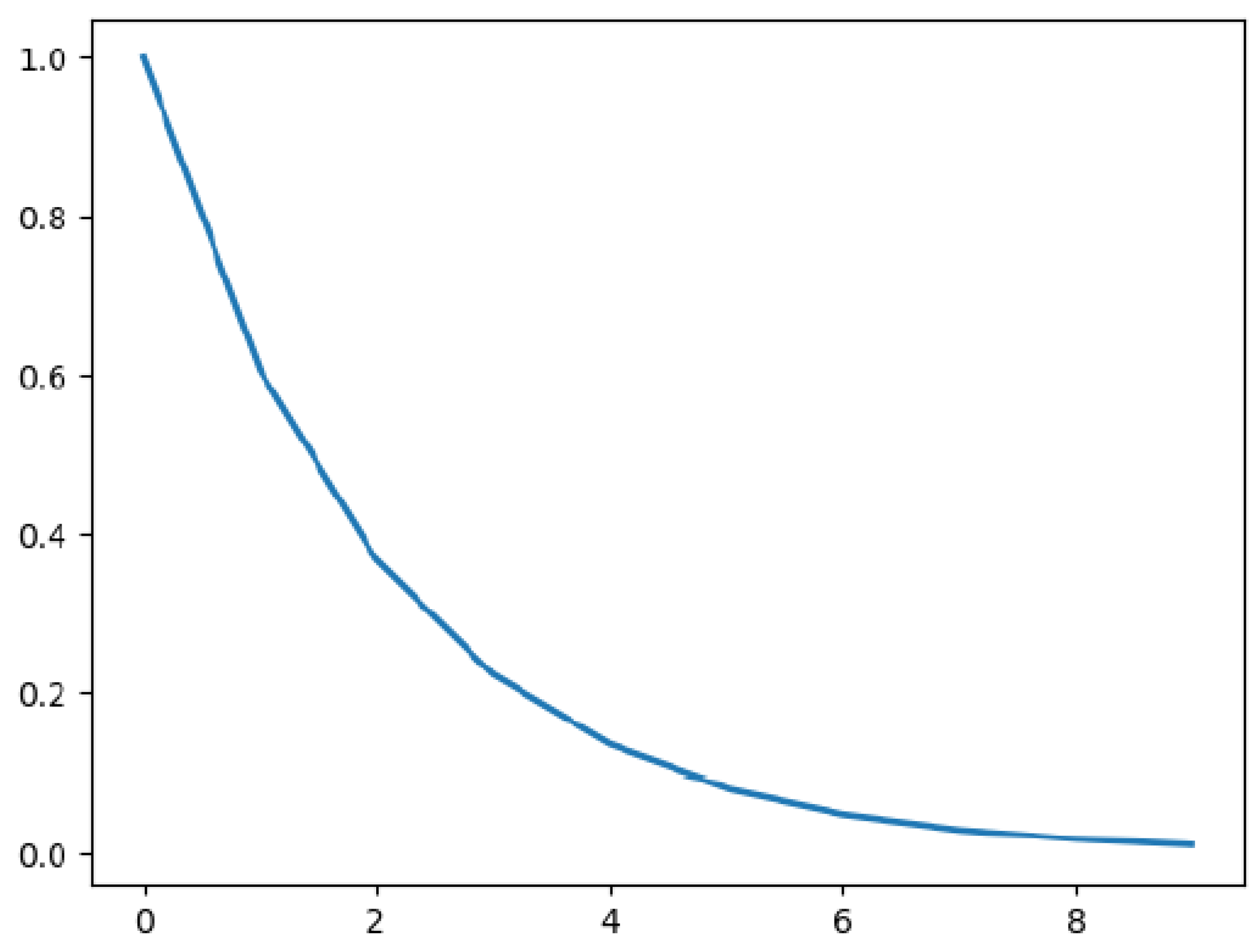
represents the attenuation coefficient of the length of relationship path, and
d represents the length of relationship strength. In addition,
is an attenuation function whose value varies continuously from 0 to 1, as illustrated in
Figure 3. The x-coordinates of
Figure 3 indicate the length of relationship strength
d.
represents the weight factor of relationship path in all paths. In general, there are multiple relationship paths between two workers. Because the length of relationship has different effects on the relationship strength, we cannot consider all paths as equivalent. Therefore, we use weighted average to calculate the indirect relationship strength for all paths.
Assume there are
n paths represented as
between worker
and worker
. The weights are
, respectively. Therefore, the indirect relationship strength for all paths is shown by Equation (
7) through improving Equation (
6).
4.1.3. Composite Relationship Strength
Based on the direct relationship strength and indirect relationship strength, the final composite relationship strength is computed by Equation (
8).
where
and
are the weights of direct relationship strength and indirect relationship strength, respectively, and
.
4.2. Geographical Relationship Strength
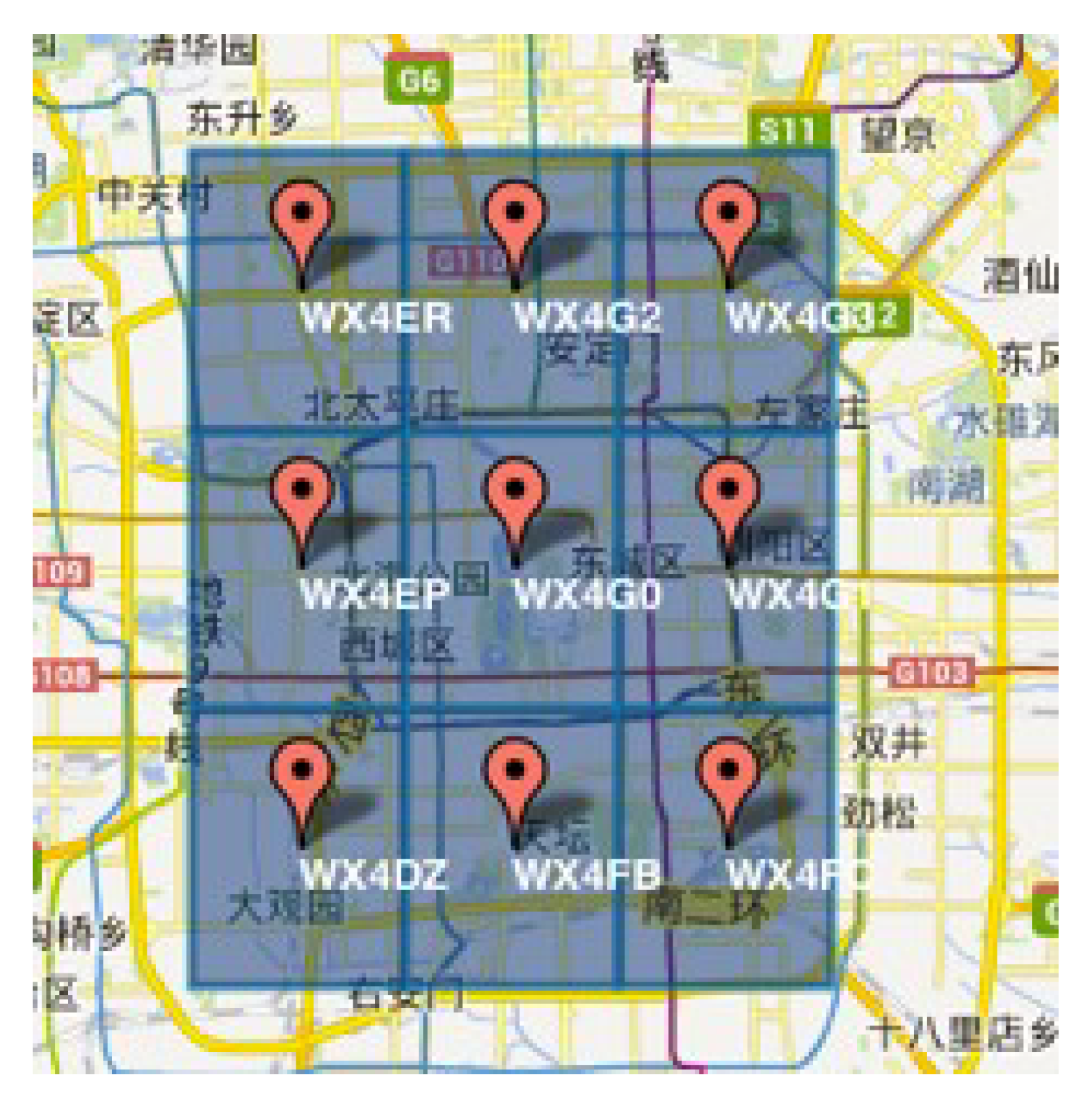
In mobile crowdsourcing, the location information is an important attribute, which can affect the efficiency of task allocation. When a worker and his friend have strong time relationship strength, but the distance between them is very large, it cannot allocate the same task for them. In this paper, we use GeoHash code to calculate the location-based relationship strength, and different ranges can be obtained according to different digits. GeoHash converts two-dimensional latitude and longitude into a string. For example,
Figure 4 shows the GeoHash strings of nine regions in Beijing, namely WX4ER, WX4G2, WX4G3, etc. Each string represents a rectangular area. That is to say, all points (latitude and longitude coordinates) in this rectangular area share the same GeoHash string, which can not only be used for the calculation of geographical relationship strength, but also protect the location privacies of workers and tasks in mobile crowdsourcing (only indicates the approximate location of the area rather than the specific point). The GeoHash string represents not a point, but a rectangular area, such as the code wx4g0ec19. The worker can post the address code to indicate that he/she stays near Beihai Park, but does not expose his/her exact position.
Algorithm 1 shows the calculation method of geographical relationship strength based on GeoHash. First, entering the latitude and longitude coordinates and of worker and worker , the coordinate format is . Then, the corresponding binary codes , , , and of latitude and longitude of the position are obtained according to the GeoHash code. We combine the GeoHash codes of latitude and longitude to generate a new string following the rule of even bit longitude, odd bit latitude. The new resulting string is processed into a code sequences , following the rules of base32 encoding. Then, the two codes are compared starting from the first position of the sequence until a different encoding is encountered to obtain .
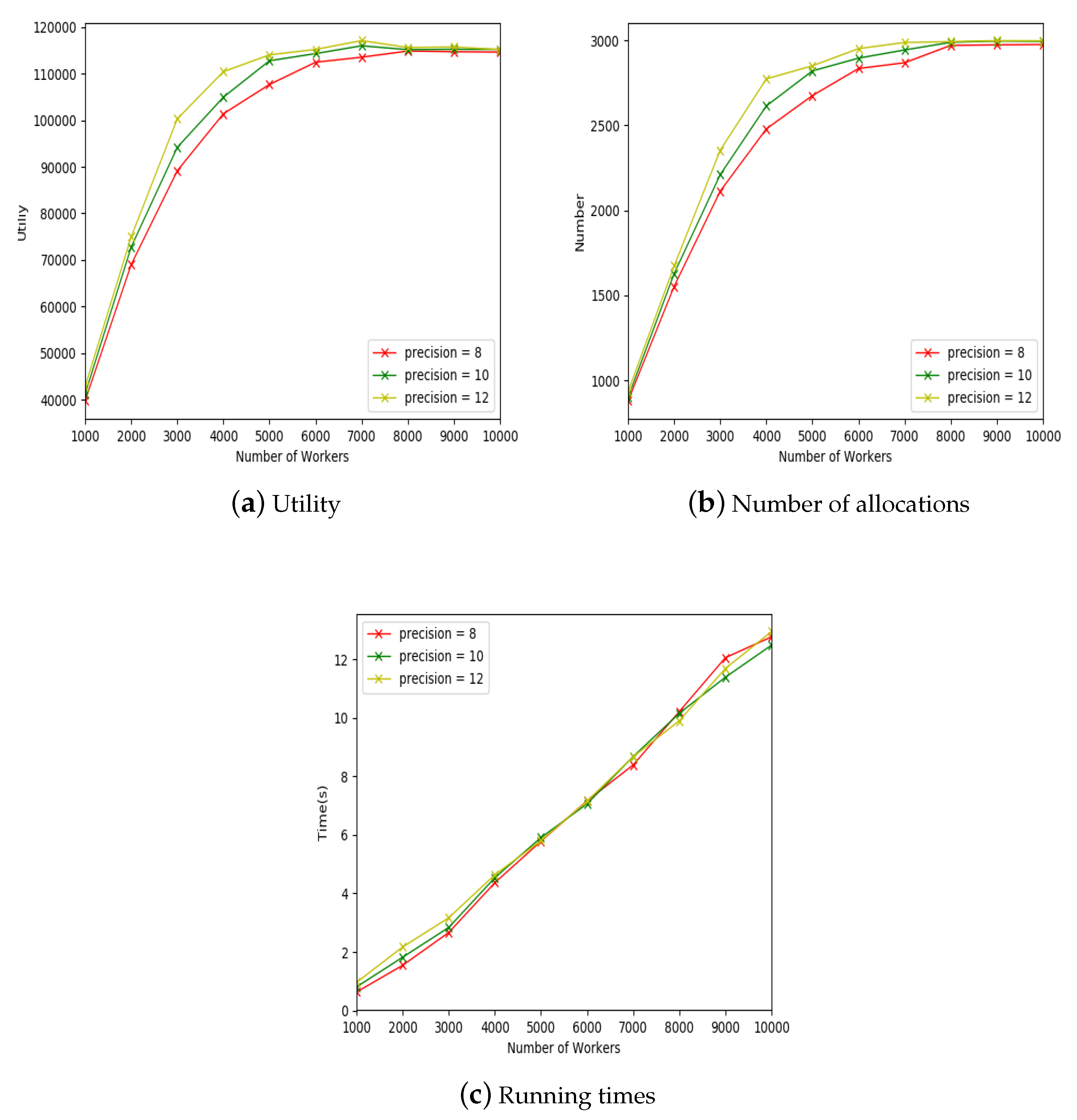
Let
be the maximal precision. We utilize Softmax activation function to represent their geographical relationship strength. The calculation of geographical relationship strength is shown by Equation (
9).
where
indicates the length of
,
.
| Algorithm 1 The algorithm. |
- Require:
, , ; - Ensure:
;
- 1:
, , , ← Calculate GeoHash binary code based on latitude and longitude; - 2:
, ← Combine , , , with 2 strings according to the principle of “even bit longitude, odd bit latitude"; - 3:
, ← Process , according to the rules of base32 encoding; - 4:
← Calculate the same string starting from the first digit of the two strings; - 5:
- 6:
return;
|
4.3. Mixed Relationship Strength
In the above two sections, the time attribute and geographical attribute are discussed. The calculation method of relationship strength between worker
and friend
is obtained by Equation (
10).
where
,
, we get the logarithm of
in order to amplify the data.
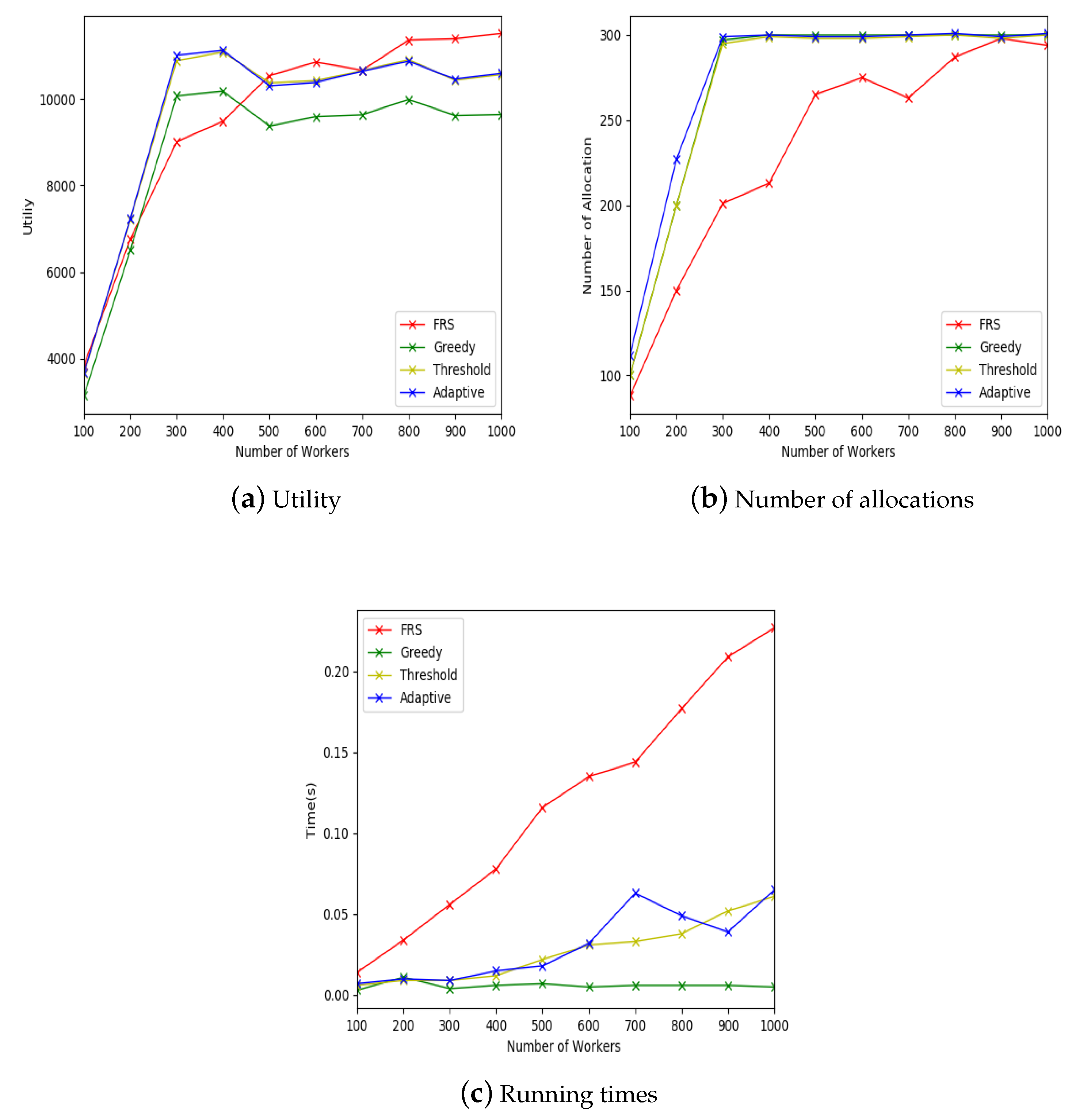
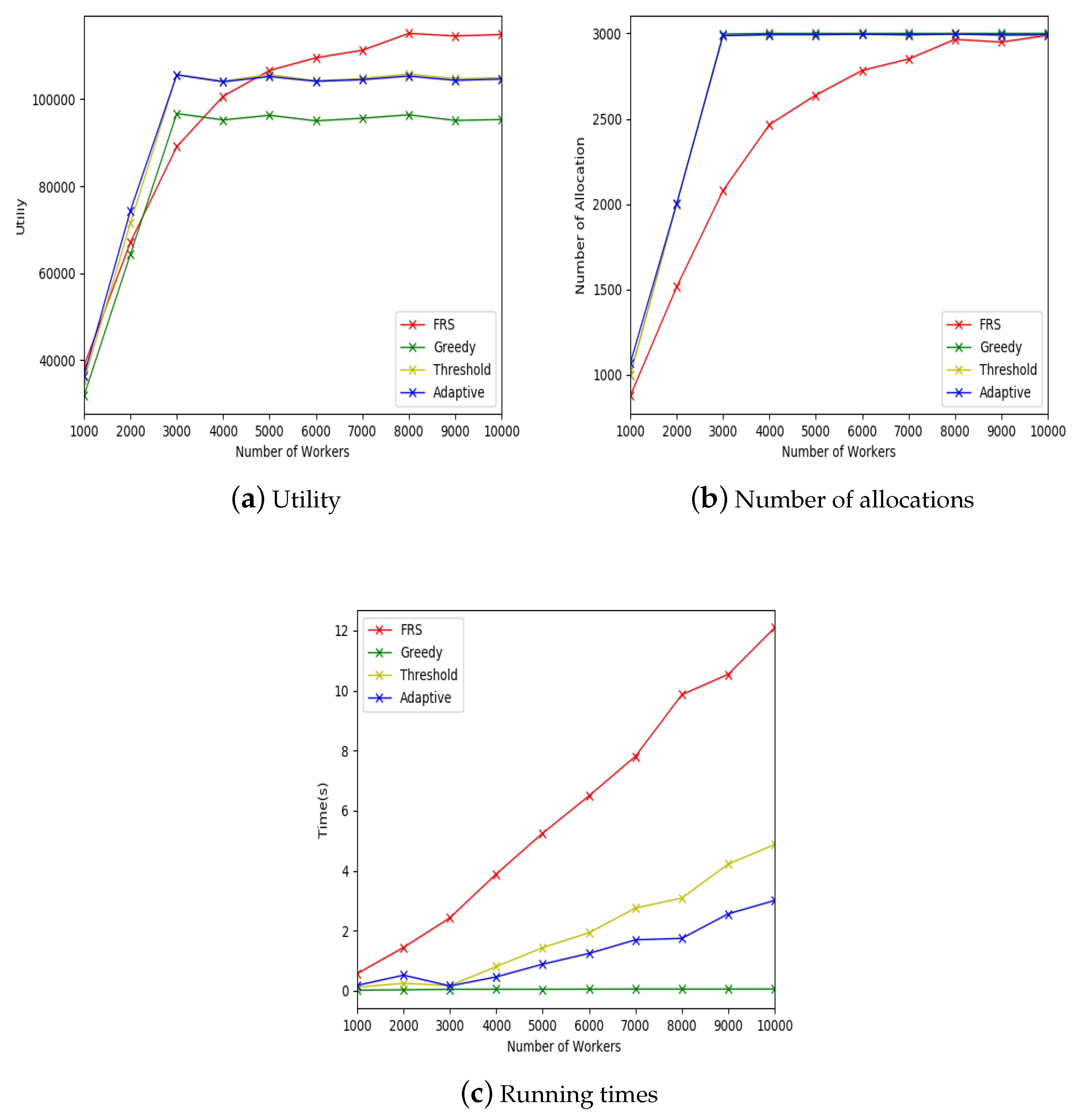
4.4. The FRS-MC Algorithm
In this section, we present the friend relationship-based task allocation model FRS-MC. Algorithm 2 shows the process of FRS-MC algorithm. The task set T, the worker set W, and the maximal utility learned through historical records are given. The tasks and workers appear randomly in mobile crowdsourcing system. The new task will be added into the set . The new worker will be added into the set , and the friends of the new worker in will be found too. If the set is empty, there is no worker in the allocated worker set who are friends of the new worker. By randomly selecting a threshold , the utilities of tasks and workers should be greater than . The value of k will be randomly selected from , where can be obtained by . can be obtained through historical records. The value of k will be generated randomly according to the probability . When the task allocation is completed, the algorithm updates the weight of threshold by the equation , and updates the values of and , correspondingly, where indicates the utility if is always used as the threshold. If the set is not empty, then we calculate the time relationship strength and geographical relationship strength of the newly appearing worker and his friends who already exist in mobile crowdsourcing system. The system selects the worker with the strongest relationship with the newly-emerged worker, and finds the category of task that this worker has done. Then, the system finds the existing tasks that have are in this category. The system then selects the task for them with the highest budget from this task set for allocation.
| Algorithm 2 The algorithm. |
- Require:
W,T,; - Ensure:
M;
- 1:
mix W,T; - 2:
shuffle ; - 3:
- 4:
- 5:
for each do - 6:
if is worker then - 7:
← Find a list of workers who are friends with the in the system - 8:
if is not Null then - 9:
for each do - 10:
Calculate the time relationship strength between and - 11:
Calculate the geographical relationship strength between and - 12:
end for - 13:
Get the categories of tasks that workers having the strongest relationship with in have performed and allocate this kind of task to - 14:
Add to M - 15:
else - 16:
Randomly choose one as the k value from according to the probability - 17:
Allocate tasks that meet all constraints and utilities of the allocation are higher than - 18:
Add to M - 19:
- 20:
Update and - 21:
end if - 22:
else - 23:
Append to - 24:
end if - 25:
end for
|













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}