Automatic Recognition of Ripening Tomatoes by Combining Multi-Feature Fusion with a Bi-Layer Classification Strategy for Harvesting Robots



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Acquisition of Images
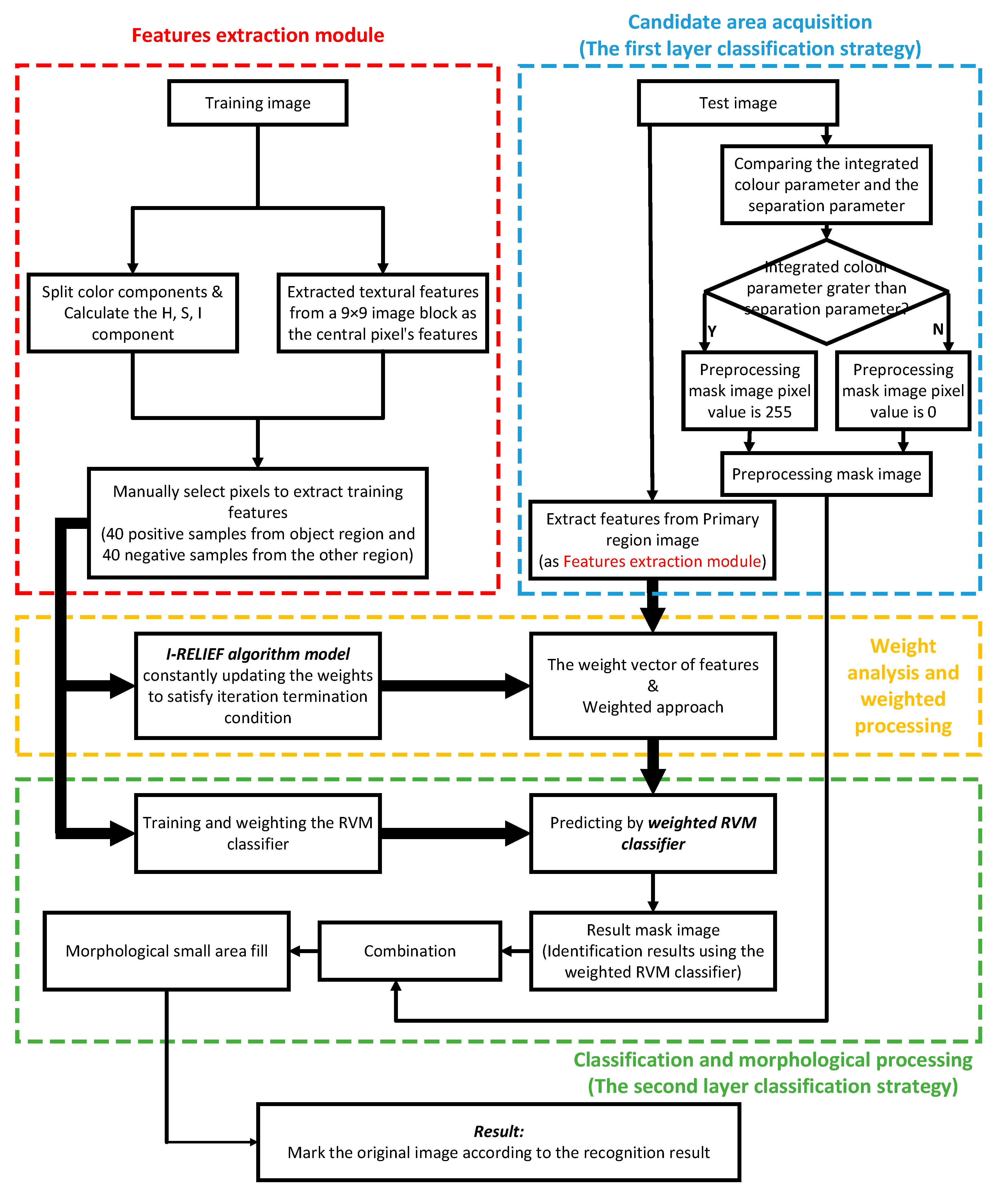
2.2. Algorithm for Automatic Recognition of Ripening Tomatoes
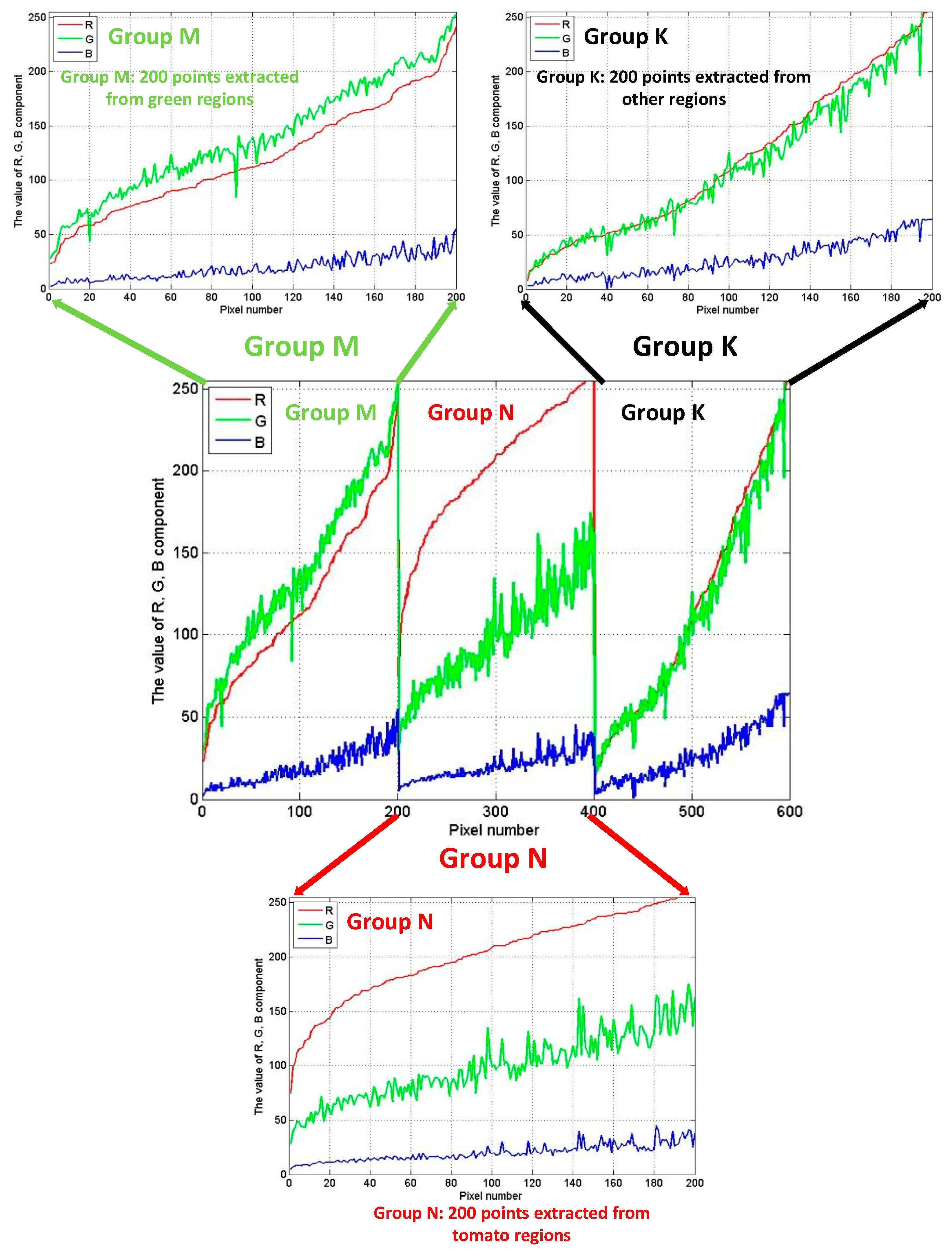
2.3. Chromatic Difference Analysis
2.4. Feature Extraction
2.5. Feature Contribution Ratio Calculation
2.6. Related Vector Machine Classifier
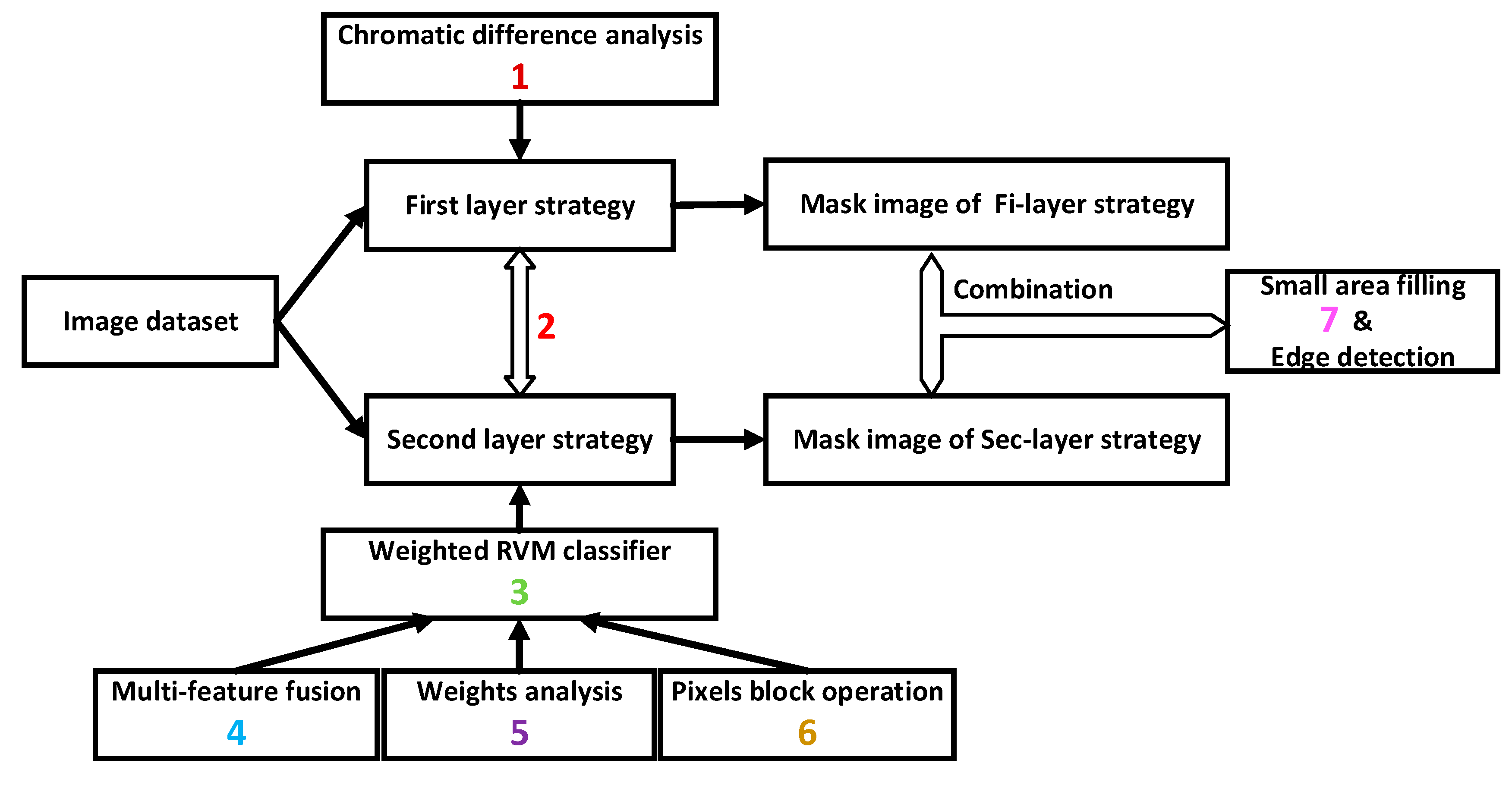
2.7. Novelty and Contributions
- (1)
- Compared with the traditional method of using component R individually in image processing, we used chromatic difference analysis as Equation (1) to replace it. The advantage of chromatic difference analysis is that the components R, G, and B are considered in the segmentation process at the same time. The result will be affected observably when using component R individually due to the interference from external factors makes the value of component R change flexibly. The negative influence of external factors will be reduced by subtraction during the chromatic difference analysis.
- (2)
- We separated the operations of the first and the second layer strategies in the study. The second layer strategy won’t deal with the results from the first layer strategy, so as to avoid the error from former strategy affecting the results of later strategy directly.
- (3)
- In the algorithm, we chose RVM classifier because of its kernel function has loosened constraint conditions. In addition, the construction process of RVM classifier is convenient and the effect of identifying is ideal. The application of RVM classifier can also be a peculiarity of this study.
- (4)
- We selected 11 dimensional features which not barely include colour features, but also include textural features in the phase of features selection. The addition of textural features improves the accuracy and applicability of the RVM classifier.
- (5)
- We determined the feature contribution ratio by weight analysis based on the iterative RELIEF feature weighting algorithm. The weighted vector takes the contribution ratio of 11 features into the process of RVM classifier training, which shows the specific character of different features. Neglecting the contribution ratio of 11 features is imprecise and we have already avoided that by this section.
- (6)
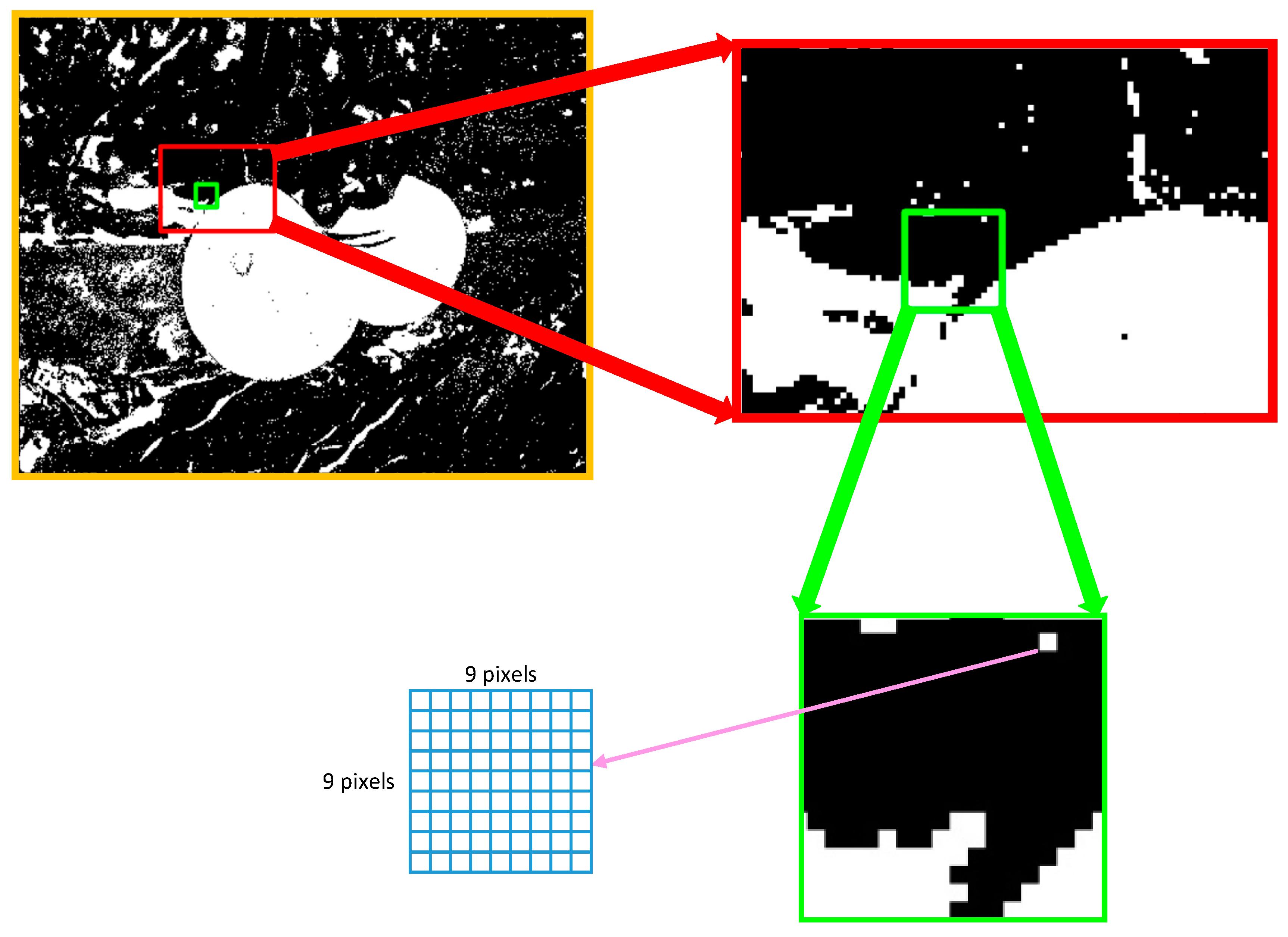
- Obviously, the manipulation of using the 9 × 9 pixels black instead of a single pixel used in feature extraction and machine learning classification sections in the study. This substitution can improve the operating speed and computing efficiency at the same time.
- (7)
- In the section of small area filling, we use the boundary points of the region as filter objects. We didn’t choose the method realize the purpose of small area filling by screening the area of connected regions, because of the difficulty of the connecting type and the speed of connected domain judgement is slowly.
3. Results and Discussions
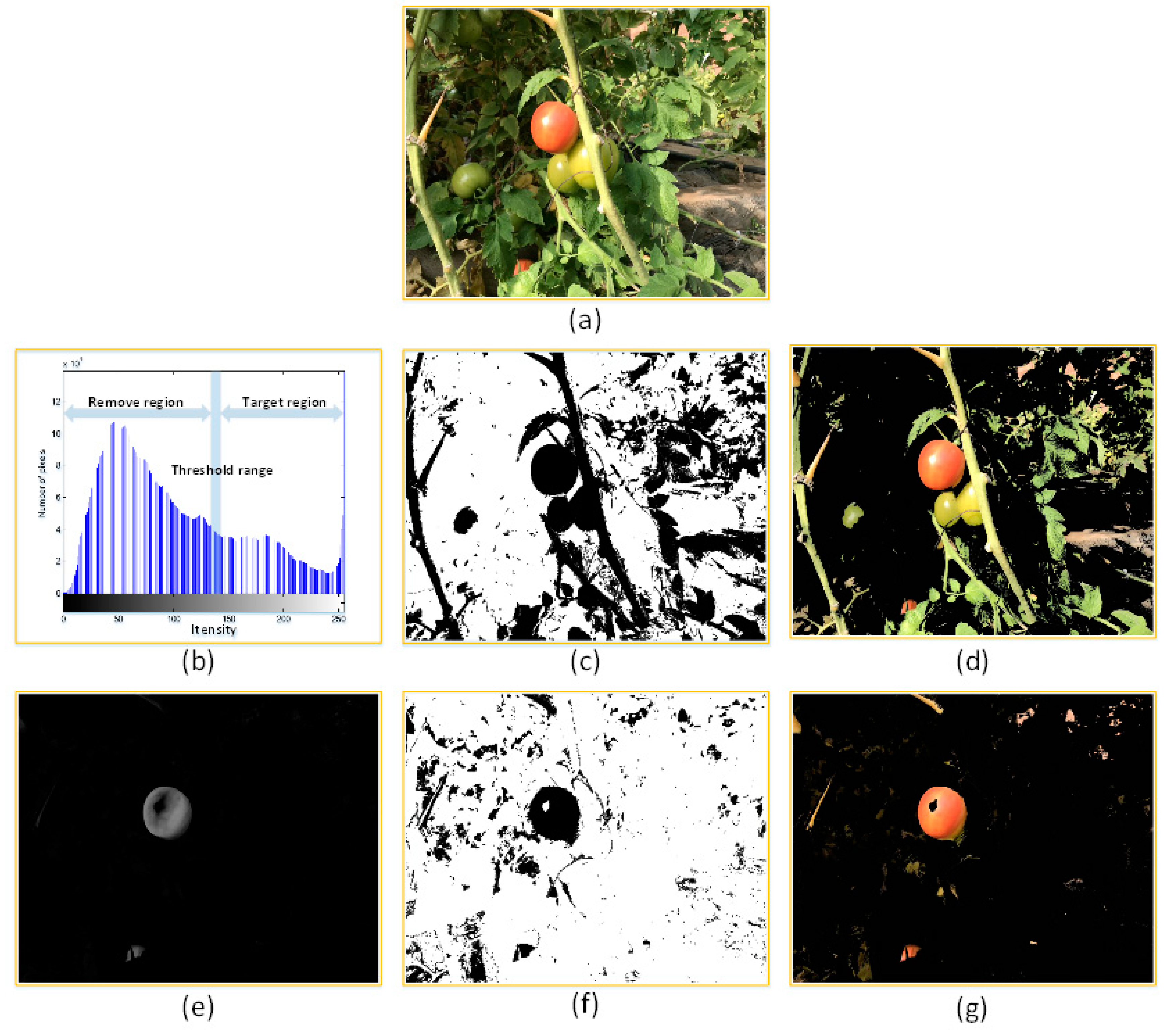
3.1. Segmentation Based on Colour Difference Analysis
3.2. Feature Weight Analysis and Determination
3.3. Identification Results Using the Weighted RVM Classifier
3.4. Results of the Bi-Layer Classification Strategy Algorithm and Final Results
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zujevs, A.; Osadcuks, V.; Ahrendt, P. Trends in Robotic Sensor Technologies for Fruit Harvesting: 2010–2015. Procedia Comput. Sci. 2015, 77, 227–233. [Google Scholar] [CrossRef]
- Chen, X.; Tao, X. Harvesting quality status and development trend of mechanical cotton harvester. IAEJ 2013, 22, 84–94. [Google Scholar]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Detecting tomatoes in greenhouse scenes by combining AdaBoost classifier and colour analysis. Biosyst. Eng. 2016, 148, 127–137. [Google Scholar] [CrossRef]
- Ye, Q.; Gu, R.; Ji, Y. Human detection based on motion object extraction and head–shoulder feature. Opt. Int. J. Light Electron Opt. 2013, 124, 3880–3885. [Google Scholar] [CrossRef]
- Feng, Q.C.; Cheng, W.; Zhou, J.J.; Wang, X. Design of structured-light vision system for tomato harvesting robot. Int. J. Agric. Biol. Eng. 2014, 7, 19–26. [Google Scholar]
- Zhang, B.; Huang, W.; Wang, C.; Gong, L.; Zhao, C.; Liu, C.; Huang, D. Computer vision recognition of stem and calyx in apples using near-infrared linear-array structured light and 3D reconstruction. Biosyst. Eng. 2015, 139, 25–34. [Google Scholar] [CrossRef]
- Kise, M.; Zhang, Q. Creating a panoramic field image using multi-spectral stereovision system. Comput. Electron. Agric. 2008, 60, 67–75. [Google Scholar] [CrossRef]
- Sumriddetchkajorn, S.; Intaravanne, Y. Two-dimensional fruit ripeness estimation using thermal imaging. In Proceedings of the International Conference on Photonics Solution, Pattaya, Thailand, 26–28 May 2013. [Google Scholar]
- Henten, E.J.V.; Hemming, J.; Tuijl, B.A.J.V.; Kornet, J.G.; Meuleman, J.; Bontsema, J.; Os, E.A.V. An Autonomous Robot for Harvesting Cucumbers in Greenhouses. Auton. Robots 2002, 13, 241–258. [Google Scholar] [CrossRef]
- Tanigaki, K.; Fujiura, T.; Imagawa, J.; Imagawa, J. Cherry-harvesting robot. Comput. Electron. Agric. 2008, 63, 65–72. [Google Scholar] [CrossRef]
- Rath, T.; Kawollek, M. Robotic harvesting of Gerbera Jamesonii based on detection and three-dimensional modeling of cut flower pedicels. Comput. Electron. Agric. 2009, 66, 85–92. [Google Scholar] [CrossRef]
- Wachs, J.P.; Stern, H.I.; Burks, T.; Alchanatis, V. Low and high-level visual feature-based apple detection from multi-modal images. Precis. Agric. 2010, 11, 717–735. [Google Scholar] [CrossRef]
- Sengupta, S.; Lee, W.S. Identification and determination of the number of immature green citrus fruit in a canopy under different ambient light conditions. Biosyst. Eng. 2014, 117, 51–61. [Google Scholar] [CrossRef]
- Lu, J.; Sang, N. Detecting Citrus Fruits and Occlusion Recovery under Natural Illumination Conditions; Elsevier Science Publishers B. V: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Maldonado, W. Automatic Green Fruit Counting in Orange Trees Using Digital Images; Elsevier Science Publishers B. V: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Bargoti, S.; Underwood, J.P. Image Segmentation for Fruit Detection and Yield Estimation in Apple Orchards. J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef]
- Li, H.; Zhang, M.; Gao, Y.; Li, M.; Ji, Y. Green ripe tomato detection method based on machine vision in greenhouse. Trans. Chin. Soc. Agric. Eng. 2017, 33, 328–334. [Google Scholar]
- Wan, P.; Toudeshki, A.; Tan, H.; Ehsani, R. A methodology for fresh tomato maturity detection using computer vision. Comput. Electron. Agric. 2018, 146, 43–50. [Google Scholar] [CrossRef]
- Witus, I.K.; On, C.K.; Alfred, R.; Ibrahim, A.A.A.; Tan, T.G.; Anthony, P. A Review of Computer Vision Methods for Fruit Recognition. Int. J. Eng. 2018, 24, 1538–1542. [Google Scholar] [CrossRef]
- Jiménez, A.R.; Jain, A.K.; Ceres, R.; Pons, J.L. Automatic fruit recognition: A survey and new results using Range/Attenuation images. Pattern Recognit. 1999, 32, 1719–1736. [Google Scholar] [CrossRef]
- Plebe, A.; Grasso, G. Localization of spherical fruits for robotic harvesting. Mach. Vis. Appl. 2001, 13, 70–79. [Google Scholar] [CrossRef]
- Xu, H.; Ye, Z.; Ying, Y. Identification of citrus fruit in a tree canopy using color information. Trans. Chin. Soc. Agric. Eng. 2005, 21, 98–101. [Google Scholar]
- Hannan, M.W.; Burks, T.F.; Bulanon, D.M. A Machine Vision Algorithm Combining Adaptive Segmentation and Shape Analysis for Orange Fruit Detection. Available online: http://www.cigrjournal.org/index.php/Ejounral/article/view/1281 (accessed on 31 January 2019).
- Linker, R.; Cohen, O.; Naor, A. Determination of the number of green apples in RGB images recorded in orchards. Comput. Electron. Agric. 2012, 81, 45–57. [Google Scholar] [CrossRef]
- Ji, W.; Zhao, D.; Cheng, F.; Xu, B.; Zhang, Y.; Wang, J. Automatic recognition vision system guided for apple harvesting robot. Comput. Electr. Eng. 2012, 38, 1186–1195. [Google Scholar] [CrossRef]
- Li, B.; Wang, M. In-Field Recognition and Navigation Path Extraction for Pineapple Harvesting Robots. Intell. Autom. Soft Comput. 2013, 19, 99–107. [Google Scholar] [CrossRef]
- Dubey, S.R.; Jalal, A.S. Application of Image Processing in Fruit and Vegetable Analysis: A Review. J. Intell. Syst. 2014, 24, 28–36. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Zou, X.; Ye, M.; Feng, W.; Li, G. Vision-based extraction of spatial information in grape clusters for harvesting robots. Biosyst. Eng. 2016, 151, 90–104. [Google Scholar] [CrossRef]
- Nguyen, B.P.; Heemskerk, H.; So, P.T.; Tucker-Kellogg, L. Superpixel-based segmentation of muscle fibers in multi-channel microscopy. BMC Syst. Biol. 2016, 10, 124. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Nguyen, B.P.; Chui, C.K.; Ong, S.H. Automated brain tumor segmentation using kernel dictionary learning and superpixel-level features. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2017. [Google Scholar]
- Arefi, A.; Motlagh, A.M.; Mollazade, K.; Teimourlou, R.F. Recognition and localization of ripen tomato based on machine vision. Aust. J. Crop Sci. 2011, 5, 1144–1149. [Google Scholar]
- Yao, L.J.; Ding, W.M.; Zhao, S.Q.; Yang, L.L. Applications of the generalized Hough transform in recognizing occluded image. Trans. Chin. Soc. Agric. Eng. 2008, 24, 97–101. [Google Scholar]
- Zhao, J.; Tow, J.; Katupitiya, J. On-tree fruit recognition using texture properties and color data. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 263–268. [Google Scholar]
- Shebiah, R.N. Fruit Recognition using Color and Texture Features. J. Emerg. Trends Comput. Inf. Sci. 2010, 1, 90–94. [Google Scholar]
- Tao, Y.; Zhou, J. Automatic apple recognition based on the fusion of color and 3D feature for robotic fruit picking. Comput. Electron. Agric. 2017, 142, 388–396. [Google Scholar] [CrossRef]
- Casasent, D.; Chen, X.W. New training strategies for RBF neural networks for X. Pattern Recognit. 2003, 36, 535–547. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Kataoka, T.; Okamoto, H.; Hata, S. Development of a real-time machine vision system for the apple harvesting robot. In Proceedings of the Sice 2004 Conference, Sapporo, Japan, 4–6 August 2004; Volume 591, pp. 595–598. [Google Scholar]
- Chinchuluun, R.; Lee, W.S.; Burks, T.F. Machine visionbased Citrus yield mapping system. Proc. Fla. State Hort. Soc. 2006, 119, 142–147. [Google Scholar]
- Laykin, S.; Alchanatis, V.; Edan, Y. On-line multi-stage sorting algorithm for agriculture products. Pattern Recognit. 2012, 45, 2843–2853. [Google Scholar] [CrossRef]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Yin, H.; Chai, Y.; Yang, S.X.; Mittal, G.S. Ripe Tomato Recognition and Localization for a Tomato Harvesting Robotic System. In Proceedings of the 2009 International Conference of Soft Computing and Pattern Recognition, Malacca, Malaysia, 4–7 December 2009. [Google Scholar]
- Nguyen, B.P.; Tay, W.L.; Chui, C.K. Robust Biometric Recognition from Palm Depth Images for Gloved Hands. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 1–6. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed]
- Bargoti, S.; Underwood, J. Deep Fruit Detection in Orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Song, Y.; Glasbey, C.A.; Horgan, G.W.; Polder, G.; Dieleman, J.A.; Van der Heijden, G.W. Automatic fruit recognition and counting from multiple images. Biosyst. Eng. 2014, 118, 203–215. [Google Scholar] [CrossRef]
- Jin, L.Z.; Jun, T.U.; Liu, C.L. A Method for Cucumber Identification Based on Iterative-RELIEF and Relevance Vector Machine. J. Shanghai Jiaotong Univ. 2013, 47, 602–606. [Google Scholar]
- Cupec, R. Crop Row Detection by Global Energy Minimization; Elsevier Science Inc.: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Unay, D.; Gosselin, B. Stem and calyx recognition on ’Jonagold’ apples by pattern recognition. J. Food Eng. 2007, 78, 597–605. [Google Scholar] [CrossRef]
- Sun, Y. Iterative RELIEF for Feature Weighting: Algorithms, Theories, and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1035. [Google Scholar] [CrossRef]
- Zhang, B.; Huang, W.; Liang, G.; Li, J.; Zhao, C.; Liu, C.; Huang, D. Computer vision detection of defective apples using automatic lightness correction and weighted RVM classifier. J. Food Eng. 2015, 146, 143–151. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse bayesian learning and the relevance vector machine. JMLR 2001, 1, 211–244. [Google Scholar]
- Majumder, S.K.; Ghosh, N.; Gupta, P.K. Relevance vector machine for optical diagnosis of cancer. Lasers Surg. Med. 2005, 36, 323–333. [Google Scholar] [CrossRef] [PubMed]
- Wei, L.; Yang, Y.; Nishikawa, R.M.; Jiang, Y. A study on several Machine-learning methods for classification of Malignant and benign clustered microcalcifications. IEEE Trans. Med. Imaging 2005, 24, 371–380. [Google Scholar] [PubMed]
- Wei, L.; Yang, Y.; Nishikawa, R.M.; Wernick, M.N.; Edwards, A. Relevance vector machine for automatic detection of clustered microcalcifications. IEEE Trans. Med. Imaging 2005, 24, 1278–1285. [Google Scholar] [PubMed]
- Demir, B.; Erturk, S. Hyperspectral Image Classification Using Relevance Vector Machines. IEEE Geosci. Remote Sens. Lett. 2007, 4, 586–590. [Google Scholar] [CrossRef]










© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Zhang, B.; Zhou, J.; Xiong, Y.; Gu, B.; Yang, X. Automatic Recognition of Ripening Tomatoes by Combining Multi-Feature Fusion with a Bi-Layer Classification Strategy for Harvesting Robots. Sensors 2019, 19, 612. https://doi.org/10.3390/s19030612
Wu J, Zhang B, Zhou J, Xiong Y, Gu B, Yang X. Automatic Recognition of Ripening Tomatoes by Combining Multi-Feature Fusion with a Bi-Layer Classification Strategy for Harvesting Robots. Sensors. 2019; 19(3):612. https://doi.org/10.3390/s19030612
Chicago/Turabian StyleWu, Jingui, Baohua Zhang, Jun Zhou, Yingjun Xiong, Baoxing Gu, and Xiaolong Yang. 2019. "Automatic Recognition of Ripening Tomatoes by Combining Multi-Feature Fusion with a Bi-Layer Classification Strategy for Harvesting Robots" Sensors 19, no. 3: 612. https://doi.org/10.3390/s19030612
APA StyleWu, J., Zhang, B., Zhou, J., Xiong, Y., Gu, B., & Yang, X. (2019). Automatic Recognition of Ripening Tomatoes by Combining Multi-Feature Fusion with a Bi-Layer Classification Strategy for Harvesting Robots. Sensors, 19(3), 612. https://doi.org/10.3390/s19030612