A Novel RGB-D SLAM Algorithm Based on Cloud Robotics


Abstract
:1. Introduction
2. Related Work
2.1. RGB-D SLAM
2.2. “Cloud+Robot” SLAM
2.2.1. DAvinCi
2.2.2. Rapyuta
2.2.3. CTAM
2.2.4. Comparison of Different Platforms
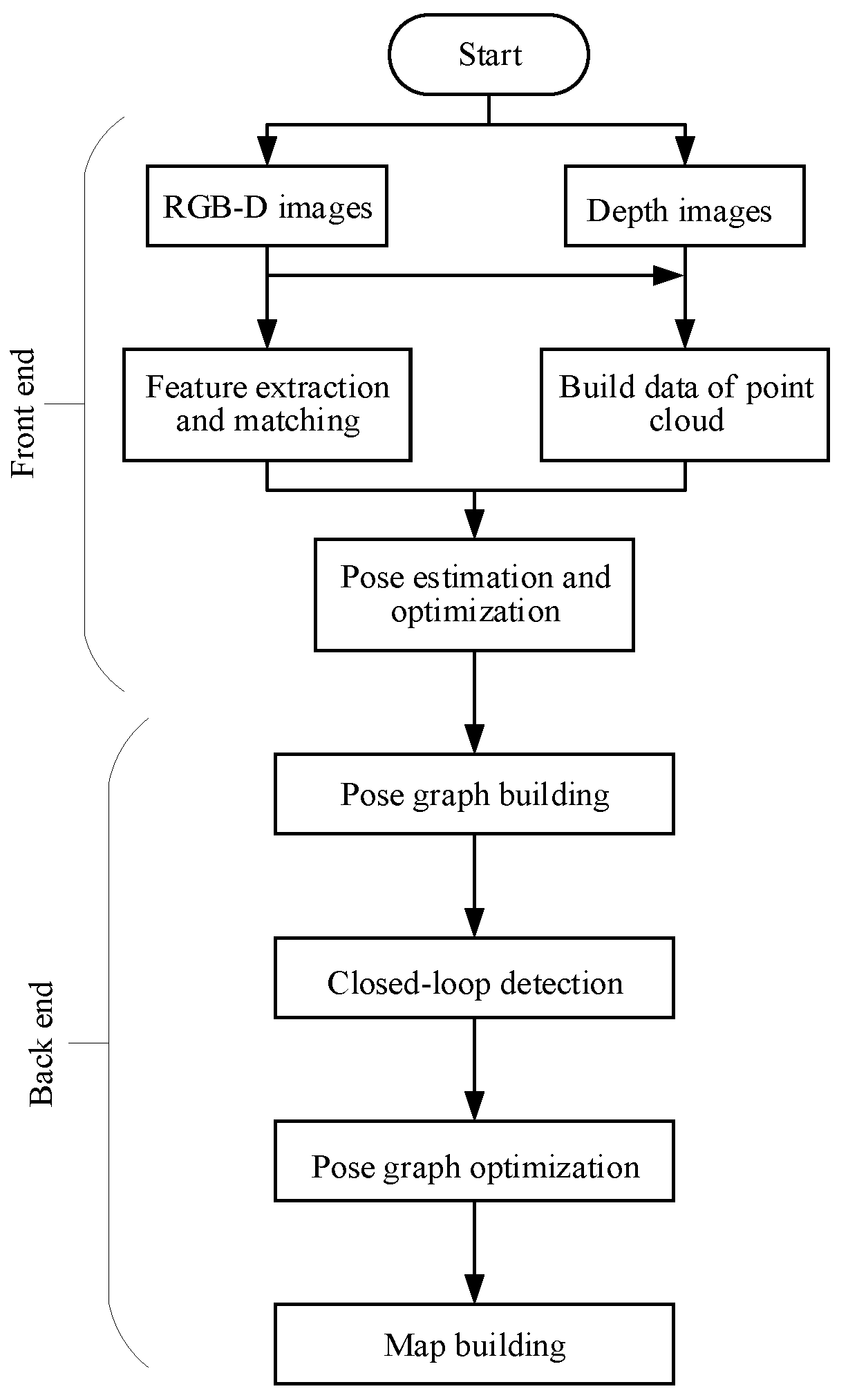
3. The Overall Algorithm Flow of Original RGB-D SLAM
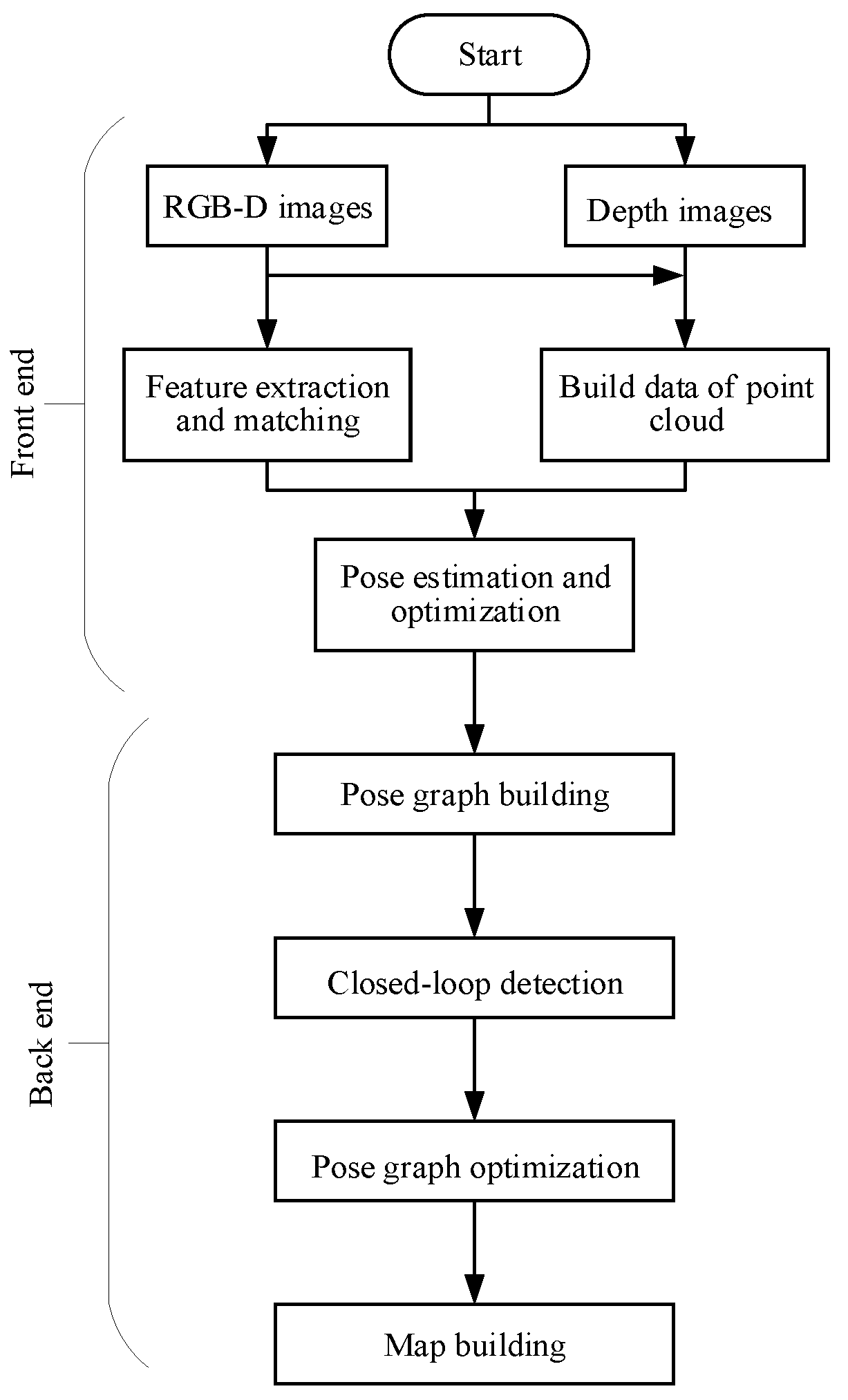
3.1. The Overall Algorithm Flow of RGB-D SLAM
3.2. Shortcomings of the Original RGB-D SLAM Algorithm
4. Improvement on the Original RGB-D SLAM Algorithm
4.1. 3D Point Cloud Registration Based on SVD Algorithm
| Algorithm 1 3D point cloud registration based on SVD algorithm |
| Input: Two-point cloud sets: , , Output:
|
4.2. Optimization of Pose Graph Based on HOG-Man
4.2.1. Hierarchical Pose-Graph
4.2.2. Linearized State Space as a Manifold
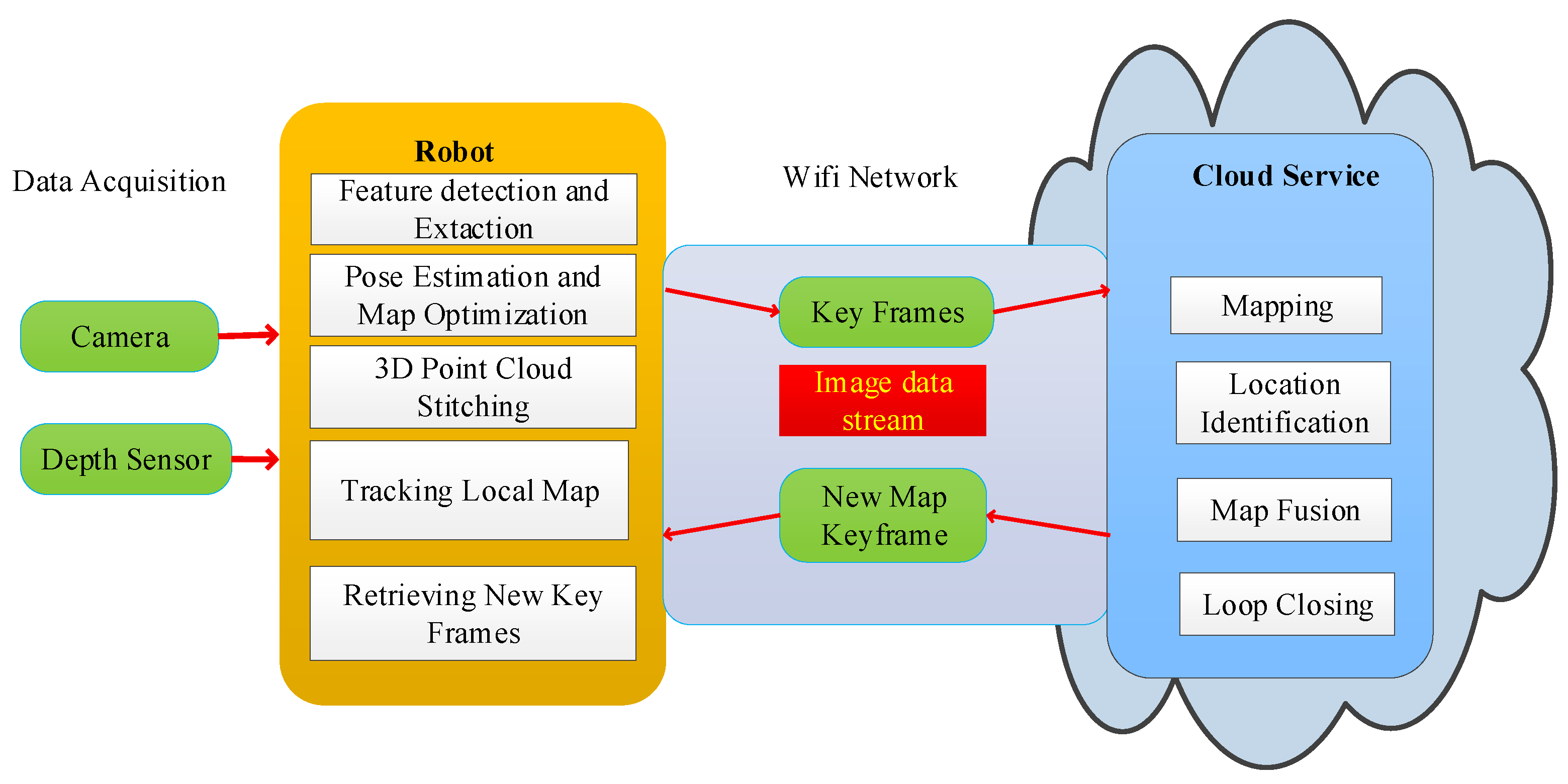
5. Design of the RGB-D SLAM Algorithm Combined with Cloud Robot
5.1. Framework of Cloud Robot
5.2. RGB-D SLAM Algorithms with Cloud Robot
5.2.1. Separation of Tracking and Map Construction
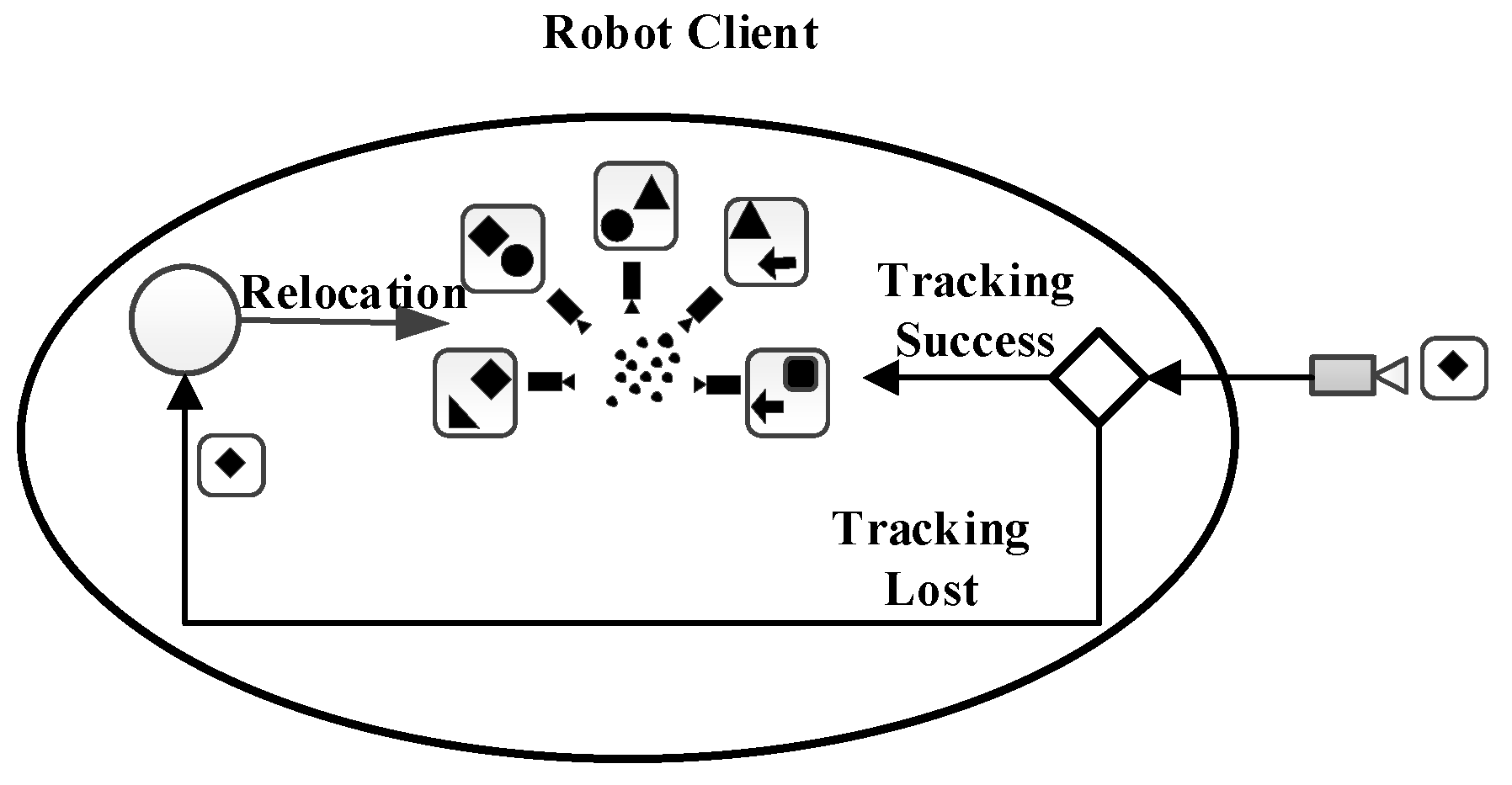
5.2.2. Location Recognition and Relocation Separation
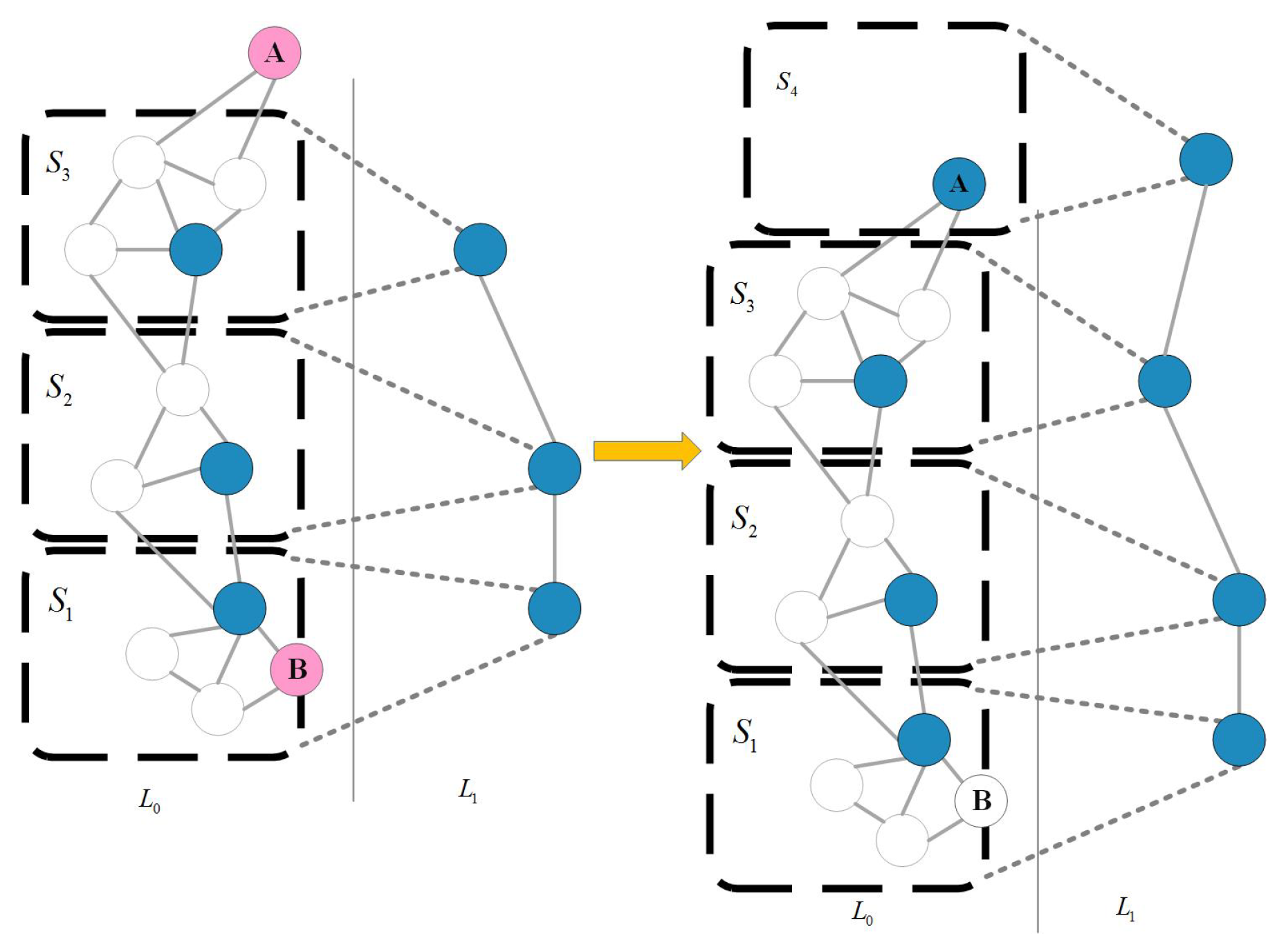
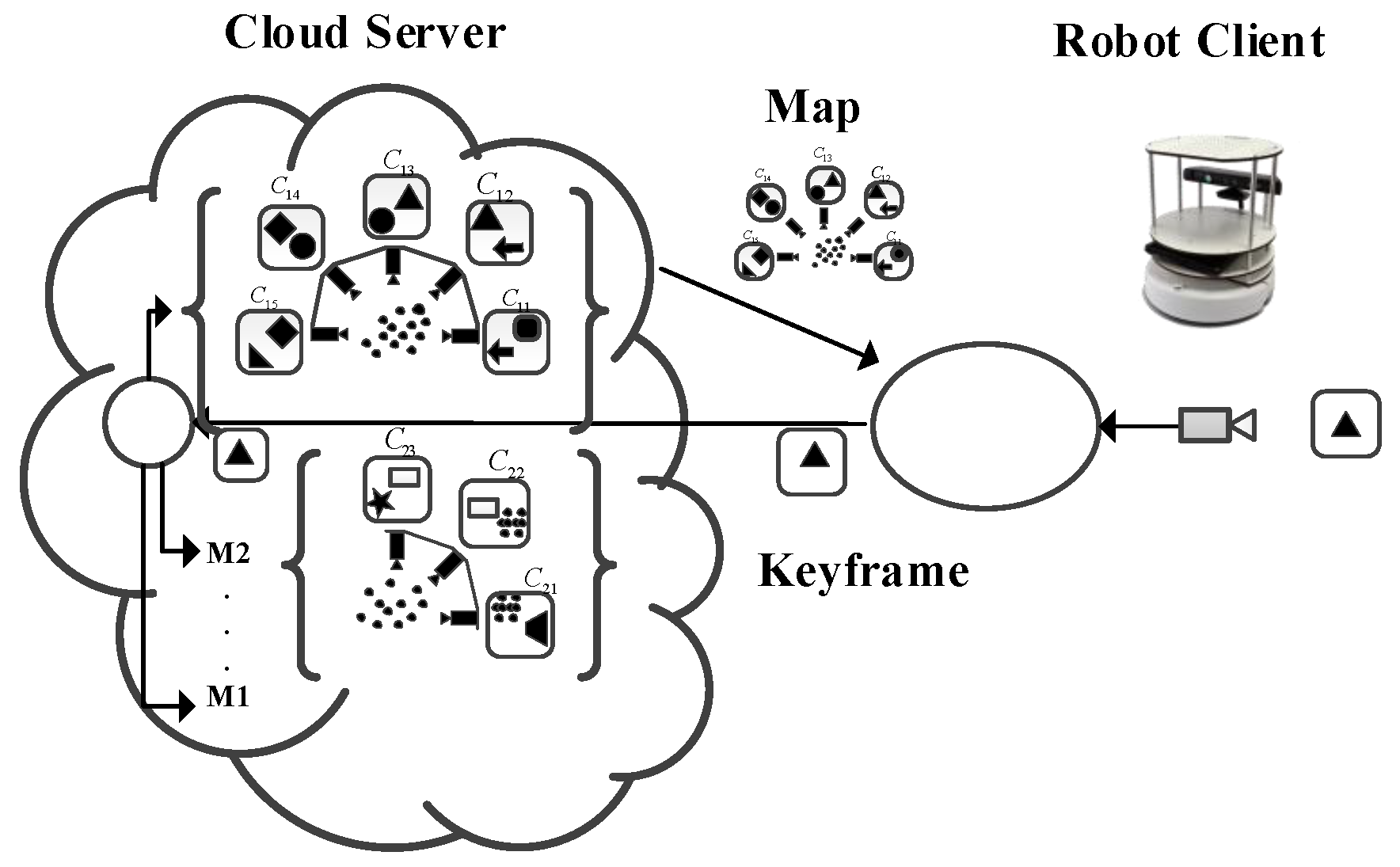
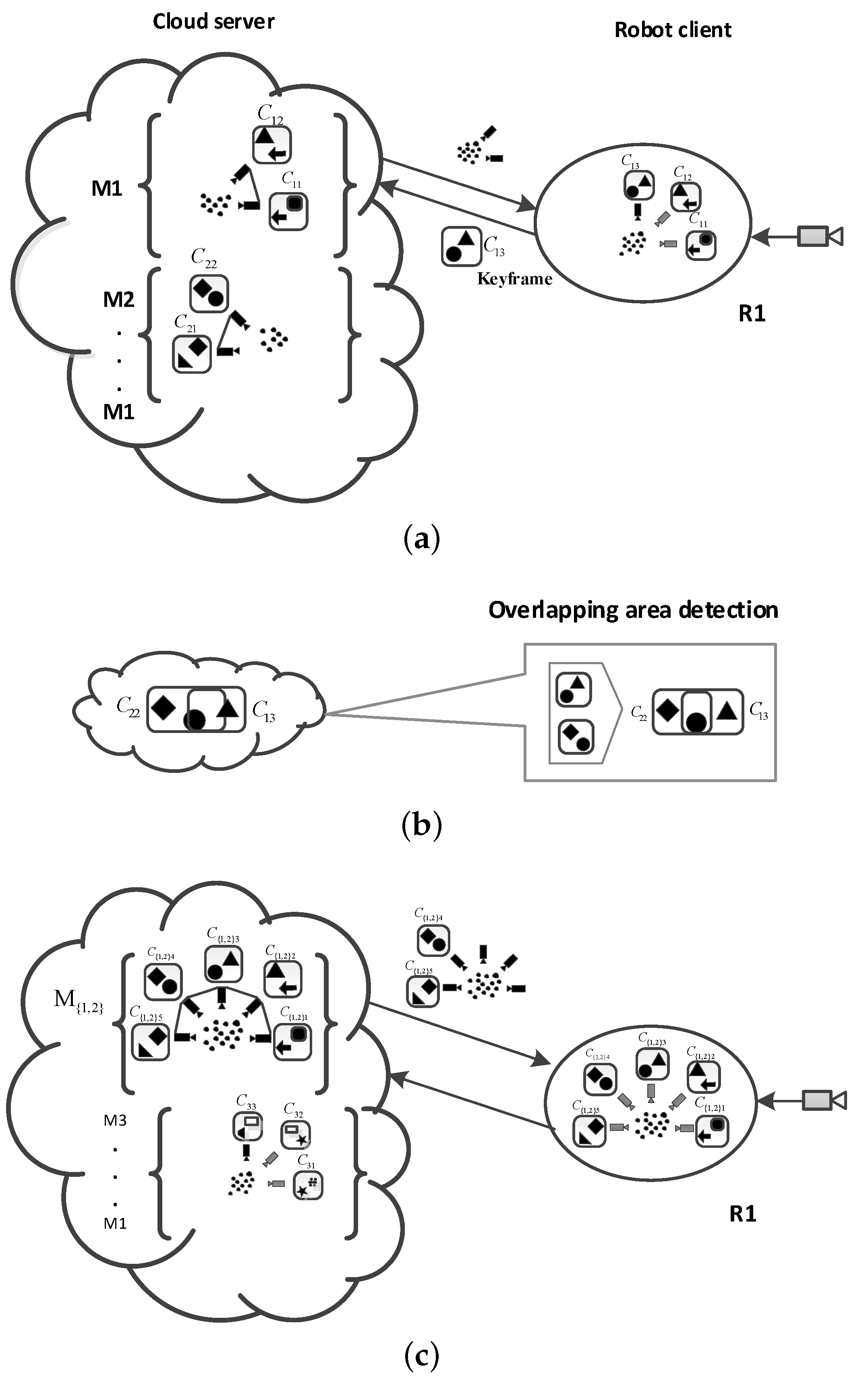
5.2.3. Cloud Map Fusion
6. Experiments
6.1. Comparison of the RGB-D SLAM Algorithm
6.2. Experimental Analysis of the RGB-D SLAM Algorithm Combined with Cloud Computing
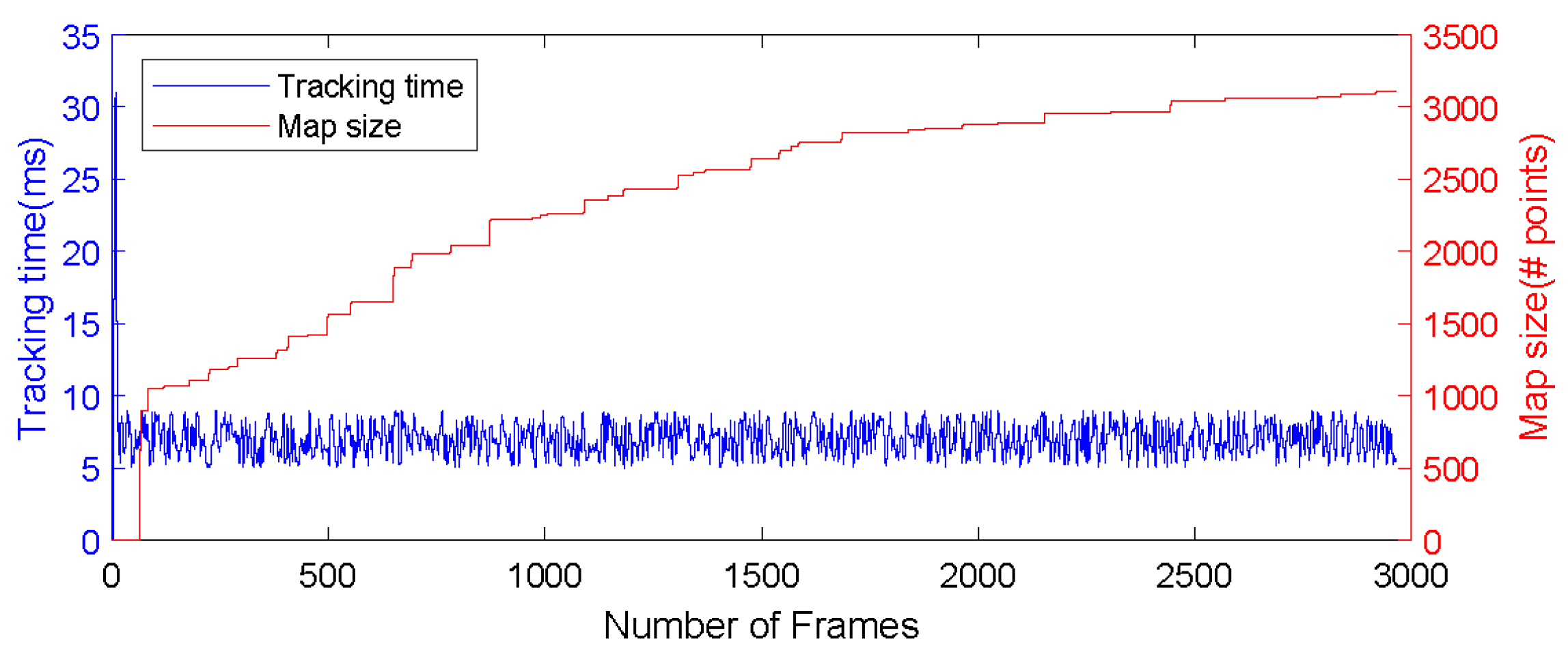
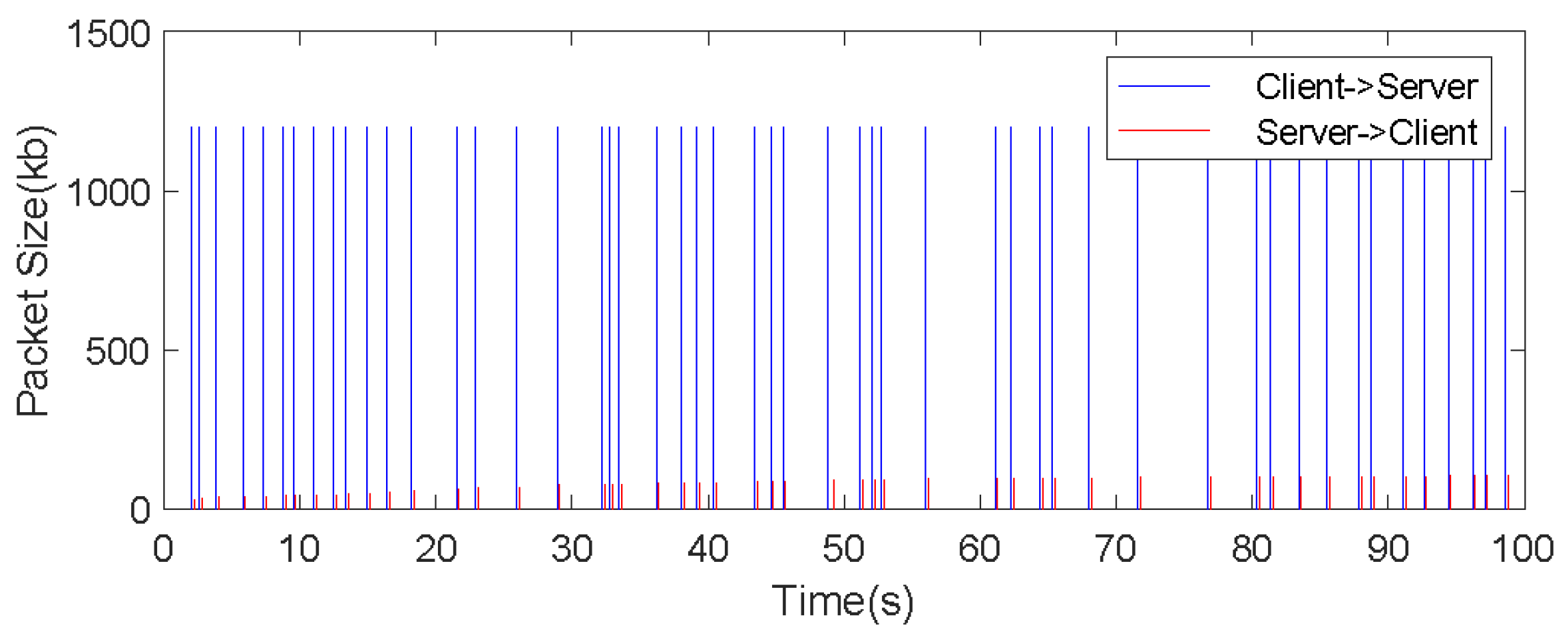
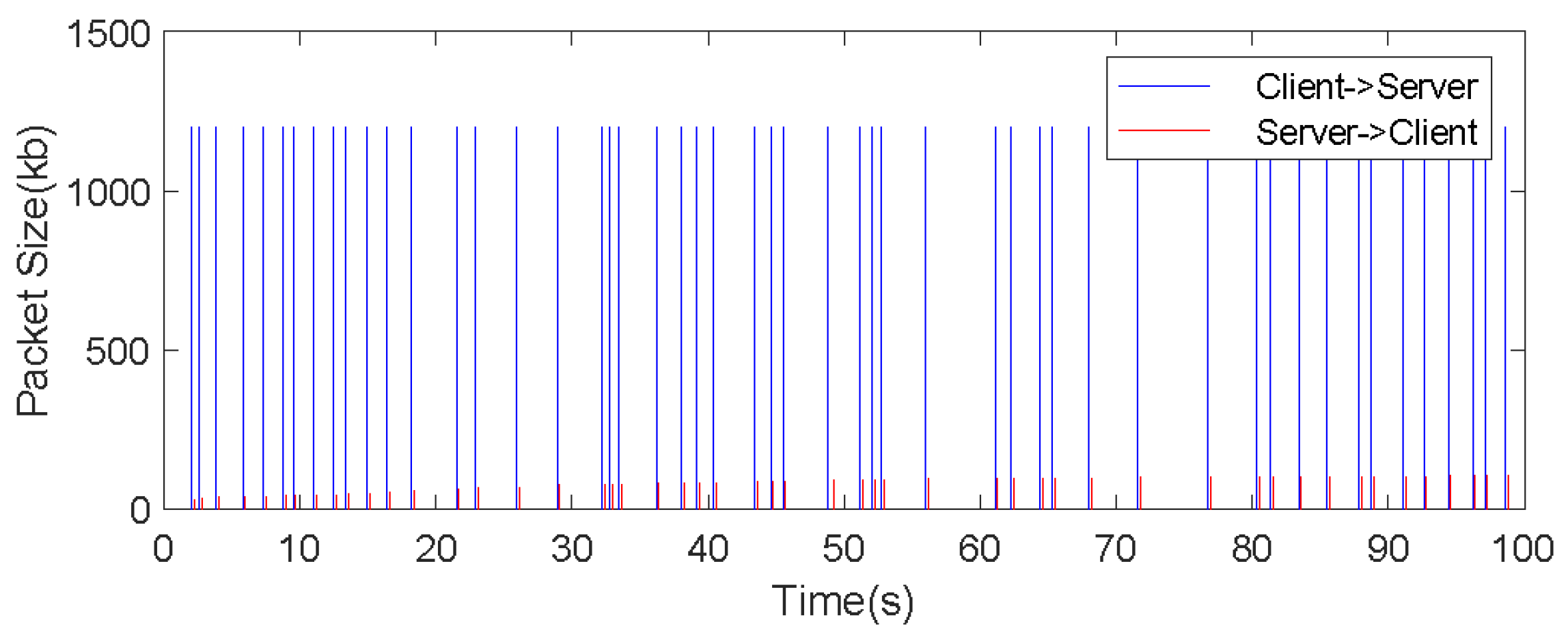
6.2.1. Computational Performance and Bandwidth Analysis
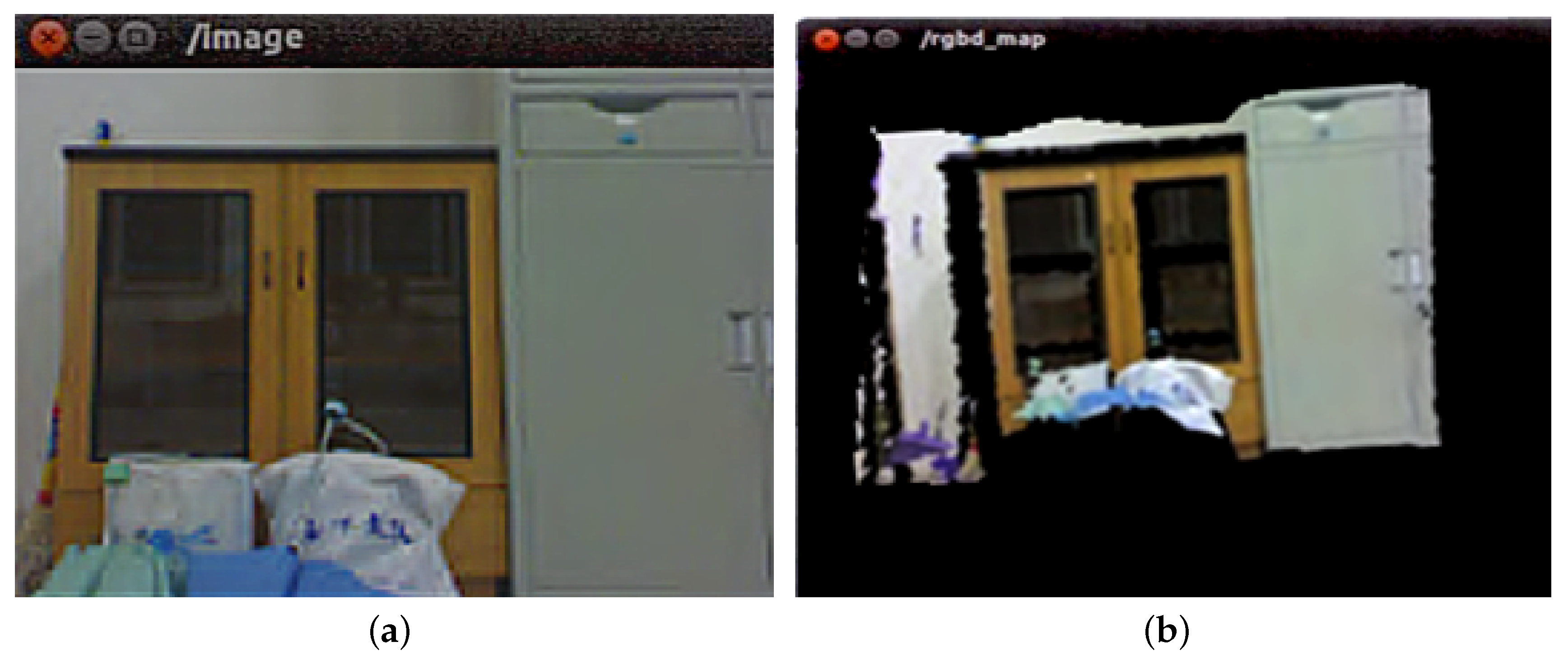
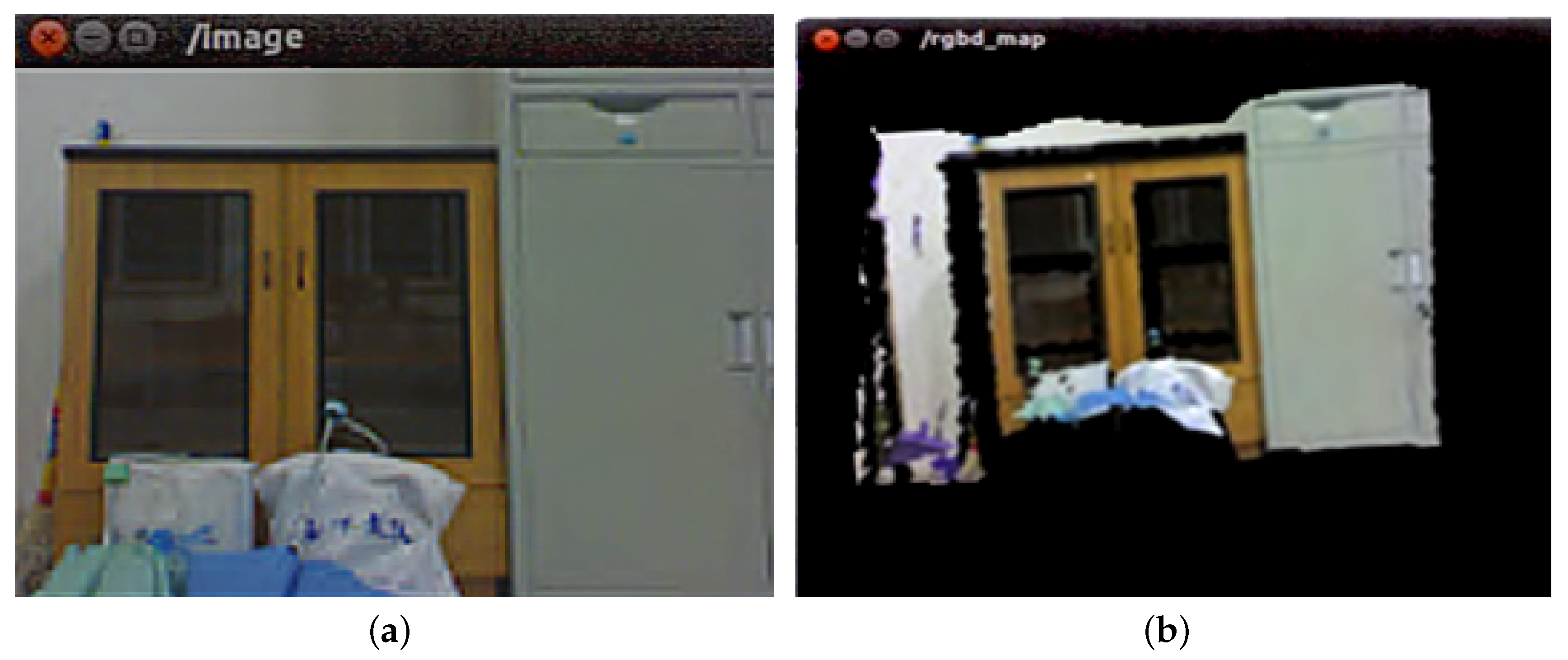
6.2.2. Fusion of Overlapping Areas
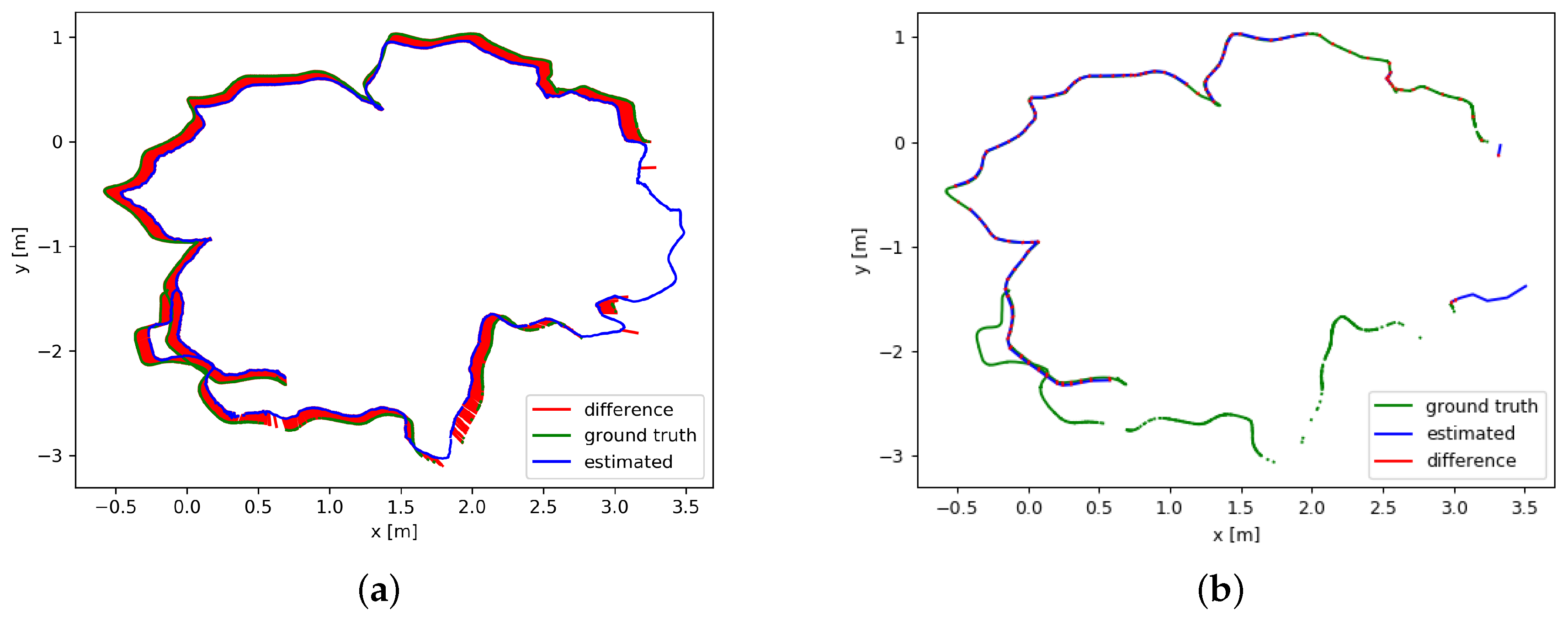
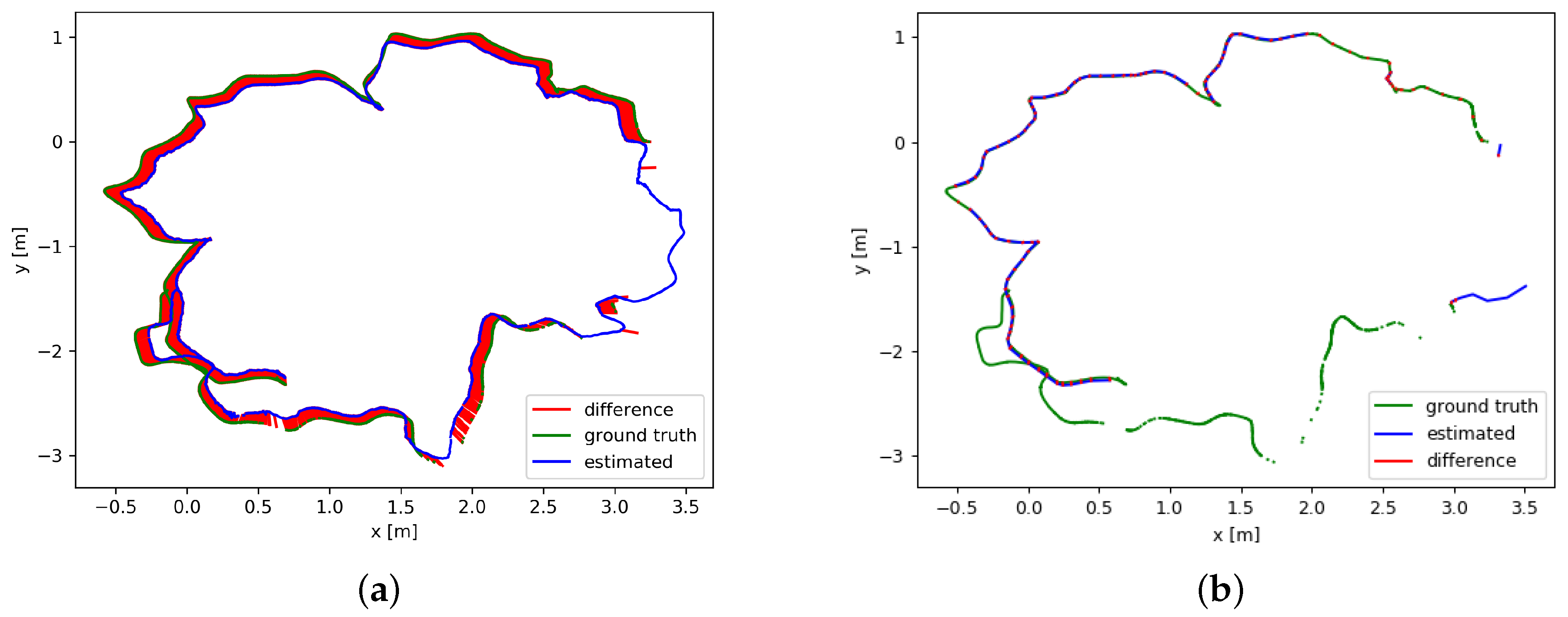
6.3. Comparison of Overall Experimental Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, R.; Liu, J.; Zhang, L.; Hang, Y. LIDAR/MEMS IMU integrated navigation (SLAM) method for a small UAV in indoor environments. In Proceedings of the 2014 DGON Inertial Sensors and Systems (ISS), Karlsruhe, Germany, 16–17 September 2014. [Google Scholar]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced Computer Vision With Microsoft Kinect Sensor: A Review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [PubMed]
- Liu, J.; Liu, Y.; Zhang, G.; Zhu, P.; Chen, Y.Q. Detecting and tracking people in real time with RGB-D camera. Pattern Recognit. Lett. 2015, 53, 16–23. [Google Scholar] [CrossRef]
- Belter, D.; Nowicki, M.; Skrzypczyński, P. Modeling spatial uncertainty of point features in feature-based RGB-D SLAM. Mach. Vis. Appl. 2018, 29, 827–844. [Google Scholar] [CrossRef]
- Whelan, T.; Kaess, M.; Johannsson, H.; Fallon, M.; Leonard, J.J.; Mcdonald, J. Real-time Large-scale Dense RGB-D SLAM with Volumetric Fusion. Int. J. Rob. Res. 2015, 34, 598–626. [Google Scholar] [CrossRef]
- Silva, B.M.F.D.; Xavier, R.S.; Nascimento, T.P.D.; Gonsalves, L.M.G. Experimental evaluation of ROS compatible SLAM algorithms for RGB-D sensors. In Proceedings of the 2017 Latin American Robotics Symposium (LARS) and 2017 Brazilian Symposium on Robotics (SBR), Curitiba, Brazil, 8–11 November 2017. [Google Scholar]
- Alexiadis, D.S.; Zioulis, N.; Zarpalas, D.; Daras, P. Fast deformable model-based human performance capture and FVV using consumer-grade RGB-D sensors. Pattern Recognit. 2018, 79, 260–278. [Google Scholar] [CrossRef]
- Ramírez De La Pinta, J.; Maestre Torreblanca, J.M.; Jurado, I.; Reyes De Cozar, S. Off the Shelf Cloud Robotics for the Smart Home: Empowering a Wireless Robot through Cloud Computing. Sensors 2017, 17, 525. [Google Scholar] [CrossRef]
- Zhu, D. IOT and big data based cooperative logistical delivery scheduling method and cloud robot system. Future Gener. Comput. Syst. 2018, 86, 709–715. [Google Scholar] [CrossRef]
- Koubaa, A.; Bennaceur, H.; Chaari, I.; Trigui, S.; Ammar, A.; Sriti, M.; Alajlan, M.; Cheikhrouhou, O.; Javed, Y. Robot Path Planning Using Cloud Computing for Large Grid Maps. In Robot Path Planning and Cooperation: Foundations, Algorithms and Experimentations; Koubaa, A., Ed.; Springer International Publishing: Cham, Switzerland, 2018; pp. 103–126. [Google Scholar]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D Mapping: Using Depth Cameras for Dense 3D Modeling of Indoor Environments. In Experimental Robotics: The 12th International Symposium on Experimental Robotics; Khatib, O., Kumar, V., Sukhatme, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 477–491. [Google Scholar]
- Liu, Y.; Zhang, H.; Guo, H.; Xiong, N.N. A FAST-BRISK Feature Detector with Depth Information. Sensors 2018, 18, 3908. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the 7th IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Grisetti, G.; Grzonka, S.; Stachniss, C.; Pfaff, P.; Burgard, W. Efficient estimation of accurate maximum likelihood maps in 3D. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 3472–3478. [Google Scholar]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environments. Int. J. Robot. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine Learning for High-speed Corner Detection. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Calonder, M.; Lepetit, V.; Fua, P. Keypoint Signatures for Fast Learning and Recognition. In Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 58–71. [Google Scholar]
- Lourakis, M.I.A.; Argyros, A.A. SBA: A Software Package for Generic Sparse Bundle Adjustment. ACM Trans. Math. Softw. 2009, 36, 2. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Endres, F.; Hess, J.; Engelhard, N.; Sturm, J.; Cremers, D.; Burgard, W. An evaluation of the RGB-D SLAM system. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1691–1696. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. G2o: A general framework for graph optimization. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Robots 2013, 34, 189–206. [Google Scholar] [CrossRef]
- Scherer, S.A.; Zell, A. Efficient onbard RGBD-SLAM for autonomous MAVs. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1062–1068. [Google Scholar]
- Grisetti, G.; Kümmerle, R.; Stachniss, C.; Frese, U.; Hertzberg, C. Hierarchical optimization on manifolds for online 2D and 3D mapping. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 273–278. [Google Scholar]
- Quang, H.P.; Quoc, N.L. Some improvements in the RGB-D SLAM system. In Proceedings of the 2015 IEEE RIVF International Conference on Computing & Communication Technologies—Research, Innovation, and Vision for Future (RIVF), Can Tho, Vietnam, 25–28 January 2015; pp. 112–116. [Google Scholar]
- Neumann, D.; Lugauer, F.; Bauer, S.; Wasza, J.; Hornegger, J. Real-time RGB-D mapping and 3-D modeling on the GPU using the random ball cover data structure. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; pp. 1161–1167. [Google Scholar]
- Lee, D.; Kim, H.; Myung, H. GPU-based real-time RGB-D 3D SLAM. In Proceedings of the 9th International Conference on Ubiquitous Robots and Ambient Intelligence, Daejeon, Korea, 26–28 November 2012; pp. 46–48. [Google Scholar]
- Brunetto, N.; Salti, S.; Fioraio, N.; Cavallari, T.; Stefano, L.D. Fusion of Inertial and Visual Measurements for RGB-D SLAM on Mobile Devices. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop, Santiago, Chile, 7–13 December 2015; pp. 148–156. [Google Scholar]
- Qayyum, U.; Ahsan, Q.; Mahmood, Z. IMU aided RGB-D SLAM. In Proceedings of the 14th International Bhurban Conference on Applied Sciences and Technology, Islamabad, Pakistan, 10–14 January 2017; pp. 337–341. [Google Scholar]
- Zhang, G.; Chen, Y. LoopSmart: Smart Visual SLAM Through Surface Loop Closure. arXiv 2018, arXiv:1801.01572. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Ylimäki, M.; Kannala, J.; Heikkilä, J. Accurate 3-D Reconstruction with RGB-D Cameras using Depth Map Fusion and Pose Refinement. arXiv 2018, arXiv:1804.08912. [Google Scholar]
- Schöps, T.; Sattler, T.; Pollefeys, M. BAD SLAM: Bundle Adjusted Direct RGB-D SLAM. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, 16–20 June 2019; pp. 134–144. [Google Scholar]
- Han, L.; Xu, L.; Bobkov, D.; Steinbach, E.; Fang, L. Real-Time Global Registration for Globally Consistent RGB-D SLAM. IEEE Trans. Robot. 2019, 35, 498–508. [Google Scholar] [CrossRef]
- Han, J.; Chen, H.; Liu, N.; Yan, C.; Li, X. CNNs-Based RGB-D Saliency Detection via Cross-View Transfer and Multiview Fusion. IEEE Trans. Cybern. 2018, 48, 3171–3183. [Google Scholar] [CrossRef]
- Arumugam, R.; Enti, V.R.; Liu, B.; Wu, X.; Baskaran, K.; Kong, F.F.; Kumar, A.S.; Meng, K.D.; Kit, G.W. DAvinCi: A cloud computing framework for service robots. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA 2010), Anchorage, AK, USA, 3–7 May 2010; pp. 3084–3089. [Google Scholar]
- Mohanarajah, G.; Hunziker, D.; D’Andrea, R.; Waibel, M. Rapyuta: A Cloud Robotics Platform. IEEE Trans. Autom. Sci. Eng. 2015, 12, 481–493. [Google Scholar] [CrossRef]
- Riazuelo, L.; Civera, J.; Montiel, J.M.M. C2TAM: A Cloud framework for cooperative tracking and mapping. Robot. Auton. Syst. 2014, 62, 401–413. [Google Scholar] [CrossRef]
- Gaboardi, F.; Pini, G.; Suardi, N. Robotic laparoendoscopic single-site radical prostatectomy (R-LESS-RP) with daVinci Single-Site® platform. Concept and evolution of the technique following an IDEAL phase 1. J. Robot. Surgery 2019, 13, 215–226. [Google Scholar] [CrossRef] [PubMed]
- Mohanarajah, G.; Usenko, V.; Singh, M.; D’Andrea, R.; Waibel, M. Cloud-Based Collaborative 3D Mapping in Real-Time With Low-Cost Robots. IEEE Trans. Aut. Sci. Eng. 2015, 12, 423–431. [Google Scholar] [CrossRef]
- Satyanarayana, A.; Kusyk, J.; Chen, Y. Design of Cloud Based Robots Using Big Data Analytics and Neuromorphic Computing. In Proceedings of the 2018 IEEE Canadian Conference on Electrical & Computer Engineering, Quebec City, QC, Canada, 13–16 May 2018. [Google Scholar]
- Mourikis, A.I.; Roumeliotis, S.I. Predicting the Performance of Cooperative Simultaneous Localization and Mapping (C-SLAM). Int. J. Robot. Res. 2006, 25, 1273–1286. [Google Scholar] [CrossRef]
- Kim, B.; Kaess, M.; Fletcher, L.; Leonard, J.; Bachrach, A.; Roy, N.; Teller, S. Multiple relative pose graphs for robust cooperative mapping. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 3185–3192. [Google Scholar]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspace. In Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Ali, S.S.; Hammad, A.; Tag Eldien, A.S. FastSLAM 2.0 tracking and mapping as a Cloud Robotics service. Comput. Electr. Eng. 2018, 69, 412–421. [Google Scholar] [CrossRef]
- Pomerleau, F.; Colas, F.; Siegwart, R. A Review of Point Cloud Registration Algorithms for Mobile Robotics. Found. Trends Robot. 2015, 4, 1–104. [Google Scholar] [CrossRef]
- Oomori, S.; Nishida, T.; Kurogi, S. Point cloud matching using singular value decomposition. Artif. Life Robot. 2016, 21, 149–154. [Google Scholar] [CrossRef]
- Arun, K.S.; Huang, T.S.; Blostein, S.D. Least-Squares Fitting of Two 3-D Point Sets. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 698–700. [Google Scholar] [CrossRef]
- Estrada, C.; Neira, J.; Tardos, J.D. Hierarchical SLAM: Real-time accurate mapping of large environments. IEEE Trans. Robot. 2005, 12, 588–596. [Google Scholar] [CrossRef]
- John, M.L. Introduction to Smooth Manifolds; Springer: New York, NY, USA, 2008. [Google Scholar]
- Freiburg Dataset. Available online: https://vision.in.tum.de/data/datasets/rgbd-dataset (accessed on 1 December 2019).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Advantages | Disadvantages |
|---|---|
| (1) No need to consider initial alignment like a monocular SLAM system | (1) RGB-D camera data contains noise and a lot of redundancy. |
| (2) No need to consume a lot of resources to compute depth like a binocular SLAM system | (2) The accuracy of feature matching and camera transformation matrix is not high |
| (3) RGB-D camera can provide rich color and depth images simultaneously | (3) Real-time performance is difficult to achieve in the construction of large-scale scene maps |
| (4) The construction of dense maps is relatively easy | |
| (5) It is helpful to realize the real-time 3D reconstruction system |
| Parameter | CTAM | Rapyuta | DAvinCi |
|---|---|---|---|
| Bandwidth | low | high | high |
| Latency | low | high | low |
| Power consumption | low | high | low |
| Registration Method | Running Time (ms) | Iterations | Average Error ( m) |
|---|---|---|---|
| Classical ICP method | 60,118 | 50 | 14.3 |
| Improved SVD method | 7183 | 10 | 8.8 |
| Index Terms | Method | |
|---|---|---|
| Original RGB-D SLAM (m) | Improved RGB-D SLAM (m) | |
| RMSE | 0.095054 | 0.009679 |
| Mean | 0.093701 | 0.008139 |
| Median | 0.094659 | 0.006937 |
| STD | 0.016023 | 0.005229 |
| MIN | 0.047141 | 0.000787 |
| MAX | 0.145821 | 0.022873 |
| Scene | Combined Cloud | Local | ||
|---|---|---|---|---|
| Data Transfer Time (ms) | Execution Time (ms) | Time Consumption (ms) | Time Consumption (ms) | |
| A | 6546 | 4856 | 11,402 | 36,406 |
| B | 5009 | 4893 | 9902 | 35,782 |
| C | 6298 | 5421 | 11,719 | 41,010 |
| D | 5974 | 4782 | 10,756 | 39,546 |
| E | 7283 | 6438 | 13,721 | 42,162 |
| Mean | 6222 | 5278 | 11,500 | 38,981 |
| Scene | Combined Cloud | Local | ||||
|---|---|---|---|---|---|---|
| Num. Frames (fps) | Energy Con. (J/10fps) | Data Size (MB) | Num. Frames (fps) | Energy Con. (J/10fps) | Data Size (MB) | |
| A | 20.28 | 4.83 | 5.67 | 1.72 | 12.94 | 10.95 |
| B | 21.25 | 5.21 | 6.88 | 1.78 | 13.97 | 11.24 |
| C | 21.64 | 4.94 | 7.53 | 1.65 | 12.98 | 11.36 |
| D | 20.92 | 5.11 | 5.43 | 1.73 | 13.32 | 11.18 |
| E | 21.35 | 5.03 | 6.92 | 1.66 | 13.38 | 11.48 |
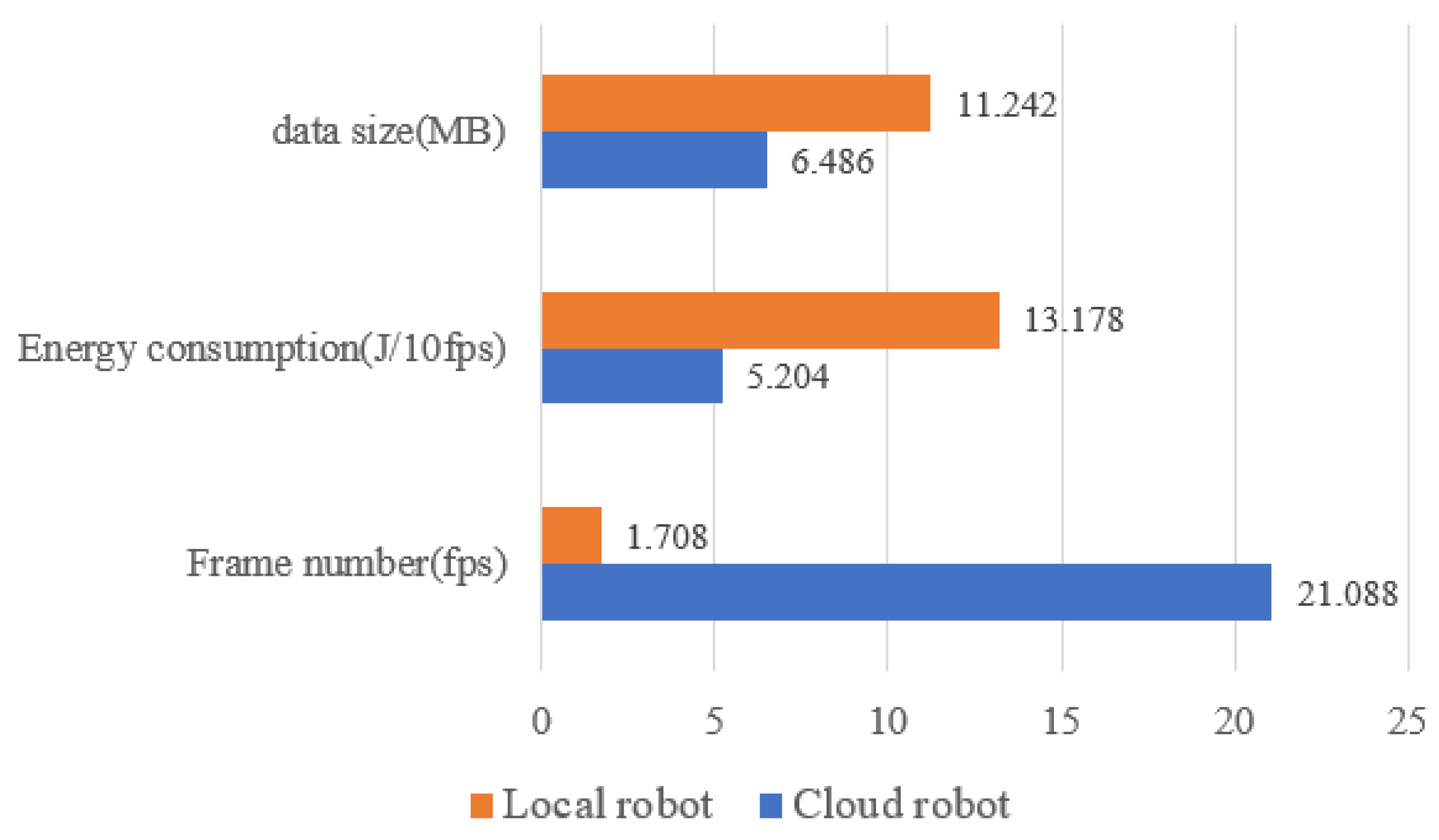
| Mean | 21.088 | 5.204 | 6.486 | 1.708 | 13.178 | 11.242 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhang, H.; Huang, C. A Novel RGB-D SLAM Algorithm Based on Cloud Robotics. Sensors 2019, 19, 5288. https://doi.org/10.3390/s19235288
Liu Y, Zhang H, Huang C. A Novel RGB-D SLAM Algorithm Based on Cloud Robotics. Sensors. 2019; 19(23):5288. https://doi.org/10.3390/s19235288
Chicago/Turabian StyleLiu, Yanli, Heng Zhang, and Chao Huang. 2019. "A Novel RGB-D SLAM Algorithm Based on Cloud Robotics" Sensors 19, no. 23: 5288. https://doi.org/10.3390/s19235288
APA StyleLiu, Y., Zhang, H., & Huang, C. (2019). A Novel RGB-D SLAM Algorithm Based on Cloud Robotics. Sensors, 19(23), 5288. https://doi.org/10.3390/s19235288