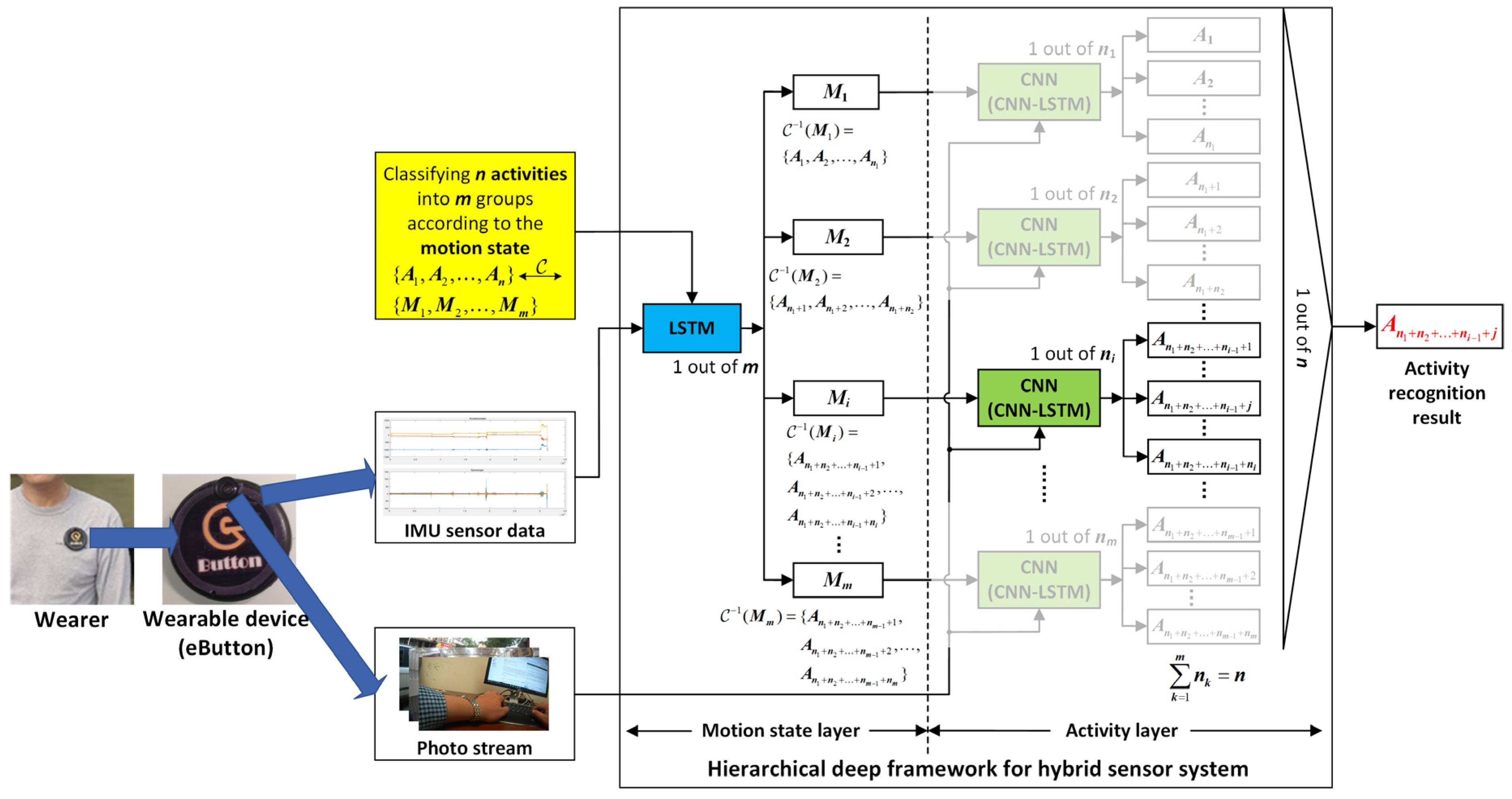
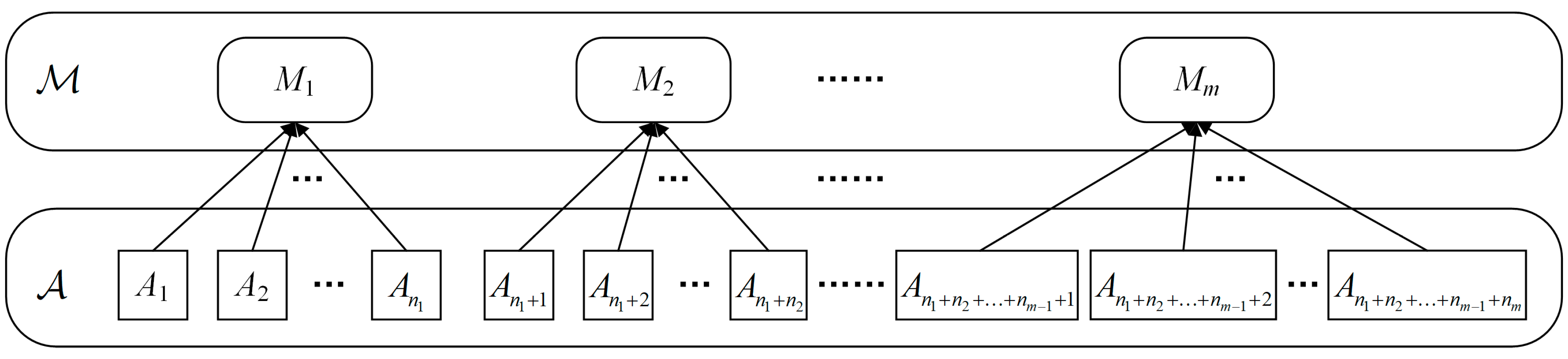
4.3.1. Results on the eButton Dataset
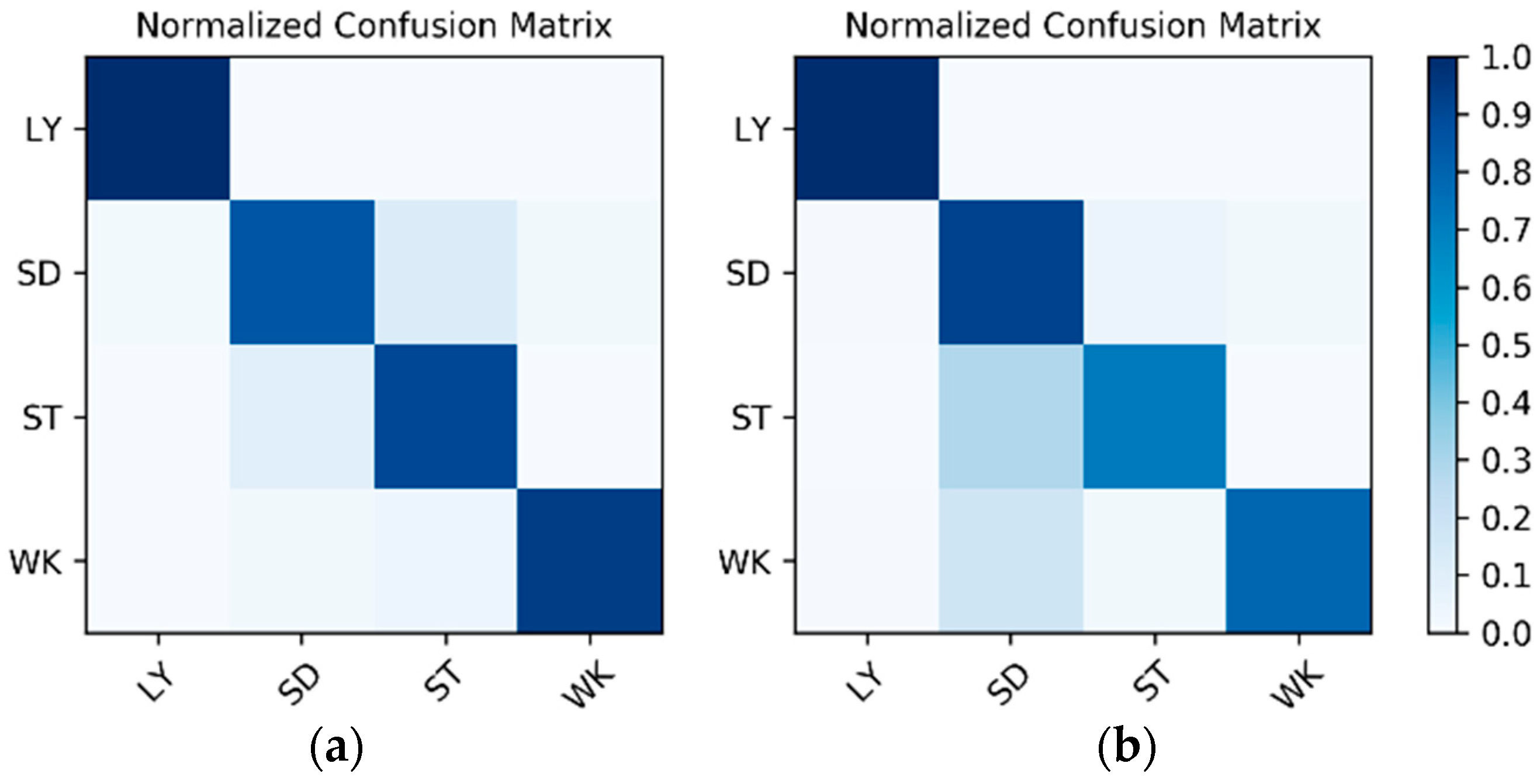
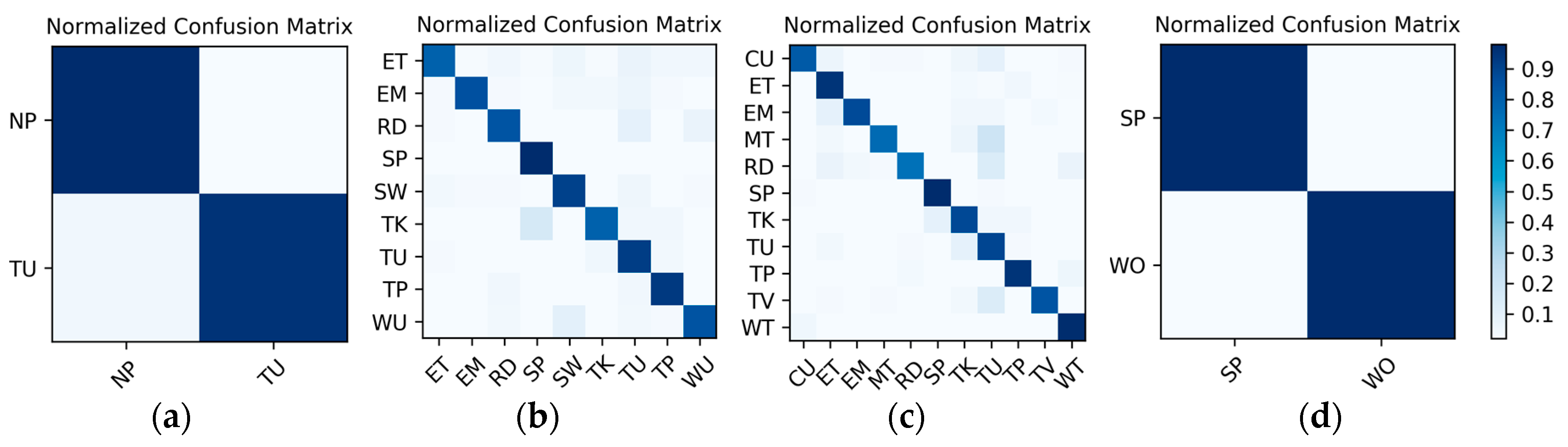
Results on the IMU sensor data: The dataset for the IMU sensor data classification test is shown in
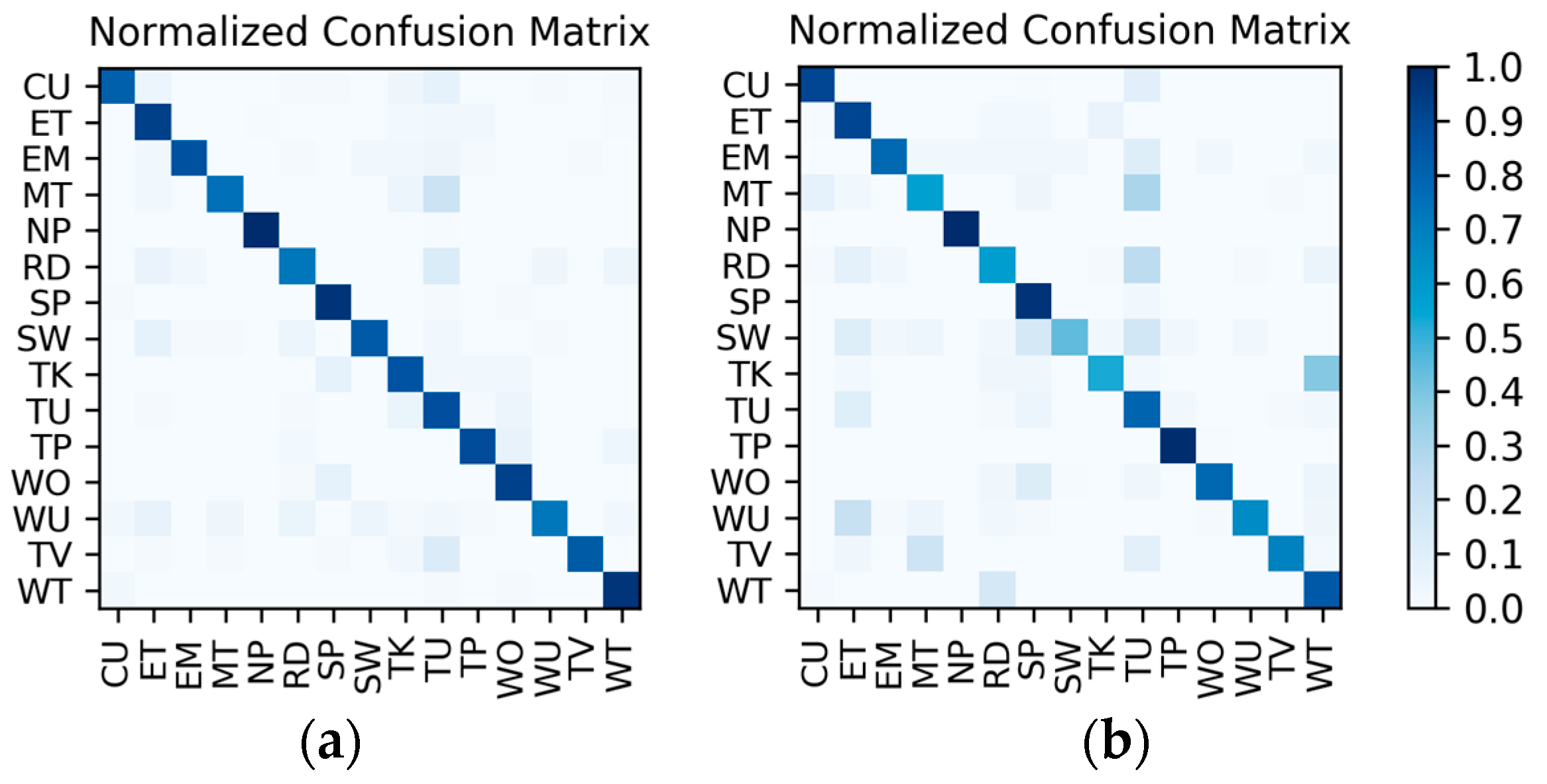
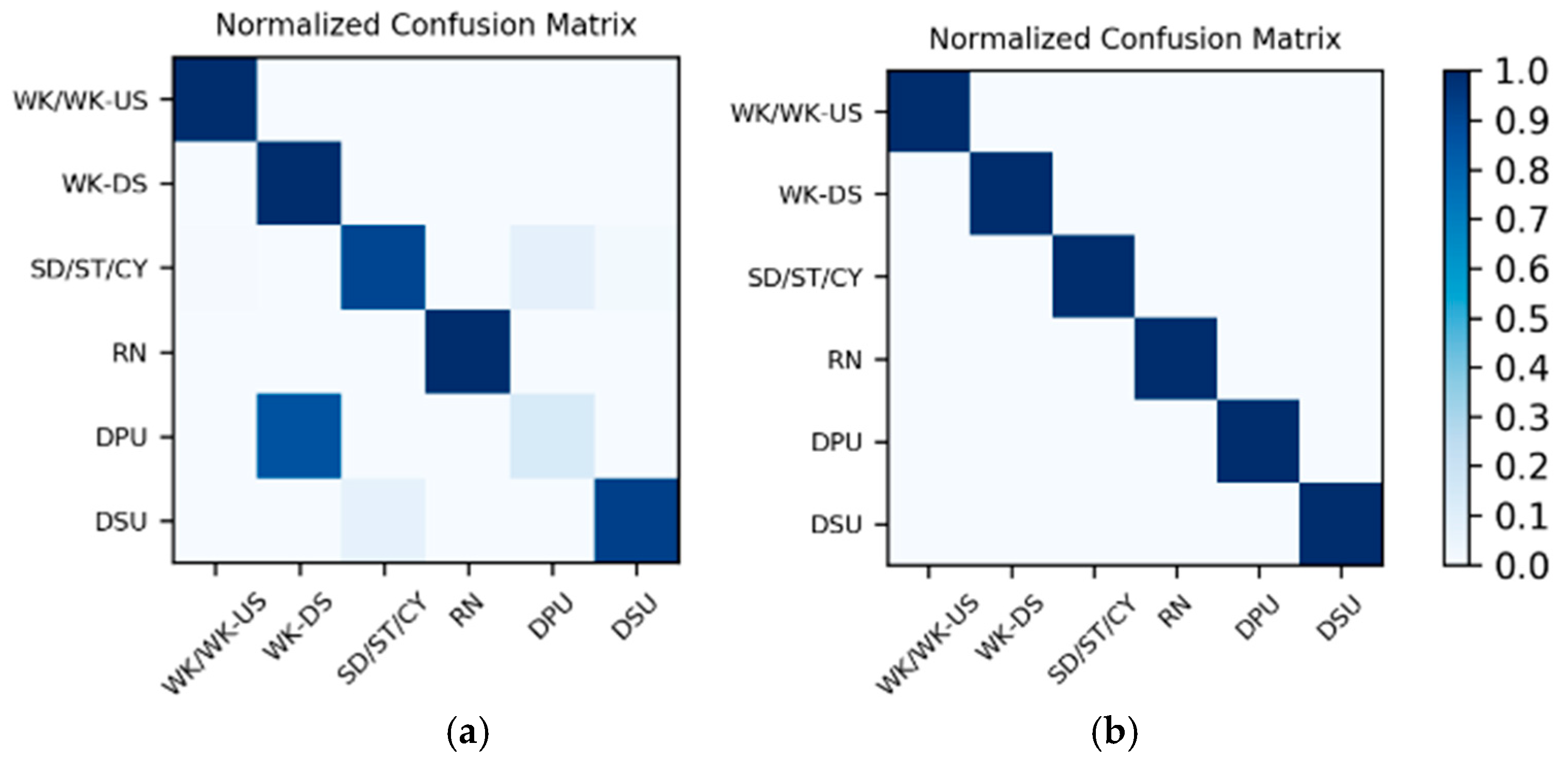
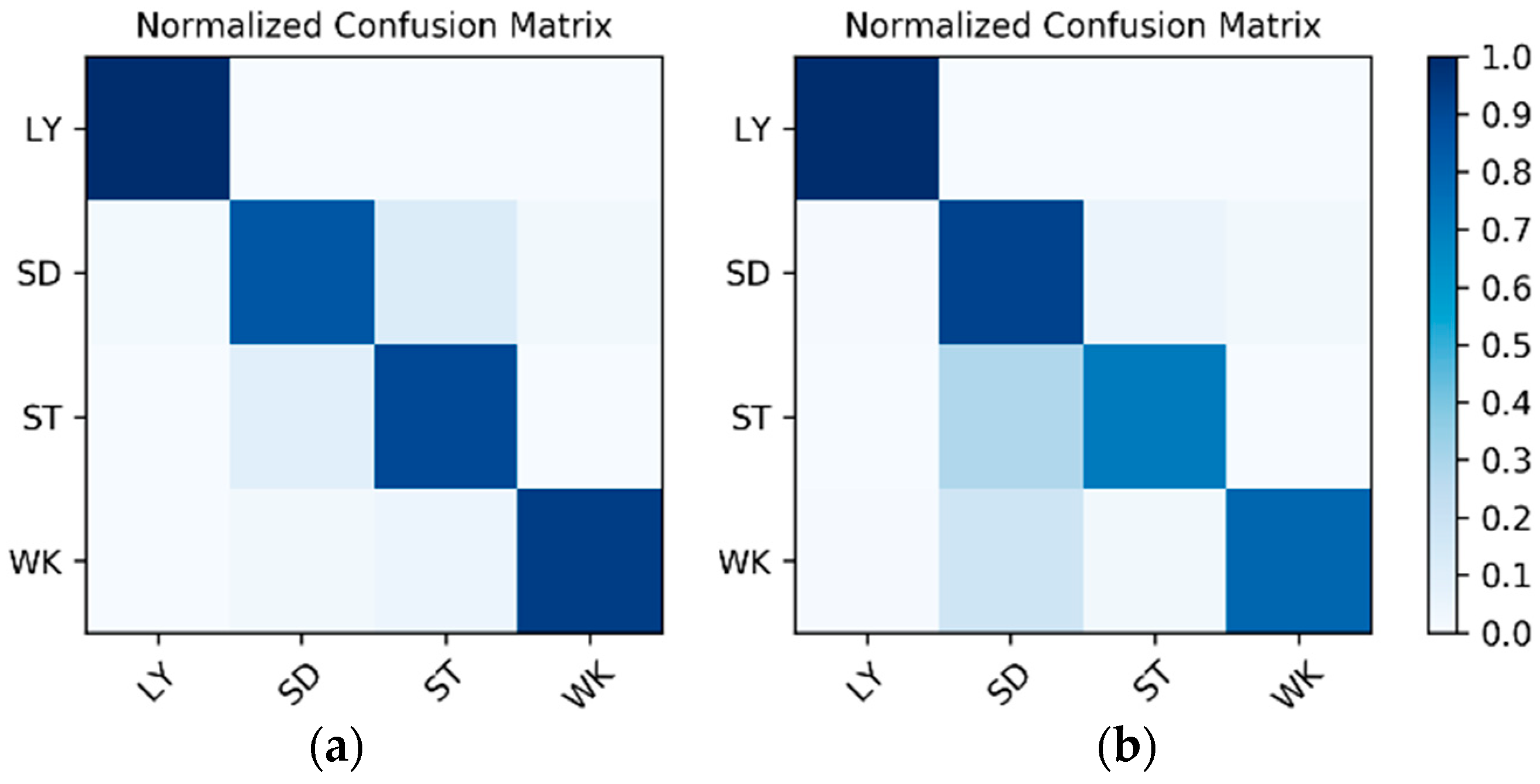
Table 1. As the dataset contains the data of two wearers, the experimental results also distinguish between the two wearers (W1 and W2). The confusion matrices for the classification results of the test set in
Table 1 are shown in
Figure 12. The
F1 accuracy is shown in
Table 5.
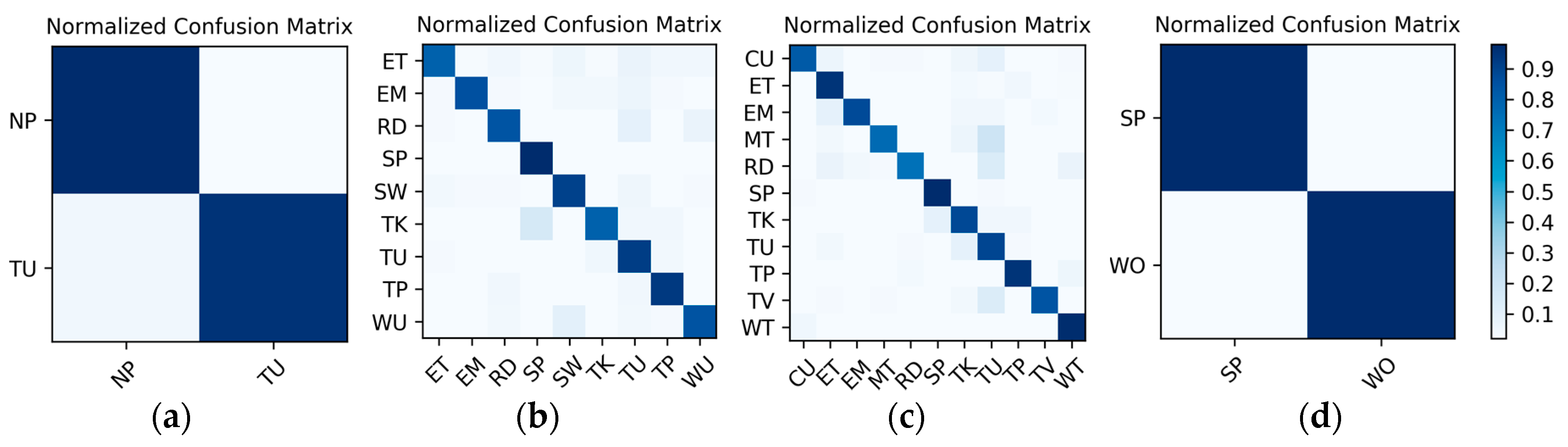
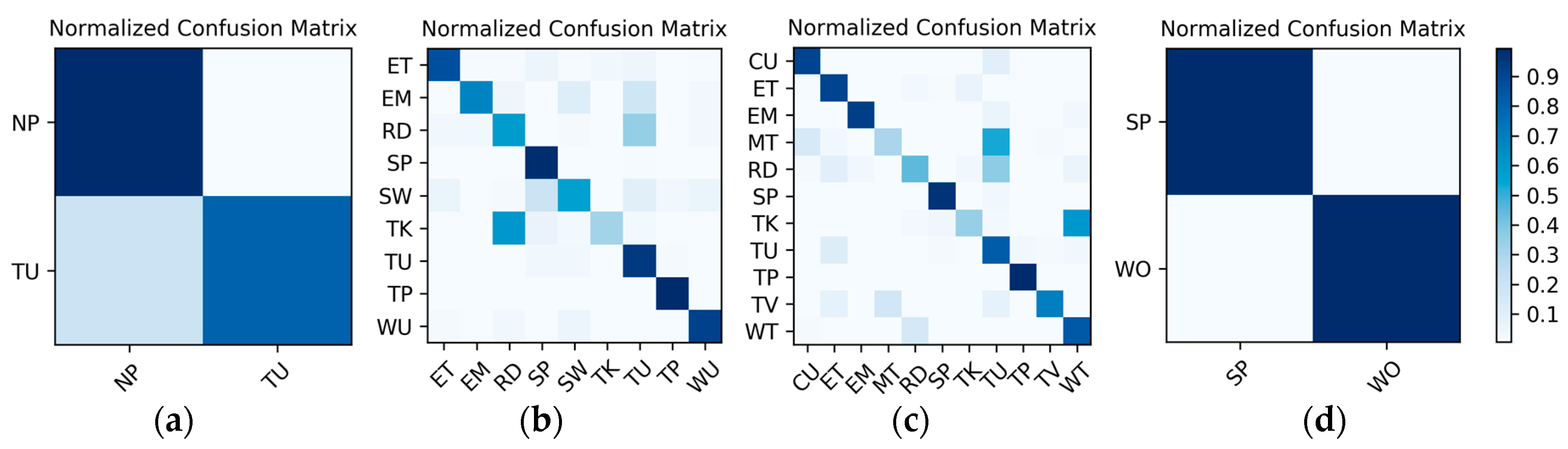
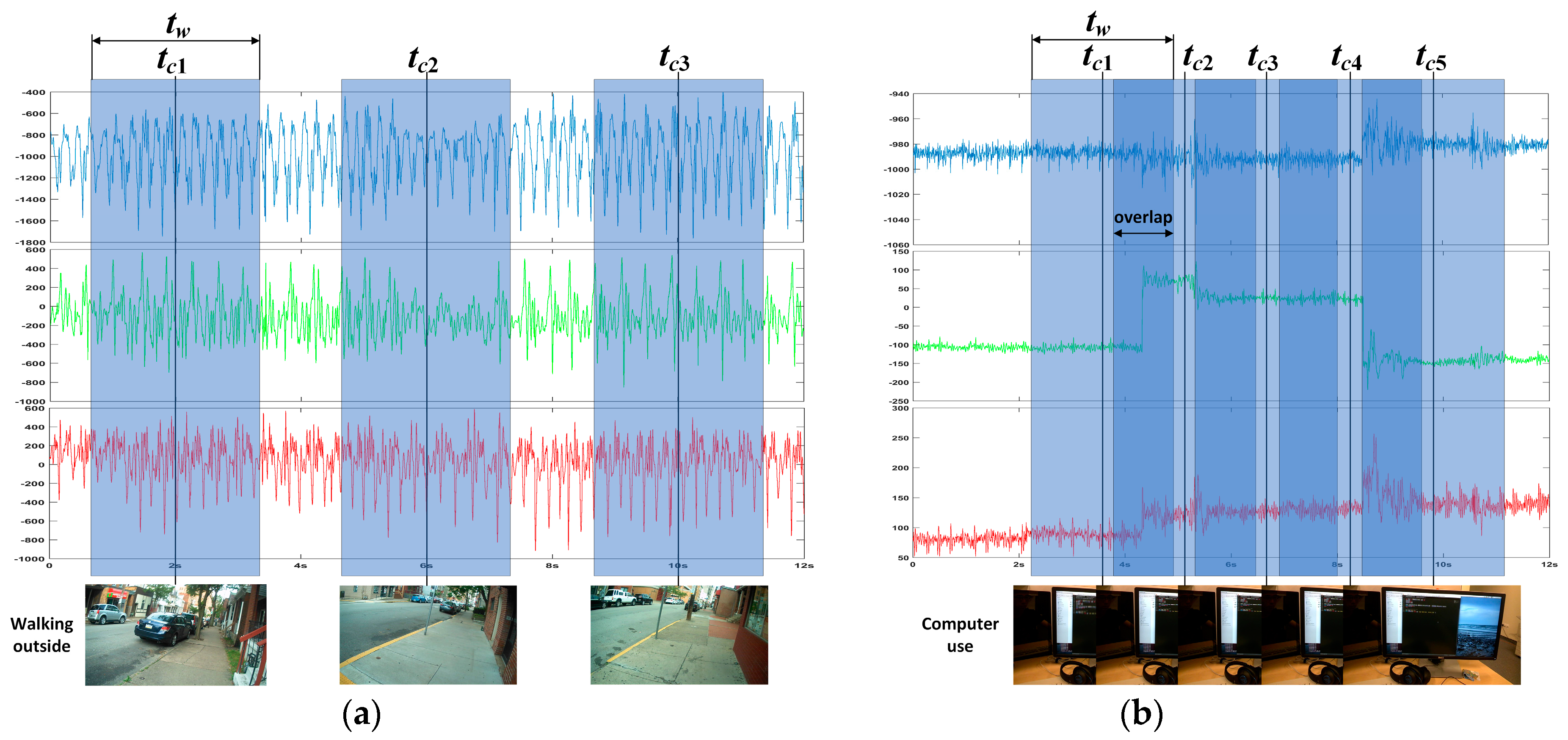
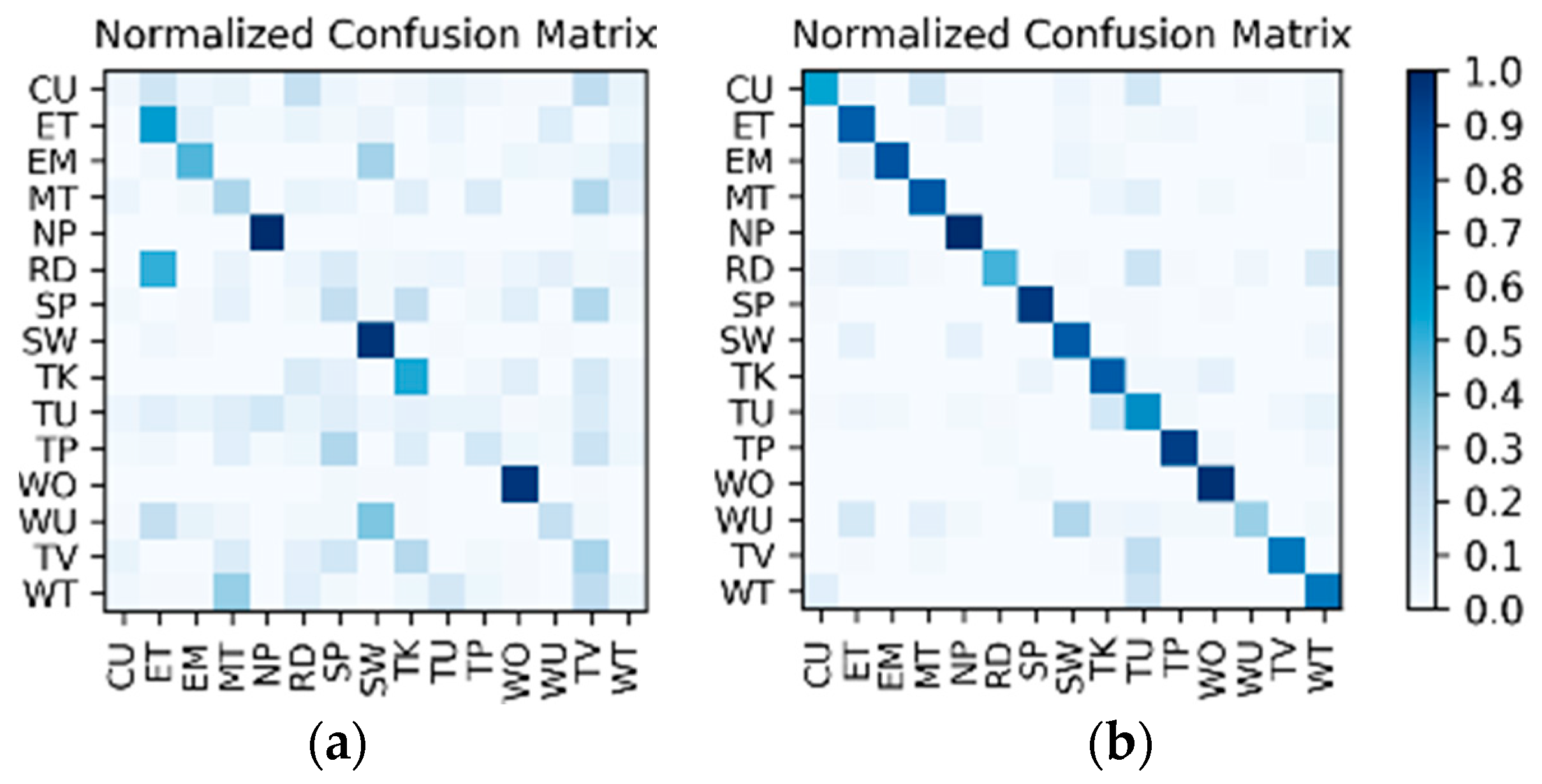
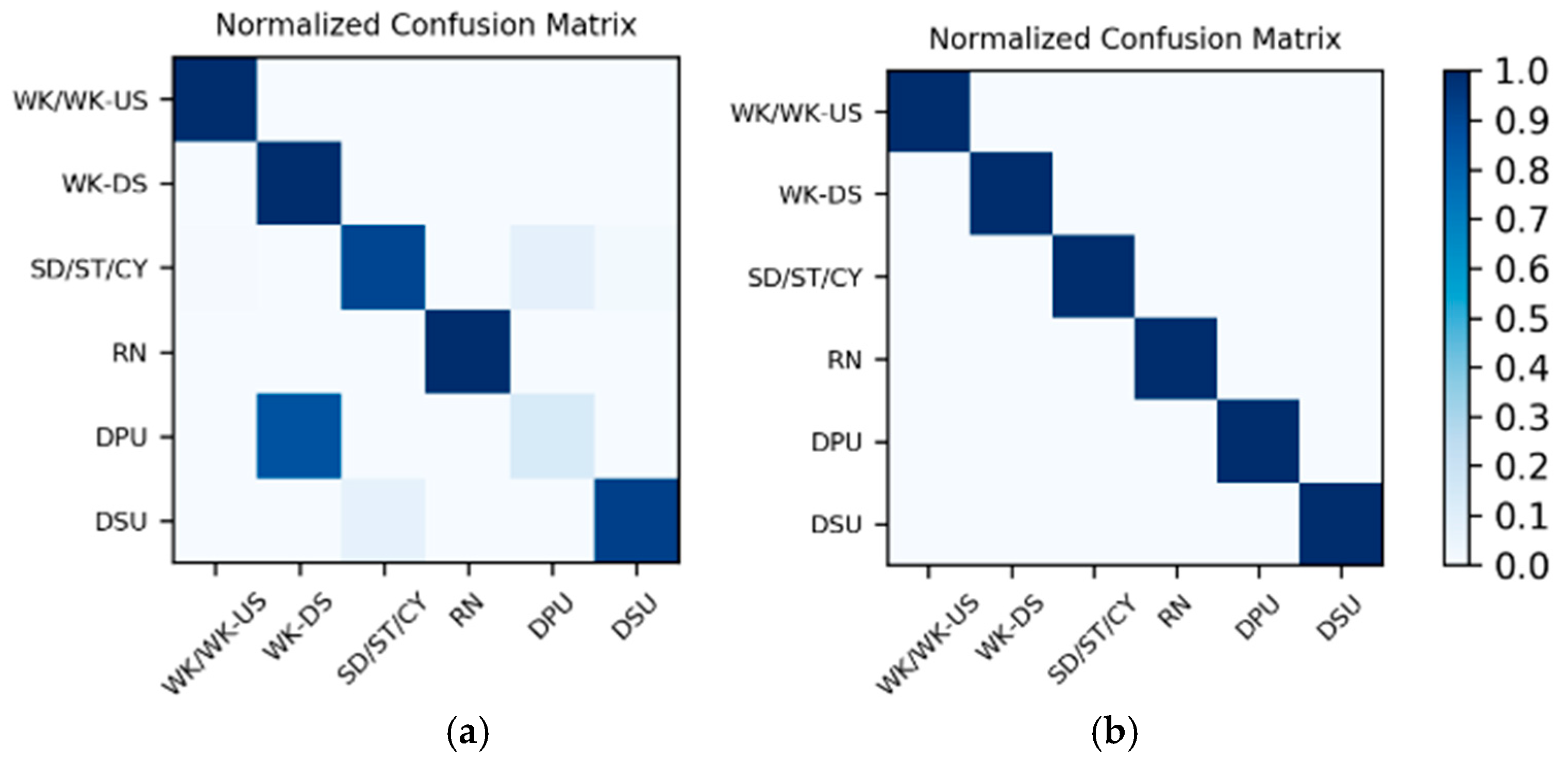
Results on the low frame rate photo stream: The dataset for the low frame rate photo stream classification test is shown in
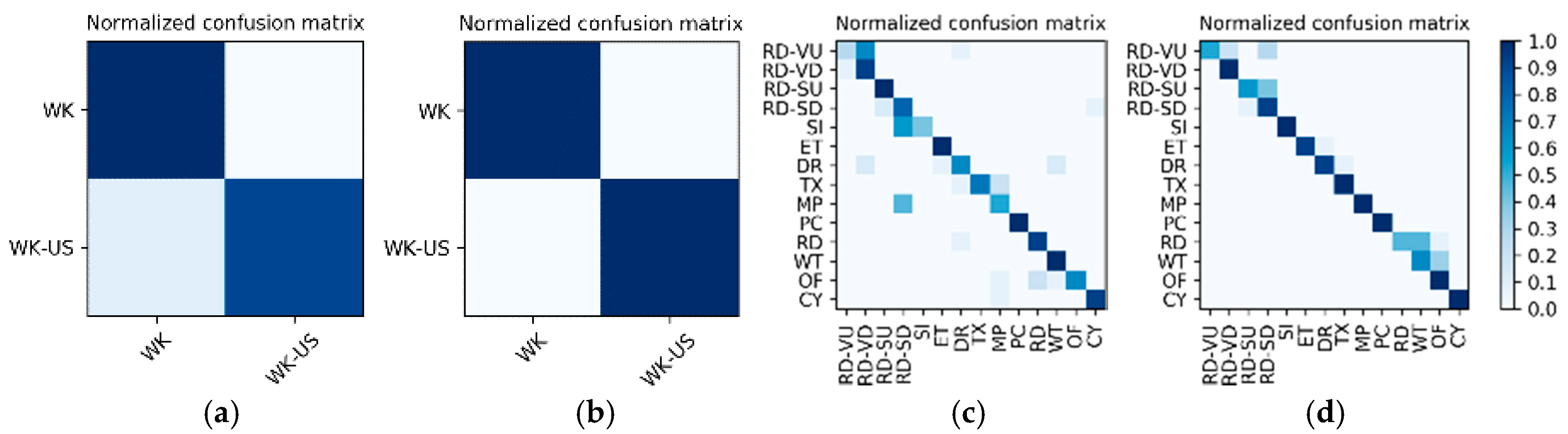
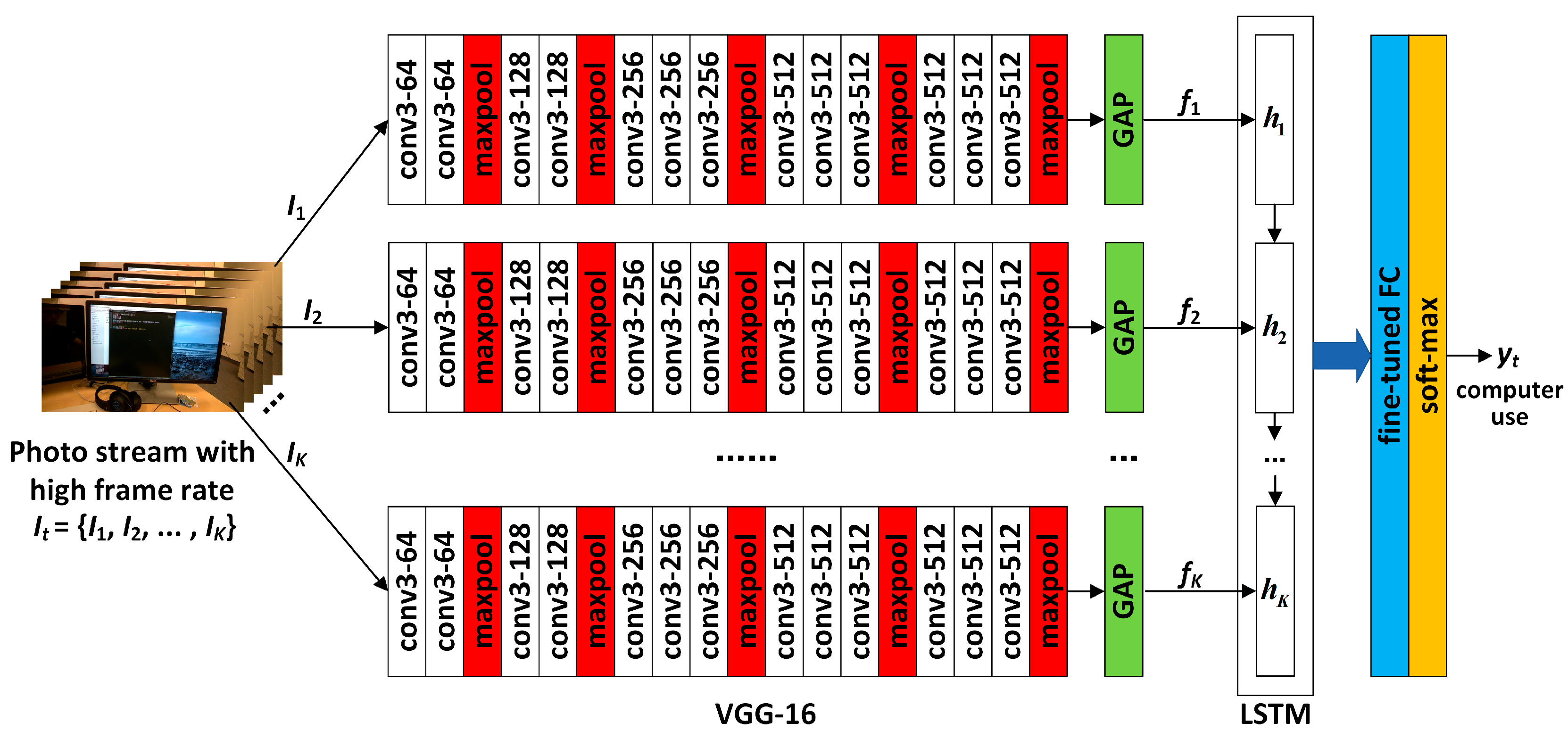
Table 2. As the photo stream is classified in the grouping defined by Equations (4) and (5) in the proposed hierarchical framework, the dataset should also be adjusted according to the grouping. The fine-tuned VGG-16 network shown in
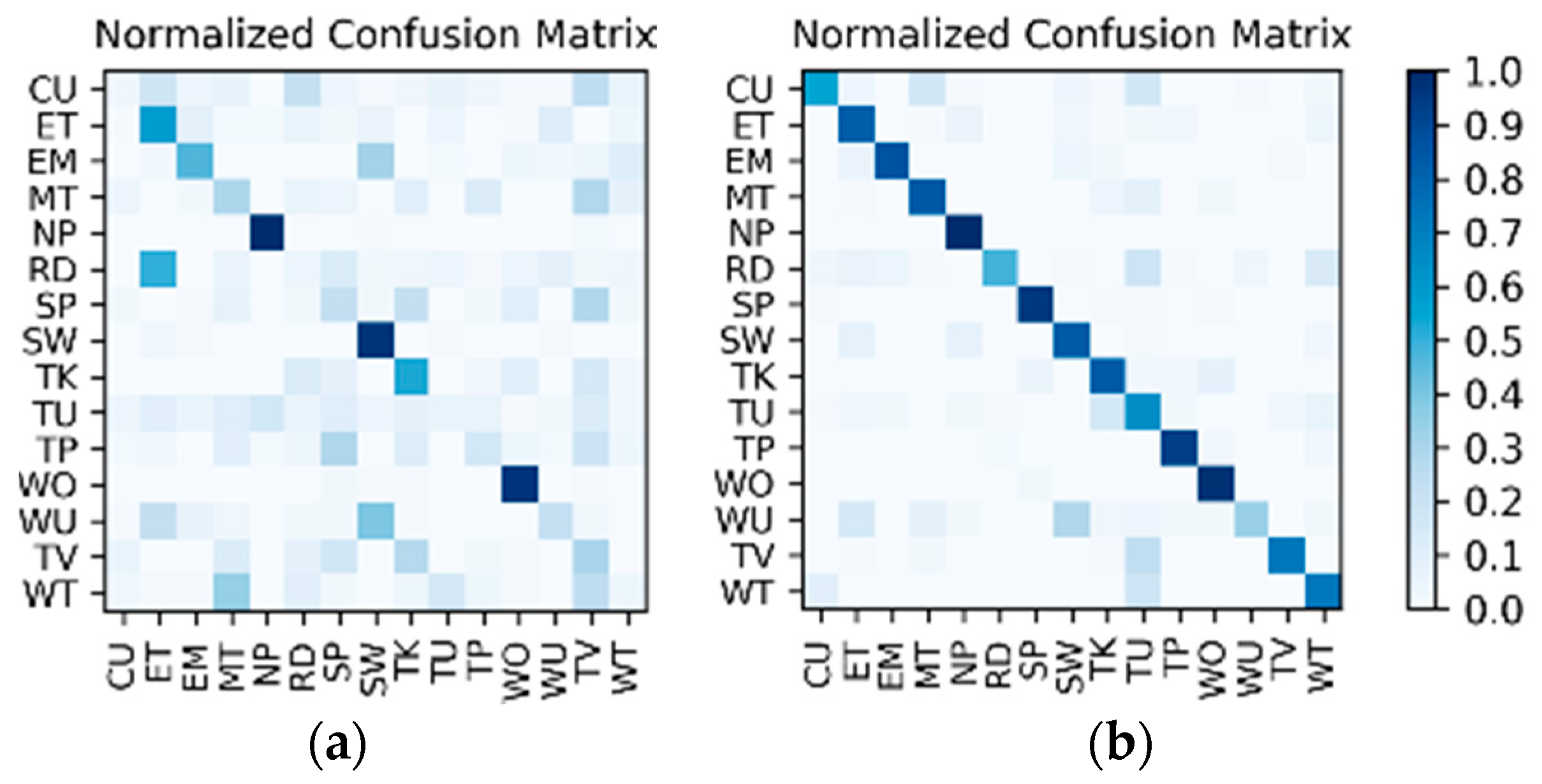
Figure 6 was set up in each of the four groups to complete the training and testing. In addition, similar to the IMU sensor data, the experimental results also distinguish the two wearers W1 and W2. The confusion matrices for the output of the
corresponding to each group are shown in
Figure 13 and
Figure 14. The
F1 accuracies for each group are shown in
Table 6,
Table 7,
Table 8 and
Table 9.
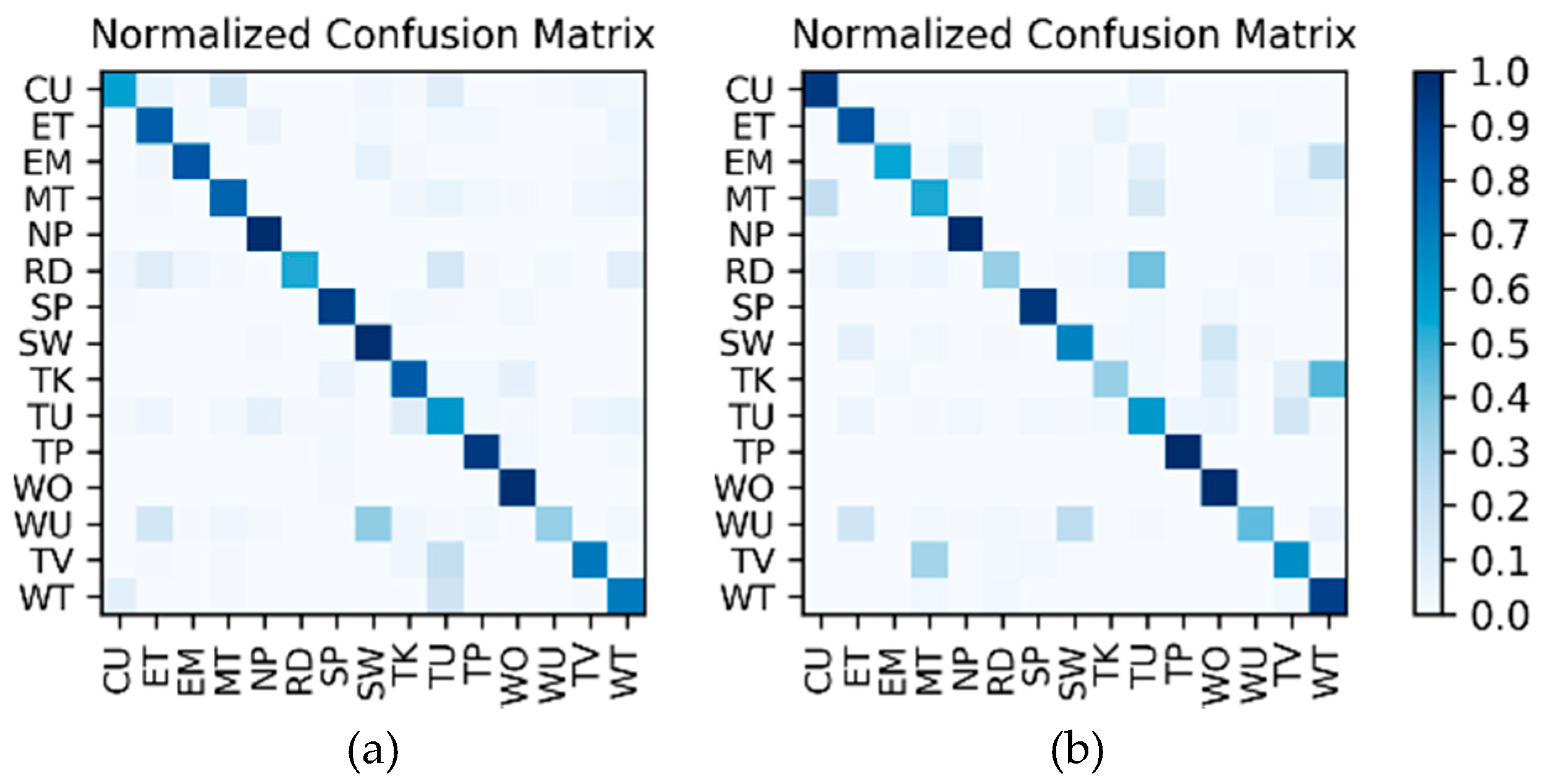
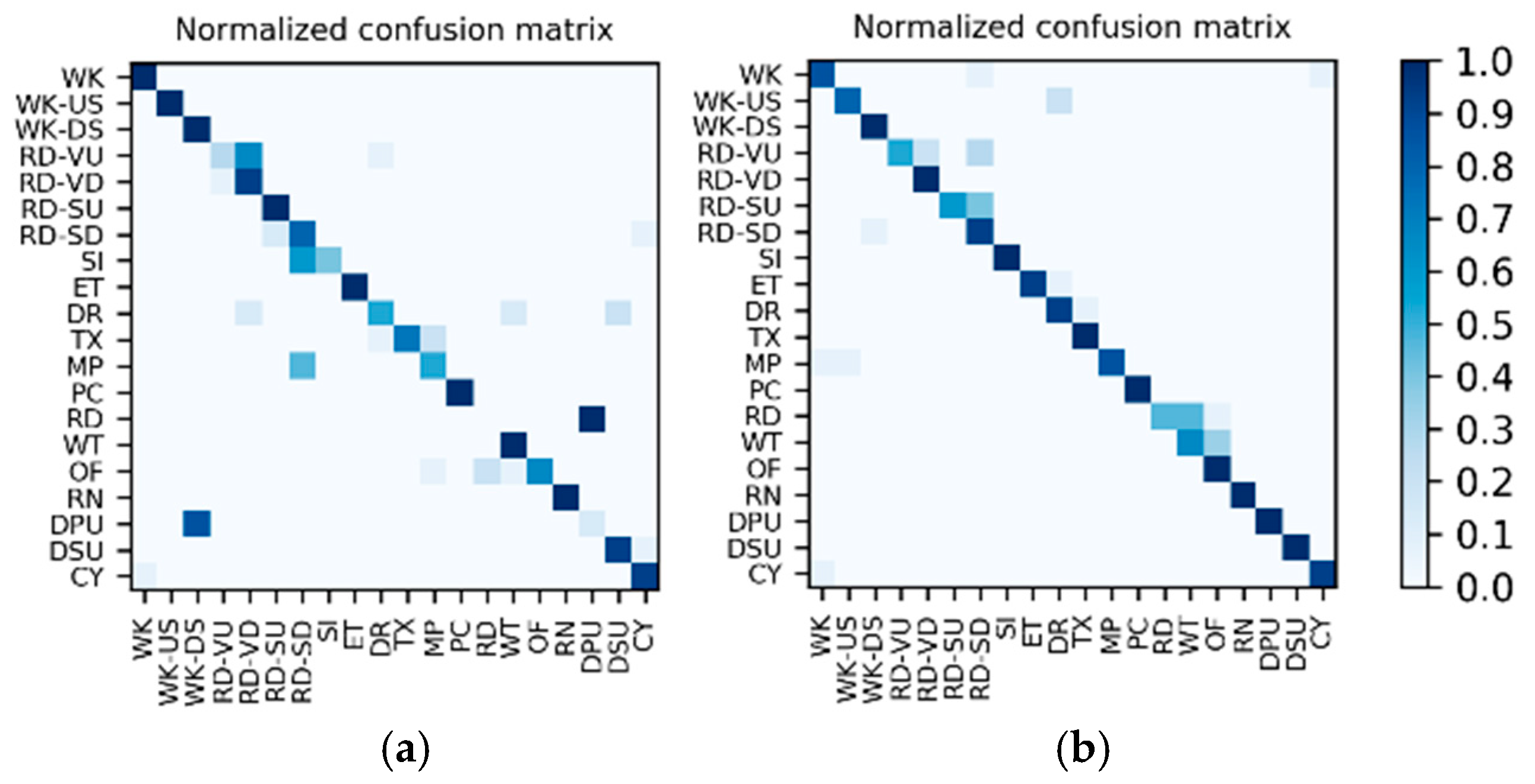
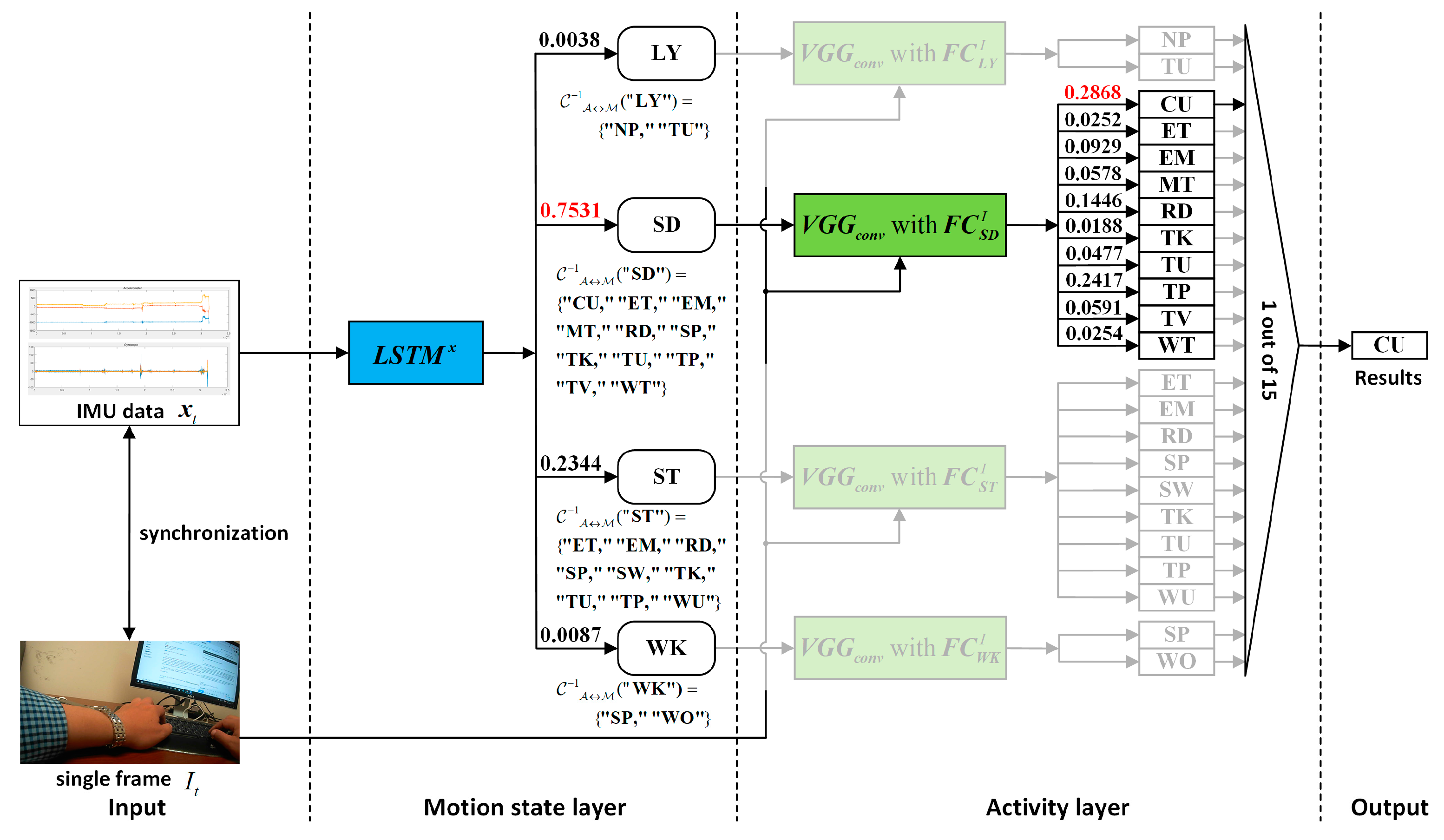
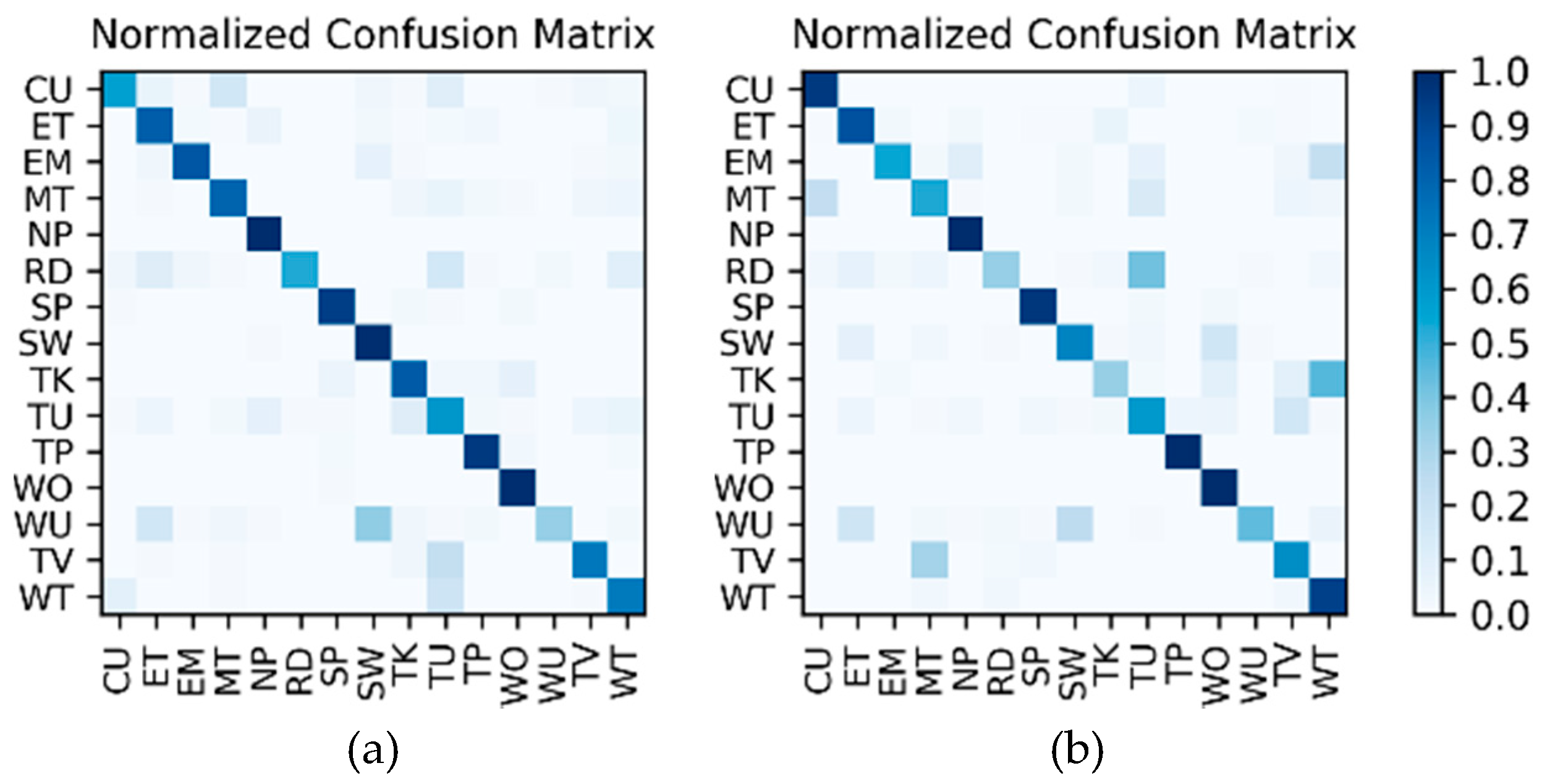
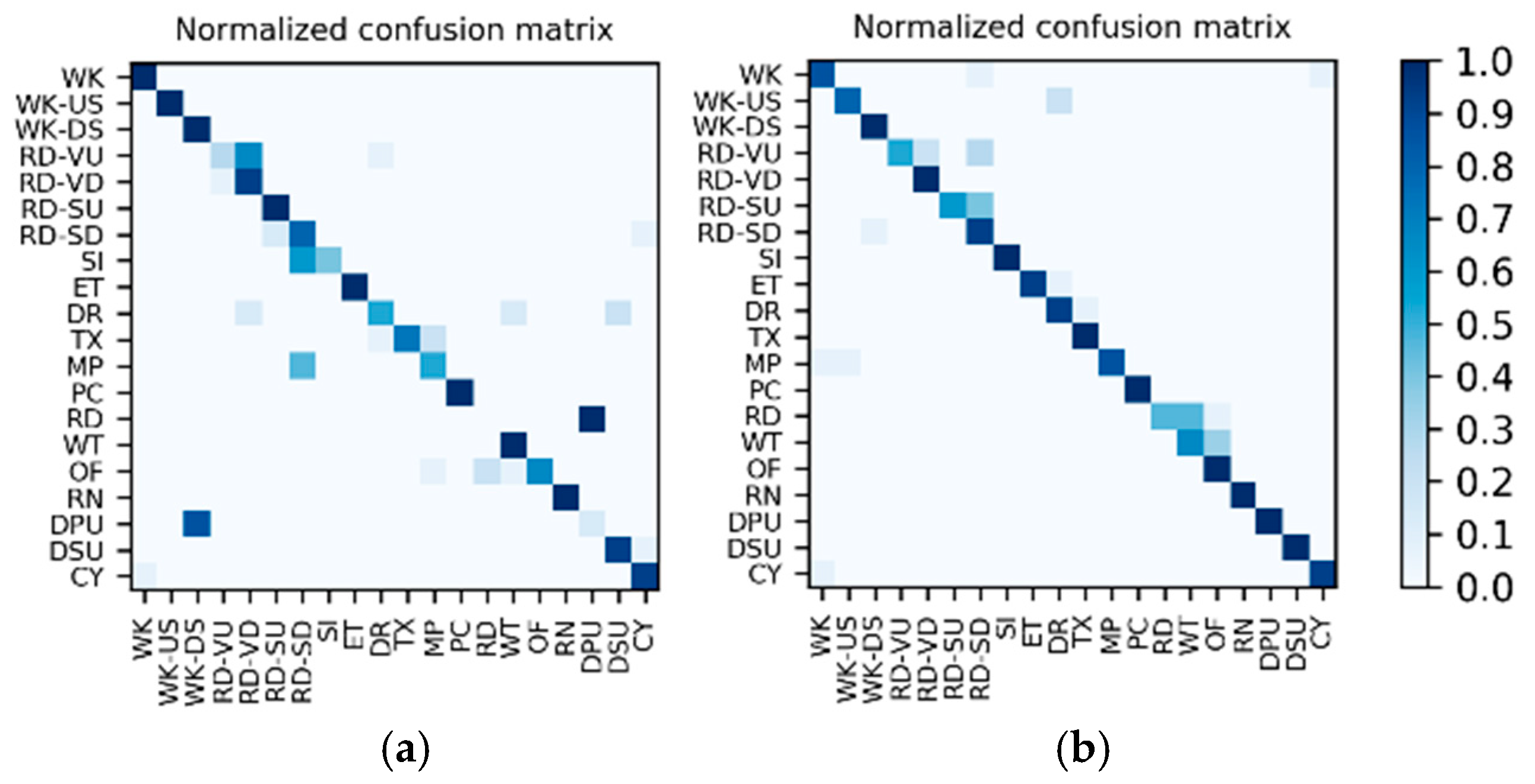
Results of the hierarchical fusion: After the training of
and fine-tuned
is completed, the sensor-based recognition results and the photo stream-based recognition results can be fused by the hierarchical framework shown in
Figure 8. The confusion matrices after fusion for W1 and W2 are shown in
Figure 15. The
F1 accuracy is shown in
Table 10.
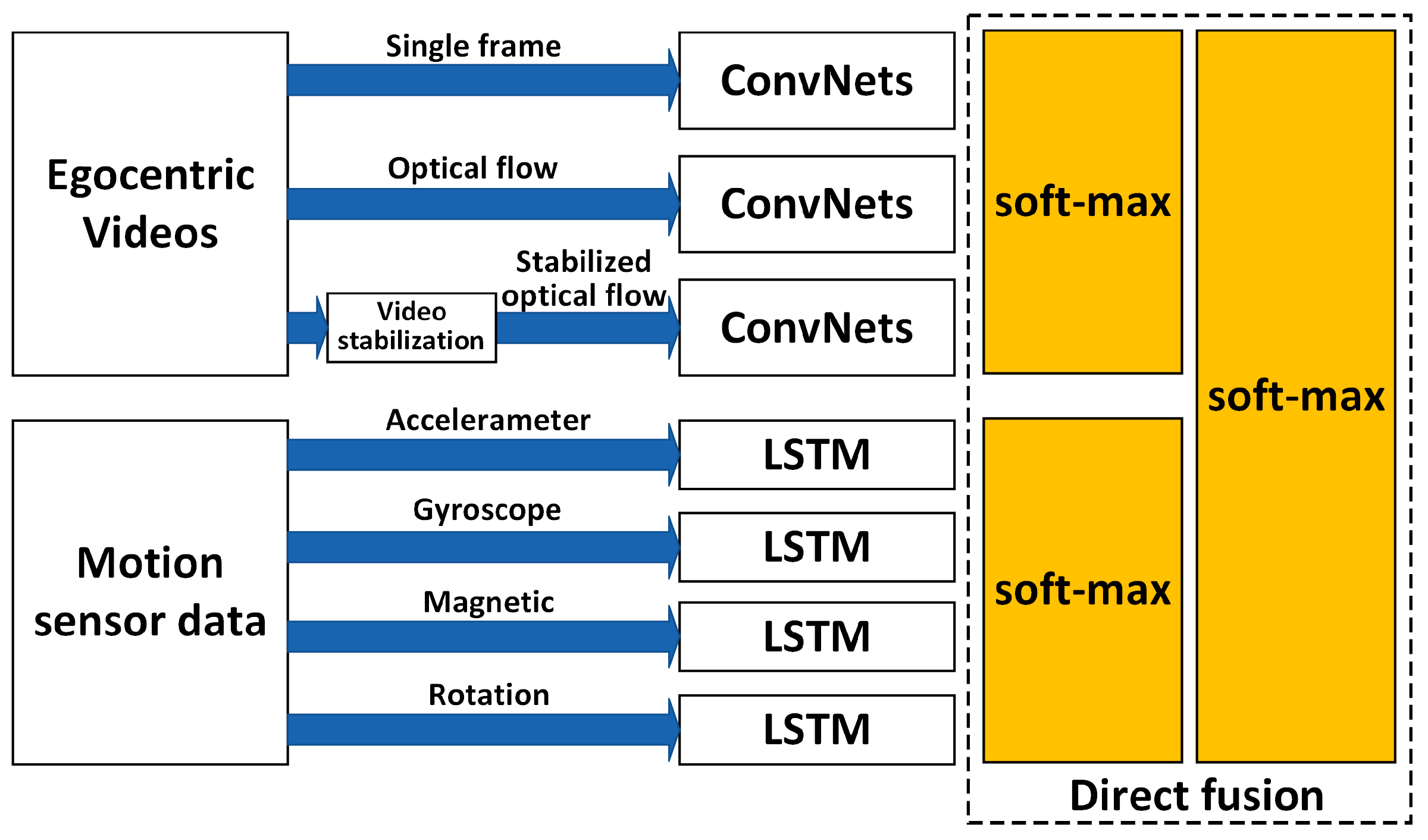
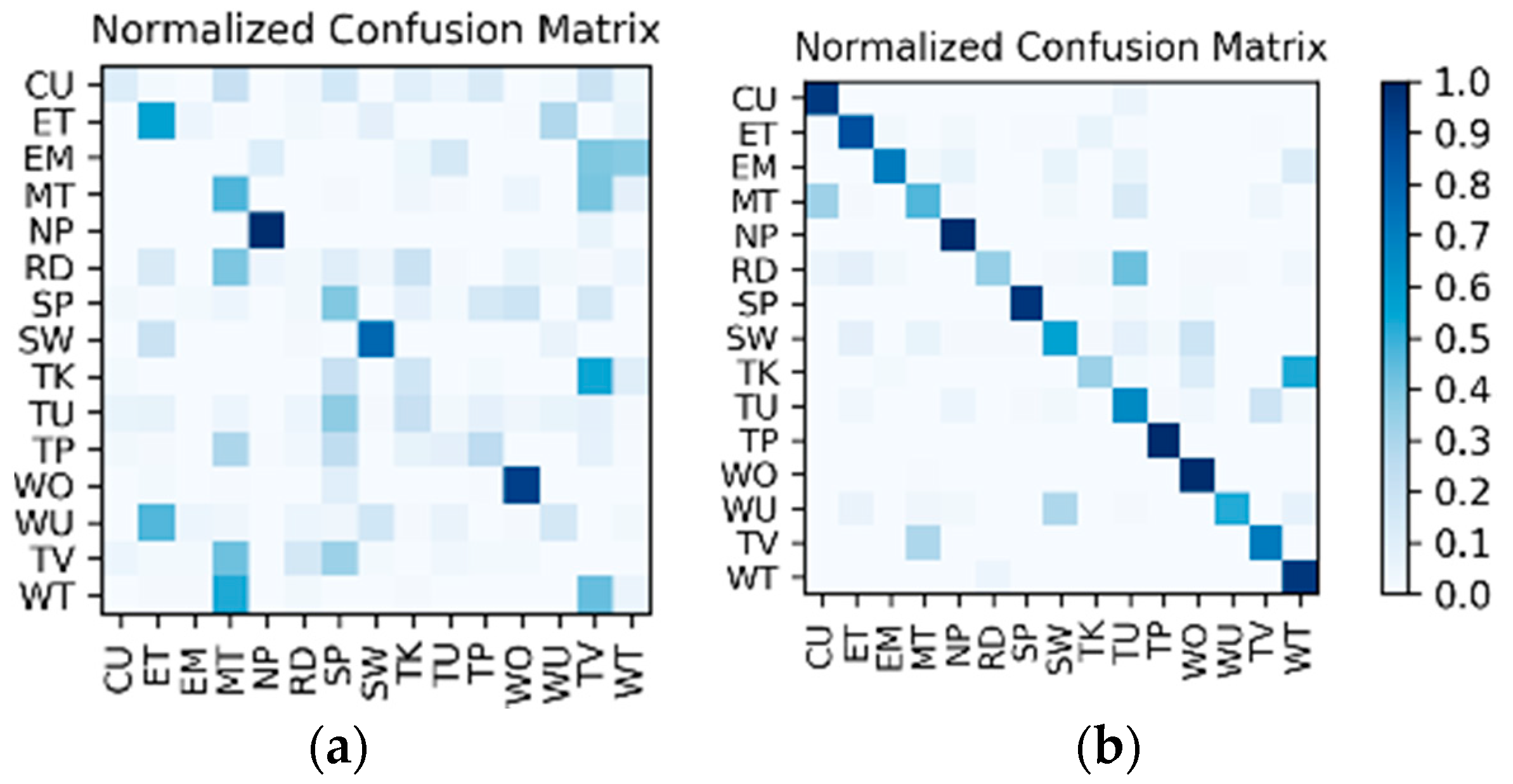
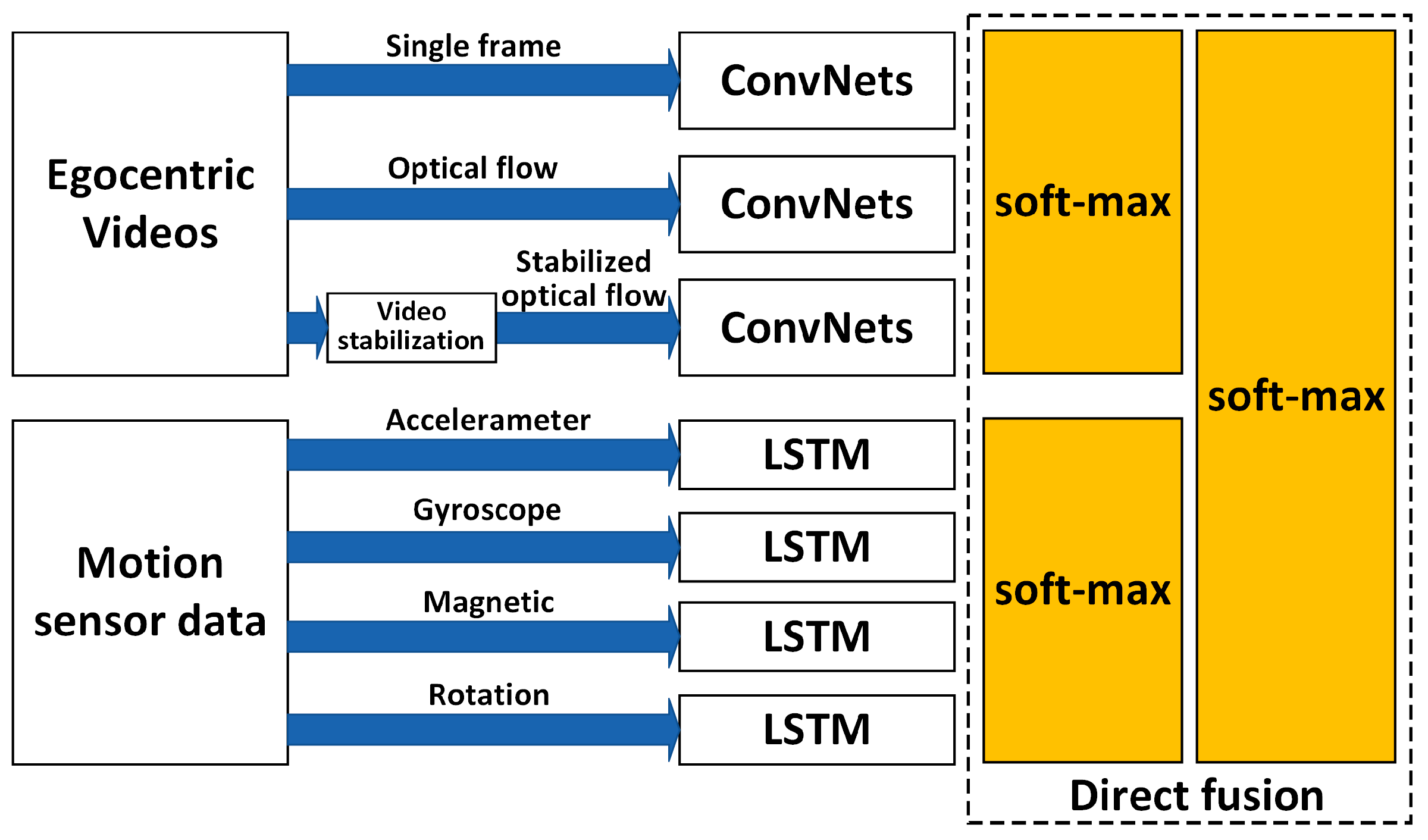
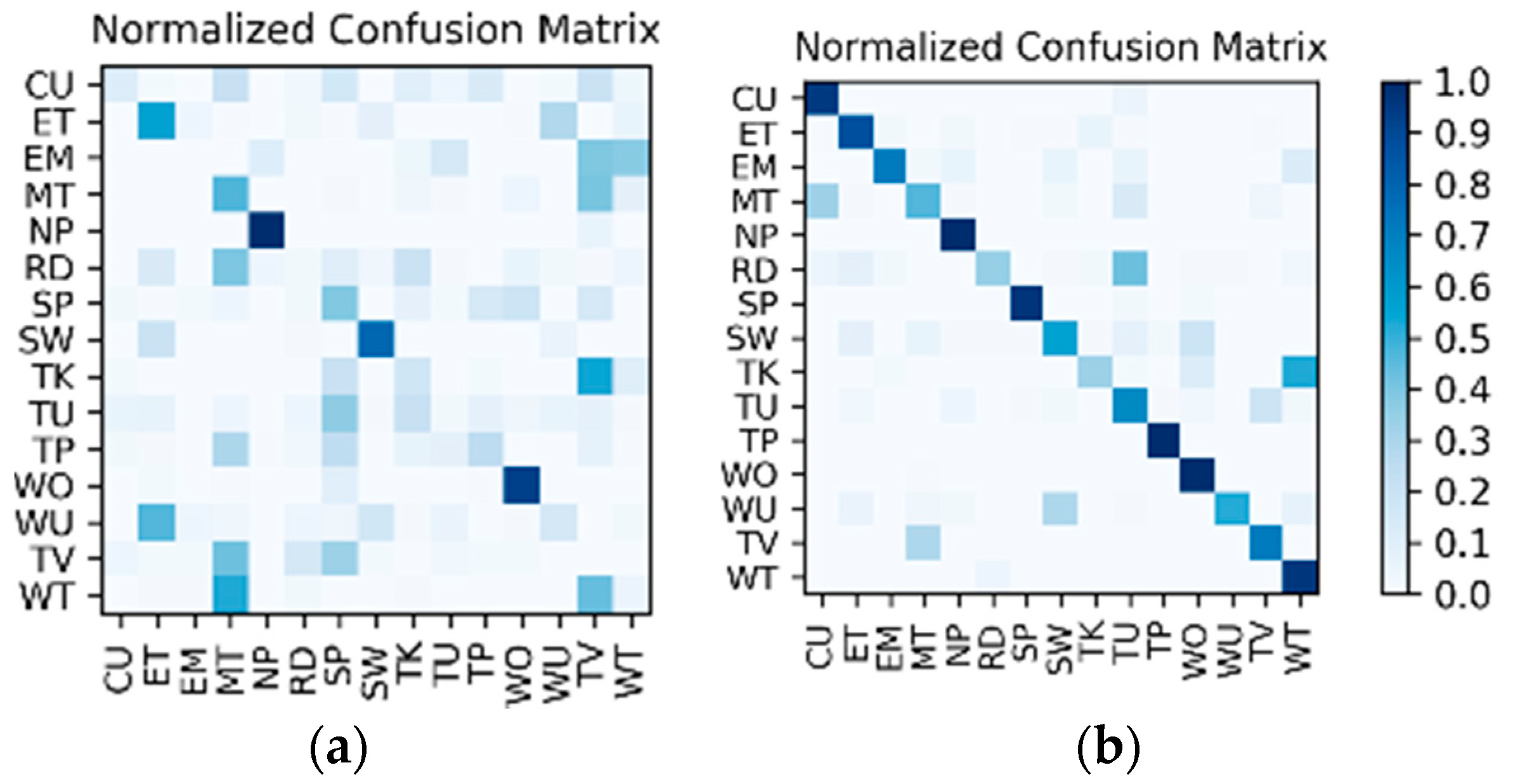
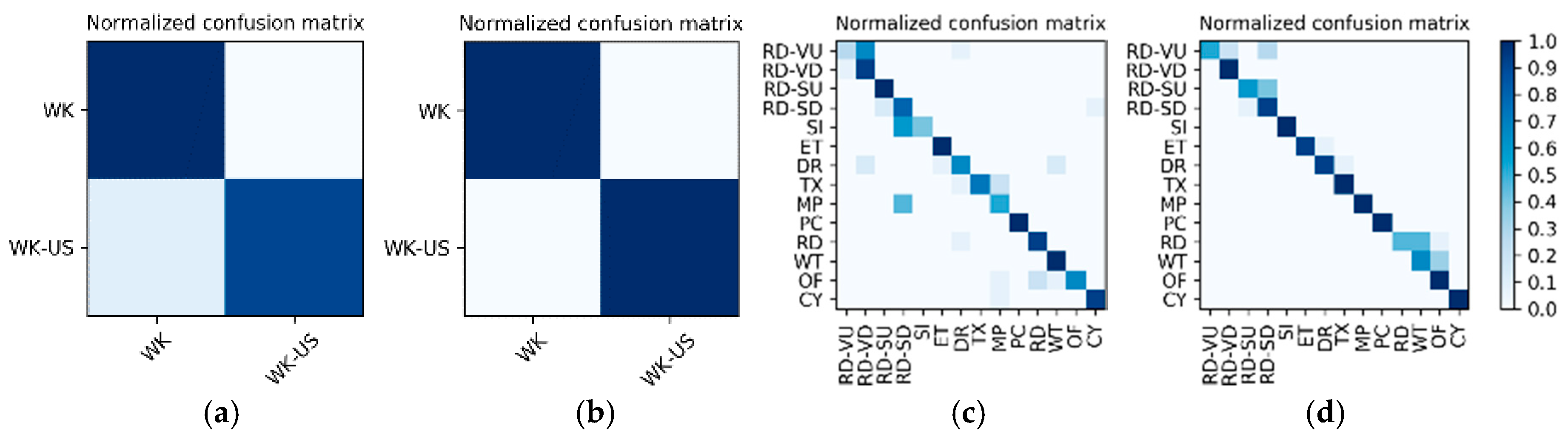
Comparison and discussion: In the direct fusion method proposed in [
14], the LSTM (for motion sensor data classification) and the ConvNets (for video classification) operate in the same classification mode, i.e., both of them are used for classifying all of the 20 activities. Therefore, when the direct fusion method is applied to the eButton Dataset, the
(for IMU motion sensor classification) and the fine-tuned
(for photo stream classification) are both used to classify all 15 activities. When both
and
work in the same classification mode, the confusion matrices of the classification results of W1 and W2 are as shown in
Figure 16 and
Figure 17, respectively. The direct fusion architecture shown in
Figure 11 is then used for fusing the classification results of
and
, and the confusion matrices of the direct fusion results are as shown in
Figure 18. The
F1 accuracy of direct fusion is shown in
Table 11. For comparison, the
F1 accuracy of the IMU sensor data alone for all 15 activities,
F1 accuracy of the photo stream alone for all 15 activities,
F1 accuracy of direct fusion, and
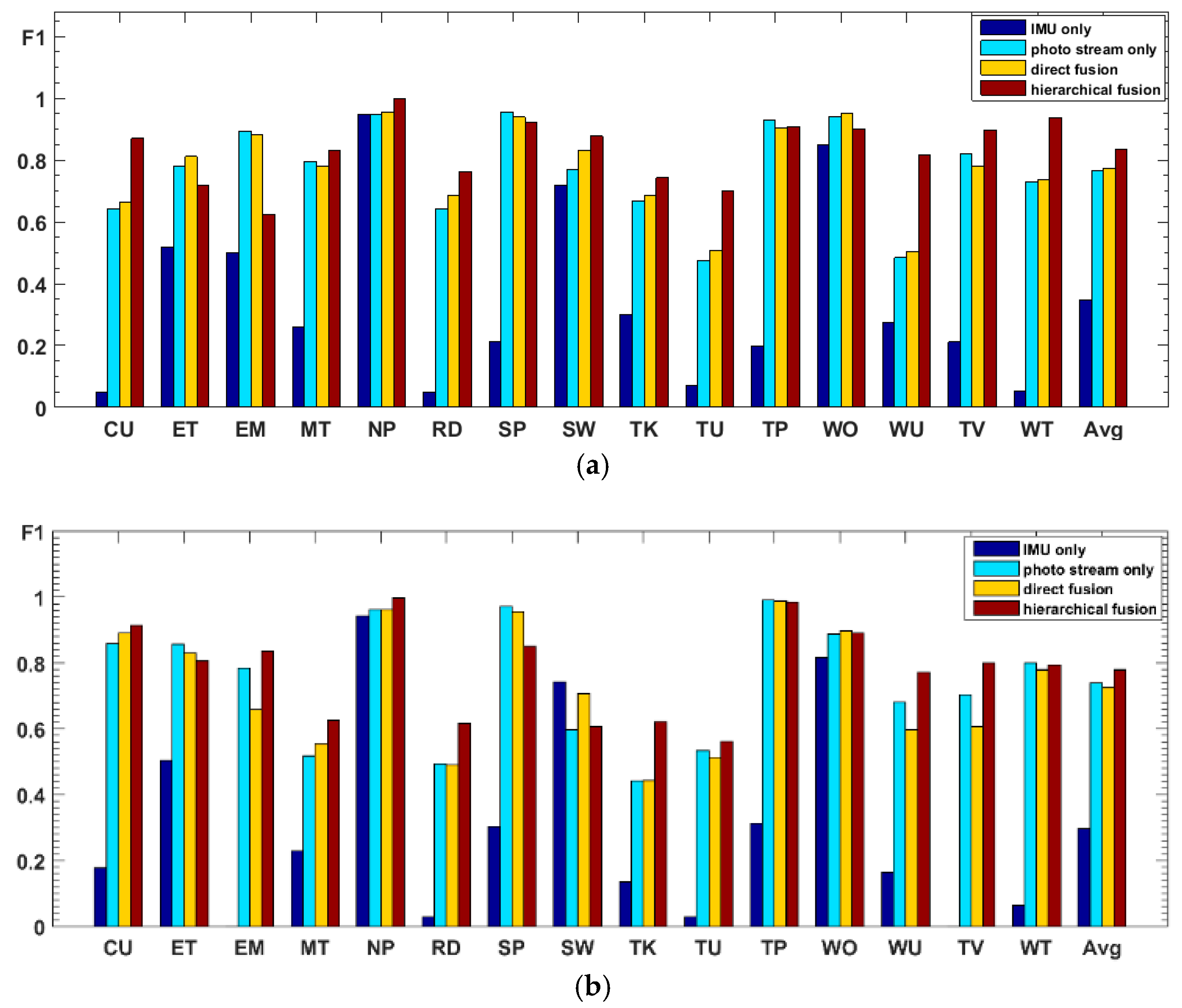
F1 accuracy of the proposed hierarchical deep fusion framework are all displayed in the same bar graph, as shown in
Figure 19.
From the comparison results in
Figure 19, it can be seen that, when the IMU data are used to classify all 15 activities, the IMU data only have good recognition results for some activities with obvious changes in motion state, such as “nap,” “sweeping,” and “walking outside.” For other activities, especially sedentary activities, the ability to distinguish is very poor, which makes the recognition results of IMU data very different from that of the photo stream. Therefore, when the recognition results of IMU data are directly fused with the results of the photo stream, the fusion results are not only not obviously improved but may even decrease (such as the recognition results of W2); i.e., the recognition results of IMU data have little or even a negative effect on the fusion process. In contrast, in the proposed hierarchical deep fusion framework, the IMU data are only used to distinguish the motion state so as to function in its best classification mode; thus, it plays a good role in promoting the fusion result. Compared with direct fusion, the fusion result of the proposed framework is a significant improvement, and the average accuracy can be increased by about 6%. Meanwhile, for the activities that are likely to occur in different motion states, such as “reading,” “talking,” “telephone use,” and “watching TV,” as they are classified into different groups with fewer candidate activities by IMU data, their recognition accuracy is substantially improved. In addition, some of the activities, such as “eating,” “walking outside,” the “entertainment” of W1, and the “sweeping” of W2, can be recognized more accurately by the direct fusion method than with the proposed hierarchical deep fusion method. The main reason is that the difference between the accuracies of the IMU data and photo stream for these activities is relatively small; thus, the results from these two kinds of sensors complement each other when directly fusing. In contrast, the proposed method uses a single sensor in each layer, which may counteract this complementary result when the single sensor misrecognizes an activity. Therefore, the direct fusion method is more suitable for applications with small sensor differences, whereas, when the sensor difference is large, the proposed method will be more competent.
4.3.2. Results on the Multimodal Dataset
Results on motion sensor data: The 200 sequences in the Multimodal Dataset are divided into 10 splits, and the training and testing are completed by leave-one-out cross-validation, which is equivalent to 10 groups of one-to-one corresponding training sets and test sets. As a result, the actual number of training and testing is 10, and there is a total of 10
corresponding to each split. For each of the 10 test results, the average accuracy calculating 10 splits is shown in
Table 12. Meanwhile, in the test results of the 10 splits, the confusion matrices corresponding to the two splits with the lowest accuracy and the highest accuracy are shown in
Figure 20.
Results on high-frame rate photo stream: The photo streams are classified into the groups defined by
in
Table 4, so the hybrid data in the Multimodal Dataset were also adjusted according to the group, and the fine-tuned VGG16-LSTM network shown in
Figure 7 was established in each of the six groups to complete the training and testing. In addition, similar to the results on motion sensor data, the VGG16-LSTM network and its test results also needed to distinguish 10 splits. In all splits, the lowest and highest accuracy confusion matrices for the VGG16-LSTM network corresponding to each group were as shown in
Figure 21. It should be noted that in the groups defined by
in
Table 4, only
and
contain multiple activities, so only these two groups needed to train the VGG16-LSTM network. Thus,
Figure 21 contains only the confusion matrices corresponding to these two groups. The average accuracy of the 10 splits for each activity in the group is shown in
Table 13 and
Table 14.
Results of the hierarchical combination: After both the recognition results of motion sensor and the recognition results of photo stream are obtained, the hierarchical fusion results can be completed by referring to the hierarchical architecture shown in
Figure 8. After fusion, among the 10 splits, the confusion matrices with the lowest and highest accuracy were as shown in
Figure 22. The average accuracy of the 10 splits for each activity to be recognized is shown in
Table 15.
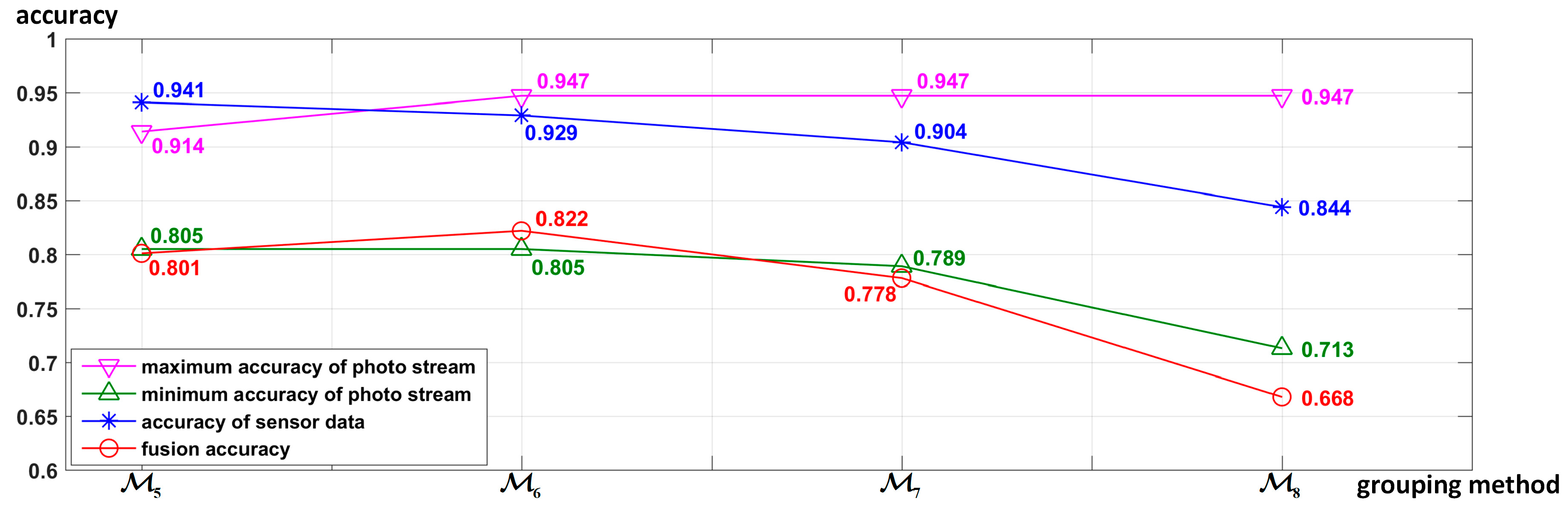
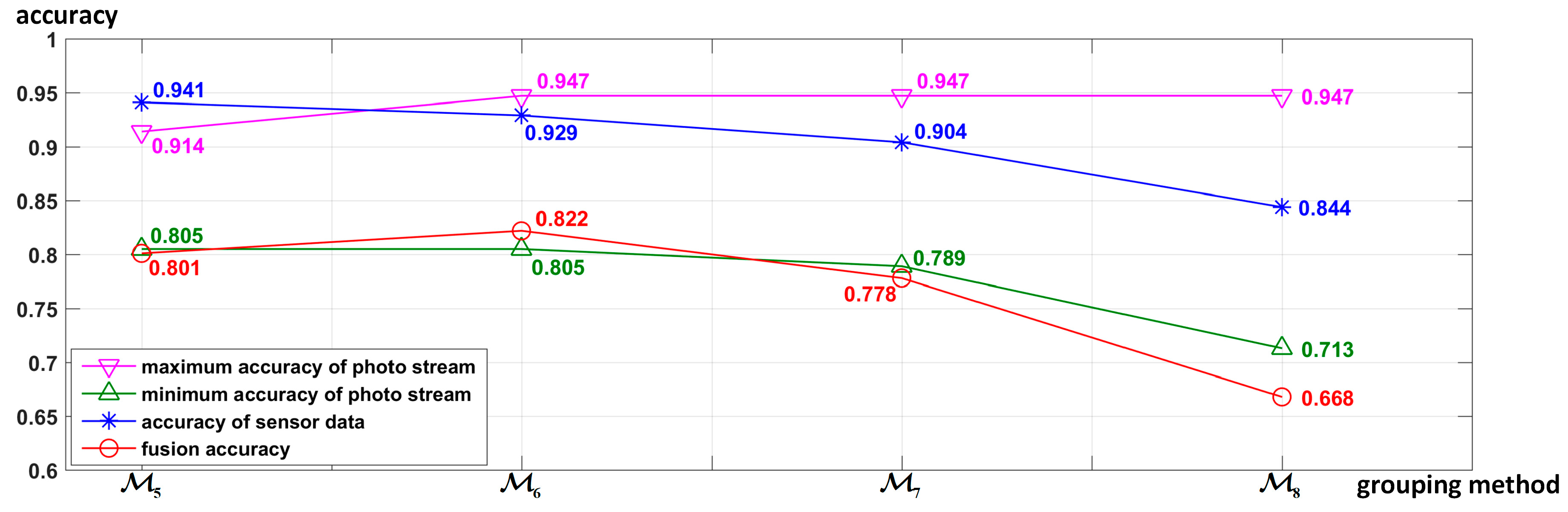
Influence of different grouping methods on fusion accuracy: As different grouping methods will change the input data and classification mode of the deep neural network classifier (LSTM, CNN, or CNN-LSTM), the grouping method will also affect the recognition results of both the motion state layer and the activity layer, which in turn will lead to different fusion accuracies. In order to evaluate the influence of different grouping methods on the fusion accuracy, the four different grouping methods shown in
Table 4 were used to perform the proposed hierarchical deep fusion framework. All of the accuracies are shown in
Figure 23. To analyze how the accuracy of different layers influences the fusion results,
Figure 23 shows both the accuracy of the motion sensor data (motion state layer) and that of the photo stream (activity layer) in each grouping method, wherein all accuracies are the average accuracy of 10 splits. Furthermore, for the photo stream, different grouping methods have different numbers of photo stream accuracies due to different numbers of groups. Therefore, to compare multiple photo stream accuracies with the fusion accuracy, only the maximum and minimum accuracies of each photo stream corresponding to different groups using each grouping method are shown in
Figure 23.
Figure 23 reveals the following: (1) The number of groups is closely related to the accuracy of the grouping. In general, the fewer the groups, the more similar activities are merged, the greater the difference between the groups, and the higher the accuracy of grouping. (2) When the number of groups decreases, the number of activities in each group increases, which usually leads to a decrease in the difference among the activities within the group, thereby reducing the recognition accuracy of the photo stream. Therefore, the number of groups should not be too large or too small, and a compromise is needed. Overall, however, the accuracy of sensor data is more closely related to the fusion accuracy, i.e., the performance of the motion state layer is more important to the fusion result than the activity layer.
Comparison and discussion: In this part, we directly compare the results of the proposed hierarchical deep fusion framework with the fusion results given in [
14] by using the multistream direct fusion method. As in the experimental results section in [
14], only the average accuracy of each stream on 10 splits (as shown in
Figure 11) and the average accuracy after direct fusion on 10 splits are given, we also list the accuracy of the corresponding items possible to complete the comparison of the algorithm results, as shown in
Table 16.
Further, we compare the time consumption of the two algorithms. As the actual time consumed by the algorithm proposed in [
14] is not reported, we can only rely on its algorithm flow to sum the time consumption estimation results of each key algorithm. In the online recognition process, as shown in
Figure 11, the algorithm flow of the algorithm proposed in [
14] mainly includes two optical flow field extraction calculations, three identical CovNets calculations, and four identical LSTM (denoted by
) calculations. During the execution of the algorithm, the video and motion sensor data are not processed synchronously; specifically, for the video, each frame in the video is processed, while for the motion sensor data, the data within the time segment are processed. Therefore, if the calculation time of the optical flow field extraction of a single frame is defined as
, the calculation time of a single
is
, and the calculation time of a single CovNets is
, the inferred range of total time consumption
for the single-frame data in [
14] is as follows:
In the online recognition process of the proposed algorithm, the algorithm flow mainly includes one
calculation for the motion state grouping and one VGG16-LSTM calculation for the single-frame image recognition in its corresponding group. Similarly, because the two LSTMs (
and
) and VGG-16 are also not processed synchronously, if the calculation time of
is
, that of VGG16-LSTM is
, and that of VGG-16 CNN is
, then the range of total time consumption
for single-frame data in the proposed algorithm is as follows
,
and
in Equation (13) can be directly measured on the experimental platform used in this paper (described in
Section 4.2). The inferred values of
and
in Equation (12) can be measured by running the same
and CovNets (constructed according to the detailed network structure described in [
14]) on our experimental platform. The measured values of the above calculation times are shown in
Table 17. It should be noted that, in the measurement process, the input data frames of the two algorithms are exactly the same. For
and
, the input data frame is a 3 s time segment, and for CovNets and VGG16-LSTM, the input frame is a single frame image scaled to 224 × 224 × 3.
According to the specific real-time optical flow algorithm (TV-L
1) used in [
14], in Equation (12) is determined to be
(with a resolution of 256 × 256 and 25 iterations) based on the measured results presented in [
49,
50], which are cited by [
14]. Substituting
and the values of
and
in
Table 17 into Equation (12), the inferred range of
can be determined to be
. Substituting the values of
,
, and
in
Table 17 into Equation (13), the range of
can be determined to be
. The frame rates corresponding to
and
are
and
, respectively. Note that
of the algorithm proposed in [
14] is much longer than
of the proposed algorithm because the optical flow calculation is very time-consuming.
As can be seen from the comparison in
Table 16, when only the motion sensor data are used to complete the recognition of all 20 activities in the activity set, the recognition accuracy is also much lower than the video-based recognition accuracy (49.5% vs. 75%). Therefore, when the direct fusion framework shown in
Figure 11 is used for fusion, the promotion of motion sensor-based results to video-based results is also limited. In contrast, by using the proposed hierarchical deep fusion framework, the number of candidate activities in the group is greatly reduced after the activities to be recognized are divided into different groups with the help of motion sensor data. As a result, the recognition accuracy of each activity is improved to some extent so that the overall average recognition accuracy after fusion is also improved. In addition, although the average recognition accuracy after hierarchical fusion is not much higher than that in [
14] (82.2% vs. 80.5%), the proposed framework does not use a time-consuming optical flow field extraction algorithm to extract the optical flow field between adjacent frames. Meanwhile, in the process of online recognition, only two deep networks (
and VGG16-LSTM) are involved in the processing of motion sensor data and photo stream (the number of online deep networks is seven in the framework proposed in [
14]), so the time complexity of the proposed hierarchical framework is much lower than that of the framework proposed in [
14] (minimum frame rate of 209 vs. 18); thus, it is more suitable for practical applications.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}