1. Introduction
Wireless sensor networks (WSNs) accumulate, analyze, and utilize data that are received wirelessly from sensor nodes, which have been used for various applications such as smart homes [
1], air purifiers [
2], and fire and disaster monitoring [
3,
4] due to their improved performance, ease of use, and low price. Sensor nodes are sometimes placed in hazardous environments, hindering the replacement of batteries or malfunctioning nodes. Furthermore, improving the battery performance of a node increases costs. Therefore, research has aimed to improve network lifetime and stability through a variety of network protocols [
5].
The low-energy adaptive clustering hierarchy (LEACH) protocol improves energy efficiency via a clustering method [
6]. When data are transmitted from a node to the base station (BS), energy consumption is affected by the distance between them. Clustering reduces the transmission distance of the nodes that are not cluster-heads (CHs), which are those that gather data from neighboring nodes for forwarding. Therefore, proper CH selection enables efficient energy consumption. In LEACH, nodes are evenly and probabilistically selected as CHs, disregarding the state and characteristics of the selected nodes, such as remaining energy, predicted energy consumption, and the number of neighboring nodes. The centralized use of information (e.g., battery status) from all nodes at the BS should be considered when selecting CHs. However, it is difficult to simultaneously acquire this information at the BS during transmission. In LEACH-C [
7], to obtain the remaining energy information from nodes, the synchronization of node information is achieved by methods such as time-division multiple access. LEACH-C not only makes a variety of information available, it also enables higher computing power at the BS than that at the nodes. Thus, such a type of centralized operation can be leveraged to improve clustering.
Clustering based on swarm intelligence is a highly accurate approach that has been widely used for optimization protocols. This approach has been included in protocols based on particle swarm optimization (PSO) [
8,
9,
10], bee colony optimization [
11,
12], ant colony optimization [
13,
14], among others. The recently proposed spider monkey optimization (SMO) mimics the behaviors of spider monkeys seeking food to quickly and accurately determine feasible solutions compared to other optimization algorithms based on swarm intelligence [
15]. Therefore, various studies have used SMO for CH selection [
16,
17,
18]. We modified the original SMO algorithm in this study to further improve CH selection.
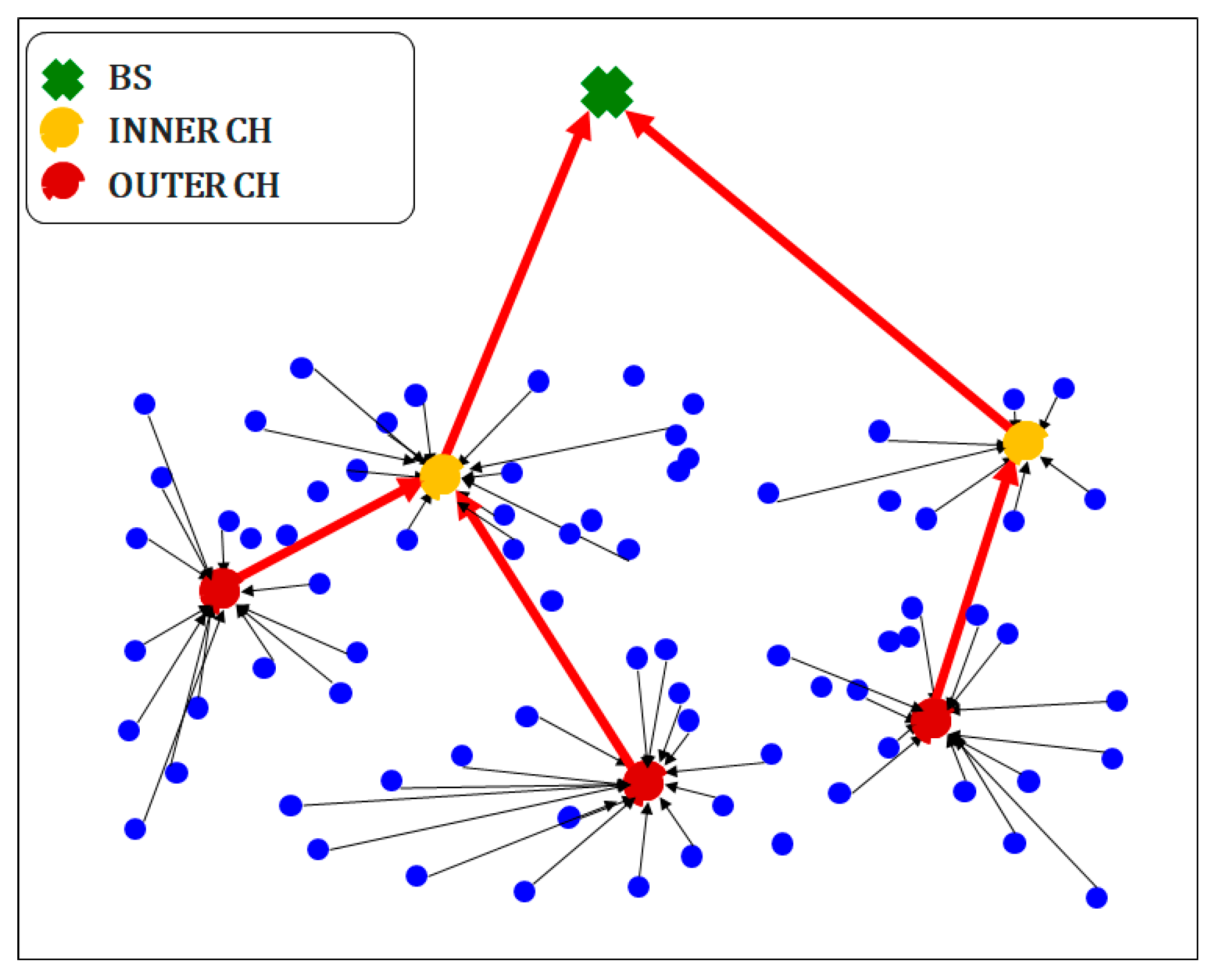
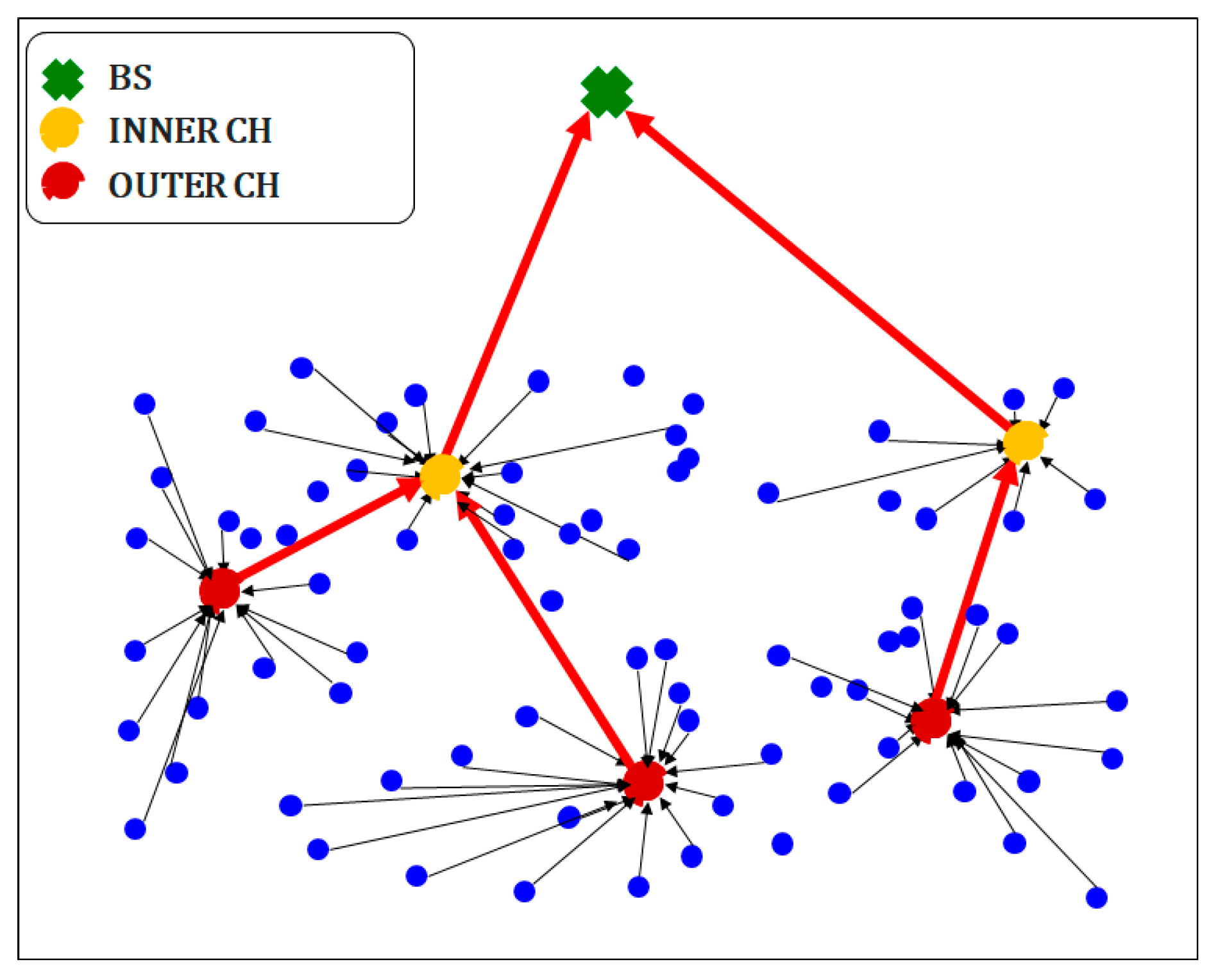
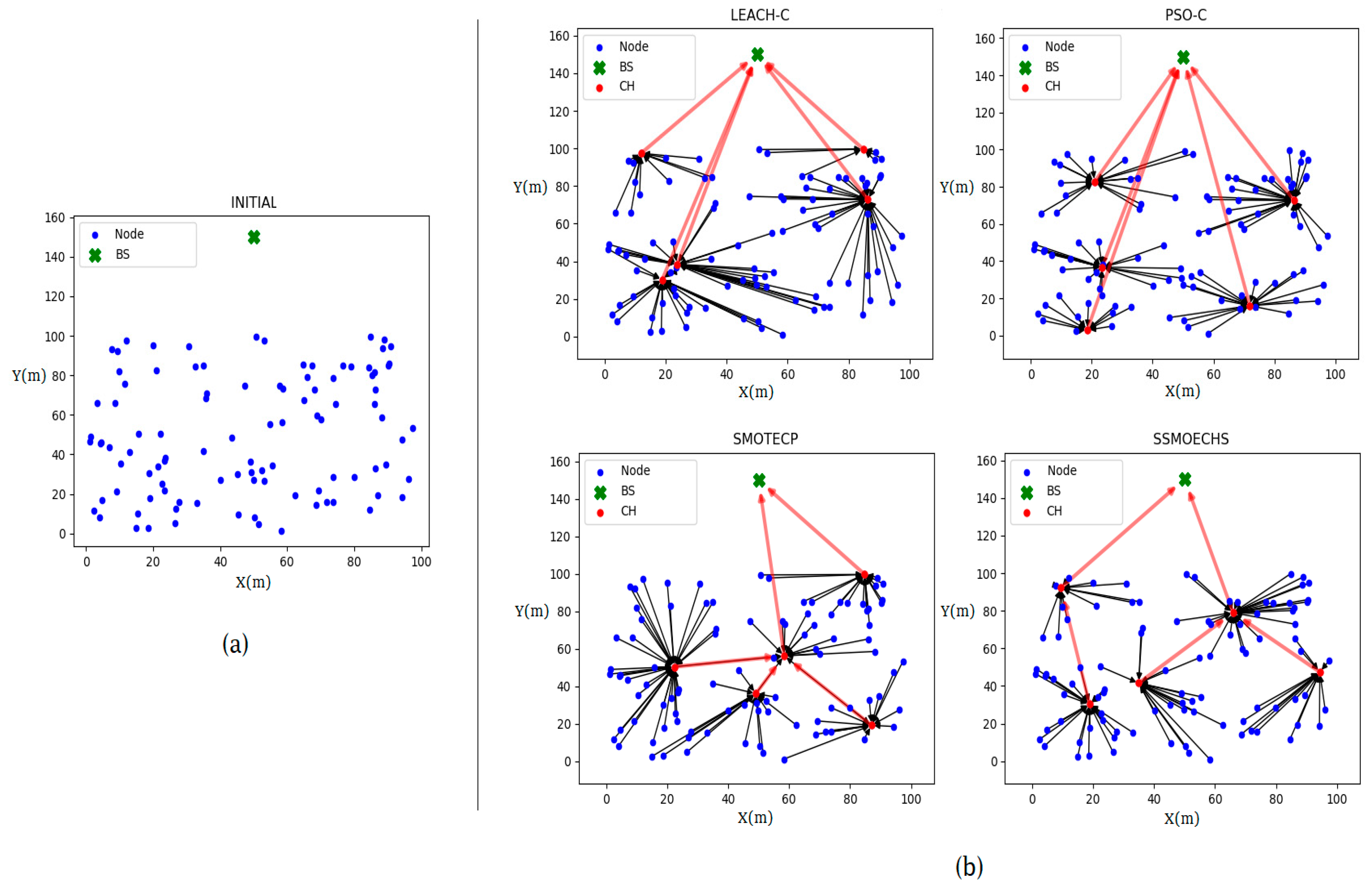
In most existing studies using clustering for WSNs, the nearest nodes to the optimal location are defined as CHs during selection. Thus, clustering mainly locates CHs at the cluster center, and operation problems may arise when the optimal CH locations differ from the actual node positions. First, the calculation burden increases when determining the nearest nodes after defining the CHs, thus increasing energy consumption and shortening the network’s lifetime. Second, the divergence between the optimal CH location and actual CH node location may be large, and a node belonging to another cluster may be mistakenly used as CH. Finally, a node may be selected as CH for multiple clusters given its closeness to the optimal location in different clusters. Consequently, the number of CH nodes may be smaller than the number of clusters, leading to suboptimal operation. Therefore, clustering should be adapted to consider the characteristics of WSNs, including the actual node locations.
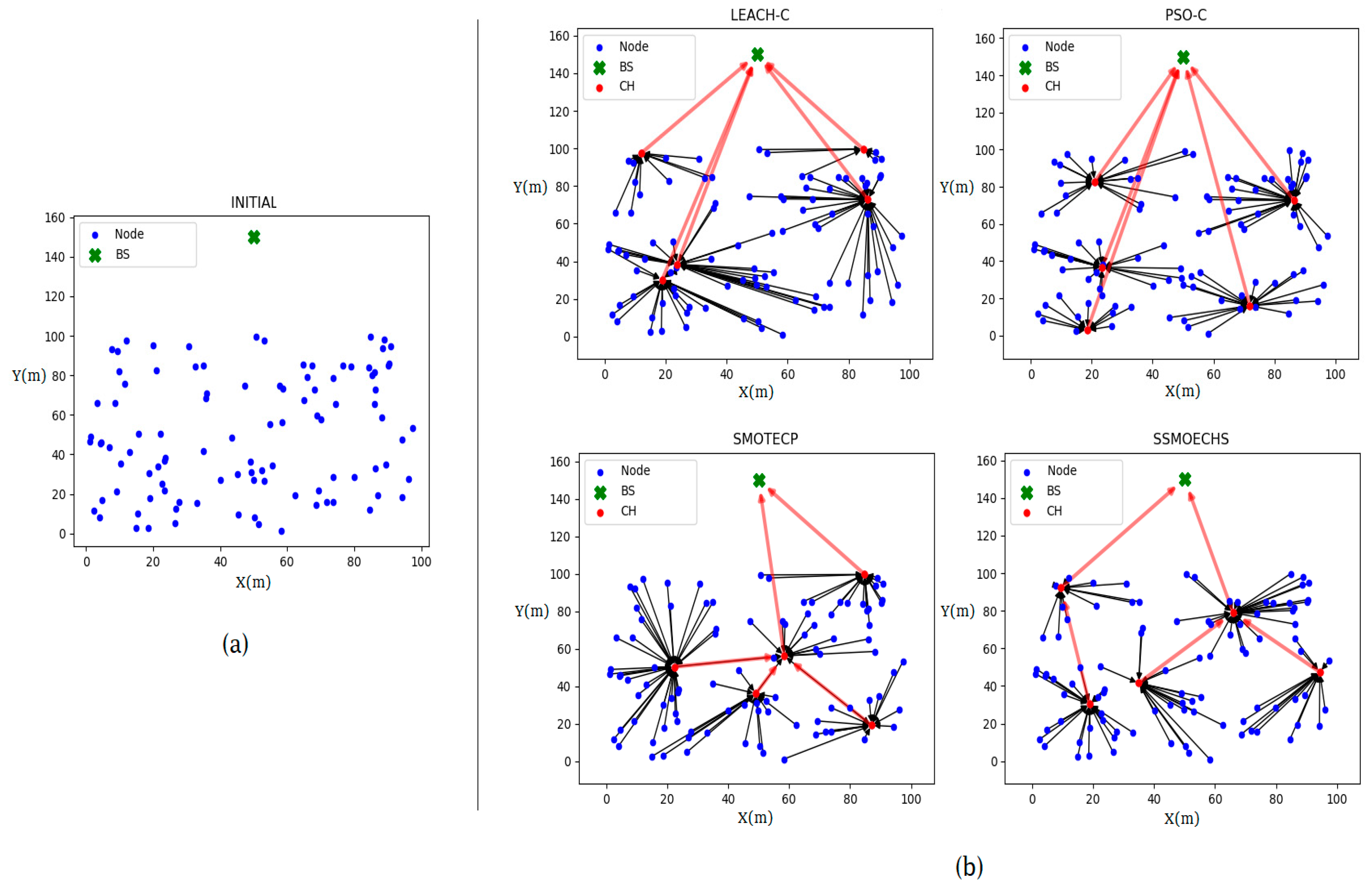
In this study, we modified SMO by using a sampling method for CH selection in WSNs. When sampling a population of nodes, their actual locations are always retrieved, thus preventing the abovementioned problems arising from the divergence between the optimal CH location and the actual node location. Moreover, multiple selections of nodes as CH among different clusters are prevented during sampling while avoiding complex computations. In fact, the modified SMO only provides optimal results from the best samples (i.e., actual node locations), as it only differs from the conventional SMO because its searching is constrained to samples. We first introduce the sampling-based SMO approach, and then we detail its application to WSNs by proposing the sampling-based SMO and energy-efficient CH selection (SSMOECHS). We also provide experimental results comparing SSMOECHS with existing protocols to illustrate CH selection and node energy efficiency over time. These results confirm that SSMOECHS improves the lifetime and stability of the WSN compared to similar protocols, namely LEACH-C [
7], PSO-C [
8], and SMOTECP [
18].
The main contributions of this work are as follows:
To the best of our knowledge, this is the first work that applies the sampling method to SMO to improve the lifetime and stability of wireless sensor nodes.
We propose the sampling-based SMO and energy-efficient CH selection (SSMOECHS).
We increase the lifetime and stability of the network through the proposed SSMOECHS.
To evaluate the performance of our protocol, we compare it with similar protocols, namely LEACH-C [
7], PSO-C [
8], and SMOTECP [
18].
The remainder of this manuscript is organized as follows.
Section 2 summarizes related work.
Section 3 introduces the sampling-based SMO, followed by the proposed SSMOECHS protocol in
Section 4.
Section 5 reports the experimental results and compares SSMOECHS with similar protocols and provides a discussion. We finally draw conclusions in
Section 6.
2. Related Work
In LEACH [
6], clustered hierarchical networks are used to increase the energy efficiency of WSNs. The clustering method selects a place for data collection (i.e., CH) per cluster. In addition, a probabilistic approach is used for CH selection, but the information of the cluster nodes, such as remaining energy, is not considered. To utilize the information of other nodes, it should be transmitted, but sending and receiving such information on wireless networks is difficult. LEACH-C [
7] uses time-division multiple access to address this problem. The BS informs each CH about the CH selection results and synchronizes transmission. The CHs also communicate with neighboring nodes and send schedules to eliminate data time lags. LEACH-C performs CH selection at other network components than the sensor nodes, which have limited computational resources. Because computations for CH selection are handled by the BS and other components, high computing power can be leveraged.
In recent years, protocols outperforming LEACH-C have been proposed, as CH selection that considers more data is feasible with improvements of computing power. In particular, swarm intelligence has been adopted in several protocols due to the high computing power currently available. PSO-C was the first protocol to utilize PSO in WSNs [
8]. After finding the locations of the optimal CHs, the nodes closest to these locations are defined as CHs. As search using PSO can provide remarkable results, optimally locating the CH increases both energy efficiency and the lifetime of the WSN. However, PSO-C selects the CH without considering the distance to the BS, possibly reducing energy efficiency during CH–BS data transmission. A PSO based Energy efficient Cluster Head Selection (PSOECHS) [
9] addresses this problem via an objective function that considers the CH–BS distance and extends the network lifetime by varying the way each node selects a CH, which allows for the control the number of nodes belonging to each cluster. Thus, energy consumption can be controlled during data reception from each CH. However, selecting a CH per sensor node demands high computational power and increases energy consumption, aspects disregarded during PSOECHS simulations.
In [
19], the amount of received data and number of nodes were adjusted by considering the coverage area of each CH, assuming that most sensor nodes are evenly distributed in the WSN. Thus, if the coverage is similar across CHs, they receive data from a similar number of nodes. Therefore, even if a node does not select a CH, the amount of received data can be adjusted. PSO-EC calculates energy distribution by fixing the coverage area and selects the energy centers as CHs [
10]. By selecting the node with the highest energy among surrounding nodes as CH, it improves energy efficiency. However, this method relies on energy distribution, undermining its performance at the initial state when node energy is evenly distributed.
SMO-C [
16] is a protocol that adopts SMO [
15], and like PSO-C, optimally locates the CH that is assigned to the nearest node. The objective function consists of two fitness values, namely node–CH distance and the energy consumed by nodes and CHs. However, energy consumption when sending data from a node to the CH is determined by the distance between adjacent nodes. Therefore, more calculations than in other protocols are required to obtain the fitness values, and the results have not shown a considerable improvement over similar protocols. In fact, the results in [
16] showed that SMO-C is not much better than LEACH. Alternatively, SMOEC [
17] has been shown to improve SMO-C by specifying the transmission protocol between CHs. Though the network lifetime is improved, stability remains an issue because certain nodes early deplete their energy.
When using clustering based on PSO and SMO, a specific location is first determined for a CH. Then, the node closest to this location is defined as CH. In SMOTECP [
18], CH selection is directly optimized to avoid this unnecessary computation. Binary SMO is adopted by considering CH selection as a binary problem [
20] where CH nodes are labeled as 1 and the others as 0 for optimization using Boolean operations. However, this method cannot control the number of CHs, because the Boolean operations retrieve a varying number of ones (i.e., CHs), which can in turn affect fitness values and undermine optimization. In addition, SMOTECP is difficult to apply in networks where the number of CHs is important.
Therefore, we addressed various important factors for CH selection in this study:
The objective function increases the energy efficiency by including the fitness value for energy consumption.
The objective function includes the fitness value for cover area to adjust the number of nodes covered by each CH.
The protocol can be used even when all nodes have the same energy (initial state).
Unnecessary operations are minimized by directly selecting nodes.
The number of CHs can be controlled and predicted.
3. Sampling-Based Spider Monkey Optimization
SMO [
15] is an optimization method inspired by the behavior of spider monkey foraging. When spider monkeys run out of food, they start exploration, and all the monkeys belonging to the group are controlled by a global leader. The global leader divides the group into several local groups as needed, and every local group is controlled by a local leader. After one round of exploration, the group members share their exploration results, and the leader moves to the location with the most abundant food resources (i.e., optimal result). This way, the global leader moves to the best location in the overall exploration results, and the local leaders move to the best location from their local groups. Exploration with local groups speeds up foraging, and the location of other monkeys prevents location biasing. Thus, SMO quickly retrieves the optimal location while avoiding local maxima.
SMO is useful for searching a specific location in a continuous environment. In WSNs, however, nodes have discrete locations. Therefore, if no node exists in some location at each round, exploration fails. Moreover, if the nearest node is selected as new destination to explore, additional operations are required to determine the nearest node. The proposed sampling-based SMO aims to find optimal feasible samples instead of locations. If the population to be sampled is composed of nodes, the results are node locations Therefore, the exploration failure problem caused by the absence of nodes in the optimized location is solved.
3.1. Sampling Probability
Samples are probabilistically extracted from the population with a sampling probability. This probability is important because we do not know the sampling results exactly, but we can infer the expected samples through the corresponding distribution. If the weight in SMO is used as sampling probability, the expected value may become zero or even negative. Therefore, the weight must be appropriately set to be used as the sampling probability in the proposed sampling-based SMO.
The sampling probability is necessary to update the samples for exploration in three phases, namely local leader, global leader, and local-leader decision phases. The local leader phase in [
15] is defined as
where
N is the number of spider monkeys,
is the updated location of the
i-th spider monkey,
is its current location,
is a random number between 0 and 1,
LL is the location of a local leader, and
is the location of a randomly selected spider monkey from the same group. If Equation (1) is expressed in terms of weights as
the weights of
,
LL and
are respectively given by
Both
and
can take negative values, and
may even make
disappear, as its expected value is 0. To prevent these problems, we used the logistic softmax function to randomize the weights. This function has been recently used in many studies for meaningful selections such as Boltzmann exploration [
21], classification using neural networks [
22], reinforcement learning, and classical statistical sampling [
23]. The logistic softmax function consists of exponential functions, which effectively prevents negative or zero weights:
where
M is the number of weights and
is the
j-th weight. Hence, we consider the sampling probability as the softmax weights for use in Equation (2):
Table 1 lists the expectation of weights (
), the notation of sampling probability, and the expectation of sampling probability (
) for each exploration phase. During each phase, different spider monkeys are selected, similar to the approach in [
15]. The abbreviations shown in the weight column in
Table 1 are as follows:
represents the
i-th spider monkey,
LL represents local leader,
GL represents global leader, and
represents a randomly selected monkey from the same group that is either the same local group in the local leader phase or the global group in the global leader phase.
We aim to select CHs, which are usually more than one. Therefore, the number of samples,
NS, is above 1, and each spider monkey must have a probability for all these
NS elements. Hence, each weight listed in
Table 1 should be expressed as an array instead of a single variable:
where
is a weight array composed of
NS copies of
. The sampling probability in Equation (4) is modified as follows:
where
M is the number of sampling probabilities, and as each spider monkey has
NS elements,
M =
.
3.2. Optimization Algorithm
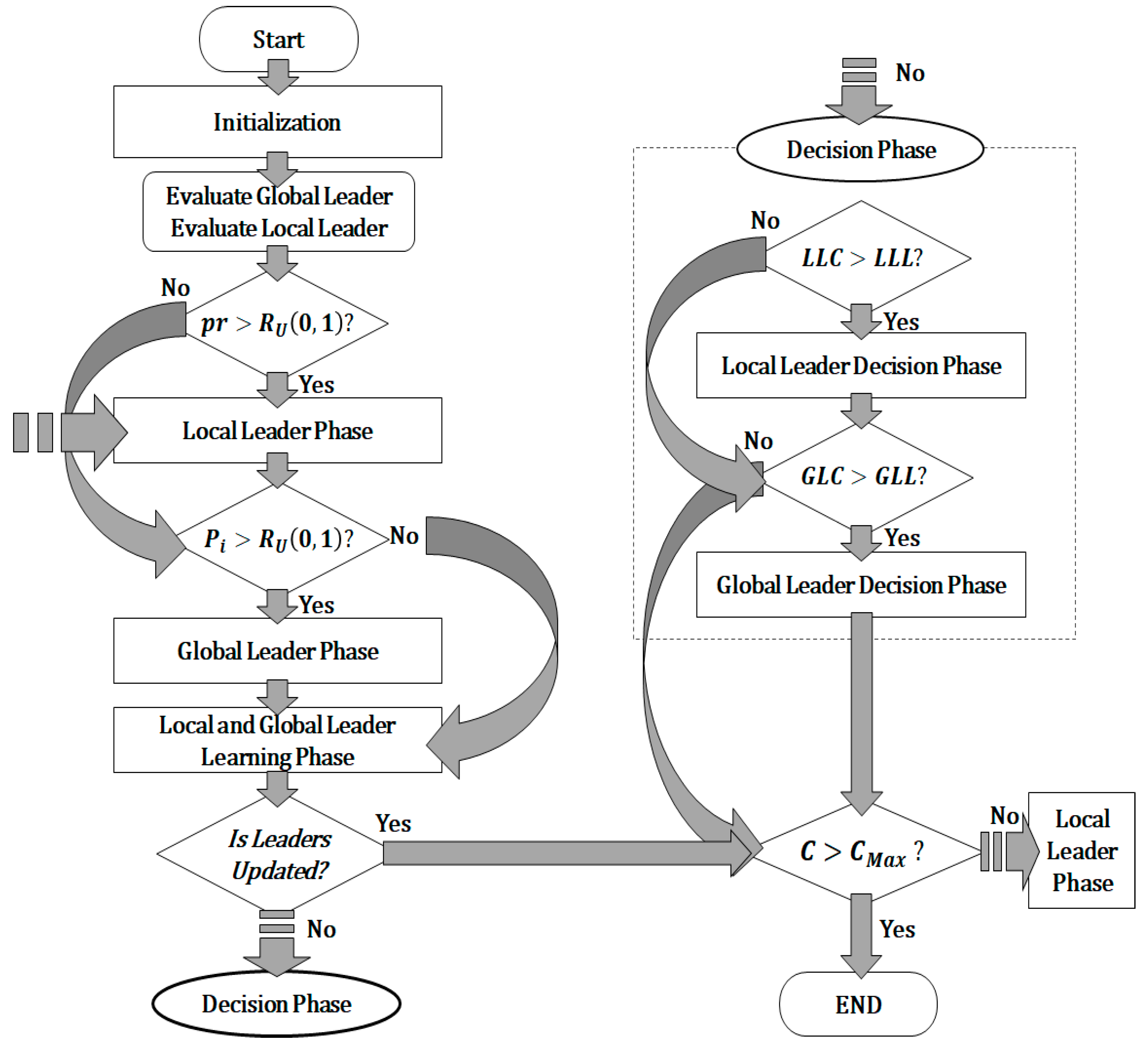
In a sampling-based SMO, exploration is divided into seven phases, similar to a conventional SMO [
15]: initialization, local leader, global leader, local-leader learning, global-leader learning, local-leader decision, and global-leader decision phases. Unlike a conventional SMO, sampling-based SMO updates the exploration samples along with the exploration location.
A sample is denoted as follows:
where Sample indicates the sample, POP is the population (sampling candidate group),
NS is the number of samples (i.e., the number of CHs in this manuscript), and Prob is the sampling probability array. As the elements of set POP have their own sampling probabilities, the size of both is
M, and each element is indexed by
j.
Figure 1 shows the overview of a sampling-based SMO. It can be seen that the sampling-based SMO consists of seven phases: initialization, local leader phase, global leader phase, local leader learning phase, global leader learning phase, and two decision phases (local leader decision phase and global leader decision phase). The subsections describe the operations performed in each of these phases.
3.2.1. Initialization
Exploration starts with initialization. Sampling is repeated
N(
Swarm Size) times in this phase to determine the initial samples per spider monkey:
where
is the exploration universe (i.e., a set containing all elements that can be sampled);
represents the uniform distribution between 0 and 1, indicating that all the elements have the same sampling probability; and
represents the samples of the
i-th spider monkey. Each spider monkey explores the fitness value of samples. Then, it selects those with the highest fitness values as initial global and local leaders.
3.2.2. Local Leader Phase
In this phase, each spider monkey
updates its samples using the samples of local leader
LL and random spider monkey
, all belonging to the same group:
where
is the population; the softmax function provides the sampling probability, which is given by Equation (6); and
pr is the perturbation rate that increases linearly from 0.1 to 0.4, increasing the search effort with the number of iterations. This is similar to that shown in [
15] and is expressed as follows.
where
C is the iteration counter and
is the maximum number of iterations.
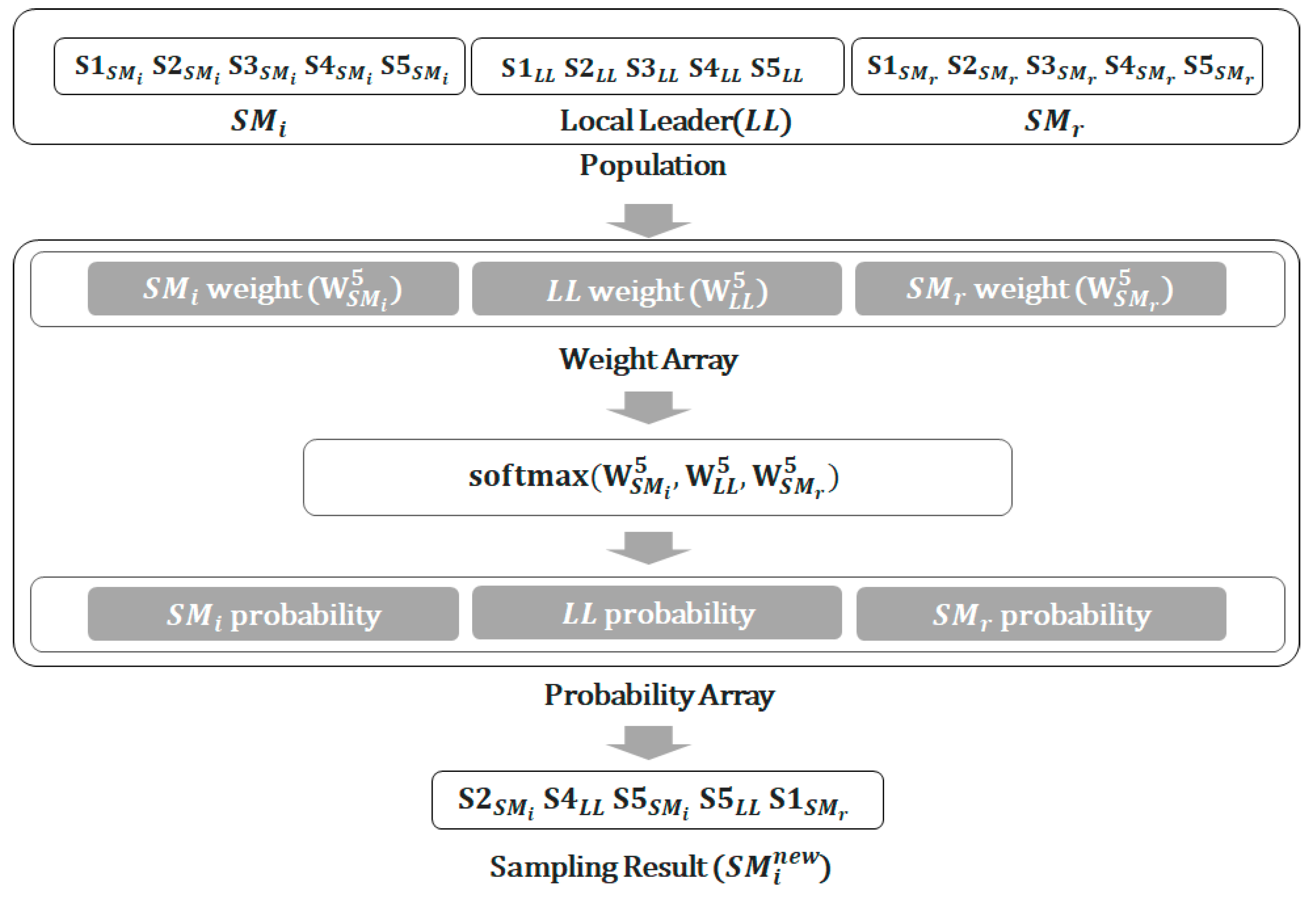
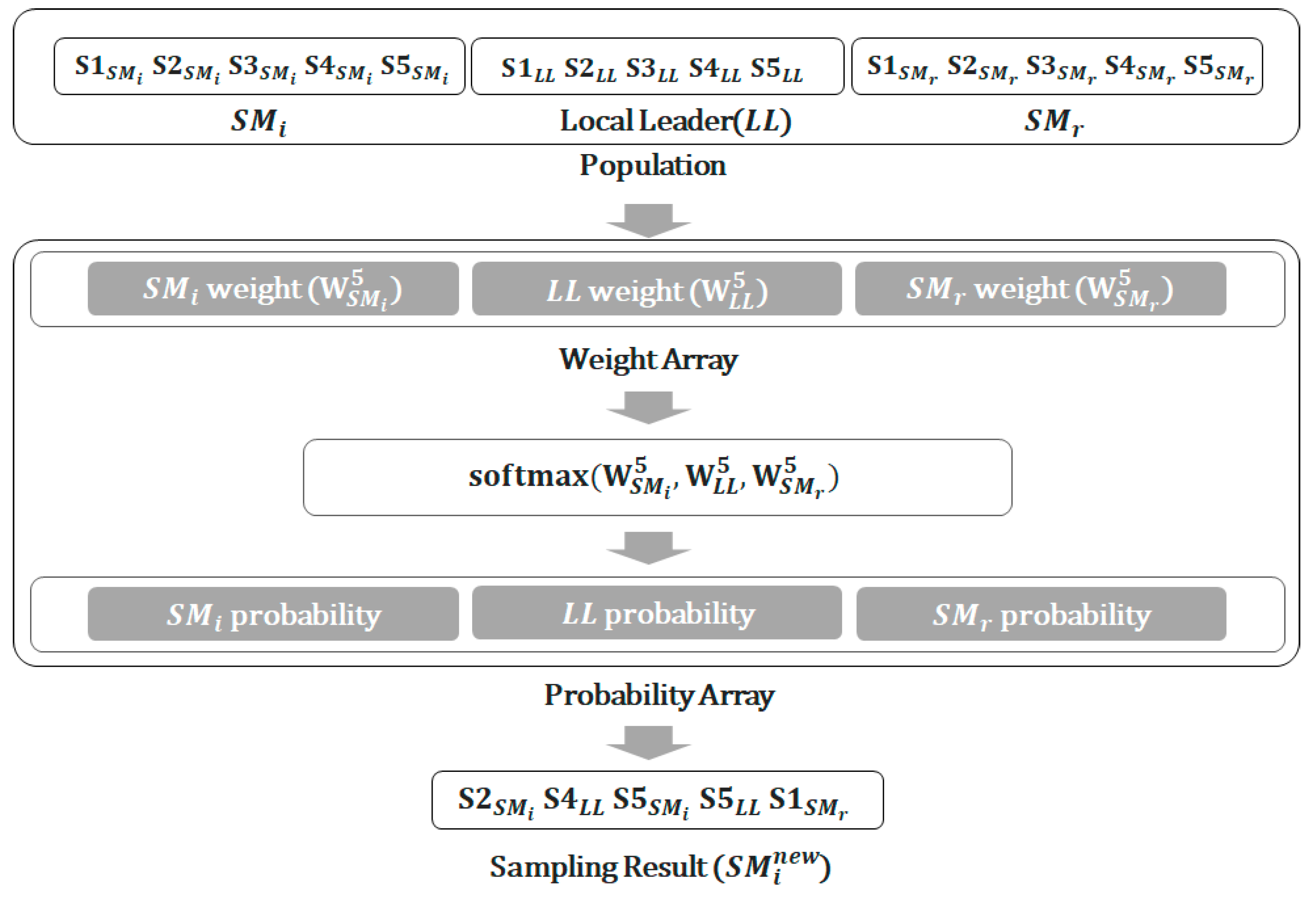
Figure 2 illustrates the procedure for the local leader phase, where
NS = 5 and the S1–S5 of each spider monkey (
,
LL and
) represent samples. For this
NS value, each spider monkey has 5 samples, and the population thus has 15 elements. As 5
NS samples are taken from the local leader phase, the number of samples per spider monkey is also 5
NS after this phase.
3.2.3. Global Leader Phase
In this phase, each spider monkey updates its samples using samples global leader
GL and randomly selected monkey
:
As shown in [
15], each spider monkey decides whether to update its samples with probability
. The higher fitness value implies more similarity to the global leader, and the probability changes with the number of iterations as follows:
where
is the fitness value of the
i-th spider monkey and MAX(
Fitnees) is the maximum value of the overall fitness value.
3.2.4. Local-Leader Learning Phase
In this phase, each local leader updates its samples with the best samples among the exploration results of the local group members. If there is no change in the samples of a local leader, the local leader count, LLC, is increased by 1.
3.2.5. Global-Leader Learning Phase
In this phase, the global leader updates its samples with the best samples among the exploration results of all the members. If there is no change in the samples of a global leader, the global leader count, GLC, is increased by 1.
3.2.6. Local-Leader Decision Phase
When the
LLC is above the local leader limit,
LLL, local leaders change the samples of members within the local group. In addition, each member simultaneously considers the samples of the global and local leaders to construct new samples to explore or initialize samples using Equation (7):
where
pr is as defined in Equation (10). This phase allows local group members to explore more samples.
3.2.7. Global-Leader Decision Phase
When the GLC is above the global leader limit, GLL, the global leader divides the entire group into several local groups, all of which have corresponding local leaders. In a sampling-based SMO, the number of local groups, LG, is increased by 1 until reaching its maximum, MG.
6. Conclusions
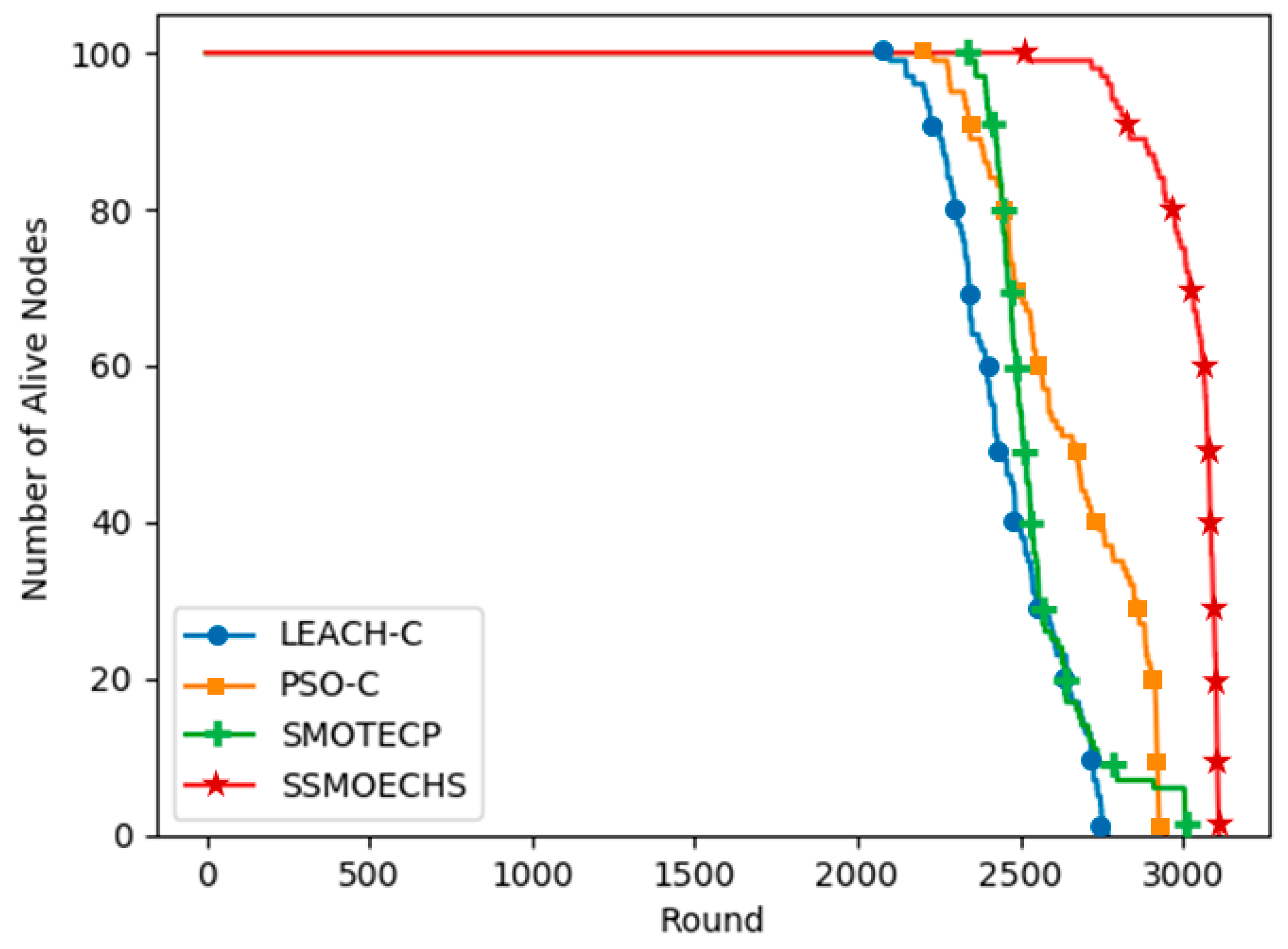
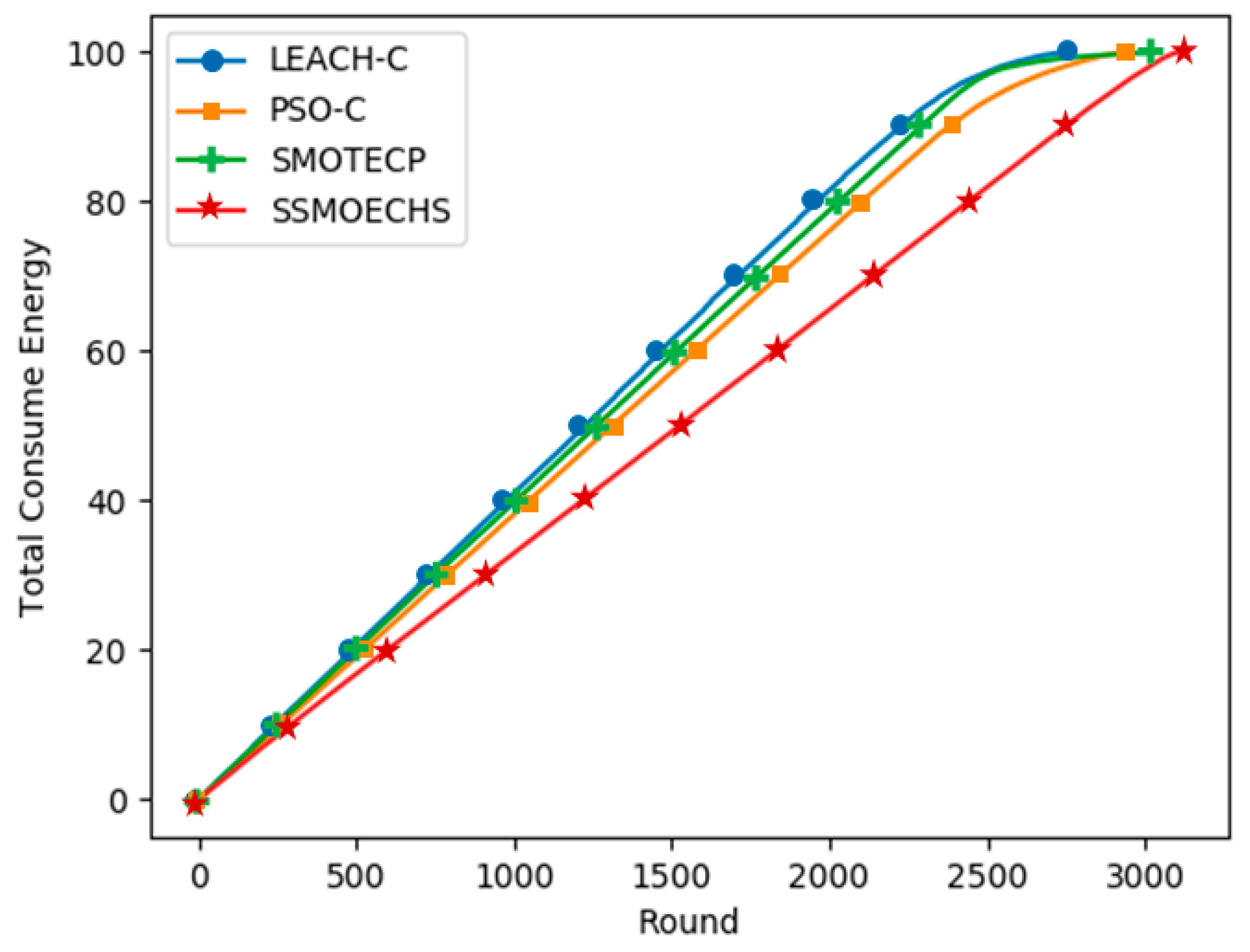
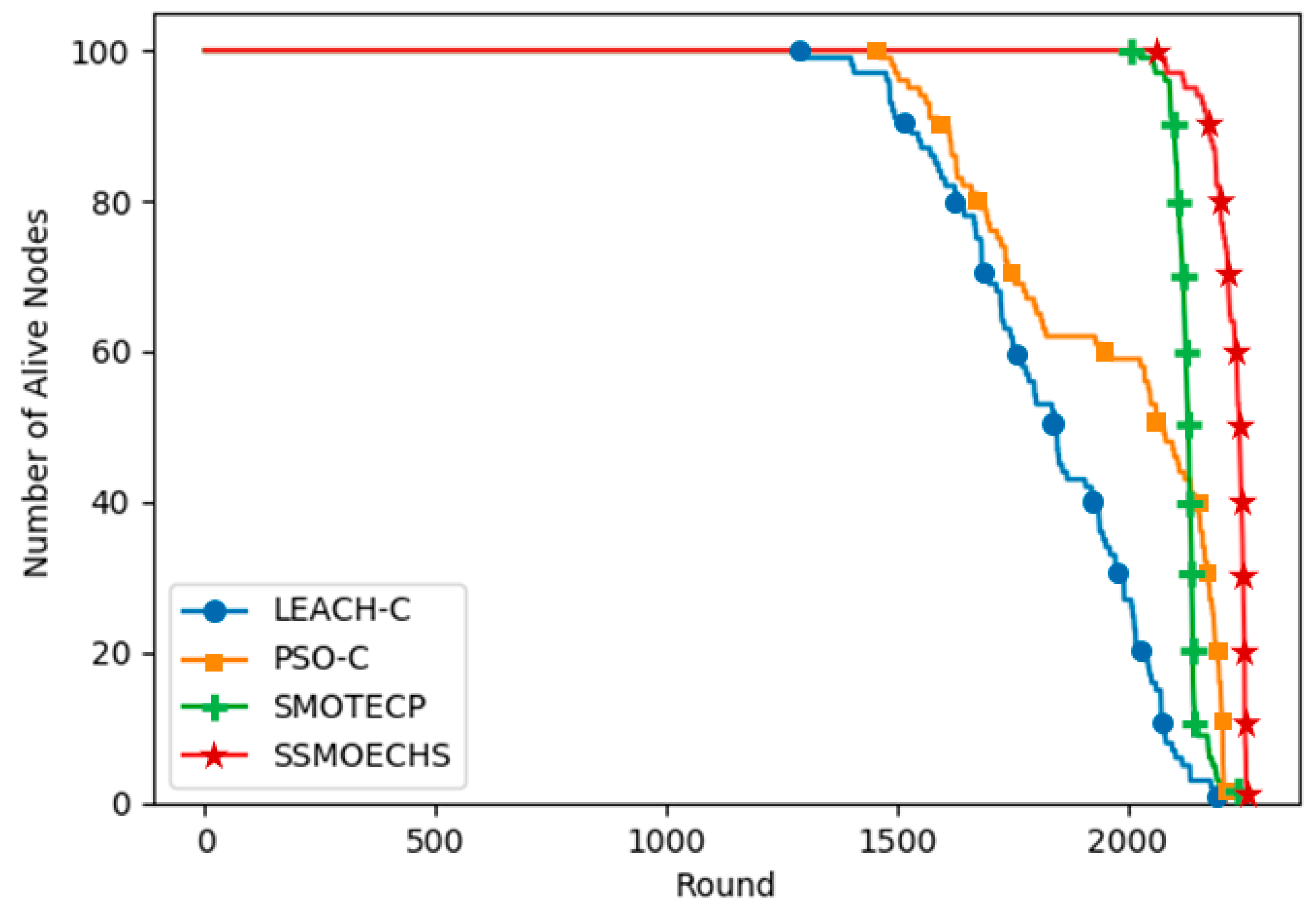
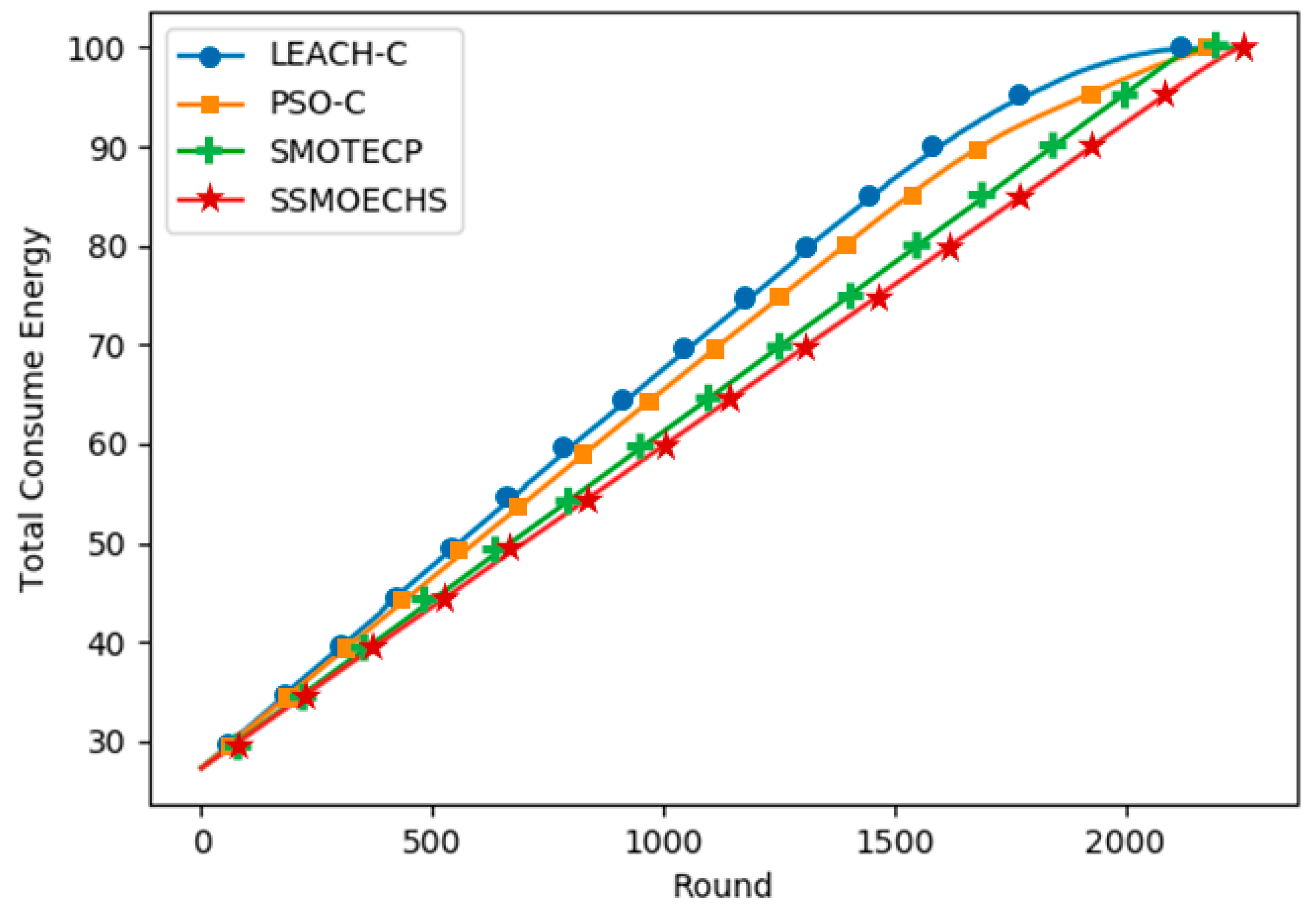
CH selection is essential to guarantee the energy efficiency in WSN protocols based on clustering. In many previous studies, the nearest nodes have been selected as CHs after finding the ideal CH location. We considered that the difference between the ideal CH location and actual CH node location can undermine energy efficiency. Therefore, we devised SSMOECHS, a CH selection method that considers actual node locations through sampling. The optimal CHs are obtained from sampling and optimized using a modified SMO algorithm, thus preventing the divergence between ideal CH location and actual CH node location and improving energy efficiency. To evaluate the proposed method, the experiment is divided into two setups: homogeneous setup and heterogeneous setup. In the homogeneous setup, SSMOECHS improved the network lifetime and stability by averages of 13.4% and 7.1%, respectively, compared to other similar protocols (LEACH-C, PSO-C, and SMOTECP). Likewise, in the heterogeneous setup, SSMOECHS improved the network lifetime and stability by averages of 34.6% and 1.8%, respectively. The superior performance of the proposed SSMOECHS was confirmed through experimental results, as it improved network lifetime and stability through efficient energy consumption. Consequently, the existing problems can be solved by changing the location-based CH selection method to the node-based CH selection method via SSMOECHS, and the network performance can be improved.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}