Waterfall Atrous Spatial Pooling Architecture for Efficient Semantic Segmentation


Abstract
1. Introduction
- We propose the Waterfall method for Atrous Spatial Pooling that achieves significant reduction in the number of parameters in our semantic segmentation network compared to current methods based on the spatial pyramid architecture.
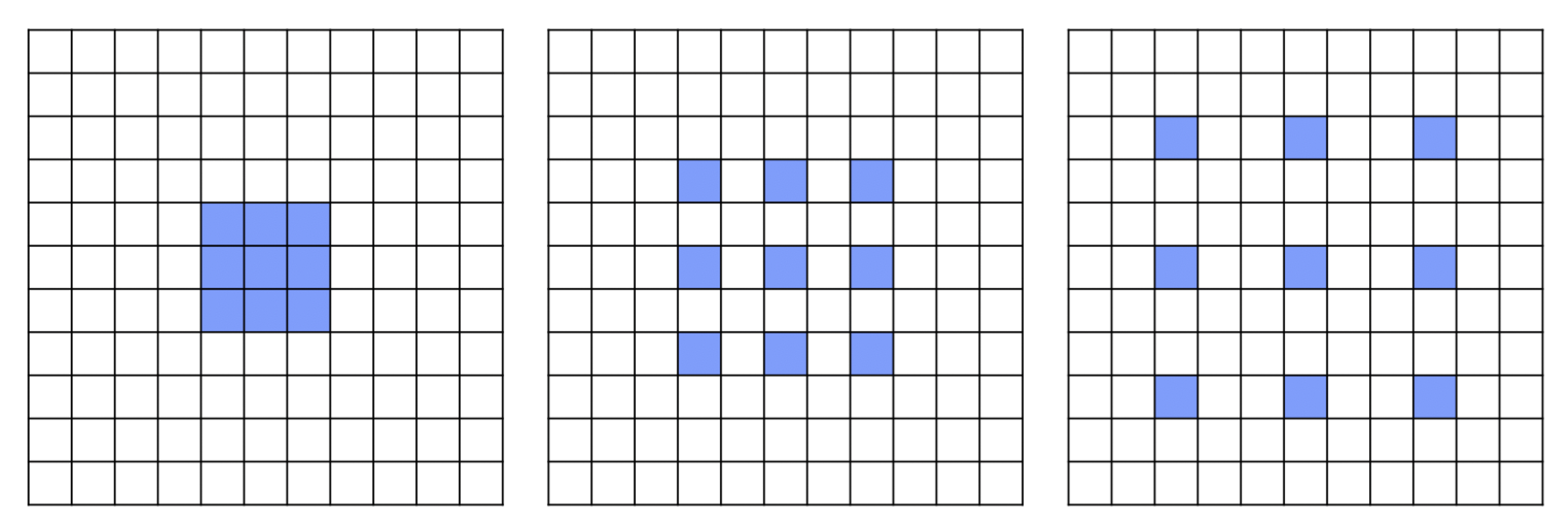
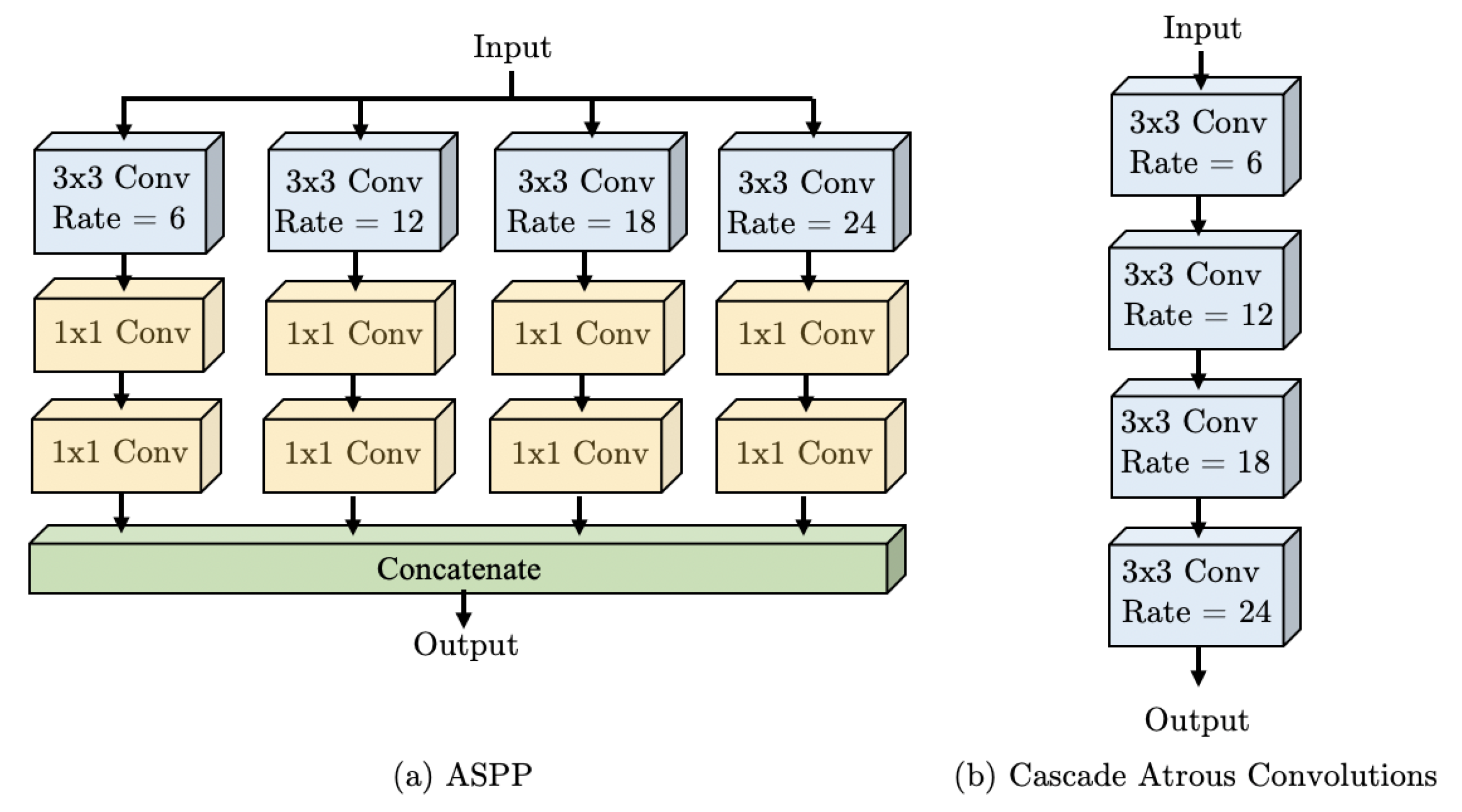
- Our approach increases the receptive field of the network by combining the benefits of cascade Atrous Convolutions with multiple fields-of-view in a parallel architecture inspired by the spatial pyramid approach.
- Our results show that the Waterfall approach achieves state-of-the-art accuracy with a significant reduction in the number of network parameters.
- Due to the superior performance of the WASP architecture, our network does not require postprocessing of the semantic segmentation result with a CRF module, making it even more efficient in terms of computational complexity.
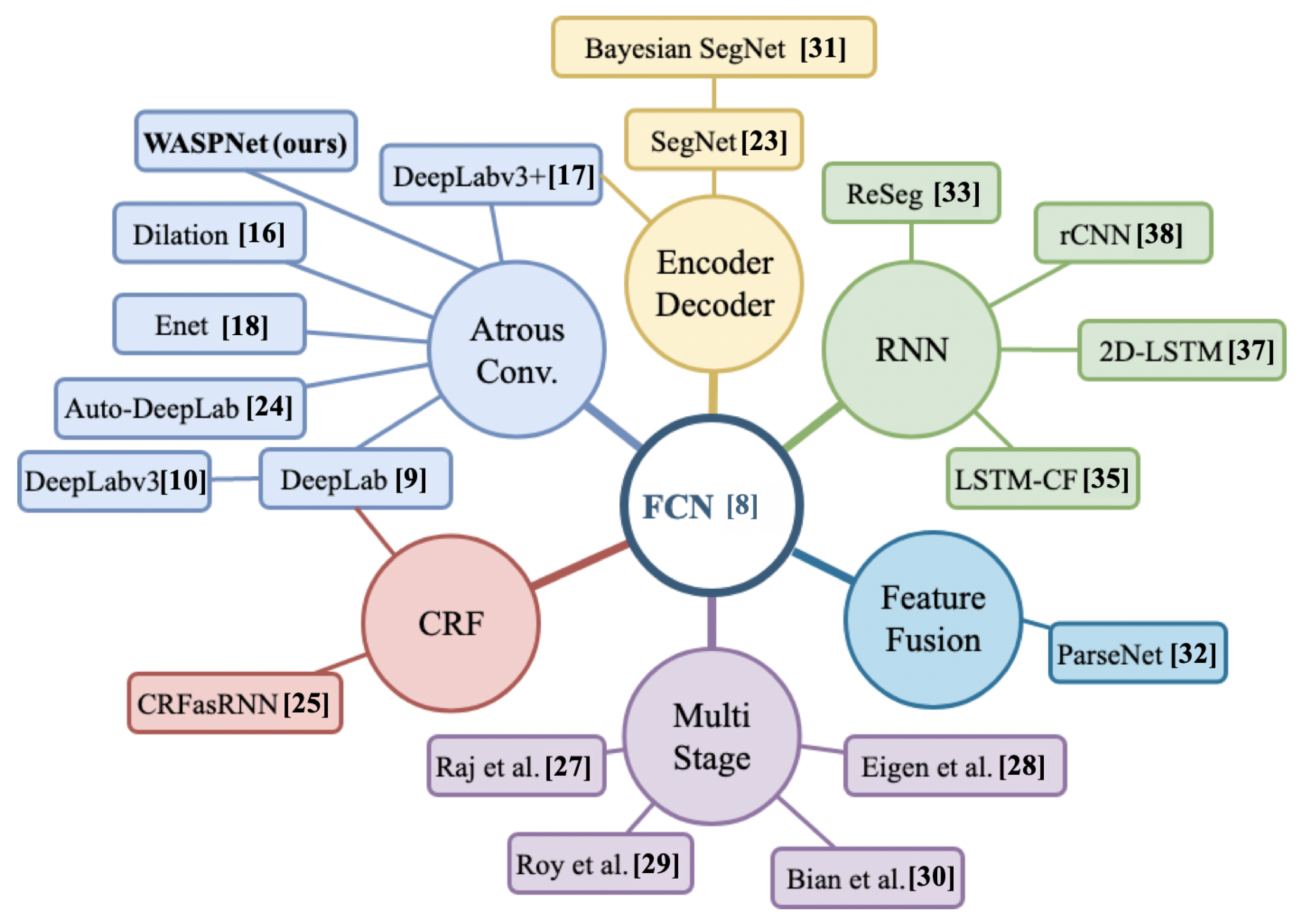
2. Related Work
2.1. Atrous Convolution
2.2. DeepLabv3
2.3. CRF
2.4. Other Methods
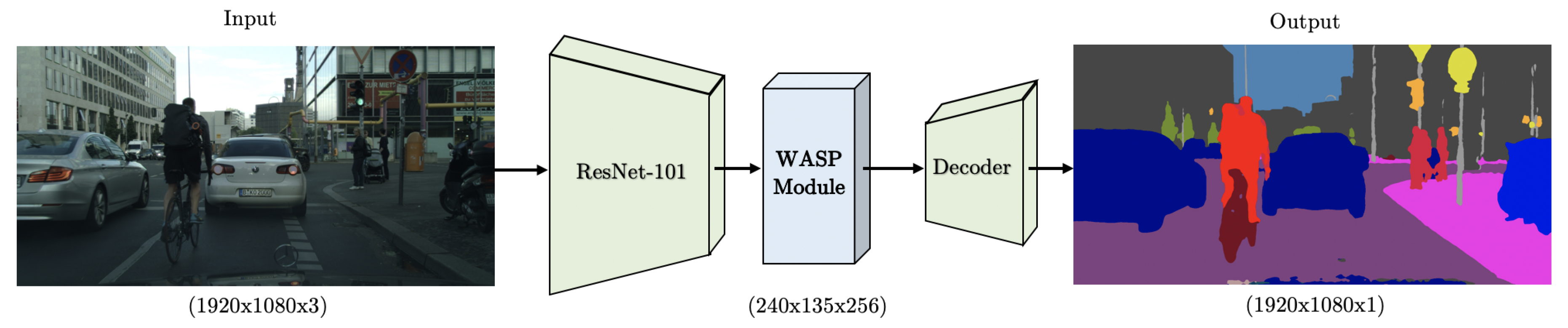
3. Methodology
3.1. Res2Net-Seg Module
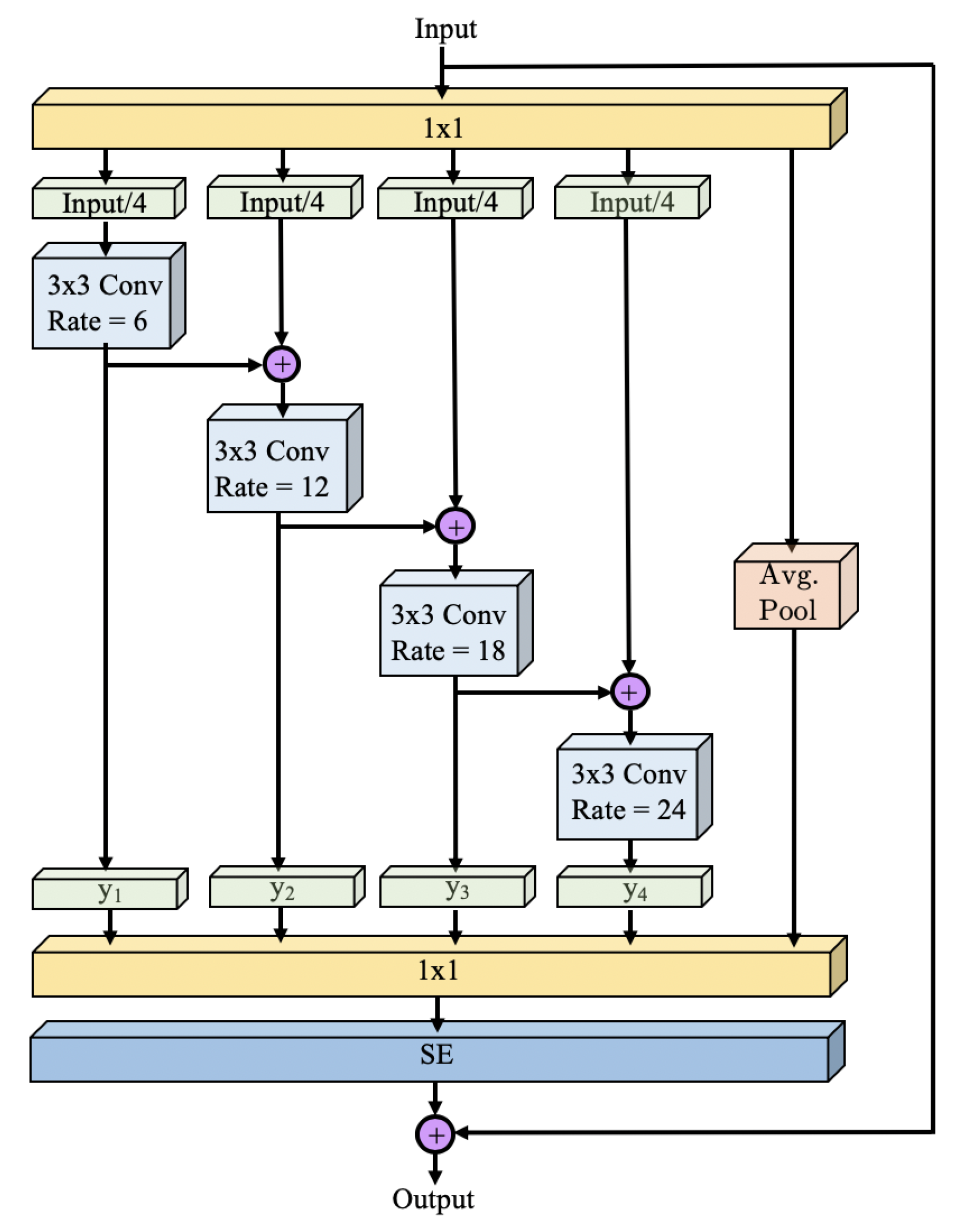
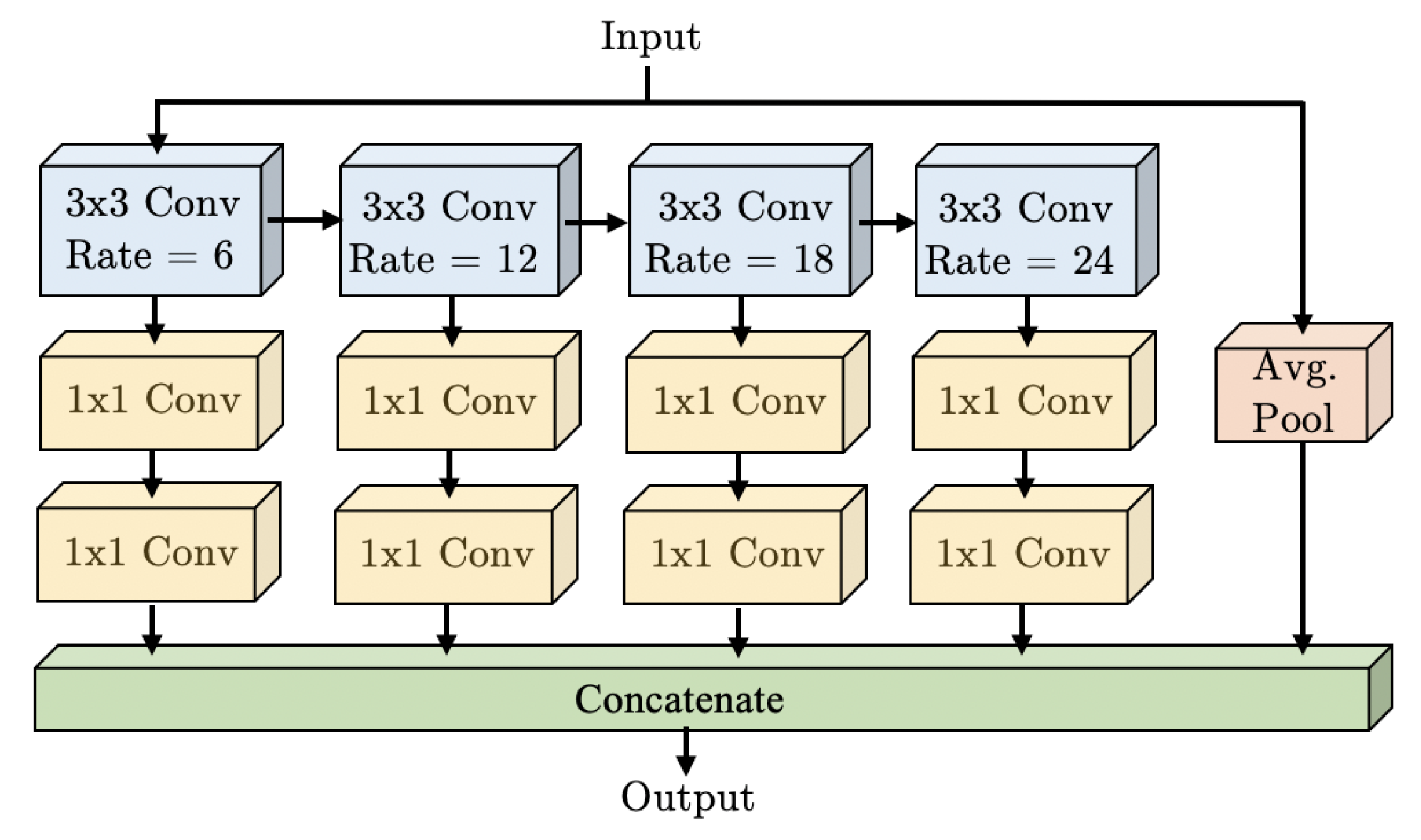
3.2. WASP Module
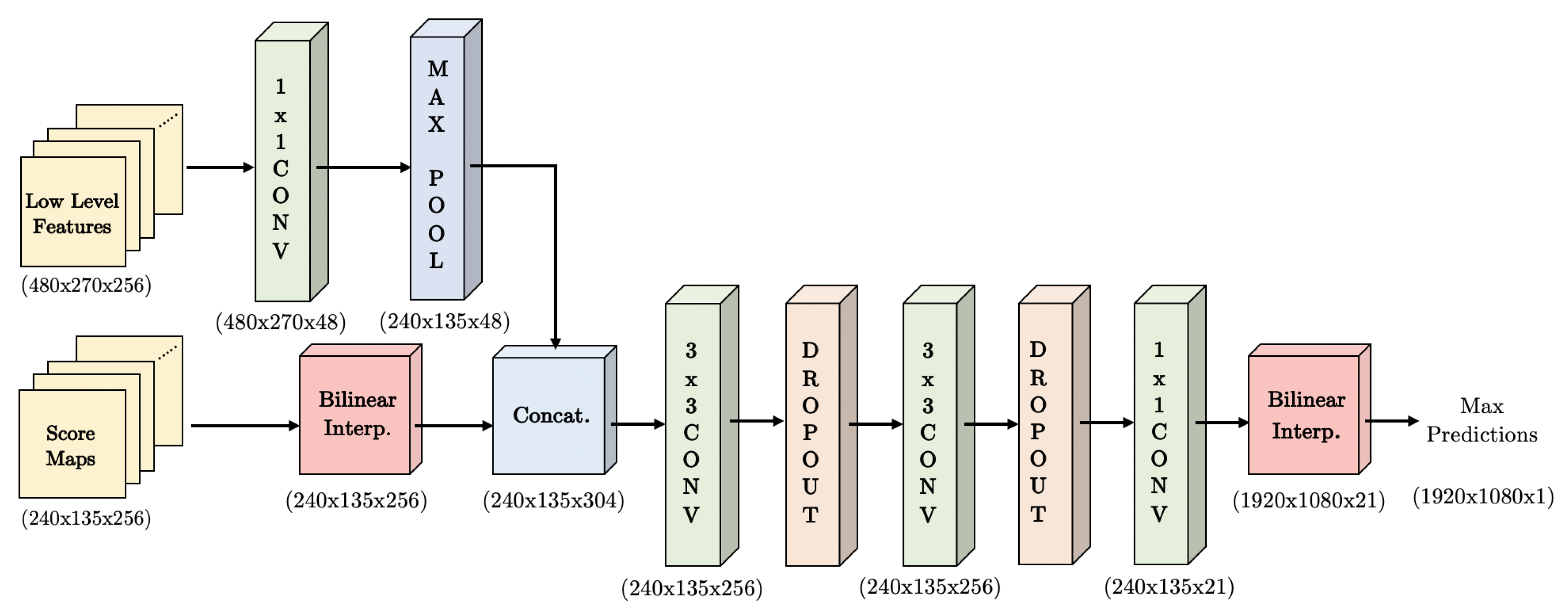
3.3. Decoder
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Simulation Parameters
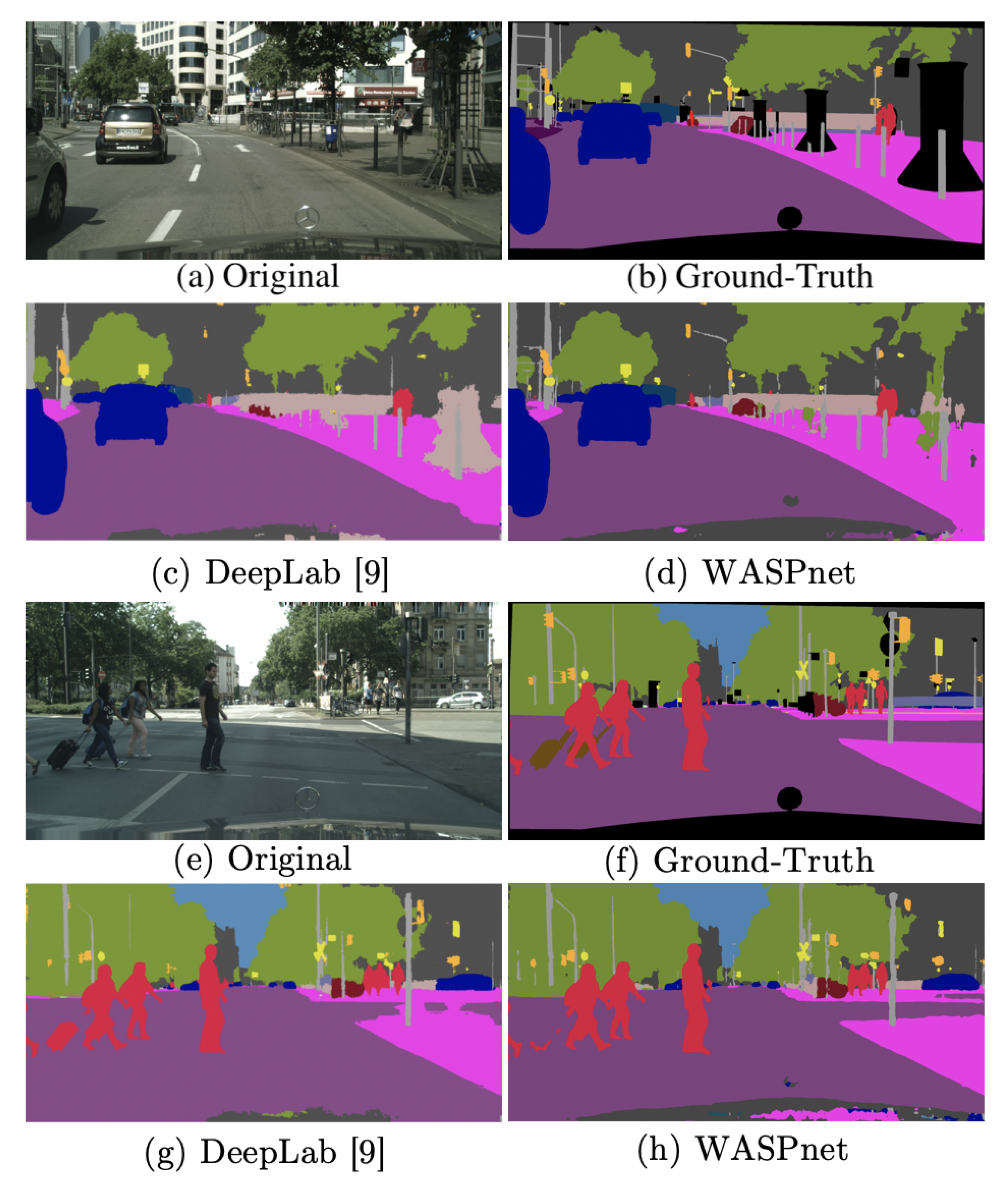
5. Results
Fail Cases
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ASPP | Atrous Spatial Pyramid Pooling |
| COCO | Common Objects in Context |
| CNN | Convolutional Neural Networks |
| CRF | Conditional Random Fields |
| ENet | Efficient Neural Network |
| FCN | Fully Convolutional Networks |
| FN | False Negative |
| FOV | Field-of-View |
| FP | False Positive |
| LSTM | Long Short-Term Memory |
| LSTM-CF | Long Short-Term Memory Context Fusion |
| rCNN | Recurrent Convolutional Neural Networks |
| mIOU | Mean Intersection over Union |
| RGB | Red, Green, and Blue |
| RNN | Recurrent Neural Networks |
| SE | Squeeze-and-Excitation |
| TP | True Positive |
| VOC | Visual Object Class |
| WASP | Waterfall Atrous Spatial Pooling |
References
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Rodríguez, J.G. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Zhu, H.; Meng, F.; Cai, J.; Lu, S. A comprehensive survey from bottom-up to semantic image segmentation and cosegmentation. J. Vis. Commun. Image Represent. 2016, 34, 12–27. [Google Scholar] [CrossRef]
- Thoma, M. A Survey of Semantic Segmentation. arXiv 2016, arXiv:1602.0654. [Google Scholar]
- Ess, A.; Müller, T.; Grabner, H.; Goo, L.J.V. Segmentation-based urban traffic scene understanding. BMVC 2009, 1, 2. [Google Scholar]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Hands Deep in Deep Learning for Hand Pose Estimation. arXiv 2015, arXiv:1502.06807. [Google Scholar]
- Fan, H.; Liu, D.; Xiong, Z.; Wu, F. Two-stage convolutional neural network for light field super-resolution. In Proceedings of the Image Processing (ICIP) 2017 IEEE International Conference, Beijing, China, 17–20 September 2017; pp. 1167–1171. [Google Scholar]
- Tzelepi, M.; Tefas, A. Deep convolutional learning for content based image retrieval. Neurocomputing 2018, 275, 2467–2478. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrel, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CFRs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–845. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the ICLR, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. arXiv 2014, arXiv:1406.4729. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the Conference of Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. arXiv 2017, arXiv:1707.02968. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv 2015, arXiv:1511.00561. [Google Scholar] [CrossRef]
- Liu, C.; Chen, L.C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Fei-Fei, L. Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentationx. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 82–92. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H.S. Conditional Random Fields as Recurrent Neural Networks. arXiv 2015, arXiv:1502.03240. [Google Scholar]
- Krähenühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. In Proceedings of the NIPS, Granada, Spain, 12–17 December 2011. [Google Scholar]
- Raj, A.; Maturana, D.; Scherer, S. Multi-Scale Convolutional Architecture for Semantic Segmentation; Robotics Institute, Carnegie Mellon University, Tech.: Pittsburgh, PA, USA, 2015. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture. arXiv 2014, arXiv:1411.4734. [Google Scholar]
- Roy, A.; Todorovic, S. A Multi-Scale CNN for Affordance Segmentation in RGB Images. In Proceedings of the IEEE European Conference on Computer Vision (ECCV), Amsterdam, the Netherlands, 11–14 October 2016; pp. 186–201. [Google Scholar]
- Bian, X.; Lim, S.N.; Zhou, N. Multiscale fully convolutional network with application to industrial inspection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–8. [Google Scholar]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding. arXiv 2015, arXiv:1511.02680. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking Wider to See Better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Visin, F.; Kastner, K.; Courville, A.C.; Bengio, Y.; Matteucci, M.; Cho, K. ReSeg: A Recurrent Neural Network for Object Segmentation. arXiv 2015, arXiv:1511.07053. [Google Scholar]
- Visin, F.; Kastner, K.; Cho, K.; Matteucci, M.; Courville, A.C.; Bengio, Y. ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks. arXiv 2015, arXiv:1505.00393. [Google Scholar]
- Li, Z.; Gan, Y.; Liang, X.; Yu, Y.; Cheng, H.; Lin, L. RGB-D Scene Labeling with Long Short-Term Memorized Fusion Model. arXiv 2016, arXiv:1604.05000. [Google Scholar]
- Li, G.; Yu, Y. Deep Contrast Learning for Salient Object Detection. arXiv 2016, arXiv:1603.01976. [Google Scholar]
- Byeon, W.; Breuel, T.M.; Raue, F.; Liwicki, M. Scene labelingwith lstm recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3547–3555. [Google Scholar]
- Pinheiro, P.H.O.; Collobert, R. Recurrent Convolutional Neural Networks for Scene Parsing. arXiv 2013, arXiv:1306.2795. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Number of Parameters | Parameter Reduction | mIOU |
|---|---|---|---|
| WASPnet-CRF (ours) | 47.482 M | 20.69% | 80.41% |
| WASPnet (ours) | 47.482 M | 20.69% | 80.22% |
| Res2Net-Seg-CRF | 50.896 M | 14.99% | 80.12% |
| Res2Net-Seg | 50.896 M | 14.99% | 78.53% |
| Deeplab-CRF [9] | 59.869 M | - | 77.69% |
| Deeplab [9] | 59.869 M | - | 76.35% |
| WASP Dilation Rates | mIOU |
|---|---|
| {2, 4, 6, 8} | 79.61% |
| {4, 8, 12, 16} | 79.72% |
| {6, 12, 18, 24} | 80.22% |
| {8, 16, 24, 32} | 79.92% |
| Architecture | Additional Training Dataset Used | mIOU |
|---|---|---|
| DeepLabv3+ [17] | JFT-300M [22] | 87.8% |
| Deeplabv3 [10] | JFT-300M [22] | 85.7% |
| Auto-DeepLab-L [24] | JFT-300M [22] | 85.6% |
| Deeplab [9] | JFT-300M [22] | 79.7% |
| WASPnet-CRF (ours) | - | 79.6% |
| WASPnet (ours) | - | 79.4% |
| Dilation [16] | - | 75.3% |
| CRFasRNN [25] | - | 74.7% |
| ParseNet [32] | - | 69.8% |
| FCN 8s [8] | - | 67.2% |
| Bayesian SegNet [31] | - | 60.5% |
| Architecture | Number of Parameters | Parameter Reduction | mIOU |
|---|---|---|---|
| WASPnet (ours) | 47.482 M | 20.69% | 74.0% |
| WASPnet-CRF (ours) | 47.482 M | 20.69% | 73.2% |
| Res2Net-Seg (ours) | 50.896 M | 14.99% | 72.1% |
| Deeplab-CRF [9] | 59.869 M | - | 71.4% |
| Deeplab [9] | 59.869 M | - | 71.0% |
| Architecture | Additional Training Dataset Used | mIOU |
|---|---|---|
| Auto-DeepLab-L [24] | Coarse Cityscapes [42] | 82.1% |
| DeepLabv3+ [17] | Coarse Cityscapes [42] | 82.1% |
| WASPnet (ours) | - | 70.5% |
| Deeplab [9] | - | 70.4% |
| Dilation [16] | - | 67.1% |
| FCN 8s [8] | - | 65.3% |
| CRFasRNN [25] | - | 62.5% |
| ENet [18] | - | 58.3% |
| SegNet [23] | - | 55.6% |
| Mask-RCNN [43] | - | 49.9% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Artacho, B.; Savakis, A. Waterfall Atrous Spatial Pooling Architecture for Efficient Semantic Segmentation. Sensors 2019, 19, 5361. https://doi.org/10.3390/s19245361
Artacho B, Savakis A. Waterfall Atrous Spatial Pooling Architecture for Efficient Semantic Segmentation. Sensors. 2019; 19(24):5361. https://doi.org/10.3390/s19245361
Chicago/Turabian StyleArtacho, Bruno, and Andreas Savakis. 2019. "Waterfall Atrous Spatial Pooling Architecture for Efficient Semantic Segmentation" Sensors 19, no. 24: 5361. https://doi.org/10.3390/s19245361
APA StyleArtacho, B., & Savakis, A. (2019). Waterfall Atrous Spatial Pooling Architecture for Efficient Semantic Segmentation. Sensors, 19(24), 5361. https://doi.org/10.3390/s19245361