4.1. Spatial Change Point Detection
Event identification is based on location state changes. As described, location refers to
moving,
stationary or
unknown. This notion of location is more limited than in other research efforts, which consider geographical locations. However, in the real world, we do not have access to the geographical coordinates 24/7. Therefore, this definition has the advantage of greater availability, which is required in a real-world application. Furthermore,
Figure 1 shows a small time shift in routine human behavior. The displayed dots are not just GPS data but a combination of Cell-ID, GPS and Google API. While a few research efforts [
24,
25] focus on extracting locations from a
combination of different location data sources (fusion), several efforts focus on collecting and mining location traces from a
single source of information [
26,
27] and have demonstrated promising results.
Note that our approach is focused on the data that is being collected from the users’ device (user-centric) and not service provider data, i.e., call detail records (CDR) [
28]. Location data can also be obtained from sources including Cell-ID, WiFi, wireless beacons, etc. Cell-ID is too imprecise to be used for location estimation, and, due to limited battery power, users often do not enable GPS. Therefore, a more reliable source, such as a combination of both WiFi and Cell-ID (which are more resource efficient in comparison to GPS alone), should be used for estimating location. In other words, a location estimation algorithm is assumed to extract location from a combination of sensors.
Our change point detection (location estimation) algorithm receives a set of actions and signal type as inputs and it returns a list of events. Actions are a 3-tuple of attribute (sensor name), value (sensor data) and timestamp. Signal type can be WiFi only (e.g., Device Analyzer data) or a combination of sensors. An event includes a location state, start time, end time, and a finite set of actions. The following shows a simplified example of raw sensor data in a time slot, i.e., between 12:00 p.m. to 12:30 p.m. Since the WiFi is not repeated, we consider this time slot as “moving”.
{{name:"call",val:"1800xxx", time:"12:02-12:03"}},
{name:"WiFi",val:"BSSDID_1", time:"12:04"},
{name:"activity",val:"walk-910s.", time:"12:04-12:18"},
{name:"WiFi",val:"BSSDID_x", time:"12:26"}.
The following shows an example of an event with four actions, after change points have been identified and annotated, i.e., “location state”.
{location_state:"moving",time:"12:00-12:30",
actions:{{name:"call",val:"1800xxx",
time:"12:02-12:03"},
{name:"WiFi",val:"BSSDID_1",
time:"12:04"},
{name:"activity",val:"walk-910sec.",
time:"12:04-12:18"},
{name:"WiFi",val:"BSSDID_x",
time:"12:26"} } }.
Note that the algorithm checks the signal type, either Wi-Fi or combination of all location signals. If both Wi-Fi and geographical location exist, the algorithm prioritizes the geographical location over Wi-Fi (due to its superior accuracy).
If it is only Wi-Fi, it searches for consecutive timestamped WiFi logs. If such a sequence exists, and all its elements (i.e., BSSID of WiFi) are unique, this is a sign of a
moving event. For example, a sequence of not repeated WiFi BSSID as
is a sign of a moving event. Therefore, a moving event (with its start time and end time) will be created and appended to the
events list. Otherwise, if it is not a moving event and there is a sequence of elements, but they are not unique (i.e., repeated BSSID), the algorithm identifies them as a
stationary event. For instance, a 60 min sequence of repeated WiFi BSSID as
presents a stationary event. If in a time interval of 60 min no WiFi signal exists at all, and all other location signals are not available either, the algorithm creates an
unknown event. The algorithm uses a time interval of 60 min because it has been identified [
1] that the temporal granularity of 60 min has the highest accuracy for routine behavior identification. In other words, this time interval could be assumed as a smoothing factor.
All events include a start time and end time. In short, when the algorithm finds a number of WiFi BSSIDs (let us say names for simplicity) repeated together, it creates a stationary event. However, if the WiFi names changes and they are not repeated, it creates a moving event. If none of the described cases exist, the algorithm creates an unknown event.
If the signal type is not just WiFi and it is a combination of GPS, Cell-ID and a 3rd party location service such as the Google Play service, the algorithm takes a different approach. If geographical coordinates exist (GPS or a similar 3rd party service), the location status is easily computed. To calculate this type of location state, it computes the difference between two consecutive geographical coordinates. If two signals have a distance more than the distance threshold and are equal to or more than the temporal threshold then the algorithm marks the target time frame (event) as moving. Otherwise, if the distance is less than and more than , it marks them as stationary. If no location signal appears after time, then the algorithm creates a new event and marks the event as unknown. This event continues until a new location change appears. When a new location signal appears (that creates a different location state), it ends the previous event. Ending an event means the algorithm closes the event with the timestamp of the last element in the dataset. Then, a new event is created with the timestamp of the new location element that has been most recently read.
Note that is a fixed number and varies between 800 to 1000 m in cell tower installations; e.g., in the city of the UbiqLog experiment, it is fixed to 800 m.
The UbiqLog dataset shows that most of the time GPS is turned off (based on its real-world nature), there are very few GPS logs and they occur mostly when users are navigating. Most location logs are from Cell-ID; and thus it is not possible to precisely estimate location (because of relying on Cell-ID instead of precise coordinate) [
25]. In particular, when the location change is noted, there is an ambiguity as to whether the location has truly changed or just the cell tower has changed (i.e., handoff). Nevertheless, there is a fixed precision associated with the location extracted from the Cell-ID. Let us assume the precision distance is
, (in the city of the UbiqLog experiment, the precision distance between Cell towers was 800 m) and a temporal precision
. To understand this problem, consider the example in
Figure 3a. There we have
. If
, this means that the user is moving. If
but the distance between
and
, then the user is inferred to be stationary and not moving. Therefore, when the algorithm calculates only the distance between two consecutive points, it might face a problem. To resolve this issue, when the location is based on Cell-ID, the algorithm calculates the location distance between
three consecutive points rather than
two.
Figure 3b shows a trace, which has a combination of GPS(G) and Cell-ID(C) locations. It shows that four Cell-IDs have been recognized and C4 has not been categorized as the same event. Based on cell tower distribution [
26],
must be 800 to 1000 m (cell tower distances) to check whether or not there is a location change or not, and five minutes has been assigned to
.
Setting
to five minutes is extracted from the evaluation conducted in the data collection experiment [
11]. Therefore, in this paper, we do not evaluate the parameter sensitivity of
,
and the time intervals.
The computational complexity of the this spatial change point detection algorithm is linear because, even if we assume all locations are Cell-ID, there is a need for a comparison of each element with its two previous ones and thus we require only comparisons (worst case scenario).
4.2. Temporal Clustering
The second step is to cluster similar user events of a person based on their spatial and temporal similarity. Events inside a cluster have the (i) same start time, (ii) same end time and (iii) same location state, which was identified in the previous stage.
We interpret similar spatio-temporal events as an indicator for a routine behavior, e.g., commuting to work, going to the park on weekends, etc. Similar events are collected in clusters. As it has been described in
Section 2, we need to handle the slope of human timing of similar events and thus use
.
can be interpreted as a reasonable “slope interval” to calculate similarities between events.
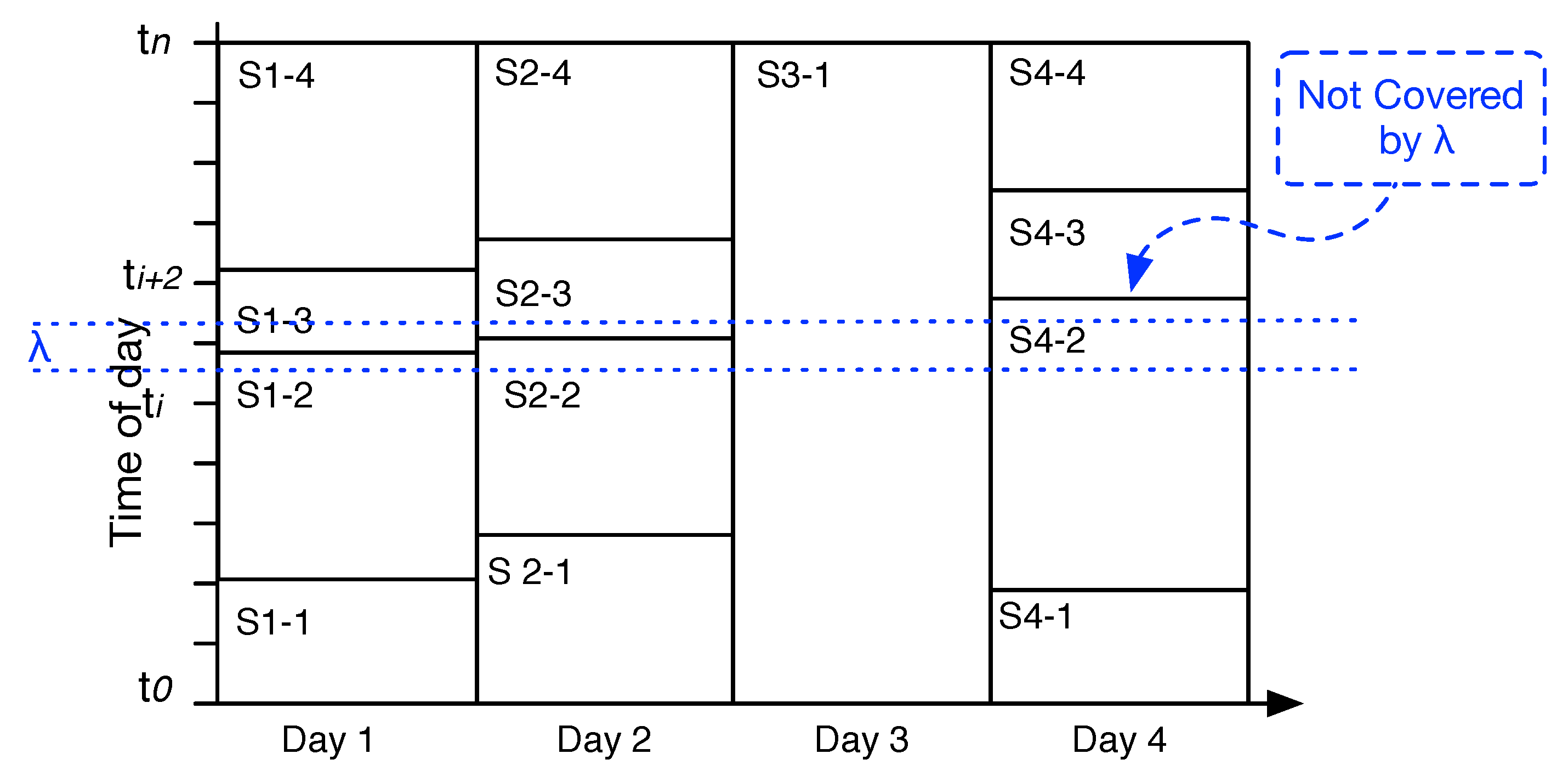
Figure 4 shows a
interval that covers the start times (lower bound) of two (visually) similar events
S1-3 and
S2-3 from two consecutive days. Clusters are not overlapped.
Algorithm 1 describes our temporal clustering approach. and a list of events, , which are ordered based on timestamps, are inputs. The algorithm iterates through all events; then, it selects the first two days through the method, line 3. is the event list of the first day and is the event list of the next day. On line 5, method compares the spatial and temporal data of two events from each day. If they are similar, and a cluster with their spatio-temporal properties exists (checked by ) then the algorithm adds both events into their respective cluster, on line 7. Otherwise, if they have similar spatio-temporal properties but no cluster exists with the similar spatio-temporal properties, the algorithm creates a new cluster on line 9 and adds both events into this new cluster. If none of the above conditions are met, both events will be added to list (list of orphan events), line 11.
Days are compared sequentially, but there are events that do not occur every day but occur frequently, such as going to the gym twice a week or events originating from weekend activities, e.g., going to the movies. To cluster these events, dissimilar events will go into the list (line 11). After the first loop, which compares all events and assigns them to their cluster, the algorithm orders the content of based on time, on line 14. Then, it starts iterating through them on line 15. If two consecutive events inside are similar, and their spatio-temporal properties are similar to one of the exiting clusters ( method on line 15 checks this condition), then these two events will be added to that existing cluster, on line 18. Moreover, these events will be removed from because now they have a cluster. If they are not passed to any cluster but their spatio-temporal properties are similar, a new cluster to host them will be created on line 20 and collect them. Nevertheless, if none of these conditions apply, these events do not have any similar events and they will be added to a list of (anomalous) events.
| Algorithm 1: Temporal clustering of events. |
 |
Human behavior slowly evolves over time [
1], which means, among other phenomena, similar events and their timings will change over time. To resolve this issue,
will be moved between days, but it is a fixed variable. In particular, the algorithm will not use one day as a benchmark and then compare the other days to that single day.
Figure 4 neglects the spatial property of an event for the sake of readability, and visualizes the problem of not moving
. The example shows four days within their temporal events identified.
S1-3 and
S2-3 could stay in the same cluster, but
S4-3 is not covered by the
threshold, despite the fact that we can see it belongs to the same cluster. In addition,
S1-2 and
S2-2 have a similar end time, but if we do not move
,
S4-2 also lacks a similar end time.
Because of a minor time variety of daily routine behaviors, the is changing. If two events are similar, which means their upper bound and lower bound are , then will be updated as the average of upper bound or lower bound between two similar events. Otherwise, will be not changed.
Each day will be compared with another day, which requires n number of comparisons. In the worst case, the content of orphan event list () is equal to and again we have about number of comparisons. This means that the complexity of this algorithm is , which is linear.
4.3. Detecting Contrasting Events
An individual’s frequent presence in the same location state at the same time does not mean she necessarily engages in exactly the same behavior. In addition, an event may be too prolonged to quantify its content. For instance, a user could stay at home for a day but have significantly different activities, such as recuperating from an illness or working from home. To identify such differences, we propose a novel contrast behavior (CB) detection approach for events
inside a cluster. Our CB detection algorithm is inspired by contrast-set mining algorithms [
13]. Some research considers contrast-set mining as a rule discovery [
29], but we have a different interpretation, tailored for mobile data that are multivariate temporal data.
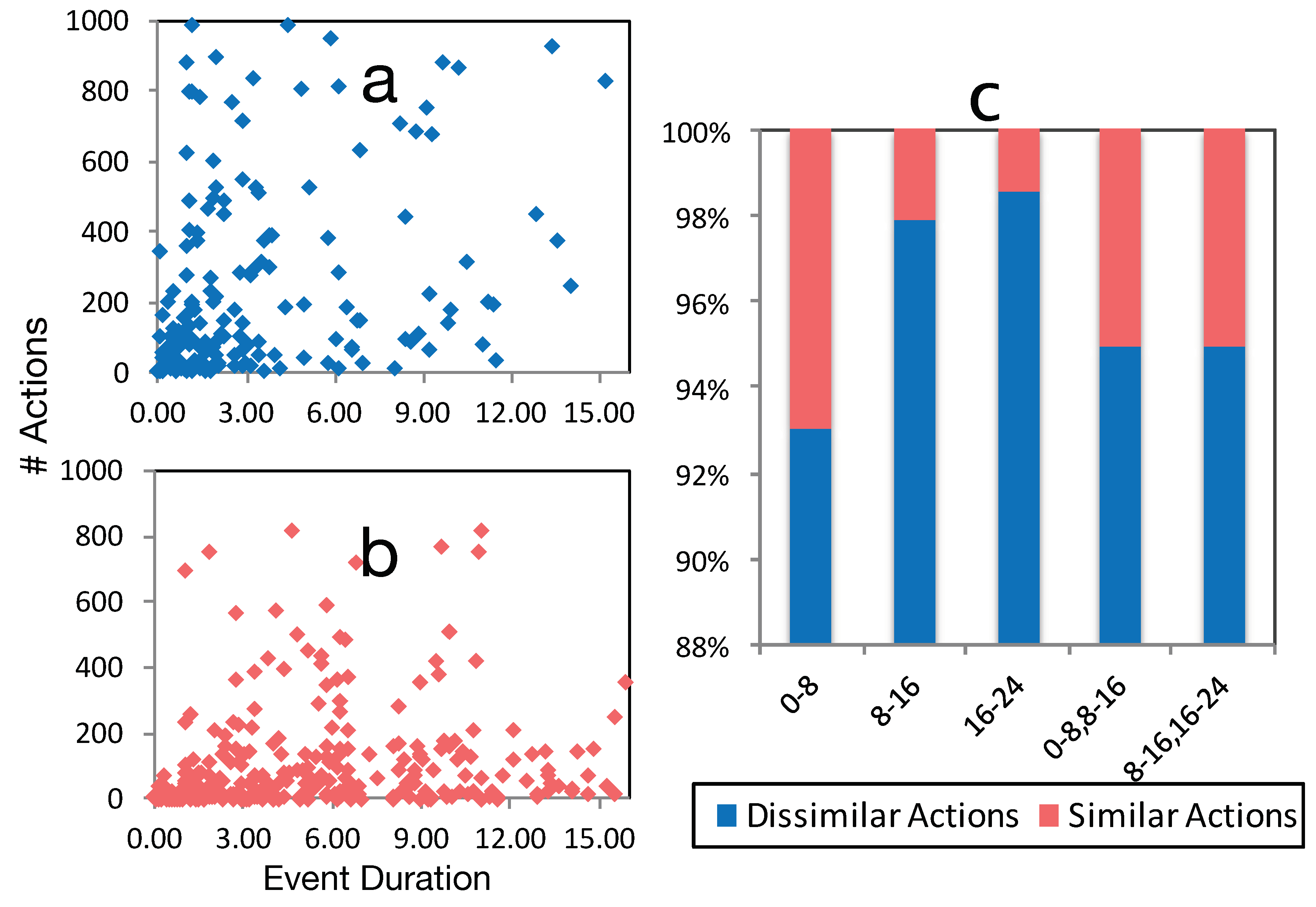
Algorithm 2 presents a method to compare the actions of each event inside a cluster. The algorithm receives a cluster, , and . As previously described, is the threshold for uncommon actions in each event. The algorithm identifies the contrasting events in each cluster and at the end reports for each cluster how many of its members (events) are contrasting and how many of them are similar. The result of this algorithm is useful for searching because it enables the search algorithms to prioritize the clusters, based on the number of similar events.
| Algorithm 2: Contrast behavior identification from events inside a cluster. |
 |
On line 2, the algorithm iterates through the number of events in a cluster (line 5) and compares each event () actions with other events inside that cluster, on line 6. The method (line 7), compares two events and, if the number of different actions is larger than the threshold, then those events are counted as contrasting behaviors. This comparison is measuring the exact similarity between each action. We did not use other similarity metrics such as Jaccard coefficient because our empirical experiments show that the number of actions of events inside the cluster are either equal or the difference is very insignificant. At the end, they are collected in the set and returned. This comparison is measuring the exact similarity between each action.
A large number of dissimilar events indicates that the user’s activities are not routine. The
value is application dependent. It also depends on the temporal event size, the purpose to which outputs are used, and how that benefits from our approach. For instance, if an event size is about a day (e.g., a device is stationary during the day) contrasting behaviors do not reveal much about the underlying semantics of the data. Assuming
n number of events are inside a cluster, each event inside a cluster is compared with other events in the cluster. Therefore, the algorithm has
comparisons and its complexity will be
. However, the number of comparisons is limited to only the number of events inside a cluster. Therefore, the number of comparisons is small (e.g., two to eight in a UbiqLog dataset) and thus the performance overhead is insignificant.
Section 5.3 reports this cost in detail.
Note that the contrast behavior detection provides a minor semantic improvement, i.e., annotation, on the actions inside a cluster and still more knowledge extraction is required on the data. In particular, contrast behaviors will be used mainly to order clusters for the search. The implementation of the annotation, such as geo-fencing, drives the conversion of sensor data to a higher level of information in the task of the application that uses our algorithms. Therefore, there is still a need for manual annotation, but our approach significantly reduces it. For instance, for the ground truth dataset, we have implemented a simple annotation, based on users’ manual labels, e.g., home, gym, work, etc. Users annotate one event only once in a cluster, and then it will be distributed among other events in that cluster.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}