Ship Type Classification by Convolutional Neural Networks with Auditory-Like Mechanisms


Abstract
1. Introduction
- The proposed convolutional neural network could transform the time domain signal into a frequency domain that is similar to gammatone spectrogram.
- Deep architecture of a neural network derived from an auditory pathway improves the classification performance of ship types.
- Auditory filters in convolutional kernals are adaptive in shape during the optimization of the network with the ship type classification task.
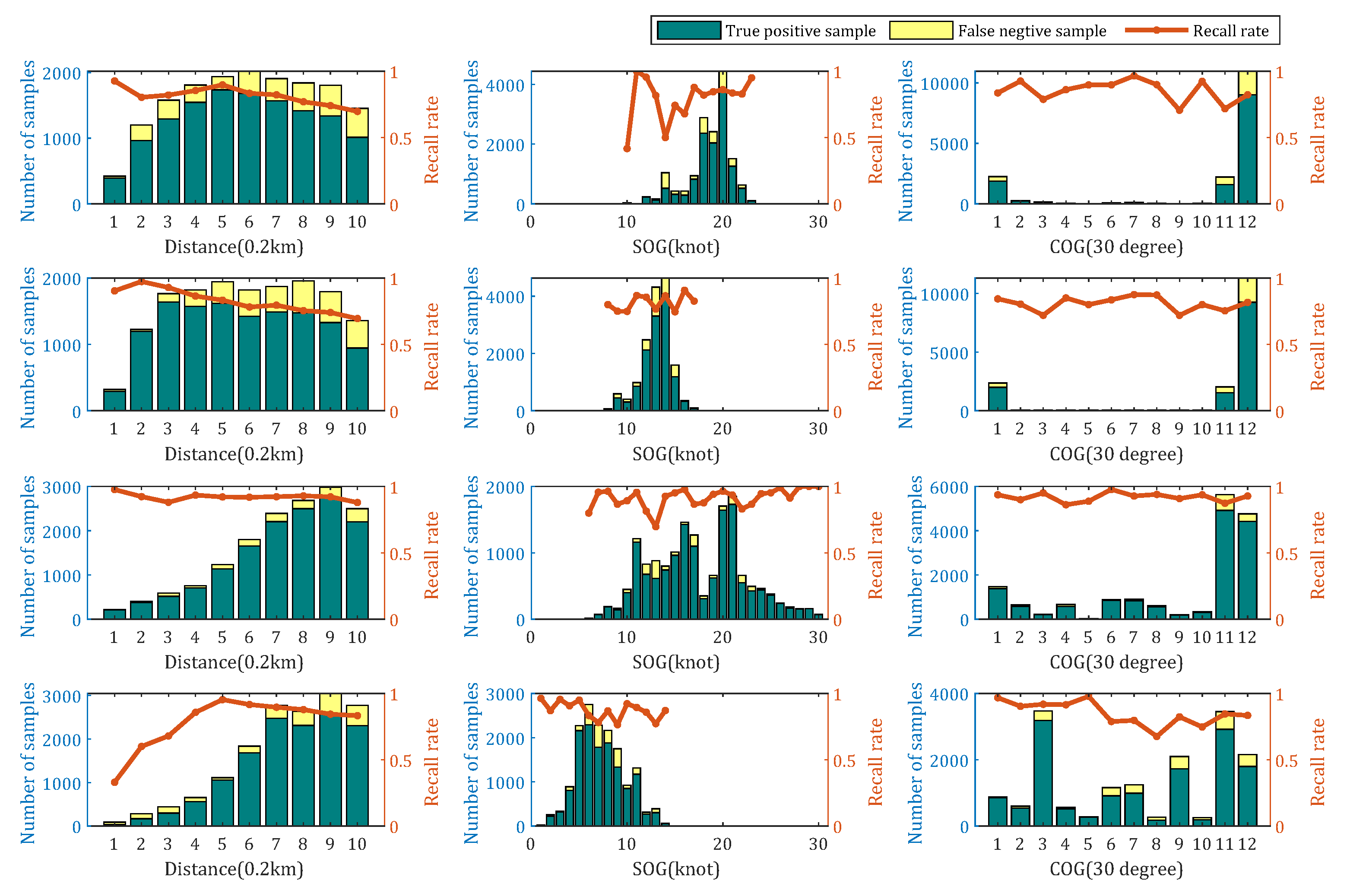
- The classification results of the model are robust to ship operative conditions. The increase of distance between ships to hydrophone has a negative effect on recognition results in most cases.
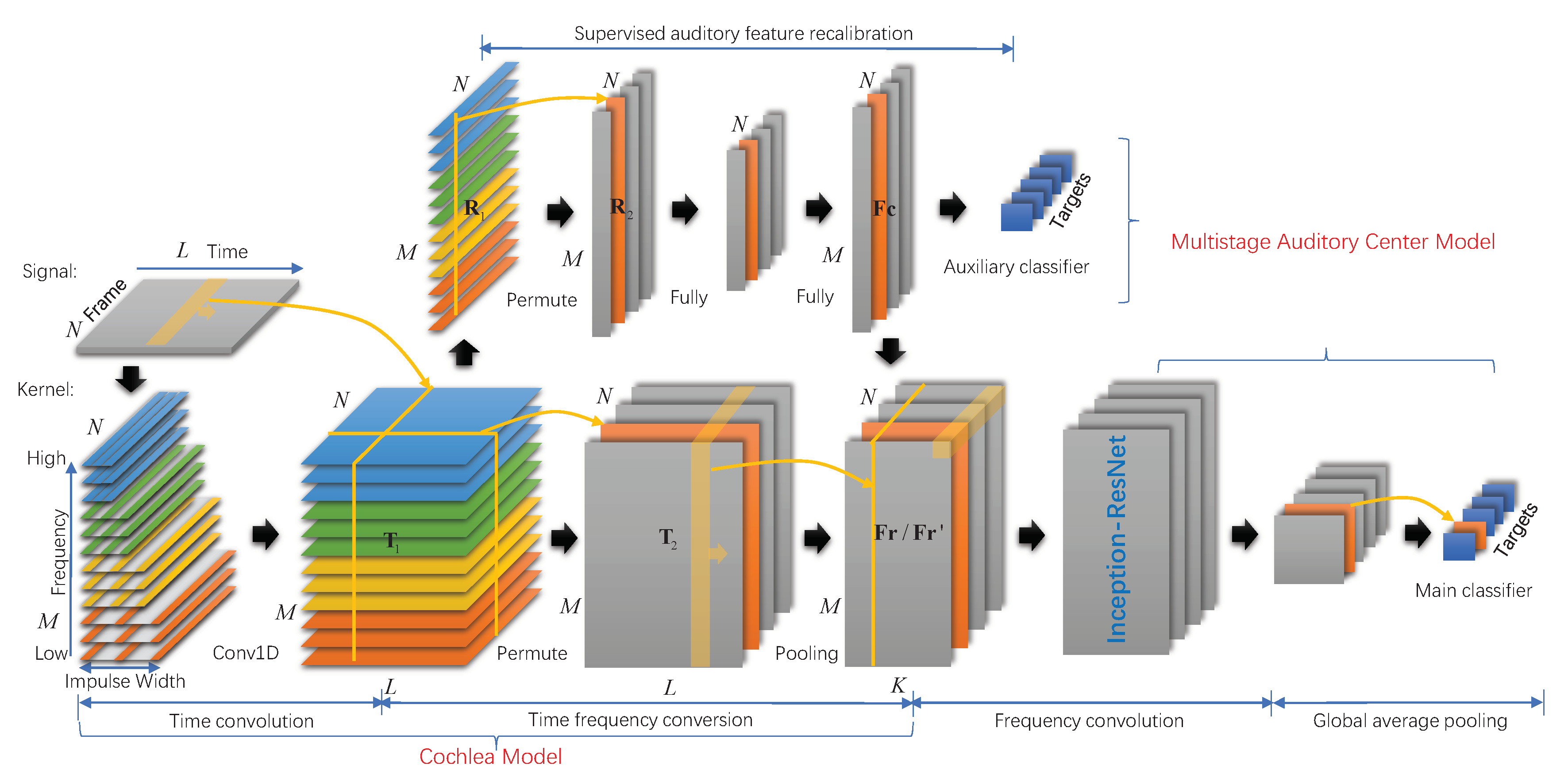
2. Model
2.1. Auditory Mechanisms
- Auditory processing is hierarchical.
- Neurons throughout the auditory pathway are always tuned to frequency.
- Auditory pathways have different neural structures.
- The auditory system has plasticity and learning properties.
2.2. Model Structure
3. Methodology
3.1. Cochlea Model for Ship Radiated Noise Modeling
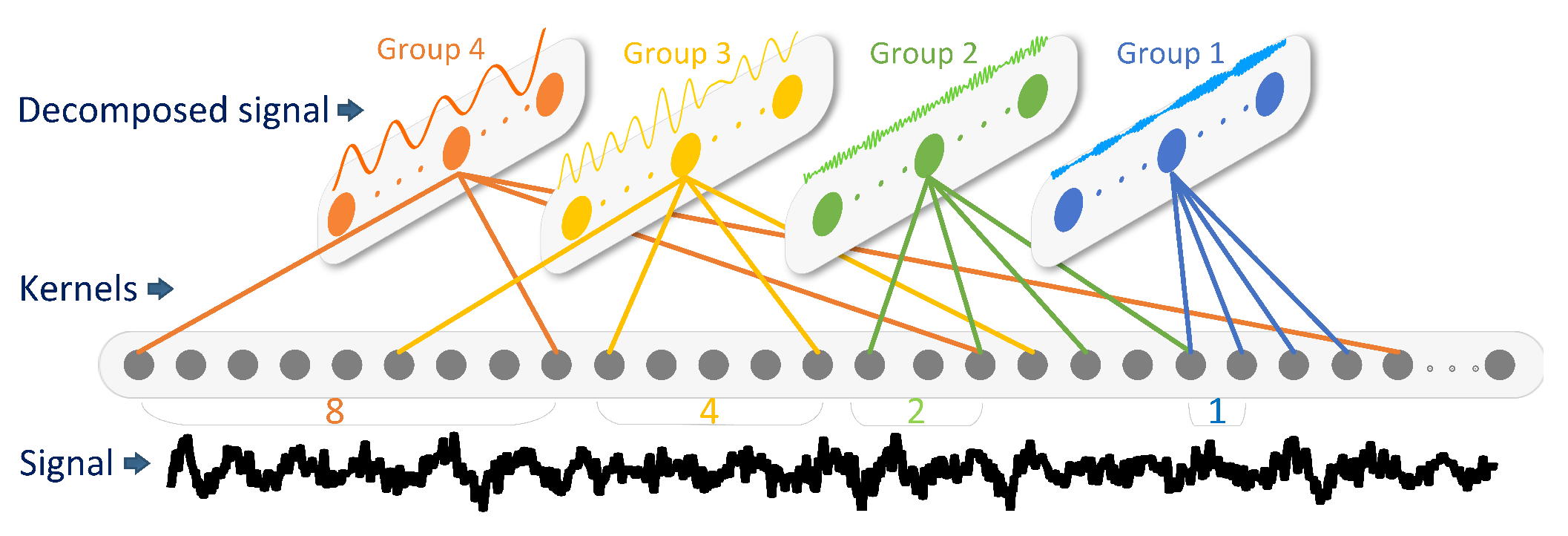
3.1.1. Time Convolutional Layer with Dilated Auditory Filters
3.1.2. Time Frequency Conversion Layer
3.2. Multistage Auditory Center Model for Feature Extraction and Classification
3.2.1. Supervised Auditory Feature Recalibration
3.2.2. Deep Architecture for Feature Learning
4. Experiment
4.1. Experimental Dataset
4.2. Classification Experiment
4.3. Operative Conditions Analysis
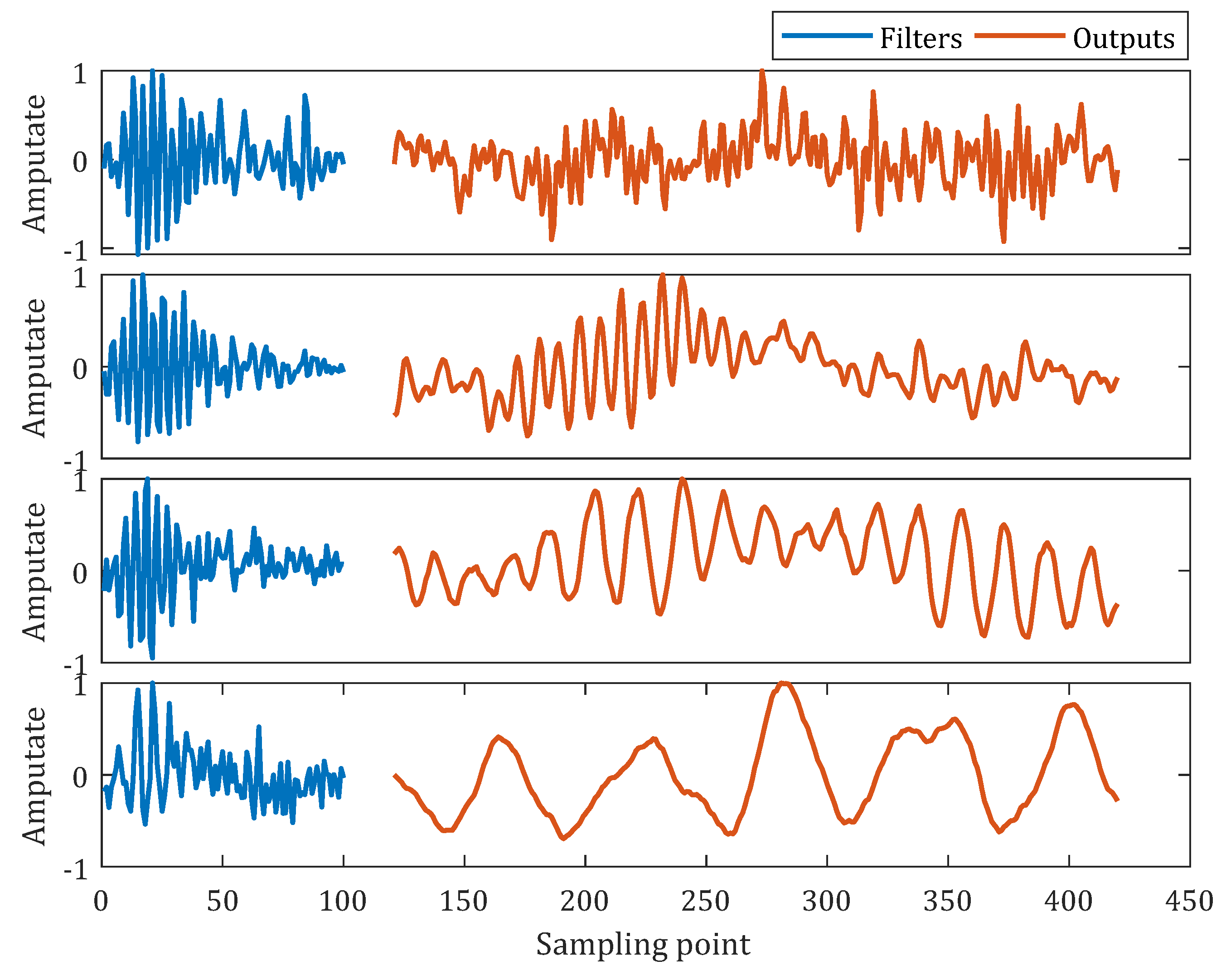
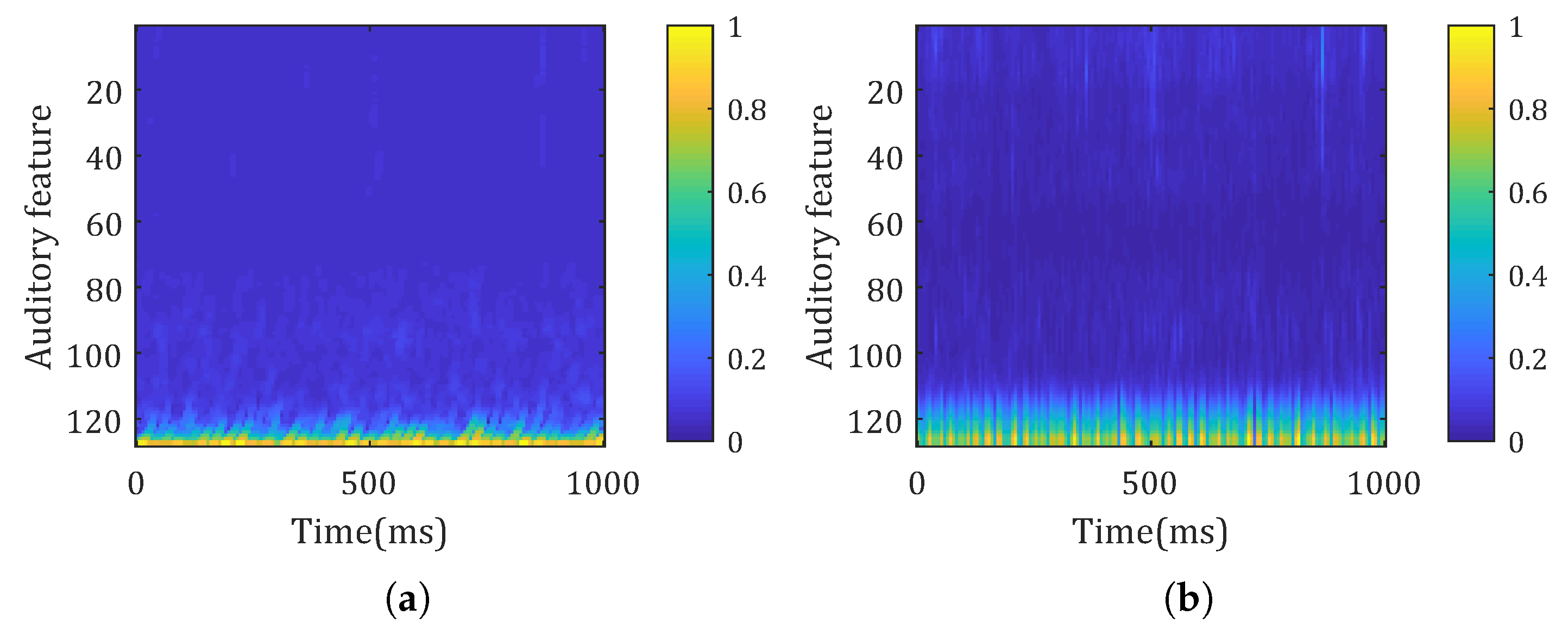
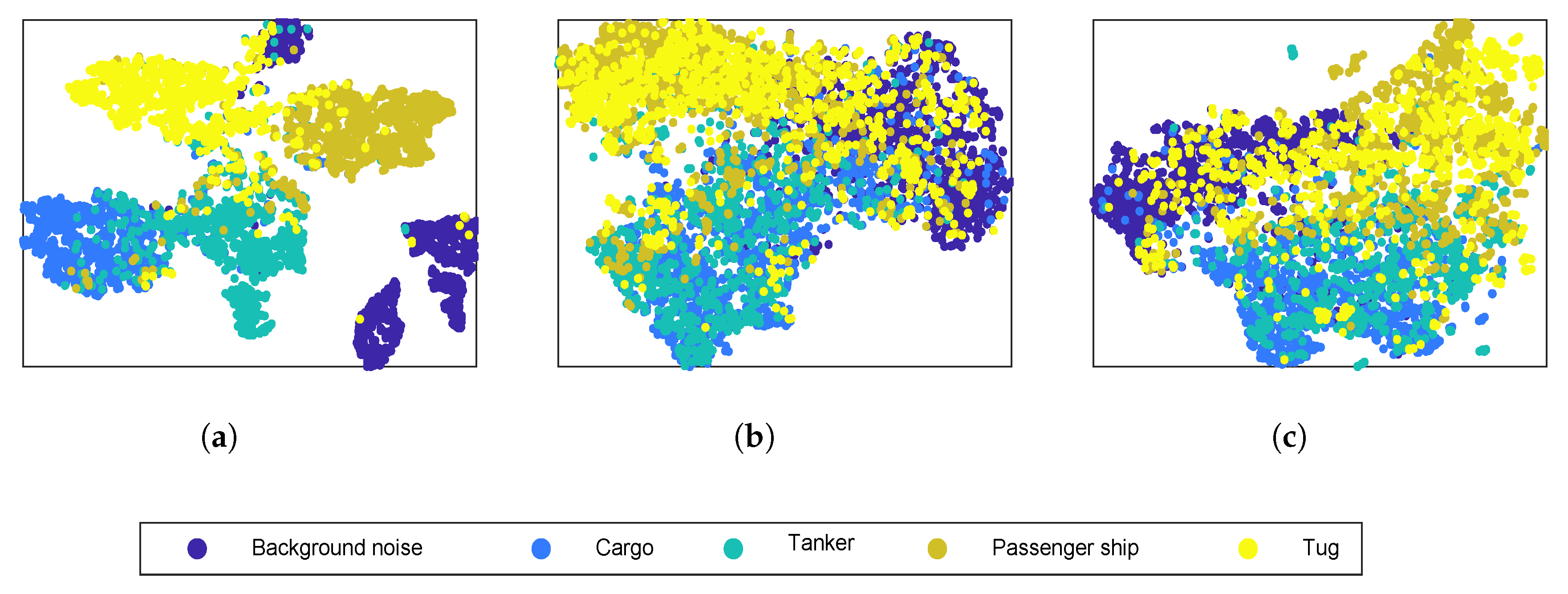
4.4. Visualization
4.4.1. Learned Auditory Filter Visualization
4.4.2. Learned Spectrogram Visualization
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Meng, Q.; Yang, S.; Piao, S. The classification of underwater acoustic target signals based on wave structure and support vector machine. J. Acoust. Soc. Am. 2014, 136, 2265. [Google Scholar] [CrossRef]
- Meng, Q.; Yang, S. A wave structure based method for recognition of marine acoustic target signals. J. Acoust. Soc. Am. 2015, 137, 2242. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, D.; Han, X.; Zhu, Z. Feature Extraction of Underwater Target Signal Using Mel Frequency Cepstrum Coefficients Based on Acoustic Vector Sensor. J. Sens. 2016, 2016, 1–11. [Google Scholar] [CrossRef]
- Mohankumar, K.; Supriya, M.; Pillai, P.S. Bispectral gammatone cepstral coefficient based neural network classifier. In Proceedings of the 2015 IEEE Underwater Technology (UT), Chennai, India, 23–25 February 2015; pp. 1–5. [Google Scholar]
- Wei, X.; Gang-Hu, L.I.; Wang, Z.Q. Underwater Target Recognition Based on Wavelet Packet and Principal Component Analysis. Comput. Simul. 2011, 28, 8–290. [Google Scholar]
- Shen, S.; Yang, H.; Li, J.; Xu, G.; Sheng, M. Auditory Inspired Convolutional Neural Networks for Ship Type Classification with Raw Hydrophone Data. Entropy 2018, 20, 990. [Google Scholar] [CrossRef]
- Yang, H.; Gan, A.; Chen, H.; Pan, Y. Underwater acoustic target recognition using SVM ensemble via weighted sample and feature selection. In Proceedings of the International Bhurban Conference on Applied Sciences and Technology, Islamabad, Pakistan, 12–16 January 2016; pp. 522–527. [Google Scholar]
- Filho, W.S.; de Seixas, J.M.; de Moura, N.N. Preprocessing passive sonar signals for neural classification. IET Radar Sonar Navig. 2011, 5, 605. [Google Scholar] [CrossRef]
- Karakos, D.; Silovsky, J.; Schwartz, R.; Hartmann, W.; Makhoul, J. Individual Ship Detection Using Underwater Acoustics. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2121–2125. [Google Scholar]
- Kamal, S.; Mohammed, S.K.; Pillai, P.R.S.; Supriya, M.H. Deep learning architectures for underwater target recognition. In Proceedings of the Ocean Electronics, Kochi, India, 23–25 October 2013; pp. 48–54. [Google Scholar]
- Cao, X.; Zhang, X.; Yu, Y.; Niu, L. Deep learning-based recognition of underwater target. In Proceedings of the IEEE International Conference on Digital Signal Processing, Beijing, China, 16–18 October 2016; pp. 89–93. [Google Scholar] [CrossRef]
- Yang, H.; Shen, S.; Yao, X.; Sheng, M.; Wang, C. Competitive Deep-Belief Networks for Underwater Acoustic Target Recognition. Sensors 2018, 18, 952. [Google Scholar] [CrossRef] [PubMed]
- Shen, S.; Yang, H.H.; Sheng, M.P. Compression of a Deep Competitive Network Based on Mutual Information for Underwater Acoustic Targets Recognition. Entropy 2018, 20, 243. [Google Scholar] [CrossRef]
- Hu, G.; Wang, K.; Peng, Y.; Qiu, M.; Shi, J.; Liu, L. Deep Learning Methods for Underwater Target Feature Extraction and Recognition. Comput. Intell. Neurosci. 2018, 2018, 1214301. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Smith, E.C.; Lewicki, M.S. Efficient auditory coding. Nature 2006, 439, 978. [Google Scholar] [CrossRef] [PubMed]
- Moore, B.C.J. Temporal integration and context effects in hearing. J. Phon. 2003, 31, 563–574. [Google Scholar] [CrossRef]
- Shamma, S. Encoding Sound Timbre in the Auditory System. IETE J. Res. 2015, 49, 145–156. [Google Scholar] [CrossRef]
- Chechik, G.; Nelken, I. Auditory abstraction from spectro-temporal features to coding auditory entities. Proc. Natl. Acad. Sci. USA 2012, 109, 18968–18973. [Google Scholar] [CrossRef] [PubMed]
- Weinberger, N.M. Experience-dependent response plasticity in the auditory cortex: Issues, characteristics, mechanisms, and functions. In Plasticity of the Auditory System; Springer: New York, NY, USA, 2004; pp. 173–227. [Google Scholar]
- Slaney, M. An Efficient Implementation of the Patterson-Holdsworth Auditory Filter Bank; Apple Computer: Cupertino, CA, USA, 1993. [Google Scholar]
- Den Oord, A.V.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.W.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Glasberg, B.R.; Moore, B.C. Derivation of auditory filter shapes from notched-noise data. Hear. Res. 1990, 47, 103–138. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2018; pp. 7132–7141. [Google Scholar]
- Gazzaniga, M.; Ivry, R.B. Cognitive Neuroscience: The Biology of the Mind: Fourth International Student Edition; WW Norton: New York, NY, USA, 2013. [Google Scholar]
- Yue, H.; Zhang, L.; Wang, D.; Wang, Y.; Lu, Z. The Classification of Underwater Acoustic Targets Based on Deep Learning Methods; CAAI 2017; Atlantis Press: Paris, France, 2017. [Google Scholar]
- Hinton, G.E. Visualizing High-Dimensional Data Using t-SNE. Vigiliae Christ. 2008, 9, 2579–2605. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Model | Accuracy (%) |
|---|---|---|
| Waveform [1,2] | SVM | 68.2 |
| MFCC [3] | BPNN | 72.1 |
| Wavelet,Waveform,MFCC,Auditory feature [7] | SVM Ensemble | 75.1 |
| Wavelet and principal component analysis [5] | BPNN | 74.6 |
| Spectral [11] | Stacked Autoencoder | 81.4 |
| Spectral [27] | CNN | 83.2 |
| Time domain | Auditory inspired CNN [6] | 81.5 |
| Time domain | Proposed | 87.2 |
| Predicted | Background | Cargo | Tanker | Passenger | Tug | Recall (%) | |
|---|---|---|---|---|---|---|---|
| Ture | |||||||
| Background | 15,824 | 1 | 202 | 20 | 173 | 97.56 | |
| Cargo | 16 | 13,152 | 2424 | 560 | 155 | 80.65 | |
| Tanker | 120 | 1479 | 13,283 | 881 | 610 | 81.13 | |
| Passenger | 133 | 356 | 233 | 14,908 | 748 | 91.02 | |
| Tug | 334 | 317 | 590 | 1098 | 14,083 | 85.76 | |
| Precision (%) | 96.33 | 85.93 | 79.39 | 85.35 | 89.31 | 87.2 | |
| Predicted | Background | Cargo | Tanker | Passenger | Tug | Recall (%) | |
|---|---|---|---|---|---|---|---|
| Ture | |||||||
| Background | 50 | 0 | 0 | 0 | 0 | 100 | |
| Cargo | 0 | 107 | 9 | 2 | 0 | 90.68 | |
| Tanker | 0 | 3 | 76 | 2 | 1 | 92.68 | |
| Passenger | 0 | 0 | 1 | 137 | 3 | 97.16 | |
| Tug | 0 | 0 | 0 | 2 | 56 | 94.92 | |
| Precision (%) | 98.04 | 97.27 | 88.37 | 95.80 | 93.33 | 94.75 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, S.; Yang, H.; Yao, X.; Li, J.; Xu, G.; Sheng, M. Ship Type Classification by Convolutional Neural Networks with Auditory-Like Mechanisms. Sensors 2020, 20, 253. https://doi.org/10.3390/s20010253
Shen S, Yang H, Yao X, Li J, Xu G, Sheng M. Ship Type Classification by Convolutional Neural Networks with Auditory-Like Mechanisms. Sensors. 2020; 20(1):253. https://doi.org/10.3390/s20010253
Chicago/Turabian StyleShen, Sheng, Honghui Yang, Xiaohui Yao, Junhao Li, Guanghui Xu, and Meiping Sheng. 2020. "Ship Type Classification by Convolutional Neural Networks with Auditory-Like Mechanisms" Sensors 20, no. 1: 253. https://doi.org/10.3390/s20010253
APA StyleShen, S., Yang, H., Yao, X., Li, J., Xu, G., & Sheng, M. (2020). Ship Type Classification by Convolutional Neural Networks with Auditory-Like Mechanisms. Sensors, 20(1), 253. https://doi.org/10.3390/s20010253