A Deep Learning-Based End-to-End Composite System for Hand Detection and Gesture Recognition



Abstract
:1. Introduction
- We have designed an end-to-end deep learning-based architecture to jointly detect and recognize static hand gestures.
- This is the first approach using focal loss-based one-stage dense object detection for the purpose of hand detection. This method achieves a high degree of accuracy for hand detection in complex and cluttered environments, such as extreme illumination changes, low-resolution images, hand variations, high levels of occlusion, and variation in shape and viewpoint.
- The proposed approach does not require any preprocessing step, including image enhancement, hands at a specific distance from the camera, or any postprocessing step.
- The approach achieves state-of-the-art performance on various publicly available benchmarks for both the hand detection and gesture recognition tasks. The proposed system was evaluated on various standard hand datasets with varying degrees of complexity in terms of the clutter environment. The approach was tested on various gestural datasets with different vocabulary sizes.
- Although there are many available datasets that were used to evaluate hand detection systems in the literature, they do not provide sufficient annotated data to train a deep learning-based hand detector. Therefore, we have collected and annotated a large dataset that includes over 41,000 hand instances to train our model.
- Finally, we have designed our system to be adaptive and be able to be retrained using different gestural datasets, making it flexible to potentially use again with another dataset containing a different hand gesture vocabulary. The gesture classification model is the only component that needs to be retrained, while the rest of the architecture stays untouched.
2. Related Works
2.1. Hand Detection
- Skin color-based approaches: Traditionally, many algorithms for hand detection rely on skin color segmentation to detect and extract hands from the background. Dardas et al. [8] proposed a thresholding method to segment hands in the hue, saturation, and value (HSV) color space after extracting other skin regions, such as the face. Mittal et al. [24] used a skin-based detector to generate hand hypotheses for the first stage of their hand detection algorithm. To improve the robustness of skin segmentation, Stergiopoulou et al. [25] used a skin-probability map (SPM) in the HSV color space for skin color classification, along with extra information, such as motion and morphology weights of hands. To further enhance the skin segmentation, some hand-crafted features such as a Gabor filter, scale invariant feature transform (SIFT) and histogram of oriented gradients (HOG) were combined to segment the skin regions of hands [26]. Combining skin detection with deep learning object detectors has also been proposed. Roy et al. [5] proposed two architectures (patch-based CNN and regression-based CNN for skin segmentation). Their main purpose was to reduce the occurrence of false positives resulting from the estimated bounding boxes of recent object detectors [14,15]. However, skin segmentation-based hand detection is not robust enough in practice and suffers from several constraints, which include skin tone variation, occlusion, background clutter, poor illumination, etc.
- Depth-based approaches: The recent development of emerging color-depth camera-based sensing techniques, such as the Microsoft KinectTM, has solved many problems related to hand gesture recognition, including hand extraction using depth data [27]. A large portion of depth-based hand detection methods still rely on the distance between the hand and the sensor [1,2,3]. However, some studies attempted to exploit certain depth features for the per-pixel segmentation of hands. Keskin et al. [28] extracted scale invariant shape features from depth images then fed them into a per-pixel randomized decision forest (RDF) classifier. The final predicted label for the whole image was determined by majority voting. Kang et al. [20] proposed a two-stage random decision forest (RDF) method for detecting and segmenting hands. The first stage RDF attempted to locate the hand region from a depth map, while the second stage segmented hands in the pixel-level by applying the RDF method to the detected regions. Although those methods have succeeded in well-prepared indoor environments, the use of depth sensors might not be feasible in all environments, such those outdoors.
- Hand-crafted features: Many hand-crafted features were also introduced to detect hands. Inspired by the success of Viola and Jone’s algorithm for face detection [29], which combines Haar-like features with an AdaBoost learning classifier, similar approaches have been proposed in [8,30,31]. Wang et al. [32] have used SIFT features and the AdaBoost learning algorithm to achieve in-plane rotation invariant hand detection. To speed up the testing process and boost accuracy, they proposed the use of the sharing feature concept. Despite its success in face detection, the framework of Viola and Jone’s was fragile when facing cluttered backgrounds, and the Haar-like features were not efficient enough to represent complex and articulate objects, such as human hands. Dalal and Triggs [33] proposed a gradient histogram feature descriptor called HOG for human detection. A variant of the HOG feature, called skin color histogram of oriented gradients (SCHOG), was proposed by Meng et al. [34] to construct a human hand detector. First, the SCHOG features were extracted by combining HOG with skin cues. Then, a support vector machine (SVM) algorithm was applied to construct a SVM-trained classifier for hand detection. Despite the improved results, the performance was still insufficient due to the large variations of hands’ appearances in unconstrained backgrounds. Mittal et al. [24] developed a two-stage hand detector. The first stage generates a hand proposal using three complementary detectors, namely, a skin-color-based detector, a deformable part model (DPM) based shape detector, and detectors with contextual cues (context detector). In the second stage, the scores of the proposals were combined and fed into a linear SVM classifier to compute the final prediction. Although the proposed detector achieved adequate precision performance, this method was computationally expensive (two minutes per image) and consequently is not feasible for real-time applications.
- Deep feature-based methods: Inspired by the recent success of convolutional neural networks, researchers have proposed numerous methods for object detection and recognition based on CNNs [14,15,21,35]. Consequently, these methods have been developed and used for hand detection. Roy et al. [5] proposed a two-stage hand detector based on the region-CNN (R-CNN) and Faster R-CNN [14,15] frameworks. Initially, they used an object detection algorithm to generate hand regions and then a CNN-based skin segmentation was used to reduce occurrences of false positives during hand detection. Deng et al. [36] built a two-stage framework to jointly detect hands and estimate their orientation. The framework applied the region proposal networks (RPN) used in Faster R-CNN to generate region proposals, then estimated hand orientation based on the region of interest (ROI) pooling features. Furthermore, they claimed that the rotation estimation and classification could mutually benefit each other. Huang et al. [19] proposed an egocentric interaction system using Faster R-CNN [15] to locate and recognize static hand gestures. Their system achieved better performance on a challenging dataset under challenging conditions. Le et al. [4,37] introduced a novel approach that combined local and global context information to enhance the robustness of the deep features. They further extended the region-fully convolutional network (R-FCN) and Faster R-CNN by aggregating multiple scale feature maps. This approach achieved satisfactory performance on two challenging datasets. Although hand detection using CNN-based methods significantly improves the detection accuracy, it yields this good accuracy at a high computational expense. An efficient and fast algorithm is still required to robustly detect hands in unconstrained scenarios.
2.2. Hand Gesture Recognition
3. Proposed System
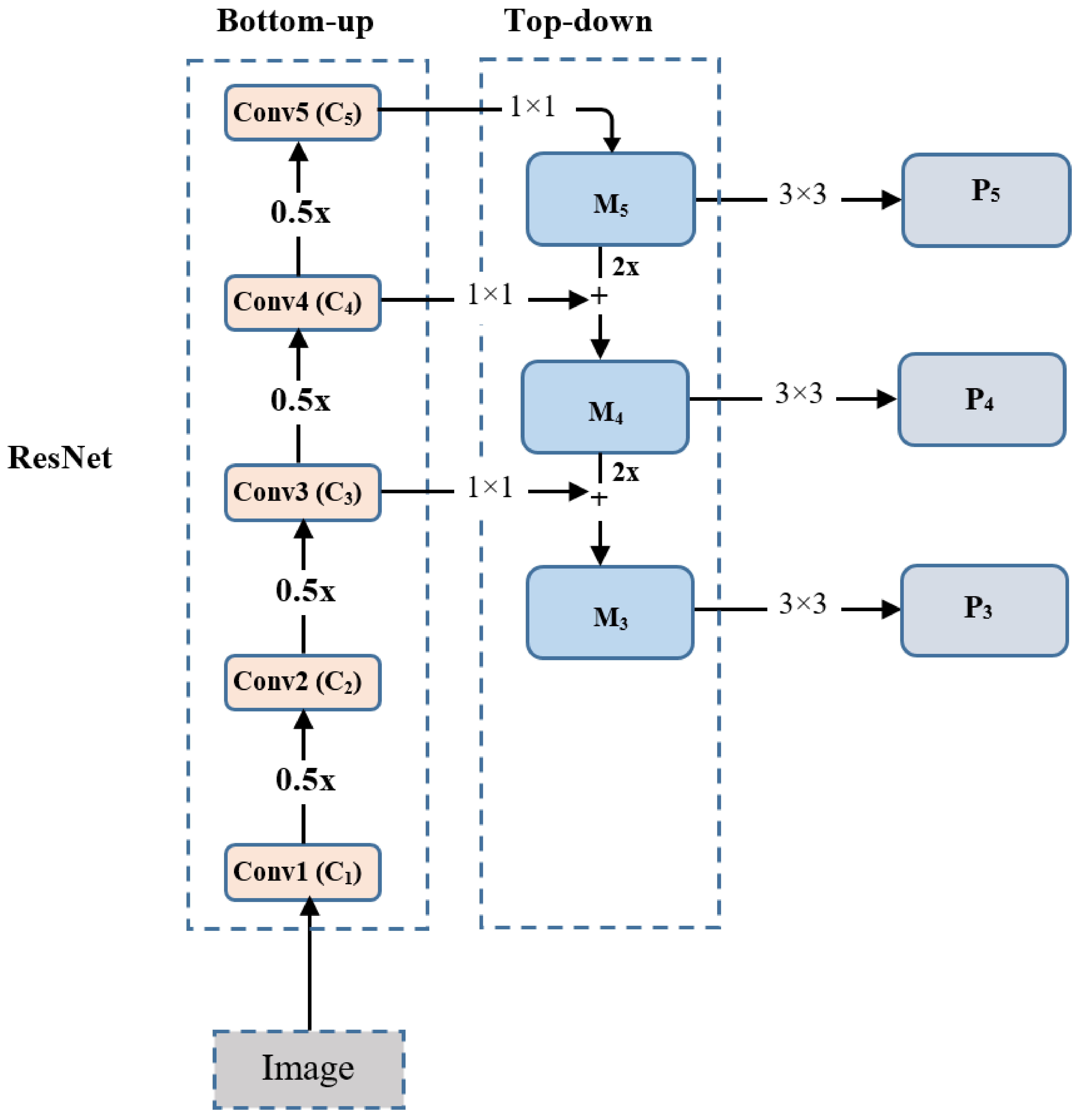
3.1. RetinaNet-Based Hand Detection
3.2. Lightweight CNN-Based Hand Gesture Recognition
4. Experiments and Discussions
4.1. Experimental Details
4.1.1. Experimental Datasets
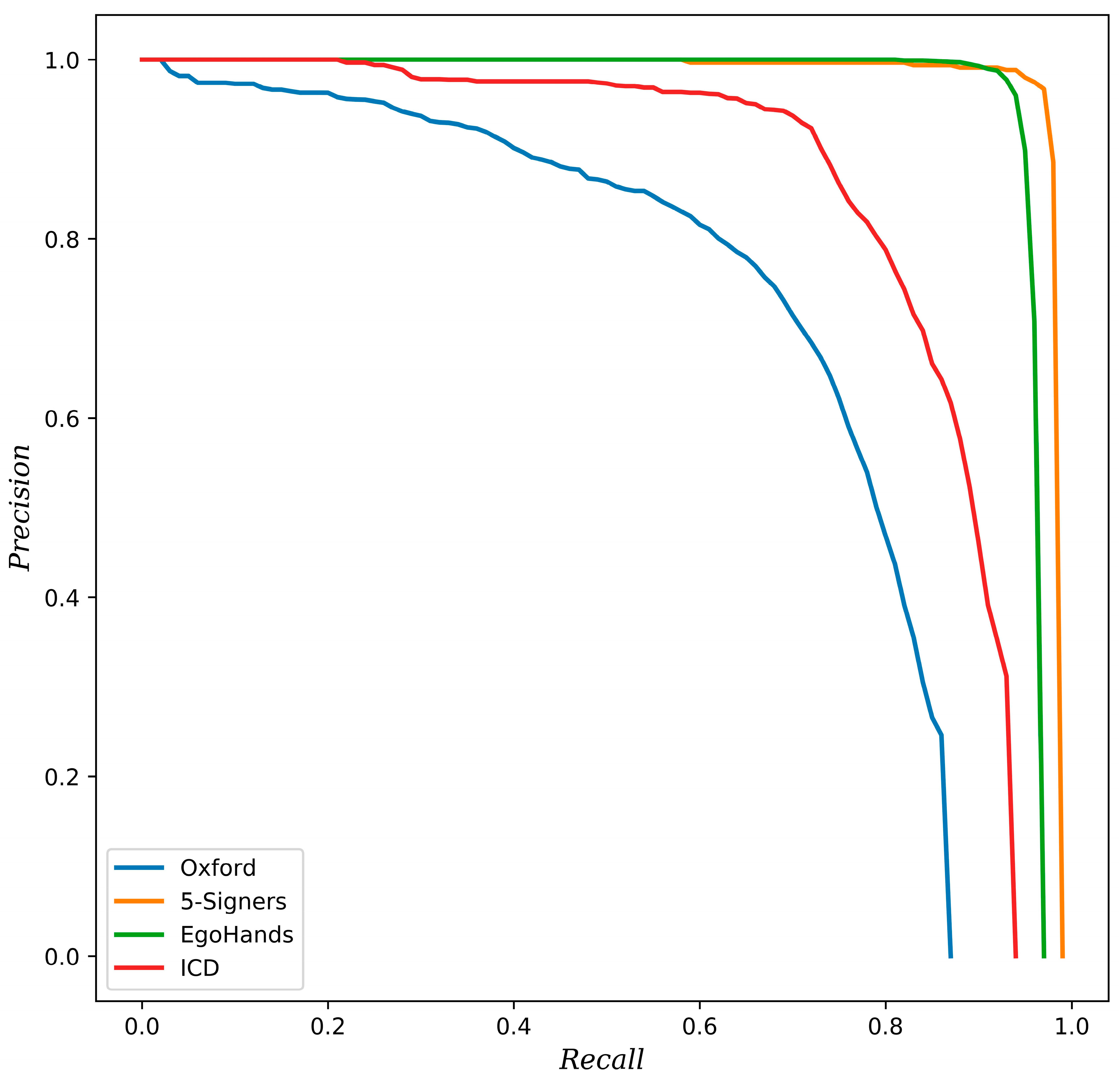
- Hand detection datasets: Due to the limited size of the existing standard datasets for hand detection, and in order to train our hand detector with sufficient data, we created a new dataset to use in our experiments. We have collected a combined dataset containing a total of 24,535 images and over 41,000 hand instances. To ensure the diversity of the data collected, the dataset combines samples from different datasets, (e.g., those from [12,24,44,45]) and other images sources. In addition, we are more interested in creating a realistic and diverse dataset in terms of viewpoints (first and third person views, etc.), the number of subjects involved, different indoor/outdoor environments, and diversity as well, in terms of the engaged hand activities (e.g., gesturing, playing, engaging in conversations, housework, etc.). It is worth mentioning that the collected dataset is not comprised of any samples from the datasets used later to evaluate the detector performance, neither those used in the gesture classification phase. The collected dataset was prepared and annotated manually with ground truth bounding-boxes. We divided the training dataset randomly into two subsets: 80% for training and the remaining 20% for the validation dataset, which was used to fine-tune the model during training. We have also used the same dataset for training in all our experiments to provide an unbiased comparison. To assess the detector performance and demonstrate the robustness and the generalization power of the hand detector, we evaluated the performance of the trained models on four different test datasets, namely, the Oxford [24], 5-signers [45], EgoHands [44], and Indian classical dance (ICD) datasets ([5]). Table 2 summarizes the characteristics of the datasets used for the training and testing of the hand detector.
- Hand gesture recognition datasets: To train and evaluate the gesture recognition performance of our proposed architecture, two hand gesture datasets were chosen because they both have publicly available data with challenging data conditions, i.e., they contain a large amount of data with a different number of classes, as detailed below.
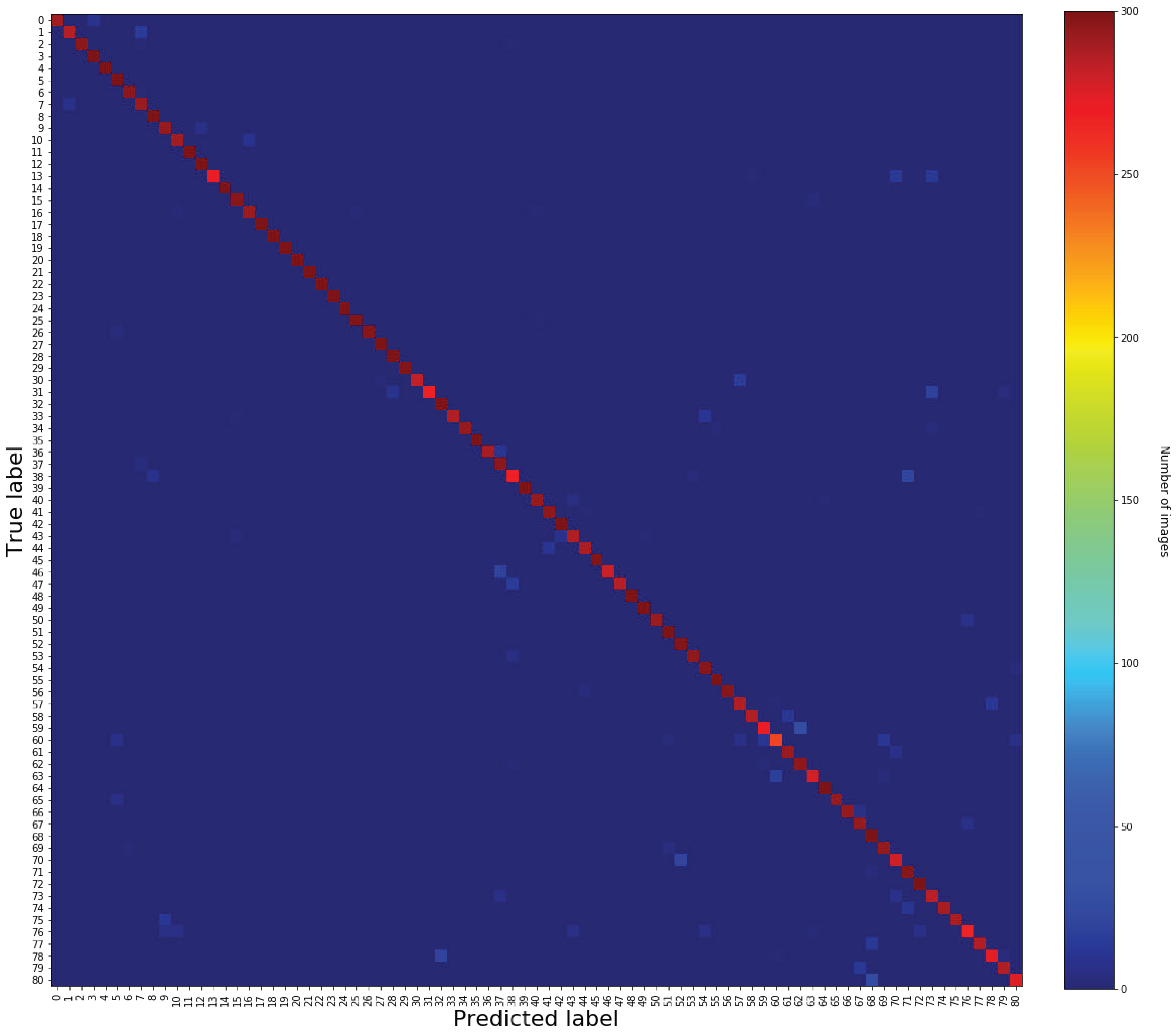
- The LaRED dataset (Available at: http://mclab.citi.sinica.edu.tw/dataset/lared/lared.html) [46] is a large RGB-D hand gesture dataset that provides ~240,000 tuple images (color image, a depth image, and a mask of the hand region). To the best of our knowledge, this is the largest hand gestures dataset, with 81 different classes (27 hand gestures in 3 different rotations). The dataset has been collected using a short-range Intel depth camera. The classes have been recorded by 10 subjects (five males and five females), and each subject was asked to perform 300 gesture images per class, repeating the same hand gesture with slight movements. This large volume of labeled data is the best-suited set of data to develop and train deep learning algorithms for practical applications. Furthermore, this dataset is extensible, since it comes with the software used to record and inspect the dataset, allowing future users to increase the dataset size by adding more subjects/gestures in the future. For the sake of our needs, we used only the color images of VGA resolution and omitted the rest of the dataset. Following the baseline approach [46], we have divided the entire dataset into two disjoint subsets, i.e., those used for training and testing. The test subset contains 10% of the total data, while the remaining is used during the training process.
- The TinyHands (In the original paper, they have not named this dataset. Therefore, we call it TinyHands as an abbreviation) gesture dataset (Available at: https://sites.google.com/view/handgesturedb/home): This dataset [47] has been captured in two distinct setup environments. Half of the dataset has been recorded with a simple background and the rest with a complex background. The complex background undergoes various illumination conditions with a highly cluttered environment. In the dataset, the gestures are performed in different locations in the image and hands occupy only a small region of the image (about 10% of the whole image in pixels). There were forty participants involved to collect this dataset. Each participant was asked to make seven different gestures, and about 1400 frames compose every instantiation of one gesture. Following the baseline approach [47], we have used a subject independent approach, where subjects who appear in the testing set are totally different from the training set. We have employed a cross-validation strategy with four repetitions, in which each repetition uses 25 subjects for training, 5 subjects for validation, and 10 subjects for testing. Table 3 summarizes the characteristics of the datasets used for hand gesture recognition.
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Experimental Results
4.2.1. Hand Detection Results
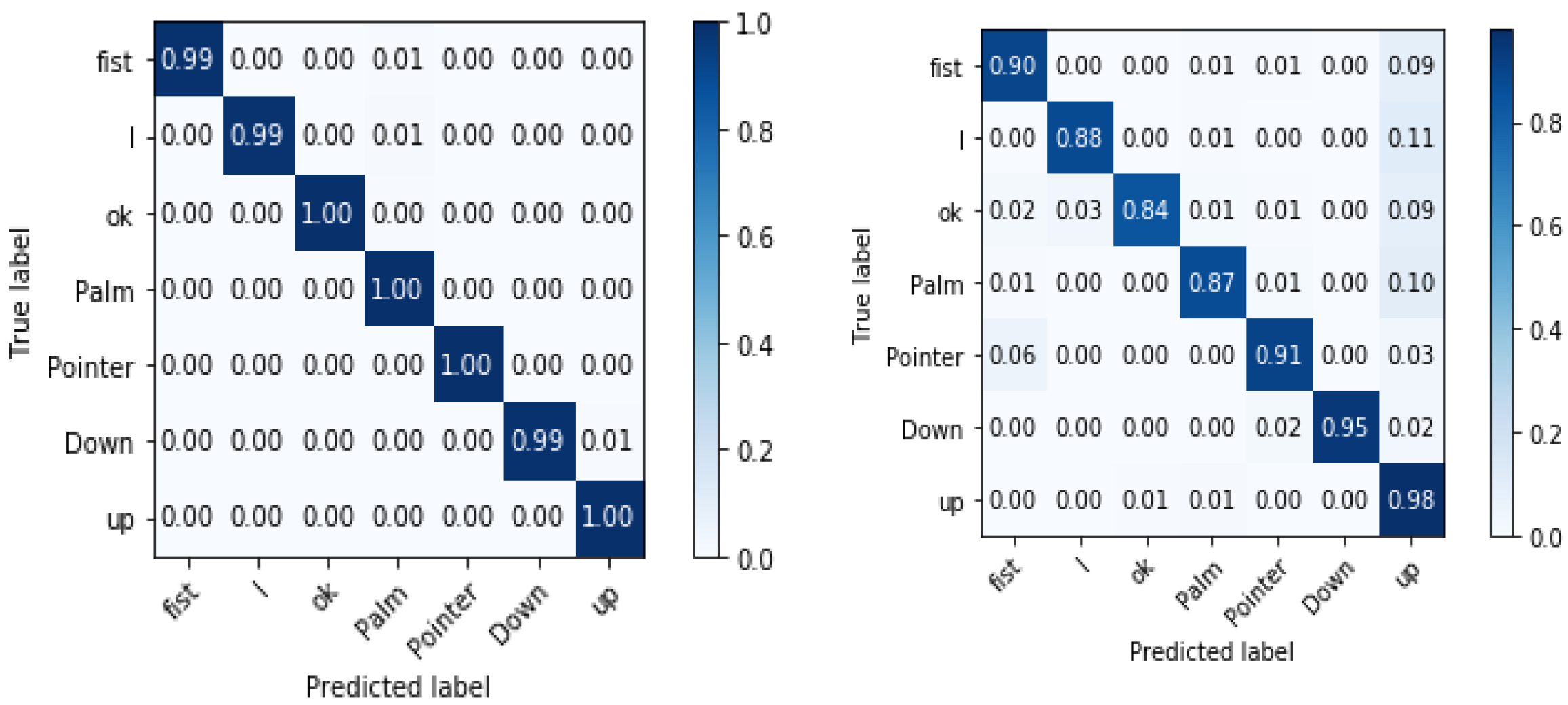
4.2.2. Hand Gesture Recognition Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4.2.3. Processing Speed of the Proposed Architecture
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ren, Z.; Yuan, J.; Zhang, Z. Robust hand gesture recognition based on finger-earth mover’s distance with a commodity depth camera. In Proceedings of the 2011 ACM Multimedia Conference and Co-Located Workshops, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1093–1096. [Google Scholar]
- Plouffe, G.; Cretu, A.M. Static and dynamic hand gesture recognition in depth data using dynamic time warping. IEEE Trans. Instrum. Meas. 2016, 65, 305–316. [Google Scholar] [CrossRef]
- Liang, C.; Song, Y.; Zhang, Y. Hand gesture recognition using view projection from point cloud. In Proceedings of the International Conference on Image Processing, (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4413–4417. [Google Scholar]
- Le, T.H.N.; Zhu, C.; Zheng, Y.; Luu, K.; Savvides, M. Robust hand detection in Vehicles. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 573–578. [Google Scholar]
- Roy, K.; Mohanty, A.; Sahay, R.R. Deep Learning Based Hand Detection in Cluttered Environment Using Skin Segmentation. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 640–649. [Google Scholar]
- Nakjai, P.; Katanyukul, T. Hand Sign Recognition for Thai Finger Spelling: An Application of Convolution Neural Network. J. Signal Process. Syst. 2019, 91, 131–146. [Google Scholar] [CrossRef]
- Tao, W.; Leu, M.C.; Yin, Z. American Sign Language alphabet recognition using Convolutional Neural Networks with multiview augmentation and inference fusion. Eng. Appl. Artif. Intell. 2018, 76, 202–213. [Google Scholar] [CrossRef]
- Dardas, N.H.; Georganas, N.D. Real-time hand gesture detection and recognition using bag-of-features and support vector machine techniques. IEEE Trans. Instrum. Meas. 2011, 60, 3592–3607. [Google Scholar] [CrossRef]
- Chevtchenko, S.F.; Vale, R.F.; Macario, V.; Cordeiro, F.R. A convolutional neural network with feature fusion for real-time hand posture recognition. Appl. Soft Comput. J. 2018, 73, 748–766. [Google Scholar] [CrossRef]
- Ong, E.J.; Bowden, R. A boosted classifier tree for hand shape detection. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 19 May 2004; pp. 889–894. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A. Efficient model-based 3D tracking of hand articulations using Kinect. In Proceedings of the 22nd British Machine Vision Conference (BMVC 2011), Dundee, UK, 29 August–2 September 2011; pp. 101.1–101.11. [Google Scholar]
- Matilainen, M.; Sangi, P.; Holappa, J.; Silvén, O. OUHANDS database for hand detection and pose recognition. In Proceedings of the 2016 6th International Conference on Image Processing Theory, Tools and Applications (IPTA 2016), Oulu, Finland, 12–15 December 2016; pp. 1–5. [Google Scholar]
- Mirehi, N.; Tahmasbi, M.; Targhi, A.T. Hand gesture recognition using topological features. Multimed. Tools Appl. 2019, 78, 13361–13386. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, Y.; Wang, X.; Liu, W.; Feng, B. Deep attention network for joint hand gesture localization and recognition using static RGB-D images. Inf. Sci. 2018, 441, 66–78. [Google Scholar] [CrossRef]
- Das, N.; Ohn-Bar, E.; Trivedi, M.M. On Performance Evaluation of Driver Hand Detection Algorithms: Challenges, Dataset, and Metrics. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, (ITSC), Las Palmas, Spain, 15–18 September 2015; pp. 2953–2958. [Google Scholar]
- Huang, Y.; Liu, X.; Zhang, X.; Jin, L. A Pointing Gesture Based Egocentric Interaction System: Dataset, Approach and Application. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 370–377. [Google Scholar]
- Kang, B.; Tan, K.H.; Jiang, N.; Tai, H.S.; Treffer, D.; Nguyen, T. Hand segmentation for hand-object interaction from depth map. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP 2017), Montreal, QC, Canada, 14–16 November 2017; pp. 259–263. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. In Technical Report; Google Inc.: Menlo Park, CA, USA, 2017. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3305. [Google Scholar]
- Mittal, A.; Zisserman, A.; Torr, P. Hand detection using multiple proposals. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; pp. 75.1–75.11. [Google Scholar]
- Stergiopoulou, E.; Sgouropoulos, K.; Nikolaou, N.; Papamarkos, N.; Mitianoudis, N. Real time hand detection in a complex background. Eng. Appl. Artif. Intell. 2014, 35, 54–70. [Google Scholar] [CrossRef]
- Li, C.; Kitani, K.M. Pixel-level hand detection in ego-centric videos. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3570–3577. [Google Scholar]
- Qian, C.; Sun, X.; Wei, Y.; Tang, X.; Sun, J. Realtime and robust hand tracking from depth. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1106–1113. [Google Scholar]
- Keskin, C.; Kiraç, F.; Kara, Y.E.; Akarun, L. Hand pose estimation and hand shape classification using multi-layered randomized decision forests. In Proceedings of the 12th European conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 852–863. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Mathias, K.; Turk, M. Robust Hand Detection 1 Introduction frequency spectrum analysis. Integr. VLSI J. 2004, 30, 614–619. [Google Scholar]
- Chen, Q.; Georganas, N.D.; Petriu, E.M. Hand gesture recognition using Haar-like features and a stochastic context-free grammar. IEEE Trans. Instrum. Meas. 2008, 57, 1562–1571. [Google Scholar] [CrossRef]
- Wang, C.C.; Wang, K.C. Hand posture recognition using adaboost with SIFT for human robot interaction. In Recent Progress in Robotics: Viable Robotic Service to Human; Lee, S., Suh, I.H., Kim, M.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 370, pp. 317–329. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Meng, X.; Lin, J.; Ding, Y. An extended HOG model: SCHOG for human hand detection. In Proceedings of the 2012 International Conference on Systems and Informatics (ICSAI 2012), Yantai, China, 19–20 May 2012; pp. 2593–2596. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Deng, X.; Zhang, Y.; Yang, S.; Tan, P.; Chang, L.; Yuan, Y.; Wang, H. Joint Hand Detection and Rotation Estimation Using CNN. IEEE Trans. Image Process. 2018, 27, 1888–1900. [Google Scholar] [CrossRef] [PubMed]
- Le, T.H.N.; Quach, K.G.; Zhu, C.; Duong, C.N.; Luu, K.; Savvides, M. Robust Hand Detection and Classification in Vehicles and in the Wild. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1203–1210. [Google Scholar]
- Pisharady, P.K.; Vadakkepat, P.; Loh, A.P. Attention based detection and recognition of hand postures against complex backgrounds. Int. J. Comput. Vis. 2013, 101, 403–419. [Google Scholar] [CrossRef]
- Oyedotun, O.K.; Khashman, A. Deep learning in vision-based static hand gesture recognition. Neural Comput. Appl. 2017, 28, 3941–3951. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Bambach, S.; Lee, S.; Crandall, D.J.; Yu, C. Lending a hand: Detecting hands and recognizing activities in complex egocentric interactions. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1949–1957. [Google Scholar]
- Buehler, P.; Everingham, M.; Huttenlocher, D.P.; Zisserman, A. Long term arm and hand tracking for continuous sign language TV broadcasts. In Proceedings of the British Machine Vision Conference 2008, Dundee, UK, 29 August–2 September 2011; pp. 1105–1114. [Google Scholar]
- Hsiao, Y.S.; Sanchez-Riera, J.; Lim, T.; Hua, K.L.; Cheng, W.H. LaRED: A large RGB-D extensible hand gesture dataset. In Proceedings of the 5th ACM Multimedia Systems Conference (MMSys 2014), Singapore, 19 March 2014; pp. 53–58. [Google Scholar]
- Bao, P.; Maqueda, A.I.; Del-Blanco, C.R.; Garciá, N. Tiny hand gesture recognition without localization via a deep convolutional network. IEEE Trans. Consum. Electron. 2017, 63, 251–257. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2014, 111, 98–136. [Google Scholar] [CrossRef]
- Chollet, F. Keras (2015). 2017. Available online: http//keras.io (accessed on 20 October 2019).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Designand Implementation (OSDI ′16), Savannah, GA, USA, 2–4 November 2016; Volume 16, pp. 265–283. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Sanchez-Riera, J.; Hua, K.L.; Hsiao, Y.S.; Lim, T.; Hidayati, S.C.; Cheng, W.H. A comparative study of data fusion for RGB-D based visual recognition. Pattern Recognit. Lett. 2016, 73, 1–6. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]





| Layer Name | Output Size | Kernel Size | Number of Filters | Stride | Number of Iterations |
|---|---|---|---|---|---|
| conv1 | 300 × 300 | 7 × 7 | 64 | 2 | 1 |
| Maxpool | 3 × 3 | 1 | 2 | 1 | |
| Conv2_x | 150 × 150 | x 3 | |||
| Conv3_x | 75 × 75 | x 4 | |||
| Conv4_x | 38 × 38 | x 6 | |||
| Conv5_x | 19 × 19 | x 3 |
| Dataset | Training (Images) | Testing (Images) | Number of Instances |
|---|---|---|---|
| Oxford | 4069 | 823 | 13,049 |
| 5-Signers | 3935 | 2000 | 8855 |
| EgoHands | 3600 | 800 | 15,053 |
| ICD | - | 675 | 1240 |
| Our Collected | 8633 | - | 9985 |
| Dataset | Number of Subjects | Number of Gestures | Resolution | Training Set | Testing Set |
|---|---|---|---|---|---|
| LaRED | 10 | 81 | 640 × 480 | ~218,700 | ~24,300 |
| TinyHands | 40 | 7 | 1920 × 1080 640 × 480 | ~294,000 | ~98,000 |
| Dataset | AP (%) | AR (%) | F1 Score (%) |
|---|---|---|---|
| Oxford | 72.1 | 45.1 | 54.9 |
| 5-signers | 97.9 | 90.1 | 93.8 |
| EgoHands | 93.1 | 94.4 | 93.7 |
| ICD | 85.5 | 67.9 | 75.7 |
| Method | Oxford | 5-Signers | EgoHands | ICD |
|---|---|---|---|---|
| R-CNN [5,14] | 31.23 | 95.56 | 57.27 | 25.69 |
| R-CNN and skin [5] | 49.51 | 97.27 | 92.96 | 35.33 |
| Faster R-CNN [5,15] | 14.22 | 29.03 | 50.00 | 24.39 |
| Faster R-CNN and Skin [5] | 31.12 | 69.00 | 96.00 | 31.88 |
| Bambach et al. [44] | N/A | N/A | 84.20 | N/A |
| Multiple proposals [24] | 48.20 | 76.67 | N/A | N/A |
| Deng et al. [36] | 58.10 | N/A | 77.10 | N/A |
| Ours | 72.10 | 97.90 | 93.10 | 85.50 |
| Dataset | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|
| LaRED Dataset | 97.33 | 97.25 | 97.29 |
| TinyHands (Simple) | 99.48 | 99.48 | 99.48 |
| TinyHands (Complex) | 91.36 | 90.41 | 90.88 |
| Input Resolution | 400 | 500 | 600 | 700 | 800 |
| Frames Per Second (FPS) | 12.05 | 10.76 | 8.76 | 7.59 | 6.44 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MOHAMMED, A.A.Q.; Lv, J.; Islam, M.S. A Deep Learning-Based End-to-End Composite System for Hand Detection and Gesture Recognition. Sensors 2019, 19, 5282. https://doi.org/10.3390/s19235282
MOHAMMED AAQ, Lv J, Islam MS. A Deep Learning-Based End-to-End Composite System for Hand Detection and Gesture Recognition. Sensors. 2019; 19(23):5282. https://doi.org/10.3390/s19235282
Chicago/Turabian StyleMOHAMMED, Adam Ahmed Qaid, Jiancheng Lv, and MD. Sajjatul Islam. 2019. "A Deep Learning-Based End-to-End Composite System for Hand Detection and Gesture Recognition" Sensors 19, no. 23: 5282. https://doi.org/10.3390/s19235282
APA StyleMOHAMMED, A. A. Q., Lv, J., & Islam, M. S. (2019). A Deep Learning-Based End-to-End Composite System for Hand Detection and Gesture Recognition. Sensors, 19(23), 5282. https://doi.org/10.3390/s19235282