A Survey of Teleceptive Sensing for Wearable Assistive Robotic Devices


Abstract
1. Introduction
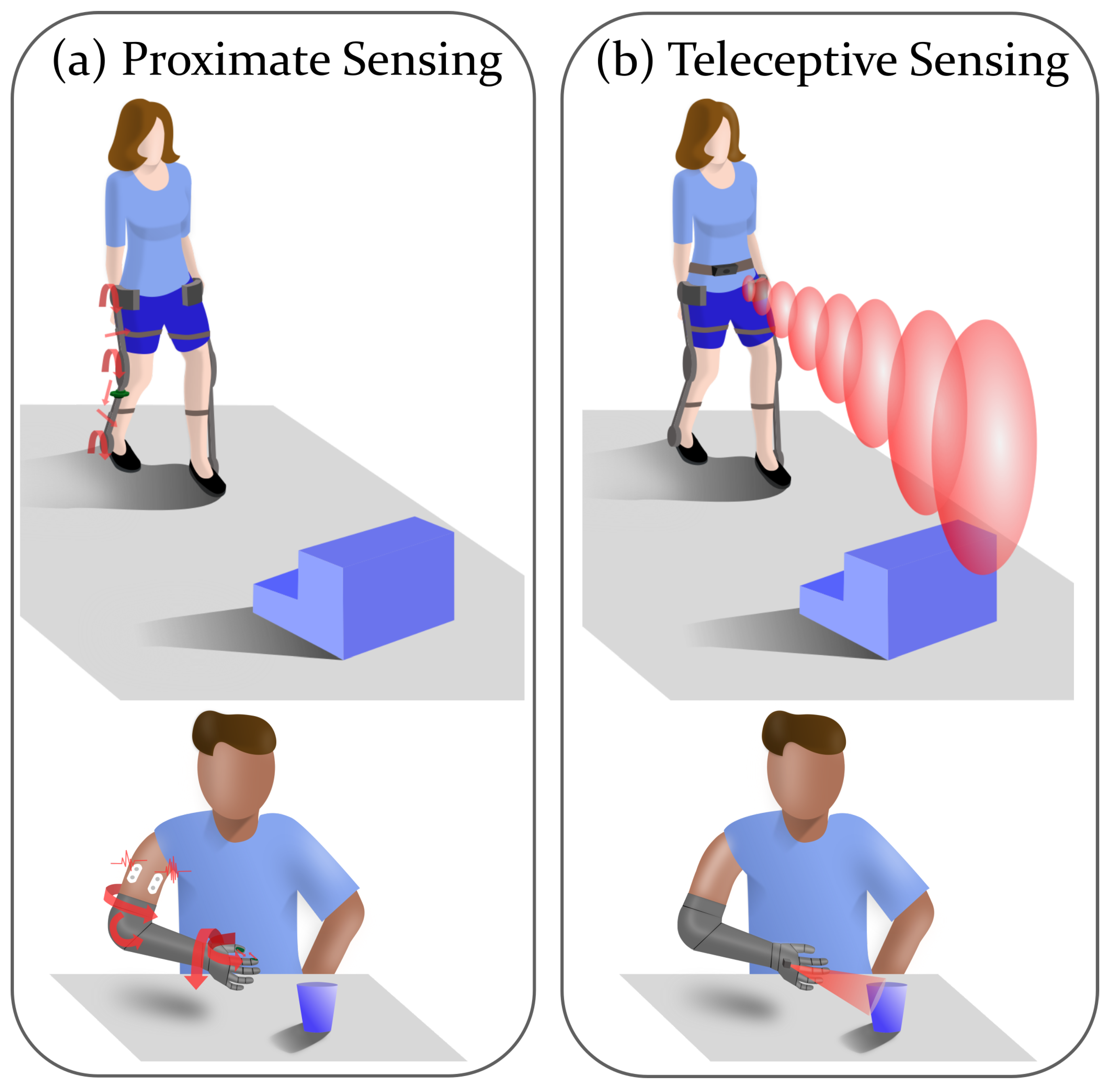
2. Teleceptive Sensing
3. Teleceptive Sensing Technology
3.1. Sensor Specifications
- Size and Weight: A wearable device should ideally be lightweight, so as not to increase users’ metabolic cost or fatigue, and be relatively unobtrusive and anthropomorphic. These requirements have previously been major factors limiting the use of these sensors for wearable devices, but advances in manufacturing and miniaturization has led to the development of some small, lightweight sensors.
- Range and Precision: The desired range and precision of a sensor depends on its ultimate application and use. A depth range of 0.5–3 m is sufficient to allow for sensing any obstacles or terrain changes within several strides of a walking subject, while identifying objects in a seated task only requires a sensing range of 5 cm–1 m. Similarly, greater signal precision is required for sensing smaller objects, or for more sensitive tasks. Some sensors can adjust depth range to allow for sensing objects of different scales or at different distances, such as the Camboard Pico Flexx [21]. The desired field of view may also be very different, depending on the specific application and sensor position.
- Frame Rate: Frame rate is an important specification to consider when selecting a sensor for use with a wearable robot. Sensors must be selected and operated at frame rates that are sufficient for motion estimation. However, there is a trade-off between data volume of high frame rate and computation time associated with processing more frames.
- Robustness: To be practical for daily use, assistive devices must be robust to different environmental conditions, such as indoor or outdoor lighting conditions, or different terrains. Additionally, they must be robust to slight differences in position from day to day. Sensor-fusion approaches could be useful in cases where a given sensor is not robust to lighting changes or a specific environmental condition. Other approaches that could also be used to minimize this effect include using frequency modulation to compensate for ambient lighting [22].
- Portability: Since the ultimate goal is to integrate teleceptive sensors into wearable assistive devices that can be used in activities of daily living in mobile scenarios, it is necessary to use lightweight sensors that work in an egocentric portable setup. This precludes the use of traditional gait or motion tracking systems that require fixed cameras and active or passive markers. Similarly, fixed-eye tracking systems are inappropriate for these purposes, despite their utility in other applications. Finally, though preliminary testing of any such sensors may be accomplished using a system tethered to a computer, ultimately any teleceptive sensor would need to be compatible with use in an embedded system.
- Cost: The high cost of wearable robotic devices has been a major source of concern. For instance, until recently in the US, no insurance companies were willing to cover the cost of a powered exoskeleton, although select insurers are now willing to consider reimbursement for these devices on a case by case basis [6]. Decreased costs may enable substantially more widespread global acceptance and use of these devices, both in home and clinical settings. Thus, teleceptive sensors need to be low cost, so as not to increase overall device costs.
3.2. Sensing Modalities
- RGB Cameras: RGB cameras operate within the range of visible light, and typically either use pixels consisting of semiconductor charge-coupled devices (CCD) or complementary metal–oxide–semiconductors (CMOS) [23]. In each case, each pixel within an RGB camera consists of a sensor that transduces light into electrical signals. RGB camera sensors typically operate within a range of 5–60 Hz, while other teleceptive sensors may operate at frame rates of 1000 Hz or more. RGB cameras have become ubiquitous; they are found in smartphones, smartwatches, virtual and augmented reality headsets, and numerous other commercially available electronic devices. This makes them the first sensor modality that many researchers turn to when considering adding teleception. Some cameras are now small enough to be unobtrusively clipped onto a belt or pocket [24,25]; however, although these cameras are low cost, have good resolution, can be reasonably small, and are easily embedded, they have some disadvantages that limit their use with wearable devices.RGB cameras are highly affected by changes in lighting conditions in each space, such as the difference between indoor and outdoor lighting. Researchers have developed methods to compensate for differences in lighting, though these are still limited in that RGB cameras will not function in very dim or very bright light [26,27,28,29]. Additionally, although many other teleceptive sensors provide three-dimensional (3D) information, traditional RGB cameras flatten the space into two dimensions and provide no information about depth. Depth information can be obtained from individual cameras or stereo pairs of cameras (see below); however, this is less direct or precise than that provided by other sensor modalities. It is possible to use an RGB camera for wearable teleception without extracting three-dimensional data, but these approaches have limited ability to predict the distance to an object or a terrain change, which may be desired. Three main approaches have been considered to obtain depth information from RGB cameras:
- (a)
- Monocular Cues: Monocular cues, such as motion parallax, relative size, occultation, depth from motion, or perspective convergence can provide cues for distance to objects within the field of view [30]. However, some monocular cues, such as relative size, occultation, and perspective convergence are generally only useful for estimating relative depth between objects, rather than absolute depth. Motion parallax and depth from motion, on the other hand can provide rough estimates of absolute depth if the movement direction and velocity of the camera is known [30].
- (b)
- Stereo Triangulation: Most commonly, stereo triangulation has been used to estimate depth from two RGB cameras. This approach uses two cameras placed at a known distance from each other, which can be calibrated using a standard approach to estimate each camera’s focal length. Epipolar geometry defines the position of an observed pixel on the image planes of each camera and, if these image planes are aligned using a rectification transformation, the distance to the observed pixel can then be computed using the focal lengths of the cameras and the distance between them [31].
- (c)
- Coded Aperture: This approach uses an estimation of blur, which will increase with increasing distance in a properly focused camera. The aperture of the camera has multiple distinct openings to allow for a unique blurring pattern, and, if the aperture mask is known, it is then possible to estimate depth from a sharp image and use this information to deblur other images and estimate the depth of pixels within these images [32]. This method is still relatively new and has not been extensively implemented in teleceptive sensors, but it is a promising method for performing depth sensing using a single RGB camera.
- (d)
- Dynamic Vision Sensors (DVS): These sensors were developed to mimic the human retina, in which signals are only produced if there is a visual change [33]. Using a DVS reduces processing requirements and is ideally suited for flow-based estimation and for high-speed recognition of changes in the field of view, without the need for a high-speed camera or computationally costly data processing or storage. These sensors do require at least a slight movement of the object or sensor for image production, but for wearable assistive devices this is likely not an issue.
- Laser/LED-Based Sensors: Though less ubiquitous than RGB cameras, Laser- and LED- (Light Emitting Diode) based sensors have become increasingly prevalent in electronic devices, including smartphones, video game systems, drones, and autonomous vehicles. At times, these sensors are combined with RGB cameras and referred to as RGB-D sensors. However, unlike passive RGB sensors, these devices are active in that a signal is emitted and then the reflected signal is sensed, compensating for changes in lighting or for ambient infrared light using frequency modulation. These devices are ideal for estimating the distance from a sensor to surfaces in the environment, as follows:
- (a)
- Slit scanners: Slit scanners or Sheet-of-Light systems, emit a flat “sheet” of light, which is moved along an object or surface. By observing the deformed shape of the light with a camera, it is possible to estimate the shape and depth of the object or surface [34]. This approach requires knowledge of the position and orientation of both the light source and camera relative to the measured object. To measure the entire environment, you can move either the light source or the object, and both of these approaches have been used by 3D scanners such as Cyberware, ShapeGrabber, ModelMaker, and Minolta’s 3D scanner [35]. This technology does require a trade-off between field of view and depth resolution, though approaches have been taken to optimize these parameters.
- (b)
- Structured light (SL): This teleceptive sensing approach was used in the first version of Microsoft Kinect. In this approach, a pattern of light (typically infrared, although other wavelengths are also used) is projected onto the environment. The pixels from the projected pattern are mapped back onto a camera to triangulate the depth of objects in space, similar to the way a stereo camera system operates [36]. To achieve accurate measurements from a structured light device, it is important to calibrate both the projector and the camera, preferably simultaneously (as proposed by Zhang, et al. in [37]).
- (c)
- Time of Flight (ToF): These sensors compute depth by measuring the delay time from when a light pulse is emitted until its reflection is returned and sensed by photo-sensitive diodes. Using this specific, very small delay, and knowing the speed of light, it is trivial to accurately compute the distance to an object [38]. ToF sensors typically use infrared light, and, depending on the specific type of sensor, may provide anywhere from a single distance measurement to a 360-degree field of view. These sensors have become miniaturized in recent years, with recent integration into smartphones [39] and AR headsets [40].
- Laser rangefinder: This is the simplest ToF sensor, which only requires a single photo-sensitive diode, as this type of sensor will only return a single depth measurement at a time [41]. These sensors can thus be used for distance estimation without significant computation; however, they do not provide as much environmental context as other teleceptive sensors discussed here. Additionally, this type of direct ToF sensor requires extremely high temporal sensitivity, to enable high precision depth measurements.
- Light Detection and Ranging (LiDAR): LiDAR has been used for several decades [42] and has become increasingly popular, particularly for autonomous vehicles, since the patent of Velodyne’s spinning LiDAR systems [43] in 2006. Using a spinning element as well as a large quantity of photo-sensitive diodes, it is possible to achieve a full 360-degree view. Although these sensors provide useful information, they are difficult to miniaturize and so are not ideal for wearable applications. An individual laser rangefinder can be operated at a much higher frequency and with lower computational cost than a full LiDAR sensor.
- Photonic Mixer Devices (PMD): PMDs modulate the outgoing light beam [44] using light-sensitive photogates and measure phase shift, rather than delay time, of the reflected light returned to each pixel to estimate the distance over the entire field of view. For each pixel, the system estimates the autocorrelation between the emitted frequency-modulated light and the returning reflected light, and uses this to estimate depth [22]. This technology reduces the need for delay precision to picoseconds, while still providing accurate depth sensing. Additionally, many of these devices use spectral filtering to reject ambient light sources and produce good depth sensing even in bright environments, including natural sunlight.
- Radar: Similar to LiDAR, radar estimates the depth of positions in space by emitting a pulse and measuring the time delay (or frequency modulation) of the reflected pulse. However, the important distinction of radar is that rather than using pulses of visible light these sensors use low-frequency radio waves [45], leading to slower depth sensing. Challenges associated with using radar include diffraction of the beam as well as source separation in the case of multiple objects. Typically, radar has worse resolution and slower performance than LiDAR, though the sensing range is much further and is less affected by occlusions as radar can pass through thin objects. Radar has been proposed extensively for use in autonomous vehicles. Additionally, the use of radar close to the body has some potential safety concerns; however, low-powered systems do not pose substantial problems.
- Ultrasonic Sensing: Unlike RGB- or Laser/LED-based systems that operate within the electromagnetic spectrum, ultrasonic sensors use high-frequency sound waves, above the audible range. Similar to ToF, ultrasonic sensors emit a pulse of sound and use the reflected sound, together with the known speed of sound propagation in the given medium (air, water, muscle, etc.), to estimate distance to the object. However, these sensors are affected by specular reflection, particularly with shiny or metallic surfaces [46].
- Sonar: Sonar is similar to ultrasonic sensing, but uses very low-frequency, rather than high-frequency, sound waves. Typically, these sensors are used under water, though in theory they could be used in other media. However, as sonar is in the audible range, use of this sensor modality in an assistive device could be quite distracting. Unlike the radio waves used in radar, ultrasonic/sonar signals are unable to pass through thin barriers, such as windows [47].
3.3. Advances in Computing
4. Teleception in Wearable Robotics
4.1. Control/Intent Recognition for Wearable Devices
4.2. Upper-Limb Prostheses and Exoskeletons
4.2.1. Grasp Prediction
4.2.2. Endpoint Control
4.3. Lower-Limb Prostheses and Exoskeletons
4.3.1. Gait Event Detection
4.3.2. Forward Prediction
4.3.3. Activity-Specific Control
5. Discussion
5.1. Barriers to Clinical Translation
5.2. Potential Directions of Research
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ToF | Time of Flight |
| SL | Structured Light |
| EMG | Electromyography |
| PID | Proportional-Integral-Derivative Controller |
| RGB | Red, Green, Blue |
| RGB-D | Red, Green, Blue-Depth |
| LiDAR | Light Detection and Ranging |
| PMD | Photonic Mixer Device |
| IMU | Inertial Measurement Unit |
| MMG | Mechanomyography |
| CNN | Convolutional Neural Network |
| SVM | Support Vector Machine |
| LSTM | Long-Short-Term-Memory |
| RANSAC | Random Sampling Consensus |
| AR | Augmented Reality |
| AB | Able-Bodied |
| TR | Transradial |
| TH | Transhumeral |
| TF | Transfemoral |
| DoF | Degree of Freedom |
| DVS | Dynamic Vision Sensor |
| FMCW | Frequency-Modulated Continuous Wave |
References
- Ottobock Inc. Bebionic Hand. Available online: https://www.ottobockus.com/prosthetics/upper-limb-prosthetics/solution-overview/bebionic-hand/ (accessed on 25 November 2019).
- BiOM. BiOM T2 Ankle. Available online: https://www.infinitetech.org/biom-ankle-foot/ (accessed on 25 November 2019).
- Ossur. iLimb Ultra. Available online: Available online: https://www.ossur.com/prosthetic-solutions/products/touch-solutions/i-limb-ultra (accessed on 25 November 2019).
- Sup, F.; Bohara, A.; Goldfarb, M. Design and control of a powered transfemoral prosthesis. Int. J. Rob. Res. 2008, 27, 263–273. [Google Scholar] [CrossRef] [PubMed]
- Bionics, E. Ekso Powered Exoskeleton. Available online: https://eksobionics.com/ (accessed on 25 November 2019).
- Rewalk. ReWalk 6.0. Available online: https://rewalk.com/ (accessed on 25 November 2019).
- Novak, D.; Riener, R. A survey of sensor fusion methods in wearable robotics. Rob. Autom. Syst. 2015, 73, 155–170. [Google Scholar] [CrossRef]
- Stein, R. Peripheral control of movement. Physiol. Rev. 1974, 54, 215–243. [Google Scholar] [CrossRef] [PubMed]
- Seidler, R.; Noll, D.; Thiers, G. Feedforward and feedback processes in motor control. Neuroimage 2004, 22, 1775–1783. [Google Scholar] [CrossRef] [PubMed]
- MacIver, M. Neuroethology: From Morphological Computation to Planning. In The Cambridge Handbook of Situated Cognition; Robbins, P., Aydede, M., Eds.; Cambridge University Press: New York, NY, USA, 2009; pp. 480–504. [Google Scholar]
- Nelson, M.E.; MacIver, M.A. Sensory acquisition in active sensing systems. J. Comp. Physiol. A 2006, 192, 573–586. [Google Scholar] [CrossRef] [PubMed]
- DeSouza, G.N.; Kak, A.C. Vision for mobile robot navigation: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 237–267. [Google Scholar] [CrossRef]
- Alphabet Inc. Waymo- Self Driving Vehicles. Available online: https://waymo.com/ (accessed on 25 November 2019).
- Mercedes Benz Automation. Available online: https://www.mercedes-benz.com/en/next/automation/ (accessed on 25 November 2019).
- Carsten, O.; Lai, F.C.H.; Barnard, Y.; Jamson, A.H.; Merat, N. Control Task Substitution in Semiautomated Driving: Does It Matter What Aspects Are Automated? Hum. Factors 2012, 54, 747–761. [Google Scholar] [CrossRef]
- Levinson, J.; Askeland, J.; Becker, J.; Dolson, J.; Held, D.; Kammel, S.; Kolter, J.Z.; Langer, D.; Pink, O.; Pratt, V. Towards Fully Autonomous Driving: Systems and Algorithms. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 3–8. [Google Scholar]
- Kruse, D.; Wen, J.T.; Radke, R.J. A Sensor-Based Dual-Arm Tele-Robotic System. IEEE Trans. Autom. Sci. Eng. 2015, 12, 4–18. [Google Scholar] [CrossRef]
- Dyson. Dyson 360 Eye-Robot Vacuum. Available online: https://www.dyson.co.uk/robot-vacuums/dyson-360-eye-overview.html (accessed on 25 November 2019).
- Simpson, R.C. Smart Wheelchairs: A Literature Review. J. Rehabil. Res. Dev. 2005, 42, 423–436. [Google Scholar] [CrossRef]
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimedia 2012, 19, 4–10. [Google Scholar] [CrossRef]
- PMD. Camboard Pico Flexx Kernel Description. Available online: http://pmdtec.com/picofamily/ (accessed on 25 November 2019).
- Ringbeck, T.; Möller, T.A.; Hagebeuker, B. Multidimensional measurement by using 3-D PMD sensors. Adv. Radio Sci. 2007, 5, 135–146. [Google Scholar] [CrossRef]
- Holst, G.C.; Lomheim, T.S. CMOS/CCD sensors and camera systems. Reconstruction 2011, 9, 2PFC. [Google Scholar]
- Google Inc. Google Clips. Available online: https://support.google.com/googleclips/answer/7545440?hl=en&ref_topic=7334536 (accessed on 25 November 2019).
- OrCam. MyMe. Available online: https://myme.orcam.com/ (accessed on 25 November 2019).
- Shan, S.; Gao, W.; Cao, B.; Zhao, D. Illumination normalization for robust face recognition against varying lighting conditions. In Proceedings of the 2003 IEEE International SOI Conference. Proceedings (Cat. No.03CH37443), Nice, France, 17 October 2003; pp. 157–164. [Google Scholar]
- Shashua, A.; Riklin-Raviv, T. The quotient image: Class-based re-rendering and recognition with varying illuminations. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 129–139. [Google Scholar] [CrossRef]
- Basri, R.; Jacobs, D.W. Lambertian reflectance and linear subspaces. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 218–233. [Google Scholar] [CrossRef]
- Belhumeur, P.N.; Kriegman, D.J. What is the set of images of an object under all possible illumination conditions? Int. J. Comput. Vision 1998, 28, 245–260. [Google Scholar] [CrossRef]
- Saxena, A.; Chung, S.H.; Ng, A.Y. Learning Depth from Single Monocular Images. Advances in Neural Information Processing Systems. Available online: http://papers.nips.cc/paper/2921-learning-depth-from-single-monocular-images.pdf (accessed on 25 November 2019).
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th Intl Joint Conf on Artificial Intelligence (IJCAI), Vancouver, BC, USA, 24–28 August 1981; pp. 674–679. [Google Scholar]
- Martinello, M.; Wajs, A.; Quan, S.; Lee, H.; Lim, C.; Woo, T.; Lee, W.; Kim, S.S.; Lee, D. Dual aperture photography: Image and depth from a mobile camera. In Proceedings of the 2015 IEEE International Conference on Computational Photography (ICCP), Houston, TX, USA, 24–26 April 2015; pp. 1–10. [Google Scholar]
- Weiss, L.; Sanderson, A.; Neuman, C. Dynamic sensor-based control of robots with visual feedback. IEEE J. Rob. Autom. 1987, 3, 404–417. [Google Scholar] [CrossRef]
- Blais, F.; Rioux, M.; Beraldin, J.A. Practical considerations for a design of a high precision 3-D laser scanner system. In Proceedings of the Optomechanical and Electro-Optical Design of Industrial Systems, Dearborn, MI, USA, 27–30 June 1988; pp. 225–246. [Google Scholar]
- Blais, F. Review of 20 years of range sensor development. J. Electron. Imaging 2004, 13, 231–243. [Google Scholar] [CrossRef]
- Bell, T.; Li, B.; Zhang, S. Structured Light Techniques and Applications. Available online: https://onlinelibrary.wiley.com/doi/full/10.1002/047134608X.W8298 (accessed on 25 November 2019).
- Zhang, S.; Huang, P.S. Novel method for structured light system calibration. Opt. Eng. 2006, 45, 083601. [Google Scholar]
- Cui, Y.; Schuon, S.; Chan, D.; Thrun, S.; Theobalt, C. 3D shape scanning with a time-of-flight camera. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1173–1180. [Google Scholar]
- LG Inc. LG G8 ThinQ. Available online: https://www.lg.com/us/mobile-phones/g8-thinq/air-motion (accessed on 25 November 2019).
- Microsoft Inc. Hololens 2 Hardware. Available online: https://www.microsoft.com/en-us/hololens/hardware (accessed on 25 November 2019).
- Lange, R.; Seitz, P. Solid-State Time-of-Flight Range Camera. IEEE J. Quantum Electron. 2001, 37, 390–397. [Google Scholar] [CrossRef]
- Kaman, C.H.; Ulich, B.L.; Mayerjak, R.; Schafer, G. Imaging Lidar System. U.S. Patent 5,231,401, 27 July 1993. [Google Scholar]
- Hall, D.S. High Definition Lidar System. U.S. Patent 7,969,558, 28 June 2011. [Google Scholar]
- Ringbeck, T.; Hagebeuker, D.I.B. A 3D Time of Flight Camera for Object Detection. Available online: https://pdfs.semanticscholar.org/c5a6/366b80ba9507891ca048c3a85e6253fd2260.pdf (accessed on 25 November 2019).
- Carmer, D.C.; Peterson, L.M. Laser radar in robotics. Proc. IEEE 1996, 84, 299–320. [Google Scholar] [CrossRef]
- Smith, R.; Self, M.; Cheeseman, P. Estimating uncertain spatial relationships in robotics. In Autonomous Robot Vehicles; Springer: New York, NY, USA, 1990; pp. 167–193. [Google Scholar]
- Elfes, A. Sonar-based real-world mapping and navigation. IEEE J. Rob. Autom. 1987, 3, 249–265. [Google Scholar] [CrossRef]
- Hazas, M.; Scott, J.; Krumm, J. Location-aware computing comes of age. Computer 2004, 37, 95–97. [Google Scholar] [CrossRef]
- Pulli, K.; Baksheev, A.; Kornyakov, K.; Eruhimov, V. Real-time computer vision with OpenCV. Commun. ACM 2012, 55, 61–69. [Google Scholar] [CrossRef]
- Carlson, T.; Millán, J.D.R. Brain-controlled wheelchairs: A robotic architecture. Rob. Autom. Mag. IEEE 2013, 20, 65–73. [Google Scholar] [CrossRef]
- Jain, S.; Argall, B. Automated perception of safe docking locations with alignment information for assistive wheelchairs. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 4997–5002. [Google Scholar]
- Corbett, E.A.; Körding, K.P.; Perreault, E.J. Real-time evaluation of a noninvasive neuroprosthetic interface for control of reach. IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 21, 674–683. [Google Scholar] [CrossRef] [PubMed]
- McMullen, D.P.; Hotson, G.; Katyal, K.D.; Wester, B.A.; Fifer, M.S.; McGee, T.G.; Harris, A.; Johannes, M.S.; Vogelstein, R.J.; Ravitz, A.D. Demonstration of a semi-autonomous hybrid brain–machine interface using human intracranial EEG, eye tracking, and computer vision to control a robotic upper limb prosthetic. IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 22, 784–796. [Google Scholar] [CrossRef] [PubMed]
- Dang, Q.; Chee, Y.; Pham, D.; Suh, Y. A virtual blind cane using a line laser-based vision system and an inertial measurement unit. Sensors 2016, 16, 95. [Google Scholar] [CrossRef]
- Wang, S.; Tian, Y. Detecting stairs and pedestrian crosswalks for the blind by RGBD camera. In Proceedings of the 2012 IEEE International Conference on Bioinformatics and Biomedicine Workshops, Philadelphia, PA, USA, 4–7 October 2012; pp. 732–739. [Google Scholar]
- Zhu, Z.; Ro, T.; Ai, L.; Khoo, W.; Molina, E.; Palmer, F. Wearable Navigation Assistance for the Vision-Impaired. U.S. Patent 14/141,742, 3 July 2014. [Google Scholar]
- Kim, Y.J.; Cheng, S.S.; Ecins, A.; Fermüller, C.; Westlake, K.P.; Desai, J.P. Towards a Robotic Hand Rehabilitation Exoskeleton for Stroke Therapy. Available online: https://asmedigitalcollection.asme.org/DSCC/proceedings-abstract/DSCC2014/46186/V001T04A006/228305 (accessed on 25 November 2019).
- Baklouti, M.; Monacelli, E.; Guitteny, V.; Couvet, S. Intelligent Assistive Exoskeleton with Vision Based Interface. In Smart Homes and Health Telematics, Proceedings of the International Conference on Smart Homes and Health Telematics ICOST, Ames, IA, USA, 28 June–2 July 2008; Springer: Berlin, Heidelberg/Germany, 2008; pp. 123–135. [Google Scholar]
- Castellini, C.; Sndini, G. Gaze tracking for robotic control in intelligent teleoperation and prosthetics. In Proceedings of the 2nd Conference on Communication by Gaze Interaction—COGAIN 2006: Gazing into the Future, Turin, Italy, 4–5 September 2006; pp. 73–77. [Google Scholar]
- Zhang, F.; Liu, M.; Huang, H. Effects of locomotion mode recognition errors on volitional control of powered above-knee prostheses. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 23, 64–72. [Google Scholar] [CrossRef]
- Madusanka, D.G.K. Development of a Vision Aided Reach-to-Grasp Path Planning and Controlling Method for Trans-Humeral Robotic Prostheses. Available online: http://dl.lib.mrt.ac.lk/handle/123/13397 (accessed on 25 November 2019).
- Krausz, N.E.; Lamotte, D.; Varanov, S.; Batzianoulis, B.; Hargrove, L.J.; Micera, S.; Billard, A. Intent Prediction Based on Biomechanical Coordination of EMG and Vision-Filtered Gaze for End-Point Control of an Arm Prosthesis. 2019. in review. [Google Scholar]
- Scandaroli, G.G.; Borges, G.A.; Ishihara, J.Y.; Terra, M.H.; da Rocha, A.F.; de Oliveira Nascimento, F.A. Estimation of Foot Orientation with Respect to Ground for an Above Knee Robotic Prosthesis. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), St. Louis, MO, USA, 10–15 October 2009; pp. 1112–1117. [Google Scholar]
- Liu, D.X.; Xu, J.; Chen, C.; Long, X.; Tao, D.; Wu, X. Vision-Assisted Autonomous Lower-Limb Exoskeleton Robot. IEEE Trans. Syst. Man Cybern. Syst. Available online: https://ieeexplore.ieee.org/abstract/document/8802297 (accessed on 25 November 2019).
- MyoMo Inc. MyoPro Orthosis. Available online: https://myomo.com/what-is-a-myopro-orthosis/ (accessed on 25 November 2019).
- Došen, S.; Popovic, D.B. Transradial Prosthesis: Artificial Vision for Control of Prehension. Artif. Organs 2010, 25, 37–48. [Google Scholar] [CrossRef]
- Dosen, S.; Cipriani, C.; Kostić, M.; Controzzi, M.; Carrozza, M.C.; Popović, D.B. Cognitive vision system for control of dexterous prosthetic hands: Experimental evaluation. J. NeuroEng. Rehabil. 2010, 7. Available online: https://jneuroengrehab.biomedcentral.com/articles/10.1186/1743-0003-7-42 (accessed on 25 November 2019). [CrossRef] [PubMed]
- Marković, M.; Došen, S.; Cipriani, C.; Popovic, D.; Farina, D. Stereovision and Augmented Reality for Closed-Loop Control of Grasping in Hand Prostheses. J. Neural Eng. 2014, 11. Available online: https://iopscience.iop.org/article/10.1088/1741-2560/11/4/046001/pdf (accessed on 25 November 2019). [CrossRef] [PubMed]
- Marković, M.; Došen, S.; Popovic, D.; Graimann, B.; Farina, D. Sensor fusion and computer vision for context-aware control of a multi degree-of-freedom. J. Neural Eng. 2015, 12. Available online: https://iopscience.iop.org/article/10.1088/1741-2560/12/6/066022/pdf (accessed on 25 November 2019). [CrossRef] [PubMed]
- Gardner, M.; Woodward, R.; Vaidyanathan, R.; Bürdet, E.; Khoo, B.C. An unobtrusive vision system to reduce the cognitive burden of hand prosthesis control. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; pp. 1279–1284. [Google Scholar]
- Giordaniello, F.; Cognolato, M.; Graziani, M.; Gijsberts, A.; Gregori, V.; Saetta, G.; Hager, A.G.M.; Tiengo, C.; Bassetto, F.; Brugger, P.; et al. Megane Pro: Myo-electricity, visual and gaze tracking data acquisitions to improve hand prosthetics. In Proceedings of the 2017 International Conference on Rehabilitation Robotics (ICORR), London, UK, 17–20 July 2017; pp. 1148–1153. [Google Scholar]
- DeGol, J.; Akhtar, A.; Manja, B.; Bretl, T. Automatic grasp selection using a camera in a hand prosthesis. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 431–434. [Google Scholar]
- Tang, S.; Ghosh, R.; Thakor, N.V.; Kukreja, S.L. Orientation estimation and grasp type detection of household objects for upper limb prostheses with dynamic vision sensor. In Proceedings of the 2016 IEEE Biomedical Circuits and Systems Conference (BioCAS), Shanghai, China, 17–19 October 2016; pp. 99–102. [Google Scholar]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128×128 120 dB 15μs Latency Asynchronous Temporal Contrast Vision Sensor. IEEE J. Solid-State Circuits 2008, 43, 566–576. [Google Scholar] [CrossRef]
- Ghazaei, G.; Alameer, A.; Degenaar, P.; Morgan, G.; Nazarpour, K. Deep learning-based artificial vision for grasp classification in myoelectric hands. J. Neural Eng. 2017, 14. Available online: https://iopscience.iop.org/article/10.1088/1741-2552/aa6802/pdf (accessed on 25 November 2019). [CrossRef]
- Bu, N.; Bandou, Y.; Fukuda, O.; Okumura, H.; Arai, K. A semi-automatic control method for myoelectric prosthetic hand based on image information of objects. In Proceedings of the 2017 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Okinawa, Japan, 24–26 November 2017; pp. 23–28. [Google Scholar]
- Taverne, L.T.; Cognolato, M.; Bützer, T.; Gassert, R.; Hilliges, O. Video-based Prediction of Hand-grasp Preshaping with Application to Prosthesis Control. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4975–4982. [Google Scholar]
- Martin, H.; Donaw, J.; Kelly, R.; Jung, Y.; Kim, J.H. A novel approach of prosthetic arm control using computer vision, biosignals, and motion capture. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Robotic Rehabilitation and Assistive Technologies (CIR2AT), Orlando, FL, USA, 9–12 December 2014; pp. 26–30. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Saudabayev, A.; Rysbek, Z.; Khassenova, R.; Varol, H.A. Human grasping database for activities of daily living with depth, color and kinematic data streams. Sci. Data 2018, 5. Available online: https://www.nature.com/articles/sdata2018101.pdf (accessed on 25 November 2019).
- Varol, H.A.; Sup, F.; Goldfarb, M. Multiclass real-time intent recognition of a powered lower limb prosthesis. IEEE Trans. Biomed. Eng. 2009, 57, 542–551. [Google Scholar] [CrossRef]
- Tao, W.; Liu, T.; Zheng, R.; Feng, H. Gait analysis using wearable sensors. Sensors 2012, 12, 2255–2283. [Google Scholar] [CrossRef]
- Roerdink, M.; Lamoth, C.J.; Beek, P.J. Online gait event detection using a large force platform embedded in a treadmill. J. Biomech. 2008, 41, 2628–2632. [Google Scholar] [CrossRef]
- O’Connor, C.M.; Thorpe, S.K.; O’Malley, M.J.; Vaughan, C.L. Automatic detection of gait events using kinematic data. Gait Posture 2007, 25, 469–474. [Google Scholar] [CrossRef] [PubMed]
- Nieto-Hidalgo, M.; Ferrández-Pastor, F.J.; Valdivieso-Sarabia, R.J.; Mora-Pascual, J.; García-Chamizo, J.M. A vision based proposal for classification of normal and abnormal gait using RGB camera. J. Biomed. Inf. 2016, 63, 82–89. [Google Scholar] [CrossRef] [PubMed]
- Hu, B.H.; Krausz, N.E.; Hargrove, L.J. A novel method for bilateral gait segmentation using a single thigh-mounted depth sensor and IMU. In Proceedings of the IEEE International Conference on Biomedical Robotics and Biomechatronics (Biorob), Enschede, The Netherlands, 26–29 August 2018; pp. 807–812. [Google Scholar]
- Zhang, F.; Fang, Z.; Liu, M.; Huang, H. Preliminary Design of a Terrain Recognition System. In Proceedings of the 2011 Annual International Conference of the IEEE EMBS (EMBC), Boston, MA, USA, 30 August–3 September 2011; pp. 5452–5455. [Google Scholar]
- Liu, M.; Wang, D.; Huang, H. Development of an Environment-Aware Locomotion Mode Recognition System for Powered Lower Limb Prostheses. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 434–443. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, S.; Figueiredo, J.; Santos, C.P. Environment-Aware Locomotion Mode Transition Prediction System. In Proceedings of the 2019 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Porto, Portugal, 24–26 April 2019. [Google Scholar]
- Krausz, N.E.; Lenzi, T.; Hargrove, L.J. Depth Sensing for Improved Control of Lower Limb Prostheses. IEEE Trans. Biomed. Eng. 2015, 62, 2576–2587. [Google Scholar] [CrossRef] [PubMed]
- Krausz, N.E.; Hargrove, L.J. Recognition of ascending stairs from 2D images for control of powered lower limb prostheses. In Proceedings of the 2015 7th International IEEE/EMBS Conference on Neural Engineering (NER), Montpellier, France, 22–24 April 2015; pp. 615–618. [Google Scholar]
- Krausz, N.E.; Hargrove, L.J. Fusion of Depth Sensing, Kinetics and Kinematics for Intent Prediction of Lower Limb Prostheses. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Seogwipo, Korea, 11–15 July 2017. [Google Scholar]
- Zhao, X.M.; Chen, W.H.; Yan, X.; Wang, J.H.; Wu, X.M. Real-Time Stairs Geometric Parameters Estimation for Lower Limb Rehabilitation Exoskeleton. In Proceedings of the 30th Chinese Control and Decision Conference (2018 CCDC), Shenyang, China, 9–11 June 2018; pp. 5018–5023. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Yan, T.; Sun, Y.; Liu, T.; Cheung, C.H.; Meng, M.Q.H. A locomotion recognition system using depth images. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6766–6772. [Google Scholar]
- Kleiner, B.; Ziegenspeck, N.; Stolyarov, R.; Herr, H.; Schneider, U.; Verl, A. A radar-based terrain mapping approach for stair detection towards enhanced prosthetic foot control. In Proceedings of the IEEE International Conference on Biomedical Robotics and Biomechatronics (Biorob), Enschede, The Netherlands, 26–29 August 2018; pp. 105–110. [Google Scholar]
- Varol, H.; Massalin, Y. A Feasibility Study of Depth Image Based Intent Recognition for Lower Limb Prostheses. In Proceedings of the Annual International Conference of the IEEE EMBS (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 5055–5058. [Google Scholar]
- Massalin, Y.; Abdrakhmanova, M.; Varol, H.A. User-Independent Intent Recognition for Lower Limb Prostheses Using Depth Sensing. IEEE Trans. Biomed. Eng. 2018, 65, 1759–1770. [Google Scholar]
- Laschowski, B.; McNally, W.; Wong, A.; McPhee, J. Preliminary Design of an Environment Recognition System for Controlling Robotic Lower-Limb Prostheses and Exoskeletons. In Proceedings of the IEEE International Conference on Rehabilitation Robotics (ICORR), Toronto, ON, Canada, 24–28 June 2019. [Google Scholar]
- Novo-Torres, L.; Ramirez-Paredes, J.P.; Villarreal, D.J. Obstacle Recognition using Computer Vision and Convolutional Neural Networks for Powered Prosthetic Leg Applications. In Proceedings of the Annual International Conference of the IEEE EMBS (EMBC), Berlin, Germany, 23–27 July 2019; pp. 3360–3363. [Google Scholar]
- Khademi, G.; Simon, D. Convolutional Neural Networks for Environmentally Aware Locomotion Mode Recognition of Lower-Limb Amputees. In Proceedings of the ASME Dynamic Systems and Control Conference (DSCC), Park City, UT, USA, 8–11 October 2019. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Available online: https://arxiv.org/abs/1409.1556 (accessed on 25 November 2019).
- Zhang, K.G.; Xiong, C.H.; Zhang, W.; Liu, H.Y.; Lai, D.Y.; Rong, Y.M.; Fu, C.L. Environmental Features Recognition for Lower Limb Prostheses Toward Predictive Walking. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 465–476. [Google Scholar] [CrossRef]
- Krausz, N.E.; Hu, B.H.; Hargrove, L. Variability Analysis of Subject- and Environment-Based Sensor Data for Forward Prediction of Wearable Lower-Limb Assistive Devices. Sensors 2019, 19, 4887. [Google Scholar] [CrossRef]
- Krausz, N.; Hargrove, L. Sensor Fusion of Depth, Kinetics and Kinematics for Forward Prediction of Locomotion Mode During Ambulation with a Transfemoral Prosthesis. 2019. in review. [Google Scholar]
- Gregg, R.D.; Lenzi, T.; Hargrove, L.J.; Sensinger, J.W. Virtual constraint control of a powered prosthetic leg: From simulation to experiments with transfemoral amputees. IEEE Trans. Rob. 2014, 30, 1455–1471. [Google Scholar] [CrossRef]
- Lenzi, T.; Hargrove, L.J.; Sensinger, J.W. Preliminary evaluation of a new control approach to achieve speed adaptation in robotic transfemoral prostheses. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 2049–2054. [Google Scholar]
- Zhang, K.; Wang, J.; Fu, C.L. Directional PointNet: 3D Environmental Classification for Wearable Robotics. arXiv 2019, arXiv:1903.06846. [Google Scholar]
- Biddiss, E.; Beaton, D.; Chau, T. Consumer design priorities for upper limb prosthetics. Disabil. Rehabil. Assist. Technol. 2007, 2, 346–357. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
| Year | Authors | Device | Online | Modality | Teleceptive Sensor | Placed | Sensing Setup | Other Sensors | Subjects | Prediction | Processing | Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grasp Preshaping | ||||||||||||
| 2010 | Došen and Popovic’ [66] | - | - | RGB and Ultrasound | EXOO-M053 Webcam, SRF04 Ultrasound | In Hand | 320 × 240 pixels | EMG | - | Object Size | Object Segmentation | 79% |
| 2010 | Došen, et al. [67] | CyberHand Prosthesis | Yes | RGB and Ultrasound | EXOO-M053 Webcam, SRF04 Ultrasound | In Hand | 320 × 240 pixels | EMG | 13 AB | Grasp Type, Object Size | Object Segmentation | 84% |
| 2014 | Markovic, et al. [68] | SmartHand Prosthesis | Yes | Stereo RGB | Vuzix AR Headset, with Stereo RGB Cameras | Glasses | 30 Hz, 640 × 480 pixels | EMG | 13 AB | Grasp Type, Hand Aperture | Geometric Model | 90% |
| 2014 | Gardner, et al. [70] | Bebionic v2 Hand | Yes | RGB | Logicam USB Webcam | In Hand | 640 × 480 pixels | MMG | 1 AB | Grasp Type | Edge Detection | 84% |
| 2015 | Markovic, et al. [69] | Michelangelo Hand, Wrist | Yes | RGB-D, ToF | Creative Senz3D RGBD Camera | Glasses | 30 Hz, 320 × 240 pixels | EMG, IMU | 10 AB, 1 TR | Grasp Type, Wrist Orientation | Geometric Model | 1 cm, 9° |
| 2016 | DeGol, et al. [72] | Slade et al Hand | Yes | RGB | PointGray Firefly MV RGB Camera | In Hand | 640 × 480 pixels | - | - | Grasp Type | CNN | 93% |
| 2016 | Tang, et al. [73] | iLimb Hand | Yes | RGB | Dynamic Vision Sensor | In Hand | 128 × 128 pixels | - | - | Object Rotation, Class | PRST-NDIST/ CNN | 96% |
| 2017 | Ghazaei, et al. [75] | iLimb Ultra, Wrist Rotator | Yes | RGB | Logitech QuickCam Chat RGB Camera | In Hand | 640 × 480 pixels, to 48 × 36 | - | 2 TR | Grasp Type | CNN | 85% |
| 2017 | Giordaniello, et al. [71] | - | - | RGB | Tobii Pro Glasses II, with RGB Camera | Glasses | 25 Hz | EMG, Gaze, Cyberglove | 7 AB | Grasp Type | Random Forest | 75% |
| 2017 | Bu, et al. [76] | Custom Arm | Yes | RGB | RGB Images | - | 256 × 256 pixels | - | 1 AB | Object Class | CNN | 90% |
| 2019 | Taverne, et al. [77] | - | - | RGB-D, SL | Orbbec Astra Mini S RGB-D Camera | Armband | 30 Hz, 320 × 240 pixels | IMU | 1 AB | Grasp Type | CNN | 96% |
| Endpoint Control | ||||||||||||
| 2014 | Martin, et al. [78] | Custom Arm | Yes | RGB-D, Structured | Microsoft Kinect v1 | Helmet | - | EMG | 1 TH | Grasp Type, Object Location | Blob Detection | - |
| 2017 | Madusanka, et al. [61] | MoBio | - | RGB, Ultrasonic | - | In Hand | - | EMG | 8 AB | Elbow Flex/ Extension | Visual Servoing | 93% |
| 2019 | Krausz, Lamotte, et al. [62] | - | - | RGB | SMI Eye Tracking Glasses, RGB Camera | Glasses | 30 Hz, 1280 × 960 pixels | EMG, Gaze, Motion Cap. | 7 AB | Object Location | Corner-Based Registration | 7 cm |
| Year | Authors | Device | Online | Modality | Teleceptive Sensor | Placed | Sensing Setup | Other Sensors | Subjects | Prediction | Processing | Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gait Segmentation | ||||||||||||
| 2018 | Hu, et al. [86] | - | - | IR ToF | Camboard Pico Flexx ToF | Right Thigh | 15 Hz, 171 × 224 pixels | IMU | 1 AB | Heel Contact and Toe Off | Leg and Ground Segmented | 6 ms |
| Forward Prediction | ||||||||||||
| 2011 | Zhang, et al. [87] | - | - | IR ToF Rangefinder | Leuze Electronic Optical Laser | Waist or Shank | 100 Hz | IMUs | 1 AB | Locomotion Activity | Distance | 98% |
| 2015 | Krausz and Hargrove [91] | - | - | RGB | Google Glass RGB | Glasses | - | - | - | Stair Recognition | Edge Detection | - |
| 2015 | Krausz, et al. [90] | - | - | RGB-D, SL | Microsoft Kinect v1 | Chest | 5 Hz, 320 × 240 pixels | - | 1 AB | Stair Recognition | Geometric Segmentation | 99% |
| 2016 | Liu, et al. [88] | Custom Knee, Otto Bock Foot | Yes | IR ToF Rangefinder | Leuze Electronic Optical Laser | Waist | 100 Hz | IMU, EMG, 6 DoF load Cell | 6 AB, 1 TF | Locomotion Activity | Decision Tree | 98% |
| 2016 | Varol, et al. [97] | - | - | RGB-D, ToF | DepthSense DS 325 RGB-D Camera | Shank | 30 Hz, 320 × 240 pixels | RGB (Annotated) | 1 AB | Locomotion Activity | Depth Difference Feats | 99% |
| 2018 | Massalin, et al. [98] | - | - | RGB-D, ToF | DepthSense DS 325 RGB-D Camera | Shank | 30 Hz, 320 × 240 pixels | RGB (Annotated) | 12 AB | Locomotion Activity | Depth Difference Feats | 95% |
| 2018 | Zhao, et al. [93] | - | - | RGB-D, ToF | Microsoft Kinect v2 | Waist | 512 × 424 pixels | IMU | - | Stair Recognition | Plane Segmentation | 1 cm |
| 2018 | Kleiner, et al. [96] | BiOM Ankle | - | Radar | 94 GHz FMCW Radar Sensor | Shank | 160 Hz | IMU | - | Stair Height | Radial Distance | ∼1 cm |
| 2018 | Yan, et al. [95] | - | - | RGB-D, SL | Xtion PRO LIVE Camera | Waist | 30 Hz, 640 × 480 pixels | - | 9 AB | Locomotion Activity | Hough Lines, etc. | 82% |
| 2019 | Laschowski [99] | - | - | RGB | GoPro Hero4 Session | Chest | 60 Hz, 1280 × 720 pixels | - | - | Locomotion Activity | CNN | 95% |
| 2019 | Novo Torres, et al. [100] | - | - | RGB | ArduCam RGB Sensor Camera | Glasses | 128 × 128 pixels | - | 2 AB | Obstacle Recognition | CNN | 90% |
| 2019 | Zhang, et al. [103] | - | - | IR ToF | Camboard Pico Flexx ToF | Thigh | 15/25 Hz, 171 × 224 pixels | IMU | 6 AB, 3 TF | Locomotion Activity | CNN | 99% |
| 2019 | Carvalho, et al. [89] | - | - | IR ToF Rangefinder | TF Mini LiDAR Laser Sensor | Waist | 100 Hz | - | 10 AB | Locomotion Activity | Decision Tree | 92% |
| 2019 | Khademi, et al. [101] | - | - | RGB | iPhone 8 | Waist | 100 Hz, 240 × 240 pixels | IMU | 4 AB | Locomotion Activity | CNN | 99% |
| 2019 | Krausz, et al. [104] | - | - | IR ToF | Camboard Pico Flexx ToF | Waist Belt | 5 Hz, 171 × 224 pixels | IMU, Gonio, EMG | 10 AB | Variability & Separability | Feature Variability | - |
| 2019 | Krausz and Hargrove [105] | OSL Knee/Ankle Prosthesis | - | IR ToF | Camboard Pico Flexx ToF | Waist Belt | 15 Hz, 171 × 224 pixels | 6 DoF Load Cell, IMUs | 1 TF | Locomotion Activity | LDA | 99% |
| 2019 | Liu, et al. [64] | VALOR Hip/Knee Exoskeleton | Stereo RGB | RealSenseD415 | Waist | 640 × 480 pixels | - | 3 AB | Obstacle Location | Geometric Segmentation | 7.5 mm | |
| Activity-Specific Control | ||||||||||||
| 2009 | Scandaroli, et al. [63] | Knee Ankle Prosthesis | - | IR ToF Rangefinder | Sharp GP2D120 Distance IR | Under Foot | 100 Hz | Gyros | - | Foot Orientation | Extended Kalman Filter | 99% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krausz, N.E.; Hargrove, L.J. A Survey of Teleceptive Sensing for Wearable Assistive Robotic Devices. Sensors 2019, 19, 5238. https://doi.org/10.3390/s19235238
Krausz NE, Hargrove LJ. A Survey of Teleceptive Sensing for Wearable Assistive Robotic Devices. Sensors. 2019; 19(23):5238. https://doi.org/10.3390/s19235238
Chicago/Turabian StyleKrausz, Nili E., and Levi J. Hargrove. 2019. "A Survey of Teleceptive Sensing for Wearable Assistive Robotic Devices" Sensors 19, no. 23: 5238. https://doi.org/10.3390/s19235238
APA StyleKrausz, N. E., & Hargrove, L. J. (2019). A Survey of Teleceptive Sensing for Wearable Assistive Robotic Devices. Sensors, 19(23), 5238. https://doi.org/10.3390/s19235238