Repeated Game Analysis of a CSMA/CA Network under a Backoff Attack


Abstract
1. Introduction
- By using repeated games, and taking into account the time, we are able to use a more complex strategy which allows all players to obtain better payoffs, thanks to the Folk Theorem. Ours is not the first work that studies the CSMA/CA backoff attack using repeated games [12]. But to the best of our knowledge, is the first one that studies the backoff attack as a repeated game using average discounted payoff. As Reference [12] indicates, not taking into account a discount factor is not very realistic in a volatile environment as wireless networks and this approach have been used in other applications, such as smart grids [19].
- We do not focus on a single equilibrium concept but study the attack using both subgame perfect equilibria and correlated equilibria concepts and solve the game analytically for the two player case. This allows us comparing both equilibria concepts in terms of payoffs and computational capabilities required in the network stations and hence, we also include several guidelines in order to implement the approach described in this work.
- We also use a negotiation algorithm that allows finding solutions to the repeated game for more than two players and discuss its scalability and application in practical problems.
2. Distributed Coordination Function in IEEE 802.11
2.1. Description of Basic Access Mechanism
2.2. Network Throughput under Backoff Modification
3. Introduction to Game Theory
3.1. Static Games
- is the number of players, numbered as .
- A is the set of actions available to all players. The pure actions available to player i are denoted by , with , being the set of actions available to player i. A is defined as . A is assumed to be a compact (i.e., bounded and closed) subset of .
- u is a continuous function that gives the game payoffs:
3.2. Repeated Games of Perfect Monitoring
- The set of histories . A history is a list of the action profiles played in periods . Thus, the history contains the past actions.
- A strategy for player i is a mapping from the set of all possible histories into the set of actions: .
- Continuation: for any history , the continuation game is the infinitely repeated game that begins in period t, following history . After playing up to time t, a strategy must consider all possible continuation histories and be a strategy for each possible or equivalently, for each concatenation of histories . In other words, a strategy must depend only on the previous history.
- The average discounted payoff to player i is given by:where is the discount factor, satisfying . Note that the payoff is normalized with the term , which allows comparing payoffs in the repeated game with the ones in the stage game.
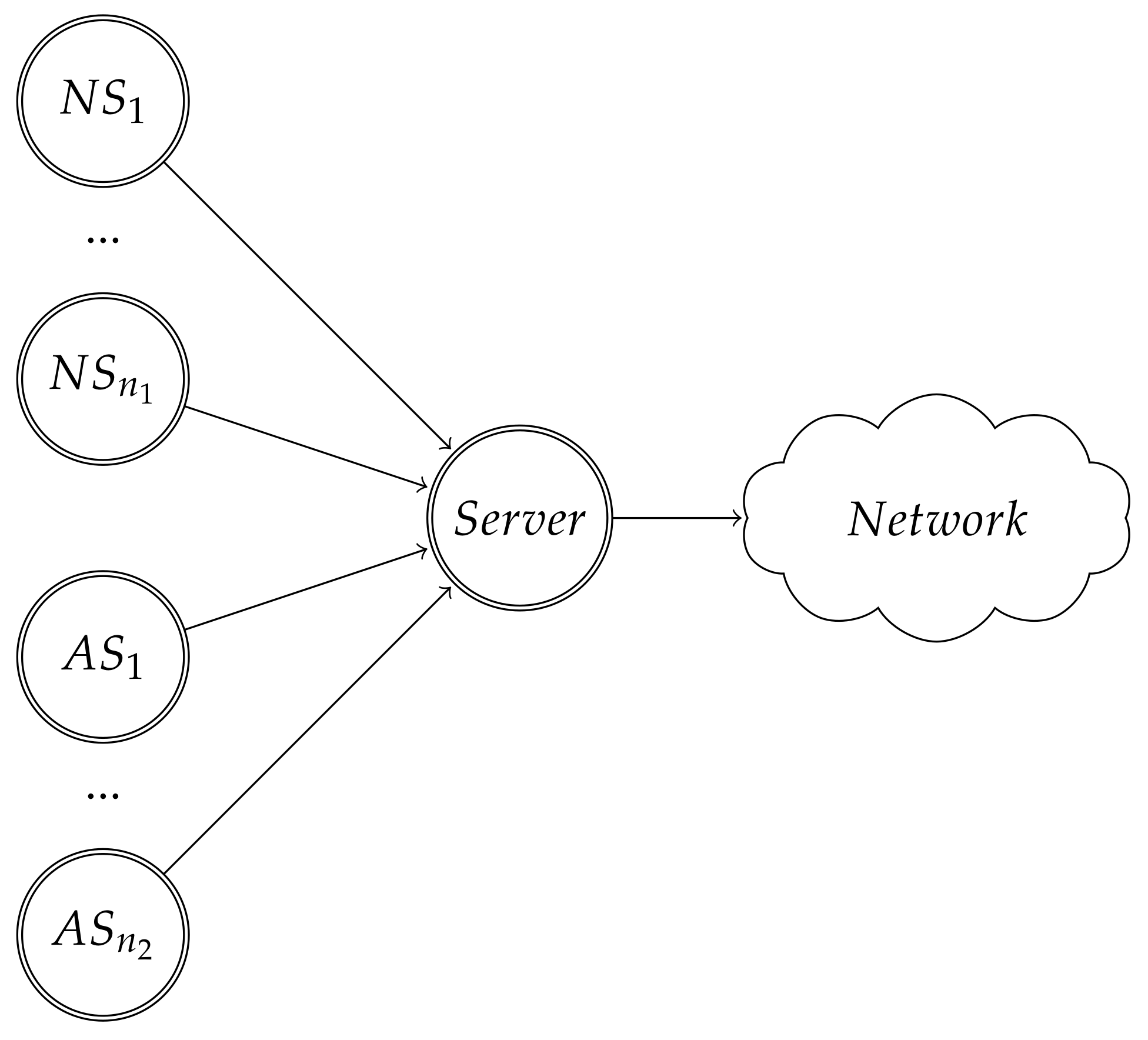
4. Problem Description
5. CSMA/CA Static Game
5.1. Nash Equilibrium Concept
5.2. Correlated Equilibrium Concept
5.3. Learning Algorithms: Regret Matching
6. CSMA/CA Repeated Game in the Two Player Case
6.1. Subgame Perfect Equilibrium Concept
- is a set of states (each state is an equivalence class).
- is the initial state.
- is a decision function that maps states to actions, where .
- is a transition function that identifies the next state of the automaton as a function of the present state and the realized action profile, where . A state is accessible from another state if the transition function links both states with some action.
6.2. SPE Solution to the CSMA/CA Game
6.3. Correlated Equilibrium Concept
6.4. Correlated Equilibrium Solution to the CSMA/CA Game
7. CSMA/CA Repeated Game with an Arbitrary Number of Players
| Algorithm 1 CA algorithm for each player i |
| Input:, , , , , |
| 1: |
| 2: if then |
| 3: |
| 4: else |
| 5: while do |
| 6: |
| Output: |
8. Simulations for the CSMA/CA Game
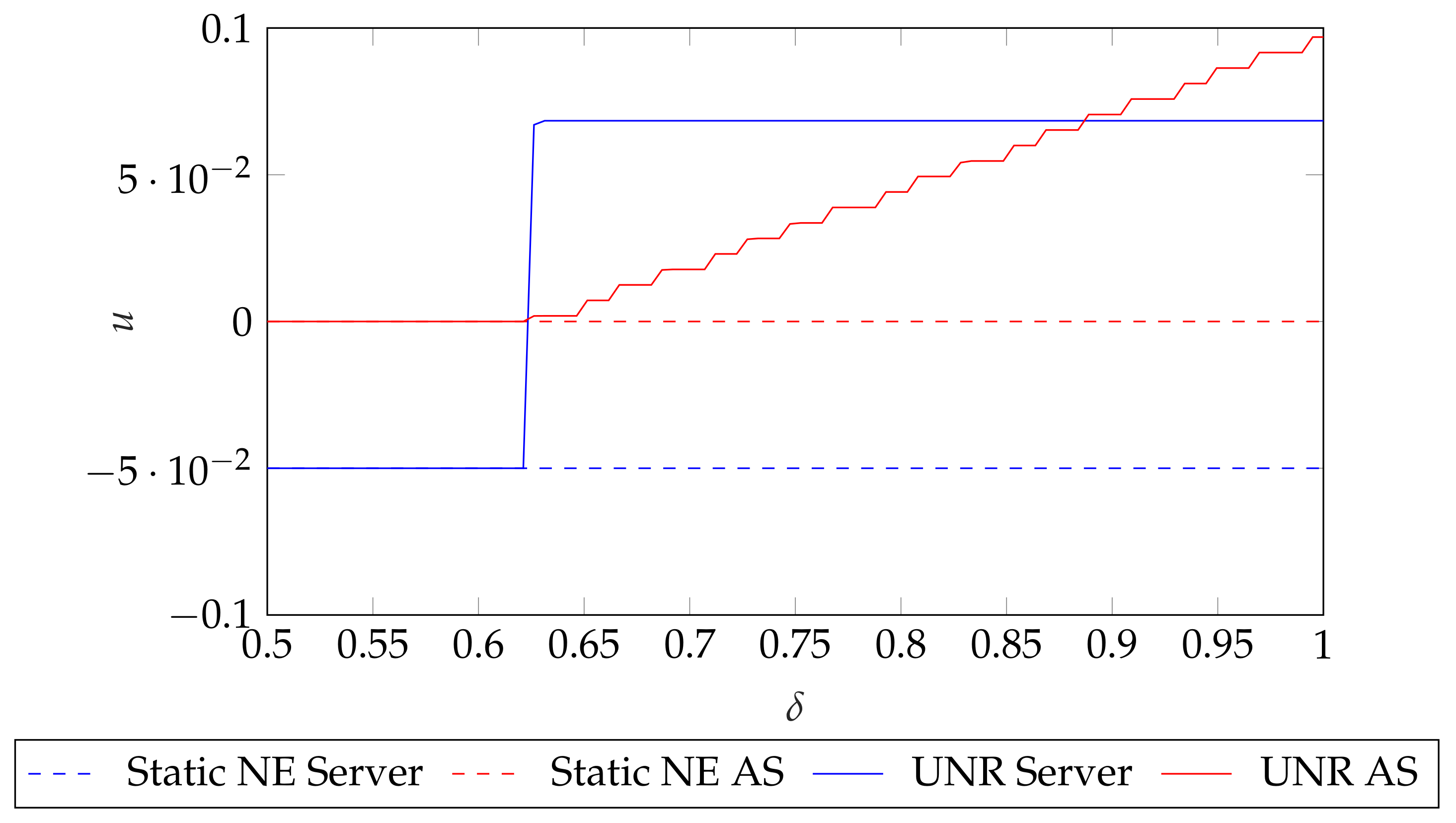
8.1. Simulation 1: Dependency with
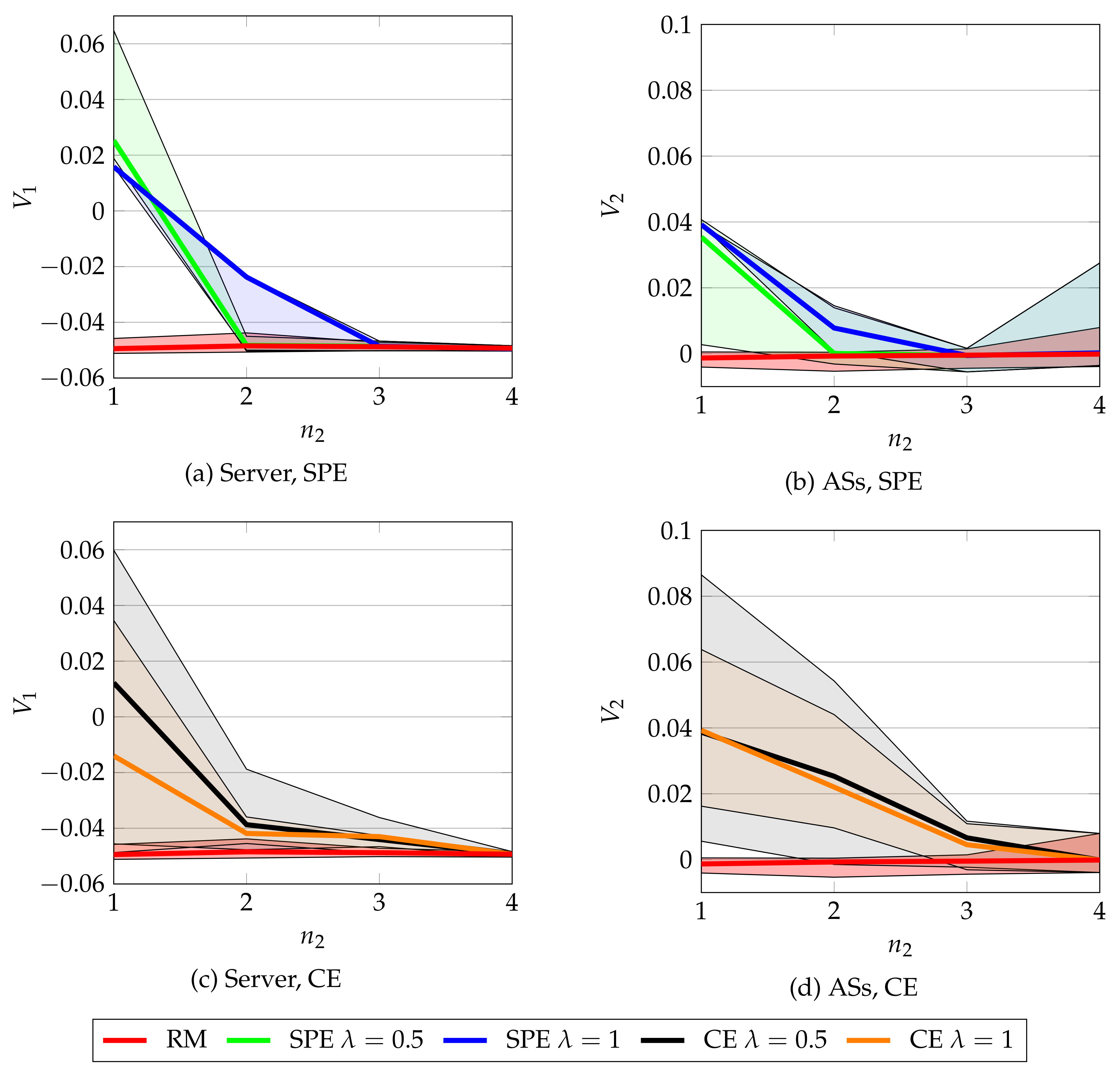
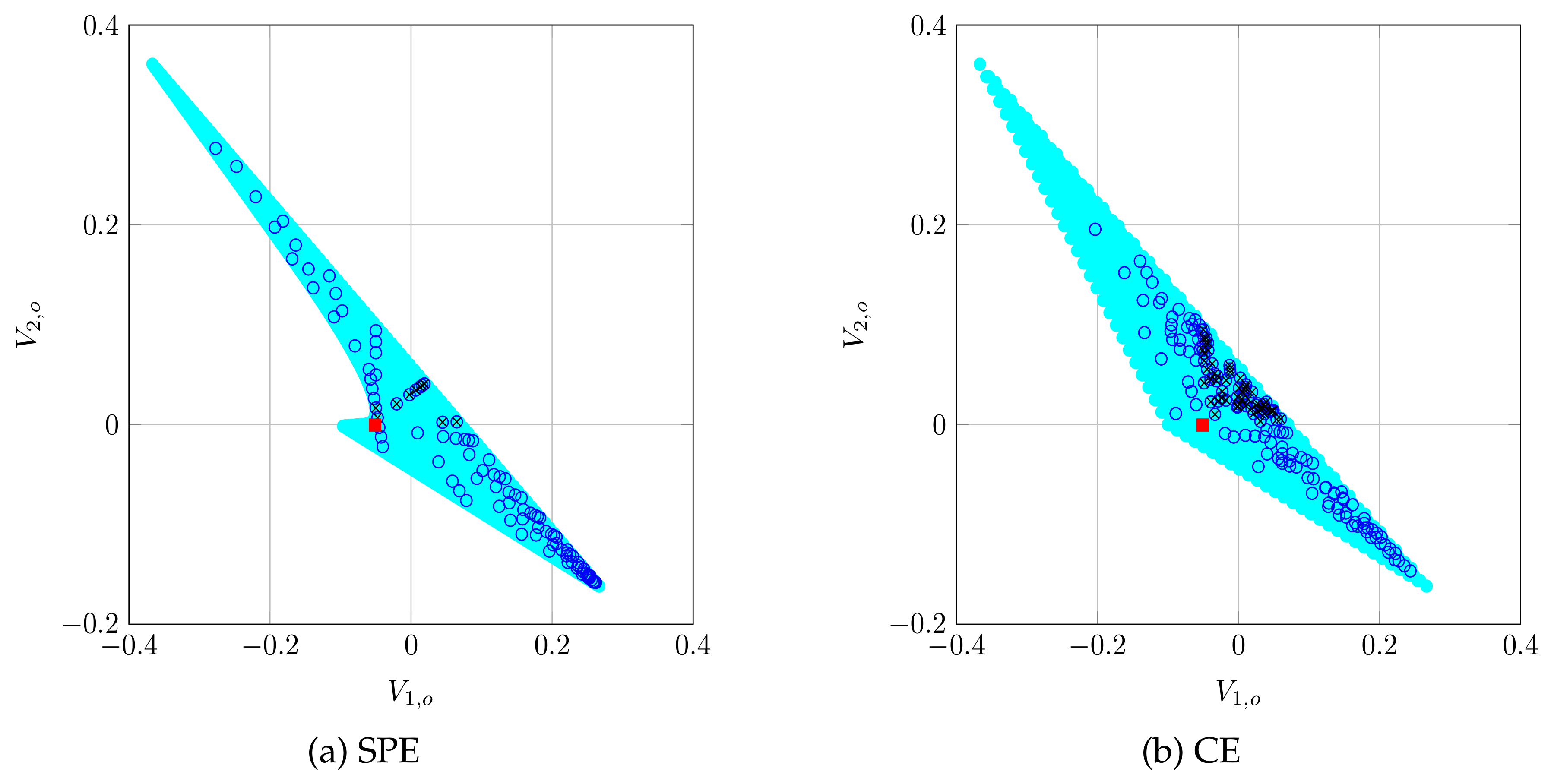
8.2. Simulation 2: Repeated CSMA/CA game solutions
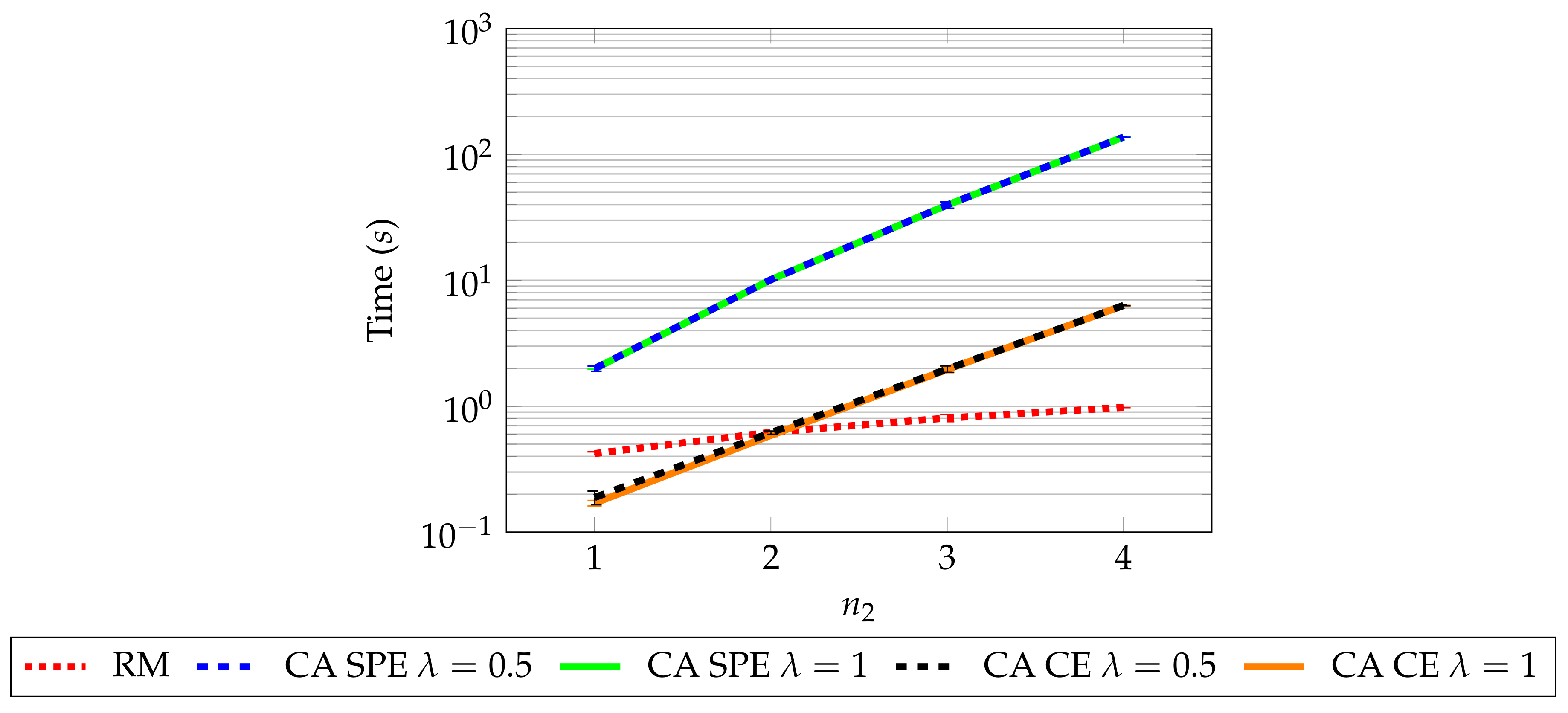
8.3. Simulation 3: Computational Resources of RM and CA
8.4. Discussion
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| A/ | Set of actions available to all players/to player i |
| AS | Attacking Station |
| CA | Communicate & Agree |
| CE | Correlated Equilibrium |
| CSMA/CA | Carrier-Sense Medium Access with Collision Avoidance |
| Contention Window | |
| DCF | Distributed Coordination Function |
| Discount factor | |
| Correlated equilibrium distribution | |
| m | Maximum backoff stage |
| MAC | Medium Access Control |
| n | Number of stations in the network |
| Number of normal stations in the network | |
| Number of attacking stations in the network | |
| Number of players | |
| NE | Nash Equilibrium |
| NS | Normal Station |
| Probability that station i observes a collision | |
| Payoff matrix for player i | |
| RM | Regret Matching |
| Throughput for station i | |
| SPE | Subgame Perfect Equilibrium |
| Strategy for player i | |
| t | Time index |
| Probability that station i transmits | |
| u | Game payoff function |
| UNR | Unforgiving Nash Reversion |
| Average discounted payoff for player i | |
| W | Minimum size of the contention window |
| y | Mixed action of player 1 |
| z | Mixed action of player 2 |
References
- IEEE Standard for Information Technology–Telecommunications and Information Exchange between Systems Local and Metropolitan Area Networks–Specific Requirements—Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications; IEEE: Piscataway, NJ, USA, 2016; pp. 1–3534. [CrossRef]
- Ye, W.; Heidemann, J.; Estrin, D. Medium access control with coordinated adaptive sleeping for wireless sensor networks. IEEE/ACM Trans. Netw. 2004, 12, 493–506. [Google Scholar] [CrossRef]
- Enz, C.C.; El-Hoiydi, A.; Decotignie, J.D.; Peiris, V. WiseNET: An ultralow-power wireless sensor network solution. Computer 2004, 37, 62–70. [Google Scholar] [CrossRef]
- Van Dam, T.; Langendoen, K. An adaptive energy-efficient MAC protocol for wireless sensor networks. In Proceedings of the 1st International Conference on Embedded Networked Sensor Systems, Los Angeles, CA, USA, 5–7 November 2003; pp. 171–180. [Google Scholar]
- Lin, P.; Qiao, C.; Wang, X. Medium access control with a dynamic duty cycle for sensor networks. In Proceedings of the Wireless Communications and Networking Conference, Atlanta, GA, USA, 21–25 March 2004; pp. 1534–1539. [Google Scholar]
- Demirkol, I.; Ersoy, C.; Alagoz, F. MAC protocols for wireless sensor networks: A survey. IEEE Commun. Mag. 2006, 44, 115–121. [Google Scholar] [CrossRef]
- Yadav, R.; Varma, S.; Malaviya, N. A survey of MAC protocols for wireless sensor networks. UbiCC J. 2009, 4, 827–833. [Google Scholar]
- Parras, J.; Zazo, S. Wireless Networks under a Backoff Attack: A Game Theoretical Perspective. Sensors 2018, 18, 404. [Google Scholar] [CrossRef] [PubMed]
- AlSkaif, T.; Zapata, M.G.; Bellalta, B. Game theory for energy efficiency in wireless sensor networks: Latest trends. J. Netw. Comput. Appl. 2015, 54, 33–61. [Google Scholar] [CrossRef]
- Akkarajitsakul, K.; Hossain, E.; Niyato, D.; Kim, D.I. Game theoretic approaches for multiple access in wireless networks: A survey. IEEE Commun. Surv. Tutor. 2011, 13, 372–395. [Google Scholar] [CrossRef]
- Ghazvini, M.; Movahedinia, N.; Jamshidi, K.; Moghim, N. Game theory applications in CSMA methods. IEEE Commun. Surv. Tutor. 2013, 15, 1062–1087. [Google Scholar] [CrossRef]
- Konorski, J. A game-theoretic study of CSMA/CA under a backoff attack. IEEE/ACM Trans. Netw. 2006, 14, 1167–1178. [Google Scholar] [CrossRef]
- Cagalj, M.; Ganeriwal, S.; Aad, I.; Hubaux, J.P. On selfish behavior in CSMA/CA networks. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; pp. 2513–2524. [Google Scholar]
- Kim, J.; Kim, K.S. Detecting Selfish Backoff Attack in IEEE 802.15. 4 CSMA/CA Using Logistic Classification. In Proceedings of the 2018 Tenth International Conference on Ubiquitous and Future Networks (ICUFN), Prague, Czech Republic, 3–6 July 2018; pp. 26–27. [Google Scholar]
- Bianchi, G. Performance analysis of the IEEE 802.11 distributed coordination function. IEEE J. Sel. Areas Commun. 2000, 18, 535–547. [Google Scholar] [CrossRef]
- Shapley, L.S. Stochastic games. Proc. Natl. Acad. Sci. USA 1953, 39, 1095–1100. [Google Scholar] [CrossRef] [PubMed]
- Fudenberg, D.; Tirole, J. Game Theory; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Mailath, G.J.; Samuelson, L. Repeated Games and Reputations: Long-run Relationships; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- AlSkaif, T.; Zapata, M.G.; Bellalta, B.; Nilsson, A. A distributed power sharing framework among households in microgrids: A repeated game approach. Computing 2017, 99, 23–37. [Google Scholar] [CrossRef]
- Basar, T.; Olsder, G.J. Dynamic Noncooperative Game Theory, 2nd ed.; SIAM: Philadelphia, PA, USA, 1999. [Google Scholar]
- Mertens, J.F.; Sorin, S.; Zamir, S. Repeated Games; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Aumann, R.J. Subjectivity and correlation in randomized strategies. J. Math. Econ. 1974, 1, 67–96. [Google Scholar] [CrossRef]
- Gilboa, I.; Zemel, E. Nash and correlated equilibria: Some complexity considerations. Games Econ. Behav. 1989, 1, 80–93. [Google Scholar] [CrossRef]
- Goldberg, P.W.; Papadimitriou, C.H. Reducibility among equilibrium problems. In Proceedings of the 38th Annual ACM Symposium on Theory of Computing, Seattle, WA, USA, 21–23 May 2006; pp. 61–70. [Google Scholar]
- Hart, S.; Mas-Colell, A. A simple adaptive procedure leading to correlated equilibrium. Econometrica 2000, 68, 1127–1150. [Google Scholar] [CrossRef]
- Hart, S.; Mas-Colell, A. Simple Adaptive Strategies: From Regret-matching to Uncoupled Dynamics; World Scientific Publishing: Singapore, 2013. [Google Scholar]
- Hoang, D.T.; Lu, X.; Niyato, D.; Wang, P.; Kim, D.I.; Han, Z. Applications of Repeated Games in Wireless Networks: A Survey. IEEE Commun. Surv. Tutor. 2015, 17, 2102–2135. [Google Scholar] [CrossRef]
- Murray, C.; Gordon, G. Finding Correlated Equilibria in General Sum Stochastic Games; Carnegie Mellon University: Pittsburgh, PA, USA, 2007. [Google Scholar]
- Dermed, M.; Charles, L. Value Methods for Efficiently Solving Stochastic Games of Complete and Incomplete Information. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, December 2013. [Google Scholar]
- Parras, J.; Zazo, S. A distributed algorithm to obtain repeated games equilibria with discounting. Appl. Math. Comput. 2020, 367, 124785. [Google Scholar] [CrossRef]
- Munos, R. Optimistic Optimization of a Deterministic Function without the Knowledge of its Smoothness. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; pp. 783–791. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| s | ||
|---|---|---|
| d |
| MAC Header | 272 bits | 1 s | |
|---|---|---|---|
| PHY header | 128 bits | 50 s | |
| ACK | 112 bits + PHY header | SIFS | 28 s |
| RTS | 160 bits + PHY header | DIFS | 128 s |
| CTS | 272 bits + PHY header | Bit rate | 1 Mbps |
| s | ||
|---|---|---|
| d |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parras, J.; Zazo, S. Repeated Game Analysis of a CSMA/CA Network under a Backoff Attack. Sensors 2019, 19, 5393. https://doi.org/10.3390/s19245393
Parras J, Zazo S. Repeated Game Analysis of a CSMA/CA Network under a Backoff Attack. Sensors. 2019; 19(24):5393. https://doi.org/10.3390/s19245393
Chicago/Turabian StyleParras, Juan, and Santiago Zazo. 2019. "Repeated Game Analysis of a CSMA/CA Network under a Backoff Attack" Sensors 19, no. 24: 5393. https://doi.org/10.3390/s19245393
APA StyleParras, J., & Zazo, S. (2019). Repeated Game Analysis of a CSMA/CA Network under a Backoff Attack. Sensors, 19(24), 5393. https://doi.org/10.3390/s19245393